


I. INTRODUCTION
Music arrangement involving a change of instrumentation (e.g. arrangement for piano, guitar, etc.) is an important process of music creation to increase the variety of music performances. Arranging a musical piece to change difficulty, for example, to make it playable for beginners, is also widely practiced. To automate these processes, systems for piano arrangement [Reference Chiu, Shan and Huang1–Reference Takamori, Sato, Nakatsuka and Morishima5], guitar arrangement [Reference Tuohy and Potter6–Reference Hori, Kameoka and Sagayama8], and orchestration [Reference Maekawa, Emura, Miura and Yanagida9,Reference Crestel and Esling10] have been studied. This study aims at a system for piano reduction, i.e. converting an ensemble score (e.g. orchestral and band scores) into a piano score that can control performance difficulty and retain as much musical fidelity to the original score as possible (Fig. 1).

Fig. 1. Overview of the proposed system for piano reduction that can control performance difficulty.
To computationally judge whether a musical score is playable, previous studies have developed conditions on the pitch and rhythmic content. For piano scores, conditions such as “there can be at most five simultaneous notes for each hand” and “simultaneous pitch spans for each hand must be <14 semitones (or so)” have been considered [Reference Onuma and Hamanaka2,Reference Huang, Chiu and Shan3]. However, these conditions cannot be thought of as necessary nor sufficient conditions for playable scores because in reality there can be a piano score with chords with more than five notes and/or spanning a large pitch interval that are conventionally played as broken chords, and even scores without chords (melodies) can be unplayable in fast tempos. In fact, it is difficult to find a complete description of playable scores that is valid in every situation because the condition depends on player's skill and can change continuously with the tempo. A possible solution is to quantify performance difficulty and use it as an indicator of playable scores in each situation of skill level, tempo, etc. [Reference Chiu and Chen11,Reference Sébastien, Ralambondrainy, Sébastien and Conruyt12].
As there is generally a trade-off between performance difficulty and musical fidelity to the original score, it is necessary to quantify musical fidelity and develop an optimization method. Music arrangers remove notes and shift pitches in an ensemble score for the piano reduction score to match a target difficulty level [Reference Onuma and Hamanaka2,Reference Nakamura and Sagayama4]. From a statistical point of view, one can assign probabilities for these edit operations and use them to quantify musical fidelity. Following the analogy with statistical machine translation [Reference Brown, Pietra, Pietra and Mercer13], if one can construct a model for the probability P(R|E) of a reduction score R given an ensemble score E, the piano reduction problem can be formulated as optimization of P(R|E) under constraints on difficulty values. A similar approach without controls of performance difficulty has been studied for guitar arrangement [Reference Hori, Yoshinaga, Fukayama, Kameoka and Sagayama7,Reference Hori, Kameoka and Sagayama8].
To realize this idea, a statistical-modeling approach for piano reduction that can control performance difficulty has been proposed in a recent conference paper [Reference Nakamura and Sagayama4]. Following the thought that fingering motion is closely related to the cost or difficulty of performance [Reference Parncutt, Sloboda, Clarke, Raekallio and Desain14–Reference Al Kasimi, Nichols and Raphael16], quantitative measures of performance difficulty were developed based on a probabilistic generative model of piano scores incorporating fingering motion [Reference Yonebayashi, Kameoka and Sagayama17,Reference Nakamura, Ono and Sagayama18]. To estimate the probability P(R|E), a hidden Markov model (HMM) integrating the piano-score model and a model representing how ensemble scores are likely to be edited was constructed. A piano reduction algorithm was developed based on the Viterbi algorithm. While the potential of the method was suggested by the results of piano reduction for one example piece, formal evaluations, and comparisons with other approaches were left for future work. There was also a problem of the optimization method that the upper bound constraints on difficulty values were often not properly satisfied, due to the limitation of the Viterbi algorithm.
In this study, we extend the work of [Reference Nakamura and Sagayama4] and propose an improved piano reduction method using iterative optimization. We also carry out systematic evaluations on the difficulty measure and the piano reduction method. In particular, we evaluate difficulty measures in terms of their ability of predicting performance errors, which is to our knowledge the first attempt in the literature to objectively evaluating performance difficulty measures. Piano reduction methods are evaluated both objectively and subjectively: an objective evaluation is conducted to examine the effect of the iterative optimization strategy; an subjective evaluation is conducted to assess the quality of the generated reduction scores. The main results are:
• The proposed difficulty measures can be used as indicators of performance errors and measures incorporating the sequential nature of piano scores can better predict performance errors.
• The proposed iterative optimization method yields better controls of difficulty than the method in [Reference Nakamura and Sagayama4].
• Both subjective difficulty and musical fidelity of generated reduction scores monotonically increase with controlled difficulty values.
• By comparing methods based on different models, it is shown that incorporating sequential dependence of pitches and fingering motion in the piano-score model improves musical naturalness and the rate of unplayable notes of reduction scores in high-difficulty cases.
The following are limitations of the current system:
• Melodic and bass notes are manually indicated.
• Score typesetting, especially estimation of voices within each hand part, is currently done manually.
Automating these processes is an undeniable direction for future work. See Section IV.D for discussions.
The rest of the paper is organized as follows. In the next section, we discuss generative piano-score models and performance difficulty measures. In Section III, we present our method for piano reduction. In Section IV, we present and discuss results of evaluation of the piano reduction method. We conclude the paper in the last section.
II. QUANTITATIVE MEASURES OF PERFORMANCE DIFFICULTY
We formulate quantitative performance difficulty measures based on probabilistic generative models of piano scores. A generative model incorporating piano fingering and simpler models are described in Section II.A and performance difficulty measures are discussed in Section II.B.
A) Generative models for piano scores
1) Models for one hand
Let us first discuss models for one hand. A piano score is represented as a sequence of pitches 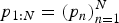 $p_{1:N}=(p_n)_{n=1}^N$ and corresponding onset times
$p_{1:N}=(p_n)_{n=1}^N$ and corresponding onset times  $t_{1:N}=(t_n)_{n=1}^N$ (N is the number of musical notes). A generative model for piano scores (piano-score model) is here defined as a model that yields the probability P(p 1:N).
$t_{1:N}=(t_n)_{n=1}^N$ (N is the number of musical notes). A generative model for piano scores (piano-score model) is here defined as a model that yields the probability P(p 1:N).
Simple piano-score models can be constructed based on the Markov model. The probability P(p 1:N) is factorized into an initial probability P(p 1) and the transition probabilities P(p n|p n−1) as
 $$P(p_{1:N})=P(p_1)\prod_{n=2}^NP(p_n\vert p_{n-1}). $$
$$P(p_{1:N})=P(p_1)\prod_{n=2}^NP(p_n\vert p_{n-1}). $$The simplest model is obtained by assuming that the initial and transition probabilities obey a uniform distribution over pitches. Writing N p = 88 for the number of possible pitches, the model yields P(p 1:N) = (1/N p)N. Since this model yields the same probability for any piano score of the same length, it is here called a no-information model.
