



An important question within the field of second language (L2) acquisition concerns how learners connect morphosyntactic forms (cues) to their meanings and come to process them during online sentence comprehension. Insights from VanPatten’s Input Processing model (e.g., VanPatten, Reference VanPatten, VanPatten and Williams2015b) and its instructional application, processing instruction (PI) (e.g., VanPatten, Reference VanPatten2004; Wong, Reference Wong and VanPatten2004) suggest that the acquisition of morphosyntactic forms and the processing mechanisms needed to use these forms online is hindered by L2 learners’ reliance on lexical-semantic or word order cues during comprehension (see also Ellis & Sagarra, Reference Ellis and Sagarra2010). While research on (PI) has shown that it helps learners process morphosyntactic forms more accurately, much previous research has relied primarily on offline measures, which may not tap implicit knowledge and do not provide a moment-by-moment window into learners’ processing behaviors. Recent research (e.g., Benati, Reference Benati2020a, Reference Benati2020c; Lee & Doherty, Reference Lee and Doherty2019; Wong & Ito, Reference Wong and Ito2018; see Benati, Reference Benati2020b) has begun to investigate the effects of PI on learners’ processing system using online measures such as eye-tracking and self-paced reading (SPR), which is necessary to make strong claims about PI’s impact on L2 learners’ processing strategies. These studies have, however, used varying approaches and produced mixed results. The present study uses a combination of offline and an online measure (an SPR task) to investigate the effects of PI on the acquisition of accusative case markers in German, focusing on how PI changes learners’ tendency to use these forms while processing sentences online.
Background and motivation
Input processing and L2 sentence processing
VanPatten’s Input Processing model (VanPatten, Reference VanPatten, VanPatten and Williams2015b) consists of a set of principles and their corollaries and provides a psycholinguistic account of the mechanisms that L2 learners use to process input. The backbone of the Input Processing model is the Primacy of Meaning and the Availability of Resources principles (see VanPatten, Reference VanPatten2004, Reference VanPatten2015a), which explain that learners primarily attend to meaning when processing input, and learners only process input for grammatical form if they have not depleted cognitive resources while processing it for meaning.
Given the primacy of meaning and limits on cognitive resources, the remaining principles of the Input Processing model specify the strategies used to filter input. One of the most important principles—and the focus of the present study—the First Noun Principle (FNP), states that “learners tend to interpret the first (pro)noun they encounter in an utterance as the subject” (VanPatten et al., Reference VanPatten, Collopy, Price, Borst and Qualin2013, p. 508; see Jackson, Reference Jackson2007; LoCoco, Reference LoCoco, VanPatten, Dvorak and Lee1987; VanPatten, Reference VanPatten1984).Footnote 1 For example, German word order is canonically subject-verb-object (SVO), but the use of case marking on articles or pronouns also allows for object-verb-subject (OVS). When processing OVS sentences, learners often fail to recognize that case-marked articles or pronouns signal OVS word order, and consequently, they often misinterpret OVS sentences like (2).


