



Introduction
Lymphatic filariasis (LF) is a major public health problem in 73 countries of Africa, Asia, Oceania and the Americas. LF affects nearly 68 million people. Furthermore, 1.1 billion people are living at the risk of infection [Reference Ramaiah and Ottesen1, 2]. After malaria, filariasis is the second most common vector-borne disease [Reference Ottesen3]. Approximately 36 million people live with the disabling effects of LF, 17 million people with chronic lymphedema and another 19 million men with hydrocele [Reference Ramaiah and Ottesen1]. The global programme to eliminate lymphatic filariasis (GPELF) was initiated in the year 2000 with the aim to eliminate LF as a public health problem by 2020, by interrupting the transmission of the parasite through an annual Mass Drug Administration (MDA) programme [Reference Ottesen3]. During the MDA programme, the populations at risk of filariasis are treated annually with a single dose of ivermectin and albendazole (IVM + ALB) in sub-Saharan Africa or with diethylcarbamazine and albendazole (DEC + ALB) in other regions for a minimum period of 5 years.
LF is a vector-borne parasitic disease mainly caused by the parasitic nematodes Wuchereria bancrofti, Brugia malayi and Brugia timori, and transmitted by the Culex or Anopheles host vectors. Filaria parasites damage the lymphatic system and cause debilitating swelling of the limbs, known as lymphedema or elephantiasis. Filariasis is prevalent in 18 states and the Union Territories of India. Approximately 600 million people reside with the risk of filariasis in 250 districts, contributing to over 40% of the global LF burden [Reference Martindale4]. In recent years, India has made a significant progress towards the elimination of LF [5]. As per the recommendation of the World Health Organization, five rounds of MDA programme (65% of coverage) with the DEC + ALB drug combination was successfully administered in LF endemic districts [5].
The transmission of filariasis is influenced by environmental, socio-economic and demographic factors and lack of knowledge about the disease spectrum. LF and hydrocele severely affect the poor populations living in low socio-economic conditions. Acute and chronic cases of LF severely affect the economy output and increase poverty in a community [6]. Therefore, prediction of the onset of filariasis, well before its occurrence, significantly improves prevention success. Hence, in the present study, data mining/machine learning (ML) algorithms are employed to predict filariasis, based on epidemiological and socio-economic data.
Computational models are very popular in many disciplines and are extensively used for epidemiological data classification, disease diagnosis and prediction too. Data mining is an interdisciplinary area combining ML, intelligent information systems, database systems, statistics and operations research. Data mining helps in extracting knowledge from data that helps in intelligent decision making. It has been applied to a variety of problems in healthcare in order to improve decision making. Based on the foregoing discussion, our problem statement is defined in the next sub-section.
Problem statement
LF is commonly known as elephantiasis and is a profoundly disfiguring disease. The chronic form of LF leads to social stigma and social exclusion, which adversely impacts the mental wellbeing of afflicted persons [Reference Bailey, Merritt and Tediosi7]. Studies indicate that 94% of the countries with the lowest Human Development Index (HDI) are endemic for LF [Reference Durrheim8]. Important risk factors for vector-borne diseases are ethnicity, occupation, education, awareness, living standards and the socio-economic status of a family [Reference Upadhyayula9, Reference Kreuels10]. Based on the studies carried out in Philippines and Guyana, it has been observed that there is a strong association between endemicity of LF and socio-economic status [Reference Tyrell11]. However, in other countries where LF is endemic, very little research has been conducted in order to understand the role of socio-economic factors on filariasis. Hence, the present study focuses on understanding the role of socio-economic factors on LF and on predicting the occurrence of LF using various ML methods. In this connection, longitudinal studies are carried out to collect epidemiological and socio-economic data on LF from Karimnagar district of Telangana. ML tools such as Naïve Bayes (NB), J48, logistic model tree (LMT), probabilistic neural network (PNN), JRip and gradient boosting machine (GBM) were employed to predict LF.
Contributions
The contributions of this study are as follows:
• We developed a dataset comprising of epidemiological and socio-economic data for 30 villages of Karimnagar district of Telangana (then in united Andhra Pradesh) from 2004 to 2007.
• We obtained important ‘if-then’ decision rules in order to develop an early warning system for the occurrence of LF.
Literature review
ML has gained immense popularity and is being exploited in several disciplines including epidemiology and public health. Due to the increase in clinical datasets, researchers applied ML techniques extensively for the diagnosis and prediction of various disease outbreaks [Reference Wiens and Shenoy12]. Dhamodharan [Reference Dhamodharan13] predicted liver disease using Bayesian classification through NB and functional tree algorithms. Vijayarani and Sudha [Reference Vijayarani and Sudha14] applied LMT, multilayer perception (MLP) and sequential minimal optimisation (SMO) algorithms to predict heart disease. Similarly, Dbritto et al. considered three different classification methods, namely NB, logistic regression and support vector machine (SVM) for predicting heart disease [Reference Dbritto, Raghavan and Joseph15]. Adamker et al. [Reference Adamker16] considered demographic and clinical data to predict hospitalisation and Shigellosis clinical diagnosis using logistic regression, SVM and neural networks. They reported F-measures of 97.4% and 96.1% for predicting hospitalisation and Shigellosis clinical diagnosis, respectively.
