



Recently, I was asked to write a contribution on spatial sampling in archaeology (Banning Reference Banning, Gillings, Hacıgüzeller and Lock2020), with case studies to illustrate best practices. To my surprise, I had difficulty finding any examples, let alone best practices, of probability sampling—spatial or otherwise—in archaeological literature of the last 20 years, aside from Orton's (Reference Orton2000) excellent book. Given that sampling theory is a critical aspect of research design and control for bias, this puzzled and concerned me.
There can be legitimate reasons not to employ probability sampling. What rattled me when I tried to find those case studies is the possibility that many archaeologists are neglecting probability sampling for the wrong reasons.
Here, I explore some possible reasons for this neglect before offering some suggestions for restoring formal sampling to a substantive role in our practice. First, however, let us review briefly the purpose and nature of probability sampling, and a brief history of its use in archaeology.
What Is Sampling?
Sampling entails two important concepts: (1) the population, or set of phenomena—such as sites, features, spaces, artifacts, bone, and charcoal fragments—whose characteristics are of interest, and (2) the sample, a subset of the population that we actually examine. Our interest in the sample is that it might tell us something about the population. In archaeology, we often have populations that consist of spaces, such as excavation squares, because we cannot enumerate populations of sites, artifacts, or “ecofacts” that we have not yet surveyed or excavated. A “sampling frame” is a list of the population's “elements” or members, or a grid or map for identifying the set of spatial elements in a spatial population. Sample size is just the number of elements in the sample, whereas sampling fraction is the sample size divided by the number of elements in the whole population, whether known or not. Even archaeologists who do not formally employ sampling theory accept that a large sample is a better basis for inferences than a very small sample.
Archaeologists sample all the time, if only because cost or other factors make examination of whole populations impractical or unethical. We also recognize that taphonomic factors can distance our sample of a “fossil assemblage” still farther from a “deposited assemblage” that may be our real population of interest (Holtzman Reference Holtzman1979; Meadow Reference Meadow1980). The question is, How confident should we be about inferences based on a small subset of a population?
For some kinds of samples, not very. “Convenience” or “opportunistic” samples are just the sites, artifacts, or plant or animal remains that come to hand, often because they are already sitting in some lab. Potentially better are “purposive samples” that result from conscious selection of certain members of the population because of the perception that they provide superior information for some purpose, such as excavation areas selected for their probability of yielding a long, stratified sequence. Samples such as these are not flawed, for certain purposes at least, but they entail the risk that they may not be “representative” of the population of interest. In other words, the sample's characteristics might not be very similar to the characteristics of the whole population. A nonrandom difference between the value of some population characteristic (statisticians call this a “parameter”) and the value of that characteristic (or “statistic”) in a sample is “bias.”
Probability sampling is a set of methods with the goal of controlling this risk of bias by ensuring that the sample is “representative” of the population so that we can estimate a parameter on the basis of a statistic. This always involves some randomness. The classic probability sampling strategies include simple random sampling with replacement, in which every “element” of the population—whether an artifact, bone fragment, space, or volume—has an equal probability of selection at each and every draw from the population. This is like picking numbers from a hat but then replacing them so that some elements can be selected more than once. Alternatively, we may remove elements once they are randomly selected (random sampling without replacement) so that the probability of selection changes as sampling progresses and no element is selected more than once. Another is systematic sampling, in which we randomly select the first element and then all the others are strictly determined by a “spacing rule.” For example, we might organize artifacts in rows, randomly select one of the first four artifacts by rolling a die (ignoring 5 and 6), and then take every fourth artifact in sequence to yield a 25% sampling fraction. Stratified sampling involves dividing the population into subpopulations (“strata”) that differ in relevant characteristics before sampling within them randomly or systematically. Systematic unaligned sampling is a specifically spatial design meant to ensure reasonably even coverage of a site or region without as much rigidity as a systematic sample (Figure 1). Most probability sampling designs are variations or combinations of these basic ones.

Figure 1. Hypothetical examples of some spatial sampling designs (after Haggett Reference Haggett1965:Figure 7.4) that were repeated in dozens of later archaeological publications: (a) simple random, (b) stratified random, (c) systematic, and (d) systematic unaligned.
Sample elements need not be spatial (Figure 2), but the fact that archaeologists can rarely specify populations of artifacts or “ecofacts” in advance often forces them to employ cluster sampling. Cluster samples occur whenever the population of interest consists of items such as artifacts, charcoal, or bone fragments, but the population actually sampled is a spatial one, such as a population of 2 × 2 m squares (Mueller Reference Mueller and Mueller1975a). Cluster samples require statistical treatment that differs from that for simple random samples (Drennan Reference Drennan2010:244–246; Orton Reference Orton2000:212–213) because of the phenomenon called “autocorrelation,” which is that observations that are close together are likely to be more similar to one another than ones that are far apart. In the case of lithics, it is likely that multiple flakes found near each other came from the same core, for example.

Figure 2. Some hypothetical examples of nonspatial samples, with selected elements in gray: (a) simple random sample of pottery sherds (the twelfth sherd selected twice), (b) 25% systematic sample of projectile points arranged in arbitrary order, and (c) stratified random sample of sediment volumes for flotation.
Multistage sampling is a variety of cluster sampling in which there is a hierarchy of clusters. For example, we might first make a stratified random selection of sites that have been excavated, then randomly select contexts or features from the selected excavations (themselves generally already samples of some kind), then analyze the entire contents of the sampled contexts.