Additional subprinciples to the FNP state that L2 learners may also rely on lexical-semantic information like animacy, plausibility, and probability (Jackson, Reference Jackson2007), as well as contextual information (VanPatten & Houston, Reference VanPatten and Houston1998, see VanPatten, Reference VanPatten2015a).
It should be noted that VanPatten’s Input Processing model is broadly consistent with research in L2 sentence processing and reflects the findings that L2 learners tend to favor the use of lexical-semantic information (e.g., Cameron, Reference Cameron2011; Sagarra, Reference Sagarra and Z.2007) and are slow to integrate morphosyntactic information (Hopp, Reference Hopp2006; Jackson, Reference Jackson2008; Keating, Reference Keating2009), especially when cognitive resources are strained (e.g., Keating, Reference Keating2009; McDonald, Reference McDonald2006; see Juffs & Harrington, Reference Juffs and Harrington2011). However, the Input Processing model is specifically concerned with how (lower proficiency) learners initially connect linguistic forms to their meaning; thus, it does not describe processing among high proficiency learners, who have been shown to acquire (morpho)syntactic structures, compute full syntactic parses online, and build representations incrementally (e.g., Hopp, Reference Hopp2006, Reference Hopp2010; Jackson, Reference Jackson2008; Jackson & Dussias, Reference Jackson and Dussias2009; Jackson & Roberts, Reference Jackson and Roberts2010; Keating, Reference Keating2009; Pliatsikas & Marinis, Reference Pliatsikas and Marinis2012; Rossi et al., Reference Rossi, Gugler, Friederici and Hahne2006; Trenkic et al., Reference Trenkic, Mirkovic and Altmann2013; Witzel & Witzel, Reference Witzel and Witzel2012). One important question, however, is how learners transition from an overreliance on lexical-semantic information to processing (morpho)syntactic information in real time, and, relevant to the present study, whether instructional methods like VanPatten’s (Reference VanPatten2004) PI can facilitate this sort of development.
Processing instruction
The instructional application of VanPatten’s Input Processing model is known as PI. Using the principles laid out in the model, PI seeks to identify why a target cue is often not connected to its meaning (i.e., its “processing problem”)—e.g., due to reliance on a first-noun strategy. In Structured Input (SI) activities, the input is manipulated so that learners must use the target cue to understand the input and complete a task (Wong, Reference Wong and VanPatten2004). For example, in referential SI activities for the target form in the present study, German accusative case markers, participants typically listen to a mixture of SVO and OVS sentences and then select a picture that matches their interpretation of the sentence (see e.g., Henry et al., Reference Henry, Culman and VanPatten2009). They then receive feedback telling them whether they processed the sentence correctly. Crucially, the input used in this picture-selection task does not contain any lexical-semantic cues (e.g., animacy), plausibility information, or context clues that learners can use to understand the sentences, and thus, they must attend to the target form. In this way, PI is a task-essential instructional intervention.
PI was first investigated by VanPatten and Cadierno (Reference VanPatten and Cadierno1993), who trained learners on clitic object pronouns and OVS word order in L2 Spanish and found that, though PI only trained comprehension of the target form, PI led to both increased comprehension and production of the target form. They therefore concluded that PI led to changes in learners’ underlying competence. Since this seminal study, many studies have replicated this basic pattern of results, showing that PI leads to increases in both comprehension and production and is effective when compared with traditional output-based instruction (e.g,. Benati, Reference Benati2001; Cadierno, Reference Cadierno1995; Cheng, Reference Cheng2002; Collentine, Reference Collentine1998; Marsden & Chen, Reference Marsden and Chen2011) or a variety of other instructional methods (Benati, Reference Benati2005; Farley, Reference Farley2001; Kasprowicz & Marsden, Reference Kasprowicz and Marsden2017; Keating & Farley, Reference Keating and Farley2008; Marsden, Reference Marsden2006; Qin, Reference Qin2008; VanPatten et al., Reference VanPatten, Inclezan, Salazar and Farley2009). Further research has explored the role of explicit information (EI) in PI, finding that SI is sufficient to cause an increased knowledge of the target form (Benati, Reference Benati and VanPatten2004; VanPatten & Oikkenon, Reference VanPatten and Oikkenon1996), but that EI may be beneficial in some circumstances (Fernández, Reference Fernández2008; Henry et al., Reference Henry, Culman and VanPatten2009; VanPatten et al., Reference VanPatten, Collopy, Price, Borst and Qualin2013). See Lee (Reference Lee2015) for a complete review of PI research over the past twenty years.
Interpreting the effects of PI
Within the PI literature detailed above, positive effects for PI or SI activities are typically interpreted following VanPatten and Cadierno (Reference VanPatten and Cadierno1993), who argued that PI alters the way learners process and extract information from the input, providing intake for the developing system. This research has relied primarily on offline pretest and posttest measures. However, recent research has begun to use online measures to investigate this claim as these methods provide more detailed moment-by-moment information about learners’ processing and performance on learning tasks. Additionally, these measures are less likely to be influenced by the use of conscious knowledge or EI (see Keating & Jegerski Reference Keating and Jegerski2015; VanPatten, Reference VanPatten2015a). Thus, these measures allow researchers to make stronger inferences about how PI alters processing strategies or attention to the target form.
Studies on PI and related instructional trainings that employ online processing measures are still relatively few (see Benati, Reference Benati2020b), but several recent studies have used these methods given the detail they provide. As Lee et al. (Reference Lee, Malovrh, Doherty and Nichols2020) discuss, these studies have investigated a diverse range of questions, including the effects of PI (or related trainings) versus other types of instruction or no-training controls (Benati, Reference Benati2020c, Reference Benati2020a; Chiuchiù & Benati, Reference Chiuchiù and Benati2020; Issa & Morgan-Short, Reference Issa and Morgan-Short2019; Lee et al., Reference Lee, Malovrh, Doherty and Nichols2020; McManus & Marsden, Reference McManus and Marsden2017, Reference McManus and Marsden2018; Wong & Ito, Reference Wong and Ito2018); EI and feedback (Dracos & Henry, Reference Dracos and Henry2018; Wong & Ito, Reference Wong and Ito2018), input enhancement (Issa & Morgan-Short, Reference Issa and Morgan-Short2019), the modality of training (Ito & Wong, Reference Ito and Wong2019), and the role of individual differences such as working memory (Dracos & Henry, Reference Dracos and Henry2021; Issa, Reference Issa and Leow2019; Lee & Doherty, Reference Lee and Doherty2020).
Most of these studies have found that PI and similar trainings change online processing behaviors (e.g., Chiuchiù & Benati, Reference Chiuchiù and Benati2020; Dracos & Henry, Reference Dracos and Henry2018; Issa & Morgan-Short, Reference Issa and Morgan-Short2019; Lee & Doherty, Reference Lee and Doherty2019; Lee et al., Reference Lee, Malovrh, Doherty and Nichols2020; Wong & Ito, Reference Wong and Ito2018). For example, an eye-tracking study by Wong and Ito (Reference Wong and Ito2018) found that PI led learners to reject a first-noun interpretation of causative faire constructions in French. Similarly, Benati (Reference Benati2020c) found that, after PI, learners’ eye movements showed smaller first noun bias and faster picture selection while they processed English causative passive sentences. Lee and Doherty (Reference Lee and Doherty2019) found that PI directed learners’ attention to grammatical information on Spanish verbs marked for the passive voice and noted that learners’ processing became more native-like after instruction. However, other studies have found mixed results or shown that training had no effect on online processing (Dracos & Henry, Reference Dracos and Henry2021; Ito & Wong, Reference Ito and Wong2019; McManus & Marsden, Reference McManus and Marsden2017). For example, Dracos & Henry (Reference Dracos and Henry2021) found that a PI-like training did not increase sensitivity to grammatical violations for Spanish subject and tense morphology. McManus and Marsden (Reference McManus and Marsden2017) found no changes in online processing behavior for the French Imparfait when learners received training in the L2 only.
It is also important to note that these studies have used a variety of methodological approaches. For example, many studies employ eye-tracking (e.g., Issa & Morgan-Short, Reference Issa and Morgan-Short2019; Ito & Wong, Reference Ito and Wong2019; Wong & Ito, Reference Wong and Ito2018), but some use SPR (Dracos & Henry, Reference Dracos and Henry2021; Lee et al., Reference Lee, Malovrh, Doherty and Nichols2020; Malovrh et al., Reference Malovrh, Lee, Doherty and Nichols2020; McManus & Marsden, Reference McManus and Marsden2017). Further, some studies measure online processing during the training task itself (e.g., Benati, Reference Benati2020c; Issa et al., Reference Issa, Morgan-Short, Villegas and Raney2015; Wong & Ito, Reference Wong and Ito2018), meaning that reported changes in processing could be related directly to either the task itself or the provision of feedback during these tasks (or both). Similarly, some studies use online tasks that mirror the task completed during training. For example, Wong and Ito (Reference Wong and Ito2018) used a forced choice task in both the PI training and in the eye-tracking task, although the eye-tracking task used a different modality (graphic rather than text-based) and did not provide feedback. Some studies, on the contrary, have tested sensitivity to the target form after training using tasks that are quite different from the training, such as SPR (Dracos & Henry, Reference Dracos and Henry2021; McManus & Marsden, Reference McManus and Marsden2017, Reference McManus and Marsden2018). While the former approaches show how PI affects processing in these specific tasks, the latter approach could provide critical evidence about how the effects of PI generalize to other types of processing tasks.
As this brief overview makes clear, this research lacks a common approach and common findings, making further study necessary. In particular, the literature would benefit from studies that allow researchers to make conclusions about how PI changes sensitivity to the target form, how training generalizes to new task types, and how learners acquire new processing routines over time.
