

I. INTRODUCTION
Recent advances and adoption of e-commerce, streaming media, and social media have created a rapidly evolving content ecosystem that includes creation, curation, moderation, distribution, consumption, and redistribution. For example, Facebook has more than 2 billion monthly active users [1], and they upload 300 million photos each day and post more than 500?000 comments every minute [2]. Netflix serves more than 250 million hours of content per day as of the beginning of 2017 [3]. Many of the online discussion forums have billions of active users and posts (http://www.thebiggestboards.com/) and it has been estimated that more than 30 billion ads are served each day on Google sites as of the end of 2012 [Reference Kim4].
The objective of content curation is to aggregate and tag content and facilitate subsequent indexing and retrieval. It is a layer, which lies between the universe of the existing content and limited time of end users. For example, curation for social media content has received much attention as online users tend to be attracted by only popular and interesting posts. Thus, it is critical to assist the users in finding the content of interest by applying techniques such as scalable indexing and retrieval of information. Curation has changed the way we receive news content (e.g. Reddit), shop online (e.g. Etsy), and share data with each other (e.g. Pinterest). It is also quickly changing the landscape of digital marketing [Reference Deshpande5] and improving the user experience for streaming video where each scene is labeled with the cast, synopsis, trivia, and fun facts (e.g. Amazon Prime Video). Traditionally, curation was performed by simply aggregating content but has been quickly commoditized as technology evolves. Nowadays, top curation sites not only bring together the best content but also introduce their unique human perspective – resulting in the blurring scope between curation and creation [Reference Deshpande5]. This trend is particularly visible for multimedia content such as Pinterest (https://www.pinterest.com/) for images and Waywire (was Magnify) (http://enterprise.waywire.com/) for video.
Online content moderation [Reference Grimes-Viort6] was born nearly at the same time as the original online forums were created during the 1970s – most voluntarily at the beginning to ensure the discussions followed certain netiquette and to prevent inappropriate topics, discussions, and content to be shared within the online community. The liability of internet intermediaries became a primary concern during the 90s (https://en.wikipedia.org/wiki/Section_230_of_the_Communications_Decency_Act). As a result, online forum owners and moderators in the USA are now protected by Section 230 of the Communications Decency Act of 1996, which states that no provider or user of an interactive computer service shall be treated as the publisher or speaker of any information provided by another information content provider (https://en.wikipedia.org/wiki/Section_230_of_the_Communications_Decency_Act). In its Digital Single Market Strategy (https://ec.europa.eu/commission/priorities/digital-single-market_en#documents), the European Commission plans to implement filtering obligations for intermediaries and introduce neighboring rights for online uses of press publications. Meanwhile, an upcoming revision of the Audio-visual Media Services Directive (http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32010L0013) would ask platforms to put in place measures to protect minors from harmful content and to protect everyone from hatred incitement. Finally, the EU Digital Single Market Strategy endorses voluntary measures as a privileged tool to curb illicit and infringing activities online (https://ec.europa.eu/commission/priorities/digital-single-market_en#documents). Several court rulings, as well as the pursuit of the moral imperatives, mandate content moderation for social media sites that can be accessed by minors. For all these reasons, most major social media and online content sites employ some form of content moderation even though they are protected from the communication decency act [Reference Roberts7]. This is mainly because the content contributed by their members or advertisers may include materials that are offensive or disturbing to the rest of the community, or contain infringing or fraudulent materials that may cause liability to the platform providers.
Initially, human subject matter experts were used to perform both content curation and moderation. However, as online communities and the amount of content they share continues to grow exponentially, both content curation and moderation are facing profound scalability challenges in the following three dimensions: (1) fast-growing content volume, (2) fast-growing community size, and (3) rapidly changing policies and guidelines due to regulations, court rulings, and various geopolitical as well as social events. Consequently, it has become increasingly difficult to produce consistent curation and moderation decisions that conform to the expectations of the digital community. For example, to address the scalability challenge, content curation standards (such as MPEG-7 [Reference Chang, Sikora and Purl8]) and algorithmic approaches for both curation and moderation [Reference Veloso, Meira, Macambira, Guedes and Almeida9–Reference Ortis, Farinella, D'amico, Addesso, Torrisi and Battiato11] have been developed. Nevertheless, these algorithmic approaches have not been able to fully substitute human moderators [Reference Gary and Siddharth12] due largely to its inability to adapt to frequently-changing policies. A symbiotic human-machine collaboration framework has emerged in the industry to address this challenge [Reference Gary and Siddharth12]. In this paper, we highlight the uniqueness of the content lifecycle emphasis in different sectors of online business and the scope of content curation and moderation common to these sections. Finally, we illustrate how to apply a cognitive orchestration framework to focus on cases that have not been previously curated or moderated to optimize the outcome.
