



1 Introduction
In English, the adverbial modification of to + infinitive phrase constructions is syntactically variable (Quirk et al. Reference Quirk, Greenbaum, Leech and Svartvik1985: 497). The adverb can come immediately before the to-phrase, in an adv + to + infinitive verb construction (1a). It can also be placed after the to-infinitive phrase, in a to + infinitive verb + (…) + adv construction, as in (1b) and (1c) (Kostadinova Reference Kostadinova, Chapman and Rawlins2020: 103). Another syntactic alternative would be to place the adverb between to and the verb in the to-phrase, in a to + adv + infinitive verb construction, similar to the example in (1d). The last construction is more commonly known by laypeople and prescriptive grammarians as the ‘split infinitive’ construction.Footnote 2
(1)
(a) She has tried consciously to stop worrying about her career. (before to-phrase)
(b) She has tried to stop consciously worrying about her career (after to-phrase)
(c) She has tried to stop worrying about her career consciously. (after to-phrase)
(d) She has tried to consciously stop worrying about her career. (within to-phrase)
(Quirk et al. Reference Quirk, Greenbaum, Leech and Svartvik1985: 497)
In this article, the last construction is not regarded as a grammatical error. Instead, adopting a variationist stance (Labov Reference Labov1972), the study considers all these to-phrase constructions to be equally valid and grammatical construction variants of the modified infinitive. This perspective contrasts with what many prescriptivists have historically claimed – that the split infinitive construction is not grammatical and should be avoided at all costs. The choice to abandon such a viewpoint is justified upon examining findings in previous linguistic investigations of the construction. Early work has identified linguistic conditions that warrant the use of the split infinitive construction, or at least make the use of the split infinitive appear more idiomatic, acceptable and/or natural (Kato Reference Kato2001; Mitrasca Reference Mitrasca2009; Mikulová Reference Mikulová2011; Koivistoinen Reference Koivistoinen2012). In other words, if one regards acceptability, naturalness and idiomaticity as correlates of grammaticality, then previous studies have identified grammatical ‘rules’ for when to split the to + infinitive construction. Researchers have found language-internal factors that constrain the syntactic variation in to-phrase use (e.g. ambiguity resolution, adverb type, etc.) (see section 2). However, the vast majority of the work on the linguistic conditioning of split infinitive use is limited to standardized varieties such as American English (AmE) and British English (BrE), which are often regarded by many as the standards of English grammar. Given that English is used around the world and has taken various developmental trajectories depending on the sociohistorical context of the region, it is unclear whether the patterns described in previous work would hold for lesser-known varieties of English, which have also been documented to exhibit variable usage in the infinitive construction (Gonzales & Dita Reference Gonzales and Dita2018).
The present study will focus on Philippine English (PhE), operationalized here as a cluster of English varieties that primarily emerged out of contact between (American) English and historically indigenous languages such as Tagalog (Thompson Reference Thompson2003; Gonzales Reference Gonzales2017; Gonzales Reference Gonzales and Macalinga Borlongan2022a). The choice to investigate PhE was partially motivated by a previous finding that PhE has the highest incidence rates of split infinitives in a comparison of twelve world Englishes (Gonzales & Dita Reference Gonzales and Dita2018: 254), and thus, higher rates of potential variation for examination. However, unlike prior work, the current study will analyze syntactic variation of infinitive constructions in an understudied ‘style’ or way of using PhE – Twitter-style PhE (Eckert & Rickford Reference Eckert and Rickford2001: 121). Instead of viewing PhE on Twitter as an inaccurate representation of PhE not worthy of study, I follow the lead of contemporary variationists (Eckert & Rickford Reference Eckert and Rickford2001; Ilbury Reference Ilbury2020) and adopt the view of Twitter-style PhE as a one of the many styles (e.g. essay style, casual dialogues style, educated style) (Bautista Reference Bautista2000) that constitute PhE. From this perspective, it is imperative to study the multiple styles of PhE and how they interact with social and linguistic variables to get a more holistic understanding of the English variety (Eckert & Rickford Reference Eckert and Rickford2001: 1).
Using the findings of previous work as a guide, I plan to identify language-internal factors that condition the alternation between split constructions and those that are not, that is, I investigate whether certain linguistic constraints identified in earlier related work on split infinitives in English apply to Twitter-style PhE. The extent to which these linguistic factors condition the variation in split infinitive use will also be examined. These findings are expected to contribute to our understanding of syntactic conventions involving the infinitive in PhE – an area of inquiry that has received very little scholarly attention (Gonzales & Dita Reference Gonzales and Dita2018).
In addition to language-internal factors, the present study will also attempt to enrich existing research and identify potential language-external factors (i.e. social, geographical and diachronic) that may also constrain the said variation. This is, to my knowledge, something that has not been investigated in Twitter-style PhE. Language-external factors have been shown to be robust predictors of linguistic variation in PhE (Gonzales Reference Gonzales2023b) and other neighboring English varieties (Starr & Balasubramaniam Reference Starr and Balasubramaniam2019; Leimgruber et al. Reference Leimgruber, Lim, Wong Gonzales and Hiramoto2021; Gonzales Reference Gonzales2022b, Reference Gonzales2023a) (see section 2). So, this article will examine the possible effects of these factors while also jointly considering the potential effects of language-internal factors. The following questions guide the article:
1. Which language-internal and language-external factors condition the variation in modified infinitives in Twitter-style PhE?
2. To what extent do these factors condition the variation in adverbFootnote 3 placement?
By answering these questions, the study hopes to narrow the glaring gap between variationist sociolinguistic research in East Asia and that of many well-known Anglophone territories (e.g. the United States). It also hopes to contribute to our understanding of internal variation in Twitter-style PhE and PhE in general, which has often been thought to be negligible, if not non-existent (Llamzon Reference Llamzon and Bautista1997; Lee & Borlongan Reference Lee, Borlongan and Macalinga Borlongan2022). Finally, from a methodological perspective, the article also hopes to (i) normalize the inclusion of language-external variables in variationist analyses in the region; (ii) popularize the use of social media data for linguistic analyses; and (iii) encourage the use of state-of-the-art machine learning techniques (e.g. Deep Learning) and stochastic and probability-based statistical modeling (e.g. Bayesian regression) in the analysis of (socio)linguistic variation in the region (Gonzales Reference Gonzales2004). The article adds to the growing body of work that utilizes these methods (MacKenzie Reference MacKenzie2020; Hiramoto et al. Reference Hiramoto, Wong Gonzales, Leimgruber, Lim, Ming Choo, Ngefac, Wolf and Hoffman2022; Levshina Reference Levshina, Schützler and Schlüter2022; Gonzales Reference Gonzales2023b).
The rest of the article is structured as follows: section 2 briefly summarizes literature that examines language-internal and language-external conditions for variation in to-infinitive constructions. This is followed by a description of the methods employed (section 3), where I present the data source and data analysis procedures. The results and discussion can be found in section 4. In section 5, I summarize the article, answer the questions posed earlier and provide some concluding remarks, including notes on future research directions.
2 Variation in the modified infinitive construction
Most of the studies on adverbial constructions address variation in the modified infinitive construction. Although some differences can be found between the data sources of these studies – English usage guides vs. novels, spoken vs. written registers – some key factors are observed to shape the syntactic alternation in modified infinitives consistently (Kato Reference Kato2001; Mitrasca Reference Mitrasca2009; Perales-Escudero Reference Perales-Escudero2011; Kostadinova Reference Kostadinova, Chapman and Rawlins2020). The bulk of these factors are language-internal – some are relevant to the infinitive, while others have to do with the nature of the adverb. Also pertinent are the prosodic and semantic properties of the utterance containing the modified infinitive.
Perhaps one of the strongest effects on modified infinitive variation is the presence of ambiguity (Quirk et al. Reference Quirk, Greenbaum, Leech and Svartvik1985: 497; Calle-Martín & Miranda-García Reference Calle-Martín, Miranda-García, Renouf and Kehoe2009: 361). Speakers tend to split the infinitive if doing so would resolve the ambiguity caused by not placing the adverb directly before the verb (Mikulová Reference Mikulová2011: 20). In sentences like (1b), for example, it is unclear whether the sentence refers to a conscious stop or a conscious worry. However, if the adverb consciously was placed between to and the infinitive, then the meaning of the utterance would be clearer (Quirk et al. Reference Quirk, Greenbaum, Leech and Svartvik1985).Footnote 4 Mikulová corroborates this in her study of the construction in popular electronic corpora (e.g. British National Corpus); she found that ‘non-native’ participants tend to use the split infinitive among themselves to achieve clarity of expression.
Another notable factor that conditions infinitive variation is the type of adverb. Scholars have observed that certain adverb class types tend to favor the splitting of the infinitive over others (Koivistoinen Reference Koivistoinen2012). Analyzing corpus data of historical and contemporary American English, Kostadinova (Reference Kostadinova, Chapman and Rawlins2020) found that adverbs of degree, manner, stance and time (e.g. really, always, usually, actually, maybe) – based on Biber & Quirk's (Reference Biber and Quirk2012) adverbial typology – tend to encourage the splitting strategy, whereas additive and restrictive adverbs tend to discourage it.Footnote 5 In other words, the odds that a to-phrase is split are lower if the adverb belongs to the additive or restrictive class of adverbs (i.e. just, only, even, too, else, also, especially, particularly). Quirk et al. (Reference Quirk, Greenbaum, Leech and Svartvik1985) in their analysis of split infinitives in contemporary English observed that split infinitive constructions tend to occur with ‘subjunctsFootnote 6 of narrow orientation’, particularly those with a grading and focus orientation (Quirk et al. Reference Quirk, Greenbaum, Leech and Svartvik1985: 497; Perales-Escudero Reference Perales-Escudero2011: 333). They observed that infinitives are often split by adverbs that do not modify how we perceive the verb, but perform a subordinate role in the sentence (e.g. amplification, emphasis) (e.g. to actually go as opposed to to willingly go) (Quirk et al. Reference Quirk, Greenbaum, Leech and Svartvik1985). Koivistoinen's (Reference Koivistoinen2012: 17) investigation of split infinitives shows that the split infinitive construction also tends to correlate with focusing adverbs (e.g. even, merely, only) in present-day English.