The present study
The goal of the present study is to investigate the effects of PI on the acquisition of accusative case markers in German, with particular focus on whether PI influences learners’ online processing performance. This study compares the effects of PI and traditional instruction (TI) using traditional offline tasks (sentence interpretation and picture description) to assess learning gains and online measures (a SPR task) to assess moment-by-moment changes to processing behavior. As noted in the previous section, these methods provide stronger evidence about any such changes than do offline tasks; they also have the potential to reveal processing behavior that is not captured by accuracy measures. This study therefore contributes to the relatively small number studies on PI that use such methods, which to date have shown mixed results. Notably, the present study also diverges from much of the prior research in that it uses an online assessment task, which does not closely resemble the training task. Thus, this study also addresses how PI facilitates changes in processing that are generalizable to different task types. The research questions are as follows:
RQ1a: To what extent does Processing Instruction (PI) lead to more accurate interpretation of accusative case markers in German than Traditional Instruction (TI)?
RQ1b: To what extent does Processing Instruction (PI) lead to more accurate production of accusative case markers in German than Traditional Instruction (TI)?
RQ2: To what extent do PI and TI lead learners to process German accusative case markers more readily when comprehending sentences online, as measured by a self-paced reading task?
Research Questions 1a and 1b focus on the offline interpretation and production assessments. In line with previous research, it is hypothesized that (a) only the PI group will show increased accuracy on both the interpretation and the production task, demonstrating increased knowledge of the underlying form and (b) the TI group will improve only on the trained skill (i.e., the production task). Research Question 2 is the primary focus of the present study and addresses online processing behavior. It is hypothesized that only the PI group will demonstrate greater sensitivity to case markers during the SPR task.
Methodology
Participants
Participants were drawn from third and fourth semester (low intermediate to intermediate level) German courses at a university in the United States (N = 159). Eligible participants met the following requirements: (1) they were native speakers of English, (2) they listed German as their primary and most proficient second language, and (3) they completed all tasks in the experiment. Only those participants who scored below 50% on OVS items in a pretest interpretation task (see below)—and thus did not demonstrate knowledge of the target form—were selected to complete the study. A final total of 51 participants were included in this study (27 male; 24 female). Participants were randomly divided into two treatment groups: The TI group (n = 26), and the PI group (n = 25).
To ensure comparability between the groups, participants completed a language background questionnaire and a written, multiple-choice proficiency test in German (University of Wisconsin Testing and Evaluation, 2006). Participants also completed a verbal working memory test based on Waters and Caplan (Reference Waters and Caplan1996). Descriptive statistics for the questionnaire and for these tests are provided in the supplemental materials (Supplement 2). Statistical analyses showed that the two groups were similar with respect to their age, years of German instruction, and time spent in a German speaking country (all t < 1). There were no differences between the groups’ scores on the proficiency task (t(49) = 0.288, p = .775) or the working memory task (t(49) = 1.535, p = .131).Footnote 2
The target form
The target form was the German masculine article den, which indicates the object of the sentence, as seen in (1) and (2). As discussed previously, L2 learners use a subject-first strategy to process input and often misinterpret OVS sentences (see LoCoco, Reference LoCoco, VanPatten, Dvorak and Lee1987 and pretest scores from Culman et al., Reference Culman, Henry and VanPatten2009; Henry et al., Reference Henry, Culman and VanPatten2009; Henry et al., Reference Henry, Jackson and DiMidio2017; Kasprowicz & Marsden, Reference Kasprowicz and Marsden2017). This strategy likely stems not just from the FNP, but also the prevalence of SVO sentences in German (between 80%–95% of transitive sentences with full NPs; Kempe & MacWhinney, Reference Kempe and MacWhinney1998; Schlesewsky et al., Reference Schlesewsky, Fanselow, Kliegl, Krems, Hemforth and Konieczny2000). Furthermore, overlap between nominative and accusative forms for feminine and neuter genders reinforces the importance of word order as a cue. Indeed, native (L1) speakers also show a subject-first bias. Studies employing SPR tasks demonstrate that L1 speakers incur processing costs in OVS sentences and show higher reading times (RTs) when they encounter disambiguating case information (e.g., Schriefers et al., Reference Schriefers, Friederici and Kühn1995). This suggests that they process case information incrementally. However, similar research has shown that less proficient L2 speakers typically wait until the end of the sentence to integrate case markers into the parse (Hopp, Reference Hopp2006; Jackson, Reference Jackson2008).
Materials
TI treatment
All of the materials used in the TI treatment are found in Supplement 1 (Training Materials) and are available in the IRIS database (http://www.iris-database.org; Marsden et al., Reference Marsden, Mackey, Plonsky, Mackey and Marsden2016). TI treatment was adapted from grammar units found in two popular college-level textbooks for beginning German (Lovik et al., Reference Lovik, Guy and Chavez2010; Moeller et al., Reference Moeller, Adolf, Hoercherl-Alden and Berger2009) and one website popular among German instructors (Thuleen, Reference Thuleen1999). These materials are not only used in L2 classrooms themselves; they are similar to other textbooks and online materials used in classrooms and recommended to students. Thus, the training was “traditional” in that it was representative of grammar training used in textbook-based curricula in many current college-level German courses (see the supplemental materials, Supplement 1).
The training consisted of EI, computer training with feedback, and production tasks. As is common for German textbooks, the EI focused on an explanation of direct objects, and it introduced the nominative- and accusative-marked definite and indefinite articles for each gender in German. Consistent with the EI in the source textbooks, there was no information about OVS word order and participants were never explicitly told to avoid a subject-first interpretation strategy. The EI was presented on a computer via E-Prime (Schneider et al., Reference Schneider, Eschmann and Zuccolotto2012) across several slides such that participants could read each individual slide as long as they wanted but could not review slides once they had moved on.
After receiving the EI, participants completed two computer activities. In the first activity, participants read target sentences and identified the direct object (or indicated that there was no direct object in the sentence). The second activity was a multiple-choice fill-in-the-blank exercise, in which participants supplied nominative and accusative definite articles. In both activities, participants received simple one-word feedback immediately after answering each question. Neither activity contained OVS sentences, as is typical for college-level grammar activities in German.
Finally, participants completed two pencil-and-paper activities in which they produced the accusative case. In the first activity, the participants saw a series of items with price tags and wrote four sentences to explain which items they would buy for their dorm rooms without exceeding their budget. In the second activity, participants checked boxes to indicate what items they and a friend own, and they wrote five sentences comparing their possessions.
PI treatment
Materials used in the PI treatment are found in Supplement 1 and are available in the IRIS database. The PI training consisted of EI, a computer-delivered referential SI activity, and two affective SI activities (see the supplemental materials, Supplement 1). The EI was derived from VanPatten et al. (Reference VanPatten, Collopy, Price, Borst and Qualin2013) and was designed to emphasize the definite articles’ function as a cue to grammatical roles. As the feminine, neuter, and plural definite articles are the same in the nominative and accusative cases, training focused on the masculine nominative and accusative articles der and den. The EI also highlighted why articles are important for determining grammatical roles and explained that OVS word order is used to emphasize the object of the sentence, often in response to a direct request for information. At the end of the EI, participants received a warning that the first noun is not always the subject of the sentence. The EI was presented via E-Prime over several slides similarly to the TI group.
After the presentation of the EI, participants in the PI group completed the referential activity, which was adapted from VanPatten et al. (Reference VanPatten, Collopy, Price, Borst and Qualin2013) and presented via E-Prime (Schneider et al., Reference Schneider, Eschmann and Zuccolotto2012). In this task, participants heard an SVO or OVS sentence while viewing two pictures: one representing the SVO interpretation of the sentence and the other representing the OVS interpretation (see Figure 1). They used the keyboard to choose the picture they thought best represented the meaning of the target sentence and then received one-word feedback on their answer. The training consisted of 38 OVS sentences and 12 SVO sentences recorded by a female native speaker of German. These items appeared in a repeating sequence of three OVS items, followed by one SVO item to ensure even distribution of the SVO distractor items.Footnote 3 Each sentence was a simple transitive construction consisting of a NP-V-NP sequence in which one NP was masculine and therefore unambiguously identified its case and grammatical role. The sentences contained only animate nouns, and both SVO and OVS interpretations were equally plausible. Further, sentences were presented without context or intonational cues.Footnote 4 Consequently, the case markings were the only cue that participants could use to comprehend the sentences.