ML techniques are effectively used for the diagnosis and prediction of Ebola based on clinical data [Reference Colubri17]. Han et al. applied ML on rodent species that carry zoonotic pathogens which cause infection to humans [Reference Han18]. Various ML algorithms such as support vector regression, step-down linear regression, gradient boosted regression tree, negative binomial regression, least absolute shrinkage and selection operator linear regression model and generalised additive model were employed to forecast dengue incidence in China [Reference Guo19]. Furthermore, MLP, SVM and NB were employed to classify Parkinson's disease-afflicted patients and healthy persons [Reference Baby, Saji and Kumar20, Reference Gao21]. Patil [Reference Patil22] proposed a hybrid prediction model for the prediction of type-2 diabetes in patients. He employed a K-means algorithm to select relevant samples, which were further classified using the C4.5 algorithm, and he reported an accuracy of 92.38% [Reference Patil22].
Similarly, maximum entropy-based niche modelling technique [Reference Phillips, Anderson and Schapire23] was applied to assess the potential distribution of LF in Africa in future climate change scenarios. Taking a cue from these studies, the present study focuses on predicting LF based on socio-economic conditions and to help implement better prevention and control measures to mitigate LF.
Proposed approach
Predictive classification modelling learns a function from training data and aims to make few errors possible when tested with previous unseen data. A large number of classification algorithms were developed and used in a variety of medical applications [Reference Wang, Minku and Yao24, Reference Menardi and Torelli25]. Medical data often suffer from imbalance issue that severely affects the classification results. To overcome this problem, a balancing method can be applied to the dataset. Popular balancing techniques include undersampling, oversampling and a hybrid of both. Undersampling refers to randomly removing samples from the majority class. Oversampling is the process of replicating minority class samples multiple times. The process of balancing data by performing undersampling and oversampling in tandem is called hybrid sampling [Reference Santosol26]. The current study is based on the classification of filariasis dataset using NB, J48, LMT, PNN, JRip and GBM. These algorithms are employed using WEKA and NeuroShell 2.0. Feature subset selection was performed using t-statistic. The performance of these algorithms is reported in terms of sensitivity, specificity, accuracy and area under ROC curve (AUC).
Methods
The experiment was divided into six steps which involve data collection, data pre-processing, data partitioning, data balancing, model building and model assessment (Fig. 1). Pseudo code of the whole process is presented as Algorithm 1 (Supplementary information).
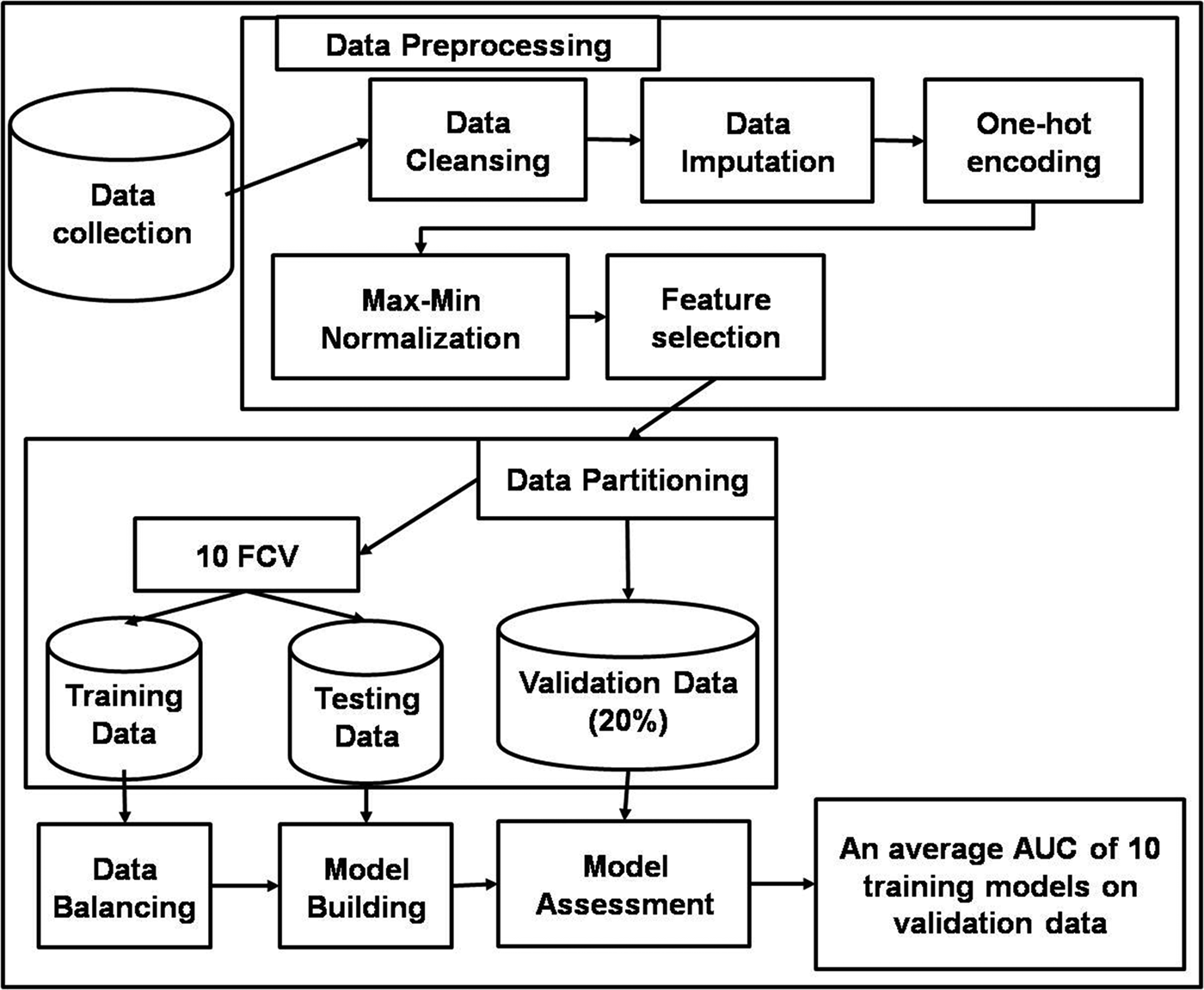
Fig. 1. Schematic diagram of the proposed methodology.
