



Impact Statement
The recurrent neural network (RNN) proposed here represents a significant step toward an end-to-end prediction of laminar-turbulent transition in boundary-layer flows. The general yet greatly simplified workflow should allow even nonexperts to apply the proposed model for predicting transition due to a variety of instability mechanisms, which is a significant advantage over traditional direct computations of the stability theory. The encoding of boundary layer profiles by the convolutional neural network and sequence-to-sequence mapping enabled by the RNN faithfully represent the amplification of flow instability along the surface, exemplifying the direct correlation of the proposed model with the underlying physics. Finally, we use a very large dataset and provide insights and best-practice guidance toward the practical deployment of neural network-based transition models in engineering environments.
1. Introduction
Laminar-turbulent transition of boundary-layer flows has a strong impact on the performance of flight vehicles across multiple flow regimes due to its effect on surface skin friction and aerodynamic heating. Predicting the transition location in computational fluid dynamics (CFD) simulations of viscous flows remains a challenging area (Slotnick et al., Reference Slotnick, Khodadoust, Alonso, Darmofal, Gropp, Lurie and Mavriplis2014). Transition to turbulence in a benign disturbance environment is typically initiated by the amplification of modal instabilities of the laminar boundary layer. Depending on the flow configuration, these instabilities can be of several types, for example, Tollmien–Schlichting (TS) waves, oblique first-mode instabilities, and planar waves of second-mode (or Mack-mode) type.
A description of transition prediction methods based on stability correlations can be found in a variety of references (Smith and Gamberoni, Reference Smith and Gamberoni1956; van Ingen, Reference van Ingen1956, Reference van Ingen2008), but we provide a brief description here to make the paper self-contained. A somewhat expanded description may also be found in Zafar et al. (Reference Zafar, Xiao, Choudhari, Li, Chang, Paredes and Venkatachari2020). The transition process begins with the excitation of linear instability waves that undergo a slow amplification in the region preceding the onset of transition. The linear amplification phase is followed by nonlinear processes that ultimately lead to turbulence. Since these nonlinear processes are relatively rapid, it becomes possible to predict the transition location based on the evolution of the most amplified instability mode. The linear amplification ratio, 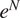 $ {e}^N $, is generally computed using the classical linear stability theory (Reshotko, Reference Reshotko1976; Mack, Reference Mack, Dwoyer and Hussaini1987; Reed et al., Reference Reed, Saric and Arnal1996; Juniper et al., Reference Juniper, Hanifi and Theofilis2014; Taira et al., Reference Taira, Brunton, Dawson, Rowley, Colonius, McKeon, Schmidt, Gordeyev, Theofilis and Ukeiley2017). The local streamwise amplification rates (
$ {e}^N $, is generally computed using the classical linear stability theory (Reshotko, Reference Reshotko1976; Mack, Reference Mack, Dwoyer and Hussaini1987; Reed et al., Reference Reed, Saric and Arnal1996; Juniper et al., Reference Juniper, Hanifi and Theofilis2014; Taira et al., Reference Taira, Brunton, Dawson, Rowley, Colonius, McKeon, Schmidt, Gordeyev, Theofilis and Ukeiley2017). The local streamwise amplification rates (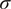 $ \sigma $) along the aerodynamic surface can be determined by solving an eigenvalue problem for the wall-normal velocity perturbation, which is governed by the Orr–Sommerfeld equation (Drazin and Reid, Reference Drazin and Reid1981). These local streamwise amplification rates corresponding to each frequency (
$ \sigma $) along the aerodynamic surface can be determined by solving an eigenvalue problem for the wall-normal velocity perturbation, which is governed by the Orr–Sommerfeld equation (Drazin and Reid, Reference Drazin and Reid1981). These local streamwise amplification rates corresponding to each frequency (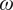 $ \omega $) are then integrated along the body curvature to obtain the logarithmic amplification of the disturbance amplitude (N-factor) for each disturbance frequency (
$ \omega $) are then integrated along the body curvature to obtain the logarithmic amplification of the disturbance amplitude (N-factor) for each disturbance frequency (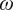 $ \omega $). The
$ \omega $). The 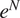 $ {e}^N $ method assumes that the occurrence of transition correlates very well with the N-factor of the most amplified instability wave reaching a critical value
$ {e}^N $ method assumes that the occurrence of transition correlates very well with the N-factor of the most amplified instability wave reaching a critical value 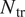 $ {N}_{\mathrm{tr}} $. For subsonic and supersonic flows, the critical N-factor (denoted herein as
$ {N}_{\mathrm{tr}} $. For subsonic and supersonic flows, the critical N-factor (denoted herein as 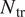 $ {N}_{\mathrm{tr}} $) has been empirically found to lie in the range between 9 and 11 (Bushnell et al., Reference Bushnell, Malik, Harvey, Zierep and Oertel1989; van Ingen, Reference van Ingen2008). Such a prediction process may be schematically illustrated as shown in Figure 1a.
$ {N}_{\mathrm{tr}} $) has been empirically found to lie in the range between 9 and 11 (Bushnell et al., Reference Bushnell, Malik, Harvey, Zierep and Oertel1989; van Ingen, Reference van Ingen2008). Such a prediction process may be schematically illustrated as shown in Figure 1a.
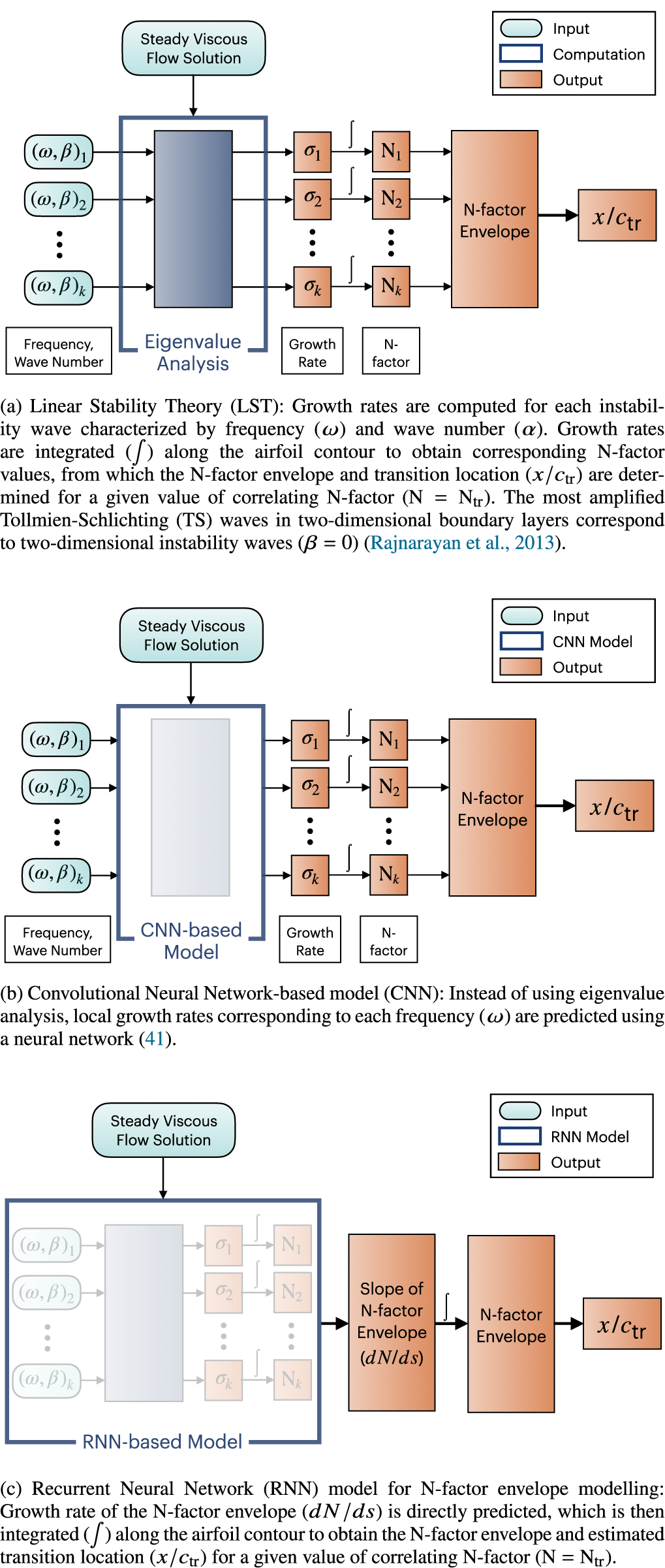
Figure 1. Comparison of transition prediction methodologies.
Linear stability computations rely on highly accurate computations of the mean boundary-layer flow. Solution of the linear stability equations is also computationally expensive and often leads to the contamination of the unstable part of the spectrum by spurious eigenvalues. The nonrobust nature of the stability computations requires a significant degree of expertise in stability theory on the user’s part, making such computations inapt for nonexpert users. For these reasons, transition prediction based on stability computations has been difficult to automate and renders its direct integration in CFD solvers rather impractical. Several aerodynamic applications involving flow separation also entail viscous–inviscid interactions. Such interactions lead to a strong coupling between transition and the overall flow field, which requires an iterative prediction approach. Hence, the integration of the transition prediction method in the overall aerodynamic prediction method remains an important area of research (Slotnick et al., Reference Slotnick, Khodadoust, Alonso, Darmofal, Gropp, Lurie and Mavriplis2014).
Several methods have been proposed as simplifications or surrogate models of the 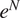 $ {e}^N $ methods, including database query techniques (Drela and Giles, Reference Drela and Giles1987; van Ingen, Reference van Ingen2008; Perraud and Durant, Reference Perraud and Durant2016) and data fitting techniques (Dagenhart, Reference Dagenhart1981; Stock and Degenhart, Reference Stock and Degenhart1989; Gaster and Jiang, Reference Gaster and Jiang1995; Langlois et al., Reference Langlois, Masson, Kafyeke and Paraschivoiu2002; Krumbein, Reference Krumbein2008; Rajnarayan and Sturdza, Reference Rajnarayan and Sturdza2013; Begou et al., Reference Begou, Deniau, Vermeersch and Casalis2017; Pinna et al., Reference Pinna, Zanus, Demange and Olazabal-Loume2018). These methods are generally based on a small set of scalar input parameters representing the mean flow parameters and relevant disturbance characteristics. However, these methods do not scale well with larger sets of parameters, which tends to limit the expressive power of the transition model based on these traditional methods (Crouch et al., Reference Crouch, Crouch and Ng2002). In particular, the shape factor is a commonly used scalar parameter to correlate the disturbance amplification rates to the mean flow of the boundary layer. However, the shape factor cannot be easily computed for many practical flows such as high speed flows over blunt leading edges, which results in a poor predictive performance of the database methods (Paredes et al., Reference Paredes, Venkatachari, Choudhari, Li, Chang, Zafar and Xiao2020).
$ {e}^N $ methods, including database query techniques (Drela and Giles, Reference Drela and Giles1987; van Ingen, Reference van Ingen2008; Perraud and Durant, Reference Perraud and Durant2016) and data fitting techniques (Dagenhart, Reference Dagenhart1981; Stock and Degenhart, Reference Stock and Degenhart1989; Gaster and Jiang, Reference Gaster and Jiang1995; Langlois et al., Reference Langlois, Masson, Kafyeke and Paraschivoiu2002; Krumbein, Reference Krumbein2008; Rajnarayan and Sturdza, Reference Rajnarayan and Sturdza2013; Begou et al., Reference Begou, Deniau, Vermeersch and Casalis2017; Pinna et al., Reference Pinna, Zanus, Demange and Olazabal-Loume2018). These methods are generally based on a small set of scalar input parameters representing the mean flow parameters and relevant disturbance characteristics. However, these methods do not scale well with larger sets of parameters, which tends to limit the expressive power of the transition model based on these traditional methods (Crouch et al., Reference Crouch, Crouch and Ng2002). In particular, the shape factor is a commonly used scalar parameter to correlate the disturbance amplification rates to the mean flow of the boundary layer. However, the shape factor cannot be easily computed for many practical flows such as high speed flows over blunt leading edges, which results in a poor predictive performance of the database methods (Paredes et al., Reference Paredes, Venkatachari, Choudhari, Li, Chang, Zafar and Xiao2020).
Neural networks provide a more generalized way of predicting the instability characteristics, while also accounting for their dependency on high-dimensional input features in a computationally efficient and robust manner. Fuller et al. (Reference Fuller, Saunders and Vandsburger1997) applied neural network methods to instability problems in predicting the instability growth rates for a jet flow. Crouch et al. (Reference Crouch, Crouch and Ng2002) used scalar parameters and the wall-normal gradient of the laminar velocity profile as an input of neural networks to predict the maximum instability growth rates. They demonstrated the generalizability of the neural network method for both TS waves and stationary crossflow instabilities. The data for the gradient of the laminar velocity profile were coarsely defined at six equidistant points across the boundary layer. A fully connected neural network was used, which assumes no spatial structure on the input data. Such treatment of boundary-layer profiles may not be well suited for other instability mechanisms involving, for instance, Mack-mode instabilities in high-speed boundary layers that require input profiles of thermodynamics quantities along with the velocity profiles (Paredes et al., Reference Paredes, Venkatachari, Choudhari, Li, Chang, Zafar and Xiao2020) or the secondary instabilities of boundary-layer flows with finite-amplitude stationary crossflow vortices that include rapid variations along both wall-normal and spanwise coordinates.
By utilizing recent developments in machine learning, Zafar et al. (Reference Zafar, Xiao, Choudhari, Li, Chang, Paredes and Venkatachari2020) proposed a transition model based on convolutional neural networks (CNNs), which has the ability to generalize across multiple instability mechanisms in an efficient and robust manner. CNNs were used to extract a set of latent features from the boundary-layer profiles, and the extracted features were used along with other scalar quantities as input to a fully connected network. The hybrid architecture was used to predict the instability growth rates for TS instabilities in two-dimensional incompressible boundary layers. The extracted latent feature showed a strong, nearly linear correlation with the analytically defined shape factor (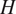 $ H $) of the boundary-layer velocity profile. The model was trained using a database of Falkner–Skan family of selfsimilar boundary-layer profiles. This CNN-based method is applicable to various instability mechanisms with higher-dimensional input features, since the boundary-layer profiles are treated in a physically consistent manner (i.e., as discrete representation of the profiles accounting for their spatial structures). It has been applied to predict the instability growth rates of Mack-mode instabilities in hypersonic flows over a moderately blunt-nosed body (Paredes et al., Reference Paredes, Venkatachari, Choudhari, Li, Chang, Zafar and Xiao2020). This particular application requires additional input features in the form of boundary-layer profiles of thermodynamic quantities such as temperature and/or density, where the CNN-based model demonstrated highly accurate predictions of the instability growth rates.
$ H $) of the boundary-layer velocity profile. The model was trained using a database of Falkner–Skan family of selfsimilar boundary-layer profiles. This CNN-based method is applicable to various instability mechanisms with higher-dimensional input features, since the boundary-layer profiles are treated in a physically consistent manner (i.e., as discrete representation of the profiles accounting for their spatial structures). It has been applied to predict the instability growth rates of Mack-mode instabilities in hypersonic flows over a moderately blunt-nosed body (Paredes et al., Reference Paredes, Venkatachari, Choudhari, Li, Chang, Zafar and Xiao2020). This particular application requires additional input features in the form of boundary-layer profiles of thermodynamic quantities such as temperature and/or density, where the CNN-based model demonstrated highly accurate predictions of the instability growth rates.
Despite clear advantages over earlier neural network-based models, the CNN-based transition model shares a few significant shortcomings with the direct integration of linear stability theory toward transition prediction. Similar to the stability theory, the CNN-based transition model is based on the predictions of the instability growth rates corresponding to each selected disturbance frequency 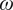 $ \omega $ (and/or the spanwise wavenumber
$ \omega $ (and/or the spanwise wavenumber 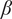 $ \beta $ in the case of three-dimensional instabilities) and every station from the input set of boundary-layer profiles. The instability growth rates for each individual disturbance are integrated along the aerodynamic surface to predict the growth in disturbance amplitude, or equivalently, the N-factor curve for each combination of frequency and spanwise wavenumber. Finally, one must determine the envelope of the N-factor curves to predict the logarithmic amplification ratio for the most amplified disturbance at each station (denoted as
$ \beta $ in the case of three-dimensional instabilities) and every station from the input set of boundary-layer profiles. The instability growth rates for each individual disturbance are integrated along the aerodynamic surface to predict the growth in disturbance amplitude, or equivalently, the N-factor curve for each combination of frequency and spanwise wavenumber. Finally, one must determine the envelope of the N-factor curves to predict the logarithmic amplification ratio for the most amplified disturbance at each station (denoted as 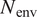 $ {N}_{\mathrm{env}} $ herein), which can then be used in conjunction with the critical N-factor (
$ {N}_{\mathrm{env}} $ herein), which can then be used in conjunction with the critical N-factor (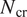 $ {N}_{\mathrm{cr}} $) based on previous experimental measurements to predict the transition location (see Figure 1b for a summary). This overall workflow not only extends over several steps, but also requires the user to estimate the range of frequencies (and/or spanwise wavenumbers) that would include the most amplified instability waves corresponding to the envelope of the N-factor curves. The selection of disturbance parameters for a given flow configuration can be somewhat challenging for nonexpert users. More important, however, the above workflow requires several redundant growth rate computations involving subdominant disturbances that do not contribute to the N-factor envelope used to apply the transition criterion, namely,
$ {N}_{\mathrm{cr}} $) based on previous experimental measurements to predict the transition location (see Figure 1b for a summary). This overall workflow not only extends over several steps, but also requires the user to estimate the range of frequencies (and/or spanwise wavenumbers) that would include the most amplified instability waves corresponding to the envelope of the N-factor curves. The selection of disturbance parameters for a given flow configuration can be somewhat challenging for nonexpert users. More important, however, the above workflow requires several redundant growth rate computations involving subdominant disturbances that do not contribute to the N-factor envelope used to apply the transition criterion, namely, 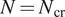 $ N={N}_{\mathrm{cr}} $. Finally, and similar to the earlier neural network models (Crouch et al., Reference Crouch, Crouch and Ng2002), the growth rate prediction during the all important first step of the above workflow only uses the local boundary-layer profiles, and hence, does not utilize any information about the prior history of a given disturbance, for example, any previously estimated instability growth rates at the upstream locations. Since the boundary-layer profiles evolve in a continuous manner, the spatial variation in the disturbance growth rate represents an analytic continuation along the aerodynamic surface. Thus, embedding the upstream history of boundary-layer profiles and/or the disturbance growth rates should lead to more accurate, robust, and computationally efficient models for the onset of transition.
