







1. Introduction
The weighted recursive graph (WRG) model is a weighted multigraph generalisation of the random recursive tree model in which each vertex has a (random) weight and out-degree
 $m\in\mathbb{N}$
. The graph process
$m\in\mathbb{N}$
. The graph process
 $(\mathcal{G}_n,n\in\mathbb{N})$
is initialised with a single vertex 1 with vertex-weight
$(\mathcal{G}_n,n\in\mathbb{N})$
is initialised with a single vertex 1 with vertex-weight
 $W_1$
, and at every step
$W_1$
, and at every step
 $n\geq 2$
, vertex n is assigned vertex-weight
$n\geq 2$
, vertex n is assigned vertex-weight
 $W_n$
and m half-edges and is added to the graph. Conditionally on the weights, each half-edge is then independently connected to a vertex i in
$W_n$
and m half-edges and is added to the graph. Conditionally on the weights, each half-edge is then independently connected to a vertex i in
 $\{1,\ldots,n-1\}$
with probability
$\{1,\ldots,n-1\}$
with probability
 $W_i/\sum_{j=1}^{n-1}W_j$
. The case
$W_i/\sum_{j=1}^{n-1}W_j$
. The case
 $m=1$
yields the weighted recursive tree (WRT) model, first introduced by Borovkov and Vatutin [Reference Borovkov and Vatutin3, Reference Borovkov and Vatutin4]. In this paper we are interested in the asymptotic behaviour of the vertex labels of vertices that attain the maximum degree in the graph, when the vertex-weights are independent and identically distributed (i.i.d.) bounded random variables. This was formerly only known for the random recursive tree model [Reference Banerjee and Bhamidi2], a special case of the WRT which is obtained when
$m=1$
yields the weighted recursive tree (WRT) model, first introduced by Borovkov and Vatutin [Reference Borovkov and Vatutin3, Reference Borovkov and Vatutin4]. In this paper we are interested in the asymptotic behaviour of the vertex labels of vertices that attain the maximum degree in the graph, when the vertex-weights are independent and identically distributed (i.i.d.) bounded random variables. This was formerly only known for the random recursive tree model [Reference Banerjee and Bhamidi2], a special case of the WRT which is obtained when
 $W_i=1$
for all
$W_i=1$
for all
 $i\in\mathbb{N}$
.
$i\in\mathbb{N}$
.
After the introduction of the WRT model by Borovkov and Vatutin, Hiesmayr and Işlak studied the height, depth, and size of the tree branches of this model. Mailler and Uribe Bravo [Reference Mailler and Uribe Bravo13], as well as Sénizergues [Reference Sénizergues17] and Sénizergues and Pain [Reference Pain and Sénizergues14, Reference Pain and Sénizergues15], study the weighted profile and height of the WRT model. Mailler and Uribe Bravo consider random vertex-weights with particular distributions, whereas Sénizergues and Pain allow for a more general model with sequences of both deterministic and random weights.
Iyer [Reference Iyer9] and the more general work by Fountoulakis and Iyer [Reference Fountoulakis and Iyer8] study the degree distribution of a large class of evolving weighted random trees, of which the WRT model is a particular example, and Lodewijks and Ortgiese [Reference Lodewijks and Ortgiese12] study the degree distribution of the WRG model. In both cases, an almost sure limiting degree distribution for the empirical degree distribution is identified. Lodewijks and Ortgiese [Reference Lodewijks and Ortgiese12] also study the maximum degree and the labels of the maximum-degree vertices of the WRG model for a large range of vertex-weight distributions. In particular, we distinguish two main cases in the behaviour of the maximum degree: when the vertex-weight distribution has unbounded support, and when it has bounded support. In the former case the behaviour and size of the labels of maximum-degree vertices are mainly controlled by a balance of vertices being old (i.e. having a small label) and having a large vertex-weight. In the latter case, because the vertex-weights are bounded, the behaviour is instead controlled by a balance of vertices being old and having a degree which significantly exceeds their expected degree.
Finally, Eslava, Lodewijks, and Ortgiese [Reference Eslava, Lodewijks and Ortgiese7] describe the asymptotic behaviour of the maximum degree in the WRT model in more detail (compared to [Reference Lodewijks and Ortgiese12]) when the vertex-weights are i.i.d. bounded random variables, under additional assumptions on the vertex-weight distribution. In particular, [Reference Eslava, Lodewijks and Ortgiese7] outlines several classes of vertex-weight distributions for which different higher-order behaviour is observed.
In this paper we identify the growth rate of the labels of vertices that attain the maximum degree, assuming only that the vertex-weights are almost surely bounded. Setting
 \begin{equation*}\theta_m\;:\!=\;1+\mathbb{E}\left[W\right]/m \quad \text{ and } \quad \mu_m\;:\!=\;1-(\theta_m-1)/(\theta_m\log\theta_m),\end{equation*}
\begin{equation*}\theta_m\;:\!=\;1+\mathbb{E}\left[W\right]/m \quad \text{ and } \quad \mu_m\;:\!=\;1-(\theta_m-1)/(\theta_m\log\theta_m),\end{equation*}
we show that the labels of vertices that attain the maximum degree are almost surely of the order
 $n^{\mu_m(1+o(1))}$
. This confirms a conjecture by Lodewijks and Ortgiese [Reference Lodewijks and Ortgiese12, Conjecture 2.11], improves a recent result of Banerjee and Bhamidi [Reference Banerjee and Bhamidi2] for the location of the maximum degree in the random recursive tree model (which is obtained by setting
$n^{\mu_m(1+o(1))}$
. This confirms a conjecture by Lodewijks and Ortgiese [Reference Lodewijks and Ortgiese12, Conjecture 2.11], improves a recent result of Banerjee and Bhamidi [Reference Banerjee and Bhamidi2] for the location of the maximum degree in the random recursive tree model (which is obtained by setting
 $\mathbb{E}\left[W\right]=1$
,
$\mathbb{E}\left[W\right]=1$
,
 $m=1$
, so that
$m=1$
, so that
 $\mu_1=1-1/(2\log 2)$
) from convergence in probability to almost sure convergence, and extends their result to the WRG model. Furthermore, for the WRT model, that is, the case
$\mu_1=1-1/(2\log 2)$
) from convergence in probability to almost sure convergence, and extends their result to the WRG model. Furthermore, for the WRT model, that is, the case
 $m=1$
, under an additional assumption on the vertex-weight distribution, we are able to provide a central limit theorem for the rescaled labels of uniform vertices
$m=1$
, under an additional assumption on the vertex-weight distribution, we are able to provide a central limit theorem for the rescaled labels of uniform vertices
 $v_1,\ldots, v_k$
with
$v_1,\ldots, v_k$
with
 $k\in\mathbb{N}$
, conditionally on the event that the in-degree of vertex
$k\in\mathbb{N}$
, conditionally on the event that the in-degree of vertex
 $v_i$
is at least
$v_i$
is at least
 $d_i$
for each
$d_i$
for each
 $i\in[k]$
, for a range of values of the
$i\in[k]$
, for a range of values of the
 $d_i$
. Finally, for several specific cases of vertex-weight distribution, we prove the joint convergence of the rescaled degree and label of high-degree vertices to a marked point process. The points in this marked point process are defined in terms of a Poisson point process on
$d_i$
. Finally, for several specific cases of vertex-weight distribution, we prove the joint convergence of the rescaled degree and label of high-degree vertices to a marked point process. The points in this marked point process are defined in terms of a Poisson point process on
 $\mathbb{R}$
, and the marks are Gaussian random variables. These additional assumptions on the vertex-weight distribution are similar to the assumptions made by Eslava, Lodewijks, and Ortgiese in [Reference Eslava, Lodewijks and Ortgiese7] to provide higher-order asymptotic results for the growth rate of the maximum degree in the WRT model, but relax a particular technical condition used in [Reference Eslava, Lodewijks and Ortgiese7], and our results allow for an extension of their results as well.
$\mathbb{R}$
, and the marks are Gaussian random variables. These additional assumptions on the vertex-weight distribution are similar to the assumptions made by Eslava, Lodewijks, and Ortgiese in [Reference Eslava, Lodewijks and Ortgiese7] to provide higher-order asymptotic results for the growth rate of the maximum degree in the WRT model, but relax a particular technical condition used in [Reference Eslava, Lodewijks and Ortgiese7], and our results allow for an extension of their results as well.
Notation. Throughout the paper we use the following notation: we let
 $\mathbb{N}\;:\!=\;\{1,2,\ldots\}$
denote the natural numbers, set
$\mathbb{N}\;:\!=\;\{1,2,\ldots\}$
denote the natural numbers, set
 $\mathbb{N}_0\;:\!=\;\{0,1,\ldots\}$
to include zero, and let
$\mathbb{N}_0\;:\!=\;\{0,1,\ldots\}$
to include zero, and let
 $[t]\;:\!=\;\{i\in\mathbb{N}\;:\; i\leq t\}$
for any
$[t]\;:\!=\;\{i\in\mathbb{N}\;:\; i\leq t\}$
for any
 $t\geq 1$
. For
$t\geq 1$
. For
 $x\in\mathbb{R}$
, we let
$x\in\mathbb{R}$
, we let
 $\lceil x\rceil\;:\!=\;\inf\{n\in\mathbb{Z}\;:\; n\geq x\}$
and
$\lceil x\rceil\;:\!=\;\inf\{n\in\mathbb{Z}\;:\; n\geq x\}$
and
 $\lfloor x\rfloor\;:\!=\;\sup\{n\in\mathbb{Z}\;:\; n\leq x\}$
. For
$\lfloor x\rfloor\;:\!=\;\sup\{n\in\mathbb{Z}\;:\; n\leq x\}$
. For
 $x\in \mathbb{R}$
,
$x\in \mathbb{R}$
,
 $k\in\mathbb{N}$
, we let
$k\in\mathbb{N}$
, we let
 $(x)_k\;:\!=\;x(x-1)\cdots (x-(k-1))$
and
$(x)_k\;:\!=\;x(x-1)\cdots (x-(k-1))$
and
 $(x)_0\;:\!=\;1$
and use the notation
$(x)_0\;:\!=\;1$
and use the notation
 $\bar d$
to denote a k-tuple
$\bar d$
to denote a k-tuple
 $d=(d_1,\ldots, d_k)$
(the size of the tuple will be clear from the context), where the
$d=(d_1,\ldots, d_k)$
(the size of the tuple will be clear from the context), where the
 $d_1,\ldots, d_k$
are either numbers or sets. For sequences
$d_1,\ldots, d_k$
are either numbers or sets. For sequences
 $(a_n,b_n)_{n\in\mathbb{N}}$
such that
$(a_n,b_n)_{n\in\mathbb{N}}$
such that
 $b_n$
is positive for all n, we say that
$b_n$
is positive for all n, we say that
 $a_n=o(b_n)$
,
$a_n=o(b_n)$
,
 $a_n=\omega(b_n)$
,
$a_n=\omega(b_n)$
,
 $a_n\sim b_n$
, or
$a_n\sim b_n$
, or
 $a_n=\mathcal{O}(b_n)$
if
$a_n=\mathcal{O}(b_n)$
if
 $\lim_{n\to\infty} a_n/b_n=0$
, if
$\lim_{n\to\infty} a_n/b_n=0$
, if
 $\lim_{n\to\infty} |a_n|/b_n=\infty$
, if
$\lim_{n\to\infty} |a_n|/b_n=\infty$
, if
 $\lim_{n\to\infty} a_n/b_n=1$
, or if there exists a constant
$\lim_{n\to\infty} a_n/b_n=1$
, or if there exists a constant
 $C>0$
such that
$C>0$
such that
 $|a_n|\leq Cb_n$
for all
$|a_n|\leq Cb_n$
for all
 $n\in\mathbb{N}$
, respectively. For random variables
$n\in\mathbb{N}$
, respectively. For random variables
 $X,(X_n)_{n\in\mathbb{N}}$
we let
$X,(X_n)_{n\in\mathbb{N}}$
we let
 $X_n\buildrel {d}\over{\longrightarrow} X$
,
$X_n\buildrel {d}\over{\longrightarrow} X$
,
 $X_n\buildrel {\mathbb{P}}\over{\longrightarrow} X$
, and
$X_n\buildrel {\mathbb{P}}\over{\longrightarrow} X$
, and
 $X_n\buildrel {a.s.}\over{\longrightarrow} X$
respectively denote convergence in distribution, convergence in probability, and almost sure convergence of
$X_n\buildrel {a.s.}\over{\longrightarrow} X$
respectively denote convergence in distribution, convergence in probability, and almost sure convergence of
 $X_n$
to X. We let
$X_n$
to X. We let
 $\Phi\;:\;\mathbb{R}\to(0,1)$
denote the cumulative density function of a standard normal random variable, and for a set
$\Phi\;:\;\mathbb{R}\to(0,1)$
denote the cumulative density function of a standard normal random variable, and for a set
 $B\subseteq \mathbb{R}$
we abuse this notation to also define
$B\subseteq \mathbb{R}$
we abuse this notation to also define
 $\Phi(B)\;:\!=\;\int_B \phi(x)\,\textrm{d} x$
, where
$\Phi(B)\;:\!=\;\int_B \phi(x)\,\textrm{d} x$
, where
 $\phi(x)\;:\!=\; \Phi'(x)$
denotes the probability density function of a standard normal random variable. It will be clear from the context which of the two definitions is to be applied. Finally, we use the conditional probability measure
$\phi(x)\;:\!=\; \Phi'(x)$
denotes the probability density function of a standard normal random variable. It will be clear from the context which of the two definitions is to be applied. Finally, we use the conditional probability measure
 $\mathbb{P}_W\!\left(\cdot\right)\;:\!=\;\mathbb{P}(\!\cdot\! |(W_i)_{i\in\mathbb{N}})$
and conditional expectation
$\mathbb{P}_W\!\left(\cdot\right)\;:\!=\;\mathbb{P}(\!\cdot\! |(W_i)_{i\in\mathbb{N}})$
and conditional expectation
 $\mathbb{E}_W[\!\cdot\!]\;:\!=\;\mathbb{E}\left[\cdot|(W_i)_{i\in\mathbb{N}}\right]$
, where the
$\mathbb{E}_W[\!\cdot\!]\;:\!=\;\mathbb{E}\left[\cdot|(W_i)_{i\in\mathbb{N}}\right]$
, where the
 $(W_i)_{i\in\mathbb{N}}$
are the i.i.d. vertex-weights of the WRG model.
$(W_i)_{i\in\mathbb{N}}$
are the i.i.d. vertex-weights of the WRG model.
2. Definitions and main results
We define the weighted recursive graph (WRG) as follows.
Definition 2.1. (Weighted recursive graph.) Let
 $(W_i)_{i\geq 1}$
be a sequence of i.i.d. copies of a random variable W such that
$(W_i)_{i\geq 1}$
be a sequence of i.i.d. copies of a random variable W such that
 $\mathbb{P}({W>0})=1$
, let
$\mathbb{P}({W>0})=1$
, let
 $m\in\mathbb{N}$
, and set
$m\in\mathbb{N}$
, and set
 \begin{equation*} S_n\;:\!=\;\sum_{i=1}^nW_i. \end{equation*}
\begin{equation*} S_n\;:\!=\;\sum_{i=1}^nW_i. \end{equation*}
We construct the weighted recursive graph (WRG) as follows:
-
1. Initialise the graph with a single vertex 1, the root, and assign to the root a vertex-weight
 $W_1$
. We let
$\mathcal{G}_1$
denote this graph.
$W_1$
. We let
$\mathcal{G}_1$
denote this graph. -
2. For
$n\geq 1$
, introduce a new vertex
$n+1$
and assign to it the vertex-weight
$W_{n+1}$
and m half-edges. Conditionally on
$\mathcal{G}_n$
, independently connect each half-edge to some vertex
$i\in[n]$
with probability
$W_i/S_n$
. Let
$\mathcal{G}_{n+1}$
denote this graph.









We treat
 $\mathcal{G}_n$
as a directed graph, where edges are directed from new vertices towards old vertices. Moreover, we assume throughout this paper that the vertex-weights are bounded almost surely.
$\mathcal{G}_n$
as a directed graph, where edges are directed from new vertices towards old vertices. Moreover, we assume throughout this paper that the vertex-weights are bounded almost surely.
Remark 2.1.
-
(i) Note that the edge connection probabilities remain unchanged if we multiply each weight by the same constant. In particular, we assume without loss of generality (in the case of bounded vertex-weights) that
$x_0\;:\!=\;\sup\{x\in\mathbb{R}\,|\, \mathbb{P}({W\leq x})<1\}=1$
. -
(ii) It is possible to extend the definition of the WRG to the case of random out-degree. Specifically, we can allow that vertex
$n+1$
connects to
$\textit{every}$
vertex
$i\in[n]$
independently with probability
$W_i/S_n$
, and the results presented in this paper still hold under this extension.





Throughout, for any
 $n\in\mathbb{N}$
and
$n\in\mathbb{N}$
and
 $i\in[n]$
, we write
$i\in[n]$
, we write
 \begin{equation*}\mathcal{Z}_n(i)\;:\!=\;\text{in-degree of vertex} \textit{i} \text{in}\mathcal{G}_n.\end{equation*}
\begin{equation*}\mathcal{Z}_n(i)\;:\!=\;\text{in-degree of vertex} \textit{i} \text{in}\mathcal{G}_n.\end{equation*}
This paper presents the asymptotic behaviour of the labels of high-degree vertices, the maximum-degree vertices in particular. To that end, we define
 \begin{equation} I_n\;:\!=\;\inf\{i\in[n]\;:\; \mathcal{Z}_n(i)\geq \mathcal{Z}_n(j)\text{ for all }j\in[n]\}.\end{equation}
\begin{equation} I_n\;:\!=\;\inf\{i\in[n]\;:\; \mathcal{Z}_n(i)\geq \mathcal{Z}_n(j)\text{ for all }j\in[n]\}.\end{equation}
We now present our first result, which confirms [Reference Lodewijks and Ortgiese12, Conjecture 2.11].
Theorem 2.1. (Labels of the maximum-degree vertices.) Consider the WRG model as in Definition 2.1 with vertex-weights
 $(W_i)_{i\in\mathbb{N}}$
, which are i.i.d. copies of a positive random variable W such that
$(W_i)_{i\in\mathbb{N}}$
, which are i.i.d. copies of a positive random variable W such that
 $x_0\;:\!=\;\sup\{x>0\;:\;\mathbb{P}({W\leq x})<1\}=1$
. Let
$x_0\;:\!=\;\sup\{x>0\;:\;\mathbb{P}({W\leq x})<1\}=1$
. Let
 $\theta_m\;:\!=\;1+\mathbb{E}\left[W\right]/m$
and recall
$\theta_m\;:\!=\;1+\mathbb{E}\left[W\right]/m$
and recall
 $I_n$
from (2.1). Then
$I_n$
from (2.1). Then
 \begin{equation*} \frac{\log I_n}{\log n}\buildrel {a.s.}\over{\longrightarrow} 1-\frac{\theta_m-1}{\theta_m\log\theta_m}\;=\!:\;\mu_m. \end{equation*}
\begin{equation*} \frac{\log I_n}{\log n}\buildrel {a.s.}\over{\longrightarrow} 1-\frac{\theta_m-1}{\theta_m\log\theta_m}\;=\!:\;\mu_m. \end{equation*}
Remark 2.2.
-
(i) The result also holds for
$\widetilde I_n\;:\!=\;\sup\{i\in\mathbb{N}\;:\; \mathcal{Z}_n(i)\geq \mathcal{Z}_n(j)\text{ for all }j\in[n]\}$
, so that all vertices that attain the maximum degree have a label that is almost surely of the order
$n^{\mu_m(1+o(1))}$
. In fact, the result holds for vertices with ‘near-maximum’ degree as well—that is, for vertices with degree
$\log_{\theta_m}\!n-i_n$
, where
$i_n\to\infty$
and
$i_n=o(\!\log n)$
. -
(ii) As discussed in Remark 2.1(ii), the result presented in Theorem 2.1, including the additional results discussed in Item (i) above, also holds in the case of random out-degree.





When we consider the weighted recursive tree (WRT) model, that is, the WRG model as in Definition 2.1 with
 $m=1$
, we can provide higher-order results for the labels of high-degree vertices. Here, high-degree means that the degree diverges with n. These results are already known for the random recursive tree model, as proved by the author in [Reference Lodewijks11]. To extend these higher-order results to the more general WRT model, additional assumptions on the vertex-weight distribution are required, which are as follows.
$m=1$
, we can provide higher-order results for the labels of high-degree vertices. Here, high-degree means that the degree diverges with n. These results are already known for the random recursive tree model, as proved by the author in [Reference Lodewijks11]. To extend these higher-order results to the more general WRT model, additional assumptions on the vertex-weight distribution are required, which are as follows.
Assumption 2.1. (Vertex-weight distribution.) The vertex-weights
 $W,(W_i)_{i\in\mathbb{N}}$
are i.i.d. strictly positive random variables whose distribution satisfies the following condition:
$W,(W_i)_{i\in\mathbb{N}}$
are i.i.d. strictly positive random variables whose distribution satisfies the following condition:
-
(C1) The essential supremum of the distribution is one;
$x_0\;:\!=\;\sup\{x\in \mathbb{R}\;:\;\mathbb{P}({W\leq x})<1\}=1$
. -
Additionally, we may require the following conditions:
-
(C2) There exist
$a,c_1>0$
,
$\tau\in(0,1),$
and
$x_0\geq 1$
such that
$\mathbb{P}({W\geq 1-1/x})\geq a{\textrm{e}}^{-c_1x^\tau}$
for all
$x\geq x_0$
. -
(C3) There exist
$C,\rho>0$
and
$x_0\in(0,1)$
such that
$\mathbb{P}({W\leq x})\leq Cx^\rho$
for all
$x\in[0,x_0]$
. -
Finally, we may assume the vertex-weights satisfy one of the following cases:
-
Atom: The vertex-weights follow a distribution that has an atom at one, i.e. there exists
$q_0\in(0,1]$
such that
$\mathbb{P}({W=1})=q_0$
. Note that
$q_0=1$
recovers the random recursive tree model. -
Beta: The vertex-weights follow a beta distribution: for some
$\alpha,\beta>0$
and with
$\Gamma$
the gamma function, (2.2)
\begin{equation} \mathbb{P}({W\geq x})=\int_x^1 \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}s^{\alpha-1}(1-s)^{\beta-1}\,\textrm{d} s, \qquad x\in[0,1]. \end{equation}
-
Gamma: The vertex-weights follow a distribution that satisfies, for some
$b\in\mathbb{R}$
,
$c_1>0$
, and
$\tau\geq 1$
such that
$b\leq 0$
if
$\tau>1$
or
$bc_1\leq 1$
when
$\tau=1$
, (2.3)
\begin{equation} \mathbb{P}({W\geq x})=(1-x)^{-b}{\textrm{e}}^{-(x/(c_1(1-x)))^\tau}, \qquad x\in[0,1). \end{equation}
























Remark 2.3.
-
(i) Condition C1 naturally follows from the model definition, and is also stated in Remark 2.1(i). Condition C2 provides a family of vertex-weight distributions for which we can prove a central-limit-theorem-type result for the labels of high-degree vertices. Informally, for vertex-weights with a tail distribution that decays at a sub-exponential rate as it approaches one, it holds that
where
\begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v)\geq d,v\geq n\exp\!(\!-\!(1-\theta^{-1})d+x\sqrt{(1-\theta^{-1})^2d})\right)\approx \mathbb{P}\left(\mathcal{Z}_n(v)\geq d\right)(1-\Phi(x)), \end{equation*}
$\theta\;:\!=\;\theta_1=1+\mathbb{E}\left[W\right]$
, v is a vertex selected uniformly at random from [n],
$x\in\mathbb{R}$
is fixed, and
$d=d(n)$
is an integer-valued sequence that diverges with n. This general result can be used to prove the desired result.
Condition C3 follows from [Reference Eslava, Lodewijks and Ortgiese7]. There, this condition is necessary to make it possible to precisely determine the asymptotic behaviour of
$\mathbb{P}(\mathcal{Z}_n(v)\geq d)$
, where
$d=d(n)\in\mathbb{N}$
is an integer-valued sequence and v is a vertex selected uniformly at random from [n]. It is only needed here in a part of Theorem 2.2. -
(ii) The gamma case derives its name from the fact that
$X\;:\!=\;(1-W)^{-1}$
is distributed as a gamma random variable, conditionally on
$X\geq 1$
. The condition on the parameters ensures that the probability density function is non-negative on [0,1). -
(iii) We observe that both the atom and beta cases satisfy Conditions C1 and C2, whereas the gamma case does not satisfy Condition C2. Indeed, the behaviour observed in the latter case is different from the behaviour observed for vertex-weight distributions that do satisfy Condition C2. More broadly speaking, from the perspective of extreme value theory, any distribution that falls within the Weibull maximum domain of attraction satisfies Condition C2 (e.g. the beta distribution), as do a large range of distributions with bounded support that fall within the Gumbel maximum domain of attraction (e.g.
$W=1-1/X$
, with X a log-normal random variable, conditionally on
$X\geq 1$
). An example of a vertex-weight whose distribution does not satisfy Condition C2 is
$W=1-1/X$
, where X is a standard normal random variable, conditionally on
$X\geq 1$
, which is similar to the gamma case with
$\tau=2$
. For more details on the precise classification of these domains, we refer to [Reference Resnick16].













The following result identifies the rescaling of the label of high-degree vertices (where high-degree denotes a degree that diverges to infinity with n). In particular, it outlines behaviour outside of the range of Theorem 2.1, both for degrees that are smaller and degrees that are larger than the maximum degree.
Theorem 2.2. (Central limit theorem for high-degree vertex labels.) Consider the WRT model, that is, the WRG model as in Definition 2.1 with
 $m=1$
, with vertex-weights
$m=1$
, with vertex-weights
 $(W_i)_{i\in\mathbb{N}}$
which satisfy Conditions C1 and C2 in Assumption 2.1. Fix
$(W_i)_{i\in\mathbb{N}}$
which satisfy Conditions C1 and C2 in Assumption 2.1. Fix
 $k\in\mathbb{N}$
, let
$k\in\mathbb{N}$
, let
 $(d_i)_{i\in[k]}$
be k integer-valued sequences that diverge as
$(d_i)_{i\in[k]}$
be k integer-valued sequences that diverge as
 $n\to\infty$
, and define
$n\to\infty$
, and define
 \begin{equation*} c_i\;:\!=\;\limsup_{n\to\infty}\frac{d_i}{\log n},\qquad i\in[k]. \end{equation*}
\begin{equation*} c_i\;:\!=\;\limsup_{n\to\infty}\frac{d_i}{\log n},\qquad i\in[k]. \end{equation*}
First, assume
 $c_i\in[0,1/\log\theta)$
for all
$c_i\in[0,1/\log\theta)$
for all
 $i\in[k]$
. Then the tuple
$i\in[k]$
. Then the tuple
 \begin{equation*} \bigg(\frac{\log v_i -(\!\log n-(1-\theta^{-1})d_i)}{\sqrt{(1-\theta^{-1})^2d_i}}\bigg)_{i\in[k]}, \end{equation*}
\begin{equation*} \bigg(\frac{\log v_i -(\!\log n-(1-\theta^{-1})d_i)}{\sqrt{(1-\theta^{-1})^2d_i}}\bigg)_{i\in[k]}, \end{equation*}
conditionally on the event
 $\mathcal{Z}_n(v_i)\geq d_i$
for all
$\mathcal{Z}_n(v_i)\geq d_i$
for all
 $i\in[k]$
, converges in distribution to
$i\in[k]$
, converges in distribution to
 $(M_i)_{i\in[k]}$
, which are k independent standard normal random variables. If we additionally assume that Condition C3 of Assumption 2.1 holds, then the result holds for
$(M_i)_{i\in[k]}$
, which are k independent standard normal random variables. If we additionally assume that Condition C3 of Assumption 2.1 holds, then the result holds for
 $(c_i)_{i\in[k]}\in[1/\log\theta,\theta/(\theta-1))^k$
as well.
$(c_i)_{i\in[k]}\in[1/\log\theta,\theta/(\theta-1))^k$
as well.
Remark 2.4.
-
(i) Theorem 2.2 covers vertex-weight distributions that fall in the atom and beta cases as well. As observed in Remark 2.3(iii), such distributions already satisfy Conditions C1 and C2 (the other families of distributions outlined in (iii) are also covered by Theorem 2.2).
-
(ii) Condition C3 allows us to extend Theorem 2.2 to a wider range of degrees
$d_i$
, as it enables us to use [Reference Eslava, Lodewijks and Ortgiese7, Proposition 5.1] (given as Proposition 3.1). This result provides an asymptotic expression for
$\mathbb{P}(\mathcal{Z}_n(v)\geq d)$
, where v is a vertex selected uniformly at random from [n]. This result can be avoided when the degrees
$d_i$
are not too large (i.e.
$\ll \log(n)/\log \theta$
), so that Condition C3 is not required in those cases. We observe that the beta case satisfies Condition C3.




The following corollary is an immediate result from Theorem 2.2.
Corollary 2.1. With the same definitions and assumptions as in Theorem 2.2, additionally assume that for each
 $i\in[k]$
,
$i\in[k]$
,
 \begin{equation*} |d_i-c_i\log n|=o\big(\sqrt{\log n}\big). \end{equation*}
\begin{equation*} |d_i-c_i\log n|=o\big(\sqrt{\log n}\big). \end{equation*}
Then the tuple
 \begin{equation*} \bigg(\frac{\log v_i -(1-c_i(1-\theta^{-1}))\log n}{\sqrt{c_i(1-\theta^{-1})^2\log n}}\bigg)_{i\in[k]}, \end{equation*}
\begin{equation*} \bigg(\frac{\log v_i -(1-c_i(1-\theta^{-1}))\log n}{\sqrt{c_i(1-\theta^{-1})^2\log n}}\bigg)_{i\in[k]}, \end{equation*}
conditionally on the event
 $\mathcal{Z}_n(v_i)\geq d_i$
for all
$\mathcal{Z}_n(v_i)\geq d_i$
for all
 $i\in[k]$
, converges in distribution to
$i\in[k]$
, converges in distribution to
 $(M_i)_{i\in[k]}$
, which are k independent standard normal random variables. Assuming that Condition C3 of Assumption 2.1 holds allows us to extend the result to
$(M_i)_{i\in[k]}$
, which are k independent standard normal random variables. Assuming that Condition C3 of Assumption 2.1 holds allows us to extend the result to
 $c_i\in[1/\log \theta,\theta/(\theta-1))$
for all
$c_i\in[1/\log \theta,\theta/(\theta-1))$
for all
 $i\in[k]$
as well.
$i\in[k]$
as well.
Remark 2.5. In both Theorem 2.2 and Corollary 2.1, the same results can be obtained when working with the conditional event
 $\{\mathcal{Z}_n(v_i)= d_i, i\in[k]\}$
rather than
$\{\mathcal{Z}_n(v_i)= d_i, i\in[k]\}$
rather than
 $\{\mathcal{Z}_n(v_i)\geq d_i, i\in[k]\}$
, with an almost identical proof.
$\{\mathcal{Z}_n(v_i)\geq d_i, i\in[k]\}$
, with an almost identical proof.
Theorem 2.2 is very general, in the sense that Condition C2 is a mild condition satisfied by a wide range of distributions. In contrast, the behaviour of the maximum degree is much more dependent on the precise behaviour of the vertex-weight distribution (see, for example, [Reference Eslava, Lodewijks and Ortgiese7, Theorems 2.6 and 2.7]). The labels of high-degree vertices are much less influenced by the underlying vertex-weight distribution. We provide a heuristic explanation of this fact in Section 3.
When more precise information regarding the vertex-weight distribution is available, as in the atom, beta, and gamma cases, even more can be proved. We state a result for the atom case here. It shows the distributional convergence of degrees and their labels in the WRT under proper rescaling. Let us set
 $\theta\;:\!=\;\theta_1$
,
$\theta\;:\!=\;\theta_1$
,
 $\mu\;:\!=\;\mu_1=1-(\theta-1)/(\theta\log\theta)$
, and define
$\mu\;:\!=\;\mu_1=1-(\theta-1)/(\theta\log\theta)$
, and define
 $\sigma^2\;:\!=\;1-(\theta-1)^2/(\theta^2\log \theta)$
.
$\sigma^2\;:\!=\;1-(\theta-1)^2/(\theta^2\log \theta)$
.
Theorem 2.3. (Degrees and labels in the atom case.) Consider the WRT model, that is, the WRG model as in Definition 2.1 with
 $m=1$
, with vertex-weights
$m=1$
, with vertex-weights
 $(W_i)_{i\in\mathbb{N}}$
which satisfy the atom case in Assumption 2.1. Let
$(W_i)_{i\in\mathbb{N}}$
which satisfy the atom case in Assumption 2.1. Let
 $v^1,v^2,\ldots, v^n$
be the vertices in the tree in decreasing order of their in-degree (where ties are split uniformly at random), let
$v^1,v^2,\ldots, v^n$
be the vertices in the tree in decreasing order of their in-degree (where ties are split uniformly at random), let
 $d_n^i$
and
$d_n^i$
and
 $\ell_n^i$
denote respectively the in-degree and the label of
$\ell_n^i$
denote respectively the in-degree and the label of
 $v^i$
for
$v^i$
for
 $i\in[n]$
, and fix
$i\in[n]$
, and fix
 $\varepsilon\in[0,1]$
. Let
$\varepsilon\in[0,1]$
. Let
 $\varepsilon_n\;:\!=\;\log_\theta n-\lfloor \log_\theta n\rfloor$
, and let
$\varepsilon_n\;:\!=\;\log_\theta n-\lfloor \log_\theta n\rfloor$
, and let
 $(n_j)_{j\in\mathbb{N}}$
be a positive, diverging integer sequence such that
$(n_j)_{j\in\mathbb{N}}$
be a positive, diverging integer sequence such that
 $\varepsilon_{n_j}\to\varepsilon$
as
$\varepsilon_{n_j}\to\varepsilon$
as
 $j\to\infty$
. Finally, let
$j\to\infty$
. Finally, let
 $(P_i)_{i\in\mathbb{N}}$
be the points of the Poisson point process
$(P_i)_{i\in\mathbb{N}}$
be the points of the Poisson point process
 $\mathcal {P}$
on
$\mathcal {P}$
on
 $\mathbb{R}$
with intensity measure
$\mathbb{R}$
with intensity measure
 $\lambda(x)=q_0\theta^{-x}\log \theta\,\textrm{d} x$
, in decreasing order, and let
$\lambda(x)=q_0\theta^{-x}\log \theta\,\textrm{d} x$
, in decreasing order, and let
 $(M_i)_{i\in\mathbb{N}}$
be a sequence of i.i.d. standard normal random variables. Then, as
$(M_i)_{i\in\mathbb{N}}$
be a sequence of i.i.d. standard normal random variables. Then, as
 $j\to\infty$
,
$j\to\infty$
,
 \begin{equation*} \left(d_{n_j}^i-\lfloor \log_\theta n_j\rfloor, \frac{\log(\ell_{n_j}^i)-\mu\log n_j}{\sqrt{(1-\sigma^2)\log n_j}}\right)_{i\in[n_j]}\buildrel {d}\over{\longrightarrow} (\lfloor P_i+\varepsilon\rfloor , M_i)_{i\in\mathbb{N}}. \end{equation*}
\begin{equation*} \left(d_{n_j}^i-\lfloor \log_\theta n_j\rfloor, \frac{\log(\ell_{n_j}^i)-\mu\log n_j}{\sqrt{(1-\sigma^2)\log n_j}}\right)_{i\in[n_j]}\buildrel {d}\over{\longrightarrow} (\lfloor P_i+\varepsilon\rfloor , M_i)_{i\in\mathbb{N}}. \end{equation*}
Remark 2.6. We can view the convergence result in Theorem 2.3 in terms of the weak convergence of marked point processes. Indeed, we can order the points in the marked point process
 \begin{equation*} \mathcal {M}\mathcal {P}^{(n)}\;:\!=\;\sum_{i=1}^n \delta_{(\mathcal{Z}_n(i)-\lfloor \log_\theta n\rfloor, (\!\log i-\mu\log n)/\sqrt{(1-\sigma^2)\log n})} \end{equation*}
\begin{equation*} \mathcal {M}\mathcal {P}^{(n)}\;:\!=\;\sum_{i=1}^n \delta_{(\mathcal{Z}_n(i)-\lfloor \log_\theta n\rfloor, (\!\log i-\mu\log n)/\sqrt{(1-\sigma^2)\log n})} \end{equation*}
in decreasing order with respect to the first argument of the tuples, where
 $\delta$
is a Dirac measure.
$\delta$
is a Dirac measure.
Moreover, Theorem 2.3 extends [Reference Eslava, Lodewijks and Ortgiese7, Theorem 2.5] to a wider range of vertex-weight distributions. Specifically, let us define
 $\mathbb{Z}^*\;:\!=\;\mathbb{Z}\cup\{\infty\}$
and
$\mathbb{Z}^*\;:\!=\;\mathbb{Z}\cup\{\infty\}$
and
 $\mathcal {M}^\#_{\mathbb{Z}^*\times \mathbb{R}}, \mathcal {M}^\#_{\mathbb{Z}^*},$
to be the spaces of boundedly finite measures on
$\mathcal {M}^\#_{\mathbb{Z}^*\times \mathbb{R}}, \mathcal {M}^\#_{\mathbb{Z}^*},$
to be the spaces of boundedly finite measures on
 $\mathbb{Z}^*\times \mathbb{R}$
and
$\mathbb{Z}^*\times \mathbb{R}$
and
 $\mathbb{Z}^*$
, respectively, and define
$\mathbb{Z}^*$
, respectively, and define
 $T\;:\;\mathcal {M}^\#_{\mathbb{Z}^*\times \mathbb{R}}\to \mathcal {M}^\#_{\mathbb{Z}^*}$
for
$T\;:\;\mathcal {M}^\#_{\mathbb{Z}^*\times \mathbb{R}}\to \mathcal {M}^\#_{\mathbb{Z}^*}$
for
 $\mathcal {M}\mathcal {P}\in \mathcal {M}^\#_{\mathbb{Z}^*\times \mathbb{R}}$
by
$\mathcal {M}\mathcal {P}\in \mathcal {M}^\#_{\mathbb{Z}^*\times \mathbb{R}}$
by
 $T( \mathcal {M}\mathcal {P})\;:\!=\; \sum_{(x_1,x_2)\in \mathcal {M}\mathcal {P}}\delta_{x_1}$
.
$T( \mathcal {M}\mathcal {P})\;:\!=\; \sum_{(x_1,x_2)\in \mathcal {M}\mathcal {P}}\delta_{x_1}$
.
 $T( \mathcal {M}\mathcal {P})$
is the restriction of the marked process
$T( \mathcal {M}\mathcal {P})$
is the restriction of the marked process
 $\mathcal {M}\mathcal {P}$
to its first coordinate, i.e. to the ground process
$\mathcal {M}\mathcal {P}$
to its first coordinate, i.e. to the ground process
 $\mathcal {P}\;:\!=\;T(\mathcal {M}\mathcal {P})$
. Since T is continuous and
$\mathcal {P}\;:\!=\;T(\mathcal {M}\mathcal {P})$
. Since T is continuous and
 $\mathcal {M}\mathcal {P}^{(n)}\in \mathcal {M}^\#_{\mathbb{Z}^*\times \mathbb{R}}$
, it follows from the continuous mapping theorem that Theorem 2.3 implies Theorem 2.5 in [Reference Eslava, Lodewijks and Ortgiese7] without the need for Condition C3.
$\mathcal {M}\mathcal {P}^{(n)}\in \mathcal {M}^\#_{\mathbb{Z}^*\times \mathbb{R}}$
, it follows from the continuous mapping theorem that Theorem 2.3 implies Theorem 2.5 in [Reference Eslava, Lodewijks and Ortgiese7] without the need for Condition C3.
Similar results hold in the beta case as well. In the gamma case slightly different behaviour is observed, with additional higher-order terms required in the rescaling of the labels of high-degree vertices. We have deferred the results regarding these two cases to Section 7, since they are similar in nature to Theorems 2.2 and 2.3 but of independent interest. Moreover, the results in Theorems 2.2 and 2.3, as well as the results presented in Section 7, also hold when we consider the WRT with random out-degree, as discussed in Remark 2.1.
Discussion, open problems, and outline of the paper
For the proof of Theorem 2.1, only the asymptotic growth-rate of the maximum degree of the WRG model, as proved by Lodewijks and Ortgiese in [Reference Lodewijks and Ortgiese12, Theorem 2.9, bounded case] (given as Theorem 3.1 here), is required to prove the growth rate of the location of the maximum degree in the WRG model. The proof uses a slightly more careful approach than the proof of [Reference Lodewijks and Ortgiese12, Theorem 2.9, bounded case], which allows us to determine the range of vertices which attain the maximum degree.
In recent work by Eslava, Lodewijks, and Ortgiese [Reference Eslava, Lodewijks and Ortgiese7], more refined asymptotic behaviour for the maximum degree is presented for the WRT model, that is, the WRG model with
 $m=1$
, under additional assumptions on the vertex-weight distribution. Here we refine the proofs of [Reference Eslava, Lodewijks and Ortgiese7] to allow for an extension of the results there and to obtain higher-order results for the location of high-degree vertices. Whether any of these results can be extended to the case
$m=1$
, under additional assumptions on the vertex-weight distribution. Here we refine the proofs of [Reference Eslava, Lodewijks and Ortgiese7] to allow for an extension of the results there and to obtain higher-order results for the location of high-degree vertices. Whether any of these results can be extended to the case
 $m>1$
is an open problem to date.
$m>1$
is an open problem to date.
Finally, more involved results can be proved for the random recursive tree model. There, the joint convergence of the labels and depths of and the graph distance between high-degree vertices can be obtained, as shown by the author in [Reference Lodewijks11, Theorems 2.2 and 2.4]. The analysis of the random recursive tree in [Reference Lodewijks11] relies heavily on a different construction of the tree compared to the WRG and WRT models, which can be viewed as a construction backward in time. This methodology can be applied to the random recursive tree only, and allows for a simplification of the dependence between degree, depth, and label of a vertex. Whether these results can be extended to the weighted tree case is unclear, but such an extension would surely need a different approach.
The paper is organised as follows. In Section 3 we provide a short, non-rigorous, and intuitive argument as to why the result presented in Theorem 2.1 for the WRG model holds, and we briefly discuss the approach to proving the other results stated in Section 2. Section 4 is devoted to proving Theorem 2.1. In Section 5 we introduce some intermediate results related to the WRT model and use these to prove Theorems 2.2 and 2.3. We prove the intermediate results in Section 6. We discuss the additional results (similar to Theorems 2.2 and 2.3) for the beta and gamma cases in Section 7. Finally, the appendix contains several technical lemmas that are used in some of the proofs.
3. Heuristic ideas behind the main results and preliminary results
In this section we present some heuristic, non-rigorous ideas that underpin the main results, as presented in Theorems 2.1, 2.2, and 2.3 (as well as the results presented in Section 7), and we also give some preliminary results required throughout the paper.
3.1. Heuristic ideas
To understand why the maximum degree of WRG model is attained by vertices with labels of order
 $n^{\mu_m(1+o(1))}$
, where
$n^{\mu_m(1+o(1))}$
, where
 $\mu_m\;:\!=\;1-(\theta_m-1)/(\theta_m\log\theta_m)$
, we first state the following observation: for
$\mu_m\;:\!=\;1-(\theta_m-1)/(\theta_m\log\theta_m)$
, we first state the following observation: for
 $m\in\mathbb{N}$
, define
$m\in\mathbb{N}$
, define
 $f_m\;:\;(0,1)\to \mathbb{R}_+$
by
$f_m\;:\;(0,1)\to \mathbb{R}_+$
by
 \begin{equation} f_m(x)\;:\!=\;\frac{1}{\log \theta_m}\bigg(\frac{(1-x)\log \theta_m}{\theta_m-1}-1-\log\!\bigg(\frac{(1-x)\log \theta_m}{\theta_m-1}\bigg)\!\bigg),\qquad x\in(0,1).\end{equation}
\begin{equation} f_m(x)\;:\!=\;\frac{1}{\log \theta_m}\bigg(\frac{(1-x)\log \theta_m}{\theta_m-1}-1-\log\!\bigg(\frac{(1-x)\log \theta_m}{\theta_m-1}\bigg)\!\bigg),\qquad x\in(0,1).\end{equation}
It is readily checked that
 $f_m$
has a unique fixed point
$f_m$
has a unique fixed point
 $x^*_m$
in (0,1), namely
$x^*_m$
in (0,1), namely
 $x^*_m=\mu_m$
, and that
$x^*_m=\mu_m$
, and that
 $f_m(x)>x$
for all
$f_m(x)>x$
for all
 $x\in(0,1)$
,
$x\in(0,1)$
,
 $x\neq \mu_m$
. Then, using a Chernoff bound on
$x\neq \mu_m$
. Then, using a Chernoff bound on
 $\mathcal{Z}_n(i)$
(i.e. using a Markov bound on
$\mathcal{Z}_n(i)$
(i.e. using a Markov bound on
 $\exp\!(t\mathcal{Z}_n(i))$
for
$\exp\!(t\mathcal{Z}_n(i))$
for
 $t>0$
and determining the value of t that minimises the upper bound) yields
$t>0$
and determining the value of t that minimises the upper bound) yields
 \begin{equation} \mathbb{P}_W\!\left(\mathcal{Z}_n(i)\geq \log_{\theta_m}\!n\right)\leq \exp\!(\!-\!\log_{\theta_m}\!n(u_i-1-\log u_i)),\end{equation}
\begin{equation} \mathbb{P}_W\!\left(\mathcal{Z}_n(i)\geq \log_{\theta_m}\!n\right)\leq \exp\!(\!-\!\log_{\theta_m}\!n(u_i-1-\log u_i)),\end{equation}
where
 \begin{equation*}u_i=\frac{mW_i}{\log_{\theta_m}\!n}\sum_{j=i}^{n-1}\frac{1}{S_j}.\end{equation*}
\begin{equation*}u_i=\frac{mW_i}{\log_{\theta_m}\!n}\sum_{j=i}^{n-1}\frac{1}{S_j}.\end{equation*}
Here we use the quantity
 $\log_{\theta_m}\! n$
, as this (asymptotically) is the size of the maximum degree. Let us now assume that
$\log_{\theta_m}\! n$
, as this (asymptotically) is the size of the maximum degree. Let us now assume that
 $i\sim n^\beta$
for some
$i\sim n^\beta$
for some
 $\beta\in(0,1)$
. By Lemma 3.3, almost surely
$\beta\in(0,1)$
. By Lemma 3.3, almost surely
 \begin{equation*}\sum_{j=i}^{n-1}1/S_j =(1+o(1))\log(n/i)/\mathbb{E}\left[W\right]=(1+o(1))(1-\beta)\log (n)/\mathbb{E}\left[W\right],\end{equation*}
\begin{equation*}\sum_{j=i}^{n-1}1/S_j =(1+o(1))\log(n/i)/\mathbb{E}\left[W\right]=(1+o(1))(1-\beta)\log (n)/\mathbb{E}\left[W\right],\end{equation*}
so that
 \begin{equation*}u_i\leq \frac{m(1-\beta)\log \theta_m}{\mathbb{E}\left[W\right]}(1+o(1))=\frac{(1-\beta)\log \theta_m}{\theta_m-1}(1+o(1))<1\end{equation*}
\begin{equation*}u_i\leq \frac{m(1-\beta)\log \theta_m}{\mathbb{E}\left[W\right]}(1+o(1))=\frac{(1-\beta)\log \theta_m}{\theta_m-1}(1+o(1))<1\end{equation*}
almost surely, where the final inequality holds for all n sufficiently large, as
 $\log(1+x)\leq x$
for all
$\log(1+x)\leq x$
for all
 $x>-1$
. Moreover, the o(1) term is independent of i. As
$x>-1$
. Moreover, the o(1) term is independent of i. As
 $x\mapsto x-1-\log x$
is decreasing on (0,1), we can use the almost sure upper bound on
$x\mapsto x-1-\log x$
is decreasing on (0,1), we can use the almost sure upper bound on
 $u_i$
in (3.2), combined with (3.1), to obtain
$u_i$
in (3.2), combined with (3.1), to obtain
 \begin{equation*}\mathbb{P}_W\!\left(\mathcal{Z}_n(i)\geq \log_{\theta_m}\! n\right)\leq\exp\!(\!-\!f_m(\beta)\log n(1+o(1)) ).\end{equation*}
\begin{equation*}\mathbb{P}_W\!\left(\mathcal{Z}_n(i)\geq \log_{\theta_m}\! n\right)\leq\exp\!(\!-\!f_m(\beta)\log n(1+o(1)) ).\end{equation*}
Note that this upper bound depends on i only via
 $i\sim n^\beta$
. We perform a union bound over
$i\sim n^\beta$
. We perform a union bound over
 $\{i\in[n]\;:\; i\leq n^{\mu_m-\varepsilon}\text{ or }i\geq n^{\mu_m+\varepsilon}\}$
. As the sum obtained from the union bound can be well approximated by an integral, we arrive at
$\{i\in[n]\;:\; i\leq n^{\mu_m-\varepsilon}\text{ or }i\geq n^{\mu_m+\varepsilon}\}$
. As the sum obtained from the union bound can be well approximated by an integral, we arrive at
 \begin{equation*}\mathbb P\bigg(\max_{i\in[n]\backslash [n^{\mu_m-\varepsilon}, n^{\mu_m+\varepsilon}]}\mathcal{Z}_n(i) \geq \log_{\theta_m}\! n\bigg)\leq \int_{(0,1)\backslash (\mu_m-\varepsilon,\mu_m+\varepsilon)}\!\!\!\!\!\!\!\!\exp\!((\beta-f_m(\beta))\log n(1+o(1)))\,\textrm{d} \beta.\end{equation*}
\begin{equation*}\mathbb P\bigg(\max_{i\in[n]\backslash [n^{\mu_m-\varepsilon}, n^{\mu_m+\varepsilon}]}\mathcal{Z}_n(i) \geq \log_{\theta_m}\! n\bigg)\leq \int_{(0,1)\backslash (\mu_m-\varepsilon,\mu_m+\varepsilon)}\!\!\!\!\!\!\!\!\exp\!((\beta-f_m(\beta))\log n(1+o(1)))\,\textrm{d} \beta.\end{equation*}
It follows from the properties of the function
 $f_m$
(as stated below (3.1)) that this integral converges to zero with n.
$f_m$
(as stated below (3.1)) that this integral converges to zero with n.
To obtain the more precise behaviour of the labels of high-degree vertices, as in (among others) Theorem 2.2, the precise evaluation of the union bound in the approach sketched above no longer suffices. Instead, for any
 $k\in\mathbb{N}$
, we derive in Proposition 5.1 the asymptotic expression
$k\in\mathbb{N}$
, we derive in Proposition 5.1 the asymptotic expression
 \begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, v_i>\ell_i, i\in[k]\right)\approx \prod_{i=1}^k \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\!\mathbb{P}_W\!\left(X_i\leq\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\bigg], \end{equation}
\begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, v_i>\ell_i, i\in[k]\right)\approx \prod_{i=1}^k \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\!\mathbb{P}_W\!\left(X_i\leq\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\bigg], \end{equation}
where
 $v_1, \ldots,v_k$
are k vertices selected uniformly at random from [n] without replacement,
$v_1, \ldots,v_k$
are k vertices selected uniformly at random from [n] without replacement,
 $\theta\;:\!=\;\theta_1=1+\mathbb{E}\left[W\right]$
, and
$\theta\;:\!=\;\theta_1=1+\mathbb{E}\left[W\right]$
, and
 $X_i\sim\text{Gamma}(d_i+1,1)$
for each
$X_i\sim\text{Gamma}(d_i+1,1)$
for each
 $i\in[k]$
, under certain assumptions on the
$i\in[k]$
, under certain assumptions on the
 $d_i$
and
$d_i$
and
 $\ell_i$
. Heuristically, this follows from the fact that
$\ell_i$
. Heuristically, this follows from the fact that
 $S_j\approx j\mathbb{E}\left[W\right]$
and
$S_j\approx j\mathbb{E}\left[W\right]$
and
 \begin{equation*} \mathcal{Z}_n(j)=\sum_{i=j+1}^n \text{Ber}\bigg(\frac{W_j}{S_{i-1}}\bigg)\approx \text{Poi}\bigg(\sum_{i=j+1}^n \frac{W_j}{i\mathbb{E}\left[W\right]}\bigg)\approx \text{Poi}\bigg(\frac{W_j}{\theta-1}\log(n/j)\bigg). \end{equation*}
\begin{equation*} \mathcal{Z}_n(j)=\sum_{i=j+1}^n \text{Ber}\bigg(\frac{W_j}{S_{i-1}}\bigg)\approx \text{Poi}\bigg(\sum_{i=j+1}^n \frac{W_j}{i\mathbb{E}\left[W\right]}\bigg)\approx \text{Poi}\bigg(\frac{W_j}{\theta-1}\log(n/j)\bigg). \end{equation*}
By conditioning on the value of v, we thus have (with
 $k=1$
for simplicity and dropping indices)
$k=1$
for simplicity and dropping indices)
 \begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v)\geq d, v>\ell\right)\approx \mathbb{P}\left(\text{Poi}\bigg(\frac{W}{\theta-1}\log(n/v)\bigg)\geq d,v>\ell\right), \end{equation*}
\begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v)\geq d, v>\ell\right)\approx \mathbb{P}\left(\text{Poi}\bigg(\frac{W}{\theta-1}\log(n/v)\bigg)\geq d,v>\ell\right), \end{equation*}
where we can remove the index of the vertex-weight because it does not influence the probability, since the weights are i.i.d. We first observe that
 $v/n\buildrel {d}\over{\longrightarrow} U$
, where U is a uniform random variable on (0,1). Second, we have that
$v/n\buildrel {d}\over{\longrightarrow} U$
, where U is a uniform random variable on (0,1). Second, we have that
 $T\;:\!=\;\log(1/U)$
is a rate-one exponential random variable, independent of everything else. Finally, the duality between Poisson and gamma random variables via Poisson processes yields that we can approximate the right-hand side by
$T\;:\!=\;\log(1/U)$
is a rate-one exponential random variable, independent of everything else. Finally, the duality between Poisson and gamma random variables via Poisson processes yields that we can approximate the right-hand side by
 \begin{equation*} \mathbb{P}\left(X\leq \frac{W}{\theta-1}T, T\leq \log(n/\ell)\right)=\mathbb{P}\left(X\leq T_W, T_W\leq \frac{W}{\theta-1}\log(n/\ell)\right), \end{equation*}
\begin{equation*} \mathbb{P}\left(X\leq \frac{W}{\theta-1}T, T\leq \log(n/\ell)\right)=\mathbb{P}\left(X\leq T_W, T_W\leq \frac{W}{\theta-1}\log(n/\ell)\right), \end{equation*}
where
 $X\sim\text{Gamma}(d,1)$
and
$X\sim\text{Gamma}(d,1)$
and
 $T_W\;:\!=\;WT/(\theta-1)$
. Note that
$T_W\;:\!=\;WT/(\theta-1)$
. Note that
 $T_W$
is exponential with rate
$T_W$
is exponential with rate
 $(\theta-1)/W$
, conditionally on W. Setting
$(\theta-1)/W$
, conditionally on W. Setting
 $x\;:\!=\;W\log(n/\ell)/(\theta-1)$
and conditioning on both W and X, we obtain
$x\;:\!=\;W\log(n/\ell)/(\theta-1)$
and conditioning on both W and X, we obtain
 \begin{equation*} \mathbb{P}_W\!\left(X\leq T_W\leq x\,|\, X\right)=\mathbb{1}_{\{X\leq x\}}\int_X^x \frac{\theta-1}{W}{\textrm{e}}^{-(\theta-1)t/W}\,\textrm{d} t=\mathbb{1}_{\{X\leq x\}}\big({\textrm{e}}^{-(\theta-1) X/W}-{\textrm{e}}^{-(\theta-1) x/W}\big). \end{equation*}
\begin{equation*} \mathbb{P}_W\!\left(X\leq T_W\leq x\,|\, X\right)=\mathbb{1}_{\{X\leq x\}}\int_X^x \frac{\theta-1}{W}{\textrm{e}}^{-(\theta-1)t/W}\,\textrm{d} t=\mathbb{1}_{\{X\leq x\}}\big({\textrm{e}}^{-(\theta-1) X/W}-{\textrm{e}}^{-(\theta-1) x/W}\big). \end{equation*}
Taking the expected value with respect to X then yields
 \begin{equation*} \mathbb{P}_W\!\left(X\leq T_W\leq x\right)=\bigg(1+\frac{\theta-1}{W}\bigg)^{-d}\mathbb{P}_W\!\left(X'\leq x\right)-{\textrm{e}}^{-(\theta-1)x/W}\mathbb{P}(X\leq x), \end{equation*}
\begin{equation*} \mathbb{P}_W\!\left(X\leq T_W\leq x\right)=\bigg(1+\frac{\theta-1}{W}\bigg)^{-d}\mathbb{P}_W\!\left(X'\leq x\right)-{\textrm{e}}^{-(\theta-1)x/W}\mathbb{P}(X\leq x), \end{equation*}
where
 $X'\sim\text{Gamma}(d,1+(\theta-1)/W)$
, conditionally on W. As
$X'\sim\text{Gamma}(d,1+(\theta-1)/W)$
, conditionally on W. As
 $X\overset d=(1+(\theta-1)/W)X' \sim \text{Gamma}(d,1)$
, by substituting the definition of x we obtain
$X\overset d=(1+(\theta-1)/W)X' \sim \text{Gamma}(d,1)$
, by substituting the definition of x we obtain
 \begin{equation*} \bigg(\frac{W}{\theta-1+W}\bigg)^d\mathbb{P}_W\!\left(X\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)-\frac\ell n\mathbb{P}_W\!\left(X\leq \frac{W}{\theta-1}\log(n/\ell)\right). \end{equation*}
\begin{equation*} \bigg(\frac{W}{\theta-1+W}\bigg)^d\mathbb{P}_W\!\left(X\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)-\frac\ell n\mathbb{P}_W\!\left(X\leq \frac{W}{\theta-1}\log(n/\ell)\right). \end{equation*}
Conditions on d and
 $\ell$
will allow us to show that the second term is negligible with respect to the first term and hence is an error term. Taking the expected value with respect to W then approximately yields (3.3). This result can be used to obtain more precise statements regarding the label of high-degree vertices, as well as the size of the maximum degree in the tree.
$\ell$
will allow us to show that the second term is negligible with respect to the first term and hence is an error term. Taking the expected value with respect to W then approximately yields (3.3). This result can be used to obtain more precise statements regarding the label of high-degree vertices, as well as the size of the maximum degree in the tree.
We finally comment on Condition C2 and Theorem 2.2. For vertex-weight distributions that satisfy this condition, we can show (as in Lemma A.1 in the appendix) that the main contribution to
 \begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v)\geq d\right)\approx\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^d\right] \end{equation*}
\begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v)\geq d\right)\approx\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^d\right] \end{equation*}
comes from values of W close to one, namely at
 $W=1-Cd^{-\beta}$
for some constant
$W=1-Cd^{-\beta}$
for some constant
 $C>0$
and
$C>0$
and
 $\beta>1/2$
(or even closer to one). Consequently, one would expect this to be the same for the right-hand side of (3.3). Substituting this value of W roughly yields (again dropping indices and setting
$\beta>1/2$
(or even closer to one). Consequently, one would expect this to be the same for the right-hand side of (3.3). Substituting this value of W roughly yields (again dropping indices and setting
 $C=1$
for simplicity)
$C=1$
for simplicity)
 \begin{equation*}\mathbb{E}\left[\Bigg(\frac{W}{\theta-1+W}\Bigg)^d\right]\mathbb{P}\left(X\leq\Bigg(\frac{\theta}{\theta-1}+\frac{1}{d^\beta(\theta-1)}\Bigg)\log (n/\ell)\right). \end{equation*}
\begin{equation*}\mathbb{E}\left[\Bigg(\frac{W}{\theta-1+W}\Bigg)^d\right]\mathbb{P}\left(X\leq\Bigg(\frac{\theta}{\theta-1}+\frac{1}{d^\beta(\theta-1)}\Bigg)\log (n/\ell)\right). \end{equation*}
When we set, for
 $z\in\mathbb{R}$
,
$z\in\mathbb{R}$
,
 \begin{equation*} \ell\;:\!=\;n\exp\!\big(\!-\!(1-\theta^{-1})(\mathbb{E}\left[X\right] - z\sqrt{\textrm{Var}(X)})\big)\approx n\exp\!\big(\!-\!(1-\theta^{-1})(d-z\sqrt{d})), \end{equation*}
\begin{equation*} \ell\;:\!=\;n\exp\!\big(\!-\!(1-\theta^{-1})(\mathbb{E}\left[X\right] - z\sqrt{\textrm{Var}(X)})\big)\approx n\exp\!\big(\!-\!(1-\theta^{-1})(d-z\sqrt{d})), \end{equation*}
this simplifies to
 \begin{equation*} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^d\right]\mathbb{P}\left(\frac{X-\mathbb{E}\left[X\right]}{\sqrt{\textrm{Var}(X)}}\leq -z+\frac{\mathbb{E}\left[X\right](1+o(1))}{\theta d^\beta\sqrt{\textrm{Var}(X)}}\right). \end{equation*}
\begin{equation*} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^d\right]\mathbb{P}\left(\frac{X-\mathbb{E}\left[X\right]}{\sqrt{\textrm{Var}(X)}}\leq -z+\frac{\mathbb{E}\left[X\right](1+o(1))}{\theta d^\beta\sqrt{\textrm{Var}(X)}}\right). \end{equation*}
Now, the probability tends to
 $1-\Phi(z)$
by the central limit theorem when d diverges with n, since
$1-\Phi(z)$
by the central limit theorem when d diverges with n, since
 $\mathbb{E}\left[X\right]=d+1$
and
$\mathbb{E}\left[X\right]=d+1$
and
 $d^\beta\sqrt{\textrm{Var}(X)}\sim d^{1/2+\beta}\gg d$
as
$d^\beta\sqrt{\textrm{Var}(X)}\sim d^{1/2+\beta}\gg d$
as
 $\beta>1/2$
. This thus shows that
$\beta>1/2$
. This thus shows that
 $\log v$
is approximately normal and provides the asymptotic mean and variance.
$\log v$
is approximately normal and provides the asymptotic mean and variance.
For tail distributions that decay at a faster rate near one, the main contribution to the expected value is made for
 $W=1-d^{-\beta}$
with
$W=1-d^{-\beta}$
with
 $\beta\leq 1/2$
, for which this argument does not hold. Here, we require additional higher-order terms in the rescaling of the labels of high-degree vertices. An example of such a family of distributions is presented in the gamma case of Assumption 2.1. Theorem 7.2 provides, to some extent, the behaviour of the labels in this case.
$\beta\leq 1/2$
, for which this argument does not hold. Here, we require additional higher-order terms in the rescaling of the labels of high-degree vertices. An example of such a family of distributions is presented in the gamma case of Assumption 2.1. Theorem 7.2 provides, to some extent, the behaviour of the labels in this case.
3.2. Preliminaries
Here we present some known results that are needed throughout the paper. The first result states the almost sure convergence of the maximum degree in the WRG model, as in [Reference Lodewijks and Ortgiese12, Theorem 2.9].
Theorem 3.1. (Maximum degree in WRGs with bounded random weights [Reference Lodewijks and Ortgiese12].) Consider the WRG model as in Definition 2.1 with almost surely bounded vertex-weights and
 $m\in\mathbb{N}$
. Then
$m\in\mathbb{N}$
. Then
 \begin{equation*} \max_{i\in[n]}\frac{\mathcal{Z}_n(i)}{\log_{\theta_m}\!n}\buildrel {a.s.}\over{\longrightarrow} 1. \end{equation*}
\begin{equation*} \max_{i\in[n]}\frac{\mathcal{Z}_n(i)}{\log_{\theta_m}\!n}\buildrel {a.s.}\over{\longrightarrow} 1. \end{equation*}
The following result concerns the asymptotic behaviour of the limiting (tail) degree distribution
 $p_{\geq d}$
and
$p_{\geq d}$
and
 $p_d$
, defined as
$p_d$
, defined as
 \begin{equation*} p_{\geq d}\;:\!=\;\mathbb{E}\left[\bigg(\frac{W}{\theta_m-1+W}\bigg)^d\right], \qquad p_d\;:\!=\;\mathbb{E}\left[\frac{\theta_m-1}{\theta_m-1+W}\bigg(\frac{W}{\theta_m-1+W}\bigg)^d\right], \end{equation*}
\begin{equation*} p_{\geq d}\;:\!=\;\mathbb{E}\left[\bigg(\frac{W}{\theta_m-1+W}\bigg)^d\right], \qquad p_d\;:\!=\;\mathbb{E}\left[\frac{\theta_m-1}{\theta_m-1+W}\bigg(\frac{W}{\theta_m-1+W}\bigg)^d\right], \end{equation*}
of the weighted recursive graph as d diverges, which combines (parts of) Theorem 2.7 from [Reference Lodewijks and Ortgiese12] and Lemmas 5.5, 7.1, and 7.3 from [Reference Eslava, Lodewijks and Ortgiese7]. For the purposes of this paper, we state the result for the case
 $m=1$
only.
$m=1$
only.
Theorem 3.2. (Asymptotic behaviour of
 $p_{\geq d}$
[Reference Eslava, Lodewijks and Ortgiese7, Reference Lodewijks and Ortgiese12]). Consider the WRT with vertex-weights
$p_{\geq d}$
[Reference Eslava, Lodewijks and Ortgiese7, Reference Lodewijks and Ortgiese12]). Consider the WRT with vertex-weights
 $(W_i)_{i\in\mathbb{N}}$
, i.i.d. copies of a non-negative random variable W which satisfies Condition C1. Recall that
$(W_i)_{i\in\mathbb{N}}$
, i.i.d. copies of a non-negative random variable W which satisfies Condition C1. Recall that
 $\theta\;:\!=\;\theta_1=1+\mathbb{E}\left[W\right]$
. Then, for any
$\theta\;:\!=\;\theta_1=1+\mathbb{E}\left[W\right]$
. Then, for any
 $\xi>0$
and d sufficiently large,
$\xi>0$
and d sufficiently large,
 \begin{equation*} (\theta+\xi)^{-d}\leq p_d\leq p_{\geq d}\leq \theta^{-d}. \end{equation*}
\begin{equation*} (\theta+\xi)^{-d}\leq p_d\leq p_{\geq d}\leq \theta^{-d}. \end{equation*}
Moreover, consider the different cases in Assumption 2.1:
-
• If W satisfies the atom case for some
$q_0\in(0,1]$
,
\begin{equation*} p_{\geq d}=q_0\theta^{-d}(1+o(1)). \end{equation*}
-
• If W satisfies the beta case for some
$\alpha,\beta>0$
,
\begin{equation*} p_{\geq d}=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)}(1-\theta^{-1})^{-\beta} d^{-\beta}\theta^{-d}\big(1+\mathcal{O}(1/k)\big). \end{equation*}
-
• If W satisfies the gamma case for some
$b\in\mathbb{R}$
,
$c_1>0$
, and
$\tau= 1$
such that
$bc_1\leq 1$
, then with
\begin{equation*} p_{\geq d}=Cd^{b/2+1/4}{\textrm{e}}^{-2\sqrt{c_1^{-1}(1-\theta^{-1})d}}\theta^{-d}\big(1+\mathcal{O}(1/\sqrt d)\big), \end{equation*}
$C\;:\!=\;{\textrm{e}}^{c_1^{-1}(1-\theta^{-1})/2}\sqrt{\pi}c_1^{-1/4+b/2}(1-\theta^{-1})^{1/4+b/2}.$