The rest of the paper is organized as follows: Section II describes the related work. Governance models for content curation and moderation and the process of deriving rules from community standards and policies are discussed in Section III. Section IV describes the total context awareness concept. A reference architecture for content curation and moderation is described in Section V. Section VI describes the outcome-driven framework for content curation and moderation. This paper is concluded and summarized in Section VII.
II. RELATED WORK AND INDUSTRY PRACTICE
A) Content lifecycle
The content lifecycle, as shown in Fig. 1, starts with content creation, followed by content curation, content moderation, content distribution, content consumption, and potential redistribution. These phases are heavily interdependent with one another and may trigger the execution of other phases via feedback loops. The boundary between content creation and content aggregation has blurred in recent years. In addition, the media distributor will often adjust recommendations of content for the consumers by continuously monitoring their consumption pattern. Conversely, the consumers could also raise concerns or complaints to the moderators for further investigations.

Fig. 1. Content lifecycle.
The content lifecycle varies depending on the overall context of the application area as shown below:
E-commerce: e-commerce marketplaces such as Alibaba, Walmart, eBay, Jet.com, wish.com, Amazon, Newegg, and Bonanza enable vendors and sellers to submit product content (images and text descriptions), categorization, and enable customers to post product and vendor reviews. Curation of the images and video is often required in terms of intended gender and detailed categories. Moderation is also required to ensure there is no counterfeit brands, copyright infringement, inappropriate images, and disallowed products.
Social media: members of social media constantly post multimodal content (text, image, video). This content needs to be curated (such as time and place) as well as moderated (for disturbing or offensive content). Social media firms are increasingly assuming the editorial responsibility of journalism, including identifying potential fake news.
Online advertisement: online advertisement may also have multimodal content (text, image, and video) and often require content moderation to ensure the content is compliant with the business policy where the online advertisement will be placed.
Streaming media: streaming media has increasingly demanded for real-time annotation of the content (actor/actress, trivia). These annotations are currently produced through content curation.
Gaming: gaming communities are becoming online marketplaces where moderation of virtual goods and streaming media are an integral part of the environment. It is often mandatory to prevent objectionable content to be distributed within the online gaming community.
E-learning: curation is playing an increasingly important role in the fast-growing e-learning environment to ensure that the needs of online learners are addressed. Typical curation techniques for e-learning include content aggregation, a distillation of most relevant sources, identification of topical trends, fusing of study materials from different perspectives to offer a fresh perspective, or organization of the materials according to a customized curriculum [Reference Pappas13].
B) Content curation
Content curation is the process of discovering, gathering, grouping, organizing, or sharing information relevant to a piece of information (e.g. web pages, documents, images, or video), a topic, or area of interest. Content curation is not a new phenomenon. Museums and galleries have had curators to select items for collection and display dating all the way back to Ancient Rome. Content curation was envisioned as the next wave of challenges for online content during the early 90s in an NSF-sponsored Digital Library Initiative [Reference Fox and Sornil14] and in the early 2000s in semantic web as advocated by the Internet pioneer Berners-Lee [Reference Berners-Lee, Hendler and Lassila15]. The scope of content curation includes [Reference Bhargava16]:
Annotation: includes abstracting, summarizing, quoting, retitling, storyboarding, and parallelizing [Reference Deshpande17]. The original semantic web concept morphed into Linked Data [Reference Bizer, Heath and Berners-Lee18], Freebase [Reference Bollacker, Evans, Paritosh, Sturge and Taylor19], and Google Knowledge Vault [Reference Dong20]. Substantial progress has also been made in the standardization of multimedia content annotation such as images and video with the definition of the MPEG-7 standard [Reference Chang, Sikora and Purl8]. MPEG-7 was designed with algorithmic curation in mind so that the descriptor for the content can be automatically computed from the multimedia in one or more modalities of audio, images, and video [Reference Benitez21].
Aggregation: gathers the most relevant information about a topic in a single location. Portals such as Yahoo during the early days of the Internet pioneered in this area. This is also an area where algorithmic approaches have been routinely applied to web and image content.
Distillation: curates information into a more simplistic format where only the most important or relevant ideas are shared. Both text and video summarization approaches have been applied to automate the curation process.
