



1. Introduction
The structure of contact networks among individuals shapes the dynamics of contagion processes in a population such as the number of individuals infected, their spatial distributions and speed of spreading [Reference Newman1–Reference Barrat, Barthélemy and Vespignani4]. For example, a heterogeneous degree distribution, where the degree is the number of neighbouring nodes that a node has, and a short average distance between nodes are two factors that usually enhance epidemic spreading on networks. In fact, empirical contact networks often vary over time on a time scale comparable to or faster than that of epidemic dynamics, probably most famously owing to mobility of human or animal individuals. This observation has naturally led to the investigation of how features of such temporal (i.e., time-varying) networks and statistical properties of contact events, such as distributions of inter-contact times, temporal correlation in inter-contact times and appearance and disappearance of nodes and edges, affect outcomes of contagion processes [Reference Holme and Saramäki5–Reference Moody10].
The concurrency is a feature of temporal contact networks that has been investigated in both mathematical and field epidemiology for over two decades, while many of these studies do not specifically refer to temporal networks [Reference Moody and Benton11–Reference Watts and May19]. Concurrency generally refers to multiple partnerships of an individual that overlap in time. Concurrency has been examined in particular in the context of sexually transmitted infections such as HIV, specifically regarding whether or not the concurrency was high in sub-Saharan Africa and, if so, whether or not the high concurrency enhanced HIV spreading there [Reference Moody and Benton11–Reference Kretzschmar and Morris13, Reference Aral20–Reference Foxman, Newman, Percha, Holmes and Aral23]. Suppose that a partnership between individuals
 $i$
and
$i$
and
 $j$
overlaps one between
$j$
overlaps one between
 $i$
and
$i$
and
 $j^\prime$
for some time. Such concurrency may promote epidemic spreading because rapid transmission from
$j^\prime$
for some time. Such concurrency may promote epidemic spreading because rapid transmission from
 $j$
to
$j$
to
 $j^\prime$
through
$j^\prime$
through
 $i$
and vice versa is possible during the concurrent partnerships (see Figure 1(a)). In contrast, if a partnership between
$i$
and vice versa is possible during the concurrent partnerships (see Figure 1(a)). In contrast, if a partnership between
 $i$
and
$i$
and
 $j$
occurs before that between
$j$
occurs before that between
 $i$
and
$i$
and
 $j'$
without an overlap, i.e., without concurrency, the transmission from
$j'$
without an overlap, i.e., without concurrency, the transmission from
 $j$
to
$j$
to
 $j'$
can still occur in various different ways, but the transmission from
$j'$
can still occur in various different ways, but the transmission from
 $j'$
to
$j'$
to
 $j$
does not (see Figure 1(b)).
$j$
does not (see Figure 1(b)).
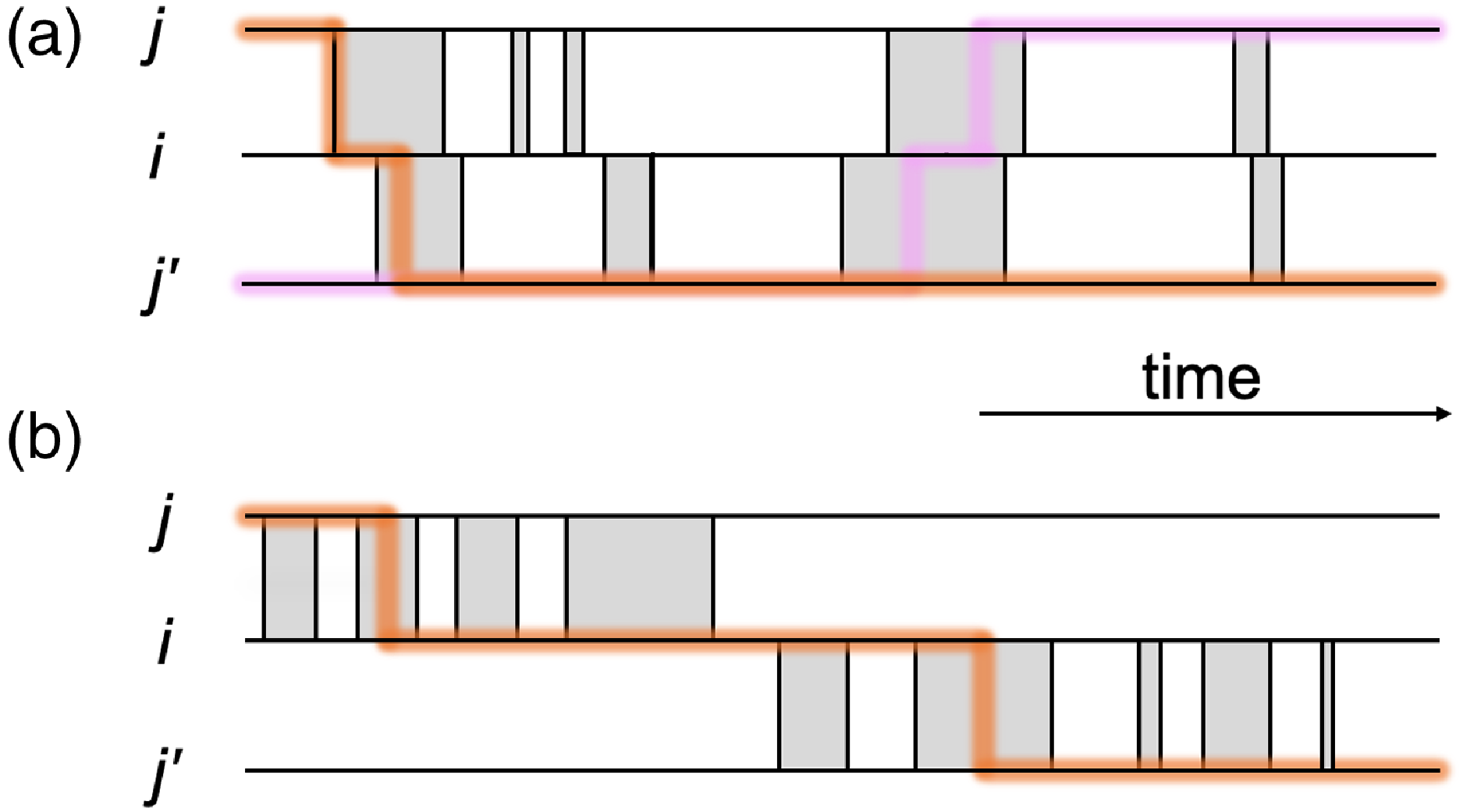
Figure 1. Schematic of part of temporal networks with different amounts of concurrency. We depict two edges sharing a node in each case. (a) Concurrent partnerships. (b) Non-concurrent partnerships. A shaded box represents a duration for which a partnership is present on the edge. The thick lines are examples of time-respecting paths transmitting infection from
 $j$
to
$j$
to
 $j'$
(shown in orange) or from
$j'$
(shown in orange) or from
 $j'$
to
$j'$
to
 $j$
(shown in magenta). This figure is inspired by Figure 1 in ref. [Reference Masuda, Miller and Holme15] and Figure 1 in ref. [Reference Miller and Slim27].
$j$
(shown in magenta). This figure is inspired by Figure 1 in ref. [Reference Masuda, Miller and Holme15] and Figure 1 in ref. [Reference Miller and Slim27].
Modelling studies are diverse in how to quantify the amount of concurrency. Many studies measure the concurrency through the mean degree, or the average contact rate for nodes [Reference Watts and May19, Reference Doherty, Shiboski, Ellen, Adimora and Padian24–Reference Eames and Keeling26]. However, in these cases, it is hard to say whether an increased epidemic size owes to a high density of edges or a large amount of concurrency [Reference Masuda, Miller and Holme15, Reference Miller and Slim27–Reference Bauch and Rand29]. In studies of epidemic processes on static networks, it is a stylised fact that epidemic spreading is enhanced if there are many edges with all other things being equal. Another line of theoretical and computational approach to concurrency quantifies concurrency by the heterogeneity in the degree distribution of the network [Reference Morris and Kretzschmar12, Reference Kretzschmar and Morris13, Reference Masuda, Miller and Holme15]. However, the results that a high concurrency in this sense enhances epidemic spreading is equivalent to an established result in static network epidemiology that heterogeneous degree distributions lead to a small epidemic threshold, thus promoting epidemic spreading [Reference Pastor-Satorras, Castellano, Mieghem and Vespignani2–Reference Barrat, Barthélemy and Vespignani4, Reference Pastor-Satorras and Vespignani30]. In some studies, the authors investigated the effect of concurrency by carefully ensuring that the degree distribution (and hence the average degree) stays the same across the comparisons while they manipulate the amount of concurrency [Reference Miller and Slim27–Reference Bauch and Rand29]. These studies suggest that, despite the different definitions of the concurrency employed in these studies, higher concurrency increases epidemic spreading (but see [Reference Miller and Slim27] for different results). However, mathematical models that enable us to analyse the effect of concurrency by fixing the structure of the static network are still scarce.
In the present study, we focus on effects of concurrency on epidemic spreading for an arbitrary static network on top of which partnerships, infection events and recovery events occur. In this manner, we aim to study the effect of concurrency without being affected by the effect of the network structure itself. We consider three temporal network models that have different amounts of concurrency while keeping the probability that each edge is available the same across comparisons. In terms of a concurrency measure, we analytically evaluate the amount of concurrency of edges sharing a node for the three models as well as other properties of the models. Then, we numerically study effects of concurrency on epidemic spreading using the stochastic susceptible-infectious-susceptible (SIS) and susceptible-infectious-recovered (SIR) models.
The Python codes for generating the numerical results in this article are available at Github (https://github.com/RuodanL/concurrency).
2. Temporal network models
We introduce three models of undirected and unweighted temporal networks in continuous time, which we build from independent Markov processes occurring on a given static network. We use these models to compare temporal networks that have the same time-aggregated network but different amounts of concurrency. Let
 $G$
be an undirected and unweighted static network with node set
$G$
be an undirected and unweighted static network with node set
 $V = \left \{1, \ldots, N\right \}$
and edge set
$V = \left \{1, \ldots, N\right \}$
and edge set
 $E = \left \{e_i\right \}_{i=1}^{M}$
, where
$E = \left \{e_i\right \}_{i=1}^{M}$
, where
 $N$
is the number of nodes and
$N$
is the number of nodes and
 $M$
is the number of edges. We assume that the network
$M$
is the number of edges. We assume that the network
 $G$
has no self-loops. In the temporal network constructed based on undirected and unweighted static network
$G$
has no self-loops. In the temporal network constructed based on undirected and unweighted static network
 $G$
, by definition, each edge
$G$
, by definition, each edge
 $e_i \in E$
is either active (i.e., temporarily present) or inactive (i.e., temporarily absent) at any given time
$e_i \in E$
is either active (i.e., temporarily present) or inactive (i.e., temporarily absent) at any given time
 $t \in \mathbb{R}$
and switches between the active and inactive states over time. We denote by
$t \in \mathbb{R}$
and switches between the active and inactive states over time. We denote by
 $\mathcal{G}$
the temporal network and by
$\mathcal{G}$
the temporal network and by
 $\mathcal{G}(t)$
the instantaneous network in
$\mathcal{G}(t)$
the instantaneous network in
 $\mathcal{G}$
observed at time
$\mathcal{G}$
observed at time
 $t$
.
$t$
.
2.1. Model 1
Let
 $\tau _1$
and
$\tau _1$
and
 $\tau _2$
be the duration of the active state of and the inactive state of an edge, respectively. In our model 1, we assume that
$\tau _2$
be the duration of the active state of and the inactive state of an edge, respectively. In our model 1, we assume that
 $\tau _1$
is independently drawn from probability density
$\tau _1$
is independently drawn from probability density
 $\psi _1(\tau _1)$
each time the edge switches from the inactive to the active state. Similarly, we draw
$\psi _1(\tau _1)$
each time the edge switches from the inactive to the active state. Similarly, we draw
 $\tau _2$
independently from probability density
$\tau _2$
independently from probability density
 $\psi _2(\tau _2)$
each time the edge switches from the active to the inactive state. The duration
$\psi _2(\tau _2)$
each time the edge switches from the active to the inactive state. The duration
 $\tau _1$
or
$\tau _1$
or
 $\tau _2$
for different edges obeys the same distributions but is drawn independently for the different edges. When
$\tau _2$
for different edges obeys the same distributions but is drawn independently for the different edges. When
 $\psi _1(\tau _1)$
and
$\psi _1(\tau _1)$
and
 $\psi _2(\tau _2)$
are both exponential distributions, the stochastic dynamics of the state of each edge obeys independent continuous-time Markov processes with two states, and our model 1 reduces to previously proposed models [Reference Zhang, Moore and Newman31, Reference Clementi, Macci, Monti, Pasquale and Silvestri32].
$\psi _2(\tau _2)$
are both exponential distributions, the stochastic dynamics of the state of each edge obeys independent continuous-time Markov processes with two states, and our model 1 reduces to previously proposed models [Reference Zhang, Moore and Newman31, Reference Clementi, Macci, Monti, Pasquale and Silvestri32].
2.2. Model 2
In models 2 and 3, we assume that each node independently obeys a continuous-time Markov process with two states, which we refer to as the high-activity and low-activity states. Each node independently switches between the high-activity state, denoted by
 $h$
, and the low-activity state, denoted by
$h$
, and the low-activity state, denoted by
 $\ell$
. Let
$\ell$
. Let
 $a$
be the rate at which the state of a node changes from
$a$
be the rate at which the state of a node changes from
 $\ell$
to
$\ell$
to
 $h$
, and let
$h$
, and let
 $b$
be the rate at which the state of a node changes from
$b$
be the rate at which the state of a node changes from
 $h$
to
$h$
to
 $\ell$
. In model 2, each edge
$\ell$
. In model 2, each edge
 $(u, v) \in E$
, where
$(u, v) \in E$
, where
 $u, v \in V$
, is active at any given time if and only if both
$u, v \in V$
, is active at any given time if and only if both
 $u$
and
$u$
and
 $v$
are in the
$v$
are in the
 $h$
state. The dynamics of a single edge in model 2 is schematically shown in Figure 2. The model resembles the so-called AND model in [Reference Fonseca dos Reis, Li and Masuda33]. An intuitive interpretation of model 2 is that two individuals chat with each other if and only if both of them want to.
$h$
state. The dynamics of a single edge in model 2 is schematically shown in Figure 2. The model resembles the so-called AND model in [Reference Fonseca dos Reis, Li and Masuda33]. An intuitive interpretation of model 2 is that two individuals chat with each other if and only if both of them want to.
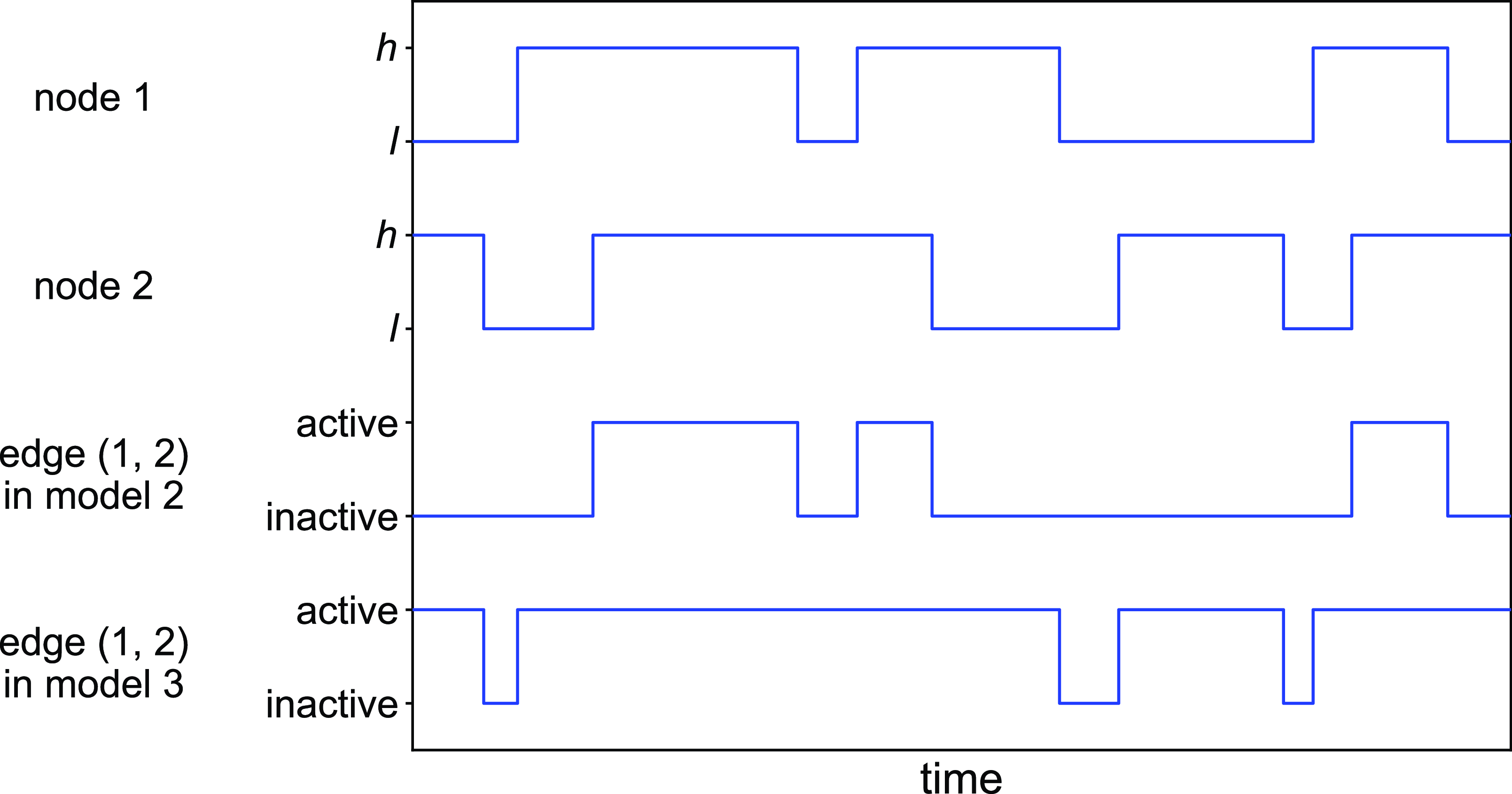
Figure 2. Schematic illustration of models 2 and 3. In model 2, edge
 $(1, 2)$
is active if and only if both node
$(1, 2)$
is active if and only if both node
 $1$
and node
$1$
and node
 $2$
are in the
$2$
are in the
 $h$
state. Otherwise, the edge is inactive. In model 3, edge
$h$
state. Otherwise, the edge is inactive. In model 3, edge
 $(1, 2)$
is active if and only if either node
$(1, 2)$
is active if and only if either node
 $1$
or node
$1$
or node
 $2$
is in the
$2$
is in the
 $h$
state.
$h$
state.
2.3. Model 3
Model 3 is a variant of model 2. As in model 2, we assume that each node independently switches between the high-activity and low-activity states at rates
 $a$
and
$a$
and
 $b$
. In model 3, the edge between two nodes is active if and only if either node is in the
$b$
. In model 3, the edge between two nodes is active if and only if either node is in the
 $h$
state (see Figure 2 for a schematic). This model resembles the OR model proposed in [Reference Fonseca dos Reis, Li and Masuda33]. The intuition behind model 3 is that one person can start conversation with another person whenever either person wants to talk regardless of whether the other person wants to.
$h$
state (see Figure 2 for a schematic). This model resembles the OR model proposed in [Reference Fonseca dos Reis, Li and Masuda33]. The intuition behind model 3 is that one person can start conversation with another person whenever either person wants to talk regardless of whether the other person wants to.
3. Concurrency for the three models
In this section, we first define a concurrency index for temporal networks in which partnership on each edge appears and disappears over time. Then, we calculate and compare the concurrency index and related measures for models 1, 2 and 3.
3.1. Definition of a concurrency index
Consider a temporal network
 $\mathcal{G}$
that is constructed on the underlying static network
$\mathcal{G}$
that is constructed on the underlying static network
 $G$
and defined for time
$G$
and defined for time
 $t \in [0, T]$
. We refer to
$t \in [0, T]$
. We refer to
 $G$
as the aggregate network. If two edges in
$G$
as the aggregate network. If two edges in
 $\mathcal{G}$
sharing a node in
$\mathcal{G}$
sharing a node in
 $G$
are both active at
$G$
are both active at
 $t \in \mathbb{R}$
, we say that the two edges are concurrent at time
$t \in \mathbb{R}$
, we say that the two edges are concurrent at time
 $t$
; see Figure 1(a) for an example. Consider a pair of edges sharing a node in the aggregate network, denoted by
$t$
; see Figure 1(a) for an example. Consider a pair of edges sharing a node in the aggregate network, denoted by
 $e_i$
and
$e_i$
and
 $e_j$
, where
$e_j$
, where
 $e_i, e_j \in E$
. In fact, the likelihood that
$e_i, e_j \in E$
. In fact, the likelihood that
 $e_i$
and
$e_i$
and
 $e_j$
are concurrent at time
$e_j$
are concurrent at time
 $t$
depends on how likely each single edge is active at time
$t$
depends on how likely each single edge is active at time
 $t$
. We define a concurrency index that takes into account of this factor. To this end, we first define the set of time for which an edge
$t$
. We define a concurrency index that takes into account of this factor. To this end, we first define the set of time for which an edge
 $e \in E$
is active by
$e \in E$
is active by
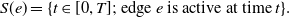 \begin{equation} S(e) = \{ t \in [0, T]; \text{ edge } e \text{ is active at time } t \}. \end{equation}
\begin{equation} S(e) = \{ t \in [0, T]; \text{ edge } e \text{ is active at time } t \}. \end{equation}
We define the concurrency for the edge pair
 $\{ e_i, e_j \} \in \mathcal{S}$
by
$\{ e_i, e_j \} \in \mathcal{S}$
by
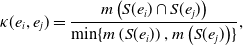 \begin{equation} \kappa (e_i, e_j) = \frac{ m\left (S(e_i) \cap S(e_j)\right ) }{\min \{ m\left ( S(e_i) \right ), m\left ( S(e_j) \right ) \}}, \end{equation}
\begin{equation} \kappa (e_i, e_j) = \frac{ m\left (S(e_i) \cap S(e_j)\right ) }{\min \{ m\left ( S(e_i) \right ), m\left ( S(e_j) \right ) \}}, \end{equation}
where
 $m$
denotes the Lebesgue measure, and
$m$
denotes the Lebesgue measure, and
 $\mathcal{S}$
is the set of edge pairs that share a node in
$\mathcal{S}$
is the set of edge pairs that share a node in
 $G$
. Note that
$G$
. Note that
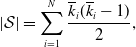 \begin{equation} \left | \mathcal{S} \right | = \sum _{i=1}^N \frac{\overline{k}_i (\overline{k}_i-1)}{2}, \end{equation}
\begin{equation} \left | \mathcal{S} \right | = \sum _{i=1}^N \frac{\overline{k}_i (\overline{k}_i-1)}{2}, \end{equation}
where
 $\overline{k}_i$
is the degree of the
$\overline{k}_i$
is the degree of the
 $i$
th node in
$i$
th node in
 $G$
[Reference Morris and Kretzschmar12, Reference Kretzschmar and Morris13]. The numerator on the right-hand side of equation (3.2) is equal to the length of time for which both
$G$
[Reference Morris and Kretzschmar12, Reference Kretzschmar and Morris13]. The numerator on the right-hand side of equation (3.2) is equal to the length of time for which both
 $e_i$
and
$e_i$
and
 $e_j$
are active. The denominator is a normalisation constant to discount the fact that the numerator would be large if the two edges are active for long time. Because any edge
$e_j$
are active. The denominator is a normalisation constant to discount the fact that the numerator would be large if the two edges are active for long time. Because any edge
 $e$
in the aggregate network
$e$
in the aggregate network
 $G$
should be active sometime in
$G$
should be active sometime in
 $[0, T]$
, the denominator is always positive; otherwise, we should exclude
$[0, T]$
, the denominator is always positive; otherwise, we should exclude
 $e$
from
$e$
from
 $G$
.
$G$
.
We define the concurrency index for temporal network
 $\mathcal{G}$
by
$\mathcal{G}$
by
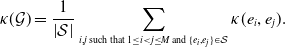 \begin{align} \kappa (\mathcal{G}) & = \frac{1}{\left | \mathcal{S} \right |} \sum _{i, j \text{ such that } 1\le i \lt j\le M \text{ and } \{ e_i, e_j \} \in \mathcal{S}} \kappa (e_i, e_j). \end{align}
\begin{align} \kappa (\mathcal{G}) & = \frac{1}{\left | \mathcal{S} \right |} \sum _{i, j \text{ such that } 1\le i \lt j\le M \text{ and } \{ e_i, e_j \} \in \mathcal{S}} \kappa (e_i, e_j). \end{align}
It holds true that
 $0 \le \kappa (\mathcal{G}) \le 1$
because
$0 \le \kappa (\mathcal{G}) \le 1$
because
 $0 \le \kappa (e_i, e_j) \le 1$
. For empirical or numerical data,
$0 \le \kappa (e_i, e_j) \le 1$
. For empirical or numerical data,
 $[0, T]$
is the observation time window. For a stochastic temporal network model, we calculate
$[0, T]$
is the observation time window. For a stochastic temporal network model, we calculate
 $S(e)$
as the expectation and in the limit of
$S(e)$
as the expectation and in the limit of
 $T\to \infty$
such that
$T\to \infty$
such that
 $\kappa (\mathcal{G})$
is a deterministic quantity.
$\kappa (\mathcal{G})$
is a deterministic quantity.
Differently from
 $\kappa _3$
, a concurrency index proposed in seminal studies [Reference Morris and Kretzschmar12, Reference Kretzschmar and Morris13] (also see for [Reference Masuda, Miller and Holme15] a review),
$\kappa _3$
, a concurrency index proposed in seminal studies [Reference Morris and Kretzschmar12, Reference Kretzschmar and Morris13] (also see for [Reference Masuda, Miller and Holme15] a review),
 $\kappa (\mathcal{G})$
is not affected by the degree distribution of the aggregate network
$\kappa (\mathcal{G})$
is not affected by the degree distribution of the aggregate network
 $G$
. It should be noted that the calculation of
$G$
. It should be noted that the calculation of
 $\kappa (e_i, e_j)$
and hence
$\kappa (e_i, e_j)$
and hence
 $\kappa (\mathcal{G})$
requires the information about the aggregate network, i.e.,
$\kappa (\mathcal{G})$
requires the information about the aggregate network, i.e.,
 $\mathcal{S}$
.
$\mathcal{S}$
.
