



1. Introduction
Interacting multi-particle systems are ubiquitous in a wide variety of scientific disciplines with application areas reaching from atomic scales over the human scale to the astronomical scale. For instance, large-scale multi-agent models are used to understand the coordinated movement of animal groups [Reference Couzin, Krause, Franks and Levin19, Reference Parrish and Edelstein-Keshet51] or crowds of people [Reference Albi, Bongini, Cristiani and Kalise1, Reference Cristiani, Piccoli and Tosin20]. Especially fascinating in this context is that such complex and often intelligent behaviour – phenomena known as self-organisation and swarm intelligence – emerge from seemingly simple rules of interaction [Reference Vicsek and Zafeiris56]. This intriguing capabilities have drawn researchers’ attention towards designing interacting particle systems for specific purposes in various disciplines. In applied mathematics in particular, agent-based optimisation algorithms look back on a long and successful history of empirically achieving state-of-the-art performance on challenging global unconstrained problems of the form
 \begin{equation*} x^* = \operatorname *{\arg \min }_{x\in \mathbb {R}^d}{\mathcal {E}}(x). \end{equation*}
\begin{equation*} x^* = \operatorname *{\arg \min }_{x\in \mathbb {R}^d}{\mathcal {E}}(x). \end{equation*}
Here,
 ${\mathcal{E}}\, :\, \mathbb{R}^d\rightarrow \mathbb{R}$
denotes a possibly nonconvex and nonsmooth high-dimensional objective function, whose global minimiser
${\mathcal{E}}\, :\, \mathbb{R}^d\rightarrow \mathbb{R}$
denotes a possibly nonconvex and nonsmooth high-dimensional objective function, whose global minimiser
 $x^*$
is assumed to exist and be unique for the remainder of this work. Well-known representatives of this family are Evolutionary Programming [Reference Fogel24], Genetic Algorithms [Reference Holland38], Particle Swarm Optimisation [Reference Kennedy and Eberhart43] and Ant Colony Optimisation [Reference Dorigo and Blum23]. They belong to the broad class of so-called metaheuristics [Reference Back, Fogel and Michalewicz4, Reference Blum and Roli6], which are methods orchestrating an interaction between local improvement procedures and global strategies, deterministic and stochastic processes, to eventually design an efficient and robust procedure for searching the solution space of the objective function
$x^*$
is assumed to exist and be unique for the remainder of this work. Well-known representatives of this family are Evolutionary Programming [Reference Fogel24], Genetic Algorithms [Reference Holland38], Particle Swarm Optimisation [Reference Kennedy and Eberhart43] and Ant Colony Optimisation [Reference Dorigo and Blum23]. They belong to the broad class of so-called metaheuristics [Reference Back, Fogel and Michalewicz4, Reference Blum and Roli6], which are methods orchestrating an interaction between local improvement procedures and global strategies, deterministic and stochastic processes, to eventually design an efficient and robust procedure for searching the solution space of the objective function
 $\mathcal{E}$
.
$\mathcal{E}$
.
Motivated by both the substantiated success of metaheuristics in applications and the lack of rigorous theoretical guarantees about their convergence and performance, the authors of [Reference Pinnau, Totzeck, Tse and Martin52] proposed consensus-based optimisation (CBO), which follows the spirit of metaheuristics but allows for a rigorous theoretical analysis [Reference Carrillo, Choi, Totzeck and Tse12, Reference Carrillo, Jin, Li and Zhu14, Reference Fornasier, Klock and Riedl28, Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29, Reference Ha, Jin and Kim33, Reference Ha, Jin and Kim34]. By taking inspiration from consensus formation in opinion dynamics [Reference Hegselmann and Krause36], CBO methods use
 $N$
particles
$N$
particles
 $X^1,\dots,X^N$
to explore the energy landscape of the objective
$X^1,\dots,X^N$
to explore the energy landscape of the objective
 $\mathcal{E}$
and to eventually form a consensus about the location of the global minimiser
$\mathcal{E}$
and to eventually form a consensus about the location of the global minimiser
 $x^*$
. In its original form [Reference Pinnau, Totzeck, Tse and Martin52], the dynamics of each particle
$x^*$
. In its original form [Reference Pinnau, Totzeck, Tse and Martin52], the dynamics of each particle
 $X^i$
, which is governed by a stochastic differential equation (SDE), is subject to two competing forces. A deterministic drift term pulls the particles towards a so-called consensus point, which is an instantaneously computed weighted average of the positions of all particles and approximates the global minimiser
$X^i$
, which is governed by a stochastic differential equation (SDE), is subject to two competing forces. A deterministic drift term pulls the particles towards a so-called consensus point, which is an instantaneously computed weighted average of the positions of all particles and approximates the global minimiser
 $x^*$
the best possible given the currently available information. The resulting contractive behaviour is counteracted by the second term which is stochastic in nature and thereby features the exploration of the energy landscape of the objective function. Its magnitude and therefore its explorative power scales with the distance of the individual particle from the consensus point, which encourages particles far away to explore larger regions of the domain, while particles already close advance their position only locally.
$x^*$
the best possible given the currently available information. The resulting contractive behaviour is counteracted by the second term which is stochastic in nature and thereby features the exploration of the energy landscape of the objective function. Its magnitude and therefore its explorative power scales with the distance of the individual particle from the consensus point, which encourages particles far away to explore larger regions of the domain, while particles already close advance their position only locally.
In this work, motivated by the numerical evidence presented below as well as other recent papers such as [Reference Grassi and Pareschi32, Reference Schillings, Totzeck and Wacker54, Reference Totzeck and Wolfram55], we consider a more elaborate variant of this dynamics which exhibits the two following additional drift terms.
-
• The first is a drift towards the historical best position of the particular particle. To store such information, we follow the work [Reference Grassi and Pareschi32], where the authors introduce for each particle an additional state variable
 $Y^i$
, which can be regarded as the memory of the respective particle
$X^i$
. In contrast to the original dynamics, an individual particle is therefore described by the tuple
$(X^i,Y^i)$
. Moreover, the consensus point is no longer computed from the instantaneous positions
$X^i$
, but the historical best positions
$Y^i$
.
$Y^i$
, which can be regarded as the memory of the respective particle
$X^i$
. In contrast to the original dynamics, an individual particle is therefore described by the tuple
$(X^i,Y^i)$
. Moreover, the consensus point is no longer computed from the instantaneous positions
$X^i$
, but the historical best positions
$Y^i$
. -
• The second term is a drift in the direction of the negative gradient of
$\mathcal{E}$
evaluated at the current position of the respective particle
$X^i$
.







Both terms are accompanied by associated noise terms. We now make the CBO dynamics with memory effects and gradient information rigorous by providing a formal description of the interacting particle system. A visualisation of the dynamics with all relevant quantities and forces is provided in Figure 1. Given a finite time horizon
 $T\gt 0$
, and user-specified parameters
$T\gt 0$
, and user-specified parameters
 $\alpha,\beta,\theta,\kappa,\lambda _1,\sigma _1\gt 0$
and
$\alpha,\beta,\theta,\kappa,\lambda _1,\sigma _1\gt 0$
and
 $\lambda _2,\lambda _3,\sigma _2,\sigma _3\geq 0$
, the dynamics is given by the system of SDEs
$\lambda _2,\lambda _3,\sigma _2,\sigma _3\geq 0$
, the dynamics is given by the system of SDEs
 \begin{align} &\begin{aligned}dX_{t}^i = & -\lambda _1\!\left (X_{t}^i-y_{\alpha }(\widehat \rho _{Y,t}^N)\right ) dt -\lambda _2\!\left (X_{t}^i-Y_{t}^i\right ) dt -\lambda _3\nabla{\mathcal{E}}(X_{t}^i) \,dt \\ & +\sigma _1 D\!\left (X_{t}^i-y_{\alpha }(\widehat \rho _{Y,t}^N)\right ) dB_{t}^{1,i} +\sigma _2 D\!\left (X_{t}^i-Y_{t}^i\right ) dB_{t}^{2,i} +\sigma _3 D\!\left (\nabla{\mathcal{E}}(X_{t}^i)\right ) dB_{t}^{3,i},\end{aligned} \end{align}
\begin{align} &\begin{aligned}dX_{t}^i = & -\lambda _1\!\left (X_{t}^i-y_{\alpha }(\widehat \rho _{Y,t}^N)\right ) dt -\lambda _2\!\left (X_{t}^i-Y_{t}^i\right ) dt -\lambda _3\nabla{\mathcal{E}}(X_{t}^i) \,dt \\ & +\sigma _1 D\!\left (X_{t}^i-y_{\alpha }(\widehat \rho _{Y,t}^N)\right ) dB_{t}^{1,i} +\sigma _2 D\!\left (X_{t}^i-Y_{t}^i\right ) dB_{t}^{2,i} +\sigma _3 D\!\left (\nabla{\mathcal{E}}(X_{t}^i)\right ) dB_{t}^{3,i},\end{aligned} \end{align}
 \begin{align} & dY_{t}^i = \kappa \left (X_{t}^i-Y_{t}^i\right ) S^{\beta,\theta }\!\left (X_{t}^i, Y_{t}^i\right ) dt \end{align}
\begin{align} & dY_{t}^i = \kappa \left (X_{t}^i-Y_{t}^i\right ) S^{\beta,\theta }\!\left (X_{t}^i, Y_{t}^i\right ) dt \end{align}

Figure 1. A visualisation of the CBO dynamics (1.1) with memory effects and gradient information. Particles with positions
 $X^1,\dots,X^N$
(yellow dots with their trajectories) explore the energy landscape of the objective
$X^1,\dots,X^N$
(yellow dots with their trajectories) explore the energy landscape of the objective
 $\mathcal{E}$
in search of the global minimiser
$\mathcal{E}$
in search of the global minimiser
 $x^*$
(green star). Each particle stores its local historical best position
$x^*$
(green star). Each particle stores its local historical best position
 $Y^i_t$
(yellow circles). The dynamics of the position
$Y^i_t$
(yellow circles). The dynamics of the position
 $X^i_t$
of each particle is governed by three deterministic terms with associated random noise terms (visualised by depicting eight possible realisations with differently shaded green arrows). A global drift term (dark blue arrow) drags the particle towards the consensus point
$X^i_t$
of each particle is governed by three deterministic terms with associated random noise terms (visualised by depicting eight possible realisations with differently shaded green arrows). A global drift term (dark blue arrow) drags the particle towards the consensus point
 $y_{\alpha} (\widehat{\rho }_{Y,t}^N)$
(orange circle), which is computed as a weighted (visualised through colour opacity) average of the particles’ historical best positions. A local drift term (light blue arrow) imposes movement towards the respective local best position
$y_{\alpha} (\widehat{\rho }_{Y,t}^N)$
(orange circle), which is computed as a weighted (visualised through colour opacity) average of the particles’ historical best positions. A local drift term (light blue arrow) imposes movement towards the respective local best position
 $Y^i_t$
. A gradient drift term (purple arrow) exerts a force in the direction
$Y^i_t$
. A gradient drift term (purple arrow) exerts a force in the direction
 $-\nabla{\mathcal{E}}(X^i_t)$
.
$-\nabla{\mathcal{E}}(X^i_t)$
.
for
 $i=1,\dots,N$
and where
$i=1,\dots,N$
and where
 $((B_{t}^{m,i})_{t\geq 0})_{i=1,\dots,N}$
are independent standard Brownian motions in
$((B_{t}^{m,i})_{t\geq 0})_{i=1,\dots,N}$
are independent standard Brownian motions in
 $\mathbb{R}^d$
for
$\mathbb{R}^d$
for
 $m\in \{1,2,3\}$
. The system is complemented with independent initial data
$m\in \{1,2,3\}$
. The system is complemented with independent initial data
 $(X_0^i,Y_0^i)_{i=1,\dots,N}$
, typically such that
$(X_0^i,Y_0^i)_{i=1,\dots,N}$
, typically such that
 $X_0^i=Y_0^i$
for all
$X_0^i=Y_0^i$
for all
 $i=1,\dots,N$
. A numerical implementation of the scheme usually originates from an Euler-Maruyama time discretisation of equation (1.1). The first term appearing in the SDE for the position
$i=1,\dots,N$
. A numerical implementation of the scheme usually originates from an Euler-Maruyama time discretisation of equation (1.1). The first term appearing in the SDE for the position
 $X_{t}^i$
, i.e., in the first line of equation (1.1a), is the drift towards the consensus point
$X_{t}^i$
, i.e., in the first line of equation (1.1a), is the drift towards the consensus point
 \begin{align} y_{\alpha }({\widehat \rho _{Y,t}^N}) \,:\!=\, \int y \frac{\omega _{\alpha }(y)}{\left \|{\omega _{\alpha }}\right \|_{L_1(\widehat \rho _{Y,t}^N)}}\,d\widehat \rho _{Y,t}^N(y), \quad \text{with}\quad \omega _{\alpha }(y) \,:\!=\, \exp ({-}\alpha{\mathcal{E}}(y)). \end{align}
\begin{align} y_{\alpha }({\widehat \rho _{Y,t}^N}) \,:\!=\, \int y \frac{\omega _{\alpha }(y)}{\left \|{\omega _{\alpha }}\right \|_{L_1(\widehat \rho _{Y,t}^N)}}\,d\widehat \rho _{Y,t}^N(y), \quad \text{with}\quad \omega _{\alpha }(y) \,:\!=\, \exp ({-}\alpha{\mathcal{E}}(y)). \end{align}
Here,
 $\widehat \rho _{Y,t}^N$
denotes the random empirical measure of the particles’ historical best positions, i.e.,
$\widehat \rho _{Y,t}^N$
denotes the random empirical measure of the particles’ historical best positions, i.e.,
 $\widehat \rho _{Y,t}^N\,:\!=\,\frac{1}{N} \sum _{i=1}^N\delta _{Y_{t}^i}$
. Definition (1.2) is motivated by the fact that
$\widehat \rho _{Y,t}^N\,:\!=\,\frac{1}{N} \sum _{i=1}^N\delta _{Y_{t}^i}$
. Definition (1.2) is motivated by the fact that
 $y_{\alpha }({\widehat \rho _{Y,t}^N})\approx \operatorname *{\arg \min }_{i\in \{1,\dots,N\}}{\mathcal{E}}(Y_t^i)$
as
$y_{\alpha }({\widehat \rho _{Y,t}^N})\approx \operatorname *{\arg \min }_{i\in \{1,\dots,N\}}{\mathcal{E}}(Y_t^i)$
as
 $\alpha \rightarrow \infty$
under reasonable assumptions. The first term in the second line of equation (1.1a) is with the consensus drift associated diffusion term, which injects randomness into the dynamics and thereby features the explorative nature of the algorithm. The two commonly studied diffusion types are isotropic [Reference Carrillo, Choi, Totzeck and Tse12, Reference Fornasier, Klock and Riedl28, Reference Pinnau, Totzeck, Tse and Martin52] and anisotropic [Reference Carrillo, Jin, Li and Zhu14, Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29] diffusion with
$\alpha \rightarrow \infty$
under reasonable assumptions. The first term in the second line of equation (1.1a) is with the consensus drift associated diffusion term, which injects randomness into the dynamics and thereby features the explorative nature of the algorithm. The two commonly studied diffusion types are isotropic [Reference Carrillo, Choi, Totzeck and Tse12, Reference Fornasier, Klock and Riedl28, Reference Pinnau, Totzeck, Tse and Martin52] and anisotropic [Reference Carrillo, Jin, Li and Zhu14, Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29] diffusion with
 \begin{equation} D\!\left (\,\cdot \,\right ) = \begin{cases} \left \|{\,\cdot \,}\right \|_2 \mathsf{Id},& \text{for isotropic diffusion,}\\ \operatorname{diag}\left (\,\cdot \,\right )\!,& \text{for anisotropic diffusion}, \end{cases} \end{equation}
\begin{equation} D\!\left (\,\cdot \,\right ) = \begin{cases} \left \|{\,\cdot \,}\right \|_2 \mathsf{Id},& \text{for isotropic diffusion,}\\ \operatorname{diag}\left (\,\cdot \,\right )\!,& \text{for anisotropic diffusion}, \end{cases} \end{equation}
where
 $\mathsf{Id}\in \mathbb{R}^{d\times d}$
is the identity matrix and
$\mathsf{Id}\in \mathbb{R}^{d\times d}$
is the identity matrix and
 $\operatorname{diag}:\;\mathbb{R}^{d} \rightarrow \mathbb{R}^{d\times d}$
the operator mapping a vector onto a diagonal matrix with the vector as its diagonal. Despite the potential of the dynamics getting trapped in affine subspaces, the coordinate-dependent scaling of anisotropic diffusion has proven to be beneficial for the performance of the method in high-dimensional applications by allowing for dimension-independent convergence rates [Reference Carrillo, Jin, Li and Zhu14, Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29]. For this reason, we restrict our attention to the case of anisotropic noise in what follows. Nevertheless, theoretically similar results as the ones presented in this work can be obtained also for the isotropic case. The second term in the first line of equation (1.1a) is the drift towards the historical best position of the respective particle. In contrast to the global nature of the consensus drift, which incorporates information from all
$\operatorname{diag}:\;\mathbb{R}^{d} \rightarrow \mathbb{R}^{d\times d}$
the operator mapping a vector onto a diagonal matrix with the vector as its diagonal. Despite the potential of the dynamics getting trapped in affine subspaces, the coordinate-dependent scaling of anisotropic diffusion has proven to be beneficial for the performance of the method in high-dimensional applications by allowing for dimension-independent convergence rates [Reference Carrillo, Jin, Li and Zhu14, Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29]. For this reason, we restrict our attention to the case of anisotropic noise in what follows. Nevertheless, theoretically similar results as the ones presented in this work can be obtained also for the isotropic case. The second term in the first line of equation (1.1a) is the drift towards the historical best position of the respective particle. In contrast to the global nature of the consensus drift, which incorporates information from all
 $N$
particles, this term depends only on the past of the specific particle. To store such information about the history of each particle [Reference Grassi and Pareschi32], an additional state variable
$N$
particles, this term depends only on the past of the specific particle. To store such information about the history of each particle [Reference Grassi and Pareschi32], an additional state variable
 $Y^i$
is introduced for every particle, which evolves according to equation (1.1b), where
$Y^i$
is introduced for every particle, which evolves according to equation (1.1b), where
 \begin{align} S^{\beta,\theta }(x,y) = \frac{1}{2}\big (1+\theta +\tanh \!\big (\beta \left ({\mathcal{E}}(y)-{\mathcal{E}}(x)\right )\!\big )\big ) \end{align}
\begin{align} S^{\beta,\theta }(x,y) = \frac{1}{2}\big (1+\theta +\tanh \!\big (\beta \left ({\mathcal{E}}(y)-{\mathcal{E}}(x)\right )\!\big )\big ) \end{align}
is chosen throughout this article, which is an approximation to the Heaviside function
 $H(x,y) = \mathbb{1}_{{\mathcal{E}}(x)\lt{\mathcal{E}}(y)}$
as
$H(x,y) = \mathbb{1}_{{\mathcal{E}}(x)\lt{\mathcal{E}}(y)}$
as
 $\theta \rightarrow 0$
and
$\theta \rightarrow 0$
and
 $\beta \rightarrow \infty$
. The variable
$\beta \rightarrow \infty$
. The variable
 $Y_{t}^i$
can therefore be regarded as the memory of the
$Y_{t}^i$
can therefore be regarded as the memory of the
 $i$
th particle, i.e., as the location of the in-time best-seen position of
$i$
th particle, i.e., as the location of the in-time best-seen position of
 $X^i$
up to time
$X^i$
up to time
 $t$
. This can be understood most easily when discretising (1.1b) as
$t$
. This can be understood most easily when discretising (1.1b) as
 \begin{align*} Y_{k+1}^i = Y_{k}^i + \Delta t\kappa \left (X_{k+1}^i-Y_{k}^i\right ) S^{\beta,\theta }\!\left (X_{k+1}^i, Y_{k}^i\right ) \end{align*}
\begin{align*} Y_{k+1}^i = Y_{k}^i + \Delta t\kappa \left (X_{k+1}^i-Y_{k}^i\right ) S^{\beta,\theta }\!\left (X_{k+1}^i, Y_{k}^i\right ) \end{align*}
and noting that with parameter choices
 $\kappa =1/\Delta t$
,
$\kappa =1/\Delta t$
,
 $\theta =0$
and
$\theta =0$
and
 $\beta \gg 1$
it holds
$\beta \gg 1$
it holds
 $Y_{k+1}^i = X_{k+1}^i$
if
$Y_{k+1}^i = X_{k+1}^i$
if
 ${\mathcal{E}}(X_{k+1}^i) \lt{\mathcal{E}}(Y_{k}^i)$
and
${\mathcal{E}}(X_{k+1}^i) \lt{\mathcal{E}}(Y_{k}^i)$
and
 $Y_{k+1}^i = Y_{k}^i$
else. The third term in the first line of equation (1.1a) is the drift in the direction of the negative gradient of
$Y_{k+1}^i = Y_{k}^i$
else. The third term in the first line of equation (1.1a) is the drift in the direction of the negative gradient of
 $\mathcal{E}$
, which is a local and instantaneous contribution. The remaining two terms are noise terms, which are associated with the formerly described memory and gradient drifts.
$\mathcal{E}$
, which is a local and instantaneous contribution. The remaining two terms are noise terms, which are associated with the formerly described memory and gradient drifts.
A theoretical convergence analysis of CBO can be carried out either by directly investigating the microscopic system (1.1) or its numerical time discretisation, as promoted for instance in a simplified setting in the works [Reference Ha, Jin and Kim33, Reference Ha, Jin and Kim34], or alternatively, as done for example in [Reference Carrillo, Choi, Totzeck and Tse12, Reference Carrillo, Jin, Li and Zhu14, Reference Fornasier, Huang, Pareschi and Sünnen26, Reference Fornasier, Klock and Riedl28, Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29], by analysing the macroscopic behaviour of the particle density through a mean-field limit associated with (1.1). Formally, such mean-field limit is given by the self-consistent nonlinear and nonlocal SDE
 \begin{align} & \begin{aligned}d\overline{X}_{t} & = -\lambda _1\!\left (\overline{X}_{t}-y_{\alpha }(\rho _{Y,t})\right ) dt -\lambda _2\!\left (\overline{X}_{t}-\overline{Y}_{t}\right ) dt -\lambda _3\nabla{\mathcal{E}}(\overline{X}_{t}) \,dt\\ &\quad +\sigma _1 D\!\left (\overline{X}_{t}-y_{\alpha }(\rho _{Y,t})\right ) d B_{t}^{1} +\sigma _2 D\!\left (\overline{X}_{t}-\overline{Y}_{t}\right ) d B_{t}^{2} +\sigma _3 D\!\left (\nabla{\mathcal{E}}(\overline{X}_{t})\right ) d B_{t}^{3},\end{aligned} \end{align}
\begin{align} & \begin{aligned}d\overline{X}_{t} & = -\lambda _1\!\left (\overline{X}_{t}-y_{\alpha }(\rho _{Y,t})\right ) dt -\lambda _2\!\left (\overline{X}_{t}-\overline{Y}_{t}\right ) dt -\lambda _3\nabla{\mathcal{E}}(\overline{X}_{t}) \,dt\\ &\quad +\sigma _1 D\!\left (\overline{X}_{t}-y_{\alpha }(\rho _{Y,t})\right ) d B_{t}^{1} +\sigma _2 D\!\left (\overline{X}_{t}-\overline{Y}_{t}\right ) d B_{t}^{2} +\sigma _3 D\!\left (\nabla{\mathcal{E}}(\overline{X}_{t})\right ) d B_{t}^{3},\end{aligned} \end{align}
 \begin{align} & d\overline{Y}_{t} = \kappa \left (\overline{X}_{t}-\overline{Y}_{t}\right ) S^{\beta,\theta }\!\left (\overline{X}_{t}, \overline{Y}_{t}\right ) dt, \end{align}
\begin{align} & d\overline{Y}_{t} = \kappa \left (\overline{X}_{t}-\overline{Y}_{t}\right ) S^{\beta,\theta }\!\left (\overline{X}_{t}, \overline{Y}_{t}\right ) dt, \end{align}
which is complemented with initial datum
 $(\overline{X}_{0},\overline{Y}_{0})\sim \rho _0$
, and where
$(\overline{X}_{0},\overline{Y}_{0})\sim \rho _0$
, and where
 $\rho _t = \rho (t) = \textrm{Law}\left (\overline{X}_{t},\overline{Y}_{t}\right )$
with marginal law
$\rho _t = \rho (t) = \textrm{Law}\left (\overline{X}_{t},\overline{Y}_{t}\right )$
with marginal law
 $\rho _{Y,t}$
of
$\rho _{Y,t}$
of
 $\overline{Y}_t$
given by
$\overline{Y}_t$
given by
 $\rho _{Y,t} = \rho _{Y}(t, \,\cdot \,) = \int d\rho _t(\,\cdot \,,y)$
. The measure
$\rho _{Y,t} = \rho _{Y}(t, \,\cdot \,) = \int d\rho _t(\,\cdot \,,y)$
. The measure
 $\rho \in\mathcal{C}([0,T],\mathcal{P}(\mathbb{R}^d\times \mathbb{R}^d))$
in particular weakly satisfies the Fokker-Planck equation
$\rho \in\mathcal{C}([0,T],\mathcal{P}(\mathbb{R}^d\times \mathbb{R}^d))$
in particular weakly satisfies the Fokker-Planck equation
 \begin{equation} \begin{aligned} \partial _t\rho _t &= \textrm{div}_x \big ( \big ( \lambda _1\!\left (x - y_{\alpha }({\rho _{Y,t}})\right ) + \lambda _2\!\left (x-y\right ) + \lambda _3\nabla{\mathcal{E}}(x) \big )\rho _t \big ) + \textrm{div}_y \big (\big (\kappa (y-x)S^{\beta,\theta }(x,y)\big )\rho _t\big ) \\ &\quad + \frac{1}{2}\sum _{k=1}^d\partial ^2_{x_kx_k}\left (\left (\sigma _1^2D\!\left (x-y_{\alpha }({\rho _{Y,t}})\right )_{kk}^2 + \sigma _2^2D\!\left (x-y\right )_{kk}^2 + \sigma _3^2D\!\left (\nabla{\mathcal{E}}(x)\right )_{kk}^2\right )\rho _t\right ), \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \partial _t\rho _t &= \textrm{div}_x \big ( \big ( \lambda _1\!\left (x - y_{\alpha }({\rho _{Y,t}})\right ) + \lambda _2\!\left (x-y\right ) + \lambda _3\nabla{\mathcal{E}}(x) \big )\rho _t \big ) + \textrm{div}_y \big (\big (\kappa (y-x)S^{\beta,\theta }(x,y)\big )\rho _t\big ) \\ &\quad + \frac{1}{2}\sum _{k=1}^d\partial ^2_{x_kx_k}\left (\left (\sigma _1^2D\!\left (x-y_{\alpha }({\rho _{Y,t}})\right )_{kk}^2 + \sigma _2^2D\!\left (x-y\right )_{kk}^2 + \sigma _3^2D\!\left (\nabla{\mathcal{E}}(x)\right )_{kk}^2\right )\rho _t\right ), \end{aligned} \end{equation}
see Definition 2.1. Working with the partial differential equation (PDE) (1.6) instead of the interacting particle system (1.1) typically permits to employ more powerful technical tools, which result in stronger and deterministic statements about the long-time behaviour of the average agent density
 $\rho$
. This analysis approach is rigorously justified by the mean-field approximation, i.e., the fact that the empirical particle measure
$\rho$
. This analysis approach is rigorously justified by the mean-field approximation, i.e., the fact that the empirical particle measure
 $\widehat \rho _{t}^N\,:\!=\,\frac{1}{N}\sum _{i=1}^N\delta _{(X_{t}^i,Y_{t}^i)}$
converges in some sense to the mean-field law
$\widehat \rho _{t}^N\,:\!=\,\frac{1}{N}\sum _{i=1}^N\delta _{(X_{t}^i,Y_{t}^i)}$
converges in some sense to the mean-field law
 $\rho _t$
as the number of particles
$\rho _t$
as the number of particles
 $N$
tends to infinity. For the original CBO dynamics, a qualitative result about convergence in distribution is provided in [Reference Huang and Qiu39], which is based on a tightness argument in the path space. More precisely, the authors of that work show that the sequence
$N$
tends to infinity. For the original CBO dynamics, a qualitative result about convergence in distribution is provided in [Reference Huang and Qiu39], which is based on a tightness argument in the path space. More precisely, the authors of that work show that the sequence
 $\{\widehat \rho ^N\}_{N\geq 2}$
of
$\{\widehat \rho ^N\}_{N\geq 2}$
of
 $\mathcal{C}([0,T],\mathcal{P}(\mathbb{R}^d))$
-valued random variables is tight, which permits to employ Prokhorov’s theorem to obtain, up to a subsequence, some limiting measure, which turns out to be deterministic and at the same time satisfy the associated mean-field PDE. A more desirable quantitative approximation result, on the other hand, can be established by proving propagation of chaos, i.e., by establishing for instance
$\mathcal{C}([0,T],\mathcal{P}(\mathbb{R}^d))$
-valued random variables is tight, which permits to employ Prokhorov’s theorem to obtain, up to a subsequence, some limiting measure, which turns out to be deterministic and at the same time satisfy the associated mean-field PDE. A more desirable quantitative approximation result, on the other hand, can be established by proving propagation of chaos, i.e., by establishing for instance
 \begin{align*} \max _{i=1,\dots,N} \sup _{t\in [0,T]} \mathbb{E}\left \|{(X_{t}^i,Y_{t}^i)-(\overline{X}_{t}^i,\overline{Y}_{t}^i)}\right \|_2^2 \leq CN^{-1} \qquad \text{ as } N\rightarrow \infty, \end{align*}
\begin{align*} \max _{i=1,\dots,N} \sup _{t\in [0,T]} \mathbb{E}\left \|{(X_{t}^i,Y_{t}^i)-(\overline{X}_{t}^i,\overline{Y}_{t}^i)}\right \|_2^2 \leq CN^{-1} \qquad \text{ as } N\rightarrow \infty, \end{align*}
where
 $(\overline{X}_{t}^i,\overline{Y}_{t}^i)$
denote
$(\overline{X}_{t}^i,\overline{Y}_{t}^i)$
denote
 $N$
i.i.d. copies of the mean-field dynamics (1.5). For the original variant of unconstrained CBO, this was first done in [Reference Fornasier, Klock and Riedl28, Section 3.3]. To keep the focus of this work on the long-time behaviour of the CBO variant (1.6), a rigorous analysis of the mean-field approximation is left for future considerations.
$N$
i.i.d. copies of the mean-field dynamics (1.5). For the original variant of unconstrained CBO, this was first done in [Reference Fornasier, Klock and Riedl28, Section 3.3]. To keep the focus of this work on the long-time behaviour of the CBO variant (1.6), a rigorous analysis of the mean-field approximation is left for future considerations.
Before summarising the contributions of the present paper, let us put our work into context by providing a comprehensive literature overview about the history, developments and achievements of CBO.
Versatility and flexibility of CBO: a literature overview
Since its introduction in the work [Reference Pinnau, Totzeck, Tse and Martin52], CBO has gained a significant amount of attention from various research groups. This has led to a vast variety of different developments, of both theoretical and applied nature, as well as what concerns the mathematical modelling and numerical analysis of the method. By interpreting CBO as a stochastic relaxation of gradient descent, the recent work [Reference Riedl, Klock, Geldhauser and Fornasier53] even establishes a connection between the worlds of derivative-free and gradient-based optimisation.
A first rigorous but local convergence proof of the mean-field limit of CBO to global minimisers is provided for the cases of isotropic and anisotropic diffusion in [Reference Carrillo, Choi, Totzeck and Tse12, Reference Carrillo, Jin, Li and Zhu14], respectively. By analysing the time-evolution of the variance of the law of the mean-field dynamics
 $\rho _t$
and proving its exponential decay towards zero, the authors first establish consensus formation at some stationary point before they ensure that this consensus is actually close to the global minimiser. A similarly flavoured approach is pursued in [Reference Ha, Jin and Kim33, Reference Ha, Jin and Kim34], however, directly for the fully in-time discrete microscopic system and in the simplified setting, where the same Brownian motion is used for all agents, which limits the exploration capabilities of the method. In contrast, in the recent works [Reference Fornasier, Klock and Riedl28, Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29], the authors, again for the isotropic and anisotropic CBO variant, respectively, investigate the time-evolution of the Wasserstein-
$\rho _t$
and proving its exponential decay towards zero, the authors first establish consensus formation at some stationary point before they ensure that this consensus is actually close to the global minimiser. A similarly flavoured approach is pursued in [Reference Ha, Jin and Kim33, Reference Ha, Jin and Kim34], however, directly for the fully in-time discrete microscopic system and in the simplified setting, where the same Brownian motion is used for all agents, which limits the exploration capabilities of the method. In contrast, in the recent works [Reference Fornasier, Klock and Riedl28, Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29], the authors, again for the isotropic and anisotropic CBO variant, respectively, investigate the time-evolution of the Wasserstein-
 $2$
distance between the law
$2$
distance between the law
 $\rho _t$
and a Dirac delta at the global minimiser. This is also the strategy which we pursue in this paper. By proving the exponential decay of
$\rho _t$
and a Dirac delta at the global minimiser. This is also the strategy which we pursue in this paper. By proving the exponential decay of
 $W_2(\rho _t,\delta _{x^*})$
to zero, consensus at the desired location follows immediately. Moreover, by providing a probabilistic quantitative result about the mean-field approximation, the authors give a first, and so far unique, holistic global convergence proof for the implementable, i.e., discretised numerical CBO algorithm in the unconstrained case. The results about the mean-field approximation of the latter papers were partially inspired by the series of works [Reference Fornasier, Huang, Pareschi and Sünnen25–Reference Fornasier, Huang, Pareschi and Sünnen27], in which the authors constrain the particle dynamics of CBO to compact hypersurfaces and prove local convergence of the numerical scheme to minimisers by adapting the technique of [Reference Carrillo, Choi, Totzeck and Tse12, Reference Carrillo, Jin, Li and Zhu14]. This ensures a beneficial compactness of the stochastic processes, which simplifies the convergence of the interacting particle dynamics to the mean-field dynamics. In the unconstrained case, such intrinsic compactness is replaced by the fact that the dynamics are bounded with high probability, which is sufficient to establish convergence in probability. Further related works about CBO for optimisations with constraints include the papers [Reference Ha, Kang and Kim35, Reference Kim, Kang, Kim, Ha and Yang44], where a problem on the Stiefel manifold is approached, and the works [Reference Borghi, Herty and Pareschi9, Reference Carrillo, Totzeck and Vaes15], where the constrained optimisation is recast into a penalised problem. The philosophy of using an interacting swarm of particles to approach various relevant problems in science and engineering has promoted several variations of the original CBO algorithm for minimisation. Amongst them are methods based on consensus dynamics to tackle multi-objective optimisation problems [Reference Borghi, Herty and Pareschi7, Reference Borghi, Herty and Pareschi8, Reference Klamroth, Stiglmayr and Totzeck45], saddle point problems [Reference Huang, Qiu and Riedl40], the search for several minimisers simultaneously [Reference Bungert, Wacker and Roith10] or the sampling from certain distributions [Reference Carrillo, Hoffmann, Stuart and Vaes13].
$W_2(\rho _t,\delta _{x^*})$
to zero, consensus at the desired location follows immediately. Moreover, by providing a probabilistic quantitative result about the mean-field approximation, the authors give a first, and so far unique, holistic global convergence proof for the implementable, i.e., discretised numerical CBO algorithm in the unconstrained case. The results about the mean-field approximation of the latter papers were partially inspired by the series of works [Reference Fornasier, Huang, Pareschi and Sünnen25–Reference Fornasier, Huang, Pareschi and Sünnen27], in which the authors constrain the particle dynamics of CBO to compact hypersurfaces and prove local convergence of the numerical scheme to minimisers by adapting the technique of [Reference Carrillo, Choi, Totzeck and Tse12, Reference Carrillo, Jin, Li and Zhu14]. This ensures a beneficial compactness of the stochastic processes, which simplifies the convergence of the interacting particle dynamics to the mean-field dynamics. In the unconstrained case, such intrinsic compactness is replaced by the fact that the dynamics are bounded with high probability, which is sufficient to establish convergence in probability. Further related works about CBO for optimisations with constraints include the papers [Reference Ha, Kang and Kim35, Reference Kim, Kang, Kim, Ha and Yang44], where a problem on the Stiefel manifold is approached, and the works [Reference Borghi, Herty and Pareschi9, Reference Carrillo, Totzeck and Vaes15], where the constrained optimisation is recast into a penalised problem. The philosophy of using an interacting swarm of particles to approach various relevant problems in science and engineering has promoted several variations of the original CBO algorithm for minimisation. Amongst them are methods based on consensus dynamics to tackle multi-objective optimisation problems [Reference Borghi, Herty and Pareschi7, Reference Borghi, Herty and Pareschi8, Reference Klamroth, Stiglmayr and Totzeck45], saddle point problems [Reference Huang, Qiu and Riedl40], the search for several minimisers simultaneously [Reference Bungert, Wacker and Roith10] or the sampling from certain distributions [Reference Carrillo, Hoffmann, Stuart and Vaes13].
In the same vein and also in the spirit of this work, the original CBO method itself has undergone several modifications allowing for a more complex dynamics. This includes the use of particles with memory [Reference Grassi, Huang, Pareschi and Qiu31, Reference Totzeck and Wolfram55], the integration of momentum [Reference Chen, Jin and Lyu17], the usage of jump-diffusion processes [Reference Kalise, Sharma and Tretyakov42] and the exploitation of on-the-fly extracted higher-order differential information through inferred gradients based on point evaluations of the objective function [Reference Schillings, Totzeck and Wacker54]. It moreover turned out that the renowned particle swarm optimisation method (PSO) [Reference Kennedy and Eberhart43] can be formulated and regarded as a second-order generalisation of CBO [Reference Cipriani, Huang and Qiu18, Reference Grassi and Pareschi32]. This insight has enabled to adapt the for CBO-developed analysis techniques to rigorously prove the convergence of PSO [Reference Huang, Qiu and Riedl41].
