



1. Introduction
We consider the problem of predicting outstanding claims costs from insurance contracts whose coverage periods have expired but for which not all claims are known to the insurer. Such prediction tasks are referred to as claims reserving. The chain ladder method is arguably the most widespread and well-known technique for claims reserving based on claims data organized in run-off triangles, with cells indexed by accident year and development year. The chain ladder method is a deterministic prediction method for predicting the not yet known southeast corner (target triangle) based on the observed northwest corner (historical triangle) of a square with cell values representing accumulated total claims amounts. The square and historical triangle can easily be generalized to rectangle and trapezoid, reflecting claims data for more historical accident years. However, we will here consider the traditional setup in order to simplify comparison with influential papers. We refer to the text book (Wüthrich and Merz, Reference Wüthrich and Merz2008) by Wüthrich and Merz for an overview of methods for claims reserving.
Important contributions appeared in the 1990s presenting stochastic models and properties of parametric stochastic models that give rise to the chain ladder predictor. Mack (Reference Mack1993) presented three model properties, known as the distribution-free chain ladder model, that together with weighted least squares estimation give rise to the chain ladder predictor. Renshaw and Verrall (Reference Renshaw and Verrall1998) showed that independent Poisson distributed cell values for incremental total claims amounts, together with Maximum Likelihood estimation of parameters for row and column effects, give rise to the chain ladder predictor. The Poisson model is inconsistent with the distribution-free chain ladder.
The most impressive contribution of Mack (Reference Mack1993) is the estimator of conditional mean squared error of prediction. The key contribution is the estimator of the contribution of parameter estimation error to conditional mean squared error of prediction. A number of papers have derived the same estimator based on different approaches to statistical estimation in settings consistent with the distribution-free chain ladder, see for example Merz and Wüthrich (Reference Merz and Wüthrich2008), Röhr (Reference Röhr2016), Diers et al. (Reference Diers, Linde and Hahn2016), Gisler (2019), and Lindholm et al. (Reference Lindholm, Lindskog and Wahl2020).
Different approaches to the estimation of, and estimators of, prediction error for the chain ladder method sparked some scientific debate, both regarding which stochastic model underlies the chain ladder methods, see for example the papers by Mack and Venter (Reference Mack and Venter2000) and Verrall and England (Reference Verrall and England2000), and regarding prediction error estimation for the chain ladder method, see Buchwalder et al. (Reference Buchwalder, Bühlmann, Merz and Wüthrich2006), Gisler (2006), Mack et al. (Reference Mack, Quarg and Braun2006), and Venter (Reference Venter2006). Gisler revisited, in Gisler (2021), different estimators for conditional mean squared error in the setting of the distribution-free chain ladder. Ultimately, Mack’s estimator of conditional mean squared error of prediction has stood the test of time.
The main contribution of the present paper is that we show that a simple but natural compound Poisson model is fully compatible with both the chain ladder predictor and Mack’s estimator of conditional mean squared error of prediction, although the model is incompatible with Mack’s distribution-free chain ladder, as long as we consider an insurance portfolio with sufficiently large exposure (e.g., accumulated total claims amounts based on sufficiently many contracts). The Poisson model considered by Renshaw and Verrall (Reference Renshaw and Verrall1998) is a special case of the compound Poisson model we consider, and consequently also their Poisson model gives rise to Mack’s estimator of conditional mean squared error of prediction.
The rest of the paper is organized as follows. Section 2 presents the stochastic model we consider, both a simple model called the special model and a more general model. The special model is a classical insurance loss model (independent compound Poisson processes in each cell of the run-off triangle of incremental total claims amounts). Section 3 recalls Mack’s distribution-free chain ladder. Section 4 presents asymptotic results that demonstrate that we can retrieve Mack’s classical estimators in model setting that are incompatible with the distribution-free chain ladder. Section 5 presents a numerical example that illustrates the theoretical results in Section 4. The proofs are found in Section 6.
2. The model
We will focus on a simple yet general class of models for the number of reported claims and the cost of these claims. In line with classical reserving methods based on claims data organized in run-off triangles, we consider T accident years and T development years. For
 $i,t\in \mathcal{T}=\{1,\dots,T\}$
, let
$i,t\in \mathcal{T}=\{1,\dots,T\}$
, let
 $C^{\alpha}_{i,t}$
denote the accumulated total claims amount due to accident events in accident year i that are paid up to and including development year t. The parameter
$C^{\alpha}_{i,t}$
denote the accumulated total claims amount due to accident events in accident year i that are paid up to and including development year t. The parameter
 $\alpha$
is a measure of exposure, such as the number of contracts of not yet fully developed accident years. We will analyze asymptotics as
$\alpha$
is a measure of exposure, such as the number of contracts of not yet fully developed accident years. We will analyze asymptotics as
 $\alpha\to\infty$
and use the findings to motivate the use of well-established predictors and estimators in settings that are not consistent with model assumptions used to derive the classical results for the chain ladder method. A given claims reserving situation of course corresponds to a single, typically large, number
$\alpha\to\infty$
and use the findings to motivate the use of well-established predictors and estimators in settings that are not consistent with model assumptions used to derive the classical results for the chain ladder method. A given claims reserving situation of course corresponds to a single, typically large, number
 $\alpha$
. As in any other situation where asymptotic arguments are the basis for approximation, we embed the prediction problem in a sequence of prediction problems, indexed by
$\alpha$
. As in any other situation where asymptotic arguments are the basis for approximation, we embed the prediction problem in a sequence of prediction problems, indexed by
 $\alpha$
.
$\alpha$
.
The special model is simply a set of independent Cramér–Lundberg (compound Poisson) models, indexed by accident year and development year, with a common claim size distribution with finite variance and positive mean, where exposure parameter
 $\alpha$
plays the role of time in the Cramér–Lundberg models. For
$\alpha$
plays the role of time in the Cramér–Lundberg models. For
 $i,t\in \mathcal{T}$
, consider the incremental total claims amount
$i,t\in \mathcal{T}$
, consider the incremental total claims amount
 $X^{\alpha}_{i,t}$
due to accident events in accident year i that are paid during development year t:
$X^{\alpha}_{i,t}$
due to accident events in accident year i that are paid during development year t:
 $X^{\alpha}_{i,1}=C^{\alpha}_{i,1}$
and
$X^{\alpha}_{i,1}=C^{\alpha}_{i,1}$
and
 $X^{\alpha}_{i,t}=C^{\alpha}_{i,t}-C^{\alpha}_{i,t-1}$
for
$X^{\alpha}_{i,t}=C^{\alpha}_{i,t}-C^{\alpha}_{i,t-1}$
for
 $t\geq 2$
. Consider constants
$t\geq 2$
. Consider constants
 $\lambda_1,\dots,\lambda_T\in (0,\infty)$
and
$\lambda_1,\dots,\lambda_T\in (0,\infty)$
and
 $q_1,\dots,q_T\in (0,1)$
with
$q_1,\dots,q_T\in (0,1)$
with
 $\sum_{t=1}^{T}q_t=1$
. For each
$\sum_{t=1}^{T}q_t=1$
. For each
 $i,t\in \mathcal{T}$
,
$i,t\in \mathcal{T}$
,
 $(X^{\alpha}_{i,t})_{\alpha\geq 0}$
is a Cramér–Lundberg model with representation:
$(X^{\alpha}_{i,t})_{\alpha\geq 0}$
is a Cramér–Lundberg model with representation:
 \begin{align*}X^{\alpha}_{i,t}=\sum_{k=1}^{N^{\alpha}_{i,t}}Z_{i,t,k}, \quad \alpha\geq 0,\end{align*}
\begin{align*}X^{\alpha}_{i,t}=\sum_{k=1}^{N^{\alpha}_{i,t}}Z_{i,t,k}, \quad \alpha\geq 0,\end{align*}
where
 $(N^{\alpha}_{i,t})_{\alpha\geq 0}$
is a homogeneous Poisson process with intensity
$(N^{\alpha}_{i,t})_{\alpha\geq 0}$
is a homogeneous Poisson process with intensity
 $\lambda_iq_t\in (0,\infty)$
, independent of the i.i.d. sequence
$\lambda_iq_t\in (0,\infty)$
, independent of the i.i.d. sequence
 $(Z_{i,t,k})_{k=1}^{\infty}$
. The claim size variables satisfy
$(Z_{i,t,k})_{k=1}^{\infty}$
. The claim size variables satisfy
 $Z_{i,t,k}\stackrel{d}{=} Z$
for all i, t, k for some Z with finite variance and positive mean. Moreover, the compound Poisson processes
$Z_{i,t,k}\stackrel{d}{=} Z$
for all i, t, k for some Z with finite variance and positive mean. Moreover, the compound Poisson processes
 $(X^{\alpha}_{i,t})_{\alpha\geq 0}$
,
$(X^{\alpha}_{i,t})_{\alpha\geq 0}$
,
 $(i,t)\in \mathcal{T}\times \mathcal{T}$
, are independent. Note that the counting variable
$(i,t)\in \mathcal{T}\times \mathcal{T}$
, are independent. Note that the counting variable
 $N^{\alpha}_{i,t}$
has a Poisson distribution with mean
$N^{\alpha}_{i,t}$
has a Poisson distribution with mean
 $\alpha\lambda_iq_t$
. Hence,
$\alpha\lambda_iq_t$
. Hence,
 $N^{\alpha}_{i,1}+\dots+N^{\alpha}_{i,T}$
has a Poisson distribution with mean
$N^{\alpha}_{i,1}+\dots+N^{\alpha}_{i,T}$
has a Poisson distribution with mean
 $\alpha\lambda_i$
, from which it is seen that the distribution of the total number of claims is allowed to depend on the index of the accident year. Note also that the parameter
$\alpha\lambda_i$
, from which it is seen that the distribution of the total number of claims is allowed to depend on the index of the accident year. Note also that the parameter
 $\alpha$
in
$\alpha$
in
 $(N^{\alpha}_{i,t})_{\alpha\geq 0}$
allows us to understand effects arising by varying the exposure
$(N^{\alpha}_{i,t})_{\alpha\geq 0}$
allows us to understand effects arising by varying the exposure
 $\alpha\lambda_i$
. The parameter
$\alpha\lambda_i$
. The parameter
 $\alpha$
should not be interpreted as “time.”
$\alpha$
should not be interpreted as “time.”
We want to highlight the special case of the special model obtained by letting
 $Z\equiv 1$
. In this case, the special model is simply a set of independent homogeneous Poisson processes, indexed by accident year and development year. In particular, for a fixed
$Z\equiv 1$
. In this case, the special model is simply a set of independent homogeneous Poisson processes, indexed by accident year and development year. In particular, for a fixed
 $\alpha$
, we obtain the model considered by Renshaw and Verrall (Reference Renshaw and Verrall1998) as a model underlying the chain ladder method since it gives rise to the chain ladder predictor (see Section 3) upon replacing unknown parameters by their Maximum Likelihood estimates.
$\alpha$
, we obtain the model considered by Renshaw and Verrall (Reference Renshaw and Verrall1998) as a model underlying the chain ladder method since it gives rise to the chain ladder predictor (see Section 3) upon replacing unknown parameters by their Maximum Likelihood estimates.
2.1. The general model
Several of the statements in Section 4 hold for a wider class of models than the special model. The general model, (GM1)–(GM4), allows us to write
 \begin{align*}C^{\alpha}_{i,t}=\sum_{k=1}^{M^{\alpha}_i}Z_{i,k} I\{D_{i,k}\leq t\},\end{align*}
\begin{align*}C^{\alpha}_{i,t}=\sum_{k=1}^{M^{\alpha}_i}Z_{i,k} I\{D_{i,k}\leq t\},\end{align*}
where
 $M^{\alpha}_i$
denotes the number of accident events in accident year i,
$M^{\alpha}_i$
denotes the number of accident events in accident year i,
 $Z_{i,k}$
denotes the size of the kth such claim, and
$Z_{i,k}$
denotes the size of the kth such claim, and
 $D_{i,k}$
denotes the corresponding development year, the indicator
$D_{i,k}$
denotes the corresponding development year, the indicator
 $I\{D_{i,k}\leq t\}$
equals 1 if
$I\{D_{i,k}\leq t\}$
equals 1 if
 $D_{i,k}\leq t$
. For instance,
$D_{i,k}\leq t$
. For instance,
 $D_{i,k}\leq 2$
means that the kth claim from accident events in accident year i was settled no more than two years from the beginning of accident year i. The properties GM1–GM4 together constitute the general model:
$D_{i,k}\leq 2$
means that the kth claim from accident events in accident year i was settled no more than two years from the beginning of accident year i. The properties GM1–GM4 together constitute the general model:
-
(GM1)
 $(D_{1,k},Z_{1,k})_{k=1}^{\infty}, \dots, (D_{T,k},Z_{T,k})_{k=1}^{\infty}$
are i.i.d. sequences. The common distribution of the terms
$(D_{i,k},Z_{i,k})$
does not depend on the accident year i. With (D, Z) denoting a generic such pair,
\begin{align*}\mathrm{E}[Z^2]\lt \infty \quad\text{and}\quad \mathrm{E}[ZI\{D=t\}]\gt 0 \quad\text{for each } t\in\mathcal{T}.\end{align*}
$(D_{1,k},Z_{1,k})_{k=1}^{\infty}, \dots, (D_{T,k},Z_{T,k})_{k=1}^{\infty}$
are i.i.d. sequences. The common distribution of the terms
$(D_{i,k},Z_{i,k})$
does not depend on the accident year i. With (D, Z) denoting a generic such pair,
\begin{align*}\mathrm{E}[Z^2]\lt \infty \quad\text{and}\quad \mathrm{E}[ZI\{D=t\}]\gt 0 \quad\text{for each } t\in\mathcal{T}.\end{align*}
-
(GM2) For each i,
$(D_{i,k},Z_{i,k})_{k=1}^{\infty}$
and
$M^{\alpha}_i$
are independent. -
(GM3)
$\{M^{\alpha}_1,(D_{1,k},Z_{1,k})_{k=1}^{\infty}\}, \dots, \{M^{\alpha}_T,(D_{T,k},Z_{T,k})_{k=1}^{\infty}\}$
are independent. -
(GM4) For each i, there exists
$\lambda_i\in (0,\infty)$
such that
$M^{\alpha}_i/\alpha \stackrel{\mathrm{a.s.}}{\to} \lambda_i$
as
$\alpha\to\infty$
.









By (GM3), claims data variables are independent if they correspond to different accident years. However, the components of (D, Z) are possibly dependent, allowing for the distribution of claim size to depend on development year. Note that we allow for exposures to vary between accident years, reflected in possibly different parameters
 $\lambda_1,\dots,\lambda_T$
in statement (GM4). Note also that the incremental total claims amounts
$\lambda_1,\dots,\lambda_T$
in statement (GM4). Note also that the incremental total claims amounts
 $X^{\alpha}_{i,s}$
and
$X^{\alpha}_{i,s}$
and
 $X^{\alpha}_{i,t}$
,
$X^{\alpha}_{i,t}$
,
 $s\neq t$
, are in general not independent (unless
$s\neq t$
, are in general not independent (unless
 $M^{\alpha}_i$
is Poisson distributed).
$M^{\alpha}_i$
is Poisson distributed).
In order to derive Mack’s estimator in Mack (Reference Mack1993) of conditional mean squared error of prediction for the chain ladder predictor, we must consider a special case of the general model:
-
(SM2) D and Z are independent.
-
(SM3) For each i,
$(M^{\alpha}_i)_{\alpha\geq 0}$
is a homogeneous Poisson process with intensity
$\lambda_i\in (0,\infty)$
.


The properties (SM1)–(SM3) together form an alternative way of specifying the special model. Since (SM3) implies (GM4), the special model is a special case of the general model.
