


1. Introduction
Second language learners do not perceive second language speech sounds in a vacuum.Footnote 1 They have already become “tuned in” to perceiving specific phonetic categories found in their first language and “tuned out” to non-native phonological contrasts. Researchers studying this phenomenon have devised a number of theoretical models to account for patterns observed in non-native speech perception, to classify the ways non-native phones are discriminated and contrasted in relation to native categories (Best, Reference Best and Strange1995; Escudero Reference Escudero2005, Reference Escudero, Boersma and Hammann2009), and to ascertain how difficult it is for L2 learners to establish new phonetic categories. These models include the Perceptual Assimilation Model (PAM: Best Reference Best, Boysson-Bardies, Schonen, Jusczyk, Mac-Neilage and Morton1993, Reference Best, Rovee-Collier and Lipsitt1994a, Reference Best, Goodman and Nusbaum1994b, Reference Best and Strange1995), followed by PAM-L2 (Best and Tyler Reference Best, Tyler, Munro and Bohn2007); Second Language Linguistic Perception (L2LP: Escudero Reference Escudero, Boersma and Hammann2009); and the Speech Learning Model (SLM: Flege Reference Flege and Strange1995). Yet nonnative speech perception research has not been equally concerned with all aspects of perception. Non-native consonant contrasts have been more widely studied than vowels (see Tyler et al. Reference Tyler, Best, Faber and Levitt2014 for an overview), while vowels have usually been studied without varying the consonantal contexts (see Levy and Strange Reference Levy and Strange2008 for an overview). PAM studies have focused on non-native naïve listeners, whereas PAM-L2, SLM and L2LP have focused on L2 learners with a defined length of stay in L2-dominant environments. Meanwhile, studies on learners learning an L2 in a formalized classroom setting in an L1-dominant country have been scarce. Moreover, in the few studies conducted on L2 vowel perception, not many language combinations were studied. We can nevertheless hypothesize that perceptual attunement to the L1 may prove particularly costly during L2 acquisition when a learner's L1 has an average 5-7 vowel system (Maddieson Reference Maddieson1984: 128), and the L2 has a particularly rich vocalic system of up to more than a dozen vowels.
This article attempts to address some of the limitations of previous research on non-native perception of vowel contrasts by investigating aspects of English vowel perception among L2 learners of English. The study described herein focused on testing English vowel perception in the neighborhood of bilabial, alveolar and velar consonants (Levy and Strange Reference Levy and Strange2008), and used participants with a uniform level of proficiency (advanced) to examine their perception of vowels in a target language (English) that has twice as many contrasts as their L1 (Polish).
1.1 Vowel perception in second language studies: the Perceptual Assimilation Model and Natural Referent Vowel framework
The Perceptual Assimilation Model (PAM: Best Reference Best, Boysson-Bardies, Schonen, Jusczyk, Mac-Neilage and Morton1993, Reference Best, Rovee-Collier and Lipsitt1994a, Reference Best, Goodman and Nusbaum1994b, Reference Best and Strange1995; Best and Tyler Reference Best, Tyler, Munro and Bohn2007) views speech perception as a process dependent on recognizing phonological distinctiveness and phonological constancy within a language. When learning an L2 or FL, learners need to shift their attention to higher-order phonetic invariants that distinguish one category from another, and disregard information irrelevant for a given L2/FL contrast. In PAM, discrimination is predicted to vary depending on how contrasting non-native phones are categorized and goodness-rated in terms of native language phonological categories. In the case of two-category assimilation (TC), namely when the L2 phones are assimilated to different native phonological categories, discrimination is expected to be excellent. In contrast, in single-category assimilation (SC), the L2 phones are heard as equally good or poor versions of the same native phonological category, and discrimination is predicted to be poor. Alternatively, two L2 phones may be assimilated to the same L1 phonological category, but one of them judged to be a better exemplar of it than the other. Such a case is called category goodness assimilation (CG), and is expected to result in worse discrimination rates than in TC, but better rates than in SC. Another scenario is for an L2 phone to be uncategorized in terms of L1 phonemes. This happens when an L2 phone is assimilated to the same extent to two or more L1 categories. Such a scenario may result in either uncategorized-uncategorized contrasts (UU) or uncategorized-categorized contrasts (UC). Discrimination in UU can vary from poor to excellent, depending on the phonetic similarities between the two L2 phones and to the phonological categories in the L1, whereas discrimination in UC should be very good, as it crosses a category boundary in the L1. Likewise, for non-assimilable phones (NA), predictions are based on their non-speech auditory similarity. Non-assimilable vowels, however, are unlikely to exist (Tyler et al. Reference Tyler, Best, Faber and Levitt2014: 6).
The Natural Referent Vowel framework (NRV) (Polka and Bohn Reference Polka and Bohn2003, Reference Polka and Bohn2011) tries to account for asymmetries in the detection of a change from one vowel quality to another. A change from a series of more peripheral vowels to a less peripheral vowel seems to be more difficult to detect than a change in the opposite direction. These asymmetries have been attested for native and non-native vowels at six months of age, but only for non-native contrasts at 12 months and in adulthood.
Tyler et al. (Reference Tyler, Best, Faber and Levitt2014) have noted that research on language-specific tuning in speech perception primarily examined consonants. In order to see whether vowel perception in second language acquisition is governed by the same principles as postulated by PAM and NRV, they tested American English speakers’ perception of six non-native contrasts. They found that vowel discrimination depended on assimilation patterns as predicted by PAM. Asymmetries hypothesized by NRV, however, were found only in the case of SC assimilations, which was taken to suggest that assimilation types might influence the ways that peripheral vowels affect vowel perception. Non-native vowel contrasts that cross a phonological boundary, that is, TC and CU (Categorized – Uncategorized) assimilation types, mitigated the effects of vowel peripherality on perceptual asymmetries. Tyler et al. (Reference Tyler, Best, Faber and Levitt2014) concluded that peripheral vowels may influence adult non-native vowel discrimination when native phonological distinctions do not interfere, as in the case of CG, SC and UU. The present article provides data on English vowel perception from Polish advanced learners of English. In this configuration, the L2 has twice as many vowels as the L1. Such an arrangement should allow for various patterns of assimilation and for observations to be made about discrimination performance below ceiling levels. Consequently, it should be possible to examine perceptual asymmetries according to NRV.
1.2 The effects of place of articulation of adjacent consonants on vowel perception
The English vowels in the present article were recorded in three consonantal contexts, in order to allow for observations of the effects of place of articulation of adjacent consonants on vowel discrimination and categorization. Most studies examining cross-language vowel perception have used vowels in isolation, in monosyllables or in bisyllabic words in a single phonetic context. Therefore, relatively little is known about the influence of the place of articulation of a neighboring consonant on L2 vowel perception. Since the phonetic context may influence the phonetic realization of phonological segments, it would seem likely that differences in consonantal context could influence L2 vowel categorization and discrimination.
Strange et al. (Reference Strange, Akahane-Yamada, Kubo, Trent and Nishi2001) examined whether patterns in the assimilation of American English vowels by adult Japanese listeners (six years of English instruction, little exposure to spoken English) differed as a function of the context in which the vowels were produced and presented. They found that the patterns of spectral assimilation for several vowels varied systematically alongside the consonantal context. The short/checked American English vowels /ɪ ε ʌ/ were not categorized over 50% of the time in terms of a single Japanese category for all consonantal contexts. The assimilation patterns of other vowels, including /ʊ ɔː ɑː/ and /oʊ/, two of which have close counterparts in Japanese, were more stable across contexts. Moreover, the consonantal environment did not influence the perception of vowel height. The study thus indicated that the places of articulation of neighboring consonants can affect L2 vowel perception, but that the effects vary depending on the specific vowels involved and their similarity to L1 vowels, and according to vowel advancement rather than vowel height.
Levy and Strange (Reference Levy and Strange2008) examined the effects of language experience and consonantal context on French vowel perception discrimination by experienced and inexperienced American English listeners. The inexperienced group discriminated French vowels surrounded by alveolar consonants /dVt/ less accurately than in a bilabial context /bVp/. The authors ascribed the difference to the perceived relationship between front and back French vowels and back American English vowels, which are fronted in alveolar contexts. The experienced group, however, revealed no context effects, which would suggest that learning L2 coarticulatory rules is feasible.
By examining English vowel perception in different consonantal contexts by Polish advanced learners, the present study aims to contribute to the discussion of the effect of consonants’ place of articulation on the perception of L2 vowels. Previous research has suggested that variations in vowel production stemming from differences in the neighboring consonants’ places of articulation tend to be systematically reflected in patterns of assimilation to different L1 categories (Strange et al. Reference Strange, Akahane-Yamada, Kubo, Trent and Nishi2001). However, it is one of the tasks in L2 learning not to attend to within-L2 category variations (due to allophony, stylistic or free variations) and pay attention only to variations that cross an L2 phonemic boundary. Therefore, in the initial stages of L2 acquisition, contextual variations in L2 vowels may induce different assimilation targets. For example, we expect that English high back centralized vowels, which are fronted in alveolar contexts in English, may be perceived differently than in bilabial or velar contexts. More advanced learners with combined instruction (mean 7 years) and stay-abroad experience (12–38 months), however, have been shown to perceive L2 vowels consistently, disregarding contextual variations (Levy and Strange Reference Levy and Strange2008). It seems that various places of articulation of adjacent consonants may promote different assimilation patterns in the vowels, but in initial stages of L2 acquisition.
1.3 Perceptual studies of foreign language acquisition
Mainstream perception studies involving non-native sounds have been carried out among learners who are immigrants living in a community where their L2 is a dominant language (Flege Reference Flege and Strange1995, other studies inspired by SLM, and Best and Tyler Reference Best, Tyler, Munro and Bohn2007), or among listeners for whom the stimuli were completely novel, as they came from a language they had never learnt (Best Reference Best and Strange1995 and studies inspired by PAM). Few perception studies of foreign language acquisition (FLA) have been carried out in a classroom setting. Best and Tyler (Reference Best, Tyler, Munro and Bohn2007: 19) specify the characteristics of FLA as follows: (1) the target language is not widely used, (2) it does not extend significantly outside the classroom, (3) the emphasis is generally on formal instruction focused on vocabulary and grammar rather than on live conversation, and (4) the source of L2 input is either L1-accented speech or, at best, speech by native L2 speakers using diverse L2 varieties, and thus learners are confronted with an incorrect or variable model of L2 phonetic details. Differences between SLA and FLA warrant the need to study speech perception in these two cases separately; in this regard, the present article is situated within FLA speech perception studies.
1.4 Comparison of Polish and English vowel systems
There is little published data on the production and perception of British English vowels by Polish learners. The present study examined how advanced Polish learners of English perceive English vowels in three different consonantal contexts. In contrast to British English, which has 11 monophthong vowels appearing in stressed positions: /iː ɪ e æ ʌ ɜː ɑː ɒ ɔː uː ʊ/ (Wells Reference Wells1962, Deterding Reference Deterding1997, Hawkins and Midgley Reference Hawkins and Midgley2005), Polish has a relatively small vowel inventory with six oral vowels: /i ɨ e a ɔ u/ (Wierzchowska Reference Wierzchowska1980, Dłuska Reference Dłuska1981, Jassem Reference Jassem2003) with no distinctions in tenseness or duration (though some of the vowels have nasalized variants). Polish learners of English thus need to learn to perceive about twice as many vowel contrasts as they have in their L1. This means learning to perceive both tenseness and smaller formant differences (both in the F1/F2 plane and in F3 relations indicative of lip rounding) as phonologically contrastive. There have been no comprehensive studies published on English vowel perception by Polish learners. Bogacka (Reference Bogacka, Daskalaki, Katsos, Mavrogiorgos and Reeve2004) examined the perception of English high vowels by Polish learners and found that the participants relied heavily on temporal cues for both /iː-ɪ/ and /uː-ʊ/ continua and that their reliance on spectral cues was very weak. Rojczyk (Reference Rojczyk, Dziubalska-Kołaczyk, Wrembel and Kul2010) studied the role of duration in the perception of English /æ/ and /ʌ/ by Polish learners. Listeners identified stimuli with a longer duration as /æ/ and those with a shorter duration as /ʌ/ irrespective of their spectral characteristics. It is worth noting that Polish uses neither duration nor tenseness as vowel cues. In addition, Porzuczek (Reference Porzuczek, Arabski, Gabryś-Barker and Łyda2007) showed that Polish learners find it difficult to modify length cues when distinguishing between short and long vowels.
