



1 Introduction
Among the better-known features of Colloquial Singapore English (CSE, also known as Singlish) are its discourse particles: derived from various substrate languages, they are monosyllabic and typically restricted to the clause-final position (see e.g. Wee Reference Wee2003; Reference Starr, Hall-Lew, Moore and PodesvaStarr forthcoming). These particles have been subjected to extensive scholarly attention focusing on their origins (e.g. Lim Reference Lim2007), their syntax and pragmatics (e.g. Gupta Reference Gupta and Fischer2006; Hiramoto Reference Hiramoto2012), and their ethnic and social distribution (e.g. Platt Reference Platt, Steele and Threadgold1987; Khoo Reference Khoo2012; Smakman & Wagenaar Reference Smakman and Wagenaar2013). In their role as discourse markers, they are excellent diagnostic features of informality and have achieved something of a stereotypical status, often drawn upon for the purpose of indexing national identity. This is perhaps best illustrated by the presence of such particles (particularly the hyper-stereotypical lah) in pop-culture artefacts, including internet memes, as well as on products such as t-shirts and other touristic souvenirs. While many of these particles have been described in a fair bit of detail, there remain uncertainties as to their exact behaviour in use and their variation across social factors. Ethnicity is one such factor which has attracted some attention (Platt Reference Platt, Steele and Threadgold1987; Begum & Kandiah Reference Begum, Kandiah and Schneider1997; Gupta Reference Gupta and Fischer2006; Leimgruber Reference Leimgruber2009; Smakman & Wagenaar Reference Smakman and Wagenaar2013; Botha Reference Botha2018), but the corpora involved were often small and not revealing enough for a proper variationist analysis. This is what we attempt to address in this article, using CoSEM, the Corpus of Singapore English Messages, a large corpus of text messages gathered from 2017 to 2019.
2 Background
The island of Singapore, located in Southeast Asia at the southern tip of the Malay Peninsula, is a small (approximately 720 square kilometres, resident population of around 5 million) multi-ethnic city-state. While settlements of regional importance have existed on the island for several centuries, the history of modern Singapore is typically taken to begin with the arrival of the British in 1819, at which point the island was populated almost entirely by the indigenous Malays, bar a few dozen Chinese (Turnbull Reference Turnbull1989). The British invested heavily in their presence there, establishing a tariff-free port on the lucrative and strategically important entrance to the Malacca Straits, a key point on the trade routes linking China and Europe (Wong Reference Wong2016). As a direct result of the now more supraregional relevance of the port city, migrants began arriving from various places, some brought in more forcefully than others (e.g. convicts out of British India), and some drawn by the colony's economic promise (see e.g. Leimgruber Reference Leimgruber2013a: 3–4). While the Malays were still in the majority in the first census in 1824, three years later immigrants from southern China had arrived in such numbers that they became the dominant ethnic group in the city (Leimgruber Reference Leimgruber2013a: 3). These Chinese migrants, however, came from regions within China that were ‘perceived as culturally and linguistically distinctive’ (Chew Reference Chew2013: 47). The languages they spoke were typically Southern Min (Hokkien, Teochew, Hainanese) and Cantonese, languages that have low levels of mutual intelligibility, resulting in high internal heterogeneity – as shown, for instance, in the separate school systems run by the respective ethnolinguistic groups (see e.g. Starr & Hiramoto Reference Starr and Hiramoto2019: 5). Mandarin, the present-day official Chinese language of Singapore, was not present in any significant proportion in the early days of the colony. Even after independence, it took several decades for Mandarin to become relevant in the local ecology: it was used as a home language by a mere 0.1 per cent of the population in 1957 (Kuo Reference Kuo, Afendras and Kuo1980; see also figure 1), and only after the launch of the Speak Mandarin Campaign in 1979 did Mandarin gradually establish itself as a serious competitor in Singaporean homes (see e.g. Bokhorst-Heng Reference Bokhorst-Heng and Blommaert1999; Teo Reference Teo2005; Starr & Kapoor Reference Starr and Kapoor2020), a language shift largely at the expense of the traditionally spoken varieties of Chinese.
