



1. Introduction
Efficient aircraft operations require the knowledge of current performance of the aircraft. The performance depends on many aerodynamic and engines features which evolve throughout the life cycle of the aircraft. For instance, the degradation of the engines may modify the aircraft specific range up to 1.3% per year if no engine replacement is carried out (Airbus, 2002). Further aircraft physical features may change overtime due to accumulations of impurities on the surface (leading to an increase of the drag), rough or deformed surfaces, damaged seals, and so on (see for instance Airbus, 2001). In particular, performance may differ from an aircraft to another one of the same type due to different cycles, flight hours, or maintenance.
Given this deterioration, monitoring systems have been developed by the manufacturers (Krajček et al., Reference Krajček, Nikolić and Domitrović2015). Those systems measure the difference between expected behavior obtained through heavy numerical simulations and wind tunnel tests, and data recorded during very specific in-flight conditions. Given this difference, most manufacturers propose to modify a performance index to adjust the theoretical fuel consumption to the current one. This leads to more accurate fuel predictions when planning the flight operations. However, according to Krajček et al. (Reference Krajček, Nikolić and Domitrović2015), such monitoring systems have limitations, for example, the incapacity of dissociating the influence of aerodynamic or engines features on the evolution of performance, since it is only described by the performance index.
In view of this, a flexible methodology designed to build models for features which reflect the current performance of an aircraft would be relevant to improve flight planning operations in the end. Such a methodology is proposed in the present paper.
The underlying idea of our approach is that the real performance of an aircraft should be reflected by its data recorded in recent flights. Here, we consider data from the Quick Access Recorder (QAR) which contain features of different types such as the altitude, the true airspeed or the engine power, sampled every second. To exploit these data, we propose to model statistically features of interest and to fit these models on the recorded data with off-the-shelf machine learning algorithms. The resulting estimators are then expected to take into account the actual performance of the aircraft, thus leading to a far more precise description of its performance.
To illustrate our method, we propose to model the drag and lift coefficients. It is common in the aeronautic literature to model the drag and lift forces through these coefficients, which quantify drag and lift independently from the wing size, airspeed, and air density (McCormick, Reference McCormick1995, chapter 2). In particular, the coefficients are used to somewhat capture very complex phenomena such as friction and permit to deduce the lift-to-drag ratio (Loftin, Reference Loftin1985, chapter 7), which plays a key role in assessing the performance of the aircraft.
The choice of these two aerodynamic coefficients is also motivated by the fact that neither of those coefficients is recorded by the aircraft (as a matter of fact, the drag and lift forces are also not recorded), highlighting the flexibility of this statistical approach. Indeed, this issue is bypassed by leveraging physical relationships to obtain approximated but explicit and deterministic formulas for the drag and lift coefficients. The statistical models are then fitted to approximated train data and their learning errors are computed on test sets. It is noteworthy that the models have to depend on features set by the user since they are aimed at being exploited by aeronautic softwares, such as those embedded in the Flight Management System of the aircraft. This explains in particular why physical models which may depend on other features, may not be used in such a setting.
This approach induces an additional error which we refer to as a physical approximation error, coming from the approximated data. To assess the prediction accuracy of the fitted models, this approximation error has to be taken into consideration. In a general setting within which we introduce our approach, we propose bounds for the mean absolute error and relative error between the true value of the output and the predicted value from the model. These bounds depend explicitly on the physical approximation and the learning errors and are then applied in the present aeronautic setting. Note that in a slightly different setting, the problem can be interpreted as with errors on the response variable (Buonaccorsi, Reference Buonaccorsi1996), which is a particular case of the general framework of errors-in-variables models (Schennach, Reference Schennach2016; Fuller, Reference Fuller2009). For such problems, a statistical model is assumed on the distribution of the observed surrogate response variable given the unobserved response variable, for instance, the additive measurement error model (Carroll and Ruppert, Reference Carroll and Ruppert1988).
A similar approach to model unobserved aerodynamic variables has been proposed in Sun et al. (Reference Sun, Hoekstra and Ellerbroek2018). In this paper, the authors aim at estimating the drag polar (i.e., a specific quadratic model for the drag coefficient depending on the lift one) by using a stochastic total energy model. Their approach is based on a Markov Chain Monte Carlo (MCMC) sampler to estimate posterior probability distributions of their parameters of interest. Similarly to our methodology, they exploit physical formulas to obtain approximate values for unobserved variables. Nevertheless, neither the associated error nor its impact on the prediction accuracy are taken into account in their analysis.
At this stage, let us stress that our aim is to propose a flexible methodology which is sufficiently generic to be used in any data-intensive engineering discipline. We show that this methodology can be straightforwardly applied to an aeronautic setting and that it leads to accurate predictions for two aerodynamic features, verifying in particular expected tendencies. This is illustrated with extensive numerical tests on recorded flight data. However, let us note that comparing the performance resulting from our estimated models to those provided by the manufacturers is unfortunately out of reach: in general, the manufacturers performance models are not publicly available (for commercial reasons) and therefore cannot be used for academic research.
The paper is organized as follows: in Section 2, we first propose an abstract formulation of the problem of modeling a variable for which only approximated data are available. Lemmas 1 and 2 provide the above mentioned bounds for the prediction error. Section 3 aims at specifying the aeronautic setting of interest. Let us mention that we restrict our study to the cruise phase for which physical approximation errors values are available, however, our method is actually not limited to this particular phase. Numerical results based on real flight data are presented and discussed in Section 4, and the paper closes on avenues for future work in Section 5.
2. Statistical Modeling
In this section, we consider a general setting where one aims at explaining a real-valued random variable
 $ {Y}^{*} \in \mathcal{Y}\subseteq \mathrm{\mathbb{R}} $
through a function
$ {Y}^{*} \in \mathcal{Y}\subseteq \mathrm{\mathbb{R}} $
through a function
 $ {f}^{*} $
depending on the vector
$ {f}^{*} $
depending on the vector
 $ X\in \mathcal{X}\subseteq {\mathrm{\mathbb{R}}}^{d_{\mathcal{X}}} $
. We formulate this as the following regression problem:
$ X\in \mathcal{X}\subseteq {\mathrm{\mathbb{R}}}^{d_{\mathcal{X}}} $
. We formulate this as the following regression problem:
 $$ {Y}^{*}={f}^{*}(X)+\varepsilon, $$
$$ {Y}^{*}={f}^{*}(X)+\varepsilon, $$
where
 $ \varepsilon $
denotes a noise variable standing for unexplained determinants of
$ \varepsilon $
denotes a noise variable standing for unexplained determinants of
 $ {Y}^{*} $
. Nevertheless, in our setting,
$ {Y}^{*} $
. Nevertheless, in our setting,
 $ {Y}^{*} $
is a latent variable: no direct observation for
$ {Y}^{*} $
is a latent variable: no direct observation for
 $ {Y}^{*} $
is available, turning the direct estimation of
$ {Y}^{*} $
is available, turning the direct estimation of
