


No CrossRef data available.
Published online by Cambridge University Press: 27 September 2021
We study linear subset regression in the context of the high-dimensional overall model 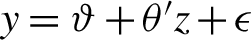 $y = \vartheta +\theta ' z + \epsilon $ with univariate response y and a d-vector of random regressors z, independent of
$y = \vartheta +\theta ' z + \epsilon $ with univariate response y and a d-vector of random regressors z, independent of 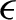 $\epsilon $. Here, “high-dimensional” means that the number d of available explanatory variables is much larger than the number n of observations. We consider simple linear submodels where y is regressed on a set of p regressors given by
$\epsilon $. Here, “high-dimensional” means that the number d of available explanatory variables is much larger than the number n of observations. We consider simple linear submodels where y is regressed on a set of p regressors given by 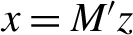 $x = M'z$, for some
$x = M'z$, for some  $d \times p$ matrix M of full rank
$d \times p$ matrix M of full rank  $p < n$. The corresponding simple model, that is,
$p < n$. The corresponding simple model, that is, 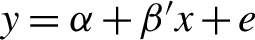 $y=\alpha +\beta ' x + e$, is usually justified by imposing appropriate restrictions on the unknown parameter
$y=\alpha +\beta ' x + e$, is usually justified by imposing appropriate restrictions on the unknown parameter 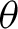 $\theta $ in the overall model; otherwise, this simple model can be grossly misspecified in the sense that relevant variables may have been omitted. In this paper, we establish asymptotic validity of the standard F-test on the surrogate parameter
$\theta $ in the overall model; otherwise, this simple model can be grossly misspecified in the sense that relevant variables may have been omitted. In this paper, we establish asymptotic validity of the standard F-test on the surrogate parameter 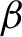 $\beta $, in an appropriate sense, even when the simple model is misspecified, that is, without any restrictions on
$\beta $, in an appropriate sense, even when the simple model is misspecified, that is, without any restrictions on 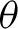 $\theta $ whatsoever and without assuming Gaussian data.
$\theta $ whatsoever and without assuming Gaussian data.
The first author’s research was partially supported by FWF projects P 26354-N26 and P 28233-N32.
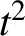 ${t}^2$
tests. I. Location and scale. Communications in Statistics. Theory and Methods 20, 249–259.CrossRefGoogle Scholar
${t}^2$
tests. I. Location and scale. Communications in Statistics. Theory and Methods 20, 249–259.CrossRefGoogle Scholar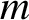 $m$
-estimators of
$m$
-estimators of
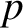 $p$
regression parameters when
$p$
regression parameters when
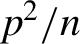 ${p}^2/ n$
is large. I. Consistency. Annals of Statististics 12, 1298–1309.Google Scholar
${p}^2/ n$
is large. I. Consistency. Annals of Statististics 12, 1298–1309.Google Scholar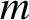 $m$
-estimators of
$m$
-estimators of
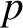 $p$
regression parameters when
$p$
regression parameters when
 ${p}^2/ n$
is large. II. Normal approximation. Annals of Statistics 13, 1403–1417.CrossRefGoogle Scholar
${p}^2/ n$
is large. II. Normal approximation. Annals of Statistics 13, 1403–1417.CrossRefGoogle Scholar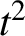 ${t}^2$
tests. II. Series expansions. Communications in Statistics. Theory and Methods 20, 97–108.Google Scholar
${t}^2$
tests. II. Series expansions. Communications in Statistics. Theory and Methods 20, 97–108.Google Scholar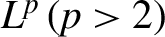 ${L}^p\left(p>2\right)$
, spanned by sequences of independent random variables. Israel Journal of Mathematics 8, 273–303.CrossRefGoogle Scholar
${L}^p\left(p>2\right)$
, spanned by sequences of independent random variables. Israel Journal of Mathematics 8, 273–303.CrossRefGoogle Scholar You have
Access
You have
Access
 Open access
Open access