Remark 3.1. The final results which consider the different cases of Assumption 2.1 also hold for
 $p_d$
instead of
$p_d$
instead of
 $p_{\geq d}$
when one adds a multiplicative constant
$p_{\geq d}$
when one adds a multiplicative constant
 $1-\theta^{-1}$
to the right-hand side.
$1-\theta^{-1}$
to the right-hand side.
The following proposition provides an asymptotic expression for the tail degree distribution of k typical vertices under certain conditions [Reference Eslava, Lodewijks and Ortgiese7, Proposition 5.1].
Proposition 3.1. (Distribution of typical vertex degrees [Reference Eslava, Lodewijks and Ortgiese7]). Consider the WRT model, that is, the WRG as in Definition 2.1 with
 $m=1$
, with vertex-weights
$m=1$
, with vertex-weights
 $(W_i)_{i\in[n]}$
which are i.i.d. copies of a positive random variable W that satisfies Conditions C1 and C3 of Assumption 2.1. Fix
$(W_i)_{i\in[n]}$
which are i.i.d. copies of a positive random variable W that satisfies Conditions C1 and C3 of Assumption 2.1. Fix
 $k\in\mathbb{N}$
,
$k\in\mathbb{N}$
,
 $c\in(0,\theta/(\theta-1))$
, and let
$c\in(0,\theta/(\theta-1))$
, and let
 $(v_i)_{i\in[k]}$
be k vertices selected uniformly at random without replacement from [n]. Then, uniformly over
$(v_i)_{i\in[k]}$
be k vertices selected uniformly at random without replacement from [n]. Then, uniformly over
 $d_i\leq c\log n$
,
$d_i\leq c\log n$
,
 $i\in[k]$
,
$i\in[k]$
,
 \begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i,i\in[k]\right)= \prod_{i=1}^k \mathbb{E}\left[\bigg(\frac{W}{\mathbb{E}\left[W\right]+W}\bigg)^{d_i}\right](1+o(1)). \end{equation*}
\begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i,i\in[k]\right)= \prod_{i=1}^k \mathbb{E}\left[\bigg(\frac{W}{\mathbb{E}\left[W\right]+W}\bigg)^{d_i}\right](1+o(1)). \end{equation*}
Finally, we have the following three technical lemmas. The first deals with concentration of sums of i.i.d. random variables and the second with particular multiple integrals that we use in one of the proofs.
Lemma 3.1. (Bounds on partial sums of vertex-weights [Reference Eslava, Lodewijks and Ortgiese7, Lemma A.2].) Let
 $(W_i)_{i\in\mathbb{N}}$
be i.i.d. copies of a random variable W with mean
$(W_i)_{i\in\mathbb{N}}$
be i.i.d. copies of a random variable W with mean
 $\mathbb{E}\left[W\right]\in(0,1]$
. Let
$\mathbb{E}\left[W\right]\in(0,1]$
. Let
 $\eta\in(0,1), \delta\in(0,1/2)$
,
$\eta\in(0,1), \delta\in(0,1/2)$
,
 $k\in\mathbb{N}$
, and set
$k\in\mathbb{N}$
, and set
 $\zeta_n\;:\!=\;n^{-\delta \eta}/\mathbb{E}\left[W\right]$
. Consider the events
$\zeta_n\;:\!=\;n^{-\delta \eta}/\mathbb{E}\left[W\right]$
. Consider the events
 \begin{align*} E_n^{(1)}&\;:\!=\;\Bigg\{ \sum_{\ell=1}^j W_\ell \in ((1-\zeta_n)\mathbb{E}\left[W\right]j,(1+\zeta_{n})\mathbb{E}\left[W\right]j),\text{ for all } n^{ \eta}\leq j\leq n\Bigg\},\\[5pt] E_n^{(2)}&\;:\!=\;\Bigg\{\sum_{\ell=k+1 }^j W_\ell\in((1-\zeta_n)\mathbb{E}\left[W\right]j,(1+\zeta_n)\mathbb{E}\left[W\right]j),\text{ for all } n^{ \varepsilon}\leq j\leq n\Bigg\}. \end{align*}
\begin{align*} E_n^{(1)}&\;:\!=\;\Bigg\{ \sum_{\ell=1}^j W_\ell \in ((1-\zeta_n)\mathbb{E}\left[W\right]j,(1+\zeta_{n})\mathbb{E}\left[W\right]j),\text{ for all } n^{ \eta}\leq j\leq n\Bigg\},\\[5pt] E_n^{(2)}&\;:\!=\;\Bigg\{\sum_{\ell=k+1 }^j W_\ell\in((1-\zeta_n)\mathbb{E}\left[W\right]j,(1+\zeta_n)\mathbb{E}\left[W\right]j),\text{ for all } n^{ \varepsilon}\leq j\leq n\Bigg\}. \end{align*}
Then, for any
 $\gamma>0$
and any
$\gamma>0$
and any
 $i\in\{1,2\}$
, for all n large,
$i\in\{1,2\}$
, for all n large,
 \begin{equation*} \mathbb{P}\left(\big(E_n^{(i)}\big)^c\right)\leq n^{-\gamma}. \end{equation*}
\begin{equation*} \mathbb{P}\left(\big(E_n^{(i)}\big)^c\right)\leq n^{-\gamma}. \end{equation*}
Lemma 3.2. ([Reference Eslava, Lodewijks and Ortgiese7, Lemma A.4].) For any
 $k\in\mathbb{N}$
and any
$k\in\mathbb{N}$
and any
 $0< a\leq b<\infty$
,
$0< a\leq b<\infty$
,
 \begin{equation*} \int_a^b \int_{x_1}^b\cdots \int_{x_{k-1}}^b \prod_{j=1}^kx_j^{-1}\,\textrm{d} x_k\ldots\textrm{d} x_1= \frac{(\!\log(b/a))^k}{k!}. \end{equation*}
\begin{equation*} \int_a^b \int_{x_1}^b\cdots \int_{x_{k-1}}^b \prod_{j=1}^kx_j^{-1}\,\textrm{d} x_k\ldots\textrm{d} x_1= \frac{(\!\log(b/a))^k}{k!}. \end{equation*}
Similarly, for any
 $k\in\mathbb{N}$
and any
$k\in\mathbb{N}$
and any
 $0< a\leq b-k<\infty$
,
$0< a\leq b-k<\infty$
,
 \begin{equation*} \int_{a+1}^b\int_{x_1+1}^b\cdots \int_{x_{k-1}+1}^b\prod_{j=1}^{k}x_{j}^{-1}\,\textrm{d} x_k\ldots \textrm{d} x_1\geq \frac{(\!\log(b/(a+k)))^k}{k!}. \end{equation*}
\begin{equation*} \int_{a+1}^b\int_{x_1+1}^b\cdots \int_{x_{k-1}+1}^b\prod_{j=1}^{k}x_{j}^{-1}\,\textrm{d} x_k\ldots \textrm{d} x_1\geq \frac{(\!\log(b/(a+k)))^k}{k!}. \end{equation*}
Lemma 3.3. ([Reference Lodewijks and Ortgiese12, Lemma 5.1].) Let
 $(W_i)_{i\in\mathbb{N}}$
be a sequence of strictly positive i.i.d. random variables which are almost surely bounded. Then there exists an almost surely finite random variable Y such that
$(W_i)_{i\in\mathbb{N}}$
be a sequence of strictly positive i.i.d. random variables which are almost surely bounded. Then there exists an almost surely finite random variable Y such that
 \begin{equation*} \sum_{j=1}^{n-1}\frac{1}{S_j}-\frac{1}{\mathbb{E}\left[W\right]}\log n\buildrel {a.s.}\over{\longrightarrow} Y. \end{equation*}
\begin{equation*} \sum_{j=1}^{n-1}\frac{1}{S_j}-\frac{1}{\mathbb{E}\left[W\right]}\log n\buildrel {a.s.}\over{\longrightarrow} Y. \end{equation*}
This lemma implies, in particular, that for any
 $i=i(n)$
such that i diverges with n and
$i=i(n)$
such that i diverges with n and
 $i=o(n)$
as
$i=o(n)$
as
 $n\to\infty$
, almost surely,
$n\to\infty$
, almost surely,
 \begin{equation}\begin{aligned} \sum_{j=i}^{n-1}\frac{1}{S_j}=\frac{1}{\mathbb{E}\left[W\right]}\log(n/i)(1+o(1)),\qquad \sum_{j=1}^{n-1}\frac{1}{S_j}=\frac{1}{\mathbb{E}\left[W\right]}\log(n)(1+o(1)). \end{aligned} \end{equation}
\begin{equation}\begin{aligned} \sum_{j=i}^{n-1}\frac{1}{S_j}=\frac{1}{\mathbb{E}\left[W\right]}\log(n/i)(1+o(1)),\qquad \sum_{j=1}^{n-1}\frac{1}{S_j}=\frac{1}{\mathbb{E}\left[W\right]}\log(n)(1+o(1)). \end{aligned} \end{equation}
4. Location of the maximum-degree vertices
For ease of writing, let us set
 $\mu_m\;:\!=\;1-(\theta_m-1)/(\theta_m\log\theta_m)$
, where we recall that
$\mu_m\;:\!=\;1-(\theta_m-1)/(\theta_m\log\theta_m)$
, where we recall that
 $\theta_m\;:\!=\;1+\mathbb{E}\left[W\right]/m$
. To make the intuitive idea presented in Section 3 precise, we use a careful union bound on the events
$\theta_m\;:\!=\;1+\mathbb{E}\left[W\right]/m$
. To make the intuitive idea presented in Section 3 precise, we use a careful union bound on the events
 $\{\max_{1\leq i\leq n^{\mu_m-\varepsilon}}\mathcal{Z}_n(i)\geq (1-\eta)\log_{\theta_m}\!n\}$
and
$\{\max_{1\leq i\leq n^{\mu_m-\varepsilon}}\mathcal{Z}_n(i)\geq (1-\eta)\log_{\theta_m}\!n\}$
and
 $\{\max_{n^{\mu_m+\varepsilon}\leq i\leq n}\mathcal{Z}_n(i)\geq (1-\eta)\log_{\theta_m}\! n\}$
for arbitrary and fixed
$\{\max_{n^{\mu_m+\varepsilon}\leq i\leq n}\mathcal{Z}_n(i)\geq (1-\eta)\log_{\theta_m}\! n\}$
for arbitrary and fixed
 $\varepsilon>0$
and some sufficiently small
$\varepsilon>0$
and some sufficiently small
 $\eta>0$
.
$\eta>0$
.
Proof of Theorem 2.1. As in the proofs of [Reference Lodewijks and Ortgiese12, Theorem 2.9] and [Reference Devroye and Lu6, Theorem 1], we first prove the convergence holds in probability, and then discuss how to improve it to almost sure convergence.
We take
 $\eta\in(0,1-\log(\theta_m)/(\theta_m-1))$
and write
$\eta\in(0,1-\log(\theta_m)/(\theta_m-1))$
and write
 \begin{align} \mathbb{P}_W\!\left(\Big|\frac{\log I_n}{\log n}-\mu_m\Big|\geq \varepsilon\right) \leq {}&\mathbb{P}_W\!\left(\big\{I_n\leq n^{\mu_m-\varepsilon}\}\cap \{\max_{i\in[n]}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\big\}\right)\nonumber\\[5pt] &+\mathbb{P}_W\!\left(\{I_n\geq n^{\mu_m+\varepsilon}\big\}\cap \{\max_{i\in[n]}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\big\}\right)\nonumber\\[5pt] &+\mathbb{P}_W\!\left(\max_{i\in[n]}\mathcal{Z}_n(i) < (1-\eta)\log_{\theta_m}\!n\right). \end{align}
\begin{align} \mathbb{P}_W\!\left(\Big|\frac{\log I_n}{\log n}-\mu_m\Big|\geq \varepsilon\right) \leq {}&\mathbb{P}_W\!\left(\big\{I_n\leq n^{\mu_m-\varepsilon}\}\cap \{\max_{i\in[n]}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\big\}\right)\nonumber\\[5pt] &+\mathbb{P}_W\!\left(\{I_n\geq n^{\mu_m+\varepsilon}\big\}\cap \{\max_{i\in[n]}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\big\}\right)\nonumber\\[5pt] &+\mathbb{P}_W\!\left(\max_{i\in[n]}\mathcal{Z}_n(i) < (1-\eta)\log_{\theta_m}\!n\right). \end{align}
We start by dealing with the first two terms on the right-hand side, and then use Theorem 3.1 to deal with the final term. The first two probabilities can be bounded from above by
 \begin{equation} \mathbb{P}_W\!\left( \max_{i\in[n^{\mu_m-\varepsilon}]}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\right)+\mathbb{P}_W\!\left(\max_{n^{\mu_m+\varepsilon}\leq i\leq n}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\right). \end{equation}
\begin{equation} \mathbb{P}_W\!\left( \max_{i\in[n^{\mu_m-\varepsilon}]}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\right)+\mathbb{P}_W\!\left(\max_{n^{\mu_m+\varepsilon}\leq i\leq n}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\right). \end{equation}
The aim is thus to show that vertices with a label ‘far away’ from
 $n^{\mu_m}$
are unlikely to have a high degree. With
$n^{\mu_m}$
are unlikely to have a high degree. With
 $I_n^-\;:\!=\;n^{\mu_m-\varepsilon}$
,
$I_n^-\;:\!=\;n^{\mu_m-\varepsilon}$
,
 $I_n^+\;:\!=\;n^{\mu_m+\varepsilon}$
, we first apply a union bound to obtain the upper bound
$I_n^+\;:\!=\;n^{\mu_m+\varepsilon}$
, we first apply a union bound to obtain the upper bound
 \begin{equation*} \sum_{i\in[n]\backslash [I_n^-,I_n^+]}\mathbb{P}_W\!\left(\mathcal{Z}_n(i)\geq (1-\eta)\log_{\theta_m}\!n\right). \end{equation*}
\begin{equation*} \sum_{i\in[n]\backslash [I_n^-,I_n^+]}\mathbb{P}_W\!\left(\mathcal{Z}_n(i)\geq (1-\eta)\log_{\theta_m}\!n\right). \end{equation*}
With the same approach that leads to the upper bound in (3.2), that is, using a Chernoff bound with
 $t=\log((1-\eta)\log_{\theta_m}\!n)-\log\!\big(mW_i\sum_{j=i}^{n-1}1/S_j\big)$
, we arrive at the upper bound
$t=\log((1-\eta)\log_{\theta_m}\!n)-\log\!\big(mW_i\sum_{j=i}^{n-1}1/S_j\big)$
, we arrive at the upper bound
 \begin{equation}\begin{aligned} \sum_{i\in[n]\backslash [I_n^-,I_n^+]}\!\!\!\!\!\!\!{\textrm{e}}^{-t(1-\eta)\log_{\theta_m}\!\!n}\prod_{j=i}^{n-1}\bigg(1+\big({\textrm{e}}^t-1\big)\frac{W_i}{S_j}\bigg)^m\leq\sum_{i\in[n]\backslash [I_n^-,I_n^+]}\!\!\!\!\!\!{\textrm{e}}^{-(1-\eta)\log_{\theta_m}\!\!n(u_i-1-\log u_i)}, \end{aligned} \end{equation}
\begin{equation}\begin{aligned} \sum_{i\in[n]\backslash [I_n^-,I_n^+]}\!\!\!\!\!\!\!{\textrm{e}}^{-t(1-\eta)\log_{\theta_m}\!\!n}\prod_{j=i}^{n-1}\bigg(1+\big({\textrm{e}}^t-1\big)\frac{W_i}{S_j}\bigg)^m\leq\sum_{i\in[n]\backslash [I_n^-,I_n^+]}\!\!\!\!\!\!{\textrm{e}}^{-(1-\eta)\log_{\theta_m}\!\!n(u_i-1-\log u_i)}, \end{aligned} \end{equation}
where
 \begin{equation*} u_i\;:\!=\;\frac{mW_i}{(1-\eta)\log_{\theta_m}\!n}\sum_{j=i}^{n-1} \frac{1}{S_j}. \end{equation*}
\begin{equation*} u_i\;:\!=\;\frac{mW_i}{(1-\eta)\log_{\theta_m}\!n}\sum_{j=i}^{n-1} \frac{1}{S_j}. \end{equation*}
We now set
 \begin{equation*} \begin{aligned} \delta\;:\!=\;\min\bigg\{{}&\frac{1-\eta}{2\log\theta_m}\bigg(\frac{\log\theta_m}{(\theta_m-1)(1-\eta)}-1-\log\!\bigg(\frac{\log\theta_m}{(\theta_m-1)(1-\eta)}\bigg)\!\bigg),\\[5pt] &-\frac{(\theta_m-1)(1-\eta)}{2\log \theta_m}W_0\big(\!-\!\theta_m^{-1/(1-\eta)}{\textrm{e}}^{-1}\big)\bigg\}, \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \delta\;:\!=\;\min\bigg\{{}&\frac{1-\eta}{2\log\theta_m}\bigg(\frac{\log\theta_m}{(\theta_m-1)(1-\eta)}-1-\log\!\bigg(\frac{\log\theta_m}{(\theta_m-1)(1-\eta)}\bigg)\!\bigg),\\[5pt] &-\frac{(\theta_m-1)(1-\eta)}{2\log \theta_m}W_0\big(\!-\!\theta_m^{-1/(1-\eta)}{\textrm{e}}^{-1}\big)\bigg\}, \end{aligned} \end{equation*}
with
 $W_0$
the (main branch of the) W Lambert function, the inverse of
$W_0$
the (main branch of the) W Lambert function, the inverse of
 $f\;:\;[\!-\!1,\infty)\to [\!-\!1/{\textrm{e}},\infty)$
,
$f\;:\;[\!-\!1,\infty)\to [\!-\!1/{\textrm{e}},\infty)$
,
 $f(x)\;:\!=\;x{\textrm{e}}^x$
. Note that, when
$f(x)\;:\!=\;x{\textrm{e}}^x$
. Note that, when
 $\varepsilon$
is sufficiently small,
$\varepsilon$
is sufficiently small,
 $\delta\in(0,\min\{\mu_m-\varepsilon,1-\mu_m-\varepsilon\})$
. We use this
$\delta\in(0,\min\{\mu_m-\varepsilon,1-\mu_m-\varepsilon\})$
. We use this
 $\delta$
to split the union bound in (4.3) into three parts,
$\delta$
to split the union bound in (4.3) into three parts,
 \begin{align} R_1&\;:\!=\;\sum_{i=1}^{\lfloor n^{\delta}\rfloor} {\textrm{e}}^{-(1-\eta)\log_{\theta_m}\!\!n(u_i-1-\log u_i)},\nonumber\\[5pt] R_2&\;:\!=\;\sum_{i=\lceil n^{1-\delta}\rceil}^n {\textrm{e}}^{-(1-\eta)\log_{\theta_m}\!\!n(u_i-1-\log u_i)},\nonumber\\[5pt] R_3&\;:\!=\;\sum_{i\in [n^\delta, n^{1-\delta}]\backslash [I_n^-,I_n^+]}{\textrm{e}}^{-(1-\eta)\log_{\theta_m}\!\!n(u_i-1-\log u_i)}, \end{align}
\begin{align} R_1&\;:\!=\;\sum_{i=1}^{\lfloor n^{\delta}\rfloor} {\textrm{e}}^{-(1-\eta)\log_{\theta_m}\!\!n(u_i-1-\log u_i)},\nonumber\\[5pt] R_2&\;:\!=\;\sum_{i=\lceil n^{1-\delta}\rceil}^n {\textrm{e}}^{-(1-\eta)\log_{\theta_m}\!\!n(u_i-1-\log u_i)},\nonumber\\[5pt] R_3&\;:\!=\;\sum_{i\in [n^\delta, n^{1-\delta}]\backslash [I_n^-,I_n^+]}{\textrm{e}}^{-(1-\eta)\log_{\theta_m}\!\!n(u_i-1-\log u_i)}, \end{align}
and we aim to show that each of these terms converges to zero with n almost surely. For
 $R_1$
we use that, uniformly in
$R_1$
we use that, uniformly in
 $i\leq n^\delta$
, almost surely
$i\leq n^\delta$
, almost surely
 \begin{equation} u_i\leq \frac{m}{(1-\eta)\log_{\theta_m}\!n}\sum_{j=1}^{n-1}\frac{1}{S_j}=\frac{\log\theta_m}{(1-\eta)(\theta_m-1)}(1+o(1)), \end{equation}
\begin{equation} u_i\leq \frac{m}{(1-\eta)\log_{\theta_m}\!n}\sum_{j=1}^{n-1}\frac{1}{S_j}=\frac{\log\theta_m}{(1-\eta)(\theta_m-1)}(1+o(1)), \end{equation}
where the final step follows from Lemma 3.3. Using the fact that the upper bound is at most 1 by the choice of
 $\eta$
and that
$\eta$
and that
 $x\mapsto x-1-\log x$
is decreasing on (0,1), and applying this in
$x\mapsto x-1-\log x$
is decreasing on (0,1), and applying this in
 $R_1$
in (4.4), we bound
$R_1$
in (4.4), we bound
 $R_1$
from above by
$R_1$
from above by
 \begin{equation} \begin{aligned} \sum_{i=1}^{\lfloor n^\delta\rfloor}{}&\exp\!\bigg(\!-\!\frac{(1-\eta)\log n}{\log\theta_m}\bigg( \frac{\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\bigg)\\[5pt] ={}&\exp\!\bigg(\!\log n\bigg(\delta-\frac{1-\eta}{\log\theta_m}\bigg( \frac{\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\bigg), \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \sum_{i=1}^{\lfloor n^\delta\rfloor}{}&\exp\!\bigg(\!-\!\frac{(1-\eta)\log n}{\log\theta_m}\bigg( \frac{\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\bigg)\\[5pt] ={}&\exp\!\bigg(\!\log n\bigg(\delta-\frac{1-\eta}{\log\theta_m}\bigg( \frac{\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\bigg), \end{aligned} \end{equation}
which converges to zero by the choice of
 $\delta$
. In a similar way, uniformly in
$\delta$
. In a similar way, uniformly in
 $n^{1-\delta}\leq i\leq n$
, almost surely
$n^{1-\delta}\leq i\leq n$
, almost surely
 \begin{equation} u_i\leq \frac{m}{(1-\eta)\log_{\theta_m}\!n}\sum_{j=\lceil n^{1-\delta}\rceil }^{n-1}\frac{1}{S_j}=\frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}(1+o(1)), \end{equation}
\begin{equation} u_i\leq \frac{m}{(1-\eta)\log_{\theta_m}\!n}\sum_{j=\lceil n^{1-\delta}\rceil }^{n-1}\frac{1}{S_j}=\frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}(1+o(1)), \end{equation}
so that we can bound
 $R_2$
from above by
$R_2$
from above by
 \begin{equation}\begin{aligned} \sum_{i= \lceil n^{1-\delta}\rceil}^n\!\!\!\!\!\!{}&\exp\!\bigg(\!-\!(1-\eta)\log_{\theta_m}\! n\bigg( \frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\bigg)\\[5pt] ={}&\exp\!\bigg(\!\log n\bigg(1-\frac{1-\eta}{\log\theta_m}\bigg( \frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\bigg). \end{aligned}\end{equation}
\begin{equation}\begin{aligned} \sum_{i= \lceil n^{1-\delta}\rceil}^n\!\!\!\!\!\!{}&\exp\!\bigg(\!-\!(1-\eta)\log_{\theta_m}\! n\bigg( \frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\bigg)\\[5pt] ={}&\exp\!\bigg(\!\log n\bigg(1-\frac{1-\eta}{\log\theta_m}\bigg( \frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\bigg). \end{aligned}\end{equation}
Again, by the choice of
 $\delta$
, the exponent is strictly negative, so that the upper bound converges to zero with n. It remains to bound
$\delta$
, the exponent is strictly negative, so that the upper bound converges to zero with n. It remains to bound
 $R_3$
. We aim to approximate the sum by an integral, using the same approach as in the proof of [Reference Lodewijks and Ortgiese12, Theorem 2.9, bounded case]. We first bound
$R_3$
. We aim to approximate the sum by an integral, using the same approach as in the proof of [Reference Lodewijks and Ortgiese12, Theorem 2.9, bounded case]. We first bound
 $u_i\leq m(H_n-H_i)/((1-\eta)\log_{\theta_m}\! n)\;=\!:\;\widetilde u_i$
almost surely for any
$u_i\leq m(H_n-H_i)/((1-\eta)\log_{\theta_m}\! n)\;=\!:\;\widetilde u_i$
almost surely for any
 $i\in[n]$
, where
$i\in[n]$
, where
 $H_n\;:\!=\;\sum_{j=1}^{n-1}1/S_j$
. Then we define
$H_n\;:\!=\;\sum_{j=1}^{n-1}1/S_j$
. Then we define
 $u\;:\;(0,\infty)\to \mathbb{R}$
and
$u\;:\;(0,\infty)\to \mathbb{R}$
and
 $\phi\;:\;(0,\infty)\to\mathbb{R}$
by
$\phi\;:\;(0,\infty)\to\mathbb{R}$
by
 \begin{equation*} u(x)\;:\!=\;\bigg(1-\frac{\log x}{\log n}\bigg)\frac{\log\theta_m}{(1-\eta)(\theta_m-1)} \quad \text{and}\quad \phi(x)\;:\!=\;x-1-\log x, \qquad x>0. \end{equation*}
\begin{equation*} u(x)\;:\!=\;\bigg(1-\frac{\log x}{\log n}\bigg)\frac{\log\theta_m}{(1-\eta)(\theta_m-1)} \quad \text{and}\quad \phi(x)\;:\!=\;x-1-\log x, \qquad x>0. \end{equation*}
For i in
 $[n^\delta, n^{1-\delta}]\backslash [I_n^-,I_n^+]$
such that
$[n^\delta, n^{1-\delta}]\backslash [I_n^-,I_n^+]$
such that
 $i=n^{\beta+o(1)}$
for some
$i=n^{\beta+o(1)}$
for some
 $\beta\in[\delta,1-\delta]$
(where the o(1) is independent of
$\beta\in[\delta,1-\delta]$
(where the o(1) is independent of
 $\beta$
) and
$\beta$
) and
 $x\in[i,i+1)$
,
$x\in[i,i+1)$
,
 \begin{align} |\phi(\widetilde u_i)-\phi(u(x))|\leq{}& |\widetilde u_i-u(x)|+|\log(\widetilde u_i/u(x))|\nonumber\\[5pt] ={}&\Bigg|\frac{\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg(1-\frac{\log x}{\log n}\bigg)-\frac{\log\theta_m}{(1-\eta)(\theta_m-1)\log n}\sum_{j=i}^{n-1}\frac{1}{S_j}\Bigg|\nonumber\\[5pt] &+\Bigg|\log\!\Bigg(\frac{\mathbb{E}\left[W\right]}{\log n-\log x}\sum_{j=i}^{n-1}\frac{1}{S_j}\Bigg)\Bigg|. \end{align}
\begin{align} |\phi(\widetilde u_i)-\phi(u(x))|\leq{}& |\widetilde u_i-u(x)|+|\log(\widetilde u_i/u(x))|\nonumber\\[5pt] ={}&\Bigg|\frac{\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg(1-\frac{\log x}{\log n}\bigg)-\frac{\log\theta_m}{(1-\eta)(\theta_m-1)\log n}\sum_{j=i}^{n-1}\frac{1}{S_j}\Bigg|\nonumber\\[5pt] &+\Bigg|\log\!\Bigg(\frac{\mathbb{E}\left[W\right]}{\log n-\log x}\sum_{j=i}^{n-1}\frac{1}{S_j}\Bigg)\Bigg|. \end{align}
By (3.4) and since i diverges with n, we have
 $\sum_{j=i}^{n-1}1/S_j-\log(n/i)/\mathbb{E}\left[W\right]=o(1)$
almost surely as
$\sum_{j=i}^{n-1}1/S_j-\log(n/i)/\mathbb{E}\left[W\right]=o(1)$
almost surely as
 $n\to\infty$
. Applying this to the right-hand side of (4.9) yields
$n\to\infty$
. Applying this to the right-hand side of (4.9) yields
 \begin{equation*} |\phi(\widetilde u_i)-\phi(u(x))|\leq \frac{\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg|\frac{\log x-\log i}{\log n}\bigg|+\bigg|\log\!\bigg(1+\frac{\log x-\log i+o(1)}{\log n-\log x}\bigg)\bigg|. \end{equation*}
\begin{equation*} |\phi(\widetilde u_i)-\phi(u(x))|\leq \frac{\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg|\frac{\log x-\log i}{\log n}\bigg|+\bigg|\log\!\bigg(1+\frac{\log x-\log i+o(1)}{\log n-\log x}\bigg)\bigg|. \end{equation*}
Since
 $x\geq i\geq n^\delta$
and
$x\geq i\geq n^\delta$
and
 $|x-i|\leq 1$
, we thus obtain that, uniformly in
$|x-i|\leq 1$
, we thus obtain that, uniformly in
 $[n^\delta, n^{1-\delta}]\backslash [I_n^-,I_n^+]$
and
$[n^\delta, n^{1-\delta}]\backslash [I_n^-,I_n^+]$
and
 $x\in[i,i+1)$
, we have
$x\in[i,i+1)$
, we have
 $|\phi(\widetilde u_i)-\phi(u(x))|=o(1/(n^\varepsilon\log n))$
almost surely as
$|\phi(\widetilde u_i)-\phi(u(x))|=o(1/(n^\varepsilon\log n))$
almost surely as
 $n\to\infty$
. Applying this to
$n\to\infty$
. Applying this to
 $R_3$
in (4.4) yields the upper bound
$R_3$
in (4.4) yields the upper bound
 \begin{align} \sum_{i\in [n^\delta, n^{1-\delta}]\backslash [I_n^-,I_n^+]}\!\!\!\!\!\!\!\!\!\!{}&{\textrm{e}}^{-(1-\eta)\phi(\widetilde u_i)\log_{\theta_m}\! n}\nonumber\\[5pt] \leq{}& \sum_{i\in [n^\delta, n^{1-\delta}]\backslash [I_n^-,I_n^+]}\int_i^{i+1}{\textrm{e}}^{-(1-\eta)\log_{\theta_m}\! n( \phi(u(x))+|\phi(\widetilde u_i)-\phi(u(x))|)}\,\textrm{d} x\nonumber\\[5pt] \leq {}&(1+o(1))\int_{[n^\delta,n^{1-\delta}]\backslash [I_n^-I_n^+]}{\textrm{e}}^{-(1-\eta)\phi(u(x))\log_{\theta_m}\! n}\,\textrm{d} x. \end{align}
\begin{align} \sum_{i\in [n^\delta, n^{1-\delta}]\backslash [I_n^-,I_n^+]}\!\!\!\!\!\!\!\!\!\!{}&{\textrm{e}}^{-(1-\eta)\phi(\widetilde u_i)\log_{\theta_m}\! n}\nonumber\\[5pt] \leq{}& \sum_{i\in [n^\delta, n^{1-\delta}]\backslash [I_n^-,I_n^+]}\int_i^{i+1}{\textrm{e}}^{-(1-\eta)\log_{\theta_m}\! n( \phi(u(x))+|\phi(\widetilde u_i)-\phi(u(x))|)}\,\textrm{d} x\nonumber\\[5pt] \leq {}&(1+o(1))\int_{[n^\delta,n^{1-\delta}]\backslash [I_n^-I_n^+]}{\textrm{e}}^{-(1-\eta)\phi(u(x))\log_{\theta_m}\! n}\,\textrm{d} x. \end{align}
Using the variable transformation
 $w=\log x/\log n$
and setting
$w=\log x/\log n$
and setting
 $U\;:\!=\;[\delta,1-\delta]\backslash[\mu_m-\varepsilon,\mu_m+\varepsilon]$
yields
$U\;:\!=\;[\delta,1-\delta]\backslash[\mu_m-\varepsilon,\mu_m+\varepsilon]$
yields
 \begin{align} (1{}&+o(1))\int_{U}\exp\!\bigg(\!-\!\log n\frac{1-\eta}{\log \theta_m}\phi\bigg(\frac{(1-w)\log \theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)n^w\log n \, \textrm{d} w\nonumber\\[5pt] &=(1+o(1))\int_{U}\exp\!\bigg(\!-\!\log n\bigg(\frac{1-\eta}{\log \theta_m}\phi\bigg(\frac{(1-w)\log \theta_m}{(1-\eta)(\theta_m-1)}\bigg)-w\bigg)+\log\log n\bigg) \, \textrm{d} w. \end{align}
\begin{align} (1{}&+o(1))\int_{U}\exp\!\bigg(\!-\!\log n\frac{1-\eta}{\log \theta_m}\phi\bigg(\frac{(1-w)\log \theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)n^w\log n \, \textrm{d} w\nonumber\\[5pt] &=(1+o(1))\int_{U}\exp\!\bigg(\!-\!\log n\bigg(\frac{1-\eta}{\log \theta_m}\phi\bigg(\frac{(1-w)\log \theta_m}{(1-\eta)(\theta_m-1)}\bigg)-w\bigg)+\log\log n\bigg) \, \textrm{d} w. \end{align}
We now observe that the mapping
 \begin{equation*} w\mapsto \frac{1-\eta}{\log \theta_m}\phi\bigg(\frac{(1-w)\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg) \end{equation*}
\begin{equation*} w\mapsto \frac{1-\eta}{\log \theta_m}\phi\bigg(\frac{(1-w)\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg) \end{equation*}
has two fixed points, namely
 \begin{align} w^{(1)}&\;:\!=\;1+\frac{(1-\eta)(\theta_m-1)}{\theta_m\log\theta_m}W_0\big(\!-\!\theta_m^{-\eta/(1-\eta)}{\textrm{e}}^{-1}\big), \nonumber\\[5pt] w^{(2)}&\;:\!=\;1+\frac{(1-\eta)(\theta_m-1)}{\theta_m\log\theta_m}W_{-1}\big(\!-\!\theta_m^{-\eta/(1-\eta)}{\textrm{e}}^{-1}\big), \end{align}
\begin{align} w^{(1)}&\;:\!=\;1+\frac{(1-\eta)(\theta_m-1)}{\theta_m\log\theta_m}W_0\big(\!-\!\theta_m^{-\eta/(1-\eta)}{\textrm{e}}^{-1}\big), \nonumber\\[5pt] w^{(2)}&\;:\!=\;1+\frac{(1-\eta)(\theta_m-1)}{\theta_m\log\theta_m}W_{-1}\big(\!-\!\theta_m^{-\eta/(1-\eta)}{\textrm{e}}^{-1}\big), \end{align}
where we recall that
 $W_0$
is the inverse of
$W_0$
is the inverse of
 $f\;:\;[\!-\!1,\infty)\to [\!-\!1/{\textrm{e}},\infty)$
,
$f\;:\;[\!-\!1,\infty)\to [\!-\!1/{\textrm{e}},\infty)$
,
 $f(x)=x{\textrm{e}}^x$
, also known as the main branch of the Lambert W function, and where
$f(x)=x{\textrm{e}}^x$
, also known as the main branch of the Lambert W function, and where
 $W_{-1}$
is the inverse of
$W_{-1}$
is the inverse of
 $g\;:\;(\!-\!\infty,-1]\to (\!-\!\infty,-1/{\textrm{e}}]$
,
$g\;:\;(\!-\!\infty,-1]\to (\!-\!\infty,-1/{\textrm{e}}]$
,
 $g(x)=x{\textrm{e}}^x$
, also known as the negative branch of the Lambert W function. Moreover, we also have the inequalities
$g(x)=x{\textrm{e}}^x$
, also known as the negative branch of the Lambert W function. Moreover, we also have the inequalities
 \begin{equation} \begin{aligned} w&<\frac{1-\eta}{\log \theta_m}\phi\bigg(\frac{(1-w)\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg), \qquad w\in\big(0,w^{(2)}\big),\ w\in(w^{(1)},1), \\[5pt] w&>\frac{1-\eta}{\log \theta_m}\phi\bigg(\frac{(1-w)\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg), \qquad w\in\big(w^{(2)},w^{(1)}\big), \end{aligned} \end{equation}
\begin{equation} \begin{aligned} w&<\frac{1-\eta}{\log \theta_m}\phi\bigg(\frac{(1-w)\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg), \qquad w\in\big(0,w^{(2)}\big),\ w\in(w^{(1)},1), \\[5pt] w&>\frac{1-\eta}{\log \theta_m}\phi\bigg(\frac{(1-w)\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg), \qquad w\in\big(w^{(2)},w^{(1)}\big), \end{aligned} \end{equation}
and we claim that the following statements hold:
 \begin{equation} \forall\ \eta>0\text{ sufficiently small},\ w^{(2)}<\mu_m<w^{(1)},\quad\text{ and }\quad\; \lim_{\eta\downarrow 0}w^{(1)}=\lim_{\eta\downarrow 0}w^{(2)}=\mu_m. \end{equation}
\begin{equation} \forall\ \eta>0\text{ sufficiently small},\ w^{(2)}<\mu_m<w^{(1)},\quad\text{ and }\quad\; \lim_{\eta\downarrow 0}w^{(1)}=\lim_{\eta\downarrow 0}w^{(2)}=\mu_m. \end{equation}
We defer the proof of these inequalities and claims to the end. For now, let us use these properties and set
 $\eta$
sufficiently small so that
$\eta$
sufficiently small so that
 $\mu_m-\varepsilon<w^{(2)}<\mu_m<w^{(1)}<\mu_m+\varepsilon$
, so that
$\mu_m-\varepsilon<w^{(2)}<\mu_m<w^{(1)}<\mu_m+\varepsilon$
, so that
 $U\subset [\delta,w^{(2)})\cup (w^{(1)},1-\delta]$
. If we define
$U\subset [\delta,w^{(2)})\cup (w^{(1)},1-\delta]$
. If we define
 \begin{equation*} \phi'_{\!\!U}\;:\!=\;\inf_{w\in U}\bigg[\frac{1-\eta}{\log \theta_m}\phi\bigg(\frac{(1-w)\log \theta_m}{(1-\eta)(\theta_m-1)}\bigg)-w\bigg], \end{equation*}
\begin{equation*} \phi'_{\!\!U}\;:\!=\;\inf_{w\in U}\bigg[\frac{1-\eta}{\log \theta_m}\phi\bigg(\frac{(1-w)\log \theta_m}{(1-\eta)(\theta_m-1)}\bigg)-w\bigg], \end{equation*}
then it follows from the choice of
 $\eta$
, from (4.13), and from the definition of U that
$\eta$
, from (4.13), and from the definition of U that
 $\phi'_{\!\!U}>0$
, so that the integral in (4.11) can be bounded from above by
$\phi'_{\!\!U}>0$
, so that the integral in (4.11) can be bounded from above by
 \begin{equation} (1+o(1))\exp\!\Big(\!-\!\phi'_{\!\!U}\log n+\log\log n\Big), \end{equation}
\begin{equation} (1+o(1))\exp\!\Big(\!-\!\phi'_{\!\!U}\log n+\log\log n\Big), \end{equation}
which converges to zero with n. We have thus established that
 $R_1, R_2, R_3$
converge to zero almost surely as n tends to infinity. Combined, this yields that the upper bound in (4.3) converges to zero almost surely, so that, using (4.2), we find that
$R_1, R_2, R_3$
converge to zero almost surely as n tends to infinity. Combined, this yields that the upper bound in (4.3) converges to zero almost surely, so that, using (4.2), we find that
 \begin{align} \mathbb P_W{}&\Big(\big\{I_n\leq n^{\mu_m-\varepsilon}\}\cap \{\max_{i\in[n]}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\big\}\Big)\nonumber\\[5pt] &+\mathbb{P}_W\!\left(\{I_n\geq n^{\mu_m+\varepsilon}\big\}\cap \{\max_{i\in[n]}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\big\}\right)\buildrel {a.s.}\over{\longrightarrow} 0, \end{align}
\begin{align} \mathbb P_W{}&\Big(\big\{I_n\leq n^{\mu_m-\varepsilon}\}\cap \{\max_{i\in[n]}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\big\}\Big)\nonumber\\[5pt] &+\mathbb{P}_W\!\left(\{I_n\geq n^{\mu_m+\varepsilon}\big\}\cap \{\max_{i\in[n]}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\big\}\right)\buildrel {a.s.}\over{\longrightarrow} 0, \end{align}
We now return to (4.1). Taking the mean yields
 \begin{equation*}\begin{aligned} \limsup_{n\to\infty}\mathbb{P}\!\left(\Big|\frac{\log I_n}{\log n}-\mu_m\Big|\geq \varepsilon\!\right)\leq{}& \!\limsup_{n\to\infty}\mathbb E\bigg[\mathbb{P}_W\!\left(\!\big\{I_n\leq n^{\mu_m-\varepsilon}\}\cap \{\max_{i\in[n]}\mathcal{Z}_n(i) \geq (1-\eta)\!\log_{\theta_m}\!n\big\}\!\right)\\[5pt] {}&+\mathbb{P}_W\!\left(\{I_n\geq n^{\mu_m+\varepsilon}\big\}\cap \{\max_{i\in[n]}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\big\}\right)\!\bigg]\\[5pt] &+\limsup_{n\to\infty}\mathbb{P}\!\left(\max_{i\in[n]}\mathcal{Z}_n(i)<(1-\eta)\log_{\theta_m}\! n\right). \end{aligned}\end{equation*}
\begin{equation*}\begin{aligned} \limsup_{n\to\infty}\mathbb{P}\!\left(\Big|\frac{\log I_n}{\log n}-\mu_m\Big|\geq \varepsilon\!\right)\leq{}& \!\limsup_{n\to\infty}\mathbb E\bigg[\mathbb{P}_W\!\left(\!\big\{I_n\leq n^{\mu_m-\varepsilon}\}\cap \{\max_{i\in[n]}\mathcal{Z}_n(i) \geq (1-\eta)\!\log_{\theta_m}\!n\big\}\!\right)\\[5pt] {}&+\mathbb{P}_W\!\left(\{I_n\geq n^{\mu_m+\varepsilon}\big\}\cap \{\max_{i\in[n]}\mathcal{Z}_n(i) \geq (1-\eta)\log_{\theta_m}\!n\big\}\right)\!\bigg]\\[5pt] &+\limsup_{n\to\infty}\mathbb{P}\!\left(\max_{i\in[n]}\mathcal{Z}_n(i)<(1-\eta)\log_{\theta_m}\! n\right). \end{aligned}\end{equation*}
Using the uniform integrability of the conditional probability (this is clearly the case as the conditional probability is bounded from above by one) combined with (4.16) implies that the first limsup on the right-hand side equals zero. The second limsup also equals zero by Theorem 3.1. Since
 $\varepsilon>0$
is arbitrary, this proves that
$\varepsilon>0$
is arbitrary, this proves that
 $\log I_n/\log n\buildrel {\mathbb{P}}\over{\longrightarrow} \mu_m$
.
$\log I_n/\log n\buildrel {\mathbb{P}}\over{\longrightarrow} \mu_m$
.
Now that we have obtained the convergence in probability of
 $\log I_n/\log n$
to
$\log I_n/\log n$
to
 $\mu_m$
, we strengthen it to almost sure convergence. We obtain this by constructing the following inequalities: first, for any
$\mu_m$
, we strengthen it to almost sure convergence. We obtain this by constructing the following inequalities: first, for any
 $\varepsilon\in(0,\mu_m)$
, using the monotonicity of
$\varepsilon\in(0,\mu_m)$
, using the monotonicity of
 $\max_{i\in[n^{\mu_m-\varepsilon}]}\mathcal{Z}_n(i)$
and
$\max_{i\in[n^{\mu_m-\varepsilon}]}\mathcal{Z}_n(i)$
and
 $\log_{\theta_m}\!n$
,
$\log_{\theta_m}\!n$
,
 \begin{equation*} \begin{aligned} \sup_{2^N\leq n}\!\frac{\max_{i\in[ n^{\mu_m-\varepsilon}]}\mathcal{Z}_n(i)}{\log_{\theta_m}\!n}&=\sup_{k\in\mathbb{N}}\sup_{2^{N+(k-1)}\leq n<2^{N+k}}\!\!\!\frac{\max_{i\in[ n^{\mu_m-\varepsilon}]}\mathcal{Z}_n(i)}{\log_{\theta_m}\!n}\\[5pt] &\leq \sup_{N\leq n}\frac{\max_{i\in[2^{(n+1)(\mu_m-\varepsilon)}]}\mathcal{Z}_{2^{n+1}}(i)}{n\log_{\theta_m}\!2}. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \sup_{2^N\leq n}\!\frac{\max_{i\in[ n^{\mu_m-\varepsilon}]}\mathcal{Z}_n(i)}{\log_{\theta_m}\!n}&=\sup_{k\in\mathbb{N}}\sup_{2^{N+(k-1)}\leq n<2^{N+k}}\!\!\!\frac{\max_{i\in[ n^{\mu_m-\varepsilon}]}\mathcal{Z}_n(i)}{\log_{\theta_m}\!n}\\[5pt] &\leq \sup_{N\leq n}\frac{\max_{i\in[2^{(n+1)(\mu_m-\varepsilon)}]}\mathcal{Z}_{2^{n+1}}(i)}{n\log_{\theta_m}\!2}. \end{aligned} \end{equation*}
With only a minor modification, we can obtain a similar result for
 $\max_{n^{\mu_m+\varepsilon}\leq i\leq n}\mathcal{Z}_n(i)$
, where now
$\max_{n^{\mu_m+\varepsilon}\leq i\leq n}\mathcal{Z}_n(i)$
, where now
 $\varepsilon\in(0,1-\mu_m)$
. Here, we can no longer use that this maximum is monotone. Rather, we write
$\varepsilon\in(0,1-\mu_m)$
. Here, we can no longer use that this maximum is monotone. Rather, we write
 \begin{equation*} \begin{aligned} \sup_{2^N\leq n}\!\frac{\max_{ n^{\mu_m+\varepsilon}\leq i\leq n}\mathcal{Z}_n(i)}{\log_{\theta_m}\!n}&=\sup_{k\in\mathbb{N}}\sup_{2^{N+(k-1)}\leq n<2^{N+k}}\!\!\!\frac{\max_{n^{\mu_m+\varepsilon}\leq i\leq n}\mathcal{Z}_n(i)}{\log_{\theta_m}\!n}\\[5pt] &\leq \sup_{k\in\mathbb{N}}\frac{\max_{2^{(N+(k-1))(\mu_m+\varepsilon)}\leq i\leq 2^{N+k}}\mathcal{Z}_{2^{N+k}}(i)}{(N+(k-1))\log_{\theta_m}\!2}\\[5pt] &=\sup_{N\leq n}\frac{\max_{2^{n(\mu_m+\varepsilon)}\leq i\leq 2^{n+1}}\mathcal{Z}_{2^{n+1}}(i)}{n\log_{\theta_m}\!2}. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \sup_{2^N\leq n}\!\frac{\max_{ n^{\mu_m+\varepsilon}\leq i\leq n}\mathcal{Z}_n(i)}{\log_{\theta_m}\!n}&=\sup_{k\in\mathbb{N}}\sup_{2^{N+(k-1)}\leq n<2^{N+k}}\!\!\!\frac{\max_{n^{\mu_m+\varepsilon}\leq i\leq n}\mathcal{Z}_n(i)}{\log_{\theta_m}\!n}\\[5pt] &\leq \sup_{k\in\mathbb{N}}\frac{\max_{2^{(N+(k-1))(\mu_m+\varepsilon)}\leq i\leq 2^{N+k}}\mathcal{Z}_{2^{N+k}}(i)}{(N+(k-1))\log_{\theta_m}\!2}\\[5pt] &=\sup_{N\leq n}\frac{\max_{2^{n(\mu_m+\varepsilon)}\leq i\leq 2^{n+1}}\mathcal{Z}_{2^{n+1}}(i)}{n\log_{\theta_m}\!2}. \end{aligned} \end{equation*}
It thus follows that for any
 $\eta>0$
, the inequalities
$\eta>0$
, the inequalities
 \begin{equation} \limsup_{n\to\infty} \frac{\max_{i\in[n^{\mu_m-\varepsilon}]}\mathcal{Z}_n(i)}{(1-\eta)\log_{\theta_m}\!n}\leq 1,\quad\limsup_{n\to\infty}\frac{\max_{n^{\mu_m+\varepsilon}\leq i\leq n}\mathcal{Z}_n(i)}{(1-\eta)\log_{\theta_m}\!n}\leq 1, \quad \mathbb P_W\text{-a.s.,} \end{equation}
\begin{equation} \limsup_{n\to\infty} \frac{\max_{i\in[n^{\mu_m-\varepsilon}]}\mathcal{Z}_n(i)}{(1-\eta)\log_{\theta_m}\!n}\leq 1,\quad\limsup_{n\to\infty}\frac{\max_{n^{\mu_m+\varepsilon}\leq i\leq n}\mathcal{Z}_n(i)}{(1-\eta)\log_{\theta_m}\!n}\leq 1, \quad \mathbb P_W\text{-a.s.,} \end{equation}
are implied by
 \begin{align} \limsup_{n\to\infty}\frac{\max_{i\in[2^{(n+1)(\mu_m-\varepsilon)}]}\mathcal{Z}_{2^{n+1}}(i)}{(1-\eta) n\log_{\theta_m}\!2}&\leq 1,\quad &\mathbb P_W-\text{a.s.},&\nonumber\\[5pt] \limsup_{n\to\infty} \frac{\max_{2^{n(\mu_m+\varepsilon)}\leq i\leq 2^{n+1}}\mathcal{Z}_{2^{n+1}}(i)}{(1-\eta) n\log_{\theta_m}\!2}&\leq 1,\quad &\mathbb P_W-\text{a.s.},& \end{align}
\begin{align} \limsup_{n\to\infty}\frac{\max_{i\in[2^{(n+1)(\mu_m-\varepsilon)}]}\mathcal{Z}_{2^{n+1}}(i)}{(1-\eta) n\log_{\theta_m}\!2}&\leq 1,\quad &\mathbb P_W-\text{a.s.},&\nonumber\\[5pt] \limsup_{n\to\infty} \frac{\max_{2^{n(\mu_m+\varepsilon)}\leq i\leq 2^{n+1}}\mathcal{Z}_{2^{n+1}}(i)}{(1-\eta) n\log_{\theta_m}\!2}&\leq 1,\quad &\mathbb P_W-\text{a.s.},& \end{align}
respectively. We start by proving the first inequality in (4.18). Define
 \begin{equation*} \begin{aligned} \mathcal E_n^1&\;:\!=\;\bigg\{\max_{i\in[2^{(n+1)(\mu_m-\varepsilon)}]}\mathcal{Z}_{2^{n+1}}(i)> (1-\eta)n\log_{\theta_m}\!2\bigg\}, \\[5pt] \mathcal E_n^2&\;:\!=\;\bigg\{\max_{2^{n(\mu_m+\varepsilon)}\leq i\leq 2^{n+1}}\mathcal{Z}_{2^{n+1}}(i)>(1-\eta)n\log_{\theta_m}\! 2\bigg\}. \end{aligned}\end{equation*}
\begin{equation*} \begin{aligned} \mathcal E_n^1&\;:\!=\;\bigg\{\max_{i\in[2^{(n+1)(\mu_m-\varepsilon)}]}\mathcal{Z}_{2^{n+1}}(i)> (1-\eta)n\log_{\theta_m}\!2\bigg\}, \\[5pt] \mathcal E_n^2&\;:\!=\;\bigg\{\max_{2^{n(\mu_m+\varepsilon)}\leq i\leq 2^{n+1}}\mathcal{Z}_{2^{n+1}}(i)>(1-\eta)n\log_{\theta_m}\! 2\bigg\}. \end{aligned}\end{equation*}
Let us abuse notation to write
 $I_n^-=2^{(n+1)(\mu_m-\varepsilon)}$
,
$I_n^-=2^{(n+1)(\mu_m-\varepsilon)}$
,
 $I_n^+=2^{n(\mu_m+\varepsilon)}$
. By a union bound, we again find
$I_n^+=2^{n(\mu_m+\varepsilon)}$
. By a union bound, we again find
 \begin{align} \mathbb{P}\left(\mathcal E_n^1\cup \mathcal E_n^2\right)\leq{}& \sum_{i=1}^{\lfloor 2^{(n+1)\delta}\rfloor }\mathbb{P}\left(\mathcal{Z}_{2^{n+1}}(i)>(1-\eta)n\log_{\theta_m}\!2\right)\nonumber \\[5pt] &+\sum_{i=\lceil 2^{(n+1)(1-\delta)}\rceil }^{2^{n+1}}\mathbb{P}\left(\mathcal{Z}_{2^{n+1}}(i)>(1-\eta)n\log_{\theta_m}\!2\right)\nonumber \\[5pt] &+\sum_{i\in[ 2^{(n+1)\delta},2^{(n+1)(1-\delta)}]\backslash [I_n^-,I_n^+]}\mathbb{P}\left(\mathcal{Z}_{2^{n+1}}(i)>(1-\eta)n \log_{\theta_m}\! 2\right), \end{align}
\begin{align} \mathbb{P}\left(\mathcal E_n^1\cup \mathcal E_n^2\right)\leq{}& \sum_{i=1}^{\lfloor 2^{(n+1)\delta}\rfloor }\mathbb{P}\left(\mathcal{Z}_{2^{n+1}}(i)>(1-\eta)n\log_{\theta_m}\!2\right)\nonumber \\[5pt] &+\sum_{i=\lceil 2^{(n+1)(1-\delta)}\rceil }^{2^{n+1}}\mathbb{P}\left(\mathcal{Z}_{2^{n+1}}(i)>(1-\eta)n\log_{\theta_m}\!2\right)\nonumber \\[5pt] &+\sum_{i\in[ 2^{(n+1)\delta},2^{(n+1)(1-\delta)}]\backslash [I_n^-,I_n^+]}\mathbb{P}\left(\mathcal{Z}_{2^{n+1}}(i)>(1-\eta)n \log_{\theta_m}\! 2\right), \end{align}
and these three sums are the equivalents of
 $R_1,R_2,R_3$
in (4.4). We again take
$R_1,R_2,R_3$
in (4.4). We again take
 $\eta$
small enough so that
$\eta$
small enough so that
 $\mu_m-\varepsilon<w^{(2)}<\mu_m<w^{(1)}<\mu_m+\varepsilon$
, where we recall
$\mu_m-\varepsilon<w^{(2)}<\mu_m<w^{(1)}<\mu_m+\varepsilon$
, where we recall
 $w^{(1)}, w^{(2)}$
from (4.12). With the same steps as in (4.3), (4.5), and (4.6), we obtain that we can almost surely bound the first sum on the right-hand side from above by
$w^{(1)}, w^{(2)}$
from (4.12). With the same steps as in (4.3), (4.5), and (4.6), we obtain that we can almost surely bound the first sum on the right-hand side from above by
 \begin{equation*}\begin{aligned} \sum_{i=1}^{\lfloor 2^{(n+1)\delta}\rfloor}{}&\exp\!\bigg(\!-\!\frac{(1-\eta)n\log 2}{\log\theta_m}\bigg( \frac{\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\bigg)\\[5pt] ={}&\exp\!\bigg(n\log 2\bigg(\delta-\frac{1-\eta}{\log\theta_m}\bigg( \frac{\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\!\bigg), \end{aligned} \end{equation*}
\begin{equation*}\begin{aligned} \sum_{i=1}^{\lfloor 2^{(n+1)\delta}\rfloor}{}&\exp\!\bigg(\!-\!\frac{(1-\eta)n\log 2}{\log\theta_m}\bigg( \frac{\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\bigg)\\[5pt] ={}&\exp\!\bigg(n\log 2\bigg(\delta-\frac{1-\eta}{\log\theta_m}\bigg( \frac{\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\!\bigg), \end{aligned} \end{equation*}
which is summable by the choice of
 $\delta$
. Similarly, using the same steps as in (4.7) and (4.8), we can almost surely bound the second sum on the right-hand side of (4.19) from above by
$\delta$
. Similarly, using the same steps as in (4.7) and (4.8), we can almost surely bound the second sum on the right-hand side of (4.19) from above by
 \begin{equation*}\begin{aligned} \sum_{i= \lceil 2^{(n+1)(1-\delta)}\rceil}^{2^n}\!\!\!\!\!\!{}&\exp\!\bigg(\!-\!\frac{(1-\eta)n\log 2}{\log \theta_m}\bigg( \frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\bigg)\\[5pt] ={}&\exp\!\bigg(\!n\log 2\bigg(\!1-\frac{1-\eta}{\log\theta_m}\bigg(\!\frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\!\frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\!\bigg), \end{aligned}\end{equation*}
\begin{equation*}\begin{aligned} \sum_{i= \lceil 2^{(n+1)(1-\delta)}\rceil}^{2^n}\!\!\!\!\!\!{}&\exp\!\bigg(\!-\!\frac{(1-\eta)n\log 2}{\log \theta_m}\bigg( \frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\bigg)\\[5pt] ={}&\exp\!\bigg(\!n\log 2\bigg(\!1-\frac{1-\eta}{\log\theta_m}\bigg(\!\frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}-1-\log\!\bigg(\!\frac{\delta\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)(1+o(1))\!\bigg), \end{aligned}\end{equation*}
which again is summable by the choice of
 $\delta$
. Finally, the last sum on the right-hand side of (4.19) can be approximated by an integral, as in (4.10). By the choice of
$\delta$
. Finally, the last sum on the right-hand side of (4.19) can be approximated by an integral, as in (4.10). By the choice of
 $\eta$
, we can then use the same steps as in (4.11)–(4.15) to obtain the almost sure upper bound
$\eta$
, we can then use the same steps as in (4.11)–(4.15) to obtain the almost sure upper bound
 \begin{equation*} (1+o(1))\exp\!\Big(\!-\!n\phi'_{\!\!U}\log 2(1+o(1))+\log n+\mathcal O(1)\Big), \end{equation*}
\begin{equation*} (1+o(1))\exp\!\Big(\!-\!n\phi'_{\!\!U}\log 2(1+o(1))+\log n+\mathcal O(1)\Big), \end{equation*}
which again is summable. As a result,
 $\mathbb P_W$
-almost surely,
$\mathbb P_W$
-almost surely,
 $\mathcal E_n^1\cup \mathcal E_n^2$
occurs only finitely often by the Borel–Cantelli lemma. This implies that both bounds in (4.18) hold, and these imply the bounds in (4.17). Defining the events
$\mathcal E_n^1\cup \mathcal E_n^2$
occurs only finitely often by the Borel–Cantelli lemma. This implies that both bounds in (4.18) hold, and these imply the bounds in (4.17). Defining the events
 \begin{equation*} \begin{aligned} \mathcal C^1_n&\;:\!=\;\{|\log I_n/\log n-\mu_m|\geq \varepsilon\}, \quad \mathcal C^2_n\;:\!=\;\big\{I_n\leq n^{\mu_m-\varepsilon}\big\}, \quad \mathcal C^3_n\;:\!=\;\big\{I_n\geq n^{\mu_m+\varepsilon}\big\},\\[5pt] \mathcal C^4_n&\;:\!=\;\big\{\max_{i\in[n]}\mathcal{Z}_n(i)> (1-\eta)\log_{\theta_m}\!n\big\}, \end{aligned}\end{equation*}
\begin{equation*} \begin{aligned} \mathcal C^1_n&\;:\!=\;\{|\log I_n/\log n-\mu_m|\geq \varepsilon\}, \quad \mathcal C^2_n\;:\!=\;\big\{I_n\leq n^{\mu_m-\varepsilon}\big\}, \quad \mathcal C^3_n\;:\!=\;\big\{I_n\geq n^{\mu_m+\varepsilon}\big\},\\[5pt] \mathcal C^4_n&\;:\!=\;\big\{\max_{i\in[n]}\mathcal{Z}_n(i)> (1-\eta)\log_{\theta_m}\!n\big\}, \end{aligned}\end{equation*}
we can use the same approach as in (4.1) to bound
 \begin{equation*} \sum_{n=1}^\infty \mathbb{1}_{\mathcal C^1_n}\leq \sum_{n=1}^\infty \mathbb{1}_{\mathcal C^2_n\cap \mathcal C^4_n}+\mathbb{1}_{\mathcal C^3_n\cap\mathcal C^4_n}+\mathbb{1}_{(\mathcal C^4_n)^c}. \end{equation*}
\begin{equation*} \sum_{n=1}^\infty \mathbb{1}_{\mathcal C^1_n}\leq \sum_{n=1}^\infty \mathbb{1}_{\mathcal C^2_n\cap \mathcal C^4_n}+\mathbb{1}_{\mathcal C^3_n\cap\mathcal C^4_n}+\mathbb{1}_{(\mathcal C^4_n)^c}. \end{equation*}
By the proof of Theorem 3.1 given in [Reference Lodewijks and Ortgiese12],
 $(\mathcal C^4_n)^c$
occurs for finitely many n
$(\mathcal C^4_n)^c$
occurs for finitely many n
 $\mathbb P_W$
-almost surely (not just
$\mathbb P_W$
-almost surely (not just
 $\mathbb P$
-almost surely, as follows directly from Theorem 3.1). The bounds in (4.17) imply that,
$\mathbb P$
-almost surely, as follows directly from Theorem 3.1). The bounds in (4.17) imply that,
 $\mathbb P_W$
-almost surely, the events
$\mathbb P_W$
-almost surely, the events
 $\mathcal C^2_n\cap\mathcal C^4_n$
and
$\mathcal C^2_n\cap\mathcal C^4_n$
and
 $\mathcal C^3_n\cap \mathcal C^4_n$
occur for only finitely many n, via similar reasoning as in (4.2). Combining these statements, we obtain that
$\mathcal C^3_n\cap \mathcal C^4_n$
occur for only finitely many n, via similar reasoning as in (4.2). Combining these statements, we obtain that
 $\mathcal C^1_n$
occurs only finitely many times
$\mathcal C^1_n$
occurs only finitely many times
 $\mathbb P_W$
-almost surely. As a final step we write
$\mathbb P_W$
-almost surely. As a final step we write
 \begin{equation*} \begin{aligned} \mathbb P({}&\forall\, \varepsilon>0\ \exists\, N\in \mathbb{N}\;:\; \forall\, n\geq N\ |\log I_n/\log n-\mu_m|<\varepsilon)\\[5pt] &=\mathbb{E}\left[\mathbb{P}_W\!\left(\forall\, \varepsilon>0\, \exists\, N\in \mathbb{N}\;:\; \forall\, n\geq N |\log I_n/\log n-\mu_m|<\varepsilon\right)\right]=1, \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \mathbb P({}&\forall\, \varepsilon>0\ \exists\, N\in \mathbb{N}\;:\; \forall\, n\geq N\ |\log I_n/\log n-\mu_m|<\varepsilon)\\[5pt] &=\mathbb{E}\left[\mathbb{P}_W\!\left(\forall\, \varepsilon>0\, \exists\, N\in \mathbb{N}\;:\; \forall\, n\geq N |\log I_n/\log n-\mu_m|<\varepsilon\right)\right]=1, \end{aligned} \end{equation*}
so that
 $\log I_n/\log n\xrightarrow{\mathbb P\text{-a.s.}} \mu_m$
.
$\log I_n/\log n\xrightarrow{\mathbb P\text{-a.s.}} \mu_m$
.
It remains to prove the inequalities in (4.13) and the claims in (4.14). Let us start with the inequalities in (4.13). We compute
 \begin{equation*} \frac{\textrm{d} }{\textrm{d} w}\bigg(w-\frac{1-\eta}{\log\theta_m}\phi\bigg(\frac{(1-w)\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)=1+\frac{1}{\theta_m-1}-\frac{1-\eta}{\log \theta_m}\frac{1}{1-w}, \end{equation*}
\begin{equation*} \frac{\textrm{d} }{\textrm{d} w}\bigg(w-\frac{1-\eta}{\log\theta_m}\phi\bigg(\frac{(1-w)\log\theta_m}{(1-\eta)(\theta_m-1)}\bigg)\!\bigg)=1+\frac{1}{\theta_m-1}-\frac{1-\eta}{\log \theta_m}\frac{1}{1-w}, \end{equation*}
which equals zero when
 $w=w^*\;:\!=\;1-(1-\eta)(\theta_m-1)/(\theta_m\log\theta_m)$
, is positive when
$w=w^*\;:\!=\;1-(1-\eta)(\theta_m-1)/(\theta_m\log\theta_m)$
, is positive when
 $w\in(0,w^*)$
, and is negative when
$w\in(0,w^*)$
, and is negative when
 $w\in(w^*,1)$
. Moreover, as
$w\in(w^*,1)$
. Moreover, as
 $W_0(x)\geq -1$
for all
$W_0(x)\geq -1$
for all
 $x\in[\!-\!1/{\textrm{e}},\infty)$
and
$x\in[\!-\!1/{\textrm{e}},\infty)$
and
 $ W_{-1}(x)\leq -1$
for all
$ W_{-1}(x)\leq -1$
for all
 $x\in[\!-\!1/{\textrm{e}},0)$
, it follows from the definition of
$x\in[\!-\!1/{\textrm{e}},0)$
, it follows from the definition of
 $w^{(1)}$
and
$w^{(1)}$
and
 $w^{(2)}$
in (4.12) that
$w^{(2)}$
in (4.12) that
 $w^{(2)}<w^*<w^{(1)}$
for any choice of
$w^{(2)}<w^*<w^{(1)}$
for any choice of
 $\eta>0$
. This implies both inequalities in (4.13).
$\eta>0$
. This implies both inequalities in (4.13).
We now prove the claims in (4.14). Again using that
 $W_0(x)\geq -1$
for all
$W_0(x)\geq -1$
for all
 $x\in[\!-\!1/{\textrm{e}},\infty)$
directly yields
$x\in[\!-\!1/{\textrm{e}},\infty)$
directly yields
 $w^{(1)}>\mu_m$
. The inequality
$w^{(1)}>\mu_m$
. The inequality
 $w^{(2)}<\mu_m$
is implied by
$w^{(2)}<\mu_m$
is implied by
 \begin{equation*} W_{-1}\big(\!-\!\theta_m^{-\eta/(1-\eta)}{\textrm{e}}^{-1}\big)<-\frac{1}{1-\eta}, \end{equation*}
\begin{equation*} W_{-1}\big(\!-\!\theta_m^{-\eta/(1-\eta)}{\textrm{e}}^{-1}\big)<-\frac{1}{1-\eta}, \end{equation*}
or, equivalently,
 \begin{equation*} -\theta_m^{-\eta/(1-\eta)}{\textrm{e}}^{-1}>-\frac{1}{1-\eta}{\textrm{e}}^{-1/(1-\eta)}. \end{equation*}
\begin{equation*} -\theta_m^{-\eta/(1-\eta)}{\textrm{e}}^{-1}>-\frac{1}{1-\eta}{\textrm{e}}^{-1/(1-\eta)}. \end{equation*}
Setting
 $\beta\;:\!=\;1/(1-\eta)$
yields
$\beta\;:\!=\;1/(1-\eta)$
yields
 \begin{equation*} \frac{\theta_m}{{\textrm{e}}}<\beta \bigg(\frac{\theta_m}{{\textrm{e}}}\bigg)^{\beta}. \end{equation*}
\begin{equation*} \frac{\theta_m}{{\textrm{e}}}<\beta \bigg(\frac{\theta_m}{{\textrm{e}}}\bigg)^{\beta}. \end{equation*}
This inequality is then satisfied when
 $\beta\in(1,W_{-1}(\!\log(\theta_m/{\textrm{e}})\theta_m/{\textrm{e}})/\log(\theta_m/{\textrm{e}}))$
, or, equivalently, when
$\beta\in(1,W_{-1}(\!\log(\theta_m/{\textrm{e}})\theta_m/{\textrm{e}})/\log(\theta_m/{\textrm{e}}))$
, or, equivalently, when
 $\eta\in(0,1-\log(\theta_m/{\textrm{e}})/W_{-1}(\!\log(\theta_m/{\textrm{e}})\theta_m/{\textrm{e}}))$
, as required. By the definition of
$\eta\in(0,1-\log(\theta_m/{\textrm{e}})/W_{-1}(\!\log(\theta_m/{\textrm{e}})\theta_m/{\textrm{e}}))$
, as required. By the definition of
 $w^{(1)}$
and
$w^{(1)}$
and
 $w^{(2)}$
in (4.12) and since
$w^{(2)}$
in (4.12) and since
 $\mu_m\;:\!=\;1-(\theta_m-1)/(\theta_m\log \theta_m)$
, the second claim in (4.14) directly follows from the continuity of
$\mu_m\;:\!=\;1-(\theta_m-1)/(\theta_m\log \theta_m)$
, the second claim in (4.14) directly follows from the continuity of
 $W_0$
and
$W_0$
and
 $W_{-1}$
and since
$W_{-1}$
and since
 $W_0(\!-\!1/{\textrm{e}})=W_{-1}(\!-\!1/{\textrm{e}})=-1$
, which concludes the proof.
$W_0(\!-\!1/{\textrm{e}})=W_{-1}(\!-\!1/{\textrm{e}})=-1$
, which concludes the proof.
5. Higher-order behaviour of the location of high-degree vertices
In this section we provide more detailed insight into the behaviour of the degree and location of high-degree vertices in the WRT model, that is, the WRG model with out-degree
 $m=1$
. Under additional assumptions on the vertex-weights, as in Assumption 2.1, we are able to extend the result of Theorem 2.1 to higher-order results for the location, as well as to all high-degree vertices, rather than just the maximum-degree vertices.
$m=1$
. Under additional assumptions on the vertex-weights, as in Assumption 2.1, we are able to extend the result of Theorem 2.1 to higher-order results for the location, as well as to all high-degree vertices, rather than just the maximum-degree vertices.
The approach taken here is an improvement of the methodology used by Eslava, Lodewijks, and Ortgiese in [Reference Eslava, Lodewijks and Ortgiese7] to study the maximum degree of the WRT model with bounded vertex-weights. In this section we improve and extend the results of [Reference Eslava, Lodewijks and Ortgiese7].
The approach used in [Reference Eslava, Lodewijks and Ortgiese7] is to obtain a precise asymptotic estimate for the probability that k vertices
 $v_1,\ldots, v_k$
, selected uniformly at random without replacement from [n], have degrees at least
$v_1,\ldots, v_k$
, selected uniformly at random without replacement from [n], have degrees at least
 $d_1, \ldots, d_k$
, respectively, for any
$d_1, \ldots, d_k$
, respectively, for any
 $k\in\mathbb{N}$
. One of the difficulties in proving this estimate is to show that the probability of this event, conditionally on
$k\in\mathbb{N}$
. One of the difficulties in proving this estimate is to show that the probability of this event, conditionally on
 ${\mathcal{E}}_n\;:\!=\;\cup_{i=1}^k \{v_i\leq n^{\eta}\}$
for some arbitrarily small
${\mathcal{E}}_n\;:\!=\;\cup_{i=1}^k \{v_i\leq n^{\eta}\}$
for some arbitrarily small
 $\eta>0$
, is sufficiently small. On
$\eta>0$
, is sufficiently small. On
 ${\mathcal{E}}_n$
it is harder to control sums of the first
${\mathcal{E}}_n$
it is harder to control sums of the first
 $v_i$
vertex-weights, as one cannot apply the law of large numbers easily, as opposed to when conditioning on
$v_i$
vertex-weights, as one cannot apply the law of large numbers easily, as opposed to when conditioning on
 ${\mathcal{E}}_n^c$
. This is eventually overcome by assuming that the vertex-weight distribution satisfies Condition C3, which limits the range of vertex-weight distributions for which the results discussed in [Reference Eslava, Lodewijks and Ortgiese7] hold.
${\mathcal{E}}_n^c$
. This is eventually overcome by assuming that the vertex-weight distribution satisfies Condition C3, which limits the range of vertex-weight distributions for which the results discussed in [Reference Eslava, Lodewijks and Ortgiese7] hold.
Here, we compute an asymptotic estimate for the probability that the degree of
 $v_i$
is at least
$v_i$
is at least
 $d_i$
and that
$d_i$
and that
 $v_i$
is at least
$v_i$
is at least
 $\ell_i$
for all
$\ell_i$
for all
 $i\in[k]$
, where the
$i\in[k]$
, where the
 $(\ell_i)_{i\in[k]}$
satisfy
$(\ell_i)_{i\in[k]}$
satisfy
 $\ell_i\geq n^\eta$
for all
$\ell_i\geq n^\eta$
for all
 $i\in[k]$
and some
$i\in[k]$
and some
 $\eta\in(0,1)$
. The two main advantages of considering this event are that the issues described in the previous paragraph are circumvented, and that for a correct parametrisation of the
$\eta\in(0,1)$
. The two main advantages of considering this event are that the issues described in the previous paragraph are circumvented, and that for a correct parametrisation of the
 $\ell_i$
we obtain some precise results on the location of high-degree vertices.
$\ell_i$
we obtain some precise results on the location of high-degree vertices.
5.1. Convergence of marked point processes via finite-dimensional distributions
We first discuss some theoretical preparations for proving Theorem 2.3, after which we state the intermediate results that we need to use in the proofs of Theorems 2.2 and 2.3. Recall the following notation:
 $d_n^i$
and
$d_n^i$
and
 $\ell_n^i$
denote the degree and label, respectively, of the vertex with the ith-largest degree,
$\ell_n^i$
denote the degree and label, respectively, of the vertex with the ith-largest degree,
 $i\in[n]$
, where ties are split uniformly at random. Let us write
$i\in[n]$
, where ties are split uniformly at random. Let us write
 $\theta=\theta_1\;:\!=\;1+\mathbb{E}\left[W\right]$
,
$\theta=\theta_1\;:\!=\;1+\mathbb{E}\left[W\right]$
,
 $\mu=\mu_1\;:\!=\;1-(\theta-1)/(\theta\log \theta)$
, and define
$\mu=\mu_1\;:\!=\;1-(\theta-1)/(\theta\log \theta)$
, and define
 $\sigma^2\;:\!=\;1-(\theta-1)^2/(\theta^2\log \theta)$
. To prove Theorem 2.3, we view the tuples
$\sigma^2\;:\!=\;1-(\theta-1)^2/(\theta^2\log \theta)$
. To prove Theorem 2.3, we view the tuples
 \begin{equation*}\bigg(d_n^i-\lfloor \log_\theta n\rfloor, \frac{\log \ell_n^i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\bigg)_{ i\in[n]}\end{equation*}
\begin{equation*}\bigg(d_n^i-\lfloor \log_\theta n\rfloor, \frac{\log \ell_n^i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\bigg)_{ i\in[n]}\end{equation*}
as a marked point process, where the rescaled degrees form the points and the rescaled labels form the marks of the points. Let
 $\mathbb{Z}^*\;:\!=\;\mathbb{Z} \cup \{\infty\}$
, and endow
$\mathbb{Z}^*\;:\!=\;\mathbb{Z} \cup \{\infty\}$
, and endow
 $\mathbb{Z}^*$
with the metric
$\mathbb{Z}^*$
with the metric
 $d(i,j)=|2^{-i}-2^{-j}|$
and
$d(i,j)=|2^{-i}-2^{-j}|$
and
 $d(i,\infty)=2^{-i}$
for
$d(i,\infty)=2^{-i}$
for
 $ i,j\in\mathbb{Z}$
. We work with
$ i,j\in\mathbb{Z}$
. We work with
 $\mathbb{Z}^*$
rather than
$\mathbb{Z}^*$
rather than
 $\mathbb{Z}$
, as the sets
$\mathbb{Z}$
, as the sets
 $[i,\infty]$
for
$[i,\infty]$
for
 $i\in\mathbb{Z}$
are then compact, which provides an advantage later on. Let
$i\in\mathbb{Z}$
are then compact, which provides an advantage later on. Let
 $\mathcal {P}$
be a Poisson point process on
$\mathcal {P}$
be a Poisson point process on
 $\mathbb{R}$
with intensity
$\mathbb{R}$
with intensity
 $\lambda( x)\;:\!=\;q_0\theta^{-x}\log \theta\,\textrm{d} x$
, and let
$\lambda( x)\;:\!=\;q_0\theta^{-x}\log \theta\,\textrm{d} x$
, and let
 $(\xi_x)_{x\in\mathcal {P}}$
be independent standard normal random variables. For
$(\xi_x)_{x\in\mathcal {P}}$
be independent standard normal random variables. For
 $\varepsilon\in[0,1]$
, we define the ground process
$\varepsilon\in[0,1]$
, we define the ground process
 $\mathcal {P}^\varepsilon$
on
$\mathcal {P}^\varepsilon$
on
 $\mathbb{Z}^*$
and the marked processes
$\mathbb{Z}^*$
and the marked processes
 $\mathcal {M}\mathcal {P}^\varepsilon$
on
$\mathcal {M}\mathcal {P}^\varepsilon$
on
 $\mathbb{Z}^*\times \mathbb{R}$
by
$\mathbb{Z}^*\times \mathbb{R}$
by
 \begin{equation}\mathcal {P}^\varepsilon\;:\!=\;\sum_{x\in\mathcal {P}}\delta_{\lfloor x+\varepsilon\rfloor}, \qquad \mathcal {M}\mathcal {P}^\varepsilon\;:\!=\;\sum_{x\in \mathcal {P}}\delta_{(\lfloor x+\varepsilon\rfloor, \xi_x)},\end{equation}
\begin{equation}\mathcal {P}^\varepsilon\;:\!=\;\sum_{x\in\mathcal {P}}\delta_{\lfloor x+\varepsilon\rfloor}, \qquad \mathcal {M}\mathcal {P}^\varepsilon\;:\!=\;\sum_{x\in \mathcal {P}}\delta_{(\lfloor x+\varepsilon\rfloor, \xi_x)},\end{equation}
where
 $\delta$
is a Dirac measure. Similarly, we can define
$\delta$
is a Dirac measure. Similarly, we can define
 \begin{equation*}\mathcal {P}^{(n)}\;:\!=\;\sum_{i=1}^n \delta_{\mathcal{Z}_n(i)-\lfloor\log_\theta n\rfloor}, \qquad \mathcal {M}\mathcal {P}^{(n)}\;:\!=\;\sum_{i=1}^n \delta_{(\mathcal{Z}_n(i)-\lfloor\log_\theta n\rfloor, (\!\log i-\mu\log n)/\sqrt{(1-\sigma^2)\log n})}.\end{equation*}
\begin{equation*}\mathcal {P}^{(n)}\;:\!=\;\sum_{i=1}^n \delta_{\mathcal{Z}_n(i)-\lfloor\log_\theta n\rfloor}, \qquad \mathcal {M}\mathcal {P}^{(n)}\;:\!=\;\sum_{i=1}^n \delta_{(\mathcal{Z}_n(i)-\lfloor\log_\theta n\rfloor, (\!\log i-\mu\log n)/\sqrt{(1-\sigma^2)\log n})}.\end{equation*}
We then let
 $\mathcal {M}_{\mathbb{Z}^*}^\#$
and
$\mathcal {M}_{\mathbb{Z}^*}^\#$
and
 $ \mathcal {M}_{\mathbb{Z}^*\times\mathbb{R}}^\#$
, respectively, be the spaces of boundedly finite measures on
$ \mathcal {M}_{\mathbb{Z}^*\times\mathbb{R}}^\#$
, respectively, be the spaces of boundedly finite measures on
 $\mathbb{Z}^*$
and
$\mathbb{Z}^*$
and
 $ \mathbb{Z}^*\times \mathbb{R}$
(which, in this case, corresponds to locally finite measures) equipped with the vague topology. We observe that
$ \mathbb{Z}^*\times \mathbb{R}$
(which, in this case, corresponds to locally finite measures) equipped with the vague topology. We observe that
 $\mathcal {P}^{(n)}$
and
$\mathcal {P}^{(n)}$
and
 $\mathcal {P}^\varepsilon$
are random elements of
$\mathcal {P}^\varepsilon$
are random elements of
 $\mathcal {M}_{\mathbb{Z}^*}^\#$
, and
$\mathcal {M}_{\mathbb{Z}^*}^\#$
, and
 $\mathcal {M}\mathcal {P}^{(n)}$
and
$\mathcal {M}\mathcal {P}^{(n)}$
and
 $\mathcal {M}\mathcal {P}^\varepsilon$
are random elements of
$\mathcal {M}\mathcal {P}^\varepsilon$
are random elements of
 $ \mathcal {M}_{\mathbb{Z}^*\times \mathbb{R}}^\#$
. Theorem 2.3 is then equivalent to the weak convergence of
$ \mathcal {M}_{\mathbb{Z}^*\times \mathbb{R}}^\#$
. Theorem 2.3 is then equivalent to the weak convergence of
 $\mathcal {M}\mathcal {P}^{(n_j)}$
to
$\mathcal {M}\mathcal {P}^{(n_j)}$
to
 $\mathcal {M}\mathcal {P}^\varepsilon$
in
$\mathcal {M}\mathcal {P}^\varepsilon$
in
 $\mathcal {M}_{\mathbb{Z}^*\times \mathbb{R}}^\#$
along suitable subsequences
$\mathcal {M}_{\mathbb{Z}^*\times \mathbb{R}}^\#$
along suitable subsequences
 $(n_j)_{j\in\mathbb{N}}$
, as we can order the points in the definition of
$(n_j)_{j\in\mathbb{N}}$
, as we can order the points in the definition of
 $\mathcal {M}\mathcal {P}^{(n)}$
(and
$\mathcal {M}\mathcal {P}^{(n)}$
(and
 $\mathcal {M}\mathcal {P}^\varepsilon$
) in decreasing order of their degrees (of the points
$\mathcal {M}\mathcal {P}^\varepsilon$
) in decreasing order of their degrees (of the points
 $x\in \mathcal {P}$
). We remark that the weak convergence of
$x\in \mathcal {P}$
). We remark that the weak convergence of
 $\mathcal {P}^{(n_j)}$
to
$\mathcal {P}^{(n_j)}$
to
 $\mathcal {P}^{\varepsilon}$
in
$\mathcal {P}^{\varepsilon}$
in
 $\mathcal {M}_{\mathbb{Z}^*}^\#$
along subsequences when the vertex-weights of the WRT belong to the atom case is established in [Reference Eslava, Lodewijks and Ortgiese7] (and it is established for the particular case of the random recursive tree by Addario-Berry and Eslava in [Reference Addario-Berry and Eslava1]). We extend these results, among others, to the tuple of degree and label.
$\mathcal {M}_{\mathbb{Z}^*}^\#$
along subsequences when the vertex-weights of the WRT belong to the atom case is established in [Reference Eslava, Lodewijks and Ortgiese7] (and it is established for the particular case of the random recursive tree by Addario-Berry and Eslava in [Reference Addario-Berry and Eslava1]). We extend these results, among others, to the tuple of degree and label.
The approach we shall use to prove the weak convergence of
 $\mathcal {M}\mathcal {P}^{(n_j)}$
is to show that its finite-dimensional distributions (FDDs) converge along subsequences. The FDDs of a random measure
$\mathcal {M}\mathcal {P}^{(n_j)}$
is to show that its finite-dimensional distributions (FDDs) converge along subsequences. The FDDs of a random measure
 $\mathcal {P}$
are defined as the joint distributions, for all finite families of bounded Borel sets
$\mathcal {P}$
are defined as the joint distributions, for all finite families of bounded Borel sets
 $(B_1, \ldots, B_k)$
, of the random variables
$(B_1, \ldots, B_k)$
, of the random variables
 $(\mathcal {P}(B_1), \ldots, \mathcal {P}(B_k))$
; see [Reference Daley and Vere-Jones5, Definition 9.2.II]. Moreover, by [Reference Daley and Vere-Jones5, Proposition 9.2.III], the distribution of a random measure
$(\mathcal {P}(B_1), \ldots, \mathcal {P}(B_k))$
; see [Reference Daley and Vere-Jones5, Definition 9.2.II]. Moreover, by [Reference Daley and Vere-Jones5, Proposition 9.2.III], the distribution of a random measure
 $\mathcal {P}$
on
$\mathcal {P}$
on
 $\mathcal {X}$
is completely determined by the FDDs for all finite families
$\mathcal {X}$
is completely determined by the FDDs for all finite families
 $(B_1, \ldots, B_k)$
of disjoint sets from a semiring
$(B_1, \ldots, B_k)$
of disjoint sets from a semiring
 $\mathcal {A}$
that generates
$\mathcal {A}$
that generates
 $\mathcal {B}(\mathcal {X})$
. In our case, we consider the marked point process
$\mathcal {B}(\mathcal {X})$
. In our case, we consider the marked point process
 $\mathcal {M}\mathcal {P}^{(n)}$
on
$\mathcal {M}\mathcal {P}^{(n)}$
on
 $\mathcal {X}\;:\!=\;\mathbb{Z}^*\times \mathbb{R}$
; see (5.1). Hence, we let
$\mathcal {X}\;:\!=\;\mathbb{Z}^*\times \mathbb{R}$
; see (5.1). Hence, we let
 \begin{equation*}\mathcal {A}\;:\!=\;\{\{j\}\times (a,b]\;:\; j\in \mathbb{Z}, a,b\in \mathbb{R}\}\cup \{[j,\infty]\times (a,b]\;:\; j\in \mathbb{Z}, a,b\in \mathbb{R}\}\end{equation*}
\begin{equation*}\mathcal {A}\;:\!=\;\{\{j\}\times (a,b]\;:\; j\in \mathbb{Z}, a,b\in \mathbb{R}\}\cup \{[j,\infty]\times (a,b]\;:\; j\in \mathbb{Z}, a,b\in \mathbb{R}\}\end{equation*}
be the semiring that generates
 $\mathcal {B}(\mathbb{Z}^*\times \mathbb{R})$
. The choice of the metric on
$\mathcal {B}(\mathbb{Z}^*\times \mathbb{R})$
. The choice of the metric on
 $\mathbb{Z}^*$
is convenient, since now weak convergence in
$\mathbb{Z}^*$
is convenient, since now weak convergence in
 $\mathbb{Z}^*\times \mathbb{R}$
is equivalent to the convergence of the FDDs by [Reference Daley and Vere-Jones5, Theorem 11.1.VII]. So the weak convergence of the measure
$\mathbb{Z}^*\times \mathbb{R}$
is equivalent to the convergence of the FDDs by [Reference Daley and Vere-Jones5, Theorem 11.1.VII]. So the weak convergence of the measure
 $\mathcal {M}\mathcal {P}^{(n_j)}$
to
$\mathcal {M}\mathcal {P}^{(n_j)}$
to
 $\mathcal {M}\mathcal {P}^\varepsilon$
in
$\mathcal {M}\mathcal {P}^\varepsilon$
in
 $\mathcal {M}^\#_{\mathbb{Z}^*\times \mathbb{R}}$
is equivalent to the convergence of the FDDs of
$\mathcal {M}^\#_{\mathbb{Z}^*\times \mathbb{R}}$
is equivalent to the convergence of the FDDs of
 $\mathcal {M}\mathcal {P}^{(n_j)}$
to the FDDs of
$\mathcal {M}\mathcal {P}^{(n_j)}$
to the FDDs of
 $\mathcal {M}\mathcal {P}^\varepsilon$
. It thus suffices to prove the joint convergence of the counting measures of finite collections of disjoint subsets of
$\mathcal {M}\mathcal {P}^\varepsilon$
. It thus suffices to prove the joint convergence of the counting measures of finite collections of disjoint subsets of
 $\mathcal {A}$
. In particular, the weak convergence of
$\mathcal {A}$
. In particular, the weak convergence of
 $\mathcal {M}\mathcal {P}^{n_j}$
implies the distributional convergence of
$\mathcal {M}\mathcal {P}^{n_j}$
implies the distributional convergence of
 $X_{\geq j}^{(n_j)}(B)=\mathcal {M}\mathcal {P}^{(n_\ell)}([j,\infty))$
for any
$X_{\geq j}^{(n_j)}(B)=\mathcal {M}\mathcal {P}^{(n_\ell)}([j,\infty))$
for any
 $\{j\}\times B\in \mathcal{A}$
.
$\{j\}\times B\in \mathcal{A}$
.
Recall the Poisson point process
 $\mathcal {P}$
used in the definition of
$\mathcal {P}$
used in the definition of
 $\mathcal {P}^\varepsilon$
in (5.1) and enumerate its points in decreasing order. That is, let
$\mathcal {P}^\varepsilon$
in (5.1) and enumerate its points in decreasing order. That is, let
 $P_i$
denote the ith-largest point of
$P_i$
denote the ith-largest point of
 $\mathcal {P}$
(with ties broken uniformly at random). We observe that this is well-defined, since
$\mathcal {P}$
(with ties broken uniformly at random). We observe that this is well-defined, since
 $\mathcal {P}([x,\infty))<\infty$
almost surely for any
$\mathcal {P}([x,\infty))<\infty$
almost surely for any
 $x\in \mathbb{R}$
. Let
$x\in \mathbb{R}$
. Let
 $(M_i)_{i\in\mathbb{N}}$
be a sequence of i.i.d. standard normal random variables. For
$(M_i)_{i\in\mathbb{N}}$
be a sequence of i.i.d. standard normal random variables. For
 $\{j\}\times B\in \mathcal {A}$
, we then define
$\{j\}\times B\in \mathcal {A}$
, we then define
 \begin{equation} \begin{aligned} X^{(n)}_j(B)&\;:\!=\;\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)=\lfloor \log_\theta n\rfloor +j, \frac{\log i-(\!\log n-(1-\theta^{-1})(\lfloor \log_\theta n\rfloor +j))}{\sqrt{(1-\theta^{-1})^2(\lfloor \log_\theta n\rfloor+j)}}\in B\bigg\}\bigg|,\\[5pt] X^{(n)}_{\geq j}(B)&\;:\!=\;\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)\geq\lfloor \log_\theta n\rfloor +j, \frac{\log i-(\!\log n-(1-\theta^{-1})(\lfloor \log_\theta n\rfloor +j))}{\sqrt{(1-\theta^{-1})^2(\lfloor \log_\theta n\rfloor+j)}}\in B\bigg\}\bigg|,\\[5pt] \widetilde X^{(n)}_j(B)&\;:\!=\;\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)=\lfloor \log_\theta n\rfloor +j, \frac{\log i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\in B\bigg\}\bigg|,\\[5pt] \widetilde X^{(n)}_{\geq j}(B)&\;:\!=\;\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)\geq\lfloor \log_\theta n\rfloor +j, \frac{\log i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\in B\bigg\}\bigg|,\\[5pt] X_j(B)&\;:\!=\;\bigg|\bigg\{i\in\mathbb{N}\;:\; \lfloor P_i+\varepsilon\rfloor = j, M_i\in B\bigg\}\bigg|,\\[5pt] X_{\geq j}(B)&\;:\!=\;\bigg|\bigg\{i\in\mathbb{N}\;:\; \lfloor P_i+\varepsilon\rfloor \geq j, M_i\in B\bigg\}\bigg|.\end{aligned} \end{equation}
\begin{equation} \begin{aligned} X^{(n)}_j(B)&\;:\!=\;\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)=\lfloor \log_\theta n\rfloor +j, \frac{\log i-(\!\log n-(1-\theta^{-1})(\lfloor \log_\theta n\rfloor +j))}{\sqrt{(1-\theta^{-1})^2(\lfloor \log_\theta n\rfloor+j)}}\in B\bigg\}\bigg|,\\[5pt] X^{(n)}_{\geq j}(B)&\;:\!=\;\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)\geq\lfloor \log_\theta n\rfloor +j, \frac{\log i-(\!\log n-(1-\theta^{-1})(\lfloor \log_\theta n\rfloor +j))}{\sqrt{(1-\theta^{-1})^2(\lfloor \log_\theta n\rfloor+j)}}\in B\bigg\}\bigg|,\\[5pt] \widetilde X^{(n)}_j(B)&\;:\!=\;\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)=\lfloor \log_\theta n\rfloor +j, \frac{\log i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\in B\bigg\}\bigg|,\\[5pt] \widetilde X^{(n)}_{\geq j}(B)&\;:\!=\;\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)\geq\lfloor \log_\theta n\rfloor +j, \frac{\log i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\in B\bigg\}\bigg|,\\[5pt] X_j(B)&\;:\!=\;\bigg|\bigg\{i\in\mathbb{N}\;:\; \lfloor P_i+\varepsilon\rfloor = j, M_i\in B\bigg\}\bigg|,\\[5pt] X_{\geq j}(B)&\;:\!=\;\bigg|\bigg\{i\in\mathbb{N}\;:\; \lfloor P_i+\varepsilon\rfloor \geq j, M_i\in B\bigg\}\bigg|.\end{aligned} \end{equation}
Using these random variables is justified, as
 $\widetilde X_j^{(n)}(B)=\mathcal {M}\mathcal {P}^{(n)}(\{j\}\times B)$
,
$\widetilde X_j^{(n)}(B)=\mathcal {M}\mathcal {P}^{(n)}(\{j\}\times B)$
,
 $\widetilde X_{\geq j}^{(n)}(B)=\mathcal {M}\mathcal {P}^{(n)}([j,\infty]\times B)$
, and
$\widetilde X_{\geq j}^{(n)}(B)=\mathcal {M}\mathcal {P}^{(n)}([j,\infty]\times B)$
, and
 $X_j(B)=\mathcal {M}\mathcal {P}^\varepsilon(\{j\}\times B)$
and
$X_j(B)=\mathcal {M}\mathcal {P}^\varepsilon(\{j\}\times B)$
and
 $X_{\geq j}(B)=\mathcal {M}\mathcal {P}^\varepsilon([j,\infty]\times B)$
. Furthermore, when
$X_{\geq j}(B)=\mathcal {M}\mathcal {P}^\varepsilon([j,\infty]\times B)$
. Furthermore, when
 $j=o(\sqrt{\log n})$
, we have
$j=o(\sqrt{\log n})$
, we have
 $X_j^{(n)}(B)\approx \widetilde X^{(n)}_j(B)$
,
$X_j^{(n)}(B)\approx \widetilde X^{(n)}_j(B)$
,
 $X_{\geq j}^{(n)}(B)\approx \widetilde X_{\geq j}^{(n)}(B)$
. For any
$X_{\geq j}^{(n)}(B)\approx \widetilde X_{\geq j}^{(n)}(B)$
. For any
 $K\in\mathbb{N}$
, take any (fixed) increasing integer sequence
$K\in\mathbb{N}$
, take any (fixed) increasing integer sequence
 $(j_k)_{k\in[K]}$
with
$(j_k)_{k\in[K]}$
with
 $0\leq K'\;:\!=\;\min\{k\;:\; j_{k+1}=j_K\}$
and any sequence
$0\leq K'\;:\!=\;\min\{k\;:\; j_{k+1}=j_K\}$
and any sequence
 $(B_k)_{k\in[K]}$
with
$(B_k)_{k\in[K]}$
with
 $B_k=(a_k,b_k]\in\mathcal {B}(\mathbb{R})$
for some
$B_k=(a_k,b_k]\in\mathcal {B}(\mathbb{R})$
for some
 $a_k,b_k\in\mathbb{R}$
and such that
$a_k,b_k\in\mathbb{R}$
and such that
 $B_k\cap B_\ell=\varnothing$
when
$B_k\cap B_\ell=\varnothing$
when
 $j_k=j_\ell$
and
$j_k=j_\ell$
and
 $k\neq \ell$
. The conditions on the sets
$k\neq \ell$
. The conditions on the sets
 $B_k$
ensure that the elements
$B_k$
ensure that the elements
 $\{j_1\}\times B_1, \ldots, \{j'_{\!\!K}\}\times B_{K'}, \{j_{K'+1},\ldots\}\times B_{K'+1}, \ldots, \{j_K,\ldots\}\times B_K$
of
$\{j_1\}\times B_1, \ldots, \{j'_{\!\!K}\}\times B_{K'}, \{j_{K'+1},\ldots\}\times B_{K'+1}, \ldots, \{j_K,\ldots\}\times B_K$
of
 $\mathcal {A}$
are disjoint. We are thus required to prove the joint distributional convergence of the random variables
$\mathcal {A}$
are disjoint. We are thus required to prove the joint distributional convergence of the random variables
 \begin{equation}\bigg(\widetilde X_{j_1}^{(n)}(B_1),\ldots,\widetilde X^{(n)}_{j_{K'}}\big(B_{K'}\big),\widetilde X^{(n)}_{\geq j_{K'+1}}\big(B_{K'+1}\big),\ldots,\widetilde X_{\geq j_K}^{(n)}(B_K)\bigg),\end{equation}
\begin{equation}\bigg(\widetilde X_{j_1}^{(n)}(B_1),\ldots,\widetilde X^{(n)}_{j_{K'}}\big(B_{K'}\big),\widetilde X^{(n)}_{\geq j_{K'+1}}\big(B_{K'+1}\big),\ldots,\widetilde X_{\geq j_K}^{(n)}(B_K)\bigg),\end{equation}
to prove Theorem 2.3.
5.2. Intermediate results
We first state some intermediate results which are required to prove Theorems 2.2 and 2.3; afterwards, we prove these theorems. We defer the proof of the intermediate results to Section 6.
The first result provides precise and general asymptotic bounds for the joint distribution of the degree and label of vertices selected uniformly at random from [n]. We recall
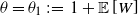 $\theta=\theta_1\;:\!=\;1+\mathbb{E}\left[W\right]$
. We then formulate the following result.
$\theta=\theta_1\;:\!=\;1+\mathbb{E}\left[W\right]$
. We then formulate the following result.
Proposition 5.1. (Degree and label of typical vertices.) Consider the WRT model, that is, the WRG as in Definition 2.1 with
 $m=1$
, with vertex-weights
$m=1$
, with vertex-weights
 $(W_i)_{i\in[n]}$
which are i.i.d. copies of a positive random variable W that satisfies Condition C1 of Assumption 2.1. Fix
$(W_i)_{i\in[n]}$
which are i.i.d. copies of a positive random variable W that satisfies Condition C1 of Assumption 2.1. Fix
 $k\in\mathbb{N}$
,
$k\in\mathbb{N}$
,
 $c\in(0,\theta/(\theta-1))$
,
$c\in(0,\theta/(\theta-1))$
,
 $\eta\in(0,1)$
, and let
$\eta\in(0,1)$
, and let
 $(v_i)_{i\in[k]}$
be k vertices selected uniformly at random without replacement from [n]. For non-negative integers
$(v_i)_{i\in[k]}$
be k vertices selected uniformly at random without replacement from [n]. For non-negative integers
 $(d_i)_{i\in[k]}$
such that
$(d_i)_{i\in[k]}$
such that
 $d_i\leq c\log n$
,
$d_i\leq c\log n$
,
 $i\in[k]$
, let
$i\in[k]$
, let
 $(\ell_i)_{i\in[k]}\in \mathbb{R}_+^k$
be such that they satisfy
$(\ell_i)_{i\in[k]}\in \mathbb{R}_+^k$
be such that they satisfy
 $\ell_i\leq n\exp\!(\!-\!(1-\zeta)(1-\theta^{-1})(d_i+1))$
and
$\ell_i\leq n\exp\!(\!-\!(1-\zeta)(1-\theta^{-1})(d_i+1))$
and
 $\ell_i\geq n^\eta$
for all n large, for any
$\ell_i\geq n^\eta$
for all n large, for any
 $\zeta>0$
and each
$\zeta>0$
and each
 $i\in[k]$
, and let
$i\in[k]$
, and let
 $X_i\sim\textrm{Gamma}(d_i+1,1)$
,
$X_i\sim\textrm{Gamma}(d_i+1,1)$
,
 $i\in[k]$
. Then, uniformly over
$i\in[k]$
. Then, uniformly over
 $d_i\leq c\log n$
,
$d_i\leq c\log n$
,
 $i\in[k]$
,
$i\in[k]$
,
 \begin{equation}\begin{aligned} \mathbb P({}&\mathcal{Z}_n(v_i)=d_i, v_i> \ell_i, i\in[k])\\[5pt] &=(1+o(1))\prod_{i=1}^k\mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(X_i<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right]. \end{aligned}\end{equation}
\begin{equation}\begin{aligned} \mathbb P({}&\mathcal{Z}_n(v_i)=d_i, v_i> \ell_i, i\in[k])\\[5pt] &=(1+o(1))\prod_{i=1}^k\mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(X_i<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right]. \end{aligned}\end{equation}
Moreover, when
 $d_i=d_i(n)$
diverges with n and with
$d_i=d_i(n)$
diverges with n and with
 $\widetilde X_i\sim\textit{Gamma}(d_i+\lfloor d_i^{1/4}\rfloor+1,1)$
,
$\widetilde X_i\sim\textit{Gamma}(d_i+\lfloor d_i^{1/4}\rfloor+1,1)$
,
 $i\in[k]$
,
$i\in[k]$
,
 \begin{equation} \begin{aligned} \mathbb P({}&\mathcal{Z}_n(v_i)\geq d_i, v_i> \ell_i, i\in[k])&\\[5pt] &\leq(1+o(1))\prod_{i=1}^k \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(X_i<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right],\\[5pt] \mathbb P({}&\mathcal{Z}_n(v_i)\geq d_i, v_i> \ell_i, i\in[k])\\[5pt] &\geq(1+o(1))\prod_{i=1}^k \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(\widetilde X_i<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right]. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \mathbb P({}&\mathcal{Z}_n(v_i)\geq d_i, v_i> \ell_i, i\in[k])&\\[5pt] &\leq(1+o(1))\prod_{i=1}^k \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(X_i<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right],\\[5pt] \mathbb P({}&\mathcal{Z}_n(v_i)\geq d_i, v_i> \ell_i, i\in[k])\\[5pt] &\geq(1+o(1))\prod_{i=1}^k \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(\widetilde X_i<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right]. \end{aligned} \end{equation}
Remark 5.1.
-
(i) We conjecture that the additional condition that
$d_i$
diverges with n for all
$i\in[k]$
is sufficient but not necessary for the result in (5.5) to hold, and that a sharper lower bound, using
$X_i$
instead of
$\widetilde X_i$
, can be achieved. These minor differences arise only because of the nature of our proof. However, the results in Proposition 5.1 are sufficiently strong for the purposes of this paper. -
(ii) Lemma A.1 and Corollary A.1 in the appendix provide asymptotic estimates for the probability in (5.5) when the vertex-weight distribution satisfies Condition C2, or satisfies the atom, beta, or gamma case from Assumption 2.1, for a particular parametrisation of
$d_i, \ell_i$
,
$i\in[k]$
. -
(iii) Proposition 5.1 also holds when we consider the definition of the WRT model with random out-degree, as discussed in Remark 2.1(ii). For the interested reader, we refer to the discussion after the proof of [Reference Eslava, Lodewijks and Ortgiese7, Lemma 5.10] for the (minor) adaptations required, which also suffice for the proof of Proposition 5.1.






