


I. INTRODUCTION
With the development of deep learning, image data become more and more accessible to researchers and engineers. Many companies of different industrial areas such as finance technology company or automobile manufacture may accumulate a large amount of license plate images. These license plate images are probably obtained in different scenes, which has different influences on the image recognition task. For this reason, automatic identification of license plate is a significant research topic since the environments to identify a license plate may be unknown. Our research to recognize vehicle license plate (VLP) in natural scene is to identify the characters on images regardless of the environment where the image is obtained.
Traditional license plate recognition systems are mostly based on aknown environment. For example, a set of images may be derived from the automobile on the highway. While an image is obtained from a car in the parking lot, the traditional system may have relatively poor performance on the image recognition task. Concretely, fixed cameras, fixed shooting angles, similar illumination, and even the same moving directions should be known with the traditional systems.
In reality, license plate images taken in natural scenes have different shooting angles and illumination parameters. As a result, recognition license plate in natural scene has two main challenges. On one hand, auto-detect license plate from giving images is necessary; on the other, it is hard to segment characters accurately.
In the license plate detection module, we first use SSD model [Reference Liu1] to detect license plate. Then we perform image processing techniques to correct license plate blocks detected in the previous step. Since charactersegmentation is a challenge, we propose a framework for the recognition process that could avoid license plate character segmentation.
The main contributions of this paper are summarized as three aspects. (A) We deploy a complete system to recognize VLP in natural scene; (B) an automatic encoder–decoder model (DCNN-RNN) is presented to recognize VLP; (C) we apply a gate mechanism to the encoder.
The rest of the paper is organized as follow: in Section II, we describe the present model in detail. We summarize the experimental setup and report experimental results in Section III, and related work and conclusions are in Sections IV and V, respectively.
II. RELATED WORK
A) License plate detection
License plate detection inputs a real-life image and outputs potential license plate bounding boxes. Although there are lots of existing algorithms to detect license plate under certain natural environment, it is still a challenging problem to detect the license plate well under arbitrary natural environment. There are four types of algorithms for this problem [Reference Du2,Reference Hongliang and Changping3]: edge-based, color-based, texture-based, and character-based.
Edge-based approaches try to find large edge-density regions as the license plates. In [Reference Chen and Luo4], an improved Prewitt arithmetic operator is a method used to locate license plate position. Rasheed et al. [Reference Rasheed, Naeem and Ishaq5] applied canny operator to detect regions and used Hough transform to find the best vertical and horizontal boundaries of the license plate. Edge-based approaches benefit with fast speed, while they are sensitive to useless background edges. Color-based algorithms are based on the fact that the color of VLPs is different from others in most cases. HSI color model in [Reference Deb and Jo6] is used to detect the candidateVLP region. Then the algorithm uses rectangularity, aspect ratio, and edge density to distinguish license plates. The disadvantage of the color-based method is that they can not drop out other objects with almost the same color.
Texture-based models try to detect by unconventional pixel density distribution in plate regions. In [Reference Giannoukos7], sliding concentric window algorithm is applied to identify license plate by its local irregularity property.