$ N={N}_{\mathrm{cr}} $. Finally, and similar to the earlier neural network models (Crouch et al., Reference Crouch, Crouch and Ng2002), the growth rate prediction during the all important first step of the above workflow only uses the local boundary-layer profiles, and hence, does not utilize any information about the prior history of a given disturbance, for example, any previously estimated instability growth rates at the upstream locations. Since the boundary-layer profiles evolve in a continuous manner, the spatial variation in the disturbance growth rate represents an analytic continuation along the aerodynamic surface. Thus, embedding the upstream history of boundary-layer profiles and/or the disturbance growth rates should lead to more accurate, robust, and computationally efficient models for the onset of transition.
A recurrent neural network (RNN) is a promising approach for modeling the history effects. The RNN is a general-purpose architecture for modeling sequence transduction using an internal state (memory) that selectively keeps track of the information at the preceding steps during the sequence (Graves, Reference Graves2012). RNNs provide a combination of multivariate internal state as well as nonlinear state-to-state dynamics, which make it particularly well-suited for dynamic system modeling. Faller and Schreck (Reference Faller and Schreck1997) exploited these attributes of RNNs to predict unsteady boundary-layer development and separation over a wing surface. The RNN architectures have also been used for the modeling of several other complex dynamic systems ranging from near-wall turbulence (Guastoni et al., Reference Guastoni, Srinivasan, Azizpour, Schlatter and Vinuesa2019), the detection of extreme weather events (Wan et al., Reference Wan, Vlachas, Koumoutsakos and Sapsis2018), and the spatiotemporal dynamics of chaotic systems (Vlachas et al., Reference Vlachas, Pathak, Hunt, Sapsis, Girvan, Ott and Koumoutsakos2020), among others.
The feature extraction capability of CNN and the sequence-to-sequence mapping enabled by RNN provide a direct correlation with the underlying physics of transition, exemplifying the machine learning models motivated by the physics of the problem, for example, in the modeling of turbulence (Wang et al., Reference Wang, Wu and Xiao2017; Wu et al., Reference Wu, Xiao and Paterson2018b; Duraisamy et al., Reference Duraisamy, Iaccarino and Xiao2019). Transport equation-based models, such as the well-known Langtry–Menter 4-equation model Menter et al. (Reference Menter, Langtry and Völker2006), are based on empirical transition correlations that are based on local mean flow parameters, therefore the connection with the underlying physics of the transition process is significantly weaker as compared to stability-based correlation, whether it involves direct computations of linear stability characteristics or a proxy thereto as represented within the proposed RNN model. This paper is aimed at exploiting the sequential dependency of mean boundary-layer flow properties to directly predict maximum growth rates among all unstable modes at a sequence of stations along the airfoil surface. Such sequential growth rates can then be integrated along the airfoil surface to determine the N-factor envelope and corresponding transition location, as has been schematically illustrated in Figure 1c. To this end, an extensive airfoil database has been used that documents mean flow features and linear stability characteristics for a large set of airfoils at a range of flow conditions (Reynolds numbers and angles of attack). Furthermore, we provide insight on the similarity of stability characteristics among different families of airfoils and how a neural network trained on one set of airfoils can generalize to other ones, possibly at different flow conditions.
The rest of the manuscript is organized as follows. The proposed RNN model is introduced in Section 2 along with the input and output features. Section 3 presents the airfoil database used to develop and evaluate the proposed transition model. Section 4 presents the results and discussion for different training and testing cases, which provide insight toward subsampling of training datasets for achieving a reasonable predictive performance from the RNN model. Section 5 concludes the paper.
2. Recurrent Neural Network
A neural network consists of successive composition of linear mapping and nonlinear squashing functions, which aims to learn the underlying relationship between an input vector (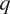 $ q $) and an output vector (
$ q $) and an output vector ( $ y $) from a given set of training data. The series of functions are organized as a sequence of layers, each containing several neurons that represent specific mathematical functions. The mathematical functions in each layer are parameterized by the weight (
$ y $) from a given set of training data. The series of functions are organized as a sequence of layers, each containing several neurons that represent specific mathematical functions. The mathematical functions in each layer are parameterized by the weight (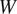 $ W $) and bias (
$ W $) and bias ( $ b $). Intermediate layers between the input layer (
$ b $). Intermediate layers between the input layer (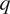 $ q $) and output layer (
$ q $) and output layer ( $ y $) are known as hidden layers. The functional mapping of a neural network with a single hidden layer can be expressed as:
$ y $) are known as hidden layers. The functional mapping of a neural network with a single hidden layer can be expressed as:
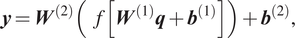 $$ \boldsymbol{y}={\boldsymbol{W}}^{(2)}\left(f\left[{\boldsymbol{W}}^{(1)}\boldsymbol{q}+{\boldsymbol{b}}^{(1)}\right]\right)+{\boldsymbol{b}}^{(2)}, $$
$$ \boldsymbol{y}={\boldsymbol{W}}^{(2)}\left(f\left[{\boldsymbol{W}}^{(1)}\boldsymbol{q}+{\boldsymbol{b}}^{(1)}\right]\right)+{\boldsymbol{b}}^{(2)}, $$where 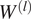 $ {W}^{(l)} $ and
$ {W}^{(l)} $ and 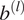 $ {b}^{(l)} $ represent the weight matrix and bias vector for the lth layer, respectively, and
$ {b}^{(l)} $ represent the weight matrix and bias vector for the lth layer, respectively, and 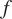 $ f $ is an activation function. Activation functions enable the representation of complex functional mapping by introducing nonlinearity in the composite functions. The training of a neural network is a process of learning the weights and biases with the objective of fitting the training data.
$ f $ is an activation function. Activation functions enable the representation of complex functional mapping by introducing nonlinearity in the composite functions. The training of a neural network is a process of learning the weights and biases with the objective of fitting the training data.
RNNs are architectures with internal memory (known as the hidden states), which make them particularly suitable for sequential data such as time series, spatial sequences, and words in a text. The RNN processes the sequence of inputs in a step-by-step manner while selectively passing the information across a sequence of steps encoded in a hidden state. At any given step  $ i $, the RNN operates on the current input vector (
$ i $, the RNN operates on the current input vector (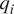 $ {q}_i $) in the sequence and the hidden state
$ {q}_i $) in the sequence and the hidden state 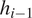 $ {h}_{i-1} $ passed on from the previous step, to produce an updated hidden state
$ {h}_{i-1} $ passed on from the previous step, to produce an updated hidden state 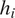 $ {h}_i $ and an output
$ {h}_i $ and an output 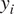 $ {y}_i $. Figure 2 shows the schematic of a recurrent neural network. Multiple RNNs can be stacked over each other, as shown in Figure 3, to provide a deep RNN. The functional mapping for an architecture with
$ {y}_i $. Figure 2 shows the schematic of a recurrent neural network. Multiple RNNs can be stacked over each other, as shown in Figure 3, to provide a deep RNN. The functional mapping for an architecture with 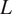 $ L $ layers of RNN stacked over each other can be expressed as:
$ L $ layers of RNN stacked over each other can be expressed as:
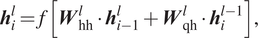 $$ {\boldsymbol{h}}_i^l=f\left[{\boldsymbol{W}}_{\mathrm{hh}}^l\cdot {\boldsymbol{h}}_{i-1}^l+{\boldsymbol{W}}_{\mathrm{qh}}^l\cdot {\boldsymbol{h}}_i^{l-1}\right], $$
$$ {\boldsymbol{h}}_i^l=f\left[{\boldsymbol{W}}_{\mathrm{hh}}^l\cdot {\boldsymbol{h}}_{i-1}^l+{\boldsymbol{W}}_{\mathrm{qh}}^l\cdot {\boldsymbol{h}}_i^{l-1}\right], $$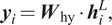 $$ {\boldsymbol{y}}_i={\boldsymbol{W}}_{\mathrm{hy}}\cdot {\boldsymbol{h}}_i^L, $$
$$ {\boldsymbol{y}}_i={\boldsymbol{W}}_{\mathrm{hy}}\cdot {\boldsymbol{h}}_i^L, $$where 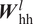 $ {\boldsymbol{W}}_{\mathrm{hh}}^l $,
$ {\boldsymbol{W}}_{\mathrm{hh}}^l $, 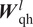 $ {\boldsymbol{W}}_{\mathrm{qh}}^l $, and
$ {\boldsymbol{W}}_{\mathrm{qh}}^l $, and 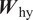 $ {\boldsymbol{W}}_{\mathrm{hy}} $ are the model parameters corresponding to the mapping from a previous hidden state to subsequent hidden state, from an input vector to a hidden state, and from a hidden state to an output vector, respectively. The model parameters (
$ {\boldsymbol{W}}_{\mathrm{hy}} $ are the model parameters corresponding to the mapping from a previous hidden state to subsequent hidden state, from an input vector to a hidden state, and from a hidden state to an output vector, respectively. The model parameters (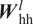 $ {\boldsymbol{W}}_{\mathrm{hh}}^l $ and
$ {\boldsymbol{W}}_{\mathrm{hh}}^l $ and 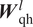 $ {\boldsymbol{W}}_{\mathrm{qh}}^l $) have sequential invariance across each layer, that is, the input vector and hidden state at each step along the sequence are processed by the same parameters within a given layer of the RNN architecture. For the first layer,
$ {\boldsymbol{W}}_{\mathrm{qh}}^l $) have sequential invariance across each layer, that is, the input vector and hidden state at each step along the sequence are processed by the same parameters within a given layer of the RNN architecture. For the first layer, 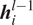 $ {\boldsymbol{h}}_i^{l-1} $ is equivalent to the input vector
$ {\boldsymbol{h}}_i^{l-1} $ is equivalent to the input vector 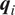 $ {\boldsymbol{q}}_i $, while for subsequent layers,
$ {\boldsymbol{q}}_i $, while for subsequent layers, 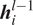 $ {\boldsymbol{h}}_i^{l-1} $ denotes the hidden state from the previous layer at the current step. In this manner, a multilayer RNN transmits the information encoded in the hidden state to the next step in the current layer and to the current step of the next layer by implementing Equation (2a). For the sake of brevity, the bias terms have not been mentioned in these equations.
$ {\boldsymbol{h}}_i^{l-1} $ denotes the hidden state from the previous layer at the current step. In this manner, a multilayer RNN transmits the information encoded in the hidden state to the next step in the current layer and to the current step of the next layer by implementing Equation (2a). For the sake of brevity, the bias terms have not been mentioned in these equations.
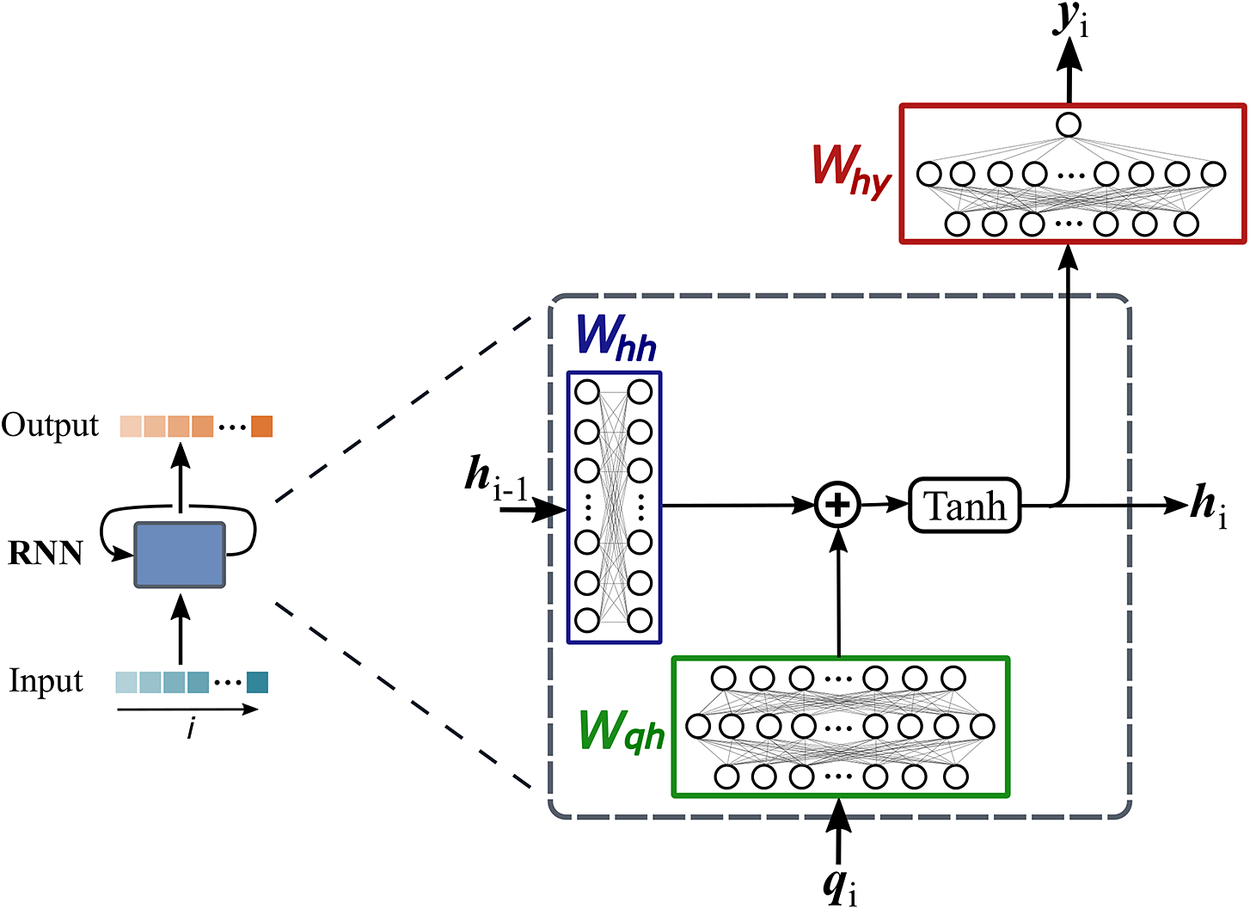
Figure 2. Schematic of the recurrent neural network (RNN) cell shown as a blue box on the left. Within each RNN cell, the arrangement of the weight matrices is shown on the right. At any step 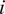 $ i $ of the sequence, the RNN cell takes input
$ i $ of the sequence, the RNN cell takes input 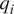 $ {q}_i $ and previous hidden state
$ {q}_i $ and previous hidden state 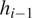 $ {h}_{i-1} $, and provides updated hidden state
$ {h}_{i-1} $, and provides updated hidden state 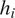 $ {h}_i $ and output
$ {h}_i $ and output 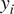 $ {y}_i $.
$ {y}_i $.
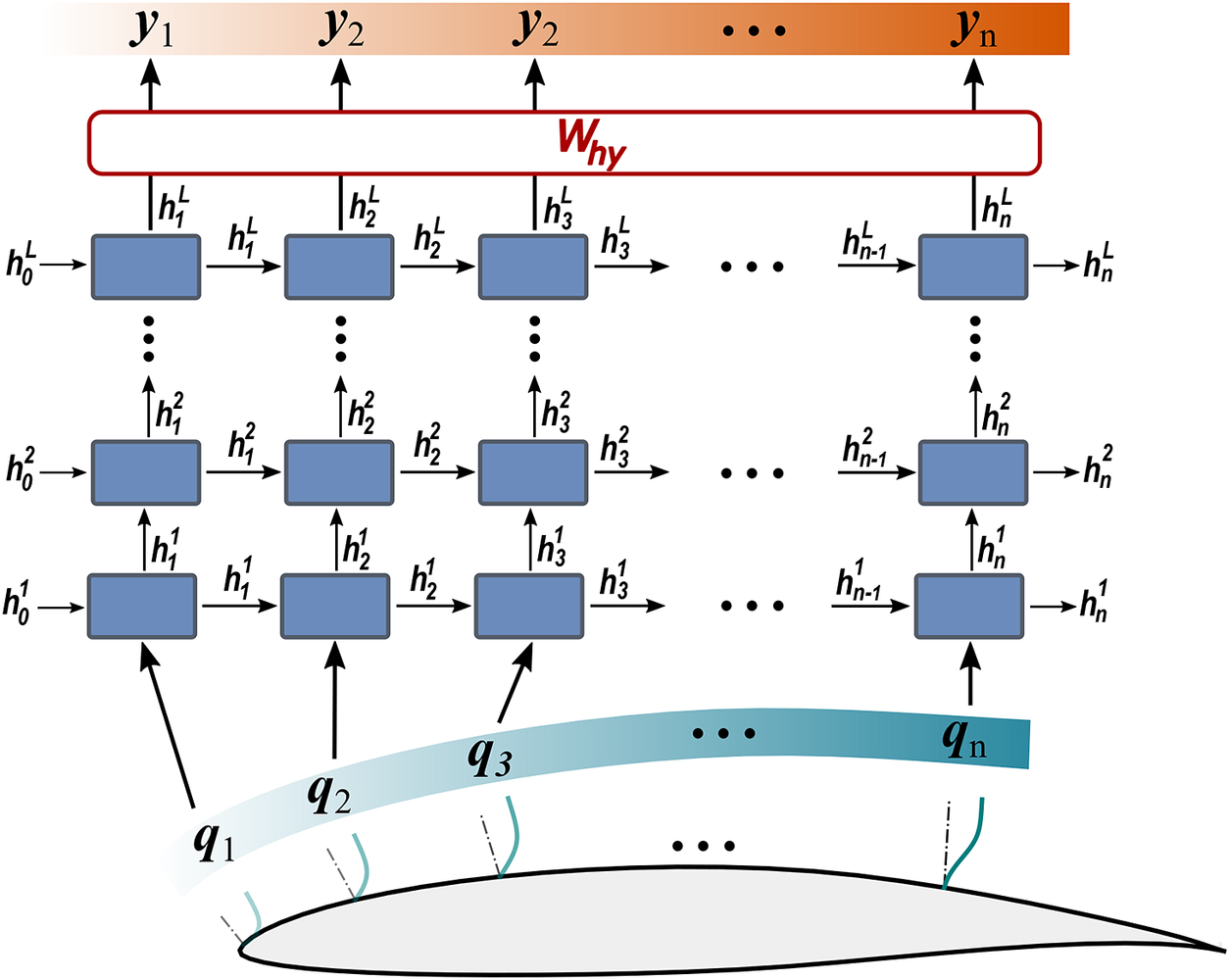
Figure 3. Sequences of input features and output for deep recurrent neural network (RNN) architecture have been illustrated with respect to stations along the airfoil surface.