A more realistic model can be build by incorporating sequential dependence of pitches. For example, a statistical tendency called pitch proximity, that successive pitches tend to be close to each other, can be incorporated in initial and transition probabilities described with Gaussians:
 $$P(p_1=p) \propto {Gauss}(p;p_0,\sigma_p^2)+\epsilon,$$
$$P(p_1=p) \propto {Gauss}(p;p_0,\sigma_p^2)+\epsilon,$$ $$P(p_n=p\,\vert \,p_{n-1}=p') \propto {Gauss}(p;p',\sigma_p^2)+\epsilon.$$
$$P(p_n=p\,\vert \,p_{n-1}=p') \propto {Gauss}(p;p',\sigma_p^2)+\epsilon.$$Here, Gauss( · ;μ, σ 2) denotes a Gaussian distribution with mean μ and standard deviation σ, p 0 is a reference pitch to define the initial probability, and ε is a small positive constant for smoothing the probability for pitch transitions with a large leap. We call this model a Gaussian model.
Although the Gaussian model can capture the tendency of pitch proximity, the simplification can lead to unrealistic consequences. First, pitch transitions involving 10 or 11 semitones have higher probabilities than octave motions, which opposes the reality [Reference Nakamura, Ono and Sagayama18]. Second, since the model does not distinguish white keys and black keys, it yields the same probability for piano scores transposed to any keys, which opposes the fact that “simpler keys” involving less black keys are more frequently used. In general, the difficulty or naturalness of a piano score changes when it is transposed to another key since the geometry of the piano keyboard requires different fingering motions [Reference Chiu and Chen11]. To solve this, it is necessary to construct a model that describes fingering motions in addition to pitch transitions.
A model (called fingering model) incorporating fingering motions and the geometry of the piano keyboard has been proposed in [Reference Nakamura, Ono and Sagayama18]. The model is based on HMM, which has been first applied to the piano fingering model in [Reference Yonebayashi, Kameoka and Sagayama17]. In general, we can introduce a stochastic variable f n representing a finger used to play the nth note. The variable f n takes one of the following five values: 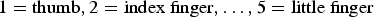 $1=\hbox {thumb}, 2=\hbox {index finger},\ldots ,5=\hbox {little finger}$.Footnote 1 According to the model (Fig. 2), a fingering motion
$1=\hbox {thumb}, 2=\hbox {index finger},\ldots ,5=\hbox {little finger}$.Footnote 1 According to the model (Fig. 2), a fingering motion  $f_{1:N}=(f_n)_{n=1}^N$ is first generated by an initial probability P(f 1) and transition probabilities P(f n|f n−1). Next, a pitch sequence p 1:N is generated conditionally on f 1:N: the first pitch is generated by P(p 1|f 1) and the succeeding pitches are generated by P(p n|p n−1, f n−1, f n), which describes the probability that a pitch would appear following the previous pitch and the previous and current fingers. Thus, the joint probability of pitches and fingering motion P(p 1:N, f 1:N) is given as
$f_{1:N}=(f_n)_{n=1}^N$ is first generated by an initial probability P(f 1) and transition probabilities P(f n|f n−1). Next, a pitch sequence p 1:N is generated conditionally on f 1:N: the first pitch is generated by P(p 1|f 1) and the succeeding pitches are generated by P(p n|p n−1, f n−1, f n), which describes the probability that a pitch would appear following the previous pitch and the previous and current fingers. Thus, the joint probability of pitches and fingering motion P(p 1:N, f 1:N) is given as
 $$P(f_1)P(p_1\vert f_1)\prod_{n=2}^NP(f_n\vert f_{n-1})P(p_n\vert p_{n-1},f_{n-1},f_n).$$
$$P(f_1)P(p_1\vert f_1)\prod_{n=2}^NP(f_n\vert f_{n-1})P(p_n\vert p_{n-1},f_{n-1},f_n).$$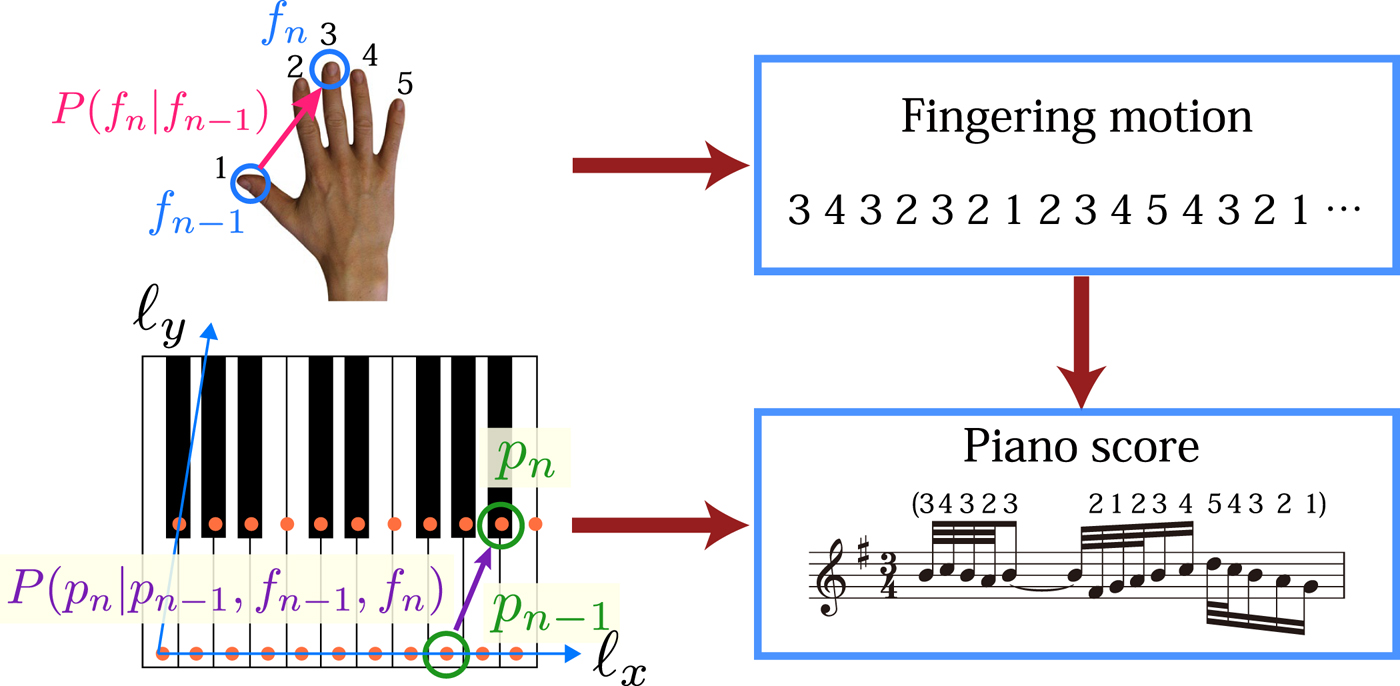
Fig. 2. Piano-score model incorporating fingering motion.
In general, the parameters of the fingering model can be learned from music data with pitches and annotated fingerings. For want of a sufficient amount of data, the probability P(p n|p n−1, f n−1, f n), which have 882 · 52 parameters, cannot be trained effectively in a direct way. We thus introduce simplifying assumptions to reduce the number of parameters. First, we assume that the probability depends on pitches through their geometrical positions on the keyboard (Fig. 2). The coordinate on the keyboard of a pitch p is represented as ℓ (p) = (ℓx(p), ℓy(p)). We also assume translational symmetry in the x-direction and time-inversion symmetry, which is expressed as
 $$\eqalign{&P(p_n=p\,\vert \,p_{n-1}=p',f_{n-1}=f',f_{n}=f)\cr &\quad=F(\ell_x(p)-\ell_x(p'),\ell_y(p)-\ell_y(p');f',f)\cr &\quad=F(\ell_x(p')-\ell_x(p),\ell_y(p')-\ell_y(p);f,f')}.$$
$$\eqalign{&P(p_n=p\,\vert \,p_{n-1}=p',f_{n-1}=f',f_{n}=f)\cr &\quad=F(\ell_x(p)-\ell_x(p'),\ell_y(p)-\ell_y(p');f',f)\cr &\quad=F(\ell_x(p')-\ell_x(p),\ell_y(p')-\ell_y(p);f,f')}.$$We also assume reflection symmetry between left and right hands. The above model can be extended to including chords, by sequencing the contained notes from low pitch to high pitch [Reference Al Kasimi, Nichols and Raphael16]. With the fingering model, one can estimate the fingering f 1:N from a given sequence of pitches p 1:N by calculating the maximum of the probability P(f 1:N|p 1:N) ∝ P(p 1:N, f 1:N). This maximization can be computed by the Viterbi algorithm [Reference Rabiner19].
