



Introduction
The evolution in the diversity of human and animal pathologies has been favoured through time by a continuously increasing number of factors. Migrations, travel and trade, abuse in medical or veterinary practices (antibiotics prescriptions, drugs for humans made from animal products) are among the major factors. Others could be added to the list such as climate changes and the risks of bioterrorism acts.
In this highly evolving context, the early assessment of an emerging risk of a disease in a given population, as well as the epidemiological survey are powerful tools for efficient controlled prevention. Important parameters such as the incubation time, contagion process, transmissibility and more specifically spread, are of crucial priority to predict. This allows the quick gain of the necessary knowledge for the medical community to act in an ordered and predictable environment. The good prediction of these key parameters allows, in general, acceptable management of a disease by the concerned authorities. It also permits the enhancement of the capabilities of a given nation to face unexpected dangerous pandemics with high control, order, and success. As a consequence, the battle against the disease could be softer in terms of fatalities and the economy. Good initial evaluation requires a suitable surveillance system for diagnosis methods. In parallel, available statistical methods and models are highly recommended for computing the risk of amplification of the disease. This is done directly from the first detected cases regardless of the total final magnitude in time or size and the real cause of this magnitude (direct or indirect transmissibility of the disease). Therefore, facing the occurrence of a new phenomenon as for the COVID-19 is highly advised to verify whether it is sporadic or not. Specific precautions should be taken at the onset of an outbreak.
In this paper, we would like to investigate the novel coronavirus (COVID-19) in a statistical approach. This virus belongs to a large family of viruses that may cause severe ill cases in humans or animals. The first cases of COVID-19 were announced in December 2019 in Wuhan, China.
The new virus targets the lower part in the respiratory system causing mild to severe cases of lung infections (pneumonia), thus requiring a special treatment. In contrast to its predecessors from the same family, the challenge with this novel coronavirus is its enigmatic approach of spreading in human. It spreads primarily through droplets of saliva or discharge from the mouth or nose when an infected person coughs or sneezes.
Indirectly, it could be transmitted from contact with contaminated surfaces or objects and then touching critical parts of the body such as the mouth, nose, eyes and so on [1].
The first known case of COVID-19 was revealed in China and the disease began to spread among people to become a global pandemic in a short period.
Infected people from different regions in the world entered Lebanon and transmitted the virus to Lebanese individuals. In a short while, the Lebanese authorities found the infection within their borders. The number of cases increased rapidly, and only within a few days, Lebanon itself became an infected area.
At the time of writing this paper, several studies had been conducted using various statistical and mathematical models to predict the probable evolution of this epidemic in the world [Reference Benvenuto2–Reference Haidar7]. Herein, we propose a new simple probabilistic method based on the record theory. This method proved to be interesting for the accurate calculation of the probability of reaching a new record as well as studying the propagation of COVID-19.
The records theory has been successfully applied in several scientific areas like hydrology, meteorology, epidemiology, sports and natural phenomena (see for details [Reference Khraibani8–Reference Gulati14]). In this study, we used a non-parametric test developed by Khraibani et al. in 2015 [Reference Khraibani8] and based on the number of records for the early detection of emerging events.
We consider S 1 < ⋅ ⋅ ⋅ < S n be the first n independent occurrence of a new event and let {ΔS n: n ≥ 1} be the sequence of real random variables that represent the waiting time between two successive events. In the context of random variables independent and identically distributed (i.i.d.) {ΔS n}, the emergence is characterised by the smallest ΔS n (S n, S n−1 are very close together) and the test statistic used is the process of lower records (ΔS n)−1.
The authors propose for the study a robust and exact non-parametric test statistic against exponential growth to detect an emerging phenomenon. Their proposed statistic N n is based on the number of observed records and an important characteristic of N n, the probability distribution being independent of the observations. Moreover, they consider H 0:ρ = 1 (the event remains sporadic) and H 1:ρ > 1 (the event is an emerging new phenomenon), and they assume that ΔS n has an exponential distribution with an unknown parameter λ > 0. In the case where ρ > 1 they assume that there is an exponential growth in S 1, S 2, …, S n, which are independent continuous random variables but not necessarily identically distributed. In case of ρ = 1, S 1, S 2, …, S n are independent and identical (i.i.d.). It is of importance to note that ρ denotes the ‘constant rate of the exponential growth of the sequence’ [Reference Khraibani8]. The records theory is quite advanced for i.i.d. random variables with continuous cumulative distribution function (CDF). In our setting, the interest of the records theory from the inference point of view consists of the robustness of the distribution of the indices of records and the distribution of the number of records since these distributions may be exactly calculated and are moreover independent of under H 0 and H 1. Therefore, it is particularly interesting for the early detection of an emergent phenomenon based on a small number of observations. It is also to be underlined that record theory focuses on the records values and records times of extreme events, a characteristic that enriches the analysis of potential results. Record times are taken into account through specific random variables called record indicators [Reference Rocco15]. We apply here the records theory on the daily prevalence data of the unprecedented COVID-19 in Lebanon from the 21st of February 2020 until the 13th of March 2020. The data were collected from the official website of Johns Hopkins University [16].
Methods
Records sequences and notation
Let (Ω, F, P) be a probability space. A random variable X is an F-measurable function X:Ω → ℝ. An observation X n is called an upper record noted R n if it is at least as large as the maximum of all preceding observations: X n > max {X 1, …, X n−1}. Note that R 1 = X 1 trivial record. We also define δn as a record indicator variable of the nth observation, that is δ1 = 1 (the first observation is a trivial record), and, for n > 1,