Note that the special model allows for different representations/interpretations. For instance, if there are
 $\alpha\lambda_i/\gamma$
contracts that may cause claim events during accident year i, and if each such contract, independently, gives rise to a
$\alpha\lambda_i/\gamma$
contracts that may cause claim events during accident year i, and if each such contract, independently, gives rise to a
 $\mathrm{Pois}(\gamma)$
number of claims payments, then we may write
$\mathrm{Pois}(\gamma)$
number of claims payments, then we may write
 \begin{align*}C^{\alpha}_{i,t}=\sum_{j=1}^{\alpha\lambda_i/\gamma}\sum_{k=1}^{O_{i,j}}Z_{i,j,k} I\{D_{i,j,k}\leq t\},\quad M^{\alpha}_i=\sum_{j=1}^{\alpha\lambda_i/\gamma}O_{i,j},\end{align*}
\begin{align*}C^{\alpha}_{i,t}=\sum_{j=1}^{\alpha\lambda_i/\gamma}\sum_{k=1}^{O_{i,j}}Z_{i,j,k} I\{D_{i,j,k}\leq t\},\quad M^{\alpha}_i=\sum_{j=1}^{\alpha\lambda_i/\gamma}O_{i,j},\end{align*}
where
 $(O_{i,j})_{j=1}^{\infty}$
is an i.i.d. sequence of
$(O_{i,j})_{j=1}^{\infty}$
is an i.i.d. sequence of
 $\mathrm{Pois}(\gamma)$
-distributed random variables independent of the i.i.d. sequences
$\mathrm{Pois}(\gamma)$
-distributed random variables independent of the i.i.d. sequences
 $(D_{i,j,k},Z_{i,j,k})_{k=1}^{\infty}$
,
$(D_{i,j,k},Z_{i,j,k})_{k=1}^{\infty}$
,
 $j\geq 1$
, with
$j\geq 1$
, with
 $(D_{i,j,k},Z_{i,j,k})\stackrel{d}{=} (D,Z)$
.
$(D_{i,j,k},Z_{i,j,k})\stackrel{d}{=} (D,Z)$
.
3. Mack’s distribution-free chain ladder
The arguably most well-known method for claims reserving is the chain ladder method. In the seminal paper (Mack, Reference Mack1993), Thomas Mack presented properties, see (3.1) and (3.2) below, for conditional distributions of accumulated total claims amounts that, together with (3.3) below, make the chain ladder prediction method the optimal prediction method for predicting outstanding claims amounts. However, the main contribution of Mack (Reference Mack1993) is the explicit estimator (see (3.4) below) of the conditional mean squared error of the chain ladder predictor.
With
 $C_{i,t}$
denoting the accumulated total claims amount up to and including development year t for accidents during accident year i, Mack considered the following assumptions for the data generating process: for
$C_{i,t}$
denoting the accumulated total claims amount up to and including development year t for accidents during accident year i, Mack considered the following assumptions for the data generating process: for
 $t=1,\dots,T-1$
, there exist constants
$t=1,\dots,T-1$
, there exist constants
 $f_{\mathrm{MCL}t}\gt 0$
and
$f_{\mathrm{MCL}t}\gt 0$
and
 $\sigma_{\mathrm{MCL}t}^2\geq 0$
such that
$\sigma_{\mathrm{MCL}t}^2\geq 0$
such that
 \begin{align}&\mathrm{E}[C_{i,t+1} \,|\, C_{i,1},\dots,C_{i,t}]=f_{\mathrm{MCL}t}C_{i,t}, \quad t=1,\dots,T-1, \end{align}
\begin{align}&\mathrm{E}[C_{i,t+1} \,|\, C_{i,1},\dots,C_{i,t}]=f_{\mathrm{MCL}t}C_{i,t}, \quad t=1,\dots,T-1, \end{align}
 \begin{align}&\mathrm{var}(C_{i,t+1}\,|\, C_{i,1},\dots,C_{i,t})=\sigma_{\mathrm{MCL}t}^2C_{i,t}, \quad t=1,\dots,T-1, \end{align}
\begin{align}&\mathrm{var}(C_{i,t+1}\,|\, C_{i,1},\dots,C_{i,t})=\sigma_{\mathrm{MCL}t}^2C_{i,t}, \quad t=1,\dots,T-1, \end{align}
and
 \begin{align}(C_{1,1},\dots,C_{1,T}), \dots, (C_{T,1},\dots,C_{T,T}) \quad\text{are independent}.\end{align}
\begin{align}(C_{1,1},\dots,C_{1,T}), \dots, (C_{T,1},\dots,C_{T,T}) \quad\text{are independent}.\end{align}
The conditions (3.1), (3.2), and (3.3) together are referred to as Mack’s distribution-free chain ladder model. The parameters
 $f_{\mathrm{MCL}t}$
and
$f_{\mathrm{MCL}t}$
and
 $\sigma^2_{\mathrm{MCL}t}$
are estimated by:
$\sigma^2_{\mathrm{MCL}t}$
are estimated by:
 \begin{align*}\widehat{f}_{t}=\frac{\sum_{i=1}^{T-t}C_{i,t+1}}{\sum_{i=1}^{T-t}C_{i,t}}\quad \text{and} \quad\widehat{\sigma}^2_{t}=\frac{1}{T-t-1}\sum_{i=1}^{T-t}C_{i,t}\bigg(\frac{C_{i,t+1}}{C_{i,t}}-\widehat{f}_{t}\bigg)^2,\end{align*}
\begin{align*}\widehat{f}_{t}=\frac{\sum_{i=1}^{T-t}C_{i,t+1}}{\sum_{i=1}^{T-t}C_{i,t}}\quad \text{and} \quad\widehat{\sigma}^2_{t}=\frac{1}{T-t-1}\sum_{i=1}^{T-t}C_{i,t}\bigg(\frac{C_{i,t+1}}{C_{i,t}}-\widehat{f}_{t}\bigg)^2,\end{align*}
respectively. We refer to Mack (Reference Mack1993) for properties of these parameter estimators.
The property (3.2) for the conditional variance is very difficult to assess from data in the form of run-off triangles on which the chain ladder method is applied. We refer to Mack (Reference Mack1994) for tests assessing the assumptions of Mack’s distribution-free chain ladder. Moreover, it is notoriously difficult to find stochastic models that satisfy this property. Note that the special model, see Section 2, does not satisfy Mack’s conditions: neither (3.1) nor (3.2) hold. By Theorem 3.3.6. in Mikosch (Reference Mikosch2009) for the special model,
 \begin{align*}\sum_{k=1}^{M^{\alpha}_i}Z_{i,k} I\{D_{i,k}\leq t\} \quad \text{and} \quad \sum_{k=1}^{M^{\alpha}_i}Z_{i,k} I\{D_{i,k}=t+1\}\end{align*}
\begin{align*}\sum_{k=1}^{M^{\alpha}_i}Z_{i,k} I\{D_{i,k}\leq t\} \quad \text{and} \quad \sum_{k=1}^{M^{\alpha}_i}Z_{i,k} I\{D_{i,k}=t+1\}\end{align*}
are independent. Consequently, for the special model,
 \begin{align*}\mathrm{E}[C^{\alpha}_{i,t+1}\,|\, C^{\alpha}_{i,1},\dots,C^{\alpha}_{i,t}]=C^{\alpha}_{i,t}+\mathrm{E}[M^{\alpha}_i]\mathrm{P}(D=t+1)\mathrm{E}[Z]\end{align*}
\begin{align*}\mathrm{E}[C^{\alpha}_{i,t+1}\,|\, C^{\alpha}_{i,1},\dots,C^{\alpha}_{i,t}]=C^{\alpha}_{i,t}+\mathrm{E}[M^{\alpha}_i]\mathrm{P}(D=t+1)\mathrm{E}[Z]\end{align*}
and
 \begin{align*}\mathrm{var}(C^{\alpha}_{i,t+1}\,|\, C^{\alpha}_{i,1},\dots,C^{\alpha}_{i,t})=\mathrm{E}[M^{\alpha}_i]\mathrm{P}(D=t+1)\mathrm{E}[Z^2].\end{align*}
\begin{align*}\mathrm{var}(C^{\alpha}_{i,t+1}\,|\, C^{\alpha}_{i,1},\dots,C^{\alpha}_{i,t})=\mathrm{E}[M^{\alpha}_i]\mathrm{P}(D=t+1)\mathrm{E}[Z^2].\end{align*}
It is shown in Theorem 1 below that large exposure limits, as
 $\alpha\to\infty$
, do exist for estimators
$\alpha\to\infty$
, do exist for estimators
 $\widehat{f}_t$
and
$\widehat{f}_t$
and
 $\widehat{\sigma}_t^2$
. The constant (a.s. convergence) limit for the parameter estimator
$\widehat{\sigma}_t^2$
. The constant (a.s. convergence) limit for the parameter estimator
 $\widehat{f}_t$
has a meaningful interpretation in terms of the general model we consider, and the parameter estimators
$\widehat{f}_t$
has a meaningful interpretation in terms of the general model we consider, and the parameter estimators
 $\widehat{f}_t$
can be transformed into estimators of parameters of our model, see Remark 4. However, Mack’s parameter estimator
$\widehat{f}_t$
can be transformed into estimators of parameters of our model, see Remark 4. However, Mack’s parameter estimator
 $\widehat{\sigma}_t^2$
converges in distribution to a nondegenerate random variable. Hence, although
$\widehat{\sigma}_t^2$
converges in distribution to a nondegenerate random variable. Hence, although
 $\widehat{\sigma}_t^2$
will generate numerical values that may seem reasonable, such values do not correspond to outcomes of random variables converging to a parameter.
$\widehat{\sigma}_t^2$
will generate numerical values that may seem reasonable, such values do not correspond to outcomes of random variables converging to a parameter.
The main contribution of Mack’s paper (Mack, Reference Mack1993) is the derivation of an estimator of the conditional mean squared error of prediction:
 \begin{align*}\mathrm{E}\big[(C_{i,T}-\widehat{C}_{i,T})^2 \,\big|\, \mathcal{D}\big],\end{align*}
\begin{align*}\mathrm{E}\big[(C_{i,T}-\widehat{C}_{i,T})^2 \,\big|\, \mathcal{D}\big],\end{align*}
where
 $\mathcal{D}$
is the
$\mathcal{D}$
is the
 $\sigma$
-algebra generated by the data observed at the time of prediction:
$\sigma$
-algebra generated by the data observed at the time of prediction:
 $\{C_{j,t}\;:\;j,t\in\mathcal{T},j+t\leq T+1\}$
. The
$\{C_{j,t}\;:\;j,t\in\mathcal{T},j+t\leq T+1\}$
. The
 $\mathcal{D}$
-measurable estimator derived by Mack of
$\mathcal{D}$
-measurable estimator derived by Mack of
 $\mathrm{E}[(C_{i,T}-\widehat{C}_{i,T})^2 \mid \mathcal{D}]$
is (see Theorem 3 in Mack, Reference Mack1993)
$\mathrm{E}[(C_{i,T}-\widehat{C}_{i,T})^2 \mid \mathcal{D}]$
is (see Theorem 3 in Mack, Reference Mack1993)
 \begin{align}(\widehat{C}_{i,T})^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t}{\widehat{f}^2_t}\bigg(\frac{1}{\widehat{C}_{i,t}}+\frac{1}{\sum_{j=1}^{T-t}C_{j,t}}\bigg),\end{align}
\begin{align}(\widehat{C}_{i,T})^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t}{\widehat{f}^2_t}\bigg(\frac{1}{\widehat{C}_{i,t}}+\frac{1}{\sum_{j=1}^{T-t}C_{j,t}}\bigg),\end{align}
where
 $\widehat{C}_{i,T-i+1}=C_{i,T-i+1}$
and
$\widehat{C}_{i,T-i+1}=C_{i,T-i+1}$
and
 $\widehat{C}_{i,t}=C_{i,T-i+1}\prod_{s=T-i+1}^{t-1}\widehat{f}_s$
for
$\widehat{C}_{i,t}=C_{i,T-i+1}\prod_{s=T-i+1}^{t-1}\widehat{f}_s$
for
 $t\gt T-i+1$
. We will show that when considering the special model (SM1)–(SM3), large exposure asymptotics naturally lead to Mack’s estimator of conditional mean squared error of prediction despite the fact that the special model is inconsistent with Mack’s distribution-free chain ladder. Hence, the chain ladder predictor
$t\gt T-i+1$
. We will show that when considering the special model (SM1)–(SM3), large exposure asymptotics naturally lead to Mack’s estimator of conditional mean squared error of prediction despite the fact that the special model is inconsistent with Mack’s distribution-free chain ladder. Hence, the chain ladder predictor
 $\widehat{C}_{i,T}=C_{i,T-i+1}\prod_{s=T-i+1}^{T-1}\widehat{f}_s$
may be used together with an assessment of its accuracy by (3.4) without having to rely on the validity of (3.1) and (3.2) of Mack’s distribution-free chain ladder.
$\widehat{C}_{i,T}=C_{i,T-i+1}\prod_{s=T-i+1}^{T-1}\widehat{f}_s$
may be used together with an assessment of its accuracy by (3.4) without having to rely on the validity of (3.1) and (3.2) of Mack’s distribution-free chain ladder.
4. Large exposure asymptotics
We will next present the main results, motivating the use of the chain ladder method and Mack’s estimator of conditional mean squared error of prediction, in the setting of the general or special model. Recall that, for
 $i,t\in \mathcal{T}$
,
$i,t\in \mathcal{T}$
,
 $C^{\alpha}_{i,t}=\sum_{k=1}^{M^{\alpha}_i}Z_{i,k}I\{D_{i,k}\leq t\}$
. Let
$C^{\alpha}_{i,t}=\sum_{k=1}^{M^{\alpha}_i}Z_{i,k}I\{D_{i,k}\leq t\}$
. Let
 $\chi^2_{\nu}$
denote a random variable with a chi-squared distribution with
$\chi^2_{\nu}$
denote a random variable with a chi-squared distribution with
 $\nu$
degrees of freedom. Let
$\nu$
degrees of freedom. Let
 $\mathrm{N}_T(\mu,\Sigma)$
denote the T-dimensional normal distribution with mean
$\mathrm{N}_T(\mu,\Sigma)$
denote the T-dimensional normal distribution with mean
 $\mu$
and covariance matrix
$\mu$
and covariance matrix
 $\Sigma$
. In what follows, convergence of random variables should be understood as convergence as
$\Sigma$
. In what follows, convergence of random variables should be understood as convergence as
 $\alpha\to\infty$
.
$\alpha\to\infty$
.
Theorem 1. Consider the general model (GM1)–(GM4). For each
 $t\in\mathcal{T}$
with
$t\in\mathcal{T}$
with
 $t\leq T-1$
,
$t\leq T-1$
,
 \begin{align}\widehat{f}_{t}=&\frac{\sum_{i=1}^{T-t}C^{\alpha}_{i,t+1}}{\sum_{i=1}^{T-t}C^{\alpha}_{i,t}}\stackrel{\mathrm{a.s.}}{\to} \frac{\mathrm{E}[ZI\{D\leq t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]}=f_{t}.\end{align}
\begin{align}\widehat{f}_{t}=&\frac{\sum_{i=1}^{T-t}C^{\alpha}_{i,t+1}}{\sum_{i=1}^{T-t}C^{\alpha}_{i,t}}\stackrel{\mathrm{a.s.}}{\to} \frac{\mathrm{E}[ZI\{D\leq t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]}=f_{t}.\end{align}
For each
 $i\in\mathcal{T}$
with
$i\in\mathcal{T}$
with
 $i\geq 2$
,
$i\geq 2$
,
 \begin{align}\frac{C^{\alpha}_{i,T-i+1}\prod_{t=T-i+1}^{T-1}\widehat{f}_t}{C^{\alpha}_{i,T}} \stackrel{\mathrm{a.s.}}{\to} 1.\end{align}
\begin{align}\frac{C^{\alpha}_{i,T-i+1}\prod_{t=T-i+1}^{T-1}\widehat{f}_t}{C^{\alpha}_{i,T}} \stackrel{\mathrm{a.s.}}{\to} 1.\end{align}
For each
 $t\in\mathcal{T}$
with
$t\in\mathcal{T}$
with
 $t\leq T-2$
,
$t\leq T-2$
,
 \begin{align}\widehat{\sigma}^2_{t}=\frac{1}{T-t-1}\sum_{i=1}^{T-t}C^{\alpha}_{i,t}\bigg(\frac{C^{\alpha}_{i,t+1}}{C^{\alpha}_{i,t}}-\widehat{f}_{t}\bigg)^2 \stackrel{d}{\to}\sigma^2_t \frac{\chi^2_{T-t-1}}{T-t-1},\end{align}
\begin{align}\widehat{\sigma}^2_{t}=\frac{1}{T-t-1}\sum_{i=1}^{T-t}C^{\alpha}_{i,t}\bigg(\frac{C^{\alpha}_{i,t+1}}{C^{\alpha}_{i,t}}-\widehat{f}_{t}\bigg)^2 \stackrel{d}{\to}\sigma^2_t \frac{\chi^2_{T-t-1}}{T-t-1},\end{align}
where
 \begin{align*}\sigma^2_t = (f_t-1)\bigg(\frac{\mathrm{E}[Z^2 I\{D=t+1\}]}{\mathrm{E}[Z I\{D=t+1\}]}+(f_t-1)\frac{\mathrm{E}[Z^2 I\{D\leq t\}]}{\mathrm{E}[Z I\{D\leq t\}]}\bigg).\end{align*}
\begin{align*}\sigma^2_t = (f_t-1)\bigg(\frac{\mathrm{E}[Z^2 I\{D=t+1\}]}{\mathrm{E}[Z I\{D=t+1\}]}+(f_t-1)\frac{\mathrm{E}[Z^2 I\{D\leq t\}]}{\mathrm{E}[Z I\{D\leq t\}]}\bigg).\end{align*}
Remark 1. We do not index
 $\widehat{f}_{t}$
and
$\widehat{f}_{t}$
and
 $\widehat{\sigma}^2_{t}$
by the exposure parameter
$\widehat{\sigma}^2_{t}$
by the exposure parameter
 $\alpha$
. It should be clear from the context whether
$\alpha$
. It should be clear from the context whether
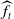 $\widehat{f}_{t}$
should be seen as an element in a convergent sequence or simply as a function of the given data. Similarly for
$\widehat{f}_{t}$
should be seen as an element in a convergent sequence or simply as a function of the given data. Similarly for
 $\widehat{\sigma}^2_{t}$
.