In the collection of formerly referenced works and beyond, CBO has demonstrated to be a valuable method for a wide scope of applications reaching from the phase retrieval or robust subspace detection problem in signal processing [Reference Fornasier, Huang, Pareschi and Sünnen26, Reference Fornasier, Huang, Pareschi and Sünnen27], over the training of neural networks for image classification in machine learning [Reference Carrillo, Jin, Li and Zhu14, Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29] as well as in the setting of clustered federated learning [Reference Carrillo, Trillos, Li and Zhu16], to asset allocation in finance [Reference Bae, Ha, Kang, Lim, Min and Yoo5]. It has been furthermore employed to approximate low-frequency functions in the presence of high-frequency noise and to the task of solving PDEs with low-regularity solutions [Reference Chen, Jin and Lyu17].
Contributions
In view of the various developments and the wide scope of applications, a theoretical understanding of the long-time behaviour of the in practical applications employed CBO methods is of paramount interest. In this work, we analyse a variant of CBO which incorporates memory effects as well as gradient information from a theoretical and numerical perspective. As demonstrated concisely in Figure 2 and more comprehensively in Section 4, the herein investigated dynamics, which is more involved than standard CBO, proves to be beneficial in applications in machine learning and compressed sensing. Despite this additional complexity, by employing the analysis technique devised in [Reference Fornasier, Klock and Riedl28, Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29], we are able to provide rigorous mean-field-type convergence guarantees to the global minimiser, which describe the behaviour of the method in the large-particle limit and allow to draw conclusions about the typically observed performance in the practicable regime. Our results for CBO with memory effects and gradient information hold for a vast class of objective functions under minimal assumptions on the initialisation of the method. Moreover, the proof reveals how to leverage further, in other applications advantageous, forces in the dynamics while still being amenable to theory and allowing for provable global convergence.

Figure 2. A demonstration of the benefits of memory effects and gradient information in CBO methods. In both settings (a) and (b) the depicted success probabilities are averaged over
 $100$
runs of CBO and the implemented scheme is given by a Euler-Maruyama discretisation of equation (1.1) with time horizon
$100$
runs of CBO and the implemented scheme is given by a Euler-Maruyama discretisation of equation (1.1) with time horizon
 $T=20$
, discrete time step size
$T=20$
, discrete time step size
 $\Delta t=0.01$
,
$\Delta t=0.01$
,
 $\alpha =100$
,
$\alpha =100$
,
 $\beta =\infty$
,
$\beta =\infty$
,
 $\theta =0$
,
$\theta =0$
,
 $\kappa =1/\Delta t$
,
$\kappa =1/\Delta t$
,
 $\lambda _1=1$
and
$\lambda _1=1$
and
 $\sigma _1=\sqrt{1.6}$
. In (a) we plot the success probability of CBO without (left separate column) and with (right phase diagram) memory effects for different values of the parameter
$\sigma _1=\sqrt{1.6}$
. In (a) we plot the success probability of CBO without (left separate column) and with (right phase diagram) memory effects for different values of the parameter
 $\lambda _2$
, i.e., for different strengths of the memory drift, when optimising the Rastrigin function
$\lambda _2$
, i.e., for different strengths of the memory drift, when optimising the Rastrigin function
 ${\mathcal{E}}(x) = \sum _{k=1}^d x_k^2 + \frac{5}{2} (1-\cos (2\pi x_k))$
in dimension
${\mathcal{E}}(x) = \sum _{k=1}^d x_k^2 + \frac{5}{2} (1-\cos (2\pi x_k))$
in dimension
 $d=4$
. As remaining parameters we choose
$d=4$
. As remaining parameters we choose
 $\sigma _2=\lambda _1\sigma _1$
and
$\sigma _2=\lambda _1\sigma _1$
and
 $\lambda _3=\sigma _3=0$
, i.e., no gradient information is involved. We observe that an increasing amount of memory drift improves the success probability significantly, even in the case where, theoretically, there are no convergence guarantees anymore, see Theorem 2.5 and Corollary 2.6. Section 4.2 provides further details. In (b) we depict the success probability of CBO without (left separate column) and with (right phase diagram) gradient information for different values of the parameter
$\lambda _3=\sigma _3=0$
, i.e., no gradient information is involved. We observe that an increasing amount of memory drift improves the success probability significantly, even in the case where, theoretically, there are no convergence guarantees anymore, see Theorem 2.5 and Corollary 2.6. Section 4.2 provides further details. In (b) we depict the success probability of CBO without (left separate column) and with (right phase diagram) gradient information for different values of the parameter
 $\lambda _3$
, i.e., for different strengths of the gradient drift, when solving a compressed sensing problem in dimension
$\lambda _3$
, i.e., for different strengths of the gradient drift, when solving a compressed sensing problem in dimension
 $d=200$
with sparsity
$d=200$
with sparsity
 $s=8$
. On the vertical axis we depict the number of measurements
$s=8$
. On the vertical axis we depict the number of measurements
 $m$
, from which we try to recover the sparse signal by solving the associated
$m$
, from which we try to recover the sparse signal by solving the associated
 $\ell _1$
-regularised problem (LASSO). As remaining parameters we use merely
$\ell _1$
-regularised problem (LASSO). As remaining parameters we use merely
 $N=10$
particles, choose
$N=10$
particles, choose
 $\sigma _3=0$
and
$\sigma _3=0$
and
 $\lambda _2=\sigma _2=0$
, i.e., no memory drift is involved. We observe that gradient information is required to be able to identify the correct sparse solution and standard CBO would fail in such task. Section 4.4 provides more details.
$\lambda _2=\sigma _2=0$
, i.e., no memory drift is involved. We observe that gradient information is required to be able to identify the correct sparse solution and standard CBO would fail in such task. Section 4.4 provides more details.
1.1. Organisation
In Section 2, after providing details about the existence of solutions to the macroscopic SDE (1.5) and the associated PDE (1.6), we present and discuss our main theoretical contribution. It is about the convergence of CBO with memory effects and gradient information, as given in equation (1.1), to the global minimiser of the objective function in mean-field law, see [Reference Fornasier, Klock and Riedl28, Definition 1]. More precisely, we show that the mean-field dynamics (1.5) and (1.6) converge with exponential rate to the global minimiser. Section 3 contains the proof details of this result. In Section 4, we numerically demonstrate the benefits of the additional memory effects and gradient information of the previously analysed CBO variant. We in particular present applications of CBO in machine learning and compressed sensing, before we conclude the paper in Section 5.
For the sake of reproducible research, in the GitHub repository https://github.com/KonstantinRiedl/CBOGlobalConvergenceAnalysis we provide the Matlab code implementing the CBO algorithm with memory effects and gradient information analysed in this work.
1.2. Notation
Given a set
 $A\subset \mathbb{R}^d$
, we write
$A\subset \mathbb{R}^d$
, we write
 $(A)^c$
to denote its complement, i.e.,
$(A)^c$
to denote its complement, i.e.,
 $(A)^c\,:\!=\,\{z\in \mathbb{R}^d:z\not \in A\}$
. For
$(A)^c\,:\!=\,\{z\in \mathbb{R}^d:z\not \in A\}$
. For
 $\ell _{\infty}$
balls in
$\ell _{\infty}$
balls in
 $\mathbb{R}^d$
with centre
$\mathbb{R}^d$
with centre
 $z$
and radius
$z$
and radius
 $r$
, we write
$r$
, we write
 $B^\infty _{r}(z)$
. The space of continuous functions
$B^\infty _{r}(z)$
. The space of continuous functions
 $f:X\rightarrow Y$
is denoted by
$f:X\rightarrow Y$
is denoted by
 $\mathcal{C}(X,Y)$
, with
$\mathcal{C}(X,Y)$
, with
 $X\subset \mathbb{R}^n$
and a suitable topological space
$X\subset \mathbb{R}^n$
and a suitable topological space
 $Y$
. For
$Y$
. For
 $X\subset \mathbb{R}^n$
open and for
$X\subset \mathbb{R}^n$
open and for
 $Y=\mathbb{R}^m$
, the function space
$Y=\mathbb{R}^m$
, the function space
 $\mathcal{C}^k_{c}(X,Y)$
contains functions
$\mathcal{C}^k_{c}(X,Y)$
contains functions
 $f\in\mathcal{C}(X,Y)$
that are
$f\in\mathcal{C}(X,Y)$
that are
 $k$
-times continuously differentiable and have compact support.
$k$
-times continuously differentiable and have compact support.
 $Y$
is omitted in the case of real-valued functions. The operator
$Y$
is omitted in the case of real-valued functions. The operator
 $\nabla$
denotes the standard gradient of a function on
$\nabla$
denotes the standard gradient of a function on
 $\mathbb{R}^d$
.
$\mathbb{R}^d$
.
In this paper, we mostly study laws of stochastic processes,
 $\rho \in\mathcal{C}([0,T],\mathcal{P}(\mathbb{R}^d))$
, and we refer to a snapshot of such law at time
$\rho \in\mathcal{C}([0,T],\mathcal{P}(\mathbb{R}^d))$
, and we refer to a snapshot of such law at time
 $t$
by writing
$t$
by writing
 $\rho _t\in\mathcal{P}(\mathbb{R}^d)$
. Here,
$\rho _t\in\mathcal{P}(\mathbb{R}^d)$
. Here,
 $\mathcal{P}(\mathbb{R}^d)$
denotes the set of all Borel probability measures
$\mathcal{P}(\mathbb{R}^d)$
denotes the set of all Borel probability measures
 $\varrho$
over
$\varrho$
over
 $\mathbb{R}^d$
. In
$\mathbb{R}^d$
. In
 $\mathcal{P}_p(\mathbb{R}^d)$
we moreover collect measures
$\mathcal{P}_p(\mathbb{R}^d)$
we moreover collect measures
 $\varrho \in\mathcal{P}(\mathbb{R}^d)$
with finite
$\varrho \in\mathcal{P}(\mathbb{R}^d)$
with finite
 $p$
th moment. For any
$p$
th moment. For any
 $1\leq p\lt \infty$
,
$1\leq p\lt \infty$
,
 $W_p$
denotes the Wasserstein-
$W_p$
denotes the Wasserstein-
 $p$
distance between two Borel probability measures
$p$
distance between two Borel probability measures
 $\varrho _1,\varrho _2\in\mathcal{P}_p(\mathbb{R}^d)$
, see, e.g., [Reference Ambrosio, Gigli and Savaré2].
$\varrho _1,\varrho _2\in\mathcal{P}_p(\mathbb{R}^d)$
, see, e.g., [Reference Ambrosio, Gigli and Savaré2].
 $\mathbb{E}(\varrho )$
denotes the expectation of a probability measure
$\mathbb{E}(\varrho )$
denotes the expectation of a probability measure
 $\varrho$
.
$\varrho$
.
2. Global convergence in mean-field law
In the first part of this section, we provide an existence result about solutions of the nonlinear macroscopic SDE (1.5), respectively, the associated Fokker-Planck equation (1.6). Thereafter we specify the class of studied objective functions and present the main theoretical result about the convergence of the dynamics (1.5) and (1.6) to the global minimiser.
Throughout this work, we consider the – in typical applications beneficial – case of CBO with anisotropic diffusion, i.e.,
 $D\!\left (\,\cdot \,\right ) = \operatorname{diag}\left (\,\cdot \,\right )$
in equations (1.1), (1.5) and (1.6), and also equation (2.1) below. However, up to minor modifications, analogous results can be obtained for isotropic diffusion.
$D\!\left (\,\cdot \,\right ) = \operatorname{diag}\left (\,\cdot \,\right )$
in equations (1.1), (1.5) and (1.6), and also equation (2.1) below. However, up to minor modifications, analogous results can be obtained for isotropic diffusion.
2.1. Definition and existence of weak solutions
Let us begin by rigorously defining weak solutions of the Fokker-Planck equation (1.6).
Definition 2.1.
Let
 $\rho _0 \in\mathcal{P}(\mathbb{R}^d\times \mathbb{R}^d)$
,
$\rho _0 \in\mathcal{P}(\mathbb{R}^d\times \mathbb{R}^d)$
,
 $T \gt 0$
. We say
$T \gt 0$
. We say
 $\rho \in\mathcal{C}([0,T],\mathcal{P}(\mathbb{R}^d\times \mathbb{R}^d))$
satisfies the Fokker-Planck equation (
1.6
) with initial condition
$\rho \in\mathcal{C}([0,T],\mathcal{P}(\mathbb{R}^d\times \mathbb{R}^d))$
satisfies the Fokker-Planck equation (
1.6
) with initial condition
 $\rho _0$
in the weak sense in the time interval
$\rho _0$
in the weak sense in the time interval
 $[0,T]$
, if we have for all
$[0,T]$
, if we have for all
 $\phi \in\mathcal{C}_c^2(\mathbb{R}^d\times \mathbb{R}^d)$
and all
$\phi \in\mathcal{C}_c^2(\mathbb{R}^d\times \mathbb{R}^d)$
and all
 $t \in (0,T)$
$t \in (0,T)$
 \begin{equation} \begin{aligned} &\frac{d}{dt}\!\iint \phi (x,y) \,d\rho _t(x,y) = -\! \iint \kappa S^{\beta,\theta }(x,y) \left \langle y-x,\nabla _y\phi (x,y) \right \rangle d\rho _t(x,y)\\ &\quad -\! \iint \lambda _1\!\left \langle x \!-\! y_{\alpha }({\rho _{Y,t}}), \!\nabla _x \phi (x,y) \right \rangle \!+\! \lambda _2\!\left \langle x\!-\!y,\!\nabla _x\phi (x,y) \right \rangle \!+\! \lambda _3\!\left \langle \nabla{\mathcal{E}}(x), \!\nabla _x \phi (x,y) \right \rangle d\rho _t(x,y)\\ &\quad + \frac{1}{2} \iint \!\sum _{k=1}^d \!\left (\sigma _1^2D\!\left (x\!-\!y_{\alpha }({\rho _{Y,t}})\right )_{kk}^2 \!\!+\! \sigma _2^2D\!\left (x\!-\!y\right )_{kk}^2 \!\!+\! \sigma _3^2D\!\left (\nabla{\mathcal{E}}(x)\right )_{kk}^2 \!\right ) \!\partial ^2_{x_kx_k} \phi (x,y) \,d\rho _t(x,y) \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\frac{d}{dt}\!\iint \phi (x,y) \,d\rho _t(x,y) = -\! \iint \kappa S^{\beta,\theta }(x,y) \left \langle y-x,\nabla _y\phi (x,y) \right \rangle d\rho _t(x,y)\\ &\quad -\! \iint \lambda _1\!\left \langle x \!-\! y_{\alpha }({\rho _{Y,t}}), \!\nabla _x \phi (x,y) \right \rangle \!+\! \lambda _2\!\left \langle x\!-\!y,\!\nabla _x\phi (x,y) \right \rangle \!+\! \lambda _3\!\left \langle \nabla{\mathcal{E}}(x), \!\nabla _x \phi (x,y) \right \rangle d\rho _t(x,y)\\ &\quad + \frac{1}{2} \iint \!\sum _{k=1}^d \!\left (\sigma _1^2D\!\left (x\!-\!y_{\alpha }({\rho _{Y,t}})\right )_{kk}^2 \!\!+\! \sigma _2^2D\!\left (x\!-\!y\right )_{kk}^2 \!\!+\! \sigma _3^2D\!\left (\nabla{\mathcal{E}}(x)\right )_{kk}^2 \!\right ) \!\partial ^2_{x_kx_k} \phi (x,y) \,d\rho _t(x,y) \end{aligned} \end{equation}
and
 $\lim _{t\rightarrow 0}\rho _t = \rho _0$
(in the sense of weak convergence of measures).
$\lim _{t\rightarrow 0}\rho _t = \rho _0$
(in the sense of weak convergence of measures).
For solutions of the mean-field dynamics (1.5) and (1.6), we have the following existence result.
Theorem 2.2.
Let
 $T \gt 0$
,
$T \gt 0$
,
 $\rho _0 \in\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d)$
. Let
$\rho _0 \in\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d)$
. Let
 ${\mathcal{E}}\, :\, \mathbb{R}^d\rightarrow \mathbb{R}$
with
${\mathcal{E}}\, :\, \mathbb{R}^d\rightarrow \mathbb{R}$
with
 $\underline{\mathcal{E}} \gt -\infty$
satisfy for some constants
$\underline{\mathcal{E}} \gt -\infty$
satisfy for some constants
 $C_1,C_2 \gt 0$
the conditions
$C_1,C_2 \gt 0$
the conditions
 \begin{align} \left |{{\mathcal{E}}(x)-{\mathcal{E}}(x')}\right | &\leq C_1\left (\left \|{x}\right \|_2 + \|{x'}\|_2\right )\|{x-x'}\|_2, \quad \text{for all } x,x' \in \mathbb{R}^d, \end{align}
\begin{align} \left |{{\mathcal{E}}(x)-{\mathcal{E}}(x')}\right | &\leq C_1\left (\left \|{x}\right \|_2 + \|{x'}\|_2\right )\|{x-x'}\|_2, \quad \text{for all } x,x' \in \mathbb{R}^d, \end{align}
 \begin{align}{\mathcal{E}}(x) - \underline{\mathcal{E}} &\leq C_2 \left (1 + \|{x}\|_2^2\right ), \quad \text{for all } x \in \mathbb{R}^d, \end{align}
\begin{align}{\mathcal{E}}(x) - \underline{\mathcal{E}} &\leq C_2 \left (1 + \|{x}\|_2^2\right ), \quad \text{for all } x \in \mathbb{R}^d, \end{align}
and either
 $\sup _{x \in \mathbb{R}^d}{\mathcal{E}}(x) \lt \infty$
or
$\sup _{x \in \mathbb{R}^d}{\mathcal{E}}(x) \lt \infty$
or
 \begin{align}{\mathcal{E}}(x) - \underline{\mathcal{E}} \geq C_3\left \|{x}\right \|_2^2,\quad \text{for all } \left \|{x}\right \|_2 \geq C_4 \end{align}
\begin{align}{\mathcal{E}}(x) - \underline{\mathcal{E}} \geq C_3\left \|{x}\right \|_2^2,\quad \text{for all } \left \|{x}\right \|_2 \geq C_4 \end{align}
for some
 $C_3,C_4 \gt 0$
. Furthermore, in the case of an active gradient drift in the CBO dynamcis (
1.5
), i.e., if
$C_3,C_4 \gt 0$
. Furthermore, in the case of an active gradient drift in the CBO dynamcis (
1.5
), i.e., if
 $\lambda _3\not =0$
, let
$\lambda _3\not =0$
, let
 ${\mathcal{E}}\in\mathcal{C}^1(\mathbb{R}^d)$
and obey additionally
${\mathcal{E}}\in\mathcal{C}^1(\mathbb{R}^d)$
and obey additionally
 \begin{align} \left \|{\nabla{\mathcal{E}}(x)-\nabla{\mathcal{E}}(x')}\right \|_2 &\leq \widetilde{L}_{\nabla{\mathcal{E}}} \|{x-x'}\|_2, \quad \text{for all } x,x' \in \mathbb{R}^d \end{align}
\begin{align} \left \|{\nabla{\mathcal{E}}(x)-\nabla{\mathcal{E}}(x')}\right \|_2 &\leq \widetilde{L}_{\nabla{\mathcal{E}}} \|{x-x'}\|_2, \quad \text{for all } x,x' \in \mathbb{R}^d \end{align}
for some
 $\widetilde{L}_{\nabla{\mathcal{E}}}\gt 0$
. Then, if
$\widetilde{L}_{\nabla{\mathcal{E}}}\gt 0$
. Then, if
 $(\overline{X}_0, \overline{Y}_0)$
is distributed according to
$(\overline{X}_0, \overline{Y}_0)$
is distributed according to
 $\rho _0$
, there exists a nonlinear process
$\rho _0$
, there exists a nonlinear process
 $(\overline{X}, \overline{Y}) \in\mathcal{C}([0,T],\mathbb{R}^d\times \mathbb{R}^d)$
satisfying (
1.5
) with associated law
$(\overline{X}, \overline{Y}) \in\mathcal{C}([0,T],\mathbb{R}^d\times \mathbb{R}^d)$
satisfying (
1.5
) with associated law
 $\rho = \textrm{Law}\big ((\overline{X}, \overline{Y})\big )$
having regularity
$\rho = \textrm{Law}\big ((\overline{X}, \overline{Y})\big )$
having regularity
 $\rho \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
and being a weak solution to the Fokker-Planck equation (
1.6
) with
$\rho \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
and being a weak solution to the Fokker-Planck equation (
1.6
) with
 $\rho (0)=\rho _0$
.
$\rho (0)=\rho _0$
.
Assumption (2.2) requires that
 $\mathcal{E}$
is locally Lipschitz continuous with the Lipschitz constant being allowed to have linear growth. This entails in particular that the objective has at most quadratic growth at infinity as formulated explicitly in Assumption (2.3), which can be seen when choosing
$\mathcal{E}$
is locally Lipschitz continuous with the Lipschitz constant being allowed to have linear growth. This entails in particular that the objective has at most quadratic growth at infinity as formulated explicitly in Assumption (2.3), which can be seen when choosing
 $x'=x^*$
and
$x'=x^*$
and
 $C_2=2C_1\max \{1,\left \|{x^*}\right \|_2^2\}$
in (2.2). Assumption (2.4), on the other hand, assumes that
$C_2=2C_1\max \{1,\left \|{x^*}\right \|_2^2\}$
in (2.2). Assumption (2.4), on the other hand, assumes that
 $\mathcal{E}$
also has at least quadratic growth in the farfield, i.e., overall it grows quadratically far away from
$\mathcal{E}$
also has at least quadratic growth in the farfield, i.e., overall it grows quadratically far away from
 $x^*$
. Alternatively,
$x^*$
. Alternatively,
 $\mathcal{E}$
may be bounded from above. Since the objective
$\mathcal{E}$
may be bounded from above. Since the objective
 $\mathcal{E}$
can be usually modified for the purpose of analysis outside a sufficiently large region, these growth conditions are not really restrictive. In case of an additional gradient drift term in the dynamics, i.e.,
$\mathcal{E}$
can be usually modified for the purpose of analysis outside a sufficiently large region, these growth conditions are not really restrictive. In case of an additional gradient drift term in the dynamics, i.e.,
 $\lambda _3\not =0$
, the objective naturally needs to be continuously differentiable. Furthermore, Assumption (2.5) imposes
$\lambda _3\not =0$
, the objective naturally needs to be continuously differentiable. Furthermore, Assumption (2.5) imposes
 $\mathcal{E}$
to be
$\mathcal{E}$
to be
 $\widetilde{L}_{\nabla{\mathcal{E}}}$
-smooth, i.e., having an
$\widetilde{L}_{\nabla{\mathcal{E}}}$
-smooth, i.e., having an
 $\widetilde{L}_{\nabla{\mathcal{E}}}$
-Lipschitz continuous gradient.
$\widetilde{L}_{\nabla{\mathcal{E}}}$
-Lipschitz continuous gradient.
Remark 2.3.
The regularity
 $\rho \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
obtained in Theorem
2.2 above is an immediate consequence of the regularity of the initial condition
$\rho \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
obtained in Theorem
2.2 above is an immediate consequence of the regularity of the initial condition
 $\rho _0 \in\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d)$
. It allows to extend the test function space
$\rho _0 \in\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d)$
. It allows to extend the test function space
 $\mathcal{C}^{\infty }_{c}(\mathbb{R}^d\times \mathbb{R}^d)$
in Definition 2.1 to the larger space
$\mathcal{C}^{\infty }_{c}(\mathbb{R}^d\times \mathbb{R}^d)$
in Definition 2.1 to the larger space
 \begin{equation} \begin{aligned}\mathcal{C}^2_{*}(\mathbb{R}^d\times \mathbb{R}^d) \,:\!=\,\big \{\phi \in\mathcal{C}^2(\mathbb{R}^d\times \mathbb{R}^d):\, &\left |{\partial _{x_k}\phi (x,y)}\right | \leq C_{\phi} (1\!+\!\|{x}\|_2\!+\!\|{y}\|_2) \text{ for some } C_{\phi} \!\gt \!0\\ &\,\text{and } \sup _{(x,y)\in \mathbb{R}^d\times \mathbb{R}^d}\max _{k=1,\dots,d}|\partial ^2_{x_kx_k} \phi (x,y)| \lt \infty \big \}, \end{aligned} \end{equation}
\begin{equation} \begin{aligned}\mathcal{C}^2_{*}(\mathbb{R}^d\times \mathbb{R}^d) \,:\!=\,\big \{\phi \in\mathcal{C}^2(\mathbb{R}^d\times \mathbb{R}^d):\, &\left |{\partial _{x_k}\phi (x,y)}\right | \leq C_{\phi} (1\!+\!\|{x}\|_2\!+\!\|{y}\|_2) \text{ for some } C_{\phi} \!\gt \!0\\ &\,\text{and } \sup _{(x,y)\in \mathbb{R}^d\times \mathbb{R}^d}\max _{k=1,\dots,d}|\partial ^2_{x_kx_k} \phi (x,y)| \lt \infty \big \}, \end{aligned} \end{equation}
as can be seen from the proof of Theorem 2.2, which we sketch in what follows.
Proof sketch of Theorem 2.2. The proof is based on the Leray-Schauder fixed point theorem and follows the steps taken in [Reference Carrillo, Choi, Totzeck and Tse12, Theorems 3.1, 3.2].
Step 1: For a given function
 $u\in \mathcal{C}([0,T],\mathbb{R}^d)$
and an initial measure
$u\in \mathcal{C}([0,T],\mathbb{R}^d)$
and an initial measure
 $\rho _0\in\mathcal{P}_4(\mathbb{R}^d)$
, according to standard SDE theory [Reference Arnold3, Chapters 6], we can uniquely solve the auxiliary SDE
$\rho _0\in\mathcal{P}_4(\mathbb{R}^d)$
, according to standard SDE theory [Reference Arnold3, Chapters 6], we can uniquely solve the auxiliary SDE
 \begin{align*} &\begin{aligned} d\widetilde{X}_{t} = \begin{aligned}[t] &\!-\lambda _1\big (\widetilde{X}_{t}-u_t\big )\, dt -\lambda _2\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )\, dt -\lambda _3\nabla{\mathcal{E}}(\widetilde{X}_{t}) \,dt\\ &\!+\sigma _1 D\big (\widetilde{X}_{t}-u_t\big )\, d B_{t}^{1} +\sigma _2 D\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )\, d B_{t}^{2} +\sigma _3 D\big (\nabla{\mathcal{E}}(\widetilde{X}_{t})\big )\, d B_{t}^{3} \end{aligned} \end{aligned}\\ &\mspace{1mu}d\widetilde{Y}_{t} = \kappa \big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )\, S^{\beta,\theta }\big (\widetilde{X}_{t}, \widetilde{Y}_{t}\big )\, dt \end{align*}
\begin{align*} &\begin{aligned} d\widetilde{X}_{t} = \begin{aligned}[t] &\!-\lambda _1\big (\widetilde{X}_{t}-u_t\big )\, dt -\lambda _2\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )\, dt -\lambda _3\nabla{\mathcal{E}}(\widetilde{X}_{t}) \,dt\\ &\!+\sigma _1 D\big (\widetilde{X}_{t}-u_t\big )\, d B_{t}^{1} +\sigma _2 D\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )\, d B_{t}^{2} +\sigma _3 D\big (\nabla{\mathcal{E}}(\widetilde{X}_{t})\big )\, d B_{t}^{3} \end{aligned} \end{aligned}\\ &\mspace{1mu}d\widetilde{Y}_{t} = \kappa \big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )\, S^{\beta,\theta }\big (\widetilde{X}_{t}, \widetilde{Y}_{t}\big )\, dt \end{align*}
with
 $(\widetilde{X}_0,\widetilde{Y}_0)\sim \rho _0$
. This is due to the fact that the coefficients of the drift and diffusion terms are locally Lipschitz continuous and have at most linear growth, which, in turn, is a consequence of the assumptions on
$(\widetilde{X}_0,\widetilde{Y}_0)\sim \rho _0$
. This is due to the fact that the coefficients of the drift and diffusion terms are locally Lipschitz continuous and have at most linear growth, which, in turn, is a consequence of the assumptions on
 $\mathcal{E}$
as well as the smoothness of
$\mathcal{E}$
as well as the smoothness of
 $S^{\beta,\theta }$
as defined in (1.4). This induces
$S^{\beta,\theta }$
as defined in (1.4). This induces
 $\widetilde{\rho} _t=\textrm{Law}\big ((\widetilde{X}_t,\widetilde{Y}_t)\big )$
. Moreover, the assumed regularity of the initial distribution
$\widetilde{\rho} _t=\textrm{Law}\big ((\widetilde{X}_t,\widetilde{Y}_t)\big )$
. Moreover, the assumed regularity of the initial distribution
 $\rho _0 \in\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d)$
allows to obtain a fourth-order moment estimate of the form
$\rho _0 \in\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d)$
allows to obtain a fourth-order moment estimate of the form
 $\mathbb{E}\big [\|{\widetilde{X}_t}\|_2^4+\|{\widetilde{Y}_t}\|_2^4\big ] \leqslant \big (1+2\mathbb{E}\big [\|{\widetilde{X}_0}\|_2^4+\|{\widetilde{Y}_0}\|_2^4\big ]\big )e^{ct}$
, see, e.g. [Reference Arnold3, Chapter 7]. So, in particular,
$\mathbb{E}\big [\|{\widetilde{X}_t}\|_2^4+\|{\widetilde{Y}_t}\|_2^4\big ] \leqslant \big (1+2\mathbb{E}\big [\|{\widetilde{X}_0}\|_2^4+\|{\widetilde{Y}_0}\|_2^4\big ]\big )e^{ct}$
, see, e.g. [Reference Arnold3, Chapter 7]. So, in particular,
 $\widetilde{\rho} \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
.
$\widetilde{\rho} \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
.
Step 2: For some test function
 $\phi \in\mathcal{C}^2_{*}(\mathbb{R}^d\times \mathbb{R}^d)$
as defined in (2.6), by Itô’s formula, we derive
$\phi \in\mathcal{C}^2_{*}(\mathbb{R}^d\times \mathbb{R}^d)$
as defined in (2.6), by Itô’s formula, we derive
 \begin{equation*} \begin{split} &d\phi (\widetilde{X}_t,\widetilde{Y}_t) = \nabla _x\phi (\widetilde{X}_t,\widetilde{Y}_t) \cdot \left ({-}\lambda _1\big (\widetilde{X}_{t}-u_t\big ) -\lambda _2\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big ) -\lambda _3\nabla{\mathcal{E}}(\widetilde{X}_{t})\right ) dt \\ &\quad \quad \, + \nabla _y\phi (\widetilde{X}_t,\widetilde{Y}_t) \cdot \left (\kappa \big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )\, S^{\beta,\theta }\big (\widetilde{X}_{t}, \widetilde{Y}_{t}\big )\right ) dt \\ &\quad \quad \, + \frac{1}{2} \sum _{k=1}^d \partial ^2_{x_kx_k}\phi (\widetilde{X}_t,\widetilde{Y}_t)\left (\sigma _1^2 D\big (\widetilde{X}_{t}-u_t\big )_{kk}^2 \!+\! \sigma _2^2 D\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )_{kk}^2 \!+\! \sigma _3^2 D\big (\nabla{\mathcal{E}}(\widetilde{X}_{t})\big )_{kk}^2\right )dt \\ &\quad \quad \, + \nabla _x\phi (\widetilde{X}_t,\widetilde{Y}_t) \cdot \left (\sigma _1 D\big (\widetilde{X}_{t}-u_t\big )\, d B_{t}^{1} + \sigma _2 D\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )\, d B_{t}^{2} + \sigma _3 D\big (\nabla{\mathcal{E}}(\widetilde{X}_{t})\big )\, d B_{t}^{3}\right ) \end{split} \end{equation*}
\begin{equation*} \begin{split} &d\phi (\widetilde{X}_t,\widetilde{Y}_t) = \nabla _x\phi (\widetilde{X}_t,\widetilde{Y}_t) \cdot \left ({-}\lambda _1\big (\widetilde{X}_{t}-u_t\big ) -\lambda _2\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big ) -\lambda _3\nabla{\mathcal{E}}(\widetilde{X}_{t})\right ) dt \\ &\quad \quad \, + \nabla _y\phi (\widetilde{X}_t,\widetilde{Y}_t) \cdot \left (\kappa \big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )\, S^{\beta,\theta }\big (\widetilde{X}_{t}, \widetilde{Y}_{t}\big )\right ) dt \\ &\quad \quad \, + \frac{1}{2} \sum _{k=1}^d \partial ^2_{x_kx_k}\phi (\widetilde{X}_t,\widetilde{Y}_t)\left (\sigma _1^2 D\big (\widetilde{X}_{t}-u_t\big )_{kk}^2 \!+\! \sigma _2^2 D\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )_{kk}^2 \!+\! \sigma _3^2 D\big (\nabla{\mathcal{E}}(\widetilde{X}_{t})\big )_{kk}^2\right )dt \\ &\quad \quad \, + \nabla _x\phi (\widetilde{X}_t,\widetilde{Y}_t) \cdot \left (\sigma _1 D\big (\widetilde{X}_{t}-u_t\big )\, d B_{t}^{1} + \sigma _2 D\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )\, d B_{t}^{2} + \sigma _3 D\big (\nabla{\mathcal{E}}(\widetilde{X}_{t})\big )\, d B_{t}^{3}\right ) \end{split} \end{equation*}
After taking the expectation, applying Fubini’s theorem and observing that the stochastic integrals of the form
 $\mathbb{E}\int _0^t\nabla _x\phi (\widetilde{X}_t,\widetilde{Y}_t)\cdot D(\,\cdot \,)\,dB_t$
vanish as a consequence of [Reference Øksendal50, Theorem 3.2.1(iii)] due to the established regularity
$\mathbb{E}\int _0^t\nabla _x\phi (\widetilde{X}_t,\widetilde{Y}_t)\cdot D(\,\cdot \,)\,dB_t$
vanish as a consequence of [Reference Øksendal50, Theorem 3.2.1(iii)] due to the established regularity
 $\widetilde{\rho} \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
and
$\widetilde{\rho} \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
and
 $\phi \in\mathcal{C}^2_{*}(\mathbb{R}^d\times \mathbb{R}^d)$
, we obtain
$\phi \in\mathcal{C}^2_{*}(\mathbb{R}^d\times \mathbb{R}^d)$
, we obtain
 \begin{equation*} \begin{split} &\frac{d}{dt}\mathbb{E}\phi (\widetilde{X}_t,\widetilde{Y}_t) = -\mathbb{E}\nabla _x\phi (\widetilde{X}_t,\widetilde{Y}_t) \cdot \left (\lambda _1\big (\widetilde{X}_{t}-u_t\big ) +\lambda _2\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big ) +\lambda _3\nabla{\mathcal{E}}(\widetilde{X}_{t})\right ) \\ &\quad \ + \mathbb{E} \nabla _y\phi (\widetilde{X}_t,\widetilde{Y}_t) \cdot \left (\kappa \big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big ) S^{\beta,\theta }\big (\widetilde{X}_{t}, \widetilde{Y}_{t}\big )\right ) \\ &\quad \ + \frac{1}{2} \sum _{k=1}^d \partial ^2_{x_kx_k}\phi (\widetilde{X}_t,\widetilde{Y}_t)\left (\sigma _1^2 D\big (\widetilde{X}_{t}-u_t\big )_{kk}^2 \!+\! \sigma _2^2 D\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )_{kk}^2 \!+\! \sigma _3^2 D\big (\nabla{\mathcal{E}}(\widetilde{X}_{t})\big )_{kk}^2\right ) \end{split} \end{equation*}
\begin{equation*} \begin{split} &\frac{d}{dt}\mathbb{E}\phi (\widetilde{X}_t,\widetilde{Y}_t) = -\mathbb{E}\nabla _x\phi (\widetilde{X}_t,\widetilde{Y}_t) \cdot \left (\lambda _1\big (\widetilde{X}_{t}-u_t\big ) +\lambda _2\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big ) +\lambda _3\nabla{\mathcal{E}}(\widetilde{X}_{t})\right ) \\ &\quad \ + \mathbb{E} \nabla _y\phi (\widetilde{X}_t,\widetilde{Y}_t) \cdot \left (\kappa \big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big ) S^{\beta,\theta }\big (\widetilde{X}_{t}, \widetilde{Y}_{t}\big )\right ) \\ &\quad \ + \frac{1}{2} \sum _{k=1}^d \partial ^2_{x_kx_k}\phi (\widetilde{X}_t,\widetilde{Y}_t)\left (\sigma _1^2 D\big (\widetilde{X}_{t}-u_t\big )_{kk}^2 \!+\! \sigma _2^2 D\big (\widetilde{X}_{t}-\widetilde{Y}_{t}\big )_{kk}^2 \!+\! \sigma _3^2 D\big (\nabla{\mathcal{E}}(\widetilde{X}_{t})\big )_{kk}^2\right ) \end{split} \end{equation*}
according to the fundamental theorem of calculus. This shows that
 $\widetilde{\rho} \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
satisfies the Fokker-Planck equation
$\widetilde{\rho} \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
satisfies the Fokker-Planck equation
 \begin{equation} \begin{aligned} &\frac{d}{dt}\iint \phi (x,y) \,d\widetilde{\rho} _t(x,y) = - \iint \kappa S^{\beta,\theta }(x,y) \left \langle y-x,\nabla _y\phi (x,y) \right \rangle d\widetilde{\rho} _t(x,y)\\ &\quad \ - \iint \lambda _1\left \langle x - u_t, \nabla _x \phi (x,y) \right \rangle + \lambda _2\left \langle x-y,\nabla _x\phi (x,y) \right \rangle + \lambda _3\left \langle \nabla{\mathcal{E}}(x), \nabla _x \phi (x,y) \right \rangle d\widetilde{\rho} _t(x,y)\\ &\quad \ + \frac{1}{2} \iint \sum _{k=1}^d \left (\sigma _1^2D\!\left (x-u_t\right )_{kk}^2 + \sigma _2^2D\!\left (x-y\right )_{kk}^2 + \sigma _3^2D\!\left (\nabla{\mathcal{E}}(x)\right )_{kk}^2 \right ) \partial ^2_{x_kx_k} \phi (x,y) \,d\widetilde{\rho} _t(x,y) \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\frac{d}{dt}\iint \phi (x,y) \,d\widetilde{\rho} _t(x,y) = - \iint \kappa S^{\beta,\theta }(x,y) \left \langle y-x,\nabla _y\phi (x,y) \right \rangle d\widetilde{\rho} _t(x,y)\\ &\quad \ - \iint \lambda _1\left \langle x - u_t, \nabla _x \phi (x,y) \right \rangle + \lambda _2\left \langle x-y,\nabla _x\phi (x,y) \right \rangle + \lambda _3\left \langle \nabla{\mathcal{E}}(x), \nabla _x \phi (x,y) \right \rangle d\widetilde{\rho} _t(x,y)\\ &\quad \ + \frac{1}{2} \iint \sum _{k=1}^d \left (\sigma _1^2D\!\left (x-u_t\right )_{kk}^2 + \sigma _2^2D\!\left (x-y\right )_{kk}^2 + \sigma _3^2D\!\left (\nabla{\mathcal{E}}(x)\right )_{kk}^2 \right ) \partial ^2_{x_kx_k} \phi (x,y) \,d\widetilde{\rho} _t(x,y) \end{aligned} \end{equation}
The remainder is identical to the cited reference and is summarised below for completeness.
