

I. INTRODUCTION
In this paper, we address the problem of checkerboard artifacts in convolutional neural networks (CNNs) [Reference Krizhevsky, Sutskever and Hinton1]. Recently, CNNs have been widely studied in a variety of computer vision tasks such as image classification [Reference He, Zhang, Ren and Sun2,Reference Huang, Liu, Maaten and van der Weinberger3], semantic segmentation [Reference Noh, Hong and Han4,Reference Shelhamer, Long and Darrell5], super-resolution (SR) imaging [Reference Dong, Loy, He and Tang6,Reference Ledig7], and image generation [Reference Radford, Metz and Chintala8], and they have achieved superior performances. However, CNNs often generate periodic artifacts, referred to as checkerboard artifacts, in both of two processes: forward-propagation of upsampling layers and backpropagation of convolutional layers [Reference Odena, Dumoulin and Olah9].
In CNNs, it is well-known that checkerboard artifacts are generated by the operations of deconvolution [Reference Zeiler, Taylor and Fergus10,Reference Vincent and Francesco22,Reference Shi, Caballero, Theis, Huszar, Aitken and Ledig23] and sub-pixel convolution [Reference Shi11] layers. To overcome these artifacts, smoothness constraints [Reference Dosovitskiy12], post-processing [Reference Johnson, Alahi and Li13], initialization schemes [Reference Aitken, Ledig, Theis, Caballero, Wang and Shi14], and different upsampling layer designs [Reference Odena, Dumoulin and Olah9,Reference Gao, Yuan, Wang and Ji15,Reference Wojna16] have been proposed. Most of them cannot avoid checkerboard artifacts perfectly, although they reduce the artifacts. Among them, Odena et al. [Reference Odena, Dumoulin and Olah9] demonstrated that checkerboard artifacts can be perfectly avoided by using resize convolution layers instead of deconvolution ones. However, resize convolution layers cannot be directly applied to upsampling layers such as deconvolution and sub-pixel convolution ones, so this method requires not only a large amount of memory but it also has high computational costs. In addition, it cannot be applied to the backpropagation of convolutional layers.
Checkerboard artifacts have been studied to design linear multirate systems including filter banks and wavelets [Reference Harada, Muramatsu and Kiya17–Reference Iwai, Iwahashi and Kiya20]. In addition, it is well-known that the artifacts are caused by the time-variant property of interpolators in multirate systems, and a condition for avoiding these artifacts has have been given [Reference Harada, Muramatsu and Kiya17–Reference Harada, Muramatu and Kiya19]. However, this condition for linear systems cannot be applied to CNNs due to the non-linearity of CNNs.
In this paper, we extend the conventional avoidance condition for CNNs and apply a proposed structure to typical CNNs to confirm whether the novel structure is effective. Experimental results demonstrate that the proposed structure can perfectly avoid generating checkerboard artifacts caused by both processes, while keeping the excellent properties that CNNs have. As a result, it is confirmed that the proposed structure allows us to offer CNNs without any checkerboard artifacts. This paper is an extension of a conference paper [Reference Sugawara, Shiota and Kiya21].
II. PREPARATION
Checkerboard artifacts in CNNs and work related to checkerboard artifacts are reviewed here.
A) Checkerboard artifacts in CNNs
In CNNs, it is well-known that checkerboard artifacts are caused by two processes: forward-propagation of upsampling layers and backpropagation of convolutional layers. This paper focuses on these two issues in CNNs [Reference Odena, Dumoulin and Olah9,Reference Aitken, Ledig, Theis, Caballero, Wang and Shi14,Reference Sugawara, Shiota and Kiya21].
When CNNs include upsampling layers, there is a possibility that they will generate checkerboard artifacts, which is the first issue, referred to as issue A. Deconvolution [Reference Vincent and Francesco22,Reference Shi, Caballero, Theis, Huszar, Aitken and Ledig23], sub-pixel convolution [Reference Shi11], and resize convolution [Reference Odena, Dumoulin and Olah9] layers are well-known to include upsampling layers, respectively. Deconvolution layers have many names, including fractionally-strided convolutional layer and transposed convolutional layer, as described in [Reference Shi, Caballero, Theis, Huszar, Aitken and Ledig23]. In this paper, the term “Deconvolution” has the same meaning as others.
Checkerboard artifacts are also generated by the backward pass of convolutional layers, which is the second issue, referred to as issue B. We will mainly consider issue A in the following discussion, since issue B is reduced to issue A under some conditions.
B) SR methods using CNNs
SR methods using CNNs are classified into two classes as shown in Fig. 1. Interpolation-based methods [Reference Dong, Loy, He and Tang6,Reference Dong, Loy, He and Tang24–Reference Tai, Yang and Liu27], referred to as “class A,” do not generate any checkerboard artifacts in CNNs, due to the use of an interpolated image as an input to a network. In other words, CNNs in this class do not have any upsampling layers.