 $ {f}^{*} $
impossible. Our idea here is to propose an estimator for a surrogate of
$ {f}^{*} $
impossible. Our idea here is to propose an estimator for a surrogate of
 $ {Y}^{*} $
for which data can be obtained. To do so, suppose that there exists a relationship between
$ {Y}^{*} $
for which data can be obtained. To do so, suppose that there exists a relationship between
 $ {Y}^{*} $
and observed variables contained in a vector
$ {Y}^{*} $
and observed variables contained in a vector
 $ Z\in \mathcal{Z}\subseteq {\mathrm{\mathbb{R}}}^{d_{\mathcal{Z}}} $
, which can be observed together with
$ Z\in \mathcal{Z}\subseteq {\mathrm{\mathbb{R}}}^{d_{\mathcal{Z}}} $
, which can be observed together with
 $ X $
. More precisely, we suppose that there exists a known and explicit function
$ X $
. More precisely, we suppose that there exists a known and explicit function
 $ \varphi :\mathcal{Z}\to \mathrm{\mathbb{R}} $
such that
$ \varphi :\mathcal{Z}\to \mathrm{\mathbb{R}} $
such that
 $$ {\unicode{x1D53C}}_{Y^{*},Z}\left[|{Y}^{*}-\varphi (Z)|\right]\leqslant r, $$
$$ {\unicode{x1D53C}}_{Y^{*},Z}\left[|{Y}^{*}-\varphi (Z)|\right]\leqslant r, $$
where
 $ r>0 $
is known, and we let
$ r>0 $
is known, and we let
 $ {\unicode{x1D53C}}_A $
denote the expectation with respect to a random variable
$ {\unicode{x1D53C}}_A $
denote the expectation with respect to a random variable
 $ A $
. Thus, the variable
$ A $
. Thus, the variable
 $ Y:= \varphi (Z) $
can be considered as an approximation of
$ Y:= \varphi (Z) $
can be considered as an approximation of
 $ {Y}^{*} $
, coming from a physical formula for instance. The error
$ {Y}^{*} $
, coming from a physical formula for instance. The error
 $ \eta :{\mathcal{Y}}^{*}\times \mathcal{Z}\to \mathrm{\mathbb{R}} $
of this approximation is defined as follows
$ \eta :{\mathcal{Y}}^{*}\times \mathcal{Z}\to \mathrm{\mathbb{R}} $
of this approximation is defined as follows
 $$ \forall \left({y}^{*},z\right)\in \mathcal{Y}\times \mathcal{Z}, \eta \left({y}^{*},z\right):= {y}^{*}-\varphi (z), $$
$$ \forall \left({y}^{*},z\right)\in \mathcal{Y}\times \mathcal{Z}, \eta \left({y}^{*},z\right):= {y}^{*}-\varphi (z), $$
and will be named the physical approximation error. We consider then the following regression problem
 $$ Y=f(X)+\epsilon . $$
$$ Y=f(X)+\epsilon . $$
Note that
 $ \varphi (Z) $
is actually a model for the latent variable
$ \varphi (Z) $
is actually a model for the latent variable
 $ {Y}^{*} $
, but our aim is to model this variable via the input
$ {Y}^{*} $
, but our aim is to model this variable via the input
 $ X $
and not
$ X $
and not
 $ Z $
, motivating the problem (2). For instance, such a requirement arises in industrial contexts where inputs of some specialist softwares may differ from the variables involved in physical equations. If we assume that we have access to
$ Z $
, motivating the problem (2). For instance, such a requirement arises in industrial contexts where inputs of some specialist softwares may differ from the variables involved in physical equations. If we assume that we have access to
 $ n $
random observations
$ n $
random observations
 $ \left({x}_i,{z}_i\right) $
(realizations from
$ \left({x}_i,{z}_i\right) $
(realizations from
 $ X $
and
$ X $
and
 $ Z $
), we can derive observations for
$ Z $
), we can derive observations for
 $ Y $
as follows
$ Y $
as follows
 $$ \forall i=1,\dots, n, {y}_i:= \varphi \left({z}_i\right), $$
$$ \forall i=1,\dots, n, {y}_i:= \varphi \left({z}_i\right), $$
leading to a training set
 $ \mathcal{D}:= {\left({x}_i,{y}_i\right)}_{i=1}^n $
. Contrary to the original problem (1) for which no training set is available, an estimator
$ \mathcal{D}:= {\left({x}_i,{y}_i\right)}_{i=1}^n $
. Contrary to the original problem (1) for which no training set is available, an estimator
 $ \hat{f} $
for the model
$ \hat{f} $
for the model
 $ f $
can be derived by solving the following minimization problem:
$ f $
can be derived by solving the following minimization problem:
 $$ \hat{f}\in \arg {\min}_{g\in \mathcal{H}}\sum \limits_{i=1}^n\mathrm{\ell}\left({y}_i,g\left({x}_i\right)\right), $$
$$ \hat{f}\in \arg {\min}_{g\in \mathcal{H}}\sum \limits_{i=1}^n\mathrm{\ell}\left({y}_i,g\left({x}_i\right)\right), $$
where the hypothesis class
 $ \mathcal{H} $
and the loss function
$ \mathcal{H} $
and the loss function
 $ \mathrm{\ell}:{\mathrm{\mathbb{R}}}^2\to \mathrm{\mathbb{R}} $
are generic at this stage. For instance, one may consider the class of polynomials and the squared error loss.
$ \mathrm{\ell}:{\mathrm{\mathbb{R}}}^2\to \mathrm{\mathbb{R}} $
are generic at this stage. For instance, one may consider the class of polynomials and the squared error loss.
Let us now upper bound the mean of the absolute value of the total error, defined by
 $ {Y}^{*}-\hat{f}(X) $
. In other words, the total error is the error between the unobserved variable
$ {Y}^{*}-\hat{f}(X) $
. In other words, the total error is the error between the unobserved variable
 $ {Y}^{*} $
and the predicted value
$ {Y}^{*} $
and the predicted value
 $ \hat{f}(X) $
given the training set
$ \hat{f}(X) $
given the training set
 $ \mathcal{D} $
. Note that the total error can be decomposed as follows:
$ \mathcal{D} $
. Note that the total error can be decomposed as follows:
 $$ {Y}^{*}-\hat{f}(X)=\eta \left({Y}^{*},Z\right)+\left(Y-\hat{f}(X)\right). $$
$$ {Y}^{*}-\hat{f}(X)=\eta \left({Y}^{*},Z\right)+\left(Y-\hat{f}(X)\right). $$
This is actually given by the sum of the physical approximation error
 $ \eta \left({Y}^{*},Z\right) $
and another error term
$ \eta \left({Y}^{*},Z\right) $
and another error term
 $ Y-\hat{f}(X) $
which will be named the learning error. Indeed it comes from the statistical approximation of
$ Y-\hat{f}(X) $
which will be named the learning error. Indeed it comes from the statistical approximation of
 $ Y $
by
$ Y $
by
 $ \hat{f}(X) $
and depends specifically on the training set
$ \hat{f}(X) $
and depends specifically on the training set
 $ \mathcal{D} $
, on the chosen model
$ \mathcal{D} $
, on the chosen model
 $ f $
and the algorithm to compute the estimator.
$ f $
and the algorithm to compute the estimator.
Lemma 1. We have
 $$ {\unicode{x1D53C}}_{X,{Y}^{*}}\left[|{Y}^{\star }-\hat{f}(X)|\right]\leqslant r+{\unicode{x1D53C}}_{X,Z}\left[|Y-\hat{f}(X)|\right]. $$
$$ {\unicode{x1D53C}}_{X,{Y}^{*}}\left[|{Y}^{\star }-\hat{f}(X)|\right]\leqslant r+{\unicode{x1D53C}}_{X,Z}\left[|Y-\hat{f}(X)|\right]. $$
Proof. By conditioning on
 $ Z $
, we have
$ Z $
, we have
 $$ {\displaystyle \begin{array}{l}{\unicode{x1D53C}}_{X,{Y}^{*}}\left[|{Y}^{*}-\hat{f}(X)|\right]={\unicode{x1D53C}}_Z\left[{\unicode{x1D53C}}_{X,{Y}^{*}\mid Z}\left[|{Y}^{*}-\hat{f}(X)| \left|Z\right.\right]\right]\\ {}\operatorname{}\leqslant {\unicode{x1D53C}}_Z\left[{\unicode{x1D53C}}_{X,{Y}^{*}\mid Z}\left[|\eta \left({Y}^{*},Z\right)| \left|Z\right.\right]\right]+{\unicode{x1D53C}}_Z\left[{\unicode{x1D53C}}_{X,{Y}^{*}\mid Z}\left[|Y-\hat{f}(X)| \left|Z\right.\right]\right]\\ {}\operatorname{}={\unicode{x1D53C}}_{Y^{*},Z}\left[|\eta \left({Y}^{*},Z\right)|\right]+{\unicode{x1D53C}}_{X,Z}\left[|Y-\hat{f}(X)|\right]\\ {}\operatorname{}\leqslant r+{\unicode{x1D53C}}_{X,Z}\left[|Y-\hat{f}(X)|\right];\end{array}} $$
$$ {\displaystyle \begin{array}{l}{\unicode{x1D53C}}_{X,{Y}^{*}}\left[|{Y}^{*}-\hat{f}(X)|\right]={\unicode{x1D53C}}_Z\left[{\unicode{x1D53C}}_{X,{Y}^{*}\mid Z}\left[|{Y}^{*}-\hat{f}(X)| \left|Z\right.\right]\right]\\ {}\operatorname{}\leqslant {\unicode{x1D53C}}_Z\left[{\unicode{x1D53C}}_{X,{Y}^{*}\mid Z}\left[|\eta \left({Y}^{*},Z\right)| \left|Z\right.\right]\right]+{\unicode{x1D53C}}_Z\left[{\unicode{x1D53C}}_{X,{Y}^{*}\mid Z}\left[|Y-\hat{f}(X)| \left|Z\right.\right]\right]\\ {}\operatorname{}={\unicode{x1D53C}}_{Y^{*},Z}\left[|\eta \left({Y}^{*},Z\right)|\right]+{\unicode{x1D53C}}_{X,Z}\left[|Y-\hat{f}(X)|\right]\\ {}\operatorname{}\leqslant r+{\unicode{x1D53C}}_{X,Z}\left[|Y-\hat{f}(X)|\right];\end{array}} $$
note that we have used the triangle inequality applied to (3) to obtain (5).
In the case where the order of magnitude of the learning error is smaller than the one of
 $ r, $
Lemma 1 shows in particular that trying to compute a more precise estimator will have little consequence on the above bound of the total error.
$ r, $
Lemma 1 shows in particular that trying to compute a more precise estimator will have little consequence on the above bound of the total error.