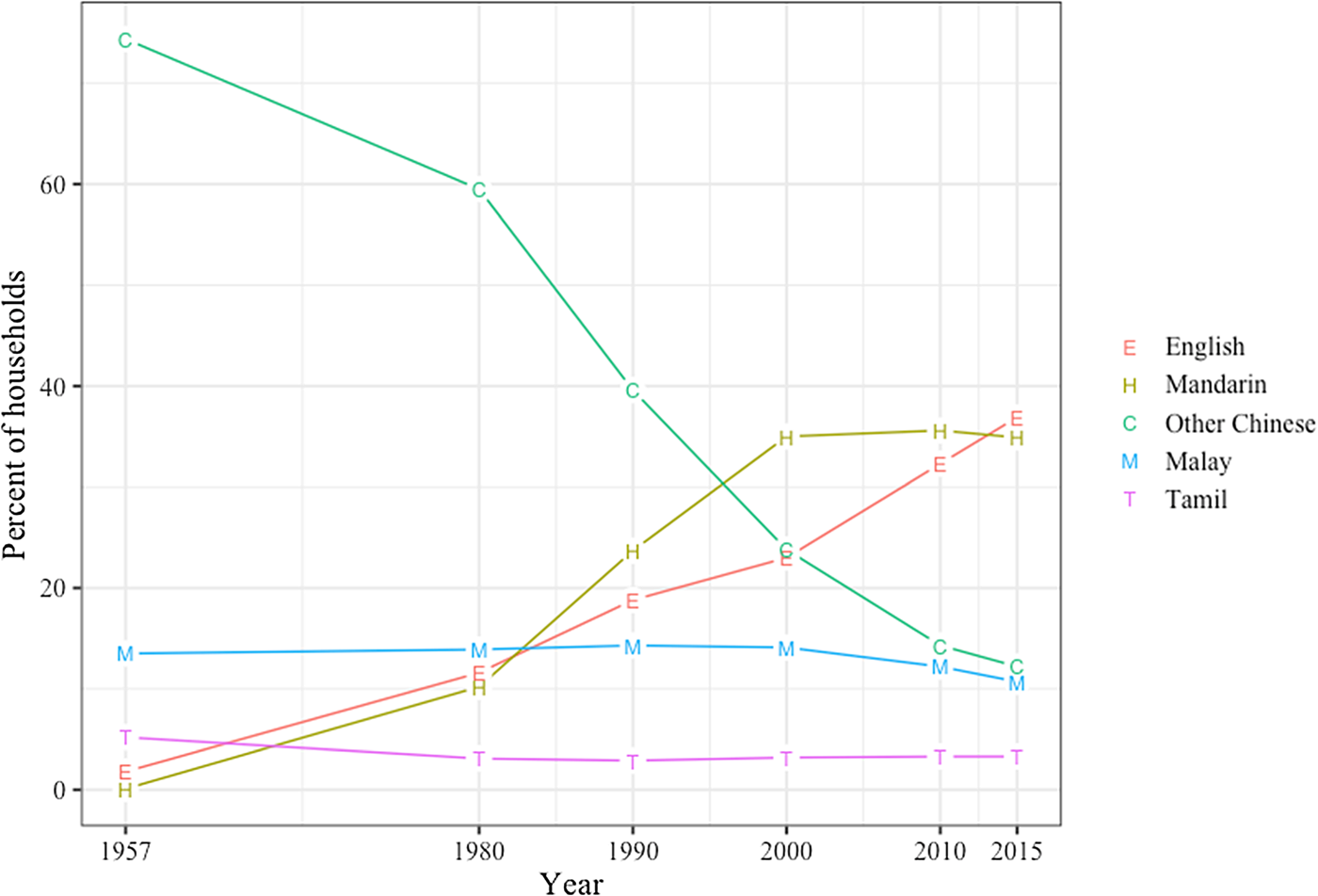
Figure 1. Changes in responses to the census item ‘language predominantly used at home’, 1957–2015 (Leimgruber, Siemund & Terassa Reference Leimgruber, Siemund and Terassa2018)
The Malay population of Singapore was relegated to minority status very soon after the foundation of the colony, at 42 per cent by the first census in 1824, and 13 per cent today (Department of Statistics 2016). The Malays came to Singapore from different parts of the Malay Archipelago, and spoke various Malayo-Polynesian languages including Malay, Boyanese and Javanese (Cavallaro & Ng Reference Cavallaro, Ng, Siemund and Leimgruber2020). Chew (Reference Chew2013: 38–43) points out that members of these various ethnic groups, like the Chinese immigrants, originally also considered themselves separate, with a pan-Malay identity emerging only gradually. Unlike Chinese languages among the Chinese, however, the Malay language is firmly entrenched in the Malay population, with 78 per cent reporting its use at home in a 2015 household survey (as opposed to 62 per cent of Chinese reporting using any Chinese variety). Language shift within the Malay community, where it exists, is solely in the direction of English (Cavallaro & Ng Reference Cavallaro, Ng, Siemund and Leimgruber2020); the Malay language, with its official and national status, however, has seen little change in use rates over the last sixty years’ censuses (see figure 1).