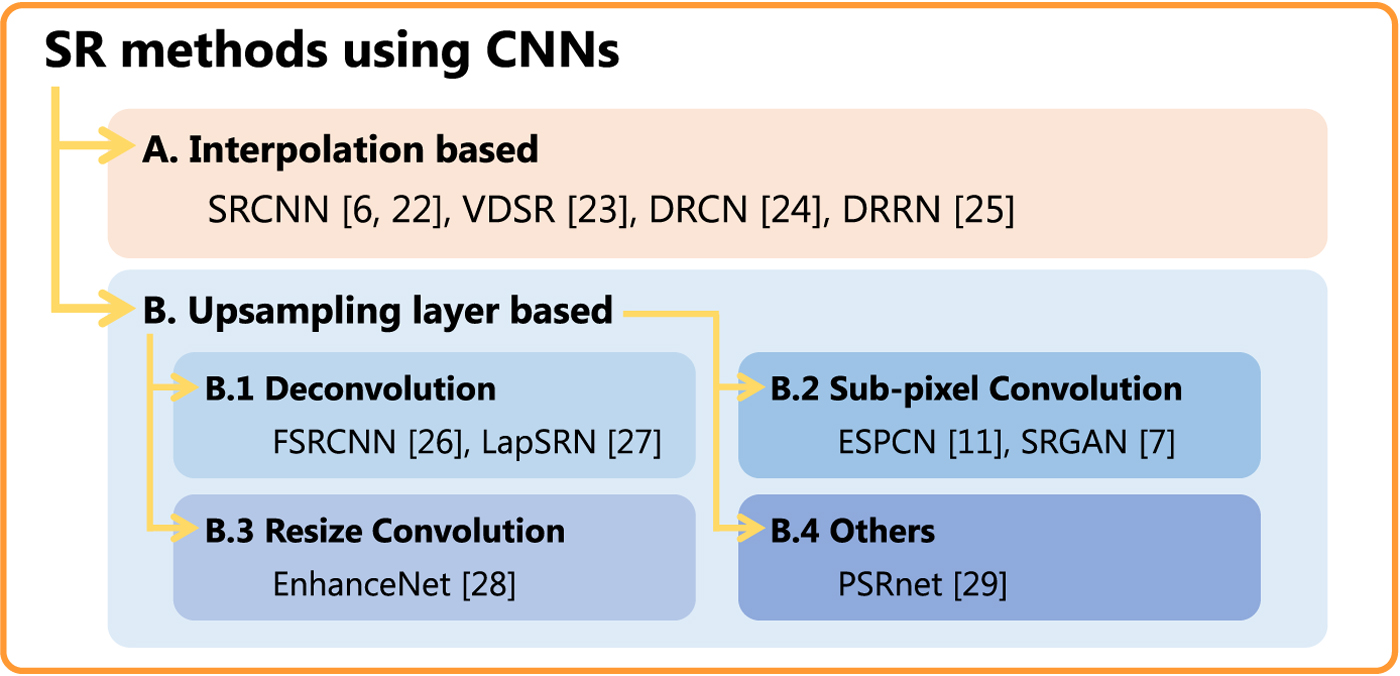
Fig. 1. Classification of SR methods using CNNs. There is a possibility that SR methods will generate checkerboard artifacts, when CNNs include upsampling layers.
When CNNs include upsampling layers, there is a possibility that CNNs will generate checkerboard artifacts. This class, called “class B” in this paper, has provided numerous excellent SR methods [Reference Ledig7,Reference Shi11,Reference Dong, Loy and Tang28–Reference Sugawara, Shiota and Kiya33] that can be executed faster than those in class A. Class B is also classified into a number of sub-classes according to the type of upsampling layer. This paper focuses on class B.
CNNs are illustrated in Fig. 2 for an SR problem, as in [Reference Shi11], where the CNNs consist of two convolutional layers and one upsampling layer. I LR and  $f_c^{(l)}(I_{LR})$ are a low-resolution (LR) image and c-th channel feature map at layer l, and f(I LR) is an output of the network. The two layers have learnable weights, biases, and ReLU as an activation function, where the weight at layer l has K l × K l as a spatial size and N l as the number of feature maps.
$f_c^{(l)}(I_{LR})$ are a low-resolution (LR) image and c-th channel feature map at layer l, and f(I LR) is an output of the network. The two layers have learnable weights, biases, and ReLU as an activation function, where the weight at layer l has K l × K l as a spatial size and N l as the number of feature maps.