Figure 1. Example items from referential activity (picture-selection task) in PI training.

Figure 2. Example item from production task.

Figure 3. Model results for Segment 1, Masculine-First sentences.

Figure 4. Model results for Segment 3, Masculine-Second sentences.
Finally, participants completed two affective activities adapted from Farley (Reference Farley2004) and used by Henry et al. (Reference Henry, Jackson and DiMidio2017). In these activities, participants read a series of OVS sentences relating to interpersonal relationships and marked their opinions about these statements. These activities did not have correct answers, and thus acted primarily as an input flood, exposing the participants to more OVS sentences in a different communicative context (see also Marsden & Chen, Reference Marsden and Chen2011 for a full discussion of affective activities and their function within PI training).
It should be emphasized that the TI and PI trainings were identical in that they both used EI, computer-based activities, and open-ended activities, and the quality and quantity of corrective feedback was identical.Footnote 5 Thus, the differences between the TI and PI trainings lie solely in the principles of PI (Lee & VanPatten, Reference Lee and VanPatten2003): the PI training concentrated on one form (the masculine accusative), it used both aural and written input, and attention to the meaning of the target form was required for successful completion of the tasks. Most importantly, the PI activities were designed to compel the participants to process the target form instead of relying on a first-noun strategy. The TI training, on the other hand, presented multiple forms at once, focused on accurate identification and production of the target forms, and included reliable animacy, plausibility, context, and word order cues (by only including SVO sentences) that mediated the interpretation of the input.
Assessment measures
The full set of assessment measures used in this study are found in Supplement 3 (Assessment Materials) and available in the IRIS database. The primary means of assessing the offline effects of training was a written pretest/posttest consisting of a sentence interpretation task and a production task. There were two versions of the test, which were counterbalanced among participants.
The sentence interpretation task consisted of four SVO and four OVS sentences mixed with 12 distractor items.Footnote 6 Each target item was followed by a Yes/No comprehension question targeting successful interpretation of grammatical roles, as seen in (3). Questions were presented in English so that participants could not simply match the articles between the sentence and the comprehension question.