The third-largest ethnic group with official recognition in Singapore is the Indian group. At 9 per cent, it is the smallest (Department of Statistics 2016) and it is also the most linguistically heterogeneous in that the languages lumped together under the Indian heading come from the Dravidian (Tamil, Telugu, Malayalam, etc.) and Indo-Aryan (Punjabi, Gujarati, Hindi, etc.) language families. Tamil, the official language, is spoken by 38 per cent of Indian Singaporeans (Starr & Balasubramaniam Reference Starr and Balasubramaniam2019), and is the default ‘mother tongue’ taught to Indian pupils at school. Recent reforms to make other Indian languages (Gujarati, Hindi, Punjabi, Bengali and Urdu) available as options have proven most popular in the case of Hindi, which saw its intake double within six years (from 3,771 in 2011 to 7,199 in 2017; Jain & Wee Reference Jain and Wee2019: 7–8). Indians are also the ethnic group with the highest percentage reporting English as a dominant home language (44 per cent in 2015).
English, in general, has had great success in terms of language shift to it from other languages. As can be gleaned from figure 1, while there is not much change (in terms of percentages) for Malay and Tamil, a massive decrease in non-Mandarin varieties of Chinese can be observed, particularly from the 1980s onwards, from 67 to almost 17 per cent. This loss is compensated for by a concurrent rise of Mandarin and English, languages which have seen their share increase dramatically in the same period. In the case of Mandarin, this is clearly the result of a concerted language policy to actively promote Mandarin and actively discourage the so-called ‘dialects’.Footnote 2 The very visible Speak Mandarin Campaign, with its posters and school-based activities, is just one element of this policy; the structure of the education system, the regulation of language in the media (see e.g. Leimgruber Reference Leimgruber, Siemund, Gogolin, Edith Schulz and Davydova2013b: 245–6) and pronouncements by the political elite all follow the same goal of increasing Mandarin use and proficiency (Lim, Chen & Hiramoto Reference Lim, Chen and Hiramoto2021). English, meanwhile, has experienced similar success, due to other kinds of language policies. English enjoys the unofficial status of the country's ‘working language’; it is the sole medium of instruction in schools, and the language of the armed forces, of the government and generally of any white-collar workplace. While language shift towards English is not the stated aim of policymakers (which is ‘English-knowing bilingualism’, to quote Pakir Reference Pakir1991), educational and socioeconomic pressures combine to make the acquisition of English the most viable goal and the one into which the most resources are invested. The consequence is visible in figure 1: the latest Household Survey from 2015 indicates that English has now overtaken Mandarin as the most common home language in Singapore.
Regardless of the reasons behind this shift, the fact is that English has been, over the last few decades, spoken by an increasing share of the population, either as a ‘dominant home language’ (as per the census measure), as a first language outside the home, or as an additional language used in a variety of settings and domains. These include, as mentioned, the education system, most workplaces and the armed forces (in which male Singaporeans compulsorily serve for two years). Such high degrees of use in a wide range of settings and domains unsurprisingly led to the emergence of a local vernacular form of English, known as Colloquial Singapore English (CSE, or Singlish), which has spread to large parts of the population.
