



No CrossRef data available.
Published online by Cambridge University Press: 19 September 2022
It was recently proven that the correlation function of the stationary version of a reflected Lévy process is nonnegative, nonincreasing, and convex. In another branch of the literature it was established that the mean value of the reflected process starting from zero is nondecreasing and concave. In the present paper it is shown, by putting them in a common framework, that these results extend to substantially more general settings. Indeed, instead of reflected Lévy processes, we consider a class of more general stochastically monotone Markov processes. In this setup we show monotonicity results associated with a supermodular function of two coordinates of our Markov process, from which the above-mentioned monotonicity and convexity/concavity results directly follow, but now for the class of Markov processes considered rather than just reflected Lévy processes. In addition, various results for the transient case (when the Markov process is not in stationarity) are provided. The conditions imposed are natural, in that they are satisfied by various frequently used Markovian models, as illustrated by a series of examples.
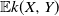 $\mathbb{E} k(X,Y)$
when the marginals are fixed. Z. Wahrscheinlichkeitsth. 36, 285–294.CrossRefGoogle Scholar
$\mathbb{E} k(X,Y)$
when the marginals are fixed. Z. Wahrscheinlichkeitsth. 36, 285–294.CrossRefGoogle Scholar