Data collection
Study area
The study was undertaken in 30 villages of Karimnagar district, Telangana (the then Andhra Pradesh) from 2004 to 2007. Karimnagar district lies 18°25′48″N, 79°9′90″E and is situated on the banks of river Manair, a tributary of the Godavari. The population of surveyed villages (30 villages) included either agriculturists or people engaged as labourers in the agricultural activity. The topography of the district is generally hilly and the altitude varies from 117 to 431 m between the villages where the study was undertaken. Karimnagar experiences dry climatic conditions with hot summers and cool winter. The southwest monsoon provides maximum rainfall to Karimnagar district.
Data details
Epidemiological and socio-economic data were collected from the respondents/participants selected from all parts of the villages using a stratified random sampling methodology. The data were collected simultaneously by involving two sets of health volunteers. The socio-economic details were collected only from people who were involved in the epidemiological study.
Epidemiological data
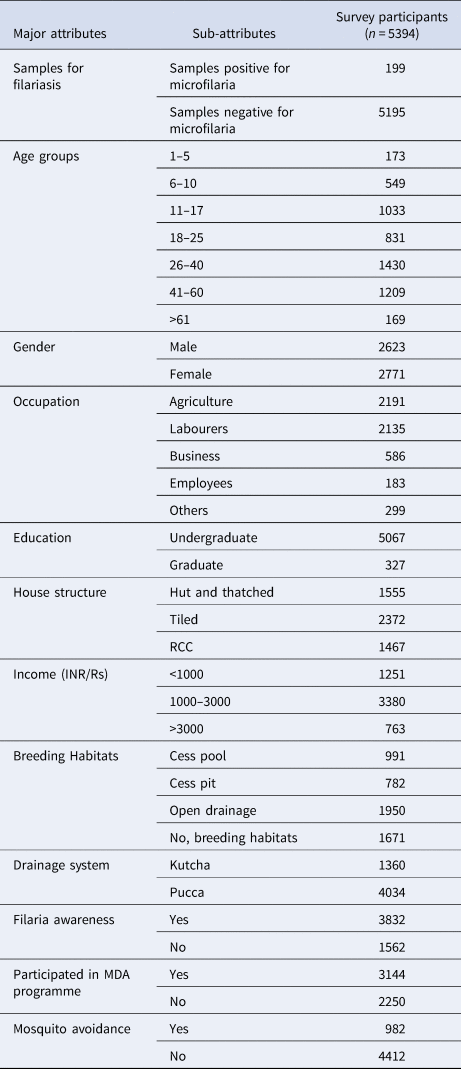
Using the finger prick method, 20 µl of the blood sample was collected from randomly selected 40 households per village (five persons from each household; 40 × 5 = 200 samples) between 20.00 and 23.00 h. During the epidemiological survey, 5394 blood smears were collected (Table 1) from 30 villages (approximately 200 samples from each village), stained with JSB-II (Jaswant-Singh-Bhattacherji) stain and then checked under a microscope for microfilaria (MF) [Reference Mutheneni27].
Table 1. Epidemiological and socio-economic attributes for the prediction of filariasis
Socio-economic data
Socio-economic factors such as age, gender, use of mosquito avoidance measures (e.g. bed net, coils or no protection measures), awareness on filariasis, number of children in a family, place of residence, family's monthly income, house structure (living in a hut, thatched, tiled and reinforced cement concrete (RCC) structure), education details, occupation information, vector breeding habitats and participation in MDA programme have a possible influence on filariasis. The data were collected through interviewing the head of the family and other family members with a structured questionnaire (Table1).
Both epidemiological and socio-economic data were combined by using SQL query. From the combined table attributes, namely age, sex, house type, breeding habitat, drainage system, mosquito avoidance, awareness on filariasis, MDA and the target/class variable of filariasis were selected.
Data pre-processing
The merged datasets based on the head of the family as a common factor were cleaned. We removed discrepancy in the data points such as extra spaces before or after categorical values, uses of mixed cases and unnecessary symbols. Subsequently, normalisation was performed to bring the data in the range of [0, 1] using max-min normalisation. The details of feature selection, data partitioning and data balancing are presented in the following sections.
Feature selection
Feature selection is mainly used to select a subset of relevant features for building a robust learning model. Five feature selection methods namely gain ratio (GR), information gain, χ 2, correlation and t-statistic-based feature selection methods were employed to select the most relevant features. Out of these feature selection methods, the GR feature selection method yielded the best performance. This method is briefly discussed here with the corresponding results.