We end this section by comparing the total error with the mean value of
 $ {Y}^{*} $
in the following lemma. More precisely, we upper bound the ratio between the means of the absolute value of the total error and of
$ {Y}^{*} $
in the following lemma. More precisely, we upper bound the ratio between the means of the absolute value of the total error and of
 $ {Y}^{*} $
by an explicit and calculable quantity. This ratio, which can be reported as a percentage by multiplying it by 100, provides a relative measure of accuracy for the estimator
$ {Y}^{*} $
by an explicit and calculable quantity. This ratio, which can be reported as a percentage by multiplying it by 100, provides a relative measure of accuracy for the estimator
 $ \hat{f} $
. We also mention that it agrees with the Weighted Absolute Percentage Error (WAPE) in the classical case where
$ \hat{f} $
. We also mention that it agrees with the Weighted Absolute Percentage Error (WAPE) in the classical case where
 $ \hat{f} $
is an estimator for
$ \hat{f} $
is an estimator for
 $ {Y}^{*} $
.
$ {Y}^{*} $
.
Lemma 2.
Suppose that
 $ {\unicode{x1D53C}}_Z\left[\varphi (Z)\right]>r $
. Then
$ {\unicode{x1D53C}}_Z\left[\varphi (Z)\right]>r $
. Then
 $ \unicode{x1D53C}\left[{Y}^{*}\right] $
is positive and we have
$ \unicode{x1D53C}\left[{Y}^{*}\right] $
is positive and we have
 $$ \frac{{\unicode{x1D53C}}_{X,{Y}^{*}}\left[|{Y}^{*}-\hat{f}(X)|\right]}{\unicode{x1D53C}\left[{Y}^{*}\right]}\leqslant \frac{r+{\unicode{x1D53C}}_{X,Z}\left[|Y-\hat{f}(X)|\right]}{{\unicode{x1D53C}}_Z\left[\varphi (Z)\right]-r}. $$
$$ \frac{{\unicode{x1D53C}}_{X,{Y}^{*}}\left[|{Y}^{*}-\hat{f}(X)|\right]}{\unicode{x1D53C}\left[{Y}^{*}\right]}\leqslant \frac{r+{\unicode{x1D53C}}_{X,Z}\left[|Y-\hat{f}(X)|\right]}{{\unicode{x1D53C}}_Z\left[\varphi (Z)\right]-r}. $$
Proof. We have
 $$ {\unicode{x1D53C}}_{Y^{*},Z}\left[\varphi (Z)-{Y}^{*}\right]\leqslant \left|{\unicode{x1D53C}}_{Y^{*},Z}\left[{Y}^{*}-\varphi (Z)\right]\right|\leqslant {\unicode{x1D53C}}_{Y^{*},Z}\left[|{Y}^{*}-\varphi (Z)|\right], $$
$$ {\unicode{x1D53C}}_{Y^{*},Z}\left[\varphi (Z)-{Y}^{*}\right]\leqslant \left|{\unicode{x1D53C}}_{Y^{*},Z}\left[{Y}^{*}-\varphi (Z)\right]\right|\leqslant {\unicode{x1D53C}}_{Y^{*},Z}\left[|{Y}^{*}-\varphi (Z)|\right], $$
where we have applied Jensen’s inequality to the absolute value function to obtain the second inequality. Moreover the linearity of the expected value and the assumption
 $$ {\unicode{x1D53C}}_{Y^{*},Z}\left[|{Y}^{*}-\varphi (Z)|\right]\leqslant r $$
$$ {\unicode{x1D53C}}_{Y^{*},Z}\left[|{Y}^{*}-\varphi (Z)|\right]\leqslant r $$
lead to
 $$ {\unicode{x1D53C}}_Z\left[\varphi (Z)\right]-r\leqslant \unicode{x1D53C}\left[{Y}^{*}\right]. $$
$$ {\unicode{x1D53C}}_Z\left[\varphi (Z)\right]-r\leqslant \unicode{x1D53C}\left[{Y}^{*}\right]. $$
Since
 $ {\unicode{x1D53C}}_Z\left[\varphi (Z)\right] $
is supposed to be larger than
$ {\unicode{x1D53C}}_Z\left[\varphi (Z)\right] $
is supposed to be larger than
 $ r $
, we deduce that
$ r $
, we deduce that
 $ \unicode{x1D53C}\left[{Y}^{*}\right]>0 $
. Then we can take the inverse of inequality (7) and combine the result with inequality (4) to obtain (6).□
$ \unicode{x1D53C}\left[{Y}^{*}\right]>0 $
. Then we can take the inverse of inequality (7) and combine the result with inequality (4) to obtain (6).□
In the following sections, we apply this abstract approach to model aerodynamic variables together with total error bounds. However it is noteworthy that this data-centric approach is sufficiently generic to be exploited in other disciplines.
3. Application to Aircraft Performance
We now move to modeling, the drag coefficient
 $ {C}_D^{*} $
and the lift coefficient
$ {C}_D^{*} $
and the lift coefficient
 $ {C}_L^{*} $
for a given narrow-body aircraft type for cruise conditions by exploiting recorded flight dataFootnote
1. The predicted values of these coefficients are then expected to reflect real flights conditions. For instance, the coefficients
$ {C}_L^{*} $
for a given narrow-body aircraft type for cruise conditions by exploiting recorded flight dataFootnote
1. The predicted values of these coefficients are then expected to reflect real flights conditions. For instance, the coefficients
 $ {C}_D^{*} $
and
$ {C}_D^{*} $
and
 $ {C}_L^{*} $
are used to establish the drag polar, which contains the aerodynamics of the aircraft (Anderson, Reference Anderson1999, section 2.9). As it is classically assumed in the aeronautics literature (see for instance Sun et al., Reference Sun, Hoekstra and Ellerbroek2018), our models for these coefficients will depend on the angle of attack
$ {C}_L^{*} $
are used to establish the drag polar, which contains the aerodynamics of the aircraft (Anderson, Reference Anderson1999, section 2.9). As it is classically assumed in the aeronautics literature (see for instance Sun et al., Reference Sun, Hoekstra and Ellerbroek2018), our models for these coefficients will depend on the angle of attack
 $ \alpha $
and on the Mach number
$ \alpha $
and on the Mach number
 $ M $
.
$ M $
.
Nevertheless, the coefficients
 $ {C}_D^{*} $
and
$ {C}_D^{*} $
and
 $ {C}_L^{*} $
are neither observed nor measured by the sensors of the aircraft during the flight. We therefore leverage the approach developed in Section 2. Following this approach, the main task is to determine approximated yet accurate formulas for the coefficients together with bounds for the physical approximation errors. With these approximations, we will be able to build data sets for approximated
$ {C}_L^{*} $
are neither observed nor measured by the sensors of the aircraft during the flight. We therefore leverage the approach developed in Section 2. Following this approach, the main task is to determine approximated yet accurate formulas for the coefficients together with bounds for the physical approximation errors. With these approximations, we will be able to build data sets for approximated
 $ {C}_D^{*} $
and
$ {C}_D^{*} $
and
 $ {C}_L^{*} $
which are expected to reflect on the actual aerodynamics of the aircraft. Models for
$ {C}_L^{*} $
which are expected to reflect on the actual aerodynamics of the aircraft. Models for
 $ {C}_D^{*} $
and
$ {C}_D^{*} $
and
 $ {C}_L^{*} $
(depending on the angle of attack and Mach number) will then be trained on these datasets and their total errors will be bounded by using Lemma 1.
$ {C}_L^{*} $
(depending on the angle of attack and Mach number) will then be trained on these datasets and their total errors will be bounded by using Lemma 1.
Prior to this, we emphasize that the method proposed in this paper is not limited to the present setting. It can be extended to other variables, aircraft types or phases, subject to available physical formulas and data.
For the sake of readability, Table 1 provides the names, the symbols and the SI units of the main physical variables used in the rest of this paper. In addition, the correspondence between the abstract variables and maps defined in Section 2 and the aeronautic ones is presented in Table 2.
Table 1. Names, symbols and units of variables.