3.2. Model 1
To calculate the concurrency index for the three models of temporal networks, we first derive the probability of an arbitrary edge being active in the equilibrium for each model. In model 1, consider an arbitrary edge in the static network
 $G$
. The mean duration for which the edge is active and that for which the edge is inactive are given by
$G$
. The mean duration for which the edge is active and that for which the edge is inactive are given by
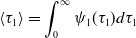 \begin{align} \langle \tau _1\rangle & = \int _{0}^{\infty } \psi _1(\tau _1) d\tau _1 \end{align}
\begin{align} \langle \tau _1\rangle & = \int _{0}^{\infty } \psi _1(\tau _1) d\tau _1 \end{align}
and
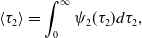 \begin{align} \langle \tau _2\rangle & = \int _{0}^{\infty } \psi _2(\tau _2) d\tau _2, \end{align}
\begin{align} \langle \tau _2\rangle & = \int _{0}^{\infty } \psi _2(\tau _2) d\tau _2, \end{align}
respectively. Owing to the renewal reward theorem [Reference Ross34], the probability that the edge is active in the equilibrium, denoted by
 $q^*$
, is given by
$q^*$
, is given by
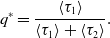 \begin{equation} q^*=\frac{\langle \tau _1\rangle }{\langle \tau _1\rangle +\langle \tau _2\rangle }. \end{equation}
\begin{equation} q^*=\frac{\langle \tau _1\rangle }{\langle \tau _1\rangle +\langle \tau _2\rangle }. \end{equation}
The concurrency index,
 $\kappa (\mathcal{G})$
, which we simply refer to as
$\kappa (\mathcal{G})$
, which we simply refer to as
 $\kappa$
in the following text, is equal to the ratio of the time for which the two edges sharing a node are both active to the time for which an edge is active. Because the states of different edges are independent of each other, we obtain
$\kappa$
in the following text, is equal to the ratio of the time for which the two edges sharing a node are both active to the time for which an edge is active. Because the states of different edges are independent of each other, we obtain
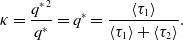 \begin{equation} \kappa =\frac{{q^{*}}^2}{q^*} = q^{*} = \frac{\langle \tau _1\rangle }{\langle \tau _1\rangle +\langle \tau _2\rangle }. \end{equation}
\begin{equation} \kappa =\frac{{q^{*}}^2}{q^*} = q^{*} = \frac{\langle \tau _1\rangle }{\langle \tau _1\rangle +\langle \tau _2\rangle }. \end{equation}
The special case of model 1 in which the edge activation and deactivation occur as Poisson processes is equivalent to previously proposed models [Reference Zhang, Moore and Newman31, Reference Clementi, Macci, Monti, Pasquale and Silvestri32]. In this case, using
 $\psi _1(\tau _1)=\lambda _1e^{-\lambda _1\tau _1}$
and
$\psi _1(\tau _1)=\lambda _1e^{-\lambda _1\tau _1}$
and
 $\psi _2(\tau _2)=\lambda _2e^{-\lambda _2\tau _2}$
, we obtain
$\psi _2(\tau _2)=\lambda _2e^{-\lambda _2\tau _2}$
, we obtain
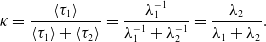 \begin{align} \kappa & = \frac{\langle \tau _1\rangle }{\langle \tau _1\rangle +\langle \tau _2\rangle } = \frac{\lambda _1^{-1}}{\lambda _1^{-1}+\lambda _2^{-1}} = \frac{\lambda _2}{\lambda _1+\lambda _2}. \end{align}
\begin{align} \kappa & = \frac{\langle \tau _1\rangle }{\langle \tau _1\rangle +\langle \tau _2\rangle } = \frac{\lambda _1^{-1}}{\lambda _1^{-1}+\lambda _2^{-1}} = \frac{\lambda _2}{\lambda _1+\lambda _2}. \end{align}
3.3. Model 2
To analyse model 2, let us consider a pair of neighbouring nodes
 $v_1$
and
$v_1$
and
 $v_2$
in the static network
$v_2$
in the static network
 $G$
. Let
$G$
. Let
 $p^*_h$
and
$p^*_h$
and
 $p^*_\ell$
be the probability that an arbitrary node in
$p^*_\ell$
be the probability that an arbitrary node in
 $G$
is in state
$G$
is in state
 $h$
and
$h$
and
 $\ell$
in the equilibrium, respectively. Denote by
$\ell$
in the equilibrium, respectively. Denote by
 $p^*_{s_1s_2}$
the probability that node
$p^*_{s_1s_2}$
the probability that node
 $v_i$
is in state
$v_i$
is in state
 $s_i \in \{ h, \ell \}$
in the equilibrium, where
$s_i \in \{ h, \ell \}$
in the equilibrium, where
 $i \in \{1, 2\}$
. Because the duration of the high-activity state and that of the low-activity state of a node obey the exponential distributions with mean
$i \in \{1, 2\}$
. Because the duration of the high-activity state and that of the low-activity state of a node obey the exponential distributions with mean
 $1/b$
and
$1/b$
and
 $1/a$
, respectively, we apply the renewal reward theorem [Reference Ross34] to obtain
$1/a$
, respectively, we apply the renewal reward theorem [Reference Ross34] to obtain
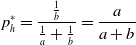 \begin{equation} p^*_h = \frac{\frac{1}{b}}{\frac{1}{a}+\frac{1}{b}} = \frac{a}{a+b} \end{equation}
\begin{equation} p^*_h = \frac{\frac{1}{b}}{\frac{1}{a}+\frac{1}{b}} = \frac{a}{a+b} \end{equation}
and
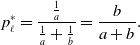 \begin{equation} p^*_\ell = \frac{\frac{1}{a}}{\frac{1}{a}+\frac{1}{b}} = \frac{b}{a+b}. \end{equation}
\begin{equation} p^*_\ell = \frac{\frac{1}{a}}{\frac{1}{a}+\frac{1}{b}} = \frac{b}{a+b}. \end{equation}
Because the states of different nodes are independent, we obtain
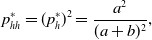 \begin{align} p_{hh}^{*} & = (p^*_h)^2 = \frac{a^2}{(a+b)^2}, \end{align}
\begin{align} p_{hh}^{*} & = (p^*_h)^2 = \frac{a^2}{(a+b)^2}, \end{align}
 \begin{align} p_{h\ell }^{*} & = p_{\ell h}^{*} = p^*_hp^*_\ell = \frac{ab}{(a+b)^2}, \end{align}
\begin{align} p_{h\ell }^{*} & = p_{\ell h}^{*} = p^*_hp^*_\ell = \frac{ab}{(a+b)^2}, \end{align}
and
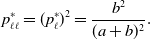 \begin{equation} p_{\ell \ell }^{*} = (p^*_\ell )^2 = \frac{b^2}{(a+b)^2}. \end{equation}
\begin{equation} p_{\ell \ell }^{*} = (p^*_\ell )^2 = \frac{b^2}{(a+b)^2}. \end{equation}
Therefore, the probability that an edge is active in the equilibrium is given by
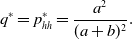 \begin{equation} q^* = p_{hh}^{*} = \frac{a^2}{(a+b)^2}. \end{equation}
\begin{equation} q^* = p_{hh}^{*} = \frac{a^2}{(a+b)^2}. \end{equation}
To derive the concurrency for model 2, we consider a pair of edges sharing a node in
 $G$
, denoted by
$G$
, denoted by
 $(v_1, v_2)$
and
$(v_1, v_2)$
and
 $(v_2, v_3)$
. Denote by
$(v_2, v_3)$
. Denote by
 $p_{s_1s_2s_3}$
the probability that node
$p_{s_1s_2s_3}$
the probability that node
 $v_i$
is in state
$v_i$
is in state
 $s_i \in \{ h, \ell \}$
, where
$s_i \in \{ h, \ell \}$
, where
 $i=1$
,
$i=1$
,
 $2$
and
$2$
and
 $3$
. Similar to the analysis of
$3$
. Similar to the analysis of
 $q^*$
for model 2, we obtain the following stationary probabilities:
$q^*$
for model 2, we obtain the following stationary probabilities:
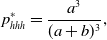 \begin{align} p_{hhh}^{*} & = \frac{a^3}{(a+b)^3}, \end{align}
\begin{align} p_{hhh}^{*} & = \frac{a^3}{(a+b)^3}, \end{align}
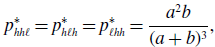 \begin{align} p_{hh\ell }^{*} & = p_{h\ell h}^{*} = p_{\ell hh}^{*} = \frac{a^2b}{(a+b)^3}, \end{align}
\begin{align} p_{hh\ell }^{*} & = p_{h\ell h}^{*} = p_{\ell hh}^{*} = \frac{a^2b}{(a+b)^3}, \end{align}
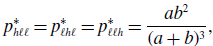 \begin{align} p_{h\ell \ell }^{*} & = p_{\ell h\ell }^{*} = p_{\ell \ell h}^{*} = \frac{ab^2}{(a+b)^3}, \end{align}
\begin{align} p_{h\ell \ell }^{*} & = p_{\ell h\ell }^{*} = p_{\ell \ell h}^{*} = \frac{ab^2}{(a+b)^3}, \end{align}
 \begin{align} p_{\ell \ell \ell }^{*} & = \frac{b^3}{(a+b)^3}. \end{align}
\begin{align} p_{\ell \ell \ell }^{*} & = \frac{b^3}{(a+b)^3}. \end{align}
Therefore, we obtain
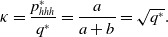 \begin{equation} \kappa =\frac{p_{hhh}^{*}}{q^*} = \frac{a}{a+b} = \sqrt{q^*}. \end{equation}
\begin{equation} \kappa =\frac{p_{hhh}^{*}}{q^*} = \frac{a}{a+b} = \sqrt{q^*}. \end{equation}
3.4. Model 3
Similarly, for model 3, we obtain
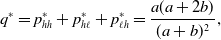 \begin{equation} q^* = p_{hh}^{*} + p_{h\ell }^{*} + p_{\ell h}^{*} = \frac{a(a+2b)}{(a+b)^2}, \end{equation}
\begin{equation} q^* = p_{hh}^{*} + p_{h\ell }^{*} + p_{\ell h}^{*} = \frac{a(a+2b)}{(a+b)^2}, \end{equation}
and
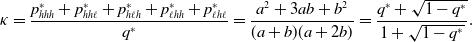 \begin{equation} \kappa =\frac{p_{hhh}^{*}+p_{hh\ell }^{*}+p_{h\ell h}^{*}+p_{\ell hh}^{*}+p_{\ell h\ell }^{*}}{q^*} = \frac{a^2+3ab+b^2}{(a+b)(a+2b)}=\frac{q^*+\sqrt{1-q^*}}{1+\sqrt{1-q^*}}. \end{equation}
\begin{equation} \kappa =\frac{p_{hhh}^{*}+p_{hh\ell }^{*}+p_{h\ell h}^{*}+p_{\ell hh}^{*}+p_{\ell h\ell }^{*}}{q^*} = \frac{a^2+3ab+b^2}{(a+b)(a+2b)}=\frac{q^*+\sqrt{1-q^*}}{1+\sqrt{1-q^*}}. \end{equation}
3.5. Comparison among the three models
A large fluctuation of
 $\mathcal{G}(t)$
over time may impact concurrency [Reference Masuda, Miller and Holme15]. In this section, we compare the amount of concurrency between the three models.
$\mathcal{G}(t)$
over time may impact concurrency [Reference Masuda, Miller and Holme15]. In this section, we compare the amount of concurrency between the three models.
Proposition 1.
Model 2 is more concurrent than model 1 given that
 $q^*$
is the same between the two models.
$q^*$
is the same between the two models.
Proof. Because
 $q^*$
is the same between the two models and
$q^*$
is the same between the two models and
 $0\lt q^*\lt 1$
, we obtain
$0\lt q^*\lt 1$
, we obtain
 $\sqrt{q^*} \gt q^*$
using equations (3.8) and (3.20). Therefore, model 2 is more concurrent than model 1.
$\sqrt{q^*} \gt q^*$
using equations (3.8) and (3.20). Therefore, model 2 is more concurrent than model 1.
Proposition 2.
Model 3 is more concurrent than model 1 given that
 $q^*$
is the same between the two models.
$q^*$
is the same between the two models.
Proof. Because
 $q^*$
is the same between the two models and
$q^*$
is the same between the two models and
 $0\lt q^*\lt 1$
, we obtain
$0\lt q^*\lt 1$
, we obtain
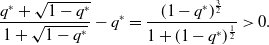 \begin{align} \frac{q^*+\sqrt{1-q^*}}{1+\sqrt{1-q^*}} - q^* = \frac{(1-q^*)^{\frac{3}{2}}}{1+(1-q^*)^{\frac{1}{2}}} \gt 0. \end{align}
\begin{align} \frac{q^*+\sqrt{1-q^*}}{1+\sqrt{1-q^*}} - q^* = \frac{(1-q^*)^{\frac{3}{2}}}{1+(1-q^*)^{\frac{1}{2}}} \gt 0. \end{align}
Therefore, model 3 is more concurrent than model 1.
Proposition 3.
Given that
 $q^*$
is the same between models 2 and 3,
$q^*$
is the same between models 2 and 3,
-
(i) model 3 is more concurrent than model 2 if
 $0\lt q^*\lt \frac{1}{2}$
,
$0\lt q^*\lt \frac{1}{2}$
, -
(ii) model 3 is less concurrent than model 2 if
$\frac{1}{2}\lt q^*\leq 1$
, -
(iii) model 3 is equally concurrent to model 2 if
$q^*=\frac{1}{2}$
.



Proof. For the sake of the present proof, let
 $a_2$
and
$a_2$
and
 $a_3$
be the rate at which the state of a node changes from
$a_3$
be the rate at which the state of a node changes from
 $\ell$
to
$\ell$
to
 $h$
for models 2 and 3, respectively. Likewise, let
$h$
for models 2 and 3, respectively. Likewise, let
 $b_2$
and
$b_2$
and
 $b_3$
be the rate at which the state of a node changes from
$b_3$
be the rate at which the state of a node changes from
 $h$
to
$h$
to
 $\ell$
for models 2 and 3, respectively. By imposing that
$\ell$
for models 2 and 3, respectively. By imposing that
 $q^*$
is the same between the two models, we obtain
$q^*$
is the same between the two models, we obtain
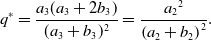 \begin{equation} q^* = \frac{a_3(a_3+2b_3)}{(a_3+b_3)^2} = \frac{{a_2}^2}{\left (a_2+b_2\right )^2}. \end{equation}
\begin{equation} q^* = \frac{a_3(a_3+2b_3)}{(a_3+b_3)^2} = \frac{{a_2}^2}{\left (a_2+b_2\right )^2}. \end{equation}
Therefore, the difference in the concurrency between the two models, given by equations (3.20) and (3.22), is given by
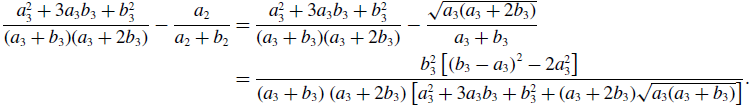 \begin{align} \frac{a_3^2+3a_3b_3+b_3^2}{(a_3+b_3)(a_3+2b_3)} - \frac{a_2}{a_2+b_2} & = \frac{a_3^2+3a_3b_3+b_3^2}{(a_3+b_3)(a_3+2b_3)} - \frac{\sqrt{a_3(a_3+2b_3)}}{a_3+b_3} \nonumber \\ & = \frac{b_3^2\left [\left (b_3-a_3\right )^2-2a_3^2\right ]}{\left (a_3+b_3\right )\left (a_3+2b_3\right )\left [a_3^2+3a_3b_3+b_3^2+(a_3+2b_3)\sqrt{a_3(a_3+b_3)}\right ]}. \end{align}
\begin{align} \frac{a_3^2+3a_3b_3+b_3^2}{(a_3+b_3)(a_3+2b_3)} - \frac{a_2}{a_2+b_2} & = \frac{a_3^2+3a_3b_3+b_3^2}{(a_3+b_3)(a_3+2b_3)} - \frac{\sqrt{a_3(a_3+2b_3)}}{a_3+b_3} \nonumber \\ & = \frac{b_3^2\left [\left (b_3-a_3\right )^2-2a_3^2\right ]}{\left (a_3+b_3\right )\left (a_3+2b_3\right )\left [a_3^2+3a_3b_3+b_3^2+(a_3+2b_3)\sqrt{a_3(a_3+b_3)}\right ]}. \end{align}
Therefore, the concurrency of model 3 is larger than that of model 2 if and only if
 $b_3\gt (1+\sqrt{2})a_3$
, which is equivalent to
$b_3\gt (1+\sqrt{2})a_3$
, which is equivalent to
 $q^* = \frac{a_3(a_3+2b_3)}{(a_3+b_3)^2} = \frac{1+2\frac{b_3}{a_3}}{\left (1+\frac{b_3}{a_3}\right )^2} \lt \frac{1}{2}$
.
$q^* = \frac{a_3(a_3+2b_3)}{(a_3+b_3)^2} = \frac{1+2\frac{b_3}{a_3}}{\left (1+\frac{b_3}{a_3}\right )^2} \lt \frac{1}{2}$
.
Using equations (3.8), (3.20), and (3.22), we compare the amount of concurrency for models 1, 2, and 3 in Figure 3. We find that, when
 $q^*\gt 1/2$
, the concurrency index for model 2 is only slightly larger than that for model 3.
$q^*\gt 1/2$
, the concurrency index for model 2 is only slightly larger than that for model 3.
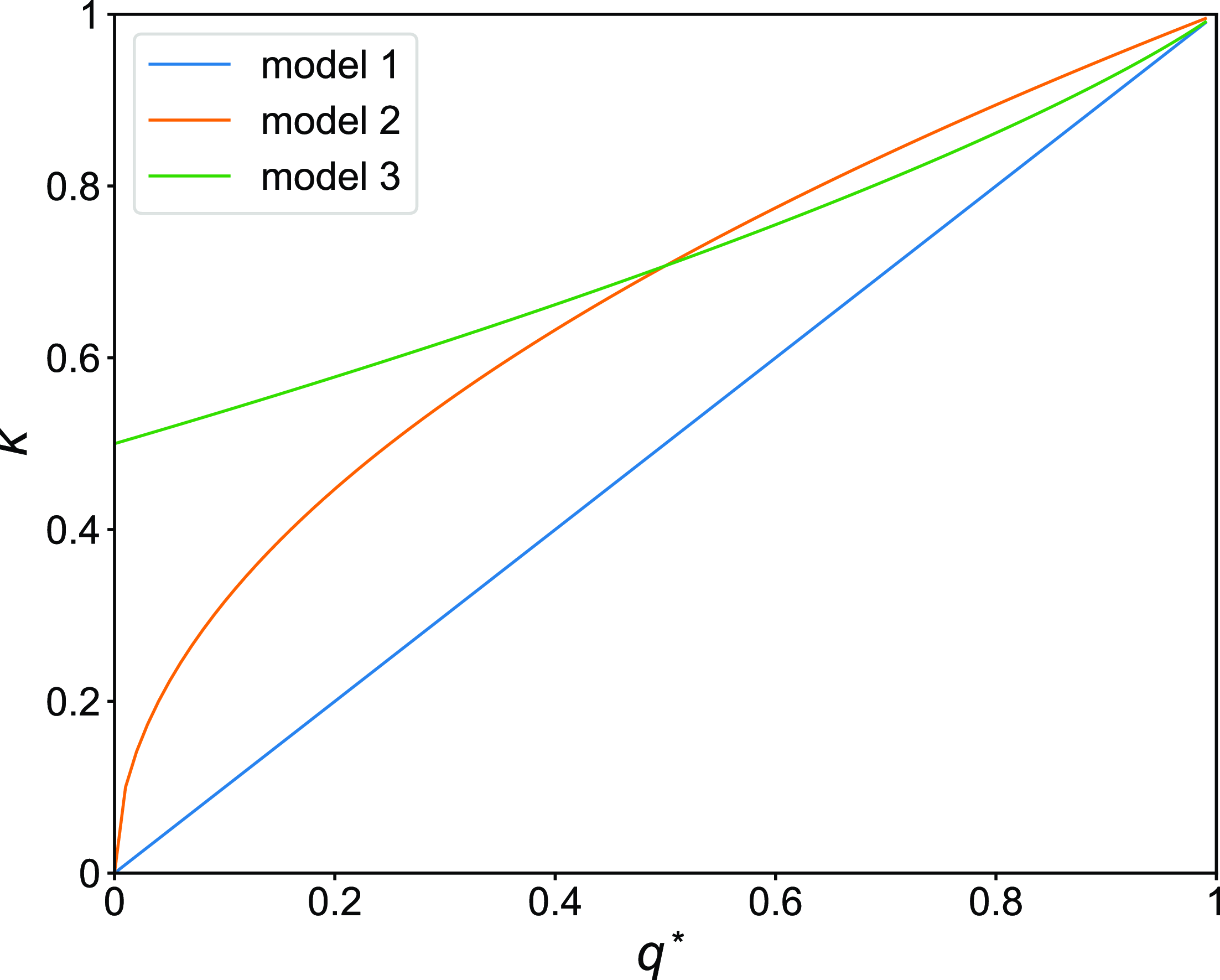
Figure 3. Concurrency index,
 $\kappa$
, as a function of the stationary probability that an edge is active,
$\kappa$
, as a function of the stationary probability that an edge is active,
 $q^*$
, for models 1, 2 and 3.
$q^*$
, for models 1, 2 and 3.
3.6. Fluctuations in the node’s degree
Consider the degree of individual nodes or its average over all nodes at any given time
 $t$
. Let us fix their expectation and compare their statistical fluctuations, such as the standard deviation, across different models. In a model with a higher concurrency, edges sharing a node in the aggregate network are more likely to be simultaneously active or inactive, which makes the statistical fluctuation of the degree larger. Therefore, we anticipate that the concurrency of a temporal network model and the statistical fluctuation in the node’s degree are interrelated. In this section, we establish such relationships for each of the three models. Let
$t$
. Let us fix their expectation and compare their statistical fluctuations, such as the standard deviation, across different models. In a model with a higher concurrency, edges sharing a node in the aggregate network are more likely to be simultaneously active or inactive, which makes the statistical fluctuation of the degree larger. Therefore, we anticipate that the concurrency of a temporal network model and the statistical fluctuation in the node’s degree are interrelated. In this section, we establish such relationships for each of the three models. Let
 $A=(A_{ij})_{N \times N}$
be the adjacency matrix of static network
$A=(A_{ij})_{N \times N}$
be the adjacency matrix of static network
 $G$
.
$G$
.
To analyse the fluctuation in the node’s degree in model 1, we define random variables by
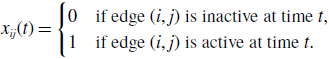 \begin{equation} x_{ij}(t) = \begin{cases} 0 & \text{if edge $(i, j)$ is inactive at time $t$}, \\ 1 & \text{if edge $(i, j)$ is active at time $t$}. \end{cases} \end{equation}
\begin{equation} x_{ij}(t) = \begin{cases} 0 & \text{if edge $(i, j)$ is inactive at time $t$}, \\ 1 & \text{if edge $(i, j)$ is active at time $t$}. \end{cases} \end{equation}
The adjacency matrix of the temporal network at time
 $t$
,
$t$
,
 $\mathcal{G}(t)$
, of model 1 is given by the
$\mathcal{G}(t)$
, of model 1 is given by the
 $N\times N$
matrix
$N\times N$
matrix
 $B(t)=(B_{ij}(t))$
, where
$B(t)=(B_{ij}(t))$
, where
 $B_{ij}(t)=A_{ij}x_{ij}(t)$
(with
$B_{ij}(t)=A_{ij}x_{ij}(t)$
(with
 $i, j \in \{1, \ldots, N\}$
). Let
$i, j \in \{1, \ldots, N\}$
). Let
 $k_i(t) \equiv \sum _{j=1}^N B_{ij}(t)$
be the degree of the
$k_i(t) \equiv \sum _{j=1}^N B_{ij}(t)$
be the degree of the
 $i$
th node in network
$i$
th node in network
 $\mathcal{G}(t)$
. The average degree at time
$\mathcal{G}(t)$
. The average degree at time
 $t$
is given by
$t$
is given by
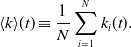 \begin{equation} \langle k\rangle (t) \equiv \frac{1}{N} \sum _{i=1}^N k_i(t). \end{equation}
\begin{equation} \langle k\rangle (t) \equiv \frac{1}{N} \sum _{i=1}^N k_i(t). \end{equation}
In the following text, we omit
 $t$
because we discuss the fluctuations in
$t$
because we discuss the fluctuations in
 $k_i(t)$
and
$k_i(t)$
and
 $\langle k \rangle (t)$
in the equilibrium.
$\langle k \rangle (t)$
in the equilibrium.
Proposition 4.
For model 1, it holds true that
 $k_i\sim B(\overline{k}_i, q^*)$
and
$k_i\sim B(\overline{k}_i, q^*)$
and
 $\langle k\rangle \sim \frac{2}{N}B\left (M, q^*\right )$
, where
$\langle k\rangle \sim \frac{2}{N}B\left (M, q^*\right )$
, where
 $B(\cdot, \cdot )$
represents the binomial distribution. (We remind that
$B(\cdot, \cdot )$
represents the binomial distribution. (We remind that
 $\overline{k}_i$
is the degree of the
$\overline{k}_i$
is the degree of the
 $i$
th node in
$i$
th node in
 $G$
and that
$G$
and that
 $M$
is the number of edges in
$M$
is the number of edges in
 $G$
.)
$G$
.)
Proof. For a proposition
 $C$
, define the indicator function by
$C$
, define the indicator function by
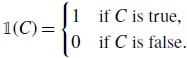 \begin{equation} \mathbb{1}(C) = \begin{cases} 1 &\text{if } C \text{ is true},\\ 0 &\text{if } C \text{ is false}. \end{cases} \end{equation}
\begin{equation} \mathbb{1}(C) = \begin{cases} 1 &\text{if } C \text{ is true},\\ 0 &\text{if } C \text{ is false}. \end{cases} \end{equation}
For a node
 $i$
, we obtain
$i$
, we obtain
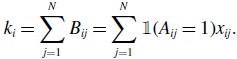 \begin{align} k_i = \sum _{j=1}^N B_{ij} = \sum _{j=1}^N \mathbb{1}(A_{ij}=1) x_{ij}. \end{align}
\begin{align} k_i = \sum _{j=1}^N B_{ij} = \sum _{j=1}^N \mathbb{1}(A_{ij}=1) x_{ij}. \end{align}
Because
 $x_{ij}$
are independent and identically distributed Bernoulli random variables and
$x_{ij}$
are independent and identically distributed Bernoulli random variables and
 $k_i$
is the sum of
$k_i$
is the sum of
 $\overline{k}_i$
terms,
$\overline{k}_i$
terms,
 $k_i$
obeys
$k_i$
obeys
 $B\left (\overline{k}_i, q^*\right )$
.
$B\left (\overline{k}_i, q^*\right )$
.
Because we have assumed that the network is undirected, we obtain
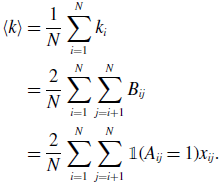 \begin{align} \langle k\rangle & = \frac{1}{N} \sum _{i=1}^N k_i\nonumber \\ & = \frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^N B_{ij}\nonumber \\ & = \frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^N \mathbb{1}(A_{ij}=1)x_{ij}. \end{align}
\begin{align} \langle k\rangle & = \frac{1}{N} \sum _{i=1}^N k_i\nonumber \\ & = \frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^N B_{ij}\nonumber \\ & = \frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^N \mathbb{1}(A_{ij}=1)x_{ij}. \end{align}
Because there are
 $M$
terms that comprise the summation,
$M$
terms that comprise the summation,
 $\langle k\rangle$
obeys
$\langle k\rangle$
obeys
 $\frac{2}{N}B\left (M, q^*\right )$
.
$\frac{2}{N}B\left (M, q^*\right )$
.
We denote the expectation by
 $\mathbb{E}$
and the variance by
$\mathbb{E}$
and the variance by
 $\sigma ^2$
; the standard deviation is equal to
$\sigma ^2$
; the standard deviation is equal to
 $\sigma$
. Using Proposition 4, we obtain
$\sigma$
. Using Proposition 4, we obtain
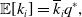 \begin{align} \mathbb{E}[k_i] & = \overline{k}_iq^*, \end{align}
\begin{align} \mathbb{E}[k_i] & = \overline{k}_iq^*, \end{align}
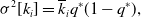 \begin{align} \sigma ^2[k_i] & = \overline{k}_iq^*(1-q^*), \end{align}
\begin{align} \sigma ^2[k_i] & = \overline{k}_iq^*(1-q^*), \end{align}
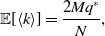 \begin{align} \mathbb{E}[\langle k\rangle ] & = \frac{2Mq^*}{N}, \end{align}
\begin{align} \mathbb{E}[\langle k\rangle ] & = \frac{2Mq^*}{N}, \end{align}
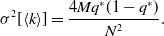 \begin{align} \sigma ^2[\langle k\rangle ] & = \frac{4Mq^*(1-q^*)}{N^2}. \end{align}
\begin{align} \sigma ^2[\langle k\rangle ] & = \frac{4Mq^*(1-q^*)}{N^2}. \end{align}
To analyse models 2 and 3, we define
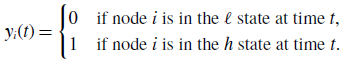 \begin{equation} y_{i}(t) = \begin{cases} 0 & \text{if node $i$ is in the $\ell $ state at time $t$}, \\ 1 & \text{if node $i$ is in the $h$ state at time $t$}. \end{cases} \end{equation}
\begin{equation} y_{i}(t) = \begin{cases} 0 & \text{if node $i$ is in the $\ell $ state at time $t$}, \\ 1 & \text{if node $i$ is in the $h$ state at time $t$}. \end{cases} \end{equation}
The adjacency matrix of
 $\mathcal{G}(t)$
for model 2 is given by
$\mathcal{G}(t)$
for model 2 is given by
 $B(t)=(B_{ij}(t))$
, where
$B(t)=(B_{ij}(t))$
, where
 $B_{ij}(t)=A_{ij}y_{i}(t)y_{j}(t)$
. Using this expression, we can prove the following proposition.
$B_{ij}(t)=A_{ij}y_{i}(t)y_{j}(t)$
. Using this expression, we can prove the following proposition.
Proposition 5. For model 2, we obtain
 \begin{align} \mathbb{E}[k_i] =& \overline{k}_i\left (\frac{a}{a+b}\right )^2, \end{align}
\begin{align} \mathbb{E}[k_i] =& \overline{k}_i\left (\frac{a}{a+b}\right )^2, \end{align}
 \begin{align} \sigma ^2[k_i] =& \frac{\overline{k}_ia^2b}{(a+b)^3}\left (1+\frac{\overline{k}_ia}{a+b}\right ), \end{align}
\begin{align} \sigma ^2[k_i] =& \frac{\overline{k}_ia^2b}{(a+b)^3}\left (1+\frac{\overline{k}_ia}{a+b}\right ), \end{align}
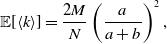 \begin{align} \mathbb{E}[\langle k\rangle ] =& \frac{2M}{N}\left (\frac{a}{a+b}\right )^2, \end{align}
\begin{align} \mathbb{E}[\langle k\rangle ] =& \frac{2M}{N}\left (\frac{a}{a+b}\right )^2, \end{align}
 \begin{align} \sigma ^2[\langle k\rangle ] =& \frac{4M}{N^2}\left (\frac{a}{a+b}\right )^2 + \frac{4M(M-1)}{N^2}\left (\frac{a}{a+b}\right )^3 - \frac{8}{N^2}\left (\frac{a}{a+b}\right )^3\frac{b}{a+b}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ & - \frac{4M^2}{N^2}\left (\frac{a}{a+b}\right )^4. \end{align}
\begin{align} \sigma ^2[\langle k\rangle ] =& \frac{4M}{N^2}\left (\frac{a}{a+b}\right )^2 + \frac{4M(M-1)}{N^2}\left (\frac{a}{a+b}\right )^3 - \frac{8}{N^2}\left (\frac{a}{a+b}\right )^3\frac{b}{a+b}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ & - \frac{4M^2}{N^2}\left (\frac{a}{a+b}\right )^4. \end{align}
We prove Proposition 5 in Appendix A.
The adjacency matrix of
 $\mathcal{G}(t)$
for model 3 is given by
$\mathcal{G}(t)$
for model 3 is given by
 $B(t)=(B_{ij}(t))$
, where
$B(t)=(B_{ij}(t))$
, where
 $B_{ij}=A_{ij}\left [1 - \left (1 - y_i(t)\right )\left (1 - y_j(t)\right )\right ]$
. Using this expression, we can prove the following proposition.
$B_{ij}=A_{ij}\left [1 - \left (1 - y_i(t)\right )\left (1 - y_j(t)\right )\right ]$
. Using this expression, we can prove the following proposition.
Proposition 6. For model 3, we obtain
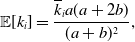 \begin{align} \mathbb{E}[k_i] =& \frac{\overline{k}_ia(a+2b)}{(a+b)^2}, \end{align}
\begin{align} \mathbb{E}[k_i] =& \frac{\overline{k}_ia(a+2b)}{(a+b)^2}, \end{align}
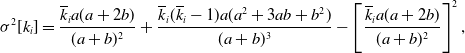 \begin{align} \sigma ^2[k_i] =& \frac{\overline{k}_ia(a+2b)}{(a+b)^2}+\frac{\overline{k}_i(\overline{k}_i-1)a(a^2+3ab+b^2)}{(a+b)^3}-\left [\frac{\overline{k}_ia(a+2b)}{(a+b)^2}\right ]^2, \end{align}
\begin{align} \sigma ^2[k_i] =& \frac{\overline{k}_ia(a+2b)}{(a+b)^2}+\frac{\overline{k}_i(\overline{k}_i-1)a(a^2+3ab+b^2)}{(a+b)^3}-\left [\frac{\overline{k}_ia(a+2b)}{(a+b)^2}\right ]^2, \end{align}
 \begin{align} \mathbb{E}[\langle k\rangle ] =& \frac{2Ma(a+2b)}{N(a+b)^2}, \end{align}
\begin{align} \mathbb{E}[\langle k\rangle ] =& \frac{2Ma(a+2b)}{N(a+b)^2}, \end{align}
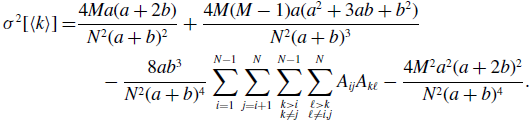 \begin{align} \sigma ^2[\langle k\rangle ] =& \frac{4Ma(a+2b)}{N^2(a+b)^2}+\frac{4M(M-1)a(a^2+3ab+b^2)}{N^2(a+b)^3}\nonumber \\ & \quad \ - \frac{8ab^3}{N^2(a+b)^4}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell } - \frac{4M^2a^2(a+2b)^2}{N^2(a+b)^4}. \end{align}
\begin{align} \sigma ^2[\langle k\rangle ] =& \frac{4Ma(a+2b)}{N^2(a+b)^2}+\frac{4M(M-1)a(a^2+3ab+b^2)}{N^2(a+b)^3}\nonumber \\ & \quad \ - \frac{8ab^3}{N^2(a+b)^4}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell } - \frac{4M^2a^2(a+2b)^2}{N^2(a+b)^4}. \end{align}
We prove Proposition 6 in Appendix B.