Character-based algorithms detect license plate via examining the presence of characters in the image. Lin [Reference Lin, Tang and Huang8] published an algorithm using image saliency to locate license plate. These approaches segment out characters with a high recall to the image saliency map. After that, it applies a rolling window on the selected characters to compute some detailed properties in image saliency and finally detect the license plate. Recent work in license plate recognition applies deep neural network to the recognition task [Reference Li and Shen9]. This approach implemented the character segmentation method, which is different to the pipeline of our solution.
B) Optional character recognition
Character sequence recognition is directly related to VLP recognition. There are two methods which are well established by other researchers, the input segmentation (INSEG) method and the output segmentation (OUTSEG) method. The INSEG algorithm aims at determining the possible segmentation points of the characters in a certain sequence. Only when points containing a possible character are chosen to go through the recognizer, it generates a sequence that contains all the most likely characters, which are selected by another algorithm like Viterbi [Reference Weissman10]. Some approaches to determine the points for a possible character are connected component analysis [Reference Weissman10]. In the OUTSEG approach, unlike the INSEG, many characters are generated by sweeping a rolling window over the entire image with small steps. At each step, the contents of the windows will be treated as a tentative character. Then, all the tentative characters come through the recognition machine. The final sequence is selected if the corresponding actual characters overlap significantly over the image [Reference Zhang and Zhang11]. INSEG and OUTSEG methods have problems: the recognizer is not able to gather enough useful information, when the partition of the image is inputted into the recognition machine.
III. APPROACH
A) System description
Our VLP recognize framework is shown in Fig. 1. It contains three steps: (1) VLP detection, (2) license plate adjustment, and (3) license plate recognition. We first apply SSD model or VLP detection [Reference Simonyan and Zisserman12]. Then, an image processing algorithm is applied for license plate adjustment. For license plate recognition, we propose DCNN-RNN neural network to improve the accuracy of vehicle character recognition.
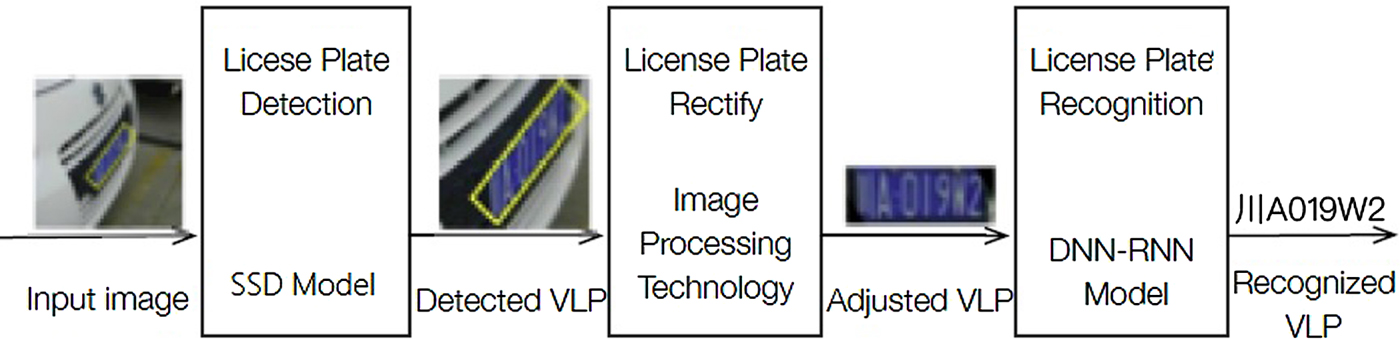
Fig. 1. The framework of the proposed vehicle license plate (VLP) detection and recognition system which contains three essential parts: detection, adjusting, recognition.
1) Vehicle license plate detection.
VLP detection is to detect the rectangle of the license plate in the image obtained in natural scene. We apply SSD model to detect the structure which is based on VGG16 [Reference Simonyan and Zisserman12] network.
We normalize the scale of the image in the input layer. In the training phase, according to the default box and the ground truth overlap rate, we find the corresponding positive sample. We also enlarge the training dataset by cropping, mirroring, and adding noise. The VGG-16 convolution layer is adopted to sample the multi-scale feature on the image. According to the granularity of the feature map extracted from different layers, we select the target bounding box with various scales. The prediction results for each target bounding box contain both the category and the confidence, and then the final prediction result is selected on the basis of the maximum inhibition criterion.
The superiority of this license plate detection model is that it could avoid multiple extractionof the characters of the overlapping images in the candidate frame, like Faster-RCNN [Reference Girshick13]. This model just extracts feature once, so it achieves efficient license plate detection. The training set has 9597 images, containing five color classes: blue plate, yellow plate, white plate, black plate, and green plate.
2) Vehicle license plate adjustment.
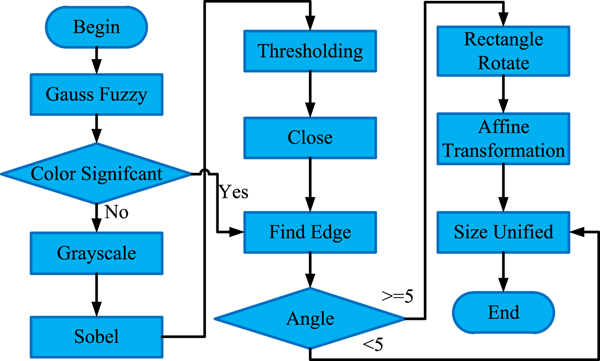
The aim of VLP adjusting is to correct the incline license plate. We adopt traditional image processing algorithms to rectify the license plate. The pipeline of the algorithm is shown in Fig. 3(a). First, we take a series of operations to find the circumscribed rectangle of the license plate. Then, the rectangle must be corrected if the angle of the license plate is too large. After that, all the license plates are adjusted to the front visual angle. Finally, we normalize the size of the license plate, which is acted as the input of the following recognition part. Figure 2 shows our correct results.