In addition to adverb type, the length of the adverb may also play a role in conditioning the syntactic variation in modified infinitives. The placement of the adverb has been found to be sensitive to the number of syllables in the adverb relative to the number of syllables in the verb. The numbers show that adverbs tend to be placed in a to + adv + verb construction if the adverb is shorter than the verb or if the adverb and verb have the same number of syllables; however, if the adverb has more syllables than the verb, it tends to come after the verb (Kostadinova Reference Kostadinova, Chapman and Rawlins2020). This is at least true in the case of American English.
An effect on split infinitive variation that tends to be discounted or tip-toed around in the literature is the prosody of modified infinitives, particularly the rhythm and stress of the adverb and the verb (Crystal Reference Crystal1984; Calle-Martín & Miranda-García Reference Calle-Martín, Miranda-García, Renouf and Kehoe2009: 356). It has been claimed that split infinitives tend to appear in rhythmically neat constructions (i.e. the ‘natural’ te-tum te-tum rhythm as reflected in the unstressed–stressed unstressed–stressed or U–S U–S stress sequence). Correlations between the split infinitive construction and ‘natural’ rhythm patterns have been commonly cited as evidence for this despite the existence of some outlier cases (e.g. to better prepare, to BE-tter pre-PARE, U S-U U-S) (Crystal Reference Crystal1984; Perales-Escudero Reference Perales-Escudero2011). For example, the phrase to boldly go has a rhythmic pattern that is very ‘neat’ (e.g. to BOLD-ly GO, U S-U S) compared to the other constructions (e.g. boldly to go, S-U U S; to go boldly, U S S-U), which contain a consecutive sequence of weak or strong syllables (Crystal Reference Crystal1984: 30; Calle-Martín & Miranda-García Reference Calle-Martín, Miranda-García, Renouf and Kehoe2009). The tendency for split constructions to appear in constructions that are rhythmically ‘natural’ suggests that the split construction tends to be used if it contributes to the ‘natural’ rhythm (table 1, example for Condition D) and is avoided if the placement of the adverb in between the to-phrase (adverb before the verb) disrupts it. The reported preference for ‘natural’ constructions is claimed to be reflected in the four prosodic conditions (i.e. Conditions A to D) identified by Calle-Martín & Miranda-García that appear to favor the use of split infinitive constructions. I summarize them in table 1 (see Calle-Martín & Miranda-García Reference Calle-Martín, Miranda-García, Renouf and Kehoe2009 for a detailed explanation).
Table 1. Stress and rhythm conditions for modified infinitive constructions (Calle-Martín & Miranda-García Reference Calle-Martín, Miranda-García, Renouf and Kehoe2009: 356) S = stressed, U = unstressed, ? = claimed to be rare

It is worth noting that some scholars have questioned the role of rhythm and stress in shaping the choice of modified infinitive construction. Using corpus evidence, Perales-Escudero (Reference Perales-Escudero2011: 331) argues that adverb type is a better predictor of split infinitive (dis)use than prosody.
Conventionality (e.g. idiomaticity, collocations) could be another significant factor explaining split infinitive use. It has been shown that some pre-constructed phrases associate strongly with specific lects and registers (Perales-Escudero Reference Perales-Escudero2011: 332). In the context of academic registers, for example, certain split infinitive constructions tend to appear more frequently in academic discourse (e.g. to better verb, to effectively verb). Aside from register-specific conventions, there also exist collocational tendencies in dialects. The research on World Englishes, for example, has shown that different dialects of English can have preferred split infinitive patterns (Gonzales & Dita Reference Gonzales and Dita2018). Using the International Corpus of English (ICE), Gonzales & Dita (Reference Gonzales and Dita2018) discovered that English varieties worldwide have different sets of infinitive collocates. In Hong Kong English (HKE), for example, to really verb and to further verb constructions are the most popular, whereas in PhE, the most popular adverb splitters include really, further, just, immediately, fully, better, finally and completely (Calle-Martín & Romero-Barranco Reference Calle-Martín and Romero-Barranco2014; Gonzales & Dita Reference Gonzales and Dita2018: 250). Speakers of PhE may, for instance, adopt ‘endonormative’ grammar standards (Schneider Reference Schneider2003: 255) and use local split infinitive collocational patterns, even when other linguistic factors like ambiguity and prosody favor their disuse. The tendency to use chunks would not be surprising given that collocations and idiomatic expressions are an important component of (native) language.
There is much less research on the potential effects of language-external factors on modified infinitive variation. One of the few studies that considers these factors is that of Kostadinova (Reference Kostadinova, Chapman and Rawlins2020), who explained the variation using diachronic variables as well as ‘prescriptivism-related predictors’ or prescriptivist ideological variables (Kostadinova Reference Kostadinova, Chapman and Rawlins2020: 110). Kostadinova found that the odds of an infinitive being split have increased over time. Moreover, she found that ideological orientation (e.g. adherence to prescriptivism) influences variation. Speakers who use constructions that are commonly proscribed (e.g. the use of passives, sentence-initial and/but, less with plural nouns, discourse particle like) tend to split the infinitive as well. In other words, those who are not concerned about using non-prescriptivist forms would also be unconcerned about using split infinitives (Kostadinova Reference Kostadinova, Chapman and Rawlins2020: 112). Where sociodemographic factors are concerned, there is evidence that region can condition variation (Calle-Martín & Romero-Barranco Reference Calle-Martín and Romero-Barranco2014), but, to my knowledge, evidence of the conditioning effect of age and sex on infinitive variation has yet to be discovered.
3 Methods
3.1 Data source
The Twitter Corpus of Philippine Englishes (TCOPE) was used for this study (Gonzales Reference Gonzales2023b). The TCOPE is a 135-million-word corpus that was created from roughly 27 million tweets sampled from 29 major cities in the Philippines (figure 1). The data included cover the years 2010 to 2021, with roughly 5 to 17 million words per year. The corpus was selected because at least part of it is open access, and the data were sampled from many rural and urban cities in the country. In addition to geographical metadata, each utterance in the TCOPE is linked to the public Twitter profiles of the tweeter, where information about age and sex may be gleaned or derived using computational methods (Wang et al. Reference Wang, Hale, Adelani, Grabowicz, Hartmann, Flöck and Jurgens2019; Gonzales Reference Gonzales2004). The availability of socio-demographic metadata makes TCOPE the optimal dataset to investigate sociolinguistic variation in the use of modified infinitives in PhE because other PhE corpora do not contain such information. Furthermore, because the TCOPE is available in program-readable format (e.g. spreadsheet form), coding each utterance for linguistic factors is possible with the help of natural language processing packages. The corpus is also large enough that the results can be claimed to reflect one facet of PhE use – PhE as used in computer-mediated-communication (CMC) or more specifically, Twitter. It offers an opportunity to enrich work on the nature of PhE, as most of the work on PhE have only been limited to selected written and spoken styles (e.g. essays, monologues, dialogues) used by adults (e.g. the Philippine component of the International Corpus of English or ICE-PH) (Bautista Reference Bautista2004). The TCOPE can be used for the study of Twitter-style PhE (Eckert & Rickford Reference Eckert and Rickford2001; Ilbury Reference Ilbury2020). Finally, the TCOPE is also one of the very few corpora in the Philippines that contains part-of-speech and dependency parsing information derived using nltk and spaCy (Bird, Klein & Loper Reference Bird, Klein and Loper2009; Honnibal et al. Reference Honnibal, Montani, Van Landeghem and Boyd2020). This information is useful for the efficient extraction of modified infinitive constructions, as the next subsection will show.
