


1. Introduction
It is alarming that recent climate changes (especially, the continued changes in frequency and intensity of high-temperature events) could lead to severe reduction in wheat production and higher variability in wheat yields (Gourdji et al., Reference Gourdji, Mathews, Reynolds, Crossa and Lobell2013; Lobell, Sibley, and Ortiz-Monasterio, Reference Lobell, Sibley and Ortiz-Monasterio2012; Tack, Barkley, and Nalley, Reference Tack, Barkley and Nalley2014, Reference Tack, Barkley and Nalley2015a; Tubiello et al., Reference Tubiello, Rosenzweig, Goldberg, Jagtap and Jones2002). Among a variety of risk management strategies, diversification has been perceived as an effective risk management tool for mitigating yield risk caused by diverse growing conditions and unpredictable climate (Barry and Ellinger, Reference Barry and Ellinger2012; Boggess, Anaman, and Hanson, Reference Boggess, Anaman and Hanson1985; Bradshaw, Dolan, and Smit, Reference Bradshaw, Dolan and Smit2004; Knutson et al., Reference Knutson, Smith, Anderson and Richardson1998; Sonka and Patrick, Reference Sonka, Patrick and Barry1984). For agriculture, diversification may take several forms. For example, the producers may increase the number of farm locations (i.e., geographic diversification) to reduce risk associated with location-specific weather conditions and with stochastic price (or demand) shocks to local markets. Another method of diversification is to broaden the existing marketable activities by, for example, adding value to existing production (i.e., enterprise diversification) to produce better cash flow for the business. Diversification may also take the form of growing more than one field crop (i.e., crop diversification) or more than one variety of a particular crop (i.e., varietal diversification).
Of these many forms of agricultural diversification, varietal diversification seems to be the most cost-effective method for wheat producers to manage yield risk. Moreover, recent studies by Tack, Barkley, and Nalley (Reference Tack, Barkley and Nalley2014) and Tack et al. (Reference Tack, Barkley, Rife, Poland and Nalley2015) show that warming and drought affect production of different wheat varieties in different ways. Therefore, planting more than one wheat variety each year potentially forms a natural insurance against the risk associated with yield loss from changing climate and growing conditions. The question is how to determine the optimal mix of wheat varieties. Portfolio theory, initially developed by Markowitz (Reference Markowitz1952), provides a unique optimal (at least in-sample) solution given the producers’ chosen level of risk. In particular, the theory suggests that wheat varietal diversification could reduce yield risk and, consequently, income risk, through less-than-unit correlations among yields of different wheat varieties. To determine the optimal allocation of land to the various wheat varieties, the analysis often proceeds by constructing a traditional mean-variance frontier. In crop variety selection, several studies applied the mean-variance framework and showed that farm profitability could be enhanced through mean-variance optimization (Barkley, Peterson, and Shroyer, Reference Barkley, Peterson and Shroyer2010; Mortenson et al., Reference Mortenson, Parsons, Pendell and Haley2012; Nalley and Barkley, Reference Nalley and Barkley2010; Nalley et al., Reference Nalley, Barkley, Watkins and Hignight2009).
A major drawback of the standard mean-variance analysis is that it uses variance, which treats both upside and downside risk as the same, as the risk measure. Because the producers often consider the upside risk to be favorable, the use of variance seems to be inappropriate. The only case in which upside and downside risk are the same, and, thus, variance is a correct measure of risk, is when crop yields or profits are normally distributed. However, in reality, agricultural yields have been shown to be nonnormal (Atwood, Shaik, and Watts, Reference Atwood, Shaik and Watts2003; Day, Reference Day1965; Gallagher, Reference Gallagher1987; Ramirez, Misra, and Field, Reference Ramirez, Misra and Field2003). Given that the producers are only concerned with the downside risk, some studies used expected shortfall (ES) or conditional value at risk (VaR), which measures the risk of the actual yield being far below the expected yield (i.e., the downside risk), as the risk measure (for applications of ES in agriculture, see, e.g., Larsen, Leatham, and Sukcharoen, Reference Larsen, Leatham and Sukcharoen2015; Strauss et al., Reference Strauss, Fuss, Szolgayová and Schmid2009; Zylstra, Kilmer, and Uryasev, Reference Zylstra, Kilmer and Uryasev2003). One could then use a mean-ES model, instead of the mean-variance model, to determine an optimal proportion of each crop variety to be planted.
Even though researchers are well aware that crop yields may not be normally distributed and that wheat producers are particularly concerned with the downside risk, to our best knowledge, none of the existing studies have applied the mean-ES model to the wheat variety selection problem. This study is, therefore, the first study to explore the potential benefits of the mean-ES approach as a technique to select wheat varieties. Particularly, we compare optimal wheat variety mixes obtained from the mean-variance framework with those from the mean-ES model and then examine potential gains from applying the two portfolio optimization methods to wheat variety selection. Understanding how different optimization models perform in the context of wheat variety selection provides useful insights for designing optimal mixes of wheat varieties to plant. In addition, our study adds to earlier studies on wheat variety selection by applying the methods to a different data set. Although the previous studies applied portfolio theory to wheat variety selection decisions in Kansas (Barkley, Peterson, and Shroyer, Reference Barkley, Peterson and Shroyer2010), Colorado (Mortenson et al., Reference Mortenson, Parsons, Pendell and Haley2012), the Yaqui Valley of northwestern Mexico (Nalley and Barkley, Reference Nalley and Barkley2010), and the Texas High Plains (Park et al., Reference Park, Cho, Bevers, Amosson and Rudd2012), we consider the wheat selection problem in Texas Blacklands. The location is chosen based on data availability and the lack of previous research. Last but not least, unlike previous studies that evaluate the performance of the optimization models on the period over which the model is estimated (i.e., the optimization or in-sample period), the present study looks at how well the models perform the year after the estimation period. This is a better way to evaluate the performance of optimization strategies because, in reality, wheat producers must make decisions regarding which varieties to be planted next year before the next-year yield data exist.