Another important type is Probability Proportional to Size, or PPS sampling (Orton Reference Orton2000:34). This involves randomly or systematically placed dots or lines over a region, site, thin section, pollen slide, or other area. Only sites, artifacts, or mineral or pollen grains that the dots or lines intersect are included in the sample. Because the dots or lines are more likely to intersect large items than small ones, it is necessary to correct for this effect to avoid bias.
In general, probability sampling is preferable to convenience or purposive sampling whenever we should be concerned whether or not the sample is representative of a population—and, consequently, suitable for making valid inferences about it. Convenience sampling is acceptable for some clearly defined purposes when probability sampling is impossible or impractical, and purposive sampling can be preferable when we have very specific hypotheses whose efficient evaluation requires targeted, rather than randomized, observations.
The Rise of Archaeological Probability Sampling
What was it that once made sampling theory appeal to archaeologists? Its perception as “scientific,” no doubt, was a contributing factor. As the previous section suggests, a better incentive was that, by controlling sources of bias, it permits valid conclusions about populations when observing entire populations is impossible, undesirable, wasteful, or unethical. Sampling allows us to evaluate the strength of claims about populations with less worry that results are due to chance or, worse, our own preconceptions (Drennan Reference Drennan2010:80–82; Orton Reference Orton2000:6–9).
Some of the earliest attention to sampling in archaeology concerned sample size. Phillips and colleagues (Reference Phillips, Ford and Griffin1951) made frequent reference to samples of sites and pottery, and especially the adequacy of sample sizes for seriation. In one instance, they even drew a random sample of sherds (Reference Phillips, Ford and Griffin1951:77). They did not, however, employ formal methods to decide what constituted an “adequate” sample size, and sampling did not attract much explicit attention from archaeologists until the 1960s (Rootenberg Reference Rootenberg1964; Vescelius Reference Vescelius, Dole and Carneiro1960).
Binford (Reference Binford1964) was particularly influential in archaeologists’ adoption of probability sampling, presenting it as a key element of research design. He summarized the main sampling strategies reviewed in the last section and identified different kinds of populations and the role of depositional history in their definition. He also recognized that confounding factors—such as vegetation, construction, land use, and accessibility—could complicate sampling designs and inferences from spatial samples.
He also inadvertently fostered some misconceptions. Despite advocating nuanced decisions on sample size earlier in the article, Binford dismissed attention to sample size as “quite complicated,” and continued with, “for purposes of argument, . . . we will assume that a 20% areal coverage within each sampling stratum has been judged sufficient” (Reference Binford1964:434). Although this was just a simplifying example, later archaeologists often took 20% as a recommended sampling fraction. Similarly, some archaeologists seem to have taken his mention of soil type as grounds for stratification as received wisdom, and they used soil maps to stratify spatial samples whether or not this made sense. Despite his assertion that probability sampling should occur “on all levels of data collection” (Reference Binford1964:440), both this article and much of the literature it inspired strongly privilege sampling in regional surveys, with less attention to sampling sites, assemblages, or artifacts (but see Orton Reference Orton2000).
Soon, sampling appeared in texts used to educate the next generation of archaeologists (Ragir Reference Ragir, Heizer and Graham1967; Watson et al. Reference Watson, LeBlanc and Redman1971). Most focused on the basic spatial sampling designs. Generally lacking was discussion of when probability sampling was appropriate and how to define populations or plan effective stratified or cluster samples.
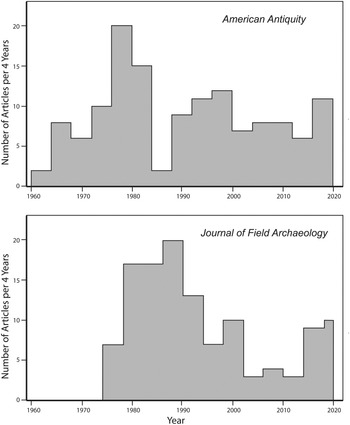
An outpouring of literature on sampling in regional survey (e.g., Cowgill Reference Cowgill and Gardin1970, Reference Cowgill and Mueller1975; Judge et al. Reference Judge, Ebert, Hitchcock and Mueller1975; Lovis Reference Lovis1976; Williams et al. Reference Williams, Thomas, Bettinger and Redman1973), surface collection (Redman and Watson Reference Redman and Jo Watson1970), excavation (Hill Reference Hill1970), zooarchaeology (Ambrose Reference Ambrose1967), and artifact analysis (Cowgill Reference Cowgill1964) also appeared. There were more general reviews (Mueller Reference Mueller1975b; O'Brien and Lewarch Reference O'Brien and Lewarch1979; Redman Reference Redman1974) and desktop simulations of sampling designs (Mueller Reference Mueller1974; Plog Reference Plog and Flannery1976). Sampling soon saw application outside North America (e.g., Cherry et al. Reference Cherry, Gamble and Shennan1978; MacDonald et al. Reference MacDonald, Pavlish and Banning1979; Redman and Watson Reference Redman and Jo Watson1970), and the number of articles in American Antiquity that discussed or used probability sampling grew rapidly until 1980 (Figure 3).

Figure 3. The frequency of articles with substantive discussion of sampling or based at least partly on explicit probability samples in American Antiquity (1960–2019) and Journal of Field Archaeology (1974–2019). Note that there was an interruption in Journal of Field Archaeology from 2002 until early 2004 and that 2018–2019 have five articles (10 per four years).
Then, the literature shifted to more focused topics, such as determining sample sizes (Dunnell Reference Dunnell and Green1984; Leonard Reference Leonard1987; McManamon Reference McManamon and Snow1981; Nance Reference Nance1981), ensuring that absences of certain classes are not due only to sampling error (Nance Reference Nance1981), or sampling shell middens (Campbell Reference Campbell1981).