Like deep feed-forward neural networks, deep RNNs can lead to more expressive models. However, the depth of an RNN can have multiple interpretations. In general, RNN architectures with multiple RNN layers stacked over each other are considered deep RNNs, as shown in Figure 3. Such deep RNN architectures have multiple internal memories (hidden states), one in each RNN layer. RNN architectures with multiple recurrent hidden states, stacked over each other, can model varying levels of dependencies (i.e., from short-term to long-term) in each hidden state (Hermans and Schrauwen, Reference Hermans and Schrauwen2013). These stacked-RNN architectures can still be considered shallow networks with limited expressivity, as all model parameters (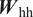 $ {\boldsymbol{W}}_{\mathrm{hh}} $,
$ {\boldsymbol{W}}_{\mathrm{hh}} $, 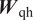 $ {\boldsymbol{W}}_{\mathrm{qh}} $, and
$ {\boldsymbol{W}}_{\mathrm{qh}} $, and 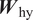 $ {\boldsymbol{W}}_{\mathrm{hy}} $) are generally represented by single linear layers. To allow for more complex functional representation, these single linear layers can be replaced by multiple nonlinear layers. Pascanu et al. (Reference Pascanu, Gulcehre, Cho and Bengio2014) has shown that introducing depth via multiple nonlinear layers to represent
$ {\boldsymbol{W}}_{\mathrm{hy}} $) are generally represented by single linear layers. To allow for more complex functional representation, these single linear layers can be replaced by multiple nonlinear layers. Pascanu et al. (Reference Pascanu, Gulcehre, Cho and Bengio2014) has shown that introducing depth via multiple nonlinear layers to represent 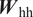 $ {\boldsymbol{W}}_{\mathrm{hh}} $,
$ {\boldsymbol{W}}_{\mathrm{hh}} $, 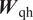 $ {\boldsymbol{W}}_{\mathrm{qh}} $, and
$ {\boldsymbol{W}}_{\mathrm{qh}} $, and 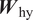 $ {\boldsymbol{W}}_{\mathrm{hy}} $ can lead to better expressivity of the RNN model. For the transition modeling problem addressed in this paper, multiple nonlinear layers are used within each RNN cell to express the complex physical mapping between the input features and output, as shown in Figure 2. Such architecture resulted in better learning and predictive capability of the RNN model.
$ {\boldsymbol{W}}_{\mathrm{hy}} $ can lead to better expressivity of the RNN model. For the transition modeling problem addressed in this paper, multiple nonlinear layers are used within each RNN cell to express the complex physical mapping between the input features and output, as shown in Figure 2. Such architecture resulted in better learning and predictive capability of the RNN model.
The underlying physics of transition does not require long term memory, unlike natural language processing for which more involved models like long short-term memory (LSTM) and transformers have proved to be very effective. For the transition problem, keeping track of last one or two stations have proved to be sufficient. In a study at the start of this research work, an informal investigation showed no advantage of LSTMs over RNNs, despite their added complexity and higher training cost.
With this perspective, the RNN model being proposed in this paper maps the sequential dependency of mean boundary-layer flow properties as input features to instability growth rates corresponding to the N-factor envelope as output features. Such input and output features, summarized in Table 1, have been taken at a sequence of stations along the airfoil surface as shown in Figure 3. Mean boundary-layer flow properties have been introduced in terms of the Reynolds number (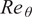 $ {\mathit{\operatorname{Re}}}_{\theta } $) based on the local momentum thickness of the boundary layer, the velocity boundary-layer profile (
$ {\mathit{\operatorname{Re}}}_{\theta } $) based on the local momentum thickness of the boundary layer, the velocity boundary-layer profile (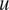 $ u $), and its derivatives (
$ u $), and its derivatives (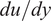 $ du/ dy $ and
$ du/ dy $ and 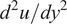 $ {d}^2u/{ d y}^2 $). Zafar et al. (Reference Zafar, Xiao, Choudhari, Li, Chang, Paredes and Venkatachari2020) proposed a convolutional neural network model that encodes the information from boundary-layer profiles to a vector of latent features while accounting for the spatial patterns in the input profiles (Michelén-Ströfer et al., Reference Michelén-Ströfer, Wu, Xiao and Paterson2018; Wu et al., Reference Wu, Yin and Xiao2018a). Such a treatment of boundary-layer profiles allows the trained neural network models to generalize to all practical flows with different instability mechanisms (Paredes et al., Reference Paredes, Venkatachari, Choudhari, Li, Chang, Zafar and Xiao2020).
$ {d}^2u/{ d y}^2 $). Zafar et al. (Reference Zafar, Xiao, Choudhari, Li, Chang, Paredes and Venkatachari2020) proposed a convolutional neural network model that encodes the information from boundary-layer profiles to a vector of latent features while accounting for the spatial patterns in the input profiles (Michelén-Ströfer et al., Reference Michelén-Ströfer, Wu, Xiao and Paterson2018; Wu et al., Reference Wu, Yin and Xiao2018a). Such a treatment of boundary-layer profiles allows the trained neural network models to generalize to all practical flows with different instability mechanisms (Paredes et al., Reference Paredes, Venkatachari, Choudhari, Li, Chang, Zafar and Xiao2020).
Table 1. Input features and output for the RNN model.

The RNN model presented in this paper builds upon this idea and further combines CNN with RNN to account for nonlocal physics in both streamwise and wall-normal directions. This is shown in Figure 4. The hyperparameters of the proposed neural network have been empirically tuned to yield adequate complexity for learning all the required information, without causing an overfitting of the training data. After such hyperparameter tuning of the neural network model, early stopping was not required. With the boundary-layer profiles defined by using 41 equidistant points in the wall-normal direction, the CNN architecture contains 3 convolutional layers with 6, 8, and 4 channels, respectively, in those layers. Kernel size of 3  $ \times $ 1 has been used in each convolutional layer. Rectified linear unit (ReLU) is used as the activation function. The CNN encodes the spatial information in the boundary-layer profiles along each station to a vector of latent features,
$ \times $ 1 has been used in each convolutional layer. Rectified linear unit (ReLU) is used as the activation function. The CNN encodes the spatial information in the boundary-layer profiles along each station to a vector of latent features,  $ \Psi $. The results are not significantly sensitive to the number of latent features in the vector
$ \Psi $. The results are not significantly sensitive to the number of latent features in the vector 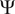 $ \Psi $. However, following a sensitivity study on the size of latent features, the number of elements in
$ \Psi $. However, following a sensitivity study on the size of latent features, the number of elements in 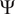 $ \Psi $ has been set to 8. The latent features
$ \Psi $ has been set to 8. The latent features 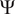 $ \Psi $ extracted from the boundary-layer profiles are then concatenated with
$ \Psi $ extracted from the boundary-layer profiles are then concatenated with 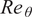 $ {\mathit{\operatorname{Re}}}_{\theta } $ at each station,
$ {\mathit{\operatorname{Re}}}_{\theta } $ at each station, ![]() which provides the sequential input features for the RNN architecture to predict the local growth rate of the most amplified instability mode, or equivalently, the slope (
which provides the sequential input features for the RNN architecture to predict the local growth rate of the most amplified instability mode, or equivalently, the slope (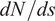 $ dN/ ds $) of the N-factor envelope at a sequence of stations along the airfoil surface. Each RNN cell (Figure 2) consists of nonlinear mappings from the input to the hidden state
$ dN/ ds $) of the N-factor envelope at a sequence of stations along the airfoil surface. Each RNN cell (Figure 2) consists of nonlinear mappings from the input to the hidden state 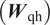 $ \left({\boldsymbol{W}}_{\mathrm{qh}}\right) $ and from the hidden state to the output (
$ \left({\boldsymbol{W}}_{\mathrm{qh}}\right) $ and from the hidden state to the output (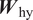 $ {\boldsymbol{W}}_{\mathrm{hy}} $), with each mapping involving two hidden layers with 72 neurons each. The rectified linear activation function (ReLU) is used to introduce nonlinearity in these layers. The hidden state is represented by a vector of length 9 and a linear layer is used for the mapping
$ {\boldsymbol{W}}_{\mathrm{hy}} $), with each mapping involving two hidden layers with 72 neurons each. The rectified linear activation function (ReLU) is used to introduce nonlinearity in these layers. The hidden state is represented by a vector of length 9 and a linear layer is used for the mapping 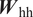 $ {\boldsymbol{W}}_{\mathrm{hh}} $ between the hidden states. The RNN architecture consists of three RNN layers stacked over each other, with corresponding three internal memories (hidden states), each representing varying level of dependency (short to long term) between the output at the current station and the input at the current as well as the preceding stations.
$ {\boldsymbol{W}}_{\mathrm{hh}} $ between the hidden states. The RNN architecture consists of three RNN layers stacked over each other, with corresponding three internal memories (hidden states), each representing varying level of dependency (short to long term) between the output at the current station and the input at the current as well as the preceding stations.
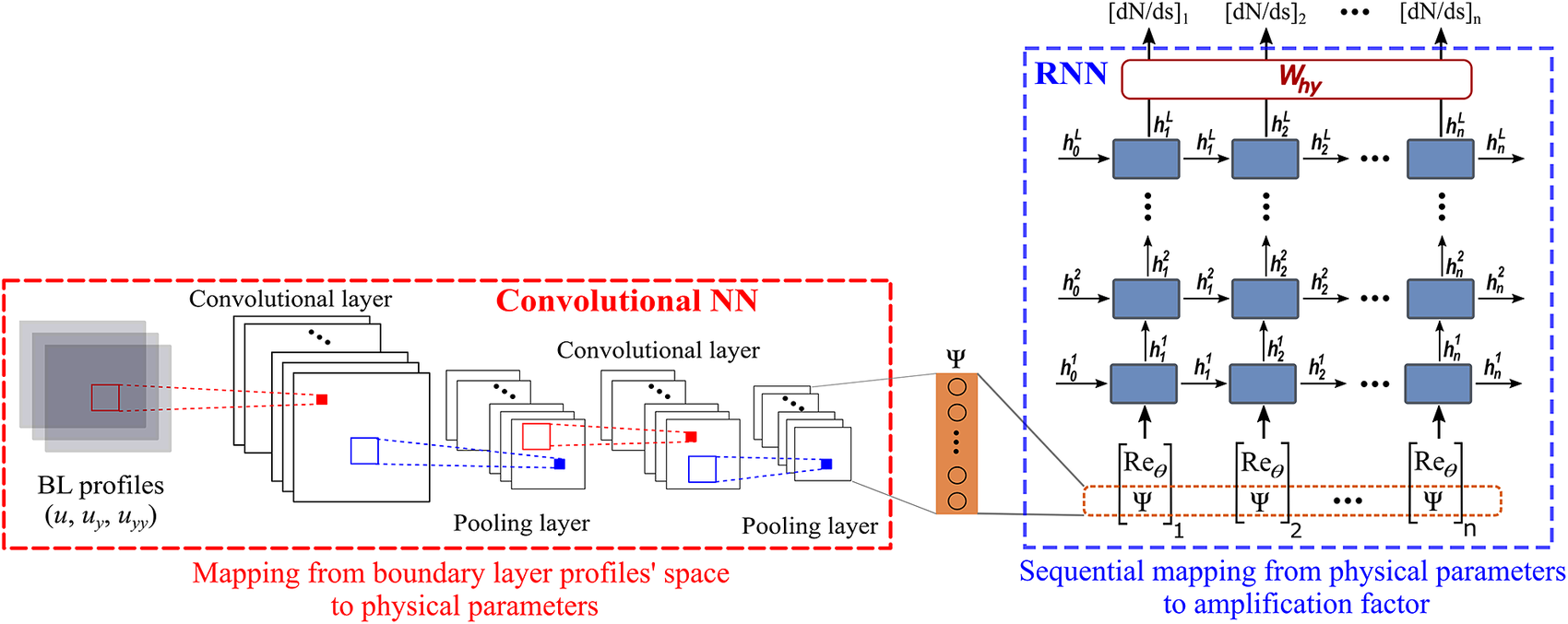
Figure 4. Proposed neural network for transition modeling. Convolutional neural network encodes the information from boundary-layer profiles (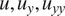 $ u,{u}_y,{u}_{yy} $) into latent features (
$ u,{u}_y,{u}_{yy} $) into latent features (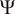 $ \Psi $) at each station. RNN processes the input features (
$ \Psi $) at each station. RNN processes the input features (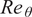 $ {\mathit{\operatorname{Re}}}_{\theta } $ and
$ {\mathit{\operatorname{Re}}}_{\theta } $ and  $ \Psi $) in sequential manner to predict the growth rate (
$ \Psi $) in sequential manner to predict the growth rate (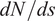 $ dN/ ds $) of the N-factor envelope.
$ dN/ ds $) of the N-factor envelope.
As the CNN architecture is intrinsically dependent on the shape of the training data, the architecture can be tuned to different shapes of training data and the proposed model is expected to maintain its efficiency and accuracy. Future work will explore the vector-cloud neural network Zhou et al. (Reference Zhou, Han and Xiao2021) which can deal with any number of arbitrarily arranged grid points across the boundary layer profiles. Since empirical tuning of hyperparemeters provided good results, we did not undertake an extensive optimization of the whole model. In a related unpublished work, more extensive hyperparameter optimization resulted in minor adjustments of the CNN architecture with comparable results.
3. Database of Linear Amplification Characteristics for Airfoil Boundary Layers
A large database of the linear stability characteristics of two-dimensional incompressible boundary-layer flows over a broad set of airfoils was generated for the training and evaluation of the proposed model. These boundary-layer flows can support the amplification of TS waves and the most amplified TS waves at any location along the airfoil correspond to two-dimensional disturbances (i.e., spanwise wavenumber 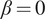 $ \beta =0 $). This database documents the amplification characteristics of unstable TS waves under the quasiparallel, no-curvature approximation. A value of
$ \beta =0 $). This database documents the amplification characteristics of unstable TS waves under the quasiparallel, no-curvature approximation. A value of 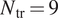 $ {N}_{\mathrm{tr}}=9 $ has been empirically found to correlate with the onset of laminar-turbulent transition in benign freestream disturbance environments characteristic of external flows at flight altitudes. The airfoil contours were obtained from public domain sources, such as the UIUC Airfoil Coordinates Database (UIUC Applied Aerodynamics Group, 2020). Linear stability characteristics for laminar boundary-layer flows were computed using a combination of potential flow solutions (Drela, Reference Drela and Mueller1989) and a boundary-layer solver (Wie, Reference Wie1992). The computational codes used are industry standard and have been used in number of research works over the years. Inviscid computations using panel method have been performed with 721 points around the airfoil. For boundary layer solver, 300–400 grid points have been considered in wall normal direction using a second order finite difference scheme. We note that the focus of this database is on transition due to TS waves in attached boundary layers, and therefore, flows involving a separation bubble (which cannot be computed with the viscous–inviscid-interactive procedure adopted herein) are not considered in the present work.
$ {N}_{\mathrm{tr}}=9 $ has been empirically found to correlate with the onset of laminar-turbulent transition in benign freestream disturbance environments characteristic of external flows at flight altitudes. The airfoil contours were obtained from public domain sources, such as the UIUC Airfoil Coordinates Database (UIUC Applied Aerodynamics Group, 2020). Linear stability characteristics for laminar boundary-layer flows were computed using a combination of potential flow solutions (Drela, Reference Drela and Mueller1989) and a boundary-layer solver (Wie, Reference Wie1992). The computational codes used are industry standard and have been used in number of research works over the years. Inviscid computations using panel method have been performed with 721 points around the airfoil. For boundary layer solver, 300–400 grid points have been considered in wall normal direction using a second order finite difference scheme. We note that the focus of this database is on transition due to TS waves in attached boundary layers, and therefore, flows involving a separation bubble (which cannot be computed with the viscous–inviscid-interactive procedure adopted herein) are not considered in the present work.