2) Models for both hands
A piano-score model with the left- and right-hand parts can be obtained by first constructing a model for each hand part and then combining the two models. If musical notes are already assigned to two hand parts, such a combined model can be obtained directly. On the other hand, if the part assignment is not given, as in the piano reduction problem, the model should be able to describe the probability for all cases of part assignment.
Such a model for piano music with unknown hand parts can be constructed based on the merged-output HMM [Reference Nakamura, Ono and Sagayama18,Reference Nakamura, Yoshii and Sagayama20]. The idea is to combine outputs from two component Markov models or HMMs, respectively, describing the two hand parts. We here describe a model combining two fingering models. First, the hand part (left or right) associated with a note p n is represented by an additional stochastic variable η n ∈ {L, R}. The generative process of η n is described with a Bernoulli distribution: P(η n = η) = α η with α L + α R = 1. If η n is determined, then the pitch is generated by the corresponding component model. For each η ∈ {L, R}, let 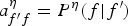 $a^\eta _{f'f}=P^\eta (f\vert f')$ and
$a^\eta _{f'f}=P^\eta (f\vert f')$ and  $b^\eta _{f'f}(p',p)=F^\eta ({\bi \ell} (p)-{\bi \ell} (p');f',f)$ denote the fingering and pitch transition probabilities of the component model. This process can be described as an HMM with a state space indexed by k = (η, f L, p L, f R, p R) with the following initial and transition probabilities:
$b^\eta _{f'f}(p',p)=F^\eta ({\bi \ell} (p)-{\bi \ell} (p');f',f)$ denote the fingering and pitch transition probabilities of the component model. This process can be described as an HMM with a state space indexed by k = (η, f L, p L, f R, p R) with the following initial and transition probabilities:
 $$\eqalign{&P(k_n=k\,\vert \,k_{n-1}=k')\cr &\quad =\left\{\matrix{\alpha_La^L_{f'^Lf^L}b^L_{f'^Lf^L}(p'^L,p^L)\delta_{f'^Rf^R}\delta_{p'^Rp^R}, \hfill &\eta=L \hfill; \cr \alpha_Ra^R_{f'^Rf^R}b^R_{f'^Rf^R}(p'^R,p^R)\delta_{f'^Lf^L}\delta_{p'^Lp^L}, \hfill &\eta=R, \hfill}\right. \cr &P(p_n=p\,\vert \,k_n=k)=\delta_{pp^\eta},}$$
$$\eqalign{&P(k_n=k\,\vert \,k_{n-1}=k')\cr &\quad =\left\{\matrix{\alpha_La^L_{f'^Lf^L}b^L_{f'^Lf^L}(p'^L,p^L)\delta_{f'^Rf^R}\delta_{p'^Rp^R}, \hfill &\eta=L \hfill; \cr \alpha_Ra^R_{f'^Rf^R}b^R_{f'^Rf^R}(p'^R,p^R)\delta_{f'^Lf^L}\delta_{p'^Lp^L}, \hfill &\eta=R, \hfill}\right. \cr &P(p_n=p\,\vert \,k_n=k)=\delta_{pp^\eta},}$$where δ denotes Kronecker's delta.
Using this model, one can estimate the sequence of latent variables k 1:N from a pitch sequence p 1:N. This can be done by maximizing the probability P(k 1:N | p 1:N) ∝ P(k 1:N, p 1:N). The most probable sequence 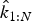 $\hat {k}_{1:N}$ has the information of the optimal configuration of hands
$\hat {k}_{1:N}$ has the information of the optimal configuration of hands  $\hat {\eta }_{1:N}$, which yields separated two hand parts and the optimal fingering for both hands (
$\hat {\eta }_{1:N}$, which yields separated two hand parts and the optimal fingering for both hands ( $\hat {f}^L_{1:N}$ and
$\hat {f}^L_{1:N}$ and 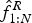 $\hat {f}^R_{1:N}$). For more details, see [Reference Nakamura, Ono and Sagayama18]. The Gaussian model and the no-information model can be similarly extended to models for both hands.
$\hat {f}^R_{1:N}$). For more details, see [Reference Nakamura, Ono and Sagayama18]. The Gaussian model and the no-information model can be similarly extended to models for both hands.
B) Performance difficulty
1) Difficulty measures
One can define a quantitative measure of performance difficulty based on the cost of music performance. From the statistical viewpoint, a natural choice is the probabilistic cost, which is the negative logarithm of a probability. To include the dependence on tempo, we define a performance difficulty as the time rate of the probabilistic cost
 $$D(t)=-{\ln}\,P({\bi p}(t))/\Delta t.$$
$$D(t)=-{\ln}\,P({\bi p}(t))/\Delta t.$$Here, Δt is a time width, p(t) is the sequence of pitches in the time range [t − Δt/2, t + Δt/2], and P(p(t)) is defined with one of the piano-score models in Section II.A. With the fingering model, one can use the joint probability of pitches and fingering to define a difficulty measure [Reference Nakamura, Ono and Sagayama18]:
 $$D(t)=-{\ln}\,P({\bi p}(t),{\bi f}(t))/\Delta t,$$
$$D(t)=-{\ln}\,P({\bi p}(t),{\bi f}(t))/\Delta t,$$
where f(t) denotes the fingering corresponding to the pitches p(t). If the fingering is unknown, one can substitute the maximum-probability estimate  $\hat{\bi f}(t)$ in equation (7). For each note n with onset time t n, we write D(n) = D(t n).
$\hat{\bi f}(t)$ in equation (7). For each note n with onset time t n, we write D(n) = D(t n).
The difficulty measure can be defined for each hand part using the pitches in that hand part and a piano-score model for one hand, which is denoted by D L(t) or D R(t). In addition, the total difficulty can be defined as the sum of difficulties for both hands: D B(t) = D L(t) + D R(t). The quantity D B(t) can be relevant as well as D L(t) and D R(t) since the difficulty can be high even if difficulties for individual hand parts are not so high.
In previous studies [Reference Chiu and Chen11,Reference Sébastien, Ralambondrainy, Sébastien and Conruyt12], features such as playing speed, note density, pitch entropy, hand displacement rate, hand stretch, and fingering complexity have been considered to estimate the difficulty level of piano scores. These features are incorporated in the above difficulty measures, although in an implicit manner. If one uses the no-information model, the difficulty measure takes into account the note density and playing speed. With the Gaussian model, pitch entropy and hand displacement rate, and hand stretch are incorporated in addition. With the fingering model, fingering complexity is further incorporated.