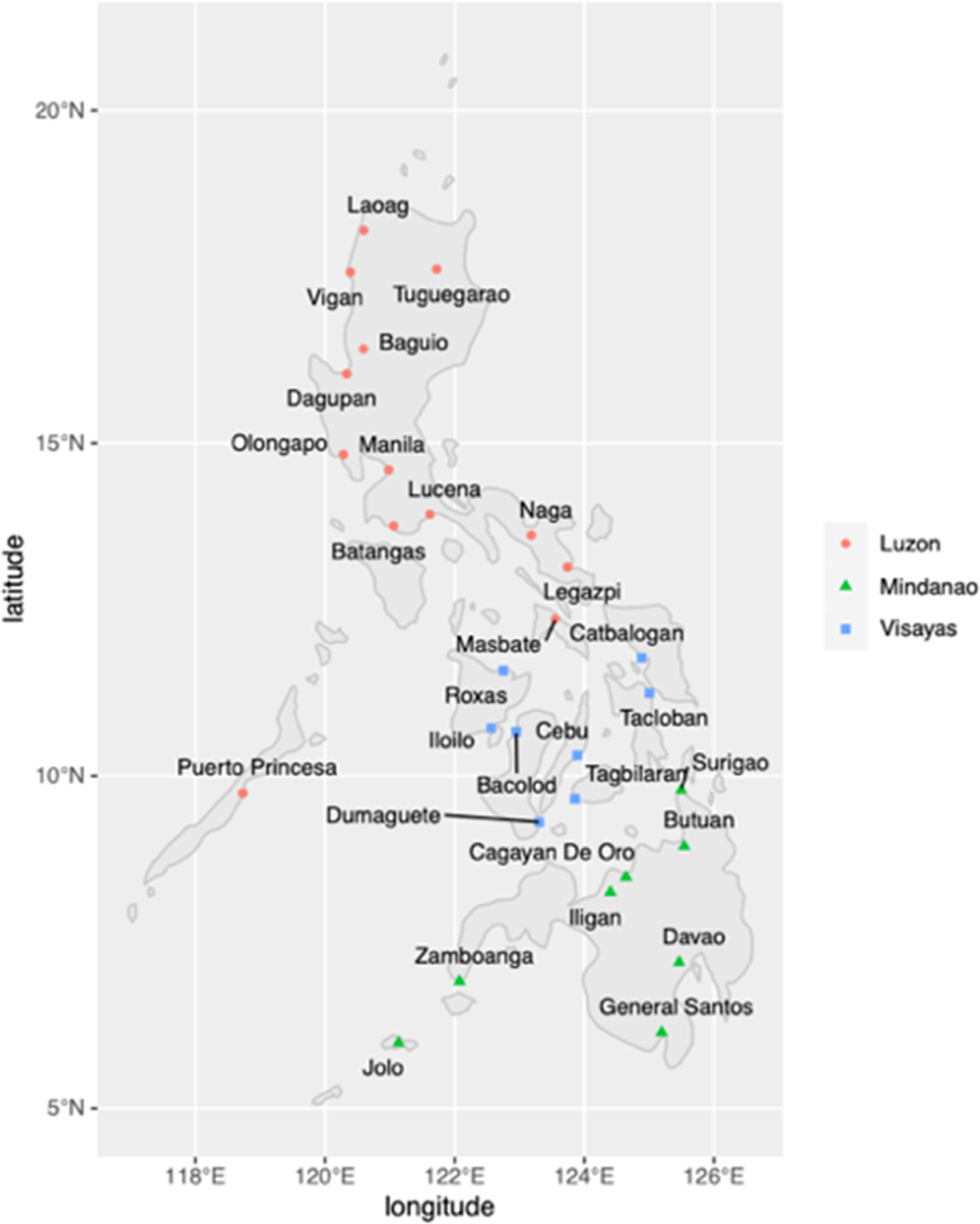
Figure 1. Cities from which the TCOPE was sampled, grouped by the three sociopolitical regions of the Philippines. Figures were adopted from the corpus overview papers (Gonzales Reference Gonzales2023b)
3.2 Data pre-processing
In this investigation, I am interested in analyzing the syntactic variable of adverb phrase placement in modified infinitives, which has three variants:

The first step in obtaining data was to search the TCOPE for tokens that followed any of these three modified infinitive patterns. I used a self-developed program, Twitter Corpus Suite (TCS), to extract the utterances efficiently. TCS takes in a regular expression (RegEx) and other parameter values (e.g. sampling size, corpus to be analyzed, filtering options, type of search) and returns a spreadsheet file containing data that match the RegEx and set parameters (figure 2).
Figure 2. Graphical user interface of Twitter Corpus Suite (COPE)
The following RegEx search strings were input in the program:
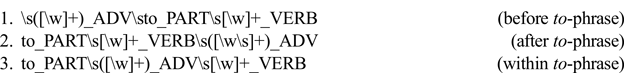
Tokens that followed the adv + to + infinitive verb construction were coded as ‘pre’, whereas tokens following the to + infinitive verb + adv construction were coded as ‘post’. Those that conform to the to + adv + infinitive verb pattern were coded as ‘split’. Because I intend to analyze the patterns of modified infinitive variation using language-external and language-internal factors/predictors identified in the literature (see full list in section 3.3), each of the utterances was also coded for these factors using Natural Language Processing (NLP) tools in Python and in R.
For the predictors relevant to adverb type, I utilized the grepl function in base R. The package helped me classify modified infinitive constructions based on whether the construction contains an adverb of a certain type (i.e. additive/restrictive, subjunct), using the adverb typology of Quirk et al. (Reference Quirk, Greenbaum, Leech and Svartvik1985) and Biber & Quirk (Reference Biber and Quirk2012). I also used the same package to help me identify the adverbs that are very frequently used in PhE to split the infinitive, based on the PhE frequency list in Gonzales & Dita (Reference Gonzales and Dita2018). As for the factors related to number of syllables and prosody (e.g. stress), I utilized a prosodic parser from the prosodic package in Python (Heuser, Falk & Anttila Reference Heuser, Falk and Anttila2010) to help me extract the stress patterns of the verbs and adverbs in the modified infinitives.Footnote 7 I was also able to measure the length of the adverbs and verbs with respect to number of syllables using the parser and another independent syllable counter in R – quanteda (Benoit et al. Reference Benoit, Watanabe, Wang, Nulty, Obeng, Müller and Matsuo2018). The predictor related to ambiguity and distance was derived by simply counting the number of words from the infinitive verb to the end of the sentence, minus the adverb.
Self-reported age and sex/gender data in the TCOPE cannot be directly extracted; however, as mentioned earlier, computational methods can be employed to acquire stylistic/presented age and gender based on Twitter profile information (Gonzales Reference Gonzales2004). This is ideal because for my analysis, I will be viewing ‘age’ and ‘sex/gender’ as ‘age presentation’ and ‘sex/gender presentation’, aligning with the social constructionist framework. According to this perspective, gender and age are social constructs, meaning they are not inherent traits but rather emerge from how we express and perform them through various means like clothing, behavior and other aspects (Eckert Reference Eckert1989). This framework is well suited for analyzing Twitter data because social media serves as a significant platform for negotiating and constructing identities. Much of the stylized representation of gender and age occurs through the use of images and language on these platforms.
The tool I used is Wang et al.'s (Reference Wang, Hale, Adelani, Grabowicz, Hartmann, Flöck and Jurgens2019) M3 demographic inference tool: it receives a Twitter identification number as input (available in the TCOPE), analyzes the profile image, username, screen name and biography of the Twitter user, and outputs the stylistic/presented age, sex and entity-type (i.e. organization, non-organization) of the user in terms of probability with relatively high precision and recall (Macro-F1: Gender = 0.918, Age = 0.522,Footnote 8 Entity-type = 0.898) (Wang et al. Reference Wang, Hale, Adelani, Grabowicz, Hartmann, Flöck and Jurgens2019; Gonzales Reference Gonzales2004). The tool is computationally intensive, so I am unable to derive the demographic information for all extracted tokens that matched the RegEx patterns (n = 350,266). Therefore, I downsized the dataset through random sampling. Non-split utterances dominated the dataset and the utterances with split infinitives were few relative to the total number of non-split utterances. So, the downsizing was done disproportionately to ensure that roughly 50 percent of the dataset contained split infinitives and 50 percent contained to-phrases that do not have an adverb within.
After acquiring the socio-demographic variables, I assessed and attempted to improve the quality of the data by removing tokens that were tweeted by organizations (e.g. corporate Twitter data) and tokens where the adverb is too, which is categorically placed after the infinitive in English. Retweets and duplicate tweets were also removed. Furthermore, my research assistant and I went over the dataset and filtered out utterances that were (i) mistakenly extracted by the RegEx algorithm (e.g. I am trying to demonstrate that someone is always listening. <COPE-TW-CEB-2020-06:232146>), (ii) contained idiomatic expressions (e.g. to get even) and (iii) involved verbs and adverbs in indigenous Philippine languages (e.g. na ‘already’, din ‘also’). The original dataset contained 10,240 utterances, but after the pre-processing and careful filtering, only 7,958 tokens remained (to + adv + infinitive verb = 4,425, adv + to + infinitive verb = 1,927, to + infinitive verb (+ …) + adv = 1,606).
3.3 Data analysis
In this article, I analyze and describe patterns of variation hoping to gain insights on Twitter-style PhE only. As mentioned earlier, Twitter-style PhE only constitutes a part of PhE, so I try to avoid generalizing about PhE using TCOPE data whenever possible. A conservative approach seemed to be the best way forward given that language on Twitter sometimes diverges from language in other communication platforms, partially due to platform-specific features such as character count or increased use of emojis and other multimodal resources (Tagliamonte & Denis Reference Tagliamonte and Denis2008; Davies & Fuchs Reference Davies and Fuchs2015; Jenkins Reference Jenkins2015; Bohmann Reference Bohmann and Squires2016).