This research should provide useful information for agricultural producers who aim at improving variety selection and developing a new strategy to cope with a hotter climate.Footnote 1 The remainder of this study proceeds as follows: Section 2 describes the mean-variance and mean-ES optimization methods. Section 3 is then devoted to describing the data. Section 4 discusses the results of portfolio optimizations. Finally, Section 5 summarizes and concludes.
2. Optimization Methods
This study focuses on a single-period wheat variety selection problem because wheat producers can change the varieties planted each year. To identify the optimal mix of wheat varieties, previous studies applied the standard mean-variance optimization framework. However, the choice of variance as a risk measure is only appropriate when wheat yields are normally distributed. Given the possibility that wheat yields are nonnormally distributed, a downside risk measure such as ES is preferable.
Another measure of downside risk is VaR, which also addresses the said limitation of variance as a risk measure. Nonetheless, for nonnormal distributions, VaR does not possess the subadditivity property, one of the properties that a risk measure should have (for more details, see Artzner et al., Reference Artzner, Delbaen, Eber and Heath1999). Without the subadditivity property, the VaR of a portfolio of two varieties may be greater than that of each individual variety, suggesting that varietal diversification should be discouraged. In this case, VaR is not convex (for definition of convexity, see Rockafellar and Uryasev, Reference Rockafellar and Uryasev2000), making it difficult to solve the optimization problem because multiple local solutions may exist (Mausser and Rosen, Reference Mausser and Rosen1998). This implies that when the underlying distributions of crop yields are nonnormal, the portfolio optimization problem based on VaR should be avoided. An alternative to the VaR is the portfolio optimization based on ES, which is a downside risk measure that has been found to be subadditive and convex even without the normality assumption (Rockafellar and Uryasev, Reference Rockafellar and Uryasev2000). Therefore, when wheat yields are nonnormally distributed, the mean-ES model is preferable to the mean-variance model and the mean-VaR model for the problem of wheat variety selection.
In the following sections, we first provide an overview of the traditional mean-variance model, which serves as a benchmark in our analysis. We then describe the mean-ES model and discuss our data-smoothing and simulation procedure used to calculate ES.
2.1. The Mean-Variance Model
The first model used in this study to derive efficient portfolios of wheat varieties is the traditional mean-variance model developed by Markowitz (Reference Markowitz1952). Similar to Barkley, Peterson, and Shroyer (Reference Barkley, Peterson and Shroyer2010), Nalley and Barkley (Reference Nalley and Barkley2010), Nalley et al. (Reference Nalley, Barkley, Watkins and Hignight2009), and Mortenson et al. (Reference Mortenson, Parsons, Pendell and Haley2012), it is assumed that a wheat producer's objective is to choose the optimal share of total acres allocated to each wheat variety. Let αi be the share of total acres allocated to variety i, where i = 1, . . ., n; yi be the yield mean of variety i; and σij be the covariance of yields for varieties i and j. Then, the portfolio yield (i.e., the weighted average yield) is defined as
 $$\begin{equation}
Y = \mathop \sum \limits_i {\alpha _i}{y_i},
\end{equation}$$
$$\begin{equation}
Y = \mathop \sum \limits_i {\alpha _i}{y_i},
\end{equation}$$and the portfolio variance (i.e., total farm variety yield variance) is defined as
 $$\begin{equation}
V = \mathop \sum \limits_i \mathop \sum \limits_j {\alpha _i}{\alpha _j}{\sigma _{ij}}.
\end{equation}$$
$$\begin{equation}
V = \mathop \sum \limits_i \mathop \sum \limits_j {\alpha _i}{\alpha _j}{\sigma _{ij}}.
\end{equation}$$ The mean-variance analysis selects the optimal mix of wheat varieties by minimizing the portfolio variance subject to the constraints of portfolio yield being equal to the (positive) target yield of 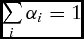 $\mathop \sum \limits_i {\alpha _i} = 1$ and of nonnegative share of wheat variety i. Mathematically, this optimization problem is formulated as follows:
$\mathop \sum \limits_i {\alpha _i} = 1$ and of nonnegative share of wheat variety i. Mathematically, this optimization problem is formulated as follows:
 $$\begin{equation}
\mathop {\min }\limits_{{\alpha _1}, \ldots ,{\alpha _n}} \mathop \sum \limits_i \mathop \sum \limits_j {\alpha _i}{\alpha _j}{\sigma _{ij}},
\end{equation}$$
$$\begin{equation}
\mathop {\min }\limits_{{\alpha _1}, \ldots ,{\alpha _n}} \mathop \sum \limits_i \mathop \sum \limits_j {\alpha _i}{\alpha _j}{\sigma _{ij}},
\end{equation}$$subject to:
 $$\begin{equation}
\mathop \sum \limits_i {\alpha _i}{y_i} = \lambda
\end{equation}$$\\
$$\begin{equation}
\mathop \sum \limits_i {\alpha _i}{y_i} = \lambda
\end{equation}$$\\
 $$\begin{equation}
\mathop \sum \limits_i {\alpha _i} = 1
\end{equation}$$\\
$$\begin{equation}
\mathop \sum \limits_i {\alpha _i} = 1
\end{equation}$$\\
 $$\begin{equation}
{\alpha _i} \ge 0{\rm{\ for\ all\ }}i.