$\widehat{\sigma}^2_{t}$
.
Remark 2. For the convergence in (4.1) and (4.2), it is not necessary to assume that
 $M^{\alpha}_{1},\dots,M^{\alpha}_{T}$
are independent. If D and Z are independent, then the limit expressions in (4.1) and (4.3) simplify
$M^{\alpha}_{1},\dots,M^{\alpha}_{T}$
are independent. If D and Z are independent, then the limit expressions in (4.1) and (4.3) simplify
 \begin{align*}f_t=\frac{\sum_{s=1}^{t+1}q_s}{\sum_{s=1}^{t}q_s}, \quad\sigma^2_t=(f_t-1)f_t\frac{\mathrm{E}[Z^2]}{\mathrm{E}[Z]}=\frac{q_{t+1}\sum_{s=1}^{t+1}q_s}{(\sum_{s=1}^{t}q_s)^2} \frac{\mathrm{E}[Z^2]}{\mathrm{E}[Z]},\end{align*}
\begin{align*}f_t=\frac{\sum_{s=1}^{t+1}q_s}{\sum_{s=1}^{t}q_s}, \quad\sigma^2_t=(f_t-1)f_t\frac{\mathrm{E}[Z^2]}{\mathrm{E}[Z]}=\frac{q_{t+1}\sum_{s=1}^{t+1}q_s}{(\sum_{s=1}^{t}q_s)^2} \frac{\mathrm{E}[Z^2]}{\mathrm{E}[Z]},\end{align*}
where
 $q_t=\mathrm{P}(D=t)$
.
$q_t=\mathrm{P}(D=t)$
.
Remark 3. The convergence (4.2) supports the use of the chain ladder predictor:
 \begin{align*}\widehat{C}_{i,T}=C_{i,T-i+1}\widehat{f}_{T-i+1} \cdot \ldots \cdot \widehat{f}_{T-1}\end{align*}
\begin{align*}\widehat{C}_{i,T}=C_{i,T-i+1}\widehat{f}_{T-i+1} \cdot \ldots \cdot \widehat{f}_{T-1}\end{align*}
whose prediction error is studied in Mack (Reference Mack1993) and (Reference Mack1994). However, (4.3) says that from numerical estimates
 $\widehat{\sigma}^2_{t}$
we may not conclude that there is empirical evidence in support of the assumption (3.2) of Mack’s distribution-free chain ladder.
$\widehat{\sigma}^2_{t}$
we may not conclude that there is empirical evidence in support of the assumption (3.2) of Mack’s distribution-free chain ladder.
Remark 4. It follows from (4.1) that
 \begin{align*}\bigg(\frac{1}{\prod_{s=1}^{T-1}\widehat{f}_s},\frac{\widehat{f}_{1}-1}{\prod_{s=1}^{T-1}\widehat{f}_s},\frac{(\widehat{f}_{2}-1)\widehat{f}_1}{\prod_{s=1}^{T-1}\widehat{f}_s},\dots,\frac{(\widehat{f}_{T-1}-1)\prod_{s=1}^{T-2}\widehat{f}_s}{\prod_{s=1}^{T-1}\widehat{f}_s}\bigg)\end{align*}
\begin{align*}\bigg(\frac{1}{\prod_{s=1}^{T-1}\widehat{f}_s},\frac{\widehat{f}_{1}-1}{\prod_{s=1}^{T-1}\widehat{f}_s},\frac{(\widehat{f}_{2}-1)\widehat{f}_1}{\prod_{s=1}^{T-1}\widehat{f}_s},\dots,\frac{(\widehat{f}_{T-1}-1)\prod_{s=1}^{T-2}\widehat{f}_s}{\prod_{s=1}^{T-1}\widehat{f}_s}\bigg)\end{align*}
converges a.s. to the probability vector
 $(\widetilde{q}_1,\dots,\widetilde{q}_T)$
, where
$(\widetilde{q}_1,\dots,\widetilde{q}_T)$
, where
 $\widetilde{q}_t=\mathrm{E}[Z]^{-1}\mathrm{E}[ZI\{D=t\}]$
. In particular, if D and Z are independent, then
$\widetilde{q}_t=\mathrm{E}[Z]^{-1}\mathrm{E}[ZI\{D=t\}]$
. In particular, if D and Z are independent, then
 $(\widetilde{q}_1,\dots,\widetilde{q}_T)=(q_1,\dots,q_T)$
, where
$(\widetilde{q}_1,\dots,\widetilde{q}_T)=(q_1,\dots,q_T)$
, where
 $q_t=\mathrm{P}(D=t)$
. Hence, the estimators
$q_t=\mathrm{P}(D=t)$
. Hence, the estimators
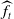 $\widehat{f}_t$
can be transformed into consistent estimators of the delay probabilities. Note that independence between D and Z includes the special case
$\widehat{f}_t$
can be transformed into consistent estimators of the delay probabilities. Note that independence between D and Z includes the special case
 $Z\equiv 1$
corresponding to considering data on the number of claims.
$Z\equiv 1$
corresponding to considering data on the number of claims.
4.1. Conditional mean squared error of prediction
The natural measure of prediction error is
 \begin{align}\mathrm{E}\big[(C^{\alpha}_{i,T}-\widehat{C}^{\alpha}_{i,T})^2 \,\big|\, \mathcal{D}^{\alpha}\big],\end{align}
\begin{align}\mathrm{E}\big[(C^{\alpha}_{i,T}-\widehat{C}^{\alpha}_{i,T})^2 \,\big|\, \mathcal{D}^{\alpha}\big],\end{align}
where
 $\mathcal{D}^{\alpha}$
is the
$\mathcal{D}^{\alpha}$
is the
 $\sigma$
-algebra generated by
$\sigma$
-algebra generated by
 $\{C^{\alpha}_{j,t}:j,t\in\mathcal{T},j+t\leq T+1\}$
, the run-off triangle that is fully observed at the time of prediction. We are considering large exposure limits and the conditional expectation (4.4) diverges as
$\{C^{\alpha}_{j,t}:j,t\in\mathcal{T},j+t\leq T+1\}$
, the run-off triangle that is fully observed at the time of prediction. We are considering large exposure limits and the conditional expectation (4.4) diverges as
 $\alpha\to\infty$
(the divergence of (4.4) is a consequence of the convergence in (4.5) below). However, we show (Theorems 2, 3, and 4 together with Remark 10) that there exists a random variable L such that the standardized (division by
$\alpha\to\infty$
(the divergence of (4.4) is a consequence of the convergence in (4.5) below). However, we show (Theorems 2, 3, and 4 together with Remark 10) that there exists a random variable L such that the standardized (division by
 $C^{\alpha}_{i,T-i+1}$
) mean squared error of prediction converges in distribution:
$C^{\alpha}_{i,T-i+1}$
) mean squared error of prediction converges in distribution:
 \begin{align}\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-\widehat{C}^{\alpha}_{i,T})^2}{C^{\alpha}_{i,T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg]\stackrel{d}{\to} L,\end{align}
\begin{align}\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-\widehat{C}^{\alpha}_{i,T})^2}{C^{\alpha}_{i,T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg]\stackrel{d}{\to} L,\end{align}
and that the limit L has a natural
 $\mathcal{D}^{\alpha}$
-measurable estimator
$\mathcal{D}^{\alpha}$
-measurable estimator
 $\widehat{L}^{\alpha}$
(Remarks 5, 6, and 8). Consequently, the natural estimator of the prediction error (4.4) is
$\widehat{L}^{\alpha}$
(Remarks 5, 6, and 8). Consequently, the natural estimator of the prediction error (4.4) is
 $C^{\alpha}_{i,T-i+1}\widehat{L}^{\alpha}$
:
$C^{\alpha}_{i,T-i+1}\widehat{L}^{\alpha}$
:
 \begin{align*}\mathrm{E}\big[(C^{\alpha}_{i,T}-\widehat{C}^{\alpha}_{i,T})^2 \,\big|\, \mathcal{D}^{\alpha}\big]=C^{\alpha}_{i,T-i+1} \mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-\widehat{C}^{\alpha}_{i,T})^2}{C^{\alpha}_{i,T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg]\approx C^{\alpha}_{i,T-i+1}\widehat{L}^{\alpha}.\end{align*}
\begin{align*}\mathrm{E}\big[(C^{\alpha}_{i,T}-\widehat{C}^{\alpha}_{i,T})^2 \,\big|\, \mathcal{D}^{\alpha}\big]=C^{\alpha}_{i,T-i+1} \mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-\widehat{C}^{\alpha}_{i,T})^2}{C^{\alpha}_{i,T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg]\approx C^{\alpha}_{i,T-i+1}\widehat{L}^{\alpha}.\end{align*}
Our aim is to arrive at an estimator of conditional mean squared error of prediction that coincides with Mack’s estimator (3.4), and this is not in general true in the setting of the general model. Therefore, we need to consider the special model (SM1)–(SM3).
Combining Theorems 2, 3, and 4 and Remarks 5, 6, and 8 below, we show that
 \begin{align}C^{\alpha}_{i,T-i+1}\widehat{L}^{\alpha}=(\widehat{C}^{\alpha}_{i,T})^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t}{\widehat{f}^2_t}\bigg(\frac{1}{\widehat{C}^{\alpha}_{i,t}}+\frac{1}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}\bigg)\end{align}
\begin{align}C^{\alpha}_{i,T-i+1}\widehat{L}^{\alpha}=(\widehat{C}^{\alpha}_{i,T})^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t}{\widehat{f}^2_t}\bigg(\frac{1}{\widehat{C}^{\alpha}_{i,t}}+\frac{1}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}\bigg)\end{align}
which coincides with the estimator of conditional mean squared error of prediction obtained by Mack in (Reference Mack1993). Note that in (4.6), we use the notation
 \begin{align*}\widehat{C}^{\alpha}_{i,T-i+1}=C^{\alpha}_{i,T-i+1}, \quad\widehat{C}^{\alpha}_{i,t}=C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{t-1}\widehat{f}_s, \quad t\gt T-i+1.\end{align*}
\begin{align*}\widehat{C}^{\alpha}_{i,T-i+1}=C^{\alpha}_{i,T-i+1}, \quad\widehat{C}^{\alpha}_{i,t}=C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{t-1}\widehat{f}_s, \quad t\gt T-i+1.\end{align*}
Note that
 $C^{\alpha}_{i,T-i+1}$
is independent of
$C^{\alpha}_{i,T-i+1}$
is independent of
 $\widehat{f}_{T-i+1},\dots,\widehat{f}_{T-1}$
, since the latter estimators are functions of only data from accident years
$\widehat{f}_{T-i+1},\dots,\widehat{f}_{T-1}$
, since the latter estimators are functions of only data from accident years
 $\leq i-1$
. Hence,
$\leq i-1$
. Hence,
 $\widehat{C}^{\alpha}_{i,T}=C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}\widehat{f}_s$
is a product of two independent factors. In order to verify the convergence in (4.5), note that the left-hand side in (4.5) can be expressed as:
$\widehat{C}^{\alpha}_{i,T}=C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}\widehat{f}_s$
is a product of two independent factors. In order to verify the convergence in (4.5), note that the left-hand side in (4.5) can be expressed as:
 \begin{align}&\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}f_s)^2}{C^{\alpha}_{i,T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg] \end{align}
\begin{align}&\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}f_s)^2}{C^{\alpha}_{i,T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg] \end{align}
 \begin{align}&\quad+C^{\alpha}_{i,T-i+1}\bigg(\prod_{s=T-i+1}^{T-1}f_s-\prod_{s=T-i+1}^{T-1}\widehat{f}_s\bigg)^2 \end{align}
\begin{align}&\quad+C^{\alpha}_{i,T-i+1}\bigg(\prod_{s=T-i+1}^{T-1}f_s-\prod_{s=T-i+1}^{T-1}\widehat{f}_s\bigg)^2 \end{align}
 \begin{align}&\quad+2\mathrm{E}\bigg[C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}f_s\,\bigg|\, \mathcal{D}^{\alpha}\bigg]\bigg(\prod_{s=T-i+1}^{T-1}f_s-\prod_{s=T-i+1}^{T-1}\widehat{f}_s\bigg) .\end{align}
\begin{align}&\quad+2\mathrm{E}\bigg[C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}f_s\,\bigg|\, \mathcal{D}^{\alpha}\bigg]\bigg(\prod_{s=T-i+1}^{T-1}f_s-\prod_{s=T-i+1}^{T-1}\widehat{f}_s\bigg) .\end{align}
In the literature, the first term (4.7) (upon multiplication by
 $C^{\alpha}_{i,T-i+1}$
) is referred to as process variance, and the second term (4.8) (upon multiplication by
$C^{\alpha}_{i,T-i+1}$
) is referred to as process variance, and the second term (4.8) (upon multiplication by
 $C^{\alpha}_{i,T-i+1}$
) is referred to as estimation error. In the setting of the distribution-free chain ladder, (4.7) is a conditional variance. However, in our setting (the general or special model, see Section 2), this term is not a conditional variance. Hence, we will not use the terminology “process variance.” Note that the two factors in (4.9) are independent because of independent accident years. This fact will enable us to study the asymptotic behavior of (4.9), convergence in distribution, and verify that the limit distribution has zero mean.
$C^{\alpha}_{i,T-i+1}$
) is referred to as estimation error. In the setting of the distribution-free chain ladder, (4.7) is a conditional variance. However, in our setting (the general or special model, see Section 2), this term is not a conditional variance. Hence, we will not use the terminology “process variance.” Note that the two factors in (4.9) are independent because of independent accident years. This fact will enable us to study the asymptotic behavior of (4.9), convergence in distribution, and verify that the limit distribution has zero mean.
Theorem 2 shows that the second term (4.8) converges in distribution in the setting of the general model. Theorem 3 shows that the first term (4.7) converges in distribution in the setting of the special model. In fact, the Poisson assumption for the counting variables is not needed for convergence in distribution. However, we need it in order to obtain an estimator of conditional mean squared error of prediction that coincides with the estimator derived in Mack (Reference Mack1993). Theorem 4 shows that the third term (4.9) converges in distribution in the setting of the special model. Remark 10 clarifies that the sum of the terms converges in distribution in the setting of the special model.
