



No CrossRef data available.
Published online by Cambridge University Press: 12 April 2024
We explore the limiting spectral distribution of large-dimensional random permutation matrices, assuming the underlying population distribution possesses a general dependence structure. Let 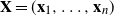 $\textbf X = (\textbf x_1,\ldots,\textbf x_n)$
$\textbf X = (\textbf x_1,\ldots,\textbf x_n)$ 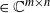 $\in \mathbb{C} ^{m \times n}$ be an
$\in \mathbb{C} ^{m \times n}$ be an 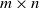 $m \times n$ data matrix after self-normalization (n samples and m features), where
$m \times n$ data matrix after self-normalization (n samples and m features), where 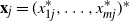 $\textbf x_j = (x_{1j}^{*},\ldots, x_{mj}^{*} )^{*}$. Specifically, we generate a permutation matrix
$\textbf x_j = (x_{1j}^{*},\ldots, x_{mj}^{*} )^{*}$. Specifically, we generate a permutation matrix 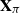 $\textbf X_\pi$ by permuting the entries of
$\textbf X_\pi$ by permuting the entries of 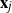 $\textbf x_j$
$\textbf x_j$ 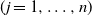 $(j=1,\ldots,n)$ and demonstrate that the empirical spectral distribution of
$(j=1,\ldots,n)$ and demonstrate that the empirical spectral distribution of 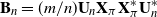 $\textbf {B}_n = ({m}/{n})\textbf{U} _{n} \textbf{X} _\pi \textbf{X} _\pi^{*} \textbf{U} _{n}^{*}$ weakly converges to the generalized Marčenko–Pastur distribution with probability 1, where
$\textbf {B}_n = ({m}/{n})\textbf{U} _{n} \textbf{X} _\pi \textbf{X} _\pi^{*} \textbf{U} _{n}^{*}$ weakly converges to the generalized Marčenko–Pastur distribution with probability 1, where 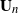 $\textbf{U} _n$ is a sequence of
$\textbf{U} _n$ is a sequence of 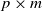 $p \times m$ non-random complex matrices. The conditions we require are
$p \times m$ non-random complex matrices. The conditions we require are 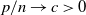 $p/n \to c >0$ and
$p/n \to c >0$ and 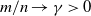 $m/n \to \gamma > 0$.
$m/n \to \gamma > 0$.