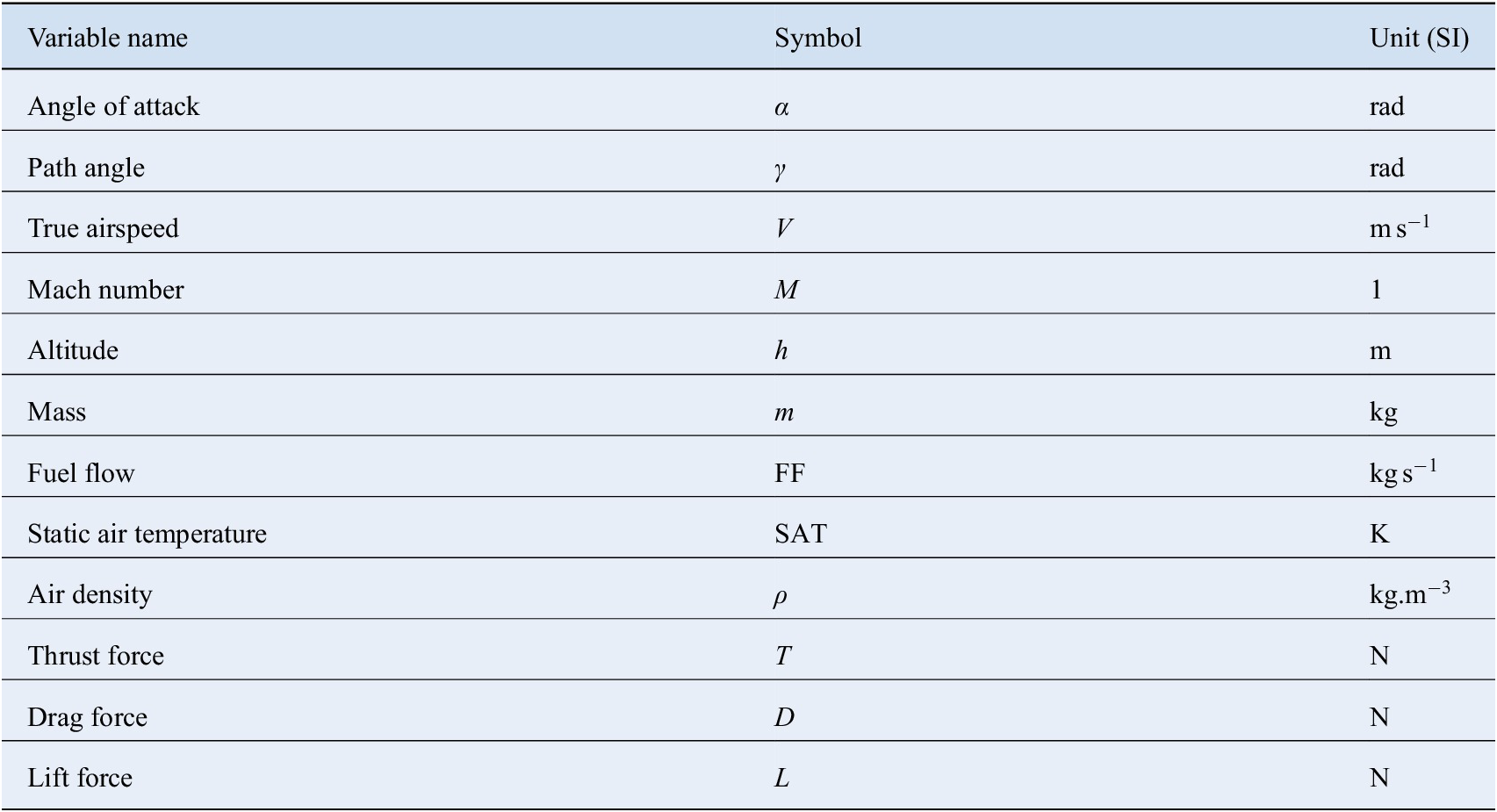
Table 2. Correspondence between abstract variables defined in Section 2 and the physical variables.

Let us stress that the approximations we exploit here are actually derived from flight dynamics equations, whose accuracy depends on still existing physical models. In particular, we will use substantially the following approximated formula for the specific fuel consumption, noted here
 $ {C}_{\mathrm{SR}}^{*} $
, from Roux (Reference Roux2005, p. 41):
$ {C}_{\mathrm{SR}}^{*} $
, from Roux (Reference Roux2005, p. 41):
 $$ {C}_{\mathrm{SR}}:= \left(\left({a}_1(h)\lambda +{a}_2(h)\right)M+\left({b}_1(h)\lambda +{b}_2(h)\right)\right)\sqrt{\frac{\mathrm{SAT}}{{\mathrm{SAT}}_0}}+\left(7.4\mathrm{e}-13\left({\varepsilon}_c-30\right)h+c\right)\left({\varepsilon}_c-30\right) , $$
$$ {C}_{\mathrm{SR}}:= \left(\left({a}_1(h)\lambda +{a}_2(h)\right)M+\left({b}_1(h)\lambda +{b}_2(h)\right)\right)\sqrt{\frac{\mathrm{SAT}}{{\mathrm{SAT}}_0}}+\left(7.4\mathrm{e}-13\left({\varepsilon}_c-30\right)h+c\right)\left({\varepsilon}_c-30\right) , $$
where
•
 $ {\mathrm{SAT}}_0 $
is the temperature at sea level. Following the International Standard Atmosphere, it is set to 288.15 K;
$ {\mathrm{SAT}}_0 $
is the temperature at sea level. Following the International Standard Atmosphere, it is set to 288.15 K;
•
 $ \lambda $
is the bypass ratio which depends on the turbofan engines; here this value is fixed because we consider a single airliner type;
$ \lambda $
is the bypass ratio which depends on the turbofan engines; here this value is fixed because we consider a single airliner type;
•
 $ {\varepsilon}_c $
is the engine pressure ratio, which is also fixed here; and
$ {\varepsilon}_c $
is the engine pressure ratio, which is also fixed here; and
•
 $ {a}_1,{a}_2,{b}_1,{b}_2 $
are linear piecewise functions (depending on the altitude) and
$ {a}_1,{a}_2,{b}_1,{b}_2 $
are linear piecewise functions (depending on the altitude) and
 $ c $
a constant which are given in Roux (Reference Roux2005, table 2.8).
$ c $
a constant which are given in Roux (Reference Roux2005, table 2.8).
As pointed out by Roux (Reference Roux2002), this model improves the classical one of Torenbeek (Reference Torenbeek1982) and its mean relative error and its standard deviation for cruise conditions are given in Roux (Reference Roux2002, p. 66): they are equal respectively to 3.68% and 4.48%. Thus the coefficient
 $ {C}_{\mathrm{SR}}^{*} $
satisfies the following equation
$ {C}_{\mathrm{SR}}^{*} $
satisfies the following equation
 $$ {C}_{\mathrm{SR}}^{*}={C}_{\mathrm{SR}}\left(\mathrm{SAT},h,M\right)+\eta \left({C}_{\mathrm{SR}}^{*},\mathrm{SAT},h,M\right) $$
$$ {C}_{\mathrm{SR}}^{*}={C}_{\mathrm{SR}}\left(\mathrm{SAT},h,M\right)+\eta \left({C}_{\mathrm{SR}}^{*},\mathrm{SAT},h,M\right) $$
where
 $$ {\unicode{x1D53C}}_{C_{\mathrm{SR}}^{*},\mathrm{SAT},h,M}\left[\frac{\mid \eta \left({C}_{\mathrm{SR}}^{*},\mathrm{SAT},h,M\right)\mid }{C_{\mathrm{SR}}^{*}}\right]=3.68\times {10}^{-2} , $$
$$ {\unicode{x1D53C}}_{C_{\mathrm{SR}}^{*},\mathrm{SAT},h,M}\left[\frac{\mid \eta \left({C}_{\mathrm{SR}}^{*},\mathrm{SAT},h,M\right)\mid }{C_{\mathrm{SR}}^{*}}\right]=3.68\times {10}^{-2} , $$
over the cruise domain.
We establish now physical approximations for
 $ {C}_D^{*} $
and
$ {C}_D^{*} $
and
 $ {C}_L^{*} $
in the case of a flight in a vertical plane and under the approximation that the Earth is locally flat. By applying Newton’s second law to a body (modeling the aircraft) of mass
$ {C}_L^{*} $
in the case of a flight in a vertical plane and under the approximation that the Earth is locally flat. By applying Newton’s second law to a body (modeling the aircraft) of mass
 $ m $
moving in an air mass with no wind variations and by projecting the resulting equation onto the body frame, one obtains the following differential equations:
$ m $
moving in an air mass with no wind variations and by projecting the resulting equation onto the body frame, one obtains the following differential equations:
 $$ \left\{\begin{array}{l}m \dot{V}=T\cos \alpha -D- mg\sin \gamma \\ {}m V \dot{\gamma}=T\sin \alpha +L- mg\cos \gamma \end{array}\right. , $$
$$ \left\{\begin{array}{l}m \dot{V}=T\cos \alpha -D- mg\sin \gamma \\ {}m V \dot{\gamma}=T\sin \alpha +L- mg\cos \gamma \end{array}\right. , $$
where
 $ g $
is the value of gravitational acceleration on Earth (here rounded to 9.81 m s
$ g $
is the value of gravitational acceleration on Earth (here rounded to 9.81 m s
 $ {}^{-2} $
) and
$ {}^{-2} $
) and
 $ \dot{x} $
denotes the time-derivative of any physical variable
$ \dot{x} $
denotes the time-derivative of any physical variable
 $ x $
. We refer for instance to Rommel (Reference Rommel2018) for a detailed derivation of the above relations. Moreover, we have the following relations:
$ x $
. We refer for instance to Rommel (Reference Rommel2018) for a detailed derivation of the above relations. Moreover, we have the following relations:
 $$ \left\{\begin{array}{l}\mathrm{FF}={C}_{\mathrm{SR}}^{*} T\\ {}D=\frac{1}{2} \rho {V}^2 S {C}_D^{*}\\ {}L=\frac{1}{2} \rho {V}^2 S {C}_L^{*}\end{array}\right. , $$
$$ \left\{\begin{array}{l}\mathrm{FF}={C}_{\mathrm{SR}}^{*} T\\ {}D=\frac{1}{2} \rho {V}^2 S {C}_D^{*}\\ {}L=\frac{1}{2} \rho {V}^2 S {C}_L^{*}\end{array}\right. , $$
with
 $ S $
denoting the wing-surface of the aircraft; note that this value is fixed in our setting. From the system (12), we clearly have
$ S $
denoting the wing-surface of the aircraft; note that this value is fixed in our setting. From the system (12), we clearly have
 $$ \left\{\begin{array}{l}T=\frac{\mathrm{FF}}{C_{\mathrm{SR}}^{*}}\\ {}{C}_D^{*}=\frac{2}{\rho {V}^2 S} D\\ {}{C}_L^{*}=\frac{2}{\rho {V}^2 S} L\end{array}\right. . $$
$$ \left\{\begin{array}{l}T=\frac{\mathrm{FF}}{C_{\mathrm{SR}}^{*}}\\ {}{C}_D^{*}=\frac{2}{\rho {V}^2 S} D\\ {}{C}_L^{*}=\frac{2}{\rho {V}^2 S} L\end{array}\right. . $$
Combining the system (11) with the preceding relations gives
 $$ \left\{\begin{array}{l}{C}_D^{*}=\frac{2}{\rho {V}^2 S} \left(\cos \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}^{*}}-m \dot{V}- mg\sin \gamma \right)\\ {}{C}_L^{*}=\frac{2}{\rho {V}^2 S} \left(-\sin \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}^{*}}+m V \dot{\gamma}+ mg\cos \gamma \right)\end{array}\right. . $$
$$ \left\{\begin{array}{l}{C}_D^{*}=\frac{2}{\rho {V}^2 S} \left(\cos \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}^{*}}-m \dot{V}- mg\sin \gamma \right)\\ {}{C}_L^{*}=\frac{2}{\rho {V}^2 S} \left(-\sin \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}^{*}}+m V \dot{\gamma}+ mg\cos \gamma \right)\end{array}\right. . $$
Apart from the specific fuel consumption
 $ {C}_{\mathrm{SR}}^{*} $
, all the variables appearing in the right-hand sides of the system (13) are either recorded by the aircraft or easily calculable from other recorded variables via well-known physical relations.