Fig. 2. The correct results after license plate adjusting.

Fig. 3. The process of vehicle license plate adjusting adopts several image processing algorithms.
3) Vehicle license plate recognition.
VLP recognition is the most vital building block of our system. We choose the deep learning models to recognize the characters on the license plate, which consists of a deep convolution network for feature extracting and a stacked RNN for character recognition as shown in Fig. 4. First, DCNN layer is selected for extracting the features from the image that have been sliced. Then, the obtained feature sequence is input into the RNN Layers for recognizing characters in the row from left to right in order, in which multiple features identify one character. Finally, we process the result by the Translation Layer and define the recognition result in accordance with the char dictionary of the license plate. The specific theory will be described in detail in the next section.

Fig. 4. (a) Overall structure of our sequence labeling-based model for Chinese plate recognition chooses DCNN to encode input image and stack RNN to decode deep features to characters. (b) The details of DCNN part.
B) DCNN-RNN
It is natural to use convolutional operation to scan the images which contain a row of characters and use the recurrent neural network to predict the characters. Following, we build a network that includes deep convolutional neural networks and recurrent neural networks, and we name it DCNN-RNN.
1) Encoder
Giving an image X ∈ R w×h with a standard size, the network automatically extracts a sequence of feature vectors H = 〈H 1, …H T〉:
 $$ {H}_1 = DCNN(X),$$
$$ {H}_1 = DCNN(X),$$where T is the sequence length, and we set it 16 in our system.
 $$ {H}_2 = MLP({X}),$$
$$ {H}_2 = MLP({X}),$$where MLP is a multilayer perceptron layer.
 $$ {H} = {g} \odot {H}_1 + (1-{ g}) \odot {H}_2,$$
$$ {H} = {g} \odot {H}_1 + (1-{ g}) \odot {H}_2,$$where g is a gating mechanism, which transports the raw information from input X to feature vectors H. g = σ(W TX + b), W T is the square matrices.
By adding a gating mechanism to the neural network, it is possible to selectively preserve and output information through the gate, which solves the problem of information disappearing in the process of transmission. The convolution neural network with gating mechanism through the global shared weight connection enhanced the relationship between the front and back, so that we can extract more abstract features in larger context within the context.
2) Decoder
In the decoder layer, we use a recurrent neural network to predict vehicle characters. Long short-term memory (LSTM) [Reference Hochreiter and Schmidhuber14] is used as basic cell:
 $$ S_t = LSTM({H_{t-1}}, S_{t-1})$$
$$ S_t = LSTM({H_{t-1}}, S_{t-1})$$and the probability distribution over the label space is estimated by:
 $$ \widehat{y}_t = softmax({W}S_t),$$
$$ \widehat{y}_t = softmax({W}S_t),$$where W ∈ R o×c, o is LSTM cell size and c is the number of vehicle characters.
We choose the argmax of the k-th output being the k-th character of the VLP and the CTC [Reference Graves and Gomez15] loss is calculated as the objection:
 $$ loss = \displaystyle{1 \over m}\sum_{i}^{m} CTC(DCNN {\rm -}RNN({X}_i), y_i),$$
$$ loss = \displaystyle{1 \over m}\sum_{i}^{m} CTC(DCNN {\rm -}RNN({X}_i), y_i),$$where m is the number of samples and y i is the ground truth vehicle character sequence.
IV. EXPERIMENTS
To evaluate the effectiveness of our proposed model, we conduct experiments on two datasets: Caltech Cars 1999 which is a standard dataset and PingAnCarPL which is collected by our own. The more details about dataset and training settings can be found in next parts.
A) Datasets
A sufficient training dataset is essential to the success of deep neural networks. To train our model, we collected a large VLP dataset which primarily contains Chinese and USA license plate. All stages of training apply to our own dataset, while the test carries on both datasets.
• Caltech Cars 1999 is a standard dataset which consists 126 images of cars rear with 896 × 896 jpg format. The images are taken in the Caltech parking lots, which contain a US license plate with the cluttered background, such as trees, grass, wall, etc.
• PingAnCarPL is a dataset collected by our own from natural scenes. It contains 100 000 images of cars (with 700 × 700 jpg format) including 31 words of provinces in China and two special kinds of VLP. The data are processed into two parts for the different stages, which are used to train the license plate detection model and the license plate character recognition model, respectively.
B) Training
For the license plate detection model, we implement the network based on SSD using Caffe framework. For the license plate recognition model, we perform DCNN-RNN under Torch framework. The training of the two models is independent of each other.
In training the license plate detection phases, we use the original images in PingAnCarPL(a) dataset, shown in Table 1, whose size is normalized to 512 × 512. We extract seven candidate rectangular boxes in each convolution layer, and the aspect ratio of these candidate boxes is {1, 2, 3, 4, 1/2, 1/3, 1/4}. There are five classes: blue plate (general plate), yellow plate (coach car plate), white plate (police car plate), black plate (car plate with foreign elements), green plate (clean energy license plate). The color information of license plate will help to adjust the plate blocks that are detected by license plate detection model. In training the license plate recognition phases, we use the plate blocks that have been corrected by image processing before, shown in Table 2, whose size is normalized to 136 * 36. Batch size is tuned over 128, 256. We tune on two optimization schemes: stochastic gradient descent and Adam [Reference Kingma, Ba and Adam16] with start learning rate lr over {0.1, 0.05}. We employ a decreasing learning rate lr = lr/(10 × epoch) for all layers. Our experiments are carried out on NVIDIA M60 GPU.
Table 1. Statistics of our dataset PingAnCarPL(a). Image is the number of VLP images, Class means the class of license plate.