Step 3: Setting
 $\mathcal{T} u\,:\!=\,y_{\alpha }({\widetilde{\rho} _Y})\in \mathcal{C}([0,T],\mathbb{R}^d)$
provides the self-mapping property of the map
$\mathcal{T} u\,:\!=\,y_{\alpha }({\widetilde{\rho} _Y})\in \mathcal{C}([0,T],\mathbb{R}^d)$
provides the self-mapping property of the map
 \begin{align*}\mathcal{T}\;:\;\mathcal{C}([0,T],\mathbb{R}^d)\rightarrow\mathcal{C}([0,T],\mathbb{R}^d), \quad u\mapsto \mathcal{T}u=y_{\alpha }({\widetilde{\rho} _Y}), \end{align*}
\begin{align*}\mathcal{T}\;:\;\mathcal{C}([0,T],\mathbb{R}^d)\rightarrow\mathcal{C}([0,T],\mathbb{R}^d), \quad u\mapsto \mathcal{T}u=y_{\alpha }({\widetilde{\rho} _Y}), \end{align*}
which is compact as a consequence of a stability estimate for the consensus point [Reference Carrillo, Choi, Totzeck and Tse12, Lemma 3.2]. More precisely, as shown in the cited result, it holds
 $\|{y_{\alpha }({\widetilde{\rho} _{Y,t}})-y_{\alpha }({\widetilde{\rho} _{Y,s}})}\|_2 \lesssim W_2(\widetilde{\rho} _{Y,t},\widetilde{\rho} _{Y,s})$
for
$\|{y_{\alpha }({\widetilde{\rho} _{Y,t}})-y_{\alpha }({\widetilde{\rho} _{Y,s}})}\|_2 \lesssim W_2(\widetilde{\rho} _{Y,t},\widetilde{\rho} _{Y,s})$
for
 $\widetilde{\rho} _{Y,t},\widetilde{\rho} _{Y,s}\in\mathcal{P}_4(\mathbb{R}^d)$
. Together with the Hölder-
$\widetilde{\rho} _{Y,t},\widetilde{\rho} _{Y,s}\in\mathcal{P}_4(\mathbb{R}^d)$
. Together with the Hölder-
 $1/2$
continuity of the Wasserstein-
$1/2$
continuity of the Wasserstein-
 $2$
distance
$2$
distance
 $W_2(\widetilde{\rho} _{Y,t},\widetilde{\rho} _{Y,s})$
, this ensures the claimed compactness of
$W_2(\widetilde{\rho} _{Y,t},\widetilde{\rho} _{Y,s})$
, this ensures the claimed compactness of
 $\mathcal{T}$
.
$\mathcal{T}$
.
Step 4: Then, for
 $u=\vartheta\mathcal{T} u$
with
$u=\vartheta\mathcal{T} u$
with
 $\vartheta \in [0,1]$
, there exists
$\vartheta \in [0,1]$
, there exists
 $\rho \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
satisfying (2.7) with marginal
$\rho \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
satisfying (2.7) with marginal
 $\rho _Y$
such that
$\rho _Y$
such that
 $u=\vartheta y_{\alpha }({\rho _Y})$
. For such
$u=\vartheta y_{\alpha }({\rho _Y})$
. For such
 $u$
, a uniform bound can be obtained either thanks to the boundedness or the growth condition of
$u$
, a uniform bound can be obtained either thanks to the boundedness or the growth condition of
 $\mathcal{E}$
required in the statement. An application of the Leray-Schauder fixed point theorem concludes the proof by providing a solution to (1.5).
$\mathcal{E}$
required in the statement. An application of the Leray-Schauder fixed point theorem concludes the proof by providing a solution to (1.5).
2.2. Main result
We now present the main theoretical result about global mean-field law convergence of CBO with memory effects and gradient information for objectives that satisfy the following conditions.
Definition 2.4 (Assumptions). Throughout, we are interested in functions
 ${\mathcal{E}} \in\mathcal{C}(\mathbb{R}^d)$
, for which
${\mathcal{E}} \in\mathcal{C}(\mathbb{R}^d)$
, for which
-
A1 there exists a unique
$x^*\in \mathbb{R}^d$
such that
${\mathcal{E}}(x^*)=\inf _{x\in \mathbb{R}^d}{\mathcal{E}}(x)\,=\!:\,\underline{\mathcal{E}}$
, and
-
A2 there exist
${\mathcal{E}}_{\infty },R_0,\eta \gt 0$
, and
$\nu \in (0,\infty )$
such that
(2.8)
\begin{align} \left \|{x-x^*}\right \|_{\infty} &\leq \frac{1}{\eta }({\mathcal{E}}(x)-\underline{\mathcal{E}})^{\nu } \quad \text{for all } x \in B^\infty _{R_0}(x^*), \end{align}
(2.9)
\begin{align} {\mathcal{E}}_{\infty } &\lt{\mathcal{E}}(x)-\underline{\mathcal{E}}\quad \text{for all } x \in \big (B^\infty _{R_0}(x^*)\big )^c. \end{align}






Furthermore, for the case of an additional gradient drift component, i.e., if
 $\lambda _3\not =0$
, we additionally require that
$\lambda _3\not =0$
, we additionally require that
 ${\mathcal{E}}\in\mathcal{C}^1(\mathbb{R}^d)$
and that
${\mathcal{E}}\in\mathcal{C}^1(\mathbb{R}^d)$
and that
-
A3 there exist
$C_{\nabla{\mathcal{E}}} \gt 0$
such that
(2.10)
\begin{align} \left \|{\nabla{\mathcal{E}}(x)}\right \|_2 \leq C_{\nabla{\mathcal{E}}}\left \|{x-x^*}\right \|_2 \quad \text{for all } x \in \mathbb{R}^d. \end{align}


In the case, where no gradient drift is present, i.e.,
 $\lambda _3=0$
in equations (1.1), (1.5) and (1.6), the objective function
$\lambda _3=0$
in equations (1.1), (1.5) and (1.6), the objective function
 $\mathcal{E}$
is only required to be continuous and satisfy Assumptions A1 and A2. While the former merely imposes that the infimum is attained at
$\mathcal{E}$
is only required to be continuous and satisfy Assumptions A1 and A2. While the former merely imposes that the infimum is attained at
 $x^*$
, the latter can be regarded as a tractability condition of the energy landscape of
$x^*$
, the latter can be regarded as a tractability condition of the energy landscape of
 $\mathcal{E}$
[Reference Fornasier, Huang, Pareschi and Sünnen26, Reference Fornasier, Klock and Riedl28]. More precisely, the inverse continuity condition (2.8) ensures that
$\mathcal{E}$
[Reference Fornasier, Huang, Pareschi and Sünnen26, Reference Fornasier, Klock and Riedl28]. More precisely, the inverse continuity condition (2.8) ensures that
 $\mathcal{E}$
is locally coercive in some neighbourhood of the global minimiser
$\mathcal{E}$
is locally coercive in some neighbourhood of the global minimiser
 $x^*$
. Condition (2.9), on the other hand, guarantees that in the farfield
$x^*$
. Condition (2.9), on the other hand, guarantees that in the farfield
 $\mathcal{E}$
is bounded away from the minimal value by at least
$\mathcal{E}$
is bounded away from the minimal value by at least
 ${\mathcal{E}}_{\infty }$
. This in particular excludes objectives for which
${\mathcal{E}}_{\infty }$
. This in particular excludes objectives for which
 ${\mathcal{E}}(x)\approx \underline{\mathcal{E}}$
far away from
${\mathcal{E}}(x)\approx \underline{\mathcal{E}}$
far away from
 $x^*$
. Note that A2 actually already implies the uniqueness of
$x^*$
. Note that A2 actually already implies the uniqueness of
 $x^*$
requested in A1. In case of an additional gradient drift term in the dynamics, i.e.,
$x^*$
requested in A1. In case of an additional gradient drift term in the dynamics, i.e.,
 $\lambda _3\not =0$
, the objective naturally needs to be continuously differentiable. Furthermore, in Assumption A3 we impose that the gradient
$\lambda _3\not =0$
, the objective naturally needs to be continuously differentiable. Furthermore, in Assumption A3 we impose that the gradient
 $\nabla{\mathcal{E}}$
grows at most linearly. This is a significantly weaker assumption compared to typical smoothness assumptions about
$\nabla{\mathcal{E}}$
grows at most linearly. This is a significantly weaker assumption compared to typical smoothness assumptions about
 $\mathcal{E}$
in the optimisation literature (in particular in the analysis of stochastic gradient descent), where Lipschitz-continuity of the gradient of
$\mathcal{E}$
in the optimisation literature (in particular in the analysis of stochastic gradient descent), where Lipschitz-continuity of the gradient of
 $\mathcal{E}$
is required [Reference Moulines and Bach49].
$\mathcal{E}$
is required [Reference Moulines and Bach49].
We are now ready to state the main theoretical result. Its proof is deferred to Section 3. For the reader’s convenience let us recall that
 \begin{equation*} W_2^2\left (\rho _t,\delta _{(x^*,x^*)}\right ) = \iint \! \left (\left \|{x-x^*}\right \|_2^2 + \left \|{y -x^*}\right \|_2^2\right ) d\rho _t(x,y), \end{equation*}
\begin{equation*} W_2^2\left (\rho _t,\delta _{(x^*,x^*)}\right ) = \iint \! \left (\left \|{x-x^*}\right \|_2^2 + \left \|{y -x^*}\right \|_2^2\right ) d\rho _t(x,y), \end{equation*}
which motivates to investigate the behaviour of the Lyapunov functional
 $\mathcal{V}(\rho _t)$
as introduced in (2.11) below.
$\mathcal{V}(\rho _t)$
as introduced in (2.11) below.
Theorem 2.5.
Let
 ${\mathcal{E}}\in\mathcal{C}(\mathbb{R}^d)$
satisfy A1 and A2. Furthermore, in the case of an active gradient drift in the CBO dynamcis (
1.5
), i.e., if
${\mathcal{E}}\in\mathcal{C}(\mathbb{R}^d)$
satisfy A1 and A2. Furthermore, in the case of an active gradient drift in the CBO dynamcis (
1.5
), i.e., if
 $\lambda _3\not =0$
, let
$\lambda _3\not =0$
, let
 ${\mathcal{E}}\in\mathcal{C}^1(\mathbb{R}^d)$
obey in addition A3. Moreover, let
${\mathcal{E}}\in\mathcal{C}^1(\mathbb{R}^d)$
obey in addition A3. Moreover, let
 $\rho _0 \in\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d)$
be such that
$\rho _0 \in\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d)$
be such that
 $(x^*,x^*)\in \operatorname{supp}(\rho _0)$
. Let us define the functional
$(x^*,x^*)\in \operatorname{supp}(\rho _0)$
. Let us define the functional
 \begin{equation} \mathcal{V}(\rho _t) \,:\!=\, \frac{1}{2} \iint \! \left (\left \|{x-x^*}\right \|_2^2 + \left \|{y-x}\right \|_2^2\right ) d\rho _t(x,y), \end{equation}
\begin{equation} \mathcal{V}(\rho _t) \,:\!=\, \frac{1}{2} \iint \! \left (\left \|{x-x^*}\right \|_2^2 + \left \|{y-x}\right \|_2^2\right ) d\rho _t(x,y), \end{equation}
and the rates
 \begin{align} \chi _1 &\,:\!=\, \min \left \{\lambda _1 \!-\! \lambda _2 \!-\! 3\lambda _3 C_{\nabla{\mathcal{E}}} \!-\! 2\sigma _1^2 \!-\! 2\sigma _3^2C_{\nabla{\mathcal{E}}}^2, 2\kappa \theta \!+\! \lambda _2 \!-\! \lambda _1 \!-\! \lambda _3 C_{\nabla{\mathcal{E}}} \!-\! 2\sigma _2^2\right \}, \end{align}
\begin{align} \chi _1 &\,:\!=\, \min \left \{\lambda _1 \!-\! \lambda _2 \!-\! 3\lambda _3 C_{\nabla{\mathcal{E}}} \!-\! 2\sigma _1^2 \!-\! 2\sigma _3^2C_{\nabla{\mathcal{E}}}^2, 2\kappa \theta \!+\! \lambda _2 \!-\! \lambda _1 \!-\! \lambda _3 C_{\nabla{\mathcal{E}}} \!-\! 2\sigma _2^2\right \}, \end{align}
 \begin{align} \chi _2 &\,:\!=\, \max \left \{3\lambda _1 \!+\! \lambda _2 \!+\! 3\lambda _3 C_{\nabla{\mathcal{E}}} \!-\! 2\sigma _1^2 \!+\! 2\sigma _3^2C_{\nabla{\mathcal{E}}}^2, 2\kappa \theta \!+\! 3\lambda _2 \!+\! \lambda _1 \!+\! \lambda _3 C_{\nabla{\mathcal{E}}} \!-\! 2\sigma _2^2\right \}, \end{align}
\begin{align} \chi _2 &\,:\!=\, \max \left \{3\lambda _1 \!+\! \lambda _2 \!+\! 3\lambda _3 C_{\nabla{\mathcal{E}}} \!-\! 2\sigma _1^2 \!+\! 2\sigma _3^2C_{\nabla{\mathcal{E}}}^2, 2\kappa \theta \!+\! 3\lambda _2 \!+\! \lambda _1 \!+\! \lambda _3 C_{\nabla{\mathcal{E}}} \!-\! 2\sigma _2^2\right \}, \end{align}
which we assume to be strictly positive through a sufficient choice of the parameters of the CBO dynamics. Furthermore, provided that
 $\mathcal{V}(\rho _0)\gt 0$
, fix any
$\mathcal{V}(\rho _0)\gt 0$
, fix any
 $\varepsilon \in (0,\mathcal{V}(\rho _0))$
,
$\varepsilon \in (0,\mathcal{V}(\rho _0))$
,
 $\vartheta \in (0,1)$
and define the time horizon
$\vartheta \in (0,1)$
and define the time horizon
 \begin{equation} T^* \,:\!=\, \frac{1}{(1-\vartheta )\chi _1}\log \left (\frac{\mathcal{V}(\rho _0)}{\varepsilon }\right ). \end{equation}
\begin{equation} T^* \,:\!=\, \frac{1}{(1-\vartheta )\chi _1}\log \left (\frac{\mathcal{V}(\rho _0)}{\varepsilon }\right ). \end{equation}
Then, there exists
 $\alpha _0 \gt 0$
, depending (among problem-dependent quantities) also on
$\alpha _0 \gt 0$
, depending (among problem-dependent quantities) also on
 $\varepsilon$
and
$\varepsilon$
and
 $\vartheta$
, such that for all
$\vartheta$
, such that for all
 $\alpha \gt \alpha _0$
, if
$\alpha \gt \alpha _0$
, if
 $\rho \in\mathcal{C}([0,T^*],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
is a weak solution to the Fokker-Planck equation (
1.6
) on the time interval
$\rho \in\mathcal{C}([0,T^*],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
is a weak solution to the Fokker-Planck equation (
1.6
) on the time interval
 $[0,T^*]$
with initial condition
$[0,T^*]$
with initial condition
 $\rho _0$
, we have
$\rho _0$
, we have
 \begin{equation} \mathcal{V}(\rho _T) = \varepsilon \quad \text{with}\quad T \in \left [\frac{(1-\vartheta )\chi _1}{(1+\vartheta/2)\chi _2}T^*,T^*\right ]. \end{equation}
\begin{equation} \mathcal{V}(\rho _T) = \varepsilon \quad \text{with}\quad T \in \left [\frac{(1-\vartheta )\chi _1}{(1+\vartheta/2)\chi _2}T^*,T^*\right ]. \end{equation}
Furthermore, on the time interval
 $[0,T]$
,
$[0,T]$
,
 $\mathcal{V}(\rho _t)$
decays at least exponentially fast, i.e., for all
$\mathcal{V}(\rho _t)$
decays at least exponentially fast, i.e., for all
 $t\in [0,T]$
it holds
$t\in [0,T]$
it holds
 \begin{equation} W_2^2(\rho _t,\delta _{(x^*,x^*)}) \leq 6\mathcal{V}(\rho _t) \leq 6\mathcal{V}(\rho _0) \exp \left ({-}(1-\vartheta )\chi _1 t\right ). \end{equation}
\begin{equation} W_2^2(\rho _t,\delta _{(x^*,x^*)}) \leq 6\mathcal{V}(\rho _t) \leq 6\mathcal{V}(\rho _0) \exp \left ({-}(1-\vartheta )\chi _1 t\right ). \end{equation}
Theorem 2.5 proves the exponentially fast convergence of the law
 $\rho$
of the dynamics (1.5) to the global minimiser
$\rho$
of the dynamics (1.5) to the global minimiser
 $x^*$
of
$x^*$
of
 $\mathcal{E}$
under a minimal assumption about the initial distribution
$\mathcal{E}$
under a minimal assumption about the initial distribution
 $\rho _0$
. The result in particular allows to devise a strategy for the parameter choices of the method. Namely, fixing the parameters
$\rho _0$
. The result in particular allows to devise a strategy for the parameter choices of the method. Namely, fixing the parameters
 $\lambda _2, \lambda _3,\sigma _1,\sigma _2,\sigma _3$
and
$\lambda _2, \lambda _3,\sigma _1,\sigma _2,\sigma _3$
and
 $\theta$
, choosing
$\theta$
, choosing
 $\lambda _1$
and consecutively
$\lambda _1$
and consecutively
 $\kappa$
such that
$\kappa$
such that
 \begin{align*} \lambda _1 \gt \lambda _2 + 3\lambda _3 C_{\nabla{\mathcal{E}}} + 2\sigma _1^2 + 2\sigma _3^2C_{\nabla{\mathcal{E}}}^2 \quad \text{and} \quad \kappa \gt \frac{1}{2\theta } \left ( - \lambda _2 + \lambda _1 + \lambda _3 C_{\nabla{\mathcal{E}}} + 2\sigma _2^2\right ) \end{align*}
\begin{align*} \lambda _1 \gt \lambda _2 + 3\lambda _3 C_{\nabla{\mathcal{E}}} + 2\sigma _1^2 + 2\sigma _3^2C_{\nabla{\mathcal{E}}}^2 \quad \text{and} \quad \kappa \gt \frac{1}{2\theta } \left ( - \lambda _2 + \lambda _1 + \lambda _3 C_{\nabla{\mathcal{E}}} + 2\sigma _2^2\right ) \end{align*}
ensures that the convergence rate
 $\chi _1$
is strictly positive. Since
$\chi _1$
is strictly positive. Since
 $\chi _2\geq \chi _1$
,
$\chi _2\geq \chi _1$
,
 $\chi _2\gt 0$
as well. Given a desired accuracy
$\chi _2\gt 0$
as well. Given a desired accuracy
 $\varepsilon$
, by consulting the proof in Section 3.4, we can further derive an estimate on the lower bound of
$\varepsilon$
, by consulting the proof in Section 3.4, we can further derive an estimate on the lower bound of
 $\alpha$
, namely
$\alpha$
, namely
 \begin{align*} \alpha _0 \sim d+\log 16d + \log \left (\frac{\mathcal{V}(\rho _0)}{\varepsilon }\right ) - \log c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )- \log \rho _0\big (B^\infty _{r}(x^*)\times B^\infty _{r}(x^*)\big ) \end{align*}
\begin{align*} \alpha _0 \sim d+\log 16d + \log \left (\frac{\mathcal{V}(\rho _0)}{\varepsilon }\right ) - \log c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )- \log \rho _0\big (B^\infty _{r}(x^*)\times B^\infty _{r}(x^*)\big ) \end{align*}
for some suitably small
 $r\in (0,R_0)$
, which, like the hidden constant, may depend on
$r\in (0,R_0)$
, which, like the hidden constant, may depend on
 $\varepsilon$
. The choice of the first set of parameters, in particular what concerns the drift towards the historical best and in the direction of the negative gradient, requires some manual hyperparameter tuning and depends on the problem at hand. We will see this also in Section 4, where we conduct numerical experiments in different application areas.
$\varepsilon$
. The choice of the first set of parameters, in particular what concerns the drift towards the historical best and in the direction of the negative gradient, requires some manual hyperparameter tuning and depends on the problem at hand. We will see this also in Section 4, where we conduct numerical experiments in different application areas.
Eventually, with (2.13) one can determine the maximal time horizon
 $T^*$
, until which the Lyapunov functional
$T^*$
, until which the Lyapunov functional
 $\mathcal{V}(\rho _t)$
is guaranteed to have reached the prescribed
$\mathcal{V}(\rho _t)$
is guaranteed to have reached the prescribed
 $\varepsilon$
. The exact time point
$\varepsilon$
. The exact time point
 $T$
, where
$T$
, where
 $\mathcal{V}(\rho _T) = \varepsilon$
, is characterised more concretely in equation (2.14). Due to the presence of memory effects and gradient information, which might counteract the consensus drift of CBO, it seems challenging to specify
$\mathcal{V}(\rho _T) = \varepsilon$
, is characterised more concretely in equation (2.14). Due to the presence of memory effects and gradient information, which might counteract the consensus drift of CBO, it seems challenging to specify
 $T$
more closely. However, in the case of standard CBO,
$T$
more closely. However, in the case of standard CBO,
 $T$
turns out to be equal to
$T$
turns out to be equal to
 $T^*$
up to a factor depending merely on
$T^*$
up to a factor depending merely on
 $\vartheta$
, see, e.g., [Reference Fornasier, Klock and Riedl28].
$\vartheta$
, see, e.g., [Reference Fornasier, Klock and Riedl28].
In fact, this result can be retrieved as a special case of the subsequent Corollary 2.6, where we state an analogous convergence result for the CBO dynamics with gradient information but without memory effect. Its respective proof follows the lines of the one of the richer dynamics in Section 3, cf. also [Reference Fornasier, Klock and Riedl28, Theorem 12] and [Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29, Theorem 2], and it is left as an exercise to the reader interested in the technical details of the proof technique. More precisely, for the instantaneous CBO model with gradient drift,
 \begin{align} \begin{aligned}d\widetilde{X}_{t}^i & = -\lambda _1\big (\widetilde{X}_{t}^i-y_{\alpha }(\widehat{\widetilde{\rho }}_t\!^{N})\big ) \,dt -\lambda _3\nabla{\mathcal{E}}(\widetilde{X}_{t}^i) \,dt\\ &\quad +\sigma _1 D\big (\widetilde{X}_{t}^i-y_{\alpha }(\widehat{\widetilde{\rho }}_t\!^{N})\big ) \,d\widetilde{B}_{t}^{1,i} +\sigma _3 D\big (\nabla{\mathcal{E}}(\widetilde{X}_{t}^i)\big ) \,d\widetilde{B}_{t}^{3,i}, \end{aligned}\end{align}
\begin{align} \begin{aligned}d\widetilde{X}_{t}^i & = -\lambda _1\big (\widetilde{X}_{t}^i-y_{\alpha }(\widehat{\widetilde{\rho }}_t\!^{N})\big ) \,dt -\lambda _3\nabla{\mathcal{E}}(\widetilde{X}_{t}^i) \,dt\\ &\quad +\sigma _1 D\big (\widetilde{X}_{t}^i-y_{\alpha }(\widehat{\widetilde{\rho }}_t\!^{N})\big ) \,d\widetilde{B}_{t}^{1,i} +\sigma _3 D\big (\nabla{\mathcal{E}}(\widetilde{X}_{t}^i)\big ) \,d\widetilde{B}_{t}^{3,i}, \end{aligned}\end{align}
where
 $\widehat{\widetilde{\rho }}_t\!^{N}\,:\!=\,\frac{1}{N}\sum _{i=1}^N\delta _{\widetilde{X}_{t}^i}$
and to which the associated mean-field Fokker-Planck equation reads
$\widehat{\widetilde{\rho }}_t\!^{N}\,:\!=\,\frac{1}{N}\sum _{i=1}^N\delta _{\widetilde{X}_{t}^i}$
and to which the associated mean-field Fokker-Planck equation reads
 \begin{align} \begin{aligned}\partial _t\widetilde{\rho} _t &= \textrm{div} \big ( \big ( \lambda _1\left (x - y_{\alpha }(\widetilde{\rho} _{t})\right ) + \lambda _3\nabla{\mathcal{E}}(x) \big )\widetilde{\rho} _t \big ) \\ &\quad + \frac{1}{2}\sum _{k=1}^d\partial ^2_{x_kx_k}\left (\left (\sigma _1^2D\!\left (x-y_{\alpha }(\widetilde{\rho} _{t})\right )_{kk}^2 + \sigma _3^2D\!\left (\nabla{\mathcal{E}}(x)\right )_{kk}^2\right )\widetilde{\rho} _t\right ), \end{aligned}\end{align}
\begin{align} \begin{aligned}\partial _t\widetilde{\rho} _t &= \textrm{div} \big ( \big ( \lambda _1\left (x - y_{\alpha }(\widetilde{\rho} _{t})\right ) + \lambda _3\nabla{\mathcal{E}}(x) \big )\widetilde{\rho} _t \big ) \\ &\quad + \frac{1}{2}\sum _{k=1}^d\partial ^2_{x_kx_k}\left (\left (\sigma _1^2D\!\left (x-y_{\alpha }(\widetilde{\rho} _{t})\right )_{kk}^2 + \sigma _3^2D\!\left (\nabla{\mathcal{E}}(x)\right )_{kk}^2\right )\widetilde{\rho} _t\right ), \end{aligned}\end{align}
we have the following convergence result.
Corollary 2.6.
Let
 ${\mathcal{E}}\in\mathcal{C}(\mathbb{R}^d)$
satisfy A1 and A2. Furthermore, in the case of an active gradient drift, i.e., if
${\mathcal{E}}\in\mathcal{C}(\mathbb{R}^d)$
satisfy A1 and A2. Furthermore, in the case of an active gradient drift, i.e., if
 $\lambda _3\not =0$
, let
$\lambda _3\not =0$
, let
 ${\mathcal{E}}\in\mathcal{C}^1(\mathbb{R}^d)$
obey in addition A3. Moreover, let
${\mathcal{E}}\in\mathcal{C}^1(\mathbb{R}^d)$
obey in addition A3. Moreover, let
 $\widetilde{\rho} _0 \in\mathcal{P}_4(\mathbb{R}^d)$
be such that
$\widetilde{\rho} _0 \in\mathcal{P}_4(\mathbb{R}^d)$
be such that
 $x^*\in \operatorname{supp}(\widetilde{\rho} _0)$
. Let us define the functional
$x^*\in \operatorname{supp}(\widetilde{\rho} _0)$
. Let us define the functional
 \begin{equation} \widetilde{\mathcal{V}}(\widetilde{\rho} _t) \,:\!=\, \frac{1}{2} \int \! \left \|{x-x^*}\right \|_2^2 d\widetilde{\rho} _t(x), \end{equation}
\begin{equation} \widetilde{\mathcal{V}}(\widetilde{\rho} _t) \,:\!=\, \frac{1}{2} \int \! \left \|{x-x^*}\right \|_2^2 d\widetilde{\rho} _t(x), \end{equation}
and the rates
 \begin{align} \widetilde{\chi} _1 &\,:\!=\, 2\lambda _1 - 2\lambda _3 C_{\nabla{\mathcal{E}}} - \sigma _1^2 - \sigma _3^2C_{\nabla{\mathcal{E}}}^2, \end{align}
\begin{align} \widetilde{\chi} _1 &\,:\!=\, 2\lambda _1 - 2\lambda _3 C_{\nabla{\mathcal{E}}} - \sigma _1^2 - \sigma _3^2C_{\nabla{\mathcal{E}}}^2, \end{align}
 \begin{align} \widetilde{\chi} _2 &\,:\!=\, 2\lambda _1 + 2\lambda _3 C_{\nabla{\mathcal{E}}} - \sigma _1^2 + \sigma _3^2C_{\nabla{\mathcal{E}}}^2, \end{align}
\begin{align} \widetilde{\chi} _2 &\,:\!=\, 2\lambda _1 + 2\lambda _3 C_{\nabla{\mathcal{E}}} - \sigma _1^2 + \sigma _3^2C_{\nabla{\mathcal{E}}}^2, \end{align}
which we assume to be strictly positive through a sufficient choice of the parameters of the CBO dynamics. Furthermore, provided that
 $\widetilde{\mathcal{V}}(\widetilde{\rho} _0)\gt 0$
, fix any
$\widetilde{\mathcal{V}}(\widetilde{\rho} _0)\gt 0$
, fix any
 $\varepsilon \in (0,\widetilde{\mathcal{V}}(\widetilde{\rho} _0))$
,
$\varepsilon \in (0,\widetilde{\mathcal{V}}(\widetilde{\rho} _0))$
,
 $\vartheta \in (0,1)$
and define the time horizon
$\vartheta \in (0,1)$
and define the time horizon
 \begin{equation} \widetilde T^* \,:\!=\, \frac{1}{(1-\vartheta )\widetilde{\chi} _1}\log \bigg (\frac{\widetilde{\mathcal{V}}(\widetilde{\rho} _0)}{\varepsilon }\bigg ). \end{equation}
\begin{equation} \widetilde T^* \,:\!=\, \frac{1}{(1-\vartheta )\widetilde{\chi} _1}\log \bigg (\frac{\widetilde{\mathcal{V}}(\widetilde{\rho} _0)}{\varepsilon }\bigg ). \end{equation}
Then, there exists
 $\widetilde{\alpha}_0 \gt 0$
, depending (among problem-dependent quantities) also on
$\widetilde{\alpha}_0 \gt 0$
, depending (among problem-dependent quantities) also on
 $\varepsilon$
and
$\varepsilon$
and
 $\vartheta$
, such that for all
$\vartheta$
, such that for all
 $\alpha \gt \widetilde{\alpha}_0$
, if
$\alpha \gt \widetilde{\alpha}_0$
, if
 $\widetilde{\rho} \in\mathcal{C}([0,T^*],\mathcal{P}_4(\mathbb{R}^d))$
is a weak solution to the Fokker-Planck equation (
2.17
) on the time interval
$\widetilde{\rho} \in\mathcal{C}([0,T^*],\mathcal{P}_4(\mathbb{R}^d))$
is a weak solution to the Fokker-Planck equation (
2.17
) on the time interval
 $[0,\widetilde T^*]$
with initial condition
$[0,\widetilde T^*]$
with initial condition
 $\widetilde{\rho} _0$
, we have
$\widetilde{\rho} _0$
, we have
 \begin{equation} \widetilde{\mathcal{V}}(\widetilde{\rho} _{\widetilde{T}}) = \varepsilon \quad \text{with}\quad \widetilde{T} \in \left [\frac{(1-\vartheta )\widetilde{\chi} _1}{(1+\vartheta/2)\widetilde{\chi} _2}\widetilde{T}^*,\widetilde{T}^*\right ]. \end{equation}
\begin{equation} \widetilde{\mathcal{V}}(\widetilde{\rho} _{\widetilde{T}}) = \varepsilon \quad \text{with}\quad \widetilde{T} \in \left [\frac{(1-\vartheta )\widetilde{\chi} _1}{(1+\vartheta/2)\widetilde{\chi} _2}\widetilde{T}^*,\widetilde{T}^*\right ]. \end{equation}
Furthermore, on the time interval
 $[0,\widetilde{T}]$
,
$[0,\widetilde{T}]$
,
 $\widetilde{\mathcal{V}}(\widetilde{\rho}_t)$
decays at least exponentially fast, i.e., for all
$\widetilde{\mathcal{V}}(\widetilde{\rho}_t)$
decays at least exponentially fast, i.e., for all
 $t\in [0,\widetilde{T}]$
it holds
$t\in [0,\widetilde{T}]$
it holds
 \begin{equation} W_2^2(\widetilde{\rho} _t,\delta _{x^*}) = 2\widetilde{\mathcal{V}}(\widetilde{\rho}_t) \leq 2\widetilde{\mathcal{V}}(\widetilde{\rho}_0) \exp \left ({-}(1-\vartheta )\widetilde{\chi}_1 t\right ). \end{equation}
\begin{equation} W_2^2(\widetilde{\rho} _t,\delta _{x^*}) = 2\widetilde{\mathcal{V}}(\widetilde{\rho}_t) \leq 2\widetilde{\mathcal{V}}(\widetilde{\rho}_0) \exp \left ({-}(1-\vartheta )\widetilde{\chi}_1 t\right ). \end{equation}
3. Proof details for Section 2.2
In what follows, we provide the proof details for the global mean-field law convergence result of CBO with memory effects and gradient information, Theorem 2.5. The entire section can be read as a proof sketch with Corollaries 3.3 and 3.5, Propositions 3.6 and 3.8 containing the key individual statements. How to combine these results rigorously to complete the proof of Theorem 2.5 is then covered in detail in Section 3.4.
Remark 3.1.
Without loss of generality, we assume
 $\underline{\mathcal{E}} = 0$
throughout this section.
$\underline{\mathcal{E}} = 0$
throughout this section.
3.1. Evolution of the mean-field limit
Recall that our overall goal is to establish the convergence of the dynamics (1.6) to a Dirac delta at the global minimiser
 $x^*$
with respect to the Wasserstein-
$x^*$
with respect to the Wasserstein-
 $2$
distance, i.e.,
$2$
distance, i.e.,
 \begin{equation*} W_2\!\left (\rho _t, \delta _{(x^*,x^*)}\right ) \rightarrow 0 \quad \text {as} \quad t\rightarrow \infty. \end{equation*}
\begin{equation*} W_2\!\left (\rho _t, \delta _{(x^*,x^*)}\right ) \rightarrow 0 \quad \text {as} \quad t\rightarrow \infty. \end{equation*}
To this end, we analyse the decay behaviour of the functional
 $\mathcal{V}(\rho _t)$
as defined in (2.11), i.e.,
$\mathcal{V}(\rho _t)$
as defined in (2.11), i.e.,
 $\mathcal{V}(\rho _t) = \frac{1}{2} \iint \!\big (\!\left \|{x-x^*}\right \|_2^2 + \left \|{y-x}\right \|_2^2\!\big )\,d\rho _t(x,y)$
. More precisely, we will show its exponential decay with a rate controllable through the parameters of the CBO method.
$\mathcal{V}(\rho _t) = \frac{1}{2} \iint \!\big (\!\left \|{x-x^*}\right \|_2^2 + \left \|{y-x}\right \|_2^2\!\big )\,d\rho _t(x,y)$
. More precisely, we will show its exponential decay with a rate controllable through the parameters of the CBO method.
Let us start below with deriving the evolution inequalities for the functionals
 \begin{equation*} \mathcal{X}(\rho _t) = \frac {1}{2} \iint \! \left \|{x-x^*}\right \|_2^2 d\rho _t(x,y) \quad \text {and}\quad \mathcal{Y}(\rho _t) = \frac {1}{2} \iint \! \left \|{y-x}\right \|_2^2 d\rho _t(x,y). \end{equation*}
\begin{equation*} \mathcal{X}(\rho _t) = \frac {1}{2} \iint \! \left \|{x-x^*}\right \|_2^2 d\rho _t(x,y) \quad \text {and}\quad \mathcal{Y}(\rho _t) = \frac {1}{2} \iint \! \left \|{y-x}\right \|_2^2 d\rho _t(x,y). \end{equation*}
Lemma 3.2.