Elevation: intends to identify a larger trend or insight from daily postings. Algorithmic approaches have been developed to identify trending within online forums, user groups, and blogs – including sentiment analysis.
Mashup/Assimilation: are uniquely curated juxtapositions where existing content is fused or assimilated to create a new point of view. Assimilation of multiple perspectives is often model-driven or hypothesis-driven. For example, assimilating photographs into 3D models or panorama images have been demonstrated in Microsoft Photosynth [Reference Uricchio22,Reference Pomaska23]. Using hypothesis to identify the best explanation for the available evidence has been also been previously demonstrated.
Chronology: brings together historical information and organizes it based on its temporal sequence to show an evolving understanding of a topic. Automatic chronological curation requires temporal information extraction [Reference Ling and Weld24] to determine the temporal order of the events.
C) Content moderation
Content moderation is the process of reviewing and deciding whether the submitted content (text, image, video, ads) is not objectionable to the broader online community. There are several perspectives to categorize different types of content moderation [Reference Grimes-Viort6]:
Pre- versus post-moderation: the content is submitted to a queue in pre-moderation to be checked by a moderator before it is visible to the community. This approach is likely to provide maximal protection for content consumers – but the loss of instant gratification of content is likely to discourage participation from the online community. Post-moderation in contrast displays the content instantaneously but replicates it to content moderation queue so that it can be reviewed later if it is reported to be inappropriate. Both approaches are difficult to scale with the growing size of online communities and increasingly complex legal liabilities [Reference Ta and Rubin25].
Proactive versus reactive moderation: in proactive moderation, the content is always reviewed regardless whether the content can be visible immediately or not. Reactive moderation, on the other hand, will trigger moderation only when the posted content is being flagged by the community. Reactive moderation usually allows any member in a community to flag the content that is visible, and is likely to be more scalable with respect to the growth of the content and community.
Centralized versus federated moderation: in centralized moderation, the responsibility of who will be responsible for the initial decision and subsequent approval process is well defined. In federated moderation, in contrast, the decision is rendered by a distributed group or community with a pre-established federated governance model.
Manual versus automatic moderation: recent rapid prog- ress in the areas of natural language processing and computer vision has enabled more automatic moderation of text, image, and video. Those items that might not be able to be automatically moderated can always fall back to human moderators for additional review or assurance.
III. GOVERNANCE MODEL AND ASSURANCE PROCESS
Content curation and moderation are often enforced by a set of assurance rules to ensure that the policies set by a digital community are being followed. These rules are derived from curation or moderation policies, which are in turn set up by a governance model through the community standard as shown in Fig. 2. The governance model within an online community can be self-governed, centralized, or federated:
Self-governed: the establishment of the policy for curation and/or moderation is entirely open to every member of the community and there is no enforcement. This type of governance model often leads to chaos as witnessed during early days of many online forums and social media.
Centralized: the establishment and enforcement of the policy are often carried out by a closed committee of the online platform while the members of the community do not have the opportunity to participate and contribute to the committee.
Federated: the policy is established by an open committee consisting of stakeholders of the community with a well-established community standard. The policy is continuously reviewed and revised by this committee. The enforcement of the policy is carried out by the committee or the operating group reporting to the committee with a due process for the members of the communities to appeal the decisions.