\end{equation}$$
$$\begin{equation}
{\alpha _i} \ge 0{\rm{\ for\ all\ }}i.
\end{equation}$$The solution to this problem is given as α = (α1, . . ., αn) for each λ. From this, we attain an optimized portfolio variance V for each λ, from which we obtain the mean-variance efficiency frontier. The nonlinear mean-variance model is programmed in Microsoft Excel and solved using the Microsoft Excel Solver tool.
2.2. The Mean–Expected Shortfall Model
The second model used to estimate the optimal mix of wheat varieties is the mean-ES, or mean-ES model. The only difference between the mean-ES model and the traditional mean-variance model is that the mean-ES model minimizes the ES instead of the portfolio variance.
In this study, ES is defined as
 $$\begin{equation}
E{S_\beta } = - E\left[{Y|Y \le q} \right],
\end{equation}$$
$$\begin{equation}
E{S_\beta } = - E\left[{Y|Y \le q} \right],
\end{equation}$$where q is the βth percentile of the portfolio yield distribution (i.e., Pr[Y ≤ q] = β). This study considers the parameter β equal to 0.1, 0.05, and 0.01. In words, ES is the expected portfolio yield loss; it represents the negative of the mean of portfolio yields that are lower than the βth percentile. We calculate ESs at the 10%, 5%, and 1% levels using a semiparametric simulation method to be discussed in the next subsection.
Let 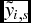 ${\tilde y_{i,s}}$ be the simulated yield of variety i for the sth iteration (with s = 1, . . ., 10, 000). Using the same notation as given previously, portfolio optimization based on ES by a simulation-based method is formulated as follows:
${\tilde y_{i,s}}$ be the simulated yield of variety i for the sth iteration (with s = 1, . . ., 10, 000). Using the same notation as given previously, portfolio optimization based on ES by a simulation-based method is formulated as follows:
 $$\begin{equation}
\mathop {\min }\limits_{{\alpha _1}, \ldots ,{\alpha _n}} - E\ \left[{\mathop \sum \limits_i {\alpha _i}{{\tilde y}_{i,s}}|\mathop \sum \limits_i {\alpha _i}{{\tilde y}_{i,s}} \le q} \right],
\end{equation}$$
$$\begin{equation}
\mathop {\min }\limits_{{\alpha _1}, \ldots ,{\alpha _n}} - E\ \left[{\mathop \sum \limits_i {\alpha _i}{{\tilde y}_{i,s}}|\mathop \sum \limits_i {\alpha _i}{{\tilde y}_{i,s}} \le q} \right],
\end{equation}$$subject to:
 $$\begin{equation}
\left( {\frac{1}{S}} \right)\mathop \sum \limits_s \mathop \sum \limits_i {\alpha _i}{\tilde y_{i,s}} = \phi
\end{equation}$$\\
$$\begin{equation}
\left( {\frac{1}{S}} \right)\mathop \sum \limits_s \mathop \sum \limits_i {\alpha _i}{\tilde y_{i,s}} = \phi
\end{equation}$$\\
 $$\begin{equation}
\mathop \sum \limits_i {\alpha _i} = 1
\end{equation}$$\\
$$\begin{equation}
\mathop \sum \limits_i {\alpha _i} = 1
\end{equation}$$\\
 $$\begin{equation}
{\alpha _i} \ge 0{\rm{\ for\ all\ }}i.
\end{equation}$$
$$\begin{equation}
{\alpha _i} \ge 0{\rm{\ for\ all\ }}i.
\end{equation}$$The solution to this problem is given as α = (α1, . . ., αn) for each ϕ. From this, we attain an optimized portfolio ES, ES β, for each ϕ, from which we obtain the mean-ES efficiency frontier. The problem of minimizing portfolio ES is solved using the Microsoft Excel Solver tool. We also use Matlab Financial Toolbox to calculate the mean-ES efficient portfolios to validate the results obtained by the Excel Solver program.
2.3. Data-Smoothing and Simulation Procedure
There are three main methods for calculating ES: the nonparametric historical simulation method, the semiparametric simulation method, and the parametric method. On the one hand, the historical simulation method does not require any parametric assumption about the distribution of wheat yields. However, the method assumes stationarity (i.e., future yields will be similar to the past yields). This is a very strong assumption, especially when only limited historical observations are available. Given the shortness of relevant historical data of wheat variety yields, the historical simulation method is not appropriate. On the other hand, the parametric method assumes that wheat variety yields follow a particular multivariate probability distribution. The mean-variance approach relies on the use of a multivariate normal distribution. If yields are assumed to be normally distributed, both mean-variance and mean-ES models lead to the same optimal mixes of wheat varieties. In addition, as mentioned previously, several studies find that some crop yields are not normally distributed. Therefore, the mean-ES analysis in this study takes a nonnormal characteristic of wheat variety yields into consideration. Still, the parametric simulation method is inherently subject to misspecification of the distribution. Finally, the semiparametric simulation method is a hybrid of the nonparametric and parametric approaches and, thus, offers more flexibility in term of modeling the distributions for random variables. This study, therefore, uses the semiparametric simulation method to simulate the distributions of wheat variety yields and compute the corresponding value of portfolio ES.