During the 1970s, much research still used purposive sampling or ignored this sampling wave. Even authors who did not embrace sampling, however, tended to be somewhat apologetic, offering caveats about their samples’ usefulness or describing their research as preliminary.
The Fall of Probability Sampling in Archaeology
Articles published in American Antiquity since 1960 and Journal of Field Archaeology, two long-lived journals that regularly publish articles on archaeological methods (Figure 3 and Supplemental Text 1), show that substantive discussion or mentions of sampling in the statistical sense peaked about 1980 in the former and 1990 in the latter, then declined, albeit with some recovery in the late 1990s and again in the last few years, never returning to pre-1990 levels. What these graphs do not reveal is that articles prior to 1985 tend to be about sampling, while most after 1990 just mention having used some kind of random or systematic sample, usually without presenting any details. Those few about sampling in the later period usually pertain to sample-size issues in zooarchaeology and paleoethnobotany rather than to research design more generally. It is hard to imagine that there was nothing further to say about probability sampling or that it had become too routine to warrant comment, especially as research in statistics developed considerably after 1970 (e.g., Orton Reference Orton2000:11; Thompson and Seber Reference Thompson and Seber1996).
Remarkably, a common claim of the 1990s is that some pattern “is highly unlikely to result from sampling error or random chance” (e.g., Falconer Reference Falconer1995:405), despite relying on small or non-probabilistic samples. Other authors acknowledge bias in their data but go on to analyze them as though they are unbiased, or describe “sampling designs” expected to provide representative samples by standardizing sampling elements without reference to probability sampling (e.g., Bayman Reference Bayman1996:407; Walsh Reference Walsh1998:582).
A blistering critique (Hole Reference Hole1980) that exposed flaws in then-recent archaeological sampling—including arbitrary sampling fractions, the suppression of standard error through impractically small sample elements, and the ignoring of prior information—foreshadowed this decline. Hole (Reference Hole1980:232), however, was not criticizing sampling per se, just its misapplications. Even though some authors judged her critique as extreme (Nance and Ball Reference Nance and Ball1986; Scheps Reference Scheps1982), the fact that none of the 17 articles that cited it from 1981 to 1999, according to Google Scholar, advocated abandoning probability sampling suggests that it had little or no role in decreasing interest or expertise in sampling. The following sections consider more likely candidates.
The Post-Processual Critique
During the 1980s, attacks on sometimes pseudoscientific or dehumanizing examples of New Archaeology engendered an anti-science rhetoric that may have made probability sampling a victim. Shanks and Tilley led this attack by arguing that mathematical approaches entail assumptions that theory is value free, and that “categories of analysis are necessarily designed to enable certain calculations to be made” (Reference Shanks and Tilley1987:57). McAnany and Rowe (Reference McAnany and Rowe2015) explicitly connect rejection of probability sampling with the post-processual paradigm. More recently, Sørensen (Reference Sørensen2017) argues against a new “scientific turn” that devalues the humanities and fetishizes “scientific facts.” What he criticizes explicitly, however, is not really the use of samples but the use of inadequate ones (Sørensen Reference Sørensen2017:106). This is not a problem with science; it just underscores the need for better sampling.
Furthermore, adherents of the interpretive paradigm still base inferences on samples and analyze data as though they represent something more than the sample itself. Even Shanks and Tilley (Reference Shanks and Tilley1987:173–174) explicitly used stratified sampling in their analysis of beer cans and based bar graphs and principal components analysis on this sample (Shanks and Tilley Reference Shanks and Tilley1987:173–189; see also Cowgill Reference Cowgill1993; VanPool and VanPool Reference VanPool and VanPool1999; Watson Reference Watson1990).
Similarly, Shanks (Reference Shanks1999) relies on the quantitative distribution of motifs in a “sample of 2,000 Korinthian pots” (Reference Shanks1999:40). This is an opportunistic sample of “all complete pots known” to Shanks, but he expects them to represent populations of artifacts and the people who made them, such as the pottery of “archaic Korinth” (Shanks Reference Shanks1999:2, 9, 10, 151). He further generalizes about the “early city state,” an even more abstract population (Shanks Reference Shanks1999:210–213), and wonders if his sample is “somewhat biased” for some purposes (Reference Shanks1999:41).
Apparently, formal sampling and generalization from sample to population are not incompatible with interpretive archaeology. Just as “atheoretical” archaeologists inescapably use theory (Johnson Reference Johnson1999:xiv, 6–8), avowedly anti-science archaeologists still use statistical reasoning and sampling. Their anti-science rhetoric, however, may still have had a chilling influence on explicit archaeological sampling.
The “Full-Coverage” Program
When Fish and Kowalewski (Reference Fish and Kowalewski1990) published The Archaeology of Regions, “full-coverage survey” had already begun to trend. Its premise that small samples are an inadequate basis for some kinds of research is undeniable (Banning Reference Banning2002:155): a small sample can never capture all nuances of a settlement system and suffers from “the Teotihuacan effect”—the risk of omitting key sites in a settlement system (Flannery Reference Flannery and Flannery1976:159). The solution, according to most authors in this volume, is to survey an entire landscape at somewhat consistent intensity.
Its classic example is the Valley of Mexico survey. Rather than only examining a subset, surveyors examined every “accessible” space within a “universe” of spatial units with pedestrian transect intervals ranging from 15 to more than 75 m, but typically 40–50 m (Parsons Reference Parsons, Fish and Kowalewski1990:11; Sanders et al. Reference Sanders, Parsons and Santley1979:24).
