



No CrossRef data available.
Published online by Cambridge University Press: 24 May 2024
We consider a Poisson autoregressive process whose parameters depend on the past of the trajectory. We allow these parameters to take negative values, modelling inhibition. More precisely, the model is the stochastic process 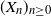 $(X_n)_{n\ge0}$ with parameters
$(X_n)_{n\ge0}$ with parameters 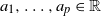 $a_1,\ldots,a_p \in \mathbb{R}$,
$a_1,\ldots,a_p \in \mathbb{R}$, 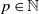 $p\in\mathbb{N}$, and
$p\in\mathbb{N}$, and 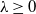 $\lambda \ge 0$, such that, for all
$\lambda \ge 0$, such that, for all 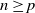 $n\ge p$, conditioned on
$n\ge p$, conditioned on 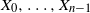 $X_0,\ldots,X_{n-1}$,
$X_0,\ldots,X_{n-1}$, 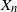 $X_n$ is Poisson distributed with parameter
$X_n$ is Poisson distributed with parameter 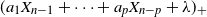 $(a_1 X_{n-1} + \cdots + a_p X_{n-p} + \lambda)_+$. This process can be regarded as a discrete-time Hawkes process with inhibition and a memory of length p. In this paper we initiate the study of necessary and sufficient conditions of stability for these processes, which seems to be a hard problem in general. We consider specifically the case
$(a_1 X_{n-1} + \cdots + a_p X_{n-p} + \lambda)_+$. This process can be regarded as a discrete-time Hawkes process with inhibition and a memory of length p. In this paper we initiate the study of necessary and sufficient conditions of stability for these processes, which seems to be a hard problem in general. We consider specifically the case 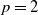 $p = 2$, for which we are able to classify the asymptotic behavior of the process for the whole range of parameters, except for boundary cases. In particular, we show that the process remains stochastically bounded whenever the solution to the linear recurrence equation
$p = 2$, for which we are able to classify the asymptotic behavior of the process for the whole range of parameters, except for boundary cases. In particular, we show that the process remains stochastically bounded whenever the solution to the linear recurrence equation 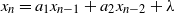 $x_n = a_1x_{n-1} + a_2x_{n-2} + \lambda$ remains bounded, but the converse is not true. Furthermore, the criterion for stochastic boundedness is not symmetric in
$x_n = a_1x_{n-1} + a_2x_{n-2} + \lambda$ remains bounded, but the converse is not true. Furthermore, the criterion for stochastic boundedness is not symmetric in 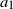 $a_1$ and
$a_1$ and 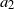 $a_2$, in contrast to the case of non-negative parameters, illustrating the complex effects of inhibition.
$a_2$, in contrast to the case of non-negative parameters, illustrating the complex effects of inhibition.
 $\infty$
) processes. Stoch. Process. Appl. 126, 2494–2525.CrossRefGoogle Scholar
$\infty$
) processes. Stoch. Process. Appl. 126, 2494–2525.CrossRefGoogle Scholar