1.5 Research questions
As mentioned above, the present article is based on a study of the perception of 11 British English monophthongs by Polish advanced learners of English acquiring L2 in a formal classroom setting. The aspects of perception investigated were discrimination and assimilation with goodness ratings and (dis-)similarity ratings, which allowed the following research questions to be addressed:
(1) For advanced learners in a formal learning setting and an L1-dominant environment, do discrimination rates for English vowel contrasts depend on assimilation types, as predicted by PAM?
The predictions of PAM have previously been confirmed for non-native, unfamiliar consonants (e.g., Best and Strange Reference Best and Strange1992, Best et al. Reference Best, McRoberts and Sithole1988) and vowels (Tyler et al. Reference Tyler, Best, Faber and Levitt2014, Faris et al. Reference Faris, Best and Tyler2016). Best and Tyler (Reference Best, Tyler, Munro and Bohn2007) proposed a version of the model tailored to L2 learners in L2-dominant, naturalistic settings. Although differences between L2 learning in naturalistic and formal settings certainly influence the process and the effects of L2 learning, it is hypothesized in the present study that the cognitive capacities responsible for L2 speech perception remain the same, and therefore in a formal learning setting the same principles relating to L2 speech perception apply as in naturalistic settings, so discrimination rates are dependent on assimilation patterns.
(2) Do Polish advanced learners of English find it more difficult to detect a change from a more to a less peripheral vowel than to detect a change in the opposite direction, as predicted by NRV?
NRV's predictions have been confirmed for native and non-native vowels at 6 months of age, but only for non-native contrasts at 12 months and in adulthood. Tyler et al. (Reference Tyler, Best, Faber and Levitt2014) concluded that peripheral vowels may influence adult non-native vowel discrimination when native phonological distinctions do not interfere, as in the case of CG, SC and UU. The present study will test whether advanced L2 learners perceive L2 vowels as non-native contrasts or whether a familiarity with the vowels rules out perceptual asymmetry.
(3) How are English vowels assimilated to Polish vowel categories?
This is a descriptive question. Theories of second language speech perception assume that second-language sounds are assimilated to the closest native categories. Crucially, the closest native categories need to be established on the basis of perception tests, not phonological proximity. Since English has twice as many vowels as Polish does, we can hypothesize that two or more English vowels will be assimilated to one Polish category, but probably with varying goodness ratings.
(4) How are (dis-)similarity ratings related to discrimination results?
This study examines discrimination rates typically obtained for PAM studies and (dis-)similarity ratings. It is hypothesized that the more similar the two vowels are judged to be, the lower the discrimination rate will be.
(5) Do patterns of perceptual assimilation of the 11 British English vowels to the six Polish vowel categories, discrimination rates and (dis-)similarity ratings all differ systematically based on the place of articulation of the preceding and following consonants? Are English vowels with no close counterpart in Polish assimilated to different Polish vowel categories as a function of consonantal context?
We expect the places of articulation of neighboring consonants to have some influence on vowel perception, but for advanced learners, such effects should not be prevalent, as advanced learners should have developed context-independent perception patterns (cf. Levy and Strange Reference Levy and Strange2008).
2. Method
To address the research questions posed above, perception of English vowels by Polish advanced learners of English was examined. This section presents the stimuli used in the experiment, the participants, and the procedure.
2.1 Stimuli
A male adult native speaker of Standard Southern British English was recorded in an anechoic chamber in the Center for Speech and Language Processing at Adam Mickiewicz University in Poznań. He was instructed to read a list of carrier sentences containing nonsenseFootnote 2 words to elicit the production of 11 British English vowels /iː ɪ e æ ɜː ʌ ɑː ɒ ɔː uː ʊ/ in three homorganic CVC structures where lenis consonants /b d g/ were used. The vowel stimuli were both read and then presented to the listeners in closed bilabial /bVb/, alveolar /dVd/ and velar /gVg/ syllables. Closed syllables seemed to be the only legitimate choice for investigating natural English vowel perception,Footnote 3 as English lax vowels cannot occur in open syllables (Hammond Reference Hammond, Carnie, Harley and Willie2003). Using lenis consonants syllable-finally might have lengthened the vowels (Raphael Reference Raphael1975) and made them easier to perceive than before fortis consonants. The target sentences were presented to the speaker on PowerPoint slides in a booth. The speaker viewed a screen displaying two sentences, the first of which contained a real word that rhymed with the desired nonsense word in the second sentence, displayed below, for example: “In sock and hotter we have /ɒ/.” and “In bob and bobber we have /ɒ/.”. The monosyllabic word containing the vowel in question from the second sentence was later cut out and used in perception experiments – in the sample sentence, this would be the word bob. The order of the sentences in each list containing the 11 vowels in a given context was randomized. The speaker read four blocks from each list in each consonantal context. Recordings were made using a Toshiba laptop computer through an Edirol UA-25 USB audio interface. The experimenter spoke English with the speaker and monitored the recording through headphones. During the recording, the stimuli were digitized directly as computer files using Praat software (Boersma and Weenink Reference Boersma and Weenink2015), with a sample rate of 22,050 Hz, 16-bit resolution, and a mono channel.
The tokens used for the experiment were those produced by the speaker in the second, third and fourth blocks (the first blocks were treated as warm-ups, and the stimuli were subsequently chosen so that they matched for pitch). Their formant values were measured and compared before the selection of the tokens for the perception tests was made. A monolingual native speaker of British English was consulted to judge whether the chosen tokens were typical instances of the target vowel. He was able to identify all targets accurately and with reported ease. The digital files containing the full sentences (e.g., “In bob and bobber we have /ɒ/”) were then edited so that only the nonsense monosyllables (e.g., bob) remained for presentation to listeners. From these files, listening tests were created.
Figure 1 displays the spectral characteristics of the 11 British English vowels uttered by the speaker in the three contexts during the experiment. The plot indicates the F1 and F2 values measured at the temporal midpoint of the CVC syllables.
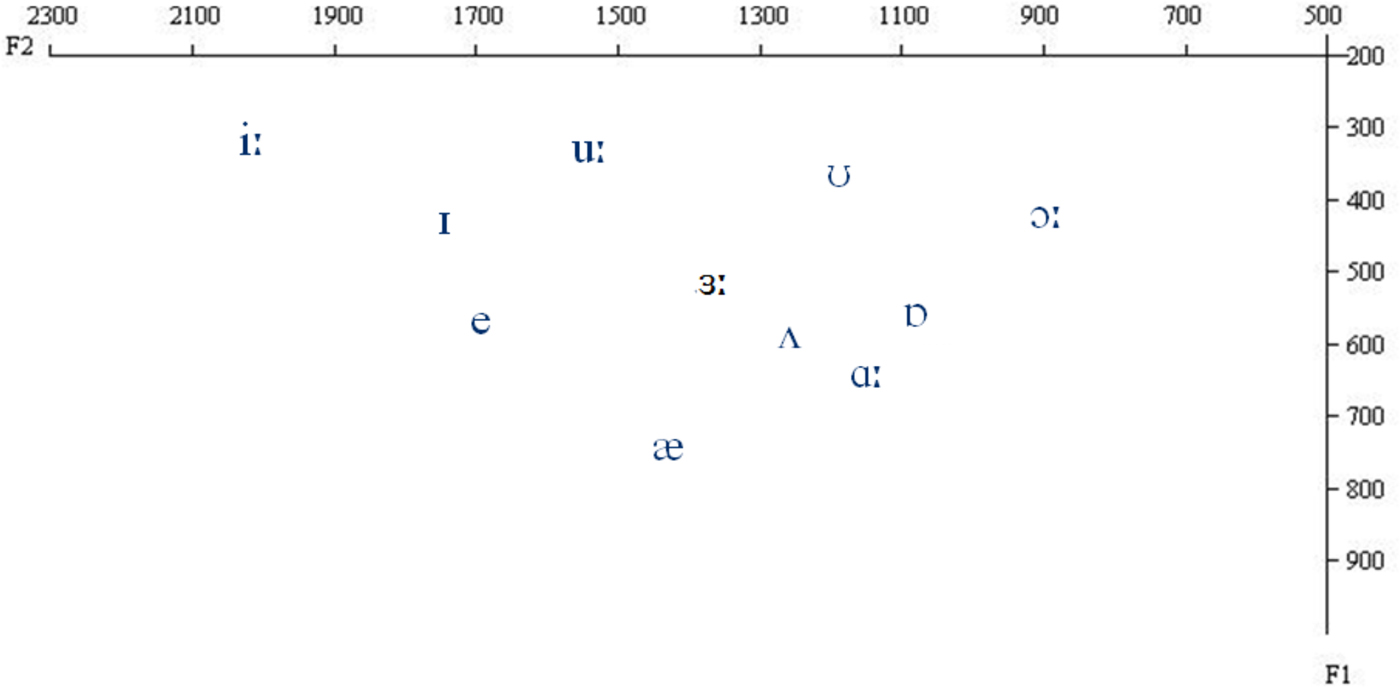
Figure 1: Average F1/F2 vowel spaces in Hertz of Southern Standard British English vowels in bilabial, alveolar and velar contexts recorded by a native speaker for the purpose of the present experiments.
2.2 Participants
Thirty-five students, with a mean age of 19 years 11 months, all first-year English majors at Adam Mickiewicz University in Poznań, Poland, took part in the experiment. They reported no hearing disorders. According to the Common European Framework of Reference for Languages, their knowledge of English was at a B2 level, which means they were upper intermediate students who could understand the main ideas of a complex text or interact with a degree of fluency with native speakers. The tests were carried out at the beginning of the participants’ first academic year in order to minimize the influence of university courses in English pronunciation and English phonetics and phonology on the results. Only two participants knew another foreign language at a level higher than B1 (the majority of the participants had a basic knowledge of either German, French or Spanish at A1/A2 levels). B1-level learners can understand the main points of utterance on familiar matters and can talk about familiar matters.
2.3 Procedure
The perception tests for this study were chosen and designed to evaluate the perception of English vowels by Polish listeners without the need to resort to phonetic symbols or orthographic labels. Following previous studies testing PAM predictions for both consonants (e.g., Best and Strange Reference Best and Strange1992, Best et al. Reference Best, McRoberts and Sithole1988) and vowels (Tyler et al. Reference Tyler, Best, Faber and Levitt2014), the participants completed a discrimination task and a category identification task with a goodness rating. Additionally, participants completed a (dis-)similarity rating task.
For the first test, participants completed a categorial discrimination oddity test. Ten contrasts were examined: /iː-ɪ, e-ɪ, e-æ, e-ɜː, e-ʌ, æ-ʌ, ʌ-ɒ, ɑː-ʌ, ɔː-ɒ, uː-ʊ/. These were chosen with aim of examining English vowels that are close to one another in the F1/F2 vowel space. Each of the 10 vowel pairs was incorporated into a triad, where A was a stimulus from one English vowel category and B was a stimulus from a contrasting vowel category. All six triad combinations, that is AAB, ABA, ABB, BBA, BAB, BAA were presented randomly during the test. The six triad combinations were assigned one contrast each, with the exception of the BAA and BBA types, which were assigned two contrasts. Each contrast was presented to a given listener twice in two consonantal contexts (either bilabial, alveolar or velar) and in two trial types (AAB, ABB, BAA, BBA, ABA, BAB) (see Appendix 1, Table 5), so that 40 responses were elicited from each participant. This step, which did not require all the contrasts in all consonantal contexts in all triad combinations, was taken to ensure that the task was not so long that it prevented the other two tasks from being performed during the same session.
To encourage listeners to focus on the phonetic category identity rather than the sheer physical identity of the stimuli, a categorial discrimination procedure was employed. In each triad, one stimulus was always the odd one, although the other two, while representing the same phonological category in the L2, were never physically identical: A1A2B1, A1B1B2, etc. Such a procedure prevented listeners from making simple acoustic identity judgments. This paradigm tests only those acoustic differences that influence category identity, and avoids the dilemma of notation of the responses. Additionally, the ISI (interstimulus interval) was relatively long to encourage phonological processing (ISI = 1 s, and the intertrial interval = 6 s).
Following the discrimination tests, participants performed an identification task, where they matched the English auditory stimulus with a Polish vowel label and rated the vowel's goodness in terms of its similarity to the chosen Polish vowel on a scale from 1 (barely matching the Polish vowel) to 7 (well matching). The labels in the identification task were six Polish orthographic vowel symbols: i, y, e, a, o and u. Polish vowel orthography is transparent, so using orthographic labels was judged to be clear to the participants, who had not been familiarized with IPA vowel symbols prior to the experiment. In this task, each participant listened to each of the 11 English vowels in each consonantal context (33 responses were elicited from each participant).
Participants also rated 12 pairings of English vowels for their perceived (dis-)similarity: /iː-ɪ, e-ɪ, e-æ, e-ɜː, e-ʌ, æ-ʌ, ʌ-ɒ, ɑː-ʌ, ɔː-ɒ, uː-ʊ, ʊ-ɜː, ɒ-ɑː/. Each pair was tested in three consonantal conditions (bilabial, alveolar and velar), yielding 36 vowel pairs to rate for each speaker. The stimuli were presented randomly. The participants were asked to indicate how dissimilar the vowels in the presented nonce words were, using a scale from 1 (barely similar) to 7 (very similar), and to make a guess if in doubt.
3. Results
In PAM studies, participants first complete discrimination tasks and then categorization tasks. In the series of experiments reported here, (dis-)similarity tasks were also completed at the end of the session. The results section, however, first describe the categorization results (section 3.1), as assimilation types are crucial for reporting the discrimination results (section 3.2). The (dis-)similarity ratings are presented in section 3.3.
3.1 Categorization results
The mean percentage of Polish vowel label selections for each stimulus syllable are presented in Table 1, along with the mean category goodness ratings for these selections. These values were obtained by averaging all participants’ ratings for a given stimulus/Polish vowel label pairing. An English vowel was deemed to be categorized if the same Polish vowel category was chosen to represent it in more than 70% of the cases (following Bundgaard-Nielsen et al. Reference Bundgaard-Nielsen, Best and Tyler2011, Antoniou et al. Reference Antoniou, Tyler and Best2012, Tyler et al. Reference Tyler, Best, Faber and Levitt2014).
Table 1: Mean percent categorization and goodness rating (in parentheses) of English vowel stimuli in terms of Polish vowel categories represented by orthographic letters.