CSE has been widely described in the literature (see, inter alia, Platt Reference Platt1975; Gupta Reference Gupta1994; Foley et al. Reference Foley, Kandiah, Bao, Gupta, Alsagoff, Ho, Wee, Talib and Bokhorst-Heng1998; Lim Reference Lim2004; Low & Brown Reference Low and Brown2005; Deterding Reference Deterding2007; Leimgruber Reference Leimgruber2013a). Based on these studies, structural features such as copula-deletion, pro-drop and the kena passive construction, among others, can be explained by the variety's continuous contact with Sinitic and Malay languages. It features lexical admixture primarily from Hokkien and Malay; its grammatical structures come mostly from Chinese (or Sinitic) languages. In the phonology, CSE shares features with other Asian Englishes (consonant cluster reduction, final devoicing, non-contrastive vowel length, fewer instances of schwa, etc.). Among the more stereotypical features of CSE are the substrate-derived discourse particles under investigation here; they are widely used and recognised in Singapore. The substrate languages present in the country explained above certainly had a role to play with regard to these particles: Chinese languages feature many such discourse particles (Lim Reference Lim2007), as does Malay (Yap et al. Reference Yap, Chan, Wong and Tay2016), whereas Indian languages typically do not (but see Baskaran Reference Baskaran1988). The existence of CSE has long been considered a problem by policymakers, mostly because it is seen as having a negative influence on Standard English proficiency. The standard form is, of course, the one taught in schools and the one encouraged by authorities as key to maintaining the country's performance in the globalised economy. CSE, on the other hand, is largely used in informal contexts, resulting in what Gupta (Reference Gupta1994) identifies as a classic diglossia. In addition to its informal character, the vernacular has also taken on additional societal roles, as it is deployed in language use and conceptualised in terms of cultural orientation (Alsagoff Reference Alsagoff2010) or indexicality (Leimgruber Reference Leimgruber2012). The cultural and national indexing facilitated by CSE is also what affords it a certain amount of covert prestige (see the attitudes expressed in, e.g., Leimgruber Reference Leimgruber2014; Siemund, Schulz & Schweinberger Reference Siemund, Schulz and Schweinberger2014; Leimgruber, Siemund & Terassa Reference Leimgruber, Siemund and Terassa2018), to the extent that a select few features of the variety were even allowed by decision makers to appear in visual displays during the country's fiftieth anniversary of independence in 2015 (Hiramoto Reference Hiramoto2019: 457). It is fair to say, however, that the basic top-down policy orientation of minimising the use of CSE remains largely intact (Wee Reference Wee2011).
3 Discourse particles
Given the sociolinguistic context established in the preceding section, we now turn to an explanation of the discourse particles, a central feature of CSE in most descriptions of the variety. The particle lah, for instance, appears in virtually all accounts of CSE, going back to the earliest works (e.g. Richards & Tay Reference Richards, Tay and Crewe1977; Kwan-Terry Reference Kwan-Terry1978; Bell & Ser Reference Bell and Quee Ser1983). While lah is undoubtedly of non-English origin, it is important to remember that the class of discourse markers in CSE also includes general English markers such as you know, I mean, well or man (see e.g. Gupta Reference Gupta1992; Choo Reference Choo2016). In what follows, however, the focus will be on discourse particles that are of non-English origin and fulfil the clause-final requirement. This includes the stereotypical lah, but a range of others too, illustrated in the following examples of online text messages from the CoSEM corpus (introduced in section 5):
(1) If you feel sad then stop spreading this bad fact about him la
‘If you feel sad, then just stop spreading this bad fact about him.’
(COSEM:17CF15-35382-21CHF-2015)
(2) Wah u very free ah
‘Wow, you are very free, aren't you?’
(COSEM:17CF31-4573-19CHF-2016)
(3) I think everyone plan timetable first bah
‘I think it's best if everyone plans their timetable first.’
(COSEM:17CF07-13341-22CHM-2016)
(4) 30th got school meh it's a Sunday Leh
‘Are you certain there is school on the 30th? It's a Sunday!’
(COSEM:17CF34-211-20CHF-2012)
(5) I find the black emojis dam funny lor
‘I just find the black emojis damn funny.’
(COSEM:17CF07-8854-21CHF-2015)
(6) Sit where?? Still drizzling sia haha
‘Where should we sit? It's still drizzling haha.’
(COSEM:17CM02-4764-21CHM-2016)
(7) Quite obvious what Footnote 3
‘It's quite obvious, isn't it?’
(COSEM:17IF03-3157-20INF-2014)
A primary objective of existing research discussing these particles is usually to describe their semantics and pragmatics. Table 1 gives an overview of some of the more commonly described particles of CSE and their definitions, as provided by various scholars. Some of these definitions are more straightforward than others, and sometimes scholars fail to agree on an exact definition. The particle leh, for example, has been reported as the equivalent of ‘what about’ in questions involving comparisons (Platt Reference Platt, Steele and Threadgold1987), whereas for Wee (Reference Wee and Lim2004) it marks tentative suggestions or requests.