Kowalewski (Reference Kowalewski, Fish and Kowalewski1990) identifies the main advantages of full coverage, claiming that it captures greater variability and larger datasets, facilitates analysis of spatial structure, and is better at representing rare observations. He also highlights its flexibility of scale in that it does not force researchers to “lock in” to an analytical unit size (cf. Ebert Reference Ebert1992), and he correctly notes that much archaeological research is not about parameter estimation.
The discussants who close out The Archaeology of Regions, however, were not as convinced that full coverage was better than sampling. With surveyor intervals as large as 100 m, most or all “full-coverage surveys” were actually still sampling, potentially having missed even easily detectable sites with horizontal dimensions less than the transect interval. These are really systematic transect samples, and PPS samples of sites, whose main virtue is even and somewhat consistent coverage (Cowgill Reference Cowgill, Fish and Kowalewski1990:254; Kintigh Reference Kintigh, Fish and Kowalewski1990:238). “Full coverage” does not mean anything close to 100% coverage unless transect intervals are extremely small and visibility and preservation are excellent (Given et al. Reference Given, Bernard Knapp, Meyer, Gregory, Kassianidou, Noller, Wells, Urwin and Wright1999:22; Sundstrom Reference Sundstrom1993).
Fred Plog (Reference Plog, Fish and Kowalewski1990) specifically rebuts many of Kowalewski's claims, noting that well-designed stratified samples capture variability well, whereas volume of data is correlated with survey effort, irrespective of method. The claim that full-coverage surveys perform better at capturing rare sites is true only for large, obtrusive ones, not ones that are small or unobtrusive. As most full-coverage surveys really use transects as spatial units, they are also “locked in” to their transect spacings.
Due to the fact that most full-coverage surveys are systematic PPS samples, they yield biased estimates of some parameters—such as mean site size, the proportion of small sites, and the rank-size statistic—because they underrepresent small, unobtrusive sites and artifact densities unless their practitioners correct for this (Cowgill Reference Cowgill, Fish and Kowalewski1990:252–258). None of the surveys in The Archaeology of Regions did so, however.
In the aftermath of this book and a session decrying sampling at the 1993 Theoretical Archaeology Group conference, “almost everybody was against sampling” (Kamermans Reference Kamermans, Huggett and Ryan1995:123). The “brief flirtation with survey sampling” led to “consensus . . . that best practice involves so-called ‘full-coverage’ survey” (Opitz et al. Reference Opitz, Ryzewski, Cherry and Moloney2015:524). Despite its focus on spatial sampling, this probably influenced attitudes to sampling more generally.
Misunderstanding Sampling
Certain misconceptions also discouraged interest in sampling. Binford (Reference Binford1964) had proclaimed that sampling requires populations of equal-sized spatial units. Many archaeologists found that arbitrary grids, especially of squares, were rarely practical or useful because their boundaries did not correspond with meaningful variation on the ground. Sampling universes, however, do not have to consist of any particular kind of spatial unit (Banning Reference Banning2002:86–88; Wobst Reference Wobst, Moore and Keene1983). Even as probability sampling was in its early decline, some projects successfully used sample elements that conformed to geomorphological landforms, field boundaries, or urban architectural blocks (e.g., Banning Reference Banning1996; Kuna Reference Kuna and Evžen Neustupný1998; Wallace-Hadrill Reference Wallace-Hadrill1990).
Some archaeologists worried that fixed samples fail to include rare items or represent diversity accurately. Others, however, found solutions. One is to supplement a probability sample with a purposive one (Leonard Reference Leonard1987; Peacock Reference Peacock, Cherry, Gamble and Shennan1978); it is not appropriate to combine the two kinds of samples to calculate statistics, but researchers can use the probabilistic data to make parameter estimates for common things and the purposive sample to characterize rare phenomena or establish “detection limits” on their abundance. Another is to use sequential sampling instead of a fixed sample size (Dunnell Reference Dunnell and Green1984; Leonard Reference Leonard1987; Nance Reference Nance1981; Ullah et al. Reference Ullah, Duffy and Banning2015). This involves increasing sample size until some criterion is met, such as a leveling off in diversity or relative error.
Finally, some archaeologists have the mistaken idea that sampling is a way to find sites. Spatial sampling is actually rather poor at site discovery, but this does not discount its suitability for making inferences about populations (Shott Reference Shott1985; Welch Reference Welch2013). That sampling does not ensure site discovery is not a good reason to abandon it.
Opportunity and Exchangeability
The ubiquity of opportunistic populations and samples in archaeology may also discourage interest in formal sampling. In heritage management, for example, the “population” often corresponds to a project area that depends on development plans rather than archaeological criteria. In a corridor survey for a pipeline, a project area could intersect a large site, yielding a sample of cultural remains that may or may not be representative, with little opportunity even to determine the site's size or boundaries, except in jurisdictions that offer some flexibility (e.g., Florida Division of Historical Resources 2016:14; and see below).
But this is not unique to cultural resource management (CRM). Archaeologists frequently treat an existing collection as a population, and they either sample it or study it in its entirety. Biases could result from the nature of these opportunistic samples, but that does not mean we cannot evaluate their effects (Drennan Reference Drennan2010:92). Accompanying documentation might even facilitate an effective stratified sample.