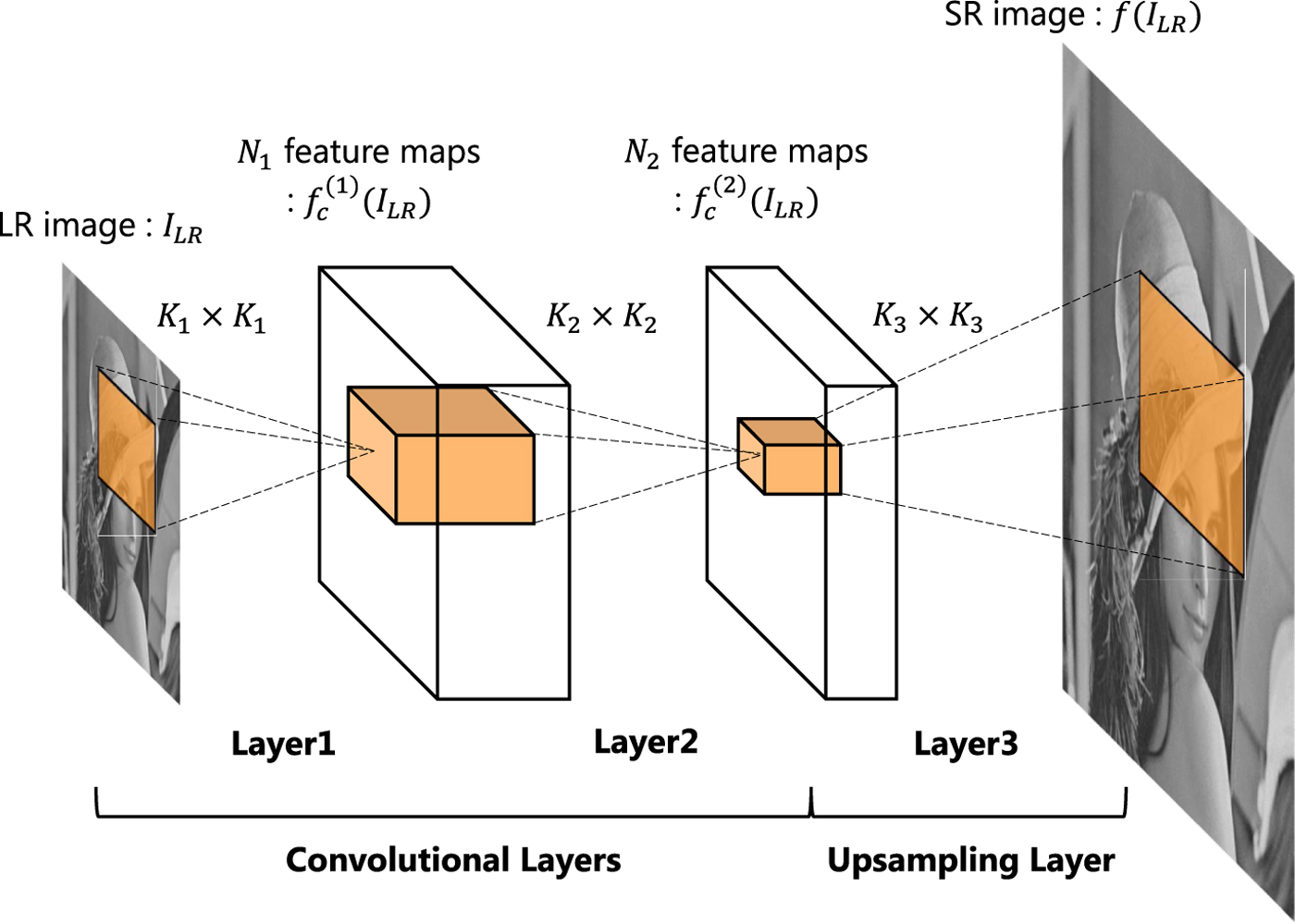
Fig. 2. CNNs with an upsampling Layer.
There are numerous algorithms for computing upsampling layers, such as deconvolution [Reference Vincent and Francesco22,Reference Shi, Caballero, Theis, Huszar, Aitken and Ledig23], sub-pixel convolution [Reference Shi11], and resize convolution [Reference Odena, Dumoulin and Olah9] ones, which are widely used in typical CNNs. In addition, recently, some excellent SR methods have been proposed [Reference Zhang, Zuo and Zhang31,Reference Zhang, Li, Li, Wang, Zhong and Fu34].
C) Works related to checkerboard artifacts
Checkerboard artifacts have been discussed by researchers for designing multirate systems including filter banks and wavelets [Reference Harada, Muramatsu and Kiya17–Reference Iwai, Iwahashi and Kiya20]. However, most research has been limited to cases of using linear systems, so it cannot be directly applied to CNNs due to the non-linearity of CNNs. Some pieces of works related to checkerboard artifacts for linear systems are summarized, here.
It is known that linear interpolators, which consist of up-samplers and linear time-invariant systems, cause checkerboard artifacts due to their periodic time-variant property [Reference Harada, Muramatsu and Kiya17–Reference Harada, Muramatu and Kiya19]. Figure 3 illustrates a linear interpolator with an up-sampler ↑ U and a linear time-invariant system H(z), where positive integer U is an upscaling factor and H(z) is the z transformation of an impulse response. The interpolator in Fig. 3(a) can be equivalently represented as a polyphase structure as shown in Fig. 3(b). The relationship between H(z) and R i(z) is given by
 $$H(z) = \sum_{i=1}^{U}R_{i}(z^{U})z^{-(U-i)},$$
$$H(z) = \sum_{i=1}^{U}R_{i}(z^{U})z^{-(U-i)},$$where R i(z) is often referred to as a polyphase filter of the filter H(z).

Fig. 3. Linear interpolators with upscaling factor U. (a) General structure, (b) polyphase structure.
The necessary and sufficient condition for avoiding checkerboard artifacts in the system is shown as
 $$R_{1}(1) = R_{2}(1) = \cdots = R_{U}(1) = G.$$
$$R_{1}(1) = R_{2}(1) = \cdots = R_{U}(1) = G.$$This condition means that all polyphase filters have the same DC value, i.e. a constant G [Reference Harada, Muramatsu and Kiya17–Reference Harada, Muramatu and Kiya19]. Note that each DC value R i(1) corresponds to the steady-state value of the unit step response in each polyphase filter R i(z). In addition, the condition of equation (2) can be also expressed as
 $$ H(z) = P(z)H_0(z),$$
$$ H(z) = P(z)H_0(z),$$where,
 $$ H_0(z) = \sum_{i=0}^{U-1} z^{-i},$$
$$ H_0(z) = \sum_{i=0}^{U-1} z^{-i},$$and H 0(z) and P(z) are an interpolation kernel of the zero-order hold with factor U and a time-invariant filter, respectively. Therefore, a linear interpolator with factor U does not generate any checkerboard artifacts, when H(z) includes H 0(z). In the case without checkerboard artifacts, the step response of the linear system has a steady-state value G as shown in Fig. 3(a). Meanwhile, the step response of the linear system has a periodic steady-state signal with the period of U, such as R 1(1), …, R U(1), if equation (3) is not satisfied.