Table 1. Major particles of Colloquial Singapore English and their definitions, in alphabetical order

The origins of the particles are equally contested. Lim (Reference Lim2007) gives a convincing historical sociolinguistic account of the origins of a selection of particles, identifying two categories that can be distinguished diachronically. The first includes lah, ah and wor, of Malay and Hokkien origin, and are the older particles, whereas lor, hor, leh, meh and mah, the origins of which Lim traces to Cantonese, are more recent additions to CSE. This idea of discourse particles, which are normally treated as a fairly fixed and closed category, being in fact a much more fluid and dynamic category that new members can readily join, is underscored by more recent work describing the less-documented particles bah (Leimgruber Reference Leimgruber2016) and sia (Khoo Reference Khoo2012; Hiramoto, Lee & Choo Reference Hiramoto, Lee and Choo2017), which entered the CSE discourse particle category fairly recently. Whereas the Malay origin of sia is fairly uncontroversial, the purported Mandarin roots of bah point to a shift away from the traditional source languages of CSE particles towards Mandarin, a newcomer to the contact situation that has only gained ground as a home language in the last thirty years or so.
4 Social variation in discourse particles
Less attention has been given, to date, to social variation in the use of the discourse particles. In a corpus of young post-secondary students’ English, Leimgruber (Reference Leimgruber2009), for instance, found that ethnicity was a significant predictor of particle use in both formal and informal settings, except between Chinese and Indians in informal settings, where they behaved similarly. The general trends were that in formal settings, the Malays used particles most commonly, followed by the Chinese and then the Indians. In informal settings too, the Chinese and Indians used particles less frequently than the Malays. This corpus-based approach suggests that there are differences in the use of particles across ethnic groups, a suggestion later taken up by Smakman & Wagenaar (Reference Smakman and Wagenaar2013). Using data from the Singapore component of the International Corpus of English (ICE-SIN), they found three types of particles: those that did not exhibit variation by ethnicity (the particles ah, lah and meh); moderate ethnic indicators (such as lor, which was used significantly more frequently by speakers of Chinese ethnicity); and absolute ethnic indicators (such as hor and leh, which were used exclusively by speakers of Chinese ethnicity).Footnote 4 Further, they contrasted particle use in inter- and intra-ethnic settings, and found that over all, there is more particle use in intra-ethnic settings. This result makes intuitive sense, seeing as such intra-ethnic settings would most likely be marked by lower levels of formality than inter-ethnic ones, in turn triggering features of informal speech such as substrate-derived discourse particles.
More recently, Botha (Reference Botha2018) compared particle use in spoken and written data, collecting, on the one hand, text messages, and on the other, recordings of informal face-to-face interaction – both, crucially, from the same group of informants. Among his findings is the fact that the particle ah occurs almost twice as often in speech as in writing. Further, he also considered a rather wide range of particles, including some that have not featured extensively in previous research (such as orh, seh and nia),Footnote 5 and found that less frequent particles are more common in written than in spoken data. We consider the inclusion of such low-frequency particles noteworthy, as they may be indicative of a natural ongoing language change towards the incorporation of an increasing number of different particles into CSE; we speculate that at least some of the less frequent particles are rather new additions to CSE. In terms of ethnicity, Botha notes that Indians use a smaller range of particles than the other two ethnicities, whereas the Chinese use a greater range of particles than the others. This finding is unsurprising because, as mentioned, Chinese varieties and Malay are known for the use of sentence-final discourse particles while Indian languages are not. Between-group preferences for certain particles were also reported, such as for the particle orh, which was used more often by Indians than Chinese but never by Malays, and the particle eh, which showed higher frequency among Malays than among Indians and Chinese.Footnote 6 Perhaps even more interesting, however, is Botha's account of the social networks in which his informants operate. He found more diversity in the particles used in ‘second-order’ zones of the networks, a fact explained as a result of the increased social distance between members, resulting in more need for overt identity construction and negotiation, a task to which discourse particles lend themselves particularly well. This, however, is in contrast to previous studies (Leimgruber Reference Leimgruber2009; Smakman & Wagenaar Reference Smakman and Wagenaar2013), which suggest that informality, and therefore closeness within a network, triggers more particle use – the opposite of the explanation offered by Botha (Reference Botha2018).