Let
 ${\mathcal{E}}\, :\, \mathbb{R}^d \rightarrow \mathbb{R}$
, and fix
${\mathcal{E}}\, :\, \mathbb{R}^d \rightarrow \mathbb{R}$
, and fix
 $\alpha,\lambda _1,\sigma _1 \gt 0$
and
$\alpha,\lambda _1,\sigma _1 \gt 0$
and
 $\lambda _2,\sigma _2,\lambda _3,\sigma _3,\beta,\kappa,\theta \geq 0$
. Moreover, let
$\lambda _2,\sigma _2,\lambda _3,\sigma _3,\beta,\kappa,\theta \geq 0$
. Moreover, let
 $T\gt 0$
and let
$T\gt 0$
and let
 $\rho \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
be a weak solution to the Fokker-Planck equation (
1.6
). Then, the functionals
$\rho \in\mathcal{C}([0,T],\mathcal{P}_4(\mathbb{R}^d\times \mathbb{R}^d))$
be a weak solution to the Fokker-Planck equation (
1.6
). Then, the functionals
 $\mathcal{X}(\rho _t)$
and
$\mathcal{X}(\rho _t)$
and
 $\mathcal{Y}(\rho _t)$
satisfy
$\mathcal{Y}(\rho _t)$
satisfy
 \begin{equation*} \begin{split} \frac{d}{dt}\!\begin{pmatrix}\mathcal{X}(\rho _t)\\\mathcal{Y}(\rho _t) \end{pmatrix} \!\leq &-\!\begin{pmatrix} 2\lambda _1 \!-\! \lambda _2 \!-\! 2\lambda _3 C_{\nabla{\mathcal{E}}} \!-\! \sigma _1^2 \!-\! \sigma _3^2C_{\nabla{\mathcal{E}}}^2 &\!\!\! -\lambda _2\!-\!\sigma _2^2 \\ -\lambda _1 \!-\! \lambda _3 C_{\nabla{\mathcal{E}}} \!-\! \sigma _1^2 \!-\! \sigma _3^2C_{\nabla{\mathcal{E}}}^2 &\!\!\! 2\kappa \theta \!+\! 2\lambda _2 \!-\! \lambda _1 \!-\! \lambda _3 C_{\nabla{\mathcal{E}}} - \sigma _2^2 \end{pmatrix}\! \begin{pmatrix}\mathcal{X}(\rho _t)\\\mathcal{Y}(\rho _t) \end{pmatrix}\\ &+ \sqrt{2}\begin{pmatrix} \left (\lambda _1\!+\!\sigma _1^2\right ) \!\sqrt{\mathcal{X}(\rho _t)} \\ \lambda _1 \sqrt{\mathcal{Y}(\rho _t)} \!+\! \sigma _1^2 \sqrt{\mathcal{X}(\rho _t)} \end{pmatrix}\!\left \|{y_{\alpha }({\rho _{Y,t}})\!-\!x^*}\right \|_2 \!+\! \frac{\sigma _1^2}{2} \!\begin{pmatrix} 1\\ 1 \end{pmatrix}\!\left \|{y_{\alpha }({\rho _{Y,t}})\!-\!x^*}\right \|_2^2, \end{split} \end{equation*}
\begin{equation*} \begin{split} \frac{d}{dt}\!\begin{pmatrix}\mathcal{X}(\rho _t)\\\mathcal{Y}(\rho _t) \end{pmatrix} \!\leq &-\!\begin{pmatrix} 2\lambda _1 \!-\! \lambda _2 \!-\! 2\lambda _3 C_{\nabla{\mathcal{E}}} \!-\! \sigma _1^2 \!-\! \sigma _3^2C_{\nabla{\mathcal{E}}}^2 &\!\!\! -\lambda _2\!-\!\sigma _2^2 \\ -\lambda _1 \!-\! \lambda _3 C_{\nabla{\mathcal{E}}} \!-\! \sigma _1^2 \!-\! \sigma _3^2C_{\nabla{\mathcal{E}}}^2 &\!\!\! 2\kappa \theta \!+\! 2\lambda _2 \!-\! \lambda _1 \!-\! \lambda _3 C_{\nabla{\mathcal{E}}} - \sigma _2^2 \end{pmatrix}\! \begin{pmatrix}\mathcal{X}(\rho _t)\\\mathcal{Y}(\rho _t) \end{pmatrix}\\ &+ \sqrt{2}\begin{pmatrix} \left (\lambda _1\!+\!\sigma _1^2\right ) \!\sqrt{\mathcal{X}(\rho _t)} \\ \lambda _1 \sqrt{\mathcal{Y}(\rho _t)} \!+\! \sigma _1^2 \sqrt{\mathcal{X}(\rho _t)} \end{pmatrix}\!\left \|{y_{\alpha }({\rho _{Y,t}})\!-\!x^*}\right \|_2 \!+\! \frac{\sigma _1^2}{2} \!\begin{pmatrix} 1\\ 1 \end{pmatrix}\!\left \|{y_{\alpha }({\rho _{Y,t}})\!-\!x^*}\right \|_2^2, \end{split} \end{equation*}
where the inequality has to be understood component-wise.
Proof. We note that the functions
 $\phi _{\mathcal{X}}(x,y) = 1/2\left \|{x-x^*}\right \|_2^2$
and
$\phi _{\mathcal{X}}(x,y) = 1/2\left \|{x-x^*}\right \|_2^2$
and
 $\phi _{\mathcal{Y}}(x,y) = 1/2\left \|{y-x}\right \|_2^2$
are in
$\phi _{\mathcal{Y}}(x,y) = 1/2\left \|{y-x}\right \|_2^2$
are in
 $\mathcal{C}^2_{*}(\mathbb{R}^d\times \mathbb{R}^d)$
and recall that
$\mathcal{C}^2_{*}(\mathbb{R}^d\times \mathbb{R}^d)$
and recall that
 $\rho$
satisfies the weak solution identity (2.1) for such test functions. Hence, by applying (2.1) with
$\rho$
satisfies the weak solution identity (2.1) for such test functions. Hence, by applying (2.1) with
 $\phi _{\mathcal{X}}$
and
$\phi _{\mathcal{X}}$
and
 $\phi _{\mathcal{Y}}$
as above, we obtain for the evolution of
$\phi _{\mathcal{Y}}$
as above, we obtain for the evolution of
 $\mathcal{X}(\rho _t)$
$\mathcal{X}(\rho _t)$
 \begin{equation} \begin{aligned} &\frac{d}{dt}\mathcal{X}(\rho _t) = - \iint \lambda _1\!\left \langle x \!-\! y_{\alpha }({\rho _{Y,t}}), x\!-\!x^* \right \rangle + \lambda _2 \!\left \langle x\!-\!y, x\!-\!x^* \right \rangle + \lambda _3 \!\left \langle \nabla{\mathcal{E}}(x), x\!-\!x^* \right \rangle d\rho _t(x,y)\\ &\qquad \qquad \;\; + \frac{1}{2} \iint \sigma _1^2\left \|{x\!-\!y_{\alpha }({\rho _{Y,t}})}\right \|_2^2 + \sigma _2^2\left \|{x\!-\!y}\right \|_2^2 + \sigma _3^2\left \|{\nabla{\mathcal{E}}(x)}\right \|_2^2 d\rho _t(x,y) \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\frac{d}{dt}\mathcal{X}(\rho _t) = - \iint \lambda _1\!\left \langle x \!-\! y_{\alpha }({\rho _{Y,t}}), x\!-\!x^* \right \rangle + \lambda _2 \!\left \langle x\!-\!y, x\!-\!x^* \right \rangle + \lambda _3 \!\left \langle \nabla{\mathcal{E}}(x), x\!-\!x^* \right \rangle d\rho _t(x,y)\\ &\qquad \qquad \;\; + \frac{1}{2} \iint \sigma _1^2\left \|{x\!-\!y_{\alpha }({\rho _{Y,t}})}\right \|_2^2 + \sigma _2^2\left \|{x\!-\!y}\right \|_2^2 + \sigma _3^2\left \|{\nabla{\mathcal{E}}(x)}\right \|_2^2 d\rho _t(x,y) \end{aligned} \end{equation}
and for the evolution of
 $\mathcal{Y}(\rho _t)$
$\mathcal{Y}(\rho _t)$
 \begin{equation} \begin{aligned} &\frac{d}{dt}\mathcal{Y}(\rho _t) = - \iint \kappa S^{\beta,\theta }(x,y) \left \|{x-y}\right \|_2^2 d\rho _t(x,y)\\ &\qquad \qquad \;\, - \iint \lambda _1\left \langle x - y_{\alpha }({\rho _{Y,t}}), x-y \right \rangle + \lambda _2 \left \|{x-y}\right \|_2^2 + \lambda _3\left \langle \nabla{\mathcal{E}}(x), x-y \right \rangle d\rho _t(x,y)\\ &\qquad \qquad \;\, + \frac{1}{2} \iint \sigma _1^2\left \|{x-y_{\alpha }({\rho _{Y,t}})}\right \|_2^2 + \sigma _2^2\left \|{x-y}\right \|_2^2 + \sigma _3^2\left \|{\nabla{\mathcal{E}}(x)}\right \|_2^2 d\rho _t(x,y). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\frac{d}{dt}\mathcal{Y}(\rho _t) = - \iint \kappa S^{\beta,\theta }(x,y) \left \|{x-y}\right \|_2^2 d\rho _t(x,y)\\ &\qquad \qquad \;\, - \iint \lambda _1\left \langle x - y_{\alpha }({\rho _{Y,t}}), x-y \right \rangle + \lambda _2 \left \|{x-y}\right \|_2^2 + \lambda _3\left \langle \nabla{\mathcal{E}}(x), x-y \right \rangle d\rho _t(x,y)\\ &\qquad \qquad \;\, + \frac{1}{2} \iint \sigma _1^2\left \|{x-y_{\alpha }({\rho _{Y,t}})}\right \|_2^2 + \sigma _2^2\left \|{x-y}\right \|_2^2 + \sigma _3^2\left \|{\nabla{\mathcal{E}}(x)}\right \|_2^2 d\rho _t(x,y). \end{aligned} \end{equation}
Here we used
 $\nabla _x\phi _{\mathcal{X}}(x,y) = x-x^*$
,
$\nabla _x\phi _{\mathcal{X}}(x,y) = x-x^*$
,
 $\nabla _y\phi _{\mathcal{X}}(x,y)=0$
,
$\nabla _y\phi _{\mathcal{X}}(x,y)=0$
,
 $\partial ^2_{x_kx_k} \phi _{\mathcal{X}}(x,y) = 1$
,
$\partial ^2_{x_kx_k} \phi _{\mathcal{X}}(x,y) = 1$
,
 $\nabla _x\phi _{\mathcal{Y}}(x,y) = x-y$
,
$\nabla _x\phi _{\mathcal{Y}}(x,y) = x-y$
,
 $\nabla _y\phi _{\mathcal{Y}}(x,y)=y-x$
and
$\nabla _y\phi _{\mathcal{Y}}(x,y)=y-x$
and
 $\partial ^2_{x_kx_k} \phi _{\mathcal{Y}}(x,y) = 1$
. Let us now collect auxiliary estimates in (3.3a)–(3.3g), which turn out to be useful in establishing upper bounds for (3.1) and (3.2). Using standard tools such as Cauchy-Schwarz and Young’s inequality we have
$\partial ^2_{x_kx_k} \phi _{\mathcal{Y}}(x,y) = 1$
. Let us now collect auxiliary estimates in (3.3a)–(3.3g), which turn out to be useful in establishing upper bounds for (3.1) and (3.2). Using standard tools such as Cauchy-Schwarz and Young’s inequality we have
 \begin{align} -\left \langle x-y, x-x^* \right \rangle &\leq \left \|{x-y}\right \|_2\left \|{x-x^*}\right \|_2 \leq \frac{1}{2}\!\left (\left \|{x-y}\right \|_2^2+\left \|{x-x^*}\right \|_2^2\right ), \end{align}
\begin{align} -\left \langle x-y, x-x^* \right \rangle &\leq \left \|{x-y}\right \|_2\left \|{x-x^*}\right \|_2 \leq \frac{1}{2}\!\left (\left \|{x-y}\right \|_2^2+\left \|{x-x^*}\right \|_2^2\right ), \end{align}
 \begin{align} -\left \langle x-y_{\alpha }({\rho _{Y,t}}), x-x^* \right \rangle &= -\left \|{x-x^*}\right \|_2^2 - \left \langle x^*-y_{\alpha }({\rho _{Y,t}}), x-x^* \right \rangle \nonumber \\ &\leq -\left \|{x-x^*}\right \|_2^2 + \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2 \left \|{x-x^*}\right \|_2, \end{align}
\begin{align} -\left \langle x-y_{\alpha }({\rho _{Y,t}}), x-x^* \right \rangle &= -\left \|{x-x^*}\right \|_2^2 - \left \langle x^*-y_{\alpha }({\rho _{Y,t}}), x-x^* \right \rangle \nonumber \\ &\leq -\left \|{x-x^*}\right \|_2^2 + \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2 \left \|{x-x^*}\right \|_2, \end{align}
 \begin{align} -\left \langle x-y_{\alpha }({\rho _{Y,t}}), x-y \right \rangle &= -\left \langle x-x^*, x-y \right \rangle - \left \langle x^*-y_{\alpha }({\rho _{Y,t}}), x-y \right \rangle \nonumber \\ &\leq \frac{1}{2}\!\left (\left \|{x-y}\right \|_2^2+\left \|{x-x^*}\right \|_2^2\right ) + \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2\left \|{x-y}\right \|_2, \end{align}
\begin{align} -\left \langle x-y_{\alpha }({\rho _{Y,t}}), x-y \right \rangle &= -\left \langle x-x^*, x-y \right \rangle - \left \langle x^*-y_{\alpha }({\rho _{Y,t}}), x-y \right \rangle \nonumber \\ &\leq \frac{1}{2}\!\left (\left \|{x-y}\right \|_2^2+\left \|{x-x^*}\right \|_2^2\right ) + \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2\left \|{x-y}\right \|_2, \end{align}
 \begin{align} \left \|{x-y_{\alpha }({\rho _{Y,t}})}\right \|_2^2 &= \left \|{x-x^*}\right \|_2^2 - 2\left \langle y_{\alpha }({\rho _{Y,t}})-x^*,x-x^*\right \rangle + \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2^2 \nonumber \\ &\leq \left \|{x-x^*}\right \|_2^2 + 2\left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2\left \|{x-x^*}\right \|_2 + \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2^2, \end{align}
\begin{align} \left \|{x-y_{\alpha }({\rho _{Y,t}})}\right \|_2^2 &= \left \|{x-x^*}\right \|_2^2 - 2\left \langle y_{\alpha }({\rho _{Y,t}})-x^*,x-x^*\right \rangle + \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2^2 \nonumber \\ &\leq \left \|{x-x^*}\right \|_2^2 + 2\left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2\left \|{x-x^*}\right \|_2 + \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2^2, \end{align}
where in (3.3b)–(3.3d) we expanded the left-hand side of the scalar product and the norm by subtracting and adding
 $x^*$
. Furthermore, by means of A3 we obtain
$x^*$
. Furthermore, by means of A3 we obtain
 \begin{align} -\left \langle \nabla{\mathcal{E}}(x), x-x^* \right \rangle &\leq \left \|{\nabla{\mathcal{E}}(x)}\right \|_2\left \|{x-x^*}\right \|_2 \leq C_{\nabla{\mathcal{E}}}\left \|{x-x^*}\right \|_2^2, \end{align}
\begin{align} -\left \langle \nabla{\mathcal{E}}(x), x-x^* \right \rangle &\leq \left \|{\nabla{\mathcal{E}}(x)}\right \|_2\left \|{x-x^*}\right \|_2 \leq C_{\nabla{\mathcal{E}}}\left \|{x-x^*}\right \|_2^2, \end{align}
 \begin{align} -\left \langle \nabla{\mathcal{E}}(x), x-y \right \rangle &\leq \left \|{\nabla{\mathcal{E}}(x)}\right \|_2\left \|{x-y}\right \|_2 \leq C_{\nabla{\mathcal{E}}}\left \|{x-x^*}\right \|_2\left \|{x-y}\right \|_2 \nonumber \\ &\leq \frac{C_{\nabla{\mathcal{E}}}}{2}\left (\left \|{x-y}\right \|_2^2+\left \|{x-x^*}\right \|_2^2\right ), \end{align}
\begin{align} -\left \langle \nabla{\mathcal{E}}(x), x-y \right \rangle &\leq \left \|{\nabla{\mathcal{E}}(x)}\right \|_2\left \|{x-y}\right \|_2 \leq C_{\nabla{\mathcal{E}}}\left \|{x-x^*}\right \|_2\left \|{x-y}\right \|_2 \nonumber \\ &\leq \frac{C_{\nabla{\mathcal{E}}}}{2}\left (\left \|{x-y}\right \|_2^2+\left \|{x-x^*}\right \|_2^2\right ), \end{align}
 \begin{align} \left \|{\nabla{\mathcal{E}}(x)}\right \|_2^2 &\leq C_{\nabla{\mathcal{E}}}^2\left \|{x-x^*}\right \|_2^2. \end{align}
\begin{align} \left \|{\nabla{\mathcal{E}}(x)}\right \|_2^2 &\leq C_{\nabla{\mathcal{E}}}^2\left \|{x-x^*}\right \|_2^2. \end{align}
Integrating the bounds (3.3a), (3.3b), (3.3d), (3.3e) and (3.3g) into equation (3.1) results in the upper bound
 \begin{equation*} \begin {aligned} &\frac {d}{dt} \mathcal{X}(\rho _t) \leq - \left ( 2\lambda _1 - \lambda _2 - 2\lambda _3 C_{\nabla {\mathcal {E}}} - \sigma _1^2 - \sigma _3^2C_{\nabla {\mathcal {E}}}^2 \right ) \mathcal{X}(\rho _t) + \left (\lambda _2+\sigma _2^2\right ) \mathcal{Y}(\rho _t) \\ &\qquad \qquad \; + \sqrt {2}\left (\lambda _1+\sigma _1^2\right ) \sqrt {\mathcal{X}(\rho _t)} \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2 + \frac {\sigma _1^2}{2}\left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2^2, \end {aligned} \end{equation*}
\begin{equation*} \begin {aligned} &\frac {d}{dt} \mathcal{X}(\rho _t) \leq - \left ( 2\lambda _1 - \lambda _2 - 2\lambda _3 C_{\nabla {\mathcal {E}}} - \sigma _1^2 - \sigma _3^2C_{\nabla {\mathcal {E}}}^2 \right ) \mathcal{X}(\rho _t) + \left (\lambda _2+\sigma _2^2\right ) \mathcal{Y}(\rho _t) \\ &\qquad \qquad \; + \sqrt {2}\left (\lambda _1+\sigma _1^2\right ) \sqrt {\mathcal{X}(\rho _t)} \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2 + \frac {\sigma _1^2}{2}\left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2^2, \end {aligned} \end{equation*}
where we furthermore used that by Jensen’s inequality
 \begin{equation} \iint \left \|{x-x^*}\right \|_2 d\rho _t(x,y) \leq \sqrt{\iint \left \|{x-x^*}\right \|_2^2 d\rho _t(x,y)} =\sqrt{2\mathcal{X}(\rho _t)}. \end{equation}
\begin{equation} \iint \left \|{x-x^*}\right \|_2 d\rho _t(x,y) \leq \sqrt{\iint \left \|{x-x^*}\right \|_2^2 d\rho _t(x,y)} =\sqrt{2\mathcal{X}(\rho _t)}. \end{equation}
For equation (3.2), we first note that, by definition,
 $S^{\beta,\theta }\geq \theta$
uniformly. This combined with the bounds (3.3c), (3.3d), (3.3f) and (3.3g) allows to derive
$S^{\beta,\theta }\geq \theta$
uniformly. This combined with the bounds (3.3c), (3.3d), (3.3f) and (3.3g) allows to derive
 \begin{equation*} \begin {aligned} &\frac {d}{dt} \mathcal{Y}(\rho _t) \leq - \left (2\kappa \theta + 2\lambda _2 - \lambda _1 - \lambda _3 C_{\nabla {\mathcal {E}}} - \sigma _2^2\right ) \!\mathcal{Y}(\rho _t) + \left (\lambda _1 + \lambda _3 C_{\nabla {\mathcal {E}}} + \sigma _1^2 + \sigma _3^2C_{\nabla {\mathcal {E}}}^2 \right ) \!\mathcal{X}(\rho _t)\\ &\qquad \qquad \, + \sqrt {2}\left (\lambda _1 \sqrt {\mathcal{Y}(\rho _t)} + \sigma _1^2 \sqrt {\mathcal{X}(\rho _t)}\right ) \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2 + \frac {\sigma _1^2}{2}\left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2^2, \end {aligned} \end{equation*}
\begin{equation*} \begin {aligned} &\frac {d}{dt} \mathcal{Y}(\rho _t) \leq - \left (2\kappa \theta + 2\lambda _2 - \lambda _1 - \lambda _3 C_{\nabla {\mathcal {E}}} - \sigma _2^2\right ) \!\mathcal{Y}(\rho _t) + \left (\lambda _1 + \lambda _3 C_{\nabla {\mathcal {E}}} + \sigma _1^2 + \sigma _3^2C_{\nabla {\mathcal {E}}}^2 \right ) \!\mathcal{X}(\rho _t)\\ &\qquad \qquad \, + \sqrt {2}\left (\lambda _1 \sqrt {\mathcal{Y}(\rho _t)} + \sigma _1^2 \sqrt {\mathcal{X}(\rho _t)}\right ) \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2 + \frac {\sigma _1^2}{2}\left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2^2, \end {aligned} \end{equation*}
where we used (3.4) together with an analogous bound for
 $\iint \left \|{x-y}\right \|_2 d\rho _t(x,y)$
.
$\iint \left \|{x-y}\right \|_2 d\rho _t(x,y)$
.
Recalling that
 $\mathcal{V}(\rho _t) =\mathcal{X}(\rho _t) +\mathcal{Y}(\rho _t)$
immediately allows to obtain an evolution inequality for
$\mathcal{V}(\rho _t) =\mathcal{X}(\rho _t) +\mathcal{Y}(\rho _t)$
immediately allows to obtain an evolution inequality for
 $\mathcal{V}(\rho _t)$
of the following form.
$\mathcal{V}(\rho _t)$
of the following form.
Corollary 3.3.
Under the assumptions of Lemma
3.2
, the functional
 $\mathcal{V}(\rho _t)$
satisfies
$\mathcal{V}(\rho _t)$
satisfies
 \begin{equation} \begin{split} \frac{d}{dt}\mathcal{V}(\rho _t) &\leq -\chi _1\mathcal{V}(\rho _t) + 2\sqrt{2}\left (\lambda _1 + \sigma _1^2\right ) \sqrt{\mathcal{V}(\rho _t)}\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2 + \sigma _1^2\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2^2, \end{split} \end{equation}
\begin{equation} \begin{split} \frac{d}{dt}\mathcal{V}(\rho _t) &\leq -\chi _1\mathcal{V}(\rho _t) + 2\sqrt{2}\left (\lambda _1 + \sigma _1^2\right ) \sqrt{\mathcal{V}(\rho _t)}\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2 + \sigma _1^2\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2^2, \end{split} \end{equation}
with
 $\chi _1$
as specified in (
2.12a
).
$\chi _1$
as specified in (
2.12a
).
Analogously to the upper bounds on the time evolutions of the functionals
 $\mathcal{X}(\rho _t)$
,
$\mathcal{X}(\rho _t)$
,
 $\mathcal{Y}(\rho _t)$
and
$\mathcal{Y}(\rho _t)$
and
 $\mathcal{V}(\rho _t)$
, we can derive bounds from below as follows.
$\mathcal{V}(\rho _t)$
, we can derive bounds from below as follows.
Lemma 3.4.
Under the assumptions of Lemma
3.2
, the functionals
 $\mathcal{X}(\rho _t)$
and
$\mathcal{X}(\rho _t)$
and
 $\mathcal{Y}(\rho _t)$
satisfy
$\mathcal{Y}(\rho _t)$
satisfy
 \begin{equation*} \begin{split} \frac{d}{dt}\!\begin{pmatrix}\mathcal{X}(\rho _t)\\\mathcal{Y}(\rho _t) \end{pmatrix} \!\geq &-\!\begin{pmatrix} 2\lambda _1 \!+\! \lambda _2 \!+\! 2\lambda _3 C_{\nabla{\mathcal{E}}} \!-\! \sigma _1^2 \!+\! \sigma _3^2C_{\nabla{\mathcal{E}}}^2 &\!\!\! \lambda _2\!-\!\sigma _2^2 \\ \lambda _1 \!+\! \lambda _3 C_{\nabla{\mathcal{E}}} \!-\! \sigma _1^2 \!+\! \sigma _3^2C_{\nabla{\mathcal{E}}}^2 &\!\!\! 2\kappa \theta \!+\! 2\lambda _2 \!+\! \lambda _1 \!+\! \lambda _3 C_{\nabla{\mathcal{E}}} - \sigma _2^2 \end{pmatrix}\! \begin{pmatrix}\mathcal{X}(\rho _t)\\\mathcal{Y}(\rho _t) \end{pmatrix}\\ &- \sqrt{2}\begin{pmatrix} \left (\lambda _1\!+\!\sigma _1^2\right ) \!\sqrt{\mathcal{X}(\rho _t)} \\ \lambda _1 \sqrt{\mathcal{Y}(\rho _t)} \!+\! \sigma _1^2 \sqrt{\mathcal{X}(\rho _t)} \end{pmatrix}\!\left \|{y_{\alpha }({\rho _{Y,t}})\!-\!x^*}\right \|_2, \end{split} \end{equation*}
\begin{equation*} \begin{split} \frac{d}{dt}\!\begin{pmatrix}\mathcal{X}(\rho _t)\\\mathcal{Y}(\rho _t) \end{pmatrix} \!\geq &-\!\begin{pmatrix} 2\lambda _1 \!+\! \lambda _2 \!+\! 2\lambda _3 C_{\nabla{\mathcal{E}}} \!-\! \sigma _1^2 \!+\! \sigma _3^2C_{\nabla{\mathcal{E}}}^2 &\!\!\! \lambda _2\!-\!\sigma _2^2 \\ \lambda _1 \!+\! \lambda _3 C_{\nabla{\mathcal{E}}} \!-\! \sigma _1^2 \!+\! \sigma _3^2C_{\nabla{\mathcal{E}}}^2 &\!\!\! 2\kappa \theta \!+\! 2\lambda _2 \!+\! \lambda _1 \!+\! \lambda _3 C_{\nabla{\mathcal{E}}} - \sigma _2^2 \end{pmatrix}\! \begin{pmatrix}\mathcal{X}(\rho _t)\\\mathcal{Y}(\rho _t) \end{pmatrix}\\ &- \sqrt{2}\begin{pmatrix} \left (\lambda _1\!+\!\sigma _1^2\right ) \!\sqrt{\mathcal{X}(\rho _t)} \\ \lambda _1 \sqrt{\mathcal{Y}(\rho _t)} \!+\! \sigma _1^2 \sqrt{\mathcal{X}(\rho _t)} \end{pmatrix}\!\left \|{y_{\alpha }({\rho _{Y,t}})\!-\!x^*}\right \|_2, \end{split} \end{equation*}
where the inequality has to be understood component-wise.
Proof. By following the lines of the proof of Lemma 3.2 and noticing that in analogy to the estimates (3.3), it hold
 \begin{align} -\left \langle x-y, x-x^* \right \rangle &\geq -\left \|{x-y}\right \|_2\left \|{x-x^*}\right \|_2 \geq -\frac{1}{2}\!\left (\left \|{x-y}\right \|_2^2+\left \|{x-x^*}\right \|_2^2\right ), \end{align}
\begin{align} -\left \langle x-y, x-x^* \right \rangle &\geq -\left \|{x-y}\right \|_2\left \|{x-x^*}\right \|_2 \geq -\frac{1}{2}\!\left (\left \|{x-y}\right \|_2^2+\left \|{x-x^*}\right \|_2^2\right ), \end{align}
 \begin{align} -\left \langle x-y_{\alpha }({\rho _{Y,t}}), x-x^* \right \rangle &= -\left \|{x-x^*}\right \|_2^2 - \left \langle x^*-y_{\alpha }({\rho _{Y,t}}), x-x^* \right \rangle \nonumber \\ &\geq -\left \|{x-x^*}\right \|_2^2 - \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2 \left \|{x-x^*}\right \|_2, \end{align}
\begin{align} -\left \langle x-y_{\alpha }({\rho _{Y,t}}), x-x^* \right \rangle &= -\left \|{x-x^*}\right \|_2^2 - \left \langle x^*-y_{\alpha }({\rho _{Y,t}}), x-x^* \right \rangle \nonumber \\ &\geq -\left \|{x-x^*}\right \|_2^2 - \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2 \left \|{x-x^*}\right \|_2, \end{align}
 \begin{align} -\left \langle x-y_{\alpha }({\rho _{Y,t}}), x-y \right \rangle &= -\left \langle x-x^*, x-y \right \rangle - \left \langle x^*-y_{\alpha }({\rho _{Y,t}}), x-y \right \rangle \nonumber \\ &\geq -\frac{1}{2}\!\left (\left \|{x-y}\right \|_2^2+\left \|{x-x^*}\right \|_2^2\right ) - \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2\left \|{x-y}\right \|_2, \end{align}
\begin{align} -\left \langle x-y_{\alpha }({\rho _{Y,t}}), x-y \right \rangle &= -\left \langle x-x^*, x-y \right \rangle - \left \langle x^*-y_{\alpha }({\rho _{Y,t}}), x-y \right \rangle \nonumber \\ &\geq -\frac{1}{2}\!\left (\left \|{x-y}\right \|_2^2+\left \|{x-x^*}\right \|_2^2\right ) - \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2\left \|{x-y}\right \|_2, \end{align}
 \begin{align} \left \|{x-y_{\alpha }({\rho _{Y,t}})}\right \|_2^2 &= \left \|{x-x^*}\right \|_2^2 - 2\left \langle y_{\alpha }({\rho _{Y,t}})-x^*,x-x^*\right \rangle + \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2^2 \nonumber \\ &\geq \left \|{x-x^*}\right \|_2^2 - 2\left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2\left \|{x-x^*}\right \|_2, \end{align}
\begin{align} \left \|{x-y_{\alpha }({\rho _{Y,t}})}\right \|_2^2 &= \left \|{x-x^*}\right \|_2^2 - 2\left \langle y_{\alpha }({\rho _{Y,t}})-x^*,x-x^*\right \rangle + \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2^2 \nonumber \\ &\geq \left \|{x-x^*}\right \|_2^2 - 2\left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2\left \|{x-x^*}\right \|_2, \end{align}
as well as
 \begin{align} -\left \langle \nabla{\mathcal{E}}(x), x-x^* \right \rangle &\geq -\left \|{\nabla{\mathcal{E}}(x)}\right \|_2\left \|{x-x^*}\right \|_2 \geq -C_{\nabla{\mathcal{E}}}\left \|{x-x^*}\right \|_2^2, \end{align}
\begin{align} -\left \langle \nabla{\mathcal{E}}(x), x-x^* \right \rangle &\geq -\left \|{\nabla{\mathcal{E}}(x)}\right \|_2\left \|{x-x^*}\right \|_2 \geq -C_{\nabla{\mathcal{E}}}\left \|{x-x^*}\right \|_2^2, \end{align}
 \begin{align} -\left \langle \nabla{\mathcal{E}}(x), x-y \right \rangle &\geq -\left \|{\nabla{\mathcal{E}}(x)}\right \|_2\left \|{x-y}\right \|_2 \geq -C_{\nabla{\mathcal{E}}}\left \|{x-x^*}\right \|_2\left \|{x-y}\right \|_2 \nonumber \\ &\geq -\frac{C_{\nabla{\mathcal{E}}}}{2}\left (\left \|{x-y}\right \|_2^2+\left \|{x-x^*}\right \|_2^2\right ), \end{align}
\begin{align} -\left \langle \nabla{\mathcal{E}}(x), x-y \right \rangle &\geq -\left \|{\nabla{\mathcal{E}}(x)}\right \|_2\left \|{x-y}\right \|_2 \geq -C_{\nabla{\mathcal{E}}}\left \|{x-x^*}\right \|_2\left \|{x-y}\right \|_2 \nonumber \\ &\geq -\frac{C_{\nabla{\mathcal{E}}}}{2}\left (\left \|{x-y}\right \|_2^2+\left \|{x-x^*}\right \|_2^2\right ), \end{align}
 \begin{align} \left \|{\nabla{\mathcal{E}}(x)}\right \|_2^2 &\geq -C_{\nabla{\mathcal{E}}}^2\left \|{x-x^*}\right \|_2^2. \end{align}
\begin{align} \left \|{\nabla{\mathcal{E}}(x)}\right \|_2^2 &\geq -C_{\nabla{\mathcal{E}}}^2\left \|{x-x^*}\right \|_2^2. \end{align}
we obtain the statement by integrating the bounds into equations (3.1) and (3.2).
Corollary 3.5.
Under the assumptions of Lemma
3.2
, the functional
 $\mathcal{V}(\rho _t)$
satisfies
$\mathcal{V}(\rho _t)$
satisfies
 \begin{equation} \begin{split} \frac{d}{dt}\mathcal{V}(\rho _t) &\geq -\chi _2\mathcal{V}(\rho _t) - 2\sqrt{2}\left (\lambda _1 + \sigma _1^2\right ) \sqrt{\mathcal{V}(\rho _t)}\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2, \end{split} \end{equation}
\begin{equation} \begin{split} \frac{d}{dt}\mathcal{V}(\rho _t) &\geq -\chi _2\mathcal{V}(\rho _t) - 2\sqrt{2}\left (\lambda _1 + \sigma _1^2\right ) \sqrt{\mathcal{V}(\rho _t)}\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2, \end{split} \end{equation}
with
 $\chi _2$
as specified in (
2.12b
).
$\chi _2$
as specified in (
2.12b
).
In order to be able to apply Grönwall’s inequality to (3.5) and (3.7) with the aim of obtaining estimates of the form
 $\mathcal{V}(\rho _t) \leq\mathcal{V}(\rho _0)e^{-(1-\vartheta )\chi _1 t}$
and
$\mathcal{V}(\rho _t) \leq\mathcal{V}(\rho _0)e^{-(1-\vartheta )\chi _1 t}$
and
 $\mathcal{V}(\rho _t) \geq\mathcal{V}(\rho _0)e^{-(1-\vartheta/2)\chi _2 t}$
for some
$\mathcal{V}(\rho _t) \geq\mathcal{V}(\rho _0)e^{-(1-\vartheta/2)\chi _2 t}$
for some
 $\chi _1,\chi _2\gt 0$
and a suitable
$\chi _1,\chi _2\gt 0$
and a suitable
 $\vartheta \in (0,1)$
, it remains to control the quantity
$\vartheta \in (0,1)$
, it remains to control the quantity
 $\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2$
through the choice of the parameter
$\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2$
through the choice of the parameter
 $\alpha$
. This is the content of the next section.
$\alpha$
. This is the content of the next section.
3.2. Quantitative Laplace principle
The well-known Laplace principle [Reference Dembo and Zeitouni21, Reference Miller48, Reference Pinnau, Totzeck, Tse and Martin52] asserts that for any absolutely continuous probability distribution
 $\varrho \in\mathcal{P}(\mathbb{R}^d)$
with
$\varrho \in\mathcal{P}(\mathbb{R}^d)$
with
 $x^*\in \operatorname{supp}(\varrho )$
it holds
$x^*\in \operatorname{supp}(\varrho )$
it holds
 \begin{align} \lim \limits _{\alpha \rightarrow \infty }\left ({-}\frac{1}{\alpha }\log \left \|{\omega _{\alpha }}\right \|_{L_1(\varrho )}\right ) ={\mathcal{E}}(x^*) = \underline{\mathcal{E}}, \end{align}
\begin{align} \lim \limits _{\alpha \rightarrow \infty }\left ({-}\frac{1}{\alpha }\log \left \|{\omega _{\alpha }}\right \|_{L_1(\varrho )}\right ) ={\mathcal{E}}(x^*) = \underline{\mathcal{E}}, \end{align}
which allows to infer that the
 $\alpha$
-weighted measure
$\alpha$
-weighted measure
 $\omega _{\alpha }/\left \|{\omega _{\alpha }}\right \|_{L_1(\varrho )}\varrho$
is concentrated in a small region around the minimiser
$\omega _{\alpha }/\left \|{\omega _{\alpha }}\right \|_{L_1(\varrho )}\varrho$
is concentrated in a small region around the minimiser
 $x^*$
, provided that
$x^*$
, provided that
 $\mathcal{E}$
attains its minimum at a single point, which is however guaranteed by the inverse continuity property A2.
$\mathcal{E}$
attains its minimum at a single point, which is however guaranteed by the inverse continuity property A2.
The asymptotic nature of the result (3.8), however, does not permit to obtain the required quantitative estimates, which is the reason why the authors of [Reference Fornasier, Klock and Riedl28] proposed a quantitative nonasymptotic variant of the Laplace principle. In the following proposition, cf. [Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29, Proposition 1], we state this result for the setting of anisotropic noise considered throughout the paper.
Proposition 3.6 ([Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29, Proposition 1]). Let
 $\underline{\mathcal{E}} = 0$
,
$\underline{\mathcal{E}} = 0$
,
 $\varrho \in\mathcal{P}(\mathbb{R}^d)$
and fix
$\varrho \in\mathcal{P}(\mathbb{R}^d)$
and fix
 $\alpha \gt 0$
. For any
$\alpha \gt 0$
. For any
 $r \gt 0$
we define
$r \gt 0$
we define
 ${\mathcal{E}}_{r} \,:\!=\, \sup _{y \in B^\infty _{r}(x^*)}{\mathcal{E}}(y)$
. Then, under the inverse continuity property A2, for any
${\mathcal{E}}_{r} \,:\!=\, \sup _{y \in B^\infty _{r}(x^*)}{\mathcal{E}}(y)$
. Then, under the inverse continuity property A2, for any
 $r \in (0,R_0]$
and
$r \in (0,R_0]$
and
 $q \gt 0$
such that
$q \gt 0$
such that
 $q +{\mathcal{E}}_{r} \leq{\mathcal{E}}_{\infty }$
, we have
$q +{\mathcal{E}}_{r} \leq{\mathcal{E}}_{\infty }$
, we have
 \begin{align*} \left \|{y_{\alpha }({\varrho }) - x^*}\right \|_2 \leq \frac{\sqrt{d}(q +{\mathcal{E}}_{r})^\nu }{\eta } + \frac{\sqrt{d}\exp ({-}\alpha q)}{\varrho (B^\infty _{r}(x^*))}\int \left \|{y-x^*}\right \|_2d\varrho (y). \end{align*}
\begin{align*} \left \|{y_{\alpha }({\varrho }) - x^*}\right \|_2 \leq \frac{\sqrt{d}(q +{\mathcal{E}}_{r})^\nu }{\eta } + \frac{\sqrt{d}\exp ({-}\alpha q)}{\varrho (B^\infty _{r}(x^*))}\int \left \|{y-x^*}\right \|_2d\varrho (y). \end{align*}
Proof. The proof is a mere reformulation of the one of [Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29, Proposition 1], which is presented in what follows for the sake of completeness.