Theorem 2. Consider the general model (GM1)–(GM4). For each
 $i\in\mathcal{T}$
with
$i\in\mathcal{T}$
with
 $i\geq 2$
, there exists
$i\geq 2$
, there exists
 $\gamma_i\in(0,\infty)$
such that
$\gamma_i\in(0,\infty)$
such that
 \begin{align*}C^{\alpha}_{i,T-i+1}\bigg(\prod_{s=T-i+1}^{T-1}f_s-\prod_{s=T-i+1}^{T-1}\widehat{f}_s\bigg)^2\stackrel{d}{\to} \gamma_i^2\chi^2_1.\end{align*}
\begin{align*}C^{\alpha}_{i,T-i+1}\bigg(\prod_{s=T-i+1}^{T-1}f_s-\prod_{s=T-i+1}^{T-1}\widehat{f}_s\bigg)^2\stackrel{d}{\to} \gamma_i^2\chi^2_1.\end{align*}
If Z and D are independent, then
 \begin{align*}\gamma_i^2=\lambda_i\mathrm{E}[ZI\{D\leq T-i+1\}]\prod_{s=T-i+1}^{T-1}f_s^2\sum_{t=T-i+1}^{T-1}\frac{\sigma^2_t/f_t^2}{\sum_{j=1}^{T-t}\lambda_j \mathrm{E}[ZI\{D\leq t\}]}.\end{align*}
\begin{align*}\gamma_i^2=\lambda_i\mathrm{E}[ZI\{D\leq T-i+1\}]\prod_{s=T-i+1}^{T-1}f_s^2\sum_{t=T-i+1}^{T-1}\frac{\sigma^2_t/f_t^2}{\sum_{j=1}^{T-t}\lambda_j \mathrm{E}[ZI\{D\leq t\}]}.\end{align*}
Remark 5. Motivated by (4.1) and (4.3), we estimate
 $f_t$
by
$f_t$
by
 $\widehat{f}_t$
and
$\widehat{f}_t$
and
 $\sigma^2_t$
by
$\sigma^2_t$
by
 $\widehat{\sigma}_t^2$
. Since
$\widehat{\sigma}_t^2$
. Since
 $\alpha^{-1}C^{\alpha}_{j,t}\stackrel{\mathrm{a.s.}}{\to} \lambda_j\mathrm{E}[ZI\{D\leq t\}]$
, we estimate
$\alpha^{-1}C^{\alpha}_{j,t}\stackrel{\mathrm{a.s.}}{\to} \lambda_j\mathrm{E}[ZI\{D\leq t\}]$
, we estimate
 $\lambda_j\mathrm{E}[ZI\{D\leq t\}]$
by
$\lambda_j\mathrm{E}[ZI\{D\leq t\}]$
by
 $\alpha^{-1}C^{\alpha}_{j,t}$
. Hence, the estimator of
$\alpha^{-1}C^{\alpha}_{j,t}$
. Hence, the estimator of
 $\gamma_i^2$
is
$\gamma_i^2$
is
 \begin{align*}\widehat{\gamma}_i^2=C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}\widehat{f}_s^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t/\widehat{f}_t^2}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}.\end{align*}
\begin{align*}\widehat{\gamma}_i^2=C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}\widehat{f}_s^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t/\widehat{f}_t^2}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}.\end{align*}
Consequently, the estimator of
 \begin{align*}\big(C^{\alpha}_{i,T-i+1}\big)^2\bigg(\prod_{s=T-i+1}^{T-1}f_s-\prod_{s=T-i+1}^{T-1}\widehat{f}_s\bigg)^2\end{align*}
\begin{align*}\big(C^{\alpha}_{i,T-i+1}\big)^2\bigg(\prod_{s=T-i+1}^{T-1}f_s-\prod_{s=T-i+1}^{T-1}\widehat{f}_s\bigg)^2\end{align*}
is
 $C^{\alpha}_{i,T-i+1}\widehat{\gamma}_i^2$
which equals
$C^{\alpha}_{i,T-i+1}\widehat{\gamma}_i^2$
which equals
 \begin{align}(C^{\alpha}_{i,T-i+1})^2\prod_{s=T-i+1}^{T-1}\widehat{f}_s^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t/\widehat{f}_t^2}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}=(\widehat{C}^{\alpha}_{i,T})^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t/\widehat{f}_t^2}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}\end{align}
\begin{align}(C^{\alpha}_{i,T-i+1})^2\prod_{s=T-i+1}^{T-1}\widehat{f}_s^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t/\widehat{f}_t^2}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}=(\widehat{C}^{\alpha}_{i,T})^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t/\widehat{f}_t^2}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}\end{align}
and coincides with Mack’s estimator (see Mack, Reference Mack1993, p. 219).
Theorem 3. Consider the special model (SM1)–(SM3). For each
 $i\in\mathcal{T}$
with
$i\in\mathcal{T}$
with
 $i\geq 2$
,
$i\geq 2$
,
 \begin{align}&\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}f_s)^2}{C^{\alpha}_{T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg] \nonumber \\[5pt] &\quad=\frac{\alpha}{C^{\alpha}_{T-i+1}}\bigg(\frac{\mathrm{E}[M^{\alpha}_i]}{\alpha}\mathrm{E}[Z^2]\mathrm{P}(D\gt T-i+1)+(H^{\alpha})^2\bigg(\prod_{s=T-i+1}^{T-1}f_s-1\bigg)^2\bigg) \nonumber \\[5pt] &\quad\stackrel{d}{\to}\frac{\mathrm{E}[Z^2]}{\mathrm{E}[Z]}\bigg(\bigg(\prod_{s=T-i+1}^{T-1}f_s-1\bigg)+\bigg(\prod_{s=T-i+1}^{T-1}f_s-1\bigg)^2\chi^2_1\bigg), \end{align}
\begin{align}&\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}f_s)^2}{C^{\alpha}_{T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg] \nonumber \\[5pt] &\quad=\frac{\alpha}{C^{\alpha}_{T-i+1}}\bigg(\frac{\mathrm{E}[M^{\alpha}_i]}{\alpha}\mathrm{E}[Z^2]\mathrm{P}(D\gt T-i+1)+(H^{\alpha})^2\bigg(\prod_{s=T-i+1}^{T-1}f_s-1\bigg)^2\bigg) \nonumber \\[5pt] &\quad\stackrel{d}{\to}\frac{\mathrm{E}[Z^2]}{\mathrm{E}[Z]}\bigg(\bigg(\prod_{s=T-i+1}^{T-1}f_s-1\bigg)+\bigg(\prod_{s=T-i+1}^{T-1}f_s-1\bigg)^2\chi^2_1\bigg), \end{align}
where
 \begin{align*}(H^{\alpha})^2=\frac{(C^{\alpha}_{i,T-i+1}-\mathrm{E}[C^{\alpha}_{i,T-i+1}])^2}{\alpha}\stackrel{d}{\to} \lambda_i\mathrm{E}[Z^2]\mathrm{P}(D\leq T-i+1)\chi^2_1=H^2.\end{align*}
\begin{align*}(H^{\alpha})^2=\frac{(C^{\alpha}_{i,T-i+1}-\mathrm{E}[C^{\alpha}_{i,T-i+1}])^2}{\alpha}\stackrel{d}{\to} \lambda_i\mathrm{E}[Z^2]\mathrm{P}(D\leq T-i+1)\chi^2_1=H^2.\end{align*}
In particular, the expectation of the limit variable in (4.11) is
 \begin{align}&\frac{\lambda_i\mathrm{E}[Z^2]\mathrm{P}(D\gt T-i+1)+\mathrm{E}[H^2](\prod_{s=T-i+1}^{T-1}f_s-1)^2}{\lambda_i\mathrm{E}[Z]\mathrm{P}(D\leq T-i+1)} \nonumber \\[5pt] &\quad=\sum_{t=T-i+1}^{T-1}f_{T-i+1}\cdot\ldots\cdot f_{t-1}\sigma^2_t f_{t+1}^2\cdot\ldots\cdot f_{T-1}^2. \end{align}
\begin{align}&\frac{\lambda_i\mathrm{E}[Z^2]\mathrm{P}(D\gt T-i+1)+\mathrm{E}[H^2](\prod_{s=T-i+1}^{T-1}f_s-1)^2}{\lambda_i\mathrm{E}[Z]\mathrm{P}(D\leq T-i+1)} \nonumber \\[5pt] &\quad=\sum_{t=T-i+1}^{T-1}f_{T-i+1}\cdot\ldots\cdot f_{t-1}\sigma^2_t f_{t+1}^2\cdot\ldots\cdot f_{T-1}^2. \end{align}
Remark 6. Since (4.12) equals
 \begin{align*}\sum_{t=T-i+1}^{T-1}\bigg(\prod_{s=T-i+1}^{T-1}f_s^2\bigg)\frac{\sigma^2_t/f_t^2}{\prod_{u=T-i+1}^{t-1}f_u}=C^{\alpha}_{i.T-i+1}\prod_{s=T-i+1}^{T-1}f_s^2\sum_{t=T-i+1}^{T-1}\frac{\sigma^2_t/f_t^2}{C^{\alpha}_{i,T-i+1}\prod_{u=T-i+1}^{t-1}f_u},\end{align*}
\begin{align*}\sum_{t=T-i+1}^{T-1}\bigg(\prod_{s=T-i+1}^{T-1}f_s^2\bigg)\frac{\sigma^2_t/f_t^2}{\prod_{u=T-i+1}^{t-1}f_u}=C^{\alpha}_{i.T-i+1}\prod_{s=T-i+1}^{T-1}f_s^2\sum_{t=T-i+1}^{T-1}\frac{\sigma^2_t/f_t^2}{C^{\alpha}_{i,T-i+1}\prod_{u=T-i+1}^{t-1}f_u},\end{align*}
estimating
 $f_t$
by
$f_t$
by
 $\widehat{f}_t$
and
$\widehat{f}_t$
and
 $\sigma^2_t$
by
$\sigma^2_t$
by
 $\widehat{\sigma}^2_t$
gives the estimator of (4.12) given by:
$\widehat{\sigma}^2_t$
gives the estimator of (4.12) given by:
 \begin{align*}C^{\alpha}_{i.T-i+1}\prod_{s=T-i+1}^{T-1}\widehat{f}_s^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t/\widehat{f}_t^2}{\widehat{C}^{\alpha}_{i,t}}.\end{align*}
\begin{align*}C^{\alpha}_{i.T-i+1}\prod_{s=T-i+1}^{T-1}\widehat{f}_s^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t/\widehat{f}_t^2}{\widehat{C}^{\alpha}_{i,t}}.\end{align*}
Consequently, we estimate
 \begin{align*}C^{\alpha}_{i,T-i+1}\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}f_s)^2}{C^{\alpha}_{T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg]\end{align*}
\begin{align*}C^{\alpha}_{i,T-i+1}\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}f_s)^2}{C^{\alpha}_{T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg]\end{align*}
by
 \begin{align}(C^{\alpha}_{i.T-i+1})^2\prod_{s=T-i+1}^{T-1}\widehat{f}_s^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t/\widehat{f}_t^2}{\widehat{C}^{\alpha}_{i,t}}=(\widehat{C}^{\alpha}_{i.T})^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t/\widehat{f}_t^2}{\widehat{C}^{\alpha}_{i,t}}\end{align}
\begin{align}(C^{\alpha}_{i.T-i+1})^2\prod_{s=T-i+1}^{T-1}\widehat{f}_s^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t/\widehat{f}_t^2}{\widehat{C}^{\alpha}_{i,t}}=(\widehat{C}^{\alpha}_{i.T})^2\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t/\widehat{f}_t^2}{\widehat{C}^{\alpha}_{i,t}}\end{align}
which coincides with Mack’s estimator (see Mack, Reference Mack1993, p. 218).
Remark 7. Convergence of the conditional expectations considered in Theorem 3 does not require the Poisson assumption for the counting variables. However, we have used the fact that
 $\mathrm{E}[M^{\alpha}_i]=\mathrm{var}(M^{\alpha}_i)$
to derive the limit in (4.11). If
$\mathrm{E}[M^{\alpha}_i]=\mathrm{var}(M^{\alpha}_i)$
to derive the limit in (4.11). If
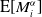 $\mathrm{E}[M^{\alpha}_i]$
and
$\mathrm{E}[M^{\alpha}_i]$
and
 $\mathrm{var}(M^{\alpha}_i)$
would increase with
$\mathrm{var}(M^{\alpha}_i)$
would increase with
 $\alpha$
at rates that differ asymptotically, then a limit corresponding to (4.11) would look differently and consequently we would arrive at an estimator of conditional mean squared error of prediction that would differ from the one obtained in Mack (Reference Mack1993).
$\alpha$
at rates that differ asymptotically, then a limit corresponding to (4.11) would look differently and consequently we would arrive at an estimator of conditional mean squared error of prediction that would differ from the one obtained in Mack (Reference Mack1993).
Note that by adding (4.10) and (4.13), one obtains the right-hand side in (4.6). Since we expressed the conditional mean squared error of prediction as a sum of three terms, it remains to show that the third term should be estimated by zero.
Theorem 4. Consider the special model (SM1)–(SM3). Let
 \begin{align*}A^{\alpha}_1&=\alpha^{-1/2}\mathrm{E}\bigg[C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}f_s\,\bigg|\, \mathcal{D}^{\alpha}\bigg], \\[5pt] A^{\alpha}_2&=\alpha^{1/2}\bigg(\prod_{s=T-i+1}^{T-1}f_s-\prod_{s=T-i+1}^{T-1}\widehat{f}_s\bigg).\end{align*}
\begin{align*}A^{\alpha}_1&=\alpha^{-1/2}\mathrm{E}\bigg[C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}f_s\,\bigg|\, \mathcal{D}^{\alpha}\bigg], \\[5pt] A^{\alpha}_2&=\alpha^{1/2}\bigg(\prod_{s=T-i+1}^{T-1}f_s-\prod_{s=T-i+1}^{T-1}\widehat{f}_s\bigg).\end{align*}
Then
 $(A^{\alpha}_1)_{\alpha\geq 0}$
and
$(A^{\alpha}_1)_{\alpha\geq 0}$
and
 $(A^{\alpha}_2)_{\alpha\geq 0}$
are independent and both converge in distribution to normally distributed random variables with zero means. In particular,
$(A^{\alpha}_2)_{\alpha\geq 0}$
are independent and both converge in distribution to normally distributed random variables with zero means. In particular,
 $(A^{\alpha}_1A^{\alpha}_2)_{\alpha\geq 0}$
converges in distribution to a random variable with zero mean.
$(A^{\alpha}_1A^{\alpha}_2)_{\alpha\geq 0}$
converges in distribution to a random variable with zero mean.
Remark 8. By Theorem 4, the third term (4.9) in the expression for the standardized mean squared error of prediction converges in distribution to a random variable with zero mean. Consequently, we estimate (4.9) by 0.
Theorem 5 analyzes the asymptotic behavior of a vector-valued process
 $(S_j^{\alpha})_{\alpha\geq 0}$
, centered by subtracting its mean process, where
$(S_j^{\alpha})_{\alpha\geq 0}$
, centered by subtracting its mean process, where
 \begin{align*}S_j^{\alpha}=\sum_{k=1}^{M^{\alpha}_j}Z_{j,k}\big(I\{D_{j,k}=1\},\dots,I\{D_{j,k}=T\}\big).\end{align*}
\begin{align*}S_j^{\alpha}=\sum_{k=1}^{M^{\alpha}_j}Z_{j,k}\big(I\{D_{j,k}=1\},\dots,I\{D_{j,k}=T\}\big).\end{align*}
From the statement in Theorem 5, we will be able to make the corresponding statements about the asymptotic behavior of the centered version of
 \begin{align*}C^{\alpha}_{j,t}=\sum_{k=1}^{M^{\alpha}_j}Z_{j,k}I\{D_{j,k}\leq t\}=\sum_{k=1}^{t}S^{\alpha}_{j,k},\end{align*}
\begin{align*}C^{\alpha}_{j,t}=\sum_{k=1}^{M^{\alpha}_j}Z_{j,k}I\{D_{j,k}\leq t\}=\sum_{k=1}^{t}S^{\alpha}_{j,k},\end{align*}
where the right-hand side is the sum of the first t components of
 $S^{\alpha}_j$
.
$S^{\alpha}_j$
.