2) Evaluation
To formally examine how the proposed measures reflect real performance difficulty, we study their relation with the rate of performance errors. We use a dataset [Reference Nakamura, Yoshii and Katayose21] consisting of 90 MIDI piano performance signals of 30 classical musical pieces; for each piece, there are performances by three different players that are recorded in international piano competitions. In the dataset, musical notes in a performance signal are matched to notes in the corresponding score and the following three types of performance errors are manually annotated: pitch error (a performed note with a corresponding note in the score but with a different pitch); extra note (a performed note without a corresponding note in the score); and missing note (a note in the score without a corresponding note in the performance). Timing errors are not annotated in the data and not considered in this study.
We calculate performance difficulty values for each onset time and calculate the number of performance errors in the time range of width Δt around the onset time. In the following, we set Δt to be 1 s. For the Gaussian model, ε = 4 × 10−4 and p 0 is C3 (C5) for the left (right) hand. Other parameters of the Gaussian and fingering models are taken from a previous study [Reference Nakamura, Ono and Sagayama18] where a different dataset was used for training.
Figure 3 shows the relation between difficulty value D B and the rate of performance errors for the three models. We see that for each model there is an onset (roughly, 10 for the no-information model, 30 for the Gaussian model, and 40 for the fingering model) below which the average number of errors is almost zero and above which it gradually increases. This suggests that the difficulty measures can be used as indicators of performance errors.

Fig. 3. Relations between the difficulty value D B and the number of performance errors. Points and bars indicate means and standard deviations. Arrows indicate onsets of performance errors (see text).
For comparative evaluation, we predict performance errors by thresholding the difficulty values and measure the predictive accuracy for the three models. Using three thresholds 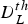 $D^{th}_L$,
$D^{th}_L$,  $D^{th}_R$, and
$D^{th}_R$, and  $D^{th}_B$, a prediction of performance errors at time t is defined positive if one of three conditions (
$D^{th}_B$, a prediction of performance errors at time t is defined positive if one of three conditions ( $D^{th}_L>D_L(t)$,
$D^{th}_L>D_L(t)$,  $D^{th}_R>D_R(t)$, and
$D^{th}_R>D_R(t)$, and  $D^{th}_B>D_B(t)$) is satisfied. We calculate the number of true positives N TP, that of false positives N FP, and that of true negatives N TN, and the following quantities are used as evaluation measures:
$D^{th}_B>D_B(t)$) is satisfied. We calculate the number of true positives N TP, that of false positives N FP, and that of true negatives N TN, and the following quantities are used as evaluation measures:
 $${\cal P} = \displaystyle{N_{TP} \over N_{TP}+N_{FP}}, \quad {\cal R} = \displaystyle{N_{TP} \over N_{TP}+N_{TN}}, \quad {\cal F}=\displaystyle{2{\cal P}{\cal R} \over {\cal P}+{\cal R}}.$$
$${\cal P} = \displaystyle{N_{TP} \over N_{TP}+N_{FP}}, \quad {\cal R} = \displaystyle{N_{TP} \over N_{TP}+N_{TN}}, \quad {\cal F}=\displaystyle{2{\cal P}{\cal R} \over {\cal P}+{\cal R}}.$$Since more frequent errors indicate larger difficulty, we can also define the following weighted quantities:
 $${\cal P}_{w} =\displaystyle{N'_{TP} \over N'_{TP}+N_{FP}},\quad {\cal R}_{w}=\displaystyle{N'_{TP} \over N'_{TP}+N'_{TN}},$$
$${\cal P}_{w} =\displaystyle{N'_{TP} \over N'_{TP}+N_{FP}},\quad {\cal R}_{w}=\displaystyle{N'_{TP} \over N'_{TP}+N'_{TN}},$$ $${\cal F}_{w} = \displaystyle{2{\cal P}_{w}{\cal R}_{w} \over {\cal P}_{w} + {\cal R}_{w}},$$
$${\cal F}_{w} = \displaystyle{2{\cal P}_{w}{\cal R}_{w} \over {\cal P}_{w} + {\cal R}_{w}},$$
where N′TP and N′TN are obtained by weighting N TP and N TN with the number of performance errors. The results are shown in Table 1 where the thresholds are optimized with respect to  ${\cal F}_{w}$ for each model. We see that the Gaussian model has the highest F measures, even though the differences are rather small. A possible reason is the relatively small size of the data used for training the fingering model. Since the Gaussian model has only one parameter σ p to train, it has better generalization ability for such small training data. Such a trade-off between model complexity and the required amount of training data is common in many machine-learning problems. We thus use the difficulty measures defined with the Gaussian model in the following.
${\cal F}_{w}$ for each model. We see that the Gaussian model has the highest F measures, even though the differences are rather small. A possible reason is the relatively small size of the data used for training the fingering model. Since the Gaussian model has only one parameter σ p to train, it has better generalization ability for such small training data. Such a trade-off between model complexity and the required amount of training data is common in many machine-learning problems. We thus use the difficulty measures defined with the Gaussian model in the following.
Table 1. Accuracies of performance error prediction.

III. PIANO REDUCTION METHOD
In the statistical formulation of piano reduction, we try to find the optimal reduction score  $\hat {R}$ that maximizes the probability P(R|E) for a given ensemble score E. In analogy with the statistical approach for machine translation [Reference Brown, Pietra, Pietra and Mercer13], we first construct generative models describing the probability P(R) and P(E|R), respectively, and integrate them for calculating P(R, E) ∝ P(R|E). We then derive optimization algorithms for piano reduction that take into account the constraints on performance difficulty values.
$\hat {R}$ that maximizes the probability P(R|E) for a given ensemble score E. In analogy with the statistical approach for machine translation [Reference Brown, Pietra, Pietra and Mercer13], we first construct generative models describing the probability P(R) and P(E|R), respectively, and integrate them for calculating P(R, E) ∝ P(R|E). We then derive optimization algorithms for piano reduction that take into account the constraints on performance difficulty values.
Prior to the main processing step, we convert an input ensemble score to a condensed score by removing redundant notes with the same pitch and simultaneous onset time (the number of such redundant notes is memorized and used later in the calculation of equation (13)). Although they are different strictly, we call such a condensed score an ensemble score in what follows. What is really meant by the symbol E is also a condensed score.
A) Model for piano reduction
To construct a generative model that yields the probability P(R, E), we integrate a piano-score model describing the probability P(R) and an edit model that describes the process yielding P(E|R). As a piano-score model, we can use either the Gaussian model or the fingering model discussed in Section II.A.2, which statistically describes the naturalness of a generated (reduction) score.
For the edit model, we assign probabilities for edit operations applied to musical notes. As in [Reference Nakamura and Sagayama4], we focus on the two most common edit operations, note deletion, and octave pitch shift. As we model the inverse process of generating an ensemble score from a piano score, we introduce probabilities of note addition and octave pitch shift in the edit model. For each note in the ensemble score, the probability that it is an added note and not originated from the piano score is denoted by β NP (“NP” for not played). In this case, the note's pitch p is drawn from a uniform distribution c unif(p). If it is originated from the piano score and the corresponding note has a pitch q, the probability of the note's pitch p denoted by c q(p) = P(p|q) is supposed to obey
 $$c_q(p)= \left\{\matrix{1-2\gamma_{oct}, \hfill & p=q; \hfill\cr \gamma_{oct}, \hfill &p=q\pm 12, \hfill}\right.$$
$$c_q(p)= \left\{\matrix{1-2\gamma_{oct}, \hfill & p=q; \hfill\cr \gamma_{oct}, \hfill &p=q\pm 12, \hfill}\right.$$where γ oct denotes the probability of an octave shift.