Now, let us compare the variance of
 $k_i$
and
$k_i$
and
 $\langle k\rangle$
among the three models under the condition that the expectation of
$\langle k\rangle$
among the three models under the condition that the expectation of
 $k_i$
and
$k_i$
and
 $\langle k\rangle$
is the same across the different models. This condition is equivalent to keeping
$\langle k\rangle$
is the same across the different models. This condition is equivalent to keeping
 $q^*$
the same across the models for each edge. The purpose of examining the variance of the node’s degree is the following. Similar to equation (3.3), the number of concurrent edge pairs at time
$q^*$
the same across the models for each edge. The purpose of examining the variance of the node’s degree is the following. Similar to equation (3.3), the number of concurrent edge pairs at time
 $t$
is given by
$t$
is given by
 $\sum _{i=1}^N k_i (k_i-1)/2$
. Because this expression contains the second moment of the degree, we expect that the variance of the degree may be related to our concurrency measure.
$\sum _{i=1}^N k_i (k_i-1)/2$
. Because this expression contains the second moment of the degree, we expect that the variance of the degree may be related to our concurrency measure.
In fact, we obtain the following results for the fluctuation of the degree, which are parallel to those for the concurrency index.
Proposition 7.
Assume that
 $\mathbb{E}[k_i]$
is the same between models 1 and 2 for any
$\mathbb{E}[k_i]$
is the same between models 1 and 2 for any
 $i\in \{1, \ldots, N\}$
. For any given
$i\in \{1, \ldots, N\}$
. For any given
 $q^*$
, the variance
$q^*$
, the variance
 $\sigma ^2[k_i]$
is larger for model 2 than model 1 if
$\sigma ^2[k_i]$
is larger for model 2 than model 1 if
 $\overline{k}_i\gt 1$
. Likewise,
$\overline{k}_i\gt 1$
. Likewise,
 $\sigma ^2[\langle k\rangle ]$
is larger for model 2 than model 1 if there exists
$\sigma ^2[\langle k\rangle ]$
is larger for model 2 than model 1 if there exists
 $i$
such that
$i$
such that
 $\overline{k}_i\gt 1$
.
$\overline{k}_i\gt 1$
.
Proof. We use subscripts 1 and 2 to represent the variance with respect to the probability distribution for models 1 and 2, respectively. We substitute equation (3.15) in equation (3.32) and use equation (3.37) to obtain
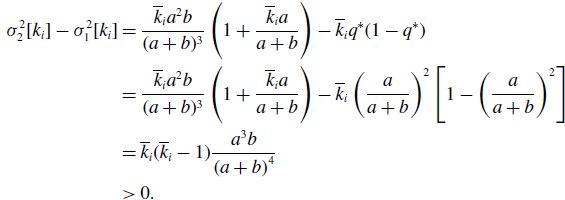 \begin{align} \sigma ^2_2[k_i] - \sigma ^2_1[k_i] & = \frac{\overline{k}_i{a}^2b}{(a+b)^3}\left (1+\frac{\overline{k}_ia}{a+b}\right )-\overline{k}_iq^*(1-q^*)\nonumber \\ & = \frac{\overline{k}_i{a}^2b}{(a+b)^3}\left (1+\frac{\overline{k}_ia}{a+b}\right ) -\overline{k}_i\left (\frac{a}{a+b}\right )^2\left [1-\left (\frac{a}{a+b}\right )^2\right ]\nonumber \\ & = \overline{k}_i(\overline{k}_i-1)\frac{{a}^3b}{\left (a+b\right )^4}\nonumber \\ & \gt 0. \end{align}
\begin{align} \sigma ^2_2[k_i] - \sigma ^2_1[k_i] & = \frac{\overline{k}_i{a}^2b}{(a+b)^3}\left (1+\frac{\overline{k}_ia}{a+b}\right )-\overline{k}_iq^*(1-q^*)\nonumber \\ & = \frac{\overline{k}_i{a}^2b}{(a+b)^3}\left (1+\frac{\overline{k}_ia}{a+b}\right ) -\overline{k}_i\left (\frac{a}{a+b}\right )^2\left [1-\left (\frac{a}{a+b}\right )^2\right ]\nonumber \\ & = \overline{k}_i(\overline{k}_i-1)\frac{{a}^3b}{\left (a+b\right )^4}\nonumber \\ & \gt 0. \end{align}
Next, we compare the variance of the average degree. Because
 $M$
is the number of edges of static network
$M$
is the number of edges of static network
 $G$
and there exists
$G$
and there exists
 $i$
such that
$i$
such that
 $\overline{k}_i\gt 1$
in
$\overline{k}_i\gt 1$
in
 $G$
, we obtain
$G$
, we obtain
 \begin{equation} \sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell } \lt \frac{M(M-1)}{2} \end{equation}
\begin{equation} \sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell } \lt \frac{M(M-1)}{2} \end{equation}
for the following reason. The right-hand side of equation (3.45) is the number of pairs of edges. The left-hand side is the number of pairs of edges that do not share a node. These two quantities are equal to each other if and only if there is no pair of edges sharing a node, i.e., when all nodes have the degree at most 1.
By substituting equation (3.15) in equation (3.34) and using equations (3.39) and (3.45), we obtain
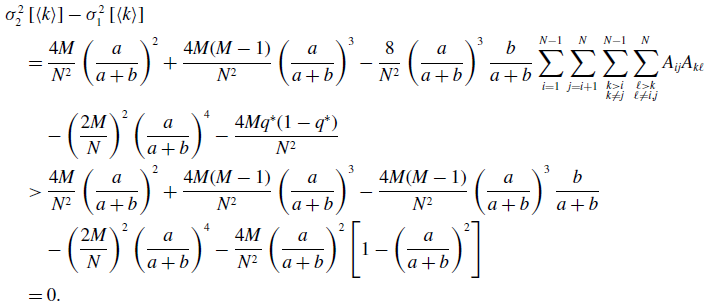 \begin{align} & \sigma ^2_2\left [\langle k\rangle \right ]-\sigma ^2_1\left [\langle k\rangle \right ] \nonumber \\ &\quad= \frac{4M}{N^2}\left (\frac{a}{a+b}\right )^2 + \frac{4M(M-1)}{N^2}\left (\frac{a}{a+b}\right )^3 - \frac{8}{N^2}\left (\frac{a}{a+b}\right )^3\frac{b}{a+b}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ & \qquad - \left (\frac{2M}{N}\right )^2 \left (\frac{a}{a+b}\right )^4 - \frac{4Mq^*(1-q^*)}{N^2}\nonumber \\ &\quad\gt \frac{4M}{N^2}\left (\frac{a}{a+b}\right )^2 + \frac{4M(M-1)}{N^2}\left (\frac{a}{a+b}\right )^3 - \frac{4M(M-1)}{N^2}\left (\frac{a}{a+b}\right )^3\frac{b}{a+b} \nonumber \\ & \qquad - \left (\frac{2M}{N}\right )^2 \left (\frac{a}{a+b}\right )^4 - \frac{4M}{N^2}\left (\frac{a}{a+b}\right )^2\left [1 - \left (\frac{a}{a+b}\right )^2\right ]\nonumber \\ &\quad= 0. \end{align}
\begin{align} & \sigma ^2_2\left [\langle k\rangle \right ]-\sigma ^2_1\left [\langle k\rangle \right ] \nonumber \\ &\quad= \frac{4M}{N^2}\left (\frac{a}{a+b}\right )^2 + \frac{4M(M-1)}{N^2}\left (\frac{a}{a+b}\right )^3 - \frac{8}{N^2}\left (\frac{a}{a+b}\right )^3\frac{b}{a+b}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ & \qquad - \left (\frac{2M}{N}\right )^2 \left (\frac{a}{a+b}\right )^4 - \frac{4Mq^*(1-q^*)}{N^2}\nonumber \\ &\quad\gt \frac{4M}{N^2}\left (\frac{a}{a+b}\right )^2 + \frac{4M(M-1)}{N^2}\left (\frac{a}{a+b}\right )^3 - \frac{4M(M-1)}{N^2}\left (\frac{a}{a+b}\right )^3\frac{b}{a+b} \nonumber \\ & \qquad - \left (\frac{2M}{N}\right )^2 \left (\frac{a}{a+b}\right )^4 - \frac{4M}{N^2}\left (\frac{a}{a+b}\right )^2\left [1 - \left (\frac{a}{a+b}\right )^2\right ]\nonumber \\ &\quad= 0. \end{align}
Proposition 8.
Assume that
 $\mathbb{E}[k_i]$
is the same between models 1 and 3 for any
$\mathbb{E}[k_i]$
is the same between models 1 and 3 for any
 $i\in \{1, \ldots, N\}$
. For any given
$i\in \{1, \ldots, N\}$
. For any given
 $q^*$
, the variance
$q^*$
, the variance
 $\sigma ^2[k_i]$
is larger for model 3 than model 1 if
$\sigma ^2[k_i]$
is larger for model 3 than model 1 if
 $\overline{k}_i\gt 1$
. Likewise,
$\overline{k}_i\gt 1$
. Likewise,
 $\sigma ^2[\langle k\rangle ]$
is larger for model 3 than model 1 if there exists
$\sigma ^2[\langle k\rangle ]$
is larger for model 3 than model 1 if there exists
 $i$
such that
$i$
such that
 $\overline{k}_i\gt 1$
.
$\overline{k}_i\gt 1$
.
Proof. We substitute equation (3.21) in equation (3.32) and use equation (3.41) to obtain
 \begin{align} & \sigma ^2_3[k_i] - \sigma ^2_1[k_i]\nonumber \\ &\quad= \overline{k}_i\frac{a(a+2b)}{\left (a+b\right )^2}+\overline{k}_i(\overline{k}_i-1)\frac{a({a}^2+3ab+{b}^2)}{\left (a+b\right )^3}-\left [\overline{k}_i\frac{a(a+2b)}{\left (a+b\right )^2}\right ]^2-\overline{k}_iq^*(1-q^*)\nonumber \\ &\quad= \overline{k}_i(\overline{k}_i-1)\frac{a{b}^3}{\left (a+b\right )^4}\nonumber \\ &\quad\gt 0. \end{align}
\begin{align} & \sigma ^2_3[k_i] - \sigma ^2_1[k_i]\nonumber \\ &\quad= \overline{k}_i\frac{a(a+2b)}{\left (a+b\right )^2}+\overline{k}_i(\overline{k}_i-1)\frac{a({a}^2+3ab+{b}^2)}{\left (a+b\right )^3}-\left [\overline{k}_i\frac{a(a+2b)}{\left (a+b\right )^2}\right ]^2-\overline{k}_iq^*(1-q^*)\nonumber \\ &\quad= \overline{k}_i(\overline{k}_i-1)\frac{a{b}^3}{\left (a+b\right )^4}\nonumber \\ &\quad\gt 0. \end{align}
By substituting equation (3.21) in equation (3.34) and using equations (3.43) and (3.45), we obtain
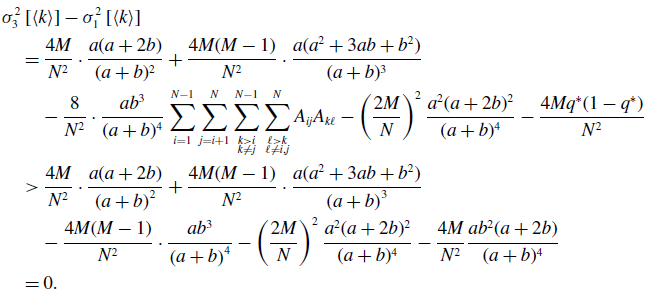 \begin{align} & \sigma ^2_3\left [\langle k\rangle \right ] - \sigma ^2_1\left [\langle k\rangle \right ] \nonumber \\ &\quad= \frac{4M}{N^2}\cdot \frac{a(a+2b)}{(a+b)^2}+\frac{4M(M-1)}{N^2}\cdot \frac{a({a}^2+3a b+{b}^2)}{(a+b)^3}\nonumber \\ & \qquad - \frac{8}{N^2}\cdot \frac{ab^3}{(a+b)^4}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell } - \left (\frac{2M}{N}\right )^2 \frac{{a}^2(a+2b)^2}{(a+b)^4} - \frac{4Mq^*(1-q^*)}{N^2}\nonumber \\ &\quad\gt \frac{4M}{N^2}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}+\frac{4M(M-1)}{N^2}\cdot \frac{a({a}^2+3ab+{b}^2)}{\left (a+b\right )^3}\nonumber \\ & \qquad - \frac{4M(M-1)}{N^2}\cdot \frac{a{b}^3}{\left (a+b\right )^4} - \left (\frac{2M}{N}\right )^2 \frac{{a}^2(a+2b)^2}{(a+b)^4} - \frac{4M}{N^2}\frac{ab^2(a+2b)}{(a+b)^4}\nonumber \\ &\quad= 0. \end{align}
\begin{align} & \sigma ^2_3\left [\langle k\rangle \right ] - \sigma ^2_1\left [\langle k\rangle \right ] \nonumber \\ &\quad= \frac{4M}{N^2}\cdot \frac{a(a+2b)}{(a+b)^2}+\frac{4M(M-1)}{N^2}\cdot \frac{a({a}^2+3a b+{b}^2)}{(a+b)^3}\nonumber \\ & \qquad - \frac{8}{N^2}\cdot \frac{ab^3}{(a+b)^4}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell } - \left (\frac{2M}{N}\right )^2 \frac{{a}^2(a+2b)^2}{(a+b)^4} - \frac{4Mq^*(1-q^*)}{N^2}\nonumber \\ &\quad\gt \frac{4M}{N^2}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}+\frac{4M(M-1)}{N^2}\cdot \frac{a({a}^2+3ab+{b}^2)}{\left (a+b\right )^3}\nonumber \\ & \qquad - \frac{4M(M-1)}{N^2}\cdot \frac{a{b}^3}{\left (a+b\right )^4} - \left (\frac{2M}{N}\right )^2 \frac{{a}^2(a+2b)^2}{(a+b)^4} - \frac{4M}{N^2}\frac{ab^2(a+2b)}{(a+b)^4}\nonumber \\ &\quad= 0. \end{align}
Proposition 9.
Assume that
 $\mathbb{E}[k_i]$
is the same between models 2 and 3 for any
$\mathbb{E}[k_i]$
is the same between models 2 and 3 for any
 $i\in \{1, \ldots, N\}$
. For any given
$i\in \{1, \ldots, N\}$
. For any given
 $q^*$
, if
$q^*$
, if
 $\overline{k}_i\gt 1$
, we obtain
$\overline{k}_i\gt 1$
, we obtain
-
(i)
$\sigma ^2_3[k_i] \gt \sigma ^2_2[k_i]$
if
$0\lt q^*\lt \frac{1}{2}$
, -
(ii)
$\sigma ^2_3[k_i] \lt \sigma ^2_2[k_i]$
if
$\frac{1}{2}\lt q^*\leq 1$
, -
(iii)
$\sigma ^2_3[k_i] = \sigma ^2_2[k_i]$
if
$q^*=\frac{1}{2}$
.






Furthermore,
 $\sigma ^2[\langle k\rangle ]$
satisfies the same relationships if there exists
$\sigma ^2[\langle k\rangle ]$
satisfies the same relationships if there exists
 $i$
such that
$i$
such that
 $\overline{k}_i\gt 1$
.
$\overline{k}_i\gt 1$
.
3.7. Duration for the edge being inactive in model 2
In model 2, an edge is active if and only if both nodes forming the edge are in the
 $h$
state, and the state of each node (i.e.,
$h$
state, and the state of each node (i.e.,
 $h$
or
$h$
or
 $\ell$
) independently obeys a continuous-time Markov process with two states. Therefore, the duration of the edge being active obeys an exponential distribution with rate
$\ell$
) independently obeys a continuous-time Markov process with two states. Therefore, the duration of the edge being active obeys an exponential distribution with rate
 $2b$
. In contrast, the duration of the edge being inactive does not obey an exponential distribution, which we characterise as follows.
$2b$
. In contrast, the duration of the edge being inactive does not obey an exponential distribution, which we characterise as follows.
Proposition 10. The probability density function of the duration of the edge being inactive in model 2 is the mixture of two exponential distributions given by
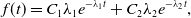 \begin{equation} f(t) = C_1\lambda _1e^{-\lambda _1t}+C_2\lambda _2e^{-\lambda _2t}, \end{equation}
\begin{equation} f(t) = C_1\lambda _1e^{-\lambda _1t}+C_2\lambda _2e^{-\lambda _2t}, \end{equation}
where
 \begin{align} \lambda _1 =& \frac{1}{2}\left (3a+b-\sqrt{a^2+6ab+b^2}\right ), \end{align}
\begin{align} \lambda _1 =& \frac{1}{2}\left (3a+b-\sqrt{a^2+6ab+b^2}\right ), \end{align}
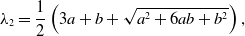 \begin{align} \lambda _2 =& \frac{1}{2}\left (3a+b+\sqrt{a^2+6ab+b^2}\right ), \end{align}
\begin{align} \lambda _2 =& \frac{1}{2}\left (3a+b+\sqrt{a^2+6ab+b^2}\right ), \end{align}
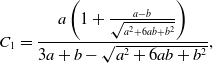 \begin{align} C_1 =& \frac{a\left (1+\frac{a-b}{\sqrt{a^2+6ab+b^2}}\right )}{3a+b-\sqrt{a^2+6ab+b^2}}, \end{align}
\begin{align} C_1 =& \frac{a\left (1+\frac{a-b}{\sqrt{a^2+6ab+b^2}}\right )}{3a+b-\sqrt{a^2+6ab+b^2}}, \end{align}
and
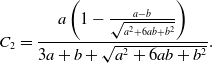 \begin{align} C_2 =& \frac{a\left (1-\frac{a-b}{\sqrt{a^2+6ab+b^2}}\right )}{3a+b+\sqrt{a^2+6ab+b^2}}. \end{align}
\begin{align} C_2 =& \frac{a\left (1-\frac{a-b}{\sqrt{a^2+6ab+b^2}}\right )}{3a+b+\sqrt{a^2+6ab+b^2}}. \end{align}
Note that it is straightforward to check
 $C_1+C_2=1$
,
$C_1+C_2=1$
,
 $C_1 \gt 0$
,
$C_1 \gt 0$
,
 $C_2 \gt 0$
and
$C_2 \gt 0$
and
 $\lambda _1 \gt 0$
.
$\lambda _1 \gt 0$
.
Proof. Consider a three-state continuous-time Markov process described as follows. Let
 $z$
(with
$z$
(with
 $z$
= 0, 1, or 2) denote the number of nodes forming an edge that are in the
$z$
= 0, 1, or 2) denote the number of nodes forming an edge that are in the
 $h$
state. We refer to the value of
$h$
state. We refer to the value of
 $z$
as the state of the three-state Markov chain without arising confusion with the single node’s state (i.e.,
$z$
as the state of the three-state Markov chain without arising confusion with the single node’s state (i.e.,
 $h$
or
$h$
or
 $\ell$
) or edge’s state (i.e., active or inactive). We initialise the stochastic dynamics of nodes by setting
$\ell$
) or edge’s state (i.e., active or inactive). We initialise the stochastic dynamics of nodes by setting
 $z=2$
, which corresponds to the edge being active. Consider a sequence of the state
$z=2$
, which corresponds to the edge being active. Consider a sequence of the state
 $z$
that starts from
$z$
that starts from
 $z=2$
at time 0 and return to
$z=2$
at time 0 and return to
 $z=2$
for the first time. Let
$z=2$
for the first time. Let
 $I_n$
be such a sequence of the
$I_n$
be such a sequence of the
 $z$
values visiting
$z$
values visiting
 $z=0$
in total
$z=0$
in total
 $n$
times before returning to
$n$
times before returning to
 $z=2$
for the first time, which we denote by
$z=2$
for the first time, which we denote by
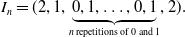 \begin{align*} I_n = (2, 1,\underbrace{0, 1, \ldots, 0, 1}_{n\, \text{repetitions of 0 and 1}},2). \end{align*}
\begin{align*} I_n = (2, 1,\underbrace{0, 1, \ldots, 0, 1}_{n\, \text{repetitions of 0 and 1}},2). \end{align*}
The duration of the edge being inactive is the difference between the time of the first passage to
 $z=2$
and the time of leaving
$z=2$
and the time of leaving
 $z=2$
last time. We denote this duration by
$z=2$
last time. We denote this duration by
 $T_n$
for the case in which
$T_n$
for the case in which
 $z=0$
is visited
$z=0$
is visited
 $n$
times before
$n$
times before
 $z=2$
is revisited for the first time.
$z=2$
is revisited for the first time.
For general
 $n$
, we obtain
$n$
, we obtain
 \begin{equation} T_n = \tau ^{\prime }_{1,1} + \tau ^{\prime \prime }_{0,1} + \tau ^{\prime }_{1,2} + \cdots + \tau ^{\prime \prime }_{0,n} + \tau ^{\prime }_{1,n+1}, \end{equation}
\begin{equation} T_n = \tau ^{\prime }_{1,1} + \tau ^{\prime \prime }_{0,1} + \tau ^{\prime }_{1,2} + \cdots + \tau ^{\prime \prime }_{0,n} + \tau ^{\prime }_{1,n+1}, \end{equation}
where
 $\tau ^{\prime }_{1,i}$
is the
$\tau ^{\prime }_{1,i}$
is the
 $i$
th duration of
$i$
th duration of
 $z=1$
, which obeys the exponential distribution with rate
$z=1$
, which obeys the exponential distribution with rate
 $a+b$
;
$a+b$
;
 $\tau ^{\prime \prime }_{0,i}$
is the
$\tau ^{\prime \prime }_{0,i}$
is the
 $i$
th duration of
$i$
th duration of
 $z=0$
, which obeys the exponential distribution with rate
$z=0$
, which obeys the exponential distribution with rate
 $2a$
. Variables
$2a$
. Variables
 $\tau ^{\prime }_{1,1}$
,
$\tau ^{\prime }_{1,1}$
,
 $\ldots$
,
$\ldots$
,
 $\tau ^{\prime }_{1,n+1}$
,
$\tau ^{\prime }_{1,n+1}$
,
 $\tau ^{\prime \prime }_{0,1}$
,
$\tau ^{\prime \prime }_{0,1}$
,
 $\ldots$
,
$\ldots$
,
 $\tau ^{\prime \prime }_{0,n}$
are independent of each other. Therefore, the Laplace transform of the distribution of
$\tau ^{\prime \prime }_{0,n}$
are independent of each other. Therefore, the Laplace transform of the distribution of
 $T_n$
is given by
$T_n$
is given by
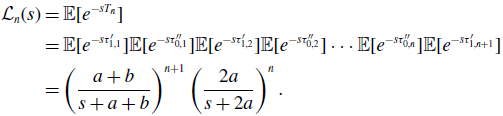 \begin{align} \mathcal{L}_n(s) & = \mathbb{E}[e^{-sT_n}] \nonumber \\ & = \mathbb{E}[e^{-s\tau ^{\prime }_{1,1}}]\mathbb{E}[e^{-s\tau ^{\prime \prime }_{0,1}}]\mathbb{E}[e^{-s\tau ^{\prime }_{1,2}}]\mathbb{E}[e^{-s\tau ^{\prime \prime }_{0,2}}] \cdots \mathbb{E}[e^{-s\tau ^{\prime \prime }_{0,n}}]\mathbb{E}[e^{-s\tau ^{\prime }_{1,n+1}}] \nonumber \\ & = \left (\frac{a+b}{s+a+b}\right )^{n+1}\left (\frac{2a}{s+2a}\right )^n. \end{align}
\begin{align} \mathcal{L}_n(s) & = \mathbb{E}[e^{-sT_n}] \nonumber \\ & = \mathbb{E}[e^{-s\tau ^{\prime }_{1,1}}]\mathbb{E}[e^{-s\tau ^{\prime \prime }_{0,1}}]\mathbb{E}[e^{-s\tau ^{\prime }_{1,2}}]\mathbb{E}[e^{-s\tau ^{\prime \prime }_{0,2}}] \cdots \mathbb{E}[e^{-s\tau ^{\prime \prime }_{0,n}}]\mathbb{E}[e^{-s\tau ^{\prime }_{1,n+1}}] \nonumber \\ & = \left (\frac{a+b}{s+a+b}\right )^{n+1}\left (\frac{2a}{s+2a}\right )^n. \end{align}
The probability that sequence
 $I_n$
occurs is given by
$I_n$
occurs is given by
 \begin{equation} \tilde{q}(n)=1\cdot \left (\frac{b}{a+b}\right )^n \cdot 1^n \cdot \frac{a}{a+b} = \frac{ab^n}{(a+b)^{n+1}}. \end{equation}
\begin{equation} \tilde{q}(n)=1\cdot \left (\frac{b}{a+b}\right )^n \cdot 1^n \cdot \frac{a}{a+b} = \frac{ab^n}{(a+b)^{n+1}}. \end{equation}
Let
 $T$
be the duration for which the edge is inactive. Using equations (3.55) and (3.56), we obtain the Laplace transform of the distribution of
$T$
be the duration for which the edge is inactive. Using equations (3.55) and (3.56), we obtain the Laplace transform of the distribution of
 $T$
as follows:
$T$
as follows:
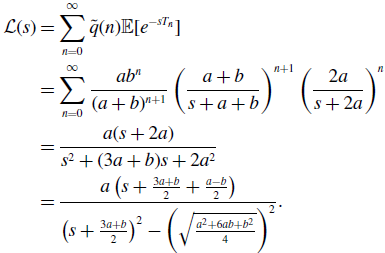 \begin{align} \mathcal{L}(s) & = \sum _{n=0}^{\infty } \tilde{q}(n)\mathbb{E}[e^{-sT_n}] \nonumber \\ & = \sum _{n=0}^{\infty } \frac{ab^n}{(a+b)^{n+1}}\left (\frac{a+b}{s+a+b}\right )^{n+1}\left (\frac{2a}{s+2a}\right )^n\nonumber \\ & = \frac{a(s+2a)}{s^2+(3a+b)s+2a^2}\nonumber \\ & = \frac{a\left (s+\frac{3a+b}{2}+\frac{a-b}{2}\right )}{\left (s+\frac{3a+b}{2}\right )^2-\left (\sqrt{\frac{a^2+6ab+b^2}{4}}\right )^2}. \end{align}
\begin{align} \mathcal{L}(s) & = \sum _{n=0}^{\infty } \tilde{q}(n)\mathbb{E}[e^{-sT_n}] \nonumber \\ & = \sum _{n=0}^{\infty } \frac{ab^n}{(a+b)^{n+1}}\left (\frac{a+b}{s+a+b}\right )^{n+1}\left (\frac{2a}{s+2a}\right )^n\nonumber \\ & = \frac{a(s+2a)}{s^2+(3a+b)s+2a^2}\nonumber \\ & = \frac{a\left (s+\frac{3a+b}{2}+\frac{a-b}{2}\right )}{\left (s+\frac{3a+b}{2}\right )^2-\left (\sqrt{\frac{a^2+6ab+b^2}{4}}\right )^2}. \end{align}
Therefore,
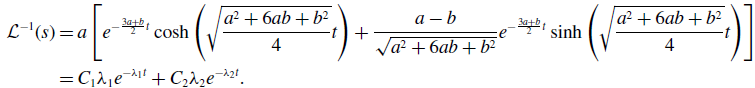 \begin{align} \mathcal{L}^{-1}(s) & = a\left [e^{-\frac{3a+b}{2}t}\cosh{\left (\sqrt{\frac{a^2+6ab+b^2}{4}}t\right )}+\frac{a-b}{\sqrt{a^2+6ab+b^2}}e^{-\frac{3a+b}{2}t}\sinh{\left (\sqrt{\frac{a^2+6ab+b^2}{4}}t\right )}\right ]\nonumber \\ & = C_1\lambda _1e^{-\lambda _1t}+C_2\lambda _2e^{-\lambda _2t}. \end{align}
\begin{align} \mathcal{L}^{-1}(s) & = a\left [e^{-\frac{3a+b}{2}t}\cosh{\left (\sqrt{\frac{a^2+6ab+b^2}{4}}t\right )}+\frac{a-b}{\sqrt{a^2+6ab+b^2}}e^{-\frac{3a+b}{2}t}\sinh{\left (\sqrt{\frac{a^2+6ab+b^2}{4}}t\right )}\right ]\nonumber \\ & = C_1\lambda _1e^{-\lambda _1t}+C_2\lambda _2e^{-\lambda _2t}. \end{align}
We verify equation (3.49) with numerical simulations for two parameter sets. The results are shown in Figure 4. The dashed curves represent the exponential distributions whose mean is the same as that of the corresponding mixture of two exponential distributions. The figure suggests that the actual duration for the edge to be inactive is distributed more heterogeneously than the exponential distribution for both parameter sets.