Bayesian theory potentially offers some respite through its concept of exchangeability (Buck et al. Reference Buck, Cavanagh and Litton1996:72–78). An opportunistic sample may be adequate for certain purposes, as long as relevant observations on the sample are not biased with respect to those purposes, even if we can expect bias with regard to other kinds of observations. A collection of Puebloan pottery formed in the 1930s, or acquired by collectors, might include more large, decorated sherds or higher decorative diversity than would the population of sherds or pots in the site of origin because of the collectors’ predispositions. Such a sample would provide biased estimates of the proportion of decorated pottery, but it might be acceptable for estimating the proportions of temper recipes in pottery fabrics, for example.
However, there is no reason to think that Bayesian exchangeability has any role in archaeologists’ attitudes to probability sampling. Few texts on archaeological analysis even mention exchangeability (Banning Reference Banning2000:88; Buck et al. Reference Buck, Cavanagh and Litton1996:72–74; Orton Reference Orton2000:21). One other does, but without naming it (Drennan Reference Drennan2010:88–92). In archaeological research literature, I was only able to find a single example (Collins-Elliott Reference Collins-Elliott2017). Clearly, those who have eschewed probability sampling have not been aware of this concept.
Undergraduate Statistical Training
Another candidate cause for the decline is archaeological training (cf. Cowgill Reference Cowgill2015; Thomas Reference Thomas1978:235, 242). A publication on teaching archaeology in the twenty-first century (Bender and Smith Reference Bender and Smith2000) ignores sampling design, or even statistics more generally, except for a single mention of sampling as a useful skill (Schuldenrein and Altschul Reference Schuldenrein, Altschul, Bender and Smith2000:63). A proposed area for reform of archaeological curriculum, “Fundamental Archaeological Skills,” is silent on research design, sampling, and statistics except to list statistics as a “basic skill” in graduate programs (Bender Reference Bender, Bender and Smith2000:33, 42). At least one article on archaeological pedagogy mentions, but does not develop, the role of sampling in field training (Berggren and Hodder Reference Berggren and Hodder2003).
A review of undergraduate textbooks leads to some interesting observations. The selection (Supplemental Text 2) includes all of the English-language textbooks I could find that cover archaeological methods, but it limits multiple-edition books to the earliest and latest editions I could access.
Renfrew and Bahn's (Reference Renfrew and Bahn2008:80–81) explication of major spatial sampling strategies is typical. After briefly mentioning non-probabilistic sampling, they describe random, stratified random, systematic, and systematic unaligned sampling designs, all in spatial application. They illustrate these with the same maps (from Haggett Reference Haggett1965:Figure 7.4) as has virtually every archaeology text that describes sampling since Stephen Plog (Reference Plog and Flannery1976:137) used them in The Early Mesoamerican Village (Figure 1). For stratified sampling, they do not mention the rationale for strata or the need to verify that strata are statistically different. As usual, sampling's justification is that “archaeologists cannot usually afford the time and money necessary to investigate fully the whole of a large site or all sites in a given region” (Renfrew and Bahn Reference Renfrew and Bahn2008:80), while they say that probability sampling allows generalizations about a site or region.
Most texts that do not specialize in quantitative methods give, at best, perfunctory attention to sampling. Not one of 54 introductory texts in my list mentions sequential sampling (Dunnell Reference Dunnell and Green1984) or the newer development, adaptive sampling (Thompson and Seber Reference Thompson and Seber1996), and only five make any mention of sample size, sampling error, or nonspatial sampling. All but two only present sampling in regional survey, and only four mention alternatives to geometrical sample elements. A few misrepresent sampling as a means to find things, especially sites, rather than to estimate parameters or test hypotheses (e.g., Muckle Reference Muckle2014:99; Thomas Reference Thomas1999:127). Seventeen more specialized texts provide a fuller discussion of sampling, but they probably reach smaller, more advanced audiences.
Turning to curriculum, explicit statistical requirements are far from universal. Although variations in how to describe undergraduate programs make comparison difficult, I was able to find information online for 24 of the 25 most highly ranked undergraduate programs internationally (Supplemental Text 3; Quacquarelli Symonds 2019). Of these, at least five (21%) require study in statistics, and eight (33%) have in-house statistical or data-analysis courses. Some may include statistics in other courses, such as science or laboratory courses. At least five have courses on research design (four have courses that may include some research design), but it is unclear whether these cover sampling. Many programs have an honors thesis or capstone course that could include sampling.
Although some archaeology programs emphasize quantitative methods, one of which even says that “quantitative skills and computing ability are indispensable” (Stanford University 2019), the overall impression is that knowledge of statistics or sampling is optional. The only article I found that explicitly addresses sampling education in archaeology (Richardson and Gajewski Reference Richardson and Gajewski2002) is not by archaeologists but by statisticians in a journal on statistics pedagogy.
Publication and Peer Review
One might also ask why the peer-review process does not lead to better explication of sampling designs. As one anonymous reviewer of this article pointed out, this is likely due to a lack of sampling and statistical expertise among a significant proportion of journal editors and manuscript reviewers who, after all, probably received training in programs much like the ones reviewed in the last section.
Archaeological Sampling in the Twenty-First Century
As the histograms in Figure 3 indicate, some twenty-first-century articles in American Antiquity and Journal of Field Archaeology do mention sampling or samples, and there has even been an encouraging “uptick” in the last few years, but rarely do they describe these explicitly as probability samples. In a disproportionate stratified random cluster sample of all research articles in American Antiquity, Journal of Archaeological Science (JAS), Journal of Field Archaeology (JFA), and Journal of Archaeological Method and Theory (JAMT) from 2000 to 2019 (Supplemental Text 4), 24 ± 1.1% of articles mention some kind of sample without specifying what kind of sample it is. Furthermore, some that explicitly use probability samples after 2000 involve samples collected in the 1980s (e.g., Varien et al. Reference Varien, Ortman, Kohler, Glowacki and Johnson2007) rather than presenting any new sample. Few acknowledge use of convenience samples (0.9 ± 0.2%), but it seems likely that most of the unspecified samples were also of this type.