$ {C}_{\mathrm{SR}}^{*} $
, all the variables appearing in the right-hand sides of the system (13) are either recorded by the aircraft or easily calculable from other recorded variables via well-known physical relations.
By inserting Equation (9) into Equation (13), we obtain the following formulas for
 $ {C}_D^{*} $
and
$ {C}_D^{*} $
and
 $ {C}_L^{*} $
:
$ {C}_L^{*} $
:
 $$ \left\{\begin{array}{l}T=\frac{\mathrm{FF}}{C_{\mathrm{SR}}}-\frac{\mathrm{FF}}{C_{\mathrm{SR}}} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}}\\ {}{C}_D^{*}=\frac{2}{\rho {V}^2 S} \left(\cos \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}}-m \dot{V}- mg\sin \gamma -\cos \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}}\right)\\ {}{C}_L^{*}=\frac{2}{\rho {V}^2 S} \left(-\sin \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}}+m V \dot{\gamma}+ mg\cos \gamma +\sin \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}}\right)\end{array}\right., $$
$$ \left\{\begin{array}{l}T=\frac{\mathrm{FF}}{C_{\mathrm{SR}}}-\frac{\mathrm{FF}}{C_{\mathrm{SR}}} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}}\\ {}{C}_D^{*}=\frac{2}{\rho {V}^2 S} \left(\cos \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}}-m \dot{V}- mg\sin \gamma -\cos \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}}\right)\\ {}{C}_L^{*}=\frac{2}{\rho {V}^2 S} \left(-\sin \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}}+m V \dot{\gamma}+ mg\cos \gamma +\sin \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}}\right)\end{array}\right., $$
where
 $ {\eta}_{C_{\mathrm{SR}}^{*}}:= \eta \left({C}_{\mathrm{SR}}^{*},\left(\mathrm{SAT},h,M\right)\right) $
for the sake of simplicity. By defining
$ {\eta}_{C_{\mathrm{SR}}^{*}}:= \eta \left({C}_{\mathrm{SR}}^{*},\left(\mathrm{SAT},h,M\right)\right) $
for the sake of simplicity. By defining
 $$ {\displaystyle \begin{array}{l}\bullet Z:= \left(\rho, V,\alpha, \mathrm{FF},\mathrm{SAT},h,M,m,\gamma \right);\\ {}\bullet {\varphi}_{C_D^{*}}(Z):= \frac{2}{\rho {V}^2 S} \left(\cos \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}\left(\mathrm{SAT},h,M\right)}-m \dot{V}- mg\sin \gamma \right);\\ {}\bullet {\eta}_{C_D^{*}}\left({C}_D^{*},Z\right):= -\frac{2 \cos \alpha }{\rho {V}^2 S} \frac{\mathrm{FF}}{C_{\mathrm{SR}}\left(\mathrm{SAT},h,M\right)} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}},\end{array}} $$
$$ {\displaystyle \begin{array}{l}\bullet Z:= \left(\rho, V,\alpha, \mathrm{FF},\mathrm{SAT},h,M,m,\gamma \right);\\ {}\bullet {\varphi}_{C_D^{*}}(Z):= \frac{2}{\rho {V}^2 S} \left(\cos \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}\left(\mathrm{SAT},h,M\right)}-m \dot{V}- mg\sin \gamma \right);\\ {}\bullet {\eta}_{C_D^{*}}\left({C}_D^{*},Z\right):= -\frac{2 \cos \alpha }{\rho {V}^2 S} \frac{\mathrm{FF}}{C_{\mathrm{SR}}\left(\mathrm{SAT},h,M\right)} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}},\end{array}} $$
we can write
 $$ {C}_D^{*}={\varphi}_{C_D^{*}}(Z)+{\eta}_{C_D^{*}}\left({C}_D^{*},Z\right), $$
$$ {C}_D^{*}={\varphi}_{C_D^{*}}(Z)+{\eta}_{C_D^{*}}\left({C}_D^{*},Z\right), $$
the variable
 $ {C}_D:= {\varphi}_{C_D^{*}}(Z) $
being the desired approximation for
$ {C}_D:= {\varphi}_{C_D^{*}}(Z) $
being the desired approximation for
 $ {C}_D^{*} $
. Similarly we obtain
$ {C}_D^{*} $
. Similarly we obtain
 $$ {C}_L^{*}={\varphi}_{C_L^{*}}(Z)+{\eta}_{C_L^{*}}\left({C}_L^{*},Z\right), $$
$$ {C}_L^{*}={\varphi}_{C_L^{*}}(Z)+{\eta}_{C_L^{*}}\left({C}_L^{*},Z\right), $$
with
 $$ {\displaystyle \begin{array}{l}\bullet {\varphi}_{C_L^{*}}(Z):= \frac{2}{\rho {V}^2 S} \left(-\sin \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}}+m V \dot{\gamma}+ mg\cos \gamma \right);\\ {}\bullet {\eta}_{C_L^{*}}\left({C}_L^{*},Z\right):= \frac{2 \sin \alpha }{\rho {V}^2 S} \frac{\mathrm{FF}}{C_{\mathrm{SR}}\left(\mathrm{SAT},h,M\right)} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}} .\end{array}} $$
$$ {\displaystyle \begin{array}{l}\bullet {\varphi}_{C_L^{*}}(Z):= \frac{2}{\rho {V}^2 S} \left(-\sin \alpha \frac{\mathrm{FF}}{C_{\mathrm{SR}}}+m V \dot{\gamma}+ mg\cos \gamma \right);\\ {}\bullet {\eta}_{C_L^{*}}\left({C}_L^{*},Z\right):= \frac{2 \sin \alpha }{\rho {V}^2 S} \frac{\mathrm{FF}}{C_{\mathrm{SR}}\left(\mathrm{SAT},h,M\right)} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}} .\end{array}} $$
Here the variable
 $ {C}_L^{*} $
is approximated by
$ {C}_L^{*} $
is approximated by
 $ {C}_L:= {\varphi}_{C_L^{*}}(Z) $
.
$ {C}_L:= {\varphi}_{C_L^{*}}(Z) $
.
For the sake of readability, we sum up in Figure 1 the relationships between the variables involved in the computations of
 $ {C}_D $
and
$ {C}_D $
and
 $ {C}_L $
.
$ {C}_L $
.

Figure 1. Relations between involved variables—black arrows correspond to deterministic relations, differentiation with respect to time is represented by blue dashed arrows and the orange dotted ones refer to physical approximations; variables in diamond-shaped boxes are the targets we aim at modeling.