GR feature selection
GR is a non-symmetrical measure and is a different form of the information gain that reduces bias [Reference Hall and Smith28]. GR enhances information gain because it offers a normalised score of a feature's contribution to an optimal information gain, based on classification decision. GR is used in an iterative process where smaller sets of features are selected in an incremental fashion. These iterations terminate when a predefined number of features remain. GR is used because one of the disparity measures and high GR for the selected feature implies that the feature is highly discriminative and useful for further classification. GR was initially used in the decision tree (C4.5). It applies normalisation to information gain score by utilizing a split information value [Reference Quinlan29]. The GR of a feature (A) can be computed as follows:
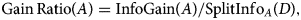
where InfoGain (A) is computed using the following formula:
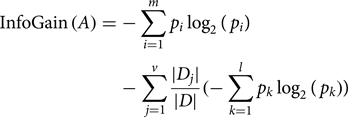
and SplitinfoA 0(D) is computed using the following formula:
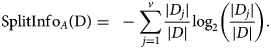
Here, $-\sum\nolimits_{i = 1}^m {p_i{\log} _2\lpar {p_i} \rpar \;}$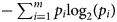 represents the entropy of an attribute A with respect to the whole dataset, {D 1, D 2, D 3, …, D v} is the set of samples formed with respect to v distinct values of A, |D j| is the cardinality of D j, |D| is the cardinality of the whole dataset and $\left( {-\sum\nolimits_{k = 1}^l {p_klog_2(p_k)}} \right)$
represents the entropy of an attribute A with respect to the whole dataset, {D 1, D 2, D 3, …, D v} is the set of samples formed with respect to v distinct values of A, |D j| is the cardinality of D j, |D| is the cardinality of the whole dataset and $\left( {-\sum\nolimits_{k = 1}^l {p_klog_2(p_k)}} \right)$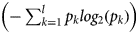 represents the entropy of A with respect to D j for the l number of classes available in D j [Reference Ravi and Ravi30].
represents the entropy of A with respect to D j for the l number of classes available in D j [Reference Ravi and Ravi30].
Data partitioning and balancing
The whole dataset was divided into three parts for training, testing and validation, respectively. We separated 20% of the original data using stratified sampling as a validation test. The validation test was considered as unseen data for the models developed to report classification measures. The remaining 80% of the data were used to experiment under 10-Fold Cross Validation (10-FCV) framework. For the purpose of 10-FCV, we employed stratified sampling to maintain the ratio of positive and negative classes in the training as well as the test part identical to that of the original dataset. To improve the classification performance, different kinds of balancing techniques were employed on the training data in each fold. SMOTE and NON-SMOTE (oversampling, undersampling and hybrid sampling) techniques were applied for data balancing. The SMOTE technique was performed in R language [Reference Chawla31, Reference Torgo32] and the non-SMOTE technique was performed through replication and removal of samples. In the oversampling method, the minority sample size was replicated to 100%, 200%, 300% and 400%, whereas 6% and 22% samples of majority classes were removed in the undersampling method. Here, the majority and minority classes belong to positive and negative classes, respectively.
Model building
WEKA is a freely available open-source data mining tool implemented in Java. It consists of standard ML/data mining algorithms. Pre-processing and classification algorithms of WEKA generated insightful and useful knowledge from the filariasis dataset. Various classification algorithms such as NB, LMT, PNN, J48 (C4.5), classification and regression tree (CART) and JRip (repeated incremental pruning to produce error reduction (RIPPER)) were employed to predict filariasis. The techniques are briefly described below:
Naïve Bayes
NB is an effective method for text classification [Reference McCallum and Nigam33]. It is a probabilistic classifier model based on the Bayes rule with an assumption of conditional independence of features [Reference John and Langley34]. It learns rapidly in various supervised classification problems.
Bayes' theorem explains the relationship between class variable ‘y’ and dependent features {x 1, …, x n} as follows:
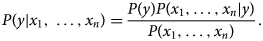
Using the naïve conditional independence assumption, the above equation can be written as
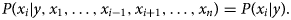
For all i, the given relationship can be simplified as

In the given equation, P(x 1, …, x n) is constant given the input. Hence, we can use the following classification rule:


We use maximum a posteriori estimation to estimate P(y) and P(x i|y).
Logistic model tree
LMT consists of a standard decision tree structure with logistic regression functions [Reference Landwehr, Hall and Frank35]. LMT starts to create a decision tree by fitting a simple linear regression function to the root node using the LogitBoost algorithm. This process is repeated for all child nodes in an iterative manner until the stopping criterion is met. After building the tree, pruning is performed using a CART algorithm.
Probabilistic neural network
PNN is a powerful classification model. The advantages of PNN over a back-propagation network include faster learning and effectiveness on small datasets [Reference Specht36]. The architecture of PNN consists of four layers, namely input, pattern, summation and output layers. The input layer directly provides samples to the pattern layer which then calculates Z = X.W, where X is the input vector and W is the weight vector. Then, the pattern layer applies a Gaussian activation function on Z. The summation unit sums the probabilities of different categories into two groups for binary classification purposes. The output unit determines the class of a sample based on the ratio of C A and C B. Here, C A is the sum of a prior probability of class A, the loss function of class A and the number of samples in the class B. Similarly, C B is the sum of a prior probability of class B, the loss function of class B and the number of samples in class A.