To deal with sparse (limited) data, we use the multivariate kernel density estimation (MVKDE) procedureFootnote 2 proposed by Richardson, Lien, and Hardaker (Reference Richardson, Lien and Hardaker2006) to smooth out irregularities in the sparse data and fit a multivariate probability distribution. The MVKDE method can be briefly summarized in two steps. The first step is to use a kernel density estimator (KDE) to construct a smooth, continuous probability density function for each variable (i.e., each yield variety) in the system. Before estimating the kernel distributions, we separate the stochastic and deterministic components of the random variables. Because yield is often a linear function of trend, we use an ordinary least squares (OLS) regression on a linear trend to identify the nonrandom components of each random variable. When the linear trend is not statistically significant, we use the simple yield means to remove the nonrandom components.
For each historical detrended (or demeaned) variety yield series, we consider the following 11 different kernel density functions: Cauchy, cosinus, double exponential, Epanechnikov, Gaussian, Parzen, quartic, semiparametric normal, triangle, triweight, and uniform. The most appropriate kernel density function for each variety is selected based on the root-mean-square error (RMSE) of the differences between the cumulative probabilities of the histogram and those of the particular kernel function. The kernel function with the smallest RMSE is chosen. In a standard cumulative distribution function, the cumulative probabilities of the minimum and maximum yields are assumed to be equal to 0 and 1, respectively. This implies that the probability of observing the historical minimum and maximum yields are equal to 0. Following Richardson, Klose, and Gray (Reference Richardson, Klose and Gray2000), we correct this problem by adding two pseudo-observations: pseudominimum and pseudomaximum. The pseudominimum (maximum) is calculated by multiplying the actual detrended or demeaned minimum (maximum) yield and 1.000001. The cumulative probabilities of the pseudominimum and pseudomaximum are then set to be equal to 0 and 1, respectively.
The second step is to simulate the chosen KDE distributions from the previous step as a multivariate distribution using the multivariate empirical (MVE) approach outlined in details by Richardson, Klose, and Gray (Reference Richardson, Klose and Gray2000). The approach is only briefly described here. The starting point is to model dependencies among wheat variety yields. Copulas are the most general method for this task. Given the shortness of the data, the choice of copulas is more or less limited to the Gaussian (or normal) copula. The only parameter matrix needed for the Gaussian copula is the correlation matrix, P n × n, calculated using actual historical detrended (or demeaned) variety yield series. The correlation matrix is then factored by the Choleski decomposition. The factored correlation matrix, R n × n, is calculated such that P = RR'. A vector of correlated standard normal deviates, C n × 1, is simulated by multiplying the factored correlation matrix, R n × n, and a vector of independent standard normal deviates, Z n × 1 (i.e., C = RZ). Each element in the vector C is then transformed to a correlated uniform standard deviate, using the error function (i.e., the integral of the standard normal distribution from negative infinity to Ci). Given the vector of correlated uniform standard deviates, U n × 1, a vector of simulated MVKDE, K n × 1, is then generated using the inverse transform function of an empirical distribution defined using the KDE distribution for each variety i. For each of the 10,000 iterations, the simulated wheat variety yields are generated using:
 $$\begin{equation}
{\tilde y_{i,s}} = {\hat y_{i,s}} + {K_{i,s}},
\end{equation}$$
$$\begin{equation}
{\tilde y_{i,s}} = {\hat y_{i,s}} + {K_{i,s}},
\end{equation}$$
where 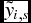 ${\tilde y_{i,s}}$ is the simulated yield of variety i for the sth iteration (with s = 1, . . ., 10, 000);
${\tilde y_{i,s}}$ is the simulated yield of variety i for the sth iteration (with s = 1, . . ., 10, 000); 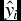 ${\hat y_i}$ is the deterministic component of yield of variety i; and K i, s is the simulated MVKDE for variety i for the sth iteration. Given the simulated variety yields, portfolio ESs are then computed using equation (7). Parameters of kernel density functions and MVE yield distribution can be estimated using Matlab or R.
${\hat y_i}$ is the deterministic component of yield of variety i; and K i, s is the simulated MVKDE for variety i for the sth iteration. Given the simulated variety yields, portfolio ESs are then computed using equation (7). Parameters of kernel density functions and MVE yield distribution can be estimated using Matlab or R.
3. Data
Data on dryland hard wheat yields for various varieties planted in Texas BlacklandsFootnote 3 are available from Texas A&M University publications on Texas Wheat Variety Trial results (Texas A&M AgriLife Extension Service, Texas A&M AgriLife Research, and AgriPro Wheat, 2008, 2009, 2010; Texas A&M AgriLife Extension Service, Texas A&M AgriLife Research, and Syngenta Wheat, 2011, 2012, 2013, 2014; Texas Cooperative Extension and Texas Agricultural Experiment Station, 2005, 2006, 2007). As pointed out by an anonymous referee, there exists a gap between in-trial (or experimental) and on-farm (or actual) yields.Footnote 4 In other words, the in-trial yields might not fully reflect on-farm performance, and, therefore, the findings of this study might be biased as a result of the unavoidable yield-gap problem. However, the upside of the trial data is that they provide valuable information that might not be otherwise available, including data for new wheat varieties.Footnote 5 In addition, a major driver of the gap between in-trial and on-farm wheat yields is the difference in on-farm production decisions, not producers’ variety selection decisions (Tack, Barkley, and Nalley, Reference Tack, Barkley and Nalley2015b). Also, the in-trial relative yields are very likely to be similar to the on-farm relative yields (Brennan, Reference Brennan1984). Therefore, the analysis based on the trial data is likely to provide reliable yield comparisons across varieties.