Using the downsized and carefully curated dataset, I analyzed the variation using a multivariate Bayesian logistic regression analysis, in line with contemporary research on variationist and general sociolinguistics work (Vasishth et al. Reference Vasishth, Nicenboim, Beckman, Li and Kong2018; MacKenzie Reference MacKenzie2020). Specifically, I ran a mixed-effects multinomial model, as the syntactic variable under study has three variants (Levshina Reference Levshina2016). I ran the Markov chain Monte Carlo (MCMC) algorithm (Franke & Roettger Reference Franke and Roettger2019; Makowski et al. Reference Makowski, Ben-Shachar, Annabel Chen and Lüdecke2019; McElreath Reference McElreath2020) with the brms package in the R environment (R Core Team 2015; Bürkner Reference Bürkner2017;). The multinomial regression model was fitted over 7,958 observations, with 30,000 iterations per chain. A total of 4 Markov chains were sampled. I also used a warm-up or burn-in period of 15,000 iterations for each chain to correct for initial sampling bias. The thinning parameter was set at 2. Weakly informative priors (i.e. normal distribution [0, 5]) were set for the intercept and slopes (Levshina Reference Levshina2016: 252). The choice of priors, at least the ones I tested (i.e. uniform, Cauchy [0,5]), did not influence the posteriors significantly. Following Vehtari et al. (Reference Vehtari, Gelman, Simpson, Carpenter and Bürkner2021: 683), I also monitored the R̂ values and Effective Sample Size (ESS) to verify convergence. To ensure proper convergence, I made sure that the R̂ value stayed within the range of 1.01 and that the ESS value remained above 400 (see model in section 4 for R̂ and ESS values).
I did not conduct a frequentist-oriented regression because although Bayesian procedures are computationally cost-intensive and show similar results as their frequentist counterparts (i.e. models with p-values), the Bayesian method allows me to interpret my results intuitively in terms of probability (Levshina Reference Levshina, Schützler and Schlüter2022). It also permits comments on the absence of an effect, whereas this is impossible within the frequentist framework (Vasishth & Nicenboim Reference Vasishth and Nicenboim2016; McElreath Reference McElreath2020).
The multinomial logistic regression model contains the following language-external and language-internal predictors, selected based on the literature on split infinitive use (see section 2). Multilevel categorical variables (e.g. island group) were coded using Weighted Helmert coding conventions (Sonderegger Reference Sonderegger2022). Random intercepts for verb lexeme, adverb lexeme and user were modeled in. However, following Levshina (Reference Levshina2016: 253), only lexemes and users with adequate tokens (i.e. tokens > 5) were considered as individual factor values. All lexemes and users with less than five utterances/tokens were conflated in the ‘other’ category.
Language-internal predictors
• Adverb type
◦ additive-restrictive vs. others
◦ subjunct vs. non-subjunct
◦ has -ly vs. others
• Reported frequency of adverb as a splitter in ICE (high vs. low)
• Length of adverb relative to the verb (syllable) – continuous
• Distance of the verb to the sentence-final boundary (degree/likelihood of potential ambiguity) – continuous
• Interaction of length and distance
• Stress and rhythm Conditions A, B, C and D (adherence/yes vs. non-adherence/no)
• Interaction of Condition D with Conditions A, B and C
Language-external factors
• Year – continuous
• Island group (Visayas vs. Luzon)
• Island group (Mindanao vs. Visayas and Luzon)
• City (Manila vs. non-Manila)
• Age presentation – continuous
• Sex/gender presentation (male-presenting vs. female-presenting)
• Interaction of age presentation and sex/gender presentation
Random intercepts
• Verb lexeme
• Adverb lexeme
• User
After obtaining the results from the summary of Bayesian posterior draws (Bürkner Reference Bürkner2017), I identify predictors that have an effect on modified infinitive variation using the probability of direction (pd) measure. A predictor is said to have an effect on the dependent variable (e.g. modified infinitive variants) if it has a median value that is far away from zero or if the credibility intervals surrounding the median do not contain zero (Levshina Reference Levshina2016; Grafmiller, Szmrecsanyi & Hinrichs Reference Grafmiller, Szmrecsanyi and Hinrichs2018; Makowski et al. Reference Makowski, Ben-Shachar, Annabel Chen and Lüdecke2019; MacKenzie Reference MacKenzie2020). The Bayesian statistical measure ‘probability of direction’ (pd) – or the proportion of posterior draws that is of the median's sign – will be used in this article to characterize the (un)certainty of existence of the effect. A higher pd (i.e. close to 1) indicates higher certainty that the positive or negative effect indicated in the median is present, whereas a lower pd (i.e. close to 0.5) indicates that the negative or positive effect could be non-existent (Makowski et al. Reference Makowski, Ben-Shachar, Annabel Chen and Lüdecke2019). For example, if the median of a predictor in this paper's model is -1.2 and its pd is 0.95, one can say that the proportion of posterior values that are less than zero is 95 percent and that only 5 percent of the values are greater than zero (Levshina Reference Levshina2016). In other words, there is a 95 percent chance that that predictor will have a negative effect on (or decrease) the likelihood to choose the pre-modification or post-modification strategy over the split infinitive strategy, as the reference category has been set to ‘split’.
4 Results and discussion
4.1 Multinomial model general results
Table 2 provides the posterior median values, standard deviation, 89 percent credible intervals based on Highest Density Interval (HDI) boundaries, along with the pd values (see section 3.3). It also includes diagnostic measures for convergence (i.e. R̂ and ESS). The table only shows the fixed effects and some random effects (i.e. intercepts) due to space constraints. The full results can be accessed online via the Open Science Framework (OSF): https://osf.io/sr2cy/
Table 2. Bayesian model posterior draw estimates for predictors influencing likelihood to split the infinitive (reference levels in boldface)

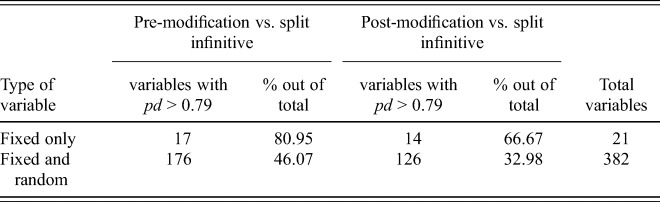
The model shows that many of the predictors have a high probability of influencing modified infinitive variation (table 3). It indicates that modified infinitive variation is highly sensitive to many of the language-internal and language-external factors included in the model.
Table 3. Proportion of factors that have a higher probability (pd > 0.79) of a non-zero effect on the likelihood of use of pre- or post-modified infinitive over the split infinitive construction
4.2 Language-internal factors
4.2.1 Non-prosodic
The multinomial model of modified infinitive variation indicates high probabilities of non-zero effects of adverb type on variation. The results, for one, show that users are more likely to avoid the split infinitive strategy in favor of pre-infinitive modification (henceforth, pre-modification) strategy if the adverb modifier is an additive or restrictive adverb (pd = 0.87) (table 2, figure 3a). However, there seems to be an opposite effect of this adverb type variable on the likelihood to select the split infinitive strategy over the post-infinitive modification (henceforth, post-modification) strategy. Users tend to prefer the split infinitive construction over post-modification when the adverb is additive or restrictive. They tend to place the adverb after the infinitive when the modified infinitive construction contains other adverb types such as adverbs of place (pd = 0.88) (table 2, figure 3a). The results all in all only partially confirm the findings of Kostadinova (Reference Kostadinova, Chapman and Rawlins2020) for AmE, which found the general avoidance of the use of the split infinitive construction with additive or restrictive adverbs. The differences in results are not surprising as Kostadinova studied modified infinitives in AmE across different styles (e.g. spoken, fiction, newspaper) whereas I focused on Twitter-style PhE. The comparison suggests that Twitter-style PhE has some characteristics of AmE, but that it also has its idiosyncrasies.
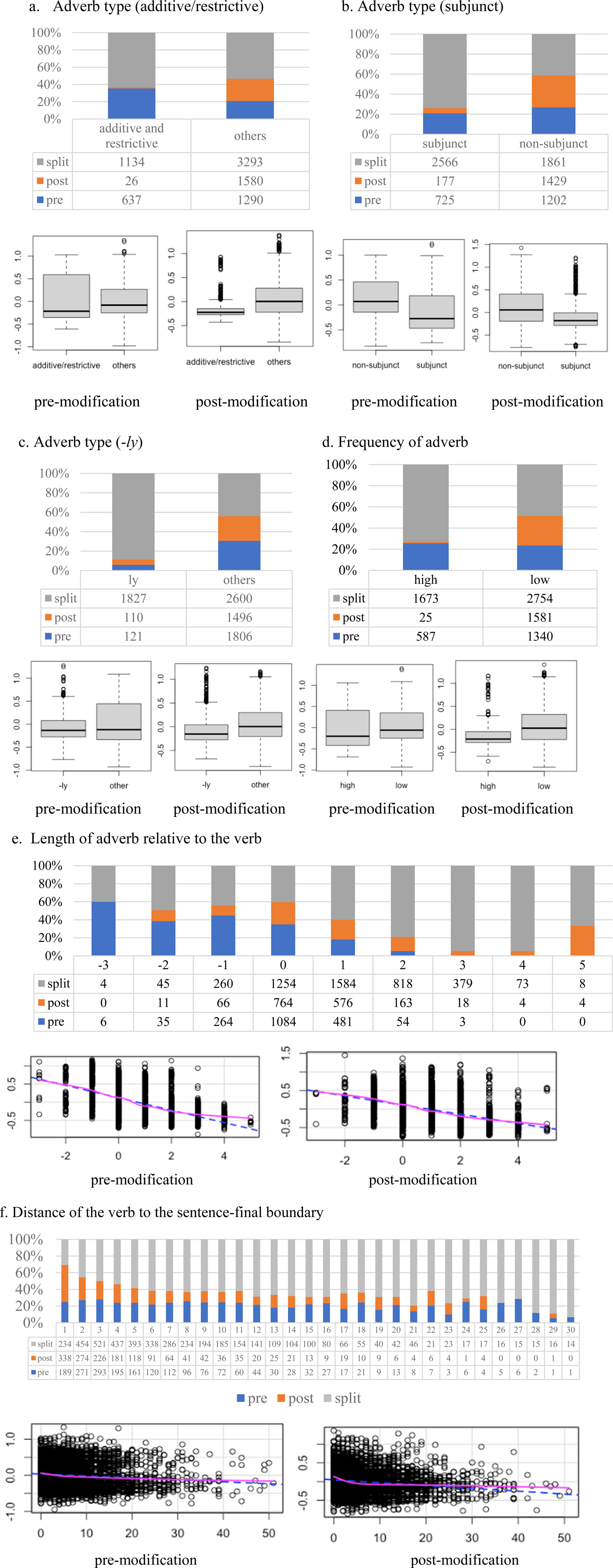
Figure 3. Distribution of modified infinitive variants by notable non-prosodic language-internal factors. Box plots and scatter plots indicate partial effects. On the y-axes of the box and scatter plots, negative values indicate likelihood to use a split infinitive, whereas positive values indicate likelihood to use pre-/post-infinitive modification.