J48 (C4.5)
J48 is a slightly modified form and an open source Java implementation of the C4.5 algorithm in WEKA [Reference Cohen37]. C4.5 generates a classification-decision tree based on a given set of labelled input data by recursive partitioning of data. The decision tree is grown using a depth-first strategy. The algorithm considers all the possible tests that can split the dataset and selects a test that gives the best information gain. For each discrete attribute, one test with an outcome of as many as the number of distinct values of the attribute is considered. For each continuous attribute, binary tests involving every distinct value of the attribute are considered. To compute information gain for each binary test, the training dataset belonging to the node in consideration is sorted for the values of the continuous attribute. The information gain of the binary cut based on each distinct value is calculated in one scan of the sorted data. This process is repeated for each continuous attribute.
Classification and regression tree
CART is one of the methods used to generate decision trees [Reference Breiman38]. CART generates/induces either classification or regression trees, depending on the nature, i.e. categorical or numerical, of the target variable. CART performs binary splitting to grow a large tree on the training data. Gini index or entropy is considered to split the node, which is the measure of node purity. A smaller value indicates that the node contains samples belonging to the same class. Weka provides the implementation of simple CART algorithm, which stops growing tree when each terminal node has less than the pre-specified number of observations. The class of the test sample is decided based on the class of the majority of samples of the given terminal node. This algorithm is also suitable for datasets with missing values.
JRip
JRip is a classification method in WEKA and is abbreviated as the RIPPER algorithm [Reference Friedman39]. RIPPER algorithm can generate meaningful classification rules based on historical data. Classes are examined according to the increasing size and an initial set of rules for a class is generated using the incremental reduced error method. It proceeds by treating all the examples of a judgement in the training data as a class. In the next step, it finds a set of rules that covers all the members of that class. Thereafter, it proceeds to the next class and does the same, repeating this until all classes have been covered.
Gradient boosting machine
GBM is an ensemble of weak prediction methods to perform classification and regression [Reference Friedman39]. It performs bias-variance trade-off to maintain the balance between bias and variance. The loss function of GBM comprises a function to model errors. In GBM, many decision trees of small heights are fitted one after another without changing the existing trees in the model. Here, a decision tree is considered as a weak learner. A gradient descent method is employed to minimise the loss function when adding the trees. For every iteration, the parameters of the trees are estimated in such a way that each tree reduces the residual loss. This process is called functional gradient descent. In this way, the output of a new tree is added to the output of the existing sequence of trees to improve the final output of the model. GBM is prone to overfitting, which is prevented by regularisation.
Model assessment criteria
The performance of all the seven models is assessed by using the following measures and are reported under the 10-FCV framework.

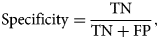
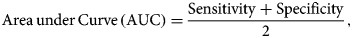
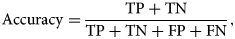
where TP, TN, FN and FP are the acronyms of true positive, true negative, false negative and false positive, respectively.
Results
During the filariasis survey, blood samples of 5394 people were collected from 30 villages of Karimnagar district, of which 2771 (51.41%) were females and 2623 (48.68%) were males. Among the 5394 blood samples, 199 were found positive for MF (3.7%) and the rest of them were found to be negative for filariasis (Table 1). Both epidemiological and socio-economic data were merged based on the name of the head of the family. After merging, only 1041 records remained, comprising 890 (85.49%) of negative cases and 151 (14.15%) of positive cases. These 1041 records were pre-processed and normalised for model development. Seven classification models namely NB, J48, JRip, LMT, CART, GBM and PNN were applied to the unbalanced data without feature selection and the results are presented in Table 2.
Table 2. The results obtained for imbalanced dataset without feature selection
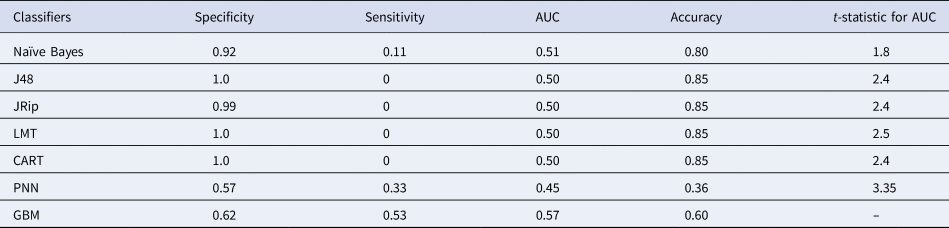
Among all ML models, GBM yielded the best AUC with 57%. To test for statistical significance, t test was performed on AUC between GBM and each of the rest of the classifiers at 1% significance level and 18 degrees of freedom. Based on the t test, GBM outperformed PNN in a statistically significant way. However, the performances of the remaining classifiers are similar to that of GBM. The performance of GBM varies for each fold, because the model depends on various parameters such as the number of decision trees, the height of the tree and the number of samples per leave node. These parameters are changed for each fold. Hence, GBM is not statistically different from the other five classifiers.