We now provide bounds for the means over the cruise phase of the absolute values of the physical approximation errors
 $ {\eta}_{C_D^{*}} $
and
$ {\eta}_{C_D^{*}} $
and
 $ {\eta}_{C_L^{*}} $
. Noting that these two variables are defined by a product in our setting, we can apply Hölder’s inequality (with a choice of exponents
$ {\eta}_{C_L^{*}} $
. Noting that these two variables are defined by a product in our setting, we can apply Hölder’s inequality (with a choice of exponents
 $ 1 $
and
$ 1 $
and
 $ +\infty $
) to obtain
$ +\infty $
) to obtain
 $$ \left\{\begin{array}{l}{\unicode{x1D53C}}_{C_D^{*},Z}\left[\left|{\eta}_{C_D^{*}}\left({C}_D^{\star },Z\right)\right|\right]\leqslant {K}_{C_D^{*}} {\unicode{x1D53C}}_{C_{\mathrm{SR}}^{*},\mathrm{SAT},h,M}\left[\frac{\mid \eta \left({C}_{\mathrm{SR}}^{*},\mathrm{SAT},h,M\right)\mid }{C_{\mathrm{SR}}^{*}}\right]\\ {}{\unicode{x1D53C}}_{C_L^{*},Z}\left[\left|{\eta}_{C_D^{*}}\left({C}_D^{*},Z\right)\right|\right]\leqslant {K}_{C_L^{*}} {\unicode{x1D53C}}_{C_{\mathrm{SR}}^{*},\mathrm{SAT},h,M}\left[\frac{\mid \eta \left({C}_{\mathrm{SR}}^{*},\mathrm{SAT},h,M\right)\mid }{C_{\mathrm{SR}}^{*}}\right]\end{array}\right. , $$
$$ \left\{\begin{array}{l}{\unicode{x1D53C}}_{C_D^{*},Z}\left[\left|{\eta}_{C_D^{*}}\left({C}_D^{\star },Z\right)\right|\right]\leqslant {K}_{C_D^{*}} {\unicode{x1D53C}}_{C_{\mathrm{SR}}^{*},\mathrm{SAT},h,M}\left[\frac{\mid \eta \left({C}_{\mathrm{SR}}^{*},\mathrm{SAT},h,M\right)\mid }{C_{\mathrm{SR}}^{*}}\right]\\ {}{\unicode{x1D53C}}_{C_L^{*},Z}\left[\left|{\eta}_{C_D^{*}}\left({C}_D^{*},Z\right)\right|\right]\leqslant {K}_{C_L^{*}} {\unicode{x1D53C}}_{C_{\mathrm{SR}}^{*},\mathrm{SAT},h,M}\left[\frac{\mid \eta \left({C}_{\mathrm{SR}}^{*},\mathrm{SAT},h,M\right)\mid }{C_{\mathrm{SR}}^{*}}\right]\end{array}\right. , $$
where
 $$ {K}_{C_D^{*}}:= \underset{\left(\rho, V,\alpha, \mathrm{FF},\mathrm{SAT},h,M,m\right)}{\sup}\left|-\frac{2 \cos \alpha }{\rho {V}^2 S} \frac{\mathrm{FF}}{C_{\mathrm{SR}}\left(\mathrm{SAT},h,M\right)}\right| ; $$
$$ {K}_{C_D^{*}}:= \underset{\left(\rho, V,\alpha, \mathrm{FF},\mathrm{SAT},h,M,m\right)}{\sup}\left|-\frac{2 \cos \alpha }{\rho {V}^2 S} \frac{\mathrm{FF}}{C_{\mathrm{SR}}\left(\mathrm{SAT},h,M\right)}\right| ; $$
 $$ {K}_{C_L^{*}}:= \underset{\left(\rho, V,\alpha, \mathrm{FF},\mathrm{SAT},h,M,m\right)}{\sup}\left|\frac{2 \sin \alpha }{\rho {V}^2 S} \frac{\mathrm{FF}}{C_{\mathrm{SR}}\left(\mathrm{SAT},h,M\right)}\right| . $$
$$ {K}_{C_L^{*}}:= \underset{\left(\rho, V,\alpha, \mathrm{FF},\mathrm{SAT},h,M,m\right)}{\sup}\left|\frac{2 \sin \alpha }{\rho {V}^2 S} \frac{\mathrm{FF}}{C_{\mathrm{SR}}\left(\mathrm{SAT},h,M\right)}\right| . $$
The supremum is over the cruise domain here and the mean absolute relative error for
 $ {C}_{\mathrm{SR}}^{*} $
is equal to
$ {C}_{\mathrm{SR}}^{*} $
is equal to
 $ 3.68\mathrm{e}-2 $
according to (10). We refer to Section 4 for values of
$ 3.68\mathrm{e}-2 $
according to (10). We refer to Section 4 for values of
 $ {K}_{C_D^{*}} $
and
$ {K}_{C_D^{*}} $
and
 $ {K}_{C_L^{*}} $
computed from the available data.
$ {K}_{C_L^{*}} $
computed from the available data.
Table 2 Similarly to Sun et al. (Reference Sun, Hoekstra and Ellerbroek2018), it is possible to obtain simpler approximated formulas for
 $ {C}_D^{*} $
and
$ {C}_D^{*} $
and
 $ {C}_L^{*} $
by assuming the following steady flight conditions with constant speed:
$ {C}_L^{*} $
by assuming the following steady flight conditions with constant speed:
1. the altitude
 $ h $
is constant and so the path angle
$ \gamma $
is equal to
$ 0 $
;
$ h $
is constant and so the path angle
$ \gamma $
is equal to
$ 0 $
;2. the angle of attack
$ \alpha $
is neglected: it is supposed to be equal to
$ 0 $
; and3. the true airspeed
$ V $
is constant and so its time-derivative
$ \dot{V} $
is equal to
$ 0 $
.








In this case, we have:
 $$ \left\{\begin{array}{l}T=\frac{\mathrm{FF}}{C_{\mathrm{SR}}}-\frac{\mathrm{FF}}{C_{\mathrm{SR}}} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}}\\ {}{C}_D^{*}=\frac{2}{\rho {V}^2 S} \left(\frac{\mathrm{FF}}{C_{\mathrm{SR}}}-\frac{\mathrm{FF}}{C_{\mathrm{SR}}} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}}\right)\\ {}{C}_L^{*}=\frac{2 mg}{\rho {V}^2 S}\end{array}\right. . $$
$$ \left\{\begin{array}{l}T=\frac{\mathrm{FF}}{C_{\mathrm{SR}}}-\frac{\mathrm{FF}}{C_{\mathrm{SR}}} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}}\\ {}{C}_D^{*}=\frac{2}{\rho {V}^2 S} \left(\frac{\mathrm{FF}}{C_{\mathrm{SR}}}-\frac{\mathrm{FF}}{C_{\mathrm{SR}}} \frac{\eta_{C_{\mathrm{SR}}^{*}}}{C_{\mathrm{SR}}^{*}}\right)\\ {}{C}_L^{*}=\frac{2 mg}{\rho {V}^2 S}\end{array}\right. . $$
In the present paper, we consider the complete formulas (13) which are likely to best preserve accuracy of the approximations and to catch real flight conditions.
4. Experiments
In this section, we present numerical results based on real flight data for the method introduced in Section 2 and applied to the aeronautic setting described in Section 3. We first detail the data and the preprocessing steps we carried out, before reporting experiments design and results.
4.1. Data description and preprocessing
We have access to 423 recorded short and medium-haul flights performed by the same narrow-body airliner, the data being recorded by the QAR. These flight data are provided by a partner airline and cannot be publicly released for commercial reasons. From this dataset, we extract all the observations for the variables contained in the vector
 $ Z $
defined in Section 3. The heading and the wind speed are also extracted to remove heading changes and high wind variations. All these variables are then smoothed by means of smoothing splines to remove the noise coming from measuring instruments and converted into the international system of units. The time-derivatives are computed on the basis of the smoothing splines. As explained in Section 3, we consider cruise phases in a vertical plane with no wind variations, so we require the following conditions to be satisfied:
$ Z $
defined in Section 3. The heading and the wind speed are also extracted to remove heading changes and high wind variations. All these variables are then smoothed by means of smoothing splines to remove the noise coming from measuring instruments and converted into the international system of units. The time-derivatives are computed on the basis of the smoothing splines. As explained in Section 3, we consider cruise phases in a vertical plane with no wind variations, so we require the following conditions to be satisfied:
-
• we keep observations from the top of climb to the top of descent without those corresponding to climb steps; from a numerical point of view, we keep time-intervals such that the standard deviations of the altitude over these intervals is smaller than an arbitrary small threshold;
-
• the heading angle of the aircraft has to be constant; from a numerical point of view, we keep intervals such that the standard deviations of the heading over these intervals is smaller than an arbitrary small threshold;
-
• the wind speed variations have to be equal to 0; from a numerical point of view, we keep intervals such that the means and the standard deviations of the time-derivative of the wind over these intervals are smaller than an arbitrary small threshold; and
-
• the lengths of the resulting intervals have to be larger than 10 s.