For any
 $a \gt 0$
, Markov’s inequality gives
$a \gt 0$
, Markov’s inequality gives
 $\|{\omega _{\alpha }}\|_{L_1(\varrho )} \geq a \varrho (\{y\, :\, \exp ({-}\alpha{\mathcal{E}}(y)) \geq a\})$
. By choosing
$\|{\omega _{\alpha }}\|_{L_1(\varrho )} \geq a \varrho (\{y\, :\, \exp ({-}\alpha{\mathcal{E}}(y)) \geq a\})$
. By choosing
 $a = \exp ({-}\alpha{\mathcal{E}}_{r})$
and noting that
$a = \exp ({-}\alpha{\mathcal{E}}_{r})$
and noting that
 \begin{align*} \varrho \left (\left \{y \in \mathbb{R}^d: \exp ({-}\alpha{\mathcal{E}}(y)) \geq \exp ({-}\alpha{\mathcal{E}}_{r})\right \}\right ) &= \varrho \left (\left \{y \in \mathbb{R}^d:{\mathcal{E}}(y) \leq{\mathcal{E}}_{r} \right \}\right ) \geq \varrho (B^\infty _{r}(x^*)), \end{align*}
\begin{align*} \varrho \left (\left \{y \in \mathbb{R}^d: \exp ({-}\alpha{\mathcal{E}}(y)) \geq \exp ({-}\alpha{\mathcal{E}}_{r})\right \}\right ) &= \varrho \left (\left \{y \in \mathbb{R}^d:{\mathcal{E}}(y) \leq{\mathcal{E}}_{r} \right \}\right ) \geq \varrho (B^\infty _{r}(x^*)), \end{align*}
we get
 $\left \|{\omega _{\alpha }}\right \|_{L_1(\varrho )} \geq \exp ({-}\alpha{\mathcal{E}}_{r})\varrho (B^\infty _{r}(x^*))$
. Now let
$\left \|{\omega _{\alpha }}\right \|_{L_1(\varrho )} \geq \exp ({-}\alpha{\mathcal{E}}_{r})\varrho (B^\infty _{r}(x^*))$
. Now let
 $\widetilde r \geq r \gt 0$
. With the definition of the consensus point
$\widetilde r \geq r \gt 0$
. With the definition of the consensus point
 $y_{\alpha }({\varrho }) = \int y \omega _{\alpha }(y)/\|{\omega _{\alpha }}\|_{L_1(\varrho )}\,d\varrho (y)$
and Jensen’s inequality, we can decompose
$y_{\alpha }({\varrho }) = \int y \omega _{\alpha }(y)/\|{\omega _{\alpha }}\|_{L_1(\varrho )}\,d\varrho (y)$
and Jensen’s inequality, we can decompose
 \begin{align*} \begin{split} \left \|{y_{\alpha }({\varrho }) - x^*}\right \|_{\infty} &\leq \int _{B^\infty _{\widetilde r}(x^*)} \left \|{y-x^*}\right \|_{\infty} \frac{\omega _{\alpha }(y)}{\left \|{\omega _{\alpha }}\right \|_{L_1(\varrho )}}\,d\varrho (y) \\ &\quad \, + \int _{\left (B^\infty _{\widetilde r}(x^*)\right )^c} \left \|{y-x^*}\right \|_{\infty} \frac{\omega _{\alpha }(y)}{\left \|{\omega _{\alpha }}\right \|_{L_1(\varrho )}}\,d\varrho (y). \end{split} \end{align*}
\begin{align*} \begin{split} \left \|{y_{\alpha }({\varrho }) - x^*}\right \|_{\infty} &\leq \int _{B^\infty _{\widetilde r}(x^*)} \left \|{y-x^*}\right \|_{\infty} \frac{\omega _{\alpha }(y)}{\left \|{\omega _{\alpha }}\right \|_{L_1(\varrho )}}\,d\varrho (y) \\ &\quad \, + \int _{\left (B^\infty _{\widetilde r}(x^*)\right )^c} \left \|{y-x^*}\right \|_{\infty} \frac{\omega _{\alpha }(y)}{\left \|{\omega _{\alpha }}\right \|_{L_1(\varrho )}}\,d\varrho (y). \end{split} \end{align*}
After noticing that the first term is bounded by
 $\widetilde r$
since
$\widetilde r$
since
 $ \left \|{y-x^*}\right \|_{\infty} \leq \widetilde r$
for all
$ \left \|{y-x^*}\right \|_{\infty} \leq \widetilde r$
for all
 $y \in B^\infty _{\widetilde r}(x^*)$
, we can continue the former with
$y \in B^\infty _{\widetilde r}(x^*)$
, we can continue the former with
 \begin{equation} \begin{split} \left \|{y_{\alpha }({\varrho }) - x^*}\right \|_{\infty} &\leq \widetilde r + \frac{1}{ \exp ({-}\alpha{\mathcal{E}}_{r})\varrho (B^\infty _{r}(x^*))}\!\int _{(B^\infty _{\widetilde r}(x^*))^c} \left \|{y-x^*}\right \|_{\infty} \omega _{\alpha }(y)\,d\varrho (y)\\ &\leq \widetilde r + \frac{\exp \left ({-}\alpha \inf _{y \in (B^\infty _{\widetilde r}(x^*))^c}{\mathcal{E}}(y)\right )}{\exp \left ({-}\alpha{\mathcal{E}}_{r})\varrho (B^\infty _{r}(x^*)\right )}\!\int _{(B^\infty _{\widetilde r}(x^*))^c}\left \|{y-x^*}\right \|_{\infty} d\varrho (y)\\ &= \widetilde r + \frac{\exp \left ({-}\alpha \left (\inf _{y \in (B^\infty _{\widetilde r}(x^*))^c}{\mathcal{E}}(y) -{\mathcal{E}}_{r}\right )\right )}{\varrho (B^\infty _{r}(x^*))}\!\int \left \|{y-x^*}\right \|_{\infty} d\varrho (y), \end{split} \end{equation}
\begin{equation} \begin{split} \left \|{y_{\alpha }({\varrho }) - x^*}\right \|_{\infty} &\leq \widetilde r + \frac{1}{ \exp ({-}\alpha{\mathcal{E}}_{r})\varrho (B^\infty _{r}(x^*))}\!\int _{(B^\infty _{\widetilde r}(x^*))^c} \left \|{y-x^*}\right \|_{\infty} \omega _{\alpha }(y)\,d\varrho (y)\\ &\leq \widetilde r + \frac{\exp \left ({-}\alpha \inf _{y \in (B^\infty _{\widetilde r}(x^*))^c}{\mathcal{E}}(y)\right )}{\exp \left ({-}\alpha{\mathcal{E}}_{r})\varrho (B^\infty _{r}(x^*)\right )}\!\int _{(B^\infty _{\widetilde r}(x^*))^c}\left \|{y-x^*}\right \|_{\infty} d\varrho (y)\\ &= \widetilde r + \frac{\exp \left ({-}\alpha \left (\inf _{y \in (B^\infty _{\widetilde r}(x^*))^c}{\mathcal{E}}(y) -{\mathcal{E}}_{r}\right )\right )}{\varrho (B^\infty _{r}(x^*))}\!\int \left \|{y-x^*}\right \|_{\infty} d\varrho (y), \end{split} \end{equation}
where for the second term we used
 $\left \|{\omega _{\alpha }}\right \|_{L_1(\varrho )} \geq \exp ({-}\alpha{\mathcal{E}}_{r})\varrho (B^\infty _{r}(x^*))$
from above. Let us now choose
$\left \|{\omega _{\alpha }}\right \|_{L_1(\varrho )} \geq \exp ({-}\alpha{\mathcal{E}}_{r})\varrho (B^\infty _{r}(x^*))$
from above. Let us now choose
 $\widetilde r = (q+{\mathcal{E}}_r)^{\nu }/\eta$
, which satisfies
$\widetilde r = (q+{\mathcal{E}}_r)^{\nu }/\eta$
, which satisfies
 $\widetilde r \geq r$
, since A2 with
$\widetilde r \geq r$
, since A2 with
 $\underline{\mathcal{E}} = 0$
and
$\underline{\mathcal{E}} = 0$
and
 $r \leq R_0$
implies
$r \leq R_0$
implies
 \begin{align*} \widetilde r = \frac{(q+{\mathcal{E}}_r)^{\nu }}{\eta } \geq \frac{{\mathcal{E}}_r^{\nu }}{\eta } = \frac{\left (\sup _{y \in B^\infty _{r}(x^*)}{\mathcal{E}}(y)\right )^{\nu }}{\eta } \geq \sup _{y \in B_{r}^\infty (x^*)}\left \|{y-x^*}\right \|_{\infty} = r. \end{align*}
\begin{align*} \widetilde r = \frac{(q+{\mathcal{E}}_r)^{\nu }}{\eta } \geq \frac{{\mathcal{E}}_r^{\nu }}{\eta } = \frac{\left (\sup _{y \in B^\infty _{r}(x^*)}{\mathcal{E}}(y)\right )^{\nu }}{\eta } \geq \sup _{y \in B_{r}^\infty (x^*)}\left \|{y-x^*}\right \|_{\infty} = r. \end{align*}
Furthermore, due to the assumption
 $q+{\mathcal{E}}_r \leq{\mathcal{E}}_{\infty }$
in the statement we have
$q+{\mathcal{E}}_r \leq{\mathcal{E}}_{\infty }$
in the statement we have
 $\widetilde r \leq{\mathcal{E}}_{\infty }^{\nu }/\eta$
, which together with the two cases of A2 with
$\widetilde r \leq{\mathcal{E}}_{\infty }^{\nu }/\eta$
, which together with the two cases of A2 with
 $\underline{\mathcal{E}} = 0$
allows to bound the infimum in (3.9) as follows
$\underline{\mathcal{E}} = 0$
allows to bound the infimum in (3.9) as follows
 \begin{align*} \inf _{y \in (B^\infty _{\widetilde r}(x^*))^c}{\mathcal{E}}(y) -{\mathcal{E}}_r \geq \min \left \{{\mathcal{E}}_{\infty }, (\eta \widetilde r)^{\frac{1}{\nu }}\right \} -{\mathcal{E}}_r = (\eta \widetilde r)^{\frac{1}{\nu }} -{\mathcal{E}}_r = (q +{\mathcal{E}}_r) -{\mathcal{E}}_r = q. \end{align*}
\begin{align*} \inf _{y \in (B^\infty _{\widetilde r}(x^*))^c}{\mathcal{E}}(y) -{\mathcal{E}}_r \geq \min \left \{{\mathcal{E}}_{\infty }, (\eta \widetilde r)^{\frac{1}{\nu }}\right \} -{\mathcal{E}}_r = (\eta \widetilde r)^{\frac{1}{\nu }} -{\mathcal{E}}_r = (q +{\mathcal{E}}_r) -{\mathcal{E}}_r = q. \end{align*}
Inserting this and the definition of
 $\,\widetilde r$
into (3.9), we get the result as a consequence of the norm equivalence
$\,\widetilde r$
into (3.9), we get the result as a consequence of the norm equivalence
 $\left \|{\,\cdot \,}\right \|_{\infty} \leq \left \|{\,\cdot \,}\right \|_2\leq \sqrt{d}\left \|{\,\cdot \,}\right \|_{\infty}$
.
$\left \|{\,\cdot \,}\right \|_{\infty} \leq \left \|{\,\cdot \,}\right \|_2\leq \sqrt{d}\left \|{\,\cdot \,}\right \|_{\infty}$
.
To eventually apply Proposition 3.6 in the setting of Corollary 3.3, i.e., to upper bound the distance of the consensus point
 $y_{\alpha }({\rho _{Y,t}})$
to the global minimiser
$y_{\alpha }({\rho _{Y,t}})$
to the global minimiser
 $x^*$
, it remains to ensure that
$x^*$
, it remains to ensure that
 $\rho _{Y,t}(B^\infty _{r}(x^*))$
is bounded away from
$\rho _{Y,t}(B^\infty _{r}(x^*))$
is bounded away from
 $0$
for a finite time horizon. We ensure that this is indeed the case in what follows.
$0$
for a finite time horizon. We ensure that this is indeed the case in what follows.
3.3. A lower bound for the probability mass
$\rho _{Y,t}(B^\infty _{r}(x^*))$

In this section, for any small radius
 $r \gt 0$
, we provide a lower bound on the probability mass of
$r \gt 0$
, we provide a lower bound on the probability mass of
 $\rho _{Y,t}(B^\infty _{r}(x^*))$
by defining a mollifier
$\rho _{Y,t}(B^\infty _{r}(x^*))$
by defining a mollifier
 $\phi _r\, :\, \mathbb{R}^d\times \mathbb{R}^d \rightarrow \mathbb{R}$
so that
$\phi _r\, :\, \mathbb{R}^d\times \mathbb{R}^d \rightarrow \mathbb{R}$
so that
 \begin{equation*} \rho _{Y,t}(B^\infty _{r}(x^*)) = \rho _{t}(\mathbb {R}^d\times B^\infty _{r}(x^*)) = \iint _{\mathbb {R}^d\times B^\infty _{r}(x^*)} 1 \, d\rho _{t}(x,y) \geq \iint \phi _r(x,y) \, d\rho _t(x,y) \end{equation*}
\begin{equation*} \rho _{Y,t}(B^\infty _{r}(x^*)) = \rho _{t}(\mathbb {R}^d\times B^\infty _{r}(x^*)) = \iint _{\mathbb {R}^d\times B^\infty _{r}(x^*)} 1 \, d\rho _{t}(x,y) \geq \iint \phi _r(x,y) \, d\rho _t(x,y) \end{equation*}
and studying the evolution of the right-hand side.
Lemma 3.7.
For
 $r \gt 0$
let
$r \gt 0$
let
 $\Omega _r \,:\!=\, \{(x,y)\in \mathbb{R}^d\times \mathbb{R}^d: \max \{\left \|{x-x^*}\right \|_{\infty}, \left \|{x-y}\right \|_{\infty} \}\lt r/2\}$
and define the mollifier
$\Omega _r \,:\!=\, \{(x,y)\in \mathbb{R}^d\times \mathbb{R}^d: \max \{\left \|{x-x^*}\right \|_{\infty}, \left \|{x-y}\right \|_{\infty} \}\lt r/2\}$
and define the mollifier
 $\phi _r\, :\, \mathbb{R}^d\times \mathbb{R}^d \rightarrow \mathbb{R}$
by
$\phi _r\, :\, \mathbb{R}^d\times \mathbb{R}^d \rightarrow \mathbb{R}$
by
 \begin{equation*} \phi _{r}(x,y) \,:\!=\, \begin {cases} \prod _{k=1}^d \exp \left (1-\frac {\left (\frac {r}{2}\right )^2}{\left (\frac {r}{2}\right )^2-\left (x-x^*\right )_k^2}\right )\exp \left (1-\frac {\left (\frac {r}{2}\right )^2}{\left (\frac {r}{2}\right )^2-\left (x-y\right )_k^2}\right ),& \text { if } (x,y)\in \Omega _r,\\ 0,& \text { else.} \end {cases} \end{equation*}
\begin{equation*} \phi _{r}(x,y) \,:\!=\, \begin {cases} \prod _{k=1}^d \exp \left (1-\frac {\left (\frac {r}{2}\right )^2}{\left (\frac {r}{2}\right )^2-\left (x-x^*\right )_k^2}\right )\exp \left (1-\frac {\left (\frac {r}{2}\right )^2}{\left (\frac {r}{2}\right )^2-\left (x-y\right )_k^2}\right ),& \text { if } (x,y)\in \Omega _r,\\ 0,& \text { else.} \end {cases} \end{equation*}
We have that
 $\textit{Im} (\phi _r) = [0,1]$
,
$\textit{Im} (\phi _r) = [0,1]$
,
 $\operatorname{supp}(\phi _r) = \Omega _r \subset B^\infty _{r/2}(x^*) \times B^\infty _{r}(x^*) \subset \mathbb{R}^d \times B^\infty _{r}(x^*)$
,
$\operatorname{supp}(\phi _r) = \Omega _r \subset B^\infty _{r/2}(x^*) \times B^\infty _{r}(x^*) \subset \mathbb{R}^d \times B^\infty _{r}(x^*)$
,
 $\phi _{r} \in\mathcal{C}_c^{\infty }(\mathbb{R}^d\times \mathbb{R}^d)$
and
$\phi _{r} \in\mathcal{C}_c^{\infty }(\mathbb{R}^d\times \mathbb{R}^d)$
and
 \begin{align*} \partial _{x_k} \phi _{r}(x,y) &= -\frac{r^2}{2} \left ( \frac{\left (x-x^*\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2} +\frac{\left (x-y\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2} \right ) \phi _{r}(x,y),\\ \partial _{y_k} \phi _{r}(x,y) &= -\frac{r^2}{2} \frac{\left (y-x\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2} \phi _{r}(x,y),\\ \partial ^2_{x_kx_k} \phi _{r}(x,y) &= \frac{r^2}{2} \left ( \left (\frac{2\left (2\left (x-x^*\right )^2_k-\left (\frac{r}{2}\right )^2\right )\left (x-x^*\right )_k^2 - \left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^4}\right )\right .\\ &\qquad +\left .\left (\frac{2\left (2\left (x-y\right )^2_k-\left (\frac{r}{2}\right )^2\right )\left (x-y\right )_k^2 - \left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^4}\right ) \right ) \phi _{r}(x,y). \end{align*}
\begin{align*} \partial _{x_k} \phi _{r}(x,y) &= -\frac{r^2}{2} \left ( \frac{\left (x-x^*\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2} +\frac{\left (x-y\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2} \right ) \phi _{r}(x,y),\\ \partial _{y_k} \phi _{r}(x,y) &= -\frac{r^2}{2} \frac{\left (y-x\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2} \phi _{r}(x,y),\\ \partial ^2_{x_kx_k} \phi _{r}(x,y) &= \frac{r^2}{2} \left ( \left (\frac{2\left (2\left (x-x^*\right )^2_k-\left (\frac{r}{2}\right )^2\right )\left (x-x^*\right )_k^2 - \left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^4}\right )\right .\\ &\qquad +\left .\left (\frac{2\left (2\left (x-y\right )^2_k-\left (\frac{r}{2}\right )^2\right )\left (x-y\right )_k^2 - \left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^4}\right ) \right ) \phi _{r}(x,y). \end{align*}
Proof. It is straightforward to check the properties of
 $\phi _r$
as it is a tensor product of classical well-studied mollifiers.
$\phi _r$
as it is a tensor product of classical well-studied mollifiers.
To keep the notation as concise as possible in what follows, let us introduce the decomposition
 \begin{equation} \partial _{x_k} \phi _{r} = \delta ^{*}_{x_k} \phi _{r} + \delta ^Y_{x_k} \phi _{r} \quad \text{and}\quad \partial ^2_{x_kx_k} \phi _{r} = \delta ^{2,*}_{x_kx_k} \phi _{r} + \delta ^{2,Y}_{x_kx_k} \phi _{r}, \end{equation}
\begin{equation} \partial _{x_k} \phi _{r} = \delta ^{*}_{x_k} \phi _{r} + \delta ^Y_{x_k} \phi _{r} \quad \text{and}\quad \partial ^2_{x_kx_k} \phi _{r} = \delta ^{2,*}_{x_kx_k} \phi _{r} + \delta ^{2,Y}_{x_kx_k} \phi _{r}, \end{equation}
where
 \begin{equation*} \delta ^{*}_{x_k} \phi _{r}(x,y) \!=\! \frac {-\frac {r^2}{2}\left (x\!-\!x^*\right )_k}{\left (\!\left (\frac {r}{2}\right )^2\!\!-\!\left (x\!-\!x^*\right )^2_k\right )^{\!2}} \phi _{r}(x,y) \ \ \text {and} \ \ \delta ^Y_{x_k} \phi _{r}(x,y) \!=\! \frac {-\frac {r^2}{2}\left (x\!-\!y\right )_k}{\left (\!\left (\frac {r}{2}\right )^2\!\!-\!\left (x\!-\!y\right )^2_k\right )^{\!2}} \phi _{r}(x,y) \end{equation*}
\begin{equation*} \delta ^{*}_{x_k} \phi _{r}(x,y) \!=\! \frac {-\frac {r^2}{2}\left (x\!-\!x^*\right )_k}{\left (\!\left (\frac {r}{2}\right )^2\!\!-\!\left (x\!-\!x^*\right )^2_k\right )^{\!2}} \phi _{r}(x,y) \ \ \text {and} \ \ \delta ^Y_{x_k} \phi _{r}(x,y) \!=\! \frac {-\frac {r^2}{2}\left (x\!-\!y\right )_k}{\left (\!\left (\frac {r}{2}\right )^2\!\!-\!\left (x\!-\!y\right )^2_k\right )^{\!2}} \phi _{r}(x,y) \end{equation*}
and analogously for
 $\delta ^{2,*}_{x_kx_k} \phi _{r}$
and
$\delta ^{2,*}_{x_kx_k} \phi _{r}$
and
 $\delta ^{2,Y}_{x_kx_k} \phi _{r}$
.
$\delta ^{2,Y}_{x_kx_k} \phi _{r}$
.
Proposition 3.8.
Let
 $T \gt 0$
,
$T \gt 0$
,
 $r \gt 0$
, and fix parameters
$r \gt 0$
, and fix parameters
 $\alpha,\lambda _1,\sigma _1 \gt 0$
as well as parameters
$\alpha,\lambda _1,\sigma _1 \gt 0$
as well as parameters
 $\lambda _2,\sigma _2,\lambda _3,\sigma _3,\beta,\kappa,\theta \geq 0$
such that
$\lambda _2,\sigma _2,\lambda _3,\sigma _3,\beta,\kappa,\theta \geq 0$
such that
 $\sigma _2\gt 0$
iff
$\sigma _2\gt 0$
iff
 $\lambda _2\not =0$
and
$\lambda _2\not =0$
and
 $\sigma _3\gt 0$
iff
$\sigma _3\gt 0$
iff
 $\lambda _3\not =0$
. Moreover, assume the validity of Assumption A3 if
$\lambda _3\not =0$
. Moreover, assume the validity of Assumption A3 if
 $\lambda _3\not =0$
. Let
$\lambda _3\not =0$
. Let
 $\rho \in\mathcal{C}([0,T],\mathcal{P}(\mathbb{R}^d\times \mathbb{R}^d))$
weakly solve the Fokker-Planck equation (
1.6
) in the sense of Definition 2.1 with initial condition
$\rho \in\mathcal{C}([0,T],\mathcal{P}(\mathbb{R}^d\times \mathbb{R}^d))$
weakly solve the Fokker-Planck equation (
1.6
) in the sense of Definition 2.1 with initial condition
 $\rho _0 \in\mathcal{P}(\mathbb{R}^d\times \mathbb{R}^d)$
and for
$\rho _0 \in\mathcal{P}(\mathbb{R}^d\times \mathbb{R}^d)$
and for
 $t \in [0,T]$
. Then, for all
$t \in [0,T]$
. Then, for all
 $t\in [0,T]$
we have
$t\in [0,T]$
we have
 \begin{align} \rho _{Y,t}(B^\infty _{r}(x^*)) &\geq \left (\iint \phi _{r}(x,y)\,d\rho _0(x,y)\right )\exp \left ({-}pt\right ) \end{align}
\begin{align} \rho _{Y,t}(B^\infty _{r}(x^*)) &\geq \left (\iint \phi _{r}(x,y)\,d\rho _0(x,y)\right )\exp \left ({-}pt\right ) \end{align}
with
 \begin{align} p &\,:\!=\, d\sum _{i=1}^3\omega _i\left (\left (1\!+\!\mathbb{1}_{i\in \{1,3\}}\right )\left (\frac{2\lambda _i C_{\Upsilon} \sqrt{c}}{(1\!-\!c)^2\frac{r}{2}} \!+\! \frac{\sigma _i^2C_{\Upsilon} ^2}{(1\!-\!c)^4\!\left (\frac{r}{2}\right )^2} \!+\! \frac{4\lambda _i^2}{\tilde{c}\sigma _i^2}\right ) \!+\! \mathbb{1}_{i=2}\frac{\sigma _2^2c}{(1\!-\!c)^4} \right ), \end{align}
\begin{align} p &\,:\!=\, d\sum _{i=1}^3\omega _i\left (\left (1\!+\!\mathbb{1}_{i\in \{1,3\}}\right )\left (\frac{2\lambda _i C_{\Upsilon} \sqrt{c}}{(1\!-\!c)^2\frac{r}{2}} \!+\! \frac{\sigma _i^2C_{\Upsilon} ^2}{(1\!-\!c)^4\!\left (\frac{r}{2}\right )^2} \!+\! \frac{4\lambda _i^2}{\tilde{c}\sigma _i^2}\right ) \!+\! \mathbb{1}_{i=2}\frac{\sigma _2^2c}{(1\!-\!c)^4} \right ), \end{align}
where, for any
 $B\lt \infty$
with
$B\lt \infty$
with
 $\sup _{t \in [0,T]}\left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2 \leq B$
,
$\sup _{t \in [0,T]}\left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2 \leq B$
,
 $C_{\Upsilon} = C_{\Upsilon} (r,B,d,C_{\nabla{\mathcal{E}}})$
is as defined in (
3.20
). Moreover,
$C_{\Upsilon} = C_{\Upsilon} (r,B,d,C_{\nabla{\mathcal{E}}})$
is as defined in (
3.20
). Moreover,
 $\omega _i=\mathbb{1}_{\lambda _i\gt 0}$
for
$\omega _i=\mathbb{1}_{\lambda _i\gt 0}$
for
 $i\in \{1,2,3\}$
and
$i\in \{1,2,3\}$
and
 $c \in (1/2,1)$
can be any constant that satisfies
$c \in (1/2,1)$
can be any constant that satisfies
 $(1-c)^2 \leq (2c-1)c$
.
$(1-c)^2 \leq (2c-1)c$
.
Remark 3.9.
In order to ensure a finite decay rate
 $p\lt \infty$
in Proposition
3.8
, it is crucial to have non-vanishing diffusions
$p\lt \infty$
in Proposition
3.8
, it is crucial to have non-vanishing diffusions
 $\sigma _1\gt 0$
,
$\sigma _1\gt 0$
,
 $\sigma _2\gt 0$
if
$\sigma _2\gt 0$
if
 $\lambda _2\not =0$
and
$\lambda _2\not =0$
and
 $\sigma _3\gt 0$
if
$\sigma _3\gt 0$
if
 $\lambda _3\not =0$
. As apparent from the formulation of the statement as well as the proof below,
$\lambda _3\not =0$
. As apparent from the formulation of the statement as well as the proof below,
 $\sigma _2$
or
$\sigma _2$
or
 $\sigma _3$
may be
$\sigma _3$
may be
 $0$
if the corresponding drift parameter,
$0$
if the corresponding drift parameter,
 $\lambda _2$
or
$\lambda _2$
or
 $\lambda _3$
, respectively, vanishes.
$\lambda _3$
, respectively, vanishes.
Proof of Proposition
3.8
. By the definition of the marginal
 $\rho _Y$
and the properties of the mollifier
$\rho _Y$
and the properties of the mollifier
 $\phi _r$
defined in Lemma 3.7, we have
$\phi _r$
defined in Lemma 3.7, we have
 \begin{align*} \rho _{Y,t}(B^\infty _{r}(x^*)) = \rho _t\big (\mathbb{R}^d \times B^\infty _{r}(x^*)\big ) \geq \rho _t(\Omega _r) \geq \iint \phi _{r}(x,y)\,d\rho _t(x,y). \end{align*}
\begin{align*} \rho _{Y,t}(B^\infty _{r}(x^*)) = \rho _t\big (\mathbb{R}^d \times B^\infty _{r}(x^*)\big ) \geq \rho _t(\Omega _r) \geq \iint \phi _{r}(x,y)\,d\rho _t(x,y). \end{align*}
Our strategy is to derive a lower bound for the right-hand side of this inequality. Using the weak solution property of
 $\rho$
as in Definition 2.1 and the fact that
$\rho$
as in Definition 2.1 and the fact that
 $\phi _{r}\in\mathcal{C}^{\infty }_c(\mathbb{R}^d\times \mathbb{R}^d)$
, we obtain
$\phi _{r}\in\mathcal{C}^{\infty }_c(\mathbb{R}^d\times \mathbb{R}^d)$
, we obtain
 \begin{equation} \begin{split} &\frac{d}{dt}\iint \phi _{r}(x,y)\,d\rho _t(x,y) =\sum _{k=1}^d \iint T^s_{k}(x,y) \,d\rho _t(x,y)\\ &\quad +\! \sum _{k=1}^d \iint \big (T^c_{1k}(x,y) \!+\! T^c_{2k}(x,y) \!+\! T^\ell _{1k}(x,y) \!+\! T^\ell _{2k}(x,y) \!+\! T^g_{1k}(x,y) \!+\! T^g_{2k}(x,y)\big ) \,d\rho _t(x,y), \end{split} \end{equation}
\begin{equation} \begin{split} &\frac{d}{dt}\iint \phi _{r}(x,y)\,d\rho _t(x,y) =\sum _{k=1}^d \iint T^s_{k}(x,y) \,d\rho _t(x,y)\\ &\quad +\! \sum _{k=1}^d \iint \big (T^c_{1k}(x,y) \!+\! T^c_{2k}(x,y) \!+\! T^\ell _{1k}(x,y) \!+\! T^\ell _{2k}(x,y) \!+\! T^g_{1k}(x,y) \!+\! T^g_{2k}(x,y)\big ) \,d\rho _t(x,y), \end{split} \end{equation}
where
 $T^s_{k}(x,y) \,:\!=\, -\kappa S^{\beta,\theta }(x,y) \left (y-x\right )_k \partial _{y_k}\phi _r(x,y)$
and
$T^s_{k}(x,y) \,:\!=\, -\kappa S^{\beta,\theta }(x,y) \left (y-x\right )_k \partial _{y_k}\phi _r(x,y)$
and
 \begin{equation*} \begin{aligned} &\, T^c_{1k}(x,y) \!\,:\!=\, \!-\lambda _1\left (x\!-\!y_{\alpha }({\rho _{Y,t}})\right )_k \partial _{x_k}\phi _r(x,y), &\!\!\!\, T^c_{2k}(x,y) &\!\,:\!=\, \!\frac{\sigma _1^2}{2} \left (x\!-\!y_{\alpha }({\rho _{Y,t}})\right )_k^2 \partial ^2_{x_kx_k} \phi _{r}(x,y), \\ &\, T^\ell _{1k}(x,y) \!\,:\!=\, \!-\lambda _2\left (x\!-\!y\right )_k \partial _{x_k}\phi _r(x,y), &\!\!\!\, T^\ell _{2k}(x,y) &\!\,:\!=\, \!\frac{\sigma _2^2}{2} \left (x\!-\!y\right )_k^2 \partial ^2_{x_kx_k} \phi _{r}(x,y), \\ &\, T^g_{1k}(x,y) \!\,:\!=\, -\lambda _3\partial _{x_k}{\mathcal{E}}(x) \partial _{x_k}\phi _r(x,y), &\!\!\!\, T^g_{2k}(x,y) &\!\,:\!=\, \!\frac{\sigma _3^2}{2} \left (\partial _{x_k}{\mathcal{E}}(x)\right )^2 \partial ^2_{x_kx_k} \phi _{r}(x,y) \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} &\, T^c_{1k}(x,y) \!\,:\!=\, \!-\lambda _1\left (x\!-\!y_{\alpha }({\rho _{Y,t}})\right )_k \partial _{x_k}\phi _r(x,y), &\!\!\!\, T^c_{2k}(x,y) &\!\,:\!=\, \!\frac{\sigma _1^2}{2} \left (x\!-\!y_{\alpha }({\rho _{Y,t}})\right )_k^2 \partial ^2_{x_kx_k} \phi _{r}(x,y), \\ &\, T^\ell _{1k}(x,y) \!\,:\!=\, \!-\lambda _2\left (x\!-\!y\right )_k \partial _{x_k}\phi _r(x,y), &\!\!\!\, T^\ell _{2k}(x,y) &\!\,:\!=\, \!\frac{\sigma _2^2}{2} \left (x\!-\!y\right )_k^2 \partial ^2_{x_kx_k} \phi _{r}(x,y), \\ &\, T^g_{1k}(x,y) \!\,:\!=\, -\lambda _3\partial _{x_k}{\mathcal{E}}(x) \partial _{x_k}\phi _r(x,y), &\!\!\!\, T^g_{2k}(x,y) &\!\,:\!=\, \!\frac{\sigma _3^2}{2} \left (\partial _{x_k}{\mathcal{E}}(x)\right )^2 \partial ^2_{x_kx_k} \phi _{r}(x,y) \end{aligned} \end{equation*}
for
 $k\in \{1,\dots,d\}$
. Since the mollifier
$k\in \{1,\dots,d\}$
. Since the mollifier
 $\phi _r$
and its derivatives vanish outside of
$\phi _r$
and its derivatives vanish outside of
 $\Omega _r$
, we restrict our attention to
$\Omega _r$
, we restrict our attention to
 $\Omega _r$
and aim for showing for all
$\Omega _r$
and aim for showing for all
 $k\in \{1,\dots,d\}$
that
$k\in \{1,\dots,d\}$
that
-
•
$T^s_{k}(x,y) \geq 0$
, -
•
$T^c_{1k}(x,y) + T^c_{2k}(x,y) \geq -p^c\phi _r(x,y)$
, -
•
$T^\ell _{1k}(x,y) + T^\ell _{2k}(x,y) \geq -p^\ell \phi _r(x,y)$
, -
•
$T^g_{1k}(x,y) + T^g_{2k}(x,y) \geq -p^g\phi _r(x,y)$




pointwise for all
 $(x,y)\in \Omega _r$
with suitable constants
$(x,y)\in \Omega _r$
with suitable constants
 $0 \leq p^\ell, p^c, p^g \lt \infty$
.
$0 \leq p^\ell, p^c, p^g \lt \infty$
.
Term
 $T^s_{k}$
: Using the expression for
$T^s_{k}$
: Using the expression for
 $\partial _{y_k} \phi _{r}$
from Lemma 3.7 and the fact that
$\partial _{y_k} \phi _{r}$
from Lemma 3.7 and the fact that
 $S^{\beta,\theta }\geq \theta/2\geq 0$
, it is easy to see that
$S^{\beta,\theta }\geq \theta/2\geq 0$
, it is easy to see that
 \begin{equation} T^s_{k}(x,y) = \frac{r^2\kappa }{2} S^{\beta,\theta }(x,y) \frac{\left (y-x\right )^2_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2}\phi _{r}(x,y) \geq 0. \end{equation}
\begin{equation} T^s_{k}(x,y) = \frac{r^2\kappa }{2} S^{\beta,\theta }(x,y) \frac{\left (y-x\right )^2_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2}\phi _{r}(x,y) \geq 0. \end{equation}
Terms
 $T^c_{1k}+T^c_{2k}$
,
$T^c_{1k}+T^c_{2k}$
,
 $T^\ell _{1k}+T^\ell _{2k}$
and
$T^\ell _{1k}+T^\ell _{2k}$
and
 $T^g_{1k}+T^g_{2k}$
: We first note that the third inequality from above holds with
$T^g_{1k}+T^g_{2k}$
: We first note that the third inequality from above holds with
 $p^\ell =0$
if
$p^\ell =0$
if
 $\lambda _2=\sigma _2=0$
and the fourth with
$\lambda _2=\sigma _2=0$
and the fourth with
 $p^g=0$
if
$p^g=0$
if
 $\lambda _3=\sigma _3=0$
.
$\lambda _3=\sigma _3=0$
.