Tables 3 and 4 indicate that feature selection methods and balancing techniques helped in increasing the classification performance. We performed oversampling of minority class by 100% (Table 3), 200%, 300% and 400% (Table 4) samples but that did not yield good results. We also performed hybrid sampling that comprises oversampling of minority class by 200% and undersampling of majority class by 22% but the results were, again, not satisfactory. The percentages of undersampling and oversampling depend on the dataset size and class proportions. PNN yielded the highest AUC and sensitivity compared to the rest of the classifiers and it statistically outperformed CART and JRip. Furthermore, PNN yielded statistically identical results to those of NB, J48, LMT and GBM. The study indicates that feature selection and balancing technique could not improve the performances of CART and JRip, whereas the performances of the rest of the classifiers improved using 100% oversampling. It also indicates that the minor improvement in the number of samples of minority class cannot affect the performance of CART and JRip.
Table 3. Results obtained using 100% oversampling and gain ratio feature selection
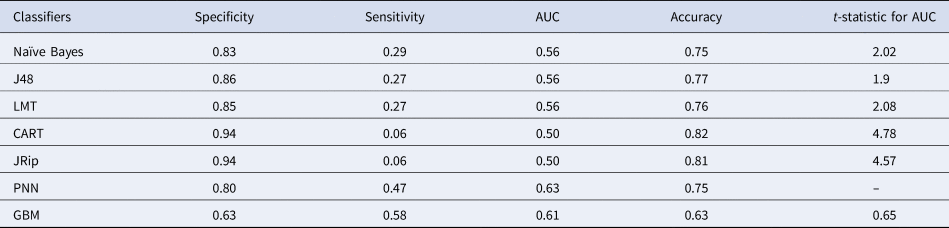
Table 4. Results obtained using 400% oversampling and gain ratio feature selection
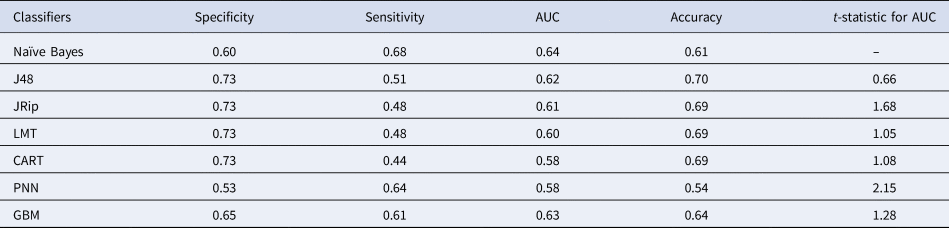
Table 4 presents the results obtained using 400% oversampling with GR feature selection based on 12 features, namely MDA, breeding habitats-open drainage and cesspit, no breeding habitats, kutcha drainage system, pucca drainage system, mosquito avoidance measures, tiled house, RCC house, awareness and gender. NB yielded the best sensitivity and AUC compared to the other models. PNN yielded the second-best sensitivity. NB and PNN do not yield any rules, whereas J48 yielded classification rules and an AUC of 62% (Table 4). The number of rules generated by the J48 algorithm is presented in Figure 2. CART algorithm yielded the best result using default parameters with an AUC of 58% (Table 4). Default parameter set includes a minimal number of instances at the terminal node 2, cost-complexity pruning set to true and heuristics method for binary split set to true. The rules obtained by using CART are presented in Figure 3. The first two rules of Figure 3 can be interpreted as follows:
(i) If MDA is false and X.drainage.system.kutcha. is false and X.breeding.habitats.cess.pool. is false and sc.age < 11.74 years and X.house.type.R.C.C. is false, then the sample belongs to the positive class. Here, the number 8.0 in (8.0/0.0) indicates the number of training samples falling in positive class and no test sample belonged to the positive class.
(ii) If MDA is false and X.drainage.system.kutcha. is false and X.breeding.habitats.cess.pool. is false and sc.age < 11.74 years and X.house.type.R.C.C. is true, then the sample belongs to negative class. Based on this rule, two training samples belonged to negative class and no test sample belonged to negative class.

Fig. 2. Tree generated using J48 algorithm.

Fig. 3. Decision rules obtained using CART.
To check for statistical significance, t test was performed between AUC obtained using NB and other classification models. It indicated that all methods are statistically similar.
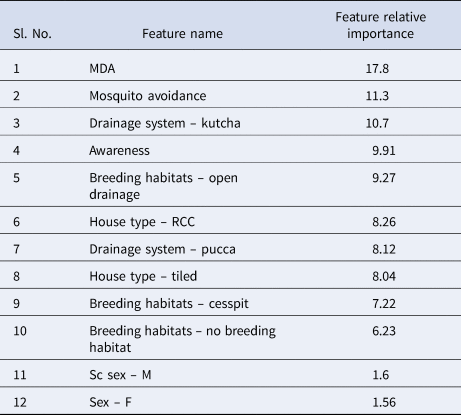
Table 5 explains the test sample dataset of filariasis based on the classification rules presented in Figure 4 and found that the ‘neg’ class was predicted accurately as ‘neg’ class by the model. In the present study, the filariasis data were subjected to classification by removing one feature at a time to test the feature capabilities. The sensitivity of the classifier decreased, which indicates the importance of the feature for filariasis prediction. After removing the feature, the model displayed a larger decrease in insensitivity when compared to the sensitivity of NB. This shows that the ‘breeding habitats’ feature has the highest impact on filariasis classification among all the features (Table 6). Similarly, relative feature importance obtained from Gini information and GBM shows that MDA, mosquito avoidance, drainage system, awareness, house type, breeding habitats and gender are important features (Table 7). ROC area under the curve is generated for the test data of onefold of 10-FCV and depicted in Figure 5.