We can integrate the fingering model in Section II.A.2 and the edit model in the following fashion based on the merged-output HMM (Fig. 4), which leads to tractable inference algorithms. For each note in the output ensemble score, indexed by m, we introduce a stochastic variable ξ m that can take one of three values {NP, L, R}. It is generated from a discrete distribution as P(ξ m = ξ) = β ξ, where parameters β ξ obey β NP + β L + β R = 1. If ξ m = NP, then its pitch p m has a probability P(p m = p) = c unif(p). If ξ m = L or R, then its pitch is generated from the component fingering model of the corresponding hand part and may undergo an octave shift. Writing f L, p L, f R, and p R for the finger and pitch variables of the two component fingering models, the latent state of the merged-output HMM is described by a set of variables r = (ξ, f L, p L, f R, p R). The transition and output probabilities are defined as
 $$\eqalign{&P(r_m=r\,\vert \,r_{m-1}=r') \cr &\quad =\left\{\matrix{\beta_{NP}\delta_{f^{L}f'^{L}}\delta_{f^{R}f'^{R}}\delta_{p^{L}p'^{L}}\delta_{p^{R}p'^{R}}, \hfill &\xi={NP}; \cr \beta_{L} a^{L}_{f'^{L}f^{L}}b^{L}_{f'^{L}f^{L}}(p'^{L},p^{L})\delta_{f^{R}f'^{R}}\delta_{p^{R}p'^{R}}, \hfill &\xi={L}; \hfill \cr \beta_{R} a^{R}_{f'^{R}f^{R}}b^{R}_{f'^{R}f^{R}}(p'^{R},p^{R})\delta_{f^{L}f'^{L}}\delta_{p^{L}p'^{L}}, \hfill &\xi={R},}\right. \cr &P(p_m=p\,\vert \,r_m=r)= \left\{\matrix{c_{unif}(p), \hfill &\xi={NP}; \hfill \cr c_{p^{L}}(p), \hfill &\xi={L}; \hfill \cr c_{p^{R}}(p), \hfill &\xi={R}. \hfill}\right.}$$
$$\eqalign{&P(r_m=r\,\vert \,r_{m-1}=r') \cr &\quad =\left\{\matrix{\beta_{NP}\delta_{f^{L}f'^{L}}\delta_{f^{R}f'^{R}}\delta_{p^{L}p'^{L}}\delta_{p^{R}p'^{R}}, \hfill &\xi={NP}; \cr \beta_{L} a^{L}_{f'^{L}f^{L}}b^{L}_{f'^{L}f^{L}}(p'^{L},p^{L})\delta_{f^{R}f'^{R}}\delta_{p^{R}p'^{R}}, \hfill &\xi={L}; \hfill \cr \beta_{R} a^{R}_{f'^{R}f^{R}}b^{R}_{f'^{R}f^{R}}(p'^{R},p^{R})\delta_{f^{L}f'^{L}}\delta_{p^{L}p'^{L}}, \hfill &\xi={R},}\right. \cr &P(p_m=p\,\vert \,r_m=r)= \left\{\matrix{c_{unif}(p), \hfill &\xi={NP}; \hfill \cr c_{p^{L}}(p), \hfill &\xi={L}; \hfill \cr c_{p^{R}}(p), \hfill &\xi={R}. \hfill}\right.}$$
The model indeed generates a piano score specified by  $(p^{L}_m,p^{R}_m)_m$ and an ensemble score specified by (p m)m.
$(p^{L}_m,p^{R}_m)_m$ and an ensemble score specified by (p m)m.

Fig. 4. Generative process of the model for piano reduction.
In the process of piano reduction, which is explained in the next section, the parameter β NP represents how much notes in the ensemble score are removed. Thus, properly adjusting β NP is crucial to control the performance difficulty of resulting reduction scores. Roughly speaking, if the note density around a note is high, it is necessary to remove more notes around that note by setting β NP large. In addition, some notes like melodic notes and bass notes are musically more important than others and should have a small probability of deletion, or small β NP in the present model. These conditions can be realized in the following form of β NP(m), which depends on each note m:
 $$\beta_{NP}(m) = \left(1 - \zeta (m) \right) e^{-\kappa h(m)},$$
$$\beta_{NP}(m) = \left(1 - \zeta (m) \right) e^{-\kappa h(m)},$$where h(m) ≥ 0 represents the musical importance of note n, κ > 0 is a coefficient to control the effect of h(m), and ζ(m) ∈ [0, 1] is a factor to control the overall rate of note deletion. If ζ(m) ≃ 1, β NP(m) ≃ 0 and almost all notes remain in the reduction score. If ζ(m) ≃ 0, β NP(m) ≃ 1 unless κh(m) is large (i.e. note m is musically important), so most musically unimportant notes will be removed.
In addition to the importance of melodic and bass notes, it is not difficult to imagine that pitches in an ensemble score that are played simultaneously by multiple instruments are musically important. Thus, the following form is used for defining musical importance h(m):
 $$h(m)={\open I} (m \in {\cal M}) + {\open I}(m\in{\cal B})+a\,{Mult}(m),$$
$$h(m)={\open I} (m \in {\cal M}) + {\open I}(m\in{\cal B})+a\,{Mult}(m),$$
where  ${\open I}({\cal C}) = 1$ if a condition
${\open I}({\cal C}) = 1$ if a condition  ${\cal C}$ is true and 0 otherwise,
${\cal C}$ is true and 0 otherwise,  ${\cal M}$ denotes the set of melodic notes,
${\cal M}$ denotes the set of melodic notes,  ${\cal B}$ denotes the set of bass notes, and Mult(m) is the multiplicity of note m, defined as the number of notes in the ensemble score having the same pitch and onset time as note m excluding m itself. The parameters κ and a are adjustable parameters, and ζ(m) is adjusted according to target difficulty values as explained in the next section.
${\cal B}$ denotes the set of bass notes, and Mult(m) is the multiplicity of note m, defined as the number of notes in the ensemble score having the same pitch and onset time as note m excluding m itself. The parameters κ and a are adjustable parameters, and ζ(m) is adjusted according to target difficulty values as explained in the next section.
B) Algorithms for piano reduction
Let us derive algorithms for piano reduction based on the model in Section III.A and the difficulty measures in Section II.B. The piano reduction problem is here formulated as finding a reduction score R that maximizes P(R|E) for a given ensemble score E with constraints on R's performance difficulty values. Specifically, we impose the following constraints for each note n in R:
 $$[D_{L}(n)\lt \widetilde{D}_{L}]\,\wedge\,[D_{R}(n)\lt \widetilde{D}_{R}]\,\wedge\,[D_{B}(n) \lt \widetilde{D}_{B}],$$
$$[D_{L}(n)\lt \widetilde{D}_{L}]\,\wedge\,[D_{R}(n)\lt \widetilde{D}_{R}]\,\wedge\,[D_{B}(n) \lt \widetilde{D}_{B}],$$
where  $\widetilde {D}_{L}$,
$\widetilde {D}_{L}$,  $\widetilde {D}_{R}$, and
$\widetilde {D}_{R}$, and  $\widetilde {D}_{B}$ are some target difficulty values.
$\widetilde {D}_{B}$ are some target difficulty values.
Without the constraints (14), finding the maximum of P(R|E) is a basic inference problem for HMMs and can be achieved with the Viterbi algorithm [Reference Rabiner19]. However, the constraints (14) cannot be easily treated because difficulty values at each note depends on the existence of other notes in the time range of Δt, which violates the Markovian assumption for the Viterbi algorithm. In other words, if we know appropriate values of ζ(m) in equation (12) for controlling difficulty values, the optimization problem is directly solvable, but finding those values is not easy.