To intermediate between signal processing field and computer vision one, the correspondence relation of some technical terms is summarized in Table 1.
Table 1. Correspondence relation of technical terms in signal processing and computer vision

III. PROPOSED METHOD
CNNs are non-linear systems, so conventional work related to checkerboard artifacts cannot be directly applied to CNNs. A condition for avoiding checkerboard artifacts in CNNs is proposed here.
A) CNNs with upsampling layers
We focus on upsampling layers in CNNs, for which there are numerous algorithms such as deconvolution [Reference Vincent and Francesco22,Reference Shi, Caballero, Theis, Huszar, Aitken and Ledig23], sub-pixel convolution [Reference Shi11], and resize convolution [Reference Odena, Dumoulin and Olah9]. For simplicity, one-dimensional CNNs will be considered in the following discussion.
It is well-known that deconvolution layers with non-unit strides cause checkerboard artifacts [Reference Odena, Dumoulin and Olah9]. Figure 4 illustrates a system representation of deconvolution layers [Reference Vincent and Francesco22,Reference Shi, Caballero, Theis, Huszar, Aitken and Ledig23] that consist of interpolators, where H c and b are a weight and a bias in which c is a channel index, respectively. The deconvolution layer in Fig. 4(a) can be equivalently represented as a polyphase structure in Fig. 4(b), where R c,n is a polyphase filter of the filter H c in which n is a filter index. This is a non-linear system due to the bias b.

Fig. 4. Deconvolution layer [Reference Vincent and Francesco22,Reference Shi, Caballero, Theis, Huszar, Aitken and Ledig23]. (a) General structure, (b) Polyphase structure.
Figure 5 illustrates sub-pixel convolution layers [Reference Shi11], where R c,n and b n are a weight and a bias, and  $f_n^{\prime }(I_{LR})$ is an intermediate feature map in channel n. Comparing Fig. 4(b) with Fig. 5, we can see that the polyphase structure in Fig. 4(b) is a special case of the sub-pixel convolution layers in Fig. 5. In other words, Fig. 5 is reduced to Fig. 4(b), when satisfying b 1 = b 2 = · · · = b U. Therefore, we will focus on sub-pixel convolution layers as a general case of upsampling layers to discuss checkerboard artifacts in CNNs.
$f_n^{\prime }(I_{LR})$ is an intermediate feature map in channel n. Comparing Fig. 4(b) with Fig. 5, we can see that the polyphase structure in Fig. 4(b) is a special case of the sub-pixel convolution layers in Fig. 5. In other words, Fig. 5 is reduced to Fig. 4(b), when satisfying b 1 = b 2 = · · · = b U. Therefore, we will focus on sub-pixel convolution layers as a general case of upsampling layers to discuss checkerboard artifacts in CNNs.
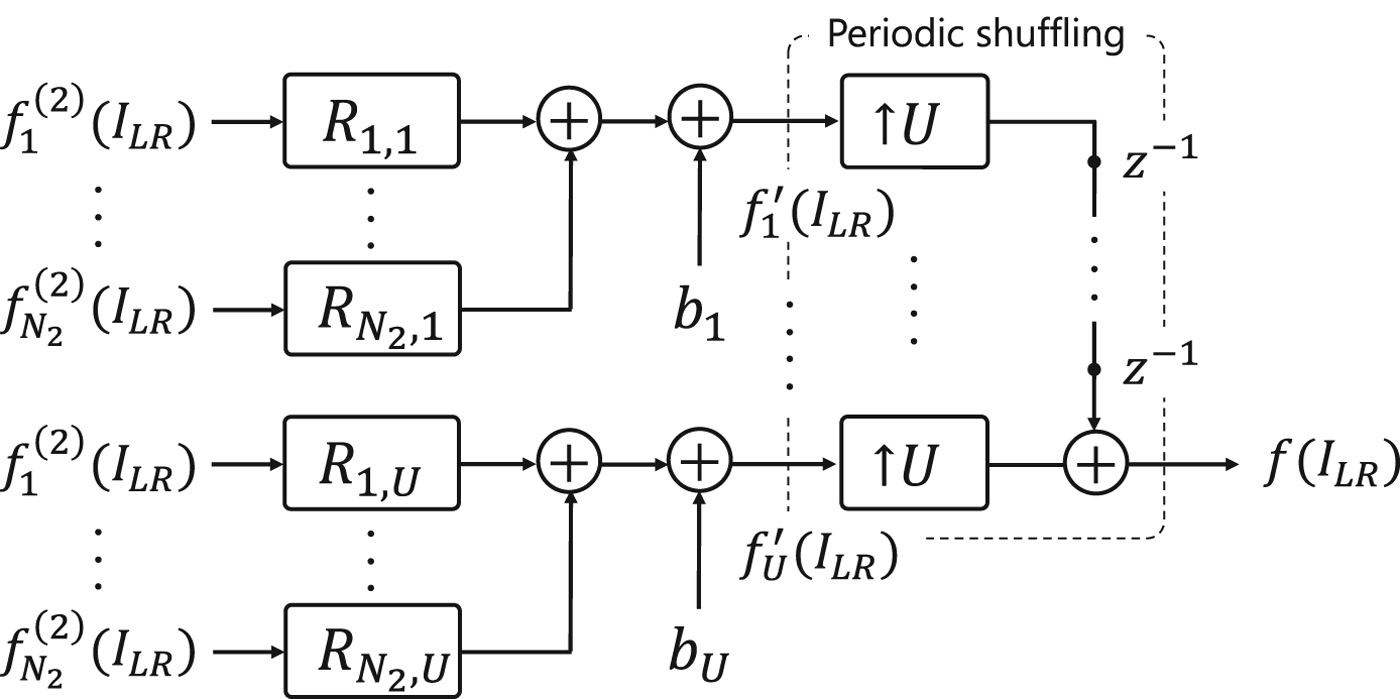
Fig. 5. Sub-pixel convolution layer [Reference Shi11].