Airfoil contours included in the database belong to different categories and were selected randomly to cover a range of practical applications. These categories include different series of NACA airfoils, natural laminar flow airfoils, low Reynolds number airfoils, rotorcraft airfoils, and airfoil contours designed for transonic flows, and so on. Selected airfoils from three of these categories have been plotted in Figure 5, which illustrates the markedly different airfoil contours included in the database. Data corresponding to both upper and lower surfaces of the airfoils has been considered, except for the symmetrical airfoil sections for which the lower-surface data have been excluded to avoid duplication, and hence, a bias in the data sampling. For reference, all 53 airfoils from the database are listed as well as plotted in Appendix A. The range of chord Reynolds numbers (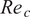 $ {\mathit{\operatorname{Re}}}_c $) included in the database extends over nearly four orders of magnitude
$ {\mathit{\operatorname{Re}}}_c $) included in the database extends over nearly four orders of magnitude 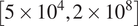 $ \left[5\times {10}^4,2\times {10}^8\right] $ and a broad range of angles of attack (AOA)
$ \left[5\times {10}^4,2\times {10}^8\right] $ and a broad range of angles of attack (AOA)  $ \left[-{6}^{\circ },{8}^{\circ}\right] $ has been considered for each of these airfoils. However, some of the boundary layers within the above range of Reynolds numbers and angles of attack are either stable or only weakly unstable (i.e., corresponding to a rather small peak N-factor,
$ \left[-{6}^{\circ },{8}^{\circ}\right] $ has been considered for each of these airfoils. However, some of the boundary layers within the above range of Reynolds numbers and angles of attack are either stable or only weakly unstable (i.e., corresponding to a rather small peak N-factor,  $ N<3 $). Those flows were excluded from the database, still yielding a total of 31,247 flow cases corresponding to the 53 airfoils in this database. Although the computational cost of generating such a database is only few hours, the associated human effort measured in hours are significantly higher since the process requires manual interventions and expert judgements to avoid spurious modes in linear stability computations. Furthermore, preprocessing of geometrical data to ensure smooth surface curvature also added significant human effort cost to the database generation.
$ N<3 $). Those flows were excluded from the database, still yielding a total of 31,247 flow cases corresponding to the 53 airfoils in this database. Although the computational cost of generating such a database is only few hours, the associated human effort measured in hours are significantly higher since the process requires manual interventions and expert judgements to avoid spurious modes in linear stability computations. Furthermore, preprocessing of geometrical data to ensure smooth surface curvature also added significant human effort cost to the database generation.
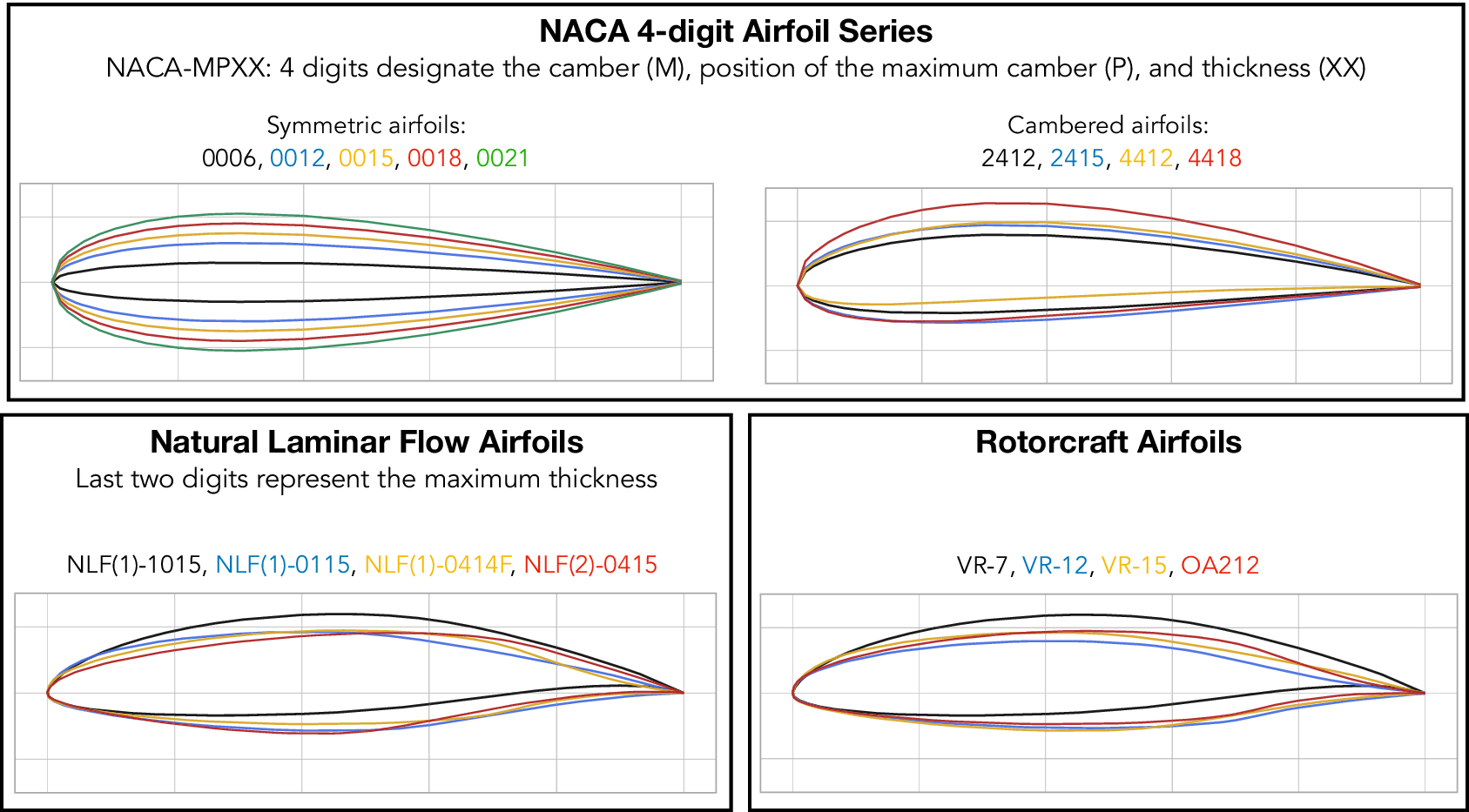
Figure 5. Airfoil sections for three airfoil families in the database. A complete list of airfoils along with their geometries is given in Appendix A.
The database documents the mean flow features and the relevant linear stability characteristics in a sequential manner along 121 streamwise stations, starting from a station close to the onset of instability and extending up to either the point where the N-factor envelope reaches  $ {N}_{\mathrm{env}}=25 $ or to the end of the chordwise domain (which can be upstream of the trailing edge if the boundary-layer solution terminates due to an incipient flow separation). We keep the sequence length fixed at 121 for all airfoils and flow conditions, which makes it more efficient in handling the data during the training and testing of the RNN model. The location of each station is defined in terms of the arc length along the airfoil surface (
$ {N}_{\mathrm{env}}=25 $ or to the end of the chordwise domain (which can be upstream of the trailing edge if the boundary-layer solution terminates due to an incipient flow separation). We keep the sequence length fixed at 121 for all airfoils and flow conditions, which makes it more efficient in handling the data during the training and testing of the RNN model. The location of each station is defined in terms of the arc length along the airfoil surface (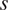 $ s $). Besides the parameters given in Table 1, sequential information for several other relevant parameters has also been included in the database, such as the chordwise location of each station (
$ s $). Besides the parameters given in Table 1, sequential information for several other relevant parameters has also been included in the database, such as the chordwise location of each station (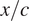 $ x/c $), local edge velocity (
$ x/c $), local edge velocity (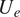 $ {U}_e $), local boundary-layer edge density (
$ {U}_e $), local boundary-layer edge density (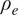 $ {\rho}_e $) and viscosity (
$ {\rho}_e $) and viscosity (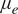 $ {\mu}_e $), boundary-layer momentum thickness (
$ {\mu}_e $), boundary-layer momentum thickness (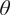 $ \theta $), and so on.
$ \theta $), and so on.
The present work is aimed at developing an RNN model, which is trained over a subset of the complete dataset, and has the ability to predict the transition location for any boundary-layer flow from the complete dataset with reasonable accuracy. Computational constraints limit the size of the training dataset for RNNs, since they are more expensive to train as compared to simple feedforward neural networks. Reducing the size of the training data via subsampling of the overall database would require the sampling process to avoid any bias toward any specific subset of the database. Such bias can have a dominant effect on the efficacy of the loss function used for training, resulting in a potential overfitting across certaint parts of the training data, and worse predictive performance for other subsets of the database. Hence, a large database of this type requires adequate sampling procedures for the selection of the training data so that the resulting model can provide a balanced representation of the entire database.
4. Results
The proposed RNN model predicts the sequence of growth rates of the most amplified disturbances, that is, the slope values of the N-factor envelope as a function of distance along the airfoil contour. The N-factor envelope can then be determined as the cumulative integral over this sequence, with the lower limit of integration corresponding to the airfoil location where the boundary-layer flow first becomes unstable (or, equivalently, the station across which the slope first changes in sign from a negative value to a positive one). The transition onset location can then be estimated as the location where the envelope reaches the critical N-factor determined via correlation with a relevant set of measurements. The sequential data are defined at a fixed number of stations for each flow, but the physical domain length can vary from case to case due to the potential onset of flow separation in a laminar boundary-layer computation. The loss function used for the training process includes a weighting function corresponding to the cell size (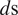 $ d\mathrm{s} $) in the vicinity of each station. Specifically, the loss function used for training the neural network is defined in terms of a weighted sum over the square of the local error:
$ d\mathrm{s} $) in the vicinity of each station. Specifically, the loss function used for training the neural network is defined in terms of a weighted sum over the square of the local error:
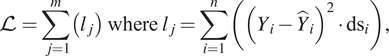 $$ \mathrm{\mathcal{L}}=\sum \limits_{j=1}^m\left({l}_j\right)\hskip2pt \mathrm{where}\hskip2pt {l}_j=\sum \limits_{i=1}^n\left({\left({Y}_i-{\hat{Y}}_i\right)}^2\cdot {\mathrm{ds}}_i\right), $$
$$ \mathrm{\mathcal{L}}=\sum \limits_{j=1}^m\left({l}_j\right)\hskip2pt \mathrm{where}\hskip2pt {l}_j=\sum \limits_{i=1}^n\left({\left({Y}_i-{\hat{Y}}_i\right)}^2\cdot {\mathrm{ds}}_i\right), $$where  $ m $ denotes the number of sequences in the dataset,
$ m $ denotes the number of sequences in the dataset, 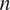 $ n $ denotes the number of stations in a sequence, and
$ n $ denotes the number of stations in a sequence, and 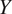 $ Y $ and
$ Y $ and  $ \hat{Y} $ represent the true and predicted values, respectively, corresponding to the output quantity. The weighting function serves to reduce the bias due to a nonuniform streamwise grid used in the boundary-layer calculation.
$ \hat{Y} $ represent the true and predicted values, respectively, corresponding to the output quantity. The weighting function serves to reduce the bias due to a nonuniform streamwise grid used in the boundary-layer calculation.
The primary performance indicator of the proposed model is the prediction of the chordwise location of the laminar-turbulent transition. However, besides its obvious dependence on the stability characteristics of the airfoil boundary layer, the transition location also depends on the disturbance environment via the correlating N-factor value, 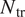 $ {N}_{\mathrm{tr}} $. The measured transition locations in a broad range of flows typically correlate with a finite band of N-factor values in the vicinity of
$ {N}_{\mathrm{tr}} $. The measured transition locations in a broad range of flows typically correlate with a finite band of N-factor values in the vicinity of 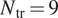 $ {N}_{\mathrm{tr}}=9 $ under a benign disturbance environment, such as those encountered by external flows at typical flight altitudes. For this reason, the predictive performance has been assessed considering the flow cases for which N-factor envelope reaches values of upto
$ {N}_{\mathrm{tr}}=9 $ under a benign disturbance environment, such as those encountered by external flows at typical flight altitudes. For this reason, the predictive performance has been assessed considering the flow cases for which N-factor envelope reaches values of upto  $ {N}_{\mathrm{env}}=13. $ To help provide a meaningful assessment of the model accuracy across a broad range of flows and correlating N-factors, three different error metrics have been defined separately from the loss function, as indicated below.
$ {N}_{\mathrm{env}}=13. $ To help provide a meaningful assessment of the model accuracy across a broad range of flows and correlating N-factors, three different error metrics have been defined separately from the loss function, as indicated below.
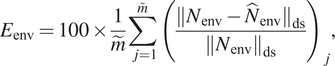 $$ {E}_{\mathrm{env}}=100\times \frac{1}{\tilde{m}}\sum \limits_{j=1}^{\overset{\sim }{m}}{\left(\frac{{\Vert {N}_{\mathrm{env}}-{\hat{N}}_{\mathrm{env}}\Vert}_{\mathrm{ds}}}{{\left\Vert {N}_{\mathrm{env}}\right\Vert}_{\mathrm{ds}}}\right)}_j, $$
$$ {E}_{\mathrm{env}}=100\times \frac{1}{\tilde{m}}\sum \limits_{j=1}^{\overset{\sim }{m}}{\left(\frac{{\Vert {N}_{\mathrm{env}}-{\hat{N}}_{\mathrm{env}}\Vert}_{\mathrm{ds}}}{{\left\Vert {N}_{\mathrm{env}}\right\Vert}_{\mathrm{ds}}}\right)}_j, $$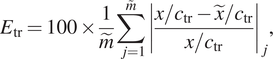 $$ {E}_{\mathrm{tr}}=100\times \frac{1}{\tilde{m}}\sum \limits_{j=1}^{\overset{\sim }{m}}{\left|\frac{x/{c}_{\mathrm{tr}}-\tilde{x}/{c}_{\mathrm{tr}}}{x/{c}_{\mathrm{tr}}}\right|}_j, $$
$$ {E}_{\mathrm{tr}}=100\times \frac{1}{\tilde{m}}\sum \limits_{j=1}^{\overset{\sim }{m}}{\left|\frac{x/{c}_{\mathrm{tr}}-\tilde{x}/{c}_{\mathrm{tr}}}{x/{c}_{\mathrm{tr}}}\right|}_j, $$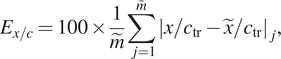 $$ {E}_{x/c}=100\times \frac{1}{\tilde{m}}\sum \limits_{j=1}^{\overset{\sim }{m}}{\left|x/{c}_{\mathrm{tr}}-\tilde{x}/{c}_{\mathrm{tr}}\right|}_j, $$
$$ {E}_{x/c}=100\times \frac{1}{\tilde{m}}\sum \limits_{j=1}^{\overset{\sim }{m}}{\left|x/{c}_{\mathrm{tr}}-\tilde{x}/{c}_{\mathrm{tr}}\right|}_j, $$where 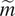 $ \tilde{m} $ denotes the number of sequences in the dataset for which the N-factor envelope reaches values of upto
$ \tilde{m} $ denotes the number of sequences in the dataset for which the N-factor envelope reaches values of upto 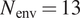 $ {N}_{\mathrm{env}}=13 $. The first error metric (
$ {N}_{\mathrm{env}}=13 $. The first error metric (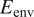 $ {E}_{\mathrm{env}} $) is based on the
$ {E}_{\mathrm{env}} $) is based on the 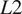 $ L2 $ norm to evaluate the accuracy of the predicted N-factor envelope (
$ L2 $ norm to evaluate the accuracy of the predicted N-factor envelope (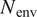 $ {N}_{\mathrm{env}} $), determined by integrating the predicted slope values
$ {N}_{\mathrm{env}} $), determined by integrating the predicted slope values 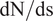 $ \mathrm{dN}/\mathrm{ds} $. To emphasize a finite band of N-factor values in the vicinity of
$ \mathrm{dN}/\mathrm{ds} $. To emphasize a finite band of N-factor values in the vicinity of 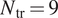 $ {N}_{\mathrm{tr}}=9 $, only the range of
$ {N}_{\mathrm{tr}}=9 $, only the range of 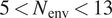 $ 5<{N}_{\mathrm{env}}<13 $ has been considered for each flow case. The second error metric (
$ 5<{N}_{\mathrm{env}}<13 $ has been considered for each flow case. The second error metric ( $ {E}_{\mathrm{tr}} $) corresponds to the relative discrepancy between the true and predicted chordwise locations of transition onset for the case of
$ {E}_{\mathrm{tr}} $) corresponds to the relative discrepancy between the true and predicted chordwise locations of transition onset for the case of  $ {N}_{\mathrm{tr}}=9 $. The third error metric (
$ {N}_{\mathrm{tr}}=9 $. The third error metric ( $ {E}_{x/c} $) relates to the absolute error in the predicted transition location, scaled by the airfoil chord length.
$ {E}_{x/c} $) relates to the absolute error in the predicted transition location, scaled by the airfoil chord length.
4.1. Demonstration of predictive performance
Selection of training data for the development of a general purpose model for the airfoil universe requires a balance between multiple requirements that may conflict with each other. It is clearly desirable for the size of the training data to be moderate enough to minimize the training cost. However, the training data must also be large enough in scope to represent the broad application space and must be designed to avoid an unfair bias toward specific subregions from the parameter space of latent features. Translating these requirements into a practical procedure is not a straightforward task. Given the availability of the large database of stability characteristics as described in the previous section, we have evaluated several different strategies for the selection of an appropriate subset of that database for the training process.