As Tyler et al. (Reference Tyler, Best, Faber and Levitt2014) have observed, using data averaged across participants can cloud the analysis of discrimination and the testing of PAM's hypotheses, as interspeaker differences may be large. Therefore, each individual participant's assimilation pattern was determined for each contrast (see Appendix 2, Table 6). Participants categorized and rated each syllable three times. If two English vowels were categorized using the same Polish vowel label, and the differences in ratings were not larger than one point on a seven-point Likert scale, they were assigned an SC type. An SC label was also given if a different category was chosen in one trial, but its goodness rating was lower than the goodness rating for the major category. A CG type was assigned to two English vowels that were categorized as the same Polish vowel, but whose goodness ratings differed by more than one point on a seven-point Likert scale. A TC label was given to pairs of English vowels that were categorized as two separate Polish vowels. An English vowel was deemed to be uncategorized if it was categorized in three different Polish categories, or if it was categorized in two categories, but the category chosen once was rated more than one point higher on a seven-point Likert scale than the category chosen twice.
Table 2 presents the frequency of individual assimilation types observed per contrast. SC patterns were observed for many contrasts, with the exception of /e-æ/ and /e-ʌ/, and predominated in the case of /uː-ʊ/, /æ-ʌ/ and /ɑː-ʌ/ contrasts, where CG patterns were also notably present. CG patterns were predominant in the case of /ɔː-ɒ/ and /e-ɜː/ contrasts. TC types were predominant in the case of /e-æ/ (100%), /e-ʌ/ (94%), /ʌ-ɒ/ (86%), /e-ɪ/ (66%) and /iː-ɪ/ (43%) contrasts. Assimilation patterns with uncategorized sounds reached 31% for the following contrasts: /iː-ɪ/, /e-ɪ/, /e-ɜː/ and 21% for /uː-ʊ/, because /ɪ/, /ɜː/ and /ʊ/ were uncategorized.
Table 2: Frequency of individual assimilation types observed per contrast (in %). Boldfaced values in frequency distribution indicate the most frequent assimilation pattern per target contrast (each column sums to 100%).