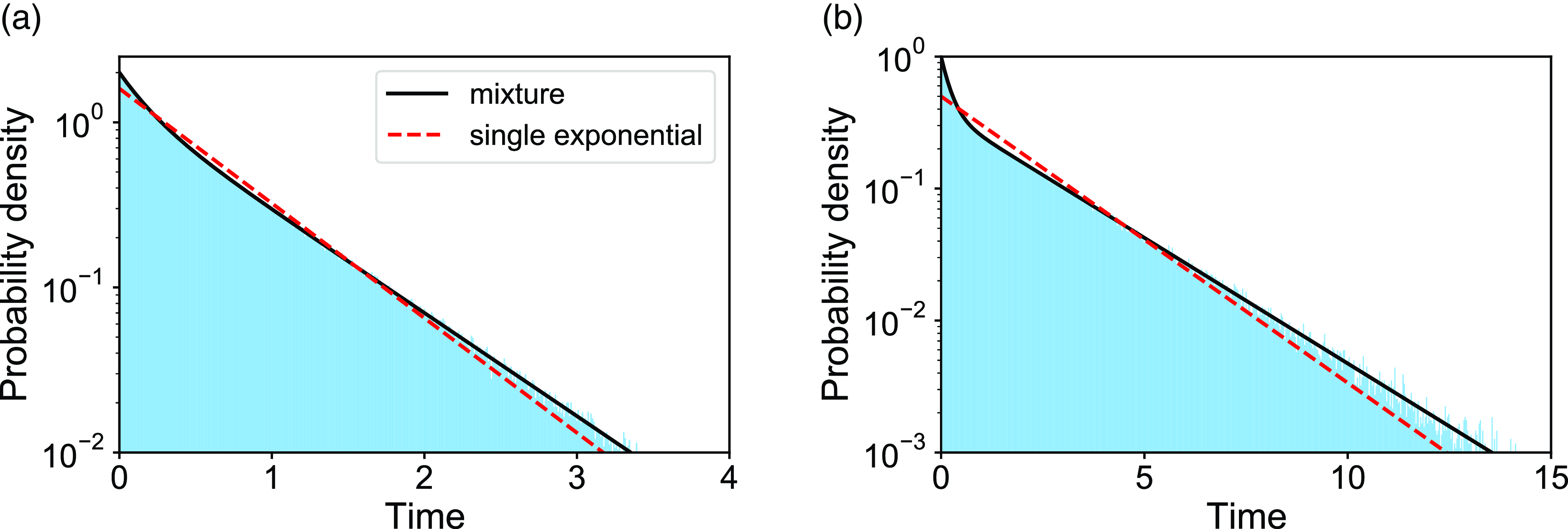
Figure 4. Distributions of the duration of the edge being inactive in model 2. The shaded bars represent numerically obtained distributions calculated on the basis of
 $5\times 10^5$
samples. The solid lines represent the mixture of two exponential distributions, i.e., equation (3.49). The dashed lines represent the exponential distribution whose mean is the same as that for equation (3.49). (a)
$5\times 10^5$
samples. The solid lines represent the mixture of two exponential distributions, i.e., equation (3.49). The dashed lines represent the exponential distribution whose mean is the same as that for equation (3.49). (a)
 $a=2.0$
,
$a=2.0$
,
 $b=1.0$
. (b)
$b=1.0$
. (b)
 $a=1.0$
,
$a=1.0$
,
 $b=2.0$
.
$b=2.0$
.
For model 3, the duration for the edge being inactive, which is equivalent to the time for which the same three-state Markov process stays in state
 $z=0$
, obeys an exponential distribution with rate
$z=0$
, obeys an exponential distribution with rate
 $2a$
. The duration for the edge being active is the first passage time to
$2a$
. The duration for the edge being active is the first passage time to
 $z=0$
since the Markov chain has left
$z=0$
since the Markov chain has left
 $z=0$
. Therefore, the duration for the edge being active for model 3 obeys the mixture of two exponential distributions given by equation (3.49), but with
$z=0$
. Therefore, the duration for the edge being active for model 3 obeys the mixture of two exponential distributions given by equation (3.49), but with
 $a$
and
$a$
and
 $b$
being swapped.
$b$
being swapped.
4. Impact of concurrency on the dynamics of the SIS and SIR models
4.1. Numerical results
4.1.1. Methods
To examine the effect of concurrency on epidemic spreading, we run the stochastic SIS and SIR models on three static networks. On each static network, we run stochastic dynamics of partnership according to model 1, 2 or 3 and compare the extent of epidemic spreading among the models. Each node takes either the susceptible, infectious, or recovered state, and the node’s state may change over time. In both SIS and SIR models, an infectious node infects each of its susceptible neighbour independently at rate
 $\beta$
, which we call the infection rate, and an infectious node recovers at rate
$\beta$
, which we call the infection rate, and an infectious node recovers at rate
 $\mu$
, which we call the recovery rate, independently of the other nodes’ states. The infection and recovery events occur as Poisson processes with the respective rates. Once an infectious node recovers, it turns into the susceptible state in the case of the SIS model and the recovered state in the case of the SIR model. Recovered nodes in the SIR model do not infect other nodes and are not infected by other nodes.
$\mu$
, which we call the recovery rate, independently of the other nodes’ states. The infection and recovery events occur as Poisson processes with the respective rates. Once an infectious node recovers, it turns into the susceptible state in the case of the SIS model and the recovered state in the case of the SIR model. Recovered nodes in the SIR model do not infect other nodes and are not infected by other nodes.
We consider three static networks. First, we use the Erdős-Rényi (ER) random graph with
 $N=200$
nodes. We independently connect each pair of nodes with probability
$N=200$
nodes. We independently connect each pair of nodes with probability
 $0.05$
. We iterated generating a network from the ER random graph until we obtained a connected network with
$0.05$
. We iterated generating a network from the ER random graph until we obtained a connected network with
 $M=1000$
edges. The second network is a network with
$M=1000$
edges. The second network is a network with
 $N=200$
nodes that has a degree distribution with a power-law tail that is proportional to
$N=200$
nodes that has a degree distribution with a power-law tail that is proportional to
 $k^{-3}$
, where
$k^{-3}$
, where
 $k$
is the degree, generated by the Barabási–Albert (BA) model [Reference Barabási and Albert35]. We assume that each incoming node has five edges to be connected to already existing nodes according to the proportional preferential attachment rule. In other words, the probability that an existing node, denoted by
$k$
is the degree, generated by the Barabási–Albert (BA) model [Reference Barabási and Albert35]. We assume that each incoming node has five edges to be connected to already existing nodes according to the proportional preferential attachment rule. In other words, the probability that an existing node, denoted by
 $v$
, forms a new edge with an incoming node is proportional to
$v$
, forms a new edge with an incoming node is proportional to
 $v$
’s degree. The initial network is a star graph on 6 nodes. The network is connected and contains
$v$
’s degree. The initial network is a star graph on 6 nodes. The network is connected and contains
 $M=975$
edges. Third, we use the largest connected component of a collaboration network among researchers who had published papers in network science up to 2006 [Reference Newman36]. The network has
$M=975$
edges. Third, we use the largest connected component of a collaboration network among researchers who had published papers in network science up to 2006 [Reference Newman36]. The network has
 $N=379$
nodes and
$N=379$
nodes and
 $M=914$
edges. The edge represents the presence of at least one paper that two authors have coauthored. We use this network as an unweighted network.
$M=914$
edges. The edge represents the presence of at least one paper that two authors have coauthored. We use this network as an unweighted network.
We set
 $\mu =1$
without loss of generality; multiplying the same constant to
$\mu =1$
without loss of generality; multiplying the same constant to
 $\beta$
,
$\beta$
,
 $\mu$
,
$\mu$
,
 $a_1$
,
$a_1$
,
 $b_1$
,
$b_1$
,
 $a_2$
,
$a_2$
,
 $b_2$
,
$b_2$
,
 $a_3$
, and
$a_3$
, and
 $b_3$
only rescales the time;
$b_3$
only rescales the time;
 $a_i$
and
$a_i$
and
 $b_i$
represent parameters
$b_i$
represent parameters
 $a$
and
$a$
and
 $b$
for model
$b$
for model
 $i$
. We run 5000 simulations for each epidemic process model (i.e., SIS or SIR), each static network, each partnership model (i.e., model 1, 2, or 3), and each parameter set. In each simulation of the SIS model, we started from the initial condition in which all nodes are infectious. This initial condition is not realistic. However, we use it with the aim of identifying the quasi-stationary fraction of infectious nodes without being affected by rapid extinction of infectious nodes that may happen with an initial condition having only a small number of infectious nodes even if the infection rate is large. In the SIS model, we measure the fraction of infectious nodes at time
$i$
. We run 5000 simulations for each epidemic process model (i.e., SIS or SIR), each static network, each partnership model (i.e., model 1, 2, or 3), and each parameter set. In each simulation of the SIS model, we started from the initial condition in which all nodes are infectious. This initial condition is not realistic. However, we use it with the aim of identifying the quasi-stationary fraction of infectious nodes without being affected by rapid extinction of infectious nodes that may happen with an initial condition having only a small number of infectious nodes even if the infection rate is large. In the SIS model, we measure the fraction of infectious nodes at time
 $t = 10^4$
and average it over
$t = 10^4$
and average it over
 $10^3$
simulations at each
$10^3$
simulations at each
 $\beta$
value. In each simulation of the SIR model, just one node selected uniformly at random is initially infectious, and all the other nodes are susceptible. For each static network, the initially infectious node is the same over the different partnership models and the different
$\beta$
value. In each simulation of the SIR model, just one node selected uniformly at random is initially infectious, and all the other nodes are susceptible. For each static network, the initially infectious node is the same over the different partnership models and the different
 $\beta$
values. For each
$\beta$
values. For each
 $\beta$
value, we average the fraction of recovered nodes at the end of the simulation over the 5000 simulations, which we call the final epidemic size.
$\beta$
value, we average the fraction of recovered nodes at the end of the simulation over the 5000 simulations, which we call the final epidemic size.
We run the simulation with model 1 using the Laplace Gillespie algorithm [Reference Masuda and Rocha37, Reference Masuda and Vestergaard38], which is an extension of the direct method of Gillespie to the case in which inter-event times are allowed to obey a mixture of exponential distributions like equation (3.49). For models 2 and 3, we run the simulation using the direct method of Gillespie because these models only involve exponential distributions of inter-event times.
Apart from the variation in the
 $\beta$
value, we consider four sets of parameter values for both SIS and SIR models. In the first set of simulations, we set
$\beta$
value, we consider four sets of parameter values for both SIS and SIR models. In the first set of simulations, we set
 $a_1=1$
,
$a_1=1$
,
 $b_1=9$
,
$b_1=9$
,
 $a_2=0.5(\sqrt{10}+1)\approx 2.08$
,
$a_2=0.5(\sqrt{10}+1)\approx 2.08$
,
 $b_2=4.5$
,
$b_2=4.5$
,
 $a_3=0.5$
, and
$a_3=0.5$
, and
 $b_3=1.5(\sqrt{10}+3)\approx 9.24$
. Then, we obtain
$b_3=1.5(\sqrt{10}+3)\approx 9.24$
. Then, we obtain
 $q^*=0.1$
for all the three partnership models. In this manner, we compare the final epidemic size for the three partnership models, which yield different amounts of concurrency, under the condition that each edge is active for the same amount of time on average. It should be noted that a large
$q^*=0.1$
for all the three partnership models. In this manner, we compare the final epidemic size for the three partnership models, which yield different amounts of concurrency, under the condition that each edge is active for the same amount of time on average. It should be noted that a large
 $q^*$
value will obviously lead to a larger final epidemic size with the other things being equal, and so it is necessary to compare the models with the
$q^*$
value will obviously lead to a larger final epidemic size with the other things being equal, and so it is necessary to compare the models with the
 $q^*$
value being fixed. We obtain a second parameter set by making the values of
$q^*$
value being fixed. We obtain a second parameter set by making the values of
 $a_1$
,
$a_1$
,
 $b_1$
,
$b_1$
,
 $a_2$
,
$a_2$
,
 $b_2$
,
$b_2$
,
 $a_3$
, and
$a_3$
, and
 $b_3$
for the first parameter set five times smaller, which implies that the nodes and edges flip their states five times more slowly than in the case of the first parameter set. Because multiplying these six parameters by the same constant does not change
$b_3$
for the first parameter set five times smaller, which implies that the nodes and edges flip their states five times more slowly than in the case of the first parameter set. Because multiplying these six parameters by the same constant does not change
 $q^*$
, we retain
$q^*$
, we retain
 $q^* = 0.1$
for the second parameter set. We refer to the first and second parameter sets as the fast and slow edge dynamics, respectively. The third parameter set is defined by
$q^* = 0.1$
for the second parameter set. We refer to the first and second parameter sets as the fast and slow edge dynamics, respectively. The third parameter set is defined by
 $a_1=1$
,
$a_1=1$
,
 $b_1=1$
,
$b_1=1$
,
 $a_2=0.5(\sqrt{2}+1)\approx 1.21$
,
$a_2=0.5(\sqrt{2}+1)\approx 1.21$
,
 $b_2=0.5$
,
$b_2=0.5$
,
 $a_3=0.5$
, and
$a_3=0.5$
, and
 $b_3=0.5(\sqrt{2}+1)\approx 1.21$
such that
$b_3=0.5(\sqrt{2}+1)\approx 1.21$
such that
 $q^*=0.5$
. We also consider a slower variant of edge dynamics by dividing these
$q^*=0.5$
. We also consider a slower variant of edge dynamics by dividing these
 $a_1$
,
$a_1$
,
 $b_1$
,
$b_1$
,
 $a_2$
,
$a_2$
,
 $b_2$
,
$b_2$
,
 $a_3$
, and
$a_3$
, and
 $b_3$
values by five. In summary, for each of the three networks and each partnership model, we have four cases each of which consists of the combination of
$b_3$
values by five. In summary, for each of the three networks and each partnership model, we have four cases each of which consists of the combination of
 $q^* \in \{0.1, 0.5\}$
and either the fast or slow edge dynamics.
$q^* \in \{0.1, 0.5\}$
and either the fast or slow edge dynamics.
4.1.2. Results for the SIS model
In this section, we examine the SIS model with partnership models
 $1$
,
$1$
,
 $2$
, and
$2$
, and
 $3$
. We first compare between partnership models
$3$
. We first compare between partnership models
 $1$
and
$1$
and
 $2$
. We recall that model 2 has a higher concurrency than model 1 when each edge is active with the same probability in the two models. To exclude the possible effects of the distribution of the duration for which the edge is active and that for which the edge is inactive, we use model
$2$
. We recall that model 2 has a higher concurrency than model 1 when each edge is active with the same probability in the two models. To exclude the possible effects of the distribution of the duration for which the edge is active and that for which the edge is inactive, we use model
 $1$
with
$1$
with
 $\psi _1(\tau _1)=2b_2e^{-2b_2\tau _1}$
and
$\psi _1(\tau _1)=2b_2e^{-2b_2\tau _1}$
and
 $\psi _2(\tau _2)=C_1\lambda _1e^{-\lambda _1\tau _2}+C_2\lambda _2e^{-\lambda _2\tau _2}$
, where
$\psi _2(\tau _2)=C_1\lambda _1e^{-\lambda _1\tau _2}+C_2\lambda _2e^{-\lambda _2\tau _2}$
, where
 $\lambda _1$
,
$\lambda _1$
,
 $\lambda _2$
,
$\lambda _2$
,
 $C_1$
, and
$C_1$
, and
 $C_2$
are given by equations (3.50), (3.51), (3.52), and (3.53), respectively, with
$C_2$
are given by equations (3.50), (3.51), (3.52), and (3.53), respectively, with
 $a = a_2$
and
$a = a_2$
and
 $b = b_2$
. In this manner, models 1 and 2 have the identical distribution of the duration of the edge being active (i.e.,
$b = b_2$
. In this manner, models 1 and 2 have the identical distribution of the duration of the edge being active (i.e.,
 $\psi _1$
) and that of the edge being inactive (i.e.,
$\psi _1$
) and that of the edge being inactive (i.e.,
 $\psi _2$
), whereas they are different in terms of the amount of concurrency.
$\psi _2$
), whereas they are different in terms of the amount of concurrency.
In Figure 5(a)–(d), we show the relationships between the infection rate and fraction of infectious nodes at
 $t=10^4$
for a network generated by the ER random graph. Figure 5(a) and (b) corresponds to
$t=10^4$
for a network generated by the ER random graph. Figure 5(a) and (b) corresponds to
 $q^*=0.1$
; Figure 5(c) and (d) corresponds to
$q^*=0.1$
; Figure 5(c) and (d) corresponds to
 $q^*=0.5$
. Figure 5(a) and (c) corresponds to the slow edge dynamics; Figure 5(b) and (d) corresponds to the fast edge dynamics. Figure 5(a)–(d) indicates that, in each of these combinations of a value of
$q^*=0.5$
. Figure 5(a) and (c) corresponds to the slow edge dynamics; Figure 5(b) and (d) corresponds to the fast edge dynamics. Figure 5(a)–(d) indicates that, in each of these combinations of a value of
 $q^*$
and speed of the edge dynamics, the epidemic threshold is smaller for model
$q^*$
and speed of the edge dynamics, the epidemic threshold is smaller for model
 $2$
than model
$2$
than model
 $1$
. As a result, the fraction of infectious nodes is larger for model
$1$
. As a result, the fraction of infectious nodes is larger for model
 $2$
than model
$2$
than model
 $1$
when the infection rate is near the epidemic threshold. These results suggest that concurrency decreases the epidemic threshold and promotes epidemic spreading when the infection rate is near the epidemic threshold, which is consistent with the main conclusions of previous studies [Reference Onaga, Gleeson and Masuda28, Reference Bauch and Rand29, Reference Onaga, Gleeson, Masuda, Holme and Saramäki39]. However, the epidemic threshold and the fraction of infectious nodes near the epidemic threshold are almost the same between models 1 and 2 when
$1$
when the infection rate is near the epidemic threshold. These results suggest that concurrency decreases the epidemic threshold and promotes epidemic spreading when the infection rate is near the epidemic threshold, which is consistent with the main conclusions of previous studies [Reference Onaga, Gleeson and Masuda28, Reference Bauch and Rand29, Reference Onaga, Gleeson, Masuda, Holme and Saramäki39]. However, the epidemic threshold and the fraction of infectious nodes near the epidemic threshold are almost the same between models 1 and 2 when
 $q^* = 0.5$
(see Figure 5(c) and (d)). Furthermore, the concurrency decreases the fraction of infectious nodes when the infection rate is sufficiently larger than the epidemic threshold, with both
$q^* = 0.5$
(see Figure 5(c) and (d)). Furthermore, the concurrency decreases the fraction of infectious nodes when the infection rate is sufficiently larger than the epidemic threshold, with both
 $q^*=0.1$
and
$q^*=0.1$
and
 $q^*=0.5$
.
$q^*=0.5$
.
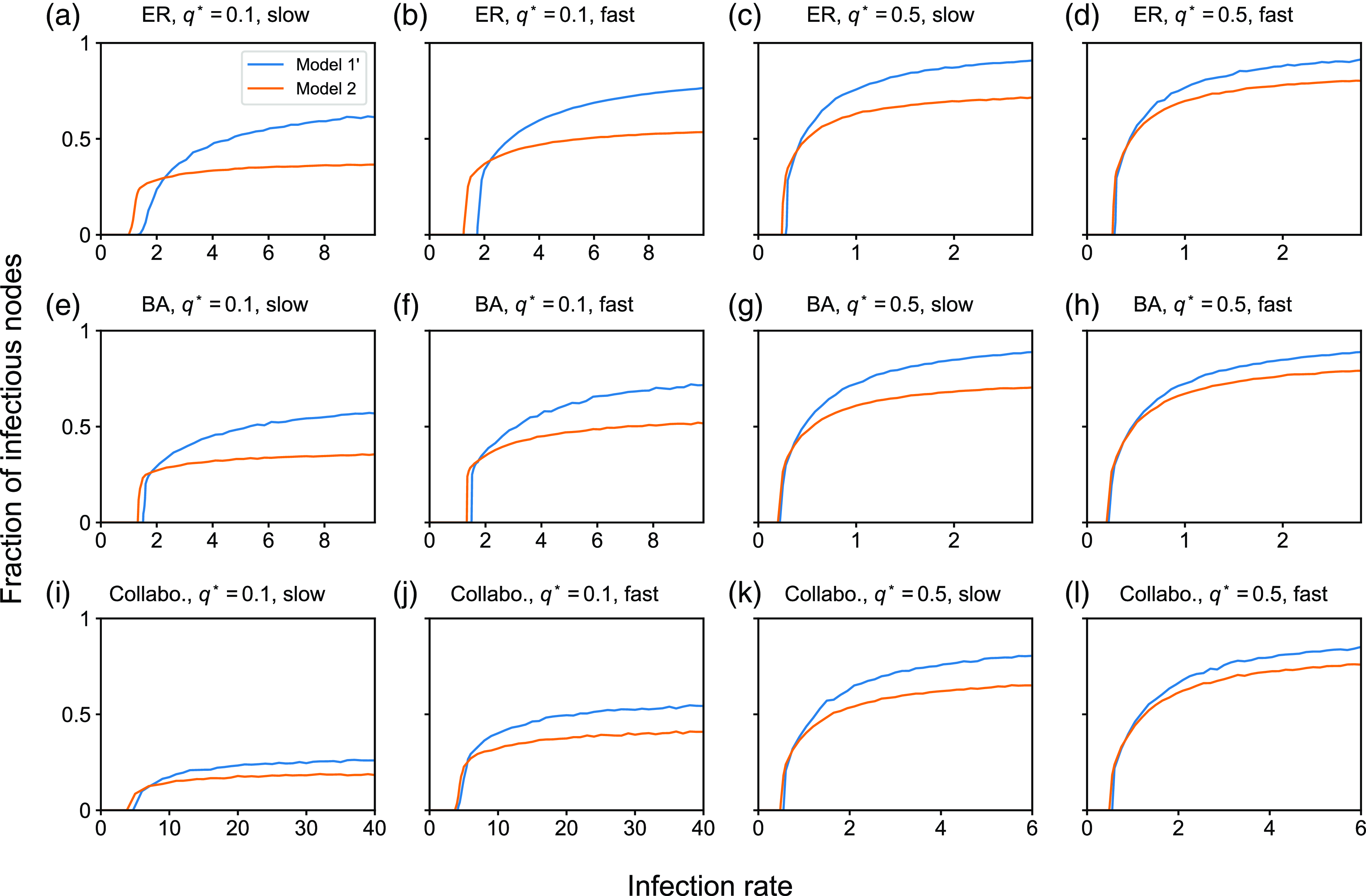
Figure 5. Comparison of the quasi-equilibrium fraction of infectious nodes in the SIS model between models
 $1$
and
$1$
and
 $2$
. (a)–(d) ER random graph. (e)–(h) BA model. (i)–(l) Collaboration network. In panels (a), (e) and (i), we set
$2$
. (a)–(d) ER random graph. (e)–(h) BA model. (i)–(l) Collaboration network. In panels (a), (e) and (i), we set
 $q^*=0.1$
and use the slow edge dynamics. In panels (b), (f) and (j), we set
$q^*=0.1$
and use the slow edge dynamics. In panels (b), (f) and (j), we set
 $q^*=0.1$
and use the fast edge dynamics. In panels (c), (g) and (k), we set
$q^*=0.1$
and use the fast edge dynamics. In panels (c), (g) and (k), we set
 $q^*=0.5$
and use the slow edge dynamics. In panels (d), (h) and (l), we set
$q^*=0.5$
and use the slow edge dynamics. In panels (d), (h) and (l), we set
 $q^*=0.5$
and use the fast edge dynamics. “Collabo.” is a shorthand for the collaboration (i.e., co-authorship) network.
$q^*=0.5$
and use the fast edge dynamics. “Collabo.” is a shorthand for the collaboration (i.e., co-authorship) network.
The results for a network generated by the BA model, shown in Figure 5(e)–(h), and those for the collaboration network, shown in Figure 5(i)–(l), are qualitatively the same as those for the ER model. Quantitatively, when
 $q^* = 0.1$
, the relative difference in the epidemic threshold between models 1 and 2 for the BA model (see Figure 5(e) and (f)) and the collaboration network (see Figure 5(i) and (j)) is smaller than for the ER random graph (see Figure 5(a) and (b)).
$q^* = 0.1$
, the relative difference in the epidemic threshold between models 1 and 2 for the BA model (see Figure 5(e) and (f)) and the collaboration network (see Figure 5(i) and (j)) is smaller than for the ER random graph (see Figure 5(a) and (b)).
Now we compare models
 $1$
and
$1$
and
 $3$
. We use model
$3$
. We use model
 $1$
with
$1$
with
 $\psi _1(\tau _1)=C_1\lambda _1e^{-\lambda _1\tau _1}+C_2\lambda _2e^{-\lambda _2\tau _1}$
, where the four parameters are given by equations (3.50), (3.51), (3.52), and (3.53), respectively, with
$\psi _1(\tau _1)=C_1\lambda _1e^{-\lambda _1\tau _1}+C_2\lambda _2e^{-\lambda _2\tau _1}$
, where the four parameters are given by equations (3.50), (3.51), (3.52), and (3.53), respectively, with
 $a = b_3$
and
$a = b_3$
and
 $b = a_3$
, and
$b = a_3$
, and
 $\psi _2(\tau _2)=2a_3e^{-2a_3\tau _2}$
. In this manner, models 1 and 3 have the identical
$\psi _2(\tau _2)=2a_3e^{-2a_3\tau _2}$
. In this manner, models 1 and 3 have the identical
 $\psi _1$
and
$\psi _1$
and
 $\psi _2$
, whereas model 3 has a larger amount of concurrency than model 1 does.
$\psi _2$
, whereas model 3 has a larger amount of concurrency than model 1 does.
We show the fraction of infectious nodes at
 $t=10^4$
for models
$t=10^4$
for models
 $1$
and
$1$
and
 $3$
for the same three underlying static networks, two values of
$3$
for the same three underlying static networks, two values of
 $q^*$
, and two speeds of edge dynamics in Figure 6. The results are qualitatively similar to the comparison between models
$q^*$
, and two speeds of edge dynamics in Figure 6. The results are qualitatively similar to the comparison between models
 $1$
and
$1$
and
 $2$
shown in Figure 5. These results with models 1 and 3 further support that concurrency decreases the epidemic threshold, whereas this effect is small for the BA model and collaboration network as well as for denser networks (i.e.,
$2$
shown in Figure 5. These results with models 1 and 3 further support that concurrency decreases the epidemic threshold, whereas this effect is small for the BA model and collaboration network as well as for denser networks (i.e.,
 $q^* = 0.5$
compared to
$q^* = 0.5$
compared to
 $q^* = 0.1$
).
$q^* = 0.1$
).
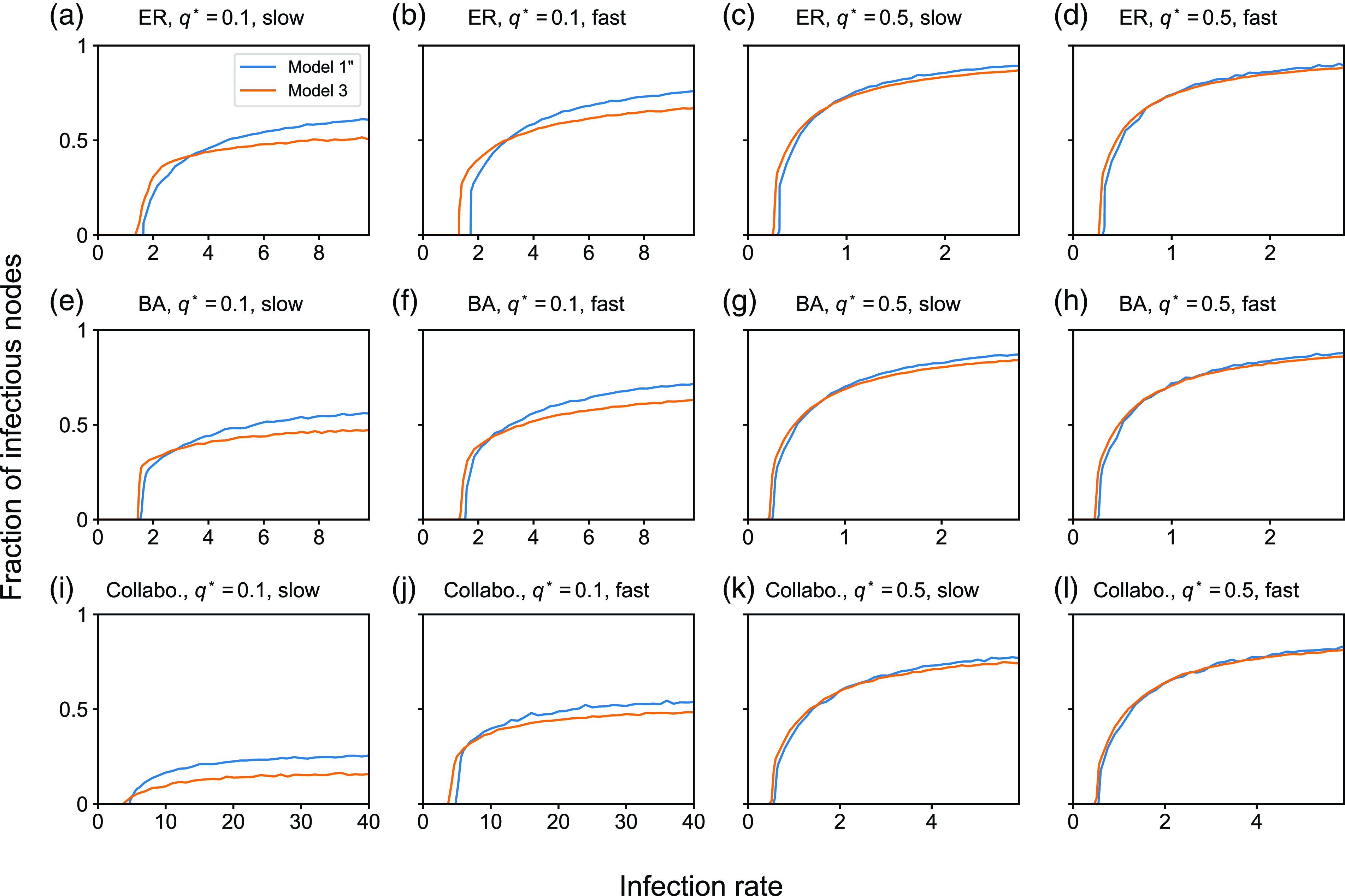
Figure 6. Comparison of the quasi-equilibrium fraction of infectious nodes in the SIS model between models
 $1$
and
$1$
and
 $3$
. (a)–(d) ER random graph. (e)–(h) BA model. (i)–(l) Collaboration network. In panels (a), (e) and (i), we set
$3$
. (a)–(d) ER random graph. (e)–(h) BA model. (i)–(l) Collaboration network. In panels (a), (e) and (i), we set
 $q^*=0.1$
and use the slow edge dynamics. In panels (b), (f) and (j), we set
$q^*=0.1$
and use the slow edge dynamics. In panels (b), (f) and (j), we set
 $q^*=0.1$
and use the fast edge dynamics. In panels (c), (g) and (k), we set
$q^*=0.1$
and use the fast edge dynamics. In panels (c), (g) and (k), we set
 $q^*=0.5$
and use the slow edge dynamics. In panels (d), (h) and (l), we set
$q^*=0.5$
and use the slow edge dynamics. In panels (d), (h) and (l), we set
 $q^*=0.5$
and use the fast edge dynamics.