We begin using a smaller portion of the available database for training purposes. This baseline case is representative of less ambitious efforts at database generation, as well as being better suited for the case involving a broader application space that includes additional flow parameters such as, for instance, nonzero Mach numbers, nonzero surface transpiration, surface heating/cooling, and so on. The baseline training set consists of five out of the total 53 airfoils, with each of these five airfoils representing a different subgroup of airfoils from Table A1, namely, the NACA0012, ONERAM6, NACA2412, NACA63-415, and NLF(1)-0416 airfoils. These airfoils correspond to airfoil indices of 2, 44, 6, 15, and 25, respectively. Here, the first two airfoils have symmetric contours whereas the latter three correspond to asymmetrical airfoil sections. Table 2 lists the various flow conditions at which boundary-layer solutions are available for each airfoil in the database. To assess the RNN model for interpolation and extrapolation with respect to the angle of attack and chord Reynolds number, respectively, flow conditions marked in red have been included in the testing dataset, while the remaining flow cases constitute the training dataset. Such an arrangement of the total available cases from these five airfoils results in a 60–40% split between the training and testing data.
Table 2. Flow conditions for all the cases in the airfoil database.

For evaluation of the RNN model, flow conditions used for model testing are marked in red color whereas the flow conditions used for training are indicated in black color.
The sequential information corresponding to the evolution of mean boundary-layer profiles along the airfoil surface has been documented in the database, with a uniform sequence length of 121 stations for all flow cases. An initial assessment was conducted to ascertain the effect of different sequence lengths. The results of this assessment are shown in Figure 6, wherein the error metrics defined in Equations (4) and (5) have been plotted for different sequence lengths. Significant improvements can be observed by reducing the sequence length from 121 to 60, the reason for which is not entirely clear. It could be one of the areas for future investigations of such models. In general, however, this trend may be related to the fact that more information sometimes lead to diluting of information and, consequently, to worse results. Further shortening of the sequence length yields relatively little benefit in terms of model accuracy for either training or test data. In fact, the accuracy of predicting the transition location worsens when the sequence length is reduced beyond 60. This observation is likely to be related to a poorer resolution of the shape of the N-factor envelope achieved when fewer stations are used across the same physical domain length along the airfoil surface. Looking at the similar trends for both error metrics, it was decided that a sequence length of 60 stations would provide an optimal choice for all of the results to be presented in this paper. Figure 6 shows that the predictive performance for the testing dataset is comparable to that for the training dataset, demonstrating the interpolating and extrapolating capability of the proposed RNN model with respect to both AOA and  $ {\operatorname{Re}}_c $.
$ {\operatorname{Re}}_c $.
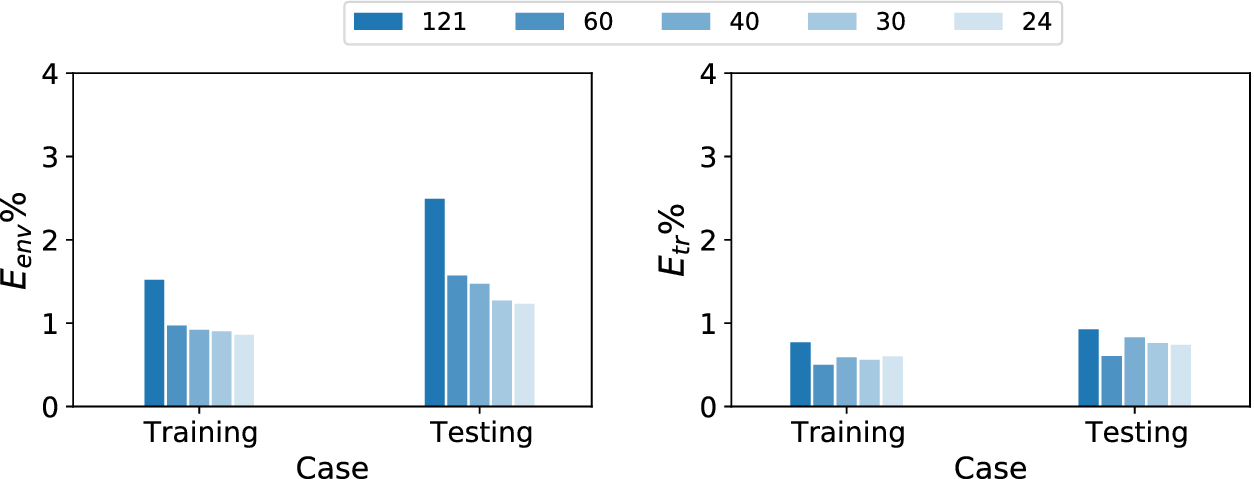
Figure 6. Comparison of prediction error percentage for training and testing datasets with different sequence lengths. Training and testing datasets have been defined based on flow conditions as given in Table 2.
Next, we assess the effect of the size of the RNN model on the prediction error. Figure 7 displays the variation in error percentage as a function of the number of learnable parameters in the RNN model. While the error metric  $ {E}_{\mathrm{env}} $ decreases as the number of learnable parameters is increased up to 5,500, the error remains nearly constant with a further increase in the number of parameters. One may deduce from these results that an RNN model with 5,500 learnable parameters provides near-optimal learning capability without causing overfitting. Consequently, this model size will be maintained for all the results presented for the current dataset. We note that the training dataset for this baseline case is of much smaller size in comparison to the complete airfoil database and that the use of a larger training dataset will most likely require a larger number of learnable parameters to enhance the learning capacity of the RNN model. Thus, the selection of model size will be discussed again when we work with somewhat larger training datasets in the following subsections.
$ {E}_{\mathrm{env}} $ decreases as the number of learnable parameters is increased up to 5,500, the error remains nearly constant with a further increase in the number of parameters. One may deduce from these results that an RNN model with 5,500 learnable parameters provides near-optimal learning capability without causing overfitting. Consequently, this model size will be maintained for all the results presented for the current dataset. We note that the training dataset for this baseline case is of much smaller size in comparison to the complete airfoil database and that the use of a larger training dataset will most likely require a larger number of learnable parameters to enhance the learning capacity of the RNN model. Thus, the selection of model size will be discussed again when we work with somewhat larger training datasets in the following subsections.
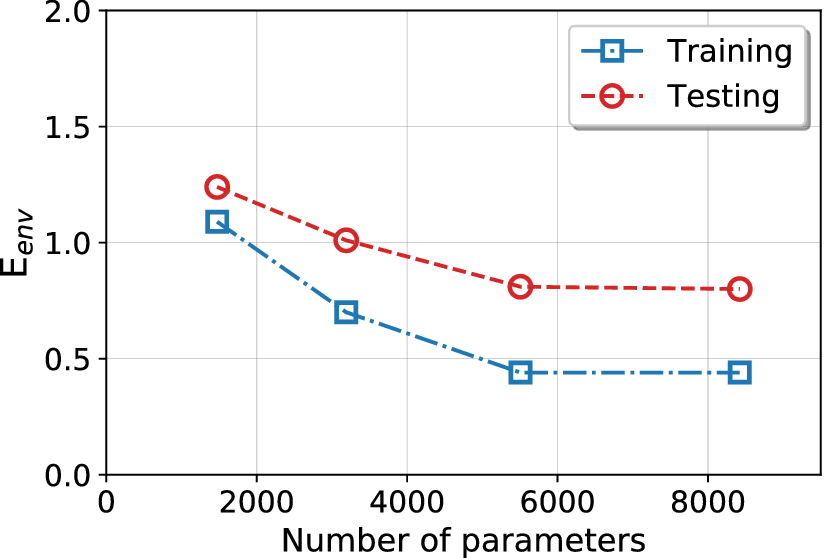
Figure 7. Training and testing errors for a range of sizes of the recurrent neural network (RNN) model indicated by the number of learnable parameters. The number of layers is kept the same while the parameters are varied proportionately in all three mappings, 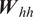 $ {\boldsymbol{W}}_{hh} $,
$ {\boldsymbol{W}}_{hh} $, 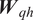 $ {\boldsymbol{W}}_{qh} $, and
$ {\boldsymbol{W}}_{qh} $, and  $ {\boldsymbol{W}}_{hy} $.
$ {\boldsymbol{W}}_{hy} $.
The architecture of the proposed neural network model has direct correlation with the underlying physics of flow transition. Previously proposed fully connected neural network-based transition models (Fuller et al., Reference Fuller, Saunders and Vandsburger1997; Crouch et al., Reference Crouch, Crouch and Ng2002) did not distinguish the evolution of flow in wall-normal and streamwise directions. At any station along airfoil surface, propagation of boundary layer flow in wall-normal direction is instantaneous (analogous to elliptic behavior of diffusion equation). Hence, Zafar et al. (Reference Zafar, Xiao, Choudhari, Li, Chang, Paredes and Venkatachari2020) used CNN to encode the information from the boundary layer profiles in wall-normal direction in a vector of latent features. Such treatment of boundary layer profiles provides a stronger correlation with the underlying physics of the flow and also allows the application of CNN-based transition model to various instability mechanisms (Paredes et al., Reference Paredes, Venkatachari, Choudhari, Li, Chang, Zafar and Xiao2020). These characteristics were clearly lacking in previously proposed neural network-based transition models.
The current work uses both CNN and RNN in tandem where the RNN has been used to encapsulate the underlying physics of streamwise evolution of flow instability along with CNN which process the boundary layer profiles in wall-normal direction. Along the streamwise direction, elliptic behavior has already been taken care of in the stability theory however hyperbolic nature of the instability amplification from upstream to downstream requires sequence-to-sequence modeling, for which RNN has been used. To assess the benefit of sequence transduction in the RNN model, its predictive performance has compared with that of a previously proposed model which does not account for the sequence information among the inputs at different stations (Zafar et al., Reference Zafar, Xiao, Choudhari, Li, Chang, Paredes and Venkatachari2020). For a fair comparison, almost equal number of learnable parameters was used for both networks. The comparison is presented in Figure 8, wherein we include the error percentages for both training and testing datasets. The testing cases have been further categorized in terms of interpolation and extrapolation with respect to the flow conditions. The results corresponding to each dataset show a clearly superior predictive performance for the RNN model vis-a-vis the fully connected neural network.
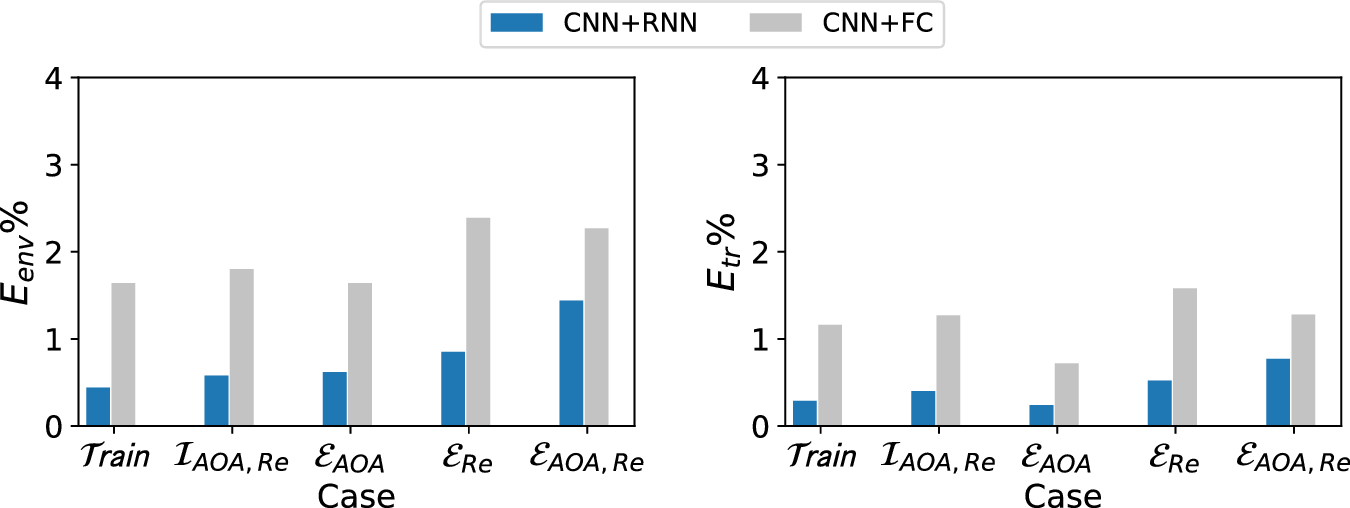
Figure 8. Comparison of results for the recurrent neural network and fully connected network. Testing cases have been subcategorized as: Interpolation with respect to both angles of attack (AOA) and Reynolds number (Re) 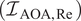 $ \left({\mathcal{I}}_{\mathrm{AOA},\operatorname{Re}}\right) $, Extrapolation with respect to AOA (
$ \left({\mathcal{I}}_{\mathrm{AOA},\operatorname{Re}}\right) $, Extrapolation with respect to AOA (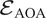 $ {\mathcal{E}}_{\mathrm{AOA}} $), Extrapolation with respect to Re (
$ {\mathcal{E}}_{\mathrm{AOA}} $), Extrapolation with respect to Re (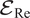 $ {\mathcal{E}}_{\mathrm{Re}} $), Extrapolation with respect to both AOA and Re (
$ {\mathcal{E}}_{\mathrm{Re}} $), Extrapolation with respect to both AOA and Re ( $ {\mathcal{E}}_{\mathrm{AOA},\operatorname{Re}} $).
$ {\mathcal{E}}_{\mathrm{AOA},\operatorname{Re}} $).
We also note that, in comparison to transition model based on fully connected neural network, the RNN model has a moderately higher training cost associated to it. For the given training data (comprising of 5 airfoil datasets with sequence length of 60) and a given model size ( $ \sim $5,500 learnable parameters), the RNN model took 29 GPU hours to train as compared to 19 GPU hours for the fully connected neural network. A single NVIDIA V100 GPU was used for training purposes.
$ \sim $5,500 learnable parameters), the RNN model took 29 GPU hours to train as compared to 19 GPU hours for the fully connected neural network. A single NVIDIA V100 GPU was used for training purposes.
In comparison to direct stability computations, the RNN model can estimate the transition location three to four orders of magnitude faster. Actual times for direct computations of linear stability can vary depending on various factors, including the specific flow and the level of resolution (in terms of the number of stations in a sequence and the number of frequencies used to determine the N-factor envelope). In that regard, the above estimate is believed to provide a reasonable, if somewhat conservative, estimate of the speed-up due to RNN.
4.2. Evaluation of predictive performance for complete database
We now perform a comparative assessment of the accuracy of the RNN models based on different selections of training datasets. These training datasets have been summarized in the Table 3. The rationale behind the selection of each training dataset from Table 3 will be outlined in the course of the discussion of the results, especially as the results for Case I provide the baseline for the selection of training data for the subsequent cases. Since the analysis is focused on the performance of the RNN model in predicting the transition location over an arbitrary airfoil, no distinction has been made between the airfoils and flow conditions used for training and testing, and all the flow cases included in the training dataset are considered alongside the cases that were not used during training. Because the sizes of the training sets from Table 3 are comparable to each other and always less than 24% of the total available data, the error metric based on the entire database was deemed to be a meaningful measure of the model’s predictive accuracy.
Table 3. Summary of training dataset cases.
Flow cases corresponding to the mentioned airfoils are included in the training dataset.
Case I (denoted as “Five Airfoils”) from Table 3 involves a training dataset that is comprised of the same five airfoils that were used in the earlier assessment of the RNN model size, comparison with fully connected network, and so on. Results for the RNN model trained using the Case I dataset are shown in Figures 9 and 10. Figure 9 presents the mean error percentages for the predicted N-factor envelope and transition location corresponding to all airfoils from the overall database. The figures have been shaded to distinguish between the different groups of airfoils belonging to the airfoil families included within the overall database. Airfoil names corresponding to the indices from Figure 9 are given in Table A1. In general, the mean error percentage for most of the airfoils is below about 3%, which demonstrates the general capability of the RNN model based on the Case I training data. Even though the model has been trained with a significantly smaller subsample of airfoils from the overall database, it is still able to predict the 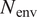 $ {N}_{\mathrm{env}} $ and transition location for the entire set of airfoils including different categories with a reasonable accuracy. Laminar to turbulent transition due to TS amplification within the attached flow region is achieved at varying numbers of flow conditions across the different airfoils, and the markers for each airfoil in the figure have been colored on the basis of the dataset size of that airfoil. This feature will be used to gain additional insights during the subsequent discussion as we describe the results for the remaining cases from Table A1.
$ {N}_{\mathrm{env}} $ and transition location for the entire set of airfoils including different categories with a reasonable accuracy. Laminar to turbulent transition due to TS amplification within the attached flow region is achieved at varying numbers of flow conditions across the different airfoils, and the markers for each airfoil in the figure have been colored on the basis of the dataset size of that airfoil. This feature will be used to gain additional insights during the subsequent discussion as we describe the results for the remaining cases from Table A1.