With Proposition 5.1 we can make rigorous the heuristic that the maximum degree is of the order
 $d_n$
when
$d_n$
when
 $p_{\geq d_n}\approx 1/n$
, where
$p_{\geq d_n}\approx 1/n$
, where
 \begin{equation} p_{\geq d}\;:\!=\;\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right], \qquad d\in\mathbb{N}_0,\end{equation}
\begin{equation} p_{\geq d}\;:\!=\;\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right], \qquad d\in\mathbb{N}_0,\end{equation}
is the limiting tail degree distribution of the WRT model. This is a consequence of the following lemma.
Lemma 5.1. Consider the WRT model, that is, the WRG as in Definition 2.1 with
 $m=1$
, with vertex-weights
$m=1$
, with vertex-weights
 $(W_i)_{i\in[n]}$
which are i.i.d. copies of a positive random variable W that satisfies Condition C1 of Assumption 2.1, and recall
$(W_i)_{i\in[n]}$
which are i.i.d. copies of a positive random variable W that satisfies Condition C1 of Assumption 2.1, and recall
 $\theta=\theta_1=1+\mathbb{E}\left[W\right]$
. Fix
$\theta=\theta_1=1+\mathbb{E}\left[W\right]$
. Fix
 $c\in(0,\theta/(\theta-1))$
and let
$c\in(0,\theta/(\theta-1))$
and let
 $(d_n)_{n\in\mathbb{N}}$
be a positive integer sequence that diverges with n such that
$(d_n)_{n\in\mathbb{N}}$
be a positive integer sequence that diverges with n such that
 $d_n\leq c\log n$
. Then
$d_n\leq c\log n$
. Then
 \begin{equation*} \lim_{n\to\infty}n\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\right]=0\quad \Rightarrow \quad \lim_{n\to\infty}\mathbb{P}\left(\max_{i\in[n]}\mathcal{Z}_n(i)\geq d_n\right)=0. \end{equation*}
\begin{equation*} \lim_{n\to\infty}n\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\right]=0\quad \Rightarrow \quad \lim_{n\to\infty}\mathbb{P}\left(\max_{i\in[n]}\mathcal{Z}_n(i)\geq d_n\right)=0. \end{equation*}
Similarly,
 \begin{equation*} \lim_{n\to\infty}n\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\right]=\infty\quad \Rightarrow \quad \lim_{n\to\infty}\mathbb{P}\left(\max_{i\in[n]}\mathcal{Z}_n(i)\geq d_n\right)=1. \end{equation*}
\begin{equation*} \lim_{n\to\infty}n\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\right]=\infty\quad \Rightarrow \quad \lim_{n\to\infty}\mathbb{P}\left(\max_{i\in[n]}\mathcal{Z}_n(i)\geq d_n\right)=1. \end{equation*}
Remark 5.2. Lemma 5.1 can be used to provide precise asymptotic values for the maximum degree in the WRT model. Under assumptions on the distribution of the vertex-weights, it is possible to determine values of
 $d_n$
for which either
$d_n$
for which either
 $\lim_{n\to\infty}np_{\geq d_n}=0$
or
$\lim_{n\to\infty}np_{\geq d_n}=0$
or
 $\lim_{n\to\infty}np_{\geq d_n}=\infty$
is met. In particular, Lemma 5.1 can be used to extend Theorems 2.6–2.7 in [Reference Eslava, Lodewijks and Ortgiese7], as well as Equation (4.6) in Theorem 4.6 of [Reference Eslava, Lodewijks and Ortgiese7], to a wider range of vertex-weight distributions. Specifically, in [Reference Eslava, Lodewijks and Ortgiese7], Condition C3 is required for a result equivalent to Lemma 5.1 to hold. This result is used to prove the aforementioned theorems. Here, however, we do not need Condition C3 for Lemma 5.1, so that these theorems can be extended to a wider range of vertex-weight distributions.
$\lim_{n\to\infty}np_{\geq d_n}=\infty$
is met. In particular, Lemma 5.1 can be used to extend Theorems 2.6–2.7 in [Reference Eslava, Lodewijks and Ortgiese7], as well as Equation (4.6) in Theorem 4.6 of [Reference Eslava, Lodewijks and Ortgiese7], to a wider range of vertex-weight distributions. Specifically, in [Reference Eslava, Lodewijks and Ortgiese7], Condition C3 is required for a result equivalent to Lemma 5.1 to hold. This result is used to prove the aforementioned theorems. Here, however, we do not need Condition C3 for Lemma 5.1, so that these theorems can be extended to a wider range of vertex-weight distributions.
We now present a proposition which asymptotically determines the joint factorial moments of the random variables
 $X_j^{(n)}(B)$
and
$X_j^{(n)}(B)$
and
 $X_{\geq j}^{(n)}(B)$
, as in (5.2), when the vertex-weight distribution satisfies the atom case. It is instrumental for the proof of Theorem 2.3.
$X_{\geq j}^{(n)}(B)$
, as in (5.2), when the vertex-weight distribution satisfies the atom case. It is instrumental for the proof of Theorem 2.3.
Proposition 5.2. Consider the WRT model, that is, the WRG model as in Definition 2.1 with
 $m=1$
, with vertex-weights
$m=1$
, with vertex-weights
 $(W_i)_{i\in[n]}$
that satisfy the atom case in Assumption 2.1 for some
$(W_i)_{i\in[n]}$
that satisfy the atom case in Assumption 2.1 for some
 $q_0\in(0,1]$
. Recall that
$q_0\in(0,1]$
. Recall that
 $\theta\;:\!=\;1+\mathbb{E}\left[W\right]$
and that
$\theta\;:\!=\;1+\mathbb{E}\left[W\right]$
and that
 $(x)_k\;:\!=\;x(x-1)\cdots (x-(k-1))$
for
$(x)_k\;:\!=\;x(x-1)\cdots (x-(k-1))$
for
 $x\in\mathbb{R}$
,
$x\in\mathbb{R}$
,
 $k\in\mathbb{N}$
, and
$k\in\mathbb{N}$
, and
 $(x)_0\;:\!=\;1$
. Fix
$(x)_0\;:\!=\;1$
. Fix
 $c\in(0,\theta/(\theta-1))$
and
$c\in(0,\theta/(\theta-1))$
and
 $K\in\mathbb{N}$
; let
$K\in\mathbb{N}$
; let
 $(j_k)_{k\in[K]}$
be a non-decreasing integer sequence with
$(j_k)_{k\in[K]}$
be a non-decreasing integer sequence with
 $0\leq K'\;:\!=\;\min\{k\;:\; j_{k+1}=j_K\}$
such that
$0\leq K'\;:\!=\;\min\{k\;:\; j_{k+1}=j_K\}$
such that
 $j_1+\log_\theta n=\omega(1)$
and
$j_1+\log_\theta n=\omega(1)$
and
 $j_K+\log_\theta n<c\log n$
; let
$j_K+\log_\theta n<c\log n$
; let
 $(B_k)_{k\in[K]}$
be a sequence of sets
$(B_k)_{k\in[K]}$
be a sequence of sets
 $B_k\in \mathcal {B}(\mathbb{R})$
such that
$B_k\in \mathcal {B}(\mathbb{R})$
such that
 $B_k\cap B_\ell=\varnothing $
when
$B_k\cap B_\ell=\varnothing $
when
 $j_k=j_\ell$
and
$j_k=j_\ell$
and
 $k\neq \ell$
; and let
$k\neq \ell$
; and let
 $(c_k)_{k\in[K]}\in \mathbb{N}_0^K$
. Recall the random variables
$(c_k)_{k\in[K]}\in \mathbb{N}_0^K$
. Recall the random variables
 $X^{(n)}_j(B)$
,
$X^{(n)}_j(B)$
,
 $X_{\geq j}^{(n)}(B)$
and
$X_{\geq j}^{(n)}(B)$
and
 $\widetilde X^{(n)}_j(B)$
,
$\widetilde X^{(n)}_j(B)$
,
 $\widetilde X_{\geq j}^{(n)}(B)$
from (5.2), and define
$\widetilde X_{\geq j}^{(n)}(B)$
from (5.2), and define
 $\varepsilon_n\;:\!=\;\log_\theta n-\lfloor \log_\theta n\rfloor$
. Then
$\varepsilon_n\;:\!=\;\log_\theta n-\lfloor \log_\theta n\rfloor$
. Then
 \begin{equation*} \begin{aligned} \mathbb{E}\left[\prod_{k=1}^{K'}\Big(X_{j_k}^{(n)}(B_k)\Big)_{c_k}\prod_{k=K'+1}^K \Big(X_{\geq j_k}^{(n)}(B_k)\Big)_{c_k}\right]={}&(1+o(1))\prod_{k=1}^{K'}\Big(q_0(1-\theta^{-1})\theta^{-j_k+\varepsilon_n}\Phi(B_k)\Big)^{c_k}\\[5pt] &\times \prod_{k=K'+1}^{K}\Big(q_0\theta^{-j_K+\varepsilon_n}\Phi(B_k)\Big)^{c_k}. \end{aligned}\end{equation*}
\begin{equation*} \begin{aligned} \mathbb{E}\left[\prod_{k=1}^{K'}\Big(X_{j_k}^{(n)}(B_k)\Big)_{c_k}\prod_{k=K'+1}^K \Big(X_{\geq j_k}^{(n)}(B_k)\Big)_{c_k}\right]={}&(1+o(1))\prod_{k=1}^{K'}\Big(q_0(1-\theta^{-1})\theta^{-j_k+\varepsilon_n}\Phi(B_k)\Big)^{c_k}\\[5pt] &\times \prod_{k=K'+1}^{K}\Big(q_0\theta^{-j_K+\varepsilon_n}\Phi(B_k)\Big)^{c_k}. \end{aligned}\end{equation*}
Moreover, when
 $j_1,\ldots, j_K=o(\sqrt{\log n})$
,
$j_1,\ldots, j_K=o(\sqrt{\log n})$
,
 \begin{equation*} \begin{aligned} \mathbb{E}\left[\prod_{k=1}^{K'}\Big(\widetilde X_{j_k}^{(n)}(B_k)\Big)_{c_k}\prod_{k=K'+1}^K \Big(\widetilde X_{\geq j_k}^{(n)}(B_k)\Big)_{c_k}\right]={}&(1+o(1))\prod_{k=1}^{K'}\Big(q_0(1-\theta^{-1})\theta^{-j_k+\varepsilon_n}\Phi(B_k)\Big)^{c_k}\\[5pt] &\times \prod_{k=K'+1}^{K}\Big(q_0\theta^{-j_K+\varepsilon_n}\Phi(B_k)\Big)^{c_k}. \end{aligned}\end{equation*}
\begin{equation*} \begin{aligned} \mathbb{E}\left[\prod_{k=1}^{K'}\Big(\widetilde X_{j_k}^{(n)}(B_k)\Big)_{c_k}\prod_{k=K'+1}^K \Big(\widetilde X_{\geq j_k}^{(n)}(B_k)\Big)_{c_k}\right]={}&(1+o(1))\prod_{k=1}^{K'}\Big(q_0(1-\theta^{-1})\theta^{-j_k+\varepsilon_n}\Phi(B_k)\Big)^{c_k}\\[5pt] &\times \prod_{k=K'+1}^{K}\Big(q_0\theta^{-j_K+\varepsilon_n}\Phi(B_k)\Big)^{c_k}. \end{aligned}\end{equation*}
We can interpret the results in Proposition 5.2 as follows. Fix some
 $(j_k)_{k\in[K]}$
and
$(j_k)_{k\in[K]}$
and
 $(B_k)_{k\in[K]}$
as in the proposition (we note that the
$(B_k)_{k\in[K]}$
as in the proposition (we note that the
 $j_k$
are allowed to be functions of n, but for simplicity we do not discuss this case here). Then the result of the proposition tells us that the joint factorial moments of the random variables
$j_k$
are allowed to be functions of n, but for simplicity we do not discuss this case here). Then the result of the proposition tells us that the joint factorial moments of the random variables
 $X^{(n)}_{j_k}(B_k)$
and
$X^{(n)}_{j_k}(B_k)$
and
 $X^{(n)}_{\geq j_k}(B_k)$
are asymptotically equal to a product of terms
$X^{(n)}_{\geq j_k}(B_k)$
are asymptotically equal to a product of terms
 $(q_0(1-\theta^{-1})\theta^{-j_k+\varepsilon_n}\theta(B_k))^{c_k}$
and
$(q_0(1-\theta^{-1})\theta^{-j_k+\varepsilon_n}\theta(B_k))^{c_k}$
and
 $(q_0\theta^{-j_K+\varepsilon_n}\theta(B_k))^{c_k}$
, respectively. Since
$(q_0\theta^{-j_K+\varepsilon_n}\theta(B_k))^{c_k}$
, respectively. Since
 $\varepsilon_n$
is bounded, it converges along subsequences to some value
$\varepsilon_n$
is bounded, it converges along subsequences to some value
 $\varepsilon\in[0,1]$
. Hence, the method of moments yields that the random variables of interest are asymptotically independent and that their limits, along certain subsequences, are Poisson random variables. Thus, the number of vertices with a degree equal to, or at least,
$\varepsilon\in[0,1]$
. Hence, the method of moments yields that the random variables of interest are asymptotically independent and that their limits, along certain subsequences, are Poisson random variables. Thus, the number of vertices with a degree equal to, or at least,
 $j_k+\log_\theta n$
and a label i such that
$j_k+\log_\theta n$
and a label i such that
 \begin{equation*} \frac{\log i-(\!\log n-(1-\theta^{-1})(\lfloor \log_\theta n\rfloor +j_k))}{\sqrt{(1-\theta^{-1})^2(\lfloor \log_\theta n\rfloor +j_k)}}\in B_k \end{equation*}
\begin{equation*} \frac{\log i-(\!\log n-(1-\theta^{-1})(\lfloor \log_\theta n\rfloor +j_k))}{\sqrt{(1-\theta^{-1})^2(\lfloor \log_\theta n\rfloor +j_k)}}\in B_k \end{equation*}
is asymptotically Poisson distributed. A similar statement can be made for the random variables
 $\widetilde X^{(n)}_{j_k}(B_k)$
and
$\widetilde X^{(n)}_{j_k}(B_k)$
and
 $\widetilde X^{(n)}_{\geq j_k}(B_k)$
.
$\widetilde X^{(n)}_{\geq j_k}(B_k)$
.
A similar result can be proved for the beta and gamma cases, which we defer to Section 7.
5.3. Proofs of main results
With the intermediate results in hand, we can prove Theorems 2.2 and 2.3.
Proof of Theorem
2.2 subject to Proposition 5.1. We recall that
 $d_i$
diverges as
$d_i$
diverges as
 $n\to\infty$
for all
$n\to\infty$
for all
 $i\in[k]$
such that
$i\in[k]$
such that
 $c_i\;:\!=\;\limsup_{n\to\infty} d_i/\log n$
is strictly smaller than
$c_i\;:\!=\;\limsup_{n\to\infty} d_i/\log n$
is strictly smaller than
 $\theta/(\theta-1)$
for all
$\theta/(\theta-1)$
for all
 $i\in[k]$
, and for
$i\in[k]$
, and for
 $(x_i)_{i\in[k]}\in \mathbb{R}^k$
fixed, we define
$(x_i)_{i\in[k]}\in \mathbb{R}^k$
fixed, we define
 \begin{equation*} \ell_i\;:\!=\;n\exp\!(\!-\!(1-\theta^{-1})d_i+x_i\sqrt{(1-\theta^{-1})^2d_i}), \qquad i\in[k]. \end{equation*}
\begin{equation*} \ell_i\;:\!=\;n\exp\!(\!-\!(1-\theta^{-1})d_i+x_i\sqrt{(1-\theta^{-1})^2d_i}), \qquad i\in[k]. \end{equation*}
We first observe that by this definition,
 \begin{equation*} \bigg\{\frac{\log v_i-(\!\log n-(1-\theta^{-1})d_i)}{\sqrt{(1-\theta^{-1})^2d_i}}\geq x_i, i\in[k]\bigg\}=\{v_i>\ell_i, i\in[k]\}. \end{equation*}
\begin{equation*} \bigg\{\frac{\log v_i-(\!\log n-(1-\theta^{-1})d_i)}{\sqrt{(1-\theta^{-1})^2d_i}}\geq x_i, i\in[k]\bigg\}=\{v_i>\ell_i, i\in[k]\}. \end{equation*}
Furthermore, we note that there exists an
 $\eta>0$
such that, for all
$\eta>0$
such that, for all
 $i\in[k]$
, we have
$i\in[k]$
, we have
 $\ell_i\geq n^\eta$
and
$\ell_i\geq n^\eta$
and
 $\ell_i\leq n\exp\!(\!-\!(1-\zeta)(1-\theta^{-1})(d_i+1))$
for all
$\ell_i\leq n\exp\!(\!-\!(1-\zeta)(1-\theta^{-1})(d_i+1))$
for all
 $\zeta>0$
and all n sufficiently large. Hence, the conditions in Proposition 5.1 are satisfied. We then write
$\zeta>0$
and all n sufficiently large. Hence, the conditions in Proposition 5.1 are satisfied. We then write
 \begin{equation*} \mathbb{P}\left(v_i\geq \ell_i, i\in[k]\,|\, \mathcal{Z}_n(v_i)\geq d_i, i\in[k]\right)=\frac{\mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, v_i\geq \ell_i, i\in[k]\right)}{\mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i,i\in[k]\right)}. \end{equation*}
\begin{equation*} \mathbb{P}\left(v_i\geq \ell_i, i\in[k]\,|\, \mathcal{Z}_n(v_i)\geq d_i, i\in[k]\right)=\frac{\mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, v_i\geq \ell_i, i\in[k]\right)}{\mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i,i\in[k]\right)}. \end{equation*}
We now combine Proposition 5.1 with Lemma A.1 in the appendix. As we assume that the vertex-weight distribution satisfies Conditions C1 and C2 of Assumption 2.1, it follows that
 \begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, v_i>\ell_i, i\in[k]\right)=(1+o(1))\prod_{i=1}^k p_{\geq d_i}(1-\Phi(x_i)), \end{equation}
\begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, v_i>\ell_i, i\in[k]\right)=(1+o(1))\prod_{i=1}^k p_{\geq d_i}(1-\Phi(x_i)), \end{equation}
where we recall
 $p_{\geq d}$
from (5.6). It thus remains to show that
$p_{\geq d}$
from (5.6). It thus remains to show that
 \begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, i\in[k]\right)=(1+o(1))\prod_{i=1}^k p_{\geq d_i}. \end{equation}
\begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, i\in[k]\right)=(1+o(1))\prod_{i=1}^k p_{\geq d_i}. \end{equation}
We first assume that
 $c_i<1/\log \theta$
for all
$c_i<1/\log \theta$
for all
 $i\in[k]$
. We can then take any
$i\in[k]$
. We can then take any
 $\varepsilon\in(0,\mu)$
, and for all n sufficiently large,
$\varepsilon\in(0,\mu)$
, and for all n sufficiently large,
 $n^{\mu-\varepsilon}\leq n\exp\!(\!-\!(1-\theta^{-1})(d_i+1))$
holds for all
$n^{\mu-\varepsilon}\leq n\exp\!(\!-\!(1-\theta^{-1})(d_i+1))$
holds for all
 $i\in[k]$
. It then follows from Proposition 5.1 (with
$i\in[k]$
. It then follows from Proposition 5.1 (with
 $\ell_i=n^{\mu-\varepsilon}$
for all
$\ell_i=n^{\mu-\varepsilon}$
for all
 $i\in[k]$
) and Lemma A.2 that
$i\in[k]$
) and Lemma A.2 that
 \begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, i\in[k]\right)\geq\mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i,v_i\geq n^{\mu-\varepsilon}, i\in[k]\right)=(1+o(1))\prod_{i=1}^k p_{\geq d_i}. \end{equation}
\begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, i\in[k]\right)\geq\mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i,v_i\geq n^{\mu-\varepsilon}, i\in[k]\right)=(1+o(1))\prod_{i=1}^k p_{\geq d_i}. \end{equation}
It remains to prove a matching upper bound, for which we use that for any
 $\eta>0$
small,
$\eta>0$
small,
 \begin{equation} \begin{aligned} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i,i\in[k]\right)\leq{}& \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i,v_i\geq n^\eta,i\in[k]\right)\\[5pt] &+\mathbb{P}\left(\Big(\cap_{i=1}^k \{\mathcal{Z}_n(v_i)\geq d_i\}\Big)\cap \Big(\cup_{i=1}^k \{v_i<n^\eta\}\Big)\right). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i,i\in[k]\right)\leq{}& \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i,v_i\geq n^\eta,i\in[k]\right)\\[5pt] &+\mathbb{P}\left(\Big(\cap_{i=1}^k \{\mathcal{Z}_n(v_i)\geq d_i\}\Big)\cap \Big(\cup_{i=1}^k \{v_i<n^\eta\}\Big)\right). \end{aligned} \end{equation}
The first term on the right-hand side can be dealt with in the same manner as (5.9) by setting
 $\eta=\mu-\varepsilon$
with
$\eta=\mu-\varepsilon$
with
 $\varepsilon$
sufficiently close to
$\varepsilon$
sufficiently close to
 $\mu$
. We write the second term as
$\mu$
. We write the second term as
 \begin{equation} \begin{aligned} \sum_{j=1}^k{}& \sum_{\substack{S\subseteq[k]\\ |S|=j}}\mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, i\in[k], v_j<n^\eta, j\in S, v_m>n^\eta, m\in S^c\right)\\[5pt] &\leq \sum_{j=1}^k \sum_{\substack{S\subseteq[k]\\ |S|=j}}\mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, v_i>n^\eta, i\in S^c\right)\mathbb{P}\left(v_j<n^\eta, j\in S\right)\\[5pt] &\leq \sum_{j=1}^k \sum_{\substack{S\subseteq[k]\\ |S|=j}} (1+o(1)) n^{-j(1-\eta)}\prod_{i\in S^c}p_{\geq d_i}, \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \sum_{j=1}^k{}& \sum_{\substack{S\subseteq[k]\\ |S|=j}}\mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, i\in[k], v_j<n^\eta, j\in S, v_m>n^\eta, m\in S^c\right)\\[5pt] &\leq \sum_{j=1}^k \sum_{\substack{S\subseteq[k]\\ |S|=j}}\mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, v_i>n^\eta, i\in S^c\right)\mathbb{P}\left(v_j<n^\eta, j\in S\right)\\[5pt] &\leq \sum_{j=1}^k \sum_{\substack{S\subseteq[k]\\ |S|=j}} (1+o(1)) n^{-j(1-\eta)}\prod_{i\in S^c}p_{\geq d_i}, \end{aligned} \end{equation}
where we use that the uniform vertices
 $(v_i)_{i\in S}$
are independent of everything else, and where we take care of the other probability in the second line in the same manner as the first term on the right-hand side of (5.10). We now use Theorem 3.2 to bound
$(v_i)_{i\in S}$
are independent of everything else, and where we take care of the other probability in the second line in the same manner as the first term on the right-hand side of (5.10). We now use Theorem 3.2 to bound
 $p_{\geq d}\geq (\theta+\xi)^{-d}= \exp\!(\!-\!d\log(\theta+\xi))$
for any
$p_{\geq d}\geq (\theta+\xi)^{-d}= \exp\!(\!-\!d\log(\theta+\xi))$
for any
 $\xi>0$
and d sufficiently large. Since
$\xi>0$
and d sufficiently large. Since
 $c_i<1/\log\theta$
for all
$c_i<1/\log\theta$
for all
 $i\in[k]$
, it thus follows that for
$i\in[k]$
, it thus follows that for
 $\xi$
and
$\xi$
and
 $\eta$
sufficiently small,
$\eta$
sufficiently small,
 $n^{-(1-\eta)}=o(p_{\geq d_i})$
for all
$n^{-(1-\eta)}=o(p_{\geq d_i})$
for all
 $i\in[k]$
. Hence, the final line of (5.11) is
$i\in[k]$
. Hence, the final line of (5.11) is
 $o(\prod_{i=1}^k p_{\geq d_i})$
. In (5.10), we thus find that
$o(\prod_{i=1}^k p_{\geq d_i})$
. In (5.10), we thus find that
 \begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i,i\in[k]\right)\leq(1+o(1))\prod_{i=1}^k p_{\geq d_i}. \end{equation*}
\begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i,i\in[k]\right)\leq(1+o(1))\prod_{i=1}^k p_{\geq d_i}. \end{equation*}
Combined with (5.9), this proves (5.8) and thus the desired result.
To extend the proof to
 $c_i\in[1/\log \theta,\theta/(\theta-1))$
, we observe that the lower bound in (5.9) is still valid when we choose
$c_i\in[1/\log \theta,\theta/(\theta-1))$
, we observe that the lower bound in (5.9) is still valid when we choose
 $\varepsilon$
sufficiently close to
$\varepsilon$
sufficiently close to
 $\mu$
so that
$\mu$
so that
 $n^{\mu-\varepsilon}\leq n\exp\!(\!-\!(1-\theta^{-1})(d_i+1))$
still holds for all
$n^{\mu-\varepsilon}\leq n\exp\!(\!-\!(1-\theta^{-1})(d_i+1))$
still holds for all
 $i\in[k]$
—to be more precise, when we let
$i\in[k]$
—to be more precise, when we let
 $\varepsilon\in(c(1-\theta^{-1})-(1-\mu),\mu)$
, where
$\varepsilon\in(c(1-\theta^{-1})-(1-\mu),\mu)$
, where
 $c\in(\max_{i\in[k]}c_i,\theta/(\theta-1))$
. The upper bound, however, no longer suffices, since the error terms on the right-hand side of (5.11) no longer decay sufficiently fast. Instead, we require Condition C3 of Assumption 2.1. With this condition and since
$c\in(\max_{i\in[k]}c_i,\theta/(\theta-1))$
. The upper bound, however, no longer suffices, since the error terms on the right-hand side of (5.11) no longer decay sufficiently fast. Instead, we require Condition C3 of Assumption 2.1. With this condition and since
 $c_i<\theta/(\theta-1)$
for all
$c_i<\theta/(\theta-1)$
for all
 $i\in[k]$
, we can apply Proposition 3.1. This yields
$i\in[k]$
, we can apply Proposition 3.1. This yields
 \begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, i\in[k]\right)=(1+o(1))\prod_{i=1}^k p_{\geq d_i}. \end{equation*}
\begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, i\in[k]\right)=(1+o(1))\prod_{i=1}^k p_{\geq d_i}. \end{equation*}
Combined with (5.7), this implies the same result.
Using Remark A.1(i)–(ii) (together with Proposition 3.1 for the case
 $c_i\in[1/\log \theta,\theta/(\theta-1))$
for all
$c_i\in[1/\log \theta,\theta/(\theta-1))$
for all
 $i\in[k]$
), a similar result can be proved when conditioning on the event
$i\in[k]$
), a similar result can be proved when conditioning on the event
 $\{\mathcal{Z}_n(v_i)= d_i, i\in[k]\}$
, as claimed in Remark 2.5.
$\{\mathcal{Z}_n(v_i)= d_i, i\in[k]\}$
, as claimed in Remark 2.5.
Proof of Theorem
2.3 subject to Proposition 5.2. As discussed before (5.2), it suffices to prove the weak convergence of
 $\mathcal {M}\mathcal {P}^{(n_j)}$
to
$\mathcal {M}\mathcal {P}^{(n_j)}$
to
 $\mathcal {M}\mathcal {P}^\varepsilon$
along subsequences
$\mathcal {M}\mathcal {P}^\varepsilon$
along subsequences
 $(n_j)_{j\in\mathbb{N}}$
such that
$(n_j)_{j\in\mathbb{N}}$
such that
 $\varepsilon_{n_j}\to \varepsilon\in[0,1]$
as
$\varepsilon_{n_j}\to \varepsilon\in[0,1]$
as
 $j\to\infty$
. In turn, this is implied by the convergence of the FDDs, i.e., by the joint convergence of the counting measures in (5.3).
$j\to\infty$
. In turn, this is implied by the convergence of the FDDs, i.e., by the joint convergence of the counting measures in (5.3).
We recall that the points
 $P_i$
in the definition of the variables
$P_i$
in the definition of the variables
 $X_j(B)$
,
$X_j(B)$
,
 $X_{\geq j}(B)$
in (5.2) are the points of the Poisson point process
$X_{\geq j}(B)$
in (5.2) are the points of the Poisson point process
 $\mathcal {P}$
with intensity measure
$\mathcal {P}$
with intensity measure
 $\lambda(x)\;:\!=\; q_0\theta^{-x}\log \theta\,\textrm{d} x$
in decreasing order. As a result, as the random variables
$\lambda(x)\;:\!=\; q_0\theta^{-x}\log \theta\,\textrm{d} x$
in decreasing order. As a result, as the random variables
 $(M_i)_{i\in\mathbb{N}}$
are i.i.d. and also independent of
$(M_i)_{i\in\mathbb{N}}$
are i.i.d. and also independent of
 $\mathcal {P}$
, we have
$\mathcal {P}$
, we have
 $X_j(B)\sim \text{Poi}(\lambda_j(B))$
,
$X_j(B)\sim \text{Poi}(\lambda_j(B))$
,
 $X_{\geq j}(B)\sim \text{Poi}((1-\theta^{-1})^{-1}\lambda_j(B))$
, where
$X_{\geq j}(B)\sim \text{Poi}((1-\theta^{-1})^{-1}\lambda_j(B))$
, where
 \begin{equation*} \lambda_j(B)=q_0(1-\theta^{-1})\theta^{-j+\varepsilon}\Phi(B)=q_0(1-\theta^{-1})\theta^{-j+\varepsilon}\mathbb{P}\left(M_1\in B\right). \end{equation*}
\begin{equation*} \lambda_j(B)=q_0(1-\theta^{-1})\theta^{-j+\varepsilon}\Phi(B)=q_0(1-\theta^{-1})\theta^{-j+\varepsilon}\mathbb{P}\left(M_1\in B\right). \end{equation*}
We also recall that
 $(n_\ell)_{\ell\in\mathbb{N}}$
is a subsequence such that
$(n_\ell)_{\ell\in\mathbb{N}}$
is a subsequence such that
 $\varepsilon_{n_\ell}\to \varepsilon$
as
$\varepsilon_{n_\ell}\to \varepsilon$
as
 $\ell\to\infty$
. We now take
$\ell\to\infty$
. We now take
 $c\in(1/\log \theta,\theta/(\theta-1))$
and for any
$c\in(1/\log \theta,\theta/(\theta-1))$
and for any
 $K\in\mathbb{N}$
consider any fixed non-decreasing integer sequence
$K\in\mathbb{N}$
consider any fixed non-decreasing integer sequence
 $(j_k)_{k\in[K]}$
. It follows from the choice of c and the fact that the
$(j_k)_{k\in[K]}$
. It follows from the choice of c and the fact that the
 $j_k$
are fixed with respect to n that
$j_k$
are fixed with respect to n that
 $j_1+\log_\theta n=\omega(1)$
and that
$j_1+\log_\theta n=\omega(1)$
and that
 $j_K+\log_\theta n <c\log n$
for all large n. Moreover, let
$j_K+\log_\theta n <c\log n$
for all large n. Moreover, let
 $K'\;:\!=\;\min\{k\;:\; j_{k+1}=j_K\}$
and let
$K'\;:\!=\;\min\{k\;:\; j_{k+1}=j_K\}$
and let
 $(B_k)_{k\in[K]}$
be a sequence of sets in
$(B_k)_{k\in[K]}$
be a sequence of sets in
 $\mathcal {B}(\mathbb{R})$
such that
$\mathcal {B}(\mathbb{R})$
such that
 $B_k\cap B_\ell=\varnothing$
when
$B_k\cap B_\ell=\varnothing$
when
 $j_k=j_\ell$
and
$j_k=j_\ell$
and
 $k\neq \ell$
.
$k\neq \ell$
.
We obtain from Proposition 5.2 that, for any
 $(c_k)_{k\in[K]}\in \mathbb{N}_0^K$
, and since
$(c_k)_{k\in[K]}\in \mathbb{N}_0^K$
, and since
 $j_1,\ldots, j_K$
are fixed,
$j_1,\ldots, j_K$
are fixed,
 \begin{equation*} \begin{aligned} \lim_{n\to\infty}\mathbb E\Bigg[\prod_{k=1}^{K'}\Big(\widetilde X_{j_k}^{(n_\ell)}(B_k)\Big)_{c_k}\prod_{k=K'+1}^K\!\!\Big(\widetilde X_{\geq j_k}^{(n_\ell)}(B_k)\Big)_{c_k} \Bigg] &=\prod_{k=1}^{K'}\lambda_{j_k}^{c_k}\prod_{k=K'+1}^K((1-\theta^{-1})^{-1}\lambda_{j_k})^{c_k}\\[5pt] &=\mathbb E\Bigg[\prod_{k=1}^{K'}\Big(X_{j_k}(B_k)\Big)_{c_k}\prod_{k=K'+1}^K\!\!\Big(X_{\geq j_k}(B_k)\Big)_{c_k} \Bigg], \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \lim_{n\to\infty}\mathbb E\Bigg[\prod_{k=1}^{K'}\Big(\widetilde X_{j_k}^{(n_\ell)}(B_k)\Big)_{c_k}\prod_{k=K'+1}^K\!\!\Big(\widetilde X_{\geq j_k}^{(n_\ell)}(B_k)\Big)_{c_k} \Bigg] &=\prod_{k=1}^{K'}\lambda_{j_k}^{c_k}\prod_{k=K'+1}^K((1-\theta^{-1})^{-1}\lambda_{j_k})^{c_k}\\[5pt] &=\mathbb E\Bigg[\prod_{k=1}^{K'}\Big(X_{j_k}(B_k)\Big)_{c_k}\prod_{k=K'+1}^K\!\!\Big(X_{\geq j_k}(B_k)\Big)_{c_k} \Bigg], \end{aligned} \end{equation*}
where the last step follows from the independence property of (marked) Poisson point processes and the choice of the sequences
 $(j_k, B_k)_{k\in[K]}$
. The method of moments [Reference Janson, Luczak and Rucinski10, Section
$(j_k, B_k)_{k\in[K]}$
. The method of moments [Reference Janson, Luczak and Rucinski10, Section
 $6.1$
] then concludes the proof.
$6.1$
] then concludes the proof.
6. Proof of intermediate results
In this section we prove the intermediate results introduced in Section 5 that were used to prove some of the main results presented in Section 2. We start by proving Lemmas 5.1 and 5.2 (subject to Proposition 5.1) and finally prove Proposition 5.1, which requires the most work and hence is deferred to the end of the section.
Proof of Lemma
5.1 subject to Proposition 5.1. Fix
 $\varepsilon\in(0\vee (c(1-\theta^{-1})-(1-\mu)),\mu)$
. We note that such an
$\varepsilon\in(0\vee (c(1-\theta^{-1})-(1-\mu)),\mu)$
. We note that such an
 $\varepsilon$
exists, since
$\varepsilon$
exists, since
 $c<\theta/(\theta-1)$
. We start with the first implication. By Theorem 2.1 and a union bound we have
$c<\theta/(\theta-1)$
. We start with the first implication. By Theorem 2.1 and a union bound we have