The production task consisted of four picture-series—two target series and two distractor series. As in Figure 2, each series contained three pictures, a question prompt, and vocabulary relating to the pictures. Participants were instructed to use the pictures to respond to the prompt and write at least one sentence per picture to tell a story. The target items depicted a person interacting with a masculine person or object in each of the three pictures. Thus, an appropriate response to the picture specifically elicited the masculine articles der and den. Participants were not limited to three sentences, nor were they required to use the verbs presented to them.
The online effects of training were investigated through a SPR task administered before and after training. This task tested the sensitivity to case marking through a comparison of RTs on SVO and OVS sentences. Given that OVS sentences are far less frequent in German and require more complex structure building than SVO sentences, effortful processing and longer RTs are expected on the disambiguating segments (i.e., masculine nouns) of OVS sentences. That is, if the accusative den is read in NP1, or if the nominative der is read in NP2, surprisal effects should lead to increased RTs. Thus, if participants were to show increased RTs on OVS relative to SVO sentences, as has been seen in research with L1 speakers (Schriefers et al., Reference Schriefers, Friederici and Kühn1995), this would provide evidence that L2 German learners are sensitive to case-marking information and use it to assign grammatical roles.
The SPR task was presented in a phrase-by-phrase noncumulative moving window design (Just et al., Reference Just, Carpenter and Woolley1982) using E-Prime (Schneider et al., Reference Schneider, Eschmann and Zuccolotto2012). In this task, participants were first presented with a fixation cross to mark the beginning of the sentence. When they pressed the spacebar on the keyboard, they saw the first phrase in the sentence followed by dashes representing the position of the words in the remainder of the sentence. Using the spacebar, they advanced through the phrases until they reached the end of the sentence. Only one phrase was visible to them at a time. Following each sentence, participants answered a comprehension question in English to ensure that they read the sentence for meaning.
In total, the SPR task consisted of 72 items and comprehension questions, including 24 experimental sentences and 48 fillers. The 24 experimental sentences consisted of an NP-V-NP sequence followed by one or two prepositional phrases. Each sentence included one masculine NP and one NP that was either feminine or neuter. There were four versions of each sentence, created by crossing two variables: word order (SVO or OVS) and placement of the masculine nouns (i.e., the disambiguating noun). The quadruplets were divided into five to seven regions for presentation in the SPR task.
For each sentence, the masculine noun is the point of disambiguation, and thus was used as a critical region for the analyses. The two regions that followed the critical regions were spillover regions. In (4), bold-faced type indicates critical regions, italicized type represents the spillover regions, and slashes indicate the division of the sentences.