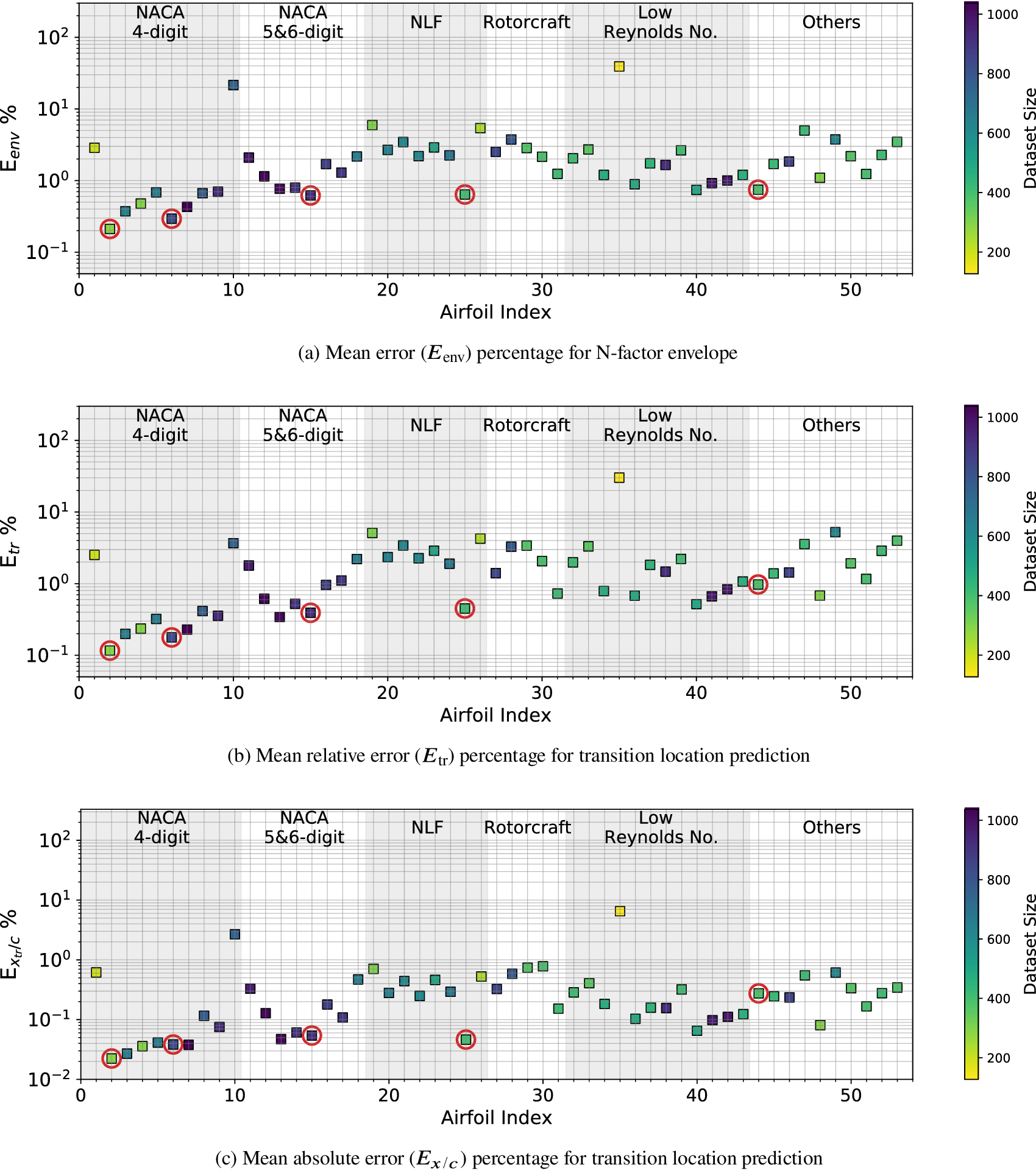
Figure 9. Mean error percentage for each airfoil in the database, corresponding to training dataset of Case I (five airfoils) given in Table 3. Airfoils corresponding to training dataset have been encircled in red color. Markers’ color represent the dataset size (number of flow cases) of each airfoil in the database.

Figure 10. Relative error ( $ {E}_{\mathrm{tr}} $) percentage for all flow cases, corresponding to training dataset of Case I (five airfoils) given in Table 3. Green markers (filled circles) show only 1% of the randomly sampled flow cases. The contour shows the kernel density estimated from all the flow cases. Darker region indicates higher probability density. The horizontal lines appearing in the contour plots such as that near an error of 0.2% are due to technical reason (bins have been defined in linear-scale while the vertical axis of the plot is in log-scale) and do not depict any real discontinuity.
$ {E}_{\mathrm{tr}} $) percentage for all flow cases, corresponding to training dataset of Case I (five airfoils) given in Table 3. Green markers (filled circles) show only 1% of the randomly sampled flow cases. The contour shows the kernel density estimated from all the flow cases. Darker region indicates higher probability density. The horizontal lines appearing in the contour plots such as that near an error of 0.2% are due to technical reason (bins have been defined in linear-scale while the vertical axis of the plot is in log-scale) and do not depict any real discontinuity.
Predictive performance as a function of the angle of attack and chord Reynolds number is shown in Figure 10, which indicates the distribution of error percentage across the overall database via a color map for the kernel density estimate. In addition, 1% of randomly sampled data points from the overall database have also been included as green dots within the figure. No bias in predictive errors toward specific flow conditions may be observed within the figure, indicating that the model is able to yield comparable accuracy across the entire range of flow conditions. The transition locations for most of the flow cases is predicted with a relative error percentage of (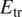 $ {E}_{\mathrm{tr}} $)
$ {E}_{\mathrm{tr}} $) 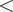 $ < $ 2%, as shown by the higher density region with a darker color in the color map from Figure 10.
$ < $ 2%, as shown by the higher density region with a darker color in the color map from Figure 10.
Results for Case I, shown in Figure 9, indicate a few outlying airfoils corresponding to a high error percentage in the predictions of the RNN model. In particular, the average error in the prediction of the N-factor envelope for the LRN(1)-1007 airfoil is significantly higher (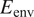 $ {E}_{\mathrm{env}} $ > 30%) as compared to that for most of the other airfoils. LRN(1)-1007, designed for high lift and low drag at Re =
$ {E}_{\mathrm{env}} $ > 30%) as compared to that for most of the other airfoils. LRN(1)-1007, designed for high lift and low drag at Re = 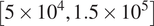 $ \left[5\times {10}^4,\mathrm{1.5}\times {10}^5\right] $, has a peculiar airfoil contour and aerodynamic behavior, which is markedly different with respect to the other airfoils in the training dataset. This may explain why the predictive error percentage for the LRN(1)-1007 airfoil is higher by almost an order of magnitude. Similarly, the NACA 6712 airfoil with a highly aft-cambered airfoil section also has a significantly higher error percentage (
$ \left[5\times {10}^4,\mathrm{1.5}\times {10}^5\right] $, has a peculiar airfoil contour and aerodynamic behavior, which is markedly different with respect to the other airfoils in the training dataset. This may explain why the predictive error percentage for the LRN(1)-1007 airfoil is higher by almost an order of magnitude. Similarly, the NACA 6712 airfoil with a highly aft-cambered airfoil section also has a significantly higher error percentage (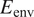 $ {E}_{\mathrm{env}} $ > 20%). In comparison, the predictive performance for the other NACA airfoils is reasonably good, with the average absolute error in predicting the transition location below 1% for most of those airfoils.
$ {E}_{\mathrm{env}} $ > 20%). In comparison, the predictive performance for the other NACA airfoils is reasonably good, with the average absolute error in predicting the transition location below 1% for most of those airfoils.
Augmenting the training dataset from Case I with additional data provides the most obvious way of improving on the predictive performance of the above RNN model. Several different strategies for data augmentation were evaluated in the course of this work, and they are denoted as Cases II, III, and IV in Table A1. For Case II, 100 randomly selected flow cases from every other airfoil have been added to the training dataset from Case I. Even though these data augmentation causes the size of the training dataset to increase almost threefold with respect to that in Case I, the inclusion of flow cases for every airfoil within the training dataset leads to significantly improved predictive performance of the RNN model. The results for Case II are shown in Figure 11. The overall prediction error percentages have decreased significantly in comparison with Case I, and the maximum absolute error in predicting the transition location 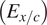 $ \left({E}_{x/c}\right) $ for any airfoil has reduced from
$ \left({E}_{x/c}\right) $ for any airfoil has reduced from 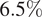 $ 6.5\% $ in Case I to approximately 1% in Case II.
$ 6.5\% $ in Case I to approximately 1% in Case II.
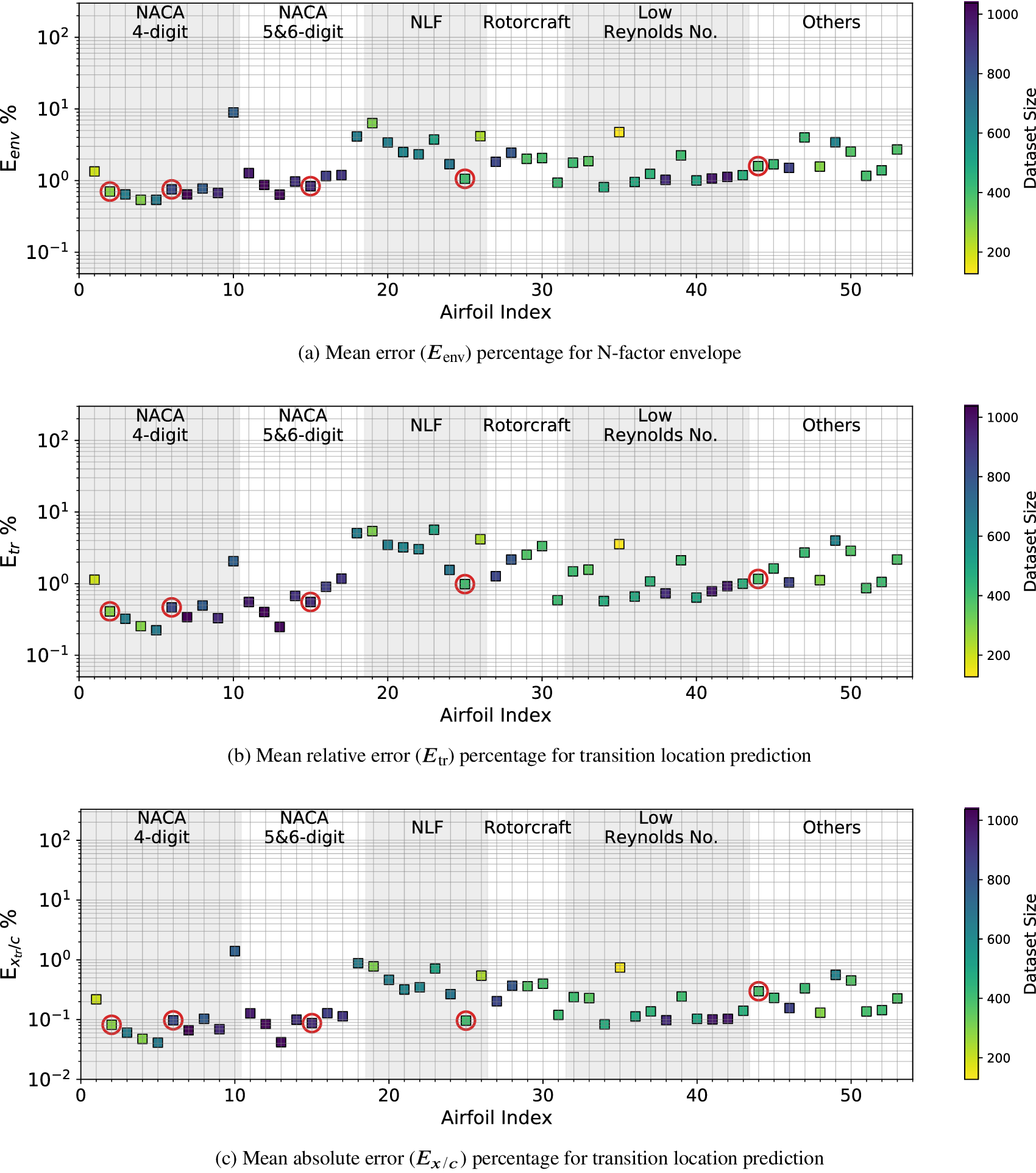
Figure 11. Mean error percentage for each airfoil in the database, corresponding to training dataset of Case II (random augmentation) given in Table 3. Airfoils corresponding to training dataset have been encircled in red color. Markers’ color represent the dataset size (number of flow cases) of each airfoil in the database.
For Case III, the training dataset has been augmented by including an additional set of airfoils for which the average error ( $ {E}_{\mathrm{env}} $) is greater than 3%. Five such airfoils, mentioned in Table 3, along with the original five airfoils from Case I constitute the training dataset for Case III. Results for this training case are plotted in Figure 12. The figure shows that, despite a larger size of the training dataset with respect to that in Case I, the predictive performance for Case III has worsened. The overall trend can be summarized by looking at the group of natural laminar flow airfoils in Figure 12, for which the model predictions are now significantly worse (7% <
$ {E}_{\mathrm{env}} $) is greater than 3%. Five such airfoils, mentioned in Table 3, along with the original five airfoils from Case I constitute the training dataset for Case III. Results for this training case are plotted in Figure 12. The figure shows that, despite a larger size of the training dataset with respect to that in Case I, the predictive performance for Case III has worsened. The overall trend can be summarized by looking at the group of natural laminar flow airfoils in Figure 12, for which the model predictions are now significantly worse (7% < 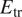 $ {E}_{\mathrm{tr}} $ < 13%), except for those airfoils that have been included within the training dataset (0.7% <
$ {E}_{\mathrm{tr}} $ < 13%), except for those airfoils that have been included within the training dataset (0.7% <  $ {E}_{\mathrm{tr}} $ < 2%). This observation points to a possible overfitting of the data by the RNN model under consideration. Hence, one may conclude that the augmentation of the original set by five additional airfoils does not provide a good representation of the overall database.
$ {E}_{\mathrm{tr}} $ < 2%). This observation points to a possible overfitting of the data by the RNN model under consideration. Hence, one may conclude that the augmentation of the original set by five additional airfoils does not provide a good representation of the overall database.
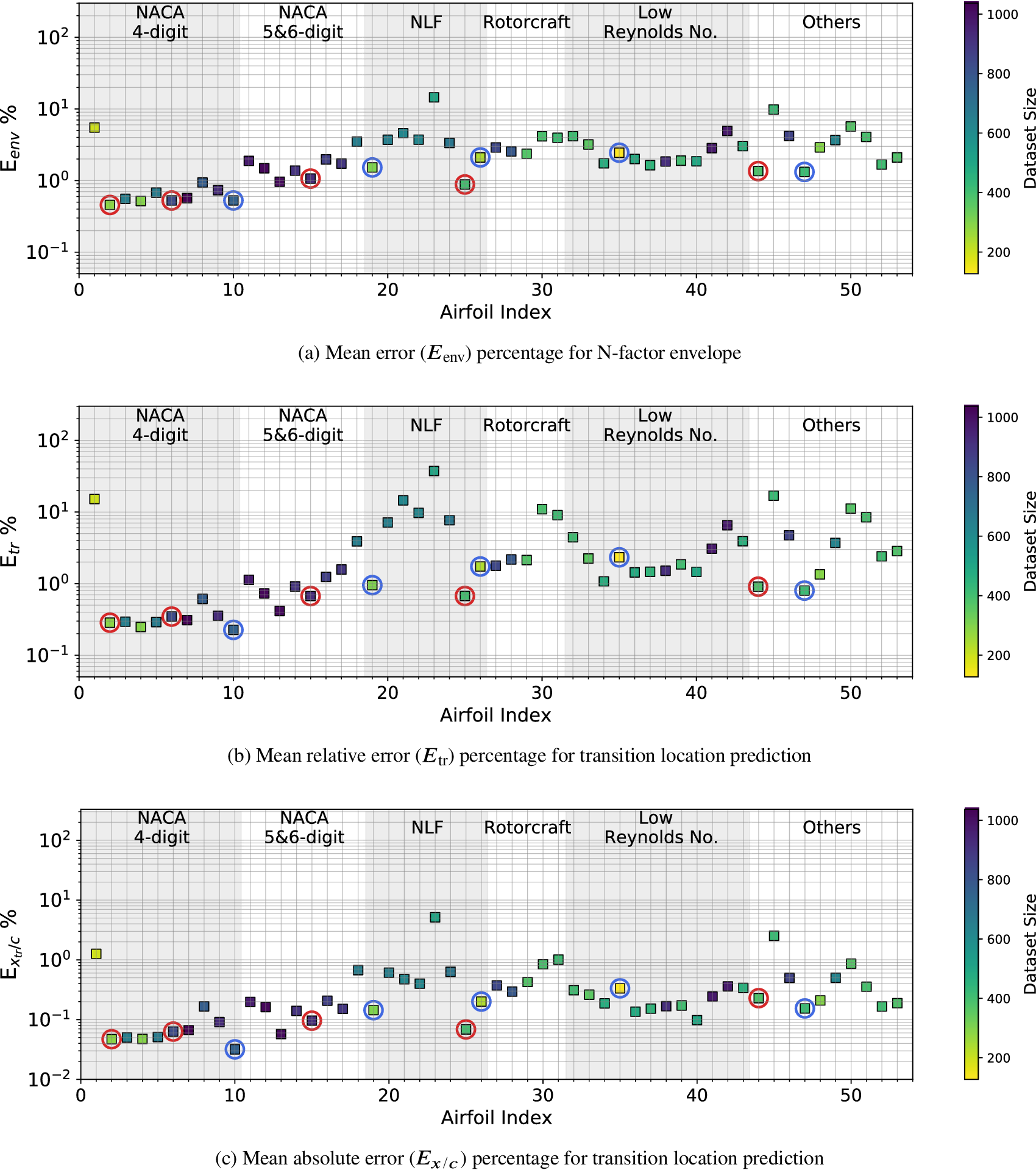
Figure 12. Mean error percentage for each airfoil in the database, corresponding to training dataset of Case III (augmented airfoils set) given in Table 3. Airfoils corresponding to training dataset have been encircled, where airfoils already in the training dataset from Case I have been encircled in red color, while the augmented set of airfoils have been encircled in blue color. Markers’ color represent the dataset size (number of flow cases) of each airfoil in the database.