Therefore, in what follows we assume that
 $\lambda _2,\sigma _2,\lambda _3,\sigma _3\gt 0$
. In order to lower bound the three terms from above, we arrange the summands by using the abbreviations introduced in (3.10) as follows. For
$\lambda _2,\sigma _2,\lambda _3,\sigma _3\gt 0$
. In order to lower bound the three terms from above, we arrange the summands by using the abbreviations introduced in (3.10) as follows. For
 $T^c_{1k}+T^c_{2k}$
, we have
$T^c_{1k}+T^c_{2k}$
, we have
 \begin{align} &T^c_{1k}(x,y)+T^c_{2k}(x,y)\nonumber \\ &\qquad \,= -\lambda _1\left (x-y_{\alpha }({\rho _{Y,t}})\right )_k \delta ^{*}_{x_k} \phi _{r}(x,y) + \frac{\sigma _1^2}{2} \left (x-y_{\alpha }({\rho _{Y,t}})\right )_k^2 \delta ^{2,*}_{x_kx_k} \phi _{r}(x,y) \end{align}
\begin{align} &T^c_{1k}(x,y)+T^c_{2k}(x,y)\nonumber \\ &\qquad \,= -\lambda _1\left (x-y_{\alpha }({\rho _{Y,t}})\right )_k \delta ^{*}_{x_k} \phi _{r}(x,y) + \frac{\sigma _1^2}{2} \left (x-y_{\alpha }({\rho _{Y,t}})\right )_k^2 \delta ^{2,*}_{x_kx_k} \phi _{r}(x,y) \end{align}
 \begin{align} &\qquad \quad \,\,-\lambda _1\left (x-y_{\alpha }({\rho _{Y,t}})\right )_k \delta ^Y_{x_k} \phi _{r}(x,y) + \frac{\sigma _1^2}{2} \left (x-y_{\alpha }({\rho _{Y,t}})\right )_k^2 \delta ^{2,Y}_{x_kx_k} \phi _{r}(x,y), \end{align}
\begin{align} &\qquad \quad \,\,-\lambda _1\left (x-y_{\alpha }({\rho _{Y,t}})\right )_k \delta ^Y_{x_k} \phi _{r}(x,y) + \frac{\sigma _1^2}{2} \left (x-y_{\alpha }({\rho _{Y,t}})\right )_k^2 \delta ^{2,Y}_{x_kx_k} \phi _{r}(x,y), \end{align}
for
 $T^\ell _{1k}+T^\ell _{2k}$
we have
$T^\ell _{1k}+T^\ell _{2k}$
we have
 \begin{align} &T^\ell _{1k}(x,y)+T^\ell _{2k}(x,y)\nonumber \\ &\qquad \,=-\lambda _2\left (x-y\right )_k \delta ^{*}_{x_k} \phi _{r}(x,y) + \frac{\sigma _2^2}{2} \left (x-y\right )_k^2 \delta ^{2,*}_{x_kx_k} \phi _{r}(x,y) \end{align}
\begin{align} &T^\ell _{1k}(x,y)+T^\ell _{2k}(x,y)\nonumber \\ &\qquad \,=-\lambda _2\left (x-y\right )_k \delta ^{*}_{x_k} \phi _{r}(x,y) + \frac{\sigma _2^2}{2} \left (x-y\right )_k^2 \delta ^{2,*}_{x_kx_k} \phi _{r}(x,y) \end{align}
 \begin{align} &\qquad \quad \,\,-\lambda _2\left (x-y\right )_k \delta ^Y_{x_k} \phi _{r}(x,y) + \frac{\sigma _2^2}{2} \left (x-y\right )_k^2 \delta ^{2,Y}_{x_kx_k} \phi _{r}(x,y) \end{align}
\begin{align} &\qquad \quad \,\,-\lambda _2\left (x-y\right )_k \delta ^Y_{x_k} \phi _{r}(x,y) + \frac{\sigma _2^2}{2} \left (x-y\right )_k^2 \delta ^{2,Y}_{x_kx_k} \phi _{r}(x,y) \end{align}
and for
 $T^g_{1k}+T^g_{2k}$
we have
$T^g_{1k}+T^g_{2k}$
we have
 \begin{align} &T^g_{1k}(x,y)+T^g_{2k}(x,y)\nonumber \\ &\qquad \,=-\lambda _3\partial _{x_k}{\mathcal{E}}(x) \delta ^{*}_{x_k} \phi _{r}(x,y) + \frac{\sigma _3^2}{2} (\partial _{x_k}{\mathcal{E}}(x))^2 \delta ^{2,*}_{x_kx_k} \phi _{r}(x,y) \end{align}
\begin{align} &T^g_{1k}(x,y)+T^g_{2k}(x,y)\nonumber \\ &\qquad \,=-\lambda _3\partial _{x_k}{\mathcal{E}}(x) \delta ^{*}_{x_k} \phi _{r}(x,y) + \frac{\sigma _3^2}{2} (\partial _{x_k}{\mathcal{E}}(x))^2 \delta ^{2,*}_{x_kx_k} \phi _{r}(x,y) \end{align}
 \begin{align} &\qquad \quad \,\,-\lambda _3\partial _{x_k}{\mathcal{E}}(x) \delta ^Y_{x_k} \phi _{r}(x,y) + \frac{\sigma _3^2}{2} (\partial _{x_k}{\mathcal{E}}(x))^2 \delta ^{2,Y}_{x_kx_k} \phi _{r}(x,y). \end{align}
\begin{align} &\qquad \quad \,\,-\lambda _3\partial _{x_k}{\mathcal{E}}(x) \delta ^Y_{x_k} \phi _{r}(x,y) + \frac{\sigma _3^2}{2} (\partial _{x_k}{\mathcal{E}}(x))^2 \delta ^{2,Y}_{x_kx_k} \phi _{r}(x,y). \end{align}
We now treat each of the two-part sums in (3.15a), (3.15b), (3.16a), (3.16b), (3.17a) and (3.17b) separately by employing a technique similar to the one used in the proof of [Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29, Proposition 2], which was developed originally to prove [Reference Fornasier, Klock and Riedl28, Proposition 20].
Terms (3.15a), (3.16a) and (3.17a): Owed to their similar structure (in particular with respect to the denominator of the derivatives
 $\delta ^{*}_{x_k} \phi _{r}$
and
$\delta ^{*}_{x_k} \phi _{r}$
and
 $\delta ^{2,*}_{x_kx_k} \phi _{r}$
), we can treat the three sums (3.15a), (3.16a) and (3.17a) simultaneously. Therefore, we consider the general formulation
$\delta ^{2,*}_{x_kx_k} \phi _{r}$
), we can treat the three sums (3.15a), (3.16a) and (3.17a) simultaneously. Therefore, we consider the general formulation
 \begin{equation} -\lambda \Upsilon _k(x,y) \delta ^{*}_{x_k} \phi _{r}(x,y) + \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) \delta ^{2,*}_{x_kx_k} \phi _{r}(x,y) \,=\!:\, T^*_{1k}(x,y)+T^*_{2k}(x,y), \end{equation}
\begin{equation} -\lambda \Upsilon _k(x,y) \delta ^{*}_{x_k} \phi _{r}(x,y) + \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) \delta ^{2,*}_{x_kx_k} \phi _{r}(x,y) \,=\!:\, T^*_{1k}(x,y)+T^*_{2k}(x,y), \end{equation}
which matches (3.15a) when
 $\Upsilon _k(x,y) = (x-y_{\alpha }({\rho _{Y,t}}))_k$
,
$\Upsilon _k(x,y) = (x-y_{\alpha }({\rho _{Y,t}}))_k$
,
 $\lambda =\lambda _1$
and
$\lambda =\lambda _1$
and
 $\sigma =\sigma _1$
, (3.16a) when
$\sigma =\sigma _1$
, (3.16a) when
 $\Upsilon _k(x,y) = (x-y)_k$
,
$\Upsilon _k(x,y) = (x-y)_k$
,
 $\lambda =\lambda _2$
and
$\lambda =\lambda _2$
and
 $\sigma =\sigma _2$
, and (3.17a) when
$\sigma =\sigma _2$
, and (3.17a) when
 $\Upsilon _k(x,y) = \partial _{x_k}{\mathcal{E}}(x)$
,
$\Upsilon _k(x,y) = \partial _{x_k}{\mathcal{E}}(x)$
,
 $\lambda =\lambda _3$
and
$\lambda =\lambda _3$
and
 $\sigma =\sigma _3$
.
$\sigma =\sigma _3$
.
To achieve the desired lower bound over
 $\Omega _r$
, we introduce the subsets
$\Omega _r$
, we introduce the subsets
 \begin{align*} K^*_{1k} &\,:\!=\, \left \{(x,y) \in \mathbb{R}^d\times \mathbb{R}^d\, :\, \left |{\left (x-x^*\right )_k}\right | \gt \frac{\sqrt{c}}{2}r\right \} \end{align*}
\begin{align*} K^*_{1k} &\,:\!=\, \left \{(x,y) \in \mathbb{R}^d\times \mathbb{R}^d\, :\, \left |{\left (x-x^*\right )_k}\right | \gt \frac{\sqrt{c}}{2}r\right \} \end{align*}
and
 \begin{align*} \begin{aligned} &K^*_{2k} \,:\!=\, \Bigg \{(x,y) \in \mathbb{R}^d\times \mathbb{R}^d\, :\, -\lambda \Upsilon _k(x,y) \left (x-x^*\right )_k \left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )_k^2\right )^2 \\ &\qquad \qquad \qquad \qquad \qquad \qquad \qquad \gt \tilde{c}\left (\frac{r}{2}\right )^2\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-x^*\right )_k^2\Bigg \}, \end{aligned} \end{align*}
\begin{align*} \begin{aligned} &K^*_{2k} \,:\!=\, \Bigg \{(x,y) \in \mathbb{R}^d\times \mathbb{R}^d\, :\, -\lambda \Upsilon _k(x,y) \left (x-x^*\right )_k \left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )_k^2\right )^2 \\ &\qquad \qquad \qquad \qquad \qquad \qquad \qquad \gt \tilde{c}\left (\frac{r}{2}\right )^2\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-x^*\right )_k^2\Bigg \}, \end{aligned} \end{align*}
where
 $\tilde{c} \,:\!=\, 2c-1\in (0,1)$
. For fixed
$\tilde{c} \,:\!=\, 2c-1\in (0,1)$
. For fixed
 $k$
, we now decompose
$k$
, we now decompose
 $\Omega _r$
according to
$\Omega _r$
according to
 \begin{align*} \Omega _r = \big ((K_{1k}^{*})^c \cap \Omega _r\big ) \cup \big (K^*_{1k} \cap (K_{2k}^{*})^c \cap \Omega _r\big ) \cup \big (K^*_{1k} \cap K^*_{2k} \cap \Omega _r\big ). \end{align*}
\begin{align*} \Omega _r = \big ((K_{1k}^{*})^c \cap \Omega _r\big ) \cup \big (K^*_{1k} \cap (K_{2k}^{*})^c \cap \Omega _r\big ) \cup \big (K^*_{1k} \cap K^*_{2k} \cap \Omega _r\big ). \end{align*}
In the following, we treat each of these three subsets separately.
Subset
 $(K_{1k}^{*})^c \cap \Omega _r$
: We have
$(K_{1k}^{*})^c \cap \Omega _r$
: We have
 $\left |{\left (x-x^*\right )_k}\right | \leq \frac{\sqrt{c}}{2}r$
for each
$\left |{\left (x-x^*\right )_k}\right | \leq \frac{\sqrt{c}}{2}r$
for each
 $(x,y) \in (K_{1k}^*)^c$
, which can be used to independently derive lower bounds for both summands in (3.18). For the first, we insert the expression for
$(x,y) \in (K_{1k}^*)^c$
, which can be used to independently derive lower bounds for both summands in (3.18). For the first, we insert the expression for
 $\delta ^{*}_{x_k} \phi _{r}(x,y)$
to get
$\delta ^{*}_{x_k} \phi _{r}(x,y)$
to get
 \begin{equation} \begin{aligned} T^*_{1k}(x,y) &= \frac{r^2}{2}\lambda \Upsilon _k(x,y) \frac{\left (x-x^*\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2}\phi _{r}(x,y) \\ &\geq -\frac{r^2}{2} \!\lambda \frac{\left |{\Upsilon _k(x,y)}\right |\!\left |{\left (x-x^*\right )_k}\right |}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2}\phi _r(x,y) \geq - \frac{2\lambda C_{\Upsilon} \sqrt{c}}{(1-c)^2\frac{r}{2}}\phi _r(x,y) \\ &\,=\!:\, -p^{*,\Upsilon }_{1}\phi _r(x,y), \end{aligned} \end{equation}
\begin{equation} \begin{aligned} T^*_{1k}(x,y) &= \frac{r^2}{2}\lambda \Upsilon _k(x,y) \frac{\left (x-x^*\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2}\phi _{r}(x,y) \\ &\geq -\frac{r^2}{2} \!\lambda \frac{\left |{\Upsilon _k(x,y)}\right |\!\left |{\left (x-x^*\right )_k}\right |}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2}\phi _r(x,y) \geq - \frac{2\lambda C_{\Upsilon} \sqrt{c}}{(1-c)^2\frac{r}{2}}\phi _r(x,y) \\ &\,=\!:\, -p^{*,\Upsilon }_{1}\phi _r(x,y), \end{aligned} \end{equation}
where, in the last inequality, we used that
 $(x,y)\in \Omega _r$
, the definition of
$(x,y)\in \Omega _r$
, the definition of
 $B$
and Assumption A3 to get the bound
$B$
and Assumption A3 to get the bound
 \begin{equation} \begin{split} \left |{\Upsilon _k(x,y)}\right | &= \begin{cases} \left |{(x-y_{\alpha }({\rho _{Y,t}}))_k}\right | \leq \frac{r}{2}+B, &\text{if }\Upsilon _k(x,y) = (x-y_{\alpha }({\rho _{Y,t}}))_k, \\ \left |{(x-y)_k}\right | \leq \frac{r}{2}, &\text{if }\Upsilon _k(x,y) = (x-y)_k, \\ \left |{\partial _{x_k}{\mathcal{E}}(x)}\right | \leq \left \|{\nabla{\mathcal{E}}(x)}\right \|_2 \leq C_{\nabla{\mathcal{E}}}\left \|{x-x^*}\right \|_2\\ \qquad \leq C_{\nabla{\mathcal{E}}}d\left \|{x-x^*}\right \|_{\infty} \leq C_{\nabla{\mathcal{E}}}d\frac{r}{2} &\text{if }\Upsilon _k(x,y) = \partial _{x_k}{\mathcal{E}}(x). \end{cases}\\ &\leq \max \left \{\frac{r}{2}+B, C_{\nabla{\mathcal{E}}}d\frac{r}{2}\right \} \,=\!:\, C_{\Upsilon} (r,B,d,C_{\nabla{\mathcal{E}}}). \end{split} \end{equation}
\begin{equation} \begin{split} \left |{\Upsilon _k(x,y)}\right | &= \begin{cases} \left |{(x-y_{\alpha }({\rho _{Y,t}}))_k}\right | \leq \frac{r}{2}+B, &\text{if }\Upsilon _k(x,y) = (x-y_{\alpha }({\rho _{Y,t}}))_k, \\ \left |{(x-y)_k}\right | \leq \frac{r}{2}, &\text{if }\Upsilon _k(x,y) = (x-y)_k, \\ \left |{\partial _{x_k}{\mathcal{E}}(x)}\right | \leq \left \|{\nabla{\mathcal{E}}(x)}\right \|_2 \leq C_{\nabla{\mathcal{E}}}\left \|{x-x^*}\right \|_2\\ \qquad \leq C_{\nabla{\mathcal{E}}}d\left \|{x-x^*}\right \|_{\infty} \leq C_{\nabla{\mathcal{E}}}d\frac{r}{2} &\text{if }\Upsilon _k(x,y) = \partial _{x_k}{\mathcal{E}}(x). \end{cases}\\ &\leq \max \left \{\frac{r}{2}+B, C_{\nabla{\mathcal{E}}}d\frac{r}{2}\right \} \,=\!:\, C_{\Upsilon} (r,B,d,C_{\nabla{\mathcal{E}}}). \end{split} \end{equation}
For the second summand, we insert the expression for
 $\delta ^{2,*}_{x_kx_k} \phi _{r}(x,y)$
to obtain
$\delta ^{2,*}_{x_kx_k} \phi _{r}(x,y)$
to obtain
 \begin{equation} \begin{aligned} T^*_{2k}(x,y) &=\frac{\sigma ^2}{2} \Upsilon _k^2(x,y) \delta ^{2,*}_{x_kx_k} \phi _{r}(x,y)\\ &=\sigma ^2 \left (\frac{r}{2}\right )^2 \Upsilon _k^2(x,y) \frac{2\left (2\left (x\!-\!x^*\right )^2_k\!-\!\left (\frac{r}{2}\right )^2\right )\left (x\!-\!x^*\right )_k^2 \!-\! \left (\left (\frac{r}{2}\right )^2\!-\!\left (x\!-\!x^*\right )^2_k\right )^2}{\left (\left (\frac{r}{2}\right )^2-\left (x\!-\!x^*\right )^2_k\right )^4} \phi _{r}(x,y)\\ &\geq - \frac{\sigma ^2C_{\Upsilon} ^2}{(1-c)^4\left (\frac{r}{2}\right )^2}\phi _{r}(x,y) \,=\!:\, -p^{*,\Upsilon }_{2}\phi _r(x,y), \end{aligned} \end{equation}
\begin{equation} \begin{aligned} T^*_{2k}(x,y) &=\frac{\sigma ^2}{2} \Upsilon _k^2(x,y) \delta ^{2,*}_{x_kx_k} \phi _{r}(x,y)\\ &=\sigma ^2 \left (\frac{r}{2}\right )^2 \Upsilon _k^2(x,y) \frac{2\left (2\left (x\!-\!x^*\right )^2_k\!-\!\left (\frac{r}{2}\right )^2\right )\left (x\!-\!x^*\right )_k^2 \!-\! \left (\left (\frac{r}{2}\right )^2\!-\!\left (x\!-\!x^*\right )^2_k\right )^2}{\left (\left (\frac{r}{2}\right )^2-\left (x\!-\!x^*\right )^2_k\right )^4} \phi _{r}(x,y)\\ &\geq - \frac{\sigma ^2C_{\Upsilon} ^2}{(1-c)^4\left (\frac{r}{2}\right )^2}\phi _{r}(x,y) \,=\!:\, -p^{*,\Upsilon }_{2}\phi _r(x,y), \end{aligned} \end{equation}
where the last inequality uses
 $\Upsilon _k^2(x,y) \leq C_{\Upsilon} ^2$
.
$\Upsilon _k^2(x,y) \leq C_{\Upsilon} ^2$
.
Subset
 $K^*_{1k} \cap (K_{2k}^{*})^c \cap \Omega _r$
: As
$K^*_{1k} \cap (K_{2k}^{*})^c \cap \Omega _r$
: As
 $(x,y) \in K^*_{1k}$
, we have
$(x,y) \in K^*_{1k}$
, we have
 $\left |{\left (x-x^*\right )_k}\right | \gt \frac{\sqrt{c}}{2}r$
. We observe that the sum in (3.18) is nonnegative for all
$\left |{\left (x-x^*\right )_k}\right | \gt \frac{\sqrt{c}}{2}r$
. We observe that the sum in (3.18) is nonnegative for all
 $(x,y)$
in this subset whenever
$(x,y)$
in this subset whenever
 \begin{equation} \begin{aligned} &\left ({-}\lambda \Upsilon _k(x,y)\left (x-x^*\right )_k + \frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\right )\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2 \\ &\qquad \qquad \qquad \qquad \qquad \, \leq \sigma ^2\Upsilon _k^2(x,y) \left (2\left (x-x^*\right )^2_k-\left (\frac{r}{2}\right )^2\right )\left (x-x^*\right )_k^2. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\left ({-}\lambda \Upsilon _k(x,y)\left (x-x^*\right )_k + \frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\right )\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2 \\ &\qquad \qquad \qquad \qquad \qquad \, \leq \sigma ^2\Upsilon _k^2(x,y) \left (2\left (x-x^*\right )^2_k-\left (\frac{r}{2}\right )^2\right )\left (x-x^*\right )_k^2. \end{aligned} \end{equation}
The first term on the left-hand side in (3.22) can be bounded from above by exploiting that
 $v\in (K_{2k}^{*})^c$
and by using the relation
$v\in (K_{2k}^{*})^c$
and by using the relation
 $\tilde{c} = 2c-1$
. More precisely, we have
$\tilde{c} = 2c-1$
. More precisely, we have
 \begin{align*} &-\lambda \Upsilon _k(x,y)\left (x-x^*\right )_k \left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2 \leq \tilde{c}\left (\frac{r}{2}\right )^2\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-x^*\right )_k^2\\ &\quad \;\; = (2c\!-\!1)\left (\frac{r}{2}\right )^2\!\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-x^*\right )_k^2 \leq \! \left (2\left (x-x^*\right )_k^2-\left (\frac{r}{2}\right )^2\right )\!\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-x^*\right )_k^2, \end{align*}
\begin{align*} &-\lambda \Upsilon _k(x,y)\left (x-x^*\right )_k \left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2 \leq \tilde{c}\left (\frac{r}{2}\right )^2\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-x^*\right )_k^2\\ &\quad \;\; = (2c\!-\!1)\left (\frac{r}{2}\right )^2\!\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-x^*\right )_k^2 \leq \! \left (2\left (x-x^*\right )_k^2-\left (\frac{r}{2}\right )^2\right )\!\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-x^*\right )_k^2, \end{align*}
where the last inequality follows since
 $v\in K^*_{1k}$
. For the second term on the left-hand side in (3.22), we can use
$v\in K^*_{1k}$
. For the second term on the left-hand side in (3.22), we can use
 $(1-c)^2 \leq (2c-1)c$
as per assumption, to get
$(1-c)^2 \leq (2c-1)c$
as per assumption, to get
 \begin{align*} &\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2 \leq \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) (1-c)^2\left (\frac{r}{2}\right )^4 \\ &\qquad \leq \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) (2c-1)\left (\frac{r}{2}\right )^2c\left (\frac{r}{2}\right )^2 \leq \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) \left (2\left (x-x^*\right )_k^2-\left (\frac{r}{2}\right )^2\right )\left (x-x^*\right )_k^2. \end{align*}
\begin{align*} &\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2 \leq \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) (1-c)^2\left (\frac{r}{2}\right )^4 \\ &\qquad \leq \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) (2c-1)\left (\frac{r}{2}\right )^2c\left (\frac{r}{2}\right )^2 \leq \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) \left (2\left (x-x^*\right )_k^2-\left (\frac{r}{2}\right )^2\right )\left (x-x^*\right )_k^2. \end{align*}
Hence, (3.22) holds and we have that (3.18) is uniformly nonnegative on this subset.
Subset
 $K^*_{1k} \cap K^*_{2k} \cap \Omega _r$
: As
$K^*_{1k} \cap K^*_{2k} \cap \Omega _r$
: As
 $(x,y) \in K_{1k}^*$
, we have
$(x,y) \in K_{1k}^*$
, we have
 $\left |{\left (x-x^*\right )_k}\right | \gt \frac{\sqrt{c}}{2}r$
. To start with we note that the first summand of (3.18) vanishes whenever
$\left |{\left (x-x^*\right )_k}\right | \gt \frac{\sqrt{c}}{2}r$
. To start with we note that the first summand of (3.18) vanishes whenever
 $\sigma ^2\Upsilon _k^2(x,y) = 0$
, provided
$\sigma ^2\Upsilon _k^2(x,y) = 0$
, provided
 $\sigma \gt 0$
, so nothing needs to be done if
$\sigma \gt 0$
, so nothing needs to be done if
 $\Upsilon _k(x,y)=0$
. Otherwise, if
$\Upsilon _k(x,y)=0$
. Otherwise, if
 $\sigma ^2\Upsilon _k^2(x,y) \gt 0$
, we exploit
$\sigma ^2\Upsilon _k^2(x,y) \gt 0$
, we exploit
 $(x,y)\in K_{2k}^*$
to get
$(x,y)\in K_{2k}^*$
to get
 \begin{equation*} \begin{split} \frac{\Upsilon _k(x,y)\left (x-x^*\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )_k^2\right )^2} &\geq \frac{-\left |{\Upsilon _k(x,y)}\right |\left |{\left (x-x^*\right )_k}\right |}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )_k^2\right )^2}\\ &\gt \frac{2\lambda \Upsilon _k(x,y) \left (x-x^*\right )_k}{\tilde{c}\left (\frac{r}{2}\right )^2\sigma ^2\left |{\Upsilon _k(x,y)}\right |\left |{\left (x-x^*\right )_k}\right |} \geq -\frac{8\lambda }{\tilde{c}r^2\sigma ^2}. \end{split} \end{equation*}
\begin{equation*} \begin{split} \frac{\Upsilon _k(x,y)\left (x-x^*\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )_k^2\right )^2} &\geq \frac{-\left |{\Upsilon _k(x,y)}\right |\left |{\left (x-x^*\right )_k}\right |}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )_k^2\right )^2}\\ &\gt \frac{2\lambda \Upsilon _k(x,y) \left (x-x^*\right )_k}{\tilde{c}\left (\frac{r}{2}\right )^2\sigma ^2\left |{\Upsilon _k(x,y)}\right |\left |{\left (x-x^*\right )_k}\right |} \geq -\frac{8\lambda }{\tilde{c}r^2\sigma ^2}. \end{split} \end{equation*}
Using this, the first summand of (3.18) can be bounded from below by
 \begin{equation} \begin{split} T^*_{1k}(x,y) =\lambda \frac{r^2}{2}\frac{\Upsilon _k(x,y)\left (x-x^*\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2}\phi _{r}(x,y) &\geq -\frac{4\lambda ^2}{\tilde{c}\sigma ^2}\phi _{r}(x,y) \,=\!:\, -p^{*,\Upsilon }_{3}\phi _r(x,y). \end{split} \end{equation}
\begin{equation} \begin{split} T^*_{1k}(x,y) =\lambda \frac{r^2}{2}\frac{\Upsilon _k(x,y)\left (x-x^*\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2}\phi _{r}(x,y) &\geq -\frac{4\lambda ^2}{\tilde{c}\sigma ^2}\phi _{r}(x,y) \,=\!:\, -p^{*,\Upsilon }_{3}\phi _r(x,y). \end{split} \end{equation}
For the second summand, the nonnegativity of
 $\sigma ^2\Upsilon _k^2(x,y)$
implies the nonnegativity, whenever
$\sigma ^2\Upsilon _k^2(x,y)$
implies the nonnegativity, whenever
 \begin{equation*} 2\left (2\left (x-x^*\right )^2_k-\left (\frac {r}{2}\right )^2\right )\left (x-x^*\right )_k^2 \geq \left (\left (\frac {r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2. \end{equation*}
\begin{equation*} 2\left (2\left (x-x^*\right )^2_k-\left (\frac {r}{2}\right )^2\right )\left (x-x^*\right )_k^2 \geq \left (\left (\frac {r}{2}\right )^2-\left (x-x^*\right )^2_k\right )^2. \end{equation*}
This holds for
 $v\in K_{1k}^*$
, if
$v\in K_{1k}^*$
, if
 $2(2c-1)c \geq (1-c)^2$
as implied by the assumption.
$2(2c-1)c \geq (1-c)^2$
as implied by the assumption.
Term (3.16b): Recall that this term has the structure
 \begin{equation} -\lambda _2\left (x-y\right )_k \delta ^Y_{x_k} \phi _{r}(x,y) + \frac{\sigma _2^2}{2} \left (x-y\right )_k^2 \delta ^{2,Y}_{x_kx_k} \phi _{r}(x,y)\,=\!:\,T^{Y,1}_{1k}(x,y)+T^{Y,1}_{2k}(x,y). \end{equation}
\begin{equation} -\lambda _2\left (x-y\right )_k \delta ^Y_{x_k} \phi _{r}(x,y) + \frac{\sigma _2^2}{2} \left (x-y\right )_k^2 \delta ^{2,Y}_{x_kx_k} \phi _{r}(x,y)\,=\!:\,T^{Y,1}_{1k}(x,y)+T^{Y,1}_{2k}(x,y). \end{equation}
We first note that the first summand of (3.24) is always nonnegative since
 \begin{equation} T^{Y,1}_{1k}(x,y)= \lambda _2 \frac{r^2}{2}\frac{\left (x-y\right )_k^2}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2}\phi _{r}(x,y) \geq 0. \end{equation}
\begin{equation} T^{Y,1}_{1k}(x,y)= \lambda _2 \frac{r^2}{2}\frac{\left (x-y\right )_k^2}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2}\phi _{r}(x,y) \geq 0. \end{equation}
For the second summand of (3.24), a direct computation shows
 \begin{equation*} \begin{split} T^{Y,1}_{2k}(x,y) = \sigma _2^2 \left (\frac{r}{2}\right )^2 \left (x-y\right )_k^2 \frac{3\left (x-y\right )^4_k-\left (\frac{r}{2}\right )^4}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^4} \phi _{r}(x,y), \end{split} \end{equation*}
\begin{equation*} \begin{split} T^{Y,1}_{2k}(x,y) = \sigma _2^2 \left (\frac{r}{2}\right )^2 \left (x-y\right )_k^2 \frac{3\left (x-y\right )^4_k-\left (\frac{r}{2}\right )^4}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^4} \phi _{r}(x,y), \end{split} \end{equation*}
which is nonnegative on the set
 \begin{align*} K^Y_k \,:\!=\, \left \{(x,y) \in \mathbb{R}^d\times \mathbb{R}^d\, :\, \left |{\left (x-y\right )_k}\right | \gt \frac{\sqrt{c}}{2}r\right \} \end{align*}
\begin{align*} K^Y_k \,:\!=\, \left \{(x,y) \in \mathbb{R}^d\times \mathbb{R}^d\, :\, \left |{\left (x-y\right )_k}\right | \gt \frac{\sqrt{c}}{2}r\right \} \end{align*}
for any
 $c\geq 1/\sqrt{3}$
, as ensured by
$c\geq 1/\sqrt{3}$
, as ensured by
 $(1-c)^2 \leq (2c-1)c$
. On the complement
$(1-c)^2 \leq (2c-1)c$
. On the complement
 $(K^Y_k)^c$
, we have
$(K^Y_k)^c$
, we have
 $\left |{\left (x-y\right )_k}\right | \leq \frac{\sqrt{c}}{2}r$
, which can be used to bound
$\left |{\left (x-y\right )_k}\right | \leq \frac{\sqrt{c}}{2}r$
, which can be used to bound
 \begin{equation} \begin{aligned} T^{Y,1}_{2k}(x,y) &=\sigma _2^2 \left (\frac{r}{2}\right )^2 \!\left (x\!-\!y\right )_k^2 \frac{3\left (x\!-\!y\right )^4_k\!-\!\left (\frac{r}{2}\right )^4}{\left (\left (\frac{r}{2}\right )^2\!-\!\left (x\!-\!y\right )^2_k\right )^4}\phi _{r}(x,y)\\ &\geq -\frac{\sigma _2^2 c}{\left (1\!-\!c\right )^4}\phi _{r}(x,y) \,=\!:\, -p^{Y,\Upsilon _{\ell} }\phi _r(x,y). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} T^{Y,1}_{2k}(x,y) &=\sigma _2^2 \left (\frac{r}{2}\right )^2 \!\left (x\!-\!y\right )_k^2 \frac{3\left (x\!-\!y\right )^4_k\!-\!\left (\frac{r}{2}\right )^4}{\left (\left (\frac{r}{2}\right )^2\!-\!\left (x\!-\!y\right )^2_k\right )^4}\phi _{r}(x,y)\\ &\geq -\frac{\sigma _2^2 c}{\left (1\!-\!c\right )^4}\phi _{r}(x,y) \,=\!:\, -p^{Y,\Upsilon _{\ell} }\phi _r(x,y). \end{aligned} \end{equation}
Terms (3.15b) and (3.17b): The final two terms to be controlled have again a similar structure of the form
 \begin{equation} -\lambda \Upsilon _k(x,y) \delta ^Y_{x_k} \phi _{r}(x,y) + \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) \delta ^{2,Y}_{x_kx_k} \phi _{r}(x,y)\,=\!:\,T^{Y,2}_{1k}(x,y)+T^{Y,2}_{2k}(x,y), \end{equation}
\begin{equation} -\lambda \Upsilon _k(x,y) \delta ^Y_{x_k} \phi _{r}(x,y) + \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) \delta ^{2,Y}_{x_kx_k} \phi _{r}(x,y)\,=\!:\,T^{Y,2}_{1k}(x,y)+T^{Y,2}_{2k}(x,y), \end{equation}
where we recycle the notation introduced after (3.18), i.e.,
 $\Upsilon _k(x,y) = (x-y_{\alpha }({\rho _{Y,t}}))_k$
,
$\Upsilon _k(x,y) = (x-y_{\alpha }({\rho _{Y,t}}))_k$
,
 $\lambda =\lambda _1$
and
$\lambda =\lambda _1$
and
 $\sigma =\sigma _1$
in the case of (3.15b) and
$\sigma =\sigma _1$
in the case of (3.15b) and
 $\Upsilon _k(x,y) = \partial _{x_k}{\mathcal{E}}(x)$
,
$\Upsilon _k(x,y) = \partial _{x_k}{\mathcal{E}}(x)$
,
 $\lambda =\lambda _3$
and
$\lambda =\lambda _3$
and
 $\sigma =\sigma _3$
in the case of (3.17b).
$\sigma =\sigma _3$
in the case of (3.17b).
The procedure for deriving lower bounds is similar to the one at the beginning with the exception that the denominator of the derivatives
 $\delta ^Y_{x_k} \phi _{r}$
and
$\delta ^Y_{x_k} \phi _{r}$
and
 $\delta ^{2,Y}_{x_kx_k} \phi _{r}$
requires to introduce an adapted decomposition of
$\delta ^{2,Y}_{x_kx_k} \phi _{r}$
requires to introduce an adapted decomposition of
 $\Omega _r$
. To be more specific, we define the subsets
$\Omega _r$
. To be more specific, we define the subsets
 \begin{align*} K^Y_{1k} &\,:\!=\, \left \{(x,y) \in \mathbb{R}^d\times \mathbb{R}^d\, :\, \left |{\left (x-y\right )_k}\right | \gt \frac{\sqrt{c}}{2}r\right \} \end{align*}
\begin{align*} K^Y_{1k} &\,:\!=\, \left \{(x,y) \in \mathbb{R}^d\times \mathbb{R}^d\, :\, \left |{\left (x-y\right )_k}\right | \gt \frac{\sqrt{c}}{2}r\right \} \end{align*}
and
 \begin{align*} \begin{aligned} &K^Y_{2k} \,:\!=\, \Bigg \{(x,y) \in \mathbb{R}^d\times \mathbb{R}^d\, :\, -\lambda \Upsilon _k(x,y) \left (x-y\right )_k \left (\left (\frac{r}{2}\right )^2-\left (x-y\right )_k^2\right )^2 \\ &\qquad \qquad \qquad \qquad \qquad \qquad \qquad \gt \tilde{c}\left (\frac{r}{2}\right )^2\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-y\right )_k^2\Bigg \}, \end{aligned} \end{align*}
\begin{align*} \begin{aligned} &K^Y_{2k} \,:\!=\, \Bigg \{(x,y) \in \mathbb{R}^d\times \mathbb{R}^d\, :\, -\lambda \Upsilon _k(x,y) \left (x-y\right )_k \left (\left (\frac{r}{2}\right )^2-\left (x-y\right )_k^2\right )^2 \\ &\qquad \qquad \qquad \qquad \qquad \qquad \qquad \gt \tilde{c}\left (\frac{r}{2}\right )^2\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-y\right )_k^2\Bigg \}, \end{aligned} \end{align*}
where
 $\tilde{c} \,:\!=\, 2c-1\in (0,1)$
. For fixed
$\tilde{c} \,:\!=\, 2c-1\in (0,1)$
. For fixed
 $k$
, we now decompose
$k$
, we now decompose
 $\Omega _r$
according to
$\Omega _r$
according to
 \begin{align*} \Omega _r = \big ((K_{1k}^Y)^c \cap \Omega _r\big ) \cup \big (K^Y_{1k} \cap (K_{2k}^Y)^c \cap \Omega _r\big ) \cup \big (K^Y_{1k} \cap K^Y_{2k} \cap \Omega _r\big ). \end{align*}
\begin{align*} \Omega _r = \big ((K_{1k}^Y)^c \cap \Omega _r\big ) \cup \big (K^Y_{1k} \cap (K_{2k}^Y)^c \cap \Omega _r\big ) \cup \big (K^Y_{1k} \cap K^Y_{2k} \cap \Omega _r\big ). \end{align*}
In the following, we treat again each of these three subsets separately.
Subset
 $(K_{1k}^Y)^c \cap \Omega _r$
: We have
$(K_{1k}^Y)^c \cap \Omega _r$
: We have
 $\left |{\left (x-y\right )_k}\right | \leq \frac{\sqrt{c}}{2}r$
for each
$\left |{\left (x-y\right )_k}\right | \leq \frac{\sqrt{c}}{2}r$
for each
 $(x,y) \in (K_{1k}^Y)^c$
, which can be used to independently derive lower bounds for both summands in (3.27). For the first summand, we insert the expression for
$(x,y) \in (K_{1k}^Y)^c$
, which can be used to independently derive lower bounds for both summands in (3.27). For the first summand, we insert the expression for
 $\delta ^Y_{x_k} \phi _{r}(x,y)$
to get
$\delta ^Y_{x_k} \phi _{r}(x,y)$
to get
 \begin{equation} \begin{aligned} T^{Y,2}_{1k}(x,y) &= \frac{r^2}{2}\lambda \Upsilon _k(x,y) \frac{\left (x-y\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2}\phi _{r}(x,y) \\ &\geq -\frac{r^2}{2} \!\lambda \frac{\left |{\Upsilon _k(x,y)}\right |\!\left |{\left (x-y\right )_k}\right |}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2}\phi _r(x,y) \geq - \frac{2\lambda C_{\Upsilon} \sqrt{c}}{(1-c)^2\frac{r}{2}}\phi _r(x,y) \\ &\,=\!:\, -p^{Y,\Upsilon }_{1}\phi _r(x,y), \end{aligned} \end{equation}
\begin{equation} \begin{aligned} T^{Y,2}_{1k}(x,y) &= \frac{r^2}{2}\lambda \Upsilon _k(x,y) \frac{\left (x-y\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2}\phi _{r}(x,y) \\ &\geq -\frac{r^2}{2} \!\lambda \frac{\left |{\Upsilon _k(x,y)}\right |\!\left |{\left (x-y\right )_k}\right |}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2}\phi _r(x,y) \geq - \frac{2\lambda C_{\Upsilon} \sqrt{c}}{(1-c)^2\frac{r}{2}}\phi _r(x,y) \\ &\,=\!:\, -p^{Y,\Upsilon }_{1}\phi _r(x,y), \end{aligned} \end{equation}
where we recall from above that
 $\Upsilon _k(x,y) \leq C_{\Upsilon}$
, which was used in the last inequality. For the second summand, we insert the expression for
$\Upsilon _k(x,y) \leq C_{\Upsilon}$
, which was used in the last inequality. For the second summand, we insert the expression for
 $\delta ^{2,Y}_{x_kx_k} \phi _{r}(x,y)$
to obtain
$\delta ^{2,Y}_{x_kx_k} \phi _{r}(x,y)$
to obtain
 \begin{equation} \begin{aligned} T^{Y,2}_{2k}(x,y) &=\sigma ^2 \left (\frac{r}{2}\right )^2 \Upsilon _k^2(x,y) \frac{2\left (2\left (x\!-\!y\right )^2_k\!-\!\left (\frac{r}{2}\right )^2\right )\left (x\!-\!y\right )_k^2 \!-\! \left (\left (\frac{r}{2}\right )^2\!-\!\left (x\!-\!y\right )^2_k\right )^2}{\left (\left (\frac{r}{2}\right )^2\!-\!\left (x\!-\!y\right )^2_k\right )^4} \phi _{r}(x,y)\\ &\geq - \frac{\sigma ^2C_{\Upsilon} ^2}{(1-c)^4\left (\frac{r}{2}\right )^2}\phi _{r}(x,y) \,=\!:\, -p^{Y,\Upsilon }_{2}\phi _r(x,y), \end{aligned} \end{equation}
\begin{equation} \begin{aligned} T^{Y,2}_{2k}(x,y) &=\sigma ^2 \left (\frac{r}{2}\right )^2 \Upsilon _k^2(x,y) \frac{2\left (2\left (x\!-\!y\right )^2_k\!-\!\left (\frac{r}{2}\right )^2\right )\left (x\!-\!y\right )_k^2 \!-\! \left (\left (\frac{r}{2}\right )^2\!-\!\left (x\!-\!y\right )^2_k\right )^2}{\left (\left (\frac{r}{2}\right )^2\!-\!\left (x\!-\!y\right )^2_k\right )^4} \phi _{r}(x,y)\\ &\geq - \frac{\sigma ^2C_{\Upsilon} ^2}{(1-c)^4\left (\frac{r}{2}\right )^2}\phi _{r}(x,y) \,=\!:\, -p^{Y,\Upsilon }_{2}\phi _r(x,y), \end{aligned} \end{equation}
where the last inequality uses
 $\Upsilon _k^2(x,y) \leq C_{\Upsilon} ^2$
.