where
 $v_1$
is a vertex selected uniformly at random from [n]. We now apply Proposition 5.1 with
$v_1$
is a vertex selected uniformly at random from [n]. We now apply Proposition 5.1 with
 $k=1$
,
$k=1$
,
 $d_1=d_n$
,
$d_1=d_n$
,
 $\ell_1=n^{\mu-\varepsilon}$
(we observe that, since
$\ell_1=n^{\mu-\varepsilon}$
(we observe that, since
 $\varepsilon<\mu$
and by the bound on
$\varepsilon<\mu$
and by the bound on
 $d_n$
, the conditions in Proposition 5.1 for
$d_n$
, the conditions in Proposition 5.1 for
 $\ell_1$
and
$\ell_1$
and
 $d_1$
are satisfied) to obtain the upper bound
$d_1$
are satisfied) to obtain the upper bound
 \begin{align*} &\mathbb{P}\left(\max_{i\in[n]}\mathcal{Z}_n(i)\geq d_n\right)\leq n\mathbb{E}\left[\Bigg(\frac{W}{\theta-1+W}\Bigg)^{d_n} \mathbb{P}_W\!\left(X\leq \Bigg(1+\frac{W}{\theta-1}\Bigg)\log (n^{1-\mu+\varepsilon})\right)\right]\\[5pt] & (1+o(1))+o(1), \end{align*}
\begin{align*} &\mathbb{P}\left(\max_{i\in[n]}\mathcal{Z}_n(i)\geq d_n\right)\leq n\mathbb{E}\left[\Bigg(\frac{W}{\theta-1+W}\Bigg)^{d_n} \mathbb{P}_W\!\left(X\leq \Bigg(1+\frac{W}{\theta-1}\Bigg)\log (n^{1-\mu+\varepsilon})\right)\right]\\[5pt] & (1+o(1))+o(1), \end{align*}
where
 $X\sim\text{Gamma}(d+1,1)$
. We can simply bound the conditional probability from above by one, so that the assumption yields the desired implication.
$X\sim\text{Gamma}(d+1,1)$
. We can simply bound the conditional probability from above by one, so that the assumption yields the desired implication.
For the second implication, we use the Chung–Erdös inequality. If we let
 $v_1,v_2$
be two vertices selected uniformly at random without replacement from [n] and set
$v_1,v_2$
be two vertices selected uniformly at random without replacement from [n] and set
 $A_{i,n}\;:\!=\;\{\mathcal{Z}_n(i)\geq d_n\}$
, then
$A_{i,n}\;:\!=\;\{\mathcal{Z}_n(i)\geq d_n\}$
, then
 \begin{equation} \mathbb{P}\left({\max_{i\in[n]}\mathcal{Z}_n(i)\geq d_n}\right)=\mathbb{P}\left({\cup_{i=1}^n A_{i,n}}\right)\geq \mathbb{P}\left({\cup_{i=\lceil n^{\mu-\varepsilon}\rceil}^n A_{i,n}}\right)\geq \frac{\big(\sum_{i=\lceil n^{\mu-\varepsilon}\rceil}^n \mathbb{P}\left(A_{i,n}\right)\big)^2}{\sum_{i,j= \lceil n^{\mu-\varepsilon}\rceil}^n \mathbb{P}\left(A_{i,n}\cap A_{j,n}\right)}. \end{equation}
\begin{equation} \mathbb{P}\left({\max_{i\in[n]}\mathcal{Z}_n(i)\geq d_n}\right)=\mathbb{P}\left({\cup_{i=1}^n A_{i,n}}\right)\geq \mathbb{P}\left({\cup_{i=\lceil n^{\mu-\varepsilon}\rceil}^n A_{i,n}}\right)\geq \frac{\big(\sum_{i=\lceil n^{\mu-\varepsilon}\rceil}^n \mathbb{P}\left(A_{i,n}\right)\big)^2}{\sum_{i,j= \lceil n^{\mu-\varepsilon}\rceil}^n \mathbb{P}\left(A_{i,n}\cap A_{j,n}\right)}. \end{equation}
As in (6.1), we can write the numerator as
 $(n\mathbb{P}(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}))^2$
. The denominator can be written as
$(n\mathbb{P}(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}))^2$
. The denominator can be written as
 \begin{equation*} \begin{aligned} \sum_{\substack{i,j= \lceil n^{\mu-\varepsilon}\rceil\\ i\neq j}}^n \mathbb{P}\left(A_{i,n}\cap A_{j,n}\right)+\sum_{i=\lceil n^{\mu-\varepsilon}\rceil}^n \mathbb{P}(A_{i,n})={}&n(n-1)\mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_n, v_i\geq n^{\mu-\varepsilon}, i\in\{1,2\}\right)\\[5pt] &+n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right). \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \sum_{\substack{i,j= \lceil n^{\mu-\varepsilon}\rceil\\ i\neq j}}^n \mathbb{P}\left(A_{i,n}\cap A_{j,n}\right)+\sum_{i=\lceil n^{\mu-\varepsilon}\rceil}^n \mathbb{P}(A_{i,n})={}&n(n-1)\mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_n, v_i\geq n^{\mu-\varepsilon}, i\in\{1,2\}\right)\\[5pt] &+n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right). \end{aligned} \end{equation*}
By applying Proposition 5.1 to the right-hand side, we find that it equals
 \begin{equation*} \left(n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right)\right)^2(1+o(1))+n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right). \end{equation*}
\begin{equation*} \left(n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right)\right)^2(1+o(1))+n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right). \end{equation*}
It follows that the right-hand side of (6.2) equals
 \begin{equation*} \frac{n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right)}{n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right)(1+o(1))+1}. \end{equation*}
\begin{equation*} \frac{n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right)}{n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right)(1+o(1))+1}. \end{equation*}
It thus suffices to prove that the implication
 \begin{equation} \lim_{n\to\infty}n\mathbb{E}\left[\Bigg(\frac{W}{\theta-1+W}\Bigg)^{d_n}\right]=\infty\quad \Rightarrow \quad \lim_{n\to\infty}n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right)=\infty \end{equation}
\begin{equation} \lim_{n\to\infty}n\mathbb{E}\left[\Bigg(\frac{W}{\theta-1+W}\Bigg)^{d_n}\right]=\infty\quad \Rightarrow \quad \lim_{n\to\infty}n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right)=\infty \end{equation}
holds to conclude the proof. Again using Proposition 5.1, we have that
 \begin{align*} &\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right) \\[5pt] & \geq \mathbb{E}\left[\Bigg(\frac{W}{\theta-1+W}\Bigg)^{d_n}\mathbb{P}_W\!\left(\widetilde X\leq \Bigg(1+\frac{W}{\theta-1}\Bigg)\log (n^{1-\mu+\varepsilon})\right)\right](1+o(1)), \end{align*}
\begin{align*} &\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right) \\[5pt] & \geq \mathbb{E}\left[\Bigg(\frac{W}{\theta-1+W}\Bigg)^{d_n}\mathbb{P}_W\!\left(\widetilde X\leq \Bigg(1+\frac{W}{\theta-1}\Bigg)\log (n^{1-\mu+\varepsilon})\right)\right](1+o(1)), \end{align*}
where
 $\widetilde X\sim\text{Gamma}(d+\lfloor d^{1/4}\rfloor+1,1)$
. Hence, it follows from Lemma A.2 in the appendix and the choice of
$\widetilde X\sim\text{Gamma}(d+\lfloor d^{1/4}\rfloor+1,1)$
. Hence, it follows from Lemma A.2 in the appendix and the choice of
 $\varepsilon$
that
$\varepsilon$
that
 \begin{equation*} n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right)\geq n\mathbb{E}\left[\Bigg(\frac{W}{\theta-1+W}\Bigg)^{d_n}\right](1-o(1)), \end{equation*}
\begin{equation*} n\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d_n, v_1\geq n^{\mu-\varepsilon}\right)\geq n\mathbb{E}\left[\Bigg(\frac{W}{\theta-1+W}\Bigg)^{d_n}\right](1-o(1)), \end{equation*}
which implies (6.3) as desired and concludes the proof.
Proof of Proposition
5.2 subject to Proposition 5.1. Recall that
 $c\in(0,\theta/(\theta-1))$
; that
$c\in(0,\theta/(\theta-1))$
; that
 $\mu=1-(\theta-1)/(\theta\log \theta)$
,
$\mu=1-(\theta-1)/(\theta\log \theta)$
,
 $\sigma^2=1-(\theta-1)^2/(\theta^2\log \theta)$
; and that we have a non-decreasing integer sequence
$\sigma^2=1-(\theta-1)^2/(\theta^2\log \theta)$
; and that we have a non-decreasing integer sequence
 $(j_k)_{k\in[K]}$
with
$(j_k)_{k\in[K]}$
with
 $K'=\min\{k\;:\; j_{k+1}=j_K\}$
such that
$K'=\min\{k\;:\; j_{k+1}=j_K\}$
such that
 $j_1+\log_\theta n =\omega(1)$
,
$j_1+\log_\theta n =\omega(1)$
,
 $j_K+\log_\theta n<c\log n$
, as well as a sequence
$j_K+\log_\theta n<c\log n$
, as well as a sequence
 $(B_k)_{k\in[K]}$
such that
$(B_k)_{k\in[K]}$
such that
 $B_k\in \mathcal {B}(\mathbb{R})$
and
$B_k\in \mathcal {B}(\mathbb{R})$
and
 $B_k\cap B_\ell=\varnothing$
when
$B_k\cap B_\ell=\varnothing$
when
 $j_k=j_\ell$
and
$j_k=j_\ell$
and
 $k\neq \ell$
. Then let
$k\neq \ell$
. Then let
 $(c_k)_{k\in[K]}\in \mathbb{N}_0^K$
and set
$(c_k)_{k\in[K]}\in \mathbb{N}_0^K$
and set
 $M\;:\!=\;\sum_{k=1}^K c_k$
and
$M\;:\!=\;\sum_{k=1}^K c_k$
and
 $M'\;:\!=\;\sum_{k=1}^{K'}c_k$
.
$M'\;:\!=\;\sum_{k=1}^{K'}c_k$
.
We define
 $\bar d=(d_i)_{i\in[M]}\in \mathbb{Z}^M$
and
$\bar d=(d_i)_{i\in[M]}\in \mathbb{Z}^M$
and
 $\bar A=(A_i)_{i\in[M]}\subset \mathcal {B}(\mathbb{R})^M$
as follows. For each
$\bar A=(A_i)_{i\in[M]}\subset \mathcal {B}(\mathbb{R})^M$
as follows. For each
 $i\in[M]$
, find the unique
$i\in[M]$
, find the unique
 $k\in[K]$
such that
$k\in[K]$
such that
 $\sum_{\ell=1}^{k-1}c_\ell<i\leq \sum_{\ell=1}^k c_\ell$
, and set
$\sum_{\ell=1}^{k-1}c_\ell<i\leq \sum_{\ell=1}^k c_\ell$
, and set
 $d_i\;:\!=\;\lfloor \log_\theta n\rfloor +j_k, A_i\;:\!=\;B_k$
. We note that this construction implies that the first
$d_i\;:\!=\;\lfloor \log_\theta n\rfloor +j_k, A_i\;:\!=\;B_k$
. We note that this construction implies that the first
 $c_1$
-many
$c_1$
-many
 $d_i$
and
$d_i$
and
 $A_i$
equal
$A_i$
equal
 $\lfloor \log_\theta n\rfloor +j_1$
and
$\lfloor \log_\theta n\rfloor +j_1$
and
 $B_1$
, respectively, that the next
$B_1$
, respectively, that the next
 $c_2$
-many
$c_2$
-many
 $d_i$
and
$d_i$
and
 $A_i$
equal
$A_i$
equal
 $\lfloor \log_\theta n\rfloor +j_2$
and
$\lfloor \log_\theta n\rfloor +j_2$
and
 $B_2$
, respectively, etc. Moreover, we let
$B_2$
, respectively, etc. Moreover, we let
 $(v_i)_{i\in[M]}$
be M vertices selected uniformly at random without replacement from [n]. We then define the events
$(v_i)_{i\in[M]}$
be M vertices selected uniformly at random without replacement from [n]. We then define the events
 \begin{equation*} \begin{aligned} \mathcal {L}_{\bar A,\bar d}&\;:\!=\;\Bigg\{ \frac{\log v_i-(\!\log n-(1-\theta^{-1})d_i)}{\sqrt{(1-\theta^{-1})^2 d_i}}\in A_i, i\in[M]\bigg\},\\[5pt] \mathcal {D}_{\bar d}(M',M)&\;:\!=\;\{\mathcal{Z}_n(v_i)=d_i, i\in[M'], \mathcal{Z}_n(v_j)\geq d_j, M'<j\leq M\},\\[5pt] {\mathcal{E}}_{\bar d}(S)&\;:\!=\;\{\mathcal{Z}_n(v_i)\geq d_i+\mathbb{1}_{\{i\in S\}}, i\in [M]\}. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \mathcal {L}_{\bar A,\bar d}&\;:\!=\;\Bigg\{ \frac{\log v_i-(\!\log n-(1-\theta^{-1})d_i)}{\sqrt{(1-\theta^{-1})^2 d_i}}\in A_i, i\in[M]\bigg\},\\[5pt] \mathcal {D}_{\bar d}(M',M)&\;:\!=\;\{\mathcal{Z}_n(v_i)=d_i, i\in[M'], \mathcal{Z}_n(v_j)\geq d_j, M'<j\leq M\},\\[5pt] {\mathcal{E}}_{\bar d}(S)&\;:\!=\;\{\mathcal{Z}_n(v_i)\geq d_i+\mathbb{1}_{\{i\in S\}}, i\in [M]\}. \end{aligned} \end{equation*}
We know from [Reference Addario-Berry and Eslava1, Lemma 5.1] that by the inclusion–exclusion principle,
 \begin{equation*} \mathbb{P}\left(\mathcal {D}_{\bar d}(M',M)\right)=\sum_{j=0}^{M'}\sum_{\substack{ S\subseteq [M']:\\ |S|=j}}(\!-\!1)^j\mathbb{P}\left({\mathcal{E}}_{\bar d}(S)\right), \end{equation*}
\begin{equation*} \mathbb{P}\left(\mathcal {D}_{\bar d}(M',M)\right)=\sum_{j=0}^{M'}\sum_{\substack{ S\subseteq [M']:\\ |S|=j}}(\!-\!1)^j\mathbb{P}\left({\mathcal{E}}_{\bar d}(S)\right), \end{equation*}
so that intersecting the event
 $\mathcal {L}_{\bar A.\bar d}$
in the probabilities on both sides yields
$\mathcal {L}_{\bar A.\bar d}$
in the probabilities on both sides yields
 \begin{equation} \mathbb{P}\left(\mathcal {D}_{\bar d}(M',M)\cap \mathcal {L}_{\bar A,\bar d}\right)=\sum_{j=0}^{M'}\sum_{\substack{ S\subseteq [M']:\\ |S|=j}}(\!-\!1)^j\mathbb{P}\left({\mathcal{E}}_{\bar d}(S)\cap \mathcal {L}_{\bar A,\bar d}\right). \end{equation}
\begin{equation} \mathbb{P}\left(\mathcal {D}_{\bar d}(M',M)\cap \mathcal {L}_{\bar A,\bar d}\right)=\sum_{j=0}^{M'}\sum_{\substack{ S\subseteq [M']:\\ |S|=j}}(\!-\!1)^j\mathbb{P}\left({\mathcal{E}}_{\bar d}(S)\cap \mathcal {L}_{\bar A,\bar d}\right). \end{equation}
We define
 $\ell_d\;:\;\mathbb{R}\to (0,\infty)$
by
$\ell_d\;:\;\mathbb{R}\to (0,\infty)$
by
 $\ell_d(x)\;:\!=\; \exp\!\big(\!\log n-(1-\theta^{-1})d+x\sqrt{(1-\theta^{-1})^2d}\big)$
,
$\ell_d(x)\;:\!=\; \exp\!\big(\!\log n-(1-\theta^{-1})d+x\sqrt{(1-\theta^{-1})^2d}\big)$
,
 $x\in \mathbb{R}$
, abuse this notation to also write
$x\in \mathbb{R}$
, abuse this notation to also write
 $\ell_d( A)\;:\!=\;\{\ell_d(x)\;:\; x\in A\}$
for
$\ell_d( A)\;:\!=\;\{\ell_d(x)\;:\; x\in A\}$
for
 $A\subseteq \mathbb{R}$
, and note that
$A\subseteq \mathbb{R}$
, and note that
 $\mathcal {L}_{\bar A,\bar d}=\{v_i\in \ell_{d_i}(A_i), i\in[M]\}$
. We also observe, since
$\mathcal {L}_{\bar A,\bar d}=\{v_i\in \ell_{d_i}(A_i), i\in[M]\}$
. We also observe, since
 $d_i$
diverges with n for all
$d_i$
diverges with n for all
 $i\in[M]$
, that
$i\in[M]$
, that
 $\ell_{d_i+\mathbb{1}_{\{i\in S\}}}(x)=\ell_{d_i}(x(1+o(1)))$
for any
$\ell_{d_i+\mathbb{1}_{\{i\in S\}}}(x)=\ell_{d_i}(x(1+o(1)))$
for any
 $i\in[M]$
and
$i\in[M]$
and
 $x\in\mathbb{R}$
. This can be extended to the sets
$x\in\mathbb{R}$
. This can be extended to the sets
 $(A_i)_{i\in[M]}$
rather than
$(A_i)_{i\in[M]}$
rather than
 $x\in\mathbb{R}$
as well. As a result, we can use Corollary A.1 in the appendix (with the observations made in Remark A.1) to then obtain
$x\in\mathbb{R}$
as well. As a result, we can use Corollary A.1 in the appendix (with the observations made in Remark A.1) to then obtain
 \begin{align*} \mathbb{P}\!\left({\mathcal{E}}_{\bar d}(S)\cap \mathcal {L}_{\bar A,\bar d}(S)\right)&=(1+o(1))\prod_{i=1}^M q_0\theta^{-(d_i+\mathbb{1}_{\{i\in S\}})}\Phi(A_i)\\[5pt] &=(1+o(1))q_0^M\theta^{-|S|-\sum_{i=1}^M d_i}\prod_{i=1}^M \Phi(A_i). \end{align*}
\begin{align*} \mathbb{P}\!\left({\mathcal{E}}_{\bar d}(S)\cap \mathcal {L}_{\bar A,\bar d}(S)\right)&=(1+o(1))\prod_{i=1}^M q_0\theta^{-(d_i+\mathbb{1}_{\{i\in S\}})}\Phi(A_i)\\[5pt] &=(1+o(1))q_0^M\theta^{-|S|-\sum_{i=1}^M d_i}\prod_{i=1}^M \Phi(A_i). \end{align*}
Using this in (6.4) we arrive at
 \begin{equation}\begin{aligned} \mathbb{P}\left(\mathcal {D}_{\bar d}(M',M)\cap \mathcal {L}_{\bar A,\bar d}\right)&=(1+o(1))q_0^M \theta^{-\sum_{i=1}^M d_i}\prod_{i=1}^M\Phi(A_i)\sum_{j=0}^{M'}\sum_{\substack{ S\subseteq [M']:\\ |S|=j}}(\!-\!1)^j \theta^{-j}\\[5pt] &=(1+o(1))q_0^M \theta^{-\sum_{i=1}^M d_i}(1-\theta^{-1})^{M'}\prod_{i=1}^M\Phi(A_i), \end{aligned} \end{equation}
\begin{equation}\begin{aligned} \mathbb{P}\left(\mathcal {D}_{\bar d}(M',M)\cap \mathcal {L}_{\bar A,\bar d}\right)&=(1+o(1))q_0^M \theta^{-\sum_{i=1}^M d_i}\prod_{i=1}^M\Phi(A_i)\sum_{j=0}^{M'}\sum_{\substack{ S\subseteq [M']:\\ |S|=j}}(\!-\!1)^j \theta^{-j}\\[5pt] &=(1+o(1))q_0^M \theta^{-\sum_{i=1}^M d_i}(1-\theta^{-1})^{M'}\prod_{i=1}^M\Phi(A_i), \end{aligned} \end{equation}
where the
 $1+o(1)$
and the product on the right-hand side are independent of S and j and can therefore be taken out of the double sum. Now, recall the definition of the variables
$1+o(1)$
and the product on the right-hand side are independent of S and j and can therefore be taken out of the double sum. Now, recall the definition of the variables
 $X_j^{(n)}(B)$
,
$X_j^{(n)}(B)$
,
 $X_{\geq j}^{(n)}(B)$
as in (5.2). Combining (6.4) and (6.5), we arrive at
$X_{\geq j}^{(n)}(B)$
as in (5.2). Combining (6.4) and (6.5), we arrive at
 \begin{equation}\begin{aligned} \mathbb E\Bigg[\prod_{k=1}^{K'}\Big(X_{j_k}^{(n)}(B_k)\Big)_{c_k}\prod_{k=K'+1}^K \Big(X_{\geq j_k}^{(n)}(B_k)\Big)_{c_k}\Bigg] &=(n)_M \mathbb{P}\left( \mathcal {D}_{\bar d}(M',M)\cap \mathcal {L}_{\bar A.\bar d} \right)\\[5pt] &\sim q_0^M \theta^{M\log_\theta n-\sum_{i=1}^M d_i}(1-\theta^{-1})^{M'}\prod_{i=1}^M\Phi(A_i), \end{aligned}\end{equation}
\begin{equation}\begin{aligned} \mathbb E\Bigg[\prod_{k=1}^{K'}\Big(X_{j_k}^{(n)}(B_k)\Big)_{c_k}\prod_{k=K'+1}^K \Big(X_{\geq j_k}^{(n)}(B_k)\Big)_{c_k}\Bigg] &=(n)_M \mathbb{P}\left( \mathcal {D}_{\bar d}(M',M)\cap \mathcal {L}_{\bar A.\bar d} \right)\\[5pt] &\sim q_0^M \theta^{M\log_\theta n-\sum_{i=1}^M d_i}(1-\theta^{-1})^{M'}\prod_{i=1}^M\Phi(A_i), \end{aligned}\end{equation}
since
 $(n)_M\;:\!=\;n(n-1)\cdots (n-(M-1))=(1+o(1))n^M$
, and where we recall that
$(n)_M\;:\!=\;n(n-1)\cdots (n-(M-1))=(1+o(1))n^M$
, and where we recall that
 $a_n\sim b_n$
denotes
$a_n\sim b_n$
denotes
 $\lim_{n\to\infty}a_n/b_n=1$
. We now recall that there are exactly
$\lim_{n\to\infty}a_n/b_n=1$
. We now recall that there are exactly
 $c_k$
-many
$c_k$
-many
 $d_i$
and
$d_i$
and
 $A_i$
that equal
$A_i$
that equal
 $\lfloor \log_2n\rfloor +j_k$
and
$\lfloor \log_2n\rfloor +j_k$
and
 $B_k$
, respectively, for each
$B_k$
, respectively, for each
 $k\in[K]$
, and that
$k\in[K]$
, and that
 $j_{K'+1}=\ldots =j_K$
, so that
$j_{K'+1}=\ldots =j_K$
, so that
 \begin{equation*} \begin{aligned} \prod_{i=1}^M \Phi(A_i)&=\prod_{k=1}^K \Phi(B_k)^{c_k},\\[5pt] M\log_\theta n-M'-\sum_{i=1}^M d_i &= -\sum_{k=1}^{K'}(j_k+1-\varepsilon_n)c_k-\sum_{k=K'+1}^K (j_K-\varepsilon_n)c_k, \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \prod_{i=1}^M \Phi(A_i)&=\prod_{k=1}^K \Phi(B_k)^{c_k},\\[5pt] M\log_\theta n-M'-\sum_{i=1}^M d_i &= -\sum_{k=1}^{K'}(j_k+1-\varepsilon_n)c_k-\sum_{k=K'+1}^K (j_K-\varepsilon_n)c_k, \end{aligned} \end{equation*}
which, combined with (6.6), finally yields
 \begin{equation*} \begin{aligned} \mathbb E\Bigg[\!\prod_{k=1}^{K'}\!\bigg(\!X_{j_k}^{(n)}(B_k)\!\bigg)_{c_k}\prod_{k=K'+1}^K\!\! \bigg(\!X_{\geq j_k}^{(n)}(B_k)\!\bigg)_{c_k}\!\Bigg]\!={}&(1+o(1))\prod_{k=1}^{K'} \big(q_0(1-\theta^{-1})\theta^{-j_k+\varepsilon_n}\Phi(B_k)\big)^{c_k}\\[5pt] &\times \prod_{k=K'+1}^K \big(q_0\theta^{-j_K+\varepsilon_n}\Phi(B_k)\big)^{c_k}. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \mathbb E\Bigg[\!\prod_{k=1}^{K'}\!\bigg(\!X_{j_k}^{(n)}(B_k)\!\bigg)_{c_k}\prod_{k=K'+1}^K\!\! \bigg(\!X_{\geq j_k}^{(n)}(B_k)\!\bigg)_{c_k}\!\Bigg]\!={}&(1+o(1))\prod_{k=1}^{K'} \big(q_0(1-\theta^{-1})\theta^{-j_k+\varepsilon_n}\Phi(B_k)\big)^{c_k}\\[5pt] &\times \prod_{k=K'+1}^K \big(q_0\theta^{-j_K+\varepsilon_n}\Phi(B_k)\big)^{c_k}. \end{aligned} \end{equation*}
To prove the second result, we observe that for
 $j_1,\ldots, j_K=o(\sqrt{\log n})$
,
$j_1,\ldots, j_K=o(\sqrt{\log n})$
,
 \begin{equation*} \frac{\log v_i-(\!\log n-(1-\theta^{-1})d_i)}{\sqrt{(1-\theta^{-1})^2 d_i}}=\frac{\log v_i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}(1+o(1))+o(1). \end{equation*}
\begin{equation*} \frac{\log v_i-(\!\log n-(1-\theta^{-1})d_i)}{\sqrt{(1-\theta^{-1})^2 d_i}}=\frac{\log v_i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}(1+o(1))+o(1). \end{equation*}
Hence, the same steps as above can be applied to the random variables
 $\widetilde X^{(n)}_j(B)$
,
$\widetilde X^{(n)}_j(B)$
,
 $\widetilde X^{(n)}_{\geq j}(B)$
to obtain the desired result.
$\widetilde X^{(n)}_{\geq j}(B)$
to obtain the desired result.
Finally, we prove Proposition 5.1. This result extends and improves Proposition 3.1 and [Reference Eslava, Lodewijks and Ortgiese7, Lemma 5.10], which one could think of as an analogous result with
 $\ell_i=n^\varepsilon$
for all
$\ell_i=n^\varepsilon$
for all
 $i\in[k]$
and some
$i\in[k]$
and some
 $\varepsilon>0$
small. We split the proof of the proposition into three main parts. We first prove an upper bound for (5.4), then prove a matching lower bound for (5.4) (up to error terms), and finally prove (5.5).
$\varepsilon>0$
small. We split the proof of the proposition into three main parts. We first prove an upper bound for (5.4), then prove a matching lower bound for (5.4) (up to error terms), and finally prove (5.5).
Proof of Proposition
5.1, Equation (5.4), upper bound. We assume without loss of generality that
 $\ell_1, \ldots, \ell_k$
are integer-valued. (If they are not, we can use
$\ell_1, \ldots, \ell_k$
are integer-valued. (If they are not, we can use
 $\lceil \ell_1\rceil, \ldots, \lceil \ell_k\rceil$
, which yields the same result.) By first conditioning on the value of
$\lceil \ell_1\rceil, \ldots, \lceil \ell_k\rceil$
, which yields the same result.) By first conditioning on the value of
 $v_1, \ldots, v_k$
, we obtain
$v_1, \ldots, v_k$
, we obtain
 \begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_i)= d_i, v_i>\ell_i, i\in[k]\right)=\frac{1}{(n)_k}\sum_{j_1=\ell_1+1}^n \sum_{\substack{j_2=\ell_2+1\\ j_2\neq j_1}}^n \cdots \sum_{\substack{j_k=\ell_k+1\\ j_k\neq j_{k-1}, \ldots, j_1}}^n \mathbb{P}\left(\mathcal{Z}_n(j_i)=d_i, i\in[k]\right). \end{equation*}
\begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_i)= d_i, v_i>\ell_i, i\in[k]\right)=\frac{1}{(n)_k}\sum_{j_1=\ell_1+1}^n \sum_{\substack{j_2=\ell_2+1\\ j_2\neq j_1}}^n \cdots \sum_{\substack{j_k=\ell_k+1\\ j_k\neq j_{k-1}, \ldots, j_1}}^n \mathbb{P}\left(\mathcal{Z}_n(j_i)=d_i, i\in[k]\right). \end{equation*}
If we let
 $\mathcal {P}_k$
be the set of all permutations on [k], we can write the sums on the right-hand side as
$\mathcal {P}_k$
be the set of all permutations on [k], we can write the sums on the right-hand side as
 \begin{equation} \frac{1}{(n)_k}\sum_{\pi\in\mathcal {P}_k}\sum_{j_{\pi(1)}=\ell_{\pi(1)}}^n \sum_{j_{\pi(2)}=(\ell_{\pi(2)}\vee j_{\pi(1)})+1}^n \cdots \sum_{j_{\pi(k)}=(\ell_{\pi(k)}\vee j_{\pi(k-1)})+1}^n \mathbb{P}\left(\mathcal{Z}_n(j_i)=d_i, i\in[k]\right). \end{equation}
\begin{equation} \frac{1}{(n)_k}\sum_{\pi\in\mathcal {P}_k}\sum_{j_{\pi(1)}=\ell_{\pi(1)}}^n \sum_{j_{\pi(2)}=(\ell_{\pi(2)}\vee j_{\pi(1)})+1}^n \cdots \sum_{j_{\pi(k)}=(\ell_{\pi(k)}\vee j_{\pi(k-1)})+1}^n \mathbb{P}\left(\mathcal{Z}_n(j_i)=d_i, i\in[k]\right). \end{equation}
To prove an upper bound for this expression, we first consider the identity permutation, i.e.
 $\pi(i)=i$
for all
$\pi(i)=i$
for all
 $i\in[k]$
, and take
$i\in[k]$
, and take
 \begin{equation} \frac{1}{(n)_k}\sum_{j_1=\ell_1}^n \sum_{j_2=(\ell_2\vee j_1)+1}^n \cdots \sum_{j_k=(\ell_k\vee j_{k-1})+1}^n \mathbb{P}\left(\mathcal{Z}_n(j_i)=d_i, i\in[k]\right). \end{equation}
\begin{equation} \frac{1}{(n)_k}\sum_{j_1=\ell_1}^n \sum_{j_2=(\ell_2\vee j_1)+1}^n \cdots \sum_{j_k=(\ell_k\vee j_{k-1})+1}^n \mathbb{P}\left(\mathcal{Z}_n(j_i)=d_i, i\in[k]\right). \end{equation}
One can think of this as all realisations
 $v_i=j_i$
,
$v_i=j_i$
,
 $i\in[k]$
, where
$i\in[k]$
, where
 $j_1<j_2<\ldots <j_k$
and
$j_1<j_2<\ldots <j_k$
and
 $j_i>\ell_i$
for all
$j_i>\ell_i$
for all
 $i\in[k]$
. (Later on we will discuss what changes when one uses other choices of
$i\in[k]$
. (Later on we will discuss what changes when one uses other choices of
 $\pi\in\mathcal {P}_k$
in (6.7).) Let us introduce the event
$\pi\in\mathcal {P}_k$
in (6.7).) Let us introduce the event
 \begin{equation} E_n^{(1)}\;:\!=\;\Bigg\{ \sum_{\ell=1}^j W_\ell \in ((1-\zeta_n)\mathbb{E}\left[W\right]j,(1+\zeta_{n})\mathbb{E}\left[W\right]j),\ \forall \ n^\eta\leq j\leq n\Bigg\}, \end{equation}
\begin{equation} E_n^{(1)}\;:\!=\;\Bigg\{ \sum_{\ell=1}^j W_\ell \in ((1-\zeta_n)\mathbb{E}\left[W\right]j,(1+\zeta_{n})\mathbb{E}\left[W\right]j),\ \forall \ n^\eta\leq j\leq n\Bigg\}, \end{equation}
where
 $\zeta_n=n^{-\delta\eta}/\mathbb{E}\left[W\right]$
for some
$\zeta_n=n^{-\delta\eta}/\mathbb{E}\left[W\right]$
for some
 $\delta\in(0,1/2)$
and where we recall that
$\delta\in(0,1/2)$
and where we recall that
 $n^\eta$
is a lower bound for all
$n^\eta$
is a lower bound for all
 $\ell_i$
,
$\ell_i$
,
 $i\in[k]$
, with
$i\in[k]$
, with
 $\eta\in(0,1)$
. It follows from Lemma 3.1 that
$\eta\in(0,1)$
. It follows from Lemma 3.1 that
 $\mathbb P((E_n^{(1)})^c)=o(n^{-\gamma})$
for any
$\mathbb P((E_n^{(1)})^c)=o(n^{-\gamma})$
for any
 $\gamma>0$
. We can hence bound (6.8) from above, for any
$\gamma>0$
. We can hence bound (6.8) from above, for any
 $\gamma>0$
, by
$\gamma>0$
, by
 \begin{equation} \begin{aligned} \frac{1}{(n)_k}\sum_{j_1=\ell_1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\!\!\!\!\!\!\!\!\mathbb E[\mathbb{P}_W\!\left(\mathcal{Z}_n(j_\ell)=m_\ell,\ell\in[k]\right)\mathbb{1}_{E_n^{(1)}}]+o(n^{-\gamma}). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \frac{1}{(n)_k}\sum_{j_1=\ell_1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\!\!\!\!\!\!\!\!\mathbb E[\mathbb{P}_W\!\left(\mathcal{Z}_n(j_\ell)=m_\ell,\ell\in[k]\right)\mathbb{1}_{E_n^{(1)}}]+o(n^{-\gamma}). \end{aligned} \end{equation}
Now, to express the first term in (6.10) we introduce the ordered indices
 $j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n$
,
$j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n$
,
 $i\in[k]$
, which denote the steps at which vertex
$i\in[k]$
, which denote the steps at which vertex
 $j_i$
increases its degree by one. Note that for every
$j_i$
increases its degree by one. Note that for every
 $i\in[k]$
these indices are distinct by definition, but we also require that
$i\in[k]$
these indices are distinct by definition, but we also require that
 $m_{s,i}\neq m_{t,h}$
for any distinct
$m_{s,i}\neq m_{t,h}$
for any distinct
 $i,h\in[k]$
,
$i,h\in[k]$
,
 $s\in[d_i]$
,
$s\in[d_i]$
,
 $t\in[d_h]$
(equality is allowed only when
$t\in[d_h]$
(equality is allowed only when
 $i=h$
and
$i=h$
and
 $s=t$
). We denote this constraint by adding an asterisk
$s=t$
). We denote this constraint by adding an asterisk
 $*$
to the summation symbol. If we also define
$*$
to the summation symbol. If we also define
 $j_{k+1}\;:\!=\;n$
, we can write the first term in (6.10) as
$j_{k+1}\;:\!=\;n$
, we can write the first term in (6.10) as
 \begin{equation*}\begin{aligned} \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\frac{1}{(n)_k}{}&\sum_{j_1=\ell_1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\mathbb E\!\left[\prod_{t=1}^k\prod_{s=1}^{d_t}\frac{W_{j_t}}{\sum_{\ell=1}^{m_{s,t}-1}W_\ell}\phantom{\times \prod_{u=1}^k\!\!\prod_{\substack{s=j_u+1\\ s\neq m_{i,t},t\in[d_i],i\in[k]}}^{j_{u+1}}\!\!\!\!\bigg(1-\frac{\sum_{\ell=1}^u W_{j_\ell}}{\sum_{\ell=1}^{s-1}W_{\ell}}\bigg)\mathbb{1}_{E_n^{(1)}}} \right.\\[5pt] & \left. \times \prod_{u=1}^k\!\!\prod_{\substack{s=j_u+1\\ s\neq m_{i,t},t\in[d_i],i\in[k]}}^{j_{u+1}}\!\!\!\!\Bigg(1-\frac{\sum_{\ell=1}^u W_{j_\ell}}{\sum_{\ell=1}^{s-1}W_{\ell}}\Bigg)\mathbb{1}_{E_n^{(1)}}\right]\!. \end{aligned} \end{equation*}
\begin{equation*}\begin{aligned} \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\frac{1}{(n)_k}{}&\sum_{j_1=\ell_1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\mathbb E\!\left[\prod_{t=1}^k\prod_{s=1}^{d_t}\frac{W_{j_t}}{\sum_{\ell=1}^{m_{s,t}-1}W_\ell}\phantom{\times \prod_{u=1}^k\!\!\prod_{\substack{s=j_u+1\\ s\neq m_{i,t},t\in[d_i],i\in[k]}}^{j_{u+1}}\!\!\!\!\bigg(1-\frac{\sum_{\ell=1}^u W_{j_\ell}}{\sum_{\ell=1}^{s-1}W_{\ell}}\bigg)\mathbb{1}_{E_n^{(1)}}} \right.\\[5pt] & \left. \times \prod_{u=1}^k\!\!\prod_{\substack{s=j_u+1\\ s\neq m_{i,t},t\in[d_i],i\in[k]}}^{j_{u+1}}\!\!\!\!\Bigg(1-\frac{\sum_{\ell=1}^u W_{j_\ell}}{\sum_{\ell=1}^{s-1}W_{\ell}}\Bigg)\mathbb{1}_{E_n^{(1)}}\right]\!. \end{aligned} \end{equation*}
We then include the terms where
 $s=m_{i,t}$
for
$s=m_{i,t}$
for
 $i\in[d_t]$
,
$i\in[d_t]$
,
 $t\in[k]$
in the second double product. To do this, we need to change the first double product to
$t\in[k]$
in the second double product. To do this, we need to change the first double product to
 \begin{equation*} \prod_{t=1}^k \prod_{s=1}^{d_t}\frac{W_{j_t}}{\sum_{\ell=1}^{m_{s,t}-1}W_\ell-\sum_{\ell=1}^k W_{j_\ell}\mathbb{1}_{\{m_{s,t}>j_\ell\}}}\leq\prod_{t=1}^k \prod_{s=1}^{d_t} \frac{W_{j_t}}{\sum_{\ell=1}^{m_{s,t}-1}W_\ell-k}; \end{equation*}
\begin{equation*} \prod_{t=1}^k \prod_{s=1}^{d_t}\frac{W_{j_t}}{\sum_{\ell=1}^{m_{s,t}-1}W_\ell-\sum_{\ell=1}^k W_{j_\ell}\mathbb{1}_{\{m_{s,t}>j_\ell\}}}\leq\prod_{t=1}^k \prod_{s=1}^{d_t} \frac{W_{j_t}}{\sum_{\ell=1}^{m_{s,t}-1}W_\ell-k}; \end{equation*}
that is, we subtract the vertex-weight
 $W_{j_\ell}$
in the numerator when the vertex
$W_{j_\ell}$
in the numerator when the vertex
 $j_\ell$
has already been introduced by step
$j_\ell$
has already been introduced by step
 $m_{s,t}$
. In the upper bound we use that the weights are bounded from above by one. We thus arrive at the upper bound
$m_{s,t}$
. In the upper bound we use that the weights are bounded from above by one. We thus arrive at the upper bound
 \begin{equation}\begin{aligned} \frac{1}{(n)_k}\sum_{j_1=\ell_1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\!\!\!\mathbb E\Bigg[{}&\prod_{t=1}^k\prod_{s=1}^{d_t}\frac{W_{j_t}}{\sum_{\ell=1}^{m_{s,t}-1}W_\ell-k}\\[5pt] &\times \prod_{u=1}^k\prod_{s=j_u+1}^{j_{u+1}}\Bigg(1-\frac{\sum_{\ell=1}^u W_{j_\ell}}{\sum_{\ell=1}^{s-1}W_\ell}\Bigg)\mathbb{1}_{E_n^{(1)}}\Bigg]. \end{aligned} \end{equation}
\begin{equation}\begin{aligned} \frac{1}{(n)_k}\sum_{j_1=\ell_1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\!\!\!\mathbb E\Bigg[{}&\prod_{t=1}^k\prod_{s=1}^{d_t}\frac{W_{j_t}}{\sum_{\ell=1}^{m_{s,t}-1}W_\ell-k}\\[5pt] &\times \prod_{u=1}^k\prod_{s=j_u+1}^{j_{u+1}}\Bigg(1-\frac{\sum_{\ell=1}^u W_{j_\ell}}{\sum_{\ell=1}^{s-1}W_\ell}\Bigg)\mathbb{1}_{E_n^{(1)}}\Bigg]. \end{aligned} \end{equation}
For ease of writing, for now we consider only the inner sum, until we actually intend to sum over the indices
 $j_1,\ldots,j_k$
later on in (6.16). We use the bounds from the event
$j_1,\ldots,j_k$
later on in (6.16). We use the bounds from the event
 $E_n^{(1)}$
defined in (6.9) to bound
$E_n^{(1)}$
defined in (6.9) to bound
 \begin{equation*} \sum_{\ell=1}^{m_{s,t}-1}W_\ell\geq (m_{s,t}-1)\mathbb{E}\left[W\right](1-\zeta_n),\qquad \sum_{\ell=1}^{s-1}W_\ell \leq s\mathbb{E}\left[W\right] (1+\zeta_n). \end{equation*}
\begin{equation*} \sum_{\ell=1}^{m_{s,t}-1}W_\ell\geq (m_{s,t}-1)\mathbb{E}\left[W\right](1-\zeta_n),\qquad \sum_{\ell=1}^{s-1}W_\ell \leq s\mathbb{E}\left[W\right] (1+\zeta_n). \end{equation*}
For n sufficiently large, we observe that
 $(m_{s,t}-1)\mathbb{E}\left[W\right](1-\zeta_n)-k\geq m_{s,t}\mathbb{E}\left[W\right](1-2\zeta_n)$
, which yields the upper bound
$(m_{s,t}-1)\mathbb{E}\left[W\right](1-\zeta_n)-k\geq m_{s,t}\mathbb{E}\left[W\right](1-2\zeta_n)$
, which yields the upper bound
 \begin{equation*} \begin{aligned} \frac{1}{(n)_k}\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\!\!\!\!\mathbb E\Bigg[\prod_{t=1}^k\prod_{s=1}^{d_t}\frac{W_{j_t}}{m_{s,t}\mathbb{E}\left[W\right] (1-2\zeta_n)} \prod_{u=1}^k\prod_{s=j_u+1}^{j_{u+1}}\!\!\bigg(1-\frac{\sum_{\ell=1}^u W_{j_\ell}}{s\mathbb{E}\left[W\right](1+\zeta_n)}\bigg)\mathbb{1}_{E_n^{(1)}}\Bigg]. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \frac{1}{(n)_k}\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\!\!\!\!\mathbb E\Bigg[\prod_{t=1}^k\prod_{s=1}^{d_t}\frac{W_{j_t}}{m_{s,t}\mathbb{E}\left[W\right] (1-2\zeta_n)} \prod_{u=1}^k\prod_{s=j_u+1}^{j_{u+1}}\!\!\bigg(1-\frac{\sum_{\ell=1}^u W_{j_\ell}}{s\mathbb{E}\left[W\right](1+\zeta_n)}\bigg)\mathbb{1}_{E_n^{(1)}}\Bigg]. \end{aligned} \end{equation*}
We can now bound the indicator from above by one. Moreover, relabelling the vertex-weights
 $W_{j_t}$
to
$W_{j_t}$
to
 $W_t$
for
$W_t$
for
 $t\in[k]$
does not change the distribution of the terms within the expected value, so that the expected value remains unchanged. We thus arrive at the upper bound
$t\in[k]$
does not change the distribution of the terms within the expected value, so that the expected value remains unchanged. We thus arrive at the upper bound