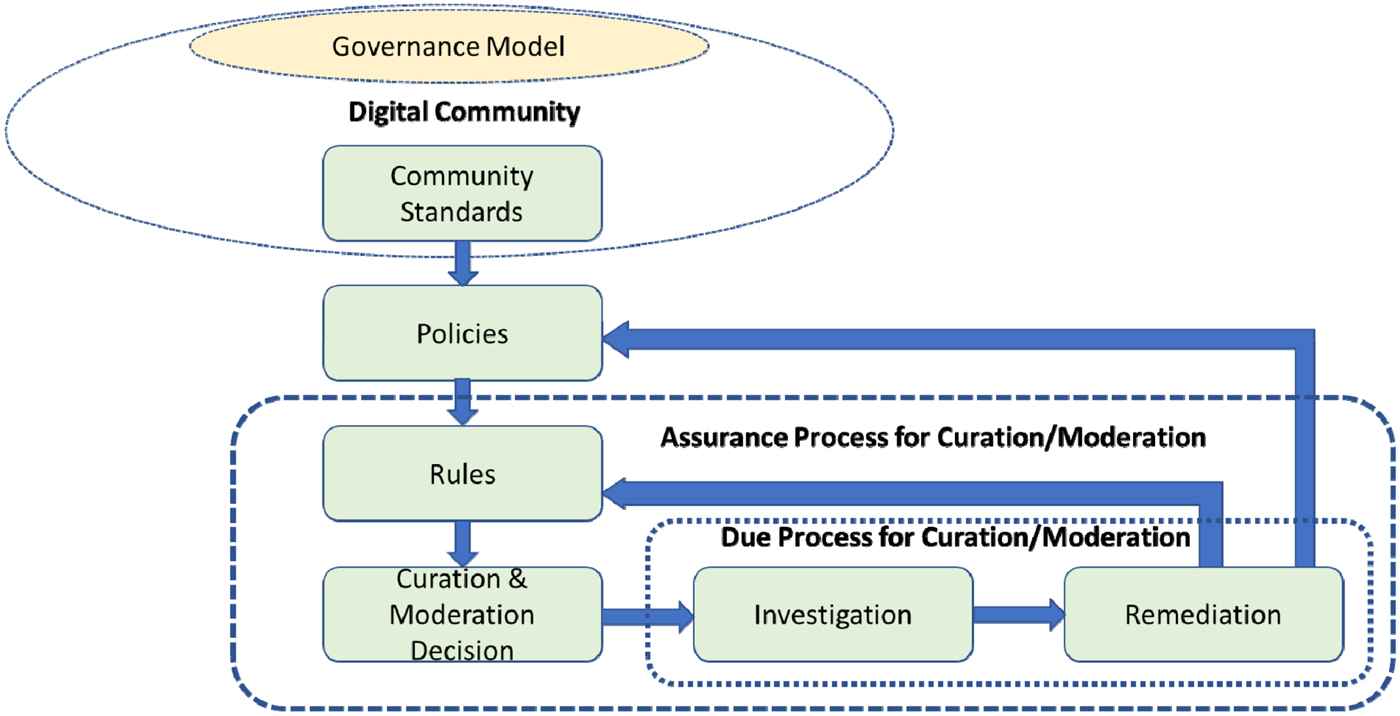
Fig. 2. Governance model for community standards of digital community.
The federated governance model is likely to be the most scalable for digital communities involving content curation and moderation. The federated governance model [Reference Handy26] is most likely to address the paradox encountered by fast-growing digital communities struggling between power and control, between check and balance, being simultaneously big and small, being simultaneously global and local, and being simultaneously centralized and distributed. Fully substantiating the federated governance model requires lowering the center of gravity of decision process, creating interdependency among stakeholders to spread the power around and avoid the risks of a central bureaucracy, creating a common law (such as the community standard) as the uniform way of doing business within the digital community, and keeping management, monitoring, and governance in segregated units to ensure check and balance [Reference Handy26]. ESIPFED [Reference Freuder, Ledley and Dahlman27] is a successful example of such a digital community with a federated governance model. The Federation of Earth Science Information Partners was founded in 1998 by NASA in response to a National Research Council (NRC) review of the Earth Observation System Data and Information System. The NRC called on NASA to develop a new, distributed structure that would be operated and managed by the earth science community that would include those responsible for all elements of earth observation, including observation and research, application and education. This digital community has grown to more than 100 partners from the original 24 and has a self-contained community model for creating, curating, dissemination, and consumption of earth science-related digital content.
Check and balance is an essential part of digital communities. The assurance process shown in Fig. 2 includes a due process for investigation and remediation of those decisions made during the curation and moderation process as members of the community may raise concerns for the curation or moderation process. The conclusion from the investigation or remediation may include updating the rules or even the policies.
Through the governance model, each digital community sets up its community standards, its content sharing policy (for user-generated content), and a set of rules to enforce the policies. Using Facebook as an example, the community standard on Bullying and Harassment (https://www.facebook.com/communitystandards#bullying-and-harassment) is as follows:
We don't tolerate bullying or harassment. We allow you to speak freely on matters and people of public interest, but remove content that appears to purposefully target private individuals with the intention of degrading or shaming them.
The policies that are to be implemented to enforce this policy include (https://www.facebook.com/communitystandards#bullying-and-harassment):
Pages that identify and shame private individuals,
Images altered to degrade private individuals,
Photos or videos of physical bullying posted to shame the victim, and
Repeatedly targeting other people with unwanted friend requests or messages
The potential rules for identifying pages and images that shame private individuals can be divided into three categories [Reference Douglas28]:
Deanonymizing doxing: personal information of a formerly anonymous individual is released.