$\Upsilon _k^2(x,y) \leq C_{\Upsilon} ^2$
.
Subset
 $K^Y_{1k} \cap (K_{2k}^Y)^c \cap \Omega _r$
: As
$K^Y_{1k} \cap (K_{2k}^Y)^c \cap \Omega _r$
: As
 $(x,y) \in K^Y_{1k}$
, we have
$(x,y) \in K^Y_{1k}$
, we have
 $\left |{\left (x-y\right )_k}\right | \gt \frac{\sqrt{c}}{2}r$
. We observe that the sum in (3.27) is nonnegative for all
$\left |{\left (x-y\right )_k}\right | \gt \frac{\sqrt{c}}{2}r$
. We observe that the sum in (3.27) is nonnegative for all
 $(x,y)$
in this subset whenever
$(x,y)$
in this subset whenever
 \begin{equation} \begin{aligned} &\left ({-}\lambda \Upsilon _k(x,y)\left (x-y\right )_k + \frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\right )\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2 \\ &\qquad \qquad \qquad \qquad \qquad \, \leq \sigma ^2\Upsilon _k^2(x,y) \left (2\left (x-y\right )^2_k-\left (\frac{r}{2}\right )^2\right )\left (x-y\right )_k^2. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\left ({-}\lambda \Upsilon _k(x,y)\left (x-y\right )_k + \frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\right )\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2 \\ &\qquad \qquad \qquad \qquad \qquad \, \leq \sigma ^2\Upsilon _k^2(x,y) \left (2\left (x-y\right )^2_k-\left (\frac{r}{2}\right )^2\right )\left (x-y\right )_k^2. \end{aligned} \end{equation}
The first term on the left-hand side in (3.30) can be bounded from above exploiting that
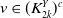 $v\in (K_{2k}^Y)^c$
and by using the relation
$v\in (K_{2k}^Y)^c$
and by using the relation
 $\tilde{c} = 2c-1$
. More precisely, we have
$\tilde{c} = 2c-1$
. More precisely, we have
 \begin{align*} &-\lambda \Upsilon _k(x,y)\left (x-y\right )_k \left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2 \leq \tilde{c}\left (\frac{r}{2}\right )^2\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-y\right )_k^2\\ &\qquad = (2c-1)\left (\frac{r}{2}\right )^2\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-y\right )_k^2 \leq \! \left (2\left (x-y\right )_k^2-\left (\frac{r}{2}\right )^2\right )\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-y\right )_k^2, \end{align*}
\begin{align*} &-\lambda \Upsilon _k(x,y)\left (x-y\right )_k \left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2 \leq \tilde{c}\left (\frac{r}{2}\right )^2\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-y\right )_k^2\\ &\qquad = (2c-1)\left (\frac{r}{2}\right )^2\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-y\right )_k^2 \leq \! \left (2\left (x-y\right )_k^2-\left (\frac{r}{2}\right )^2\right )\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (x-y\right )_k^2, \end{align*}
where the last inequality follows since
 $v\in K^Y_{1k}$
. For the second term on the left-hand side in (3.30), we can use
$v\in K^Y_{1k}$
. For the second term on the left-hand side in (3.30), we can use
 $(1-c)^2 \leq (2c-1)c$
as per assumption, to get
$(1-c)^2 \leq (2c-1)c$
as per assumption, to get
 \begin{align*} &\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2 \leq \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) (1-c)^2\left (\frac{r}{2}\right )^4 \\ &\qquad \leq \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) (2c-1)\left (\frac{r}{2}\right )^2c\left (\frac{r}{2}\right )^2 \leq \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) \left (2\left (x-y\right )_k^2-\left (\frac{r}{2}\right )^2\right )\left (x-y\right )_k^2. \end{align*}
\begin{align*} &\frac{\sigma ^2}{2} \Upsilon _k^2(x,y)\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2 \leq \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) (1-c)^2\left (\frac{r}{2}\right )^4 \\ &\qquad \leq \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) (2c-1)\left (\frac{r}{2}\right )^2c\left (\frac{r}{2}\right )^2 \leq \frac{\sigma ^2}{2} \Upsilon _k^2(x,y) \left (2\left (x-y\right )_k^2-\left (\frac{r}{2}\right )^2\right )\left (x-y\right )_k^2. \end{align*}
Hence, (3.30) holds and we have that (3.27) is uniformly nonnegative on this subset.
Subset
 $K^Y_{1k} \cap K^Y_{2k} \cap \Omega _r$
: As
$K^Y_{1k} \cap K^Y_{2k} \cap \Omega _r$
: As
 $(x,y) \in K_{1k}^Y$
, we have
$(x,y) \in K_{1k}^Y$
, we have
 $\left |{\left (x-y\right )_k}\right | \gt \frac{\sqrt{c}}{2}r$
. To start with we note that the first summand of (3.27) vanishes whenever
$\left |{\left (x-y\right )_k}\right | \gt \frac{\sqrt{c}}{2}r$
. To start with we note that the first summand of (3.27) vanishes whenever
 $\sigma ^2\Upsilon _k^2(x,y) = 0$
, provided
$\sigma ^2\Upsilon _k^2(x,y) = 0$
, provided
 $\sigma \gt 0$
, so nothing needs to be done if
$\sigma \gt 0$
, so nothing needs to be done if
 $\Upsilon _k(x,y)=0$
. Otherwise, if
$\Upsilon _k(x,y)=0$
. Otherwise, if
 $\sigma ^2\Upsilon _k^2(x,y) \gt 0$
, we exploit
$\sigma ^2\Upsilon _k^2(x,y) \gt 0$
, we exploit
 $(x,y)\in K_{2k}^Y$
to get
$(x,y)\in K_{2k}^Y$
to get
 \begin{equation*} \begin{split} \frac{\Upsilon _k(x,y)\left (x-y\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )_k^2\right )^2} &\geq \frac{-\left |{\Upsilon _k(x,y)}\right |\left |{\left (x-y\right )_k}\right |}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )_k^2\right )^2}\\ &\gt \frac{2\lambda \Upsilon _k(x,y) \left (x-y\right )_k}{\tilde{c}\left (\frac{r}{2}\right )^2\sigma ^2\left |{\Upsilon _k(x,y)}\right |\left |{\left (x-y\right )_k}\right |} \geq -\frac{8\lambda }{\tilde{c}r^2\sigma ^2}. \end{split} \end{equation*}
\begin{equation*} \begin{split} \frac{\Upsilon _k(x,y)\left (x-y\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )_k^2\right )^2} &\geq \frac{-\left |{\Upsilon _k(x,y)}\right |\left |{\left (x-y\right )_k}\right |}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )_k^2\right )^2}\\ &\gt \frac{2\lambda \Upsilon _k(x,y) \left (x-y\right )_k}{\tilde{c}\left (\frac{r}{2}\right )^2\sigma ^2\left |{\Upsilon _k(x,y)}\right |\left |{\left (x-y\right )_k}\right |} \geq -\frac{8\lambda }{\tilde{c}r^2\sigma ^2}. \end{split} \end{equation*}
Using this, the first summand of (3.27) can be bounded from below by
 \begin{equation} \begin{split} T^{Y,2}_{1k}(x,y) =\lambda \frac{r^2}{2}\frac{\Upsilon _k(x,y)\left (x-y\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2}\phi _{r}(x,y) &\geq -\frac{4\lambda ^2}{\tilde{c}\sigma ^2}\phi _{r}(x,y) \,=\!:\, -p^{Y,\Upsilon }_{3}\phi _r(x,y). \end{split} \end{equation}
\begin{equation} \begin{split} T^{Y,2}_{1k}(x,y) =\lambda \frac{r^2}{2}\frac{\Upsilon _k(x,y)\left (x-y\right )_k}{\left (\left (\frac{r}{2}\right )^2-\left (x-y\right )^2_k\right )^2}\phi _{r}(x,y) &\geq -\frac{4\lambda ^2}{\tilde{c}\sigma ^2}\phi _{r}(x,y) \,=\!:\, -p^{Y,\Upsilon }_{3}\phi _r(x,y). \end{split} \end{equation}
For the second summand, the nonnegativity of
 $\sigma ^2\Upsilon _k^2(x,y)$
implies the nonnegativity, whenever
$\sigma ^2\Upsilon _k^2(x,y)$
implies the nonnegativity, whenever
 \begin{equation*} 2\left (2\left (x-y\right )^2_k-\left (\frac {r}{2}\right )^2\right )\left (x-y\right )_k^2 \geq \left (\left (\frac {r}{2}\right )^2-\left (x-y\right )^2_k\right )^2. \end{equation*}
\begin{equation*} 2\left (2\left (x-y\right )^2_k-\left (\frac {r}{2}\right )^2\right )\left (x-y\right )_k^2 \geq \left (\left (\frac {r}{2}\right )^2-\left (x-y\right )^2_k\right )^2. \end{equation*}
This holds for
 $v\in K_{1k}^Y$
, if
$v\in K_{1k}^Y$
, if
 $2(2c-1)c \geq (1-c)^2$
as implied by the assumption.
$2(2c-1)c \geq (1-c)^2$
as implied by the assumption.
Concluding the proof: Combining the formerly established lower bounds (3.19), (3.21), (3.23), (3.25), (3.26), (3.28), (3.29) and (3.31), we obtain for the constants
 $p^c$
,
$p^c$
,
 $p^\ell$
and
$p^\ell$
and
 $p^g$
defined at the beginning of the proof
$p^g$
defined at the beginning of the proof
 \begin{equation} \begin{aligned} p^c &= p^{*,\Upsilon _c}_{1} \!+ p^{*,\Upsilon _c}_{2} \!+ p^{*,\Upsilon _c}_{3} \!+ p^{Y,\Upsilon _c}_{1} \!+ p^{Y,\Upsilon _c}_{2} \!+ p^{Y,\Upsilon _c}_{3} = 2\!\left (\frac{2\lambda _1 C_{\Upsilon} \sqrt{c}}{(1-c)^2\frac{r}{2}} \!+\! \frac{\sigma _1^2C_{\Upsilon} ^2}{(1-c)^4\!\left (\frac{r}{2}\right )^2} \!+\! \frac{4\lambda _1^2}{\tilde{c}\sigma _1^2}\right )\\ p^\ell &= p^{*,\Upsilon _{\ell} }_{1} \!+ p^{*,\Upsilon _{\ell} }_{2} \!+ p^{*,\Upsilon _{\ell} }_{3} \!+ p^{Y,\Upsilon _{\ell} } = \frac{2\lambda _2 C_{\Upsilon} \sqrt{c}}{(1-c)^2\frac{r}{2}} \!+\! \frac{\sigma _2^2C_{\Upsilon} ^2}{(1-c)^4\left (\frac{r}{2}\right )^2} \!+\! \frac{4\lambda _2^2}{\tilde{c}\sigma _2^2} \!+\! \frac{\sigma _2^2c}{(1-c)^4}\\ p^g &= p^{*,\Upsilon _g}_{1} \!+ p^{*,\Upsilon _g}_{2} \!+ p^{*,\Upsilon _g}_{3} \!+ p^{Y,\Upsilon _g}_{1} \!+ p^{Y,\Upsilon _g}_{2} \!+ p^{Y,\Upsilon _g}_{3} = 2\!\left (\frac{2\lambda _3 C_{\Upsilon} \sqrt{c}}{(1-c)^2\frac{r}{2}} \!+\! \frac{\sigma _3^2C_{\Upsilon} ^2}{(1-c)^4\!\left (\frac{r}{2}\right )^2} \!+\! \frac{4\lambda _3^2}{\tilde{c}\sigma _3^2}\right )\!. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} p^c &= p^{*,\Upsilon _c}_{1} \!+ p^{*,\Upsilon _c}_{2} \!+ p^{*,\Upsilon _c}_{3} \!+ p^{Y,\Upsilon _c}_{1} \!+ p^{Y,\Upsilon _c}_{2} \!+ p^{Y,\Upsilon _c}_{3} = 2\!\left (\frac{2\lambda _1 C_{\Upsilon} \sqrt{c}}{(1-c)^2\frac{r}{2}} \!+\! \frac{\sigma _1^2C_{\Upsilon} ^2}{(1-c)^4\!\left (\frac{r}{2}\right )^2} \!+\! \frac{4\lambda _1^2}{\tilde{c}\sigma _1^2}\right )\\ p^\ell &= p^{*,\Upsilon _{\ell} }_{1} \!+ p^{*,\Upsilon _{\ell} }_{2} \!+ p^{*,\Upsilon _{\ell} }_{3} \!+ p^{Y,\Upsilon _{\ell} } = \frac{2\lambda _2 C_{\Upsilon} \sqrt{c}}{(1-c)^2\frac{r}{2}} \!+\! \frac{\sigma _2^2C_{\Upsilon} ^2}{(1-c)^4\left (\frac{r}{2}\right )^2} \!+\! \frac{4\lambda _2^2}{\tilde{c}\sigma _2^2} \!+\! \frac{\sigma _2^2c}{(1-c)^4}\\ p^g &= p^{*,\Upsilon _g}_{1} \!+ p^{*,\Upsilon _g}_{2} \!+ p^{*,\Upsilon _g}_{3} \!+ p^{Y,\Upsilon _g}_{1} \!+ p^{Y,\Upsilon _g}_{2} \!+ p^{Y,\Upsilon _g}_{3} = 2\!\left (\frac{2\lambda _3 C_{\Upsilon} \sqrt{c}}{(1-c)^2\frac{r}{2}} \!+\! \frac{\sigma _3^2C_{\Upsilon} ^2}{(1-c)^4\!\left (\frac{r}{2}\right )^2} \!+\! \frac{4\lambda _3^2}{\tilde{c}\sigma _3^2}\right )\!. \end{aligned} \end{equation}
Together with (3.14) and by using the evolution of
 $\phi _r$
as in (3.13), we eventually obtain
$\phi _r$
as in (3.13), we eventually obtain
 \begin{equation*} \begin{split} &\frac{d}{dt}\iint \!\phi _{r}\,d\rho _t \geq -d\left (p^c + p^\ell + p^g\right ) \iint \!\phi _{r}\,d\rho _t\\ &\;\quad \,\geq -d\sum _{i=1}^3\omega _i\!\left (\!\left (1\!+\!\mathbb{1}_{i\not =2}\right )\!\left (\frac{2\lambda _i C_{\Upsilon} \sqrt{c}}{(1\!-\!c)^2\frac{r}{2}} \!+\! \frac{\sigma _i^2C_{\Upsilon} ^2}{(1\!-\!c)^4\!\left (\frac{r}{2}\right )^2} \!+\! \frac{4\lambda _i^2}{\tilde{c}\sigma _i^2}\right ) \!+\! \mathbb{1}_{i=2}\frac{\sigma _2^2c}{(1\!-\!c)^4} \!\right ) \!\!\iint \!\phi _{r}\,d\rho _t\\ &\;\quad \,= -q \iint \!\phi _{r}\,d\rho _t, \end{split} \end{equation*}
\begin{equation*} \begin{split} &\frac{d}{dt}\iint \!\phi _{r}\,d\rho _t \geq -d\left (p^c + p^\ell + p^g\right ) \iint \!\phi _{r}\,d\rho _t\\ &\;\quad \,\geq -d\sum _{i=1}^3\omega _i\!\left (\!\left (1\!+\!\mathbb{1}_{i\not =2}\right )\!\left (\frac{2\lambda _i C_{\Upsilon} \sqrt{c}}{(1\!-\!c)^2\frac{r}{2}} \!+\! \frac{\sigma _i^2C_{\Upsilon} ^2}{(1\!-\!c)^4\!\left (\frac{r}{2}\right )^2} \!+\! \frac{4\lambda _i^2}{\tilde{c}\sigma _i^2}\right ) \!+\! \mathbb{1}_{i=2}\frac{\sigma _2^2c}{(1\!-\!c)^4} \!\right ) \!\!\iint \!\phi _{r}\,d\rho _t\\ &\;\quad \,= -q \iint \!\phi _{r}\,d\rho _t, \end{split} \end{equation*}
where
 $q$
is defined implicitly and where
$q$
is defined implicitly and where
 $\omega _i=\mathbb{1}_{\lambda _i\gt 0}$
for
$\omega _i=\mathbb{1}_{\lambda _i\gt 0}$
for
 $i\in \{1,2,3\}$
. Notice that
$i\in \{1,2,3\}$
. Notice that
 $\omega _1=1$
since
$\omega _1=1$
since
 $\lambda _1\gt 0$
by assumption. An application of Grönwall’s inequality concludes the proof.
$\lambda _1\gt 0$
by assumption. An application of Grönwall’s inequality concludes the proof.
3.4. Proof of Theorem 2.5
We now have all necessary tools at hand to prove the global mean-field law convergence result for CBO with memory effects and gradient information by rigorously combining the formerly discussed statements.
Proof of Theorem
2.5. If
 $\mathcal{V}(\rho _0)=0$
, there is nothing to be shown since in this case
$\mathcal{V}(\rho _0)=0$
, there is nothing to be shown since in this case
 $\rho _0=\delta _{(x^*,x^*)}$
. Thus, let
$\rho _0=\delta _{(x^*,x^*)}$
. Thus, let
 $\mathcal{V}(\rho _0)\gt 0$
in what follows.
$\mathcal{V}(\rho _0)\gt 0$
in what follows.
Let us first choose the parameter
 $\alpha$
such that
$\alpha$
such that
 \begin{align} \alpha \gt \alpha _0 \,:\!=\, \frac{1}{q_{\varepsilon} }\Bigg (\log \left (\frac{2^{d+2}\sqrt{d}}{c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )}\right ) + \max \left \{\frac{1}{2},\frac{p}{(1-\vartheta )\chi _1}\right \}\log \left (\frac{\mathcal{V}(\rho _0)}{\varepsilon }\right )- \log \rho _0\big (\Omega _{r_{\varepsilon}/2}\big )\!\Bigg ), \end{align}
\begin{align} \alpha \gt \alpha _0 \,:\!=\, \frac{1}{q_{\varepsilon} }\Bigg (\log \left (\frac{2^{d+2}\sqrt{d}}{c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )}\right ) + \max \left \{\frac{1}{2},\frac{p}{(1-\vartheta )\chi _1}\right \}\log \left (\frac{\mathcal{V}(\rho _0)}{\varepsilon }\right )- \log \rho _0\big (\Omega _{r_{\varepsilon}/2}\big )\!\Bigg ), \end{align}
where we introduce the definitions
 \begin{align} c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right ) \,:\!=\, \min \left \{ \frac{\vartheta }{2}\frac{\chi _1}{2\sqrt{2}\left (\lambda _1+\sigma _1^2\right )}, \sqrt{\frac{\vartheta }{2}\frac{\chi _1}{\sigma _1^2}} \right \} \end{align}
\begin{align} c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right ) \,:\!=\, \min \left \{ \frac{\vartheta }{2}\frac{\chi _1}{2\sqrt{2}\left (\lambda _1+\sigma _1^2\right )}, \sqrt{\frac{\vartheta }{2}\frac{\chi _1}{\sigma _1^2}} \right \} \end{align}
as well as
 \begin{align} q_{\varepsilon} \,:\!=\, \frac{1}{2}\min \bigg \{\left (\eta \frac{c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\varepsilon }}{2\sqrt{d}}\right )^{1/\nu }\!,{\mathcal{E}}_{\infty }\bigg \} \quad \text{and}\quad r_{\varepsilon} \,:\!=\, \!\max _{s \in [0,R_0]}\left \{\max _{v \in B_s^\infty (x^*)}{\mathcal{E}}(v) \leq q_{\varepsilon} \right \}\!. \end{align}
\begin{align} q_{\varepsilon} \,:\!=\, \frac{1}{2}\min \bigg \{\left (\eta \frac{c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\varepsilon }}{2\sqrt{d}}\right )^{1/\nu }\!,{\mathcal{E}}_{\infty }\bigg \} \quad \text{and}\quad r_{\varepsilon} \,:\!=\, \!\max _{s \in [0,R_0]}\left \{\max _{v \in B_s^\infty (x^*)}{\mathcal{E}}(v) \leq q_{\varepsilon} \right \}\!. \end{align}
Moreover,
 $p$
is as given in (3.12) in Proposition 3.8 with
$p$
is as given in (3.12) in Proposition 3.8 with
 $B=c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\mathcal{V}(\rho _0)}$
in
$B=c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\mathcal{V}(\rho _0)}$
in
 $C_{\Upsilon}$
and with
$C_{\Upsilon}$
and with
 $r=r_{\varepsilon}$
. By construction,
$r=r_{\varepsilon}$
. By construction,
 $q_{\varepsilon} \gt 0$
and
$q_{\varepsilon} \gt 0$
and
 $r_{\varepsilon} \leq R_0$
. Furthermore, recalling the notation
$r_{\varepsilon} \leq R_0$
. Furthermore, recalling the notation
 ${\mathcal{E}}_{r}=\sup _{v \in B_{r}^\infty (x^*)}{\mathcal{E}}(v)$
from Proposition 3.6, we have
${\mathcal{E}}_{r}=\sup _{v \in B_{r}^\infty (x^*)}{\mathcal{E}}(v)$
from Proposition 3.6, we have
 $q_{\varepsilon} +{\mathcal{E}}_{r_{\varepsilon} } \leq 2q_{\varepsilon} \leq{\mathcal{E}}_{\infty }$
according to the definition of
$q_{\varepsilon} +{\mathcal{E}}_{r_{\varepsilon} } \leq 2q_{\varepsilon} \leq{\mathcal{E}}_{\infty }$
according to the definition of
 $r_{\varepsilon}$
. Since
$r_{\varepsilon}$
. Since
 $q_{\varepsilon} \gt 0$
, the continuity of
$q_{\varepsilon} \gt 0$
, the continuity of
 $\mathcal{E}$
ensures that there exists
$\mathcal{E}$
ensures that there exists
 $s_{q_{\varepsilon} }\gt 0$
such that
$s_{q_{\varepsilon} }\gt 0$
such that
 ${\mathcal{E}}(v)\leq q_{\varepsilon}$
for all
${\mathcal{E}}(v)\leq q_{\varepsilon}$
for all
 $v\in B_{s_{q_{\varepsilon} }}^\infty (x^*)$
, yielding also
$v\in B_{s_{q_{\varepsilon} }}^\infty (x^*)$
, yielding also
 $r_{\varepsilon} \gt 0$
.
$r_{\varepsilon} \gt 0$
.
Let us now define the time horizon
 $T_{\alpha} \geq 0$
by
$T_{\alpha} \geq 0$
by
 \begin{align} T_{\alpha} \,:\!=\, \sup \big \{t\geq 0 :\mathcal{V}(\rho _{t'}) \gt \varepsilon \text{ and } \left \|{y_{\alpha }({\rho _{Y,t'}})-x^*}\right \|_2 \lt C(t') \text{ for all } t' \in [0,t]\big \} \end{align}
\begin{align} T_{\alpha} \,:\!=\, \sup \big \{t\geq 0 :\mathcal{V}(\rho _{t'}) \gt \varepsilon \text{ and } \left \|{y_{\alpha }({\rho _{Y,t'}})-x^*}\right \|_2 \lt C(t') \text{ for all } t' \in [0,t]\big \} \end{align}
with
 $C(t)\,:\!=\,c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\mathcal{V}(\rho _t)}$
. Notice for later use that
$C(t)\,:\!=\,c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\mathcal{V}(\rho _t)}$
. Notice for later use that
 $C(0)=B$
.
$C(0)=B$
.
Our aim now is to show that
 $\mathcal{V}(\rho _{T_{\alpha} }) = \varepsilon$
with
$\mathcal{V}(\rho _{T_{\alpha} }) = \varepsilon$
with
 $T_{\alpha} \in \big [\frac{(1-\vartheta )\chi _1}{(1+\vartheta/2)\chi _2}T^*,T^*\big ]$
and that we have at least exponential decay of
$T_{\alpha} \in \big [\frac{(1-\vartheta )\chi _1}{(1+\vartheta/2)\chi _2}T^*,T^*\big ]$
and that we have at least exponential decay of
 $\mathcal{V}(\rho _{t})$
until time
$\mathcal{V}(\rho _{t})$
until time
 $T_{\alpha}$
, i.e., until the accuracy
$T_{\alpha}$
, i.e., until the accuracy
 $\varepsilon$
is reached.
$\varepsilon$
is reached.
First, however, we verify that
 $T_{\alpha} \gt 0$
, which is due to the continuity of
$T_{\alpha} \gt 0$
, which is due to the continuity of
 $t\mapsto\mathcal{V}(\rho _{t})$
and
$t\mapsto\mathcal{V}(\rho _{t})$
and
 $t\mapsto \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2$
since
$t\mapsto \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2$
since
 $\mathcal{V}(\rho _{0}) \gt \varepsilon$
and
$\mathcal{V}(\rho _{0}) \gt \varepsilon$
and
 $\left \|{y_{\alpha }({\rho _{Y,0}})-x^*}\right \|_2 \lt C(0)$
at time
$\left \|{y_{\alpha }({\rho _{Y,0}})-x^*}\right \|_2 \lt C(0)$
at time
 $0$
. While the former is a consequence of the assumption, the latter follows from Proposition 3.6 with
$0$
. While the former is a consequence of the assumption, the latter follows from Proposition 3.6 with
 $q_{\varepsilon}$
and
$q_{\varepsilon}$
and
 $r_{\varepsilon}$
as defined in (3.35), which allows to show that
$r_{\varepsilon}$
as defined in (3.35), which allows to show that
 \begin{align*} \left \|{y_{\alpha }({\rho _{Y,0}}) - x^*}\right \|_2 &\leq \frac{\sqrt{d}\left (q_{\varepsilon} \!+\!{\mathcal{E}}_{r_{\varepsilon} }\right )^\nu }{\eta } \!+\! \frac{\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,0}\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\int \left \|{y-x^*}\right \|_2d\rho _{Y,0}(y)\\ &\leq \frac{\sqrt{d}\left (q_{\varepsilon} \!+\!{\mathcal{E}}_{r_{\varepsilon} }\right )^\nu }{\eta } \!+\! \frac{\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,0}\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\iint \left \|{y-x}\right \|_2\!+\!\left \|{x-x^*}\right \|_2d\rho _{0}(x,y)\\ &\leq \frac{c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\varepsilon }}{2} \!+\! \frac{2\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,0}\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\sqrt{\mathcal{V}(\rho _0)}\\ &\leq c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\varepsilon } \lt c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\mathcal{V}(\rho _0)} = C(0). \end{align*}
\begin{align*} \left \|{y_{\alpha }({\rho _{Y,0}}) - x^*}\right \|_2 &\leq \frac{\sqrt{d}\left (q_{\varepsilon} \!+\!{\mathcal{E}}_{r_{\varepsilon} }\right )^\nu }{\eta } \!+\! \frac{\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,0}\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\int \left \|{y-x^*}\right \|_2d\rho _{Y,0}(y)\\ &\leq \frac{\sqrt{d}\left (q_{\varepsilon} \!+\!{\mathcal{E}}_{r_{\varepsilon} }\right )^\nu }{\eta } \!+\! \frac{\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,0}\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\iint \left \|{y-x}\right \|_2\!+\!\left \|{x-x^*}\right \|_2d\rho _{0}(x,y)\\ &\leq \frac{c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\varepsilon }}{2} \!+\! \frac{2\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,0}\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\sqrt{\mathcal{V}(\rho _0)}\\ &\leq c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\varepsilon } \lt c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\mathcal{V}(\rho _0)} = C(0). \end{align*}
The first inequality in the last line holds by the choice of
 $\alpha$
in (3.33) and by noticing that
$\alpha$
in (3.33) and by noticing that
 $\Omega _{r_{\varepsilon}/2}\subset \mathbb{R}^d\times B_{r_{\varepsilon} }^\infty (x^*)$
and thus
$\Omega _{r_{\varepsilon}/2}\subset \mathbb{R}^d\times B_{r_{\varepsilon} }^\infty (x^*)$
and thus
 $\rho _0(\Omega _{r_{\varepsilon}/2})\leq \rho _{Y,0}\big (B_{r_{\varepsilon} }^\infty (x^*)\big )$
.
$\rho _0(\Omega _{r_{\varepsilon}/2})\leq \rho _{Y,0}\big (B_{r_{\varepsilon} }^\infty (x^*)\big )$
.
Next, we show that the functional
 $\mathcal{V}(\rho _t)$
is sandwiched between two exponentially decaying functions with rates
$\mathcal{V}(\rho _t)$
is sandwiched between two exponentially decaying functions with rates
 $(1-\vartheta )\chi _1$
and
$(1-\vartheta )\chi _1$
and
 $(1+\vartheta/2)\chi _2$
, respectively. More precisely, we prove that, up to time
$(1+\vartheta/2)\chi _2$
, respectively. More precisely, we prove that, up to time
 $T_{\alpha}$
,
$T_{\alpha}$
,
 $\mathcal{V}(\rho _t)$
decays
$\mathcal{V}(\rho _t)$
decays
-
(i) at least exponentially fast (with rate
$(1-\vartheta )\chi _1)$
, and -
(ii) at most exponentially fast (with rate
$(1+\vartheta/2)\chi _2)$
.


To obtain (i), recall that Corollary 3.3 provides an upper bound on the time derivative of
 $\mathcal{V}(\rho _t)$
given by
$\mathcal{V}(\rho _t)$
given by
 \begin{equation} \begin{split} \frac{d}{dt}\mathcal{V}(\rho _t) &\leq -\chi _1\mathcal{V}(\rho _t) + 2\sqrt{2}\left (\lambda _1 + \sigma _1^2\right ) \sqrt{\mathcal{V}(\rho _t)}\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2 + \sigma _1^2\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2^2 \end{split} \end{equation}
\begin{equation} \begin{split} \frac{d}{dt}\mathcal{V}(\rho _t) &\leq -\chi _1\mathcal{V}(\rho _t) + 2\sqrt{2}\left (\lambda _1 + \sigma _1^2\right ) \sqrt{\mathcal{V}(\rho _t)}\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2 + \sigma _1^2\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2^2 \end{split} \end{equation}
with
 $\chi _1$
as in (2.12a) being strictly positive by assumption. By combining (3.37) and the definition of
$\chi _1$
as in (2.12a) being strictly positive by assumption. By combining (3.37) and the definition of
 $T_{\alpha}$
in (3.36), we have by construction
$T_{\alpha}$
in (3.36), we have by construction
 \begin{align*} \frac{d}{dt}\mathcal{V}(\rho _t) \leq -(1-\vartheta )\chi _1\mathcal{V}(\rho _t) \quad \text{ for all } t \in (0,T_{\alpha} ). \end{align*}
\begin{align*} \frac{d}{dt}\mathcal{V}(\rho _t) \leq -(1-\vartheta )\chi _1\mathcal{V}(\rho _t) \quad \text{ for all } t \in (0,T_{\alpha} ). \end{align*}
Analogously, for (ii), by Corollary 3.5, we obtain a lower bound on the time derivative of
 $\mathcal{V}(\rho _t)$
given by
$\mathcal{V}(\rho _t)$
given by
 \begin{equation} \begin{aligned} \frac{d}{dt}\mathcal{V}(\rho _t) &\geq -\chi _2\mathcal{V}(\rho _t) - 2\sqrt{2}\left (\lambda _1 + \sigma _1^2\right ) \sqrt{\mathcal{V}(\rho _t)}\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2 \\ &\geq -(1+\vartheta/2)\chi _2\mathcal{V}(\rho _t) \quad \text{ for all } t \in (0,T_{\alpha} ), \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \frac{d}{dt}\mathcal{V}(\rho _t) &\geq -\chi _2\mathcal{V}(\rho _t) - 2\sqrt{2}\left (\lambda _1 + \sigma _1^2\right ) \sqrt{\mathcal{V}(\rho _t)}\left \|{y_{\alpha }({\rho _{Y,t}}) - x^*}\right \|_2 \\ &\geq -(1+\vartheta/2)\chi _2\mathcal{V}(\rho _t) \quad \text{ for all } t \in (0,T_{\alpha} ), \end{aligned} \end{equation}
where the second inequality again exploits the definition of
 $T_{\alpha}$
. Grönwall’s inequality now implies for all
$T_{\alpha}$
. Grönwall’s inequality now implies for all
 $t \in [0,T_{\alpha} ]$
the upper and lower estimates
$t \in [0,T_{\alpha} ]$
the upper and lower estimates
 \begin{align}\mathcal{V}(\rho _t) &\leq\mathcal{V}(\rho _0) \exp \left ({-}(1-\vartheta )\chi _1 t\right ), \end{align}
\begin{align}\mathcal{V}(\rho _t) &\leq\mathcal{V}(\rho _0) \exp \left ({-}(1-\vartheta )\chi _1 t\right ), \end{align}
 \begin{align}\mathcal{V}(\rho _t) &\geq\mathcal{V}(\rho _0) \exp \left ({-}(1+\vartheta/2)\chi _2 t\right ), \end{align}
\begin{align}\mathcal{V}(\rho _t) &\geq\mathcal{V}(\rho _0) \exp \left ({-}(1+\vartheta/2)\chi _2 t\right ), \end{align}
thereby proving (i) and (ii). The definition of
 $T_{\alpha}$
together with the one of
$T_{\alpha}$
together with the one of
 $C(t)$
permits to control
$C(t)$
permits to control
 \begin{align} \max _{t \in [0,T_{\alpha} ]}\left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2 \leq \max _{t \in [0,T_{\alpha} ]} C(t)\leq C(0). \end{align}
\begin{align} \max _{t \in [0,T_{\alpha} ]}\left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2 \leq \max _{t \in [0,T_{\alpha} ]} C(t)\leq C(0). \end{align}
To conclude, it remains to prove
 $\mathcal{V}(\rho _{T_{\alpha} }) = \varepsilon$
with
$\mathcal{V}(\rho _{T_{\alpha} }) = \varepsilon$
with
 $T_{\alpha} \in \big [\frac{(1-\vartheta )\chi _1}{(1+\vartheta/2)\chi _2}T^*,T^*\big ]$
. To this end, we consider the following three cases separately.
$T_{\alpha} \in \big [\frac{(1-\vartheta )\chi _1}{(1+\vartheta/2)\chi _2}T^*,T^*\big ]$
. To this end, we consider the following three cases separately.
Case
 $T_{\alpha} \geq T^*$
: If
$T_{\alpha} \geq T^*$
: If
 $T_{\alpha} \geq T^*$
, the time-evolution bound of
$T_{\alpha} \geq T^*$
, the time-evolution bound of
 $\mathcal{V}(\rho _t)$
from (3.39a) combined with the definition of
$\mathcal{V}(\rho _t)$
from (3.39a) combined with the definition of
 $T^*$
in (2.13) allows to immediately infer
$T^*$
in (2.13) allows to immediately infer
 $\mathcal{V}(\rho _{T^*}) \leq \varepsilon$
. Therefore, with
$\mathcal{V}(\rho _{T^*}) \leq \varepsilon$
. Therefore, with
 $\mathcal{V}(\rho _{t})$
being continuous,
$\mathcal{V}(\rho _{t})$
being continuous,
 $\mathcal{V}(\rho _{T_{\alpha} }) = \varepsilon$
and
$\mathcal{V}(\rho _{T_{\alpha} }) = \varepsilon$
and
 $T_{\alpha} = T^*$
according to the definition of
$T_{\alpha} = T^*$
according to the definition of
 $T_{\alpha}$
in (3.36).
$T_{\alpha}$
in (3.36).