The wheat varieties considered for the analysis must satisfy the two criteria: (1) the variety appears within the publication for the year 2014; and (2) observations of the variety are available for at least five consecutive years just before the year 2014Footnote 6 (i.e., for the years 2008–2013) for the estimations of the correlation matrix and the multivariate probability distribution. Even though the data are available since the year 2005, the initial year of 2008 is selected to maximize the number of wheat varieties satisfying the previously discussed criteria. Accordingly, a total of 10 wheat varieties (Coronado, Duster, Fannin, Greer, Jackpot, TAM 111, TAM 112, TAM 304, TAM 401, and TAM W101) are included in the analysis.Footnote 7Figure 1 illustrates historical yields for the 10 selected wheat varieties for the years 2008–2013. TAM W101 constantly produces the lowest yield, whereas Duster, Greer, and TAM 304 produce relatively high yields over time. There is, however, no all-time best wheat variety, which provides a good reason for varietal diversification.

Figure 1. Historical Yields for the Selected Wheat Varieties, 2008–2013
Table 1 reports summary statistics of yields for the selected wheat varieties for the time period 2008–2013 (the optimization or in-sample period). Greer has the highest average yield (58.22 bushels per acre), followed by Duster (56.55 bushels per acre) and TAM 304 (56.34 bushels per acre). TAM W101 has the lowest average yield (38.77 bushels per acre), followed by TAM 111 (46.29 bushels per acre) and Coronado (47.97 bushels per acre). The most volatile varieties are TAM 112 (7.86 bushels per acre), Greer (7.81 bushels per acre), and TAM 401 (7.16 bushels per acre); whereas the least volatile varieties are Coronado (3.29 bushels per acre), TAM 304 (4.92 bushels per acre), and TAM W101 (5.25 bushels per acre). The coefficient of variation (CV), defined as the ratio of the standard deviation to the mean, measures the relative variability of stochastic yields. A lower CV indicates a lower risk per unit of expected yield. The CV, reported in Table 1, indicates that TAM 112, TAM W101, and Greer are the riskiest wheat varieties to plant. Coronado, TAM 304, and Fannin are the safest varieties given their coefficients of variation.
Table 1. Summary Statistics of In-Sample Yields for the Selected Wheat Varieties, 2008–2013

Table 2 documents the wheat yield data for the year 2014 (to be used for evaluating the performance of optimization models). In 2014, the varieties are ranked from the highest to lowest yields as follows: Greer, Jackpot, TAM 111, Fannin, TAM 401, TAM 304, Duster, Coronado, TAM 112, and TAM W101. Table 2 also provides the 2014 actual allocation of wheat varieties planted in Texas Blacklands. In this study, we define the “2014 actual allocation” as the percentage of total wheat acreage in Texas Blacklands planted with the 10 wheat varieties in 2014. The 2014 actual planting data are obtained from the U.S. Department of Agriculture, National Agricultural Statistics Service (USDA-NASS, 2015) publication Percent of Wheat Acres Seeded for 2014. The report suggests that wheat producers do diversify the varieties planted on their farms. The top 3 wheat varieties planted in 2014 are Fannin (39.33%), TAM 304 (34.08%), and Duster (8.24%). Two of the 10 varieties, TAM 112 and TAM W101, were not planted in Texas Blacklands in 2014. Recall that TAM 112 and TAM W101 have the highest coefficients of variation (see Table 1). Thus, it seems like the producers do avoid planting the varieties with high values of CV.
Table 2. 2014 Wheat Variety Yields and 2014 Actual Allocation of Wheat Varieties Planted in Texas Blacklands

Notes: The “2014 actual allocation” is defined as the percentage of total wheat acreage in Texas Blacklands planted with the 10 wheat varieties in 2014. Percents may not add to 100 because of rounding.
The concept of correlation lies at the heart of varietal diversification. Simply put, the objective of varietal diversification is to decrease yield risk by selecting a mix of wheat varieties whose productivities are less correlated. Table 3 reports pair-wise correlations among the selected wheat varieties for the period 2008–2013. The correlation coefficients range from −0.060 (Jackpot and TAM W101) to 0.941 (Coronado and TAM 304). As can be seen from Table 2, approximately 70% of total wheat acreage is allocated to Fannin and TAM 304. The correlation between Fannin and TAM 304 is 0.842. Because the correlation between the two varieties is less than 1, planting both varieties would offer diversification benefit to wheat producers. However, Fannin and TAM 304 are very highly correlated, so allocating a large proportion of land to only these two varieties may not be the best strategy. Put differently, further diversification benefits may be gained by choosing the better mix of wheat varieties. This study applies the mean-variance and mean-ES approaches to determine the optimal mix of wheat varieties.Footnote 8 Results of detailed analysis on the optimal varietal allocations follow.