Given the time-intervals during which the above conditions are satisfied, we sample every 10 s in each interval. This is motivated by the fact that the errors of the resulting models trained on the dataset sampled every 10 s and on the dataset without sampling are very close. Hence, sampling allows to reduce the learning time without impacting strongly the accuracy. Afterwards, the values for the approximated variables
 $ {C}_D $
and
$ {C}_D $
and
 $ {C}_L $
are computed by means of the functions
$ {C}_L $
are computed by means of the functions
 $ {\varphi}_{C_D^{*}} $
and
$ {\varphi}_{C_D^{*}} $
and
 $ {\varphi}_{C_L^{*}} $
defined in Section 3. Finally, we have 164,054 observations which are randomly split into training, validation, and test sets (70% of the dataset is used for the training, 20% for the validation, and 10% for the test).
$ {\varphi}_{C_L^{*}} $
defined in Section 3. Finally, we have 164,054 observations which are randomly split into training, validation, and test sets (70% of the dataset is used for the training, 20% for the validation, and 10% for the test).
Table 3 presents an example of a preprocessed data set (with simulated values to avoid divulgating the dataset).
Table 3. Example of a preprocessed dataset.

4.2. Experiments design
Here, we aim at estimating the following models for the approximated drag
 $ {C}_D $
and lift
$ {C}_D $
and lift
 $ {C}_L $
coefficients
$ {C}_L $
coefficients
 $$ {C}_D={f}_{C_D}\left(\alpha, M\right) \mathrm{and} {C}_L={f}_{C_L}\left(\alpha, M\right) , $$
$$ {C}_D={f}_{C_D}\left(\alpha, M\right) \mathrm{and} {C}_L={f}_{C_L}\left(\alpha, M\right) , $$
by exploiting the preprocessed data described above. To do so, we consider different classical models which are introduced in Table 4. This table also gives the considered hyper-parameters and their range. The hyper-parameters are tuned by using threefold cross-validation, the loss function being the mean squared error. Furthermore, we use an early stopping rule when fitting the gradient tree boosting model to limit the number of iterations, the validation set being used to stop iterating. The maximum number of iterations has been set to 5,000 in this case. In the end, we are interested in the three following classical error metrics: the root-square of the mean squared error, the mean absolute error and the mean absolute percent error. We use the software package LightGBM (Ke et al., Reference Ke, Meng, Finley, Wang, Chen, Ma, Ye, Liu, Guyon, Luxburg, Bengio, Wallach, Fergus, Vishwanathan and Garnett2017) as an implementation of the gradient tree boosting algorithm and we compute the other models using scikit-learn Python library (Pedregosa et al., Reference Pedregosa, Varoquaux, Gramfort, Michel, Thirion, Grisel, Blondel, Prettenhofer, Weiss, Dubourg, Vanderplas, Passos, Cournapeau, Brucher, Perrot and Duchesnay2011).
Table 4. Hyper-parameters and their range for the considered models.

4.3. Results
We performed 100 times the learning process: at each time, the preprocessed data is randomly split into training, validation and test sets and the models are estimated and tested using these sets. The means and the standard deviations of the errors computed on the test sets are given in Tables 5 and 6. We report numbers up to a precision of three decimal digits.
Table 5. Means and standard deviations of error metrics for different
 $ {C}_D $
models computed over 100 independent repetitions.
$ {C}_D $
models computed over 100 independent repetitions.

The smallest values are indicated by bolded numbers.
Abbreviations: MAE, mean absolute error; MAPE, mean absolute percent error; RMSE, mean squared error.
Table 6. Means and standard deviations of error metrics for different
 $ {C}_L $
models computed over 100 independent repetitions.
$ {C}_L $
models computed over 100 independent repetitions.

The smallest values are indicated by bolded numbers.
Abbreviations: MAE, mean absolute error; MAPE, mean absolute percent error; RMSE, mean squared error.
Figures 2–4 allow to visualize the tendencies of estimators
 $ {\hat{f}}_{C_D} $
and
$ {\hat{f}}_{C_D} $
and
 $ {\hat{f}}_{C_L} $
with respect to the Mach number for different fixed values of the angle of attack. Figures 2–4 show respectively a polynomial, a decision tree and a gradient tree boosting models.
$ {\hat{f}}_{C_L} $
with respect to the Mach number for different fixed values of the angle of attack. Figures 2–4 show respectively a polynomial, a decision tree and a gradient tree boosting models.

Figure 2. Predictions of
 $ {C}_D $
and
$ {C}_D $
and
 $ {C}_L $
from polynomial models.
$ {C}_L $
from polynomial models.

Figure 3. Predictions of
 $ {C}_D $
and
$ {C}_D $
and
 $ {C}_L $
from decision trees models. Solid lines are the raw prediction curves and dotted lines are smoothed versions (using splines).
$ {C}_L $
from decision trees models. Solid lines are the raw prediction curves and dotted lines are smoothed versions (using splines).

Figure 4. Predictions of
 $ {C}_D $
and
$ {C}_D $
and
 $ {C}_L $
from decision gradient tree boosting models. Solid lines are the raw prediction curves and dotted lines are smoothed versions (using splines).
$ {C}_L $
from decision gradient tree boosting models. Solid lines are the raw prediction curves and dotted lines are smoothed versions (using splines).
First of all, we observe that the decision tree and gradient tree boosting models lead to raw predicted curves which may be hard to interpret from an aeronautic point of view. This is especially true for the decision tree model even though its learning error is similar to those of the two other models. Since we aim here at checking whether some expected aeronautic tendencies are caught by our approach, we smooth the predicted curves by means of smoothing splines to interpret the results in an easier way. These smoothed curves are given by the dotted curves in Figures 3 and 4. Note that the use of smoothing splines is to highlight the underlying tendency, but is certainly not used as a predictive method because of well-known artefacts due to the smoothing technique.
Now we mention that 90% of Mach number data are between 0.77% and 0.80% and 90% of angle of attack data are between 1.9
 $ {}^{\circ } $
and 2.9
$ {}^{\circ } $
and 2.9
 $ {}^{\circ } $
. Then we observe that both predicted
$ {}^{\circ } $
. Then we observe that both predicted
 $ {C}_D $
and
$ {C}_D $
and
 $ {C}_L $
globally increase when the Mach number or the angle of attack increases. This global tendency is actually expected in this small range of values according to Anderson (Reference Anderson1999, part 1, chapter 2): the larger the angle of attack or the Mach number, the larger the drag and lift coefficients.
$ {C}_L $
globally increase when the Mach number or the angle of attack increases. This global tendency is actually expected in this small range of values according to Anderson (Reference Anderson1999, part 1, chapter 2): the larger the angle of attack or the Mach number, the larger the drag and lift coefficients.
Nevertheless, this natural tendency for the lift coefficient is not verified by the estimators when
 $ \alpha $
is too large, namely
$ \alpha $
is too large, namely
 $ \alpha ={2.75}^{\circ } $
or
$ \alpha ={2.75}^{\circ } $
or
 $ \alpha ={3}^{\circ } $
. This unexpected behavior can be explained by the approximated nature of the variable
$ \alpha ={3}^{\circ } $
. This unexpected behavior can be explained by the approximated nature of the variable
 $ {C}_L $
. Indeed it may behave in a way that is different from
$ {C}_L $
. Indeed it may behave in a way that is different from
 $ {C}_L^{*} $
in certain regions of the cruise domain. In this case, any estimator for
$ {C}_L^{*} $
in certain regions of the cruise domain. In this case, any estimator for
 $ {C}_L $
is likely to inherit this unexpected behavior and we believe refined aeronautics-supported approximations would bring a solution.
$ {C}_L $
is likely to inherit this unexpected behavior and we believe refined aeronautics-supported approximations would bring a solution.