The record times L n is defined by:

With these notations, $R_n = X_{L_n}$ .
.
We define the record counting process or the number of records among {X 1, …, X n} including the trivial record X 1 as


Mathematical definition of an emerging disease
The starting event is the transition between the stability state ‘0 pathogen’ (or of the state ‘equilibrium of the ecosystem of pathogens’) and the instability of this state.
The emerging process concerns the consequences of this instability over a sufficient period to become visible. It thus needs the instability to perdure with the existence of a minimum threshold over which the population of pathogens is directly or indirectly noticed and seen (Fig. 1).
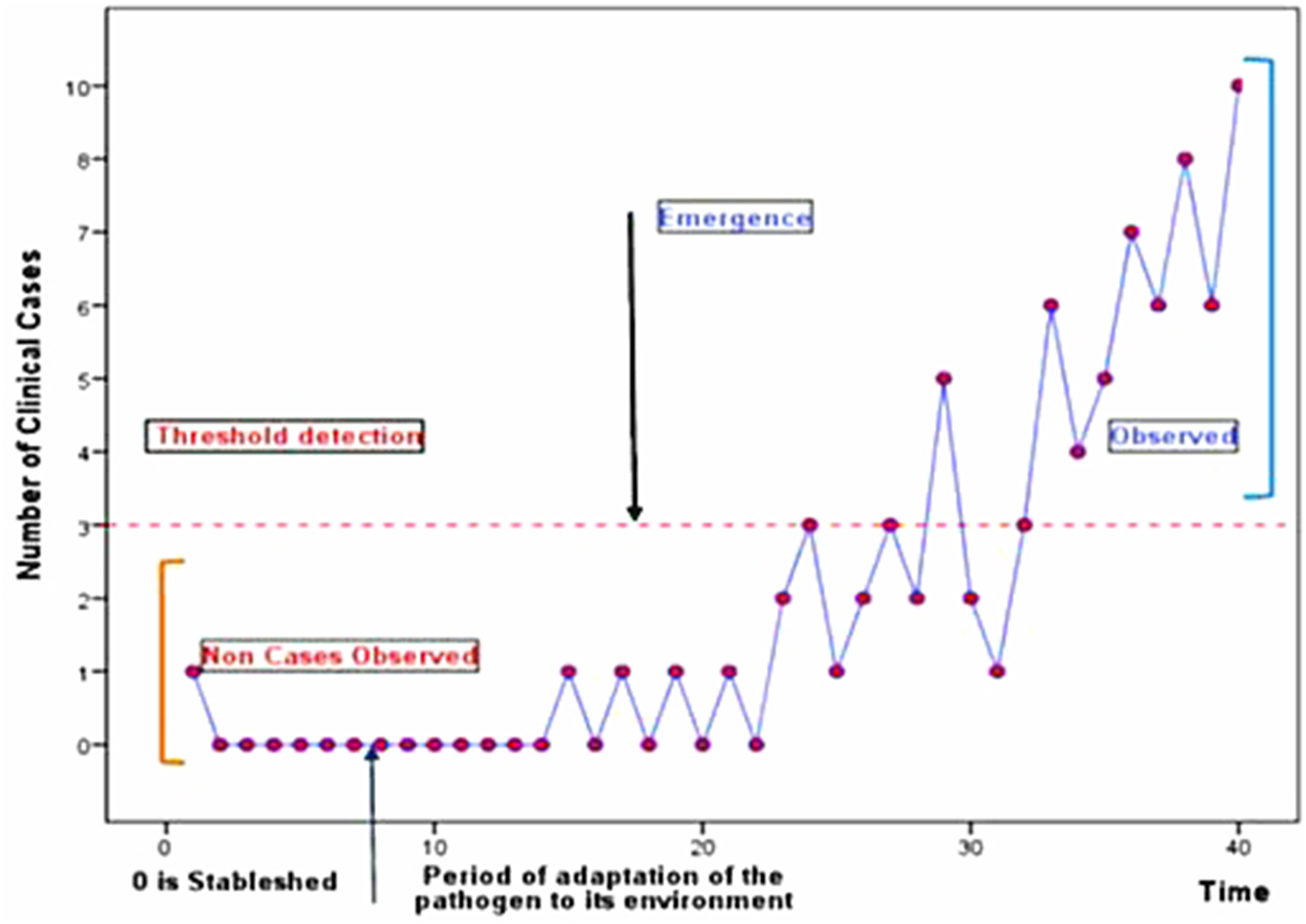
Fig. 1. Emergence of a disease.
Let Y n be the percentage of clinical cases in a population at the time n, such as Y n = f(Y n−1) and f(0) = 0. By using the Taylor's first-order series approximation near 0 and by supposing Y 0 small:



Thus


In case of a non-emerging process (H 0):

But, f(Y 1) = f(f(Y 0)) ≈ f(Y 0)f′(0) < Y 0. We obtain by recurrence that Y n : =f (n)(Y 0) remains of same order of magnitude as Y 0.
In case of an emerging process H 1: f(0) > 1 and we obtain:
f(Y 0) > Y 0 ↠ Y 1 > Y 0 thus, Y n will no more remain negligible.
We give some descriptive about the COVID-19 pandemic in Lebanon from the birth date of the virus (see Fig. 2). By theory, the true number of individuals with COVID-19 infection cannot be accurately determined regardless of the detection measures. As a consequence, we observed a few cases at the beginning of COVID-19, between the 21st and 29th of February, with no background information about the future evolution of the pandemic. In the following, we use the record test to detect the emergence of COVID-19 from a small number of observations recorded between the 21st of February and the 13th of March 2020 (see Figs. 1 and 2).

Fig. 2. Daily cumulative/emerged number of confirmed, fatal and recovered cases of Coronavirus Disease 2019 (COVID-19) in Lebanon. Data source: MOPH, 2020.
Test description
We select here the robust statistic N n as a statistic of test of H 0. In the case of sporadic events, we assume that the waiting times between two successive cases {ΔT k} are i.i.d. with a common CDF. Then H 0 is defined as