Table 3. Correlations among the Selected Wheat Varieties, 2008–2013

4. Results
In this section, we present results of the mean-variance and mean-ES optimizations. Data-smoothing and simulation results are also provided. We then compare the optimal allocations suggested by the various optimization models with the 2014 actual allocation of wheat varieties and examine potential gains (losses) from applying portfolio optimization methods to wheat variety selection with the 2014 actual allocation as the evaluation benchmark.
4.1. Mean-Variance Optimization Results
We first apply the mean-variance model to the in-sample data set (2008–2013) to derive the efficient mean-variance frontier. Figure 2 depicts the estimated mean-variance (standard deviation) frontier and shows where the 2014 actual allocation locates relative to the efficient frontier. For the in-sample analysis, the portfolio yield and standard deviation for the 2014 actual allocation are calculated from the in-sample variety yields and variances (not from the 2014 actual yields). The in-sample portfolio yield and standard deviation for the 2014 actual allocation are 54.92 bushels per acre and 4.17 bushels per acre, respectively. Results from the mean-variance model suggest that in-sample productivity (and therefore profitability) can be enhanced (or in-sample risk, as measured by variance or standard deviation, can be reduced) through varietal diversification. In other words, the 2014 actual allocation is not an optimal allocation for the period over which the model is estimated.

Figure 2. In-Sample Efficient Mean-Variance Frontier
Table 4 illustrates the optimal allocations (the percentage of each variety to be planted) corresponding to the different points of the efficient mean-variance frontier (Figure 2). For the estimation period, Greer produces the highest average yield (58.22 bushels per acre). This highest portfolio yield constitutes the highest point on the efficient mean-variance frontier with the highest standard deviation (7.81 bushels per acre). The in-sample CV of the 2014 actual allocation is 7.59% (calculated as 4.17/54.92). For wheat producers interested in increasing (at least, in-sample) portfolio yield while holding the relative variability constant, a combination of 27.22% Duster, 15.01% Greer, 3.12% Jackpot, and 54.65% TAM 304 would result in an average historical yield of 56.64 bushels per acre. This portfolio produces a higher average yield (56.64 vs. 54.92 bushels per acre), but with the CV of 7.60% (calculated as 4.31/56.64), which is just a little bit higher than the CV of the 2014 actual allocation (7.59%). As expected, similar to the previous studies (Barkley, Peterson, and Shroyer, Reference Barkley, Peterson and Shroyer2010; Mortenson et al., Reference Mortenson, Parsons, Pendell and Haley2012; Nalley and Barkley, Reference Barkley, Peterson and Shroyer2010; Nalley et al., Reference Nalley, Barkley, Watkins and Hignight2009), in-sample farm profitability could be enhanced through the mean-variance optimization. It is, nonetheless, still ambiguous about how well the mean-variance strategy performs relative to the 2014 actual allocation the year after the in-sample estimation period.
Table 4. In-Sample Mean-Variance Portfolio Analysis, 2008–2013

Note: Percents may not add to 100 because of rounding.
4.2. Mean–Expected Shortfall Optimization Results
For the mean-ES analysis, the in-sample data are fitted to a multivariate probability distribution using the MVKDE procedure discussed previously. Results from an OLS regression on a linear trend fail to indicate a statistically significant trend component at the 5% level for all variety yield data.Footnote 9 Therefore, the mean of each variety yield is used as the nonrandom component of each stochastic yield. That is, all random yields are demeaned. For each demeaned yield series, the Parzen kernel is selected, based on the minimum RMSE criterion, to smooth out irregularities in the sparse data.Footnote 10 The estimated Parzen kernel functions and the correlation matrixFootnote 11 (Table 3) are then used to simulate the random (demeaned) yields for 10,000 iterations. Given that the trend is not statistically significant, the historical yield means are used as the projected yields (the deterministic component of yields in equation 12) to simulate the wheat variety yields.
We perform two types of validation tests on the simulated random variables to check whether the simulated yields statistically reproduce the historical yield means and correlation.
First, the Hotelling's T-squared test (Johnson and Wichern, Reference Johnson and Wichern2002) is used to test if the two sets of means (simulated and historical means) are equal. At the 95% confidence level, the mean vector of the simulated data is not statistically different from the mean vector of the historical data. Second, Student's t-tests are used to test if the simulated yields are appropriately correlated. At the 99% confidence level, the correlation coefficients in the simulated data are not statistically different from their respective historical correlation coefficients.Footnote 12
Given the simulated yields of the 10 wheat varieties, optimal portfolios are derived by solving the mean-ES optimization problem discussed previously. Figure 3 displays the efficient mean-ES portfolios at the 10% level, and Table 5 reports the optimal land allocations to the various wheat varieties corresponding to the different points of the efficient mean-ES frontier at the 10% level.Footnote 13Figure 3 also displays where the 2014 actual allocation locates relative to the frontier. The portfolio yield and ES at the 10% level for the 2014 actual allocation (54.48 bushels per acre for the former and −45.32 bushels per acreFootnote 14 for the latter) are computed from the simulated yields. Obviously, the mean-ES model suggests that in-sample the 2014 actual allocation is not an optimal mix of wheat varieties, because such an allocation is not on the efficient mean-ES frontier.