We bound the final product from above by
 \begin{equation} \begin{aligned} \prod_{s=j_u+1}^{j_{u+1}}\bigg(1-\frac{\sum_{\ell=1}^u W_\ell}{s\mathbb{E}\left[W\right](1+\zeta_n)}\bigg)&\leq \exp\!\bigg(\!-\!\frac{1}{\mathbb{E}\left[W\right](1+\zeta_n)} \sum_{s=j_u+1}^{j_{u+1}}\frac{\sum_{\ell=1}^u W_\ell}{s}\bigg)\\[5pt] &\leq \exp\!\bigg(\!-\!\frac{1}{\mathbb{E}\left[W\right](1+\zeta_n)} \sum_{\ell=1}^u W_\ell \log\!\bigg(\frac{j_{u+1}}{j_u+1}\bigg)\!\bigg)\\[5pt] &= \bigg(\frac{j_{u+1}}{j_u+1}\bigg)^{-\sum_{\ell=1}^u W_\ell/(\mathbb{E}\left[W\right](1+\zeta_n))}. \end{aligned}\end{equation}
\begin{equation} \begin{aligned} \prod_{s=j_u+1}^{j_{u+1}}\bigg(1-\frac{\sum_{\ell=1}^u W_\ell}{s\mathbb{E}\left[W\right](1+\zeta_n)}\bigg)&\leq \exp\!\bigg(\!-\!\frac{1}{\mathbb{E}\left[W\right](1+\zeta_n)} \sum_{s=j_u+1}^{j_{u+1}}\frac{\sum_{\ell=1}^u W_\ell}{s}\bigg)\\[5pt] &\leq \exp\!\bigg(\!-\!\frac{1}{\mathbb{E}\left[W\right](1+\zeta_n)} \sum_{\ell=1}^u W_\ell \log\!\bigg(\frac{j_{u+1}}{j_u+1}\bigg)\!\bigg)\\[5pt] &= \bigg(\frac{j_{u+1}}{j_u+1}\bigg)^{-\sum_{\ell=1}^u W_\ell/(\mathbb{E}\left[W\right](1+\zeta_n))}. \end{aligned}\end{equation}
As the weights are almost surely bounded by one, we thus find
 \begin{equation*}\begin{aligned} \prod_{s=j_u+1}^{j_{u+1}}\bigg(1-\frac{\sum_{\ell=1}^u W_\ell}{s\mathbb{E}\left[W\right](1+\zeta_n)}\bigg)&\leq \bigg(\frac{j_{u+1}}{j_u}\bigg)^{-\sum_{\ell=1}^u W_\ell/(\mathbb{E}\left[W\right](1+\zeta_n))}\bigg(1+\frac{1}{j_u}\bigg)^{k/(\mathbb{E}\left[W\right](1+\zeta_n))}\\[5pt] &=\bigg(\frac{j_{u+1}}{j_u}\bigg)^{-\sum_{\ell=1}^u W_\ell/(\mathbb{E}\left[W\right](1+\zeta_n))}(1+o(1)). \end{aligned} \end{equation*}
\begin{equation*}\begin{aligned} \prod_{s=j_u+1}^{j_{u+1}}\bigg(1-\frac{\sum_{\ell=1}^u W_\ell}{s\mathbb{E}\left[W\right](1+\zeta_n)}\bigg)&\leq \bigg(\frac{j_{u+1}}{j_u}\bigg)^{-\sum_{\ell=1}^u W_\ell/(\mathbb{E}\left[W\right](1+\zeta_n))}\bigg(1+\frac{1}{j_u}\bigg)^{k/(\mathbb{E}\left[W\right](1+\zeta_n))}\\[5pt] &=\bigg(\frac{j_{u+1}}{j_u}\bigg)^{-\sum_{\ell=1}^u W_\ell/(\mathbb{E}\left[W\right](1+\zeta_n))}(1+o(1)). \end{aligned} \end{equation*}
Using this upper bound in (6.12) and setting
 \begin{equation*} a'_{\!\!t}\;:\!=\;\frac{W_t}{\mathbb{E}\left[W\right](1+\zeta_n)},\qquad t\in[k], \end{equation*}
\begin{equation*} a'_{\!\!t}\;:\!=\;\frac{W_t}{\mathbb{E}\left[W\right](1+\zeta_n)},\qquad t\in[k], \end{equation*}
we obtain

where in the last step we recall that
 $j_{k+1}=n$
. Since
$j_{k+1}=n$
. Since
 $d_t\leq c\log n$
for all
$d_t\leq c\log n$
for all
 $t\in[k]$
,
$t\in[k]$
,
 $j_t>\ell_t>n^\eta$
for all
$j_t>\ell_t>n^\eta$
for all
 $t\in[k]$
, and
$t\in[k]$
, and
 $\zeta_n=n^{-\delta\eta}/\mathbb{E}\left[W\right]$
, it readily follows that
$\zeta_n=n^{-\delta\eta}/\mathbb{E}\left[W\right]$
, it readily follows that