$q^*=0.5$
and use the fast edge dynamics.
4.1.3. Results for the SIR model
In this section, we examine the SIR model with the three partnership models. When comparing between models 1 and 2 and between models 1 and 3, we use the same distributions of inter-event times for model 1 as those used in Section 4.1.2.
In Figure 7(a)–(d), we show the relationships between the infection rate and final epidemic size for a network generated by the ER random graph. Figure 7(a) and (b) corresponds to
 $q^*=0.1$
; Figure 7(c) and (d) corresponds to
$q^*=0.1$
; Figure 7(c) and (d) corresponds to
 $q^*=0.5$
. Figure 7(a) and (c) corresponds to the slow edge dynamics; Figure 7(b) and (d) corresponds to the fast edge dynamics. Figure 7(a)–(d) indicates that, in each of these combinations of a value of
$q^*=0.5$
. Figure 7(a) and (c) corresponds to the slow edge dynamics; Figure 7(b) and (d) corresponds to the fast edge dynamics. Figure 7(a)–(d) indicates that, in each of these combinations of a value of
 $q^*$
and speed of the edge dynamics, the final epidemic size is larger for model
$q^*$
and speed of the edge dynamics, the final epidemic size is larger for model
 $2$
than model
$2$
than model
 $1$
when the infection rate is near the epidemic threshold. This result suggests that concurrency promotes epidemic spreading near the epidemic threshold. However, the final epidemic size near the epidemic threshold is only slightly larger for model 2 than model 1 when
$1$
when the infection rate is near the epidemic threshold. This result suggests that concurrency promotes epidemic spreading near the epidemic threshold. However, the final epidemic size near the epidemic threshold is only slightly larger for model 2 than model 1 when
 $q^*= 0.5$
(see Figure 7(c) and (d)). Furthermore, the concurrency suppresses the epidemic spreading when the infection rate, and hence the final epidemic size, is larger for both
$q^*= 0.5$
(see Figure 7(c) and (d)). Furthermore, the concurrency suppresses the epidemic spreading when the infection rate, and hence the final epidemic size, is larger for both
 $q^*=0.1$
and
$q^*=0.1$
and
 $q^*=0.5$
. All these results are similar to those for the SIS model shown in Figure 5(a)–(d) except that there is no noticeable difference in the epidemic threshold between models 1 and 2 in the case of the SIR model.
$q^*=0.5$
. All these results are similar to those for the SIS model shown in Figure 5(a)–(d) except that there is no noticeable difference in the epidemic threshold between models 1 and 2 in the case of the SIR model.
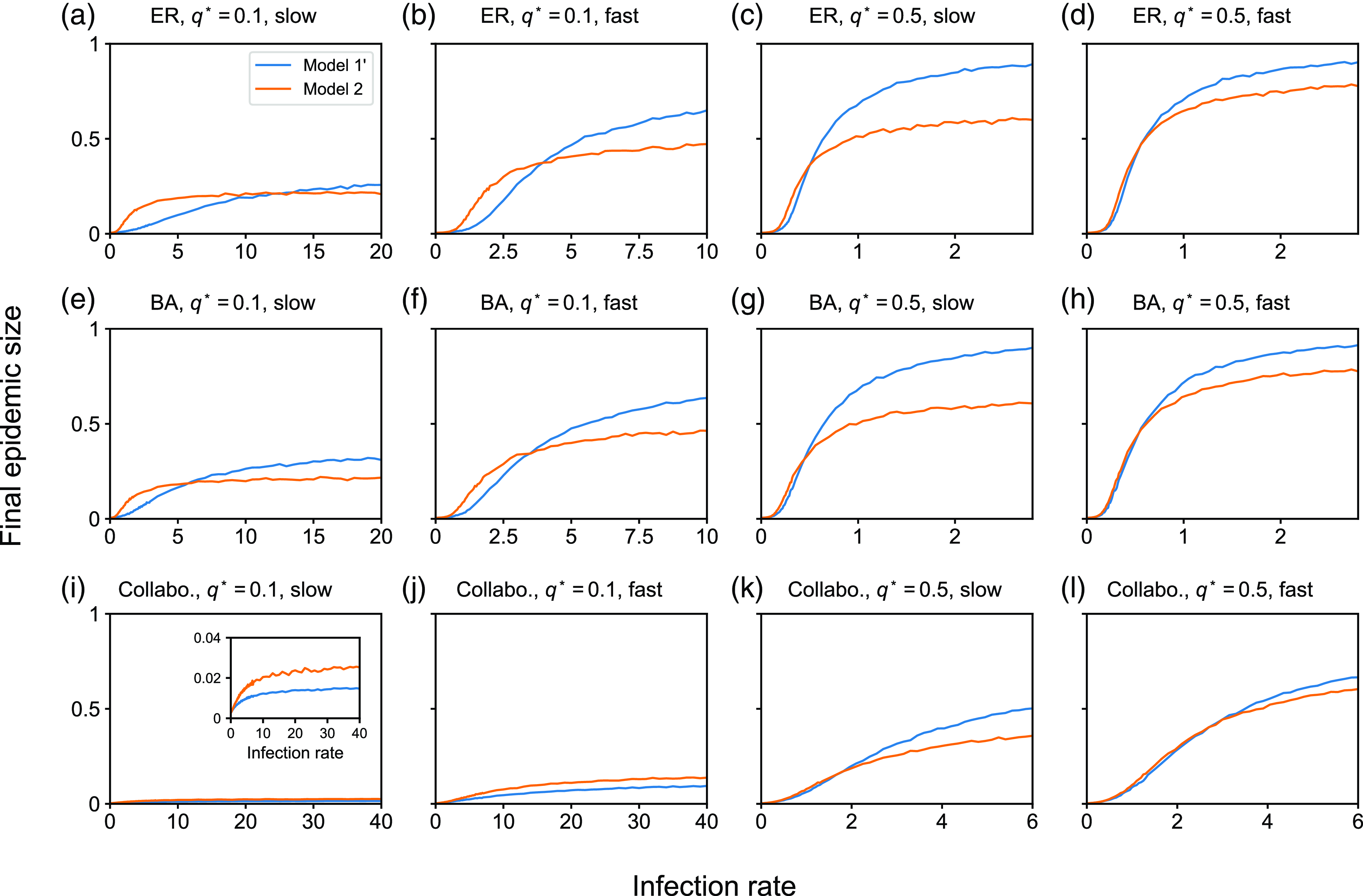
Figure 7. Comparison of the final epidemic size in the SIR model between models
 $1$
and
$1$
and
 $2$
. (a)–(d) ER random graph. (e)–(h) BA model. (i)–(l) Collaboration network. In panels (a), (e) and (i), we set
$2$
. (a)–(d) ER random graph. (e)–(h) BA model. (i)–(l) Collaboration network. In panels (a), (e) and (i), we set
 $q^*=0.1$
and use the slow edge dynamics. In panels (b), (f) and (j), we set
$q^*=0.1$
and use the slow edge dynamics. In panels (b), (f) and (j), we set
 $q^*=0.1$
and use the fast edge dynamics. In panels (c), (g) and (k), we set
$q^*=0.1$
and use the fast edge dynamics. In panels (c), (g) and (k), we set
 $q^*=0.5$
and use the slow edge dynamics. In panels (d), (h) and (l), we set
$q^*=0.5$
and use the slow edge dynamics. In panels (d), (h) and (l), we set
 $q^*=0.5$
and use the fast edge dynamics. The inset of (i) shows the magnification of the main panel because the final epidemic size is small in the entire range of the infection rate in this case.
$q^*=0.5$
and use the fast edge dynamics. The inset of (i) shows the magnification of the main panel because the final epidemic size is small in the entire range of the infection rate in this case.
The results for the BA model, shown in Figure 7(e)–(h), are similar to those for the ER random graph. The results for the collaboration network, shown in Figure 7(i)–(l), are similar to those for the ER random graph and the BA model except that, when
 $q^*=0.1$
, the final epidemic size is larger for model 2 than model 1 across the entire range of the infection rate,
$q^*=0.1$
, the final epidemic size is larger for model 2 than model 1 across the entire range of the infection rate,
 $\beta$
, that we investigated; see Figure 7(i) and (j). Because the final epidemic size has approximately plateaued for both models 1 and 2 at the largest
$\beta$
, that we investigated; see Figure 7(i) and (j). Because the final epidemic size has approximately plateaued for both models 1 and 2 at the largest
 $\beta$
value that we investigated, it is unlikely that model 1 yields a larger final epidemic size than model 2 when
$\beta$
value that we investigated, it is unlikely that model 1 yields a larger final epidemic size than model 2 when
 $\beta$
is larger. These numerical results suggest that the effect of concurrency on enhancing epidemic spreading at
$\beta$
is larger. These numerical results suggest that the effect of concurrency on enhancing epidemic spreading at
 $q^* = 0.1$
is stronger for the collaboration network than for the ER and BA models. In contrast, when
$q^* = 0.1$
is stronger for the collaboration network than for the ER and BA models. In contrast, when
 $q^*=0.5$
, the final epidemic size is not noticeably larger for model 2 than model 1 when
$q^*=0.5$
, the final epidemic size is not noticeably larger for model 2 than model 1 when
 $\beta$
is near the epidemic threshold and smaller for model 2 than model 1 when
$\beta$
is near the epidemic threshold and smaller for model 2 than model 1 when
 $\beta$
is larger (see Figure 7(k) and (l)). This result is qualitatively the same as that for the ER and BA models shown in Figure 7(c), (d), (g), and (h).
$\beta$
is larger (see Figure 7(k) and (l)). This result is qualitatively the same as that for the ER and BA models shown in Figure 7(c), (d), (g), and (h).
In Figure 8, we compare the final epidemic size in the SIR model between models
 $1$
and
$1$
and
 $3$
for the same three underlying static networks, two values of
$3$
for the same three underlying static networks, two values of
 $q^*$
, and two speeds of edge dynamics. The results are largely similar to the comparison between models
$q^*$
, and two speeds of edge dynamics. The results are largely similar to the comparison between models
 $1$
and
$1$
and
 $2$
. A notable difference from the comparison between models
$2$
. A notable difference from the comparison between models
 $1$
and
$1$
and
 $2$
is that, for the ER random graph and BA model combined with
$2$
is that, for the ER random graph and BA model combined with
 $q^*=0.1$
and the slow edge dynamics, model 3 yields a larger final epidemic size than model 1 across the entire range of the infection rate values investigated (see Figure 8(a) and (e)).
$q^*=0.1$
and the slow edge dynamics, model 3 yields a larger final epidemic size than model 1 across the entire range of the infection rate values investigated (see Figure 8(a) and (e)).
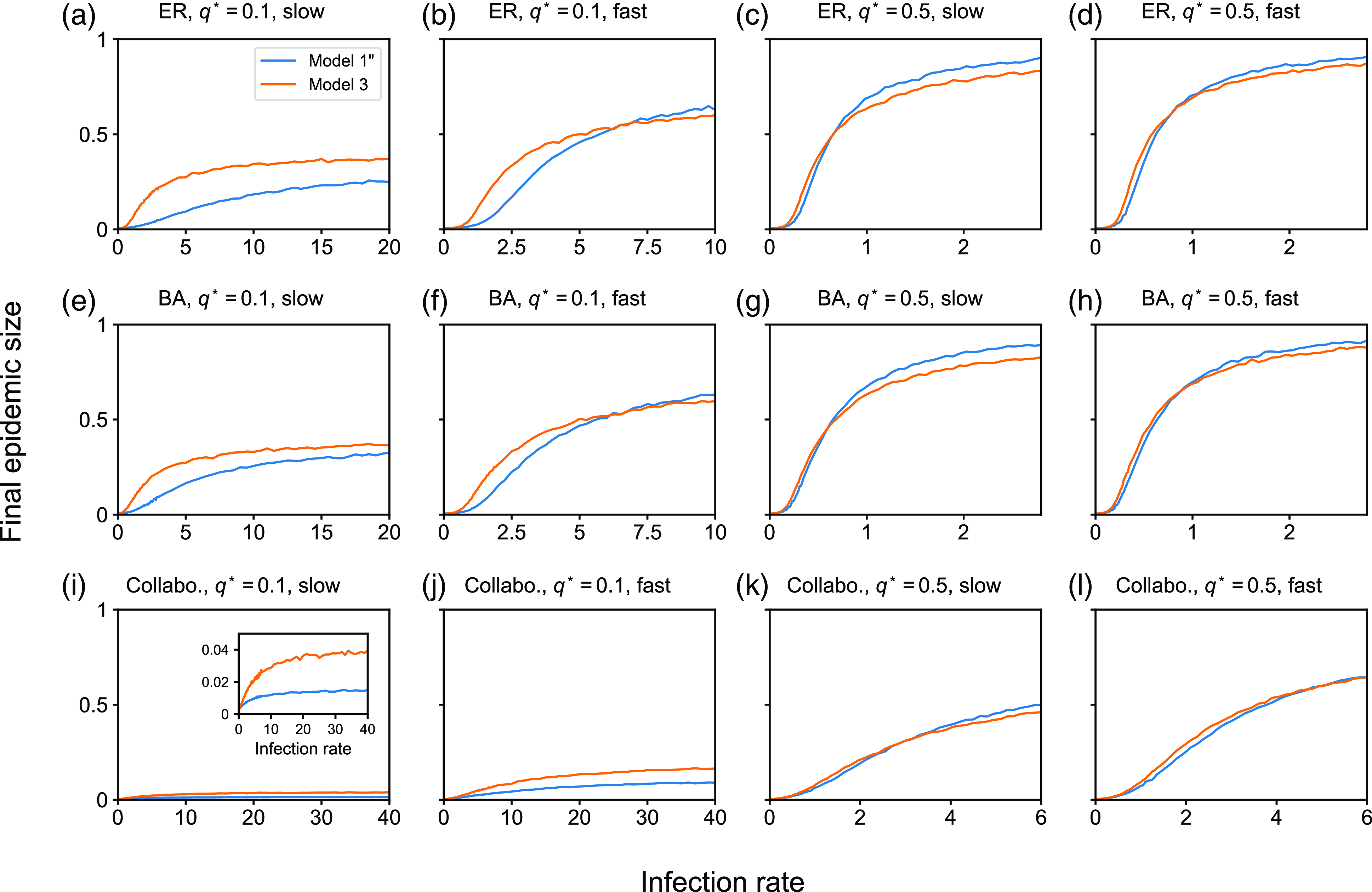
Figure 8. Comparison of the final epidemic size in the SIR model between models
 $1$
and
$1$
and
 $3$
. (a)–(d) ER random graph. (e)–(h) BA model. (i)–(l) Collaboration network. In panels (a), (e) and (i), we set
$3$
. (a)–(d) ER random graph. (e)–(h) BA model. (i)–(l) Collaboration network. In panels (a), (e) and (i), we set
 $q^*=0.1$
and use the slow edge dynamics. In panels (b), (f) and (j), we set
$q^*=0.1$
and use the slow edge dynamics. In panels (b), (f) and (j), we set
 $q^*=0.1$
and use the fast edge dynamics. In panels (c), (g) and (k), we set
$q^*=0.1$
and use the fast edge dynamics. In panels (c), (g) and (k), we set
 $q^*=0.5$
and use the slow edge dynamics. In panels (d), (h) and (l), we set
$q^*=0.5$
and use the slow edge dynamics. In panels (d), (h) and (l), we set
 $q^*=0.5$
and use the fast edge dynamics.
$q^*=0.5$
and use the fast edge dynamics.
4.2. Theoretical results
We analytically derived an expression of the epidemic threshold for the SIS model on arbitrary underlying static networks combined with partnership models 1, 2 and 3. We assume that each network composed of partnership edges lasts for time
 $h$
before switching to another partnership network and that the static network
$h$
before switching to another partnership network and that the static network
 $\mathcal{G}(t)$
in each time window of length
$\mathcal{G}(t)$
in each time window of length
 $h$
is generated as an i.i.d. In fact, our partnership models 1, 2 and 3 imply that
$h$
is generated as an i.i.d. In fact, our partnership models 1, 2 and 3 imply that
 $\mathcal{G}(t)$
at different times are correlated with each other. Therefore, the i.i.d. assumption is for facilitating theoretical analysis.
$\mathcal{G}(t)$
at different times are correlated with each other. Therefore, the i.i.d. assumption is for facilitating theoretical analysis.
We found that, to the first order of
 $h$
, the epidemic threshold is the same for the three models. We show the detail in Appendix D. This result is apparently not consistent with the numerical results for the SIS model shown in Figures 5 and 6, which support that the epidemic threshold decreases as the concurrency increases. In fact, the i.i.d. assumption made for our theoretical analysis corresponds to the limit of infinitely fast switching of edges. This is because a faster edge dynamics for a fixed value of
$h$
, the epidemic threshold is the same for the three models. We show the detail in Appendix D. This result is apparently not consistent with the numerical results for the SIS model shown in Figures 5 and 6, which support that the epidemic threshold decreases as the concurrency increases. In fact, the i.i.d. assumption made for our theoretical analysis corresponds to the limit of infinitely fast switching of edges. This is because a faster edge dynamics for a fixed value of
 $h$
implies that
$h$
implies that
 $\mathcal{G}(t)$
and
$\mathcal{G}(t)$
and
 $\mathcal{G}(t')$
, where
$\mathcal{G}(t')$
, where
 $t' \neq t$
, are less correlated with each other for given
$t' \neq t$
, are less correlated with each other for given
 $t$
and
$t$
and
 $t'$
. Therefore, we carried out additional numerical simulations by making the values of
$t'$
. Therefore, we carried out additional numerical simulations by making the values of
 $a_1$
,
$a_1$
,
 $b_1$
,
$b_1$
,
 $a_2$
,
$a_2$
,
 $b_2$
,
$b_2$
,
 $a_3$
and
$a_3$
and
 $b_3$
five times larger than those for the fast edge dynamics, i.e., 25 times larger than those for the slow edge dynamics. Then, we found that the epidemic threshold for the SIS model in the case of high concurrency (i.e., models 2 and 3) is much closer to the epidemic threshold in the case of low concurrency (i.e., model 1), as compared to when the edge dynamics are slower (i.e., Figures 5 and 6). See Figure 9 for numerical results. We conclude that the theoretical results in this section explain our numerical results when the edge dynamics are sufficiently faster than the epidemic dynamics.
$b_3$
five times larger than those for the fast edge dynamics, i.e., 25 times larger than those for the slow edge dynamics. Then, we found that the epidemic threshold for the SIS model in the case of high concurrency (i.e., models 2 and 3) is much closer to the epidemic threshold in the case of low concurrency (i.e., model 1), as compared to when the edge dynamics are slower (i.e., Figures 5 and 6). See Figure 9 for numerical results. We conclude that the theoretical results in this section explain our numerical results when the edge dynamics are sufficiently faster than the epidemic dynamics.
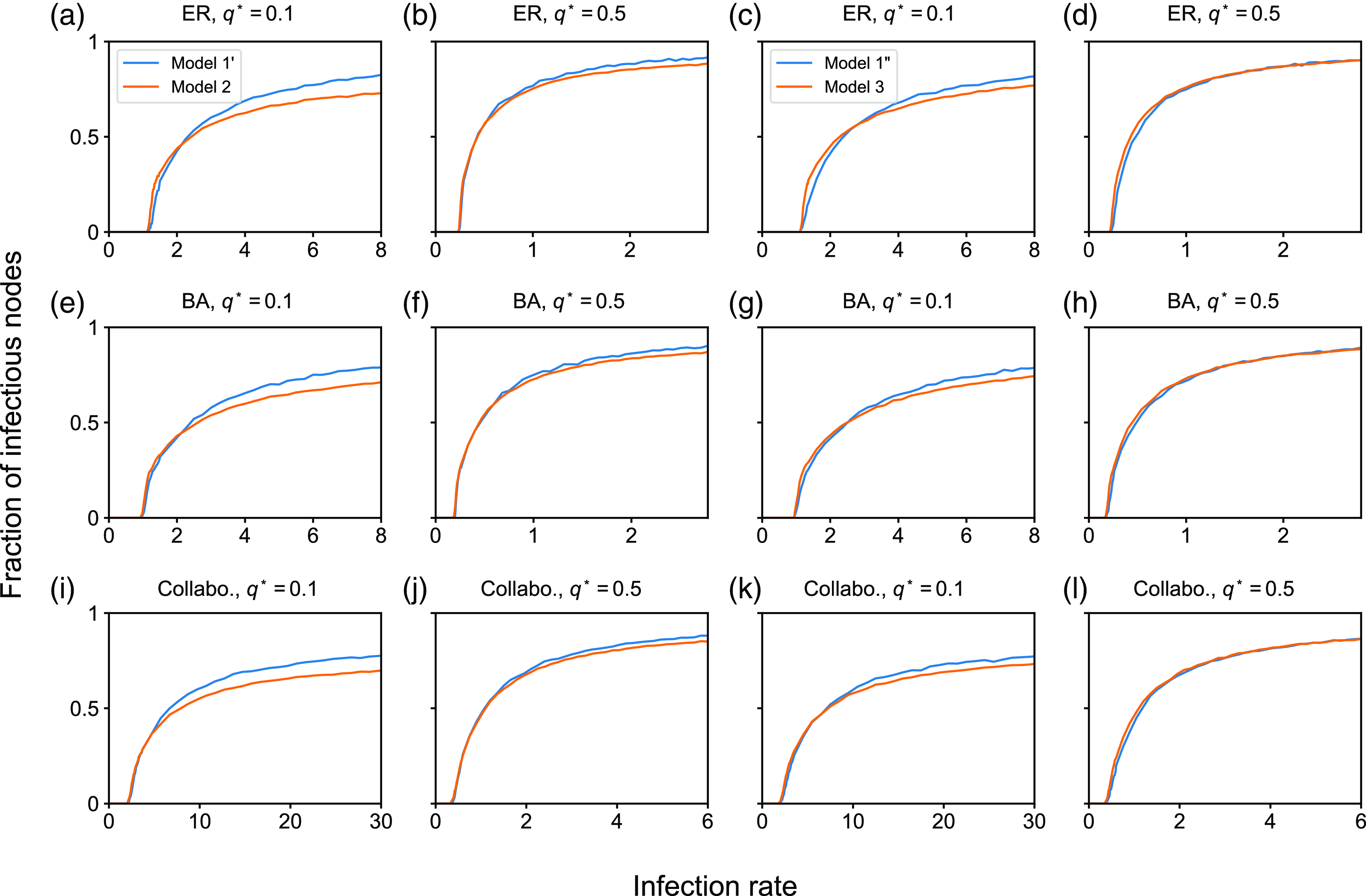
Figure 9. Comparison of the quasi-stationary fraction of infectious nodes in the SIS model among models
 $1$
,
$1$
,
 $2$
and
$2$
and
 $3$
under faster edge dynamics. We use the edge dynamics that are five times faster than the fast edge dynamics used in Figures 5 and 6. (a)–(d) ER random graph. (e)–(h) BA model. (i)–(l) Collaboration network. In panels (a), (e) and (i), we set
$3$
under faster edge dynamics. We use the edge dynamics that are five times faster than the fast edge dynamics used in Figures 5 and 6. (a)–(d) ER random graph. (e)–(h) BA model. (i)–(l) Collaboration network. In panels (a), (e) and (i), we set
 $q^*=0.1$
and compare models
$q^*=0.1$
and compare models
 $1$
and
$1$
and
 $2$
. In panels (b), (f) and (j), we set
$2$
. In panels (b), (f) and (j), we set
 $q^*=0.5$
and compare models
$q^*=0.5$
and compare models
 $1$
and
$1$
and
 $2$
. In panels (c), (g) and (k), we set
$2$
. In panels (c), (g) and (k), we set
 $q^*=0.1$
and compare models
$q^*=0.1$
and compare models
 $1$
and
$1$
and
 $3$
. In panels (d), (h) and (l), we set
$3$
. In panels (d), (h) and (l), we set
 $q^*=0.5$
and compare models
$q^*=0.5$
and compare models
 $1$
and
$1$
and
 $3$
. We remind that we cannot compare models
$3$
. We remind that we cannot compare models
 $1$
,
$1$
,
 $2$
and
$2$
and
 $3$
in a single figure panel because we need to use different variants of model
$3$
in a single figure panel because we need to use different variants of model
 $1$
in the comparison with models
$1$
in the comparison with models
 $2$
and
$2$
and
 $3$
to make the comparison fair.
$3$
to make the comparison fair.
5. Discussion
We investigated three models of edge dynamics. They allow us to generate cases with different amounts of concurrency while keeping the probability that each edge is active (i.e.,
 $q^*$
) and the structure of the aggregate network the same. We theoretically evaluated the concurrency of each model and compared it among the models. Then, we numerically observed using the stochastic SIS and SIR models that quasi-equilibrium fractions of infectious nodes and the final epidemic size, respectively, were larger for the edge dynamics models with the higher concurrency (i.e., models 2 or 3 compared to model 1) if the infection rate was near the epidemic threshold. In the SIS model, the epidemic threshold was also smaller when the concurrency was higher. These effects of the concurrency surrounding the epidemic threshold were larger when the edge dynamics is slower, i.e., with
$q^*$
) and the structure of the aggregate network the same. We theoretically evaluated the concurrency of each model and compared it among the models. Then, we numerically observed using the stochastic SIS and SIR models that quasi-equilibrium fractions of infectious nodes and the final epidemic size, respectively, were larger for the edge dynamics models with the higher concurrency (i.e., models 2 or 3 compared to model 1) if the infection rate was near the epidemic threshold. In the SIS model, the epidemic threshold was also smaller when the concurrency was higher. These effects of the concurrency surrounding the epidemic threshold were larger when the edge dynamics is slower, i.e., with
 $q^*=0.1$
than with
$q^*=0.1$
than with
 $q^*=0.5$
. At the same time, we found that the effect of concurrency on epidemic spreading was modest up to our numerical efforts. It was particularly the case for the BA model and the collaboration network, which are more realistic than the ER random graph in terms of the heterogeneity in the node’s degree. Furthermore, high concurrency suppressed epidemic spreading at large infection rates.
$q^*=0.5$
. At the same time, we found that the effect of concurrency on epidemic spreading was modest up to our numerical efforts. It was particularly the case for the BA model and the collaboration network, which are more realistic than the ER random graph in terms of the heterogeneity in the node’s degree. Furthermore, high concurrency suppressed epidemic spreading at large infection rates.
A previous study numerically showed that concurrency has a greater effect on increasing an epidemic potential in sparser networks [Reference Moody and Benton11]. They measured the epidemic potential defined by the proportion of ordered pairs of nodes that are reachable in the sense that it is possible to travel from one node to the other node along a time-respecting path in the given temporal network composed of time-stamped edges. Our results are consistent with theirs because the effect of concurrency on enhancing epidemic spreading is stronger when
 $q^*$
is smaller in all the cases investigated (see Figures 5, 6, 7, and 8). The larger effect of concurrency on epidemic spreading for sparser networks may be because networks with large
$q^*$
is smaller in all the cases investigated (see Figures 5, 6, 7, and 8). The larger effect of concurrency on epidemic spreading for sparser networks may be because networks with large
 $q^*$
, which leads to a large number of edges, have more time-respecting paths from an infectious node to susceptible nodes transmitting infection even in the absence of concurrency [Reference Moody and Benton11].
$q^*$
, which leads to a large number of edges, have more time-respecting paths from an infectious node to susceptible nodes transmitting infection even in the absence of concurrency [Reference Moody and Benton11].
Another previous study concluded that the impact of concurrency on the epidemic size is fairly limited except in an early stage of epidemic dynamics [Reference Miller and Slim27]. Despite the dependence of epidemic spreading on the density of contacts, which we discussed in the last paragraph, our findings are at large consistent with theirs. In other words, we found that the presence of concurrency little affected or even decreased the quasi-equilibrium fraction of infectious nodes in the SIS model and the final epidemic size in the SIR model in many cases, in particular for the BA model and collaboration networks. The reason why high concurrency decreases epidemic spreading at large infection rates is unclear. This phenomenon may be because, at high infection rates, infection can easily spread from nodes to nodes even without concurrency, such that many contact events on different edges, which would occur at close times in the case of high concurrency, are wasted. Note that our modelling framework guarantees that the total number of contact events on each edge is the same between low and high concurrency cases on average. Our analytical result showing that the epidemic threshold is independent of the concurrency (i.e., see Section 4.2) also supports that the impact of concurrency on enhancing epidemic spreading may not be large.
In contrast, our previous study analytically showed that the concurrency enhances epidemic spreading in terms of the epidemic threshold value for the SIS model [Reference Onaga, Gleeson and Masuda28, Reference Onaga, Gleeson, Masuda, Holme and Saramäki39]. The diversity of these results may be due to different strategies for modeling concurrency. For example, the authors of ref. [Reference Miller and Slim27] designed their dynamic network models by ensuring that the number of partners that an individual has in a long term is the same across the individuals, rendering the aggregate network the complete graph. A different study that also carefully controlled the amount of interaction for each edge to be the same across comparisons made the same homogeneity assumption [Reference Bauch and Rand29]. In contrast, refs. [Reference Onaga, Gleeson and Masuda28, Reference Onaga, Gleeson, Masuda, Holme and Saramäki39] and the present study have assumed that the number of partners that an individual has in a long term may be heterogeneously distributed. Examining similarities and differences between these existing models of concurrency, including the model proposed in the present study, is an outstanding question. This being said, an overall conclusion based on the present numerical results is that the concurrency only modestly or little influences extents of epidemic spreading in many cases. This result indicates that other factors such as static network structure [Reference Newman1–Reference Barrat, Barthélemy and Vespignani4] and burstiness [Reference Holme and Saramäki5–Reference Masuda and Lambiotte7, Reference Karsai, Jo and Kaski40] may be a larger contributor to epidemic dynamics than concurrency. Further comparing the impact of concurrency on epidemic spreading and that of other network factors warrants future work.
Concurrency is not only relevant to sexually transmitted infections, as most studies of concurrency have focused on [Reference Masuda, Miller and Holme15, Reference Aral20–Reference Foxman, Newman, Percha, Holmes and Aral23, Reference Sawers41], or even to epidemic spreading in general. Other network dynamics such as opinion formation, synchronisation and information spreading and cascading on social networks may also be affected by concurrency. Our assumption that the partnership between any given pair of individuals can reoccur after it has disappeared is unrealistic in most cases of sexual partnerships. However, this assumption is considered to be natural for describing other types of dynamic social contacts such as face-to-face encounters and online communications, which underlie social dynamics apart from sexually transmitted infections. Investigating impacts of concurrency on these different social dynamics using the present models also warrants future work.