5 The CoSEM corpus
The corpus from which the data in this article are drawn is the Corpus of Singapore English Messages (CoSEM), compiled by a team at the National University of Singapore (Hiramoto et al. Reference Hiramoto, Wong Gonzales, Lim and Leimgrubern.d.; Gonzales et al. Reference Gonzales, Hiramoto, Leimgruber and Limn.d.). It consists of WhatsApp group chats provided by undergraduates between 2016 and 2019, although more cohorts are currently being recruited. After having obtained consent from all participants, the data were anonymised and tagged for ethnicity and gender, thereby adding precious sociolinguistic information typically absent from existing corpora of Singapore English. CoSEM currently stands at around 4.6 million words (including emojis), a number that is expected to keep growing as new cohorts are added. Table 2 shows the word counts by genderFootnote 7 and ethnicity in the dataset used here. Of note is the usual bias towards the Chinese component, which is a limitation inherent to the data collection process employed, but not unlike other corpora of CSE. Nevertheless, there are a substantial number of words in the Malay and Indian components, which should enhance the corpus's representativeness. In contrast, there is a fairly balanced distribution of words for male and female participants, which will allow for meaningful normalised frequencies.
Table 2. Number of words in the Corpus of Singapore English Messages (CoSEM), by gender and ethnicity, with totals

6 Results
Table 3 gives an overview of ten frequent particles and their distribution by gender and ethnicity. For each ethnic group, the percentage of use among male and female participants is given. The last column shows that overall, in the entire dataset, 45,617 particles are used, mostly by men (58.3%). The actual particles show known trends: ah (14,216) and lah (13,616) are the high scorers, and hor (656) and wor (63) are much rarer. This is in line with previous work (e.g. Leimgruber Reference Leimgruber2009; Smakman & Wagenaar Reference Smakman and Wagenaar2013; Botha Reference Botha2018), and confirms the general pattern of occurrence of the various particles.
Table 3. Selected particles in CoSEM, arranged alphabetically. For each ethnic group, the percentage of male and female uses of the particle is given, as well as the number of times the particle appears

6.1 Ethnicity
Interesting trends become visible when taking ethnicity into account. A first overview is given in table 4, which shows individual and overall frequencies (in particles per thousand (‰) words of the respective subcorpus) of use for each particle. Several tendencies can be gleaned from this table. Overall, particle use frequencies differ from one ethnicity to the other, with the Chinese in the lead (10.28 particles per thousand words), followed by the Indians (8.81‰) and the Malays (8.73‰). The results of a linear regression implemented in the R environment (R Core Team 2013) and run on these frequencies show that the Chinese do not use significantly more or fewer particles than the rest (β = -0.008275, SE = 0.00434, p = 0.05654) and neither do the Malays (β = 0.004951, SE = 0.004139, p = 0.23158); the Indians, however, use significantly fewer particles compared to the others (β = -0.01081, SE = 0.004116, p < 0.001). This is in contrast to the findings reported by Leimgruber (Reference Leimgruber2009), where the Malays were the ethnicity found to use particles most frequently.
Table 4. Selected particles in CoSEM, arranged alphabetically. For each ethnic group, the frequency per thousand words of the particle is given, as well as the number of times the particle appears

At the level of individual particles, however, there are notable ethnic effects, as shown in table 4. Lah, for instance, seems to be used much more often by the Indians (4.11‰) than by the Chinese (2.79‰) and Malays (2.55‰), a difference that is highly significant (β = 0.365898, SE = 0.084608, p < 0.0001). Closer inspection of this difference reveals that just over half of these Indian occurrences of lah come from one and the same chat: a mixed-ethnicity conversation in which seven Chinese and four Indians interact, but in which the Indians produce more text (190,258 words vs 167,250). Within this chat, the lah particle is used more frequently by the Indians (6.24‰) than the Chinese (5.70‰), although this difference is not significant (β = -9.18662, SE = 6.55987, p = 0.1614). When individual chat files are taken into account in the general model for lah, none of them stands out as having a significant effect on lah use, including this one (β = 11.71, SE = 1455, p = 0.993579). Therefore, we can discount any distortion brought about by this one chat file, and maintain that the significant effect observed in the overall corpus holds: Indians are significantly more likely to use lah than the other ethnicities.
Regression was used to query any statistically significant differences that might appear in the various particles. Its results are given in table 5. It appears that Chinese ethnicity has a strong effect on particle use: bah, hor, leh, lor, meh and wor are all used significantly more often by Chinese participants. Conversely, ah and lah are significantly less likely to be used by participants of Chinese ethnicity. The case of lah, discussed above, suggests a strong Indian effect. In the case of sia, with its postulated origin in the Malay language, the model shows no significant effect for Malay ethnicity (β = -0.115, SE = 0.4731, p = 0.80790); contrariwise, it is again Chinese ethnicity that shows a significant positive association with the particle (β = 1.0272, SE = 0.38286, p < 0.01).