Half of the comprehension questions specifically tested the assignment of grammatical roles like the questions in the offline sentence interpretation task; the other half of the comprehension questions inquired about information found in the prepositional phrase. While it is less preferable to have comprehension questions that draw attention to the target form (Keating & Jegerski, Reference Keating and Jegerski2015; Leeser et al., Reference Leeser, Brandl, Weissglass, Trofimovich and McDonough2011), it was important to have an independent measure of sentence interpretation during this online task in order to draw some comparison to the offline task. Only 12 of the 72 sentences in the SPR focused on grammatical roles, and participants had to pay attention to all parts of the sentence in order to answer all comprehension questions.
The experimental stimuli were divided into four experimental lists. These lists were controlled so that there were no differences in word length in the regions of interest, and so that the SVO and OVS interpretations of the sentences were equally plausible. Rather than controlling for the raw frequency of the words used in the SPRT, the stimuli were controlled for familiarity by selecting the words from the textbook used in the participants’ German classes. However, a pilot experiment showed that many participants were not as familiar with the words as expected; therefore, participants were trained on the words before both the pretest and the posttest. The lists were distributed so that participants only saw one version of each sentence, and, thus, participants saw six sentences from each of the conditions described above.
Procedure
The experiment was conducted in three sessions and followed the same procedure regardless of the participants’ group. Session one was conducted in the participants’ classrooms and included the language background questionnaire, proficiency test, and the pretest (i.e., the offline sentence interpretation and production tasks). Sessions two and three were held in a quiet laboratory, and participants were tested individually. Session two was completed between 1 and 3 weeks after Session one. Session two began with the vocabulary training designed to teach participants the primary nouns and verbs used in the SPR task. In the vocabulary training, participants saw and listened to each word three times while viewing their English translation. Participants were then tested on their knowledge of the words, and they repeated words they could not identify correctly (see the supplemental materials, Supplement 1). After the vocabulary training, participants completed a working memory task to ensure comparability between participantsFootnote 7 and the pretest SPR task. Session three was completed between 4 and 6 weeks after Session two. In Session three, participants first completed a reduced version of the vocabulary training, in which they saw and listened to the words twice. This was done to ensure that participants retained the vocabulary and had seen the words in the SPR task recently, similar to the pretest. They then completed the PI or TI training, the posttest SPR task, the posttest, and a vocabulary test to ensure that they had retained the vocabulary throughout the experiment.Footnote 8
Data scoring
Sentence interpretation
For the sentence interpretation task, target SVO and OVS items were scored separately; one point was given for correct Yes/No responses, and zero points were given for incorrect responses. There was a maximum score of four points, one for each target sentence.
Written production
For the production task, separate scores were computed for production of the nominative and accusative cases. The score was computed as a ratio of the number of accurate uses to the number of obligatory occasions in each response. Thus, the maximum score was one (100%). For the purpose of this measure, both the nominative or accusative markers der or den, as well as their corresponding pronouns er and ihn, were considered to be correct if they accurately described the action depicted in the picture. An obligatory occasion was defined as a point in the sentence in which the masculine articles were necessary to complete the phrase grammatically. Participants who did not produce any obligatory occasions (e.g., if they named the characters or used alternate vocabulary to describe the pictures) could not be given a score for this task and were treated as missing data in the analyses.
SPR comprehension
In the SPR task, responses to the comprehension questions for the experimental sentences were recorded by E-Prime, along with RTs for each region. For comprehension questions that tested grammatical role assignment, scores were computed separately for SVO and OVS items and reflect a percentage of correct answers.
SPR reading times
RT data were trimmed by first removing all RTs below 200 ms and above 4,000 ms from the data; in addition, any RT outside a range of +/− 3 standard deviations from a participant’s mean RT for the experimental sentences was defined as an outlier and excluded from analyses. These trimming procedures resulted in a loss of 3.5% of the data. In addition, data were only analyzed for sentences that were correctly understood, resulting in a loss of an additional 27.6% of the data. Thus, to ensure that participants completed the tasks correctly and contributed enough data to the sample, participants were removed from the final data set if they had an overall comprehension rate less than 60% for the entire task or less than 33% for one of the experimental conditions. Four participants from the PI group were excluded from the analyses, meaning that the PI group consisted of 21 participants for the SPR task.
Data analysis
Analyses were performed using mixed-effects models, which allow flexibility for different data distributions (e.g., binomial variables) and are robust against homoscedasticity and sphericity (McManus & Marsden, Reference McManus and Marsden2019). Models were fit using the mixed() function in the R package afex Footnote 9 (Singmann et al., Reference Singmann, Bolker, Westfall, Aust and Ben-Schachar2021). For all analyses, the maximal model structure was attempted (Barr et al., Reference Barr, Levy, Scheepers and Tily2013). When the maximal model did not converge, it was systematically reduced using the procedure laid out by Singmann (Reference Singmann2021). The structure of the final model is noted in the results for each analysis. To explore significant main effects and interactions, post hoc contrasts were performed using the package emmeans (Lenth, Reference Lenth2020) and a Bonferroni adjustment for multiple comparisons.
Statistical analyses for the interpretation task and accuracy on the SPR comprehension questions focus on OVS sentences as these are the foci of the research questions in the present study. Analyses for the production task focus on the production of the accusative case.Footnote 10 These analyses were all carried out using Generalized Linear Mixed Models (GLMM) with a logit link binomial error distribution and using likelihood ratio tests. Likelihood ratio tests were used to compute p values for fixed effects. The maximal model included fixed effects of Time (Pretest vs. Posttest) and group (PI vs. TI), and the Time × Group interaction, with by-participant random slopes and intercepts for Time plus the correlation between slopes and intercepts.
Analysis of RTs for the SPR task was conducted using linear mixed effects models of log-transformed RTs, which compensated for the non-normality of these data. Separate analyses were carried out for each segment. Masculine-First and Masculine-Second sentences were analyzed separately, as the critical regions differed between them. The maximal model included the fixed effects of Time (Pretest vs. Posttest), Group (PI vs. TI), and Word Order (SVO vs. OVS) and the interactions between them. The random effects included by-subject and by-item random intercepts and random slopes for Time, Word Order, and the Time x Word Order interaction plus correlations among slopes and intercepts.
Results
Sentence interpretation
The descriptive statistics for the interpretation task are presented in Table 1. The maximal GLMM model did not converge. Results of the finalFootnote 11 model yielded an effect for Group (χ2(1) = 17.48, p < .001), Time (χ2(1) = 55.18, p = < .001), and the Group x Time interaction (χ2(1) = 46.72, p = < .001). Follow-up comparisons for the Group x Time interaction confirmed that there were no differences between the groups at pretest (OR = 0.891, SE = 0.464, z-ratio = −0.221, p = .825), but the PI group outperformed the TI group at posttest (OR = 45.834, SE = 25.815, z-ratio = 6.791; p < .001). Further comparisons showed that the PI group improved from pretest to posttest (OR = 0.0167, SE = 0.008, z-ratio = −8.318, p < .001), but the TI group did not (OR = 0.860, SE = 0.334, z-ratio = −0.387, p = .699).
Table 1. Descriptive statistics for sentence interpretation task (maximum score of four)

Note: Values for the 95% confidence interval are bootstrapped using one thousand samples
Written production
The descriptive statistics for the production task are shown in Table 2. The maximal GLMM model did not converge. Results of this final modelFootnote 12 yielded no effect for Group (χ2(1) = 0.15, p = 0.695), but there was a significant effect for Time (χ2(1) = 94.22, p = < .001), which was qualified by a Group x Time interaction (χ2(1) = 13.93, p = < .001). Follow-up comparisons for the Group x Time interaction confirmed that both groups improved from pretest to posttest (PI: OR = 0.017, SE = 0.011, z-ratio = −6.350, p < .001; TI: OR = 0.199, SE = 0.074, z-ratio = −4.319, p < .001), but there were no differences between the groups at pretest (OR = 0.417, SE = 0.385, z-ratio = −0.946, p = .343) or posttest (OR = 4.836, SE = 4.863, z-ratio = 1.567, p = .117). The interaction thus appears to be driven by the comparatively larger gains made by the PI group relative to the TI group.
Table 2. Descriptive statistics for written production task (ratio of correct to obligatory occasions)