A few sampling-related articles in these and other journals show originality or new approaches (e.g., Arakawa et al. Reference Arakawa, Nicholson and Rasic2013; Burger et al. Reference Burger, Todd, Burnett, Stohlgren and Stephens2004; Perreault Reference Perreault2011; Prasciunas Reference Prasciunas2011). We also find random sampling in simulations (e.g., Deller et al. Reference Deller, Ellis and Keron2009). Despite a few bright spots, however, most of the articles in this period make no use of sampling theory, do not explicitly identify the population they sampled, and do not account for cluster sampling in their statistics—if they provide sampling errors at all. Some in my sample use “sampling” as a synonym for “collecting” (1.3 ± 0.25% overall but almost 3% in American Antiquity and JFA) and “systematic sampling” in a nonstatistical sense (0.4 ± 0.1% but almost 2% in JAMT), or they use “sample” as a synonym for “specimen” (e.g., individual lithics 3.0 ± 0.5%, bones or bone fragments 10.7 ± 0.8%, most of the latter in JAS).
Many authors who mention “samples” actually base analyses on all available evidence, such as all the pottery excavated at a site, or all known Clovis points from a region (8.6 ± 0.7%). These are only samples in the sense of convenience samples, and they are arguably populations in the present.
One of the most common practices is to use “sample” only in the sense of a small amount of material, such as some carbon for dating or a few milligrams of an artifact removed for archaeometric analysis (carbon samples 15.3 ± 0.7%, pottery 5.3 ± 0.74%, other 20.5 ± 1.1%), selected without sampling theory. American Antiquity was most likely to refer to carbon specimens as samples. Many studies use “flotation sample” to refer to individual flotation volumes (4.5 ± 0.4%, mainly in American Antiquity and JFA) rather than the entire sample from a site or context, and we see similar usage of “soil sample” even more often (16 ± 0.8%, most often in JFA).
Articles on regional survey after 2000 often mention sampling with no reference to sampling theory (14.5 ± 8.6%). Some claim “full-coverage” but employ systematic transect samples (0.3 ± 0.16%). Some articles not in this sample claim to use stratified sampling but actually selected “tracts” within strata purposively or by convenience (e.g., Tankosić and Chidiroglou Reference Tankosić and Chidiroglou2010:13; Tartaron Reference Tartaron, Wiseman and Zachos2003:30). Many of these may have been effective in achieving their goals, but it is unclear whether stratification was effective or if they controlled biases in estimates. Among the encouraging exceptions, Parcero-Oubiña and colleagues (Reference Parcero-Oubiña, Fábrega-Álvarez, Salazar, Troncoso, Hayashida, Pino, Borie and Echenique2017) use a stratified sample of agricultural plots in Chile, having estimated the sample size they would need in each stratum to achieve desired confidence intervals, and PPS random point sampling in each stratum to select plots.
In site excavation, purposive sampling is typical, while selection of excavated contexts for detailed analysis often occurs with little or no explanation (e.g., Douglass et al. Reference Douglass, Holdaway, Fanning and Shiner2008). Excavation directors understandably use expertise and experience or, at times, deposit models (sometimes based on purposive auger samples) to decide which parts of sites might best provide evidence relevant to their research questions (Carey et al. Reference Carey, Howard, Corcoran, Knight and Heathcote2019). However, at least one study outside my sample used spatial sampling to estimate the number of features (Welch Reference Welch2013).
Justifiably, purposive sampling dominates best practice in radiocarbon dating (Calabrisotto et al. Reference Calabrisotto, Amadio, Fedi, Liccioli and Bombardieri2017), whereas sampling for micromorphology, pollen, and plant macroremains tends to be systematic within vertical columns, and selection of column locations is purposive, if described at all (e.g., Pop et al. Reference Pop, Bakels, Kuijper, Mücher and van Dijk2015). Alternatively, sampling protocols for plant remains may involve a type of cluster sample with a single, standardized sediment volume (e.g., 10 L) from every stratigraphic context or feature in an excavation (e.g., Gremillion et al. Reference Gremillion, Windingstad and Sherwood2008). At least one case involves flotation of all contexts in their entirety (Mrozowski et al. Reference Mrozowski, Franklin and Hunt2008), not a sample at all. One article explicitly calculates sample sizes needed at desired levels of error and confidence for comparing Korean assemblages of plant remains (Lee Reference Lee2012), while Hiscock (Reference Hiscock2001) explicitly addresses sample size in artifact analyses.