Fig. 4. Rules generated by the J48 algorithm.
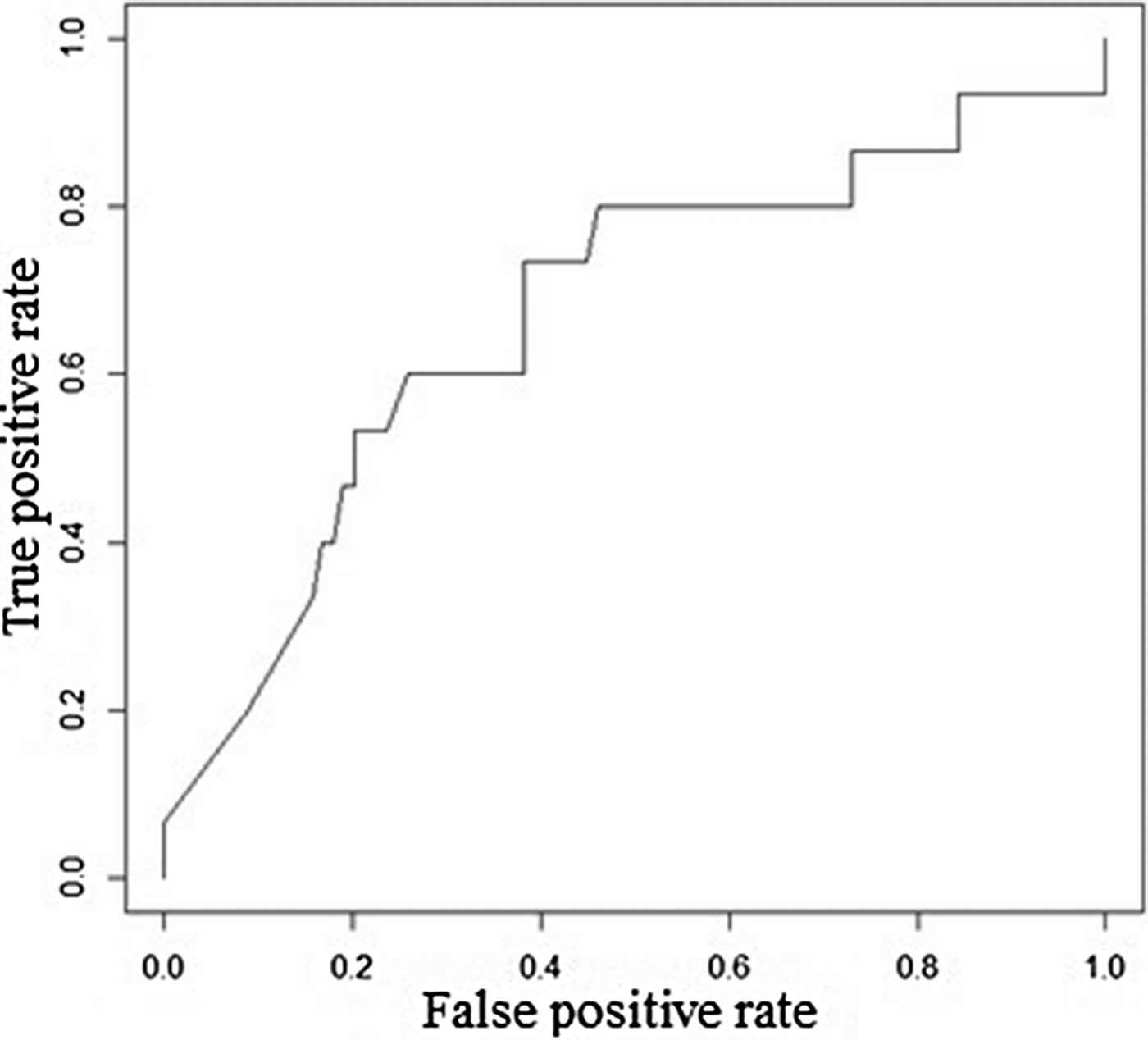
Fig. 5. ROC area under the curve for GBM.
Table 5. Test sample dataset
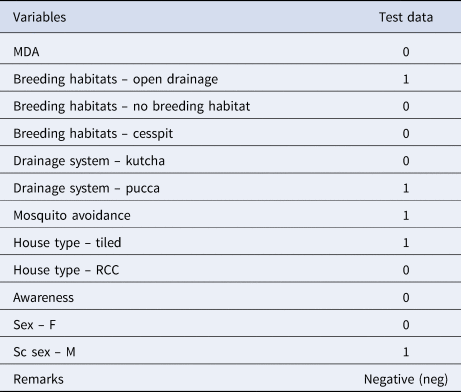
Table 6. Results obtained using a different combination of variables
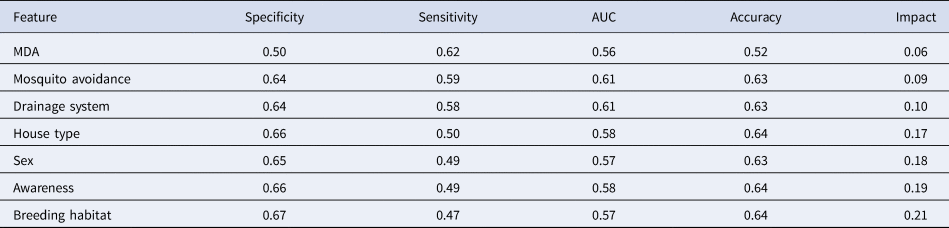
Table 7. Relative features importance obtained using GBM
Discussion
LF is a major public health concern in India. Based on the present report, LF is widely spread in Karimnagar district of Telangana. The Government of India has launched the MDA programme since 2004 in endemic districts but, still, some sporadic cases are reported in the country. This may be due to many intrinsic factors such as lack of disease awareness, low socio-economic status, vector breeding habitats in and around the house and non-participation in mass drug programme [Reference Upadhyayula9]. Hence, the present study is focused on predicting the occurrence of filariasis using various ML algorithms. ML algorithms are used extensively in epidemiological and species distribution studies [Reference Machado-Machado40, Reference Mutheneni41]. ML algorithms help to understand the complex non-linear associations between the response (disease occurrence) and explanatory variables, and control for interactions among explanatory variables [Reference Slater and Michael42].