Acknowledgements
M.O. acknowledges support from JSPS KAKENHI (under Grant No. JP21H01352). N.M. acknowledges support from AFOSR European Office (under Grant No. FA9550-19-1-7024), the Nakatani Foundation, the Sumitomo Foundation and the Japan Science and Technology Agency (JST) Moonshot R
 $\&$
D (under Grant No. JPMJMS2021).
$\&$
D (under Grant No. JPMJMS2021).
Competing interests
The authors have declared that no competing interests exist.
Appendix A: Proof of Proposition 5
In model 2, random variable
 $y_i$
obeys a Bernoulli distribution with expected value
$y_i$
obeys a Bernoulli distribution with expected value
 $\mathbb{E}[y_i] = a/(a+b)$
because
$\mathbb{E}[y_i] = a/(a+b)$
because
 $y_i = 1$
with probability
$y_i = 1$
with probability
 $a/(a+b)$
and
$a/(a+b)$
and
 $y_i = 0$
with probability
$y_i = 0$
with probability
 $b/(a+b)$
. Because
$b/(a+b)$
. Because
 $y_i$
and
$y_i$
and
 $y_j$
, where
$y_j$
, where
 $i\neq j$
, are independent of each other, we obtain
$i\neq j$
, are independent of each other, we obtain
 \begin{align} \mathbb{E}[k_i] & = \mathbb{E}\left [y_i\sum _{j=1}^N A_{ij}y_j\right ] = \sum \limits _{\substack{j=1 \\ j\neq i}}^{N} A_{ij}\mathbb{E}[y_i]\mathbb{E}[y_j] = \overline{k}_i\left (\frac{a}{a+b}\right )^2 \end{align}
\begin{align} \mathbb{E}[k_i] & = \mathbb{E}\left [y_i\sum _{j=1}^N A_{ij}y_j\right ] = \sum \limits _{\substack{j=1 \\ j\neq i}}^{N} A_{ij}\mathbb{E}[y_i]\mathbb{E}[y_j] = \overline{k}_i\left (\frac{a}{a+b}\right )^2 \end{align}
and
 \begin{align} \sigma ^2[k_i] & = \mathbb{E}[k_i^2]-\left (\mathbb{E}[k_i]\right )^2 \nonumber \\ & = \mathbb{E}\left [\sum _{j=1}^N A_{ij}^2y_{i}^2y_{j}^2\right ]+\mathbb{E}\left [\sum \limits _{\substack{j=1\\ j\neq i}}^N\sum \limits _{\substack{k=1\\ k\neq i,j}}^N A_{ij}A_{ik}y_{i}^2y_{j}y_{k}\right ]-\left (\mathbb{E}[k_i]\right )^2\nonumber \\ & = \mathbb{E}\left [\sum _{j=1}^N A_{ij}y_{i}y_{j}\right ]+\mathbb{E}\left [\sum \limits _{\substack{j=1\\ j\neq i}}^N\sum \limits _{\substack{k=1\\ k\neq i,j}}^N A_{ij}A_{ik}y_{i}y_{j}y_{k}\right ]-\left (\mathbb{E}[k_i]\right )^2\nonumber \\ & = \overline{k}_i\left (\frac{a}{a+b}\right )^2 + \overline{k}_i(\overline{k}_i-1)\left (\frac{a}{a+b}\right )^3 - \left [\overline{k}_i\left (\frac{a}{a+b}\right )^2\right ]^2\nonumber \\ & = \frac{\overline{k}_ia^2b}{(a+b)^3}\left (1+\frac{\overline{k}_ia}{a+b}\right ). \end{align}
\begin{align} \sigma ^2[k_i] & = \mathbb{E}[k_i^2]-\left (\mathbb{E}[k_i]\right )^2 \nonumber \\ & = \mathbb{E}\left [\sum _{j=1}^N A_{ij}^2y_{i}^2y_{j}^2\right ]+\mathbb{E}\left [\sum \limits _{\substack{j=1\\ j\neq i}}^N\sum \limits _{\substack{k=1\\ k\neq i,j}}^N A_{ij}A_{ik}y_{i}^2y_{j}y_{k}\right ]-\left (\mathbb{E}[k_i]\right )^2\nonumber \\ & = \mathbb{E}\left [\sum _{j=1}^N A_{ij}y_{i}y_{j}\right ]+\mathbb{E}\left [\sum \limits _{\substack{j=1\\ j\neq i}}^N\sum \limits _{\substack{k=1\\ k\neq i,j}}^N A_{ij}A_{ik}y_{i}y_{j}y_{k}\right ]-\left (\mathbb{E}[k_i]\right )^2\nonumber \\ & = \overline{k}_i\left (\frac{a}{a+b}\right )^2 + \overline{k}_i(\overline{k}_i-1)\left (\frac{a}{a+b}\right )^3 - \left [\overline{k}_i\left (\frac{a}{a+b}\right )^2\right ]^2\nonumber \\ & = \frac{\overline{k}_ia^2b}{(a+b)^3}\left (1+\frac{\overline{k}_ia}{a+b}\right ). \end{align}
We also obtain
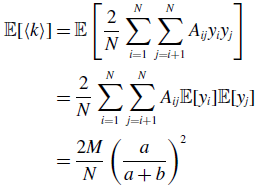 \begin{align} \mathbb{E}[\langle k\rangle ] & = \mathbb{E}\left [\frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}y_{i}y_{j}\right ]\nonumber \\ & = \frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij} \mathbb{E}[y_i]\mathbb{E}[y_j]\nonumber \\ & = \frac{2M}{N}\left (\frac{a}{a+b}\right )^2 \end{align}
\begin{align} \mathbb{E}[\langle k\rangle ] & = \mathbb{E}\left [\frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}y_{i}y_{j}\right ]\nonumber \\ & = \frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij} \mathbb{E}[y_i]\mathbb{E}[y_j]\nonumber \\ & = \frac{2M}{N}\left (\frac{a}{a+b}\right )^2 \end{align}
and
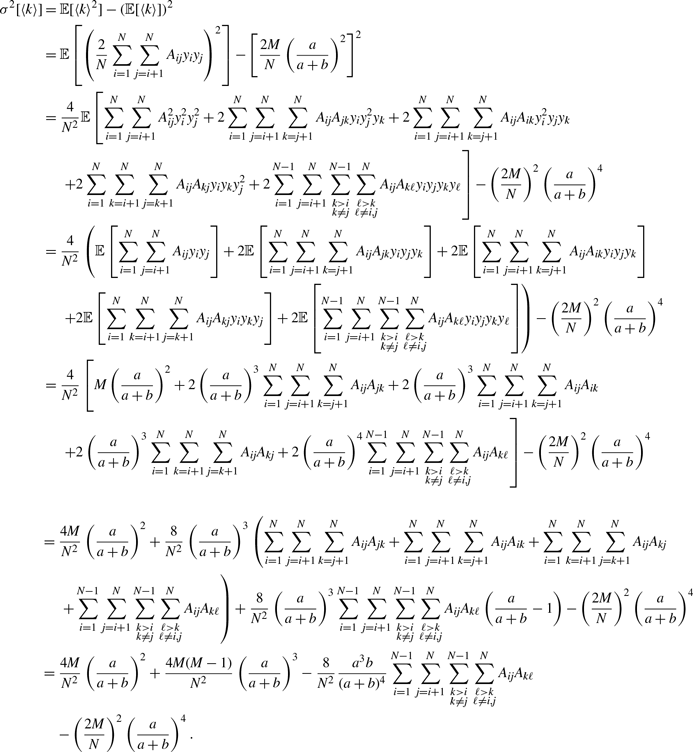 \begin{align} \sigma ^2[\langle k\rangle ] & = \mathbb{E}[\langle k\rangle ^2] - \left (\mathbb{E}[\langle k\rangle ]\right )^2\nonumber \\ & = \mathbb{E}\left [\left (\frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}y_{i}y_{j}\right )^2\right ] - \left [\frac{2M}{N}\left (\frac{a}{a+b}\right )^2\right ]^2\nonumber \\ & = \frac{4}{N^2}\mathbb{E}\left [\sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}^{2}y_{i}^{2}y_{j}^{2} + 2\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk}y_{i}y_{j}^{2}y_{k} + 2\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik}y_{i}^{2}y_{j}y_{k} \right . \nonumber \\ & \phantom{=\;\;}\left .+ 2\sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj}y_{i}y_{k}y_{j}^{2} + 2\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }y_{i}y_{j}y_{k}y_{\ell }\right ] - \left (\frac{2M}{N}\right )^2\left (\frac{a}{a+b}\right )^4\nonumber \\ & = \frac{4}{N^2}\left (\mathbb{E}\left [\sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}y_{i}y_{j}\right ] + 2\mathbb{E}\left [\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk}y_{i}y_{j}y_{k}\right ] + 2\mathbb{E}\left [\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik}y_{i}y_{j}y_{k}\right ] \right .\nonumber \\ & \phantom{=\;\;}\left . + 2\mathbb{E}\left [\sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj}y_{i}y_{k}y_{j}\right ] + 2\mathbb{E}\left [\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }y_{i}y_{j}y_{k}y_{\ell }\right ]\right ) - \left (\frac{2M}{N}\right )^2\left (\frac{a}{a+b}\right )^4\nonumber \\ & = \frac{4}{N^2}\left [M\left (\frac{a}{a+b}\right )^2 + 2\left (\frac{a}{a+b}\right )^3\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk} + 2\left (\frac{a}{a+b}\right )^3\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik}\right .\nonumber \\ & \phantom{=\;\;}\left . + 2\left (\frac{a}{a+b}\right )^3\sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj} + 2\left (\frac{a}{a+b}\right )^4\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\right ] - \left (\frac{2M}{N}\right )^2\left (\frac{a}{a+b}\right )^4\nonumber \\ & = \frac{4M}{N^2}\left (\frac{a}{a+b}\right )^2 + \frac{8}{N^2}\left (\frac{a}{a+b}\right )^3\left (\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk} + \sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik} + \sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj}\right .\nonumber \\ & \phantom{=\;\;}\left .+\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\right ) + \frac{8}{N^2}\left (\frac{a}{a+b}\right )^3\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\left (\frac{a}{a+b} - 1\right ) - \left (\frac{2M}{N}\right )^2\left (\frac{a}{a+b}\right )^4\nonumber \\ & = \frac{4M}{N^2}\left (\frac{a}{a+b}\right )^2 + \frac{4M(M-1)}{N^2}\left (\frac{a}{a+b}\right )^3 - \frac{8}{N^2}\frac{a^3b}{(a+b)^4}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ & \quad - \left (\frac{2M}{N}\right )^2\left (\frac{a}{a+b}\right )^4. \end{align}
\begin{align} \sigma ^2[\langle k\rangle ] & = \mathbb{E}[\langle k\rangle ^2] - \left (\mathbb{E}[\langle k\rangle ]\right )^2\nonumber \\ & = \mathbb{E}\left [\left (\frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}y_{i}y_{j}\right )^2\right ] - \left [\frac{2M}{N}\left (\frac{a}{a+b}\right )^2\right ]^2\nonumber \\ & = \frac{4}{N^2}\mathbb{E}\left [\sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}^{2}y_{i}^{2}y_{j}^{2} + 2\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk}y_{i}y_{j}^{2}y_{k} + 2\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik}y_{i}^{2}y_{j}y_{k} \right . \nonumber \\ & \phantom{=\;\;}\left .+ 2\sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj}y_{i}y_{k}y_{j}^{2} + 2\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }y_{i}y_{j}y_{k}y_{\ell }\right ] - \left (\frac{2M}{N}\right )^2\left (\frac{a}{a+b}\right )^4\nonumber \\ & = \frac{4}{N^2}\left (\mathbb{E}\left [\sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}y_{i}y_{j}\right ] + 2\mathbb{E}\left [\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk}y_{i}y_{j}y_{k}\right ] + 2\mathbb{E}\left [\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik}y_{i}y_{j}y_{k}\right ] \right .\nonumber \\ & \phantom{=\;\;}\left . + 2\mathbb{E}\left [\sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj}y_{i}y_{k}y_{j}\right ] + 2\mathbb{E}\left [\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }y_{i}y_{j}y_{k}y_{\ell }\right ]\right ) - \left (\frac{2M}{N}\right )^2\left (\frac{a}{a+b}\right )^4\nonumber \\ & = \frac{4}{N^2}\left [M\left (\frac{a}{a+b}\right )^2 + 2\left (\frac{a}{a+b}\right )^3\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk} + 2\left (\frac{a}{a+b}\right )^3\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik}\right .\nonumber \\ & \phantom{=\;\;}\left . + 2\left (\frac{a}{a+b}\right )^3\sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj} + 2\left (\frac{a}{a+b}\right )^4\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\right ] - \left (\frac{2M}{N}\right )^2\left (\frac{a}{a+b}\right )^4\nonumber \\ & = \frac{4M}{N^2}\left (\frac{a}{a+b}\right )^2 + \frac{8}{N^2}\left (\frac{a}{a+b}\right )^3\left (\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk} + \sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik} + \sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj}\right .\nonumber \\ & \phantom{=\;\;}\left .+\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\right ) + \frac{8}{N^2}\left (\frac{a}{a+b}\right )^3\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\left (\frac{a}{a+b} - 1\right ) - \left (\frac{2M}{N}\right )^2\left (\frac{a}{a+b}\right )^4\nonumber \\ & = \frac{4M}{N^2}\left (\frac{a}{a+b}\right )^2 + \frac{4M(M-1)}{N^2}\left (\frac{a}{a+b}\right )^3 - \frac{8}{N^2}\frac{a^3b}{(a+b)^4}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ & \quad - \left (\frac{2M}{N}\right )^2\left (\frac{a}{a+b}\right )^4. \end{align}
Appendix B: Proof of Proposition 6
For model 3, we obtain
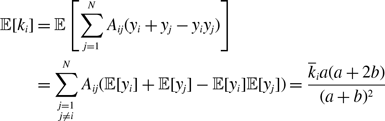 \begin{align} \mathbb{E}[k_i] & = \mathbb{E}\left [\sum _{j=1}^N A_{ij}(y_i+y_j-y_iy_j)\right ] \nonumber \\ & = \sum \limits _{\substack{j=1 \\ j\neq i}}^{N} A_{ij}(\mathbb{E}[y_i]+\mathbb{E}[y_j]-\mathbb{E}[y_i]\mathbb{E}[y_j]) = \frac{\overline{k}_ia(a+2b)}{(a+b)^2} \end{align}
\begin{align} \mathbb{E}[k_i] & = \mathbb{E}\left [\sum _{j=1}^N A_{ij}(y_i+y_j-y_iy_j)\right ] \nonumber \\ & = \sum \limits _{\substack{j=1 \\ j\neq i}}^{N} A_{ij}(\mathbb{E}[y_i]+\mathbb{E}[y_j]-\mathbb{E}[y_i]\mathbb{E}[y_j]) = \frac{\overline{k}_ia(a+2b)}{(a+b)^2} \end{align}
and
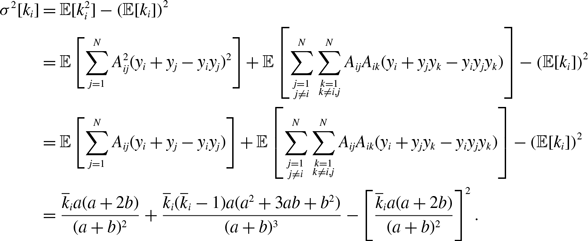 \begin{align} \sigma ^2[k_i] & = \mathbb{E}[k_i^2]-\left (\mathbb{E}[k_i]\right )^2\nonumber \\ & = \mathbb{E}\left [\sum _{j=1}^N A_{ij}^2(y_i+y_j-y_iy_j)^2\right ]+\mathbb{E}\left [\sum \limits _{\substack{j=1\\ j\neq i}}^N\sum \limits _{\substack{k=1\\ k\neq i,j}}^N A_{ij}A_{ik}(y_i+y_jy_k-y_iy_jy_k)\right ]-\left (\mathbb{E}[k_i]\right )^2\nonumber \\ & = \mathbb{E}\left [\sum _{j=1}^N A_{ij}(y_i+y_j-y_iy_j)\right ] + \mathbb{E}\left [\sum \limits _{\substack{j=1\\ j\neq i}}^N\sum \limits _{\substack{k=1\\ k\neq i,j}}^N A_{ij}A_{ik}(y_i+y_jy_k-y_iy_jy_k)\right ]-\left (\mathbb{E}[k_i]\right )^2\nonumber \\ & = \frac{\overline{k}_ia(a+2b)}{(a+b)^2}+\frac{\overline{k}_i(\overline{k}_i-1)a(a^2+3ab+b^2)}{(a+b)^3}-\left [\frac{\overline{k}_ia(a+2b)}{(a+b)^2}\right ]^2. \end{align}
\begin{align} \sigma ^2[k_i] & = \mathbb{E}[k_i^2]-\left (\mathbb{E}[k_i]\right )^2\nonumber \\ & = \mathbb{E}\left [\sum _{j=1}^N A_{ij}^2(y_i+y_j-y_iy_j)^2\right ]+\mathbb{E}\left [\sum \limits _{\substack{j=1\\ j\neq i}}^N\sum \limits _{\substack{k=1\\ k\neq i,j}}^N A_{ij}A_{ik}(y_i+y_jy_k-y_iy_jy_k)\right ]-\left (\mathbb{E}[k_i]\right )^2\nonumber \\ & = \mathbb{E}\left [\sum _{j=1}^N A_{ij}(y_i+y_j-y_iy_j)\right ] + \mathbb{E}\left [\sum \limits _{\substack{j=1\\ j\neq i}}^N\sum \limits _{\substack{k=1\\ k\neq i,j}}^N A_{ij}A_{ik}(y_i+y_jy_k-y_iy_jy_k)\right ]-\left (\mathbb{E}[k_i]\right )^2\nonumber \\ & = \frac{\overline{k}_ia(a+2b)}{(a+b)^2}+\frac{\overline{k}_i(\overline{k}_i-1)a(a^2+3ab+b^2)}{(a+b)^3}-\left [\frac{\overline{k}_ia(a+2b)}{(a+b)^2}\right ]^2. \end{align}
We also obtain
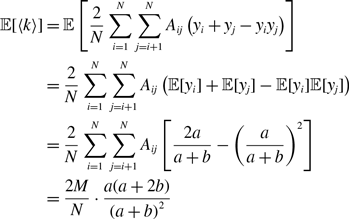 \begin{align} \mathbb{E}[\langle k\rangle ] & = \mathbb{E}\left [\frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}\left (y_i + y_j - y_iy_j\right )\right ]\nonumber \\ & = \frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}\left (\mathbb{E}[y_i] + \mathbb{E}[y_j] - \mathbb{E}[y_i]\mathbb{E}[y_j]\right )\nonumber \\ & = \frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}\left [\frac{2a}{a+b} - \left (\frac{a}{a+b}\right )^2\right ]\nonumber \\ & = \frac{2M}{N}\cdot \frac{a(a+2b)}{\left (a+b\right )^2} \end{align}
\begin{align} \mathbb{E}[\langle k\rangle ] & = \mathbb{E}\left [\frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}\left (y_i + y_j - y_iy_j\right )\right ]\nonumber \\ & = \frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}\left (\mathbb{E}[y_i] + \mathbb{E}[y_j] - \mathbb{E}[y_i]\mathbb{E}[y_j]\right )\nonumber \\ & = \frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}\left [\frac{2a}{a+b} - \left (\frac{a}{a+b}\right )^2\right ]\nonumber \\ & = \frac{2M}{N}\cdot \frac{a(a+2b)}{\left (a+b\right )^2} \end{align}
and
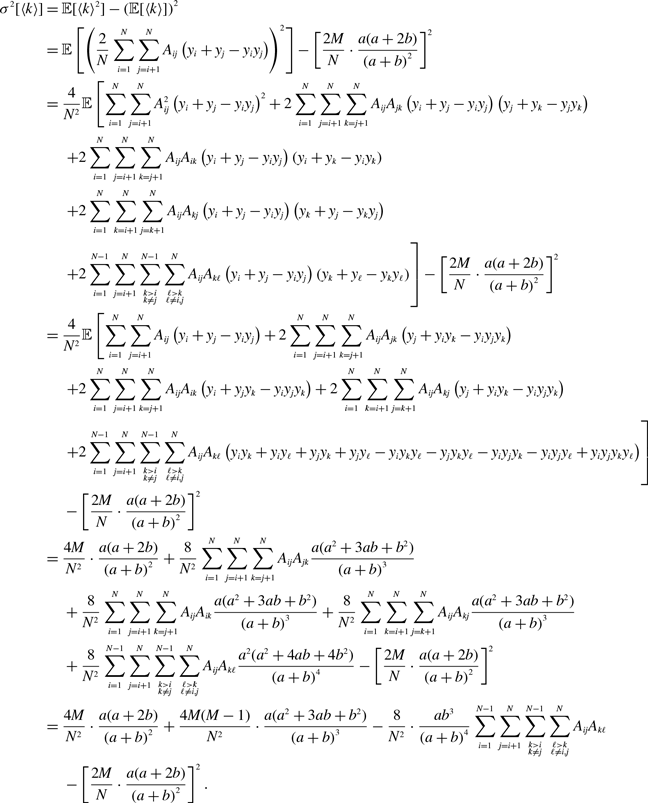 \begin{align} \sigma ^2[\langle k\rangle ] & = \mathbb{E}[\langle k\rangle ^2] - \left (\mathbb{E}[\langle k\rangle ]\right )^2\nonumber \\ & = \mathbb{E}\left [\left (\frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}\left (y_i + y_j - y_iy_j\right )\right )^2\right ] - \left [\frac{2M}{N}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}\right ]^2\nonumber \\ & = \frac{4}{N^2} \mathbb{E}\left [\sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}^2\left (y_i+y_j-y_iy_j\right )^2 + 2\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk}\left (y_i+y_j-y_iy_j\right )\left (y_j+y_k-y_jy_k\right )\right .\nonumber \\ & \phantom{=\;\;}\left .+ 2\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik}\left (y_i+y_j-y_iy_j\right )\left (y_i+y_k-y_iy_k\right )\right .\nonumber \\ & \phantom{=\;\;}\left .+ 2\sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj}\left (y_i+y_j-y_iy_j\right )\left (y_k+y_j-y_ky_j\right )\right .\nonumber \\ & \phantom{=\;\;}\left .+ 2\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\left (y_i+y_j-y_iy_j\right )\left (y_k+y_\ell -y_ky_\ell \right )\right ] - \left [\frac{2M}{N}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}\right ]^2\nonumber \\ & = \frac{4}{N^2} \mathbb{E}\left [\sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}\left (y_i+y_j-y_iy_j\right )+2\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk}\left (y_j+y_iy_k-y_iy_jy_k\right )\right .\nonumber \\ & \phantom{=\;\;}\left .+2\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik}\left (y_i+y_jy_k-y_iy_jy_k\right )+2\sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj}\left (y_j+y_iy_k-y_iy_jy_k\right )\right .\nonumber \\ & \phantom{=\;\;}\left .+2\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\left (y_iy_k+y_iy_\ell +y_jy_k+y_jy_\ell -y_iy_ky_\ell -y_jy_ky_\ell -y_iy_jy_k-y_iy_jy_\ell +y_iy_jy_ky_\ell \right )\right ]\nonumber \\ & \quad \ - \left [\frac{2M}{N}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}\right ]^2\nonumber \\ & = \frac{4M}{N^2}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}+\frac{8}{N^2}\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk}\frac{a(a^2+3ab+b^2)}{\left (a+b\right )^3}\nonumber \\ & \quad \ +\frac{8}{N^2}\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik}\frac{a(a^2+3ab+b^2)}{\left (a+b\right )^3}+\frac{8}{N^2}\sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj}\frac{a(a^2+3ab+b^2)}{\left (a+b\right )^3}\nonumber \\ & \quad \ +\frac{8}{N^2}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\frac{a^2(a^2+4ab+4b^2)}{\left (a+b\right )^4} - \left [\frac{2M}{N}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}\right ]^2\nonumber \\ & = \frac{4M}{N^2}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}+\frac{4M(M-1)}{N^2}\cdot \frac{a(a^2+3ab+b^2)}{\left (a+b\right )^3} - \frac{8}{N^2}\cdot \frac{ab^3}{\left (a+b\right )^4}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ & \quad \ - \left [\frac{2M}{N}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}\right ]^2. \end{align}
\begin{align} \sigma ^2[\langle k\rangle ] & = \mathbb{E}[\langle k\rangle ^2] - \left (\mathbb{E}[\langle k\rangle ]\right )^2\nonumber \\ & = \mathbb{E}\left [\left (\frac{2}{N} \sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}\left (y_i + y_j - y_iy_j\right )\right )^2\right ] - \left [\frac{2M}{N}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}\right ]^2\nonumber \\ & = \frac{4}{N^2} \mathbb{E}\left [\sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}^2\left (y_i+y_j-y_iy_j\right )^2 + 2\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk}\left (y_i+y_j-y_iy_j\right )\left (y_j+y_k-y_jy_k\right )\right .\nonumber \\ & \phantom{=\;\;}\left .+ 2\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik}\left (y_i+y_j-y_iy_j\right )\left (y_i+y_k-y_iy_k\right )\right .\nonumber \\ & \phantom{=\;\;}\left .+ 2\sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj}\left (y_i+y_j-y_iy_j\right )\left (y_k+y_j-y_ky_j\right )\right .\nonumber \\ & \phantom{=\;\;}\left .+ 2\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\left (y_i+y_j-y_iy_j\right )\left (y_k+y_\ell -y_ky_\ell \right )\right ] - \left [\frac{2M}{N}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}\right ]^2\nonumber \\ & = \frac{4}{N^2} \mathbb{E}\left [\sum _{i=1}^N \sum _{j=i+1}^{N} A_{ij}\left (y_i+y_j-y_iy_j\right )+2\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk}\left (y_j+y_iy_k-y_iy_jy_k\right )\right .\nonumber \\ & \phantom{=\;\;}\left .+2\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik}\left (y_i+y_jy_k-y_iy_jy_k\right )+2\sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj}\left (y_j+y_iy_k-y_iy_jy_k\right )\right .\nonumber \\ & \phantom{=\;\;}\left .+2\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\left (y_iy_k+y_iy_\ell +y_jy_k+y_jy_\ell -y_iy_ky_\ell -y_jy_ky_\ell -y_iy_jy_k-y_iy_jy_\ell +y_iy_jy_ky_\ell \right )\right ]\nonumber \\ & \quad \ - \left [\frac{2M}{N}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}\right ]^2\nonumber \\ & = \frac{4M}{N^2}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}+\frac{8}{N^2}\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{jk}\frac{a(a^2+3ab+b^2)}{\left (a+b\right )^3}\nonumber \\ & \quad \ +\frac{8}{N^2}\sum _{i=1}^N \sum _{j=i+1}^{N} \sum _{k=j+1}^{N} A_{ij}A_{ik}\frac{a(a^2+3ab+b^2)}{\left (a+b\right )^3}+\frac{8}{N^2}\sum _{i=1}^N \sum _{k=i+1}^{N} \sum _{j=k+1}^{N} A_{ij}A_{kj}\frac{a(a^2+3ab+b^2)}{\left (a+b\right )^3}\nonumber \\ & \quad \ +\frac{8}{N^2}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\frac{a^2(a^2+4ab+4b^2)}{\left (a+b\right )^4} - \left [\frac{2M}{N}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}\right ]^2\nonumber \\ & = \frac{4M}{N^2}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}+\frac{4M(M-1)}{N^2}\cdot \frac{a(a^2+3ab+b^2)}{\left (a+b\right )^3} - \frac{8}{N^2}\cdot \frac{ab^3}{\left (a+b\right )^4}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ & \quad \ - \left [\frac{2M}{N}\cdot \frac{a(a+2b)}{\left (a+b\right )^2}\right ]^2. \end{align}
Appendix C: Proof of Proposition 9
Let
 $a_2$
and
$a_2$
and
 $a_3$
be the rate at which the state of a node changes from the
$a_3$
be the rate at which the state of a node changes from the
 $\ell$
to the
$\ell$
to the
 $h$
state for models 2 and 3, respectively. Similarly, let
$h$
state for models 2 and 3, respectively. Similarly, let
 $b_2$
and
$b_2$
and
 $b_3$
be the rate at which the state of a node changes from the
$b_3$
be the rate at which the state of a node changes from the
 $h$
to
$h$
to
 $\ell$
state for models 2 and 3, respectively. Because
$\ell$
state for models 2 and 3, respectively. Because
 $q^*$
is the same between models 2 and 3 by assumption, equation (3.24) holds true. We apply equation (3.24) to equations (3.37) and (3.41) to obtain
$q^*$
is the same between models 2 and 3 by assumption, equation (3.24) holds true. We apply equation (3.24) to equations (3.37) and (3.41) to obtain
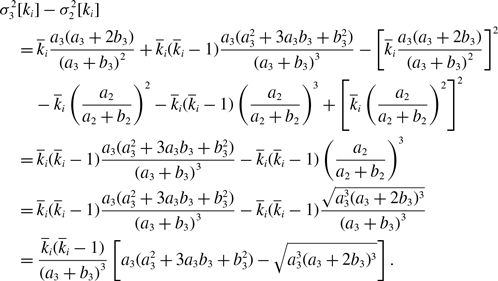 \begin{align} & \sigma ^2_3[k_i] - \sigma ^2_2[k_i]\nonumber \\ &\quad= \overline{k}_i\frac{a_3(a_3+2b_3)}{\left (a_3+b_3\right )^2}+\overline{k}_i(\overline{k}_i-1)\frac{a_3(a_3^2+3a_3b_3+b_3^2)}{\left (a_3+b_3\right )^3}-\left [\overline{k}_i\frac{a_3(a_3+2b_3)}{\left (a_3+b_3\right )^2}\right ]^2\nonumber \\ &\qquad - \overline{k}_i\left (\frac{a_2}{a_2+b_2}\right )^2 - \overline{k}_i(\overline{k}_i-1)\left (\frac{a_2}{a_2+b_2}\right )^3 + \left [\overline{k}_i\left (\frac{a_2}{a_2+b_2}\right )^2\right ]^2\nonumber \\ &\quad= \overline{k}_i(\overline{k}_i-1)\frac{a_3(a_3^2+3a_3b_3+b_3^2)}{\left (a_3+b_3\right )^3}-\overline{k}_i(\overline{k}_i-1)\left (\frac{a_2}{a_2+b_2}\right )^3\nonumber \\ &\quad= \overline{k}_i(\overline{k}_i-1)\frac{a_3(a_3^2+3a_3b_3+b_3^2)}{\left (a_3+b_3\right )^3}-\overline{k}_i(\overline{k}_i-1)\frac{\sqrt{a_3^3(a_3+2b_3)^3}}{\left (a_3+b_3\right )^3}\nonumber \\ &\quad= \frac{\overline{k}_i(\overline{k}_i-1)}{\left (a_3+b_3\right )^3}\left [a_3(a_3^2+3a_3b_3+b_3^2)-\sqrt{a_3^3(a_3+2b_3)^3}\right ]. \end{align}
\begin{align} & \sigma ^2_3[k_i] - \sigma ^2_2[k_i]\nonumber \\ &\quad= \overline{k}_i\frac{a_3(a_3+2b_3)}{\left (a_3+b_3\right )^2}+\overline{k}_i(\overline{k}_i-1)\frac{a_3(a_3^2+3a_3b_3+b_3^2)}{\left (a_3+b_3\right )^3}-\left [\overline{k}_i\frac{a_3(a_3+2b_3)}{\left (a_3+b_3\right )^2}\right ]^2\nonumber \\ &\qquad - \overline{k}_i\left (\frac{a_2}{a_2+b_2}\right )^2 - \overline{k}_i(\overline{k}_i-1)\left (\frac{a_2}{a_2+b_2}\right )^3 + \left [\overline{k}_i\left (\frac{a_2}{a_2+b_2}\right )^2\right ]^2\nonumber \\ &\quad= \overline{k}_i(\overline{k}_i-1)\frac{a_3(a_3^2+3a_3b_3+b_3^2)}{\left (a_3+b_3\right )^3}-\overline{k}_i(\overline{k}_i-1)\left (\frac{a_2}{a_2+b_2}\right )^3\nonumber \\ &\quad= \overline{k}_i(\overline{k}_i-1)\frac{a_3(a_3^2+3a_3b_3+b_3^2)}{\left (a_3+b_3\right )^3}-\overline{k}_i(\overline{k}_i-1)\frac{\sqrt{a_3^3(a_3+2b_3)^3}}{\left (a_3+b_3\right )^3}\nonumber \\ &\quad= \frac{\overline{k}_i(\overline{k}_i-1)}{\left (a_3+b_3\right )^3}\left [a_3(a_3^2+3a_3b_3+b_3^2)-\sqrt{a_3^3(a_3+2b_3)^3}\right ]. \end{align}
Therefore,
 $\sigma ^2_3[k_i] \lt \sigma ^2_2[k_i]$
if and only if
$\sigma ^2_3[k_i] \lt \sigma ^2_2[k_i]$
if and only if
 $b_3\lt (1+\sqrt{2})a_3$
, which is equivalent to
$b_3\lt (1+\sqrt{2})a_3$
, which is equivalent to
 $\frac{1}{2}\lt q^*\leq 1$
.