In heritage management, our evidence comes more from regulatory frameworks and guidelines (Supplemental Text 5) than from the articles reviewed for Supplemental Texts 1 and 4. Although much of this work looks like sampling, the main purpose of regional CRM inventory surveys in most cases is to detect and document archaeological resources, not just sample them (e.g., MTCS 2011:74). Many North American guidelines specify systematic survey by pedestrian transects or shovel tests, but their purpose is primarily site discovery, not parameter estimation (see Shott Reference Shott1985, Reference Shott1987, Reference Shott1989), and selection of in-site areas for excavation tends to be purposive (Neumann and Sanford Reference Neumann and Sanford2010:174). Some jurisdictions do offer flexibility, however. The Bureau of Land Management (BLM) “does not discuss how to design class II surveys because the methods and theories of sampling are continually being refined” (BLM 2004:21B4). Meanwhile, Wisconsin's standards explicitly address spatial probability sampling in research design (Kolb and Stevenson Reference Kolb and Stevenson1997:34). A memorandum of agreement among stakeholders in the Permian Basin has oil and gas developers pay into a pool that funds archaeological research and management in this part of New Mexico without tying it to project areas (Larralde et al. Reference Larralde, Stein and Schlanger2016; Schlanger et al. Reference Schlanger, MacDonell, Larralde and Sheen2013). This approach allows more flexible research designs (Shott Reference Shott and Wandsnider1992), including, where warranted, probability sampling.
It may not seem obvious that sampling is relevant to experimental archaeology but, for almost a century, probability has had a role in ensuring that confounding factors, such as differential skill among flintknappers or variations in bone geometry, do not compromise the results of experiments (Fisher Reference Fisher1935). In a way, experimenters sample from all possible combinations of “treatments.” Yet, sampling theory has had little impact on experimental archaeology. In introducing a volume on this topic, Outram (Reference Outram2008) makes no mention of statistical sampling or randomization, nor do any of the articles in that volume. Some articles in Ferguson (Reference Ferguson2010) and Khreisheh and colleagues (Reference Khreisheh, Davies and Bradley2013) discuss experimental controls or confounding factors, but none highlights randomization, arguably the most important protocol. Only Harry (Reference Harry and Ferguson2010:35) employs randomization but draws no attention to its importance. Of the articles in Supplemental Text 4, 8.6 ± 0.7% described experiments that made no use of randomization. Most of these were in JAS. Some encouraging exceptions highlight validity, confounding variables, and use of randomness (Lin et al. Reference Lin, Rezek and Dibble2018 and articles cited there). Excluding randomness from experimental protocols risks confusing variables of interest with such variables as experimenter fatigue or the order in which a flintknapper selects cores (cf. Daniels Reference Daniels1978).
More generally, claims for random samples often have no supporting description (e.g., Benedict Reference Benedict2009:157). It is difficult to assess whether these were true probability samples or just haphazard (“grab-bag”) convenience samples; in Supplemental Text 1, I give them the benefit of the doubt. As noted, 24% of articles in Supplemental Text 4 use samples without stating their sampling methods (31 ± 5% of articles in American Antiquity). Some researchers mix a random sample with a judgment sample without providing data that would allow us to disentangle them (e.g., Vaughn and Neff Reference Vaughn and Neff2000).
Sometimes we find such puzzling claims as “although they were collected from a single unit . . . , these bones are a fairly representative sample of the faunal assemblage” (Flad Reference Flad2005:239) or “although ⅛-inch screens can cause significant biases . . . exceptional preservation . . . along with the dearth of very small fish . . . suggest that our samples are relatively representative” (Rick et al. Reference Rick, Erlandson and Vellanoweth2001:599). One article admits that three houses constitute a small sample but claims it is a “reasonable representative sample” of some unidentified population (Hunter et al. Reference Hunter, Silliman and Landon2014:716). Baseless assertions that samples are “representative” occur in 2.8 ± 0.4% of articles in Supplemental Text 4, but they are especially prevalent in JFA (6.8 ± 2.3%). Other authors assume that a large sample size is enough to make their samples representative. It is possible that some of these projects did employ probability sampling, but if so, they did not describe it (e.g., Spencer et al. Reference Spencer, Redmond and Elson2008).
At least one study, apparently based on a convenience sample, claims that “relatively consistent” artifact densities across a site indicate that patterns identified “did not result from sampling bias” (Loendorf et al. Reference Loendorf, Fertelmes and Lewis2013:272). Another suggests that a pattern it identifies “does not stem from vagaries in sampling” (Yasur-Landau et al. Reference Yasur-Landau, Cline, Koh, Ben-Shlomo, Marom, Ratzlaff and Samet2015:612) without describing any sampling design that would have assured this. Yet another asserts that “five . . . fragments selected nonrandomly and another five . . . indiscriminately . . . comprise a random sample” (Schneider Reference Schneider2015:519).
Other authors proudly ignore statisticians’ warning that “errors introduced by using simple-random-sampling formulas for . . . cluster samples can be extremely serious” (Blalock Reference Blalock1979:571). Campbell acknowledges use of a cluster sample but implies that the “statistically-informed” are being pedantic when he claims “conventional statistics . . . have been shown to work well” (Campbell Reference Campbell2017:15). Poteate and Fitzpatrick (Reference Poteate and Fitzpatrick2013) similarly use the statistics for simple random element sampling on simulated cluster samples, yielding incorrect confidence intervals on such measures as NISP. They also ignore that there is no reason to expect a small sample to yield the same MNI or taxonomic richness as a whole population, since these are very different levels of aggregation, and call to mind Hole's (Reference Hole1980:226) disparagement of many such simulations.
These examples suggest a field that has mostly given up on sampling theory, notwithstanding Figure 3's slight uptick in the last few years and the presence of some very good exceptions to the trend. Not all archaeological research should employ probability sampling, and we all make mistakes, but some statements like those just mentioned pose serious concerns. Too many articles mention samples with no indication of whether they were probabilistic or not but treat them as representative. Many use “sample” simply to refer to specimens, selections, or fragments, and “number of samples” to mean sample size. Finally, authors of some studies that did not employ probability sampling are not shy about blaming the failure of results to meet expectations on “probable sampling error” rather than on incorrect hypotheses or methods. This poses grave challenges to the validity of the articles’ conclusions.