In this paper we perform a brief survey to gain further information about the degree of sporadicity of COVID-19 and the frequency of its increase. Our results are the outcome of a non-parametric test based on the number of records observed over time.
We present the principal ideas of the records test; if the new event (COVID-19) is an emerging event, then the waiting times {ΔT k}{1≤k≤n} between two successive events should decrease. On the other hand, for a sporadic event, the {ΔT k}{1≤k≤n} should be i.i.d. This means that N n, the number of lower records in the sequence; {ΔT k}{1≤k≤n} should show tendency to increase.
Based on this idea, Khraibani et al. [Reference Khraibani8] assumed that the waiting times are independent for each k with a continuous CDF denoted G k. In the case of sporadic events, G k is independent of k and the null hypothesis H 0:ρk = 1, k = 1, …, n is adopted. While in the case of emergent, G k increases with k. In this regard, we define the alternative hypothesis H 1:ρk > 1. More particularly, we assume that {G k} belongs to the distribution family in the form $1-\lpar {1-G} \rpar ^{{\rm \rho }_k}.$
Probability distribution of the number of record events
In this section, we give the exact probability distribution of N n. David and Barton [Reference David17] were pioneers in introducing an expression for the exact probability distribution. Recall that the distribution of N n is independent of the observations and it can be calculated exactly for any n value.
Another importance of these statistics is the ease and ability to observe some records for small n values. The random variables δ1, …, δn are independent with probabilities of success [Reference Arnold10]:

Then, the exact distribution of the number of records is independent of F and can be expressed compactly using Stirling numbers of the first kind $S_n^m$ :
:

Based on the asymptotic formula of the Stirling numbers of the first kind, we deduce the asymptotic distribution of N n for large sample sizes [Reference Renyi18]:

The computation of the P(N n ≥ m) in the i.i.d. case (H 0) are listed later.
Nevzorov [Reference Nevzorov12] gives the probability of the record indicators and the number of records in the case of variables being non-independent and identically distributed (H 1):

and

u: = (u 0, u 1, …, u n−1), s(n, m|u)being a generalised Stirling number of the first kind. We have u j = (a j − 1)(a − 1)−1a −j, 1 ≤ j ≤ n − 1.
In the following, we consider the alternative hypothesis H 1:ρk = a k, k = 1, …, n where a ≥ 1, consistent with the exponential growth of an emerging phenomenon such as an infectious disease, when a > 1, and with sporadic events, when a = 1.
Results
Illustration of the records test on COVID-19
We applied the records of COVID-19 cases in Lebanon from the date of identification of the index case until the 13th of March 2020. The first case was announced on the 21st of February 2020. The collected data consist of the birth date and the notification date of each of the COVID-19 cases identified in Lebanon during this period. Therefore, X n: = (ΔT n)−1, where ΔT n is the nth waiting time between two successive notification (resp. birth) date. We list in Table 1 our collected data.
Table 1. Waiting times between two successive cases and number of COVID-19 cases in Lebanon per day

As shown in Table 1, the number of observed records is equal to 6 (N n = 6), the record values: R 1 = 0.2, R 2 = 0.33, R 3 = 1, R 4 = 1, R 5 = 1, R 6 = 1. The records times: L 1 = 1 (21/02), L 2 = 2(26/02), L 3 = 3(29/02), L 4 = 4(01/02), L 5 = 6(05/03), L 6 = 9 (03/10).
From the figures presented above, we see the trajectory of {X n}n≤10 with the successive observed records, drawn as red circles and the number of maximal COVID-19 records between 21 February 2020 and 13 March 2020.
From equation (1), we compute under H 0 the probability to observe at least m records among n variables for any m ≤ n.
According to Table 2, the probability to observe at least m records among n variables increases with n. This table is used to compute the significance level of the test of H 0 : α = P(reject the sporadic hypothesis). We decided then to apply the results of Khraibani et al. [Reference Khraibani8] to investigate if the incidence rate of COVID-19 in Lebanon was increasing. The test statistic of interest is thus the number of lower records in the sequence X n = (ΔT n)−1. The records test of H 0 depends on the number of observed records N n and the notification dates of occurrence.
Table 2. P(N n ≥ m), for n = 10, 20 and for different values of m