$\frac{1}{2}\lt q^*\leq 1$
.
By applying equation (3.24) to equations (3.39) and (3.43) and using equation (3.45), we obtain
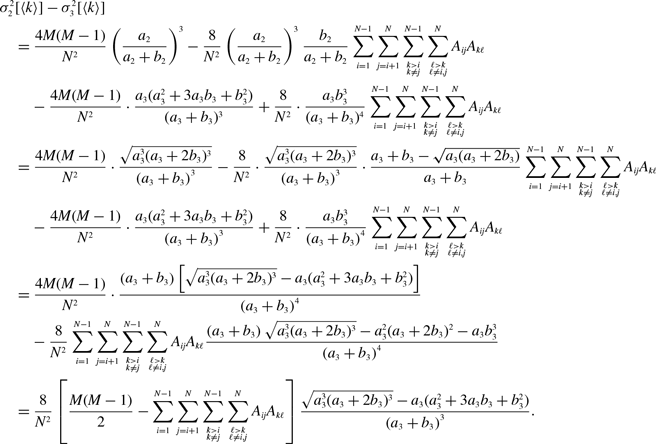 \begin{align} & \sigma ^2_2[\langle k\rangle ]-\sigma ^2_3[\langle k\rangle ]\nonumber \\&\quad = \frac{4M(M-1)}{N^2}\left (\frac{a_2}{a_2+b_2}\right )^3 - \frac{8}{N^2}\left (\frac{a_2}{a_2+b_2}\right )^3\frac{b_2}{a_2+b_2}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ & \qquad-\frac{4M(M-1)}{N^2}\cdot \frac{a_3(a_3^2+3a_3b_3+b_3^2)}{(a_3+b_3)^3} + \frac{8}{N^2}\cdot \frac{a_3b_3^3}{(a_3+b_3)^4}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\&\quad = \frac{4M(M-1)}{N^2}\cdot \frac{\sqrt{a_3^3(a_3+2b_3)^3}}{\left (a_3+b_3\right )^3}-\frac{8}{N^2}\cdot \frac{\sqrt{a_3^3(a_3+2b_3)^3}}{\left (a_3+b_3\right )^3}\cdot \frac{a_3+b_3-\sqrt{a_3(a_3+2b_3)}}{a_3+b_3}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ & \qquad -\frac{4M(M-1)}{N^2}\cdot \frac{a_3(a_3^2+3a_3b_3+b_3^2)}{\left (a_3+b_3\right )^3} +\frac{8}{N^2}\cdot \frac{a_3b_3^3}{\left (a_3+b_3\right )^4}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ &\quad= \frac{4M(M-1)}{N^2}\cdot \frac{\left (a_3+b_3\right )\left [\sqrt{a_3^3(a_3+2b_3)^3}-a_3(a_3^2+3a_3b_3+b_3^2)\right ]}{\left (a_3+b_3\right )^4}\nonumber \\ & \qquad- \frac{8}{N^2}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\frac{\left (a_3+b_3\right )\sqrt{a_3^3(a_3+2b_3)^3}-a_3^2(a_3+2b_3)^2-a_3b_3^3}{\left (a_3+b_3\right )^4}\nonumber \\ &\quad= \frac{8}{N^2}\left [\frac{M(M-1)}{2}-\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\right ]\frac{\sqrt{a_3^3(a_3+2b_3)^3}-a_3(a_3^2+3a_3b_3+b_3^2)}{\left (a_3+b_3\right )^3}. \end{align}
\begin{align} & \sigma ^2_2[\langle k\rangle ]-\sigma ^2_3[\langle k\rangle ]\nonumber \\&\quad = \frac{4M(M-1)}{N^2}\left (\frac{a_2}{a_2+b_2}\right )^3 - \frac{8}{N^2}\left (\frac{a_2}{a_2+b_2}\right )^3\frac{b_2}{a_2+b_2}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ & \qquad-\frac{4M(M-1)}{N^2}\cdot \frac{a_3(a_3^2+3a_3b_3+b_3^2)}{(a_3+b_3)^3} + \frac{8}{N^2}\cdot \frac{a_3b_3^3}{(a_3+b_3)^4}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\&\quad = \frac{4M(M-1)}{N^2}\cdot \frac{\sqrt{a_3^3(a_3+2b_3)^3}}{\left (a_3+b_3\right )^3}-\frac{8}{N^2}\cdot \frac{\sqrt{a_3^3(a_3+2b_3)^3}}{\left (a_3+b_3\right )^3}\cdot \frac{a_3+b_3-\sqrt{a_3(a_3+2b_3)}}{a_3+b_3}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ & \qquad -\frac{4M(M-1)}{N^2}\cdot \frac{a_3(a_3^2+3a_3b_3+b_3^2)}{\left (a_3+b_3\right )^3} +\frac{8}{N^2}\cdot \frac{a_3b_3^3}{\left (a_3+b_3\right )^4}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\nonumber \\ &\quad= \frac{4M(M-1)}{N^2}\cdot \frac{\left (a_3+b_3\right )\left [\sqrt{a_3^3(a_3+2b_3)^3}-a_3(a_3^2+3a_3b_3+b_3^2)\right ]}{\left (a_3+b_3\right )^4}\nonumber \\ & \qquad- \frac{8}{N^2}\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\frac{\left (a_3+b_3\right )\sqrt{a_3^3(a_3+2b_3)^3}-a_3^2(a_3+2b_3)^2-a_3b_3^3}{\left (a_3+b_3\right )^4}\nonumber \\ &\quad= \frac{8}{N^2}\left [\frac{M(M-1)}{2}-\sum _{i=1}^{N-1}\sum _{j=i+1}^N\sum \limits _{\substack{k\gt i\\k\neq j}}^{N-1}\sum \limits _{\substack{\ell \gt k\\\ell \neq i,j}}^N A_{ij}A_{k\ell }\right ]\frac{\sqrt{a_3^3(a_3+2b_3)^3}-a_3(a_3^2+3a_3b_3+b_3^2)}{\left (a_3+b_3\right )^3}. \end{align}
Therefore,
 $\sigma ^2_3[\langle k\rangle ] \lt \sigma ^2_2[\langle k\rangle ]$
if and only if
$\sigma ^2_3[\langle k\rangle ] \lt \sigma ^2_2[\langle k\rangle ]$
if and only if
 $b_3\lt (1+\sqrt{2})a_3$
, which is equivalent to
$b_3\lt (1+\sqrt{2})a_3$
, which is equivalent to
 $\frac{1}{2}\lt q^*\leq 1$
.
$\frac{1}{2}\lt q^*\leq 1$
.
Appendix D: Epidemic threshold when the network switches rapidly
In this section, we evaluate the epidemic threshold for models 1, 2 and 3 under the assumption that the time-independent networks at different times are independent of each other in each model.
We denote the identity and the zero matrices by
 $I$
and
$I$
and
 $O$
, respectively. A real matrix
$O$
, respectively. A real matrix
 $A$
(or a vector as its special case) is said to be nonnegative, denoted by
$A$
(or a vector as its special case) is said to be nonnegative, denoted by
 $A\geq 0$
, if all the entries of
$A\geq 0$
, if all the entries of
 $A$
are nonnegative. If all the entries of
$A$
are nonnegative. If all the entries of
 $A$
are positive, then
$A$
are positive, then
 $A$
is said to be positive. We say that
$A$
is said to be positive. We say that
 $A\leq B$
, where
$A\leq B$
, where
 $A$
and
$A$
and
 $B$
are of the same dimension, if
$B$
are of the same dimension, if
 $B-A\geq 0$
. A square matrix
$B-A\geq 0$
. A square matrix
 $A$
is said to be Metzler if all its off-diagonal entries are nonnegative [Reference Farina and Rinaldi42]. If
$A$
is said to be Metzler if all its off-diagonal entries are nonnegative [Reference Farina and Rinaldi42]. If
 $A$
is Metzler, it holds true that
$A$
is Metzler, it holds true that
 $e^{At} \geq 0$
for all
$e^{At} \geq 0$
for all
 $t\geq 0$
[Reference Farina and Rinaldi42]. For a Metzler matrix
$t\geq 0$
[Reference Farina and Rinaldi42]. For a Metzler matrix
 $A$
, the maximum real part of the eigenvalues of
$A$
, the maximum real part of the eigenvalues of
 $A$
is denoted by
$A$
is denoted by
 $\lambda _{\max }(A)$
. For any matrix
$\lambda _{\max }(A)$
. For any matrix
 $A$
, the spectral radius is the largest absolute value of its eigenvalues and denoted by
$A$
, the spectral radius is the largest absolute value of its eigenvalues and denoted by
 $\rho (A)$
.
$\rho (A)$
.
The SIS model is a continuous-time Markov process with
 $2^N$
possible states [Reference Pastor-Satorras, Castellano, Mieghem and Vespignani2, Reference Kiss, Miller and Simon3, Reference Van Mieghem, Omic and Kooij43] and has a unique absorbing state in which all the
$2^N$
possible states [Reference Pastor-Satorras, Castellano, Mieghem and Vespignani2, Reference Kiss, Miller and Simon3, Reference Van Mieghem, Omic and Kooij43] and has a unique absorbing state in which all the
 $N$
nodes are susceptible. Because this absorbing state is reachable from any other state, the dynamics of the SIS model reaches the disease-free absorbing equilibrium in finite time with probability one.
$N$
nodes are susceptible. Because this absorbing state is reachable from any other state, the dynamics of the SIS model reaches the disease-free absorbing equilibrium in finite time with probability one.
D.1. A lower bound on the decay rate for subgraphs
We refer to the directed edges of a given network
 $\mathcal{\overline G}$
as
$\mathcal{\overline G}$
as
 $\mathcal{\overline E}=\{e_1, \ldots, e_M\}$
, where the
$\mathcal{\overline E}=\{e_1, \ldots, e_M\}$
, where the
 $\ell$
th edge (
$\ell$
th edge (
 $1\le \ell \le M$
) is represented by
$1\le \ell \le M$
) is represented by
 $e_\ell = (i_\ell, j_\ell )$
, i.e., the edge is directed from node
$e_\ell = (i_\ell, j_\ell )$
, i.e., the edge is directed from node
 $v_{i_\ell }$
to node
$v_{i_\ell }$
to node
 $v_{j_\ell }$
. Define the incidence matrix
$v_{j_\ell }$
. Define the incidence matrix
 $\overline{C}\in \mathbb{R}^{N\times M}$
of the network
$\overline{C}\in \mathbb{R}^{N\times M}$
of the network
 $\mathcal{\overline G}$
by [Reference Newman1, Reference Wilson44]
$\mathcal{\overline G}$
by [Reference Newman1, Reference Wilson44]
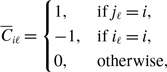 \begin{equation} \overline{C}_{i\ell } = \begin{cases} 1, & \mbox{if $j_\ell = i$}, \\ -1, & \mbox{if $i_\ell = i$}, \\ 0, & \mbox{otherwise}, \end{cases} \end{equation}
\begin{equation} \overline{C}_{i\ell } = \begin{cases} 1, & \mbox{if $j_\ell = i$}, \\ -1, & \mbox{if $i_\ell = i$}, \\ 0, & \mbox{otherwise}, \end{cases} \end{equation}
for all
 $i\in \{1, \dotsc, N\}$
and
$i\in \{1, \dotsc, N\}$
and
 $\ell \in \{1, \dotsc, M\}$
. We also define the non-backtracking matrix
$\ell \in \{1, \dotsc, M\}$
. We also define the non-backtracking matrix
 $\overline{H}\in \mathbb{R}^{M\times M}$
of
$\overline{H}\in \mathbb{R}^{M\times M}$
of
 $\mathcal{\overline G}$
by [Reference Hashimoto45, Reference Alon, Benjamini, Lubetzky and Sodin46]
$\mathcal{\overline G}$
by [Reference Hashimoto45, Reference Alon, Benjamini, Lubetzky and Sodin46]
 \begin{equation} \overline{H}_{\ell m} = \begin{cases} 1, & \mbox{if $j_\ell = i_m$ and $j_m \neq i_\ell $}, \\ 0, & \mbox{otherwise.} \end{cases} \end{equation}
\begin{equation} \overline{H}_{\ell m} = \begin{cases} 1, & \mbox{if $j_\ell = i_m$ and $j_m \neq i_\ell $}, \\ 0, & \mbox{otherwise.} \end{cases} \end{equation}
We prove the following corollary about the SIS spreading processes taking place in a subgraph of
 $\mathcal G$
.
$\mathcal G$
.
Corollary 11.
Let
 $\breve{\mathcal E}$
be a subset of
$\breve{\mathcal E}$
be a subset of
 $\mathcal{\overline E}$
. Consider the SIS model over the network
$\mathcal{\overline E}$
. Consider the SIS model over the network
 $\breve{\mathcal G} = (\mathcal V, \breve{\mathcal E})$
with the infection rate
$\breve{\mathcal G} = (\mathcal V, \breve{\mathcal E})$
with the infection rate
 $\beta \gt 0$
and recovery rate
$\beta \gt 0$
and recovery rate
 $\mu \gt 0$
. Define matrix
$\mu \gt 0$
. Define matrix
 $\breve H\in \mathbb{R}^{M\times M}$
by
$\breve H\in \mathbb{R}^{M\times M}$
by
 \begin{equation} \breve H_{\ell m} = \begin{cases} 1, & {\rm if}\ e_\ell \in \breve{\mathcal E},\ {j_\ell = i_m},\ {\rm and}\ {j_m \neq i_\ell}, \\ 0, & {\rm otherwise,} \end{cases} \end{equation}
\begin{equation} \breve H_{\ell m} = \begin{cases} 1, & {\rm if}\ e_\ell \in \breve{\mathcal E},\ {j_\ell = i_m},\ {\rm and}\ {j_m \neq i_\ell}, \\ 0, & {\rm otherwise,} \end{cases} \end{equation}
We also define the diagonal matrix
 \begin{equation} \breve \Xi ={\rm diag}(\breve \xi _1, \ldots, \breve \xi _M), \end{equation}
\begin{equation} \breve \Xi ={\rm diag}(\breve \xi _1, \ldots, \breve \xi _M), \end{equation}
where
 \begin{equation} \breve \xi _\ell = \begin{cases} 1, & {\rm if} e_\ell \in \breve{\mathcal{E}}, \\ 0,&{\rm otherwise} \end{cases} \end{equation}
\begin{equation} \breve \xi _\ell = \begin{cases} 1, & {\rm if} e_\ell \in \breve{\mathcal{E}}, \\ 0,&{\rm otherwise} \end{cases} \end{equation}
for each
 $\ell \in \{1, \dotsc, M\}$
. Then, we obtain
$\ell \in \{1, \dotsc, M\}$
. Then, we obtain
 \begin{equation} \frac{d}{dt}\begin{bmatrix} \boldsymbol{{p}}\\ \boldsymbol{{q}} \end{bmatrix} \leq \breve{\mathcal A} \begin{bmatrix} \boldsymbol{{p}}\\ \boldsymbol{{q}} \end{bmatrix}, \end{equation}
\begin{equation} \frac{d}{dt}\begin{bmatrix} \boldsymbol{{p}}\\ \boldsymbol{{q}} \end{bmatrix} \leq \breve{\mathcal A} \begin{bmatrix} \boldsymbol{{p}}\\ \boldsymbol{{q}} \end{bmatrix}, \end{equation}
where
 $\boldsymbol{{p}}(t) = \left [p_1(t), \ldots, p_N(t)\right ]^{\top }$
,
$\boldsymbol{{p}}(t) = \left [p_1(t), \ldots, p_N(t)\right ]^{\top }$
,
 $p_i(t) = \mathbb{E}[x_i(t)]$
is the probability that node
$p_i(t) = \mathbb{E}[x_i(t)]$
is the probability that node
 $v_i$
is infectious at time
$v_i$
is infectious at time
 $t$
,
$t$
,
 $^{\top }$
represents the transposition,
$^{\top }$
represents the transposition,
 $\boldsymbol{{q}}(t) = \left [ q_{i_1 j_1}(t), \ldots, q_{i_M j_M}(t) \right ]^{\top }$
,
$\boldsymbol{{q}}(t) = \left [ q_{i_1 j_1}(t), \ldots, q_{i_M j_M}(t) \right ]^{\top }$
,
 $q_{ij}(t)=\mathbb{E}[x_i(t)(1-x_j(t)]$
is the joint probability that
$q_{ij}(t)=\mathbb{E}[x_i(t)(1-x_j(t)]$
is the joint probability that
 $v_i$
is infectious and node
$v_i$
is infectious and node
 $v_j$
is susceptible at time
$v_j$
is susceptible at time
 $t$
and the
$t$
and the
 $(N+M)\times (N+M)$
matrix
$(N+M)\times (N+M)$
matrix
 $\breve{\mathcal A}$
is defined by
$\breve{\mathcal A}$
is defined by
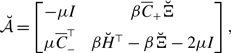 \begin{equation} \breve{\mathcal A} = \begin{bmatrix} -\mu I & && \beta \overline{C}_+\breve \Xi \\[4pt] \mu \overline{C}_-^\top & &&\beta \breve H^\top - \beta \breve \Xi -2\mu I \end{bmatrix}, \end{equation}
\begin{equation} \breve{\mathcal A} = \begin{bmatrix} -\mu I & && \beta \overline{C}_+\breve \Xi \\[4pt] \mu \overline{C}_-^\top & &&\beta \breve H^\top - \beta \breve \Xi -2\mu I \end{bmatrix}, \end{equation}
where
 $\overline{C}_+ = \max (\overline{C}, 0)$
and
$\overline{C}_+ = \max (\overline{C}, 0)$
and
 $\overline{C}_- = \max (-\overline{C}, 0)$
denote the positive and negative parts of the incidence matrix
$\overline{C}_- = \max (-\overline{C}, 0)$
denote the positive and negative parts of the incidence matrix
 $\overline{C}$
, respectively.
$\overline{C}$
, respectively.
Proof. We adapt equation (3.20) in ref. [Reference Masuda and Ogura47] to the case in which the network is defined by
 $\breve{\mathcal{G}}$
, the infection rate is independent of edges, and the recovery rate is independent of nodes. Specifically, by replacing
$\breve{\mathcal{G}}$
, the infection rate is independent of edges, and the recovery rate is independent of nodes. Specifically, by replacing
 $B'$
,
$B'$
,
 $D$
,
$D$
,
 $D_1'$
,
$D_1'$
,
 $D_2'$
in equation (3.20) in ref. [Reference Masuda and Ogura47] by
$D_2'$
in equation (3.20) in ref. [Reference Masuda and Ogura47] by
 $\beta \breve \Xi$
,
$\beta \breve \Xi$
,
 $\mu I$
,
$\mu I$
,
 $\mu I$
,
$\mu I$
,
 $\mu I$
, respectively, we obtain
$\mu I$
, respectively, we obtain
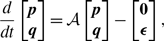 \begin{equation} \frac{d}{dt}\begin{bmatrix} \boldsymbol{{p}}\\ \boldsymbol{{q}} \end{bmatrix} = \mathcal A \begin{bmatrix} \boldsymbol{{p}}\\ \boldsymbol{{q}} \end{bmatrix} - \begin{bmatrix} \boldsymbol 0 \\ \boldsymbol \epsilon \end{bmatrix}, \end{equation}
\begin{equation} \frac{d}{dt}\begin{bmatrix} \boldsymbol{{p}}\\ \boldsymbol{{q}} \end{bmatrix} = \mathcal A \begin{bmatrix} \boldsymbol{{p}}\\ \boldsymbol{{q}} \end{bmatrix} - \begin{bmatrix} \boldsymbol 0 \\ \boldsymbol \epsilon \end{bmatrix}, \end{equation}
where
 $\boldsymbol \epsilon (t)$
is entry-wise nonnegative for every
$\boldsymbol \epsilon (t)$
is entry-wise nonnegative for every
 $t\geq 0$
. Equation (D.8) implies
$t\geq 0$
. Equation (D.8) implies
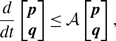 \begin{equation} \frac{d}{dt}\begin{bmatrix} \boldsymbol{{p}}\\ \boldsymbol{{q}} \end{bmatrix} \leq{\mathcal A} \begin{bmatrix} \boldsymbol{{p}}\\ \boldsymbol{{q}} \end{bmatrix}, \end{equation}
\begin{equation} \frac{d}{dt}\begin{bmatrix} \boldsymbol{{p}}\\ \boldsymbol{{q}} \end{bmatrix} \leq{\mathcal A} \begin{bmatrix} \boldsymbol{{p}}\\ \boldsymbol{{q}} \end{bmatrix}, \end{equation}
where matrix
 $\mathcal{A}$
is given by
$\mathcal{A}$
is given by
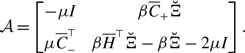 \begin{equation} \mathcal A = \begin{bmatrix} -\mu I & &&\beta \overline{C}_+\breve \Xi \\[4pt] \mu \overline{C}_-^\top &&& \beta \overline{H}^\top{\breve \Xi } - \beta \breve \Xi - 2\mu I \end{bmatrix}. \end{equation}
\begin{equation} \mathcal A = \begin{bmatrix} -\mu I & &&\beta \overline{C}_+\breve \Xi \\[4pt] \mu \overline{C}_-^\top &&& \beta \overline{H}^\top{\breve \Xi } - \beta \breve \Xi - 2\mu I \end{bmatrix}. \end{equation}
Therefore, to complete the proof, it is sufficient to show
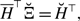 \begin{equation} \overline{H}^\top \breve \Xi = \breve H^\top, \end{equation}
\begin{equation} \overline{H}^\top \breve \Xi = \breve H^\top, \end{equation}
which proves
 $\mathcal A= \breve{\mathcal A}$
.
$\mathcal A= \breve{\mathcal A}$
.
Let us show equation (D.11). For any
 $\ell, m \in \{1, \dotsc, M\}$
, one obtains
$\ell, m \in \{1, \dotsc, M\}$
, one obtains
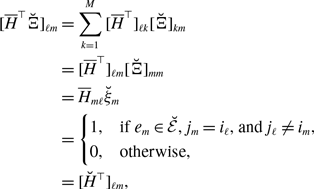 \begin{align} [\overline{H}^\top \breve \Xi ]_{\ell m} &= \sum _{k=1}^M [\overline{H}^\top ]_{\ell k} [\breve \Xi ]_{km}\notag \\ &= [\overline{H}^\top ]_{\ell m} [\breve \Xi ]_{mm}\notag \\ &= \overline{H}_{m \ell } \breve \xi _m\notag \\ &= \begin{cases} 1,&\mbox{if $e_m \in \breve{\mathcal E}$, $j_m=i_\ell $, and $j_\ell \neq i_m$}, \\ 0,&\mbox{otherwise}, \end{cases} \notag \\ &= [\breve H^\top ]_{\ell m}, \end{align}
\begin{align} [\overline{H}^\top \breve \Xi ]_{\ell m} &= \sum _{k=1}^M [\overline{H}^\top ]_{\ell k} [\breve \Xi ]_{km}\notag \\ &= [\overline{H}^\top ]_{\ell m} [\breve \Xi ]_{mm}\notag \\ &= \overline{H}_{m \ell } \breve \xi _m\notag \\ &= \begin{cases} 1,&\mbox{if $e_m \in \breve{\mathcal E}$, $j_m=i_\ell $, and $j_\ell \neq i_m$}, \\ 0,&\mbox{otherwise}, \end{cases} \notag \\ &= [\breve H^\top ]_{\ell m}, \end{align}
which proves equation (D.11).
D.2. A lower bound on the decay rate for temporal networks
Let
 $\tilde{\mathcal G}_1 = (\mathcal V, \tilde{\mathcal E}_1)$
,
$\tilde{\mathcal G}_1 = (\mathcal V, \tilde{\mathcal E}_1)$
,
 $\ldots$
,
$\ldots$
,
 $\tilde{\mathcal G}_L = (\mathcal V, \tilde{\mathcal E}_L)$
be directed and unweighted networks having the common node set
$\tilde{\mathcal G}_L = (\mathcal V, \tilde{\mathcal E}_L)$
be directed and unweighted networks having the common node set
 $\mathcal V = \{v_1, \dotsc, v_N\}$
. Let
$\mathcal V = \{v_1, \dotsc, v_N\}$
. Let
 $\{\sigma _k\}_{k=0}^\infty$
be independent and identically distributed random variables following a probability distribution on the set
$\{\sigma _k\}_{k=0}^\infty$
be independent and identically distributed random variables following a probability distribution on the set
 $\{1, \dotsc, L\}$
. Variable
$\{1, \dotsc, L\}$
. Variable
 $\sigma _k$
indexes the
$\sigma _k$
indexes the
 $k$
th network to be used. Let
$k$
th network to be used. Let
 $h\gt 0$
be arbitrary. For a real number
$h\gt 0$
be arbitrary. For a real number
 $x$
, let
$x$
, let
 $\lfloor x \rfloor$
denote the maximum integer that does not exceed
$\lfloor x \rfloor$
denote the maximum integer that does not exceed
 $x$
. Define the stochastic temporal network
$x$
. Define the stochastic temporal network
 $\mathcal G$
by
$\mathcal G$
by
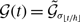 \begin{equation} \mathcal G(t) = \tilde{\mathcal G}_{\sigma _{\lfloor t/h \rfloor }} \end{equation}
\begin{equation} \mathcal G(t) = \tilde{\mathcal G}_{\sigma _{\lfloor t/h \rfloor }} \end{equation}
for all
 $t \geq 0$
. Equation (D.13) implies that
$t \geq 0$
. Equation (D.13) implies that
 $\mathcal G(kh+\tau ) = \tilde{\mathcal G}_{\sigma _{k}}$
for all
$\mathcal G(kh+\tau ) = \tilde{\mathcal G}_{\sigma _{k}}$
for all
 $k\geq 0$
and
$k\geq 0$
and
 $\tau \in [0, h)$
. In the temporal network models 1, 2 and 3 used in the main text, the states of individual edges or nodes independently repeat flipping in continuous time in a Poissonian manner, which induces network switching. Therefore, the duration for a single time-independent network,
$\tau \in [0, h)$
. In the temporal network models 1, 2 and 3 used in the main text, the states of individual edges or nodes independently repeat flipping in continuous time in a Poissonian manner, which induces network switching. Therefore, the duration for a single time-independent network,
 $h$
, is not a constant. Furthermore, the time-independent networks before and after a single flipping of an edge’s or node’s state are not independent of each other. For these two reasons, the present
$h$
, is not a constant. Furthermore, the time-independent networks before and after a single flipping of an edge’s or node’s state are not independent of each other. For these two reasons, the present
 $\mathcal G$
is not the same as models 1, 2 or 3. However, one can enforce the present
$\mathcal G$
is not the same as models 1, 2 or 3. However, one can enforce the present
 $\mathcal G$
and any of models 1, 2 and 3 to have the same probability that each type of time-independent network,
$\mathcal G$
and any of models 1, 2 and 3 to have the same probability that each type of time-independent network,
 $\tilde{\mathcal G}_{\ell }$
, occurs by setting an appropriate probability distribution for
$\tilde{\mathcal G}_{\ell }$
, occurs by setting an appropriate probability distribution for
 $\{ \tilde{\mathcal G}_1, \ldots, \tilde{\mathcal G}_L \}$
for the present
$\{ \tilde{\mathcal G}_1, \ldots, \tilde{\mathcal G}_L \}$
for the present
 $\mathcal{G}$
. We assume such a probability distribution in the following text. We consider the stochastic SIS model taking place in
$\mathcal{G}$
. We assume such a probability distribution in the following text. We consider the stochastic SIS model taking place in
 $\mathcal G$
.
$\mathcal G$
.
Definition 12.