SPR comprehension questions
The descriptive statistics for SPR comprehension accuracy are given in Table 3. Results of the maximal modelFootnote 13 yielded a significant effect for Time (χ2(1) = 6.63, p = .01), but no effect for Group (χ2(1) = 2.53, p = .112) or the Group x Time interaction (χ2(1) = 1.77, p = .184). Follow-up pairwise comparisons for Time confirmed that the effect stemmed from higher accuracy scores on the posttest (OR = 0.556, SE = 0.127, z-ratio = −2.570, p = .010).
Table 3. Descriptive statistics for SPR comprehension questions (proportion of correct answers)
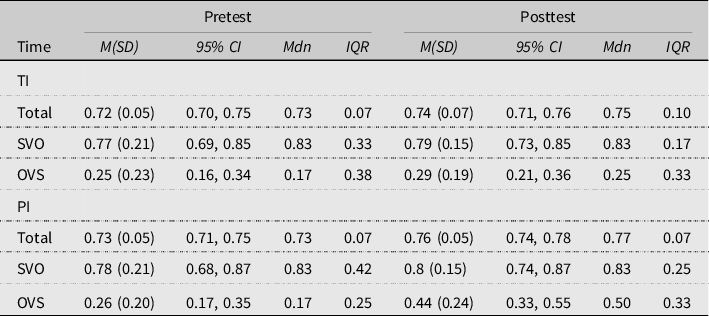
Note: Values for the 95% confidence interval are bootstrapped using one thousand samples; values for SVO and OVS sentences reflect only those items in which grammatical role assignment was tested in the comprehension question.
Given that these results differed from those of the sentence interpretation task, a post hoc analysis was conducted to disentangle changes in individual participants from overall group means and evaluate the degree to which they had maintained or abandoned a strong first noun strategy. For this analysis, the proportion of participants who scored at or above chance on the OVS sentences was calculated for each group at each test time. As can be seen in Table 4, about 24% of the participants in both groups scored at or above chance on the pretest. On the posttest, 60% of the participants in the PI group scored at or above chance, while only 30.7% of the TI group did.
Table 4. Proportion of participants scoring at or above chance on OVS sentences on the SPR task

SPR reading times
The analyses presented here focus on the disambiguating segments (Segments 1 and 3 for Masculine-First and Masculine-Second sentences, respectively). Analyses for spillover regions are presented in the supplemental materials (Supplement 2) alongside a post hoc analysis of overall RTs.
RTs for Masculine-First sentences
The mean RTs and standard deviations for Masculine-First sentences at each segment are displayed by group and condition in Table 5.
Table 5. Mean reading times (SDs) by group and condition for SPR task, Masculine-First items

For the critical segment, Segment 1 (the first NP), the maximal model did not converge. Results of the final modelFootnote 14 (Table 6, Figure 3) yielded a significant main effect for Word Order and a marginally significant main effect for Group, which were qualified by significant Time x Group and Time x Word Order x Group interactions. Pairwise comparisons for the SVO-OVS contrast (Table 7) indicated that the PI and TI groups had similar RTs on SVO and OVS sentences on the pretest. In contrast, the PI group—but not the TI group—had significantly higher RTs on OVS sentences in the posttest.
Table 6. Model results for Segment 1, Masculine-First sentences

Table 7. Results of the pairwise comparisons for the SVO-OVS contrast in Masculine-First items

RTs for Masculine-Second sentences
The mean RTs and standard deviations for Masculine-Second sentences at each segment are displayed by group and condition in Table 8.
Table 8. Mean reading times (SDs) by group and condition for SPR task, Masculine-Second items

For the critical segment, Segment 3 (the second NP), the maximal model did not converge. Results of the final modelFootnote 15 (Table 9, Figure 4), yielded no significant effects, although a marginally significant effect for Group arose because the PI group had higher RTs overall.
Table 9. Model results for Segment 3, Masculine-Second sentences