We now focus on the physical approximation errors for the drag and lift coefficients, that is to say
 $ {\eta}_{C_D^{*}} $
and
$ {\eta}_{C_D^{*}} $
and
 $ {\eta}_{C_L^{*}} $
. According to (17), the mean of the absolute value of these errors is bounded by the product between the constants
$ {\eta}_{C_L^{*}} $
. According to (17), the mean of the absolute value of these errors is bounded by the product between the constants
 $ {K}_{C_D^{*}} $
or
$ {K}_{C_D^{*}} $
or
 $ {K}_{C_L^{*}} $
with the mean absolute relative error of
$ {K}_{C_L^{*}} $
with the mean absolute relative error of
 $ {C}_{\mathrm{SR}}^{*} $
, the latter being equal to
$ {C}_{\mathrm{SR}}^{*} $
, the latter being equal to
 $ 3.68\times {10}^{-2} $
. We estimate the value of these constants by using our recorded observations: the maximal values of
$ 3.68\times {10}^{-2} $
. We estimate the value of these constants by using our recorded observations: the maximal values of
 $ {K}_{C_D^{*}} $
or
$ {K}_{C_D^{*}} $
or
 $ {K}_{C_L^{*}} $
(defined in Equations 18 and 19) are respectively equal to
$ {K}_{C_L^{*}} $
(defined in Equations 18 and 19) are respectively equal to
 $ 4.38\times {10}^{-2} $
and
$ 4.38\times {10}^{-2} $
and
 $ 2.94\times {10}^{-3} $
. Using these two values as estimators for
$ 2.94\times {10}^{-3} $
. Using these two values as estimators for
 $ {K}_{C_D^{*}} $
and
$ {K}_{C_D^{*}} $
and
 $ {K}_{C_L^{*}} $
gives the following bounds for the physical approximation errors:
$ {K}_{C_L^{*}} $
gives the following bounds for the physical approximation errors:
 $$ \left\{\begin{array}{l}{\unicode{x1D53C}}_{C_D^{*},Z}\left[|{\eta}_{C_D^{*}}\left({C}_D^{*},Z\right)|\right]\leqslant 1.61\times {10}^{-3}\\ {}{\unicode{x1D53C}}_{C_L^{*},Z}\left[|{\eta}_{C_L^{*}}\left({C}_L^{*},Z\right)|\right]\leqslant 1.08\times {10}^{-4}\end{array}\right. . $$
$$ \left\{\begin{array}{l}{\unicode{x1D53C}}_{C_D^{*},Z}\left[|{\eta}_{C_D^{*}}\left({C}_D^{*},Z\right)|\right]\leqslant 1.61\times {10}^{-3}\\ {}{\unicode{x1D53C}}_{C_L^{*},Z}\left[|{\eta}_{C_L^{*}}\left({C}_L^{*},Z\right)|\right]\leqslant 1.08\times {10}^{-4}\end{array}\right. . $$
According to the generic inequality given in Lemma 1, a bound for the mean of the absolute total error (defined in Section 2) of a given variable can be obtained by adding up the bounds for the physical approximation and learning errors. The latter is here approximated by the MAE of the estimated model. To provide an example of numerical bounds for the total errors of the drag and lift coefficients, we choose estimators
 $ {\hat{f}}_{C_D} $
and
$ {\hat{f}}_{C_D} $
and
 $ {\hat{f}}_{C_L} $
whose MAE values are equal to the MAE means given in Tables 5 and 6. Note that this choice is motivated by the fact that the standard deviations of the MAE for the different models are much smaller than the means. Following this choice, examples of bounds for the total errors are then given in Table 7.
$ {\hat{f}}_{C_L} $
whose MAE values are equal to the MAE means given in Tables 5 and 6. Note that this choice is motivated by the fact that the standard deviations of the MAE for the different models are much smaller than the means. Following this choice, examples of bounds for the total errors are then given in Table 7.
Table 7. Bounds for the mean absolute and mean relative total errors of the drag and lift coefficients using estimators
 $ {\hat{f}}_{C_D} $
and
$ {\hat{f}}_{C_D} $
and
 $ {\hat{f}}_{C_L} $
whose mean absolute error (MAE) values are equal to the MAE means given in Tables 5 and 6—Absolute and Relative refer respectively to the bounds given in Lemmas 1 and 2.
$ {\hat{f}}_{C_L} $
whose mean absolute error (MAE) values are equal to the MAE means given in Tables 5 and 6—Absolute and Relative refer respectively to the bounds given in Lemmas 1 and 2.

The empirical means of
 $ {C}_D={\varphi}_{C_D^{*}}(Z) $
and
$ {C}_D={\varphi}_{C_D^{*}}(Z) $
and
 $ {C}_L={\varphi}_{C_L^{*}}(Z) $
over our data are respectively equal to
$ {C}_L={\varphi}_{C_L^{*}}(Z) $
over our data are respectively equal to
 $$ \hat{{\unicode{x1D53C}}_Z}\left[{\varphi}_{C_D^{*}}(Z)\right]=3.23\times {10}^{-2} , \hat{{\unicode{x1D53C}}_Z}\left[{\varphi}_{C_L^{*}}(Z)\right]=5.32\times {10}^{-1} , $$
$$ \hat{{\unicode{x1D53C}}_Z}\left[{\varphi}_{C_D^{*}}(Z)\right]=3.23\times {10}^{-2} , \hat{{\unicode{x1D53C}}_Z}\left[{\varphi}_{C_L^{*}}(Z)\right]=5.32\times {10}^{-1} , $$
showing in particular that
 $ \hat{{\unicode{x1D53C}}_Z}[{\varphi}_{C_D^{*}}(Z)]>1.61\times {10}^{-3} $
and
$ \hat{{\unicode{x1D53C}}_Z}[{\varphi}_{C_D^{*}}(Z)]>1.61\times {10}^{-3} $
and
 $ \hat{{\unicode{x1D53C}}_Z}[{\varphi}_{C_L^{*}}(Z)]>1.08\times {10}^{-4} $
(we used the slight notation abuse
$ \hat{{\unicode{x1D53C}}_Z}[{\varphi}_{C_L^{*}}(Z)]>1.08\times {10}^{-4} $
(we used the slight notation abuse
 $ \hat{\unicode{x1D53C}} $
to denote the empirical mean). The hypotheses of Lemma 2 are then satisfied and we are in position to upper bound the ratios between the mean of the absolute value of the total errors and the mean values of
$ \hat{\unicode{x1D53C}} $
to denote the empirical mean). The hypotheses of Lemma 2 are then satisfied and we are in position to upper bound the ratios between the mean of the absolute value of the total errors and the mean values of
 $ {C}_D^{*} $
and
$ {C}_D^{*} $
and
 $ {C}_L^{*} $
. Numerical values expressed as a percentage for these bounds are given in Table 7.
$ {C}_L^{*} $
. Numerical values expressed as a percentage for these bounds are given in Table 7.
These results capture how classical, off-the-shelf regression methods perform and somewhat surprisingly, most methods compete on similar grounds (to the notable exception of the SVM). This suggests that most of these methods achieve a good enough complexity to capture the underlying phenomenon.
To finish, we mention that our approach is sufficiently generic to be applied to other settings, such as other flight phases. For the sake of illustration, we consider the drag coefficient during the climb phase. In this case, we exploit the climb data from our 423 available recorded flights, that is to say data for which the altitude is between 3,000 ft and the top of climb, and we apply the same preprocessing and learning steps as those described in this section. The results for the means and standard deviations of the learning errors computed over a test set are given in Table 8. We remark that these errors are much larger than those for the cruise phase. This accuracy loss can be explained by the fact that each variable during the climb phase has a larger range. For instance, the Mach number varies from 0.3 at the beginning of the climb to 0.81 at the top of climb while it varies only from 0.76 and 0.81 during the cruise. In addition, we are not in position to compute a numerical value for a bound of the physical approximation errors means for
 $ {C}_D^{*} $
. This is due to the fact that Roux (Reference Roux2002) does not estimate the physical approximation error mean coming from its model for the variable
$ {C}_D^{*} $
. This is due to the fact that Roux (Reference Roux2002) does not estimate the physical approximation error mean coming from its model for the variable
 $ {C}_{\mathrm{SR}}^{*} $
for the climb phase. Once such a quantity is available, numerical bounds for the total errors for
$ {C}_{\mathrm{SR}}^{*} $
for the climb phase. Once such a quantity is available, numerical bounds for the total errors for
 $ {C}_D^{*} $
can be derived in this case.
$ {C}_D^{*} $
can be derived in this case.
Table 8. Means and standard deviations of error metrics for different
 $ {C}_D $
models for climb phase computed over 100 independent repetitions.
$ {C}_D $
models for climb phase computed over 100 independent repetitions.

The smallest values are indicated by bolded numbers.
Abbreviations: MAE, mean absolute error; MAPE, mean absolute percent error; RMSE, mean squared error.
5. Conclusion
Our contributions are twofold: (a) we have proposed individual models trained on in-air data to improve the current aeronautic performance of individual aircrafts, rather than industry-wide calibrated parameters. This allows in particular for the search of more efficient (e.g., flight duration, speed, fuel consumption, etc.) trajectories for aircrafts and (b) we have designed a generic framework combining off-the-shelf machine learning with domain-specific approximations, which can be used in any data-intensive engineering discipline. We certainly hope that this approach can be replicated in other fields of study. We also intend to use this approach as a building block to optimizing end-to-end pipelines, for example for in-air real-time fuel optimization.
Funding Statement
This work was supported by the PERF-AI project funded by the European research program Clean Sky 2. The funder had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Competing Interest
The authors declare no competing interests.
Data Availability Statement
Data that support the findings of this study have been gathered from the Quick Access Recorder (QAR) of an aircraft operated by a private airline, hence can not be released publicly for commercial reasons.
Authorship Contributions
Formal analysis, F.D., B.G., and V.V.; Methodology, F.D., B.G., and V.V.; Software, F.D.; Writing-original draft, F.D.; Writing-review & editing, B.G. and V.V. All authors approved the final submitted draft.
Acknowledgments
The authors are grateful to Baptiste Gregorutti and Pierre Jouniaux for fruitful discussions about the conceptualization of this research and the aeronautic validation of the results. The authors are grateful to Arthur Talpaert for his substantial contribution to the code used to implement our methods.
Supplementary Materials
To view supplementary material for this article, please visit http://dx.doi.org/10.1017/dce.2020.12.





























 Open access
Open access
Comments
No Comments have been published for this article.