The decay rate of the SIS model over
 $\mathcal G$
is defined by
$\mathcal G$
is defined by
 \begin{equation} \gamma = - \limsup _{t\to \infty } \frac{\log \sum _{i=1}^N \mathbb{E}[p_i(t)]}{t}, \end{equation}
\begin{equation} \gamma = - \limsup _{t\to \infty } \frac{\log \sum _{i=1}^N \mathbb{E}[p_i(t)]}{t}, \end{equation}
where all nodes are assumed to be infected at
 $t=0$
.
$t=0$
.
Definition 12 states that
 $\sum _{i=1}^N p_i(t)$
, which is equal to the expected number of infected nodes at time
$\sum _{i=1}^N p_i(t)$
, which is equal to the expected number of infected nodes at time
 $t$
, roughly decays exponentially in time in proportion to
$t$
, roughly decays exponentially in time in proportion to
 $e^{-\gamma t}$
. Because the number of infected nodes always becomes zero in finite time, the SIS model on networks always has a positive decay rate. In fact, exact computation of the decay rate is computationally demanding because the decay rate is equal to the modulus of the largest real part of the non-zero eigenvalues of a
$e^{-\gamma t}$
. Because the number of infected nodes always becomes zero in finite time, the SIS model on networks always has a positive decay rate. In fact, exact computation of the decay rate is computationally demanding because the decay rate is equal to the modulus of the largest real part of the non-zero eigenvalues of a
 $2^N\times 2^N$
matrix representing the infinitesimal generator of the Markov chain [Reference Van Mieghem, Omic and Kooij43]. Therefore, bounds of the decay rate that only require computation of much smaller matrices are available [Reference Van Mieghem, Omic and Kooij43, Reference Masuda and Ogura47–Reference Ogura and Preciado51]. Here we develop such a bound for temporal network
$2^N\times 2^N$
matrix representing the infinitesimal generator of the Markov chain [Reference Van Mieghem, Omic and Kooij43]. Therefore, bounds of the decay rate that only require computation of much smaller matrices are available [Reference Van Mieghem, Omic and Kooij43, Reference Masuda and Ogura47–Reference Ogura and Preciado51]. Here we develop such a bound for temporal network
 $\mathcal G$
.
$\mathcal G$
.
Let us label the set of time-aggregated edges,
 $\overline{\mathcal E} = \bigcup _{\ell =1}^L \tilde{\mathcal E}_\ell$
, as
$\overline{\mathcal E} = \bigcup _{\ell =1}^L \tilde{\mathcal E}_\ell$
, as
 $\overline{\mathcal E} = \{e_1, \dotsc, e_M\}$
. Define the time-aggregated graph
$\overline{\mathcal E} = \{e_1, \dotsc, e_M\}$
. Define the time-aggregated graph
 $\overline{\mathcal G} = (\mathcal V, \overline{\mathcal E})$
. Let
$\overline{\mathcal G} = (\mathcal V, \overline{\mathcal E})$
. Let
 $\overline C \in \mathbb{R}^{N\times M}$
denote the incidence matrix of
$\overline C \in \mathbb{R}^{N\times M}$
denote the incidence matrix of
 $\overline{\mathcal G}$
. Although the notations
$\overline{\mathcal G}$
. Although the notations
 $\overline{\mathcal G}$
,
$\overline{\mathcal G}$
,
 $\overline{\mathcal E}$
and
$\overline{\mathcal E}$
and
 $\overline C$
are common to those used in Section D.1, this should not arise confusions in the following text. For each
$\overline C$
are common to those used in Section D.1, this should not arise confusions in the following text. For each
 $t\geq 0$
, let
$t\geq 0$
, let
 $\mathcal E(t)$
denote the set of edges of the network at time
$\mathcal E(t)$
denote the set of edges of the network at time
 $t$
, i.e.,
$t$
, i.e.,
 $\mathcal G(t)$
. In other words,
$\mathcal G(t)$
. In other words,
 $\mathcal E(t) = \tilde{\mathcal E}_{\sigma _{\lfloor t/h \rfloor }}$
. We also define the matrix
$\mathcal E(t) = \tilde{\mathcal E}_{\sigma _{\lfloor t/h \rfloor }}$
. We also define the matrix
 $H(t)\in \mathbb{R}^{M\times M}$
by
$H(t)\in \mathbb{R}^{M\times M}$
by
 \begin{equation} H(t)_{\ell m} = \begin{cases} 1 & \mbox{if $e_\ell \in \mathcal E(t)$, $j_\ell = i_m$, and $j_m \neq i_\ell $}, \\ 0 & \mbox{otherwise,} \end{cases} \end{equation}
\begin{equation} H(t)_{\ell m} = \begin{cases} 1 & \mbox{if $e_\ell \in \mathcal E(t)$, $j_\ell = i_m$, and $j_m \neq i_\ell $}, \\ 0 & \mbox{otherwise,} \end{cases} \end{equation}
where
 $\ell, m \in \{1, \dotsc, M\}$
, and the diagonal matrix
$\ell, m \in \{1, \dotsc, M\}$
, and the diagonal matrix
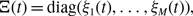 \begin{equation} \Xi (t) =\text{diag}(\xi _1(t), \ldots, \xi _M(t)), \end{equation}
\begin{equation} \Xi (t) =\text{diag}(\xi _1(t), \ldots, \xi _M(t)), \end{equation}
where
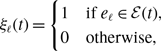 \begin{equation} \xi _\ell (t) = \begin{cases} 1&\mbox{if $e_\ell \in{\mathcal{E}}(t)$}, \\ 0&\mbox{otherwise,} \end{cases} \end{equation}
\begin{equation} \xi _\ell (t) = \begin{cases} 1&\mbox{if $e_\ell \in{\mathcal{E}}(t)$}, \\ 0&\mbox{otherwise,} \end{cases} \end{equation}
and
 $\ell \in \{1, \dotsc, M\}$
. Note that
$\ell \in \{1, \dotsc, M\}$
. Note that
 $H(t)$
is similar to but different from the non-backtracking matrix of network
$H(t)$
is similar to but different from the non-backtracking matrix of network
 $\mathcal{G}(t)$
because the definition of
$\mathcal{G}(t)$
because the definition of
 $H(t)$
does not require
$H(t)$
does not require
 $e_m \in \mathcal{E}(t)$
.
$e_m \in \mathcal{E}(t)$
.
The following proposition gives an upper bound on the decay rate of the SIS model over the temporal network
 $\mathcal G$
.
$\mathcal G$
.
Proposition 13.
Define an
 $(N+M)\times (N+M)$
random matrix
$(N+M)\times (N+M)$
random matrix
 $\mathcal A(t)$
by
$\mathcal A(t)$
by
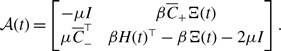 \begin{equation} \mathcal A(t) = \begin{bmatrix} -\mu I &&& \beta \overline C_+\Xi (t) \\ \mu \overline C_-^\top &&& \beta H(t)^\top - \beta \Xi (t) - 2\mu I \end{bmatrix}. \end{equation}
\begin{equation} \mathcal A(t) = \begin{bmatrix} -\mu I &&& \beta \overline C_+\Xi (t) \\ \mu \overline C_-^\top &&& \beta H(t)^\top - \beta \Xi (t) - 2\mu I \end{bmatrix}. \end{equation}
Let
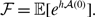 \begin{equation} \mathcal F = \mathbb{E}[e^{h\mathcal A(0)}]. \end{equation}
\begin{equation} \mathcal F = \mathbb{E}[e^{h\mathcal A(0)}]. \end{equation}
Then, the decay rate of the SIS model over the temporal network
 $\mathcal G$
is greater than or equal to
$\mathcal G$
is greater than or equal to
 $-h^{-1}\log \rho (\mathcal F)$
.
$-h^{-1}\log \rho (\mathcal F)$
.
Proof. From Corollary 11, we obtain
 \begin{equation} \frac{d}{dt}\begin{bmatrix} \boldsymbol{{p}}(t)\\ \boldsymbol{{q}}(t) \end{bmatrix} \leq \mathcal A(t) \begin{bmatrix} \boldsymbol{{p}}(t)\\ \boldsymbol{{q}}(t) \end{bmatrix}. \end{equation}
\begin{equation} \frac{d}{dt}\begin{bmatrix} \boldsymbol{{p}}(t)\\ \boldsymbol{{q}}(t) \end{bmatrix} \leq \mathcal A(t) \begin{bmatrix} \boldsymbol{{p}}(t)\\ \boldsymbol{{q}}(t) \end{bmatrix}. \end{equation}
By combining equation (D.20) and the definition of the temporal network given by equation (D.13), we obtain
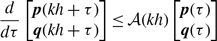 \begin{equation} \frac{d}{d\tau }\begin{bmatrix} \boldsymbol{{p}}(kh+\tau )\\ \boldsymbol{{q}}(kh+\tau ) \end{bmatrix} \leq \mathcal A(kh) \begin{bmatrix} \boldsymbol{{p}}(\tau )\\ \boldsymbol{{q}}(\tau ) \end{bmatrix} \end{equation}
\begin{equation} \frac{d}{d\tau }\begin{bmatrix} \boldsymbol{{p}}(kh+\tau )\\ \boldsymbol{{q}}(kh+\tau ) \end{bmatrix} \leq \mathcal A(kh) \begin{bmatrix} \boldsymbol{{p}}(\tau )\\ \boldsymbol{{q}}(\tau ) \end{bmatrix} \end{equation}
for all
 $k=0, 1, \ldots$
and
$k=0, 1, \ldots$
and
 $\tau \in [0, h)$
, which implies
$\tau \in [0, h)$
, which implies
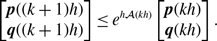 \begin{equation} \begin{bmatrix} \boldsymbol{{p}}((k+1)h)\\ \boldsymbol{{q}}((k+1)h) \end{bmatrix} \leq e^{h\mathcal A (kh)} \begin{bmatrix} \boldsymbol{{p}}(kh)\\ \boldsymbol{{q}}(kh) \end{bmatrix}. \end{equation}
\begin{equation} \begin{bmatrix} \boldsymbol{{p}}((k+1)h)\\ \boldsymbol{{q}}((k+1)h) \end{bmatrix} \leq e^{h\mathcal A (kh)} \begin{bmatrix} \boldsymbol{{p}}(kh)\\ \boldsymbol{{q}}(kh) \end{bmatrix}. \end{equation}
Because the random variables
 $\{\sigma _k\}_{k=0}^\infty$
are independently and identically distributed, we take the expectation with respect to
$\{\sigma _k\}_{k=0}^\infty$
are independently and identically distributed, we take the expectation with respect to
 $\sigma$
in equation (D.22) to obtain
$\sigma$
in equation (D.22) to obtain
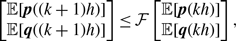 \begin{equation} \begin{bmatrix} \mathbb{E}[\boldsymbol{{p}}((k+1)h)]\\ \mathbb{E}[\boldsymbol{{q}}((k+1)h)] \end{bmatrix} \leq \mathcal F \begin{bmatrix} \mathbb{E}[\boldsymbol{{p}}(kh)]\\ \mathbb{E}[\boldsymbol{{q}}(kh)] \end{bmatrix}, \end{equation}
\begin{equation} \begin{bmatrix} \mathbb{E}[\boldsymbol{{p}}((k+1)h)]\\ \mathbb{E}[\boldsymbol{{q}}((k+1)h)] \end{bmatrix} \leq \mathcal F \begin{bmatrix} \mathbb{E}[\boldsymbol{{p}}(kh)]\\ \mathbb{E}[\boldsymbol{{q}}(kh)] \end{bmatrix}, \end{equation}
which implies
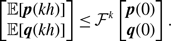 \begin{equation} \begin{bmatrix} \mathbb{E}[\boldsymbol{{p}}(kh)]\\ \mathbb{E}[\boldsymbol{{q}}(kh)] \end{bmatrix} \leq \mathcal F^k \begin{bmatrix} \boldsymbol{{p}}(0)\\ \boldsymbol{{q}}(0) \end{bmatrix}. \end{equation}
\begin{equation} \begin{bmatrix} \mathbb{E}[\boldsymbol{{p}}(kh)]\\ \mathbb{E}[\boldsymbol{{q}}(kh)] \end{bmatrix} \leq \mathcal F^k \begin{bmatrix} \boldsymbol{{p}}(0)\\ \boldsymbol{{q}}(0) \end{bmatrix}. \end{equation}
Now, let
 $\mathcal S \subset \mathbb{R}^{(N+M)\times (N+M)}$
denote the support of the random matrix
$\mathcal S \subset \mathbb{R}^{(N+M)\times (N+M)}$
denote the support of the random matrix
 $\mathcal A(0)$
. Inequality (D.21) shows that, for each sample path, there exists a matrix
$\mathcal A(0)$
. Inequality (D.21) shows that, for each sample path, there exists a matrix
 $X_{k}\in \mathcal S$
dependent on
$X_{k}\in \mathcal S$
dependent on
 $k$
such that
$k$
such that
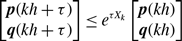 \begin{equation} \begin{bmatrix} \boldsymbol{{p}}(kh+\tau )\\ \boldsymbol{{q}}(kh+\tau ) \end{bmatrix}\leq e^{\tau X_{k}} \begin{bmatrix} \boldsymbol{{p}}(kh)\\ \boldsymbol{{q}}(kh) \end{bmatrix} \end{equation}
\begin{equation} \begin{bmatrix} \boldsymbol{{p}}(kh+\tau )\\ \boldsymbol{{q}}(kh+\tau ) \end{bmatrix}\leq e^{\tau X_{k}} \begin{bmatrix} \boldsymbol{{p}}(kh)\\ \boldsymbol{{q}}(kh) \end{bmatrix} \end{equation}
for all
 $k=0, 1, \ldots$
and
$k=0, 1, \ldots$
and
 $\tau \in [0, h)$
. Because
$\tau \in [0, h)$
. Because
 $\mathcal S$
is finite, the maximum
$\mathcal S$
is finite, the maximum
 $\Gamma = \max _{\substack{0\leq \tau \leq h, X\in \mathcal S}}\left \lVert e^{\tau X} \right \rVert$
exists and is finite. Therefore, equation (D.25) implies
$\Gamma = \max _{\substack{0\leq \tau \leq h, X\in \mathcal S}}\left \lVert e^{\tau X} \right \rVert$
exists and is finite. Therefore, equation (D.25) implies
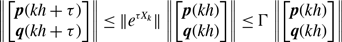 \begin{equation} \left \lVert \begin{bmatrix} \boldsymbol{{p}}(kh+\tau )\\ \boldsymbol{{q}}(kh+\tau ) \end{bmatrix} \right \rVert \leq \lVert e^{\tau X_{k}} \rVert \left \lVert \begin{bmatrix} \boldsymbol{{p}}(kh)\\ \boldsymbol{{q}}(kh) \end{bmatrix} \right \rVert \leq \Gamma \left \lVert \begin{bmatrix} \boldsymbol{{p}}(kh)\\ \boldsymbol{{q}}(kh) \end{bmatrix} \right \rVert \end{equation}
\begin{equation} \left \lVert \begin{bmatrix} \boldsymbol{{p}}(kh+\tau )\\ \boldsymbol{{q}}(kh+\tau ) \end{bmatrix} \right \rVert \leq \lVert e^{\tau X_{k}} \rVert \left \lVert \begin{bmatrix} \boldsymbol{{p}}(kh)\\ \boldsymbol{{q}}(kh) \end{bmatrix} \right \rVert \leq \Gamma \left \lVert \begin{bmatrix} \boldsymbol{{p}}(kh)\\ \boldsymbol{{q}}(kh) \end{bmatrix} \right \rVert \end{equation}
with probability one. By combining equations (D.24) and (D.26), we obtain
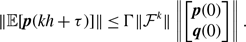 \begin{equation} \lVert \mathbb{E}[\boldsymbol{{p}}(kh+\tau )] \rVert \leq \Gamma \lVert \mathcal F^k \rVert \left \lVert \begin{bmatrix} \boldsymbol{{p}}(0)\\ \boldsymbol{{q}}(0) \end{bmatrix} \right \rVert . \end{equation}
\begin{equation} \lVert \mathbb{E}[\boldsymbol{{p}}(kh+\tau )] \rVert \leq \Gamma \lVert \mathcal F^k \rVert \left \lVert \begin{bmatrix} \boldsymbol{{p}}(0)\\ \boldsymbol{{q}}(0) \end{bmatrix} \right \rVert . \end{equation}
Equation (D.27) implies that
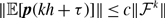 \begin{equation} \| \mathbb{E}[\boldsymbol{{p}}(kh+\tau )] \| \leq c\|\mathcal F^k\| \end{equation}
\begin{equation} \| \mathbb{E}[\boldsymbol{{p}}(kh+\tau )] \| \leq c\|\mathcal F^k\| \end{equation}
for a constant
 $c\gt 0$
. Because
$c\gt 0$
. Because
 \begin{align} \limsup _{t\to \infty }\frac{\log \sum _{i=1}^N \mathbb{E}[p_i(t)]}{t} &\leq \limsup _{t\to \infty }\frac{\log \|\mathbb{E}[\boldsymbol{{p}}(t)]\|}{t}\nonumber \\ &= \lim _{k\to \infty } \sup _{\ell \geq k} \max _{0\leq \tau \lt h}\frac{\log \|\mathbb{E}[\boldsymbol{{p}}(\ell h+\tau )]\|}{\ell h+\tau }\nonumber \\ &\leq \frac{1}{h}\lim _{k\to \infty } \sup _{\ell \geq k} \max _{0\leq \tau \lt h}\frac{\log \|\mathbb{E}[\boldsymbol{{p}}(\ell h+\tau )]\|}{\ell }, \end{align}
\begin{align} \limsup _{t\to \infty }\frac{\log \sum _{i=1}^N \mathbb{E}[p_i(t)]}{t} &\leq \limsup _{t\to \infty }\frac{\log \|\mathbb{E}[\boldsymbol{{p}}(t)]\|}{t}\nonumber \\ &= \lim _{k\to \infty } \sup _{\ell \geq k} \max _{0\leq \tau \lt h}\frac{\log \|\mathbb{E}[\boldsymbol{{p}}(\ell h+\tau )]\|}{\ell h+\tau }\nonumber \\ &\leq \frac{1}{h}\lim _{k\to \infty } \sup _{\ell \geq k} \max _{0\leq \tau \lt h}\frac{\log \|\mathbb{E}[\boldsymbol{{p}}(\ell h+\tau )]\|}{\ell }, \end{align}
inequality (D.28) implies that
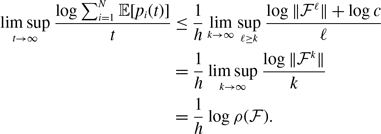 \begin{align} \limsup _{t\to \infty }\frac{\log \sum _{i=1}^N \mathbb{E}[p_i(t)]}{t} &\leq \frac{1}{h}\lim _{k\to \infty } \sup _{\ell \geq k} \frac{\log \|\mathcal F^\ell \| +\log c}{\ell }\nonumber \\ &= \frac{1}{h}\limsup _{k\to \infty }\frac{\log \|\mathcal F^k\|}{k}\nonumber \\ &= \frac{1}{h}\log \rho (\mathcal F). \end{align}
\begin{align} \limsup _{t\to \infty }\frac{\log \sum _{i=1}^N \mathbb{E}[p_i(t)]}{t} &\leq \frac{1}{h}\lim _{k\to \infty } \sup _{\ell \geq k} \frac{\log \|\mathcal F^\ell \| +\log c}{\ell }\nonumber \\ &= \frac{1}{h}\limsup _{k\to \infty }\frac{\log \|\mathcal F^k\|}{k}\nonumber \\ &= \frac{1}{h}\log \rho (\mathcal F). \end{align}
In the last equality in equation (D.30), we used the Gelfand’s formula [Reference Horn and Johnson52, Corollary 5.6.14].
D.3. Epidemic threshold for small
$h$

In this section, we consider the case in which the switching interval,
 $h$
, is sufficiently small. The first-order expansion of matrix
$h$
, is sufficiently small. The first-order expansion of matrix
 $\mathcal F$
with respect to
$\mathcal F$
with respect to
 $h$
yields
$h$
yields
 \begin{equation} \mathcal F = I + \mathbb{E}[h{\mathcal A(0)}] + O(h^2) = I + h \mathbb{E}[{\mathcal A(0)}] + O(h^2). \end{equation}
\begin{equation} \mathcal F = I + \mathbb{E}[h{\mathcal A(0)}] + O(h^2) = I + h \mathbb{E}[{\mathcal A(0)}] + O(h^2). \end{equation}
Let us assume that matrix
 $\mathbb{E}[{\mathcal A(0)}]$
is irreducible. Let
$\mathbb{E}[{\mathcal A(0)}]$
is irreducible. Let
 $\lambda _{\max }$
denote the real eigenvalue of
$\lambda _{\max }$
denote the real eigenvalue of
 $\mathbb{E}[{\mathcal A(0)}]$
with the largest real part. Then, by the Perron–Frobenius theorem and the differentiability of the eigenvalues of matrices [Reference Horn and Johnson52, Theorem 6.3.12], we obtain
$\mathbb{E}[{\mathcal A(0)}]$
with the largest real part. Then, by the Perron–Frobenius theorem and the differentiability of the eigenvalues of matrices [Reference Horn and Johnson52, Theorem 6.3.12], we obtain
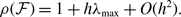 \begin{equation} \rho (\mathcal F) = 1 + h \lambda _{\max } + O(h^2). \end{equation}
\begin{equation} \rho (\mathcal F) = 1 + h \lambda _{\max } + O(h^2). \end{equation}
Therefore,
 $h^{-1}\log \rho (\mathcal F) = \lambda _{\max }=O(h)$
. The combination of this asymptotic evaluation and Proposition 13 suggests that the epidemic threshold is the value of
$h^{-1}\log \rho (\mathcal F) = \lambda _{\max }=O(h)$
. The combination of this asymptotic evaluation and Proposition 13 suggests that the epidemic threshold is the value of
 $\beta/\mu$
at which
$\beta/\mu$
at which
 $\lambda _{\text{max}} = 0$
.
$\lambda _{\text{max}} = 0$
.
We rewrite the epidemic threshold in terms of the spectral radius of the relevant matrices. As in the proof of Corollary 5 in ref. [Reference Masuda and Ogura47], we rewrite the random matrix
 $\mathcal A(0)$
as
$\mathcal A(0)$
as
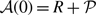 \begin{equation} \mathcal A(0) = R + \mathcal P \end{equation}
\begin{equation} \mathcal A(0) = R + \mathcal P \end{equation}
with a constant matrix
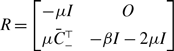 \begin{equation} R = \begin{bmatrix} -\mu I &&& O \\[4pt] \mu \bar C_{-}^\top &&& -\beta I - 2\mu I \end{bmatrix} \end{equation}
\begin{equation} R = \begin{bmatrix} -\mu I &&& O \\[4pt] \mu \bar C_{-}^\top &&& -\beta I - 2\mu I \end{bmatrix} \end{equation}
and a random matrix
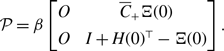 \begin{equation} \mathcal P = \beta \begin{bmatrix} O &&& \overline C_+\Xi (0) \\[4pt] O &&& I + H(0)^\top - \Xi (0) \end{bmatrix}. \end{equation}
\begin{equation} \mathcal P = \beta \begin{bmatrix} O &&& \overline C_+\Xi (0) \\[4pt] O &&& I + H(0)^\top - \Xi (0) \end{bmatrix}. \end{equation}
Then, we obtain the decomposition
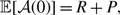 \begin{equation} \mathbb{E}[\mathcal A(0)] = R + P, \end{equation}
\begin{equation} \mathbb{E}[\mathcal A(0)] = R + P, \end{equation}
where
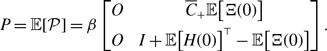 \begin{equation} P = \mathbb{E}[\mathcal P] = \beta \begin{bmatrix} O &&& \overline C_+\mathbb{E}\bigl [\Xi (0)\bigr ] \\[4pt] O &&& I +\mathbb{E}\bigl [H(0)\bigr ]^\top - \mathbb{E}\bigl [\Xi (0)\bigr ] \end{bmatrix}. \end{equation}
\begin{equation} P = \mathbb{E}[\mathcal P] = \beta \begin{bmatrix} O &&& \overline C_+\mathbb{E}\bigl [\Xi (0)\bigr ] \\[4pt] O &&& I +\mathbb{E}\bigl [H(0)\bigr ]^\top - \mathbb{E}\bigl [\Xi (0)\bigr ] \end{bmatrix}. \end{equation}
Matrix
 $R$
is Metzler, and all the eigenvalues of
$R$
is Metzler, and all the eigenvalues of
 $R$
have negative real parts. Matrix
$R$
have negative real parts. Matrix
 $P$
is nonnegative because each diagonal of
$P$
is nonnegative because each diagonal of
 $\Xi (0)$
is a
$\Xi (0)$
is a
 $\{0, 1\}$
-valued random variable. Therefore, Theorem 2.11 in ref. [Reference Damm and Hinrichsen53] implies that
$\{0, 1\}$
-valued random variable. Therefore, Theorem 2.11 in ref. [Reference Damm and Hinrichsen53] implies that
 $\lambda _{\max } \lt 0$
if and only if
$\lambda _{\max } \lt 0$
if and only if
 $\rho (R^{-1} P) \lt 1$
. Because
$\rho (R^{-1} P) \lt 1$
. Because
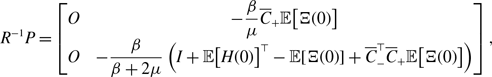 \begin{equation} R^{-1} P = \begin{bmatrix} O &&& -\dfrac \beta \mu \overline C_+\mathbb{E}\bigl [\Xi (0)\bigr ] \\[4pt] O &&& -\dfrac \beta{\beta + 2\mu }\left (I + \mathbb{E}\bigl [H(0)\bigr ]^\top - \mathbb{E}[\Xi (0)] + \overline C_{-}^\top \overline C_+\mathbb{E}\bigl [\Xi (0)\bigr ] \right ) \end{bmatrix}, \end{equation}
\begin{equation} R^{-1} P = \begin{bmatrix} O &&& -\dfrac \beta \mu \overline C_+\mathbb{E}\bigl [\Xi (0)\bigr ] \\[4pt] O &&& -\dfrac \beta{\beta + 2\mu }\left (I + \mathbb{E}\bigl [H(0)\bigr ]^\top - \mathbb{E}[\Xi (0)] + \overline C_{-}^\top \overline C_+\mathbb{E}\bigl [\Xi (0)\bigr ] \right ) \end{bmatrix}, \end{equation}
one obtains
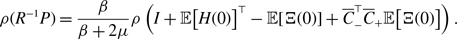 \begin{equation} \rho (R^{-1} P) = \frac{\beta }{\beta +2\mu }\rho \left (I + \mathbb{E}\bigl [H(0)\bigr ]^\top - \mathbb{E}[\Xi (0)] + \overline C_-^\top \overline C_+\mathbb{E}\bigl [\Xi (0)\bigr ] \right ). \end{equation}
\begin{equation} \rho (R^{-1} P) = \frac{\beta }{\beta +2\mu }\rho \left (I + \mathbb{E}\bigl [H(0)\bigr ]^\top - \mathbb{E}[\Xi (0)] + \overline C_-^\top \overline C_+\mathbb{E}\bigl [\Xi (0)\bigr ] \right ). \end{equation}
Equation (D.39) implies that
 $\rho (R^{-1} P) \lt 1$
if and only if
$\rho (R^{-1} P) \lt 1$
if and only if
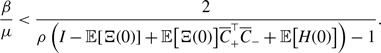 \begin{equation} \frac{\beta }{\mu } \lt \frac{2}{\rho \left (I - \mathbb{E}[\Xi (0)] + \mathbb{E}\bigl [\Xi (0)\bigr ] \overline C_+^\top \overline C_{-} + \mathbb{E}\bigl [H(0)\bigr ]\right ) - 1}. \end{equation}
\begin{equation} \frac{\beta }{\mu } \lt \frac{2}{\rho \left (I - \mathbb{E}[\Xi (0)] + \mathbb{E}\bigl [\Xi (0)\bigr ] \overline C_+^\top \overline C_{-} + \mathbb{E}\bigl [H(0)\bigr ]\right ) - 1}. \end{equation}
The right-hand side of equation (D.40) gives the epidemic threshold, which we can further as follows. Equations (D.15), (D.16) and (D.17) imply that
 $H(t) = \Xi (t) \overline{H}$
, where
$H(t) = \Xi (t) \overline{H}$
, where
 $\overline{H}$
is the non-backtracking matrix of the time-aggregated graph. (Note that this notation should not cause confusions with the definition of
$\overline{H}$
is the non-backtracking matrix of the time-aggregated graph. (Note that this notation should not cause confusions with the definition of
 $\overline{H}$
given by equation (D.2).) Therefore, we rewrite equation (D.40) as
$\overline{H}$
given by equation (D.2).) Therefore, we rewrite equation (D.40) as
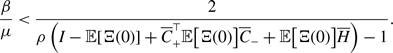 \begin{equation} \frac{\beta }{\mu } \lt \frac{2}{ \rho \left (I - \mathbb{E}[\Xi (0)] + \overline C_{+}^\top \mathbb{E}\bigl [\Xi (0)\bigr ] \overline C_{-} + \mathbb{E}\bigl [\Xi (0) \bigr ] \overline H \right ) - 1}. \end{equation}
\begin{equation} \frac{\beta }{\mu } \lt \frac{2}{ \rho \left (I - \mathbb{E}[\Xi (0)] + \overline C_{+}^\top \mathbb{E}\bigl [\Xi (0)\bigr ] \overline C_{-} + \mathbb{E}\bigl [\Xi (0) \bigr ] \overline H \right ) - 1}. \end{equation}
Therefore, the epidemic threshold, i.e., the right-hand side of equation (D.41), only depends on the expectation of
 $\Xi (0)$
, i.e.,
$\Xi (0)$
, i.e.,
 $\mathbb{E}[\Xi (0)]$
. We keep
$\mathbb{E}[\Xi (0)]$
. We keep
 $\mathbb{E}[\Xi (0)]$
constant across the different models to inspect the effect of different amounts of concurrency on epidemic spreading under the condition that the aggregate network is the same across the comparisons. Therefore, with this analysis, we do not find a difference in the epidemic threshold across our different models.
$\mathbb{E}[\Xi (0)]$
constant across the different models to inspect the effect of different amounts of concurrency on epidemic spreading under the condition that the aggregate network is the same across the comparisons. Therefore, with this analysis, we do not find a difference in the epidemic threshold across our different models.











































































 Open access
Open access