


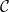
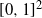
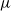
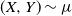
Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Cichomski, Stanisław
and
Osȩkowski, Adam
2025.
On the Existence of Extreme Coherent Distributions with No Atoms.
Journal of Theoretical Probability,
Vol. 38,
Issue. 1,