Theorem 5. Suppose that for each accident year j,
 $(M^{\alpha}_j)_{\alpha\geq 0}$
is a renewal counting process given by
$(M^{\alpha}_j)_{\alpha\geq 0}$
is a renewal counting process given by
 $M^{\alpha}_j=\sup\{m\geq 1:T_{j,m}\leq \alpha\}$
, where the steps
$M^{\alpha}_j=\sup\{m\geq 1:T_{j,m}\leq \alpha\}$
, where the steps
 $Y_{j,k}$
of the random walk
$Y_{j,k}$
of the random walk
 $T_{j,m}=\sum_{k=1}^m Y_{j,k}$
satisfy
$T_{j,m}=\sum_{k=1}^m Y_{j,k}$
satisfy
 $\mathrm{E}[Y_{j,k}]=1/\lambda_j$
and
$\mathrm{E}[Y_{j,k}]=1/\lambda_j$
and
 $\mathrm{var}(Y_{j,k})\lt \infty$
. Suppose properties (GM1) and (GM2) of the general model hold. Then
$\mathrm{var}(Y_{j,k})\lt \infty$
. Suppose properties (GM1) and (GM2) of the general model hold. Then
 \begin{align*}S_j^{\alpha}=\sum_{k=1}^{M^{\alpha}_j}Z_{j,k}\big(I\{D_{j,k}=1\},\dots,I\{D_{j,k}=T\}\big)\end{align*}
\begin{align*}S_j^{\alpha}=\sum_{k=1}^{M^{\alpha}_j}Z_{j,k}\big(I\{D_{j,k}=1\},\dots,I\{D_{j,k}=T\}\big)\end{align*}
satisfies
 $\alpha^{-1/2}(S_j^{\alpha}-\mathrm{E}[S_j^{\alpha}])\stackrel{d}{\to} \mathrm{N}_T(0,\Sigma)$
, where
$\alpha^{-1/2}(S_j^{\alpha}-\mathrm{E}[S_j^{\alpha}])\stackrel{d}{\to} \mathrm{N}_T(0,\Sigma)$
, where
 \begin{align*}\Sigma_{s,t}&=\lambda_j\mathrm{E}[Z^2I\{D=s\}I\{D=t\}]\\[5pt] &\quad+\lambda_j(\lambda_j^2\mathrm{var}(Y)-1)\mathrm{E}[ZI\{D=s\}]\mathrm{E}[ZI\{D=t\}]\end{align*}
\begin{align*}\Sigma_{s,t}&=\lambda_j\mathrm{E}[Z^2I\{D=s\}I\{D=t\}]\\[5pt] &\quad+\lambda_j(\lambda_j^2\mathrm{var}(Y)-1)\mathrm{E}[ZI\{D=s\}]\mathrm{E}[ZI\{D=t\}]\end{align*}
with
 $(D,Z)\stackrel{d}{=} (D_{j,k},Z_{j,k})$
and
$(D,Z)\stackrel{d}{=} (D_{j,k},Z_{j,k})$
and
 $Y\stackrel{d}{=} Y_{j,k}$
.
$Y\stackrel{d}{=} Y_{j,k}$
.
Note that a renewal counting process
 $(M^{\alpha}_j)_{\alpha\geq 0}$
satisfies
$(M^{\alpha}_j)_{\alpha\geq 0}$
satisfies
 $M^{\alpha}_j/\alpha \stackrel{\mathrm{a.s.}}{\to} \lambda_j$
as the exposure parameter
$M^{\alpha}_j/\alpha \stackrel{\mathrm{a.s.}}{\to} \lambda_j$
as the exposure parameter
 $\alpha\to\infty$
if the step-size distribution of the corresponding random walk
$\alpha\to\infty$
if the step-size distribution of the corresponding random walk
 $(T_{j,m})_{m\geq 1}$
has finite expectation
$(T_{j,m})_{m\geq 1}$
has finite expectation
 $1/\lambda_j$
. Hence, property (GM4) is automatically satisfied for the renewal counting process considered in Theorem 5. Theorem 5 presents sufficient conditions under which
$1/\lambda_j$
. Hence, property (GM4) is automatically satisfied for the renewal counting process considered in Theorem 5. Theorem 5 presents sufficient conditions under which
 $\alpha^{-1/2}(S_j^{\alpha}-\mathrm{E}[S_j^{\alpha}])$
converges in distribution for each accident year j. If property (GM3) holds, then the sequences
$\alpha^{-1/2}(S_j^{\alpha}-\mathrm{E}[S_j^{\alpha}])$
converges in distribution for each accident year j. If property (GM3) holds, then the sequences
 $(\alpha^{-1/2}(S_j^{\alpha}-\mathrm{E}[S_j^{\alpha}]))_{\alpha\gt 0}$
,
$(\alpha^{-1/2}(S_j^{\alpha}-\mathrm{E}[S_j^{\alpha}]))_{\alpha\gt 0}$
,
 $j=1,\dots,T$
, are independent and therefore they converge jointly in distribution.
$j=1,\dots,T$
, are independent and therefore they converge jointly in distribution.
Corollary 1. Consider the setting of Theorem 5. Let
 \begin{align*}H^{\alpha}&=\alpha^{-1/2}\big(C^{\alpha}_{i,T-i+1}-\mathrm{E}[C^{\alpha}_{i,T-i+1}]\big), \\[5pt] F^{\alpha}&=\alpha^{-1/2}\big(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}-\mathrm{E}[C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}]\big).\end{align*}
\begin{align*}H^{\alpha}&=\alpha^{-1/2}\big(C^{\alpha}_{i,T-i+1}-\mathrm{E}[C^{\alpha}_{i,T-i+1}]\big), \\[5pt] F^{\alpha}&=\alpha^{-1/2}\big(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}-\mathrm{E}[C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}]\big).\end{align*}
Then
 $(H^{\alpha},F^{\alpha})\stackrel{d}{\to} (H,F)$
, where (H,F) is jointly normally distributed with
$(H^{\alpha},F^{\alpha})\stackrel{d}{\to} (H,F)$
, where (H,F) is jointly normally distributed with
 \begin{align*}\mathrm{var}(H)&=\lambda_i \mathrm{E}[Z^2I\{D\leq T-i+1\}]+\lambda_i(\lambda_i^2\mathrm{var}(Y)-1)\mathrm{E}[ZI\{D\leq T-i+1\}]^2,\\[5pt] \mathrm{var}(F)&=\lambda_i \mathrm{E}[Z^2I\{D\gt T-i+1\}]+\lambda_i(\lambda_i^2\mathrm{var}(Y)-1)\mathrm{E}[ZI\{D\gt T-i+1\}]^2,\\[5pt] \mathrm{cov}(H,F)&=\lambda_i(\lambda_i^2\mathrm{var}(Y)-1)\mathrm{E}[ZI\{D\leq T-i+1\}]\mathrm{E}[ZI\{D\gt T-i+1\}].\end{align*}
\begin{align*}\mathrm{var}(H)&=\lambda_i \mathrm{E}[Z^2I\{D\leq T-i+1\}]+\lambda_i(\lambda_i^2\mathrm{var}(Y)-1)\mathrm{E}[ZI\{D\leq T-i+1\}]^2,\\[5pt] \mathrm{var}(F)&=\lambda_i \mathrm{E}[Z^2I\{D\gt T-i+1\}]+\lambda_i(\lambda_i^2\mathrm{var}(Y)-1)\mathrm{E}[ZI\{D\gt T-i+1\}]^2,\\[5pt] \mathrm{cov}(H,F)&=\lambda_i(\lambda_i^2\mathrm{var}(Y)-1)\mathrm{E}[ZI\{D\leq T-i+1\}]\mathrm{E}[ZI\{D\gt T-i+1\}].\end{align*}
Remark 9. If
 $(M^{\alpha}_j)_{\alpha\geq 0}$
is a homogeneous Poisson process, then
$(M^{\alpha}_j)_{\alpha\geq 0}$
is a homogeneous Poisson process, then
 $\mathrm{var}(Y)=\lambda_j^{-2}$
, the random vectors
$\mathrm{var}(Y)=\lambda_j^{-2}$
, the random vectors
 $S_j^{\alpha}$
in Theorem 5 have independent components, and
$S_j^{\alpha}$
in Theorem 5 have independent components, and
 $H^{\alpha}$
and
$H^{\alpha}$
and
 $F^{\alpha}$
in Corollary 1 are independent.
$F^{\alpha}$
in Corollary 1 are independent.
Remark 10. Theorems 2, 3, and 4 show convergence in distribution separately for the three terms (4.7), (4.8), and (4.9) of conditional mean squared error of prediction. We treat them separately since we want to emphasize that convergence to the appropriate limits occurs under different assumptions; only for two of the terms we use the compound Poisson assumption of the special model. However, the sum of the terms converges in distribution under the assumptions made in Theorem 3. This convergence of the sum is a consequence of the convergence in distribution of the random vectors
 $\alpha^{-1/2}(S_j^{\alpha}-\mathrm{E}[S_j^{\alpha}])$
in Theorem 5. That the convergence in distribution in Theorems 2, 3, and 4 can be extended to joint convergence in distribution can then be verified by combining the convergence of
$\alpha^{-1/2}(S_j^{\alpha}-\mathrm{E}[S_j^{\alpha}])$
in Theorem 5. That the convergence in distribution in Theorems 2, 3, and 4 can be extended to joint convergence in distribution can then be verified by combining the convergence of
 $\alpha^{-1/2}(S_j^{\alpha}-\mathrm{E}[S_j^{\alpha}])$
in Theorem 5 with an application of the continuous mapping theorem for weak convergence together with Slutsky’s theorem. Such an argument verifies that
$\alpha^{-1/2}(S_j^{\alpha}-\mathrm{E}[S_j^{\alpha}])$
in Theorem 5 with an application of the continuous mapping theorem for weak convergence together with Slutsky’s theorem. Such an argument verifies that
 \begin{align*}\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}\widehat{f}_s)^2}{C^{\alpha}_{T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg]\stackrel{d}{\to} L=L^{(1)}+L^{(2)}+L^{(3)},\end{align*}
\begin{align*}\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}\widehat{f}_s)^2}{C^{\alpha}_{T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg]\stackrel{d}{\to} L=L^{(1)}+L^{(2)}+L^{(3)},\end{align*}
where
 $L^{(1)}$
,
$L^{(1)}$
,
 $L^{(2)}$
, and
$L^{(2)}$
, and
 $L^{(3)}$
correspond to the limits in Theorems 2, 3, and 4.
$L^{(3)}$
correspond to the limits in Theorems 2, 3, and 4.
5. Numerical illustration
In the setting of the special model, we may simulate a run-off triangle
 $\{C^{\alpha}_{j,t}:j,t\in\mathcal{T},j+t\leq T+1\}$
and explicitly compute the standardized conditional mean squared error of prediction (standardized means division by
$\{C^{\alpha}_{j,t}:j,t\in\mathcal{T},j+t\leq T+1\}$
and explicitly compute the standardized conditional mean squared error of prediction (standardized means division by
 $C^{\alpha}_{T-i+1}$
) in (4.5) as a known function of the simulated run-off triangle. For the same run-off triangle, we may compute the standardized estimator of mean squared error by Mack,
$C^{\alpha}_{T-i+1}$
) in (4.5) as a known function of the simulated run-off triangle. For the same run-off triangle, we may compute the standardized estimator of mean squared error by Mack,
 \begin{align}\widehat{L}^{\alpha}=\frac{(\widehat{C}^{\alpha}_{i,T})^2}{C^{\alpha}_{i,T-i+1}}\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t}{\widehat{f}^2_t}\bigg(\frac{1}{\widehat{C}^{\alpha}_{i,t}}+\frac{1}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}\bigg),\end{align}
\begin{align}\widehat{L}^{\alpha}=\frac{(\widehat{C}^{\alpha}_{i,T})^2}{C^{\alpha}_{i,T-i+1}}\sum_{t=T-i+1}^{T-1}\frac{\widehat{\sigma}^2_t}{\widehat{f}^2_t}\bigg(\frac{1}{\widehat{C}^{\alpha}_{i,t}}+\frac{1}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}\bigg),\end{align}
and then compare the two random variables, or their distributions.
We first show how to explicitly compute the standardized conditional mean squared error of prediction. Since
 $C^{\alpha}_{i,T}=C^{\alpha}_{i,T-i+1}+\sum_{k=1}^{N^{\alpha}}Z_k$
with
$C^{\alpha}_{i,T}=C^{\alpha}_{i,T-i+1}+\sum_{k=1}^{N^{\alpha}}Z_k$
with
 $N^{\alpha}\sim\mathrm{Pois}(\alpha\lambda_i\sum_{t=T-i+2}^{T}q_t)$
independent of the i.i.d. sequence
$N^{\alpha}\sim\mathrm{Pois}(\alpha\lambda_i\sum_{t=T-i+2}^{T}q_t)$
independent of the i.i.d. sequence
 $(Z_k)$
, and
$(Z_k)$
, and
 \begin{align*}\mathrm{E}\bigg[\sum_{k=1}^{N^{\alpha}}Z_k\bigg]&=\mathrm{E}[N^{\alpha}]\mathrm{E}[Z], \\[5pt] \mathrm{E}\bigg[\bigg(\sum_{k=1}^{N^{\alpha}}Z_{k}\bigg)^2\bigg]&=\mathrm{E}[N^{\alpha}]\mathrm{var}(Z)+\mathrm{E}[N^{\alpha}]\mathrm{E}[Z]^2+\mathrm{E}[N^{\alpha}]^2\mathrm{E}[Z]^2,\end{align*}
\begin{align*}\mathrm{E}\bigg[\sum_{k=1}^{N^{\alpha}}Z_k\bigg]&=\mathrm{E}[N^{\alpha}]\mathrm{E}[Z], \\[5pt] \mathrm{E}\bigg[\bigg(\sum_{k=1}^{N^{\alpha}}Z_{k}\bigg)^2\bigg]&=\mathrm{E}[N^{\alpha}]\mathrm{var}(Z)+\mathrm{E}[N^{\alpha}]\mathrm{E}[Z]^2+\mathrm{E}[N^{\alpha}]^2\mathrm{E}[Z]^2,\end{align*}
we may use the independence between
 $\sum_{k=1}^{N^{\alpha}}Z_k$
and
$\sum_{k=1}^{N^{\alpha}}Z_k$
and
 $\mathcal{D}^{\alpha}$
to get
$\mathcal{D}^{\alpha}$
to get
 \begin{align}L^{\alpha}&=\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}\widehat{f}_s)^2}{C^{\alpha}_{T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg] \\[5pt] &=(C^{\alpha}_{T-i+1})^{-1}\mathrm{E}\bigg[\bigg(\sum_{k=1}^{N^{\alpha}}Z_{k}\bigg)^2\bigg]-2\bigg(\prod_{s=T-i+1}^{T-1}\widehat{f}_s-1\bigg)\mathrm{E}\bigg[\sum_{k=1}^{N^{\alpha}}Z_k\bigg] \nonumber \\[5pt] &\quad+C^{\alpha}_{i,T-i+1}\bigg(\prod_{s=T-i+1}^{T-1}\widehat{f}_s-1\bigg)^2. \nonumber\end{align}
\begin{align}L^{\alpha}&=\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}\prod_{s=T-i+1}^{T-1}\widehat{f}_s)^2}{C^{\alpha}_{T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg] \\[5pt] &=(C^{\alpha}_{T-i+1})^{-1}\mathrm{E}\bigg[\bigg(\sum_{k=1}^{N^{\alpha}}Z_{k}\bigg)^2\bigg]-2\bigg(\prod_{s=T-i+1}^{T-1}\widehat{f}_s-1\bigg)\mathrm{E}\bigg[\sum_{k=1}^{N^{\alpha}}Z_k\bigg] \nonumber \\[5pt] &\quad+C^{\alpha}_{i,T-i+1}\bigg(\prod_{s=T-i+1}^{T-1}\widehat{f}_s-1\bigg)^2. \nonumber\end{align}
From Theorems 2, 3, and 4 together with Remark 10, we know that
 $L^{\alpha}\stackrel{d}{\to} L$
and we may compute
$L^{\alpha}\stackrel{d}{\to} L$
and we may compute
 $\mathrm{E}[L]$
explicitly. We have not shown convergence in distribution for
$\mathrm{E}[L]$
explicitly. We have not shown convergence in distribution for
 $\widehat{L}^{\alpha}$
, but it follows from Theorem 1 and Slutsky’s theorem that each term in the expression for
$\widehat{L}^{\alpha}$
, but it follows from Theorem 1 and Slutsky’s theorem that each term in the expression for
 $\widehat{L}^{\alpha}$
converges in distribution, and the corresponding expectations of the limits add up to
$\widehat{L}^{\alpha}$
converges in distribution, and the corresponding expectations of the limits add up to
 $\mathrm{E}[L]$
. Hence, if we draw many realizations of run-off triangles based on the special model and convert these into a random sample from the distribution of
$\mathrm{E}[L]$
. Hence, if we draw many realizations of run-off triangles based on the special model and convert these into a random sample from the distribution of
 $L^{\alpha}-\widehat{L}^{\alpha}$
, then we expect the empirical mean to be approximately zero.
$L^{\alpha}-\widehat{L}^{\alpha}$
, then we expect the empirical mean to be approximately zero.