3.2 Discrimination results
The overall mean percentages of correct discrimination responses for each contrast are presented in Figure 2. Participants performed above chance for all contrasts (see Table 3 for results of one-sample t-tests against a chance score of 50%), although the discrimination results for various contrasts varied, ranging from excellent discrimination for the /iː-ɪ/ contrast (99% correct responses) and four other contrasts (above 90% for /e-æ, ʌ-e, ʌ-ɒ, e-ɪ/), to very good discrimination for /ɔː-ɒ/ (87%) and /e-ɜː/ (82%), and fairly poor discrimination (below 80%) for /æ-ʌ, uː-ʊ/ and /ʌ-ɑː/ contrasts.
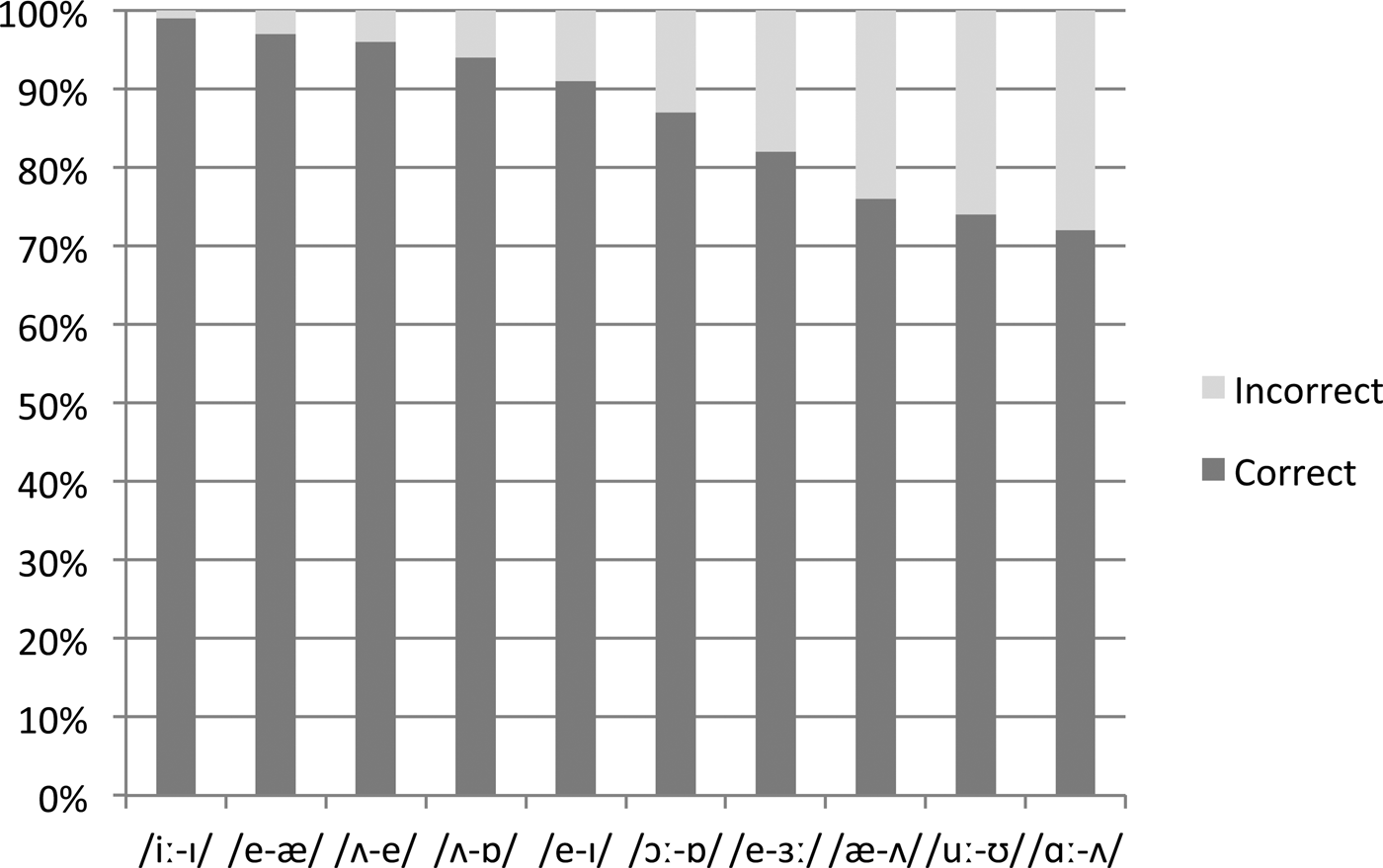
Figure 2: Mean percent correct discrimination scores for the 10 examined English vowel contrasts.
Table 3. Mean correct discrimination rate for each contrast in the experiment, listed in decreasing order, and the results of one-sample t-tests against a chance score of 50%.