In addition, I also found that the likelihood of use of the split infinitive over the other two constructions is also sensitive to the presence of adverbs identified as ‘subjuncts’ according to Quirk et al.'s (Reference Quirk, Greenbaum, Leech and Svartvik1985) description of English (table 2, figure 3b). Modified infinitives with subjuncts tend to be realized as to + adv + infinitive verb whereas those without tend to be realized as to + infinitive verb (+ …) + adv or adv + to + infinitive verb (pd =1). The results are consistent with previous research on AmE, which highlight the important role of adverb subjunct status in conditioning the variation of the modified infinitive (Quirk et al. Reference Quirk, Greenbaum, Leech and Svartvik1985; Perales-Escudero Reference Perales-Escudero2011: 331). In addition to the previous finding, the results here provide some indication that the conventions of Twitter-style PhE and contemporary AmE overlap, as the linguistic constraints governing the structure of modified infinitives in these varieties are similar.
A supplementary finding with respect to the adverb types is that adverbs with a -ly suffix (e.g. evenly) seem to favor the split infinitive construction whereas those without (e.g. again) tend to favor either the pre- (pd = 1) or post-modification constructions (pd = 1) (table 2, figure 3c). This finding is novel, as the effect of the -ly suffix on this variation has not been formally explored in previous literature. The results suggest, for Twitter-style PhE at least, that the suffix -ly should also be considered in explorations involving the modified infinitive.
Apart from the type of the adverb, I also found that the reported frequency of the adverb as a splitter in another PhE corpus conditions one's choice to use the split infinitive construction over the pre-modified construction (pd = 0.98) and the post-modified construction (pd = 0.67). Twitter users of English in the Philippines tend to split the infinitive if the adverb belongs to the list of most frequently used infinitive adverb splitters in the Philippine component of the ICE (see section 2) (table 2, figure 3d) (Gonzales & Dita Reference Gonzales and Dita2018). In other words, the choice of adverb splitters in the ICE – which was sampled across genres – mirrors the choice of adverb splitters in the TCOPE. The finding suggests that users of PhE (e.g. Twitter users, users of spoken and written PhE etc.) generally know which adverbs are more likely to appear in split infinitive constructions and which adverbs tend not to be used in the split construction in PhE. It provides some evidence of conventionalized dialect-specific linguistic practices in PhE, which seem to condition the variation observed partially.
The current study is perhaps the first to find a clear effect of length of adverb (measured via number of syllables) on the likelihood to choose the splitting strategy over pre- (pd = 1) and post-modification (pd = 1) (table 2, figure 3e). There is a higher chance of syntactic tmesis in constructions where the adverb is longer than the verb (e.g. to actually say) compared to constructions where the adverbs and verbs are of equal length (e.g. to just see) or constructions where the verb is longer than the adverb (e.g. to only actualize). This finding is at odds with previous work, which found an effect in the opposite direction: syntactic tmesis was more likely to occur in utterances where the adverb is shorter relative to the verb or in utterances where the adverb and verb have the same number of syllables (Kostadinova Reference Kostadinova, Chapman and Rawlins2020). This is a previously undocumented finding. However, when taken with the fact that Kostadinova's finding is on AmE, the findings are consistent with the literature on nativized varieties and contact languages, which have generally found that contact varieties – as independent entities – do not necessarily follow the developmental trajectory of their source languages (Thomason Reference Thomason2001; Thomason Reference Thomason2007; Gonzales et al. Reference Gonzales, Hiramoto, Leimgruber and Lim2022). It is still not immediately clear why the effect of adverb length should necessarily go in this direction in Twitter-style PhE. Is the effect another indication of variety-specific norms, or is it something else? What is clear, however, is that adverb length conditions the choice of modified infinitive construction, and the robust effect suggests that future work on the variation of this construction must include this predictor to fully account for the variation.
The distance between the to-phrase and the end of the sentence – a correlate of likelihood of ambiguity – play a role in conditioning the choice of modified infinitive construction (pd = 1). Utterances where the to-phrase is near the sentence-final boundary (i.e. utterances that leave less room for ambiguity) disfavor the use of the split infinitive, whereas utterances where the to-phrase is succeeded by constituents such as noun phrases (e.g. verbal complements) tend to favor the split construction (table 2, figure 3f). Under the assumption that the distance measure is reflective of (likelihood of) ambiguity, the finding is compatible with Quirk et al.'s (Reference Quirk, Greenbaum, Leech and Svartvik1985) description of split infinitives as an ambiguity resolution device (see section 2). Their findings suggest that if there is less ambiguity (little to no distance between to-phrase and the end of the sentence), there is less of a need to split the infinitive, which seems to be exactly what we observed. Of course, the distance measure is by no means a direct measure of ambiguity. However, I hope that the results still hold some value, as they present interesting correlations between split infinitive use and distance of the to-phrase to sentence-final boundary. They could pave the way for future research that directly analyzes ambiguity presence as a possible constraint on the use of split infinitives.
Length of adverb interacts with distance of the to-phrase to the sentence boundary to condition the choice to select the splitting strategy over the pre-modification strategy (pd = 0.95) and the post-modification strategy (pd = 0.87). The effect of distance is dependent on the length of the adverb (table 2, figure 4): the distance/ambiguity effect is non-existent in utterances where the adverb is longer than the infinitive verb because the split infinitive construction is almost always used. But this effect gradually becomes more salient as the adverb shortens relative to the verb. In short, the distance effect is most salient when the utterance has an adverb that is significantly shorter than the verb. I currently do not have a convincing explanation for this phenomenon, but the pattern warrants further investigation in the future.
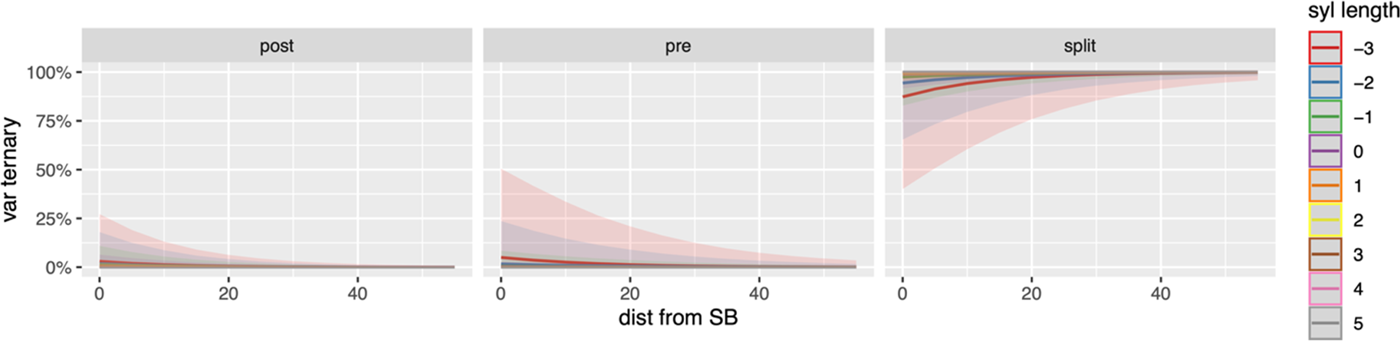
Figure 4. Marginal effects of interaction between length of adverb relative to the verb (length in syllables) and likelihood of ambiguity (distance from sentence boundary)
The model also indicates high probabilities (pd = 1) for the conditioning effect of verb and adverb lexeme on modified infinitive variation. The verb and adverb lexeme used govern the choice to split, to pre-modify, or to post-modify the infinitive. For example, modified infinitive constructions that contain adverbs like automatically, barely, drastically and possibly and verbs like affect, appear and consider are always realized as the split infinitive construction, whereas constructions that contain adverbs like enough, here, together and twice and verbs like rise, cheer and sing tend to be realized as the pre- and/or post-modified construction. The findings point to the importance of including lexeme-related factors in models of sociolinguistic variation, as these factors could have variable effects on linguistic behavior, as demonstrated here. The full distribution of adverb and verb lexemes by modified infinitive variant can be accessed online via the Open Science Framework (OSF): https://osf.io/sr2cy/
4.2.2 Prosodic
The probabilities for three of the four factors relevant to stress and rhythm – Conditions A, B and D – to influence modified infinitive variation are high. The odds of opting for a split construction over pre-modification and post-modification decrease if the verb is monosyllabic, regardless of the number of syllables in the adverb (Condition A) (pd = 1) (table 2, figure 5a, example 2). While the existence of the effect is expected, the direction of the observed effect diverge from what has been documented (Calle-Martín & Miranda-García Reference Calle-Martín, Miranda-García, Renouf and Kehoe2009): the likelihood to split the infinitive appears to have decreased instead of increased when Condition A is met.