In the present study, we used various ML algorithms such as NB, J48, JRip, LMT, CART, PNN and GBM to predict filariasis with high accuracy. These classification algorithms produced more precise estimates and corroborated with different models to strengthen the robustness of the prediction. In terms of time complexity of classifiers, we found that NB has the least time complexity, because it determines the class of a sample simply based on posterior probability. Hence, the time complexity of NB is O(n), where ‘n’ is the number of samples, J48 and CART exhibit similar time complexity, but less than JRip, LMT, PNN and GBM. The time complexity of J48 and CART depends on the computation of split information, such as information gain and Gini ratio. The computation of split information depends on the number of distinct values that appeared in the number of features and time to prune the tree. As a result, the time complexity of J48 and CART was O(mnlogn) + O(n(logn)2). JRip involves two stages, namely the building phase and the optimisation phase. Tree growing and pruning are performed in the building phase. Determination of an optimum number of rules is performed in the optimisation phase. These two processes are repeated multiple times by generating modified sets of rules at each iteration. Hence, the time complexity of JRip is O(n 2) and PNN is represented as O(n). However, the space complexity of PNN is O(n) too, which is costlier than NB, J48, CART and JRip. The space complexity of PNN depends on the pattern layer, where it stores all the samples to decide the probability of class for the given sample. LMT and GBM are ensemble methods and these involve the use of multiple models to decide the class for the given sample. Hence, the time complexity of these classifiers is higher when compared to the rest of the classifiers.
LF is mainly transmitted by the Southern house mosquito Culex quinquefasciatus, the principal vector for filariasis in India. These vectors breed where there is a lack of basic sanitary conditions and prevalence of cesspools, cesspit and kutcha drains. These cesspools, cesspits and open drainage systems help to enhance the vector breeding habitats and increase vector density which leads to a higher risk of filariasis transmission, as observed [Reference Upadhyayula9]. Similarly, the lack of a proper drainage system in the study villages, and the presence of cesspits and cesspools are observed in and around the houses, which may favour the proliferation of C. qninquefasciatus. The ML models predict that, among all the socio-economic variables, the breeding habitats highly influence the occurrence of filariasis.
ML/data mining helps public health officials in decision making and real-time prediction of disease outbreaks. J48 yielded a set of classification rules which is considered as an early warning expert system for filariasis in Telangana, India. Policy makers should make appropriate plans to improve the socio-economic status of populations through better hygiene and sanitary conditions.
Conclusions and future directions
We predicted the occurrence of filariasis based on socio-economic parameters using ML algorithms. NB yielded the best AUC (64%) using GR feature selection and 400% oversampling. Similarly, J48 yielded an AUC of 62% and yielded 23 classification rules based on six features, namely MDA, gender, mosquito avoidance, house type, breeding habitat and drainage system. From this study, it is observed that gender, house type, breeding habitats, mosquito avoidance, drainage system, participation in MDA and awareness directly influence the occurrence and spread of filariasis. Among all, the ‘breeding habitats’ feature has shown the highest specificity and impact on filariasis. Hence, the breeding habitats of mosquitoes need to be destroyed in low socio-economic zones to prevent further transmission of the parasite. The Government of India is moving towards the elimination of LF by 2020, but this study shows that filariasis is still thriving in communities even after the implementation of MDA programmes. Hence, more attention should be given to disease surveillance systems. Health awareness campaigns should be conducted to educate and increase the consumption of DEC in the target groups of endemic populations. The future direction of the study is based on the outcome of ML algorithms and an early warning system will be developed by adding some more important features such as immunological factors and climatic variables. The limitation of the study is that the method is not suitable for incremental learning if there are new data in the dataset. Therefore, in the future, incremental learning methods will be developed to address this limitation.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0950268819001481.
Acknowledgements
The authors Srinivasa Rao Mutheneni and Sriram Kumaraswamy, Madhusudhan Rao Kadiri and Phani Krishna Kondeti are grateful to the Director of the Council of Scientific and Industrial Research-Indian Institute of Chemical Technology, Hyderabad for his encouragement and support. Suryanarayana Murty Upadhyayula acknowledges support from the Ministry of Chemicals and Fertilizers, Govt. of India. CSIR-IICT communication number of the article is IICT/Pubs./2019/183.
Conflict of interest
None.















 Open access
Open access