B) Checkerboard artifacts in upsampling layers
Let us consider the unit step response in CNNs. In Fig. 2, when the input I LR is the unit step signal I step, the steady-state value of the c-th channel feature map in layer 2 is given as
 $$ \hat{f}_c^{(2)}(I_{step}) = A_c,$$
$$ \hat{f}_c^{(2)}(I_{step}) = A_c,$$where A c is a positive constant value that is decided by filters, biases, and ReLU. Therefore, from Fig. 5, the steady-state value of the n-th channel intermediate feature map is given by, for sub-pixel convolution layers,
 $$ \hat{f}_n^{\prime}(I_{step}) = \sum_{c=1}^{N_2} \, A_c \overline{R}_{c,n} + b_n,$$
$$ \hat{f}_n^{\prime}(I_{step}) = \sum_{c=1}^{N_2} \, A_c \overline{R}_{c,n} + b_n,$$
where  $\overline {R}_{c,n}$ is the DC value of the filter R c,n.
$\overline {R}_{c,n}$ is the DC value of the filter R c,n.
Generally, the condition, which corresponds to equation (2) for linear multirate systems,
 $$ \hat{f}_1^{\prime}(I_{step}) = \hat{f}_2^{\prime}(I_{step}) = \cdots = \hat{f}_U^{\prime}(I_{step})$$
$$ \hat{f}_1^{\prime}(I_{step}) = \hat{f}_2^{\prime}(I_{step}) = \cdots = \hat{f}_U^{\prime}(I_{step})$$is not satisfied, so the unit step response f(I step) has a periodic steady-state signal with the period of U. To avoid checkerboard artifacts, equation (7) has to be satisfied, as well as for linear multirate systems.
C) Upsampling layers without checkerboard artifacts
To avoid checkerboard artifacts, CNNs must have the non-periodic steady-state value in the unit step response. From equations (6), equation (7) is satisfied if
 $$ \overline{R}_{c,1} = \overline{R}_{c,2} = \cdots = \overline{R}_{c,U}, \, c = 1, 2, \ldots, N_{2}$$
$$ \overline{R}_{c,1} = \overline{R}_{c,2} = \cdots = \overline{R}_{c,U}, \, c = 1, 2, \ldots, N_{2}$$ $$ b_{1} = b_{2} = \cdots = b_{U}.$$
$$ b_{1} = b_{2} = \cdots = b_{U}.$$Note that, in this case,
 $$ \hat{f}_1^{\prime}(K \cdot I_{step}) = \hat{f}_2^{\prime}(K \cdot I_{step}) = \cdots = \hat{f}_U^{\prime}(K \cdot I_{step})$$
$$ \hat{f}_1^{\prime}(K \cdot I_{step}) = \hat{f}_2^{\prime}(K \cdot I_{step}) = \cdots = \hat{f}_U^{\prime}(K \cdot I_{step})$$is also satisfied, where K is an arbitrary constant value. However, even when each filter H c in Fig. 5 satisfies equation (2) or equation (3), equation (9) is not met, but equation (8) is met. Both equations, i.e., equations (8 and 9) have to be met to avoid checkerboard artifacts in CNNs. Therefore, we have to find a novel way of avoiding checkerboard artifacts in CNNs. Note that equations (5) and (7) correspond to values in case that the input I LR is the unit step I step. Therefore, other general inputs, the output feature map would not be the same even when equations (5) and (7) are met.
In this paper, we propose adding the kernel of the zero-order hold with factor U, i.e., H 0 in equation (4), after upsampling layers, as shown in Fig. 6. In this structure, the unit-step response outputted from H 0 have constant value as the steady state values, even when an arbitrary periodic signal with a period of U is inputted to H 0. As a result, Fig. 6 can satisfy equation (7). In other words, the steady-state values of the step response are not periodic in this case.