Table 5. General linear model querying the probability of ethnicity having a significant effect on particle use

In the case of ah, by far the most frequent particle, the Chinese participants in the corpus show significantly lower rates of use compared to the other ethnicities (β = -0.5404, SE = 0.1386, p < 0.001), confirming the findings of Botha (Reference Botha2018) but partly refuting Leimgruber (Reference Leimgruber2009) and Smakman & Wagenaar (Reference Smakman and Wagenaar2013), whose data suggest higher frequencies of ah use among Malays.Footnote 8 Finally, while mah does exhibit a higher frequency of use among Chinese, the effect is not statistically significant (β = 0.491192, SE = 0.339912, p = 0.14844). This is an interesting finding, considering previous research which found mah a marker of Chinese ethnicity (Platt Reference Platt, Steele and Threadgold1987: 395; Leimgruber Reference Leimgruber2009: 185; Botha Reference Botha2018: 271). We consider the larger (and more recent) corpus data used in this study to be a more accurate depiction of the ethnic distribution of particles in CSE, suggesting that mah, whatever its origin and erstwhile use might have been, has now crossed ethnic boundaries to no longer be directly associated solely with the Chinese group.
6.2 Gender
Several complex patterns can be observed with regard to gender (see table 6 and figure 2). The overall behaviour, which stands at 11.50 particles per thousand words among men and 8.40‰ among women, turns out to be highly significant (β = 0.03556, SE = 0.001718, p = 0.001). The same holds true for most individual particles, even where the difference in frequency is negligible: mah, for instance, is used at a comparable rate of 0.3061‰ (women, N = 701) and 0.3104‰ (men, N = 728), but this small difference of 27 particles is nonetheless significant (p < 0.001). The opposite effect is seen with leh, which women use more often, though at a slightly lower level of significance (p < 0.05). Figure 2 suggests that sia shows a strong preference among men in frequency, but this difference is not significant (p = 0.16756).

Figure 2. Particles per thousand words, by gender, arranged alphabetically
Table 6. Male and female frequencies per thousand words for each particle; general linear model querying the probability of gender having a significant effect on particle use

Sia, we may add, is not always included in the basic inventory of CSE particles. Khoo (Reference Khoo2012) provided one of the earlier treatises on sia; she identifies it as having its origin in the Malay swearword sial. It has, however, taken on meanings beyond simple swearing to include at least intensification in the form of coarseness and coolness as well as solidarity marking, in which case it indexes a casual stance, or a youth identity (Hiramoto et al. Reference Hiramoto, Lee and Choo2017). To illustrate these uses, (8) and (9) are examples of intensification, and (10) and (11) of solidarity marking.
(8) Wtf they damn mean sia
‘WTF, they are damn mean!’
(COSEM:17CF34-7510-21CHF-2012)
(9) Actually im very clueless sia
‘Actually, I'm very clueless.’
(COSEM:17CM02-2502-21CHM-2016)
(10) I need this in my life sia
‘I need this in my life!’
(COSEM:17CF12-33682-21CHM-2015)
(11) And it's like less than a month alr Sia
‘And it's like less than a month already.’
(COSEM:17CF25-5413-20MAF-2016)
The CoSEM data show that in the case of sia, ethnicity and gender interact strongly. Of all combinations, Malay men (1.65‰) use it most, whereas Malay women (0.51‰) use it least. Malay men, therefore, are significantly more likely to use the particle than any other ethnicity/gender combination (β = 0.6102, SE = 0.121, p < 0.001). The difference in frequencies between genders does not appear to be significant in the case of the Chinese (men: 1.51‰ vs women: 0.88‰) and the Indians (men: 0.94‰ vs women: 0.52‰). Our interpretation of these results is that the original Malay-language swearword meaning of sia is still latently present in the Malay population, thereby preventing Malay women from using the particle with the same frequency as their male counterparts. Meanwhile, for the Chinese and the Indians, such considerations would not be of consequence, given that proficiency in the Malay language (and thus knowledge of sial's full connotations) is limited to certain lexical items or phraseological constructions among members of the Chinese and Indian communities.