Due to the extent of the individual differences observed in PAM assimilation types, it was not viable to test PAM predictions by relying on overall correct discrimination rates for a given contrast. Therefore, following Tyler et al. (Reference Tyler, Best, Faber and Levitt2014), the analysis was conducted on the basis of the observed assimilation types, as PAM predicts different discrimination rates for different assimilation types. Very good to excellent discrimination is predicted for both TC and CU types, in which either two non-native phones are perceived as acceptable exemplars of a native phoneme or one is perceived as an acceptable exemplar and another as something that is not an exemplar of the same phoneme. Because in these cases assimilations cross a phonological boundary and are expected to be at least very good, Tyler et al. (Reference Tyler, Best, Faber and Levitt2014) called them Cross Boundary assimilations (CB). Weaker correct discrimination rates are expected for CG assimilations, because both non-native phones are heard as tokens of the same native phoneme, though they nevertheless differ in the goodness of the fit to that phoneme. Poor discrimination is expected in the case of SC, in which two non-native phones are perceived as equally good or bad exemplars of a native category. The results presented in Figure 3 confirm these expectations, namely that CB are the best discriminated assimilations, followed by CG and SC. This finding gives a positive answer to the first research question: in the case of advanced learners of a language, discrimination rates also depend on assimilation types, as predicted by PAM.

Figure 3: Mean percent correct discrimination scores for contrasts falling into Cross Boundary (TC and UC), Category Goodness (CG) and Single Category (SC) assimilation types. Dark grey bars show the results for pairs in which in the AXB trial the change of direction was from a more to less peripheral vowel. Light grey bars represent results for pairs in which in the AXB trial the change of direction was from a less to a more peripheral vowel.
With reference to the second research question, the results did not provide support for reliance on NRV. There were only non-significant differences in discrimination rates between the trials in which the change of direction was from a more to a less peripheral vowel and the reverse. This issue will be discussed in section 4.1.
3.2.1 Consonantal context in discrimination tasks
Figure 4 presents the results of a discrimination task in /bVb/, /dVd/ and /gVg/ contexts. Overall, in /bVb/ and /dVd/ contexts there were more incorrect answers than in a /gVg/ context. Participants gave correct answers in 83% of cases in a /bVb/ context, 86% in a /dVd/ and 91% in a /gVg/ context. The analysis of variance confirmed the main effect of consonantal context, F = 6.83; p = 0.001116. Paired t-tests for /bVb/, /dVd/ and /gVg/ contexts confirmed that the difference between errors as a function of context was significant in the case of /bVb/ and /gVg/ contexts (t = –2.4144; p value = 0.01595) and /dVd/ vs. /gVg/ (t = –3.6285; p value = 0.0003038) contexts, but not between /bVb/ and /dVd/ contexts (t = 1.3519; p value = 0.1768). Closer inspection of the results (see Appendix 3, Tables 7a–k) revealed that in one case the discrimination rate was particularly low: in the case of /uː-ʊ/ contrast, the alveolar context correct discrimination rate was only 47%. This might mean that back vowel fronting in an alveolar context is particularly difficult for Polish learners. These findings answer in part research question number five, which asked about the effect of the place of articulation of the neighboring consonants on vowel perception. With respect to discrimination rates, we can conclude that the /gVg/ condition yields higher discrimination rates than the /bVb/ and /dVd/ contexts, and that discrimination of English high back centralized vowels fronted in the alveolar context is especially difficult for Polish listeners.