Targeting doxing: personal information that reveals specific details of an individual's circumstances that are usually private are disclosed.
Delegitimizing doxing: intimate personal information that damages the credibility of that individual is revealed.
Even today, defining content curation and moderation rules from policies remain as an entirely manual process. There have been some attempts to automate the extraction of rights and obligations from regulations during the recent past [Reference Breaux, Vail and Anton29–Reference Breaux and Antón31]. In this prior work, the unrestricted natural language statements are re-written into restricted natural language statements before they are translated into a set of formal predicates (constraints and obligations). However, the problem of automatic translation from natural language to logic remain largely unsolved.
IV. TOTAL CONTEXT AND INFORMATION AWARENESS
The efficiency and efficacy of content curation and moderation can be greatly improved by the context of the content creation, dissemination, and consumption. Contextual information for content may include who created the content, where the content was created, when it was created, what was the environment, and how it was created. Additional information about the five Ws on the consumption end could also be used to enhance the understanding of the value chain of the content. Metadata standards such as MPEG-7 [Reference Chang, Sikora and Purl8,Reference Benitez21] for multimedia data, CSDGM [Reference Tsou32] for Digital Geospatial Metadata maintained by the Federal Geographic Data Committee, and XBRL [Reference Debreceny and Gray33] for financial reporting, have been developed within each content community to facilitate the capturing and dissemination of contextual information of the content.
Taking this approach to the extreme is to leverage total information awareness [Reference Wang, Allen, Harris and Madnick34] to construct a behavior model of the content creator both within and outside of the digital community. Such behavior model is often stitched together from spatial, temporal, and spatiotemporal information that is publicly available and/or within the digital community. Within each digital community, it is usually feasible to establish the spatial, temporal, and spatiotemporal sequence of the events and activities that occurred with each user account as they are usually logged in. These events may include the browsing history, comment postings, etc. Stitching together behaviors from both inside and outside of a digital community may be more challenging, as a simultaneous reconciliation of the identity of users and their temporal and spatiotemporal events is often required. In general, total information awareness enables a more risk-based approach for evaluating the possibility of whether the content is likely to be within the policy. This approach also requires addressing the assumed (i.e. faked) identity in the digital community to accurately assimilate the information [Reference Boshmaf35].
V. COGNITIVE FRAMEWORK FOR CONTENT CURATION AND MODERATION
One of the scalability challenges, as the volume of content and size of the digital community grows exponentially, is to curate and moderate content consistently. It is thus necessary to derive a set of consistent rule frameworks to ensure that content is curate and moderate consistently.
The landscape of curation and moderation, as shown in Fig. 3, can be defined to ensure a consistent set of rules framework:
Known known: the content is known to have been previously curated or moderated (upper right quadrant) so curation and moderation can directly follow the previously curated or moderated cases.
Unknown known: the content was previously annotated, or close to what was previously annotated but unknown to the curator or moderator (upper left quadrant). Various information retrieval, information extraction, content classification, and question answering techniques can be used to identify those previously annotated or curated content.
Known unknown: the content was known to have not been previously curated or moderated (lower right quadrant): This type of content may have to be decomposed and then resynthesized to determine whether elements have been previously curated or moderated. Decomposition of content also allows reasoning techniques to be used to inference the overall curation and moderation decisions. New rules are added to the rule framework because of these analysis-synthesis methodologies.
Unknown unknown: the content was not known to have been previously curated or moderated (lower left quadrant). Controlled experimentation may be needed to determine the best course action towards the content. This often arises for those active or interactive content (including online gaming) where the full behavior of the content cannot be determined by a snapshot of the content.

Fig. 3. Landscape of curation and moderation.
The curation of multimedia content can include structures, features, models, and semantics, as shown in Table 1 using MPEG-7 content description framework as an example. A video about a sports event type (in the semantics category) that has not been previously annotated and is not part of the taxonomy would belong to the lower left quadrant. On the other hand, this same sports video would belong to the lower right quadrant if it were from a previously known event type but had not been curated.
Table 1. MPEG-7 content description framework.

Figure 4 shows the diagram a framework for content curation and moderation enabled by cognitive computing. In this framework, cognitive computing approaches work symbiotically with human content curator/moderator to provide scalable curation/moderation capabilities with built-in continuous learning.

Fig. 4. Cognitive framework for content curation and moderation.