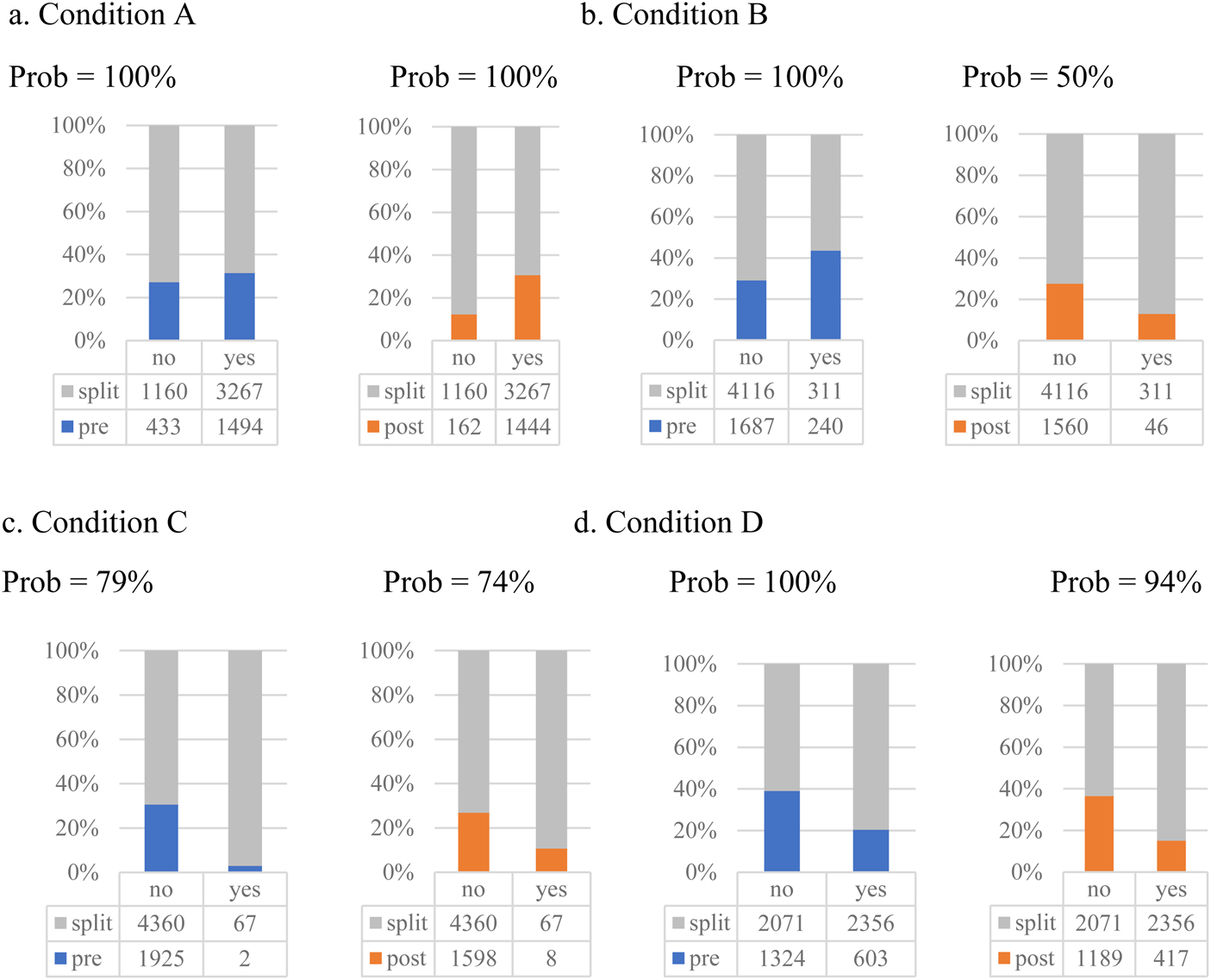
Figure 5. Distribution of modified infinitive variants by prosodic language-internal factors (main effects)
A similar effect was observed when analyzing utterances using Condition B, but the effect is only highly probable for the comparisons involving pre-modification (pd = 1) and not post-modification (pd = 0.5). The rates of pre-modification are higher in constructions with a finally stressed disyllabic verb and adverb with fewer than three syllables (Condition B) compared to constructions that do not meet this condition, contra Calle-Martín & Miranda-García (Reference Calle-Martín, Miranda-García, Renouf and Kehoe2009) (table 2, figure 5b). One would find more examples like (3) in Condition B.
Effects of Condition C on modified infinitive variation have been found in the model and are consistent with Calle-Martín & Miranda-García's proposal. Modified infinitives are realized as split infinitives more in constructions with initially stressed disyllabic verbs and trisyllabic adverbs (Condition C) compared to constructions without them. However, the probability of such an effect on the likelihood to pre-modify (pd = 0.79) or post-modify (pd = 0.74) over splitting is lower than the effect probabilities of Conditions A and B.

The effects of Condition D on the likelihood to pre-modify (pd = 1) or post-modify (pd = 0.94) instead of splitting are highly probable based on the model. They are also consistent with the literature (Crystal Reference Crystal1984; Calle-Martín & Miranda-García Reference Calle-Martín, Miranda-García, Renouf and Kehoe2009) (table 4). Users tends to opt for the split infinitive constructions if the adverb splitter contributes to the ‘natural’ te-tum te-tum rhythm (table 2, figure 5d, examples 4 and 5). This is consistent with what Crystal and Calle-Martín & Miranda-García described (table 4).
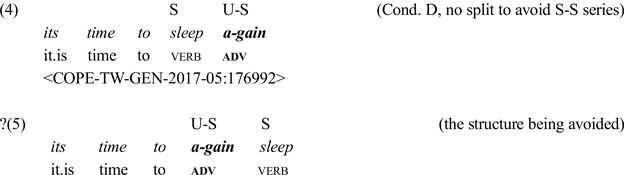
Table 4. Observed effects of stress and rhythm conditions on modified infinitive variation in previous studies vs. this study
The unexpected effects related to Conditions A and B in this study indicate that these conditions do indeed have influence on patterns of modified infinitive variation, but perhaps not to achieve ‘natural’ rhythm, as Calle-Martín & Miranda-García (Reference Calle-Martín, Miranda-García, Renouf and Kehoe2009) have argued. This is best supported by an examination of the interaction effect observed between Conditions B and D, which showed that users tend to avoid splitting infinitives in Condition B constructions if the adverb splitter contributes to ‘natural’ rhythm (table 2, figure 6c and d) (pd pre = 1, pd post = 0.85) – the opposite of what we would expect. There was also no strong evidence that users tend to choose split infinitives over pre- (pd = 0.57) or post-modification (pd = 0.74) in Condition A constructions as a means to follow this natural rhythm (figure 6a and b). So, while Calle-Martín & Miranda-García's argument that Conditions A and B play a role in conditioning modified infinitive variation is supported by evidence, their argument that these two conditions stem out of an impulse to maintain ‘natural’ rhythm appears questionable.