Figure 4: Percent errors for experimental vowel pairs in /bVb/, /dVd/ and /gVg/ contexts.
3.3 Results of dissimilarity ratings
In this experiment, participants rated the (dis-)similarity of two English vowels using a seven-point Likert scale, where 1 meant “not similar” and 7 meant “very similar”. Twelve contrasts were tested: /iː-ɪ, e-ɪ, e-æ, e-ɜː, e-ʌ, æ-ʌ, ʌ-ɒ, ɑː-ʌ, ɔː-ɒ, uː-ʊ, ʊ-ɜː, ɒ-ɑː/. Each contrast was tested in three consonantal conditions, yielding 36 trials per participant. A participant heard the two vowels embedded in two syllables with the same consonantal context, either /bVb/, /dVd/ or /gVg/, and they were asked to indicate on a seven-point scale whether they thought the two vowels were not similar (1) or very similar (7). The results of the discrimination task (see Table 4) are related to the vowel discrimination results. Low vowel pairs were considered to be the most similar: /æ-ʌ/ (4.21) and /ɑː-ʌ/ (4.02), and also happened to be the two worst discriminated ones (76% and 72% respectively). The two high rounded vowels /uː-ʊ/ were also considered similar (3.95), most likely because the two features [ + high] and [ + rounded] are associated with only one Polish /u/ category, which subsumes any L2 sounds sharing these two features. These two English vowels also posed difficulties in terms of discrimination (74% correct). The contrasts /ʌ-ɒ/ and /ɔː-ɒ/ were placed in the middle on the similarity–dissimilarity scale (3.4 and 3.36 respectively) and were also relatively well discriminated (93% and 87% respectively. The difference between their discrimination rates was not statistically significant with z = –1.82 and p-value = 0.07). There was a difference in the tongue height and the amount of lip rounding between these vowels, which may have been responsible for their relatively good discrimination, even though the vector length difference, especially between /ʌ-ɒ/, is relatively small. The /e-ɜː/ contrast was relatively difficult to discriminate (82% correct) and was also evaluated as being in the middle of the similarity – dissimilarity scale (3.27). Weaker discrimination can be ascribed to the fact that the major difference between these two vowels is in the tongue advancement only. The /iː-ɪ/ vowels were considered to be rather dissimilar (2.85) and also happened to be the best discriminated vowels (99.3% correct). The most dissimilar vowels /e-ʌ/ (2.47), /e-ɪ/ (2.31) and /e-æ/ (2.01) all had discrimination rates higher than 90% and were all categorized into different categories, with the English /e/ categorized as Polish /e/ with goodness of fit rated at 4.8, and /ʌ/, /ɪ/ and /æ/ not falling into the /e/ category; /e/ and the three other vowels in the most dissimilar contrasts were differentiated by the vowel height differences.
Table 4: Mean (dis-)similarity ratings of English vowel contrasts on a seven-point Likert scale.