For the numerical illustration, we take the claims data from Table 1 in Mack (Reference Mack1993), originally presented by Taylor and Ashe (Reference Taylor and Ashe1983), in order to choose values for the model parameters of exposure and distribution of delay. Applying the formula from Remark 4, we can transform the development factors
 $\widehat{f}_t$
corresponding to Table 1 in Mack (Reference Mack1993) into
$\widehat{f}_t$
corresponding to Table 1 in Mack (Reference Mack1993) into
 \begin{align*}(\widehat{q}_{t})_{t=1}^{T} = (0.069, 0.172, 0.180, 0.194, 0.107, 0.075, 0.069, 0.047, 0.070, 0.018).\end{align*}
\begin{align*}(\widehat{q}_{t})_{t=1}^{T} = (0.069, 0.172, 0.180, 0.194, 0.107, 0.075, 0.069, 0.047, 0.070, 0.018).\end{align*}
For the exposures, we simply use the first column of the run-off triangle in Mack (Reference Mack1993) and normalize it by dividing by its first entry (this procedure suffices for illustration, more sophisticated estimation could be considered). This yields
 \begin{align*}(\widehat{\lambda}_i)_{i=1}^T = (1.000, 0.984, 0.812, 0.868, 1.239, 1.107, 1.230, 1.005, 1.053, 0.961)\end{align*}
\begin{align*}(\widehat{\lambda}_i)_{i=1}^T = (1.000, 0.984, 0.812, 0.868, 1.239, 1.107, 1.230, 1.005, 1.053, 0.961)\end{align*}
across accident years. For simplicity, we choose
 $Z \equiv 1$
and
$Z \equiv 1$
and
 $\alpha = 4,000,000$
, which roughly corresponds to the order of magnitude as can be found in Mack (Reference Mack1993). We generate 100,000 realizations of run-off triangles and for each one compute both the true standardized conditional mean squared error (5.2) and the standardized version of Mack’s estimator of conditional mean squared error (5.1) for accident years i=3, 5, and 8. The results can be seen in Figure 1. The results are not sensitive to the value chosen for
$\alpha = 4,000,000$
, which roughly corresponds to the order of magnitude as can be found in Mack (Reference Mack1993). We generate 100,000 realizations of run-off triangles and for each one compute both the true standardized conditional mean squared error (5.2) and the standardized version of Mack’s estimator of conditional mean squared error (5.1) for accident years i=3, 5, and 8. The results can be seen in Figure 1. The results are not sensitive to the value chosen for
 $\alpha$
, and the histograms in Figure 1 are essentially indistinguishable from those with
$\alpha$
, and the histograms in Figure 1 are essentially indistinguishable from those with
 $\alpha=10,000$
. Although the distribution of the true standardized conditional mean squared error is not the same as that for the standardized version of Mack’s estimator of conditional mean squared error, as seen in Figure 1, the mean values of the empirical distributions are essentially identical.
$\alpha=10,000$
. Although the distribution of the true standardized conditional mean squared error is not the same as that for the standardized version of Mack’s estimator of conditional mean squared error, as seen in Figure 1, the mean values of the empirical distributions are essentially identical.

Figure 1. Blue histograms: standardized Mack’s estimator (5.1) of conditional mean squared error. Orange histograms: true standardized conditional mean squared error (5.2). The three plots shown correspond to accident years
 $i=3,5,8$
(left, right, bottom). For each of the three cases, the empirical means differ by less than
$i=3,5,8$
(left, right, bottom). For each of the three cases, the empirical means differ by less than
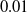 $0.01$
.
$0.01$
.
6. Proofs
Before the proof of Theorem 1, we state a result, on stochastic representations of norms of multivariate normal random vectors, that will be used in the proof of Theorem 1.
Lemma 1. If
 $W\sim \mathrm{N}_n(0,\Sigma)$
, then
$W\sim \mathrm{N}_n(0,\Sigma)$
, then
 $W^{{\mathrm{T}}}W\stackrel{d}{=} \sum_{i=1}^n \mu_iQ^2_i$
, where
$W^{{\mathrm{T}}}W\stackrel{d}{=} \sum_{i=1}^n \mu_iQ^2_i$
, where
 $Q_1,\dots,Q_n$
are independent and standard normal and
$Q_1,\dots,Q_n$
are independent and standard normal and
 $\mu_1,\dots,\mu_n$
are the eigenvalues of
$\mu_1,\dots,\mu_n$
are the eigenvalues of
 $\Sigma$
.
$\Sigma$
.
Proof of Lemma 1. Write
 $\Sigma=LL^{{\mathrm{T}}}$
and note that
$\Sigma=LL^{{\mathrm{T}}}$
and note that
 $W\stackrel{d}{=} LQ$
with
$W\stackrel{d}{=} LQ$
with
 $Q\sim \mathrm{N}_n(0,I)$
. Hence,
$Q\sim \mathrm{N}_n(0,I)$
. Hence,
 $W^{{\mathrm{T}}}W\stackrel{d}{=} Q^{{\mathrm{T}}}L^{{\mathrm{T}}}LQ$
. The matrix
$W^{{\mathrm{T}}}W\stackrel{d}{=} Q^{{\mathrm{T}}}L^{{\mathrm{T}}}LQ$
. The matrix
 $L^{{\mathrm{T}}}L$
is orthogonally diagonizable and has the same eigenvalues as
$L^{{\mathrm{T}}}L$
is orthogonally diagonizable and has the same eigenvalues as
 $\Sigma=LL^{{\mathrm{T}}}$
. Write
$\Sigma=LL^{{\mathrm{T}}}$
. Write
 $L^{{\mathrm{T}}}L=O^{{\mathrm{T}}}D O$
, where O is orthogonal and
$L^{{\mathrm{T}}}L=O^{{\mathrm{T}}}D O$
, where O is orthogonal and
 $D=\mathrm{diag}(\mu_1,\dots,\mu_n)$
. Hence,
$D=\mathrm{diag}(\mu_1,\dots,\mu_n)$
. Hence,
 \begin{align*}W^{{\mathrm{T}}}W\stackrel{d}{=} Q^{{\mathrm{T}}}L^{{\mathrm{T}}}LQ\stackrel{d}{=} Q^{{\mathrm{T}}}O^{{\mathrm{T}}}DOQ\stackrel{d}{=} Q^{{\mathrm{T}}}DQ\end{align*}
\begin{align*}W^{{\mathrm{T}}}W\stackrel{d}{=} Q^{{\mathrm{T}}}L^{{\mathrm{T}}}LQ\stackrel{d}{=} Q^{{\mathrm{T}}}O^{{\mathrm{T}}}DOQ\stackrel{d}{=} Q^{{\mathrm{T}}}DQ\end{align*}
since
 $OQ\stackrel{d}{=} Q$
.
$OQ\stackrel{d}{=} Q$
.
Proof of Theorem 1. We first prove (4.1). Note that, for
 $1\leq i_0\lt i_1\leq T$
, using Theorem 2.1 in Gut (Reference Gut2009),
$1\leq i_0\lt i_1\leq T$
, using Theorem 2.1 in Gut (Reference Gut2009),
 \begin{align*}\frac{1}{\alpha}\sum_{i=i_0}^{i_1}C^{\alpha}_{i,t+1}&=\sum_{i=i_0}^{i_1}\frac{M^{\alpha}_i}{\alpha}\frac{1}{M^{\alpha}_i}\sum_{k=1}^{M^{\alpha}_i}Z_{i,k}I\{D_{i,k}\leq t+1\} \\[5pt] &\stackrel{\mathrm{a.s.}}{\to} \mathrm{E}[ZI\{D\leq t+1\}]\sum_{i=i_0}^{i_1}\lambda_i.\end{align*}
\begin{align*}\frac{1}{\alpha}\sum_{i=i_0}^{i_1}C^{\alpha}_{i,t+1}&=\sum_{i=i_0}^{i_1}\frac{M^{\alpha}_i}{\alpha}\frac{1}{M^{\alpha}_i}\sum_{k=1}^{M^{\alpha}_i}Z_{i,k}I\{D_{i,k}\leq t+1\} \\[5pt] &\stackrel{\mathrm{a.s.}}{\to} \mathrm{E}[ZI\{D\leq t+1\}]\sum_{i=i_0}^{i_1}\lambda_i.\end{align*}
Consequently,
 \begin{align*}\frac{\sum_{i=i_0}^{i_1}C^{\alpha}_{i,t+1}}{\sum_{i=i_0}^{i_1}C^{\alpha}_{i,t}} \stackrel{\mathrm{a.s.}}{\to} \frac{\mathrm{E}[ZI\{D\leq t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]}.\end{align*}
\begin{align*}\frac{\sum_{i=i_0}^{i_1}C^{\alpha}_{i,t+1}}{\sum_{i=i_0}^{i_1}C^{\alpha}_{i,t}} \stackrel{\mathrm{a.s.}}{\to} \frac{\mathrm{E}[ZI\{D\leq t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]}.\end{align*}
In order to prove (4.2), Note that, similarly to the above,
 \begin{align*}\frac{C^{\alpha}_{i,T}}{C^{\alpha}_{i,t}}\stackrel{\mathrm{a.s.}}{\to} \frac{\mathrm{E}[ZI\{D\leq T\}]}{\mathrm{E}[ZI\{D\leq t\}]}\quad\text{and}\quad\prod_{s=t}^{T-1}\widehat{f}_s \stackrel{\mathrm{a.s.}}{\to} \frac{\mathrm{E}[ZI\{D\leq T\}]}{\mathrm{E}[ZI\{D\leq t\}]}.\end{align*}
\begin{align*}\frac{C^{\alpha}_{i,T}}{C^{\alpha}_{i,t}}\stackrel{\mathrm{a.s.}}{\to} \frac{\mathrm{E}[ZI\{D\leq T\}]}{\mathrm{E}[ZI\{D\leq t\}]}\quad\text{and}\quad\prod_{s=t}^{T-1}\widehat{f}_s \stackrel{\mathrm{a.s.}}{\to} \frac{\mathrm{E}[ZI\{D\leq T\}]}{\mathrm{E}[ZI\{D\leq t\}]}.\end{align*}
We proceed to the more involved task of proving (4.3). For
 $j=i_0,\dots,i_1$
, let
$j=i_0,\dots,i_1$
, let
 \begin{align*} W^{\alpha}_j=\frac{ \alpha^{-1/2} \Big((C^{\alpha}_{j,t+1} - C^{\alpha}_{j,t}) - \frac{\sum_{i=i_0}^{i_1} (C^{\alpha}_{i,t+1} - C^{\alpha}_{i,t})}{\sum_{i=i_0}^{i_1}C^{\alpha}_{i,t}} C^{\alpha}_{j,t} \Big)}{(\alpha^{-1}C^{\alpha}_{j,t})^{1/2}}.\end{align*}
\begin{align*} W^{\alpha}_j=\frac{ \alpha^{-1/2} \Big((C^{\alpha}_{j,t+1} - C^{\alpha}_{j,t}) - \frac{\sum_{i=i_0}^{i_1} (C^{\alpha}_{i,t+1} - C^{\alpha}_{i,t})}{\sum_{i=i_0}^{i_1}C^{\alpha}_{i,t}} C^{\alpha}_{j,t} \Big)}{(\alpha^{-1}C^{\alpha}_{j,t})^{1/2}}.\end{align*}
Some algebra shows that
 \begin{align*}\big(W^{\alpha}_j\big)^2=C^{\alpha}_{i,t}\bigg(\frac{C^{\alpha}_{i,t+1}}{C^{\alpha}_{i,t}}-\widehat{f}_{t}\bigg)^2\end{align*}
\begin{align*}\big(W^{\alpha}_j\big)^2=C^{\alpha}_{i,t}\bigg(\frac{C^{\alpha}_{i,t+1}}{C^{\alpha}_{i,t}}-\widehat{f}_{t}\bigg)^2\end{align*}
that is the jth term in the sum in the expression for
 $\widehat{\sigma}^2_t$
. The numerator of
$\widehat{\sigma}^2_t$
. The numerator of
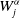 $W_j^\alpha$
can be written as:
$W_j^\alpha$
can be written as:
 \begin{align*}\begin{split}&\left( 1 - \frac{C^{\alpha}_{j,t}}{\sum_{i=i_0}^{i_1} C^{\alpha}_{i,t}}\right)\alpha^{-1/2}\sum_{k=1}^{M_j^\alpha} Z_{j,k}\left( I\{D_{j,k} = t+1\} - \frac{\mathrm{E}[ZI\{D= t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]} I\{D_{j,k} \leq t\} \right) \\[5pt] &-\frac{C^{\alpha}_{j,t}}{\sum_{i=i_0}^{i_1} C^{\alpha}_{i,t}}\alpha^{-1/2} \sum_{i=i_0, i \neq j}^{i_1} \sum_{k=1}^{M_i^\alpha} Z_{i,k}\left( I\{D_{i,k} = t+1\} - \frac{\mathrm{E}[ZI\{D= t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]} I\{D_{i,k} \leq t\} \right) .\end{split}\end{align*}
\begin{align*}\begin{split}&\left( 1 - \frac{C^{\alpha}_{j,t}}{\sum_{i=i_0}^{i_1} C^{\alpha}_{i,t}}\right)\alpha^{-1/2}\sum_{k=1}^{M_j^\alpha} Z_{j,k}\left( I\{D_{j,k} = t+1\} - \frac{\mathrm{E}[ZI\{D= t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]} I\{D_{j,k} \leq t\} \right) \\[5pt] &-\frac{C^{\alpha}_{j,t}}{\sum_{i=i_0}^{i_1} C^{\alpha}_{i,t}}\alpha^{-1/2} \sum_{i=i_0, i \neq j}^{i_1} \sum_{k=1}^{M_i^\alpha} Z_{i,k}\left( I\{D_{i,k} = t+1\} - \frac{\mathrm{E}[ZI\{D= t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]} I\{D_{i,k} \leq t\} \right) .\end{split}\end{align*}
We can now write
 $W^{\alpha}=B^{\alpha}U^{\alpha}$
, where
$W^{\alpha}=B^{\alpha}U^{\alpha}$
, where
 \begin{align*}U_{j}^\alpha = \alpha^{-1/2}\sum_{k=1}^{M_j^\alpha} Z_{k, j}\bigg( I\{D_{j,k} = t+1\} - \frac{\mathrm{E}[ZI\{D= t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]} I\{D_{j,k} \leq t\} \bigg)\end{align*}