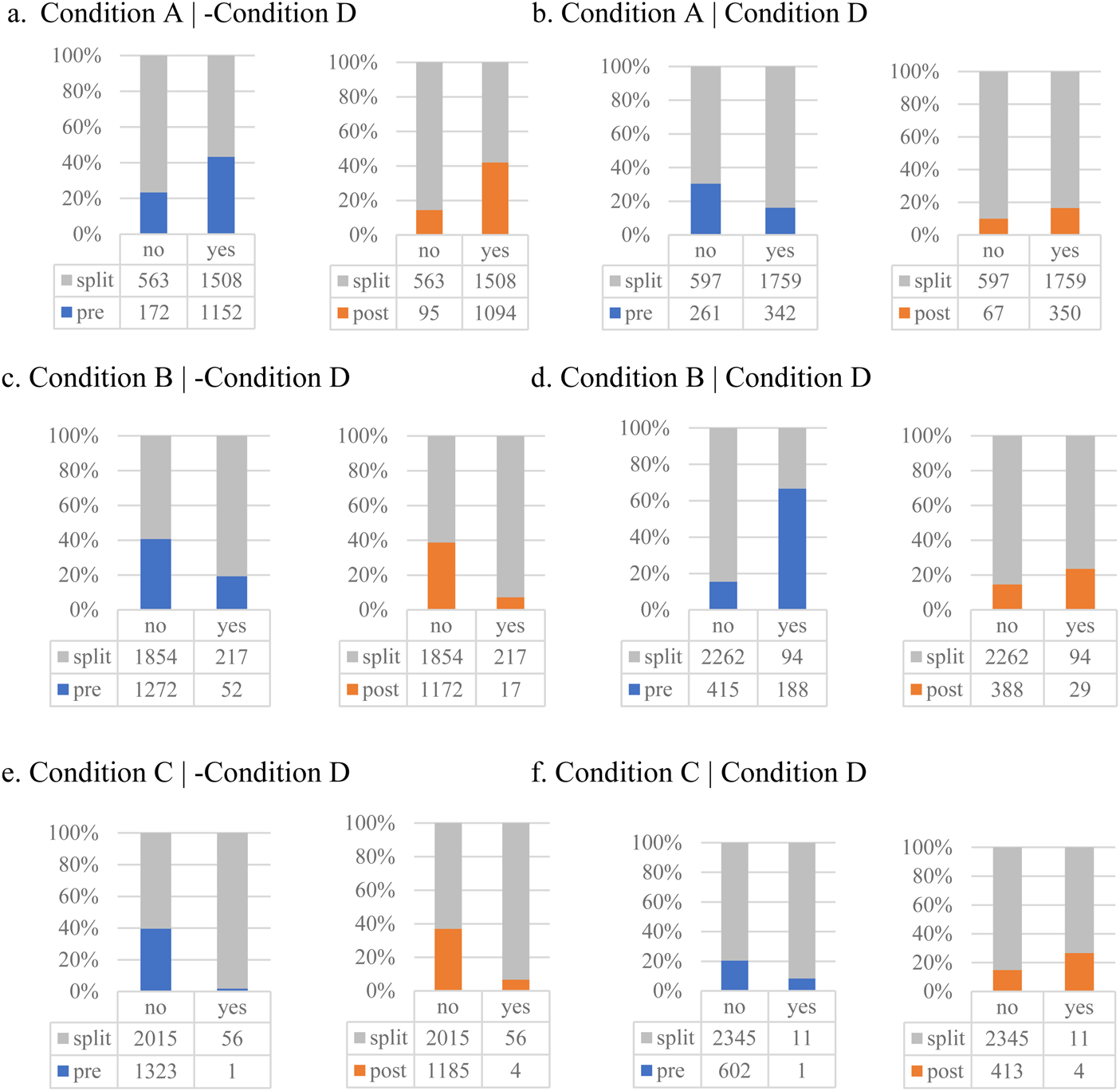
Figure 6. Distribution of modified infinitive variants – Conditions A, B and C given Condition D
Their claim that variation patterns are sensitive to Condition C due to rhythm maintenance also appears to be untenable. My findings show that speakers tend to split the infinitive instead of pre- (pd = 0.68) and post-modifying it (pd = 0.79) more in Condition C situations where the adverb splitter disrupts the ‘natural’ rhythm (figure 6e) compared to situations where the splitter contributes to the said rhythm (figure 6f).
One possible reason for the inconsistencies between the findings of this study and that of Calle-Martín & Miranda-García might have to do with the differences in the datasets, i.e. stylistic and dialectal differences between Twitter-style PhE and written and spoken AmE. However, the discrepancies might also have to do with the way the data were analyzed. Their study analyzed data using frequencies only, whereas this study incorporated a multiple multinomial statistical method that addresses potential confounding effects. It is impossible to say for certain whether identical patterns and effects would have emerged in Calle-Martín & Miranda-García's study, had the data been analyzed with the same model. What is certain, however, is that there indeed are effects of ‘natural’ rhythm (Condition D) and other stress/rhythm conditions (Conditions A, B) on modified infinitive syntactic variation and that these effects appear to be independent of each other. The findings altogether point to the crucial role of stress and rhythm in the structure of modified infinitives in English.
4.3 Language-external factors
Almost all of the language-external factors in the model have a high probability of conditioning the variation in modified infinitives. As table 2 and figure 7 show, these factors simultaneously influence the likelihood of split infinitive use. The only factor that had a relatively lower chance to condition the selection of the split infinitive strategy over pre- and post-modification is Island Group (Visayas vs. Luzon) (pd pre = 0.78, pd post = 0.68). The rates of split infinitive use between regions do not exhibit notable differences (table 2 and figure 7a), indicating a higher likelihood of homogeneity of split infinitive patterns in the English used in these regions.
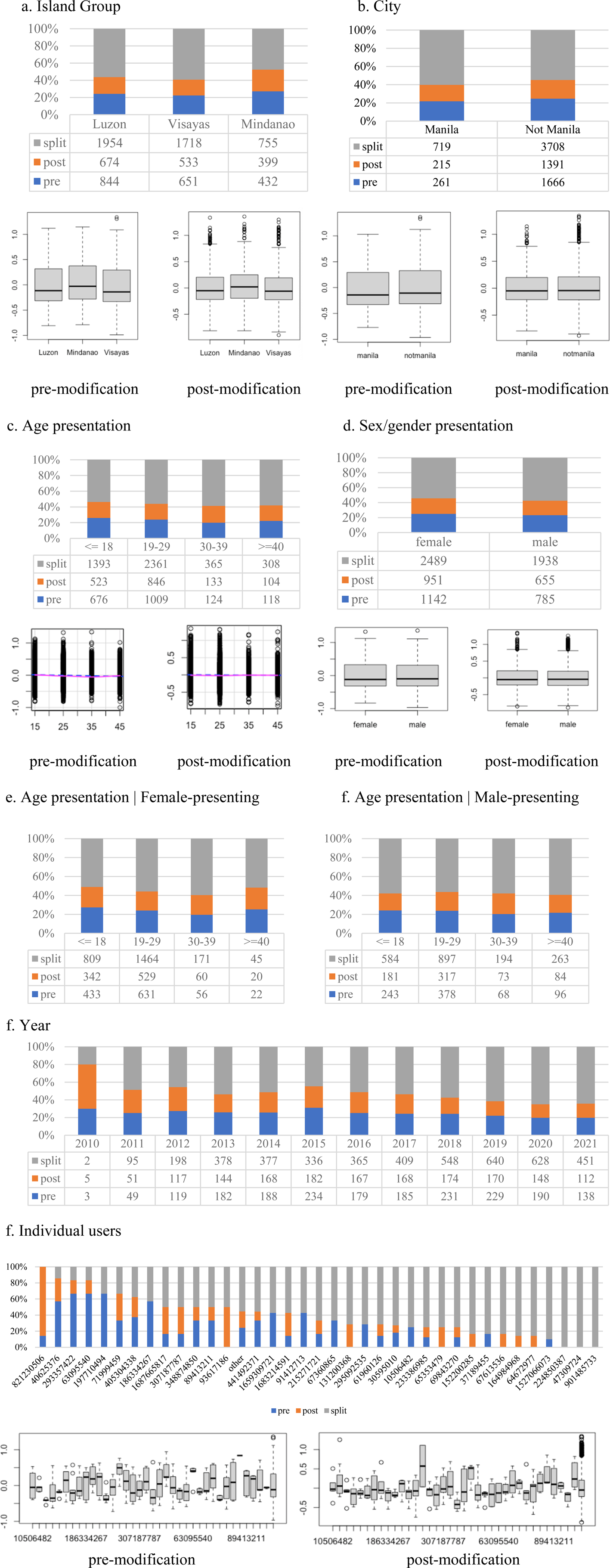
Figure 7. Distribution of modified infinitive variants by language-external factors (main effects); Box plots and scatter plots indicate partial effects. On the y-axes of the box and scatter plots, negative values indicate likelihood to use a split infinitive, whereas positive values indicate likelihood to use pre-/post-infinitive modification.
There is, however, a high chance that region conditions the variation when comparing the rates of split infinitive use in Mindanao (Southern Philippines) compared to the rates in Visayas (Central Philippines) and Luzon (Northern Philippines). The numbers show that Twitter users in the Mindanao region tend to have significantly lower rates of split infinitive use compared to those in the other two island groups (pd = 1) (table 2 and figure 7a). In other words, Mindanao users tend to be more conservative in their use of modified infinitives than Luzon and Visayas users. Due to lack of evidence, I am unable to explain this pattern, but future work can investigate the possible reasons leading to it (e.g. regional identity, variable prescriptive censure policies across regions). From a geographical perspective, the findings are, to my knowledge, perhaps among the first pieces of evidence for a north/central vs. south distinction in the PhE context.
A closer look at the data would also show the effect of city on variation. Those in Manila – the capital of the Philippines located in Luzon – tend to be more innovative and are more likely to use the split infinitive construction over the pre-modified construction (pd = 0.85) compared to non-residents of Manila (table 2 and figure 7b). Compared to non-residents, these users also tend to select the split infinitive construction over the post-modified construction more, but the likelihood of them doing so is noticeably lower (pd = 0.73). Altogether, the findings relevant to geography indicate that internal variation in Twitter-style PhE is very much present, and that the variation is constrained in part by geography. The findings corroborate previous work, which also found patterns of internal variation in (Twitter-style) PhE being sensitive to geographical location (Villanueva Reference Villanueva2016; Gonzales Reference Gonzales2017; Lee & Borlongan Reference Lee, Borlongan and Macalinga Borlongan2022; Gonzales Reference Gonzales2023b).