Feature extraction: even though the content input to the cognitive framework can range from free text, semi-structured data (often XML-based), images, video, the extracted features are invariably in the form of feature vectors. These features can be hand-crafted, curated (such as knowledge graph) or machine generated (such as those based on word embedding or deep learning). Traditionally, feature engineering which involves the selection of an appropriate set of features that optimize the performance of the curation or moderation tasks has always been the most time consuming and critical step. The advent of deep learning in recent years has substantially alleviated the burden on this task while achieving much superior performance.
Training/clustering: during the training phase, the features together with previously curated or moderated content are used for training the supervised machine learning models. In the case of the unsupervised machine learning models (such as those based on k-means), the corresponding labels are assigned to the feature vector based on results of the clusters.
Models: a wide range of supervised (with labeled training dataset) or unsupervised (without labeled training dataset) are available for automated curation and/or moderation. Recently, deep learning-based machine learning models are beginning to be applied to curation and moderation tasks for text, image, and video.
Domain knowledge and context: domain knowledge can be captured at the conceptual level (e.g. knowledge graph), structural level (such as a social network), or behavior level (such as purchase pattern) [Reference Li, Darema and Chang36]. Domain knowledge and context is often used in curation or moderation to further improve the accuracy and confidence level. The domain knowledge could be embedded in the training set to augment the input content or filter/enhance the curation/moderation decisions.
Automatic curation: for content curation, the models (mainly unsupervised) are learned to compute the relevant scoring and sort the content with respect to end-user preference model. The top-ranked content generated by models will be subject to human intervention when the confidence level is insufficient, as discussed below.
Automatic moderation: for content moderation, the models (mainly supervised) are trained to differentiate between appropriate and inappropriate content with respect to policies and rules. Like curation, the appropriate content selected by the models will be further verified by human moderators when the confidence level is insufficient.
Human-assisted decision: fully automatic curation or moderation is unlikely to achieve 100% accuracy or any other performance metrics of interest. Consequently, the machine learning-based curation or moderation should always generate the confidence level of the curated or moderated results. Human curators or moderators will intervene when the confidence level is lower than a certain threshold. Human curators or moderators will also audit the machine-generated curation or moderation. In both cases, the human decisions or corrections will be included as additional training data to continuously improve for the machine learning algorithms.
Content curation communities employing crowdsourcing approaches to curate content into a single repository have become distinct from the content creation communities [Reference Rotman, Procita, Hansen, Sims Parr and Preece37–Reference Zhong, Shah, Sundaravadivelan and Sastry39]. Automatic content curation and moderations models have been developed for image and video [Reference Veloso, Meira, Macambira, Guedes and Almeida9,1140,Reference Duh, Hirao, Kimura, Ishiguro, Iwata and Yeung41], mostly for narrowly defined domains [Reference Momeni42–Reference Veglis44]. Similar constraints also exist for specialized domains by using information extraction techniques to automate curating entities and relationships from scientific corpus [Reference Karp45]. In the case of abusive, harassment, or sexually explicit language detection, a number of benchmark datasets have been established and significant progress has been made towards automatic detection by using supervised machine learning models [Reference Guberman and Hemphill46–Reference Mulla and Palave48]. Modeling bias issues arising from automatic curation and moderation algorithms have also been studied, for example, in [Reference Binns, Veale, Van Kleek and Shadbolt49]. As a result, it is conceivable that hybrid approaches that integrate automatic content curation or moderation models with a human in the loop are likely to remain as the primary approach for the foreseeable future [Reference Glassey, Elliott, Polajnar and Azzopardi50–Reference Inyang, Ozuomba and Ezenkwu60].
VI. OUTCOME DRIVEN ORCHESTRATION FRAMEWORK
In this section, an outcome driven framework for content curation and moderation is proposed. As shown in Fig. 5, in this framework, the content measurement platform helps in capturing both the content and the context. The curation and moderation platform will expand the known, identify the unknown, and develop experimentation to transform unknown to known. The experimentation platform allows for the execution of the actual experiments. This framework is driven by the outcome – namely – the precision or accuracy of content curation and moderation or any other performance metrics defined. Compared with a traditional reactive framework where the curation and moderation are often reactive and opportunistic, this framework enables early discovery of new content patterns and trends to ensure the outcome metric for curation and moderation is kept at an optimal level.