We can thus omit the first term from (6.14) as well as use
 $a_t\;:\!=\;W_t/\mathbb{E}\left[W\right]$
instead of
$a_t\;:\!=\;W_t/\mathbb{E}\left[W\right]$
instead of
 $a'_{\!\!t}$
at the cost of an additional
$a'_{\!\!t}$
at the cost of an additional
 $1+o(1)$
term. So we obtain
$1+o(1)$
term. So we obtain
 \begin{equation*} \frac{1}{(n)_k}\ \,\sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\mathbb E\Bigg[\prod_{t=1}^k\Bigg( a_t^{d_t} (j_t/n)^{a_t}\prod_{s=1}^{d_t}\frac{1}{m_{s,t}}\Bigg) \Bigg](1+o(1)). \end{equation*}
\begin{equation*} \frac{1}{(n)_k}\ \,\sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\mathbb E\Bigg[\prod_{t=1}^k\Bigg( a_t^{d_t} (j_t/n)^{a_t}\prod_{s=1}^{d_t}\frac{1}{m_{s,t}}\Bigg) \Bigg](1+o(1)). \end{equation*}
We then bound this from above even further by no longer constraining the indices
 $m_{s,t}$
to be distinct (so that the
$m_{s,t}$
to be distinct (so that the
 $*$
in the sum is omitted). That is, for different
$*$
in the sum is omitted). That is, for different
 $t_1,t_2\in[k]$
, we allow
$t_1,t_2\in[k]$
, we allow
 $m_{s_1,t_1}=m_{s_2,t_2}$
to hold for any
$m_{s_1,t_1}=m_{s_2,t_2}$
to hold for any
 $s_1\in[d_{t_1}]$
,
$s_1\in[d_{t_1}]$
,
 $s_2\in[d_{t_2}]$
. This also allows us to interchange the sum and the first product. We bound the sums from above by multiple integrals, which yields
$s_2\in[d_{t_2}]$
. This also allows us to interchange the sum and the first product. We bound the sums from above by multiple integrals, which yields
 \begin{equation*} \begin{aligned} \frac{1}{(n)_k}\mathbb{E}\left[ \prod_{t=1}^k a_t^{d_t}(j_t/n)^{a_t} \int_{j_t}^n \int _{x_{1,t}}^n\cdots \int_{x_{d_t-1,t}}^n \prod_{s=1}^{d_t}x_{s,t}^{-1}\,\textrm{d} x_{d_t,t}\ldots\textrm{d} x_{1,t}\right](1+o(1)). \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \frac{1}{(n)_k}\mathbb{E}\left[ \prod_{t=1}^k a_t^{d_t}(j_t/n)^{a_t} \int_{j_t}^n \int _{x_{1,t}}^n\cdots \int_{x_{d_t-1,t}}^n \prod_{s=1}^{d_t}x_{s,t}^{-1}\,\textrm{d} x_{d_t,t}\ldots\textrm{d} x_{1,t}\right](1+o(1)). \end{aligned} \end{equation*}
Applying Lemma 3.2 with
 $a=j_t$
,
$a=j_t$
,
 $b=n$
, we then obtain
$b=n$
, we then obtain
 \begin{equation*} \frac{1}{(n)_k}\mathbb{E}\left[ \prod_{t=1}^k (n/j_t)^{-a_t} \frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\right](1+o(1)). \end{equation*}
\begin{equation*} \frac{1}{(n)_k}\mathbb{E}\left[ \prod_{t=1}^k (n/j_t)^{-a_t} \frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\right](1+o(1)). \end{equation*}
Reintroducing the sums over the indices
 $j_1,\ldots, j_k$
(which were omitted after (6.11)), we arrive at
$j_1,\ldots, j_k$
(which were omitted after (6.11)), we arrive at
 \begin{equation} \frac{1}{(n)_k} \sum_{j_1=\ell_1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\mathbb{E}\left[ \prod_{t=1}^k(n/j_t)^{-a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\right](1+o(1)). \end{equation}
\begin{equation} \frac{1}{(n)_k} \sum_{j_1=\ell_1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\mathbb{E}\left[ \prod_{t=1}^k(n/j_t)^{-a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\right](1+o(1)). \end{equation}
We observe that switching the order of the indices
 $j_1,\ldots,j_k$
(and their respective bounds
$j_1,\ldots,j_k$
(and their respective bounds
 $\ell_1,\ldots, \ell_k$
) achieves the same result as permuting the
$\ell_1,\ldots, \ell_k$
) achieves the same result as permuting the
 $d_1,\ldots,d_k$
and
$d_1,\ldots,d_k$
and
 $a_1,\ldots, a_k$
. Hence, if we take any
$a_1,\ldots, a_k$
. Hence, if we take any
 $\pi\in\mathcal {P}_k$
, then as in (6.7) and (6.10),
$\pi\in\mathcal {P}_k$
, then as in (6.7) and (6.10),
 \begin{equation*} \begin{aligned} \frac{1}{(n)_k}{}&\sum_{j_{\pi(1)}=\ell_{\pi(1)}}^n \sum_{j_{\pi(2)}=(\ell_{\pi(2)}\vee j_{\pi(1)})+1}^n\!\!\! \cdots\!\!\! \sum_{j_{\pi(k)}=(\ell_{\pi(k)}\vee j_{\pi(k-1)})+1}^n \!\!\!\!\!\!\mathbb{E}\left[\mathbb{P}_W\!\left(\mathcal{Z}_n(j_i)=d_i, i\in[k]\right)\mathbb{1}_{E_n^{(1)}}\right]\\[5pt] &\leq \frac{1}{(n)_k}\mathbb{E}\left[\sum_{j_{\pi(1)}=\ell_{\pi(1)}}^n\!\!\!\cdots \!\!\!\!\sum_{j_{\pi(k)}=(\ell_{\pi(k)}\vee j_{\pi(k-1)})+1}^n\prod_{t=1}^k(n/j_t)^{-a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\right]. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \frac{1}{(n)_k}{}&\sum_{j_{\pi(1)}=\ell_{\pi(1)}}^n \sum_{j_{\pi(2)}=(\ell_{\pi(2)}\vee j_{\pi(1)})+1}^n\!\!\! \cdots\!\!\! \sum_{j_{\pi(k)}=(\ell_{\pi(k)}\vee j_{\pi(k-1)})+1}^n \!\!\!\!\!\!\mathbb{E}\left[\mathbb{P}_W\!\left(\mathcal{Z}_n(j_i)=d_i, i\in[k]\right)\mathbb{1}_{E_n^{(1)}}\right]\\[5pt] &\leq \frac{1}{(n)_k}\mathbb{E}\left[\sum_{j_{\pi(1)}=\ell_{\pi(1)}}^n\!\!\!\cdots \!\!\!\!\sum_{j_{\pi(k)}=(\ell_{\pi(k)}\vee j_{\pi(k-1)})+1}^n\prod_{t=1}^k(n/j_t)^{-a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\right]. \end{aligned} \end{equation*}
As a result, reintroducing the sum over all
 $\pi\in\mathcal {P}_k$
, we arrive at
$\pi\in\mathcal {P}_k$
, we arrive at
 \begin{equation*} \begin{aligned} \frac{1}{(n)_k}{}&\sum_{\pi\in\mathcal {P}_k}\sum_{j_{\pi(1)}=\ell_{\pi(1)}}^n \sum_{j_{\pi(2)}=(\ell_{\pi(2)}\vee j_{\pi(1)})+1}^n\!\!\! \cdots\!\!\! \sum_{j_{\pi(k)}=(\ell_{\pi(k)}\vee j_{\pi(k-1)})+1}^n\!\!\!\!\!\! \mathbb{E}\left[\mathbb{P}_W\!\left(\mathcal{Z}_n(j_i)=d_i, i\in[k]\right)\mathbb{1}_{E_n^{(1)}}\right]\\[5pt] &\leq\frac{1}{(n)_k}\mathbb{E}\left[ \sum_{\pi\in\mathcal {P}_k}\sum_{j_{\pi(1)}=\ell_{\pi(1)}}^n\!\!\!\cdots\!\!\! \!\!\!\!\sum_{j_{\pi(k)}=(\ell_{\pi(k)}\vee j_{\pi(k-1)})+1}^n\prod_{t=1}^k(n/j_t)^{-a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\right](1+o(1))\\[5pt] &=\frac{1}{(n)_k}\mathbb{E}\left[ \sum_{j_1=\ell_1+1}^n\sum_{\substack{j_2=\ell_2+1\\ j_2\neq j_1}}\ldots \!\!\!\!\sum_{\substack{j_k=\ell_k+1\\ j_k\neq j_{k-1,\ldots, j_1}}}^n\prod_{t=1}^k(n/j_t)^{-a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\right](1+o(1)). \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \frac{1}{(n)_k}{}&\sum_{\pi\in\mathcal {P}_k}\sum_{j_{\pi(1)}=\ell_{\pi(1)}}^n \sum_{j_{\pi(2)}=(\ell_{\pi(2)}\vee j_{\pi(1)})+1}^n\!\!\! \cdots\!\!\! \sum_{j_{\pi(k)}=(\ell_{\pi(k)}\vee j_{\pi(k-1)})+1}^n\!\!\!\!\!\! \mathbb{E}\left[\mathbb{P}_W\!\left(\mathcal{Z}_n(j_i)=d_i, i\in[k]\right)\mathbb{1}_{E_n^{(1)}}\right]\\[5pt] &\leq\frac{1}{(n)_k}\mathbb{E}\left[ \sum_{\pi\in\mathcal {P}_k}\sum_{j_{\pi(1)}=\ell_{\pi(1)}}^n\!\!\!\cdots\!\!\! \!\!\!\!\sum_{j_{\pi(k)}=(\ell_{\pi(k)}\vee j_{\pi(k-1)})+1}^n\prod_{t=1}^k(n/j_t)^{-a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\right](1+o(1))\\[5pt] &=\frac{1}{(n)_k}\mathbb{E}\left[ \sum_{j_1=\ell_1+1}^n\sum_{\substack{j_2=\ell_2+1\\ j_2\neq j_1}}\ldots \!\!\!\!\sum_{\substack{j_k=\ell_k+1\\ j_k\neq j_{k-1,\ldots, j_1}}}^n\prod_{t=1}^k(n/j_t)^{-a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\right](1+o(1)). \end{aligned} \end{equation*}
We now bound these sums from above by allowing each index
 $j_i$
to take any value in
$j_i$
to take any value in
 $\{\ell_i+1,\ldots, n\}$
for all
$\{\ell_i+1,\ldots, n\}$
for all
 $i\in[k]$
, independent of the values of the other indices. Moreover, since the weights
$i\in[k]$
, independent of the values of the other indices. Moreover, since the weights
 $W_1,\ldots, W_k$
, and hence
$W_1,\ldots, W_k$
, and hence
 $a_1, \ldots, a_k,$
are independent, this yields the upper bound
$a_1, \ldots, a_k,$
are independent, this yields the upper bound
 \begin{equation} \prod_{t=1}^k\mathbb{E}\left[ \frac1n\sum_{j_t=\ell_t+1}^n(n/j_t)^{-a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\right](1+o(1)), \end{equation}
\begin{equation} \prod_{t=1}^k\mathbb{E}\left[ \frac1n\sum_{j_t=\ell_t+1}^n(n/j_t)^{-a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\right](1+o(1)), \end{equation}
so that we can now deal with each sum independently instead of k sums at the same time. First, we note that
 $(n/j_t)^{a_t}(\!\log(n/j_t))^{d_t}$
is increasing on
$(n/j_t)^{a_t}(\!\log(n/j_t))^{d_t}$
is increasing on
 $(0,n\exp\!(\!-\!d_t/a_t))$
, maximised at
$(0,n\exp\!(\!-\!d_t/a_t))$
, maximised at
 $n\exp\!(\!-\!d_t/a_t)$
, and decreasing on
$n\exp\!(\!-\!d_t/a_t)$
, and decreasing on
 $(n\exp\!(\!-\!d_t/a_t),n]$
for all
$(n\exp\!(\!-\!d_t/a_t),n]$
for all
 $t\in[k]$
. To provide the optimal bound, we want to know whether this maximum is attained in
$t\in[k]$
. To provide the optimal bound, we want to know whether this maximum is attained in
 $[\ell_t+1,n]$
or not—that is, whether
$[\ell_t+1,n]$
or not—that is, whether
 $n\exp\!(\!-\!d_t/a_t)\in[\ell_t+1,n]$
or not. To this end, we let
$n\exp\!(\!-\!d_t/a_t)\in[\ell_t+1,n]$
or not. To this end, we let
 \begin{equation*} c_t\;:\!=\;\limsup_{n\to\infty}\frac{d_t}{\log n}, \qquad t\in[k], \end{equation*}
\begin{equation*} c_t\;:\!=\;\limsup_{n\to\infty}\frac{d_t}{\log n}, \qquad t\in[k], \end{equation*}
and consider two cases:
-
(1)
$c_t\in[0,1/(\theta-1)]$
,
$t\in[k]$
. -
(2)
$c_t\in(1/(\theta-1),c)$
,
$t\in[k]$
.