\begin{align*}U_{j}^\alpha = \alpha^{-1/2}\sum_{k=1}^{M_j^\alpha} Z_{k, j}\bigg( I\{D_{j,k} = t+1\} - \frac{\mathrm{E}[ZI\{D= t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]} I\{D_{j,k} \leq t\} \bigg)\end{align*}
and
 $B^\alpha$
is a square matrix with entries:
$B^\alpha$
is a square matrix with entries:
 \begin{align*}B_{j, l}^\alpha =\begin{cases}\left( \alpha^{-1} C^{\alpha}_{j,t} \right)^{-1/2}\left( 1 - \frac{C^{\alpha}_{j,t}}{\sum_{i=i_0}^{i_1} C^{\alpha}_{i,t}}\right), &j = l \\[5pt] \left( \alpha^{-1} C^{\alpha}_{j,t} \right)^{-1/2}\left( - \frac{C^{\alpha}_{j,t}}{\sum_{i=i_0}^{i_1} C^{\alpha}_{i,t}}\right), &j \neq l.\end{cases}\end{align*}
\begin{align*}B_{j, l}^\alpha =\begin{cases}\left( \alpha^{-1} C^{\alpha}_{j,t} \right)^{-1/2}\left( 1 - \frac{C^{\alpha}_{j,t}}{\sum_{i=i_0}^{i_1} C^{\alpha}_{i,t}}\right), &j = l \\[5pt] \left( \alpha^{-1} C^{\alpha}_{j,t} \right)^{-1/2}\left( - \frac{C^{\alpha}_{j,t}}{\sum_{i=i_0}^{i_1} C^{\alpha}_{i,t}}\right), &j \neq l.\end{cases}\end{align*}
The multivariate Central Limit Theorem together with Theorem 1.1 in Gut (Reference Gut2009) yield
 $U^\alpha \stackrel{d}{\to} U$
, where
$U^\alpha \stackrel{d}{\to} U$
, where
 $U \sim \mathrm{N}_{i_1 - i_0 + 1}(0,c_t^2 \mathrm{diag}(\lambda_{i_0}, \dots, \lambda_{i_1}))$
with
$U \sim \mathrm{N}_{i_1 - i_0 + 1}(0,c_t^2 \mathrm{diag}(\lambda_{i_0}, \dots, \lambda_{i_1}))$
with
 \begin{align*}c_t^2 &= \mathrm{var}\bigg( Z\bigg( I\{D = t+1\} - \frac{\mathrm{E}[ZI\{D= t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]} I\{D \leq t\} \bigg) \bigg)\\[5pt] &=\mathrm{E}[Z^2I\{D = t+1\}]+\bigg(\frac{\mathrm{E}[ZI\{D= t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]}\bigg)^2\mathrm{E}[Z^2I\{D \leq t\}].\end{align*}
\begin{align*}c_t^2 &= \mathrm{var}\bigg( Z\bigg( I\{D = t+1\} - \frac{\mathrm{E}[ZI\{D= t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]} I\{D \leq t\} \bigg) \bigg)\\[5pt] &=\mathrm{E}[Z^2I\{D = t+1\}]+\bigg(\frac{\mathrm{E}[ZI\{D= t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]}\bigg)^2\mathrm{E}[Z^2I\{D \leq t\}].\end{align*}
By the strong law of large numbers,
 $B^\alpha \stackrel{\mathrm{a.s.}}{\to} B$
, where
$B^\alpha \stackrel{\mathrm{a.s.}}{\to} B$
, where
 \begin{align*}B_{j, l} = & \mathrm{E}[ZI\{D\leq t\}]^{-1/2} \cdot\begin{cases}\lambda_j^{-1/2} \left( 1 -\frac{\lambda_j}{ \sum_{i=i_0}^{i_1} \lambda_i} \right), &j = l\\[5pt] \lambda_j^{-1/2}\left(-\frac{\lambda_j}{ \sum_{i=i_0}^{i_1} \lambda_i} \right), &j \neq l.\end{cases}\end{align*}
\begin{align*}B_{j, l} = & \mathrm{E}[ZI\{D\leq t\}]^{-1/2} \cdot\begin{cases}\lambda_j^{-1/2} \left( 1 -\frac{\lambda_j}{ \sum_{i=i_0}^{i_1} \lambda_i} \right), &j = l\\[5pt] \lambda_j^{-1/2}\left(-\frac{\lambda_j}{ \sum_{i=i_0}^{i_1} \lambda_i} \right), &j \neq l.\end{cases}\end{align*}
Hence, by Slutsky’s theorem (multivariate version),
 $W^\alpha = B^\alpha U^\alpha \stackrel{d}{\to} BU = W$
, where
$W^\alpha = B^\alpha U^\alpha \stackrel{d}{\to} BU = W$
, where
 $W\sim \mathrm{N}_{i_1-i_0+1}(0,\Sigma)$
with
$W\sim \mathrm{N}_{i_1-i_0+1}(0,\Sigma)$
with
 \begin{align*}\Sigma = B\; \mathrm{cov}(U) B^{{\mathrm{T}}} = \frac{c_t^2}{\mathrm{E}[ZI\{D\leq t\}]} \widetilde \Sigma=\sigma_t^2 \widetilde \Sigma\end{align*}
\begin{align*}\Sigma = B\; \mathrm{cov}(U) B^{{\mathrm{T}}} = \frac{c_t^2}{\mathrm{E}[ZI\{D\leq t\}]} \widetilde \Sigma=\sigma_t^2 \widetilde \Sigma\end{align*}
The eigenvalues of
 $\widetilde{\Sigma}$
are
$\widetilde{\Sigma}$
are
 $\mu_1 = 1, \mu_2 = 0$
with corresponding eigenspaces:
$\mu_1 = 1, \mu_2 = 0$
with corresponding eigenspaces:
 \begin{align*}\text{Eig}_1 = \text{span}\left(\begin{bmatrix}\lambda_{i_0 + 1}^{1/2} \\[5pt] - \lambda_{i_0}^{1/2}\\[5pt] 0 \\[5pt] 0 \\[5pt] \vdots \\[5pt] 0\end{bmatrix},\begin{bmatrix}\lambda_{i_0 + 2}^{1/2} \\[5pt] 0 \\[5pt] -\lambda_{i_0}^{1/2} \\[5pt] 0 \\[5pt] \vdots \\[5pt] 0\end{bmatrix}, \dots,\begin{bmatrix}\lambda_{i_1}^{1/2} \\[5pt] 0 \\[5pt] 0\\[5pt] \vdots \\[5pt] 0 \\[5pt] - \lambda_{i_0}^{1/2}\end{bmatrix}\right), \quad \text{Eig}_0 = \text{span}\left(\begin{bmatrix}\lambda_{i_0}^{1/2} \\[5pt] \vdots \\[5pt] \lambda_{i_1}^{1/2}\end{bmatrix}\right)\end{align*}
\begin{align*}\text{Eig}_1 = \text{span}\left(\begin{bmatrix}\lambda_{i_0 + 1}^{1/2} \\[5pt] - \lambda_{i_0}^{1/2}\\[5pt] 0 \\[5pt] 0 \\[5pt] \vdots \\[5pt] 0\end{bmatrix},\begin{bmatrix}\lambda_{i_0 + 2}^{1/2} \\[5pt] 0 \\[5pt] -\lambda_{i_0}^{1/2} \\[5pt] 0 \\[5pt] \vdots \\[5pt] 0\end{bmatrix}, \dots,\begin{bmatrix}\lambda_{i_1}^{1/2} \\[5pt] 0 \\[5pt] 0\\[5pt] \vdots \\[5pt] 0 \\[5pt] - \lambda_{i_0}^{1/2}\end{bmatrix}\right), \quad \text{Eig}_0 = \text{span}\left(\begin{bmatrix}\lambda_{i_0}^{1/2} \\[5pt] \vdots \\[5pt] \lambda_{i_1}^{1/2}\end{bmatrix}\right)\end{align*}
and hence geometric multiplicities
 $i_1 - i_0$
and 1, respectively. By Lemma 1,
$i_1 - i_0$
and 1, respectively. By Lemma 1,
 \begin{align*}\sum_{i=i_0}^{i_1} W_i^2 \stackrel{d}{=} \sigma_t^2\sum_{i=i_0}^{i_1-1} Q_i^2,\end{align*}
\begin{align*}\sum_{i=i_0}^{i_1} W_i^2 \stackrel{d}{=} \sigma_t^2\sum_{i=i_0}^{i_1-1} Q_i^2,\end{align*}
where
 $Q_{i_0}, \dots, Q_{i_1 -1}$
are independent and standard normal. Altogether, we have shown that
$Q_{i_0}, \dots, Q_{i_1 -1}$
are independent and standard normal. Altogether, we have shown that
 \begin{align*}\widehat{\sigma}^2_{t}\stackrel{d}{=} \frac{1}{i_1-i_0}\sum_{i=i_0}^{i_1}\big(W^{\alpha}_i\big)^2\stackrel{d}{\to} \sigma_t^2\frac{ \chi^2_{i_1 - i_0}}{i_{1} - i_{0}}.\end{align*}
\begin{align*}\widehat{\sigma}^2_{t}\stackrel{d}{=} \frac{1}{i_1-i_0}\sum_{i=i_0}^{i_1}\big(W^{\alpha}_i\big)^2\stackrel{d}{\to} \sigma_t^2\frac{ \chi^2_{i_1 - i_0}}{i_{1} - i_{0}}.\end{align*}
Proof of Theorem 2. Write
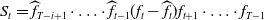 $S_t=\widehat{f}_{T-i+1}\cdot\ldots\cdot \widehat{f}_{t-1}(f_t-\widehat{f}_t)f_{t+1}\cdot\ldots\cdot f_{T-1}$
and note, as noted in Mack (Reference Mack1993), that
$S_t=\widehat{f}_{T-i+1}\cdot\ldots\cdot \widehat{f}_{t-1}(f_t-\widehat{f}_t)f_{t+1}\cdot\ldots\cdot f_{T-1}$
and note, as noted in Mack (Reference Mack1993), that
 $f_{T-i+1}\cdot\ldots\cdot f_{T-1}-\widehat{f}_{T-i+1}\cdot\ldots\cdot\widehat{f}_{T-1}=\sum_{t=T-i+1}^{T-1}S_t$
. Hence, the statement of the theorem follows if we show the appropriate convergence in distribution of
$f_{T-i+1}\cdot\ldots\cdot f_{T-1}-\widehat{f}_{T-i+1}\cdot\ldots\cdot\widehat{f}_{T-1}=\sum_{t=T-i+1}^{T-1}S_t$
. Hence, the statement of the theorem follows if we show the appropriate convergence in distribution of
 \begin{align}\frac{\alpha^{-1/2}C^{\alpha}_{i,T-i+1}}{(\alpha^{-1}C^{\alpha}_{i,T-i+1})^{1/2}}\sum_{t=T-i+1}^{T-1}S_t.\end{align}
\begin{align}\frac{\alpha^{-1/2}C^{\alpha}_{i,T-i+1}}{(\alpha^{-1}C^{\alpha}_{i,T-i+1})^{1/2}}\sum_{t=T-i+1}^{T-1}S_t.\end{align}
Write
 \begin{align*}S_t&=\bigg(\prod_{s=T-i+1}^{t-1}\widehat{f}_s\bigg)\bigg(\prod_{s=t+1}^{T-1}f_s\bigg)\bigg(\frac{\mathrm{E}[ZI\{D\leq t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]}-\frac{\sum_{j=1}^{T-t}C^{\alpha}_{j,t+1}}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}\bigg)\\[5pt] &=\frac{(\prod_{s=T-i+1}^{t-1}\widehat{f}_s)(\prod_{s=t+1}^{T-1}f_s)}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}\alpha^{1/2}\sum_{j=1}^{T-t}\bigg(\frac{M^{\alpha}_j}{\alpha}\bigg)^{1/2}U^{\alpha}_{j,t},\end{align*}
\begin{align*}S_t&=\bigg(\prod_{s=T-i+1}^{t-1}\widehat{f}_s\bigg)\bigg(\prod_{s=t+1}^{T-1}f_s\bigg)\bigg(\frac{\mathrm{E}[ZI\{D\leq t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]}-\frac{\sum_{j=1}^{T-t}C^{\alpha}_{j,t+1}}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}\bigg)\\[5pt] &=\frac{(\prod_{s=T-i+1}^{t-1}\widehat{f}_s)(\prod_{s=t+1}^{T-1}f_s)}{\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}\alpha^{1/2}\sum_{j=1}^{T-t}\bigg(\frac{M^{\alpha}_j}{\alpha}\bigg)^{1/2}U^{\alpha}_{j,t},\end{align*}
where
 \begin{align*}U^{\alpha}_{j,t}=(M^{\alpha}_j)^{-1/2}\sum_{k=1}^{M^{\alpha}_j}Z_{j,k}\bigg(\frac{\mathrm{E}[ZI\{D=t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]}I\{D_{j,k}\leq t\}-I\{D_{j,k}=t+1\}\bigg).\end{align*}
\begin{align*}U^{\alpha}_{j,t}=(M^{\alpha}_j)^{-1/2}\sum_{k=1}^{M^{\alpha}_j}Z_{j,k}\bigg(\frac{\mathrm{E}[ZI\{D=t+1\}]}{\mathrm{E}[ZI\{D\leq t\}]}I\{D_{j,k}\leq t\}-I\{D_{j,k}=t+1\}\bigg).\end{align*}
Therefore, we may write (6.1) as:
 \begin{align*}\sum_{t=T-i+1}^{T-1}B^{\alpha}_t\sum_{j=1}^{T-t}\bigg(\frac{M^{\alpha}_j}{\alpha}\bigg)^{1/2}U^{\alpha}_{j,t}=\sum_{j=1}^{i-1}\bigg(\frac{M^{\alpha}_j}{\alpha}\bigg)^{1/2}\sum_{t=T-i+1}^{T-j}B^{\alpha}_t U^{\alpha}_{j,t},\end{align*}
\begin{align*}\sum_{t=T-i+1}^{T-1}B^{\alpha}_t\sum_{j=1}^{T-t}\bigg(\frac{M^{\alpha}_j}{\alpha}\bigg)^{1/2}U^{\alpha}_{j,t}=\sum_{j=1}^{i-1}\bigg(\frac{M^{\alpha}_j}{\alpha}\bigg)^{1/2}\sum_{t=T-i+1}^{T-j}B^{\alpha}_t U^{\alpha}_{j,t},\end{align*}
where
 \begin{align*}B^{\alpha}_t=\frac{(\alpha^{-1}C^{\alpha}_{i,T-i+1})^{1/2}}{\alpha^{-1}\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}\bigg(\prod_{s=T-i+1}^{t-1}\widehat{f}_s\bigg)\bigg(\prod_{s=t+1}^{T-1}f_s\bigg).\end{align*}
\begin{align*}B^{\alpha}_t=\frac{(\alpha^{-1}C^{\alpha}_{i,T-i+1})^{1/2}}{\alpha^{-1}\sum_{j=1}^{T-t}C^{\alpha}_{j,t}}\bigg(\prod_{s=T-i+1}^{t-1}\widehat{f}_s\bigg)\bigg(\prod_{s=t+1}^{T-1}f_s\bigg).\end{align*}
We will use the facts that
 $(U^{\alpha}_{1,t})_{t=T-i+1}^{T-1}, (U^{\alpha}_{2,t})_{t=T-i+1}^{T-2}, \dots, U^{\alpha}_{i-1,T-i+1}$
are independent and that each one converges in distribution to a centered normally distributed random vector/variable and that each
$(U^{\alpha}_{1,t})_{t=T-i+1}^{T-1}, (U^{\alpha}_{2,t})_{t=T-i+1}^{T-2}, \dots, U^{\alpha}_{i-1,T-i+1}$
are independent and that each one converges in distribution to a centered normally distributed random vector/variable and that each
 $B^{\alpha}_t$
converges a.s. as
$B^{\alpha}_t$
converges a.s. as
 $\alpha\to\infty$
. A multivariate version of Slutsky’s theorem (essentially the continuous mapping theorem for weak convergence) then implies convergence in distribution of (6.1) to a centered normally distributed random variable.
$\alpha\to\infty$
. A multivariate version of Slutsky’s theorem (essentially the continuous mapping theorem for weak convergence) then implies convergence in distribution of (6.1) to a centered normally distributed random variable.