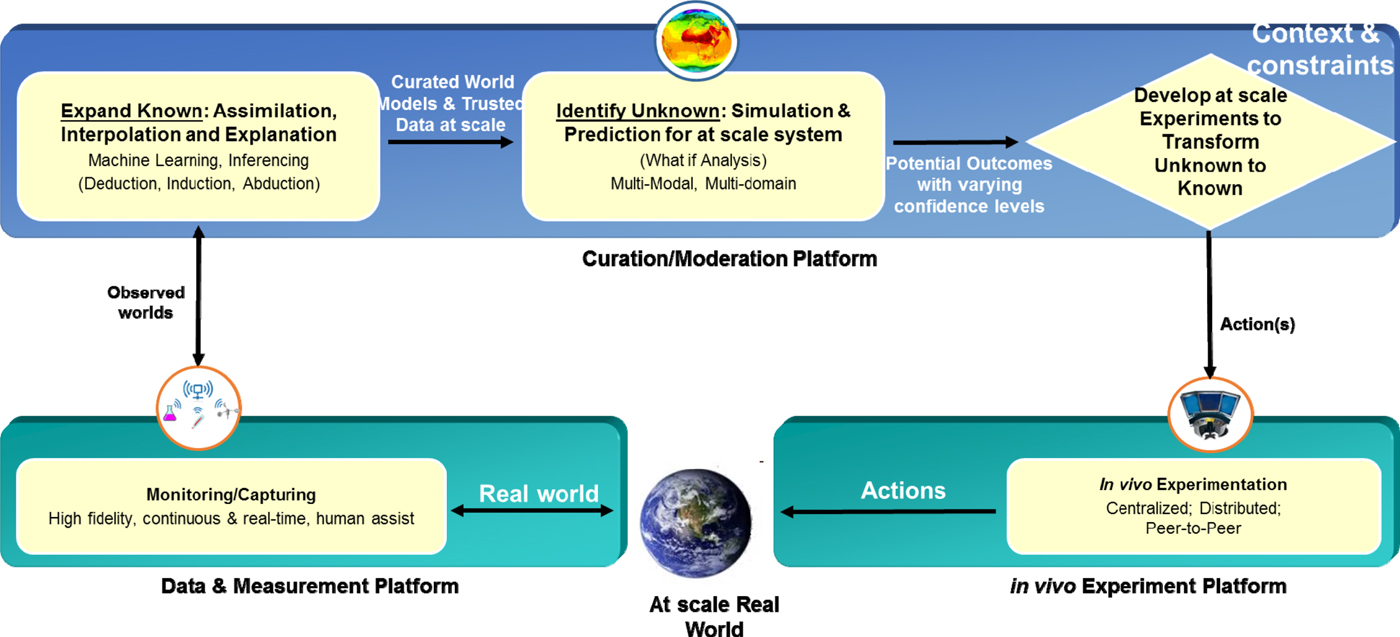
Fig. 5. Outcome driven orchestration framework for content curation/moderation.
The primary objective of this framework is to proactively identify content patterns that have not been previously curated or moderated and cannot be easily classified based on previous curated or moderated content cases. This platform also enables a symbiotic collaboration between human and machine.
Human identifies facts, machine performs inference: establishing sufficient training data for machine learning models to be able to curate or moderate accurately requires human-machine collaboration. Humans establish initial facts in the form of training data, while rule-based (deduction) or machine learning (induction) approaches are used to generalize the human curation. The content that cannot be curate or moderate with sufficient confidence will go through human or human-assisted curation or moderation.
Human synthesizes, machine analyzes: in this symbiotic collaboration between human and machine, human will perform top-down synthesis of knowledge consisting of concepts with relationships among them. The machine can then perform bottom-up analysis and pattern recognition from the vast amount of data. This top-down synthesis and bottom-up analysis can be iterated to expand the known, identify unknown, and convert unknown to known. As an example of this top-down synthesis (shown in Fig. 6), the geologist provides curation of the potential oil/gas reservoir by describing that the formation of reservoir usually involves layers of permeable structures (such as siltstone or sandstone) underneath impermeable structures (such as shale), sandwiched by vertical fault lines, and potentially with sand channels that represents ancient rivers.

Fig. 6. Example of curating complex knowledge related to the oil/gas reservoir. (1) Permeable substrate (sandy layer), (2) Convex Volume greater than X (3) Immediately below cap-rock (impermeable). 4. Deep/old enough (not too deep).
