


No CrossRef data available.
Published online by Cambridge University Press: 29 May 2024
A linear equation 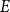 $E$ is said to be sparse if there is
$E$ is said to be sparse if there is 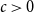 $c\gt 0$ so that every subset of
$c\gt 0$ so that every subset of 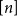 $[n]$ of size
$[n]$ of size 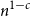 $n^{1-c}$ contains a solution of
$n^{1-c}$ contains a solution of 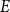 $E$ in distinct integers. The problem of characterising the sparse equations, first raised by Ruzsa in the 90s, is one of the most important open problems in additive combinatorics. We say that
$E$ in distinct integers. The problem of characterising the sparse equations, first raised by Ruzsa in the 90s, is one of the most important open problems in additive combinatorics. We say that 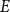 $E$ in
$E$ in 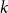 $k$ variables is abundant if every subset of
$k$ variables is abundant if every subset of 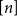 $[n]$ of size
$[n]$ of size 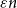 $\varepsilon n$ contains at least
$\varepsilon n$ contains at least 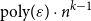 $\text{poly}(\varepsilon )\cdot n^{k-1}$ solutions of
$\text{poly}(\varepsilon )\cdot n^{k-1}$ solutions of 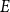 $E$. It is clear that every abundant
$E$. It is clear that every abundant 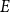 $E$ is sparse, and Girão, Hurley, Illingworth, and Michel asked if the converse implication also holds. In this note, we show that this is the case for every
$E$ is sparse, and Girão, Hurley, Illingworth, and Michel asked if the converse implication also holds. In this note, we show that this is the case for every 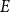 $E$ in four variables. We further discuss a generalisation of this problem which applies to all linear equations.
$E$ in four variables. We further discuss a generalisation of this problem which applies to all linear equations.
Supported in part by ERC Consolidator Grant 863438 and NSF-BSF Grant 20196.