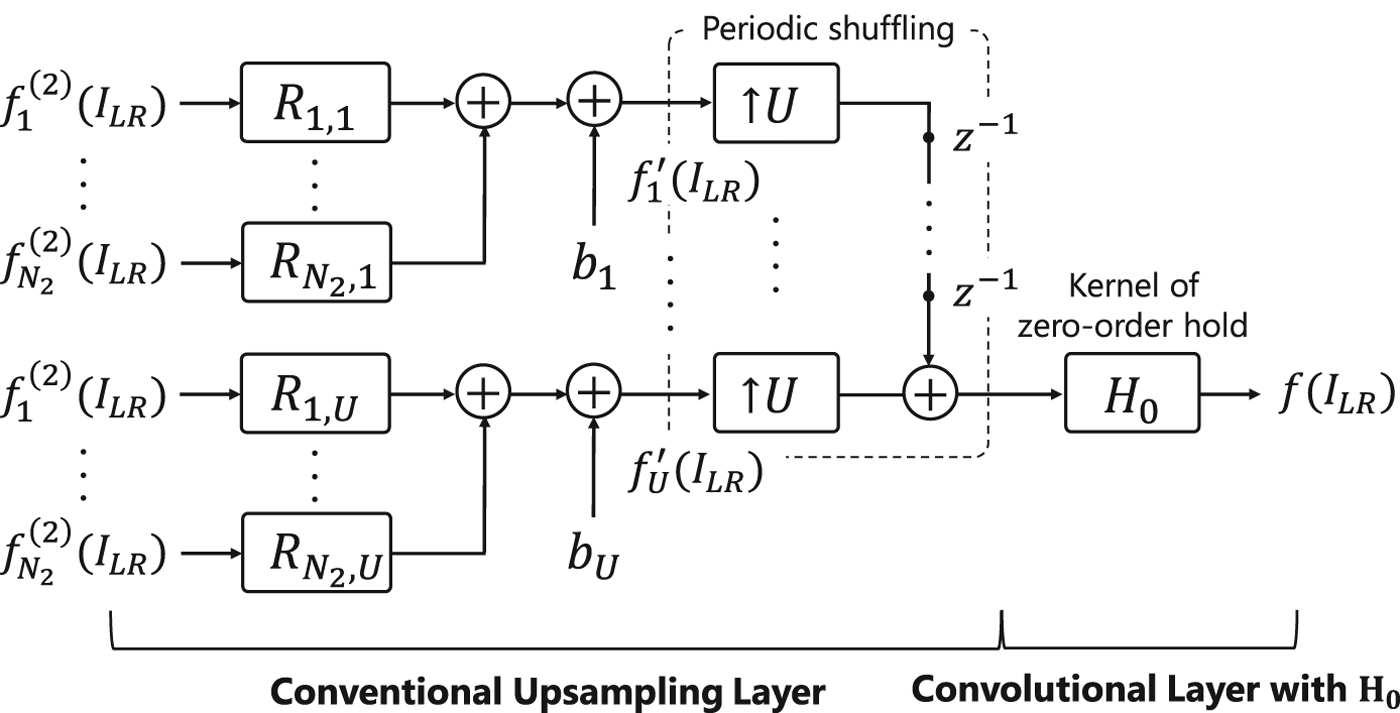
Fig. 6. Proposed upsampling layer structure without checkerboard artifacts. Kernel of zero-order hold with factor U is added after upsampling layers.
The difference between the conventional upsampling layers and the proposed structure is whether the structure has H 0 forcibly inserted for avoiding checkerboard artifacts or not. The operation of sub-pixel convolution and deconvolution layers can be interpreted as a combination of upsampling and convolution, where upsampling corresponds to the operation that is to insert (U − 1) zeros between sample values. The conventional upsampling layers do not include H 0 generally unless forcibly inserting H 0 into convolution, so checkerboard artifacts are generated.
There are three approaches to using H 0 in CNNs that differ in terms of how CNNs are trained as follows.
1) Training CNNs without H 0
The first approach for avoiding checkerboard artifacts, called “approach 1,” is to add H 0 to CNNs after training the CNNs. This approach allows us to perfectly avoid checkerboard artifacts generated by a pre-trained model.
2) Training CNNs with H 0
In approach 2, H 0 is added as a convolution layer after the upsampling layer shown in Fig. 6, and then, the CNNs with H 0 are trained. This approach also allows us to perfectly avoid checkerboard artifacts as well as approach 1. Moreover, this approach generally provides higher quality images than those of approach 1.
3) Training CNNs with H 0 inside upsampling layers
Approach 3 is applicable only to deconvolution layers, but approaches 1 and 2 can be used for both deconvolution and sub-pixel convolution layers. Deconvolution layers always satisfy equation (9), so equation (8) only has to be considered. Therefore, CNNs do not generate any checkerboard artifacts when each filter H c in Fig. 5 satisfies equation (3). In approach 3, checkerboard artifacts are avoided by convolving each filter H c with the kernel H 0 inside upsampling layers.
D) Checkerboard artifacts in gradients
It is well-known that checkerboard artifacts are also generated in gradients of convolutional layers [Reference Odena, Dumoulin and Olah9] since the operations of deconvolution layers are carried out on the backward pass to compute the gradients. Therefore, both approaches 2 and 3 can avoid checkerboard artifacts as well as for deconvolution layers. Note that, for approach 2, we have to add the kernel of the zero-order hold before convolutional layers to avoid checkerboard artifacts on the backward pass.
