



No CrossRef data available.
Published online by Cambridge University Press: 28 November 2024
In order to improve the performance of 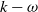 $k - \omega $ SST model in turbomachinery, previous studies have used the machine-learning (ML) technique to obtain turbulence models (for example, the ML-RANS EQ model). However, these models do not lead to satisfactory results in complex flows in turbomachinery. In this study, we use non-equilibrium training dataset to obtain a new turbulence model (i.e., the ML-RANS TR-NE-EQ model). Calculations in various cases of turbine cascade flows show that ML-RANS TR-NE-EQ model performs obviously better than ML-RANS EQ model as well as
$k - \omega $ SST model in turbomachinery, previous studies have used the machine-learning (ML) technique to obtain turbulence models (for example, the ML-RANS EQ model). However, these models do not lead to satisfactory results in complex flows in turbomachinery. In this study, we use non-equilibrium training dataset to obtain a new turbulence model (i.e., the ML-RANS TR-NE-EQ model). Calculations in various cases of turbine cascade flows show that ML-RANS TR-NE-EQ model performs obviously better than ML-RANS EQ model as well as 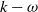 $k - \omega $ SST model.
$k - \omega $ SST model.
 ${\rm{R}}{{\rm{e}}_\tau }$
= 590, Phys. Fluids, 1999, 11, (4), pp 943–945.CrossRefGoogle Scholar
${\rm{R}}{{\rm{e}}_\tau }$
= 590, Phys. Fluids, 1999, 11, (4), pp 943–945.CrossRefGoogle Scholar $\omega $
model using kinematic vorticity for corner separation in compressor cascades, Sci. China Technol. Sci., 2016, 59, (5), pp 795–806.Google Scholar
$\omega $
model using kinematic vorticity for corner separation in compressor cascades, Sci. China Technol. Sci., 2016, 59, (5), pp 795–806.Google Scholar $re$
= 3000. part 1. subcritical disturbance, J. Fluid Mech., 1999, 398, pp 181–224.Google Scholar
$re$
= 3000. part 1. subcritical disturbance, J. Fluid Mech., 1999, 398, pp 181–224.Google Scholar