3.3.1 The effects of the place of articulation of the adjacent consonants on vowel (dis-)similarity ratings
The study also checked whether the place of articulation of adjacent consonants influences the evaluation of (dis-)similarity between pairs of English vowels. A chi-squared test showed that context influences the perception of (dis-)similarity (Chi2 = 4.09), but when Wilcoxon tests were used to compare the influence of the consonantal contexts on vowel (dis-)similarity ratings, they found no significant differences (/b-d/: T= 29, T 0.05 = 14; /d-g/: T = 25, T 0.05 = 14 and /d-g /: T = 22, T 0.05 = 14). It can therefore be concluded, with reference to the fifth research question, that the place of articulation of adjacent consonants does not consistently influence English vowel (dis-)similarity ratings by Polish advanced learners of English.
4. Discussion
This article has examined how Polish advanced learners of English perceive English monophthongs. The language combination and vowels were expected to produce a wide range of assimilation patterns showing how complex advanced L2 vowel perception can be. After Tyler et al. (Reference Tyler, Best, Faber and Levitt2014) showed that perception of non-native vowel contrasts follows the same principles that have been observed for consonant contrasts, I sought to examine the details of vowel perception in a situation where the L2 had twice as many contrasts as the L1, participants were advanced foreign language learners in a formal classroom setting, and consonantal contexts were varied in order to answer the five research questions posed in section 1.5.
4.1 Discussion of discrimination results in the light of the Perceptual Assimilation Model and the Natural Referent Vowel framework
As with the results reported by Tyler et al. (Reference Tyler, Best, Faber and Levitt2014), the present results revealed considerable inter-individual variability in the assimilation patterns for non-native vowels. Five contrasts were predominantly categorized as TC (/e-æ/, /e-ʌ/, /ʌ-ɒ/, /e-ɪ/ and /iː-ɪ/), two contrasts were categorized as CG (/ɔː-ɒ/ and /e-ɜː/), and three as SC assimilation types (/uː-ʊ/, /æ-ʌ/ and /ɑː-ʌ/). Assimilation patterns with uncategorized sounds were observed for the following contrasts: /iː-ɪ/, /e-ɪ/, /e-ɜː/ and /uː-ʊ/. Since PAM predicts that discrimination should be most accurate for TC, followed by CG and then SC, discrimination data were grouped on the basis of assimilation type. Such a grouping allowed for a comparison of discrimination rates for both cross boundary assimilation types (TC and UC) to within-category assimilation types (CG and SC). The results confirm PAM's predictions about differing discrimination rates for different types of assimilation patterns (TC/UC > CG > SC). Among the TC contrasts, we find the best discriminated vowel pairs. As in the study by Tyler et al. (Reference Tyler, Best, Faber and Levitt2014), in the present experiment, evidence was found for all assimilation types, namely SC, CG, TC, UC and UU. These findings provide a positive answer to the first research question: in the case of advanced learners of a language, discrimination rates also depend on assimilation type, as predicted by PAM.
The NRV peripherality prediction states that a change from a less to a more peripheral vowel should be easier to notice than a change from a more to a less peripheral vowel. In Tyler et al. (Reference Tyler, Best, Faber and Levitt2014), in which foreign vowels previously unknown to the listeners were tested, this prediction was true for SC. No significant effect was found for CG, but the authors suggested that this result may have been due to the small number of CG assimilations in the database. TC/UC were discriminated at the ceiling, so no effect of peripherality could be expected. In the present study many more examples of CG were found, but no effect of peripherality was found for any assimilation type. The second research question is therefore answered in the negative. There are two possible explanations: either the ISIs were too short or the participants’ perception was actually closer to that of native speakers.
It should be noted that a categorial discrimination task was used here, following Tyler et al. (Reference Tyler, Best, Faber and Levitt2014). Other studies testing NRV used a different procedure, in which participants were asked to indicate whether or not the vowel had changed in a sequence of four syllables, separated by a long ISI of two seconds (Polka and Bohn Reference Polka and Bohn2011). The problem of the choice of task stemmed from the fact that the predictions of two theories were tested in a single experiment. It seems that the task employed in the present study was more demanding, because the participants had to decide which vowel was the odd one out. The situation with the ISIs differed: it was one second in Tyler et al. (Reference Tyler, Best, Faber and Levitt2014) and in the present study, but two seconds in other NRV studies. An ISI of one second or longer usually enhances phonological processing, so both choices should have served this purpose.
The lack of a peripherality effect can be attributed to the fact that participants in the study were familiar with English vowels, as they had been learning English for several years. As the asymmetry in vowel perception has so far been attested for native and non-native contrasts in infants up to six months of age, but only for non-native contrasts at 12 months and in adulthood (Polka and Bohn Reference Polka and Bohn2011), it can be hypothesized that when non-native vowels become familiar to listeners, they do not exhibit the effects of peripherality. In this respect, their perception becomes similar to the perception of native vowels.
4.2 Discussion of categorization results
The third research question asked how English vowels are assimilated to Polish vowel categories. An examination of categorization and goodness rating results reveals some interesting patterns. Focusing on the /iː-ɪ/ contrast first, it needs to be noted that there is asymmetry in perception here. English /iː/ was perceived as Polish /i/ in 96.3% of cases, with an average goodness rating of 4.9 on a seven-point Likert scale. At the same time, English /ɪ/ was also perceived as Polish /i/ in 42.6% of cases, with a goodness rating of 4.3 points. Fifty percent of English /ɪ/ instances were perceived as Polish /ɨ/ with an average goodness rating of 4.5. These results are in line with Szpyra-Kozłowska (Reference Szpyra-Kozłowska2016), who examined the adaptation of English /ɪ/ in loanwords in Polish and found a similar pattern in an /ɪ/ categorization study, leading her to conclude that English /ɪ/ is mostly nativized as Polish /i/ in line with nativization through production (LaCharité and Paradis Reference LaCharité and Paradis2005), as a substitution that is phonologically and not phonetically or perceptually motivated. An additional argument for the important role of phonology in the perception of the /iː/-/ɪ/ contrast is that in the present study, 80% of English /ɪ/ instances in a velar context were perceived as /i/. The explanation for this finding lies in Polish phonotactics, which does not allow for /ɨ/ after velars. The result suggests that Polish learners of English upon hearing /gɪg/ repair the vowel in an illegal /CVC/ string to its nearest legal /CVC/ counterpart. It can therefore be concluded that the perception of second language vowels is governed by L1 and L2 vowel characteristics, but also by co-occurrence restrictions on consonant-vowel combinations in the L1. Bundgaard-Nielsen et al. (Reference Bundgaard-Nielsen, Kilpatrick and Baker2016) showed the same effect for English consonants when perceived in illegal Japanese /VCV/ strings by Japanese learners of English, and noticed that models of non-native and cross-language speech perception like PAM can predict perception success for non-native contrasts, but do not address the issue of how native phonotactics may influence non-native segmental perception. The present finding offers yet additional evidence that perception is modified by phonotactics.
97.5% of English /e/ instances were perceived as Polish /e/, with relatively high goodness rankings (4.8); the articulatory difference is claimed to be in the vowel height. English /ɜː/ is an uncategorized vowel, with 57% receiving /e/ categorizations and goodness rated at 3.6, 22.3% receiving /a/ categorizations and goodness rated at 3 points, and 20.6% receiving /ɨ/ categorizations and goodness rated at 4 points. The acoustic difference in both F1 and F2 in the case of English /ɜː/ was perceived as being more foreign than just a difference in vowel height between English and Polish /e/.
English low vowels are perceived by Poles in a characteristic way. Polish has only one low vowel: a central /a/. All English low vowels are perceived as Polish /a/, but with different goodness ratings. English /æ/ is categorized as Polish /a/ with the highest goodness rating results: 4.8 points. The formant values for /æ/ in the present study are typical of the current British English centralized low /æ/ as reported by Hawkins and Midgley (Reference Hawkins and Midgley2005), as opposed to the former front /æ/. The results suggest that participants considered it to be a perceptual counterpart of Polish /a/;Footnote 4 the production results obtained by Gonet et al. (Reference Gonet, Szpyra-Kozłowska, Święciński and Waniek-Klimczak2010) pointing to the Polish vowels /e/ and /a/ as substitutes for English /æ/ are therefore probably based heavily on spelling. The English /ʌ/ in 82% of instances was categorized as Polish /a/, though with slightly lower goodness ratings of 4.6 points. The remarkably back English /ɑː/ had the lowest goodness ratings as an exemplar of Polish /a/, at only 4.1 points. It can be observed that the more retracted a vowel is, the lower the goodness ratings it received. Almost 13% of English /ʌ/ cases were categorized as Polish /o/, and unsurprisingly the goodness ratings were relatively lower, at 3.7. Nevertheless, this result also suggests that any feature that differs from the features present in an L1 category yields lower goodness ratings. It is worth noting that discrepancies in vowel height are easier to spot and penalized more than those in tongue advancement.
As for the English mid back vowels /ɒ/ and /ɔː/, the participants seemed to judge /ɒ/ to be the best exemplar of the Polish /o/, as 97.2% of its instances were categorized as /o/, and the goodness ranking's average was high: 5.2 points. English /ɔː/ was perceived as Polish /o/ in 89.8% of cases, and its goodness of fit was rated at 4 points. In 10.2% of the instances it was perceived as Polish /uː/ with a goodness ranking of 3.8 points. If we assume that the height of the Polish vowel is intermediate between the two English vowels, we can see how the tenseness of /ɔː/ contributes to the vowel being judged as a worse exemplar than /ɒ/.
English /uː/ and /ʊ/ were mainly perceived as Polish /u/, but certain details need to be mentioned. 97.2% of English /uː/ instances were perceived as Polish /u/, with a goodness rating of 4.1 points. In comparison, only 78.7% of /ʊ/ instances were judged to be similar to Polish /u/ (goodness rating: 4.7) as opposed to 20.4% which were evaluated as being similar to Polish /ɨ/ (goodness rating: 3.6). The /ʊ/ instances that were perceived as /ɨ/ were only the vowels embedded in /bVb/ (20%, goodness rating 3.4) and /dVd/ (40%, goodness rating 3.7) contexts. The latter case in particular can be interpreted as a result of rounded vowel fronting in alveolar contexts. A more detailed study involving the three contexts and duration steps could permit a disentangling of the roles of vowel formants, contextual influences and duration/tenseness.
4.3 Discussion of (dis-)similarity rating results
As Flege et al. (Reference Flege, Munro and Fox1994) argue, if bilinguals establish additional phonetic categories for L2 vowels, these new vowel categories should seem dissimilar in a crowded vowel space. The higher the perceived dissimilarity between L2 vowels, the more likely it is that new phonetic categories for these vowels would be established.
With regard to the fourth research question, about the relationship between discrimination rates and (dis-)similarity ratings, in the present study, poorly discriminated pairs (/e-ɜː, æ-ʌ, uː-ʊ, ʌ-ɑː/) were the ones judged to be most similar. Judging low vowels to be similar is yet another argument for the three vowels functioning as one Polish /a/ category with various degrees of goodness. Two more contrasts (/ɒ-ɔː/ and /ʌ-ɒ/) deemed to be similar were discriminated at a rate higher than 85%. The actual difference in discrimination rates between /ɒ-ɔː/ and /e-ɜː/ was not statistically significant (z = 1.15, p-value = 0.25). Furthermore, we can claim that a difference in vowel height allowed for good discrimination of /ʌ-ɒ/. In the remaining cases, however, height differences contributed to judging vowels as dissimilar (results equal to or less than 3.01 on a seven-point Likert scale): /ɒ-ɑː/, /iː-ɪ/, /ʊ-ɜː/, /e-ʌ/, /e-ɪ/, /e-æ/. Note that differences in duration and tenseness did not enhance the perception of vowels as different. Moreover, the least similar vowel pairs, that is /e-æ/, /e-ɪ/ and /e-ʌ/ do not have duration/tenseness distinctions.
4.4 Conclusions about the effects of the place of articulation of adjacent consonants on English vowel perception
As regards the fifth research question, the place of articulation of the neighbouring consonants does not seem to play a very important role in English vowel perception by Polish advanced learners of English. In categorization, it does play a role in cases where phonotactic limitations apply in the L1. When a velar consonant is followed by /ɪ/ in English, this /ɪ/ is likely to be heard as the closest counterpart, that is /i/, because Polish phonotactics does not allow for /gɨ/ sequences, but it does allow for /gi/ sequences. In PAM's terms, /iː-ɪ/ contrast falls under the SC type in a velar context, but in a bilabial or alveolar context this might be TC or CG. In the case of /uː/ and /ʊ/, the discrimination rate was very low in an alveolar context, participants were more hesitant to categorize the two vowels in an alveolar context, and they gave vowels between alveolar consonants lower goodness ratings, probably signaling that they found it strange to hear such a centralized vowel with rounding.
In the discrimination task, vowels in a velar context seemed to be slightly easier to distinguish than vowels in bilabial or alveolar contexts. In the (dis-)similarity rating task, there was no clear effect from the consonantal context. In conclusion, the issue of the place of articulation of the neighboring consonants is worth further investigation when it comes to English back-vowel fronting and the effects of phonotactic limitations on vowel perception. The results reported by Levy and Strange (Reference Levy and Strange2008), Bundgaard-Nielsen et al. (Reference Bundgaard-Nielsen, Kilpatrick and Baker2016) and the present study show the influence that the place of articulation of neighboring consonants might exert on certain consonant-vowel combinations. It is not the case here that certain consonants made perception more or less challenging (except for discrimination in velar vs. coronal contexts). The effects of context are evident where context influences coarticulation or when there are phonotactic limitations associated with a given context.
4.5 General discussion
In the present article, three experiments testing the perception of 11 British English monophthongs by Polish advanced learners of English in a formal setting provided answers to five research questions.
With regard to assimilation patterns, SC assimilations predominated in the case of /uː-ʊ/, /æ-ʌ/ and /ɑː-ʌ/ contrasts, CG patterns dominated in the case of /ɔː-ɒ/ and /e-ɜː/ contrasts, and finally the TC dominated in the case of /e-æ/ (100%), /e-ʌ/ (94%), /ʌ-ɒ/ (86%), /e-ɪ/ (66%) and /iː-ɪ/ (43%) contrasts. There were also UC assimilation types: /iː-ɪ/, /e-ɪ/, /e-ɜː/, /uː-ʊ/, because /ɪ/, /ɜː/ and /ʊ/ were uncategorized. Higher goodness ratings were assigned to more frequent assimilation targets for a given English vowel and to lax rather than tense vowels.
As an answer to the first research question, it can be claimed that in the case of FLA, discrimination rates depend on assimilation types: CB types are the best discriminated, followed by CG and SC types. It can therefore be concluded that vowel perception in FLA follows the patterns predicted by PAM (Best Reference Best and Strange1995, Best and Tyler Reference Best, Tyler, Munro and Bohn2007).
As regards the second research question, NRV's predictions were not supported in this study. It remains to be examined with a larger sample and other kinds of tasks whether advanced learners of FL can in fact perceive FL vowels in a mode similar to native speakers, that is without referring to more peripheral vowels as anchors.
The third research question asked about assimilation of L2 English vowels to L1 Polish categories. The study provides a description of English monophthong perception by Polish advanced learners of English.
Systematic relationships between discrimination rates and (dis-)similarity ratings have been shown. These findings answer the fourth research question. The best-discriminated vowel contrasts came, as predicted, from TC assimilation types.
English low vowels proved to be difficult for Polish participants to discriminate. In the identification task they were categorized as Polish /a/, but with decreasing goodness ratings from /æ/ through /ʌ/ to /ɑː/. In the (dis-)similarity rating task, /æ-ʌ/ and /ɑː-ʌ/ were judged to be the most similar vowel pairs of all those presented. The above results suggest that /æ ʌ ɑː/ are perceived by Polish learners in terms of Polish /a/, and that tongue advancement differences between them and the tenseness of /ɑː/ are not enough to yield easy discrimination or differentiation among these three vowels.
With regard to the fifth research question, it can be stated that Polish advanced learners of English mastered L2-specific coarticulatory variations, with two exceptions. They had difficulties perceiving high back centralized vowels, which undergo fronting in alveolar contexts. They did not seem to have overcome the Polish phonotactic restriction on /ɪ/ in velar contexts.
Even though FLA is different from SLA when it comes to the frequency and quality of input, the systematic results of the present experiments seem to support the claim that perception in foreign language acquisition by advanced learners is in line with PAM's predictions.
The study's main limitation has to do with NRV. No support for NRV predictions was found. There are two possible explanations: different methodologies, or no effect of peripherality in the case of advanced learners. The discrimination task was chosen to be in line with PAM requirements, following Tyler et al. (Reference Tyler, Best, Faber and Levitt2014), who targeted both PAM and NRV for the first time. In the present article, to encourage sufficient deviation from ceiling performance, a categorial discrimination oddity task – rather than categorial AXB test in blocks – was used. Both Tyler et al. (Reference Tyler, Best, Faber and Levitt2014) and the present study used the ISI of one second. Traditionally, NRV studies used various change-detection paradigms with a two-second ISI. These are substantial methodological differences. In the light of previous research on NRV, it seems plausible that NRV effects do not apply in the case of advanced learners, especially given that Tyler et al. (Reference Tyler, Best, Faber and Levitt2014), using similar methodology, found some evidence for NRV effects in naïve listeners. Nevertheless, these discrepancies in methodology need to be minimized in further studies to allow for unambiguous conclusions.
It would also be informative to conduct a study testing the predictions of PAM and NRV by comparing second-language learners in a natural L2 setting with foreign-language classroom learners with the same language combination and similar levels of language competence.
Appendix 1
Table 5: Presentation of contrast by configuration (trial type vs. consonantal context).