It is also well-known that max-pooling layers cause high-frequency artifacts in gradients [Reference Odena, Dumoulin and Olah9]. However, these artifacts are generally different from checkerboard artifacts, so this paper does not consider these high-frequency artifacts.
IV. EXPERIMENTS AND RESULTS
The proposed structure without checkerboard artifacts was applied to typical CNNs to demonstrate its effectiveness. In the experiments, two tasks, SR imaging and image classification, were carried out.
A) Super-resolution
The proposed structure without checkerboard artifacts was applied to the SR methods using deconvolution and sub-pixel convolution layers. The experiments with CNNs were carried out under two loss functions: mean squared error (MSE) and perceptual loss.
1) Datasets for training and testing
We employed 91-image set from Yang et al. [Reference Yang, Wright, Huang and Ma35] as our training dataset. In addition, the same data augmentation (rotation and downscaling) as in [Reference Dong, Loy and Tang28] was used. As a result, a training dataset consisting of 1820 images was created for our experiments. In addition, we used two datasets, Set5 [Reference Bevilacqua, Roumy, Guillemot and Alberi-Morel36] and Set14 [Reference Zeyde, Elad and Protter37], which are often used for benchmarking, as test datasets.
To prepare a training set, we first downscaled ground truth images I HR with a bicubic kernel to create LR images I LR, where the factor U=4 was used. The ground truth images I HR were cropped into 72 × 72 pixel patches, and the LR images were also cropped 18 × 18 pixel ones, where the total number of extracted patches was 8,000. In the experiments, the luminance channel (Y) of images was used for MSE loss, and three channels (RGB) of images were used for perceptual loss.
2) Training details
Table 2 illustrates the CNNs used in the experiments, which were carried out on the basis of the CNNs in Fig. 2. For the other two layers in Fig. 2, we set (K 1, N 1) = (5, 64), (K 2, N 2) = (3, 32) as in [Reference Shi11]. In addition, all networks were trained to minimize the MSE  ${1}/{2} \Vert I_{HR}-f(I_{LR}) \Vert^{2}$ and the perceptual loss 1/2‖ϕ(I HR) − ϕ(f(I LR))‖2 averaged over the training set, where ϕ calculates feature maps at the fourth layer of a pre-trained VGG-16 model as in [Reference Johnson, Alahi and Li13]. Note that
${1}/{2} \Vert I_{HR}-f(I_{LR}) \Vert^{2}$ and the perceptual loss 1/2‖ϕ(I HR) − ϕ(f(I LR))‖2 averaged over the training set, where ϕ calculates feature maps at the fourth layer of a pre-trained VGG-16 model as in [Reference Johnson, Alahi and Li13]. Note that  $\hbox {Deconv}+{\rm H}_0$,
$\hbox {Deconv}+{\rm H}_0$,  $\hbox {Deconv}+{\rm H}_0$ (Ap. 3), and
$\hbox {Deconv}+{\rm H}_0$ (Ap. 3), and  $\hbox {Sub-pixel}+ {\rm H}_0$ in Table 2 use the proposed structure.
$\hbox {Sub-pixel}+ {\rm H}_0$ in Table 2 use the proposed structure.
Table 2. CNNs used for super-resolution tasks

For training, Adam [Reference Kingma and Ba38] with β 1 = 0.9, β 2 = 0.999 was employed as an optimizer. In addition, we set the batch size to 4 and the learning rate to 0.0001. The weights were initialized with the method described in He et al. [Reference He, Zhang, Ren and Sun39]. We trained all models for 200 K iterations. All models were implemented by using the TensorFlow framework [Reference Abadi, Agarwal and Barham40].
3) Experimental results
Figure 7 shows examples of SR images generated under perceptual loss, where mean PSNR values for each dataset are also illustrated. In this figure, (b) and (f) include checkerboard artifacts, and (c)–(e), (g)–(i) do not. Moreover, it is shown that the quality of SR images was significantly improved by avoiding the artifacts. Approaches 2 and 3 also provided better quality images than approach 1. Note that ResizeConv did not generate any artifacts, because it uses a pre-defined interpolation like in [Reference Dong, Loy, He and Tang6]. In Fig. 8, the usefulness of the proposed avoidance condition is demonstrated. It was confirmed that CNNs generated checkerboard artifacts under the conventional condition unless CNNs satisfied the proposed condition. Figure 9 shows other examples of SR images. In Fig. 9, the trend is almost the same as that in Fig. 7.

Fig. 7. Experimental results of super-resolution imaging under perceptual loss [PSNR(dB)]. (b) and (f) include checkerboard artifacts, and (c), (d), (e), (g), (h), and (i) do not.

Fig. 8. Super-resolution imaging using perceptual loss under various avoidance conditions [PSNR(dB)] (sub-pixel convolution).

Fig. 9. Super-resolution examples of “Baboon” and “Monarch” under perceptual loss. PSNR values are illustrated under each sub-figure. (b), (g), (l), and (q) include checkerboard artifacts, and other examples do not.
Table 3 illustrates the average execution time when each CNNs were run 10 times for some images in Set14. Resize-Conv has the highest computational cost in this table, although it did not generate any checkerboard artifacts. From this table, the proposed approaches have much lower computational costs than with resize convolution layers. Note that the results were obtained on a PC with a 3.30-GHz CPU and a main memory size of 16 GB.