Figure 3. In-Sample Efficient Mean–Expected Shortfall (ES) Frontier (at the 10% level)
Table 5. In-Sample Mean–Expected Shortfall Portfolio Analysis at the 10% Level, 2008–2013

Note: Percents may not add to 100 because of rounding.
Similar to the results of the mean-variance analysis, Greer produces the highest simulated yield with the highest ES (Table 5). This point corresponds to the highest point on the mean-ES frontier (Figure 3). At the low to intermediate levels of portfolio ES, it is optimal to allocate more than 60% of total acres to Duster. At the intermediate to high levels of portfolio ES, producers should plant more than 50% of Greer. The results are not unexpected, because both Duster and Greer produce relatively high yields over time (Figure 1). Even though the average yield of Duster is lower than that of Greer (56.55 vs. 58.22 bushels per acre), the historical minimum yield of Duster is higher than that of Greer (48.18 vs. 43.72 bushels per acre). This makes Duster relatively less risky from the perspective of downside risk framework. Thus, if wheat producers are more risk averse, more acres should be allocated to Duster. Again, even though it seems like the mean-ES approach could help improving in-sample farm productivity, the true performance of the strategy is still unclear.
4.3. Potential Gains from Portfolio Optimizations
As mentioned previously, the present study addresses a shortcoming of the previous studies in evaluating the performance of the optimization models. Previously, the performance of the models was evaluated on the period over which the model is estimated (i.e., the optimization or in-sample period). As an illustration, Barkley, Peterson, and Shroyer (Reference Barkley, Peterson and Shroyer2010) used data on wheat variety yields for the period 1993–2006 to derive optimal land allocation strategies based on the mean-variance optimization model. They then compared the average yield of a portfolio constructed using the actual 2006 allocation of varieties planted with that of a portfolio on the efficient frontier with the same level of variance. In practice, however, wheat producers must make decisions regarding which varieties to be planted for the year 2006 before the 2006 yield data exist. Therefore, to better evaluate the performance of optimization models, we instead look at how well the portfolio optimization strategies perform the year after the estimation period.
For comparison purposes, a potential portfolio is constructed for each portfolio optimization model by holding the risk constant at the 2014 actual level. That is, the potential portfolio for the mean-variance model is derived by maximizing the in-sample portfolio yield, subjected to the in-sample variance being equal to that computed using the 2014 actual allocation. Similarly, the potential portfolio for the mean-ES model (at the 10%, 5%, and 1% levels) is constructed by maximizing the in-sample portfolio yield, given that the in-sample ES (at the 10%, 5%, and 1% levels) is equal to that computed using the 2014 actual allocation and the estimated multivariate probability distribution. Table 6 reports the optimal allocations (the percentage of each variety to be planted) for the four potential portfolios and the percent difference from the 2014 actual wheat variety allocation. The mean-variance and mean-ES models suggest that the wheat producers should stop planting Coronado, TAM 111, and TAM 401. Recall from Table 2 that for the 2014 actual practice, a large proportion of land is allocated to planting Fannin and TAM 304, even though the two varieties are highly correlated (their correlation is 0.84). The mean-variance model, however, indicates that the wheat producers should allocate a majority of land acres to planting TAM 304 and Duster, which are much less correlated (their correlation is 0.29). Interestingly, the mean-ES models tell us that, given the 2014 actual downside risk level, the wheat producers diversify too much and that only Duster and Greer should be planted. This is not totally unexpected, because the other varieties (except TAM 304) produce lower yields than Duster and Greer for almost every year and thus do not offer much benefit in term of downside risk protection.
Table 6. Comparison of the 2014 Actual Allocation versus Optimal Allocations Suggested by the Various Optimization Models

Notes: The mean-variance model is solved by maximizing the in-sample portfolio yield, given that the in-sample variance is equal to that computed from the 2014 actual allocation. The mean–expected shortfall (ES) models (10%, 5%, and 1%) are solved by maximizing the in-sample portfolio yield, given that the in-sample ES (10%, 5%, and 1%, respectively) is equal to that computed from the 2014 actual allocation and the estimated multivariate probability distribution.
To examine potential gains (losses) from applying the various portfolio optimization methods, the wheat variety yield data for the year 2014 (Table 2) are used to compute the 2014 yield per acre from planting according to the 2014 actual allocation and according to the four potential portfolios. Table 7 reports the 2014 yield and gross profit per acre for the different allocations. The 2014 gross profit per acre is calculated using the 2014 yield per acre and the 2014 market price of wheat in Texas ($6.40 per bushel).Footnote 15 Two observations regarding the performance of the mean-variance and mean-ES approaches can be drawn from Table 7. First, at least for the year 2014, implementing the mean-variance optimization approach would not help wheat producers increase their profits. More specifically, the mean-variance portfolio produces less gross profit than the 2014 actual allocation by approximately $1.01 per acre. Second, the mean-ES portfolios (at the 10%, 5%, and 1%) generate higher gross profit than does the 2014 actual allocation. The highest (lowest) additional gross profit of $17.31 ($16.41) per acre could be obtained by implementing the mean-ES approach at the 1% (10%) level. At the 2014 wheat planted acres for Texas Blacklands (600,000 acres),Footnote 16 there could be an approximate gain in gross profit of at least $9.85 million to wheat producers in Texas Blacklands. Thus, it seems that varietal diversification based on the downside risk framework is more efficient than the traditional mean-variance method in term of wheat variety selection. One possible explanation for the better performance of the mean-ES model over the mean-variance model is that the former does not prevent the producers from upside gains. Another possible reason is that the mean-ES model is optimized based on simulated yields instead of historical yields. That is, the mean-ES takes into consideration the stochastic nature of wheat variety yields and, thus, is more suitable for the problem of wheat variety selection.