Case
 $T_{\alpha} \lt T^*$
and
$T_{\alpha} \lt T^*$
and
 $\mathcal{V}(\rho _{T_{\alpha} }) \leq \varepsilon$
: By continuity of
$\mathcal{V}(\rho _{T_{\alpha} }) \leq \varepsilon$
: By continuity of
 $\mathcal{V}(\rho _t)$
, it holds for
$\mathcal{V}(\rho _t)$
, it holds for
 $T_{\alpha}$
as defined in (3.36),
$T_{\alpha}$
as defined in (3.36),
 $\mathcal{V}(\rho _{T_{\alpha} }) = \varepsilon$
. Thus,
$\mathcal{V}(\rho _{T_{\alpha} }) = \varepsilon$
. Thus,
 $\varepsilon =\mathcal{V}(\rho _{T_{\alpha} }) \geq\mathcal{V}(\rho _0) \exp \left ({-}(1+\vartheta/2)\chi _2 T_{\alpha} \right )$
as a consequence of the time-evolution bound (3.39b). The latter can be reordered as
$\varepsilon =\mathcal{V}(\rho _{T_{\alpha} }) \geq\mathcal{V}(\rho _0) \exp \left ({-}(1+\vartheta/2)\chi _2 T_{\alpha} \right )$
as a consequence of the time-evolution bound (3.39b). The latter can be reordered as
 \begin{equation*} \frac {(1-\vartheta )\chi _1}{(1+\vartheta/2)\chi _2}T^* = \frac {1}{(1+\vartheta/2) \chi _2}\log \left (\frac {\mathcal{V}(\rho _0)}{\varepsilon }\right ) \leq T_{\alpha} \lt T^*. \end{equation*}
\begin{equation*} \frac {(1-\vartheta )\chi _1}{(1+\vartheta/2)\chi _2}T^* = \frac {1}{(1+\vartheta/2) \chi _2}\log \left (\frac {\mathcal{V}(\rho _0)}{\varepsilon }\right ) \leq T_{\alpha} \lt T^*. \end{equation*}
Case
 $T_{\alpha} \lt T^*$
and
$T_{\alpha} \lt T^*$
and
 $\mathcal{V}(\rho _{T_{\alpha} }) \gt \varepsilon$
: We will prove that this case can actually not occur by showing that
$\mathcal{V}(\rho _{T_{\alpha} }) \gt \varepsilon$
: We will prove that this case can actually not occur by showing that
 $\left \|{y_{\alpha }({\rho _{Y,T_{\alpha} }})-x^*}\right \|_2 \lt C(T_{\alpha} )$
for the
$\left \|{y_{\alpha }({\rho _{Y,T_{\alpha} }})-x^*}\right \|_2 \lt C(T_{\alpha} )$
for the
 $\alpha$
chosen in (3.33). In fact, if both
$\alpha$
chosen in (3.33). In fact, if both
 $\mathcal{V}(\rho _{T_{\alpha} })\gt \varepsilon$
and
$\mathcal{V}(\rho _{T_{\alpha} })\gt \varepsilon$
and
 $\left \|{y_{\alpha }({\rho _{Y,T_{\alpha} }})-x^*}\right \|_2 \lt C(T_{\alpha} )$
held true simultaneously, this would contradict the definition of
$\left \|{y_{\alpha }({\rho _{Y,T_{\alpha} }})-x^*}\right \|_2 \lt C(T_{\alpha} )$
held true simultaneously, this would contradict the definition of
 $T_{\alpha}$
in (3.36). To obtain this contradiction, we apply again Proposition 3.6 with
$T_{\alpha}$
in (3.36). To obtain this contradiction, we apply again Proposition 3.6 with
 $q_{\varepsilon}$
and
$q_{\varepsilon}$
and
 $r_{\varepsilon}$
as before to get
$r_{\varepsilon}$
as before to get
 \begin{align} \begin{split} \left \|{y_{\alpha }({\rho _{Y,T_{\alpha} }})-x^*}\right \|_2 &\leq \frac{\sqrt{d}\left (q_{\varepsilon} \!+\!{\mathcal{E}}_{r_{\varepsilon} }\right )^\nu }{\eta } \!+\! \frac{\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,T_{\alpha} }\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\int \left \|{y-x^*}\right \|_2d\rho _{Y,T_{\alpha} }(y)\\ &\leq \frac{\sqrt{d}\left (q_{\varepsilon} \!+\!{\mathcal{E}}_{r_{\varepsilon} }\right )^\nu }{\eta } \!+\! \frac{\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,T_{\alpha} }\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\!\iint \!\left \|{y-x}\right \|_2\!+\!\left \|{x-x^*}\right \|_2d\rho _{T_{\alpha} }(x,y)\\ &\leq \frac{c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\varepsilon }}{2} \!+\! \frac{2\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,T_{\alpha} }\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\sqrt{\mathcal{V}(\rho _{T_{\alpha} })}\\ &\lt \frac{c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\mathcal{V}(\rho _{T_{\alpha} })}}{2} \!+\! \frac{2\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,T_{\alpha} }\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\sqrt{\mathcal{V}(\rho _{T_{\alpha} })}. \end{split} \end{align}
\begin{align} \begin{split} \left \|{y_{\alpha }({\rho _{Y,T_{\alpha} }})-x^*}\right \|_2 &\leq \frac{\sqrt{d}\left (q_{\varepsilon} \!+\!{\mathcal{E}}_{r_{\varepsilon} }\right )^\nu }{\eta } \!+\! \frac{\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,T_{\alpha} }\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\int \left \|{y-x^*}\right \|_2d\rho _{Y,T_{\alpha} }(y)\\ &\leq \frac{\sqrt{d}\left (q_{\varepsilon} \!+\!{\mathcal{E}}_{r_{\varepsilon} }\right )^\nu }{\eta } \!+\! \frac{\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,T_{\alpha} }\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\!\iint \!\left \|{y-x}\right \|_2\!+\!\left \|{x-x^*}\right \|_2d\rho _{T_{\alpha} }(x,y)\\ &\leq \frac{c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\varepsilon }}{2} \!+\! \frac{2\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,T_{\alpha} }\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\sqrt{\mathcal{V}(\rho _{T_{\alpha} })}\\ &\lt \frac{c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\mathcal{V}(\rho _{T_{\alpha} })}}{2} \!+\! \frac{2\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _{Y,T_{\alpha} }\big (B_{r_{\varepsilon} }^\infty (x^*)\big )}\sqrt{\mathcal{V}(\rho _{T_{\alpha} })}. \end{split} \end{align}
Since, thanks to (3.40), we have
 $\max _{t \in [0,T_{\alpha} ]}\|{y_{\alpha }({\rho _{Y,t}})-x^*}\|_2 \leq B$
for
$\max _{t \in [0,T_{\alpha} ]}\|{y_{\alpha }({\rho _{Y,t}})-x^*}\|_2 \leq B$
for
 $B=C(0)$
, which in particular does not depend on
$B=C(0)$
, which in particular does not depend on
 $\alpha$
, Proposition 3.8 guarantees the existence of
$\alpha$
, Proposition 3.8 guarantees the existence of
 $p\gt 0$
independent of
$p\gt 0$
independent of
 $\alpha$
(but dependent on
$\alpha$
(but dependent on
 $B$
and
$B$
and
 $r_{\varepsilon}$
) with
$r_{\varepsilon}$
) with
 \begin{align*} \rho _{Y,T_{\alpha} }(B_{r_{\varepsilon} }^\infty (x^*)) &\geq \left (\iint \phi _{r_{\varepsilon} }(x,y) \,d\rho _0(x,y)\right )\exp ({-}pT_{\alpha} ) \\ &\geq \frac{1}{2^d}\,\rho _0\big (\Omega _{r_{\varepsilon}/2}\big ) \exp ({-}pT^*) \gt 0. \end{align*}
\begin{align*} \rho _{Y,T_{\alpha} }(B_{r_{\varepsilon} }^\infty (x^*)) &\geq \left (\iint \phi _{r_{\varepsilon} }(x,y) \,d\rho _0(x,y)\right )\exp ({-}pT_{\alpha} ) \\ &\geq \frac{1}{2^d}\,\rho _0\big (\Omega _{r_{\varepsilon}/2}\big ) \exp ({-}pT^*) \gt 0. \end{align*}
Here we use that
 $(x^*,x^*)\in \operatorname{supp}(\rho _0)$
to bound the initial mass
$(x^*,x^*)\in \operatorname{supp}(\rho _0)$
to bound the initial mass
 $\rho _0$
and the fact that
$\rho _0$
and the fact that
 $\phi _{r}$
from Lemma 3.7 is bounded from below on
$\phi _{r}$
from Lemma 3.7 is bounded from below on
 $\Omega _{r/2}$
by
$\Omega _{r/2}$
by
 $1/2^d$
. With this, we can continue the chain of inequalities in (3.41)3 to obtain
$1/2^d$
. With this, we can continue the chain of inequalities in (3.41)3 to obtain
 \begin{align*} \begin{split} \left \|{y_{\alpha }({\rho _{Y,T_{\alpha} }})-x^*}\right \|_2 &\lt \frac{c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\mathcal{V}(\rho _{T_{\alpha} })}}{2} + \frac{2^{d+1}\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _0\big (\Omega _{r_{\varepsilon}/2}\big ) \exp ({-}pT^*)}\sqrt{\mathcal{V}(\rho _{T_{\alpha} })}\\ &\leq c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\mathcal{V}(\rho _{T_{\alpha} })} = C(T_{\alpha} ), \end{split} \end{align*}
\begin{align*} \begin{split} \left \|{y_{\alpha }({\rho _{Y,T_{\alpha} }})-x^*}\right \|_2 &\lt \frac{c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\mathcal{V}(\rho _{T_{\alpha} })}}{2} + \frac{2^{d+1}\sqrt{d}\exp \left ({-}\alpha q_{\varepsilon} \right )}{\rho _0\big (\Omega _{r_{\varepsilon}/2}\big ) \exp ({-}pT^*)}\sqrt{\mathcal{V}(\rho _{T_{\alpha} })}\\ &\leq c\left (\vartheta,\chi _1,\lambda _1,\sigma _1\right )\sqrt{\mathcal{V}(\rho _{T_{\alpha} })} = C(T_{\alpha} ), \end{split} \end{align*}
with the first inequality in the last line holding due to the choice of
 $\alpha$
in (3.33). This gives the desired contradiction, again thanks to the continuity of
$\alpha$
in (3.33). This gives the desired contradiction, again thanks to the continuity of
 $t\mapsto\mathcal{V}(\rho _{t})$
and
$t\mapsto\mathcal{V}(\rho _{t})$
and
 $t\mapsto \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2$
.
$t\mapsto \left \|{y_{\alpha }({\rho _{Y,t}})-x^*}\right \|_2$
.
4. Numerical experiments
In the first part of this section, we comment on how to efficiently implement a numerical scheme for the CBO dynamics (1.1) which allows to integrate memory mechanisms without additional computational complexity. Afterwards, we numerically demonstrate the benefit of memory effects and gradient information at the example of interesting real-world inspired applications.
4.1. Implementational aspects
Discretising the interacting particle system (1.1) in time by means of the Euler-Maruyama method [Reference Higham37] with prescribed time step size
 $\Delta t$
results in the implementable numerical scheme
$\Delta t$
results in the implementable numerical scheme
 \begin{align} &\begin{aligned} \!X_{k+1}^i = \begin{aligned}[t] &X_{k}^i-\Delta t\lambda _1\!\left (X_{k}^i-y_{\alpha }(\widehat \rho _{Y,k}^N)\right ) -\Delta t\lambda _2\!\left (X_{k}^i-Y_{k}^i\right ) -\Delta t\lambda _3\nabla{\mathcal{E}}(X_{k}^i) \\ &\!\quad \,\,\,+\sigma _1 D\!\left (X_{k}^i-y_{\alpha }(\widehat \rho _{Y,k}^N)\right ) B_{k}^{1,i} +\sigma _2 D\!\left (X_{k}^i-Y_{k}^i\right ) B_{k}^{2,i} +\sigma _3 D\!\left (\nabla{\mathcal{E}}(X_{k}^i)\right ) B_{k}^{3,i}, \end{aligned} \end{aligned} \end{align}
\begin{align} &\begin{aligned} \!X_{k+1}^i = \begin{aligned}[t] &X_{k}^i-\Delta t\lambda _1\!\left (X_{k}^i-y_{\alpha }(\widehat \rho _{Y,k}^N)\right ) -\Delta t\lambda _2\!\left (X_{k}^i-Y_{k}^i\right ) -\Delta t\lambda _3\nabla{\mathcal{E}}(X_{k}^i) \\ &\!\quad \,\,\,+\sigma _1 D\!\left (X_{k}^i-y_{\alpha }(\widehat \rho _{Y,k}^N)\right ) B_{k}^{1,i} +\sigma _2 D\!\left (X_{k}^i-Y_{k}^i\right ) B_{k}^{2,i} +\sigma _3 D\!\left (\nabla{\mathcal{E}}(X_{k}^i)\right ) B_{k}^{3,i}, \end{aligned} \end{aligned} \end{align}
 \begin{align} &\mspace{1mu}Y_{k+1}^i = Y_{k}^i + \Delta t\kappa \left (X_{k+1}^i-Y_{k}^i\right ) S^{\beta,\theta }\!\left (X_{k+1}^i, Y_{k}^i\right ), \end{align}
\begin{align} &\mspace{1mu}Y_{k+1}^i = Y_{k}^i + \Delta t\kappa \left (X_{k+1}^i-Y_{k}^i\right ) S^{\beta,\theta }\!\left (X_{k+1}^i, Y_{k}^i\right ), \end{align}
where
 $((B_{k}^{m,i})_{k=0,\dots,K-1})_{i=1,\dots,N}$
are independent, identically distributed Gaussian random vectors in
$((B_{k}^{m,i})_{k=0,\dots,K-1})_{i=1,\dots,N}$
are independent, identically distributed Gaussian random vectors in
 $\mathbb{R}^d$
with zero mean and covariance matrix
$\mathbb{R}^d$
with zero mean and covariance matrix
 $\Delta t \mathsf{Id}$
for
$\Delta t \mathsf{Id}$
for
 $m\in \{1,2,3\}$
.
$m\in \{1,2,3\}$
.
We notice that, compared to standard CBO, see, e.g., [Reference Fornasier, Klock and Riedl28, Equation (2)], the way the historical best position is updated in (4.1b) (recall the definition of
 $S^{\beta,\theta }$
from equation (1.4)) requires one additional evaluation of the objective function per particle in each time step, which raises the computational complexity of the numerical scheme substantially if computing
$S^{\beta,\theta }$
from equation (1.4)) requires one additional evaluation of the objective function per particle in each time step, which raises the computational complexity of the numerical scheme substantially if computing
 $\mathcal{E}$
is costly and the dominating part. However, for the parameter choices
$\mathcal{E}$
is costly and the dominating part. However, for the parameter choices
 $\kappa =1/\Delta t$
,
$\kappa =1/\Delta t$
,
 $\theta =0$
and
$\theta =0$
and
 $\beta =\infty$
, in place of (4.1b), we obtain the update rule
$\beta =\infty$
, in place of (4.1b), we obtain the update rule
 \begin{equation} Y_{k+1}^i = \begin{cases} X_{k+1}^i, &\quad \text{if }{\mathcal{E}}(X_{k+1}^i) \lt{\mathcal{E}}(Y_{k}^i),\\ Y_{k}^i, &\quad \text{else}, \end{cases} \end{equation}
\begin{equation} Y_{k+1}^i = \begin{cases} X_{k+1}^i, &\quad \text{if }{\mathcal{E}}(X_{k+1}^i) \lt{\mathcal{E}}(Y_{k}^i),\\ Y_{k}^i, &\quad \text{else}, \end{cases} \end{equation}
which is how one expects a memory mechanism to be implemented. This way allows to recycle in time step
 $k$
the computations made in the previous step and thus leads to no additional computational cost as consequence of using memory effects. The memory consumption, on the other hand, is approximately twice as high as in standard CBO.
$k$
the computations made in the previous step and thus leads to no additional computational cost as consequence of using memory effects. The memory consumption, on the other hand, is approximately twice as high as in standard CBO.
4.2. A benchmark problem in optimisation: the Rastrigin function
Let us validate in this section the numerical observation made in Figure 2a in the introduction about the benefit of memory effects. Namely, it has been observed in several prior works that a higher noise level can enhance the success of CBO. To rule out that the improved performance for
 $\lambda _2\gt 0$
in Figure 2a originates solely from the larger present noise as consequence of the additional noise term associated with the memory drift, we replicate in Figure 3 the experiments with the exception of setting
$\lambda _2\gt 0$
in Figure 2a originates solely from the larger present noise as consequence of the additional noise term associated with the memory drift, we replicate in Figure 3 the experiments with the exception of setting
 $\sigma _2=0$
. The obtained results confirm that already the usage of memory effects together with a memory drift improves the performance. However, we also notice that an additional noise term further increases the success probability.
$\sigma _2=0$
. The obtained results confirm that already the usage of memory effects together with a memory drift improves the performance. However, we also notice that an additional noise term further increases the success probability.

Figure 3. Success probability of CBO without (left separate column) and with memory effects for different values of the parameter
 $\lambda _2\in [0,4]$
(right phase diagram) when optimising the Rastrigin function in dimension
$\lambda _2\in [0,4]$
(right phase diagram) when optimising the Rastrigin function in dimension
 $d=4$
in the setting of Figure 2a with the exception of setting
$d=4$
in the setting of Figure 2a with the exception of setting
 $\sigma _2=0$
. In this way we validate that the presence of memory effects is responsible for the improved performance and not just a higher noise level.
$\sigma _2=0$
. In this way we validate that the presence of memory effects is responsible for the improved performance and not just a higher noise level.
4.3. A machine learning example
As a first real-world inspired application, we now investigate the influence of memory mechanisms in a high-dimensional benchmark problem in machine learning, which is well-understood in the literature, namely the training of a shallow and a convolutional NN (CNN) classifier for the MNIST dataset of handwritten digits [Reference LeCun, Cortes and Burges47].
The experimental setting is the one of [Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29, Section 4] with tested architectures as described in Figure 4. While it is not our aim to challenge the state of the art at this task by employing very sophisticated architectures, we demonstrate that CBO is on par with stochastic gradient descent without requiring time-consuming hyperparameter tuning.

Figure 4. NN architectures used in the experiments of Section 4.3. Images are represented as
 $28\times 28$
matrices with entries in
$28\times 28$
matrices with entries in
 $[0,1]$
. For the shallow NN in (a) the input is reshaped into a vector
$[0,1]$
. For the shallow NN in (a) the input is reshaped into a vector
 $x\in \mathbb{R}^{728}$
which is then passed through a dense layer of the form
$x\in \mathbb{R}^{728}$
which is then passed through a dense layer of the form
 $\textrm{ReLU}(Wx+b)$
with trainable weights
$\textrm{ReLU}(Wx+b)$
with trainable weights
 $W\in \mathbb{R}^{10\times 728}$
and bias
$W\in \mathbb{R}^{10\times 728}$
and bias
 $b\in \mathbb{R}^{10}$
. The learnable parameters of the CNN in (b) are the kernels and the final dense layer. Both networks include a batch normalisation step after each
$b\in \mathbb{R}^{10}$
. The learnable parameters of the CNN in (b) are the kernels and the final dense layer. Both networks include a batch normalisation step after each
 $\textrm{ReLU}$
activation function and a softmax activation in the last layer in order to be able to interpret the output as a probability distribution over the digits. We denote the trainable parameters of the NN by
$\textrm{ReLU}$
activation function and a softmax activation in the last layer in order to be able to interpret the output as a probability distribution over the digits. We denote the trainable parameters of the NN by
 $\theta$
. The shallow NN has
$\theta$
. The shallow NN has
 $7850$
and the CNN
$7850$
and the CNN
 $2112$
. (Reprinted by permission from Springer Nature Customer Service Centre GmbH: Springer Nature, Applications of Evolutionary Computation, Convergence of Anisotropic Consensus-Based Optimization in Mean-Field Law, M. Fornasier, T. Klock, K. Riedl, © 2022.)
$2112$
. (Reprinted by permission from Springer Nature Customer Service Centre GmbH: Springer Nature, Applications of Evolutionary Computation, Convergence of Anisotropic Consensus-Based Optimization in Mean-Field Law, M. Fornasier, T. Klock, K. Riedl, © 2022.)
To train the learnable parameters
 $\theta$
of the NNs, we minimise the empirical risk
$\theta$
of the NNs, we minimise the empirical risk
 ${\mathcal{E}}(\theta ) = \frac{1}{M} \sum _{j=1}^M \ell (f_{\theta} (x^j),y^j)$
, where
${\mathcal{E}}(\theta ) = \frac{1}{M} \sum _{j=1}^M \ell (f_{\theta} (x^j),y^j)$
, where
 $f_{\theta}$
denotes the forward pass of the NN and
$f_{\theta}$
denotes the forward pass of the NN and
 $(x^j,y^{\,j})_{j=1}^M$
the
$(x^j,y^{\,j})_{j=1}^M$
the
 $M$
training samples consisting of image and label. As loss
$M$
training samples consisting of image and label. As loss
 $\ell$
we choose the categorical crossentropy loss
$\ell$
we choose the categorical crossentropy loss
 $\ell (\widehat{y},y)=-\sum _{k=0}^9 y_k \log \left (\widehat{y}_k\right )$
with
$\ell (\widehat{y},y)=-\sum _{k=0}^9 y_k \log \left (\widehat{y}_k\right )$
with
 $\widehat{y}=f_{\theta} (x)$
denoting the output of the NN for a sample
$\widehat{y}=f_{\theta} (x)$
denoting the output of the NN for a sample
 $(x,y)$
.
$(x,y)$
.

Figure 5. Comparison of the performances (testing accuracy and training loss) of a shallow NN (dashed lines) and a CNN (solid lines) with architectures as described in Figure 4, when trained with CBO without memory effects (lightest lines), with memory effects but without memory drift (line with intermediate opacity) and with memory effects and memory drift (darkest lines). Depicted are the accuracies on a test dataset (orange lines) and the values of the objective function
 $\mathcal{E}$
evaluated on a random sample of the training set of size 10,000 (blue lines). We observe that memory effects slightly improve the final accuracies while slowing down the training process initially.
$\mathcal{E}$
evaluated on a random sample of the training set of size 10,000 (blue lines). We observe that memory effects slightly improve the final accuracies while slowing down the training process initially.
Our implementation is the one of [Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29, Section 4], which includes concepts from [Reference Carrillo, Jin, Li and Zhu14] and [Reference Fornasier, Huang, Pareschi and Sünnen26, Section 2.2]. Firstly, mini-batching is employed when evaluating
 $\mathcal{E}$
and when computing the consensus point
$\mathcal{E}$
and when computing the consensus point
 $y_{\alpha }$
, which means that
$y_{\alpha }$
, which means that
 $\mathcal{E}$
is evaluated on a random subset of size
$\mathcal{E}$
is evaluated on a random subset of size
 $n_{\mathcal{E}}=60$
of the training dataset and
$n_{\mathcal{E}}=60$
of the training dataset and
 $y_{\alpha }$
is computed from a random subset of size
$y_{\alpha }$
is computed from a random subset of size
 $n_N=10$
of all
$n_N=10$
of all
 $N=100$
particles. Secondly, a cooling strategy for
$N=100$
particles. Secondly, a cooling strategy for
 $\alpha$
and the noise parameters is used. More precisely,
$\alpha$
and the noise parameters is used. More precisely,
 $\alpha$
is doubled each epoch, while
$\alpha$
is doubled each epoch, while
 $\sigma _1$
and
$\sigma _1$
and
 $\sigma _2$
follow the schedule
$\sigma _2$
follow the schedule
 $\sigma _{i,\text{epoch}} = \sigma _{i,0}/\log _2(\text{epoch}+2)$
for
$\sigma _{i,\text{epoch}} = \sigma _{i,0}/\log _2(\text{epoch}+2)$
for
 $i=1,2$
.
$i=1,2$
.
In Figure 5, we report the testing accuracies and the training risks evaluated at the consensus point based on a random sample of the training set of size 10,000 for both the shallow NN and the CNN when trained with one of three algorithms: standard CBO without memory effects as obtained when discretising [Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29, Equation (1)], CBO with memory effects but without memory drift as in equation (4.1) with
 $\lambda _2=\sigma _2=0$
, and CBO with memory effects and memory drift as in equation (4.1) with
$\lambda _2=\sigma _2=0$
, and CBO with memory effects and memory drift as in equation (4.1) with
 $\lambda _2=0.4$
and
$\lambda _2=0.4$
and
 $\sigma _2=\lambda _2\sigma _1$
. The remaining parameters are
$\sigma _2=\lambda _2\sigma _1$
. The remaining parameters are
 $\lambda _1=1$
,
$\lambda _1=1$
,
 $\sigma _{1,0}=\sqrt{0.4}$
,
$\sigma _{1,0}=\sqrt{0.4}$
,
 $\alpha _{\text{initial}}=50$
,
$\alpha _{\text{initial}}=50$
,
 $\beta =\infty$
,
$\beta =\infty$
,
 $\theta =0$
,
$\theta =0$
,
 $\kappa =1/\Delta t$
, and discrete time step size
$\kappa =1/\Delta t$
, and discrete time step size
 $\Delta t=0.1$
. We train for
$\Delta t=0.1$
. We train for
 $100$
epochs and use
$100$
epochs and use
 $N=100$
particles, which are initialised according to
$N=100$
particles, which are initialised according to
 $\mathcal{N}\big ((0,\dots,0)^T,\mathsf{Id}\big )$
. All results are averaged over
$\mathcal{N}\big ((0,\dots,0)^T,\mathsf{Id}\big )$
. All results are averaged over
 $5$
training runs.
$5$
training runs.
As concluded already in [Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29, Section 4], we obtain accuracies comparable to SGD, cf. [Reference LeCun, Bottou, Bengio and Haffner46, Figure 9]. Moreover, we see slightly improved results when exploiting memory effects. However, we also notice that memory mechanisms slow down the training process initially.
4.4. A compressed sensing example
In the final numerical section of this paper, we showcase an application where gradient information turns out to be indispensable for the success of CBO methods, namely an experiment in compressed sensing [Reference Foucart and Rauhut30], which has become a very active and profitable field of research since the seminal works [Reference Candès, Romberg and Tao11, Reference Donoho22] about two decades ago.
One of the most common problems encountered in engineering and technology is concerned with the inference of information about an unknown signal
 $x^*\in \mathbb{R}^d$
from (linear) measurements
$x^*\in \mathbb{R}^d$
from (linear) measurements
 $b\in \mathbb{R}^m$
. While classical linear algebra suggests that the number of measurements
$b\in \mathbb{R}^m$
. While classical linear algebra suggests that the number of measurements
 $m$
must be at least as large as the dimensionality
$m$
must be at least as large as the dimensionality
 $d$
of the signal, in many applications measurements are costly, time-consuming or both, making it desirable to reduce their number to the absolute minimum. Very often one aims at
$d$
of the signal, in many applications measurements are costly, time-consuming or both, making it desirable to reduce their number to the absolute minimum. Very often one aims at
 $m\ll d$
, since real-world signals usually live in high-dimensional spaces. In general, this would be an impossible task. However, in typical practical scenarios additional information about the quantity of interest
$m\ll d$
, since real-world signals usually live in high-dimensional spaces. In general, this would be an impossible task. However, in typical practical scenarios additional information about the quantity of interest
 $x^*$
is available, which indeed allows to reconstruct signals from few measurements
$x^*$
is available, which indeed allows to reconstruct signals from few measurements
 $b$
. An empirically observed assumption about real-world signals is compressibility, meaning that they can be well-approximated by sparse vectors, i.e., vectors whose components are for the most part zero. Exploiting sparsity enables us to solve the underdetermined system
$b$
. An empirically observed assumption about real-world signals is compressibility, meaning that they can be well-approximated by sparse vectors, i.e., vectors whose components are for the most part zero. Exploiting sparsity enables us to solve the underdetermined system
 $Ax^* = b$
efficiently in both theory and practice. Compressed sensing is concerned with the task of designing a measurement process
$Ax^* = b$
efficiently in both theory and practice. Compressed sensing is concerned with the task of designing a measurement process
 $A\in \mathbb{R}^{m\times d}$
together with a reconstruction algorithm capable of recovering the sparse solution
$A\in \mathbb{R}^{m\times d}$
together with a reconstruction algorithm capable of recovering the sparse solution
 $x^*$
from the set of solutions consistent with the measurements. This can be formulated as the nonconvex combinatorial optimisation
$x^*$
from the set of solutions consistent with the measurements. This can be formulated as the nonconvex combinatorial optimisation
 \begin{equation*} \min \left \|{x}\right \|_0 \quad \text {subject to } Ax=b, \end{equation*}
\begin{equation*} \min \left \|{x}\right \|_0 \quad \text {subject to } Ax=b, \end{equation*}
where
 $\left \|{x}\right \|_0$
is colloquially referred to as
$\left \|{x}\right \|_0$
is colloquially referred to as
 $\ell _0$
-‘norm’ and denotes the number of non-zero elements of
$\ell _0$
-‘norm’ and denotes the number of non-zero elements of
 $x$
. Solving
$x$
. Solving
 $\ell _0$
-minimisation is however NP-hard in general, which lead researchers to consider the convex relaxation
$\ell _0$
-minimisation is however NP-hard in general, which lead researchers to consider the convex relaxation
 \begin{equation} \min \left \|{x}\right \|_1 \quad \text{subject to } Ax=b. \end{equation}
\begin{equation} \min \left \|{x}\right \|_1 \quad \text{subject to } Ax=b. \end{equation}
 $\ell _1$
-minimisation is easy to solve by means of established methods from convex optimisation and provably recovers the correct solution for a suitable measurement matrix
$\ell _1$
-minimisation is easy to solve by means of established methods from convex optimisation and provably recovers the correct solution for a suitable measurement matrix
 $A$
. The remaining question is about the correct way of inferring information about the signal through measurements. Remarkably and responsible for the wide success of compressed sensing is that random matrices enjoy properties such as the null space or restricted isometry property, which guarantee successful recovery, for
$A$
. The remaining question is about the correct way of inferring information about the signal through measurements. Remarkably and responsible for the wide success of compressed sensing is that random matrices enjoy properties such as the null space or restricted isometry property, which guarantee successful recovery, for
 $m\gtrsim s\log (d/s)$
, where
$m\gtrsim s\log (d/s)$
, where
 $s$
denotes the sparsity of the signal
$s$
denotes the sparsity of the signal
 $x^*$
, i.e.,
$x^*$
, i.e.,
 $s=\left \|{x^*}\right \|_0$
. Up to the logarithmic factor in the ambient dimension
$s=\left \|{x^*}\right \|_0$
. Up to the logarithmic factor in the ambient dimension
 $d$
, this is optimal, since in theory
$d$
, this is optimal, since in theory
 $m=2s$
measurements are necessary and sufficient to reconstruct every
$m=2s$
measurements are necessary and sufficient to reconstruct every
 $s$
-sparse vector.
$s$
-sparse vector.

Figure 6. Comparison between the success probabilities of CBO without (left separate columns) and with gradient information for different values of the parameter
 $\lambda _3\in [0,4]$
(right phase diagrams) with
$\lambda _3\in [0,4]$
(right phase diagrams) with
 $N=10$
((a) and (c)) or
$N=10$
((a) and (c)) or
 $N=100$
particles ((b) and (d)) when solving the convex or nonconvex
$N=100$
particles ((b) and (d)) when solving the convex or nonconvex
 $\ell _p$
-regularised least squares problem (4.4) with
$\ell _p$
-regularised least squares problem (4.4) with
 $p=1$
and
$p=1$
and
 $\mu =$
((a) and (b)) or
$\mu =$
((a) and (b)) or
 $p=0.5$
and
$p=0.5$
and
 $\mu =$
((c) and (d)), respectively. On the vertical axis we depict the number of measurements
$\mu =$
((c) and (d)), respectively. On the vertical axis we depict the number of measurements
 $m$
, from which we try to recover the
$m$
, from which we try to recover the
 $2$
-sparse and
$2$
-sparse and
 $50$
-dimensional sparse signal. As further parameters we choose the time horizon
$50$
-dimensional sparse signal. As further parameters we choose the time horizon
 $T=20$
, discrete time step size
$T=20$
, discrete time step size
 $\Delta t=0.01$
,
$\Delta t=0.01$
,
 $\alpha =100$
,
$\alpha =100$
,
 $\beta =\infty$
,
$\beta =\infty$
,
 $\theta =0$
,
$\theta =0$
,
 $\kappa =1/\Delta t$
,
$\kappa =1/\Delta t$
,
 $\lambda _1=1$
,
$\lambda _1=1$
,
 $\lambda _2=0$
and
$\lambda _2=0$
and
 $\sigma _1=\sigma _2=\sigma _3=0$
. We discover that in both the convex and nonconvex setting reconstruction is feasible from already very few measurements. While increasing the number of optimising particles has almost no effect for the convex optimisation problem, in the nonconvex setting recovery benefits from more particles. Note that the separate columns and the left most column of the phase diagrams coincide, and are only depicted in this way to highlight that we compare also CBO.
$\sigma _1=\sigma _2=\sigma _3=0$
. We discover that in both the convex and nonconvex setting reconstruction is feasible from already very few measurements. While increasing the number of optimising particles has almost no effect for the convex optimisation problem, in the nonconvex setting recovery benefits from more particles. Note that the separate columns and the left most column of the phase diagrams coincide, and are only depicted in this way to highlight that we compare also CBO.
In the numerical experiments following, we resort to the regularised variant of the sparse recovery problem
 \begin{equation} \min \ {\mathcal{E}}(x) \quad \text{with }{\mathcal{E}}(x) = \frac{1}{2}\left \|{Ax-b}\right \|_2^2 + \mu \left \|{x}\right \|_p^p \end{equation}
\begin{equation} \min \ {\mathcal{E}}(x) \quad \text{with }{\mathcal{E}}(x) = \frac{1}{2}\left \|{Ax-b}\right \|_2^2 + \mu \left \|{x}\right \|_p^p \end{equation}
for a suitable regularisation parameter
 $\mu \gt 0$
. For
$\mu \gt 0$
. For
 $p=1$
we obtain the regularisation of (4.3), whereas for
$p=1$
we obtain the regularisation of (4.3), whereas for
 $p\lt 1$
the optimisation (4.4) becomes nonconvex. Our results in Figures 2b and 6 show that CBO with gradient information is capable of solving the convex but also the nonconvex optimisation problem (4.4) with
$p\lt 1$
the optimisation (4.4) becomes nonconvex. Our results in Figures 2b and 6 show that CBO with gradient information is capable of solving the convex but also the nonconvex optimisation problem (4.4) with
 $p=1/2$
with already very few measurements. As parameters of the CBO algorithm, which is obtained as a Euler-Maruyama discretisation of equation (1.1), we choose in both cases the time horizon
$p=1/2$
with already very few measurements. As parameters of the CBO algorithm, which is obtained as a Euler-Maruyama discretisation of equation (1.1), we choose in both cases the time horizon
 $T=20$
, time step size
$T=20$
, time step size
 $\Delta t=0.01$
,
$\Delta t=0.01$
,
 $\alpha =100$
,
$\alpha =100$
,
 $\beta =\infty$
,
$\beta =\infty$
,
 $\theta =0$
,
$\theta =0$
,
 $\kappa =1/\Delta t$
,
$\kappa =1/\Delta t$
,
 $\lambda _1=1$
,
$\lambda _1=1$
,
 $\lambda _2=0$
and
$\lambda _2=0$
and
 $\sigma _1=\sigma _2=\sigma _3=0$
. We use either
$\sigma _1=\sigma _2=\sigma _3=0$
. We use either
 $N=10$
or
$N=10$
or
 $N=100$
particles, which is specified in the respective caption. After running the CBO algorithm, a post-processing step is performed, in which the support of the suspected sparse vector is identified by checking which entries are not smaller than
$N=100$
particles, which is specified in the respective caption. After running the CBO algorithm, a post-processing step is performed, in which the support of the suspected sparse vector is identified by checking which entries are not smaller than
 $0.01$
before the final sparse solution is then obtained by solving the linear system constrained to this support.
$0.01$
before the final sparse solution is then obtained by solving the linear system constrained to this support.
The depicted success probabilities are averaged over
 $100$
runs of CBO. In Figure 2b, we solve the sparse recovery problem in the convex setting for an
$100$
runs of CBO. In Figure 2b, we solve the sparse recovery problem in the convex setting for an
 $8$
-sparse
$8$
-sparse
 $200$
-dimensional signal with
$200$
-dimensional signal with
 $p=1$
using CBO without and with gradient information with merely
$p=1$
using CBO without and with gradient information with merely
 $10$
particles. We observe that gradient information is indispensable to be able to identify the correct sparse solution and standard CBO would fail in such task. In Figure 6, we conduct a slightly lower-dimensional experiment with a
$10$
particles. We observe that gradient information is indispensable to be able to identify the correct sparse solution and standard CBO would fail in such task. In Figure 6, we conduct a slightly lower-dimensional experiment with a
 $2$
-sparse
$2$
-sparse
 $50$
-dimensional signal. Here our focus is to enter the nonconvex recovery regime by comparing the convex
$50$
-dimensional signal. Here our focus is to enter the nonconvex recovery regime by comparing the convex
 $\ell _1$
-regularised with the nonconvex
$\ell _1$
-regularised with the nonconvex
 $\ell _{1/2}$
-regularised problem. We discover that in either case reconstruction is feasible from already very few measurements. Increasing the number of optimising particles has almost no effect for the convex optimisation problem, in the nonconvex setting recovery benefits from more particles. Furthermore, the nonconvex problem demands a more moderate choice of the strength of the gradient.
$\ell _{1/2}$
-regularised problem. We discover that in either case reconstruction is feasible from already very few measurements. Increasing the number of optimising particles has almost no effect for the convex optimisation problem, in the nonconvex setting recovery benefits from more particles. Furthermore, the nonconvex problem demands a more moderate choice of the strength of the gradient.
5. Conclusions
In this paper, we investigate a variant of consensus-based optimisation (CBO) which incorporates memory effects and gradient information. By developing further and generalising the proof technique devised in [Reference Fornasier, Klock and Riedl28, Reference Fornasier, Klock, Riedl, Jiménez Laredo, Hidalgo and Babaagba29], we establish the global convergence of the underlying dynamics to the global minimiser
 $x^*$
of the objective function
$x^*$
of the objective function
 $\mathcal{E}$
in mean-field law. To this end, we analyse the time-evolution of the Wasserstein distance between the law of the mean-field CBO dynamics and a Dirac delta at the minimiser and show its exponential decay in time. Our result holds under minimal assumptions about the initial measure
$\mathcal{E}$
in mean-field law. To this end, we analyse the time-evolution of the Wasserstein distance between the law of the mean-field CBO dynamics and a Dirac delta at the minimiser and show its exponential decay in time. Our result holds under minimal assumptions about the initial measure
 $\rho _0$
and for a vast class of objective functions. The numerical benefit of such additional terms, specifically the employed memory effects and gradient information, is demonstrated at the example of a benchmark function in optimisation as well as at real-world applications such as compressed sensing and the training of neural networks for image classification.
$\rho _0$
and for a vast class of objective functions. The numerical benefit of such additional terms, specifically the employed memory effects and gradient information, is demonstrated at the example of a benchmark function in optimisation as well as at real-world applications such as compressed sensing and the training of neural networks for image classification.
By these means, we demonstrate the versatility, flexibility and customisability of the class of CBO methods, both with respect to potential application areas in practice and modifications to the underlying optimisation principles, while still being amenable to theoretical analysis.
Acknowledgements
I would like to profusely thank Massimo Fornasier for many fruitful and stimulating discussions while I was preparing this manuscript.
Financial support
This work has been funded by the German Federal Ministry of Education and Research and the Bavarian State Ministry for Science and the Arts. I, the author of this work, take full responsibility for its content. Furthermore, I acknowledge the financial support from the Technical University of Munich – Institute for Ethics in Artificial Intelligence. Moreover, I gratefully acknowledge the computer and data resources provided by the Leibniz Supercomputing Centre.
Competing interests
None.







































































 Open access
Open access