In the following, we present two strategies for optimization. In a previous study [Reference Nakamura and Sagayama4], appropriate values of ζ(m) were estimated and the Viterbi algorithm was applied once to obtain the result. A slight extension of this one-time optimization method is presented in Section III.B.1. On the other hand, if one can apply the Viterbi algorithm iteratively, it would be possible to find appropriate values of ζ(m) from tentative results, by starting from ζ(m) = 1 and gradually lessening it. This iterative optimization method is developed in Section III.B.2.
1) One-time optimization algorithm
In [Reference Nakamura and Sagayama4], appropriate values of ζ(m) were estimated by matching the expected difficulty values to the target values with the following equation:
 $$\zeta(m)={\min}\left\{\displaystyle{\widetilde{D}_{L} \over D_{L}(m)},\displaystyle{\widetilde{D}_{R} \over D_{R}(m)}\right\},$$
$$\zeta(m)={\min}\left\{\displaystyle{\widetilde{D}_{L} \over D_{L}(m)},\displaystyle{\widetilde{D}_{R} \over D_{R}(m)}\right\},$$where D L(m), etc., represent the difficulty values calculated for the ensemble score at its mth note. One can include a factor involving D B(m) in the above equation in general.
We can generalize this method by introducing a scaling factor ρ and modifying equation (15) to
 $$\zeta(m)=\rho\,{\min}\left\{\displaystyle{\widetilde{D}_{L} \over D_{L}(m)},\displaystyle{\widetilde{D}_{R} \over D_{R}(m)} \right\}. $$
$$\zeta(m)=\rho\,{\min}\left\{\displaystyle{\widetilde{D}_{L} \over D_{L}(m)},\displaystyle{\widetilde{D}_{R} \over D_{R}(m)} \right\}. $$By choosing the value of ρ, one can control the expected average of resulting difficulty values. For example, one can use a maximum value of ρ that can satisfy the constraints (14) for most outcomes.
2) Iterative optimization algorithm
For iterative optimization, the Viterbi algorithm is applied in each iteration to obtain a tentative reduction score R (i), with tentative values of ζ (i)(m) (i is an index for iterations). For each note n in R (i), we calculate the difficulty values  $D^{(i)}_{L}(n)$,
$D^{(i)}_{L}(n)$,  $D^{(i)}_{R}(n)$, and
$D^{(i)}_{R}(n)$, and 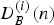 $D^{(i)}_{B}(n)$. If the constraints (14) are not all satisfied at note n, then we lessen the values of ζ(m) for all notes m in the ensemble score around n within the time range of width Δt as
$D^{(i)}_{B}(n)$. If the constraints (14) are not all satisfied at note n, then we lessen the values of ζ(m) for all notes m in the ensemble score around n within the time range of width Δt as
 $$\zeta^{(i+1)}(m)=\lambda\zeta^{(i)}(m)$$
$$\zeta^{(i+1)}(m)=\lambda\zeta^{(i)}(m)$$with some constant 0 < λ < 1.
The iterative algorithm is initialized with ζ (i = 1)(m) = 1 for all notes m. The algorithm ends when the constraints (14) are satisfied at every note in the reduction score, or the number of iterations exceed some predefined value i max. For efficient and stable computation, the Viterbi algorithm at iteration i+1 is applied only to those regions of the ensemble score where the constraints (14) are not still satisfied at iteration i. Specifically, we first construct a set of notes m in the ensemble score whose onset time t m is included in the range [t n − Δt/2, t n + Δt/2] around some onset time t n in the reduction score for which the difficulty constraints are not satisfied. This set is then split into a set Ψ of isolated regions of notes. For each such isolated region, the Viterbi algorithm is applied with fixed boundary states at one note before the beginning of the region and one note after the end.
The iterative algorithm is summarized as follows.
(i) Initialize ζ (i = 1)(m) = 1 and apply the Viterbi algorithm to the whole ensemble score.
(ii) Calculate difficulty values and obtain regions Ψ where the constraints (14) are not satisfied. Exit if Ψ is empty or i ≥ i max.
(iii) Update the control factor ζ(m) as in equation (17) and apply the Viterbi algorithm to each region of Ψ. Increment i and go back to step (ii).
IV. EVALUATION OF PIANO REDUCTION ALGORITHMS
A) Setup
To evaluate the piano reduction algorithms, we prepared a dataset of orchestral pieces of Western classical music. The dataset consists of 10 pieces by different composers and with different instrumentations; each piece has a length of around 20 bars. The list of the pieces is available in the accompanying webpage.Footnote 2
We compare one-time optimization algorithms and iterative optimization algorithms based on the Gaussian model and the fingering model; in total, we have four methods labeled as One-time Gaussian, One-time Fingering, Iterated Gaussian, and Iterated Fingering methods. The parameters of the piano-score models are set as in Section II.B.2. The other parameters are set as follows: a=0.01, κ = 11, λ = 0.85, γ oct = 0.001, and β R(m) = β L(m) = (1 − β NP(m))/2 where β NP(m) is set as in equation (12). Difficulty values are calculated with the difficulty measures using the Gaussian model with Δt = 1 s. These parameter values were fixed after some trials by one of the authors and there is room for further optimization.
As a baseline method, we also implement a method based on a simple piano-score model (called the distance model) that takes into account the distance between each note in the ensemble score and its closest melodic or bass note, but not sequential dependence of pitches. Specifically, for each note m in the ensemble score, the closest melodic or bass notes CMB(m) is obtained by first searching in the direction of onset time and then in the direction of pitches. Then the probability of its pitch p m is given as
 $$P(p_m)\propto {Gauss}(p_m;{CMB}(m),\sigma_p^2).$$
$$P(p_m)\propto {Gauss}(p_m;{CMB}(m),\sigma_p^2).$$Integrating this piano-score model into the piano reduction model in Section III.A and using the iterative optimization algorithm, a baseline Iterated Distance method is obtained.