Table 3. Execution time of super-resolution (sec)

4) Loss functions
It is well-known that perceptual loss results in sharper SR images despite lower PSNR values [Reference Johnson, Alahi and Li13,Reference Sajjadi, Schölkopf and Hirsch30], and it generates checkerboard artifacts more frequently than under MSE loss as described in [Reference Odena, Dumoulin and Olah9,Reference Johnson, Alahi and Li13,Reference Aitken, Ledig, Theis, Caballero, Wang and Shi14,Reference Blau and Michaeli41]. In Fig. 10, which demonstrates artifacts under MSE loss, (b) and (f) also include checkerboard artifacts as well as in Fig. 7, although the distortion is not that large, compared with under perceptual loss. There is a possibility that any loss function causes checkerboard artifacts, but the magnitude of checkerboard artifacts depends on a class of loss functions used for training networks. The proposed avoidance condition is useful under any loss function.

Fig. 10. Experimental results of super-resolution under MSE loss [PSNR(dB)]. (b) and (f) also include checkerboard artifacts as well as in Fig. 7, although the distortion was not that large, compared with under perceptual loss.
B) Image classification
Next, the proposed structure without checkerboard artifacts was applied to CNNs-based image classification models.
1) Datasets for training and testing
We employed two datasets, CIFAR10 and CIFAR100, which contain 32 × 32 pixel color images and consist of 50 000 training images and 10 000 test images [Reference Krizhevsky and Hinton42]. In addition, standard data augmentation (mirroring and shifting) was used. For preprocessing, the images were normalized by using the channel means and standard deviations.
2) Training details
Table 4 illustrates the CNNs used in the experiments, which were run on the basis of ResNet-110 [Reference He, Zhang, Ren and Sun2]. Note that the projection shortcut [Reference He, Zhang, Ren and Sun2] was used only for increasing the number of dimensions, and all convolutional layers with a stride of 2 in ResNet-110 were replaced by downsampling layers in Table 4.
Table 4. CNNs used for image classification tasks

All of the networks were trained by using stochastic gradient descent with momentum for 300 epochs. The learning rate was initially set to 0.1, and decreased by a factor of 10 at 150 and 225 epochs. The weights were initialized by the method introduced in [Reference He, Zhang, Ren and Sun39]. We used a weight decay of 0.0001, a momentum of 0.9, and a batch size of 64.
3) Experimental results
Figure 11 shows examples of gradients, which were computed on the backward pass of the first downsampling layer, for each CNN. In this figure, (a) includes checkerboard artifacts, and (b) and (c) do not.

Fig. 11. Gradients computed in first downsampling layer. (a) includes checkerboard artifacts, and (b) and (c) do not.
The results for CIFAR10 and CIFAR100 are illustrated in Table 5, where “+” indicates the use of the standard data augmentation. It is shown that approach 3 performed the best in this table. This trend was almost the same for the SR tasks.
Table 5. Error rates on CIFAR10, CIFAR100 datasets (%)

V. CONCLUSION
We addressed a condition for avoiding checkerboard artifacts in CNNs. A novel structure without any checkerboard artifacts was proposed by extending the conventional condition for linear systems to CNNs with non-linearity. The experimental results demonstrated that the proposed structure can perfectly avoid generating checkerboard artifacts caused by both of two processes, forward-propagation of upsampling layers and backpropagation of convolutional layers, while maintaining the excellent properties that CNNs have. As a result, the proposed structure allows us to offer CNNs without any checkerboard artifacts.
Yusuke Sugawara received his B.Eng degree from Takushoku University, Japan in 2016, and his M.Eng degree from Tokyo Metropolitan University, Japan in 2018. He graduated from Tokyo Metropolitan University, Japan in 2018. His research interests include image processing.
Sayaka Shiota received B.E., M.E., and Ph.D. degrees in intelligence and computer science, engineering, and engineering simulation from the Nagoya Institute of Technology, Nagoya, Japan in 2007, 2009, and 2012, respectively. From February 2013 to March 2014, she worked as a Project Assistant Professor at the Institute of Statistics Mathematics. In April of 2014, she joined Tokyo Metropolitan University as an Assistant Professor. Her research interests include statistical speech recognition and speaker verification. She is a member of the Acoustical Society of Japan (ASJ), the IEICE, the ISCA, APSIPA, and the IEEE.
Hitoshi Kiya Hitoshi Kiya received his B.E and M.E. degrees from Nagaoka University of Technology in 1980 and 1982, respectively, and his Dr. Eng. degree from Tokyo Metropolitan University in 1987. In 1982, he joined Tokyo Metropolitan University, where he became Full Professor in 2000. He is a Fellow of IEEE, IEICE, and ITE. He currently serves as President of APSIPA, and he served as Inaugural Vice President (Technical Activities) of APSIPA from 2009 to 2013 and Regional Director-at-Large for Region 10 of the IEEE Signal Processing Society from 2016 to 2017. He was Editorial Board Member of eight journals, including IEEE Trans. on Signal Processing, Image Processing, and Information Forensics and Security, Chair of two technical committees and Member of nine technical committees including APSIPA Image, Video, and Multimedia TC, and IEEE Information Forensics and Security TC. He has received numerous awards, including six best paper awards.

















 Open access
Open access