7 Discussion
The findings presented in this article are summarised in table 7. There are several points of interest. Firstly, Chinese ethnicity as well as male gender are positive predictors for most particles, with varying degrees of statistical significance.
Table 7. Significant predictors for each particle

Secondly, we note the possible emergence of new ethnic markers, alongside those of Smakman & Wagenaar (Reference Smakman and Wagenaar2013): bah is used almost exclusively by Chinese speakers of CSE, with Malay men quite a distance behind. This is interesting, for at least two reasons: firstly, because bah is an unusual particle in that its origins lie in Mandarin (Leimgruber Reference Leimgruber2016) and not in Hokkien or Cantonese, like the bulk of the other discourse particles. As discussed above, Mandarin only became relevant in the local linguistic ecology after the 1980s. It is now a widely used home language (dominant in one-third of households in 2015), a change in status that undoubtedly has effects on language attitudes towards the variety – attitudes which are important in considerations of language shift and change (see e.g. Thomason Reference Thomason2001). Secondly, the behaviour of bah is somewhat surprising insofar as a particle with a putative Mandarin origin, while still significantly more common among the Chinese, is making its way into non-Chinese groups. Perhaps the close contact of men from different ethnic backgrounds during the compulsory two-year-long National Service has a role to play: the armed forces generally have been found to be fertile ground for linguistic transfer of several kinds (see e.g. Berthele & Wittlin Reference Berthele and Wittlin2013; Akande Reference Akande2016).
Thirdly, some particles stand out as departing from the dominant Chinese and male effect. Lah shows a strong Indian bias. Mah is the only particle to not show any significant ethnic influence, whereas in the case of sia, the combination of Malay ethnicity and male gender predicts its use. It is safe to say, therefore, that gender and ethnicity are predictors of particle use.
8 Conclusion
The findings in this article complement the claims made by Botha (Reference Botha2018: 271) about the ethnic distribution of particles in respect to overall behaviour, but our findings depart from Botha's in the case of some particles; it is perhaps interesting to note that ah was found to be led by Indian users in Botha's study, whereas here it is the Chinese. Differences in methodology and corpus size may well explain these discrepancies. It is worth adding that ethnicity and gender alone do not account for the whole picture of variation in particle use, or in CSE in general: our model also accounted for age, on which we are not focusing in this article for lack of space. It is an important factor too, with, for example, sia being used almost exclusively by the younger generation (i.e. people under 30 years of age in CoSEM), an observation that we plan to test in future analyses of the corpus. Further, it appears that discourse particle usage may be an additional piece of evidence in support of Schneider's (Reference Schneider2007) claim that Singapore is on its way into the differentiation stage of his dynamic model, in which subnational groups begin to use language differently in order to mark distinct identities. This seems to be the case here, with ethnic groups exhibiting different types of language use. This phenomenon has also been attested in the realm of phonetics; for instance, a study by Starr & Balasubramaniam (Reference Starr and Balasubramaniam2019) found a tapped and trilled variant of /r/ to be used by Tamil Singaporeans as an index of Indianness, when otherwise the approximant [ɹ] would be used. Careful analysis of any sociolinguistic variable in the Singapore context will undoubtedly lead to the concurrent finding of instances of homogenisation and heterogenisation, as highlighted by Buschfeld (Reference Buschfeld2020). The two are certainly not mutually exclusive, and are indicative of a speech community that is stable enough to have a common core, with social subvarieties emerging, as suggested by Schneider's (Reference Schneider2007) placing of Singapore in the early stages of the differentiation phase of his model (see also Gonzales & Hiramoto Reference Gonzales and Hiramoto2020). A combination of such features, whether above or below the level of consciousness, certainly suggests the presence of ethnicity-related subvarieties of CSE.
Discourse particles have been shown to play important roles in language contact situations (Torres Reference Torres2002, Reference Torres2006; Matras Reference Matras2009: 137–44; Smith-Christmas Reference Smith-Christmas2016). Considering, as we do, discourse particles (as well as languages) to be fluid, we propose that they developed in CSE early on as a kind of lubricant required in conversations between speakers of different, mutually unintelligible languages. In other words, discourse particles were useful, pragmatically, for speakers to get their message across. At the same time, discourse particles naturally became part of the feature pool of CSE through the support of substrate languages in which the corresponding particles are well established. It is not surprising, then, that new discourse particles are still being incorporated to this day into CSE by speakers based on their conversational needs.










 Open access
Open access