Table 7. Potential Gains from Using Portfolio Optimization Models

Notes: The mean-variance model is solved by maximizing the in-sample portfolio yield, given that the in-sample variance is equal to that computed from the 2014 actual allocation. The mean–expected shortfall (ES) models (10%, 5%, and 1%) are solved by maximizing the in-sample portfolio yield, given that the in-sample ES (10%, 5%, and 1%, respectively) is equal to that computed from the 2014 actual allocation and the estimated multivariate probability distribution. For comparison purposes, historical yield variances for different wheat variety allocations are computed from the historical data, whereas the simulated yield ESs are calculated from the estimated multivariate probability distribution. The 2014 market price of wheat in Texas is $6.40 per bushel (U.S. Department of Agriculture, National Agricultural Statistics Service, 2015). The 2014 gross profit per acre is computed using the 2014 actual yields per acre (not in-sample yields per acre).
5. Conclusions
Among the various risk management strategies or tools (including geographic diversification, enterprise diversification, crop diversification, crop insurance, and derivative instruments), wheat varietal diversification can be the most cost-effective method for wheat producers to mitigate yield risk caused by diverse growing conditions and unpredictable climate. To determine the optimal mix of wheat varieties, previous studies suggested the adoption of the mean-variance portfolio optimization theory. One major drawback of the mean-variance approach is that it uses variance as the risk measure. However, variance is a correct risk measure only if the distribution of wheat variety yields is multivariate normal, but in reality, crop yields have been found to be nonnormally distributed. To correct this problem, portfolio optimization based on ES has been proposed. However, to the best of our knowledge, such an optimization method has not been applied to the problem of wheat variety selection. This study, therefore, extends the literature in wheat variety selection by comparing the performance of the mean-variance and mean-ES approaches. Such a comparison provides useful insights for designing optimal mixes of wheat varieties to plant. The mean-ES models at the 10%, 5%, and 1% levels are considered for the analysis.
Given the data on Texas Wheat Variety Trial results from 2008 to 2014 (Texas A&M AgriLife Extension Service, Texas A&M AgriLife Research, and AgriPro Wheat, 2008, 2009, 2010; Texas A&M AgriLife Extension Service, Texas A&M AgriLife Research, and Syngenta Wheat, 2011, 2012, 2013, 2014) for 10 wheat varieties planted in Texas Blacklands, we estimate the optimal mean-variance and mean-ES portfolios using the data from 2008 to 2013. The location is chosen based on data availability and the lack of previous research. The data for the year 2014 are set aside for evaluating the performance of the models. This is an improvement from the previous related studies in which the performance of the optimization models is evaluated on the period over which the model is estimated (i.e., the optimization or in-sample period). Specifically, this study looks at how well the models perform the year after the estimation period. This is a better way to evaluate the performance of optimization strategies because, in reality, wheat producers must make decisions about which varieties to be planted for the year 2014 before the 2014 yield data exist.
For the mean-ES model, we apply a kernel-based Monte Carlo simulation method to calculate ES. Specifically, we use the MVKDE procedure proposed by Richardson, Lien, and Hardaker (Reference Richardson, Lien and Hardaker2006) to smooth out irregularities in the sparse (limited) data and fit a multivariate probability distribution. The MVKDE method allows us to deal with sparse data and to depart from the multivariate normality assumption.
To evaluate the model performance, we construct a potential portfolio for each portfolio optimization model by holding the risk (variance or ES at the various levels) constant at the 2014 actual allocation level (which is defined as the percentage of total wheat acreage in Texas Blacklands planted with the 10 wheat varieties in 2014). We find that, at least for the planting year 2014, the mean-variance strategy produces less gross profit than does the 2014 actual allocation by approximately $1.01 per acre. On the other hand, the mean-ES strategies (at the 10%, 5%, and 1% levels) generate higher 2014 gross profit than the 2014 actual allocation. Specifically, additional gross profits of $16.41, $16.91, and $17.31 per acre could be obtained by using the mean-ES strategies at the 10%, 5%, and 1% levels, respectively. At the 2014 wheat planted acres for Texas Blacklands (600,000 acres), this corresponds to an approximate gain in gross profit of at least $9.85 million to wheat producers in Texas Blacklands.
Based on our results, the mean-variance model does not perform very well compared with the 2014 actual allocation, and the mean-ES model is a better tool for wheat producers to improve their choice of wheat varieties. Two possible explanations for the better performance of the mean-ES model over the mean-variance model are that the former (1) does not punish the upside gains and (2) takes into consideration the stochastic nature of wheat variety yields in the problem of wheat variety selection. However, given the shortness of relevant historical data, we are able to evaluate the performance of the models only over a 1-year period. Nevertheless, our results suggest that the mean-variance model may not be the best tool for choosing the optimal mix of wheat varieties to plant as suggested by the previous studies, and that portfolio optimization in a downside risk framework seems to be a better alternative. This research is crucial for agricultural producers who aim at improving variety selection and developing a new adaptation strategy to cope with the changing climate.











 Open access
Open access