Clearly, when
 $c\leq 1/(\theta-1)$
the second case can be omitted, so that without loss of generality we can assume
$c\leq 1/(\theta-1)$
the second case can be omitted, so that without loss of generality we can assume
 $c>1/(\theta-1)$
. In the second case, it directly follows that the maximum is almost surely attained at
$c>1/(\theta-1)$
. In the second case, it directly follows that the maximum is almost surely attained at
 \begin{equation*} n\exp\!(\!-\!d_t/a_t)\leq n\exp\!(\!-\!c_t\log n (\theta-1)(1+o(1)))=n^{1-c_t(\theta-1)(1+o(1))}=o(1), \end{equation*}
\begin{equation*} n\exp\!(\!-\!d_t/a_t)\leq n\exp\!(\!-\!c_t\log n (\theta-1)(1+o(1)))=n^{1-c_t(\theta-1)(1+o(1))}=o(1), \end{equation*}
so that the summand
 $(n/j_t)^{-a_t}(a_t\log(n/j_t))^{d_t}$
is almost surely decreasing in
$(n/j_t)^{-a_t}(a_t\log(n/j_t))^{d_t}$
is almost surely decreasing in
 $j_t$
when
$j_t$
when
 $\ell_t< j_t\leq n$
. In the first case, such a conclusion cannot be made in general and depends on the precise value of
$\ell_t< j_t\leq n$
. In the first case, such a conclusion cannot be made in general and depends on the precise value of
 $W_t$
. Therefore, the first case requires a more involved approach. We first assume Case (1) holds and discuss what simplifications can be made when Case 2 holds afterwards. In Case (1), we use Lemma A.4 to bound each sum from above by
$W_t$
. Therefore, the first case requires a more involved approach. We first assume Case (1) holds and discuss what simplifications can be made when Case 2 holds afterwards. In Case (1), we use Lemma A.4 to bound each sum from above by
 \begin{equation*} \begin{aligned} \frac{1}{n} \sum_{j_t=\ell_t+1}^n (n/j_t)^{-a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\leq \frac{1}{n} \int_{\ell_t}^n (n/x_t)^{-a_t}\frac{(a_t\log(n/x_t))^{d_t}}{d_t!}\,\textrm{d} x_t+\frac{1}{n}. \end{aligned}\end{equation*}
\begin{equation*} \begin{aligned} \frac{1}{n} \sum_{j_t=\ell_t+1}^n (n/j_t)^{-a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}\leq \frac{1}{n} \int_{\ell_t}^n (n/x_t)^{-a_t}\frac{(a_t\log(n/x_t))^{d_t}}{d_t!}\,\textrm{d} x_t+\frac{1}{n}. \end{aligned}\end{equation*}
Here, we use that the summand is at most one, since
 \begin{equation} \Big(\frac{j_t}{n}\Big)^{a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}=\mathbb{P}_W\!\left(\text{Poi}(a_t,j_t)=d_t\right)\leq 1, \end{equation}
\begin{equation} \Big(\frac{j_t}{n}\Big)^{a_t}\frac{(a_t\log(n/j_t))^{d_t}}{d_t!}=\mathbb{P}_W\!\left(\text{Poi}(a_t,j_t)=d_t\right)\leq 1, \end{equation}
irrespective of
 $a_t\in(0,\infty)$
and
$a_t\in(0,\infty)$
and
 $j_t\in\mathbb{N}$
, and where
$j_t\in\mathbb{N}$
, and where
 $\text{Poi}(a_t,j_t)$
is a Poisson random variable with rate
$\text{Poi}(a_t,j_t)$
is a Poisson random variable with rate
 $a_t\log(n/j_t)$
, conditionally on
$a_t\log(n/j_t)$
, conditionally on
 $W_t$
. In Case (2), the summand on the left-hand side is decreasing in
$W_t$
. In Case (2), the summand on the left-hand side is decreasing in
 $j_t$
, so that we arrive at an upper bound without the additional error term
$j_t$
, so that we arrive at an upper bound without the additional error term
 $1/n$
. Using a substitution
$1/n$
. Using a substitution
 $y_t\;:\!=\;\log(n/x_t)$
, we obtain
$y_t\;:\!=\;\log(n/x_t)$
, we obtain
 \begin{equation} \begin{aligned} \frac{a_t^{d_t}}{(1+a_t)^{d_t+1}}{}&\int_0^{\log(n/\ell_t)}\frac{(1+a_t)^{d_t+1}}{d_t!}y_t^{d_t}{\textrm{e}}^{-(1+a_t)y_t}\,\textrm{d} y_t+\frac1n\\[5pt] &=\frac{a_t^{d_t}}{(1+a_t)^{d_t+1}}\mathbb{P}_W\!\left(Y_t<\log(n/\ell_t)\right)+\frac1n, \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \frac{a_t^{d_t}}{(1+a_t)^{d_t+1}}{}&\int_0^{\log(n/\ell_t)}\frac{(1+a_t)^{d_t+1}}{d_t!}y_t^{d_t}{\textrm{e}}^{-(1+a_t)y_t}\,\textrm{d} y_t+\frac1n\\[5pt] &=\frac{a_t^{d_t}}{(1+a_t)^{d_t+1}}\mathbb{P}_W\!\left(Y_t<\log(n/\ell_t)\right)+\frac1n, \end{aligned} \end{equation}
where, conditionally on
 $W_t$
,
$W_t$
,
 $Y_t\sim \text{Gamma}(d_t+1,1+a_t)$
. We recall that we redefined
$Y_t\sim \text{Gamma}(d_t+1,1+a_t)$
. We recall that we redefined
 $a_t\;:\!=\;W_t/\mathbb{E}\left[W\right]=W_t/(\theta-1)$
. Since
$a_t\;:\!=\;W_t/\mathbb{E}\left[W\right]=W_t/(\theta-1)$
. Since
 $X_t\;:\!=\;(1+W_t/(\theta-1))Y_t\sim\text{Gamma}(d_t+1,1)$
, we obtain
$X_t\;:\!=\;(1+W_t/(\theta-1))Y_t\sim\text{Gamma}(d_t+1,1)$
, we obtain
 \begin{equation} \frac{\theta-1}{\theta-1+W_t}\bigg(\frac{W_t}{\theta-1+W_t}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W_t}{(\theta-1)}\bigg)\log(n/\ell_t)\right)+\frac1n. \end{equation}
\begin{equation} \frac{\theta-1}{\theta-1+W_t}\bigg(\frac{W_t}{\theta-1+W_t}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W_t}{(\theta-1)}\bigg)\log(n/\ell_t)\right)+\frac1n. \end{equation}
Using this in (6.17), we arrive at an upper bound of the form
 \begin{equation*} \prod_{t=1}^k \mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W}{(\theta-1)}\bigg)\log(n/\ell_t)\right)+\frac1n\right](1+o(1)), \end{equation*}
\begin{equation*} \prod_{t=1}^k \mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W}{(\theta-1)}\bigg)\log(n/\ell_t)\right)+\frac1n\right](1+o(1)), \end{equation*}
where we recall that in each term of the product, the additive term
 $1/n$
is present only when
$1/n$
is present only when
 $d_t$
satisfies Case (1) and can be omitted when
$d_t$
satisfies Case (1) and can be omitted when
 $d_t$
satisfies Case (2). Moreover, we have omitted the indices of the weights, as they are all i.i.d. By Lemma A.3 in the appendix, the term
$d_t$
satisfies Case (2). Moreover, we have omitted the indices of the weights, as they are all i.i.d. By Lemma A.3 in the appendix, the term
 $1/n$
can be included in the o(1) in the square brackets when
$1/n$
can be included in the o(1) in the square brackets when
 $d_t$
satisfies Case (1). Thus, we finally obtain
$d_t$
satisfies Case (1). Thus, we finally obtain
 \begin{equation} \prod_{t=1}^k \mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W}{(\theta-1)}\bigg)\log(n/\ell_t)\right)\right](1+o(1)), \end{equation}
\begin{equation} \prod_{t=1}^k \mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W}{(\theta-1)}\bigg)\log(n/\ell_t)\right)\right](1+o(1)), \end{equation}
as desired. This concludes the upper bound for the first term in (6.10). Since we can choose
 $\gamma$
arbitrarily large in the second term in (6.10), we can use the same argument as in Lemma A.3 ((A.33) through (A.36) in particular), but now using that
$\gamma$
arbitrarily large in the second term in (6.10), we can use the same argument as in Lemma A.3 ((A.33) through (A.36) in particular), but now using that
 $d_t\leq c\log n<\theta/(\theta-1)\log n$
, to obtain that the second term in (6.10) can be included in the o(1) term of the final expression of the upper bound, as well in both Case (1) and Case (2), which concludes the proof of the upper bound.
$d_t\leq c\log n<\theta/(\theta-1)\log n$
, to obtain that the second term in (6.10) can be included in the o(1) term of the final expression of the upper bound, as well in both Case (1) and Case (2), which concludes the proof of the upper bound.
We now provide a lower bound for (5.4), which uses many of the definitions and steps provided in the proof for the upper bound.
Proof of Proposition 5.1, Equation (5.4), lower bound. We define the event
 \begin{equation*} E_n^{(2)}\;:\!=\;\bigg\{\sum_{\ell=k+1 }^j W_\ell\in(\mathbb{E}\left[W\right](1-\zeta_n)j,\mathbb{E}\left[W\right](1+\zeta_n)j),\ \forall\ n^\eta\leq j\leq n\bigg\}. \end{equation*}
\begin{equation*} E_n^{(2)}\;:\!=\;\bigg\{\sum_{\ell=k+1 }^j W_\ell\in(\mathbb{E}\left[W\right](1-\zeta_n)j,\mathbb{E}\left[W\right](1+\zeta_n)j),\ \forall\ n^\eta\leq j\leq n\bigg\}. \end{equation*}
We then again have (6.7) and start by considering the identity permutation,
 $\pi(i)=i$
for all
$\pi(i)=i$
for all
 $i\in[k]$
, as in (6.8), by omitting the second term in (6.10), and using the event
$i\in[k]$
, as in (6.8), by omitting the second term in (6.10), and using the event
 $E_n^{(2)}$
instead of
$E_n^{(2)}$
instead of
 $E_n^{(1)}$
. This yields the lower bound
$E_n^{(1)}$
. This yields the lower bound
 \begin{equation*} \begin{aligned} \frac{1}{(n)_k}{}&\sum_{j_1=\ell_1+1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\!\!\!\!\!\!\!\!\mathbb E[\mathbb{P}_W\!\left(\mathcal{Z}_n(j_\ell)=m_\ell,\ell\in[k]\right)\mathbb{1}_{E_n^{(2)}}]\\[5pt] \geq{}&\frac{1}{(n)_k}\sum_{j_1=\ell_1+1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\mathbb E\!\left[\prod_{t=1}^k\prod_{s=1}^{d_t}\frac{W_{j_t}}{\sum_{\ell=1}^{m_{s,t}-1}W_\ell}\phantom{\times \prod_{u=1}^k\!\!\prod_{\substack{s=j_u+1\\ s\neq m_{i,t},t\in[d_i],i\in[k]}}^{j_{u+1}}}\right.\\[5pt] &\left.\times \prod_{u=1}^k\!\!\prod_{\substack{s=j_u+1\\ s\neq m_{i,t},t\in[d_i],i\in[k]}}^{j_{u+1}}\!\!\!\!\bigg(1-\frac{\sum_{\ell=1}^u W_{j_\ell}}{\sum_{\ell=1}^{s-1}W_{\ell}}\bigg)\mathbb{1}_{E_n^{(2)}}\right]. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \frac{1}{(n)_k}{}&\sum_{j_1=\ell_1+1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\!\!\!\!\!\!\!\!\mathbb E[\mathbb{P}_W\!\left(\mathcal{Z}_n(j_\ell)=m_\ell,\ell\in[k]\right)\mathbb{1}_{E_n^{(2)}}]\\[5pt] \geq{}&\frac{1}{(n)_k}\sum_{j_1=\ell_1+1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\mathbb E\!\left[\prod_{t=1}^k\prod_{s=1}^{d_t}\frac{W_{j_t}}{\sum_{\ell=1}^{m_{s,t}-1}W_\ell}\phantom{\times \prod_{u=1}^k\!\!\prod_{\substack{s=j_u+1\\ s\neq m_{i,t},t\in[d_i],i\in[k]}}^{j_{u+1}}}\right.\\[5pt] &\left.\times \prod_{u=1}^k\!\!\prod_{\substack{s=j_u+1\\ s\neq m_{i,t},t\in[d_i],i\in[k]}}^{j_{u+1}}\!\!\!\!\bigg(1-\frac{\sum_{\ell=1}^u W_{j_\ell}}{\sum_{\ell=1}^{s-1}W_{\ell}}\bigg)\mathbb{1}_{E_n^{(2)}}\right]. \end{aligned} \end{equation*}
We omit the constraint
 $s\neq m_{\ell,i}$
,
$s\neq m_{\ell,i}$
,
 $\ell\in[d_i]$
,
$\ell\in[d_i]$
,
 $i\in[k]$
in the final product. As this introduces more multiplicative terms smaller than one, we obtain a lower bound. Then, in the two denominators, we bound the vertex-weights
$i\in[k]$
in the final product. As this introduces more multiplicative terms smaller than one, we obtain a lower bound. Then, in the two denominators, we bound the vertex-weights
 $W_{j_1},\ldots, W_{j_k}$
from above by one and below by zero, respectively, to obtain a lower bound
$W_{j_1},\ldots, W_{j_k}$
from above by one and below by zero, respectively, to obtain a lower bound
 \begin{equation*}\begin{aligned} \frac{1}{(n)_k}\sum_{j_1=\ell_1+1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\!\!\!\!\mathbb E\Bigg[{}&\prod_{t=1}^k\prod_{s=1}^{d_t}\frac{W_{j_t}}{\sum_{\ell=1}^{m_{s,t}-1}W_\ell\mathbb{1}_{\{\ell\neq j_t,t\in[k]\}}+k}\\[5pt] &\times \prod_{u=1}^k\prod_{s=j_u+1}^{j_{u+1}}\!\!\!\bigg(\!1-\frac{\sum_{\ell=1}^u W_{j_\ell}}{\sum_{\ell=1}^{s-1}W_\ell\mathbb{1}_{\{\ell\neq j_t,t\in[k]\}}}\bigg)\mathbb{1}_{E_n^{(2)}}\!\Bigg]. \end{aligned}\end{equation*}
\begin{equation*}\begin{aligned} \frac{1}{(n)_k}\sum_{j_1=\ell_1+1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\!\!\!\!\mathbb E\Bigg[{}&\prod_{t=1}^k\prod_{s=1}^{d_t}\frac{W_{j_t}}{\sum_{\ell=1}^{m_{s,t}-1}W_\ell\mathbb{1}_{\{\ell\neq j_t,t\in[k]\}}+k}\\[5pt] &\times \prod_{u=1}^k\prod_{s=j_u+1}^{j_{u+1}}\!\!\!\bigg(\!1-\frac{\sum_{\ell=1}^u W_{j_\ell}}{\sum_{\ell=1}^{s-1}W_\ell\mathbb{1}_{\{\ell\neq j_t,t\in[k]\}}}\bigg)\mathbb{1}_{E_n^{(2)}}\!\Bigg]. \end{aligned}\end{equation*}
As a result, we can now swap the labels of
 $W_{j_t}$
and
$W_{j_t}$
and
 $W_t$
for each
$W_t$
for each
 $t\in[k]$
, which again does not change the expected value, but changes the value of the two denominators to
$t\in[k]$
, which again does not change the expected value, but changes the value of the two denominators to
 $\sum_{\ell=k+1}^{m_{s,t}}W_\ell+k$
and
$\sum_{\ell=k+1}^{m_{s,t}}W_\ell+k$
and
 $\sum_{\ell=k+1}^{m_{s,t}}W_\ell$
, respectively. After this we use the bounds in
$\sum_{\ell=k+1}^{m_{s,t}}W_\ell$
, respectively. After this we use the bounds in
 $E_n^{(2)}$
on these sums in the expected value to obtain a lower bound. Finally, we note that the (relabelled) weights
$E_n^{(2)}$
on these sums in the expected value to obtain a lower bound. Finally, we note that the (relabelled) weights
 $W_t$
,
$W_t$
,
 $t\in[k],$
are independent of
$t\in[k],$
are independent of
 $E_n^{(2)}$
, so that we can take the indicator out of the expected value. Combining all of the above steps, we arrive at the lower bound
$E_n^{(2)}$
, so that we can take the indicator out of the expected value. Combining all of the above steps, we arrive at the lower bound
 \begin{equation} \begin{aligned} \frac{1}{(n)_k}\sum_{j_1=\ell_1+1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \,{}& \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\mathbb E\Bigg[\prod_{t=1}^k \Big(\frac{W_t}{\mathbb{E}\left[W\right]}\Big)^{d_t} \prod_{s=1}^{d_t}\frac{1}{m_{s,t}(1+2\zeta_n)}\\[5pt] &\times\prod_{u=1}^k\prod_{s=j_u+1}^{j_{u+1}}\bigg(1-\frac{\sum_{\ell=1}^u W_\ell}{(s-1)\mathbb{E}\left[W\right](1-\zeta_n)}\bigg)\Bigg]\mathbb P(E_n^{(2)}).\\[5pt] \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \frac{1}{(n)_k}\sum_{j_1=\ell_1+1}^n\ldots \!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \,{}& \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\mathbb E\Bigg[\prod_{t=1}^k \Big(\frac{W_t}{\mathbb{E}\left[W\right]}\Big)^{d_t} \prod_{s=1}^{d_t}\frac{1}{m_{s,t}(1+2\zeta_n)}\\[5pt] &\times\prod_{u=1}^k\prod_{s=j_u+1}^{j_{u+1}}\bigg(1-\frac{\sum_{\ell=1}^u W_\ell}{(s-1)\mathbb{E}\left[W\right](1-\zeta_n)}\bigg)\Bigg]\mathbb P(E_n^{(2)}).\\[5pt] \end{aligned} \end{equation}
The
 $1+2\zeta_n$
in the fraction on the first line arises from the fact that, for n sufficiently large,
$1+2\zeta_n$
in the fraction on the first line arises from the fact that, for n sufficiently large,
 $(m_{s,t}-1)(1+\zeta_n)+k\leq m_{s,t}(1+2\zeta_n)$
. It follows from Lemma 3.1 that
$(m_{s,t}-1)(1+\zeta_n)+k\leq m_{s,t}(1+2\zeta_n)$
. It follows from Lemma 3.1 that
 $\mathbb P(E_n^{(2)})=1-o(n^{-\gamma})$
for any
$\mathbb P(E_n^{(2)})=1-o(n^{-\gamma})$
for any
 $\gamma>0$
. Similarly to the calculations in (6.13) and using
$\gamma>0$
. Similarly to the calculations in (6.13) and using
 $\log(1-x)\geq -x-x^2$
for x small, we obtain an almost sure lower bound for the final product, for n sufficiently large, of the form
$\log(1-x)\geq -x-x^2$
for x small, we obtain an almost sure lower bound for the final product, for n sufficiently large, of the form
 \begin{equation*} \prod_{s=j_u+1}^{j_{u+1}}\bigg(1-\frac{\sum_{\ell=1}^u W_\ell}{(s-1)\mathbb{E}\left[W\right](1-\zeta_n)}\bigg)\geq \bigg(\frac{j_{u+1}}{j_u}\bigg)^{-\sum_{\ell=1}^u W_\ell/(\mathbb{E}\left[W\right](1-\zeta_n))}(1-o(1)). \end{equation*}
\begin{equation*} \prod_{s=j_u+1}^{j_{u+1}}\bigg(1-\frac{\sum_{\ell=1}^u W_\ell}{(s-1)\mathbb{E}\left[W\right](1-\zeta_n)}\bigg)\geq \bigg(\frac{j_{u+1}}{j_u}\bigg)^{-\sum_{\ell=1}^u W_\ell/(\mathbb{E}\left[W\right](1-\zeta_n))}(1-o(1)). \end{equation*}
Using this in (6.22) yields the lower bound
 \begin{equation*} \frac{1}{(n)_k}\!\sum_{j_1=\ell_1+1}^n\ldots \!\!\!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\!\!\!\!\!\!\!\!\!\!\!\!\!(1-o(1))\bigg(\frac{1-\zeta_n}{1+2\zeta_n}\bigg)^{\sum_{t=1}^k d_t} \mathbb E\Bigg[\prod_{t=1}^k \widetilde a_t^{d_t} \Big(\frac{j_t}{n}\Big)^{\widetilde a_t}\prod_{s=1}^{d_t}\frac{1}{m_{s,t}} \Bigg], \end{equation*}
\begin{equation*} \frac{1}{(n)_k}\!\sum_{j_1=\ell_1+1}^n\ldots \!\!\!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\!\!\!\!\!\!\!\!\!\!\!\!\!(1-o(1))\bigg(\frac{1-\zeta_n}{1+2\zeta_n}\bigg)^{\sum_{t=1}^k d_t} \mathbb E\Bigg[\prod_{t=1}^k \widetilde a_t^{d_t} \Big(\frac{j_t}{n}\Big)^{\widetilde a_t}\prod_{s=1}^{d_t}\frac{1}{m_{s,t}} \Bigg], \end{equation*}
where
 $\widetilde a_t\;:\!=\;W_t/(\mathbb{E}\left[W\right](1-\zeta_n))$
. Since
$\widetilde a_t\;:\!=\;W_t/(\mathbb{E}\left[W\right](1-\zeta_n))$
. Since
 $d_t\leq c\log n$
and
$d_t\leq c\log n$
and
 $j_t\geq \ell_t\geq n^\eta$
for all
$j_t\geq \ell_t\geq n^\eta$
for all
 $t\in[k]$
, and
$t\in[k]$
, and
 $\zeta_n=n^{-\eta\delta}/\mathbb{E}\left[W\right]$
for some
$\zeta_n=n^{-\eta\delta}/\mathbb{E}\left[W\right]$
for some
 $\delta\in(0,1/2)$
, we have as in (6.15) that
$\delta\in(0,1/2)$
, we have as in (6.15) that
 \begin{equation*} \bigg(\frac{1-\zeta_n}{1+2\zeta_n}\bigg)^{\sum_{t=1}^k d_t}=1-o(1), \quad \text{and}\quad \widetilde a_t^{d_t}\Big(\frac{j_t}{n}\Big)^{\widetilde a_t}=a_t^{d_t}\Big(\frac{j_t}{n}\Big)^{a_t}(1-o(1)), \end{equation*}
\begin{equation*} \bigg(\frac{1-\zeta_n}{1+2\zeta_n}\bigg)^{\sum_{t=1}^k d_t}=1-o(1), \quad \text{and}\quad \widetilde a_t^{d_t}\Big(\frac{j_t}{n}\Big)^{\widetilde a_t}=a_t^{d_t}\Big(\frac{j_t}{n}\Big)^{a_t}(1-o(1)), \end{equation*}
where
 $a_t\;:\!=\;W_t/\mathbb{E}\left[W\right]$
. This yields
$a_t\;:\!=\;W_t/\mathbb{E}\left[W\right]$
. This yields
 \begin{equation*} \frac{1}{(n)_k}\!\sum_{j_1=\ell_1+1}^n\ldots \!\!\!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\!\!\!\!\! \mathbb E\Bigg[\prod_{t=1}^k a_t^{d_t} \Big(\frac{j_t}{n}\Big)^{ a_t}\prod_{s=1}^{d_t}\frac{1}{m_{s,t}} \Bigg](1-o(1)). \end{equation*}
\begin{equation*} \frac{1}{(n)_k}\!\sum_{j_1=\ell_1+1}^n\ldots \!\!\!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^n\ \, \sideset{}{^*}\sum_{\substack{j_i<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\!\!\!\!\! \mathbb E\Bigg[\prod_{t=1}^k a_t^{d_t} \Big(\frac{j_t}{n}\Big)^{ a_t}\prod_{s=1}^{d_t}\frac{1}{m_{s,t}} \Bigg](1-o(1)). \end{equation*}
We now bound the sum over the indices
 $m_{s,i}$
from below. We note that the expression in the expected value is decreasing in
$m_{s,i}$
from below. We note that the expression in the expected value is decreasing in
 $m_{s,i}$
, and we restrict the range of the indices to
$m_{s,i}$
, and we restrict the range of the indices to
 $j_i+\sum_{t=1}^k d_t<m_{1,i}<\ldots< i_{d_i,i}\leq n$
for all
$j_i+\sum_{t=1}^k d_t<m_{1,i}<\ldots< i_{d_i,i}\leq n$
for all
 $i \in[k]$
, but no longer constrain the indices to be distinct (so that we can drop the
$i \in[k]$
, but no longer constrain the indices to be distinct (so that we can drop the
 $*$
in the sum). In the distinct sums and the suggested lower bound, the numbers of values the
$*$
in the sum). In the distinct sums and the suggested lower bound, the numbers of values the
 $m_{s,i}$
take on equal
$m_{s,i}$
take on equal
 \begin{equation*} \prod_{i=1}^k \binom{n-(j_i-1)-\sum_{t=1}^{i-1}d_t}{d_i} \quad \text{and} \quad \prod_{i=1}^k \binom{n-(j_i-1)-\sum_{t=1}^k d_t}{d_i}, \end{equation*}
\begin{equation*} \prod_{i=1}^k \binom{n-(j_i-1)-\sum_{t=1}^{i-1}d_t}{d_i} \quad \text{and} \quad \prod_{i=1}^k \binom{n-(j_i-1)-\sum_{t=1}^k d_t}{d_i}, \end{equation*}
respectively. It is straightforward to see that the former allows for more possibilities than the latter, as
 $\binom{b}{c}> \binom{a}{c}$
when
$\binom{b}{c}> \binom{a}{c}$
when
 $b> a\geq c$
. As we omit the largest values of the expected value (since it decreases in
$b> a\geq c$
. As we omit the largest values of the expected value (since it decreases in
 $m_{s,t}$
and we omit the smallest values of
$m_{s,t}$
and we omit the smallest values of
 $m_{s,t}$
), we thus arrive at the lower bound
$m_{s,t}$
), we thus arrive at the lower bound
 \begin{equation*} \begin{aligned} \frac{1}{(n)_k} \!\!\!\sum_{j_1=\ell_1+1}^{n-\sum_{t=1}^k d_t}\!\!\!\!\ldots \!\!\!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^{n-\sum_{t=1}^k d_t}\ \, \sideset{}{^*}\sum_{\substack{j_i+\sum_{t=1}^k d_t<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\!\!\!\!\mathbb E\Bigg[\prod_{t=1}^k a_t^{d_t} \Big(\frac{j_t}{n}\Big)^{ a_t}\prod_{s=1}^{d_t}\frac{1}{m_{s,t}} \bigg](1-o(1)), \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \frac{1}{(n)_k} \!\!\!\sum_{j_1=\ell_1+1}^{n-\sum_{t=1}^k d_t}\!\!\!\!\ldots \!\!\!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^{n-\sum_{t=1}^k d_t}\ \, \sideset{}{^*}\sum_{\substack{j_i+\sum_{t=1}^k d_t<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\!\!\!\!\mathbb E\Bigg[\prod_{t=1}^k a_t^{d_t} \Big(\frac{j_t}{n}\Big)^{ a_t}\prod_{s=1}^{d_t}\frac{1}{m_{s,t}} \bigg](1-o(1)), \end{aligned} \end{equation*}
where we also restrict the upper range of the indices of the outer sums, as otherwise there would be a contribution of zero from these values of
 $j_1,\ldots,j_k$
. We now use techniques similar to those used for the proof of the upper bound to switch from summation to integration. However, because of the altered bounds on the range of the indices over which we sum and the fact that we require lower bounds rather than upper bounds, we face some more technicalities.
$j_1,\ldots,j_k$
. We now use techniques similar to those used for the proof of the upper bound to switch from summation to integration. However, because of the altered bounds on the range of the indices over which we sum and the fact that we require lower bounds rather than upper bounds, we face some more technicalities.
For now, we omit the expected value and focus on the terms
 \begin{equation} \frac{1}{(n)_k} \!\!\!\sum_{j_1=\ell_1+1}^{n-\sum_{t=1}^k d_t}\!\!\!\!\ldots \!\!\!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^{n-\sum_{t=1}^k d_t} \sum_{\substack{j_i+\sum_{t=1}^k d_t<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\prod_{t=1}^k a_t^{d_t}\Big(\frac{j_t}{n}\Big)^{ a_t}\prod_{s=1}^{d_t}\frac{1}{m_{s,t}}. \end{equation}
\begin{equation} \frac{1}{(n)_k} \!\!\!\sum_{j_1=\ell_1+1}^{n-\sum_{t=1}^k d_t}\!\!\!\!\ldots \!\!\!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^{n-\sum_{t=1}^k d_t} \sum_{\substack{j_i+\sum_{t=1}^k d_t<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\prod_{t=1}^k a_t^{d_t}\Big(\frac{j_t}{n}\Big)^{ a_t}\prod_{s=1}^{d_t}\frac{1}{m_{s,t}}. \end{equation}
We start by restricting the upper bound on the k outer sums to
 $n-2\sum_{i=1}^k d_i$
. This will prove useful later. We set
$n-2\sum_{i=1}^k d_i$
. This will prove useful later. We set
 $h_k\;:\!=\;\sum_{t=1}^k d_t$
and bound the inner sum over the indices
$h_k\;:\!=\;\sum_{t=1}^k d_t$
and bound the inner sum over the indices
 $m_{s,t}$
from below by
$m_{s,t}$
from below by
 \begin{equation*}\begin{aligned} {}&\sum_{\substack{j_i+h_k<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\prod_{t=1}^k \prod_{s=1}^{d_t}\frac{1}{m_{s,t}} \geq \prod_{t=1}^k \int_{j_t+1+h_k}^{n}\int_{x_{1,t}+1}^{n}\cdots \int_{x_{d_t-1,t}+1}^{n}\prod_{s=1}^{d_t}x_{s,t}^{-1}\,\textrm{d} x_{d_t,t}\ldots \textrm{d} x_{1,t}. \end{aligned} \end{equation*}
\begin{equation*}\begin{aligned} {}&\sum_{\substack{j_i+h_k<m_{1,i}<\ldots<m_{d_i,i}\leq n,\\ i\in[k]}}\prod_{t=1}^k \prod_{s=1}^{d_t}\frac{1}{m_{s,t}} \geq \prod_{t=1}^k \int_{j_t+1+h_k}^{n}\int_{x_{1,t}+1}^{n}\cdots \int_{x_{d_t-1,t}+1}^{n}\prod_{s=1}^{d_t}x_{s,t}^{-1}\,\textrm{d} x_{d_t,t}\ldots \textrm{d} x_{1,t}. \end{aligned} \end{equation*}
Applying Lemma 3.2 with
 $a=j_t+1+h_k$
and
$a=j_t+1+h_k$
and
 $b=n$
, and using that
$b=n$
, and using that
 $j_t\leq n-2h_k $
(recall that we restricted the upper bound on the outer sums in (6.23) to
$j_t\leq n-2h_k $
(recall that we restricted the upper bound on the outer sums in (6.23) to
 $n-2h_k$
), yields the lower bound
$n-2h_k$
), yields the lower bound
 \begin{equation*} \prod_{t=1}^k \frac{ a_t^{d_t}}{d_t!}\bigg(\!\log\!\bigg(\frac{n}{j_t +2\sum_{i=1}^k d_i}\bigg)\!\bigg)^{d_t}. \end{equation*}
\begin{equation*} \prod_{t=1}^k \frac{ a_t^{d_t}}{d_t!}\bigg(\!\log\!\bigg(\frac{n}{j_t +2\sum_{i=1}^k d_i}\bigg)\!\bigg)^{d_t}. \end{equation*}
Substituting this in (6.23) with the restriction on the outer sum discussed after (6.23) yields
 \begin{equation} \frac{1}{(n)_k} \!\!\!\sum_{j_1=\ell_1+1}^{n-2\sum_{i=1}^k d_i}\!\!\!\!\ldots \!\!\!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^{n-2\sum_{i=1}^k d_i}\prod_{t=1}^k \bigg(\frac{j_t}{n}\bigg)^{ a_t}\frac{ a_t^{d_t}}{d_t!}\bigg(\!\log\!\bigg(\frac{n}{j_t +2\sum_{i=1}^k d_i}\bigg)\!\bigg)^{d_t} . \end{equation}
\begin{equation} \frac{1}{(n)_k} \!\!\!\sum_{j_1=\ell_1+1}^{n-2\sum_{i=1}^k d_i}\!\!\!\!\ldots \!\!\!\!\!\!\sum_{j_k=(\ell_k\vee j_{k-1})+1}^{n-2\sum_{i=1}^k d_i}\prod_{t=1}^k \bigg(\frac{j_t}{n}\bigg)^{ a_t}\frac{ a_t^{d_t}}{d_t!}\bigg(\!\log\!\bigg(\frac{n}{j_t +2\sum_{i=1}^k d_i}\bigg)\!\bigg)^{d_t} . \end{equation}
To simplify the summation over
 $j_1,\ldots,j_k$
, we write the summand as
$j_1,\ldots,j_k$
, we write the summand as
 \begin{equation*} \prod_{t=1}^k\bigg(\bigg(j_t+2\sum_{i=1}^k d_i\bigg)/n\bigg)^{ a_t}\frac{ a_t^{d_t}}{d_t!}\bigg(\!\log\!\bigg(\frac{n}{j_t +2\sum_{i=1}^k d_i}\bigg)\!\bigg)^{d_t}\bigg(1-\frac{2\sum_{i=1}^k d_i}{j_t +2\sum_{i=1}^k d_i}\bigg)^{ a_t}. \end{equation*}
\begin{equation*} \prod_{t=1}^k\bigg(\bigg(j_t+2\sum_{i=1}^k d_i\bigg)/n\bigg)^{ a_t}\frac{ a_t^{d_t}}{d_t!}\bigg(\!\log\!\bigg(\frac{n}{j_t +2\sum_{i=1}^k d_i}\bigg)\!\bigg)^{d_t}\bigg(1-\frac{2\sum_{i=1}^k d_i}{j_t +2\sum_{i=1}^k d_i}\bigg)^{ a_t}. \end{equation*}
Using that
 $d_t\leq c \log n$
,
$d_t\leq c \log n$
,
 $j_t\geq \ell_t\geq n^\eta$
, and
$j_t\geq \ell_t\geq n^\eta$
, and
 $x^{ a_t}\geq x^{1/\mathbb{E}\left[W\right]}$
for
$x^{ a_t}\geq x^{1/\mathbb{E}\left[W\right]}$
for
 $x\in(0,1)$
almost surely, we can write the last term as
$x\in(0,1)$
almost surely, we can write the last term as
 $(1-o(1))$
almost surely. We then shift the bounds on the range of the sums in (6.24) by
$(1-o(1))$
almost surely. We then shift the bounds on the range of the sums in (6.24) by
 $2\sum_{i=1}^k d_i$
and let
$2\sum_{i=1}^k d_i$
and let
 $\widetilde \ell_i\;:\!=\;\ell_i+2\sum_{t=1}^k d_t$
for all
$\widetilde \ell_i\;:\!=\;\ell_i+2\sum_{t=1}^k d_t$
for all
 $ i\in[k]$
, to obtain the lower bound
$ i\in[k]$
, to obtain the lower bound
 \begin{equation*} \frac{1}{(n)_k} \sum_{j_1=\widetilde \ell_1+1}^n\sum_{j_2=(\widetilde \ell_2\vee j_1)+1}^n\!\!\!\ldots \!\!\!\sum_{j_k=(\widetilde \ell_k\vee j_{k-1})+1}^n\!\!\!\!\!\!\!\!\!\!\!\!(1-o(1))\prod_{t=1}^k \bigg(\frac{j_t}{n}\bigg)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}. \end{equation*}
\begin{equation*} \frac{1}{(n)_k} \sum_{j_1=\widetilde \ell_1+1}^n\sum_{j_2=(\widetilde \ell_2\vee j_1)+1}^n\!\!\!\ldots \!\!\!\sum_{j_k=(\widetilde \ell_k\vee j_{k-1})+1}^n\!\!\!\!\!\!\!\!\!\!\!\!(1-o(1))\prod_{t=1}^k \bigg(\frac{j_t}{n}\bigg)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}. \end{equation*}
We recall that this lower bound is achieved for the permutation
 $\pi$
such that
$\pi$
such that
 $\pi(i)=i$
for all
$\pi(i)=i$
for all
 $i\in[k]$
. As the product is invariant to permuting the indices
$i\in[k]$
. As the product is invariant to permuting the indices
 $t\in[k]$
, we can use this in (6.7) to obtain
$t\in[k]$
, we can use this in (6.7) to obtain
 \begin{equation}\begin{aligned} \frac{1}{(n)_k}{}&\sum_{\pi\in\mathcal {P}_k}\sum_{j_{\pi(1)}=\ell_{\pi(1)}}^n \sum_{j_{\pi(2)}=(\ell_{\pi(2)}\vee j_{\pi(1)})+1}^n \cdots \sum_{j_{\pi(k)}=(\ell_{\pi(k)}\vee j_{\pi(k-1)})+1}^n \mathbb{P}\left(\mathcal{Z}_n(j_i)=d_i, i\in[k]\right)\\[5pt] \geq{}&\frac{1}{(n)_k}\sum_{j_1=\widetilde \ell_1+1}^n \sum_{\substack{j_2=\widetilde \ell_2+1\\ j_2\neq j_1}}^n \cdots \sum_{\substack{j_k=\widetilde \ell_k+1\\ j_k\neq j_1,\ldots, j_{k-1}}}^n (1-o(1))\prod_{t=1}^k \mathbb{E}\left[\Big(\frac{j_t}{n}\Big)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}\right]. \end{aligned}\end{equation}
\begin{equation}\begin{aligned} \frac{1}{(n)_k}{}&\sum_{\pi\in\mathcal {P}_k}\sum_{j_{\pi(1)}=\ell_{\pi(1)}}^n \sum_{j_{\pi(2)}=(\ell_{\pi(2)}\vee j_{\pi(1)})+1}^n \cdots \sum_{j_{\pi(k)}=(\ell_{\pi(k)}\vee j_{\pi(k-1)})+1}^n \mathbb{P}\left(\mathcal{Z}_n(j_i)=d_i, i\in[k]\right)\\[5pt] \geq{}&\frac{1}{(n)_k}\sum_{j_1=\widetilde \ell_1+1}^n \sum_{\substack{j_2=\widetilde \ell_2+1\\ j_2\neq j_1}}^n \cdots \sum_{\substack{j_k=\widetilde \ell_k+1\\ j_k\neq j_1,\ldots, j_{k-1}}}^n (1-o(1))\prod_{t=1}^k \mathbb{E}\left[\Big(\frac{j_t}{n}\Big)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}\right]. \end{aligned}\end{equation}
We now want to allow for the indices
 $j_1,\ldots, j_k$
to have the same value. This way, we can more easily evaluate the sums. To do this, we distinguish between two cases in terms of the sizes of
$j_1,\ldots, j_k$
to have the same value. This way, we can more easily evaluate the sums. To do this, we distinguish between two cases in terms of the sizes of
 $d_1,\ldots, d_k$
, namely Case (1) and Case (2). In Case (1), we subtract all terms where two or more indices have the same value to avoid creating an upper bound. That is, we write the multiple sums as
$d_1,\ldots, d_k$
, namely Case (1) and Case (2). In Case (1), we subtract all terms where two or more indices have the same value to avoid creating an upper bound. That is, we write the multiple sums as
 \begin{equation*} \begin{aligned} \frac{1}{(n)_k}{}&\sum_{j_1=\widetilde \ell_1+1}^n \sum_{j_2=\widetilde \ell_2+1}^n \cdots \sum_{j_k=\widetilde \ell_k+1}^n (1-o(1))\prod_{t=1}^k \mathbb{E}\left[\Big(\frac{j_t}{n}\Big)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}\right]\\[5pt] -\frac{1}{(n)_k}{}&\sum_{m=2}^k \sum_{\substack{S\subseteq [k]\\ |S|=m}}\sum_{i\in S}\sum_{j_i=\widetilde \ell_i+1}^n\ \sideset{}{^*}\sum_{\substack{j_s=\widetilde \ell_s+1\\ s\in [k]\backslash S}}^n\!\! \mathbb{E}\left[ \prod_{u\in S}\Big(\frac{j_i}{n}\Big)^{a_u}\frac{(a_u\log(n/j_i))^{d_u}}{d_u!} \!\!\prod_{s\in [k]\backslash S}\!\!\!\Big(\frac{j_s}{n}\Big)^{d_s}\frac{(a_s\log(n/j_s))^{d_s}}{d_s!}\!\right]. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \frac{1}{(n)_k}{}&\sum_{j_1=\widetilde \ell_1+1}^n \sum_{j_2=\widetilde \ell_2+1}^n \cdots \sum_{j_k=\widetilde \ell_k+1}^n (1-o(1))\prod_{t=1}^k \mathbb{E}\left[\Big(\frac{j_t}{n}\Big)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}\right]\\[5pt] -\frac{1}{(n)_k}{}&\sum_{m=2}^k \sum_{\substack{S\subseteq [k]\\ |S|=m}}\sum_{i\in S}\sum_{j_i=\widetilde \ell_i+1}^n\ \sideset{}{^*}\sum_{\substack{j_s=\widetilde \ell_s+1\\ s\in [k]\backslash S}}^n\!\! \mathbb{E}\left[ \prod_{u\in S}\Big(\frac{j_i}{n}\Big)^{a_u}\frac{(a_u\log(n/j_i))^{d_u}}{d_u!} \!\!\prod_{s\in [k]\backslash S}\!\!\!\Big(\frac{j_s}{n}\Big)^{d_s}\frac{(a_s\log(n/j_s))^{d_s}}{d_s!}\!\right]. \end{aligned} \end{equation*}
Here, the
 $*$
in the final sum on the second line indicates that the indices
$*$
in the final sum on the second line indicates that the indices
 $j_s$
with
$j_s$
with
 $s\in [k]\backslash S$
are not allowed to have the same value, nor to be equal to
$s\in [k]\backslash S$
are not allowed to have the same value, nor to be equal to
 $j_i$
for any
$j_i$
for any
 $i\in S$
. The error term on the second line can be bounded from below by bounding the multiple sums from above, following an approach equivalent to that used in the proof of the upper bound. By (6.18) we can omit all terms
$i\in S$
. The error term on the second line can be bounded from below by bounding the multiple sums from above, following an approach equivalent to that used in the proof of the upper bound. By (6.18) we can omit all terms
 $u\neq i$
in the product over
$u\neq i$
in the product over
 $u\in S$
, as they can be bounded from above by one. Furthermore, we can omit the
$u\in S$
, as they can be bounded from above by one. Furthermore, we can omit the
 $*$
in the final sum to obtain an upper bound, so that all indices
$*$
in the final sum to obtain an upper bound, so that all indices
 $j_i$
and
$j_i$
and
 $j_s$
,
$j_s$
,
 $s\in[k]\backslash S$
, can be equal in value. Finally, let us write
$s\in[k]\backslash S$
, can be equal in value. Finally, let us write
 $S_i\;:\!=\;S\backslash \{i\}$
. It then follows from (6.17)–(6.21) that the error term is at least
$S_i\;:\!=\;S\backslash \{i\}$
. It then follows from (6.17)–(6.21) that the error term is at least
 \begin{equation*} \begin{aligned} -{}&\sum_{m=2}^k \!\frac{1+o(1)}{n^{m-1}}\! \sum_{\substack{S\subseteq [k]\\ |S|=m}}\sum_{i\in S} \prod_{t\in[k]\backslash S_i}\!\!\!\!\mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\widetilde \ell_t)\right)\right]\\[5pt] &\geq -C\sum_{m=2}^k \frac{1}{n^{m-1}}\!\!\!\!\!\!\!\!\!\! \sum_{\substack{S'\subseteq [k]\\ |S|=k-(m-1)}}\!\!\!\!\!\!\!\prod_{t\in S'}\!\mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\widetilde \ell_t)\right)\right], \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} -{}&\sum_{m=2}^k \!\frac{1+o(1)}{n^{m-1}}\! \sum_{\substack{S\subseteq [k]\\ |S|=m}}\sum_{i\in S} \prod_{t\in[k]\backslash S_i}\!\!\!\!\mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\widetilde \ell_t)\right)\right]\\[5pt] &\geq -C\sum_{m=2}^k \frac{1}{n^{m-1}}\!\!\!\!\!\!\!\!\!\! \sum_{\substack{S'\subseteq [k]\\ |S|=k-(m-1)}}\!\!\!\!\!\!\!\prod_{t\in S'}\!\mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\widetilde \ell_t)\right)\right], \end{aligned} \end{equation*}
for some large constant
 $C>0$
. It remains to take care of the main term,
$C>0$
. It remains to take care of the main term,
 \begin{equation} \begin{aligned} \frac{1}{(n)_k}{}&\sum_{j_1=\widetilde \ell_1+1}^n \sum_{j_2=\widetilde \ell_2+1}^n \cdots \sum_{j_k=\widetilde \ell_k+1}^n (1-o(1))\prod_{t=1}^k \mathbb{E}\left[\bigg(\frac{j_t}{n}\bigg)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}\right]\\[5pt] &\geq \prod_{t=1}^k\mathbb{E}\left[\frac1n \sum_{j_t=\widetilde \ell_t+1}^n\bigg(\frac{j_t}{n}\bigg)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}\right](1-o(1)). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \frac{1}{(n)_k}{}&\sum_{j_1=\widetilde \ell_1+1}^n \sum_{j_2=\widetilde \ell_2+1}^n \cdots \sum_{j_k=\widetilde \ell_k+1}^n (1-o(1))\prod_{t=1}^k \mathbb{E}\left[\bigg(\frac{j_t}{n}\bigg)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}\right]\\[5pt] &\geq \prod_{t=1}^k\mathbb{E}\left[\frac1n \sum_{j_t=\widetilde \ell_t+1}^n\bigg(\frac{j_t}{n}\bigg)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}\right](1-o(1)). \end{aligned} \end{equation}
We bound each sum from below by an integral, similarly to the proof of the upper bound. We again consider the two cases used in the upper bound, Case (1) and Case (2). In Case (2), the summand is decreasing in
 $j_t$
and hence we can replace the sum by an integral from
$j_t$
and hence we can replace the sum by an integral from
 $\ell_t$
to n. In Case (1), we use Lemma A.4 and (6.18) to obtain the lower bound
$\ell_t$
to n. In Case (1), we use Lemma A.4 and (6.18) to obtain the lower bound
 \begin{equation*} \frac1n\sum_{j_t=\widetilde \ell_t+1}^n\bigg(\frac{j_t}{n}\bigg)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}\geq \int_{\widetilde \ell_t}^n \bigg(\frac{x_t}{n}\bigg)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/x_t))^{d_t}\,\textrm{d} x_t -\frac1n. \end{equation*}
\begin{equation*} \frac1n\sum_{j_t=\widetilde \ell_t+1}^n\bigg(\frac{j_t}{n}\bigg)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}\geq \int_{\widetilde \ell_t}^n \bigg(\frac{x_t}{n}\bigg)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/x_t))^{d_t}\,\textrm{d} x_t -\frac1n. \end{equation*}
The same steps as in (6.19) and (6.20) yield that this equals
 \begin{equation*} \frac{\theta-1}{\theta-1+W_t}\bigg(\frac{W_t}{\theta-1+W_t}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W_t}{(\theta-1)}\bigg)\log(n/\widetilde \ell_t)\right)-\frac1n. \end{equation*}
\begin{equation*} \frac{\theta-1}{\theta-1+W_t}\bigg(\frac{W_t}{\theta-1+W_t}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W_t}{(\theta-1)}\bigg)\log(n/\widetilde \ell_t)\right)-\frac1n. \end{equation*}
Using this in (6.26) and combining it with the bound for the error term, we arrive at the final lower bound
 \begin{equation*} \begin{aligned} \prod_{t=1}^k{}& \mathbb{E}\left[\frac{\theta-1}{\theta-1+W_t}\bigg(\frac{W_t}{\theta-1+W_t}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W_t}{(\theta-1)}\bigg)\log(n/\widetilde \ell_t)\right)-\frac1n\right](1-o(1))\\[5pt] &-C\sum_{m=2}^k \frac{1}{n^{m-1}}\!\!\!\!\!\!\!\!\!\! \sum_{\substack{S'\subseteq [k]\\ |S|=k-(m-1)}}\!\!\!\!\!\!\!\prod_{t\in S'}\!\mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\widetilde \ell_t)\!\right)\!\right]\!. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \prod_{t=1}^k{}& \mathbb{E}\left[\frac{\theta-1}{\theta-1+W_t}\bigg(\frac{W_t}{\theta-1+W_t}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W_t}{(\theta-1)}\bigg)\log(n/\widetilde \ell_t)\right)-\frac1n\right](1-o(1))\\[5pt] &-C\sum_{m=2}^k \frac{1}{n^{m-1}}\!\!\!\!\!\!\!\!\!\! \sum_{\substack{S'\subseteq [k]\\ |S|=k-(m-1)}}\!\!\!\!\!\!\!\prod_{t\in S'}\!\mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\widetilde \ell_t)\!\right)\!\right]\!. \end{aligned} \end{equation*}
We can replace
 $\widetilde \ell_t$
with
$\widetilde \ell_t$
with
 $\ell_t$
at the cost of a
$\ell_t$
at the cost of a
 $1-o(1)$
term, since
$1-o(1)$
term, since
 $\log(n/\widetilde \ell_t)=\log(n/\ell_t)-o(1)$
. It then follows from Lemma A.3 that both the
$\log(n/\widetilde \ell_t)=\log(n/\ell_t)-o(1)$
. It then follows from Lemma A.3 that both the
 $1/n$
term on the first line and that of the second line can be incorporated into the
$1/n$
term on the first line and that of the second line can be incorporated into the
 $1-o(1)$
term.
$1-o(1)$
term.
In Case (2), we know that the summand in (6.25) is decreasing in
 $j_t$
for all
$j_t$
for all
 $t\in[k]$
. Hence, we can omit the smallest values of
$t\in[k]$
. Hence, we can omit the smallest values of
 $j_1, \ldots, j_k$
to obtain a lower bound. This yields
$j_1, \ldots, j_k$
to obtain a lower bound. This yields
 \begin{equation*} \frac{1}{(n)_k}{}\sum_{j_1=\widetilde \ell_1+1}^n \sum_{j_2=\widetilde \ell_2+2}^n \cdots \sum_{j_k=\widetilde \ell_k+k}^n (1-o(1))\prod_{t=1}^k \mathbb{E}\left[\bigg(\frac{j_t}{n}\bigg)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}\right], \end{equation*}
\begin{equation*} \frac{1}{(n)_k}{}\sum_{j_1=\widetilde \ell_1+1}^n \sum_{j_2=\widetilde \ell_2+2}^n \cdots \sum_{j_k=\widetilde \ell_k+k}^n (1-o(1))\prod_{t=1}^k \mathbb{E}\left[\bigg(\frac{j_t}{n}\bigg)^{ a_t}\frac{ 1}{d_t!}(a_t\log(n/j_t))^{d_t}\right], \end{equation*}
which can be evaluated in the same manner as in Case (1) to yield the lower bound
 \begin{equation*} \prod_{t=1}^k \mathbb{E}\left[\frac{\theta-1}{\theta-1+W_t}\bigg(\frac{W_t}{\theta-1+W_t}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W_t}{(\theta-1)}\bigg)\log(n/(\widetilde \ell_t+(t-1)))\right)\right](1-o(1)). \end{equation*}
\begin{equation*} \prod_{t=1}^k \mathbb{E}\left[\frac{\theta-1}{\theta-1+W_t}\bigg(\frac{W_t}{\theta-1+W_t}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W_t}{(\theta-1)}\bigg)\log(n/(\widetilde \ell_t+(t-1)))\right)\right](1-o(1)). \end{equation*}
Again, since
 $\log(n/(\widetilde \ell_t+(t-1)))=\log(n/\ell_t)-o(1)$
for each
$\log(n/(\widetilde \ell_t+(t-1)))=\log(n/\ell_t)-o(1)$
for each
 $t\in[k]$
, we can replace
$t\in[k]$
, we can replace
 $\widetilde \ell_t+(t-1)$
with
$\widetilde \ell_t+(t-1)$
with
 $\ell_t$
for each
$\ell_t$
for each
 $t\in[k]$
at the cost of a
$t\in[k]$
at the cost of a
 $1-o(1)$
term. We thus conclude that
$1-o(1)$
term. We thus conclude that
 \begin{equation*} \begin{aligned} \mathbb P(\mathcal{Z}_n{}&(v_i)= d_i, v_i>\ell_i,i\in[k])\\[5pt] \geq{}& (1-o(1))\prod_{t=1}^k \bigg[\mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_t)\right)\right], \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \mathbb P(\mathcal{Z}_n{}&(v_i)= d_i, v_i>\ell_i,i\in[k])\\[5pt] \geq{}& (1-o(1))\prod_{t=1}^k \bigg[\mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d_t}\mathbb{P}_W\!\left(X_t<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_t)\right)\right], \end{aligned} \end{equation*}
which concludes the proof of the lower bound.
We observe that the combination of the upper and lower bounds proves (5.4). What remains is to prove (5.5).
Proof of Proposition
5.1, Equation (5.5). We prove the two bounds in (5.5) by using (5.4). We assume that
 $d_i$
diverges with n, and we note that if
$d_i$
diverges with n, and we note that if
 \begin{equation*} d_i\leq c\log n\quad \text{and}\quad \ell_i\leq n\exp\!(\!-\!(1-\xi)(1-\theta^{-1})(d_i+1)) \end{equation*}
\begin{equation*} d_i\leq c\log n\quad \text{and}\quad \ell_i\leq n\exp\!(\!-\!(1-\xi)(1-\theta^{-1})(d_i+1)) \end{equation*}
for any
 $\xi\in(0,1)$
and for all sufficiently large n, then for any
$\xi\in(0,1)$
and for all sufficiently large n, then for any
 $j\in[\lfloor d_i^{1/4}\rfloor]$
, it also holds that
$j\in[\lfloor d_i^{1/4}\rfloor]$
, it also holds that
 \begin{equation*} d_i +j \leq c'\log n,\quad \text{and}\quad \ell_i\leq n\exp\!(\!-\!(1-\xi)(1-\theta^{-1})(d_i+j+1)), \end{equation*}
\begin{equation*} d_i +j \leq c'\log n,\quad \text{and}\quad \ell_i\leq n\exp\!(\!-\!(1-\xi)(1-\theta^{-1})(d_i+j+1)), \end{equation*}
for any
 $\xi\in(0,1)$
and for all sufficiently large n as well, where we can choose
$\xi\in(0,1)$
and for all sufficiently large n as well, where we can choose
 $c'\in(c,\theta/(\theta-1))$
arbitrarily close to c. As a result, we can write
$c'\in(c,\theta/(\theta-1))$
arbitrarily close to c. As a result, we can write
 \begin{equation*} \begin{aligned} \mathbb P(\mathcal{Z}_n{}&(v_i)\geq d_i, v_i> \ell_i, i\in[k])\\[5pt] \leq & \sum_{j_1=d_1}^{d_1+\lfloor d_1^{1/4}\rfloor}\cdots \sum_{j_k=d_k}^{d_k+\lfloor d_k^{1/4}\rfloor}\mathbb{P}\left(\mathcal{Z}_n(v_i)=j_i, v_i> \ell_i, i\in[k]\right)\\[5pt] &+\sum_{t=1}^k \mathbb{P}\left(\mathcal{Z}_n(v_t)\geq d_t+\lceil d_t^{1/4}\rceil ,\mathcal{Z}_n(v_i)\geq d_i, i\neq t, v_i>\ell_i, i\in[k]\right). \end{aligned}\end{equation*}
\begin{equation*} \begin{aligned} \mathbb P(\mathcal{Z}_n{}&(v_i)\geq d_i, v_i> \ell_i, i\in[k])\\[5pt] \leq & \sum_{j_1=d_1}^{d_1+\lfloor d_1^{1/4}\rfloor}\cdots \sum_{j_k=d_k}^{d_k+\lfloor d_k^{1/4}\rfloor}\mathbb{P}\left(\mathcal{Z}_n(v_i)=j_i, v_i> \ell_i, i\in[k]\right)\\[5pt] &+\sum_{t=1}^k \mathbb{P}\left(\mathcal{Z}_n(v_t)\geq d_t+\lceil d_t^{1/4}\rceil ,\mathcal{Z}_n(v_i)\geq d_i, i\neq t, v_i>\ell_i, i\in[k]\right). \end{aligned}\end{equation*}
We first provide an upper bound for the multiple sums on the first line. By (5.4), this equals
 \begin{equation*} \sum_{j_1=d_1}^{d_1+\lfloor d_1^{1/4}\rfloor}\!\!\!\cdots\!\!\! \sum_{j_k=d_k}^{d_k+\lfloor d_k^{1/4}\rfloor}\!\!\!\!(1+o(1))\prod_{i=1}^k \mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{j_i}\mathbb{P}_W\!\left(X_{j_i}<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\!\right)\!\right]\!, \end{equation*}
\begin{equation*} \sum_{j_1=d_1}^{d_1+\lfloor d_1^{1/4}\rfloor}\!\!\!\cdots\!\!\! \sum_{j_k=d_k}^{d_k+\lfloor d_k^{1/4}\rfloor}\!\!\!\!(1+o(1))\prod_{i=1}^k \mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{j_i}\mathbb{P}_W\!\left(X_{j_i}<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\!\right)\!\right]\!, \end{equation*}
where we write
 $X_{j_i}\sim\text{Gamma}(j_i+1,1)$
instead of
$X_{j_i}\sim\text{Gamma}(j_i+1,1)$
instead of
 $X_i$
to explicitly state the dependence on
$X_i$
to explicitly state the dependence on
 $j_i$
. If
$j_i$
. If
 $X_{j_i}\sim\text{Gamma}(j_i+1,1)$
and
$X_{j_i}\sim\text{Gamma}(j_i+1,1)$
and
 $X_{j'_{\!\!i}}\sim\text{Gamma}(j'_{\!\!i}+1,1)$
, then
$X_{j'_{\!\!i}}\sim\text{Gamma}(j'_{\!\!i}+1,1)$
, then
 $X_{j_i}$
stochastically dominates
$X_{j_i}$
stochastically dominates
 $X_{j'_{\!\!i}}$
when
$X_{j'_{\!\!i}}$
when
 $j_i>j'_{\!\!i}$
. Hence, we obtain the upper bound
$j_i>j'_{\!\!i}$
. Hence, we obtain the upper bound
 \begin{equation}\begin{aligned} \sum_{j_1=d_1}^\infty\!\!\!{}&\ldots\!\!\! \sum_{j_k=d_k}^\infty\!(1+o(1))\prod_{i=1}^k \mathbb E\bigg[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{j_i}\!\mathbb P_W\!\bigg(\!X_{d_i}\!<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\!\bigg)\bigg]\\[5pt] &=(1+o(1))\prod_{i=1}^k \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(X_i<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right], \end{aligned} \end{equation}
\begin{equation}\begin{aligned} \sum_{j_1=d_1}^\infty\!\!\!{}&\ldots\!\!\! \sum_{j_k=d_k}^\infty\!(1+o(1))\prod_{i=1}^k \mathbb E\bigg[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{j_i}\!\mathbb P_W\!\bigg(\!X_{d_i}\!<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\!\bigg)\bigg]\\[5pt] &=(1+o(1))\prod_{i=1}^k \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(X_i<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right], \end{aligned} \end{equation}
where we note that
 $X_i\equiv X_{d_i}$
by the definition of
$X_i\equiv X_{d_i}$
by the definition of
 $X_i$
and
$X_i$
and
 $X_{d_i}$
. It thus remains to show that
$X_{d_i}$
. It thus remains to show that
 \begin{equation} \sum_{t=1}^k \mathbb{P}\left(\mathcal{Z}_n(v_t)\geq d_t+\lceil d_t^{1/4}\rceil ,\mathcal{Z}_n(v_i)\geq d_i, i\neq t, v_i>\ell_i, i\in[k]\right) \end{equation}
\begin{equation} \sum_{t=1}^k \mathbb{P}\left(\mathcal{Z}_n(v_t)\geq d_t+\lceil d_t^{1/4}\rceil ,\mathcal{Z}_n(v_i)\geq d_i, i\neq t, v_i>\ell_i, i\in[k]\right) \end{equation}
is negligible compared to (6.27). We show this holds for each term in the sum, and since all
 $d_i$
,
$d_i$
,
 $i\in[k]$
, diverge, it suffices to show this holds for
$i\in[k]$
, diverge, it suffices to show this holds for
 $t=1$
. The in-degrees in the WRT model are negative quadrant dependent under the conditional probability measure
$t=1$
. The in-degrees in the WRT model are negative quadrant dependent under the conditional probability measure
 $\mathbb P_W$
. That is, by [Reference Lodewijks and Ortgiese12, Lemma 7.1], for any indices
$\mathbb P_W$
. That is, by [Reference Lodewijks and Ortgiese12, Lemma 7.1], for any indices
 $r_1, \ldots, r_k\in[n]$
,
$r_1, \ldots, r_k\in[n]$
,
 $r_i\neq r_j$
when
$r_i\neq r_j$
when
 $i\neq j$
,
$i\neq j$
,
 \begin{equation*} \mathbb{P}_W\!\left(\mathcal{Z}_n(r_i)\geq d_i, i\in[k]\right)\leq \prod_{i=1}^k \mathbb{P}_W\!\left(\mathcal{Z}_n(r_i)\geq d_i\right). \end{equation*}
\begin{equation*} \mathbb{P}_W\!\left(\mathcal{Z}_n(r_i)\geq d_i, i\in[k]\right)\leq \prod_{i=1}^k \mathbb{P}_W\!\left(\mathcal{Z}_n(r_i)\geq d_i\right). \end{equation*}
We can thus bound the term with
 $t=1$
in (6.28) from above by
$t=1$
in (6.28) from above by
 \begin{equation*} \begin{aligned} \sum_{j_1=\ell_1+1}^n{}&\sum_{\substack{j_2=\ell_2+1\\ j_2\neq j_1}}^n \cdots \sum_{\substack{j_k=\ell_k+1\\ j_k\neq j_{k-1},\ldots, j_1}}^n \mathbb{E}\left[\mathbb{P}_W\!\left(\mathcal{Z}_n(j_1)\geq d_1+\lceil d_1^{1/4}\rceil\right)\prod_{i=2}^k \mathbb{P}_W\!\left(\mathcal{Z}_n(j_i)\geq d_i\right)\right] \\[5pt] &\leq \mathbb{E}\left[\mathbb{P}_W\!\left(\mathcal{Z}_n(v_1)\geq d_1+\lceil d_1^{1/4}\rceil, v_1>\ell_1\right)\prod_{i=2}^k \mathbb{P}_W\!\left(\mathcal{Z}_n(v_i)\geq d_i, v_i>\ell_i\right)\right], \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \sum_{j_1=\ell_1+1}^n{}&\sum_{\substack{j_2=\ell_2+1\\ j_2\neq j_1}}^n \cdots \sum_{\substack{j_k=\ell_k+1\\ j_k\neq j_{k-1},\ldots, j_1}}^n \mathbb{E}\left[\mathbb{P}_W\!\left(\mathcal{Z}_n(j_1)\geq d_1+\lceil d_1^{1/4}\rceil\right)\prod_{i=2}^k \mathbb{P}_W\!\left(\mathcal{Z}_n(j_i)\geq d_i\right)\right] \\[5pt] &\leq \mathbb{E}\left[\mathbb{P}_W\!\left(\mathcal{Z}_n(v_1)\geq d_1+\lceil d_1^{1/4}\rceil, v_1>\ell_1\right)\prod_{i=2}^k \mathbb{P}_W\!\left(\mathcal{Z}_n(v_i)\geq d_i, v_i>\ell_i\right)\right], \end{aligned} \end{equation*}
where the last step follows by allowing the indices
 $j_i$
to take on any value between
$j_i$
to take on any value between
 $\ell_i+1$
and n,
$\ell_i+1$
and n,
 $i\in[k]$
. We can now deal with each of these probabilities individually instead of with all the events at the same time, which makes obtaining an explicit bound for the probability of the event
$i\in[k]$
. We can now deal with each of these probabilities individually instead of with all the events at the same time, which makes obtaining an explicit bound for the probability of the event
 $\{\mathcal{Z}_n(v_i)\geq d_i, v_i>\ell_i\}$
easier. We claim that, with a very similar approach to that in the proof of the upper bound for (5.4) (see also the steps (5.47)–(5.51) in the proof of [Reference Eslava, Lodewijks and Ortgiese7, Lemma 5.11] for the case
$\{\mathcal{Z}_n(v_i)\geq d_i, v_i>\ell_i\}$
easier. We claim that, with a very similar approach to that in the proof of the upper bound for (5.4) (see also the steps (5.47)–(5.51) in the proof of [Reference Eslava, Lodewijks and Ortgiese7, Lemma 5.11] for the case
 $\ell_1=\ldots \ell_k=n^{1-\varepsilon}$
for some
$\ell_1=\ldots \ell_k=n^{1-\varepsilon}$
for some
 $\varepsilon\in(0,1)$
), it can be shown that this expected value is bounded from above by
$\varepsilon\in(0,1)$
), it can be shown that this expected value is bounded from above by
 \begin{equation*} \begin{aligned} (1+o(1)){}&\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_1+\lceil d_1^{1/4}\rceil}\mathbb{P}_W\!\left(X_1\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_1)\right)\right]\\[5pt] &\times \prod_{i=2}^k \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(X_i\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right]\\[5pt] \leq{}& (1+o(1))\theta^{-\lceil d_1^{1/4}\rceil}\prod_{i=1}^k \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(X_i\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right]. \end{aligned}\end{equation*}
\begin{equation*} \begin{aligned} (1+o(1)){}&\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_1+\lceil d_1^{1/4}\rceil}\mathbb{P}_W\!\left(X_1\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_1)\right)\right]\\[5pt] &\times \prod_{i=2}^k \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(X_i\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right]\\[5pt] \leq{}& (1+o(1))\theta^{-\lceil d_1^{1/4}\rceil}\prod_{i=1}^k \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(X_i\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right]. \end{aligned}\end{equation*}
This upper bound can be achieved for each term in (6.28) (with
 $\lceil d_1^{1/4}\rceil$
changed accordingly), so that (6.28) is indeed negligible compared to (6.27) and hence can be included in the o(1) term in (6.27). This proves the upper bound in (5.5).
$\lceil d_1^{1/4}\rceil$
changed accordingly), so that (6.28) is indeed negligible compared to (6.27) and hence can be included in the o(1) term in (6.27). This proves the upper bound in (5.5).
For a lower bound we directly obtain
 \begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, v_i> \ell_i, i\in[k]\right)\geq \sum_{j_1=d_1}^{d_1+\lfloor d_1^{1/4}\rfloor}\cdots \sum_{j_k=d_k}^{d_k+\lfloor d_k^{1/4}\rfloor}\mathbb{P}\left(\mathcal{Z}_n(v_i)=j_i, v_i> \ell_i, i\in[k]\right). \end{equation*}
\begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, v_i> \ell_i, i\in[k]\right)\geq \sum_{j_1=d_1}^{d_1+\lfloor d_1^{1/4}\rfloor}\cdots \sum_{j_k=d_k}^{d_k+\lfloor d_k^{1/4}\rfloor}\mathbb{P}\left(\mathcal{Z}_n(v_i)=j_i, v_i> \ell_i, i\in[k]\right). \end{equation*}
With an approach similar to that used for the upper bound, we can use (5.4) and now bound the probability from below by replacing
 $X_{j_i}$
with
$X_{j_i}$
with
 $\widetilde X_i\equiv X_{d_i+\lfloor d_i^{1/4}\rfloor}$
instead of
$\widetilde X_i\equiv X_{d_i+\lfloor d_i^{1/4}\rfloor}$
instead of
 $X_{d_i}$
, to arrive at the lower bound
$X_{d_i}$
, to arrive at the lower bound
 \begin{equation*} \begin{aligned} \sum_{j_1=d_1}^{d_1+\lfloor d_1^{1/4}\rfloor}\!\!\!{}&\cdots\!\!\! \sum_{j_k=d_k}^{d_k+\lfloor d_k^{1/4}\rfloor}\!\!\!\!(1+o(1))\prod_{i=1}^k \mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{j_i}\mathbb{P}_W\!\left( X_{j_i}<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\!\right)\!\right]\\[5pt] \geq (1+{}&o(1))\prod_{i=1}^k \mathbb{E}\!\left[\!\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\bigg(1-\bigg(\frac{W}{\theta-1+W}\bigg)^{\lfloor d_i^{1/4}\rfloor}\bigg)\mathbb{P}_W\!\left(\widetilde X_i<\bigg(1+\frac{W}{\theta-1}\!\bigg)\log(n/\ell_i)\!\right)\!\right]\\[5pt] \geq(1+{}&o(1))\prod_{i=1}^k\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(\widetilde X_i<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right], \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \sum_{j_1=d_1}^{d_1+\lfloor d_1^{1/4}\rfloor}\!\!\!{}&\cdots\!\!\! \sum_{j_k=d_k}^{d_k+\lfloor d_k^{1/4}\rfloor}\!\!\!\!(1+o(1))\prod_{i=1}^k \mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{j_i}\mathbb{P}_W\!\left( X_{j_i}<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\!\right)\!\right]\\[5pt] \geq (1+{}&o(1))\prod_{i=1}^k \mathbb{E}\!\left[\!\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\bigg(1-\bigg(\frac{W}{\theta-1+W}\bigg)^{\lfloor d_i^{1/4}\rfloor}\bigg)\mathbb{P}_W\!\left(\widetilde X_i<\bigg(1+\frac{W}{\theta-1}\!\bigg)\log(n/\ell_i)\!\right)\!\right]\\[5pt] \geq(1+{}&o(1))\prod_{i=1}^k\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_i}\mathbb{P}_W\!\left(\widetilde X_i<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell_i)\right)\right], \end{aligned} \end{equation*}
where in the last step we use that
 $1-(W/(\theta-1+W))^{\lfloor d_i^{1/4}\rfloor}\geq 1-\theta^{-\lfloor d_i^{1/4}\rfloor}=1-o(1)$
almost surely, since
$1-(W/(\theta-1+W))^{\lfloor d_i^{1/4}\rfloor}\geq 1-\theta^{-\lfloor d_i^{1/4}\rfloor}=1-o(1)$
almost surely, since
 $d_i$
diverges for any
$d_i$
diverges for any
 $i\in[k]$
. This concludes the proof of the lower bound in (5.5) and hence of Proposition 5.1.
$i\in[k]$
. This concludes the proof of the lower bound in (5.5) and hence of Proposition 5.1.
7. Extended results for the beta and gamma cases
In this section we discuss two examples of vertex-weight distributions as provided in Assumption 2.1, for which results similar to those of Theorems 2.2 and 2.3 and Proposition 5.2 (where the latter two hold for the atom case) can be proved.
Example 7.1. (Beta case.) We consider a random variable W with a beta distribution, i.e. with a tail distribution as in (2.2) for some
 $\alpha,\beta>0$
. We define, for
$\alpha,\beta>0$
. We define, for
 $j\in\mathbb{Z}$
,
$j\in\mathbb{Z}$
,
 $B\in\mathcal {B}(\mathbb{R})$
,
$B\in\mathcal {B}(\mathbb{R})$
,
 \begin{equation}\begin{aligned} \widetilde X^{(n)}_j(B)&\;:\!=\;\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)=\lfloor \log_\theta n-\beta\log_\theta\log_\theta n \rfloor +j, \frac{\log i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\in B\bigg\}\bigg|,\\[5pt] \widetilde X^{(n)}_{\geq j}(B)&\;:\!=\;\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)\geq \lfloor \log_\theta n-\beta\log_\theta\log_\theta n \rfloor +j, \frac{\log i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\in B\bigg\}\bigg|,\\[5pt] \varepsilon_n&\;:\!=\;(\!\log_\theta n-\beta \log_\theta\log_\theta n)-\lfloor\log_\theta n-\beta\log_\theta\log_\theta n \rfloor,\\[5pt] c_{\alpha,\beta,\theta}&\;:\!=\;\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)}(1-\theta^{-1})^{-\beta}. \end{aligned}\end{equation}
\begin{equation}\begin{aligned} \widetilde X^{(n)}_j(B)&\;:\!=\;\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)=\lfloor \log_\theta n-\beta\log_\theta\log_\theta n \rfloor +j, \frac{\log i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\in B\bigg\}\bigg|,\\[5pt] \widetilde X^{(n)}_{\geq j}(B)&\;:\!=\;\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)\geq \lfloor \log_\theta n-\beta\log_\theta\log_\theta n \rfloor +j, \frac{\log i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\in B\bigg\}\bigg|,\\[5pt] \varepsilon_n&\;:\!=\;(\!\log_\theta n-\beta \log_\theta\log_\theta n)-\lfloor\log_\theta n-\beta\log_\theta\log_\theta n \rfloor,\\[5pt] c_{\alpha,\beta,\theta}&\;:\!=\;\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)}(1-\theta^{-1})^{-\beta}. \end{aligned}\end{equation}
Then we can formulate the following results.
Theorem 7.1. Consider the WRT model, that is, the WRG model as in Definition 2.1 with
 $m=1$
, with vertex-weights
$m=1$
, with vertex-weights
 $(W_i)_{i\in\mathbb{N}}$
which are distributed according to (2.2) for some
$(W_i)_{i\in\mathbb{N}}$
which are distributed according to (2.2) for some
 $\alpha,\beta>0$
, and recall
$\alpha,\beta>0$
, and recall
 $\theta=1+\mathbb{E}\left[W\right]$
. Let
$\theta=1+\mathbb{E}\left[W\right]$
. Let
 $v^1,v^2,\ldots, v^n$
be the vertices in the tree in decreasing order of their in-degree (where ties are split uniformly at random); let
$v^1,v^2,\ldots, v^n$
be the vertices in the tree in decreasing order of their in-degree (where ties are split uniformly at random); let
 $d_n^i$
and
$d_n^i$
and
 $\ell_n^i$
denote the in-degree and label of
$\ell_n^i$
denote the in-degree and label of
 $v^i$
, respectively; and fix
$v^i$
, respectively; and fix
 $\varepsilon\in[0,1]$
. Recall
$\varepsilon\in[0,1]$
. Recall
 $\varepsilon_n$
from (7.1) and let
$\varepsilon_n$
from (7.1) and let
 $(n_j)_{j\in\mathbb{N}}$
be a positive, diverging integer sequence such that
$(n_j)_{j\in\mathbb{N}}$
be a positive, diverging integer sequence such that
 $\varepsilon_{n_j}\to\varepsilon$
as
$\varepsilon_{n_j}\to\varepsilon$
as
 $j\to\infty$
. Finally, let
$j\to\infty$
. Finally, let
 $(P_i)_{i\in\mathbb{N}}$
be the points of the Poisson point process
$(P_i)_{i\in\mathbb{N}}$
be the points of the Poisson point process
 $\mathcal {P}$
on
$\mathcal {P}$
on
 $\mathbb{R}$
with intensity measure
$\mathbb{R}$
with intensity measure
 $\lambda(x)=c_{\alpha,\beta,\theta}\theta^{-x}\log \theta\,\textrm{d} x$
, ordered in decreasing order, let
$\lambda(x)=c_{\alpha,\beta,\theta}\theta^{-x}\log \theta\,\textrm{d} x$
, ordered in decreasing order, let
 $(M_i)_{i\in\mathbb{N}}$
be a sequence of i.i.d. standard normal random variables, and define
$(M_i)_{i\in\mathbb{N}}$
be a sequence of i.i.d. standard normal random variables, and define
 $\mu\;:\!=\;1-(\theta-1)/(\theta\log \theta)$
,
$\mu\;:\!=\;1-(\theta-1)/(\theta\log \theta)$
,
 $\sigma^2\;:\!=\;1-(\theta-1)^2/(\theta^2\log \theta)$
. Then, as
$\sigma^2\;:\!=\;1-(\theta-1)^2/(\theta^2\log \theta)$
. Then, as
 $j\to\infty$
,
$j\to\infty$
,
 \begin{equation*} \Bigg(d_{n_j}^i-\lfloor \log_\theta n_j-\beta \log_\theta \log_\theta n_j\rfloor, \frac{\log(\ell_{n_j}^i)-\mu\log n_j}{\sqrt{(1-\sigma^2)\log n_j}},i\in[n_j]\Bigg)\buildrel {d}\over{\longrightarrow} (\lfloor P_i+\varepsilon\rfloor , M_i, i\in\mathbb{N}). \end{equation*}
\begin{equation*} \Bigg(d_{n_j}^i-\lfloor \log_\theta n_j-\beta \log_\theta \log_\theta n_j\rfloor, \frac{\log(\ell_{n_j}^i)-\mu\log n_j}{\sqrt{(1-\sigma^2)\log n_j}},i\in[n_j]\Bigg)\buildrel {d}\over{\longrightarrow} (\lfloor P_i+\varepsilon\rfloor , M_i, i\in\mathbb{N}). \end{equation*}
Proposition 7.1. Consider the WRT model, that is, the WRG model as in Definition 2.1 with
 $m=1$
, with vertex-weights
$m=1$
, with vertex-weights
 $(W_i)_{i\in[n]}$
which are distributed according to (2.2) for some
$(W_i)_{i\in[n]}$
which are distributed according to (2.2) for some
 $\alpha,\beta>0$
. Recall that
$\alpha,\beta>0$
. Recall that
 $\theta\;:\!=\;1+\mathbb{E}\left[W\right]$
and that
$\theta\;:\!=\;1+\mathbb{E}\left[W\right]$
and that
 $(x)_k\;:\!=\;x(x-1)\cdots (x-(k-1))$
for
$(x)_k\;:\!=\;x(x-1)\cdots (x-(k-1))$
for
 $x\in\mathbb{R}$
,
$x\in\mathbb{R}$
,
 $k\in\mathbb{N}$
, and
$k\in\mathbb{N}$
, and
 $(x)_0\;:\!=\;1$
. Fix
$(x)_0\;:\!=\;1$
. Fix
 $K\in\mathbb{N}$
; let
$K\in\mathbb{N}$
; let
 $(j_k)_{k\in[K]}$
be a fixed non-decreasing sequence with
$(j_k)_{k\in[K]}$
be a fixed non-decreasing sequence with
 $0\leq K'\;:\!=\;\min\{k\;:\; j_{k+1}=j_K\}$
; let
$0\leq K'\;:\!=\;\min\{k\;:\; j_{k+1}=j_K\}$
; let
 $(B_k)_{k\in[K]}$
be a sequence of sets
$(B_k)_{k\in[K]}$
be a sequence of sets
 $B_k\in \mathcal {B}(\mathbb{R})$
such that
$B_k\in \mathcal {B}(\mathbb{R})$
such that
 $B_k\cap B_\ell=\varnothing $
when
$B_k\cap B_\ell=\varnothing $
when
 $j_k=j_\ell$
and
$j_k=j_\ell$
and
 $k\neq \ell$
; and let
$k\neq \ell$
; and let
 $(c_k)_{k\in[K]}\in \mathbb{N}_0^K$
. Recall the random variables
$(c_k)_{k\in[K]}\in \mathbb{N}_0^K$
. Recall the random variables
 $\widetilde X^{(n)}_j(B), \widetilde X_{\geq j}^{(n)}(B)$
and
$\widetilde X^{(n)}_j(B), \widetilde X_{\geq j}^{(n)}(B)$
and
 $\varepsilon_n, c_{\alpha,\beta,\theta}$
from (7.1). Then
$\varepsilon_n, c_{\alpha,\beta,\theta}$
from (7.1). Then
 \begin{equation*} \begin{aligned} \mathbb{E}\!\left[\prod_{k=1}^{K'}\!\bigg(\widetilde X_{j_k}^{(n)}(B_k)\bigg)_{c_k}\prod_{k=K'+1}^K \!\bigg(\widetilde X_{\geq j_k}^{(n)}(B_k)\!\bigg)_{c_k}\right]={}&(1+o(1))\prod_{k=1}^{K'}\!\bigg(\frac{c_{\alpha,\beta,\theta}(1-\theta^{-1})}{(1+\delta)^\beta}\theta^{-k+\varepsilon_n}\Phi(B_k)\bigg)^{c_k}\\[5pt] &\times \prod_{k=K'+1}^{K}\bigg(\frac{c_{\alpha,\beta,\theta}}{(1+\delta)^\beta}\theta^{-k+\varepsilon_n}\Phi(B_k)\bigg)^{c_k}. \end{aligned}\end{equation*}
\begin{equation*} \begin{aligned} \mathbb{E}\!\left[\prod_{k=1}^{K'}\!\bigg(\widetilde X_{j_k}^{(n)}(B_k)\bigg)_{c_k}\prod_{k=K'+1}^K \!\bigg(\widetilde X_{\geq j_k}^{(n)}(B_k)\!\bigg)_{c_k}\right]={}&(1+o(1))\prod_{k=1}^{K'}\!\bigg(\frac{c_{\alpha,\beta,\theta}(1-\theta^{-1})}{(1+\delta)^\beta}\theta^{-k+\varepsilon_n}\Phi(B_k)\bigg)^{c_k}\\[5pt] &\times \prod_{k=K'+1}^{K}\bigg(\frac{c_{\alpha,\beta,\theta}}{(1+\delta)^\beta}\theta^{-k+\varepsilon_n}\Phi(B_k)\bigg)^{c_k}. \end{aligned}\end{equation*}
Remark 7.1. A more general result as in Proposition 5.2 holds in this particular example as well. However, as only the factorial moments of
 $\widetilde X_j^{(n)}(B)$
,
$\widetilde X_j^{(n)}(B)$
,
 $\widetilde X_{\geq j}^{(n)}(B)$
are of interest for Theorem 7.1, these more general results are omitted here.
$\widetilde X_{\geq j}^{(n)}(B)$
are of interest for Theorem 7.1, these more general results are omitted here.
We note that the beta distribution satisfies Conditions C1, C2, and C3 of Assumption 2.1, so that this case is already captured by Theorem 2.2. Therefore, we do not need to state an analogue of this theorem here.
Theorem 7.1 and Proposition 7.1 are the analogues of Theorem 2.3 and Proposition 5.2. As the proof of the theorem presented here is very similar to the proof of Theorem 2.3 (namely, using Proposition 7.1 with a subsequence
 $n_j$
such that
$n_j$
such that
 $\varepsilon_{n_j}$
, as in (7.1), converges to some
$\varepsilon_{n_j}$
, as in (7.1), converges to some
 $\varepsilon\in[0,1]$
, combined with the method of moments), we omit it here. The proof of the proposition is very similar to the proof of Proposition 5.2 when using (A.6) from Corollary A.1 in the appendix, and is also omitted.
$\varepsilon\in[0,1]$
, combined with the method of moments), we omit it here. The proof of the proposition is very similar to the proof of Proposition 5.2 when using (A.6) from Corollary A.1 in the appendix, and is also omitted.
Example 7.2. (Gamma case.) We consider a random variable W with a tail distribution as in (2.3) for some
 $b\in \mathbb{R}$
,
$b\in \mathbb{R}$
,
 $c_1>0$
,
$c_1>0$
,
 $\tau\geq 1$
such that
$\tau\geq 1$
such that
 $b\leq 0$
when
$b\leq 0$
when
 $\tau>1 $
and
$\tau>1 $
and
 $bc_1\leq 1$
when
$bc_1\leq 1$
when
 $\tau=1$
(this condition is to ensure that the probability density function is non-negative on [0,1)). We define
$\tau=1$
(this condition is to ensure that the probability density function is non-negative on [0,1)). We define
 \begin{equation}\begin{aligned} C_{\theta,c_1}&\;:\!=\;\frac{2}{\log \theta}\sqrt{\frac{1-\theta^{-1}}{c_1}},\qquad &C\;:\!=\;{\textrm{e}}^{c_1^{-1}(1-\theta^{-1})/2}\sqrt{\pi}c_1^{-1/4+b/2}(1-\theta^{-1})^{1/4+b/2},&\\[5pt] c_{\theta,c_1}&\;:\!=\;C\theta^{C_{\theta,c_1}^2/2},\qquad &K_{\theta,c_1,\tau}\;:\!=\;\frac1\theta \bigg(\frac{\tau}{c_1^\tau(1-\theta^{-1})}\bigg)^\gamma,& \end{aligned} \end{equation}
\begin{equation}\begin{aligned} C_{\theta,c_1}&\;:\!=\;\frac{2}{\log \theta}\sqrt{\frac{1-\theta^{-1}}{c_1}},\qquad &C\;:\!=\;{\textrm{e}}^{c_1^{-1}(1-\theta^{-1})/2}\sqrt{\pi}c_1^{-1/4+b/2}(1-\theta^{-1})^{1/4+b/2},&\\[5pt] c_{\theta,c_1}&\;:\!=\;C\theta^{C_{\theta,c_1}^2/2},\qquad &K_{\theta,c_1,\tau}\;:\!=\;\frac1\theta \bigg(\frac{\tau}{c_1^\tau(1-\theta^{-1})}\bigg)^\gamma,& \end{aligned} \end{equation}
and, for
 $j\in\mathbb{Z}$
,
$j\in\mathbb{Z}$
,
 $B\in\mathcal {B}(\mathbb{R})$
,
$B\in\mathcal {B}(\mathbb{R})$
,
 \begin{equation}\begin{aligned} \widetilde X^{(n)}_j(B)\;:\!=\;{}&\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)=\big\lfloor \log_\theta n-C_{\theta,c_1}\sqrt{\log_\theta n}+(b/2+1/4) \log_\theta \log_\theta n \big\rfloor +j, \\[5pt] &\hphantom{\bigg|\bigg\{i\in[n]:}\ \frac{\log i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\in B\bigg\}\bigg|,\\[5pt] \widetilde X^{(n)}_{\geq j}(B)\;:\!=\;{}&\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)\geq \big\lfloor \log_\theta n-C_{\theta,c_1}\sqrt{\log_\theta n}+(b/2+1/4) \log_\theta \log_\theta n \big\rfloor +j,\\[5pt] &\hphantom{\bigg|\bigg\{i\in[n]:}\ \frac{\log i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\in B\bigg\}\bigg|,\\[5pt] \varepsilon_n\;:\!=\;{}&\big(\!\log_\theta n-C_{\theta,c_1}\sqrt{\log_\theta n}+(b/2+1/4) \log_\theta \log_\theta n\big )\\[5pt] &-\big\lfloor\log_\theta n-C_{\theta,c_1}\sqrt{\log_\theta n}+(b/2+1/4) \log_\theta \log_\theta n \big \rfloor. \end{aligned}\end{equation}
\begin{equation}\begin{aligned} \widetilde X^{(n)}_j(B)\;:\!=\;{}&\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)=\big\lfloor \log_\theta n-C_{\theta,c_1}\sqrt{\log_\theta n}+(b/2+1/4) \log_\theta \log_\theta n \big\rfloor +j, \\[5pt] &\hphantom{\bigg|\bigg\{i\in[n]:}\ \frac{\log i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\in B\bigg\}\bigg|,\\[5pt] \widetilde X^{(n)}_{\geq j}(B)\;:\!=\;{}&\bigg|\bigg\{i\in[n]\;:\; \mathcal{Z}_n(i)\geq \big\lfloor \log_\theta n-C_{\theta,c_1}\sqrt{\log_\theta n}+(b/2+1/4) \log_\theta \log_\theta n \big\rfloor +j,\\[5pt] &\hphantom{\bigg|\bigg\{i\in[n]:}\ \frac{\log i-\mu\log n}{\sqrt{(1-\sigma^2)\log n}}\in B\bigg\}\bigg|,\\[5pt] \varepsilon_n\;:\!=\;{}&\big(\!\log_\theta n-C_{\theta,c_1}\sqrt{\log_\theta n}+(b/2+1/4) \log_\theta \log_\theta n\big )\\[5pt] &-\big\lfloor\log_\theta n-C_{\theta,c_1}\sqrt{\log_\theta n}+(b/2+1/4) \log_\theta \log_\theta n \big \rfloor. \end{aligned}\end{equation}
Then we can formulate the following results.
Theorem 7.2. Consider the WRT model, that is, the WRG model as in Definition 2.1 with
 $m=1$
, with vertex-weights
$m=1$
, with vertex-weights
 $(W_i)_{i\in\mathbb{N}}$
which are distributed according to (2.3) for some
$(W_i)_{i\in\mathbb{N}}$
which are distributed according to (2.3) for some
 $b\in\mathbb{R}$
,
$b\in\mathbb{R}$
,
 $c_1>0$
,
$c_1>0$
,
 $\tau\geq 1$
such that
$\tau\geq 1$
such that
 $b\leq 0$
when
$b\leq 0$
when
 $\tau>1$
and
$\tau>1$
and
 $bc_1\leq 1$
when
$bc_1\leq 1$
when
 $\tau=1$
, and let
$\tau=1$
, and let
 $\gamma\;:\!=\;1/(\tau+1)$
. Fix
$\gamma\;:\!=\;1/(\tau+1)$
. Fix
 $k\in\mathbb{N}$
,
$k\in\mathbb{N}$
,
 $c\in(0,\theta/(\theta-1))$
; let
$c\in(0,\theta/(\theta-1))$
; let
 $(d_i)_{i\in[k]}$
be k integer-valued sequences that diverge as
$(d_i)_{i\in[k]}$
be k integer-valued sequences that diverge as
 $n\to\infty$
, such that
$n\to\infty$
, such that
 $d_i\leq c\log n$
for all
$d_i\leq c\log n$
for all
 $i\in[k]$
; and let
$i\in[k]$
; and let
 $(v_i)_{i\in[k]}$
be k distinct vertices selected uniformly at random without replacement from [n]. For
$(v_i)_{i\in[k]}$
be k distinct vertices selected uniformly at random without replacement from [n]. For
 $\tau\in[1,2)$
, the tuple
$\tau\in[1,2)$
, the tuple
 \begin{equation*} \bigg(\frac{\log v_i -(\!\log n-(1-\theta^{-1})(d_i+K_{\theta,c_1,\tau}d_i^{1-\gamma}))}{\sqrt{(1-\theta^{-1})^2d_i }}\bigg)_{i\in[k]}, \end{equation*}
\begin{equation*} \bigg(\frac{\log v_i -(\!\log n-(1-\theta^{-1})(d_i+K_{\theta,c_1,\tau}d_i^{1-\gamma}))}{\sqrt{(1-\theta^{-1})^2d_i }}\bigg)_{i\in[k]}, \end{equation*}
conditionally on the event
 $\mathcal{Z}_n(v_i)\geq d_i$
for all
$\mathcal{Z}_n(v_i)\geq d_i$
for all
 $i\in[k]$
, converges in distribution to
$i\in[k]$
, converges in distribution to
 $(M_i)_{i\in[k]}$
, where the
$(M_i)_{i\in[k]}$
, where the
 $M_i$
are i.i.d. standard normal random variables, and with
$M_i$
are i.i.d. standard normal random variables, and with
 $K_{\theta,c_1,\tau}$
as in (7.2).
$K_{\theta,c_1,\tau}$
as in (7.2).
Remark 7.2.
-
(i) We see here that the behaviour of the labels of high-degree vertices is different compared to Theorem 2.2, where the second-order term
$K_{\theta,c_1,\tau}d_i^{1-\gamma}$
is not present. This is due to the exponential decay of the vertex-weight tail distribution near one, which does not satisfy Condition C2, as discussed in Items (i) and (iii) of Remark 2.3, as well as in the heuristic arguments in Section 3. -
(ii) The statement of the theorem is different from that of Theorem 2.2, as there is no need to distinguish between two cases. This is due to the fact that the distribution in (2.3) satisfies Condition C3 and so the two cases can be presented as one.
-
(iii) When
$\tau=1$
, we observe that
$d_i^{1-\gamma}=\sqrt{d_i}$
, so that the tuples contain a constant term. Hence, the statement in Theorem 7.2 for
$\tau=1$
is equivalent to saying that the tuple conditionally on the event
\begin{equation*} \bigg(\frac{\log v_i -(\!\log n-(1-\theta^{-1})d_i)}{\sqrt{(1-\theta^{-1})^2d_i }}\bigg)_{i\in[k]}, \end{equation*}
$\mathcal{Z}_n(v_i)\geq d_i$
for all
$i\in[k]$
, converges in distribution to
$(M'_{\!\!i})_{i\in[k]}$
, where the
$M'_{\!\!i}$
are i.i.d.
$\mathcal{N}(\!-\!K_{\theta,c_1,1},1)$
random variables.
-
(iv) When
$\tau\geq 2$
we expect more higher-order terms to appear, which require a proof with even more precise and technical estimates and hence are not included here.