B) Quantitative evaluation of difficulty control
We first examine the effect of the iterative optimization algorithms in controlling the difficulty values of output reduction scores, in comparison with the one-time optimization algorithms. We run the four algorithms, One-time Gaussian, One-time Fingering, Iterated Gaussian, and Iterated Fingering, for the test dataset with three sets of target difficulty values  $(\widetilde {D}_{L},\widetilde {D}_{R},\widetilde {D}_{B})=(15,15,30)$, (30, 30, 40), and (40, 40, 50). For the scaling factor ρ for the one-time optimization algorithms, we test values in {0.1, 0.2, …, 1.0}. For the iterative optimization algorithms, i max is set to 50. To evaluate a reduction score R, we compute difficulty values (D L(n) etc.) for each note n in R and calculate the following measures:
$(\widetilde {D}_{L},\widetilde {D}_{R},\widetilde {D}_{B})=(15,15,30)$, (30, 30, 40), and (40, 40, 50). For the scaling factor ρ for the one-time optimization algorithms, we test values in {0.1, 0.2, …, 1.0}. For the iterative optimization algorithms, i max is set to 50. To evaluate a reduction score R, we compute difficulty values (D L(n) etc.) for each note n in R and calculate the following measures:
• Mean difficulty values
 $\{\overline {D}_{L},\overline {D}_{R},\overline {D}_{B}\}$:
(19)$$\overline{D}_{L} = \displaystyle{1 \over \#R} \sum_{n\in R}D_{L}(n) \quad {etc.}$$
$\{\overline {D}_{L},\overline {D}_{R},\overline {D}_{B}\}$:
(19)$$\overline{D}_{L} = \displaystyle{1 \over \#R} \sum_{n\in R}D_{L}(n) \quad {etc.}$$• Maximum difficulty values
$\{D^{max}_{L},D^{max}_{R}, D^{max}_{B}\}$:
(20)$$D^{max}_{L}=\max_{n\in R}\{D_{L}(n)\} \quad {etc.}$$• Out-of-range rate (proportion of regions where difficulty values exceed target values)
$\{A_{out}^{L},A_{out}^{R},A_{out}^{B}\}$:
(21)$$A_{out}^{L} = \displaystyle{\# \left\{n\in R \left\vert D_{L}(n) \right. \gt \widetilde{D}_{L}\right\} \over \# R} \quad {etc.} $$• Additional-note rate (proportion of notes in the reduction score other than melodic and bass notes) A add:
(22)$$A_{add}=\displaystyle{\#R-\#{\cal M}-\#{\cal B} \over \#{\cal M}+\#{\cal B}}.$$


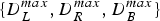




Variations of difficulty values of the reduction scores by the One-time Gaussian method are shown in Fig. 5, with corresponding values for the Iterated Gaussian method. Here, for simplicity, only difficulty values for both hands ( $\overline {D}_{B}$,
$\overline {D}_{B}$,  $D^{max}_{B}$, etc.) are shown. It is observed that for those values of ρ where
$D^{max}_{B}$, etc.) are shown. It is observed that for those values of ρ where  $A^{B}_{out}$ is equivalent to that for the iterative optimization method,
$A^{B}_{out}$ is equivalent to that for the iterative optimization method,  $\overline {D}_{B}$ and
$\overline {D}_{B}$ and 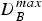 $D^{max}_{B}$ are smaller compared with the iterative optimization method. This means that with the same level of satisfaction for the difficulty constraints, results of the iterative optimization method have larger difficulty values on the average, which is a desired property. On the other hand, if ρ is increased sufficiently, it is possible for the one-time optimization algorithm to achieve the same level of
$D^{max}_{B}$ are smaller compared with the iterative optimization method. This means that with the same level of satisfaction for the difficulty constraints, results of the iterative optimization method have larger difficulty values on the average, which is a desired property. On the other hand, if ρ is increased sufficiently, it is possible for the one-time optimization algorithm to achieve the same level of  $\overline {D}_{B}$ as the iterative optimization method, but then
$\overline {D}_{B}$ as the iterative optimization method, but then  $A^{B}_{out}$ is larger, meaning that the difficulty constraints are less strictly satisfied. Analyses of difficulty values for each hand and comparison between One-time Fingering and Iterated Fingering methods reveal similar tendencies.
$A^{B}_{out}$ is larger, meaning that the difficulty constraints are less strictly satisfied. Analyses of difficulty values for each hand and comparison between One-time Fingering and Iterated Fingering methods reveal similar tendencies.

Fig. 5. Difficulty metrics for the One-time Gaussian method for varying ρ, for three cases of target difficulty values  $(\widetilde {D}_{L},\widetilde {D}_{R},\widetilde {D}_{B})$ indicated in the insets. Difficulty values are those for both hands (
$(\widetilde {D}_{L},\widetilde {D}_{R},\widetilde {D}_{B})$ indicated in the insets. Difficulty values are those for both hands ( $\overline {D}_{B}$,
$\overline {D}_{B}$,  $D^{max}_{B}$, etc.) and horizontal lines indicate corresponding values for the Iterated Gaussian method.
$D^{max}_{B}$, etc.) and horizontal lines indicate corresponding values for the Iterated Gaussian method.
The results for all three kinds of difficulty values (for each of two hands and for both hands) are shown in Table 2. Here, for one-time optimization methods, results are shown for the smallest value of ρ such that all three out-of-range rates exceed those for the corresponding iterative optimization methods. In addition to the same tendencies as found in the above analysis, one can observe that for the same level of satisfaction of difficulty constraints, the iterative optimization methods yield larger additional-note rates than the corresponding one-time optimization methods. These results indicate that the iterative optimization methods are more appropriate for controlling difficulty values.
Table 2. Comparison of average values of difficulty metrics for reduction scores. Triplet values in parentheses indicate one for left-hand part, right-hand part, and both hand parts, from left to right.

Even for iterative optimization algorithms, the out-of-range rates can be non-zero, especially for small target difficulty values. One reason for this is that for some pieces the minimal reduction score with only melodic and bass notes has difficulty values larger than the target values. Another reason is the greedy-like nature of the iterative optimization algorithms: when some regions of the reduction score is fixed and used as boundary conditions for updates, the Viterbi search sometimes cannot reduce notes even for smaller values of ζ(m). Comparing iterative optimization methods in cases of target difficulty values (30, 30, 40) and (40, 40, 50), we find that while the Iterated Gaussian method has the largest additional-note rate, it has the least values for most difficulty evaluation measures. If the additional-note rate increases with the fidelity to the original ensemble score, this indicates the Iterated Gaussian method has the ability to efficiently increase the fidelity while retaining low difficulty values. This is probably because the Gaussian model is used for calculating difficulty measures.
C) Subjective evaluation
We conduct a subjective evaluation experiment to evaluate the quality of reduction scores by the proposed algorithms.Footnote 3 In particular, we examine how much of the additional notes (notes other than melodic and bass notes) are actually playable and how the musical quality such as fidelity and difficulty changes with varying target difficulty values. For this, we asked professional piano arrangers to evaluate the piano reductions generated by the Iterated Fingering, Iterated Gaussian, and Iterated Distance methods with three sets of target difficulty values (15, 15, 30), (30, 30, 40), and (40, 40, 50). Two music arrangers participated in the evaluation and each reduction score was evaluated by one of them. Evaluators are provided manually typeset reduction scores, the input condensed scores, and corresponding audio files of the 10 tested musical pieces, which are uploaded to the accompanying demo page.Footnote 4 The evaluation metrics are as follows:
• Musical fidelity (10 steps; 1: not faithful at all, …, 10: very faithful) — How the reduction score is faithful to the original ensemble score in terms of music acoustics.
• Subjective difficulty (10 steps; 1: very easy, …, 10: very difficult) — How difficult the reduction score is for playing with two hands.
• Musical naturalness (10 steps; 1 very unnatural, …, 10: very natural) — How natural the reduction score is as a piano score.
• Number of unplayable notes N unp — How many notes and which notes should be removed from the reduction score to make it playable by a skillful pianist. We define the unplayable-note rate A unp, a quantity normalized by the number of additional notes:
(23)$$A_{unp} = \displaystyle{N_{unp} \over \#R-\#{\cal M}-\#{\cal B}}.$$

Results are summarized in Fig. 6, where statistics (mean and standard deviation) are shown for each evaluation metrics and for each method. The results in Figs 6(a) and 6(b) indicate that subjective difficulty and musical fidelity monotonically increase with the additional note rate, which confirms the ability of the proposed methods for controlling performance difficulty. For these two quantities, few differences can be found in the results for the three methods. The result in Fig. 6(c) shows that musical naturalness tends to decrease when increasing the additional-note rate. This can be understood from the fact when A add ≃ 0 the reduction score consists mostly of melodic and bass notes, which should have high naturalness, and for larger A add it becomes more demanding for the models to retain naturalness. For the highest difficulty case with target difficulty values (40, 40, 50) and A add ~ 90–100%, the Iterated Gaussian and Iterated Fingering methods outperform the baseline Iterated Distance method. This suggests the importance of incorporating sequential dependence of pitches in the piano score model for improving musical naturalness.