Can We Revive Probability Sampling?
Not all of archaeology benefits from probability sampling. We are not always interested in the “typical” or “average,” but rather in targeting significant anomalies, optimal preservation, or evidence relevant to specific hypotheses. In some contexts, however, inattention to sample quality has real consequences.
Sampling theory remains important whenever we want to generalize about or compare populations without observing them in their entirety, such as estimating total roofed area in an Iroquoian village without excavating an entire site (cf. Shott Reference Shott1987). Inattention to sampling could lead to the erroneous inference of significant difference between sites, or change over time, when there is not—or, conversely, failure to identify significant differences or changes that actually did occur.
It also has a role in experimental archaeology. Experimenters must demonstrate that they are measuring what they purport to be measuring by controlling for confounding variables, such as skill differences among participants or quality differences in materials. One tool for this is randomization, much like using a probability sample from a population of potential experimental configurations.
So, how might we encourage more serious attention to and more widespread use of thoughtful sampling in archaeology?
In place of “cookbook” descriptions of sampling, textbooks could contextualize sampling within problem-oriented research design. They could encourage students to think about certain situations in which sampling would be helpful, and other situations in which more targeted research would be more useful. The key is to ensure validity of observations and conclusions (Daniels Reference Daniels1978).
Course curricula could include courses that prepare students to understand sampling as a practical aspect of research design, not just regional or site survey. Rather than teach textbook sample designs, we could encourage students to think critically about preventing their own preconceptions or vagaries of research from yielding biased characterizations of sites, artifacts, or assemblages, or inferences of dubious validity.
We could also be more precise with terminology. Should we restrict the word “sample” to subsets of observations from a larger population? And should we replace “flotation sample,” “NAA sample,” and the like with “flotation volume,” “NAA specimen,” and so on? Even “carbon sample” deserves a better term to indicate that its selection has nothing to do with sampling theory. Oxymorons such as “sample population” and “sample parameter” have no place in our literature. We need to clarify whether a “stratified” sample is stratified in the statistical sense or just a specimen from a stratified deposit, and “systematic,” in the context of sampling, should not just be a synonym for “methodical.”
Conclusions
I suggest the following sampling “takeaways”:
(1) Probability sampling is not always appropriate but, when generalizing about or comparing populations on the basis of limited observations, failure to employ probability sampling may threaten the validity of results.
(2) Sampling is not only for spatial situations, but also assemblages of artifacts, faunal and plant remains, temper or chemical evidence in pottery or lithics, and many kinds of experiments.
(3) Cluster sampling, ubiquitous in archaeology, requires appropriate statistics for estimating variance. Ignoring this affects the outcomes of statistical tests.
(4) Some archaeological samples are PPS samples, also requiring appropriate statistics to avoid bias.
(5) Stratified sampling requires relevant prior information and follow-up evaluation to ensure that criteria for stratification were effective.
(6) Straightforward methods are available to ensure that sample sizes are adequate; arbitrary sampling fractions are worthless.
(7) When in doubt, talk to a statistician.
Sampling theory has had a rocky ride in archaeology. Negative perceptions of scientism, promotion of full-coverage survey, and flaws in past sampling-based research probably discouraged archaeologists’ interest in formal sampling methods.
Yet the need for valid inferences persists, perhaps all the more as we increasingly mine “Big Data” from legacy projects. Probability sampling has the potential, in conjunction with well-conceived purposive selection, to contribute to archaeological research designs that are thoughtful, efficient, and able to yield valid inferences. We should not let misconceptions of the 1970s or 1990s deter us from taking full advantage of its well-established methods.
Acknowledgments
I am grateful to R. Lee Lyman and several anonymous reviewers for their insightful, constructive, and extremely useful comments on previous versions of this article. I would also like to thank Gary Lock, Piraye Hacıgüzeller, and Mark Gillings for the invitation that unexpectedly led me to write it, and Sophia Arts for editorial work and assistance in compiling statistics on published articles.
Data Availability Statement
No original data were used in this article.
Supplemental Materials
For supplemental material accompanying this article, visit https://doi.org/10.1017/aaq.2020.39 .
Supplemental Text 1. List of publications in American Antiquity (1960–2019) and Journal of Field Archaeology (1974–2019) used for the histograms in Figure 3. Note that there was an interruption in Journal of Field Archaeology from 2002 until early 2004.
Supplemental Text 2. Distribution of sampling topics covered in a selection of introductory undergraduate texts, as well as some more specialized ones, over several decades. The list excludes texts that only cover culture history and, for texts with many editions, only includes one early and one recent edition.
Supplemental Text 3. The 25 highest-ranked international undergraduate programs in archaeology (Quacquarelli Symonds Limited 2019), listed alphabetically, and their 2018–2019 or 2019–2020 requirements relevant to sampling, according to program websites. Where universities had multiple archaeology programs, the table reflects the one related to anthropology or prehistory. Information that was not available publicly online is marked by (?). As no information on archaeological programs at the Sorbonne was available online, the sample size is n = 24.
Supplemental Text 4. Disproportionate stratified random cluster sample of the population of research articles and reports in American Antiquity, Journal of Archaeological Science, Journal of Field Archaeology, and Journal of Archaeological Method and Theory from January 2000 to December 2019, summarizing the proportions of articles that use “sample” or sampling in various ways, along with evaluation of the stratification's effectiveness.
Supplemental Text 5. Examples of standards and guidelines for archaeological fieldwork in the heritage (CRM) industry.





 Open access
Open access