For Case IV, the training dataset from Case I has been augmented with the flow cases from overall database that correspond to the highest predictive error percentage (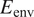 $ {E}_{\mathrm{env}} $ > 3%) associated with the RNN model from Case I. A significant improvement can be observed in the overall predictive performance of the RNN model as compared to all of the previous cases. Based on this error-based data augmentation, the absolute error percentage in the predicted transition location
$ {E}_{\mathrm{env}} $ > 3%) associated with the RNN model from Case I. A significant improvement can be observed in the overall predictive performance of the RNN model as compared to all of the previous cases. Based on this error-based data augmentation, the absolute error percentage in the predicted transition location  $ \left({E}_{x/c}\right) $ over any airfoil from the database is less than approximately 0.7%. Figure 14 shows the distribution of the error percentage as a function of the flow conditions. Due to the kind of data augmentation used for this case, one finds that most flow cases tend toward smaller error values in comparison to those in Case I (Figure 10).
$ \left({E}_{x/c}\right) $ over any airfoil from the database is less than approximately 0.7%. Figure 14 shows the distribution of the error percentage as a function of the flow conditions. Due to the kind of data augmentation used for this case, one finds that most flow cases tend toward smaller error values in comparison to those in Case I (Figure 10).
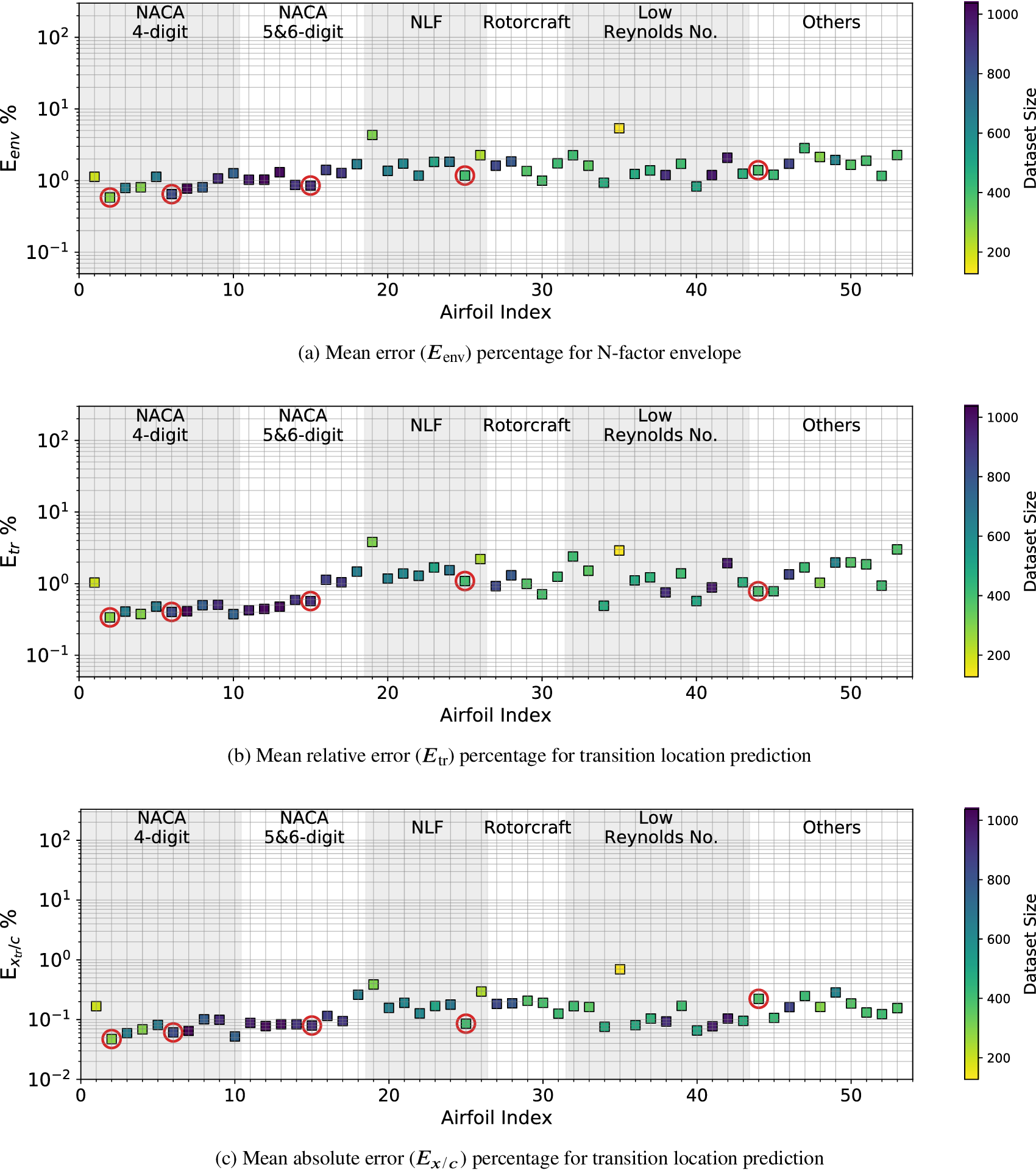
Figure 13. Mean error percentage for each airfoil in the database, corresponding to training dataset of Case IV (error-based augmentation) given in Table 3. Airfoils corresponding to training dataset have been encircled in red color. Markers’ color represent the dataset size (number of flow cases) of each airfoil in the database.
Figure 14. Relative error ( $ {E}_{\mathrm{tr}} $) percentage for all flow cases, corresponding to training dataset of Case IV given in Table 3. Green markers (filled circles) show only 1% of the randomly sampled flow cases. The contour shows the kernel density estimated from all the flow cases. Darker region indicates higher probability density. The horizontal lines appearing in the contour plots such as that near an error of 0.2% are due to technical reason (bins have been defined in linear-scale while the vertical axis of the plot is in log-scale) and do not depict any real discontinuity.
$ {E}_{\mathrm{tr}} $) percentage for all flow cases, corresponding to training dataset of Case IV given in Table 3. Green markers (filled circles) show only 1% of the randomly sampled flow cases. The contour shows the kernel density estimated from all the flow cases. Darker region indicates higher probability density. The horizontal lines appearing in the contour plots such as that near an error of 0.2% are due to technical reason (bins have been defined in linear-scale while the vertical axis of the plot is in log-scale) and do not depict any real discontinuity.
The selection of training data for the Cases II, III, and IV was based on the results of Case I, which consisted of five airfoils chosen somewhat arbitrarily (except for the attempt to include some representation from five different groups of airfoils). Although Case IV provides quite good results, such that the absolute error percentage associated with the prediction of the transition location (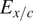 $ {E}_{x/c} $) over any airfoil is 0.7% or less, the selection of the training dataset has been made in an indirect manner on the basis of the results obtained in Case I.
$ {E}_{x/c} $) over any airfoil is 0.7% or less, the selection of the training dataset has been made in an indirect manner on the basis of the results obtained in Case I.
A more direct strategy for subsampling a training dataset from the entire database has been assessed in Case V, where a completely random subset of varying magnitudes has been selected from the overall database. Two subcases (V-A and V-B) have been assessed in this regard, as summarized in Table 3. Case V-A involves the selection of a fixed percentage of flow cases corresponding to each airfoil, which results in a different number of flow cases for each airfoil in the training dataset. As mentioned earlier, this uneven number of flow cases in the database results naturally from the fact that different airfoils achieve laminar to turbulent transition at different flow conditions and the fact that only upper surface boundary layers are retained in the case of airfoils with symmetric contours. For Case V-B, a fixed number of flow cases corresponding to each airfoil have been selected as training data in order to provide a uniform weighting to each of the airfoils. With this arrangement to define the two subcases, different sizes of training datasets have been used to analyze the variation of error percentage with respect to the size of the training dataset. The results of this study are shown in Figure 15. The figure shows that, in both cases (V-A and V-B), there is an optimal size of the training dataset that leads to a minimum prediction error. For Case V-A, a training dataset size of  $ \sim $6,200 (20% flow cases from each airfoil) provides the best predictive performance. Similarly, for Case V-B, a training dataset size of
$ \sim $6,200 (20% flow cases from each airfoil) provides the best predictive performance. Similarly, for Case V-B, a training dataset size of  $ \sim $5,300 (100 flow cases of each airfoil) provides the best predictive performance.
$ \sim $5,300 (100 flow cases of each airfoil) provides the best predictive performance.
Figure 15. Case V: Variation of error percentage with respect to training dataset size (number of flow cases).
Comparing the results for both subcases in Figure 15 shows that Case V-B provides a better prediction accuracy, which can be explained based on the error percentages of three airfoils, NLF(1)-1015, NLF(2)-0415, and LRN(1)-1007. These three airfoils with the highest percentage of error in Figure 16a correspond to a relatively smaller number of flow cases in the database, as seen from the colors of their respective markers. Because the training set in Case V-A includes a fixed percentage of flow cases for each airfoil, the above three airfoils remain relatively underweight with respect to the other airfoils with a larger number of flow cases. On the other hand, using a fixed number of flow cases for each airfoil provides a more balanced representation of the various airfoils within the training dataset, which results in a better overall predictive performance.
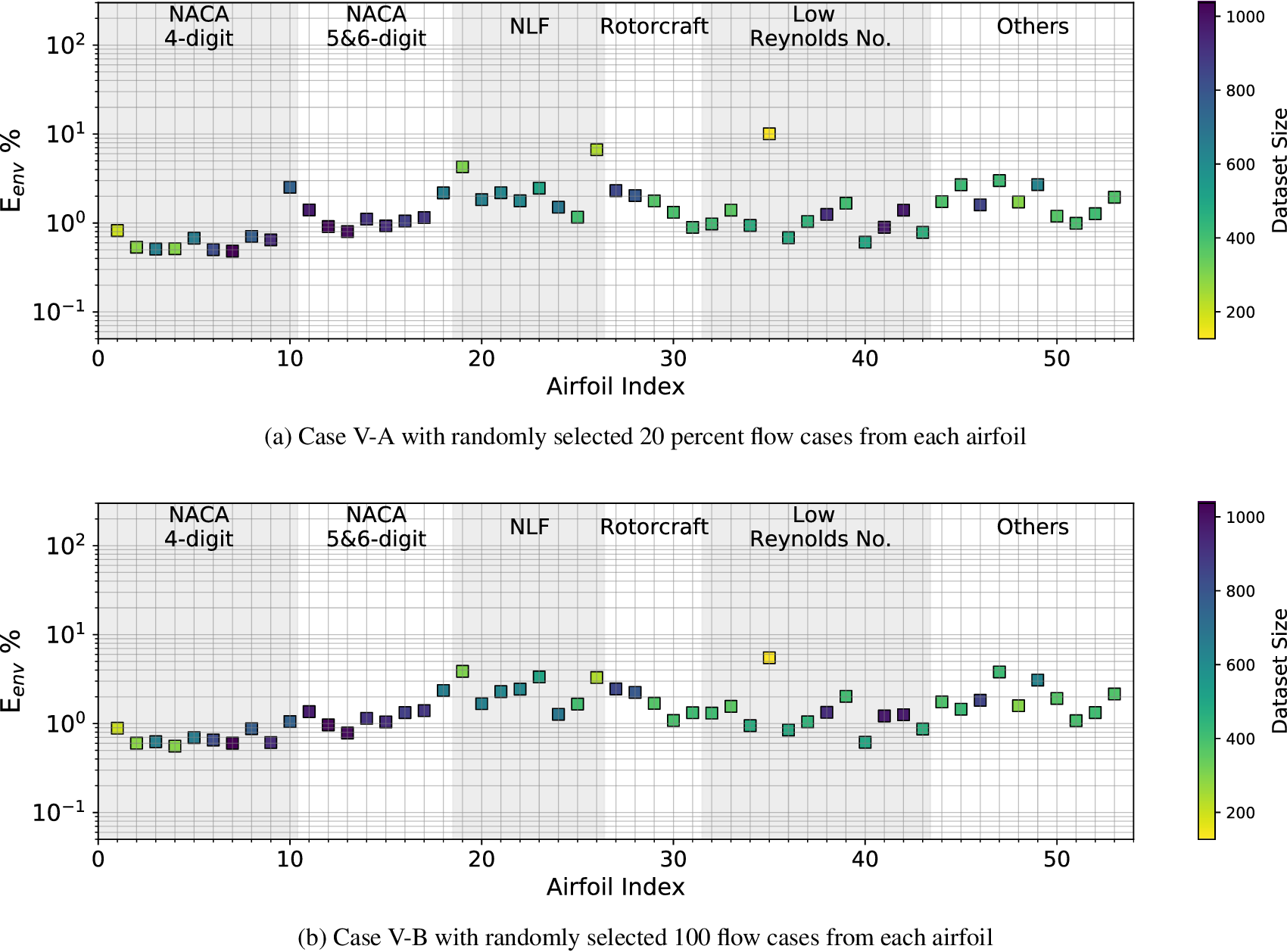
Figure 16. Comparison of mean error ( $ {E}_{\mathrm{env}} $) percentage for N-factor envelopes in Case V-A and V-B. Markers’ color represent the dataset size (number of flow cases) of each airfoil in the database.
$ {E}_{\mathrm{env}} $) percentage for N-factor envelopes in Case V-A and V-B. Markers’ color represent the dataset size (number of flow cases) of each airfoil in the database.
Results for all of the cases discussed in this section are summarized in Table 4. It is interesting to note that the results of Case V-B, which provides a more direct approach for selecting the training dataset, are very comparable in terms of prediction accuracy with the results from Case IV, which uses an indirect approach to select the training dataset and provides the best results among all of the cases discussed herein. Moreover, the training dataset for both of these cases is of almost equal size. Hence, Case V-B provides a direct and convenient approach for selecting a subset from a large database as the training data, while also yielding a good predictive performance over the entire database. Sample plots of the N-factor envelope for arbitrary combinations of airfoil contours and flow conditions are shown in Figure 17. These plots illustrate a qualitative comparison of the N-factor predictions based on the different training cases. One may clearly see that the predictions for certain flows in Cases IV and V-B are accurate even if the corresponding predictions for Cases I-III include significantly larger error.
Table 4. Results for different training dataset cases.
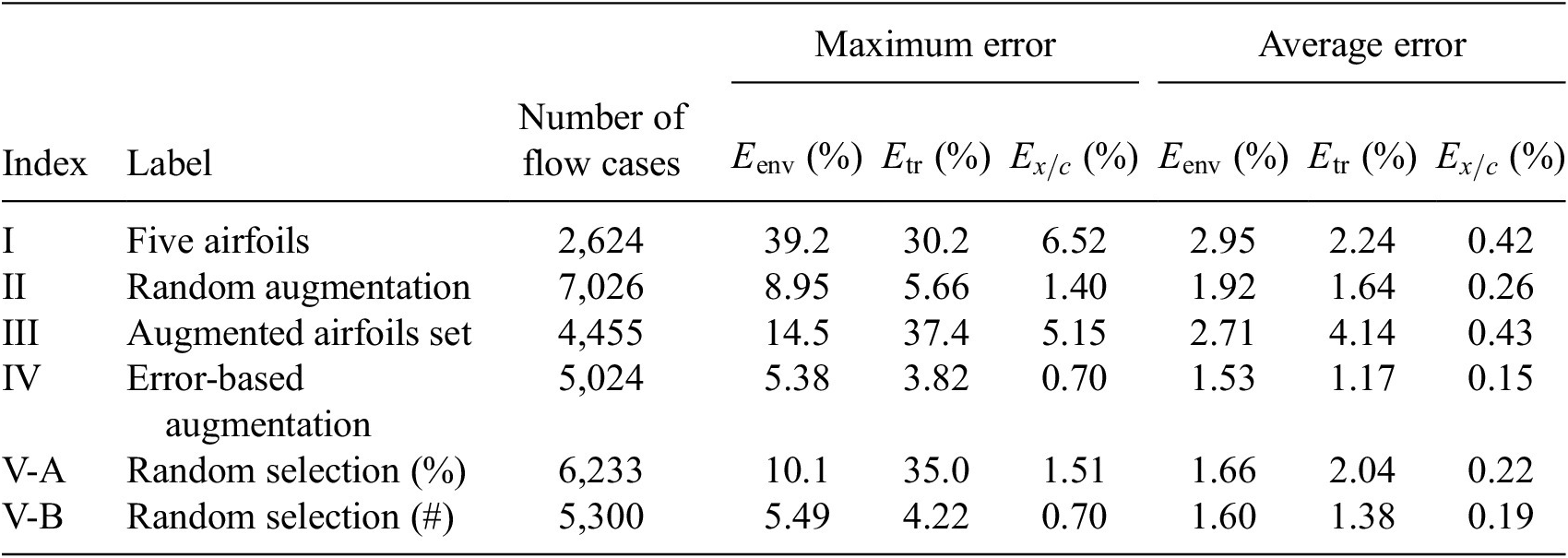
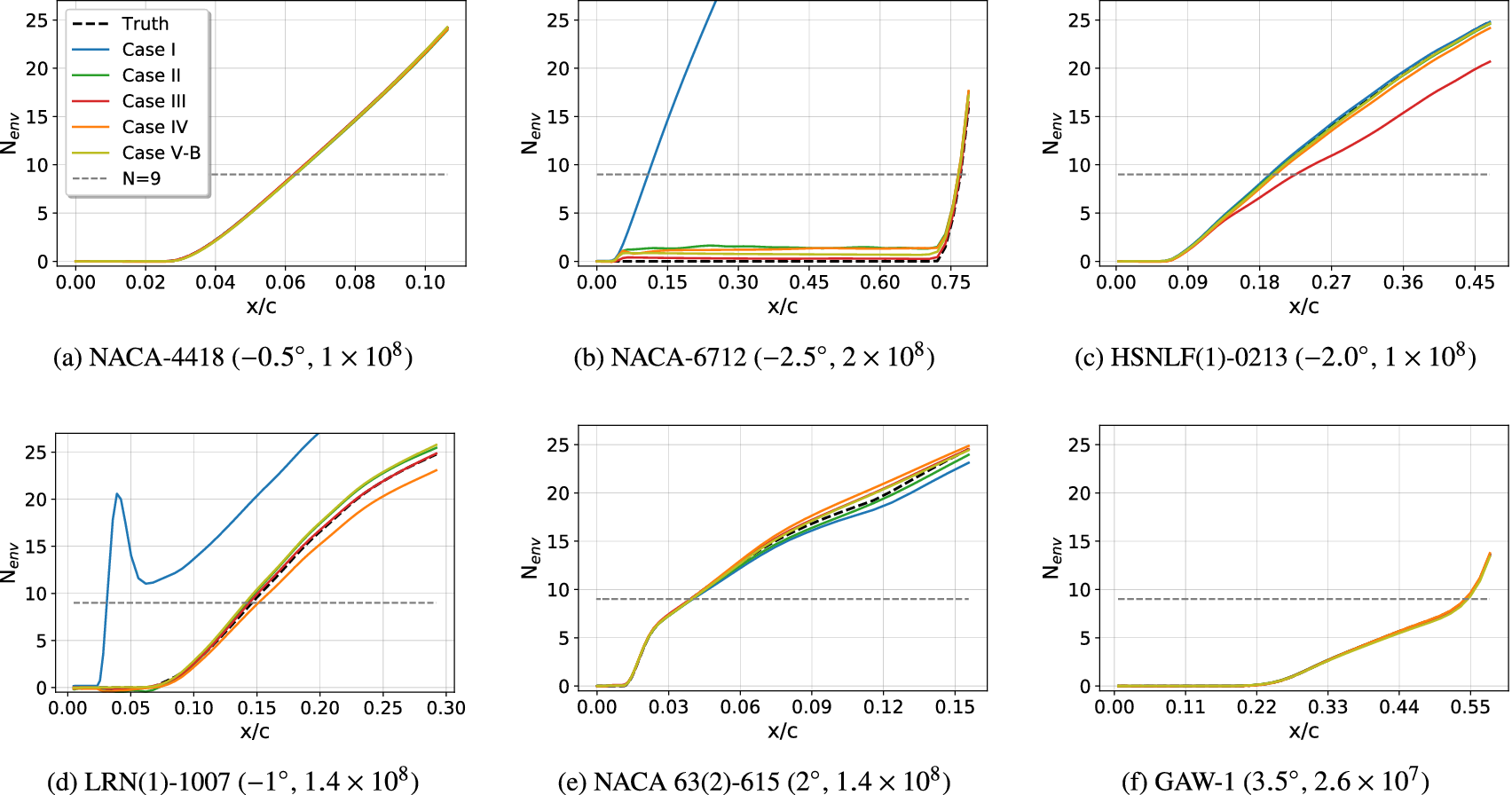
Figure 17. N-factor envelope plots for arbitrarily chosen flow cases to illustrate the comparison of prediction by different training cases. Corresponding airfoil name and flow conditions (AOA, 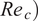 $ {\mathit{\operatorname{Re}}}_c\Big) $ have been mentioned for each plot.