Human designs experiments based on machine identification of areas of unknown: one of the challenging aspects of content curation and moderation is to proactively identify unknown broad categories without waiting for the content to appear and then trigger the need for opportunistic curation and moderation. In this area, some algorithmic approaches have been used to identify content that cannot be curated or moderated via confidence score. These algorithms work by leveraging small variations in content that has been previously curated or moderated. Humans will need to form hypothesis and design controlled experiments for testing the hypothesis. This is particularly relevant when we need to develop rules for emerging content to determine whether they are within policy. These experimentations may involve identifying and enrolling test subjects (by machine) within the digital community.
VII. CONCLUSION
In summary, rapid advances and adoption in e-commerce, streaming media, and social networks have created an evolving content ecosystem that includes creation, curation, moderation, distribution, consumption, and redistribution. The social and legal responsibilities of online platforms continue to evolve since the passing of the Communication Decency Act Section 230 in 1996. On one hand, the law allows the online platform owners to be immune from some of the liability that is usually associated with a publisher for user-generated content or third-party content. On the other hand, various legal cases in recent years both in the USA and around the world have demonstrated that these platform owners may not be immune to all liabilities in areas of infringement (copyrights or trademark), defamation, obscenity, and other harmful content to minors. Consequently, most online platform owners are taking on a more governed approach towards content curation and moderation in order to fulfill their social and legal responsibilities while ensuring that members of the online community enjoy the freedom of speech and freedom of expressions. The primary challenges faced by this fast-growing digital community are the limitations imposed by the traditional governance model and content curation/moderation approaches.
In this paper, we proposed and discussed the federated governance model as a way to address the content curation and moderation scalability challenge. In this model, stakeholders of the digital community participate in setting the community standard and the policies that govern the curation and moderation. This governance model is likely to become more prevalent as it provides the check and balance needed and ensure the establishment of a due process for potential concern and appeal of decisions made during the assurance process for content curation and moderation. Given the intimate relationship among the regulations, court rulings, and fast-moving trends within these online platforms, we believe humans are likely to be involved in the process of translating policies to rules for the assurance, as well as in taking part in the assurance, investigation and remediation process. Finally, we presented a symbiotic human-machine collaboration framework to address the scalability challenge. In this framework, the content needing to be curated or moderated can be previously curated (unknown-known), previously categorized but not yet curated (known-unknown), or potentially a new category needs to be created (unknown-unknown). An outcome optimized approach is proposed to proactively identify new content categories through the collaboration between humans and machines.
ACKNOWLEDGEMENTS
We would like to acknowledge the discussion of use cases with Kevin Collins and Colin Conners.
FINANCIAL SUPPORT
This research received no specific grant from any funding agency, commercial or not-for-profit sectors.
STATEMENT OF INTEREST
None.
Chung-Sheng Li is currently the Global Research Managing Director of Artificial Intelligence for Accenture Operations, with a focus on driving the development of new AI-enabled service offerings for Accenture Business Process Services. Previously, he has been with IBM Research between 1990 and 2016. His career includes driving research and development initiatives spanning cognitive computing, cloud computing, smarter planet, cybersecurity, and cognitive regulatory compliance. He has authored or coauthored more than 100 patents and 170 journal and conference papers (and received the best paper award from IEEE Transactions on Multimedia in 2003). He is a Fellow of the IEEE. He received BSEE from National Taiwan University, Taiwan, R.O.C., in 1984, and the MS and Ph.D. degrees in electrical engineering and computer science from the University of California, Berkeley, in 1989 and 1991, respectively.
Guanglei Xiong received his Ph.D. degree in biomedical informatics from Stanford University in 2011. He was a research scientist at Siemens Corporate Research from 2011 to 2013 and an assistant professor in the Department of Radiology, Weill Cornell Medical School from 2013 to 2016. His research interests include artificial intelligence, machine learning, computer vision, and their applications in biomedicine, marketing, and advertising. Dr. Xiong has authored over 15 journal and 20 conference papers in these fields.
Emmanuel Munguia Tapia received his MS and Ph.D. degrees from the Massachusetts Institute of Technology (MIT) and has 15 years of multi-disciplinary expertise combining machine learning, artificial intelligence, context awareness, and novel sensors to make mobile, wearable, and IoT devices smarter. He is presently a senior engineering manager in cognitive computing systems at Intel Corporation. He was previously the director of context awareness for Samsung. He was the recipient of the Samsung Gold Medal Award for creating the most innovative technology company-wide in 2014 and also the recipient of the 10-year impact award at UBICOMP 2014, the top International Joint Conference on Pervasive and Ubiquitous Computing. Emmanuel holds 36 + international publications, 10 + patents, and a degree in Engineering Leadership from the University of California Berkeley.








 Open access
Open access