Appendix 2
Table 6: Individual contrast assimilation types for each participant for each contrast.

Appendix 3
Mean percent categorization and goodness rating (in parentheses) of English vowel stimuli in terms of Polish vowel categories represented by orthographical letters, split into bilabial, alveolar and velar contexts.
Table 7a: English /i:/

Table 7b: English /ɪ/

Table 7c: English /e/

Table 7d: English /æ/

Table 7e: English /ʌ/

Table 7f: English /ɜː/
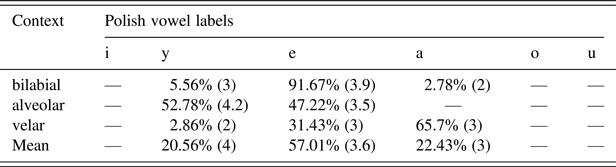
Table 7g: English /ɑː/

Table 7h: English /ɒ/
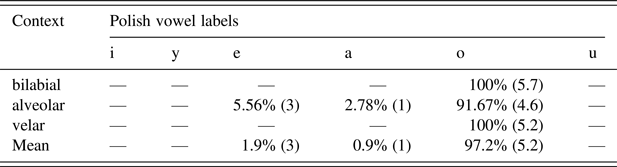
Table 7i: English /ɔː/

Table 7j: English /ʊ/

Table 7k: English /uː/























 Open access
Open access