Table 2. Statistics of our dataset PingAnCarPL(b). Image is the number of VLP blocks corrected before. Kind means the class of VLP which froms 31 Chinese provinces and two special kinds. Chars is the kind of characters in the license plate.

C) Results
The result of the license plate detection model is shown in Table 3. The average mAP rate achieves 97.24%. The mAP of the green plate is lower to other classes, because of a lot less training data. In the field of object detection, mAP represents mean average precision. Mean average precision for a set of queries is the mean of the average precision scores for each query. The results of our license plate recognition model(DCNN-RNN) are visualized in Fig. 5.
Table 3. Our license plate detection model result on PingAnCarPL(a).


Fig. 5. Samples from the PingAnCarPL.
For the whole model, we compare with other license plate recognition algorithms on two datasets. The results on Caltech Cars 1999 and the results on PingAnCarPL are shown in Tables 4 and 5. There is an incredible improvement of performance with our model on Caltech Cars 1999 and PingAnCarPL dataset. As shown in Tables 4 and 5, our method outperforms the two state-of-the-art models by a large margin.
Table 4. Comparison of plate detection results by different methods on Caltech Cars dataset.

Table 5. Comparison of plate detection results by different methods on PingAnCarPL evaluate dataset.

V. CONCLUSION
In this paper, a unified framework is presented for VLP recognition. The DCNN-RNN model is used to encode input images and stacked RNN model is applied to decode deep features to characters. Our method uses DCNN to locate the license plate, after correction using DCNN with gating mechanism it extracts the characteristics of the license plate, which could extract more abstract features in larger context within the context. Finally, leverage RNN to decode the deep features to characters, without character segmentation. Experimental results on PingAnCarPL and Caltech Cars 1999 dataset demonstrate that our proposed framework achieves state-of-the-art result compared to the traditional machine learning methods and former CNN models as shown in Fig. 6.
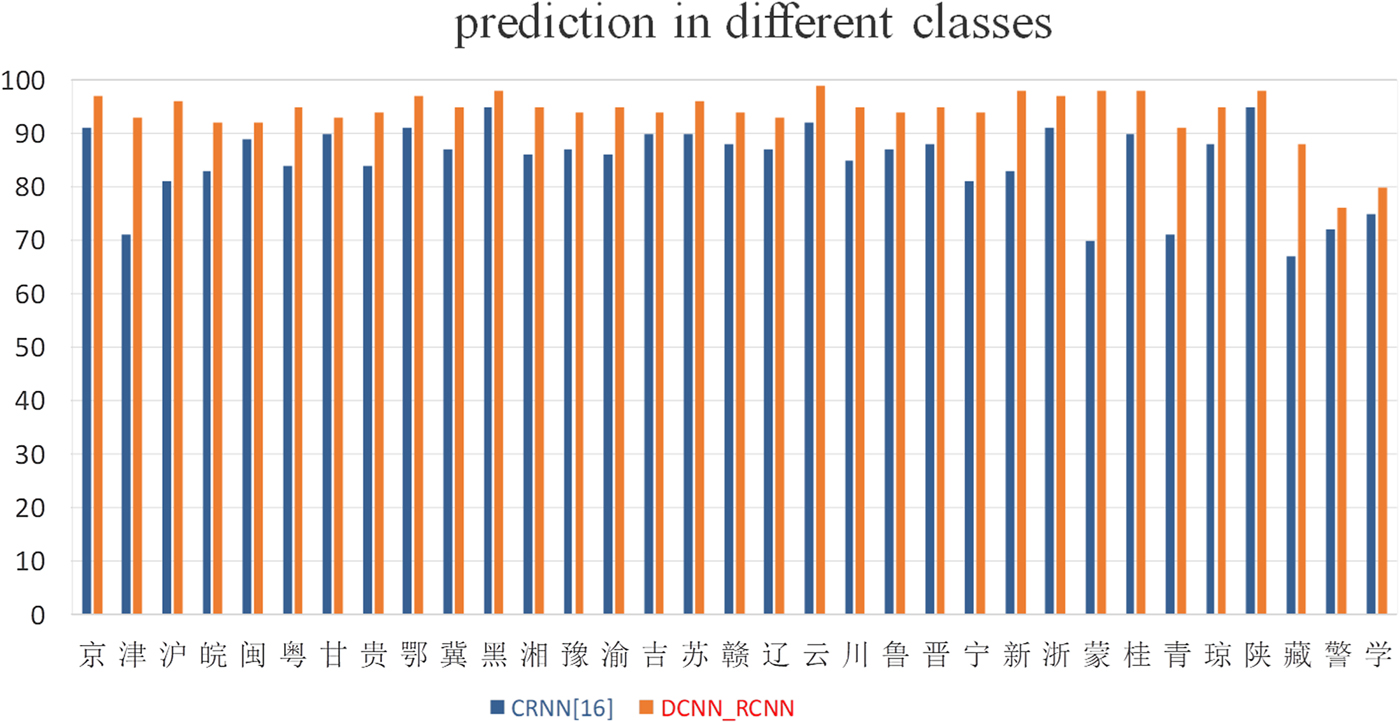
Fig. 6. Our license plate recognition model's precision in different class of PingAnCarPL(b).