$ {\mathit{\operatorname{Re}}}_c\Big) $ have been mentioned for each plot.
4.3. Working with limited database
The database of airfoil flows generated during the present effort is relatively extensive in comparison to what may be generally available in a majority of practical situations. For this reason, assessments have been made to understand the predictive performance of the RNN model in selected possible scenarios. Such assessments are based on interpolation and extrapolation with respect to the airfoil contours, under the assumption that a relatively smaller training dataset based on just a few NACA four-digit series airfoils is available. Table 5 outlines a summary of these cases and the corresponding results. Cases VI and VII provide an assessment with respect to the interpolation of airfoil contours within a family of selected symmetric and asymmetric airfoils, respectively. The resulting predictions are seen to be reasonably accurate for the testing dataset with average error of 0.12 and 0.04% of the chord length for both symmetric and asymmetric airfoils, respectively. Similarly, Case VIII targets the evaluation of model performance with respect to the extrapolation of the airfoil thickness, and again, the predictions for the testing dataset are found to be reasonably accurate with average error of 0.06% of the chord length for the given airfoil. Hence, it appears that the RNN model is able to predict well for previously unknown airfoil sections within the same family, regardless of whether the test data involves an interpolation within the distribution of the training data or an extrapolation beyond its boundaries. These findings support the selection strategy underlying Case I, which included five airfoils representing multiple groups from the overall database.
Table 5. Assessment cases for different training cases based on NACA four-digit series airfoils.
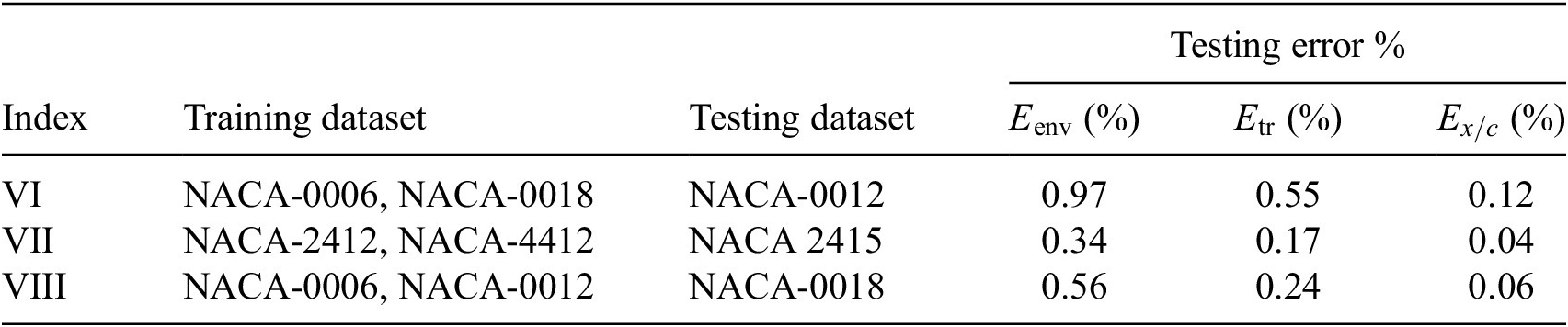
These cases have been studied to understand the model performance when a limited training dataset is available.
Assessment in Case IX involves a training dataset of five NACA four-digit series airfoils, and the predictive performance is evaluated using a testing dataset based on the rest of the airfoils. Results for this case have been shown in Table 6, where it can be observed that the predictive performance in this case is far worse in comparison to Case I, where five airfoils were taken from a different family of airfoils. Hence, a model trained using just a single family of airfoils does not extrapolate well to the other families of airfoils. Results for Case IX have also been shown in Figure 18, wherein the mean error percentages for the remaining families of airfoils are seen to be an order of magnitude higher than the error magnitudes associated with airfoils included in the training dataset. This finding reinforces the method adopted in Case I, namely, that a balanced training dataset should contain representation from different families of airfoils to achieve reasonably accurate predictive performance for the overall database.
Table 6. Results for a training dataset comprised of a single family of airfoils and a testing dataset comprised of the rest of the airfoils in the database.
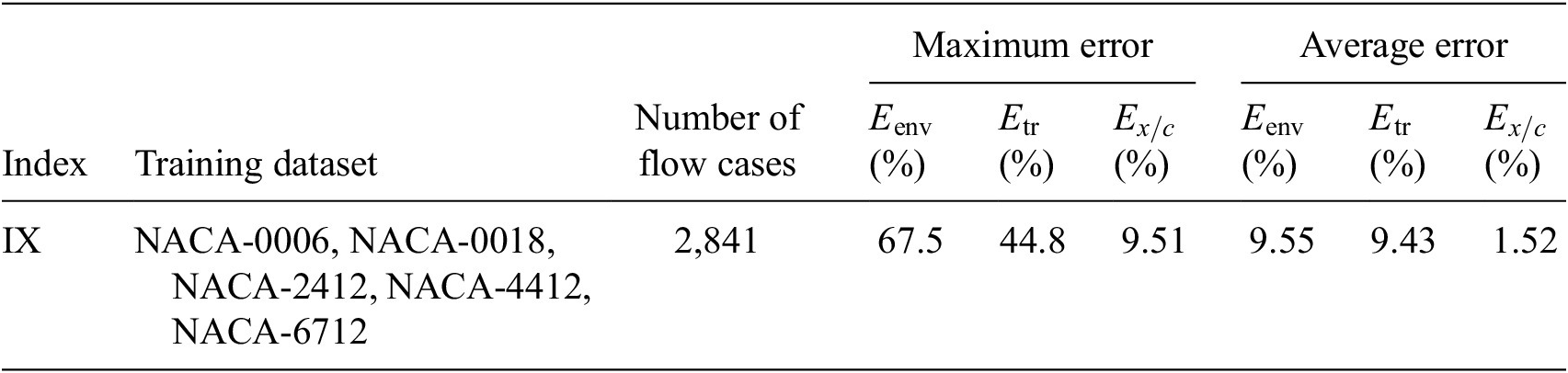
Figure 18. Mean error percentage for each airfoil in the database, corresponding to training dataset of Case IX given in Table 5. Airfoils corresponding to training dataset have been encircled in red color. Markers’ color represent the dataset size (number of flow cases) of each airfoil in the database.
5. Conclusion
A sequence-to-sequence modeling approach based on a recurrent neural network has been proposed to predict the location of laminar-turbulent transition via linear amplification characteristics of hydrodynamic instabilities in boundary-layer flows. This approach provides an end-to-end transition model, which maps the sequence of mean boundary-layer profiles to corresponding growth rates along the N-factor envelope, and then, to the estimated transition location. In this regard, a large database comprised of the linear growth characteristics of over 33,000 boundary-layer flows over 53 airfoils from a disparate range of applications has been used to train and test the proposed model. The results demonstrate that the RNN model is able to predict the transition location at various test flow conditions and for the entire range of airfoil contours with good accuracy (average error of less than 0.70% of the chord length for any given airfoil) despite being trained by a small subsample (about 16%) of the complete database. To the best of our knowledge, the database used herein is one of the largest of its kind, presumably representing a significant cross-section of the airfoil universe. To assess the techniques to facilitate the selection of representative yet computationally efficient training data, several alternate strategies have been investigated to provide insights into working with large amounts of data. The more easily realizable training set based on a small group of five airfoils (one each from five different groups of airfoil contours) forms the baseline for the selection of training data. A limited database of this type is found to result in substantial errors in transition prediction for a number of other airfoils, with average errors in transition location prediction across multiple test conditions for a single airfoil approaching as much as 6.52% of the chord length for the given airfoil. Data augmentation with additional cases from other airfoils that correspond to worst prediction errors from the baseline model is found to provide the best choice for improving the predictive performance of the RNN model, reducing the average error across all flow conditions in predicting transition location to 0.7% of the chord length for any airfoil. An alternate strategy of using a training dataset consisting of an equally weighted representation of each airfoil was also evaluated and was found to provide equally good predictive performance. Further assessments also showed that the RNN-based model is able to extrapolate/interpolate well within a family of similar airfoils and the predictive performance worsened while extrapolating the predictions to airfoil from other families.
Transition estimates based on the RNN model are easily three to four orders of magnitude faster than those based on direct stability computations. However, the main benefit of the deep learning models is an improved robustness of the prediction process, making it easier for nonexperts in laminar-turbulent transition to perform such computations. On the other hand, the deep learning models are restricted in their generalizability and this paper has addressed some of the issues related to the development of models that cover a broad space of flows. We believe the two types of models to be complementary in nature.
A significant advantage of the proposed RNN model over the previously proposed neural network-based transition models is that using the sequential information of the underlying mean flow, the RNN model is able to directly predict the required information of the N-factor envelope and the transition location, without requiring the user to define a range of critical frequencies and predicting the instability growth rates at a number of frequencies in this range. On the other hand, since the RNN model predicts the growth rates of the N-factor envelope in a sequential manner, it cannot be applied in a parallel manner, unlike conventional methods or previously proposed neural networks that can predict the local growth rates at each station in a parallel manner.
The proposed architecture processes the boundary-layer profiles at each station in a physically consistent manner using the convolutional neural network. This attribute enables its generalization to other instability mechanisms involving three-dimensional boundary-layer profiles involving crossflow velocity components or second-mode instabilities in high speed flows involving the profiles of thermodynamic quantities such as density and/or temperature. Future work could involve the application of the proposed architecture to one of the other instability mechanisms. Furthermore, since the RNN model uses input data for the boundary-layer profiles, that depends on the airfoil contour and flow conditions, future explorations could involve airfoil contours along with angle of attack and Reynolds number as global inputs to predict the N-factor envelope. Use of a vector-cloud neural network can also be explored, as it would allow the user to employ boundary layer profiles defined at any arbitrary and variable number of grid points (Zhou et al., Reference Zhou, Han and Xiao2021).
Acknowledgments
The computational resources used for this project were provided by the Advanced Research Computing (ARC) of Virginia Tech, which is gratefully acknowledged.
Funding Statement
This research was supported by the Revolutionary Computational AeroSciences discipline of NASA’s Transformational Tools and Technologies Project.
Competing Interests
The authors declare no competing interests.
Data Availability Statement
The data and code used in this work is currently proprietary and confidential; it will be considered for public release in the future.
Author Contributions
Conceptualization: M.-M.C. and H.X.; Methodology: M.-M.C., H.X., and M.-I.Z.; Data curation: P.P., M.-M.C., and M.-I.Z.; Formal analysis: M.-I.Z.; Writing-original draft: M.-I.Z. and M.-M.C.; Writing-review & editing: all. All authors approved the final submitted draft.
List of Airfoils
A listing of the 53 airfoils included in the database of stability characteristics is given in Table A1. Furthermore, a graphical catalog of all airfoil contours is also included, since that may be of interest to the readers.
Table A1. List of airfoils in the database.
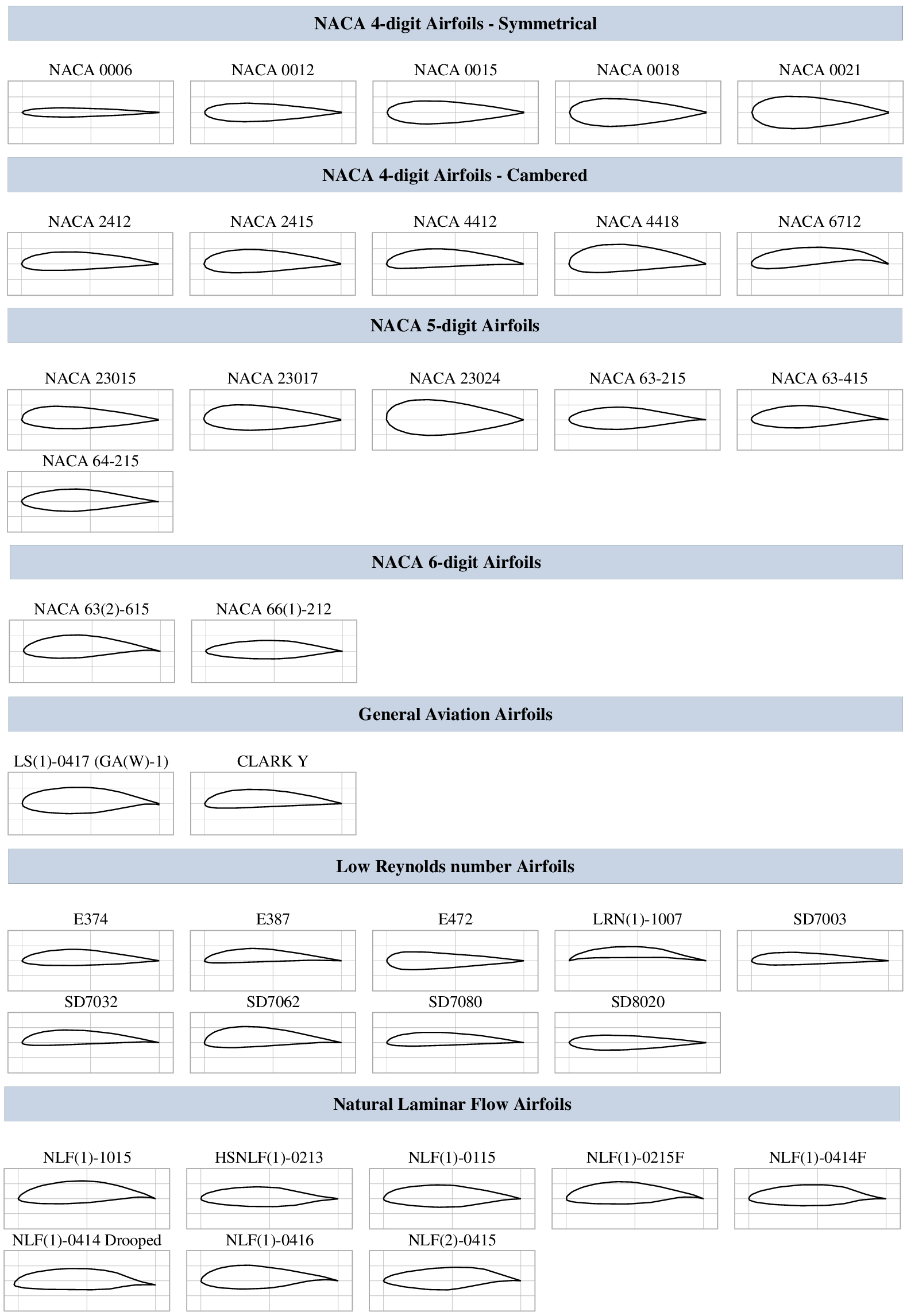

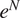
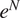
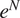















































 Open access
Open access
Comments
No Comments have been published for this article.