The results related to age presentation show that those who present as young (or rather, those are classified as younger by the Deep Learning algorithm) had splitting rates that are lower than those presenting as older (pd pre = 1, pd post = 0.99) (table 2 and figure 7c). The results on gender presentation, on the other hand, indicate a high probability that those who present as female (or classified as female) avoid splitting the infinitive over pre-modifying (pd = 0.8) or-postmodifying the infinitive (pd = 0.93) (table 2 and figure 7d). Furthermore, interestingly, individuals who present as younger and female are additionally less likely to split the infinitive compared to the rest of the population (e.g. those presenting as older males, younger males and older females) (pd pre = 0.87, pd post = 0.87) (table 2 and figure 7e). From a perspective of indexicality (Eckert & Rickford Reference Eckert and Rickford2001), it is possible that the non-use of the split infinitive – the conservative modified split infinitive variant – has acquired some indexical value related to youth and femininity due to the observed associations between young- and female-presenting speakers and the conservative variant. However, I hesitate to commit to this interpretation with certainty unless more evidence of this link can be gathered. We can, however, concretely observe a change in apparent time (Sankoff Reference Sankoff and Brown2006), meaning a generational change, such that younger-presenting users of Twitter tend to use fewer split infinitive constructions compared to older-presenting users. The results suggest that younger-presenting speakers – those presenting as younger women in particular – are leading the trend towards conservative norms in Twitter-style PhE. One thing worth noting is that, if we apply Labov's (Reference Labov1994) generalizations for language change and gender to this situation (i.e. that young women tend to lead language change or innovation in variable features that society is not conscious of) (Meyerhoff Reference Meyerhoff2018), it can be argued that the innovation in PhE is not the split infinitive construction, but rather the avoidance of such a construction. If it is indeed true that young and female-presenting individuals are (re-)introducing syntactic conservatism as a new innovation in PhE, then the findings would parallel other variationist studies on Philippine languages like Lánnang-uè, which have found younger women also leading in established innovations like a stratified mixed language phonology (Gonzales & Starr Reference Gonzales and Starr2020).
We also observe an effect of year on the observed internal variation – direct evidence of language change (pd pre = 1, pd post = 0.99). It seems that the preference for the split construction has increased over the past 11 years (table 2 and figure 7f). The findings are a welcome contribution to the relatively small amount of PhE literature discussing the diachronic dimension of PhE (Collins et al. Reference Collins, Borlongan, Lim, Yao, Pfenninger, Timofeeva, Gardner, Honkapohja, Hundt and Schreier2014; Borlongan & Dita Reference Borlongan and Dita2015; Gonzales Reference Gonzales2023b), but they seem to be at odds with the findings on apparent time in the previous paragraph, which show a decreasing preference for the split infinitive construction. However, I argue that the findings are not contradictory, but complementary. If the effect of year represents change between 2010 and 2021, and the effect of age presentation represents a change-in-progress in the year 2021 (or the present), then the results could suggest the recent gradual reversal of the split infinitive trend that has dominated in the past eleven years, led in part by young women.
Lastly, the results show that individual user factors have a high chance of conditioning variation in the modified infinitive (pd pre = 1, pd post = 1). Figure 7f shows the robust effect of these factors. One user, 821230506, did not use any split infinitives at all. Other users like 901485733 only have modified infinitives realized as the split infinitive. The bulk of users (e.g. 293356422), however, vary in their placement of the adverb in the modified infinitive construction. The results point to the importance of factoring in individual factors in explaining syntactic variability in Twitter-style PhE.
5 Conclusion
The current article has investigated syntactic variation of modified infinitives in English, focusing on the English variety used on Twitter in the Philippines (i.e. Twitter-style PhE). It centers on the syntactic alternation between the split infinitive construction (i.e. to + adv + infinitive verb), the post-modified infinitive construction (i.e. to + infinitive verb (+ …) + adv), and the pre-modified infinitive construction (i.e. adv + to + infinitive verb). The inquiry in this article seeks to determine whether the language-internal factors previously observed in studies on split infinitives in AmE (Calle-Martín & Miranda-García Reference Calle-Martín, Miranda-García, Renouf and Kehoe2009; Perales-Escudero Reference Perales-Escudero2011) and the language-external factors influencing variation in Twitter-style PhE (Gonzales Reference Gonzales2023b) play a role in conditioning the variation in the choice of modified infinitive constructions in one of AmE's offspring varieties – PhE (Thompson Reference Thompson2003).
The results of a multiple multinomial regression analysis of the data from a Bayesian standpoint reveal that the factors hypothesized to influence variation in splitting do indeed shape how the modified infinitive variable is realized. The adverb type, the reported frequency of adverb as a splitter in ICE, the length of the adverb relative to the verb, the likelihood of ambiguity, verb and adverb lexeme, and prosody (e.g. preserving the ‘natural’ rhythm) all jointly condition the syntactic variation in the modified infinitive in varying degrees. Furthermore, I discovered that this variation is also sensitive to language-external factors such as geography, age, sex, time and individual factors, part of which aligns with previous variationist research on PhE at the morphological and lexical levels of language (Gonzales Reference Gonzales2023b). But while there is strong evidence for the conditioning effects of these factors on infinitive variation, the directions of the effects do not necessarily follow all the patterns described in the (AmE) literature. I attributed some of these divergences – particularly language-internal ones – to stylistic differences between AmE and Twitter-style PhE. Or if we consider Twitter-style PhE to be partially representative of PhE, it can be said that, as a nativizedFootnote 9 variety of English, PhE can choose to pattern after its parent variety AmE; however, it can also chart its own trajectory and form its own set of conventions independent of AmE norms (Schneider Reference Schneider2003).
All in all, my findings stress the importance of the inclusion of language-internal and language-external variables in the study of split infinitives in English, particularly in PhE on Twitter. My study connects with other recent work urging more consideration of the combined role of these factors in conditioning variable processes (MacKenzie Reference MacKenzie2020; Kostadinova Reference Kostadinova, Chapman and Rawlins2020). Although this study is already comprehensive, it would be beneficial to investigate other possible predictors of modified infinitive variation. The factors that have been investigated in this study only constitute a small subset of factors that condition the syntactic variation, so future work can attempt to incorporate other predictors of splitting such as discourse focus and stylistic context into their models of modified infinitive variation, as these have been shown in the literature to robustly condition splitting (Kostadinova Reference Kostadinova, Chapman and Rawlins2020). Furthermore, follow-up work on variation in the modified infinitive construction utilizing multiple sources of PhE data across genres would be an important step in enhancing our understanding of how sociolinguistic factors structure variation in the use of split infinitives in PhE. In conjunction with the current study, such work would shed light on the complex nature of sociolinguistic variation in PhE as well as other Englishes and linguistic varieties around the world.
Like all research endeavors, this article is not without its limitations. One notable concern is the assurance of whether Twitter-style PhE truly represents an exemplar of standard or general PhE. Currently, there is a lack of extensive research on PhE that examines the degree to which Twitter-style PhE shares linguistic characteristics with other styles of PhE, such as the more conventional written and spoken forms. In other words, there is much we still do not know about Twitter-style PhE for us to comment on or compare with general PhE. Nevertheless, it is reasonable to anticipate that Twitter-style PhE would exhibit traits from both written and spoken PhE, such as a higher frequency of abbreviations, along with certain features specific to Twitter's platform, like shorter sentences and hashtags. Consequently, at this juncture, it remains challenging to determine the extent to which Twitter-style PhE represents a definitive example of general or standard PhE, assuming such a standard even exists. Aside from the difficulty of comparisons to a PhE ‘standard’, using the corpus to study Twitter-style PhE or PhE as a whole faces other challenges. A major issue arises from the fact that not all tweets collected originate from PhE users, and distinguishing PhE users from non-PhE users is not a straightforward task. Factors like ethnicity (Filipino versus others), linguistic exposure (native speakers of Philippine-type languages), identity (self-identification as Filipino), education, residence (whether born and raised in the Philippines), accent (Filipino-accented English) and others play a role in defining PhE users. However, this information is not publicly available on Twitter, making it difficult to profile users solely based on their names and profile descriptions. Furthermore, providing an operational definition of what qualifies as a PhE speaker becomes complex due to the intricate sociolinguistics of PhE. For instance, does a White Caucasian tweeter who has lived in the Philippines since birth, speaks Tagalog, but lacks a Filipino-accent when speaking English count as a PhE speaker? Similarly, what about an ethnic Filipino tweeter who attended an international school in the Philippines and speaks English with a blend of Filipino and British accents? Determining whether these individuals are PhE speakers introduces complexities. The article acknowledges the challenges and intricacies involved in identifying PhE users within Twitter corpora (or any other corpora) and attempts to simplify the analysis by assuming that the corpus is predominantly representative of PhE users, broadly defined as individuals who identify as Filipino. Despite the inevitable limitations and baggage associated with this approach, it is hoped that the substantial volume of data would compensate for the inclusion of ‘non-PhE’ user data, thereby mitigating potential noise in the analysis, as is often encountered with social media corpora.
Despite some limitations with respect to generalizability and the like, the present study has theoretical and methodological significance for the fields of variationist sociolinguistics and world Englishes. It provides empirical evidence that can help one assess the robustness of dominant theories in the fields (e.g. Labov's principles of change, developmental theories of post-colonial Englishes) (Labov Reference Labov1994; Schneider Reference Schneider2003). The findings have relevance not only for studies of split infinitives in English, but also for longstanding questions of the representation and nature of variable phenomena (MacKenzie Reference MacKenzie2020). Furthermore, the study has adopted the less commonly used Bayesian approach to analyzing data, which has been shown to facilitate intuitive, statistically sound and nuanced interpretations of the statistical results (Vasishth et al. Reference Vasishth, Nicenboim, Beckman, Li and Kong2018; McElreath Reference McElreath2020). Tools that utilize Deep Learning (Wang et al. Reference Wang, Hale, Adelani, Grabowicz, Hartmann, Flöck and Jurgens2019) were also used to help solve the problem of missing data in sociolinguistics (Gonzales Reference Gonzales2004). It is hoped that the current study will contribute to theory and method in these aspects.












 Open access
Open access