Discussion
The goal of the present study was to investigate the effects of PI on the acquisition and processing of the accusative case in German, specifically testing whether PI or TI leads to significant changes in performance accuracy in comprehension and production (RQ1a and 1b, respectively) and in learners’ processing strategies (RQ2). The results show that the PI group improved their comprehension of OVS sentences in both the offline comprehension task and the SPR task. They also improved accuracy with accusative case markers on the written production task. The TI group, on the other hand, only improved on the written production tasks. Thus, as hypothesized, only the PI group demonstrated increased knowledge of the underlying form. On the SPR task, only the PI group had increased RTs for OVS sentences, though this effect was only observed when the masculine noun (i.e., the disambiguating noun) was read first. Thus, hypothesis for RQ2 was only partially confirmed. Together, these results suggest that only the PI training pushed participants to abandon a strict first-noun strategy and process case-marking information more readily. These results are now discussed with reference to the role of PI in the development of form-meaning connections and its impact on the ability to process case cues online.
The development of form-meaning connections
Like many previous studies, the present study replicated the findings of VanPatten and Cadierno (Reference VanPatten and Cadierno1993), showing that the PI group improved on both comprehension and production measures, while the TI group improved only on production. In line with previous PI research, results from the present study seem to indicate that the PI training led these learners to realize the relationship between case-marking articles and grammatical roles and to create or strengthen form-meaning connections in the developing system, while the TI training did not.
The TI group’s improvement in the production task can be explained by the development of explicit knowledge about the target forms, especially because the production-focused practice did not require the learners to connect articles to their grammatical roles at all. Rather, the TI group simply needed to learn to produce den post-verbally in both the training and in the production assessments. Indeed, the TI training did not provide the learners with any evidence that word order is not a reliable cue to grammatical role assignment in German. On the other hand, the learners could not have completed PI training successfully without realizing the connection between the articles and grammatical roles. Presumably, this would have helped them develop the ability to process word order and case-marking morphology as separate (i.e., non-converging) cues to grammatical role and gain more detailed and more robust knowledge in the underlying system. This could explain why the PI group outperformed the TI group on the posttest comprehension measure and also improved in the production measure, despite not practicing production at any point in the training.
The use of case markings online
Together, the analyses on the SPR task showed that, at pretest, neither group used case markers to understand the comprehension questions or processed case-marking information online. On the posttest, the TI group did not significantly improve their comprehension of OVS sentences in the comprehension questions, nor did they reduce their reliance on a first-noun strategy. The analysis of RTs indicated that there were no differences in how they read SVO and OVS sentences, and thus they did not process case markers online. This is expected because the comprehension tasks indicated that they lacked the appropriate form-meaning connections needed to disambiguate between the word orders.
On the other hand, the PI group improved on the SPR comprehension questions, and fewer participants in the PI group used a strict first-noun strategy to interpret sentences on the posttest. The RTs showed that the PI group did process case marking information, but that they did so on a limited basis: participants had elevated RTs on OVS sentences in Masculine-First sentences, but not in Masculine-Second sentences. Thus, while these results clearly suggest that PI can promote incremental processing, its effects may be limited by aspects of the training (e.g., the length), salience of the target form in sentence context, or perhaps cognitive factors (see below). In addition to these primary results from the SPR RTs, it is also noteworthy that the post hoc analysis of RTs (see Supplement 2) showed that the PI group had higher RTs than the TI group across all conditions, but only in Segments 1 and 3 (the two NPs) on the posttest. This is significant given that the PI training aimed to teach learners to focus on articles as relevant cues. As there were no RT differences at other regions, it seems likely that this difference stems directly from the PI training itself and not from task effects or other external factors. Notably, this effect would be predicted if PI influences how learners direct processing resources to articles, whether they are masculine or not. That is, this could indicate that participants deliberately checked the first and second NPs for case-marking information.
The results of the SPR task, then, indicate that PI affected the processing system in two ways: (1) it helped participants identify and process the relevant cues in the input and (2) participants were better able to integrate case-marking information into their representation of the input. Thus, these results replicate effects observed by previous studies on PI (Benati, Reference Benati2020c; Chiuchiù & Benati, Reference Chiuchiù and Benati2020; Issa & Morgan-Short, Reference Issa and Morgan-Short2019; Wong & Ito, Reference Wong and Ito2018), showing that PI helps learners develop form-meaning connections and identify, attend to, and process cues in the input. However, given the null effects in the Masculine-Second sentences, it seems that PI may have a limited impact on the ability to integrate information rapidly and recover from misparses in some types of sentences. This suggests that processing routines emerge in two stages, as learners first learn to allocate attention to useful cues and are later able to integrate this information into the parse more fully.
It is unclear why the learners showed no sensitivity to word order in Masculine-Second sentences. One possibility is that this study was simply unable to capture these effects due to low statistical power, especially given a relatively small sample size and the elimination of a portion of the data. Further, it is possible that the participants treated ambiguous (non-masculine) NPs in the first segment as nominative and either (a) did not attend to case marking in the second NP or (b) were unable to fully recover from their initial SVO interpretation when they later encountered the nominative der. As hinted above, the ability to attend to morphological cues and recover from mis-parses may need time to develop, as these skills are influenced by the interaction of various internal and external factors such as working memory capacity (e.g., Dracos & Henry, Reference Dracos and Henry2021; Juffs & Harrington, Reference Juffs and Harrington2011; Keating, Reference Keating2009), the speed of lexical access (e.g., Miller, Reference Miller, Plonsky and Schierloh2011, Reference Miller2014), and task type (e.g., Leeser et al., Reference Leeser, Brandl, Weissglass, Trofimovich and McDonough2011). It is also possible that learners would be better able to integrate case information online if it were supported, for example, by implicit prosody (Dekydtspotter et al., Reference Dekydtspotter, Donaldson, Edomnds, Liljestrand Fultz and Petrush2008; Harley et al., Reference Harley, Howard and Hart1995; Hwang, Reference Hwang2007; Ying, Reference Ying1996). Future research will need to employ larger sample sizes and employ methods that can detect smaller effects; such research could shed light on how these factors—and other aspects of PI trainings—mediate the availability of native-like processing behaviors after PI. It may be particularly interesting to explore whether repeated PI interventions utilizing increasingly complex discourse can increase the efficacy of training by promoting the ability to use the forms in a wider variety of sentence types and in more complex tasks. Similarly, future research could investigate the effects of massed and distributed practice for both offline performance and online processing (see Bird, Reference Bird2010; Miles, Reference Miles2014).
In sum, the present study supports a narrow interpretation of the claim that PI changes processing behaviors (see e.g., VanPatten & Cadierno, Reference VanPatten and Cadierno1993) because PI compelled learners to direct attentional resources to and process the relevant morphosyntactic cues, but it did not lead to a target-like incremental processing pattern in all conditions. Despite this limitation, the changes that were observed are consistent with the goals of the PI training, which aimed to teach participants to attend to articles instead of simply relying on a first-noun strategy. It is also important to recognize that PI influenced these learners’ processing strategies in a task (the SPR task) that is very different from the SI activity. To the extent that this task is generalizable to a non-laboratory setting, PI would therefore be useful, not only because it aids in the development of form-meaning connections but also because changes in processing behavior should allow learners to extract meaningful information from input beyond the instructional context, creating better intake for the developing system.
Conclusions
The present study is an important contribution to PI research in that it provides evidence that PI affects learners’ online processing strategies and generalizes to different task types. It also provides evidence that learners develop native-like processing routines by first learning to attend to relevant cues and later learning to integrate this information rapidly and efficiently. More generally, this study highlights the benefits of developing psycholinguistically motivated instructional methods that are then evaluated using psycholinguistic (i.e., processing) tasks. Studies that use such an approach can not only lead to improvements in instructional materials but also add precision to the theoretical models and constructs used to develop those materials. Consequently, a combination of classroom and psycholinguistic approaches has much to offer both fields and can facilitate an informative dialogue between the disciplines.
Acknowledgements
Portions of this research were presented at the 2016 meeting of the Pacific Second Language Research Forum in Tokyo, Japan. I would like to thank Carrie Jackson for her personal support and innumerable contributions to this project. I would also like to thank Richard Page, Mike Putnam, Giuli Dussias, Bill VanPatten, Abby Massaro, Adam Baker, Melisa Dracos, Carl Blyth, Courtney Johnson Fowler, and the members of the Penn State Center for Language Science for their help in all phases of this project.
Financial Support
This research was supported in part by a National Science Foundation Dissertation Improvement Grant (BCS-1252109).
Conflict of Interest
I have no known competing interests to declare.














 Open access
Open access