Fig. 6. Subjective evaluation results. For each method, the average results for the three sets of target difficulty are indicated with points. Bars indicate their standard errors.
The result in Fig. 6(d) shows that, especially in the high difficulty regime, the unplayable-note rate is reduced by incorporating sequential dependence of pitches in the piano score model and even further so by incorporating the fingering motion. This suggests that although the same difficulty measure is used and it is not a perfect measure for describing the real difficulty of a piano score, a better piano score model can generate reduction scores with less unplayable notes.
D) Example results and discussions
Examples of piano reduction scores obtained by the Iterated Fingering method are shown in Fig. 7, together with the results of the subjective evaluation (the evaluation scores are given for the whole piece including the part not shown in the figure).Footnote 5 We see that results for larger target difficulty values have more harmonizing notes and are given larger fidelity and subjective-difficulty values. In the cases with  $(\widetilde {D}_{L},\widetilde {D}_{R},\widetilde {D}_{B})=(15,15,30)$ and (30, 30, 40), all notes are playable in the shown section and the latter case has a larger musical-naturalness value. On the other hand, there are several unplayable notes in the case with
$(\widetilde {D}_{L},\widetilde {D}_{R},\widetilde {D}_{B})=(15,15,30)$ and (30, 30, 40), all notes are playable in the shown section and the latter case has a larger musical-naturalness value. On the other hand, there are several unplayable notes in the case with  $(\widetilde {D}_{L},\widetilde {D}_{R},\widetilde {D}_{B})=(40,40,50)$, which leads to a smaller musical-naturalness value.
$(\widetilde {D}_{L},\widetilde {D}_{R},\widetilde {D}_{B})=(40,40,50)$, which leads to a smaller musical-naturalness value.

Fig. 7. Examples of piano reduction scores obtained by the Iterated Fingering method (Wagner: Prelude to Die Meistersinger von Nürnberg). For clear illustration, only the first nine bars from a 27-bar excerpt in the test data are shown. Unplayable notes indicate those identified by the evaluator.
We were informed from the evaluators (professional music arrangers) that keeping more notes in a reduction score does not always improve musical naturalness. One reason is that flexibility for performance expression can be reduced by adding too many notes. We have therefore two important directions to further improve the piano reduction methods. One is to construct a more precise fingering model and difficulty measures based on it. However, as we discussed in Section II.B.2, a more complex model typically requires more training data for appropriate learning. Since a large-scale fingering dataset is currently not available, construction of such a dataset is also an important issue. Another is to incorporate more musical knowledge in the piano reduction model, particularly on harmonic aspects (e.g. completion of chordal notes and voice leading) and cognitive aspects (e.g. restricting notes over melodic notes to avoid mishearing of melodies).
Other left issues are identification of melodic and bass notes and score typesetting for reduction scores, which are manually done currently. As for the identification of melodic and bass notes, a simple method of taking the instrument part with the highest (lowest) mean pitch as the melody (bass) part for each bar can reproduce 40.6% (57.0%) of the indications in our test data. While this calls for a more refined method for automatically estimating the melodic and bass notes, we noticed that the choice is also subjective and it may be important to leave room for user preferences.
Finally, since the evaluation is subjective, it is also important to look at multiple ratings given by different evaluators. Such a large-scale subjective evaluation would be significant for revealing finer relations between human's evaluation and the model's prediction.
V. CONCLUSION
We have described quantitative measures of performance difficulty for piano scores and a piano reduction method that can control the difficulty values based on statistical modeling. We followed the quantification of performance difficulty using statistical models proposed in [Reference Nakamura, Ono and Sagayama18] and found that the difficulty values can be used as indicators of performance errors. For the current amount of training data, we also found that the difficulty measures based on the Gaussian model yields the best accuracy of predicting performance errors. The problem of piano reduction is formalized as a statistical optimization problem following the framework of [Reference Nakamura and Sagayama4], and we improved the optimization method by proposing an iterative method. We confirmed the efficacy of the iterative optimization method and the algorithms are shown to be able to control subjective difficulty and musical fidelity. It was also found that incorporating sequential dependence and fingering motion in the piano-score model by using the Gaussian and fingering model improves generated reduction scores in terms of musical naturalness and the rate of unplayable notes. Directions for further improvements were also discussed.
Whereas it has been assumed that the same difficulty measures apply universally for all players in this study, they can be different for individual players depending on, for example, the size of hands. In the present framework, part of such individuality can be expressed by adapting the fingering model to individual players. This model adaptation can be realized in principle if one has a sufficient amount of musical scores that have been already played by an individual player. Another interesting direction is to adapt an individual's fingering model using the frequency of errors in his/her performance data, which could reduce the amount of necessary data.
A limitation of the present model is that timing errors and other rhythmic aspects are not considered. Rhythmic features may become important especially in polyrhythmic passages in which the left- and right-hand parts have contrasting rhythms (e.g. two against three rhythms). In such cases, the sum of difficulty values for the two hands may underestimate the total difficulty. To properly deal with these problems, it would be necessary to incorporate a performance timing model and interdependence between the two hands into the present framework.
The present formulation of combining a musical-score model and an edit model can also be applied to other forms of music arrangement if one replaces the piano fingering model with an appropriate score model of the target instrumentation/style and adapt the edit model for relevant edit operations. For example, if we combine a score model for jazz music and a proper edit model, it would be possible to develop a method for arranging a given piece in the rock music style (or other styles) into a piece in the jazz style.
Although this study has focused on piano arrangement, the framework can also be useful for music transcription [Reference Benetos, Dixon, Giannoulis, Kirchhoff and Klapuri22]. In music transcription, musical-score models play an important role to induce an output score to be an appropriate one that respects musical grammar, style of target music, etc. [Reference Raczyński, Vincent and Sagayama23,Reference Ycart and Benetos24]. Especially in piano transcription, results of multi-pitch detection contain a significant amount of spurious notes (false positives), which often make the transcription results unplayable [Reference Nakamura, Benetos, Yoshii and Dixon25]. By integrating the present piano-score model and an acoustic model (instead of the edit model) and applying the method for optimization developed in this study, one can impose constraints on performance difficulty of transcription results and reduce these spurious notes.
Financial Support
This study was partially supported by JSPS KAKENHI Nos. 26700020, 16H01744, 16J05486, 16H02917, and 16K0 0501, and JST ACCEL No. JPMJAC1602.
Statement of Interest
None.
Eita Nakamura received his Ph.D. degree in physics from the University of Tokyo, Tokyo, Japan, in 2012. After having been a Postdoctoral Researcher at the National Institute of Informatics, Meiji University, and Kyoto University, Kyoto, Japan, he is currently a Research Fellow of Japan Society for the Promotion of Science. His research interests include music modeling and analysis, music information processing, and statistical machine learning.
Kazuyoshi Yoshii received his M.S. and Ph.D. degrees in informatics from Kyoto University, Kyoto, Japan, in 2005 and 2008, respectively. He had been a Senior Lecturer and is currently an Associate Professor at the Graduate School of Informatics, Kyoto University, and concurrently the Leader of the Sound Scene Understanding Team, RIKEN Center for Advanced Intelligence Project, Tokyo, Japan. His research interests include music analysis, audio signal processing, and machine learning.










 Open access
Open access