Dr. Jianzong Wang is the Deputy Chief Engineer and Senior AI Director at PingAn Technology. He's responsible for worldwide PingAn Technology innovations with respect to Deep Learning, Cloud Computing, Big Data and committed use AI in Financial and Insurance Service like Smart Auto Damage Detection, Smart Outbound Robots, Virtual Reality, Voiceprint Recognition, Animal Face Identification, AI Music Composition, AI Translation, Text to Speech, Automatic Speech Translation and Crowd Sourcing. Dr. Wang is the true innovator who leads three core platforms like Deep Learning Platform, Heterogeneous Computing Platform and Smart Voice Platform in the largest financial service company within China and he is the first man who adopts Nvidia RAPIDS in China. Dr. Wang has been actively involved in numerous social activities. He is a representative of Shenzhen Futian District People's Congress. He is a senior member of the Big Data Expert Committee in China Computer Federation and vice chairman in CCF YOCSEF Shenzhen. He is also a producer of many conferences both in international and domestic.
Ms. Xinhui Liu is a senior algorithm engineer in the Intelligent Vision team of PingAn Technology, focusing on the research of computer vision and medical imaging assisted diagnosis. Graduated from Harbin Institute of Technology, majoring in computer science and technology.
Mr. Aozhi Liu is the leader of the AI Music group of PingAn Technology Deep Learning Team. He's responsible for the research of the fields of AI composition as well as Singing Audio Synthesis. He is an interdisciplinary researcher of computer science and music composition. As a senior data scientist, he is the algorithm designer of the Applet Composer for Everyone. As an artist, Mr. Aozhi Liu was a member of the Nanjing University Orchestra, who was invited to performance in different countries such as the United States, the United Kingdom, Russia, Canada, Germany and South Korea.
Dr. Xiao Jing, China “Thousand Talents Program” Distinguished Expert, is the Chief Scientist of Ping An Insurance (Group) Company of China, LTD. He received his PhD degree from Carnegie Mellon University, and has published over 50 academic papers and 90 granted US patents. Before joining Ping An, he worked as Principal Applied Scientist Lead in Microsoft Corp. and Manager of Algorithm Group in Epson Research and Development, Inc. Dr. Xiao started R&D in artificial intelligence and related fields since 1995, covering a broad range of application areas. He is now leading research and development in AI-related technologies and their applications on finance and healthcare in Ping An Group.










 Open access
Open access