Note that
 \begin{align*}B^{\alpha}_t\stackrel{\mathrm{a.s.}}{\to} \frac{(\lambda_i\mathrm{E}[ZI\{D\leq T-i+1\}])^{1/2}\prod_{s=T-i+1}^{T-1}f_s}{\sum_{j=1}^{T-t}\lambda_j\mathrm{E}[ZI\{D\leq t\}]f_t}=B_t.\end{align*}
\begin{align*}B^{\alpha}_t\stackrel{\mathrm{a.s.}}{\to} \frac{(\lambda_i\mathrm{E}[ZI\{D\leq T-i+1\}])^{1/2}\prod_{s=T-i+1}^{T-1}f_s}{\sum_{j=1}^{T-t}\lambda_j\mathrm{E}[ZI\{D\leq t\}]f_t}=B_t.\end{align*}
Note that, for each j, as
 $\alpha\to\infty$
,
$\alpha\to\infty$
,
 $(U^{\alpha}_{j,t})_{t=T-i+1}^{T-1}$
converges in distribution to a centered normal random vector with covariance matrix
$(U^{\alpha}_{j,t})_{t=T-i+1}^{T-1}$
converges in distribution to a centered normal random vector with covariance matrix
 $\Sigma$
with, for integer-valued
$\Sigma$
with, for integer-valued
 $h\gt 0$
,
$h\gt 0$
,
 \begin{align*}\Sigma_{t,t}&=(f_t-1)^2\mathrm{E}[Z^2I\{D\leq t\}]+\mathrm{E}[Z^2I\{D=t+1\}]\\[5pt] &=\sigma^2_t\mathrm{E}[ZI\{D\leq t\}], \\[5pt] \Sigma_{t,t+h}&=(f_{t+h}-1)\big((f_t-1)\mathrm{E}[Z^2I\{D\leq t\}]-\mathrm{E}[Z^2I\{D=t+1\}]\big).\end{align*}
\begin{align*}\Sigma_{t,t}&=(f_t-1)^2\mathrm{E}[Z^2I\{D\leq t\}]+\mathrm{E}[Z^2I\{D=t+1\}]\\[5pt] &=\sigma^2_t\mathrm{E}[ZI\{D\leq t\}], \\[5pt] \Sigma_{t,t+h}&=(f_{t+h}-1)\big((f_t-1)\mathrm{E}[Z^2I\{D\leq t\}]-\mathrm{E}[Z^2I\{D=t+1\}]\big).\end{align*}
If D and Z are independent, then it is seen from the above expression that
 $\Sigma$
is diagonal. In this case,
$\Sigma$
is diagonal. In this case,
 \begin{align*}\sum_{t=T-i+1}^{T-j}B^{\alpha}_t U^{\alpha}_{j,t}\stackrel{d}{\to} \mathrm{N}_1\bigg(0,\sum_{t=T-i+1}^{T-j}(B_t)^2\Sigma_{t,t}\bigg)\end{align*}
\begin{align*}\sum_{t=T-i+1}^{T-j}B^{\alpha}_t U^{\alpha}_{j,t}\stackrel{d}{\to} \mathrm{N}_1\bigg(0,\sum_{t=T-i+1}^{T-j}(B_t)^2\Sigma_{t,t}\bigg)\end{align*}
and consequently (6.1) converges in distribution to a centered normally distributed random variable with variance:
 \begin{align*}&\sum_{j=1}^{i-1}\lambda_j\sum_{t=T-i+1}^{T-j}(B_t)^2\Sigma_{t,t}=\sum_{t=T-i+1}^{T-1}(B_t)^2\Sigma_{t,t}\sum_{j=1}^{T-t}\lambda_j \\[5pt] &\quad=\lambda_i\mathrm{E}[ZI\{D\leq T-i+1\}]\prod_{s=T-i+1}^{T-1}f_s^2\sum_{t=T-i+1}^{T-1}\frac{\sigma^2_t/f_t^2}{\sum_{j=1}^{T-t}\lambda_j \mathrm{E}[ZI\{D\leq t\}]}.\end{align*}
\begin{align*}&\sum_{j=1}^{i-1}\lambda_j\sum_{t=T-i+1}^{T-j}(B_t)^2\Sigma_{t,t}=\sum_{t=T-i+1}^{T-1}(B_t)^2\Sigma_{t,t}\sum_{j=1}^{T-t}\lambda_j \\[5pt] &\quad=\lambda_i\mathrm{E}[ZI\{D\leq T-i+1\}]\prod_{s=T-i+1}^{T-1}f_s^2\sum_{t=T-i+1}^{T-1}\frac{\sigma^2_t/f_t^2}{\sum_{j=1}^{T-t}\lambda_j \mathrm{E}[ZI\{D\leq t\}]}.\end{align*}
Proof of Theorem 3. By Corollary 1,
 $(H^{\alpha},F^{\alpha})\stackrel{d}{\to} (H,F)$
, where H and F are independent and normally distributed with zero means and variances
$(H^{\alpha},F^{\alpha})\stackrel{d}{\to} (H,F)$
, where H and F are independent and normally distributed with zero means and variances
 $\mathrm{var}(H)=\lambda_i\mathrm{E}[Z^2]\mathrm{P}(D\leq T-i+1)$
and
$\mathrm{var}(H)=\lambda_i\mathrm{E}[Z^2]\mathrm{P}(D\leq T-i+1)$
and
 $\mathrm{var}(F)=\lambda_i\mathrm{E}[Z^2]\mathrm{P}(D\gt T-i+1)$
. Write
$\mathrm{var}(F)=\lambda_i\mathrm{E}[Z^2]\mathrm{P}(D\gt T-i+1)$
. Write
 $g_{T-i+1}=\frac{\mathrm{E}[ZI\{D\leq T\}]}{\mathrm{E}[ZI\{D\leq T-i+1\}]}=\prod_{s=T-i+1}^{T-1}f_s$
and note that
$g_{T-i+1}=\frac{\mathrm{E}[ZI\{D\leq T\}]}{\mathrm{E}[ZI\{D\leq T-i+1\}]}=\prod_{s=T-i+1}^{T-1}f_s$
and note that
 \begin{align*}&\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}g_{T-i+1})^2}{C^{\alpha}_{T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg] \\[5pt] &\quad=\frac{\alpha}{C^{\alpha}_{T-i+1}}\mathrm{E}\Big[\big(F^{\alpha}-H^{\alpha}(g_{T-i+1}-1)\big)^2 \,\Big|\, H^{\alpha}\Big] \\[5pt] &\quad=\frac{\alpha}{C^{\alpha}_{T-i+1}}\Big(\mathrm{E}[(F^{\alpha})^2]+(H^{\alpha})^2(g_{T-i+1}-1)^2\Big) \\[5pt] &\quad=\frac{\alpha}{C^{\alpha}_{T-i+1}}\Big(\frac{\mathrm{E}[M^{\alpha}_i]}{\alpha}\mathrm{E}[Z^2]\mathrm{P}(D\gt T-i+1)+(H^{\alpha})^2(g_{T-i+1}-1)^2\Big)\end{align*}
\begin{align*}&\mathrm{E}\bigg[\frac{(C^{\alpha}_{i,T}-C^{\alpha}_{i,T-i+1}g_{T-i+1})^2}{C^{\alpha}_{T-i+1}} \,\bigg|\, \mathcal{D}^{\alpha}\bigg] \\[5pt] &\quad=\frac{\alpha}{C^{\alpha}_{T-i+1}}\mathrm{E}\Big[\big(F^{\alpha}-H^{\alpha}(g_{T-i+1}-1)\big)^2 \,\Big|\, H^{\alpha}\Big] \\[5pt] &\quad=\frac{\alpha}{C^{\alpha}_{T-i+1}}\Big(\mathrm{E}[(F^{\alpha})^2]+(H^{\alpha})^2(g_{T-i+1}-1)^2\Big) \\[5pt] &\quad=\frac{\alpha}{C^{\alpha}_{T-i+1}}\Big(\frac{\mathrm{E}[M^{\alpha}_i]}{\alpha}\mathrm{E}[Z^2]\mathrm{P}(D\gt T-i+1)+(H^{\alpha})^2(g_{T-i+1}-1)^2\Big)\end{align*}
Since
 $C^{\alpha}_{i,T-i+1}/\alpha\stackrel{\mathrm{a.s.}}{\to} \lambda_i\mathrm{E}[Z]\mathrm{P}(D\leq T-i+1)$
and
$C^{\alpha}_{i,T-i+1}/\alpha\stackrel{\mathrm{a.s.}}{\to} \lambda_i\mathrm{E}[Z]\mathrm{P}(D\leq T-i+1)$
and
 $(H^{\alpha})^2\stackrel{d}{\to} \lambda_i\mathrm{E}[Z^2]\mathrm{P}(D\leq T-i+1)\chi^2_1$
, the conclusion follows from Slutsky’s theorem.
$(H^{\alpha})^2\stackrel{d}{\to} \lambda_i\mathrm{E}[Z^2]\mathrm{P}(D\leq T-i+1)\chi^2_1$
, the conclusion follows from Slutsky’s theorem.
Proof of Theorem 4.
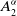 $A^{\alpha}_2$
can be expressed as:
$A^{\alpha}_2$
can be expressed as:
 \begin{align*}A^{\alpha}_2=\alpha^{1/2}\sum_{t=T-i+1}^{T-1}S_t\end{align*}
\begin{align*}A^{\alpha}_2=\alpha^{1/2}\sum_{t=T-i+1}^{T-1}S_t\end{align*}
with
 $S_t$
as in the proof of Theorem 2. Hence, the arguments in the proof of 2 shows that
$S_t$
as in the proof of Theorem 2. Hence, the arguments in the proof of 2 shows that
 $(A^{\alpha}_2)_{\alpha\geq 0}$
converges in distribution to a normally distributed random variable with zero mean. Since
$(A^{\alpha}_2)_{\alpha\geq 0}$
converges in distribution to a normally distributed random variable with zero mean. Since
 \begin{align*}\mathrm{E}[C^{\alpha}_{i,T-i+1}]&=\mathrm{E}[M^{\alpha}_i]\mathrm{E}[Z]\mathrm{P}(D\leq T-i+1), \\[5pt] \mathrm{E}[C^{\alpha}_{T} \,|\, \mathcal{D}^{\alpha}]&=C^{\alpha}_{T-i+1}+\mathrm{E}[M^{\alpha}_i]\mathrm{E}[Z]\mathrm{P}(D\gt T-i+1)\end{align*}
\begin{align*}\mathrm{E}[C^{\alpha}_{i,T-i+1}]&=\mathrm{E}[M^{\alpha}_i]\mathrm{E}[Z]\mathrm{P}(D\leq T-i+1), \\[5pt] \mathrm{E}[C^{\alpha}_{T} \,|\, \mathcal{D}^{\alpha}]&=C^{\alpha}_{T-i+1}+\mathrm{E}[M^{\alpha}_i]\mathrm{E}[Z]\mathrm{P}(D\gt T-i+1)\end{align*}
and
 $\prod_{s=T-i+1}^{T-1}f_s=\mathrm{P}(D\leq T-i+1)^{-1}$
,
$\prod_{s=T-i+1}^{T-1}f_s=\mathrm{P}(D\leq T-i+1)^{-1}$
,
 $A^{\alpha}_1$
can be expressed as:
$A^{\alpha}_1$
can be expressed as:
 \begin{align*}A^{\alpha}_1=-\frac{\mathrm{P}(D\gt T-i+1)}{\mathrm{P}(D\leq T-i+1)}\alpha^{-1/2}\big(C^{\alpha}_{i,T-i+1}-\mathrm{E}[C^{\alpha}_{i,T-i+1}]\big)\end{align*}
\begin{align*}A^{\alpha}_1=-\frac{\mathrm{P}(D\gt T-i+1)}{\mathrm{P}(D\leq T-i+1)}\alpha^{-1/2}\big(C^{\alpha}_{i,T-i+1}-\mathrm{E}[C^{\alpha}_{i,T-i+1}]\big)\end{align*}
from which convergence in distribution to a normally distributed random variable with zero mean follows immediately from Corollary 1. Since
 $(A^{\alpha}_1)_{\alpha\geq 0}$
and
$(A^{\alpha}_1)_{\alpha\geq 0}$
and
 $(A^{\alpha}_2)_{\alpha\geq 0}$
are independent, individual convergence in distribution implies joint convergence in distribution. Consequently, mapping theorem for weak convergence implies that the product converges in distribution.
$(A^{\alpha}_2)_{\alpha\geq 0}$
are independent, individual convergence in distribution implies joint convergence in distribution. Consequently, mapping theorem for weak convergence implies that the product converges in distribution.
The proof of Theorem 5 is based on the proof of Theorem 2.5.15 in Embrechts et al. (Reference Embrechts, Klüppelberg and Mikosch2003).
Proof of Theorem 5. In order to ease the notation, we drop the index j and write
 $S^{\alpha}=\sum_{k=1}^{M^{\alpha}}X_k$
. From the renewal process representation of
$S^{\alpha}=\sum_{k=1}^{M^{\alpha}}X_k$
. From the renewal process representation of
 $M^{\alpha}$
, there exists an i.i.d. sequence
$M^{\alpha}$
, there exists an i.i.d. sequence
 $(Y_k)$
independent of
$(Y_k)$
independent of
 $(X_k)$
such that the sequence
$(X_k)$
such that the sequence
 $(T_m)$
given by
$(T_m)$
given by
 $T_m=\sum_{k=1}^m Y_k$
satisfies
$T_m=\sum_{k=1}^m Y_k$
satisfies
 $M^{\alpha}=\sup\{m\geq 1:T_m\leq \alpha\}$
. Therefore,
$M^{\alpha}=\sup\{m\geq 1:T_m\leq \alpha\}$
. Therefore,
 $\lambda=1/\mathrm{E}[Y]$
and
$\lambda=1/\mathrm{E}[Y]$
and
 \begin{align*}\alpha^{-1/2}(S^{\alpha}-\mathrm{E}[S^{\alpha}])&=\alpha^{-1/2}(S^{\alpha}-\mathrm{E}[X]M^{\alpha}+\mathrm{E}[X](M^{\alpha}-\lambda\alpha))+o_{\mathrm{P}}(1)\end{align*}
\begin{align*}\alpha^{-1/2}(S^{\alpha}-\mathrm{E}[S^{\alpha}])&=\alpha^{-1/2}(S^{\alpha}-\mathrm{E}[X]M^{\alpha}+\mathrm{E}[X](M^{\alpha}-\lambda\alpha))+o_{\mathrm{P}}(1)\end{align*}
using that
 $\lim_{\alpha\to\infty}\alpha^{-1/2}(\lambda\alpha-\mathrm{E}[M^{\alpha}])=0$
by Proposition 2.5.12 in Embrechts et al. (Reference Embrechts, Klüppelberg and Mikosch2003), and where
$\lim_{\alpha\to\infty}\alpha^{-1/2}(\lambda\alpha-\mathrm{E}[M^{\alpha}])=0$
by Proposition 2.5.12 in Embrechts et al. (Reference Embrechts, Klüppelberg and Mikosch2003), and where
 $o_{\mathrm{P}}(1)$
means a remainder term converging in probability to zero as
$o_{\mathrm{P}}(1)$
means a remainder term converging in probability to zero as
 $\alpha\to\infty$
. Using (2.41) in Embrechts et al. (Reference Embrechts, Klüppelberg and Mikosch2003),
$\alpha\to\infty$
. Using (2.41) in Embrechts et al. (Reference Embrechts, Klüppelberg and Mikosch2003),
 $\alpha^{-1/2}(M^{\alpha}-\lambda\alpha)=\alpha^{-1/2}(M^{\alpha}-\lambda T_{M^{\alpha}})+o_{\mathrm{P}}(1)$
. Hence,
$\alpha^{-1/2}(M^{\alpha}-\lambda\alpha)=\alpha^{-1/2}(M^{\alpha}-\lambda T_{M^{\alpha}})+o_{\mathrm{P}}(1)$
. Hence,
 \begin{align*}\alpha^{-1/2}(S^{\alpha}-\mathrm{E}[S^{\alpha}])&=\alpha^{-1/2}\big(S^{\alpha}-\lambda\mathrm{E}[X]T_{M^{\alpha}}\big)+o_{\mathrm{P}}(1)\\[5pt] &=\alpha^{-1/2}\sum_{k=1}^{M_{\alpha}}(X_k-\lambda \mathrm{E}[X]Y_k)+o_{\mathrm{P}}(1)\\[5pt] &=\bigg(\frac{M^{\alpha}}{\alpha}\bigg)^{1/2}(M^{\alpha})^{-1/2}\sum_{k=1}^{M_{\alpha}}(X_k-\lambda \mathrm{E}[X]Y_k)+o_{\mathrm{P}}(1).\end{align*}
\begin{align*}\alpha^{-1/2}(S^{\alpha}-\mathrm{E}[S^{\alpha}])&=\alpha^{-1/2}\big(S^{\alpha}-\lambda\mathrm{E}[X]T_{M^{\alpha}}\big)+o_{\mathrm{P}}(1)\\[5pt] &=\alpha^{-1/2}\sum_{k=1}^{M_{\alpha}}(X_k-\lambda \mathrm{E}[X]Y_k)+o_{\mathrm{P}}(1)\\[5pt] &=\bigg(\frac{M^{\alpha}}{\alpha}\bigg)^{1/2}(M^{\alpha})^{-1/2}\sum_{k=1}^{M_{\alpha}}(X_k-\lambda \mathrm{E}[X]Y_k)+o_{\mathrm{P}}(1).\end{align*}
Consequently,
 $\alpha^{-1/2}(S^{\alpha}-\mathrm{E}[S^{\alpha}])\stackrel{d}{\to} \mathrm{N}_T(0,\Sigma)$
, where
$\alpha^{-1/2}(S^{\alpha}-\mathrm{E}[S^{\alpha}])\stackrel{d}{\to} \mathrm{N}_T(0,\Sigma)$
, where
 \begin{align*}\Sigma=\lambda\mathrm{cov}(X-\lambda\mathrm{E}[X]Y)=\lambda\mathrm{cov}(X)+\lambda^3\mathrm{var}(Y)\mathrm{E}[X]\mathrm{E}[X]^{{\mathrm{T}}}.\end{align*}
\begin{align*}\Sigma=\lambda\mathrm{cov}(X-\lambda\mathrm{E}[X]Y)=\lambda\mathrm{cov}(X)+\lambda^3\mathrm{var}(Y)\mathrm{E}[X]\mathrm{E}[X]^{{\mathrm{T}}}.\end{align*}
If
 $M^{\alpha}$
is Poisson distributed, then
$M^{\alpha}$
is Poisson distributed, then
 $\mathrm{var}(Y)=1/\lambda^2$
and hence
$\mathrm{var}(Y)=1/\lambda^2$
and hence
 $\Sigma=\lambda\mathrm{E}[XX^{{\mathrm{T}}}]$
is diagonal with
$\Sigma=\lambda\mathrm{E}[XX^{{\mathrm{T}}}]$
is diagonal with
 $\Sigma_{t,t}=\lambda\mathrm{E}[Z^2I\{D=t\}]$
.
$\Sigma_{t,t}=\lambda\mathrm{E}[Z^2I\{D=t\}]$
.
Competing interests
No competing interests.




 Open access
Open access