We observe five records at discrete times n = 1, 2, 3, 4, 6 (Fig. 3a). We have P(N 10 ≥ 6) = 0.0203 (see Table 2), allowing one to reject H 0 with a small error probability. From only a few reported cases, we conclude that the COVID-19 is an emerging disease in Lebanon. Also, from equation (1) and Table 2, the calculated $P \hbox{-}{\rm value}$ for the hypothesis H 0 confirm that COVID-19 in Lebanon represents an increasing phenomenon. The H 0 is then rejected, so that to calculate under H 1 the probability of the numbers of records by using equation (2).
for the hypothesis H 0 confirm that COVID-19 in Lebanon represents an increasing phenomenon. The H 0 is then rejected, so that to calculate under H 1 the probability of the numbers of records by using equation (2).

Fig. 3. (a) Records values of X n = (ΔT n)−1. (b) Number of observed COVID-19 cases per day.
Khraibani et al. [Reference Khraibani8] considered two values of a: a = 1.1 and a = 1.5, the first, corresponding to a slow emergence, and the second one, is characteristic of a quick emergence.
Based on these values of a, we can easily compute under H 1 the probability of records number, exceeding the records values m = 6, 7, 8, 9 for different values of n = 10, 20, 30 days:
From the results of Table 3, one could notice the COVID-19 in Lebanon emerges in a very rapidly with a high probability of exceeding some record values.
Table 3. P(N n ≥ m) under H 1, for n = 10, 20, 30 and for different values of m and a

By taking into account the future COVID-19 records, we compute the probabilities of waiting time to observe a new record $\lpar {{\rm \Delta }T_n^\ast } \rpar \;$ by using the following equation:
by using the following equation:

Consequently, the probabilities of observing a COVID-19 record in Lebanon for the next 5 days can be easily calculated from equation (3). For example the number of days in the database, n′ = 22 days (between 21 February 2020 and 13 March 2020), we deduce the probability of waiting time for a new record: 22/(22 + 5) ≈ 0.82; confirming the rapid growth of COVID-19 in Lebanon over a short period.
The fact that an event occurring for the first time becomes a frequently encountered phenomenon manifests itself by shortening of inter-event times which corresponds to an increasing trend in the series of observations {X 1, …, X n}. From all these observations, we conclude that our test efficiently proves that COVID-19 in Lebanon emerges very quickly resulting in a high probability of exceeding some observed record values and waiting time. The early detection of the risk of quick propagation of COVID-19 in Lebanon is of great value since it could increase the chances for adequate prevention. The existence of a good surveillance system and epidemiological surveys help in preventing the complete failure of even the most well-developed public healthcare systems in the world.
Conclusion
Facing the first time of occurrence of cases of a new disease, such as COVID-19, it is crucial to predict the degree of sporadicity or emergence of the pandemic. We propose in this paper a non-parametric exact test for the early detection of emerging events based on the number of lower records N n in X n; which X n = (ΔT n)−1 the waiting time between two successive COVID-19 cases. The method presented in this paper is a general method that could be applied for new diseases with no epidemiological information. It is a robust tool allowing the calculation of exact distribution even for small size samples. We were able, using this method, to detect the quick propagation of COVID-19 in Lebanon from a small number of cases. First, we consider the hypothesis H 0:ρk = 1 (sporadic cases), and we assume that inter-event times have an exponential distribution with unknown parameter λ > 0; then we suppose the alternative hypothesis H 1:ρk > 1; with ρk = a k and for a > 1, we obtain an exponential increase in the occurrence concentrations of the developing phenomenon.
In summary, we confirm using our test that COVID-19 is spreading very quickly in Lebanon. For the future research, we recommend better epidemiological surveillance of epidemics in order to minimise the risks of their transformation into pandemics. This prevention could preserve the health care systems of even strong countries from crash. Several other statistical methods are also to be tested in the follow-up of COVID-19 especially in Lebanon. This work is in due course in our lab.
Financial support
The research by Z. Khraibani is financed by a funding programme ‘COVID-19 flash’ from the Lebanese University LU.
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Data availability
Requests for access to the data that support this study should be made to the corresponding author, Z. Khraibani.







 Open access
Open access