


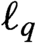

 Open access
Open access
Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Kuchibhotla, Arun K.
Kolassa, John E.
and
Kuffner, Todd A.
2022.
Post-Selection Inference.
Annual Review of Statistics and Its Application,
Vol. 9,
Issue. 1,
p.
505.
Xu, Haotian
Wang, Daren
Zhao, Zifeng
and
Yu, Yi
2024.
Change-point inference in high-dimensional regression models under temporal dependence.
The Annals of Statistics,
Vol. 52,
Issue. 3,
Li, Jiaqi
Chen, Likai
Wang, Weining
and
Wu, Wei Biao
2024.
ℓ2 inference for change points in high-dimensional time series via a Two-Way MOSUM.
The Annals of Statistics,
Vol. 52,
Issue. 2,