In the case that
 $\tau=1$
, we have a precise asymptotic expression for
$\tau=1$
, we have a precise asymptotic expression for
 $p_{\geq d}$
from Theorem 3.2. This enables us to derive the following more detailed results.
$p_{\geq d}$
from Theorem 3.2. This enables us to derive the following more detailed results.
Theorem 7.3. Consider the WRT model, that is, the WRG model in Definition 2.1 with
 $m=1$
, with vertex-weights
$m=1$
, with vertex-weights
 $(W_i)_{i\in[n]}$
which are distributed according to (2.3) for
$(W_i)_{i\in[n]}$
which are distributed according to (2.3) for
 $\tau=1$
and some
$\tau=1$
and some
 $b\in\mathbb{R}$
,
$b\in\mathbb{R}$
,
 $c_1>0$
such that
$c_1>0$
such that
 $bc_1\leq 1$
. Recall
$bc_1\leq 1$
. Recall
 $\theta=1+\mathbb{E}\left[W\right]$
and
$\theta=1+\mathbb{E}\left[W\right]$
and
 $C_{\theta,c_1},c_{\theta,c_1},$
$C_{\theta,c_1},c_{\theta,c_1},$
 $K_{\theta,c_1,1}$
from (7.2). Let
$K_{\theta,c_1,1}$
from (7.2). Let
 $v^1,v^2,\ldots, v^n$
be the vertices in the tree in decreasing order of their in-degree (where ties are split uniformly at random), let
$v^1,v^2,\ldots, v^n$
be the vertices in the tree in decreasing order of their in-degree (where ties are split uniformly at random), let
 $d_n^i$
and
$d_n^i$
and
 $\ell_n^i$
denote the in-degree and label of
$\ell_n^i$
denote the in-degree and label of
 $v^i$
, respectively, and fix
$v^i$
, respectively, and fix
 $\varepsilon\in[0,1]$
. Recall
$\varepsilon\in[0,1]$
. Recall
 $\varepsilon_n$
from (7.3) and let
$\varepsilon_n$
from (7.3) and let
 $(n_j)_{j\in\mathbb{N}}$
be a positive, diverging integer sequence such that
$(n_j)_{j\in\mathbb{N}}$
be a positive, diverging integer sequence such that
 $\varepsilon_{n_j}\to\varepsilon$
as
$\varepsilon_{n_j}\to\varepsilon$
as
 $j\to\infty$
. Finally, let
$j\to\infty$
. Finally, let
 $(P_i)_{i\in\mathbb{N}}$
be the points of the Poisson point process
$(P_i)_{i\in\mathbb{N}}$
be the points of the Poisson point process
 $\mathcal {P}$
on
$\mathcal {P}$
on
 $\mathbb{R}$
with intensity measure
$\mathbb{R}$
with intensity measure
 $\lambda(x)=c_{\theta,c_1}\theta^{-x}\log \theta\, \textrm{d} x$
, ordered in decreasing order, let
$\lambda(x)=c_{\theta,c_1}\theta^{-x}\log \theta\, \textrm{d} x$
, ordered in decreasing order, let
 $(M_{i,\theta,c_1})_{i\in\mathbb{N}}$
be a sequence of i.i.d.
$(M_{i,\theta,c_1})_{i\in\mathbb{N}}$
be a sequence of i.i.d.
 $\mathcal {N}(\!-\!K_{\theta,c_1,1},1)$
random variables, and define
$\mathcal {N}(\!-\!K_{\theta,c_1,1},1)$
random variables, and define
 $\mu\;:\!=\;1-(\theta-1)/(\theta\log \theta)$
,
$\mu\;:\!=\;1-(\theta-1)/(\theta\log \theta)$
,
 $ \sigma^2\;:\!=\;1-(\theta-1)^2/(\theta^2\log \theta)$
. Then, as
$ \sigma^2\;:\!=\;1-(\theta-1)^2/(\theta^2\log \theta)$
. Then, as
 $j\to\infty$
,
$j\to\infty$
,
 \begin{equation*}\begin{aligned} \bigg({}&d_{n_j}^i-\bigg\lfloor \log_\theta n_j-C_{\theta,c_1}\sqrt{\log_\theta n}+ \bigg(\frac b2+\frac 14\bigg)\log_\theta \log_\theta n_j\bigg\rfloor, \frac{\log(\ell_{n_j}^i)-\mu\log n_j}{\sqrt{(1-\sigma^2)\log n_j}},i\in[n_j]\bigg)\\[5pt] &\buildrel {d}\over{\longrightarrow} (\lfloor P_i+\varepsilon\rfloor , M_{i,\theta,c_1}, i\in\mathbb{N}). \end{aligned} \end{equation*}
\begin{equation*}\begin{aligned} \bigg({}&d_{n_j}^i-\bigg\lfloor \log_\theta n_j-C_{\theta,c_1}\sqrt{\log_\theta n}+ \bigg(\frac b2+\frac 14\bigg)\log_\theta \log_\theta n_j\bigg\rfloor, \frac{\log(\ell_{n_j}^i)-\mu\log n_j}{\sqrt{(1-\sigma^2)\log n_j}},i\in[n_j]\bigg)\\[5pt] &\buildrel {d}\over{\longrightarrow} (\lfloor P_i+\varepsilon\rfloor , M_{i,\theta,c_1}, i\in\mathbb{N}). \end{aligned} \end{equation*}
Proposition 7.2. Consider the WRT model, that is, the WRG model as in Definition 2.1 with
 $m=1$
, with vertex-weights
$m=1$
, with vertex-weights
 $(W_i)_{i\in[n]}$
which are distributed according to (2.3) for some
$(W_i)_{i\in[n]}$
which are distributed according to (2.3) for some
 $b\in\mathbb{R}$
,
$b\in\mathbb{R}$
,
 $c_1>0$
such that
$c_1>0$
such that
 $bc_1\leq 1$
. Recall that
$bc_1\leq 1$
. Recall that
 $\theta\;:\!=\;1+\mathbb{E}\left[W\right]$
and that
$\theta\;:\!=\;1+\mathbb{E}\left[W\right]$
and that
 $(x)_k\;:\!=\;x(x-1)\cdots (x-(k-1))$
for
$(x)_k\;:\!=\;x(x-1)\cdots (x-(k-1))$
for
 $x\in\mathbb{R}$
,
$x\in\mathbb{R}$
,
 $k\in\mathbb{N}$
, and
$k\in\mathbb{N}$
, and
 $(x)_0\;:\!=\;1$
. Fix
$(x)_0\;:\!=\;1$
. Fix
 $K\in\mathbb{N}$
; let
$K\in\mathbb{N}$
; let
 $(j_k)_{k\in[K]}$
be a fixed non-decreasing sequence with
$(j_k)_{k\in[K]}$
be a fixed non-decreasing sequence with
 $0\leq K'\;:\!=\;\min\{k\;:\; j_{k+1}=j_K\}$
; let
$0\leq K'\;:\!=\;\min\{k\;:\; j_{k+1}=j_K\}$
; let
 $(B_k)_{k\in[K]}$
be a sequence of sets
$(B_k)_{k\in[K]}$
be a sequence of sets
 $B_k\in\mathcal {B}(R)$
such that
$B_k\in\mathcal {B}(R)$
such that
 $B_k\cap B_\ell=\varnothing $
when
$B_k\cap B_\ell=\varnothing $
when
 $j_k=j_\ell$
and
$j_k=j_\ell$
and
 $k\neq \ell$
; and let
$k\neq \ell$
; and let
 $(c_k)_{k\in[K]}\in \mathbb{N}_0^K$
. Recall the random variables
$(c_k)_{k\in[K]}\in \mathbb{N}_0^K$
. Recall the random variables
 $\widetilde X^{(n)}_j(B)$
,
$\widetilde X^{(n)}_j(B)$
,
 $\widetilde X_{\geq j}^{(n)}(B)$
and the sequence
$\widetilde X_{\geq j}^{(n)}(B)$
and the sequence
 $\varepsilon_n$
from (7.3), as well as
$\varepsilon_n$
from (7.3), as well as
 $c_{\theta,c_1}$
and
$c_{\theta,c_1}$
and
 $C_{\theta,c_1}$
from (7.2), and let
$C_{\theta,c_1}$
from (7.2), and let
 $\Phi_{\theta,c_1}$
denote the cumulative distribution function of
$\Phi_{\theta,c_1}$
denote the cumulative distribution function of
 $\mathcal {N}(\!-\!1/\sqrt{c_1\theta(\theta-1)},1)$
. Then
$\mathcal {N}(\!-\!1/\sqrt{c_1\theta(\theta-1)},1)$
. Then
 \begin{equation*} \begin{aligned} \mathbb E\Bigg[ \prod_{k=1}^{K'}\!\bigg(\widetilde X_{j_k}^{(n)}(B_k)\bigg)_{c_k}\!\prod_{k=K'+1}^K\!\! \bigg(\widetilde X_{\geq j_k}^{(n)}(B_k)\bigg)_{c_k}\!\Bigg]={}&(1+o(1))\prod_{k=1}^{K'}\!\bigg(c_{\theta,c_1}(1-\theta^{-1})\theta^{-k+\varepsilon_n}\Phi_{\theta,c_1}(B_k)\!\bigg)^{c_k}\\[5pt] &\times \prod_{k=K'+1}^{K}\bigg(c_{\theta,c_1}\theta^{-k+\varepsilon_n}\Phi_{\theta,c_1}(B_k)\bigg)^{c_k}. \end{aligned}\end{equation*}
\begin{equation*} \begin{aligned} \mathbb E\Bigg[ \prod_{k=1}^{K'}\!\bigg(\widetilde X_{j_k}^{(n)}(B_k)\bigg)_{c_k}\!\prod_{k=K'+1}^K\!\! \bigg(\widetilde X_{\geq j_k}^{(n)}(B_k)\bigg)_{c_k}\!\Bigg]={}&(1+o(1))\prod_{k=1}^{K'}\!\bigg(c_{\theta,c_1}(1-\theta^{-1})\theta^{-k+\varepsilon_n}\Phi_{\theta,c_1}(B_k)\!\bigg)^{c_k}\\[5pt] &\times \prod_{k=K'+1}^{K}\bigg(c_{\theta,c_1}\theta^{-k+\varepsilon_n}\Phi_{\theta,c_1}(B_k)\bigg)^{c_k}. \end{aligned}\end{equation*}
Remark 7.3. A more general result as in Proposition 5.2 holds in this particular example as well. However, as only the factorial moments of
 $\widetilde X_j^{(n)}(B)$
,
$\widetilde X_j^{(n)}(B)$
,
 $\widetilde X_{\geq j}^{(n)}(B)$
are of interest for Theorem 7.3, these more general results are omitted here.
$\widetilde X_{\geq j}^{(n)}(B)$
are of interest for Theorem 7.3, these more general results are omitted here.
We observe that the behaviour of the labels of high-degree vertices in the above results is different from e.g. Theorem 2.2. Since the higher-order terms of the asymptotic expression for the degree are of the same order as the second-order rescaling of the label of the high-degree vertices, this causes a correlation between the higher-order behaviour of the degree and the location, so that more complex behaviour is observed.
Theorems 7.2 and 7.3 and Proposition 7.2 are the analogues of Theorems 2.2 and 2.3 and Proposition 5.2, respectively. As the proofs of the theorems presented here are very similar to the proofs of Theorems 2.2 and 2.3 (namely, one uses (A.4) rather than (A.2) in the proof of Theorem 2.2 to prove Theorem 7.2, and one uses Proposition 7.2 with a subsequence
 $n_j$
such that
$n_j$
such that
 $\varepsilon_{n_j}$
, as in (7.3), converges to some
$\varepsilon_{n_j}$
, as in (7.3), converges to some
 $\varepsilon\in[0,1]$
, combined with the method of moments to prove Theorem 7.3), we omit them here. The proof of the proposition is very similar to the proof of Proposition 5.2 using (A.4) from Lemma A.1 in the appendix, and is also omitted.
$\varepsilon\in[0,1]$
, combined with the method of moments to prove Theorem 7.3), we omit them here. The proof of the proposition is very similar to the proof of Proposition 5.2 using (A.4) from Lemma A.1 in the appendix, and is also omitted.
Appendix A
Lemma A.1. Consider the same definitions and assumptions as in Proposition 5.1. We provide the asymptotic value of
 $\mathbb{P}(\mathcal{Z}_n(v_1)\geq d, v_1>\ell)$
under several assumptions on the distribution of W and a parametrisation of
$\mathbb{P}(\mathcal{Z}_n(v_1)\geq d, v_1>\ell)$
under several assumptions on the distribution of W and a parametrisation of
 $\ell$
in terms of d. In all cases we let d diverge as
$\ell$
in terms of d. In all cases we let d diverge as
 $n\to\infty$
. We first set, for
$n\to\infty$
. We first set, for
 $x\in\mathbb{R}$
,
$x\in\mathbb{R}$
,
 \begin{equation} \ell\;:\!=\;n\exp\!(\!-\!(1-\theta^{-1})d+x\sqrt{(1-\theta^{-1})^2d}). \end{equation}
\begin{equation} \ell\;:\!=\;n\exp\!(\!-\!(1-\theta^{-1})d+x\sqrt{(1-\theta^{-1})^2d}). \end{equation}
We now distinguish between the different cases.
When W has a distribution that satisfies Conditions C1 and C2 of Assumption 2.1,
 \begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d,v_1\geq \ell\right)=\mathbb{E}\!\left[\!\bigg(\frac{W}{\theta-1+W}\!\bigg)^d\!\right](1-\Phi(x))(1+o(1))=p_{\geq d}(1-\Phi(x))(1+o(1)). \end{equation}
\begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d,v_1\geq \ell\right)=\mathbb{E}\!\left[\!\bigg(\frac{W}{\theta-1+W}\!\bigg)^d\!\right](1-\Phi(x))(1+o(1))=p_{\geq d}(1-\Phi(x))(1+o(1)). \end{equation}
Furthermore, let W satisfy the gamma case of Assumption 2.1 for some
 $b\in\mathbb{R}$
,
$b\in\mathbb{R}$
,
 $c_1>0$
,
$c_1>0$
,
 $\tau\in[1,2)$
such that
$\tau\in[1,2)$
such that
 $b\leq 0$
when
$b\leq 0$
when
 $\tau>1$
and
$\tau>1$
and
 $bc_1\leq 1$
when
$bc_1\leq 1$
when
 $\tau=1$
; set
$\tau=1$
; set
 $\gamma\;:\!=\;1/(\tau+1)$
; and for
$\gamma\;:\!=\;1/(\tau+1)$
; and for
 $x\in\mathbb{R}$
and with
$x\in\mathbb{R}$
and with
 $K_{\theta,c_1,\tau}$
as in (7.2), define
$K_{\theta,c_1,\tau}$
as in (7.2), define
 \begin{equation} \ell\;:\!=\;n\exp\!(\!-\!(1-\theta^{-1})(d+K_{\theta,c_1,\tau}d^{1-\gamma})+x\sqrt{(1-\theta^{-1})^2d}). \end{equation}
\begin{equation} \ell\;:\!=\;n\exp\!(\!-\!(1-\theta^{-1})(d+K_{\theta,c_1,\tau}d^{1-\gamma})+x\sqrt{(1-\theta^{-1})^2d}). \end{equation}
Then
 \begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d, v_1\geq \ell\right)= \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg](1-\Phi(x))(1+o(1))=p_{\geq d}(1-\Phi(x))(1+o(1)). \end{equation}
\begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d, v_1\geq \ell\right)= \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg](1-\Phi(x))(1+o(1))=p_{\geq d}(1-\Phi(x))(1+o(1)). \end{equation}
Remark A.1.
-
(i) For
$k>1$
and with
$(d_i,\ell_i)_{i\in[k]}$
satisfying the assumptions of Proposition 5.1, it follows that so that the result of Lemma A.1 can immediately be extended to the case
\begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, v_i>\ell_i, i\in[k]\right)=(1+o(1))\prod_{i=1}^k \mathbb{P}\left(\mathcal{Z}_n(v_i)\geq d_i, v_i>\ell_i\right), \end{equation*}
$k>1$
as well with
$\ell_i=n\exp\!(\!-\!(1-\theta^{-1})d_i+x_i\sqrt{(1-\theta^{-1})^2d_i})$
and
$(x_i)_{i\in[k]}\in\mathbb{R}^k$
(and a similar adaptation for (A.3)).
-
(ii) With only minor modifications to the proof, we can show that in all cases of Lemma A.1,
is satisfied. This holds in the case of k vertices, as in Item (i), as well.
\begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_1)=d, v_1>\ell\right)=(1-\theta^{-1})\mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d, v_1>\ell\right)(1+o(1)) \end{equation*}







A direct corollary of Lemma A.1 is that we can obtain several precise asymptotic expressions for
 $\mathbb{P}(\mathcal{Z}_n(v_1)\geq d,v_1\geq \ell)$
for particular choices of the random variable W, whose distribution satisfies either Conditions C1 and C2 or the gamma case, and for which we have a precise asymptotic expression for
$\mathbb{P}(\mathcal{Z}_n(v_1)\geq d,v_1\geq \ell)$
for particular choices of the random variable W, whose distribution satisfies either Conditions C1 and C2 or the gamma case, and for which we have a precise asymptotic expression for
 $p_{\geq d}$
. The asymptotics follow from combining Lemma A.1 with Theorem 3.2.
$p_{\geq d}$
. The asymptotics follow from combining Lemma A.1 with Theorem 3.2.
Corollary A.1. When W satisfies the atom case for some
 $q_0\in(0,1]$
, and with
$q_0\in(0,1]$
, and with
 $\ell $
as in (A.1),
$\ell $
as in (A.1),
 \begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d, v_1>\ell\right)=q_0\theta^{-d}(1-\Phi(x))(1+o(1)). \end{equation}
\begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d, v_1>\ell\right)=q_0\theta^{-d}(1-\Phi(x))(1+o(1)). \end{equation}
When W satisfies the beta case for some
 $\alpha,\beta>0$
, and with
$\alpha,\beta>0$
, and with
 $\ell $
as in (A.1),
$\ell $
as in (A.1),
 \begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d, v_1>\ell\right)=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)(1-\theta^{-1})^{\beta}}d^{-\beta}\theta^{-d}(1-\Phi(x))(1+o(1)). \end{equation}
\begin{equation} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d, v_1>\ell\right)=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)(1-\theta^{-1})^{\beta}}d^{-\beta}\theta^{-d}(1-\Phi(x))(1+o(1)). \end{equation}
When W satisfies the gamma case for
 $\tau=1$
and some
$\tau=1$
and some
 $b\in\mathbb{R}$
,
$b\in\mathbb{R}$
,
 $c_1>0$
such that
$c_1>0$
such that
 $bc_1\leq 1$
, and with
$bc_1\leq 1$
, and with
 $\ell$
as in (A.3),
$\ell$
as in (A.3),
 \begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d, v_1\geq \ell\right)= Cd^{b/2+1/4}{\textrm{e}}^{-2\sqrt{c_1^{-1}(1-\theta^{-1})d}}\theta^{-d}(1-\Phi(x))(1+o(1)), \end{equation*}
\begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d, v_1\geq \ell\right)= Cd^{b/2+1/4}{\textrm{e}}^{-2\sqrt{c_1^{-1}(1-\theta^{-1})d}}\theta^{-d}(1-\Phi(x))(1+o(1)), \end{equation*}
where C is as in (7.2).
Remark A.2. By the parametrisation of
 $\ell$
, the event
$\ell$
, the event
 $\{v_1>\ell\}$
is equivalent to
$\{v_1>\ell\}$
is equivalent to
 \begin{equation*} \bigg\{\frac{\log v_1-(\!\log n-(1-\theta^{-1})d_i)}{\sqrt{(1-\theta^{-1})^2d_i}}\in (x,\infty)\bigg\}. \end{equation*}
\begin{equation*} \bigg\{\frac{\log v_1-(\!\log n-(1-\theta^{-1})d_i)}{\sqrt{(1-\theta^{-1})^2d_i}}\in (x,\infty)\bigg\}. \end{equation*}
As a result, we can rewrite e.g. (A.5) as
 \begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d,\frac{\log v_1-(\!\log n-(1-\theta^{-1})d_i)}{\sqrt{(1-\theta^{-1})^2d_i}}\in (x,\infty)\right)=q_0\theta^{-d}\Phi((x,\infty))(1+o(1)), \end{equation*}
\begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d,\frac{\log v_1-(\!\log n-(1-\theta^{-1})d_i)}{\sqrt{(1-\theta^{-1})^2d_i}}\in (x,\infty)\right)=q_0\theta^{-d}\Phi((x,\infty))(1+o(1)), \end{equation*}
and it can, in fact, be generalised to any set
 $A\in\mathcal {B}(\mathbb{R})$
rather than just
$A\in\mathcal {B}(\mathbb{R})$
rather than just
 $(x,\infty)$
with
$(x,\infty)$
with
 $x\in \mathbb{R}$
. A similar notational change can be made in (A.6), (A.4), and (A.2).
$x\in \mathbb{R}$
. A similar notational change can be made in (A.6), (A.4), and (A.2).
Proof of Lemma
A.1. We first observe that for our choice of
 $\ell$
(as in both (A.1) and (A.3)), the conditions on
$\ell$
(as in both (A.1) and (A.3)), the conditions on
 $\ell$
in Proposition 5.1 are met (for n sufficiently large) since d diverges with n. By Proposition 5.1, we thus have the bounds
$\ell$
in Proposition 5.1 are met (for n sufficiently large) since d diverges with n. By Proposition 5.1, we thus have the bounds
 \begin{equation*} \begin{aligned} \mathbb P({}&\mathcal{Z}_n(v_1)\geq d, v_1>\ell)\leq(1+o(1)) \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\right],\\[5pt] \mathbb P({}&\mathcal{Z}_n(v_1)\geq d, v_1>\ell)\geq(1+o(1))\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(\widetilde X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\right], \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \mathbb P({}&\mathcal{Z}_n(v_1)\geq d, v_1>\ell)\leq(1+o(1)) \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\right],\\[5pt] \mathbb P({}&\mathcal{Z}_n(v_1)\geq d, v_1>\ell)\geq(1+o(1))\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(\widetilde X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\right], \end{aligned} \end{equation*}
where
 $X\sim\text{Gamma}(d+1,1), \widetilde X\sim\text{Gamma}(d+\lfloor d^{1/4}\rfloor +1, 1)$
. To prove the desired results, it suffices to provide an asymptotic expression for the expected values on the right-hand side. We do this for the expected value in the upper bound; the proof for the other expected value follows similarly.
$X\sim\text{Gamma}(d+1,1), \widetilde X\sim\text{Gamma}(d+\lfloor d^{1/4}\rfloor +1, 1)$
. To prove the desired results, it suffices to provide an asymptotic expression for the expected values on the right-hand side. We do this for the expected value in the upper bound; the proof for the other expected value follows similarly.
We use the following approach to prove (A.2). To obtain an upper bound, we use that
 $W\leq 1$
almost surely in the conditional probability, which yields
$W\leq 1$
almost surely in the conditional probability, which yields
 \begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d,v_1>\ell\right)\leq (1+o(1))\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right]\mathbb{P}\left(X<\frac{\theta}{\theta-1}\log(n/\ell)\right), \end{equation*}
\begin{equation*} \mathbb{P}\left(\mathcal{Z}_n(v_1)\geq d,v_1>\ell\right)\leq (1+o(1))\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right]\mathbb{P}\left(X<\frac{\theta}{\theta-1}\log(n/\ell)\right), \end{equation*}
so that it remains to prove that the probability converges to
 $1-\Phi(x)$
. By the parametrisation of
$1-\Phi(x)$
. By the parametrisation of
 $\ell$
, it follows that
$\ell$
, it follows that
 \begin{equation} \mathbb{P}\left(X<\frac{\theta}{\theta-1}\log(n/\ell)\right)=\mathbb{P}\left(X<d-x\sqrt{d}\right)=\mathbb{P}\left(\frac{X-\mathbb{E}\left[X\right]}{\sqrt{\textrm{Var}(X)}}\leq \frac{d-x\sqrt{d}-\mathbb{E}\left[X\right]}{\sqrt{\textrm{Var}(X)}}\right). \end{equation}
\begin{equation} \mathbb{P}\left(X<\frac{\theta}{\theta-1}\log(n/\ell)\right)=\mathbb{P}\left(X<d-x\sqrt{d}\right)=\mathbb{P}\left(\frac{X-\mathbb{E}\left[X\right]}{\sqrt{\textrm{Var}(X)}}\leq \frac{d-x\sqrt{d}-\mathbb{E}\left[X\right]}{\sqrt{\textrm{Var}(X)}}\right). \end{equation}
As X can be viewed as a sum of
 $d+1$
i.i.d. rate-one exponential random variables, the central limit theorem can be applied to the left-hand side in the final probability. Moreover, as
$d+1$
i.i.d. rate-one exponential random variables, the central limit theorem can be applied to the left-hand side in the final probability. Moreover, as
 $\mathbb{E}\left[X\right]=d+1$
and
$\mathbb{E}\left[X\right]=d+1$
and
 $\textrm{Var}(X)=d+1$
, it follows that the limit equals
$\textrm{Var}(X)=d+1$
, it follows that the limit equals
 $1-\Phi(x)$
, as desired.
$1-\Phi(x)$
, as desired.
To obtain a lower bound, we take some sequence
 $t_d\geq 1$
that tends to infinity with d (and hence with n). We then bound
$t_d\geq 1$
that tends to infinity with d (and hence with n). We then bound
 \begin{equation} \begin{aligned} \mathbb P({}&\mathcal{Z}_n(v_1)\geq d, v_1>\ell)\\[5pt] &\geq (1+o(1))\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{1-1/t_d\leq W\leq 1\}}\right]\mathbb{P}\left(X<\frac{\theta}{\theta-1}\bigg(1-\frac{1}{\theta t_d}\bigg)\log(n/\ell)\right). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \mathbb P({}&\mathcal{Z}_n(v_1)\geq d, v_1>\ell)\\[5pt] &\geq (1+o(1))\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{1-1/t_d\leq W\leq 1\}}\right]\mathbb{P}\left(X<\frac{\theta}{\theta-1}\bigg(1-\frac{1}{\theta t_d}\bigg)\log(n/\ell)\right). \end{aligned} \end{equation}
We can write the probability as
 \begin{equation*} \mathbb{P}\left(X<d-x\sqrt{d}-(d-x\sqrt{d})/(\theta t_d)\right). \end{equation*}
\begin{equation*} \mathbb{P}\left(X<d-x\sqrt{d}-(d-x\sqrt{d})/(\theta t_d)\right). \end{equation*}
Hence, with the same steps as in (A.7), we arrive at the same limit
 $1-\Phi(x)$
whenever
$1-\Phi(x)$
whenever
 $\sqrt{d}/t_d=o(1)$
. So, let us set
$\sqrt{d}/t_d=o(1)$
. So, let us set
 $t_d=d^\beta$
for some
$t_d=d^\beta$
for some
 $\beta\in(1/2,1/(1+\tau))$
. We observe that this interval is non-empty since
$\beta\in(1/2,1/(1+\tau))$
. We observe that this interval is non-empty since
 $\tau\in(0,1)$
. It remains to show that for this choice of
$\tau\in(0,1)$
. It remains to show that for this choice of
 $t_d$
, the expected value on the right-hand side of (A.8) with the indicator is asymptotically equal to the same expected value when the indicator is omitted. Equivalently, we require that
$t_d$
, the expected value on the right-hand side of (A.8) with the indicator is asymptotically equal to the same expected value when the indicator is omitted. Equivalently, we require that
 \begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{ W\leq1-1/t_d\}}\right]=o\bigg(\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right]\bigg). \end{equation}
\begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{ W\leq1-1/t_d\}}\right]=o\bigg(\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right]\bigg). \end{equation}
To prove this, we bound the expected value on the left-hand side from above and the one on the right-hand side from below. We start with the former. Since
 $x\mapsto x/(\theta-1+x)$
is increasing on (0,1], we directly have that
$x\mapsto x/(\theta-1+x)$
is increasing on (0,1], we directly have that
 \begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{ W\leq1-1/t_d\}}\right]\leq \bigg(\frac{1-1/t_d}{\theta-1/t_d}\bigg)^d\leq \exp\!(\!-\!(1-\theta^{-1})d/t_d)\theta^{-d}. \end{equation}
\begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{ W\leq1-1/t_d\}}\right]\leq \bigg(\frac{1-1/t_d}{\theta-1/t_d}\bigg)^d\leq \exp\!(\!-\!(1-\theta^{-1})d/t_d)\theta^{-d}. \end{equation}
To bound the other expected value from below, we let
 $\widetilde t_d\;:\!=\;t^{\widetilde\beta}$
for some
$\widetilde t_d\;:\!=\;t^{\widetilde\beta}$
for some
 $\widetilde\beta>\beta$
. As
$\widetilde\beta>\beta$
. As
 $x\mapsto x/(\theta-1+x)$
is increasing on (0,1), we obtain the lower bound
$x\mapsto x/(\theta-1+x)$
is increasing on (0,1), we obtain the lower bound
 \begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^d\right]\geq \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^d\mathbb{1}_{\{W\geq 1-1/\widetilde t_d\}}\right]\geq \bigg(\frac{1-1/\widetilde t_d}{\theta-1/\widetilde t_d}\bigg)^d\mathbb{P}\left(W\geq 1-1/\widetilde t_d\right). \end{equation}
\begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^d\right]\geq \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^d\mathbb{1}_{\{W\geq 1-1/\widetilde t_d\}}\right]\geq \bigg(\frac{1-1/\widetilde t_d}{\theta-1/\widetilde t_d}\bigg)^d\mathbb{P}\left(W\geq 1-1/\widetilde t_d\right). \end{equation}
Now, using Condition C2 from Assumption 2.1 yields for n sufficiently large the lower bound
 \begin{equation*} \bigg(\frac{1-1/\widetilde t_d}{\theta-1/\widetilde t_d}\bigg)^d a \exp\!\big(\!-\!c_1 \widetilde t_d^\tau\big). \end{equation*}
\begin{equation*} \bigg(\frac{1-1/\widetilde t_d}{\theta-1/\widetilde t_d}\bigg)^d a \exp\!\big(\!-\!c_1 \widetilde t_d^\tau\big). \end{equation*}
We then bound
 \begin{equation*} \bigg(\frac{1-1/\widetilde t_d}{\theta-1/\widetilde t_d}\bigg)^d = \theta^{-d}\bigg(1-\frac{\theta-1}{\widetilde t_d\theta-1}\bigg)^d= \theta^{-d}\exp\!(\!-\!(1-\theta^{-1})d/\widetilde t_d+\mathcal{O}(d/\widetilde t_d^2)). \end{equation*}
\begin{equation*} \bigg(\frac{1-1/\widetilde t_d}{\theta-1/\widetilde t_d}\bigg)^d = \theta^{-d}\bigg(1-\frac{\theta-1}{\widetilde t_d\theta-1}\bigg)^d= \theta^{-d}\exp\!(\!-\!(1-\theta^{-1})d/\widetilde t_d+\mathcal{O}(d/\widetilde t_d^2)). \end{equation*}
Combining these results, we obtain the lower bound
 \begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right]\geq a\exp\!(\!-\!(1-\theta^{-1})d/\widetilde t_d-c_1\widetilde t_d^\tau+\mathcal{O}(d/\widetilde t_d^2))\theta^{-d}. \end{equation}
\begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right]\geq a\exp\!(\!-\!(1-\theta^{-1})d/\widetilde t_d-c_1\widetilde t_d^\tau+\mathcal{O}(d/\widetilde t_d^2))\theta^{-d}. \end{equation}
The upper bound in (A.10) is negligible compared to this lower bound when
 $d/\widetilde t_d=o(d/t_d)$
and
$d/\widetilde t_d=o(d/t_d)$
and
 $\widetilde t_d^\tau=o(d/t_d)$
. That is, we require that
$\widetilde t_d^\tau=o(d/t_d)$
. That is, we require that
 $\beta<\widetilde \beta$
and
$\beta<\widetilde \beta$
and
 $\widetilde\beta\tau<1-\beta$
. Such a
$\widetilde\beta\tau<1-\beta$
. Such a
 $\widetilde\beta$
can be found since
$\widetilde\beta$
can be found since
 $\beta<1/(1+\tau)$
. As a result, the claim in (A.9) follows, which results in the desired lower bound and finishes the proof of (A.2).
$\beta<1/(1+\tau)$
. As a result, the claim in (A.9) follows, which results in the desired lower bound and finishes the proof of (A.2).
Finally, we prove (A.4), that is, the case when W satisfies (2.3) for some
 $b\in\mathbb{R}$
,
$b\in\mathbb{R}$
,
 $c_1>0$
and
$c_1>0$
and
 $\tau\in[1,2)$
such that
$\tau\in[1,2)$
such that
 $b\leq 0$
if
$b\leq 0$
if
 $\tau>1$
and
$\tau>1$
and
 $bc_1\leq 1$
if
$bc_1\leq 1$
if
 $\tau=1$
. Set
$\tau=1$
. Set
 $\gamma\;:\!=\;1/(\tau+1)$
. Note that this distribution does not satisfy Condition C2 in Assumption 2.1. The behaviour here is different, since the main contribution to the expected value
$\gamma\;:\!=\;1/(\tau+1)$
. Note that this distribution does not satisfy Condition C2 in Assumption 2.1. The behaviour here is different, since the main contribution to the expected value
 $\mathbb{E}\left[(W/(\theta-1+W))^d\right]$
comes from
$\mathbb{E}\left[(W/(\theta-1+W))^d\right]$
comes from
 $W=1-Kd^{-\gamma}$
for K a positive constant. At the same time, for
$W=1-Kd^{-\gamma}$
for K a positive constant. At the same time, for
 $W=1-Kd^{-\gamma}$
,
$W=1-Kd^{-\gamma}$
,
 \begin{equation*} \mathbb{P}_W\!\left(X\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)=\mathbb{P}\left(X\leq \frac{\theta}{\theta-1}\bigg(1-\frac{K}{d^{\gamma}}\bigg)\log (n/\ell)\right) \end{equation*}
\begin{equation*} \mathbb{P}_W\!\left(X\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)=\mathbb{P}\left(X\leq \frac{\theta}{\theta-1}\bigg(1-\frac{K}{d^{\gamma}}\bigg)\log (n/\ell)\right) \end{equation*}
no longer converges to the tail of a standard normal distribution when
 $\ell$
is as in (A.1), as the
$\ell$
is as in (A.1), as the
 $\log(n/\ell)/d^\gamma$
term is of the same order as the variance of X when
$\log(n/\ell)/d^\gamma$
term is of the same order as the variance of X when
 $\tau=1$
and of higher order when
$\tau=1$
and of higher order when
 $\tau>1$
. As a result, we need
$\tau>1$
. As a result, we need
 $\ell$
to be as in (A.3).
$\ell$
to be as in (A.3).
To be able to obtain the desired result, we first need a lower bound for
 $p_{\geq d}$
when
$p_{\geq d}$
when
 $\tau>1$
(for
$\tau>1$
(for
 $\tau=1$
this is already provided in Theorem 3.2). With similar steps as in (A.11)–(A.12) and with
$\tau=1$
this is already provided in Theorem 3.2). With similar steps as in (A.11)–(A.12) and with
 $t_d=(c_1^\tau(1-\theta^{-1})d/\tau)^\gamma$
, we obtain, for some constants
$t_d=(c_1^\tau(1-\theta^{-1})d/\tau)^\gamma$
, we obtain, for some constants
 $K,\widetilde K>0$
,
$K,\widetilde K>0$
,
 \begin{equation} \begin{aligned} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right]&\geq \theta^{-d} \exp\!(\!-\!(1-\theta^{-1})d/t_d-(t_d/c_1)^\tau-K d/t_d^2)\\[5pt] &=\theta^{-d}\exp\!\bigg(\!-\!\frac{\tau^\gamma}{1-\gamma}\bigg(\frac{(1-\theta^{-1})d}{c_1}\bigg)^{1-\gamma}-\widetilde K d^{1-2\gamma}\bigg), \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right]&\geq \theta^{-d} \exp\!(\!-\!(1-\theta^{-1})d/t_d-(t_d/c_1)^\tau-K d/t_d^2)\\[5pt] &=\theta^{-d}\exp\!\bigg(\!-\!\frac{\tau^\gamma}{1-\gamma}\bigg(\frac{(1-\theta^{-1})d}{c_1}\bigg)^{1-\gamma}-\widetilde K d^{1-2\gamma}\bigg), \end{aligned} \end{equation}
We now aim to find an upper and lower bound for
 \begin{equation*} \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]. \end{equation*}
\begin{equation*} \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]. \end{equation*}
We start with an upper bound. We let
 $\varepsilon\in(0,1)$
be fixed (when
$\varepsilon\in(0,1)$
be fixed (when
 $\tau=1$
) or set
$\tau=1$
) or set
 $\varepsilon=\varepsilon(d)=K_1d^{-\gamma/2}$
for some large constant
$\varepsilon=\varepsilon(d)=K_1d^{-\gamma/2}$
for some large constant
 $K_1$
(when
$K_1$
(when
 $\tau>1$
). We then bound
$\tau>1$
). We then bound
 \begin{equation} \begin{aligned} \mathbb E\bigg[{}&\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\\[5pt] \leq{}& \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{1-(1-\varepsilon)/t_d<W<1\}}\right]\\[5pt] &+\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right]\mathbb{P}\left(X\leq \frac{\theta}{\theta-1}\bigg(1-\frac{1-\varepsilon}{\theta t_d}\bigg)\log(n/\ell)\right). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \mathbb E\bigg[{}&\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\\[5pt] \leq{}& \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{1-(1-\varepsilon)/t_d<W<1\}}\right]\\[5pt] &+\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right]\mathbb{P}\left(X\leq \frac{\theta}{\theta-1}\bigg(1-\frac{1-\varepsilon}{\theta t_d}\bigg)\log(n/\ell)\right). \end{aligned} \end{equation}
We then show that the first expected value on the right-hand side is negligible compared to the second, and that the probability has a non-zero limit. We start with the expected value. By the distribution of W as in (2.3), we find
 \begin{equation*} \begin{aligned} \mathbb{E}\!\left[\!\bigg(\frac{W}{\theta-1+W}\!\bigg)^{d}\mathbb{1}_{\big\{1-\frac{1-\varepsilon}{t_d}<W<1\big\}}\!\right]&= \int_{1-(1-\varepsilon)/t_d}^1 \!\!\!\!\!\!\!\!\!\! d(\theta-1)\frac{x^{d-1}}{(\theta-1+x)^{d+1}}(1-x)^{-b}{\textrm{e}}^{-(x/(c_1(1-x)))^\tau}\textrm{d} x\\[5pt] &\leq (1+o(1))d\int_{t_d/(1-\varepsilon)}^\infty \bigg(\frac{1-1/y}{\theta-1/y}\bigg)^d y^{b-2}{\textrm{e}}^{-((y-1)/c_1)^\tau}\,\textrm{d} y. \end{aligned}\end{equation*}
\begin{equation*} \begin{aligned} \mathbb{E}\!\left[\!\bigg(\frac{W}{\theta-1+W}\!\bigg)^{d}\mathbb{1}_{\big\{1-\frac{1-\varepsilon}{t_d}<W<1\big\}}\!\right]&= \int_{1-(1-\varepsilon)/t_d}^1 \!\!\!\!\!\!\!\!\!\! d(\theta-1)\frac{x^{d-1}}{(\theta-1+x)^{d+1}}(1-x)^{-b}{\textrm{e}}^{-(x/(c_1(1-x)))^\tau}\textrm{d} x\\[5pt] &\leq (1+o(1))d\int_{t_d/(1-\varepsilon)}^\infty \bigg(\frac{1-1/y}{\theta-1/y}\bigg)^d y^{b-2}{\textrm{e}}^{-((y-1)/c_1)^\tau}\,\textrm{d} y. \end{aligned}\end{equation*}
In the last step, we used the fact that
 $x^{-1}=1+o(1)$
for
$x^{-1}=1+o(1)$
for
 $x\in(1-(1-\varepsilon)/t_d,1)$
, the fact that
$x\in(1-(1-\varepsilon)/t_d,1)$
, the fact that
 $(\theta-1)/(\theta-1+x)\leq 1$
, and a variable transformation
$(\theta-1)/(\theta-1+x)\leq 1$
, and a variable transformation
 $x=1-1/y$
. We now introduce the function
$x=1-1/y$
. We now introduce the function
 $f\;:\;(0,1)\to (0,1)$
, with
$f\;:\;(0,1)\to (0,1)$
, with
 $f(\varepsilon)=1/2+(1/2)(1+\tau\varepsilon)(1-\varepsilon)^\tau$
. Since, for all
$f(\varepsilon)=1/2+(1/2)(1+\tau\varepsilon)(1-\varepsilon)^\tau$
. Since, for all
 $\varepsilon>0$
sufficiently small,
$\varepsilon>0$
sufficiently small,
 $(1+\tau\varepsilon)(1-\varepsilon)^\tau=1-\varepsilon^2\tau(\tau+1)/2+o(\varepsilon^2)<1$
, this function satisfies
$(1+\tau\varepsilon)(1-\varepsilon)^\tau=1-\varepsilon^2\tau(\tau+1)/2+o(\varepsilon^2)<1$
, this function satisfies
 \begin{equation} f(\varepsilon)>(1+\tau\varepsilon)(1-\varepsilon)^\tau>(1-\varepsilon)^{\tau+1}, \quad\text{and}\quad f(\varepsilon)<1,\qquad \text{for all }\varepsilon\in(0,1). \end{equation}
\begin{equation} f(\varepsilon)>(1+\tau\varepsilon)(1-\varepsilon)^\tau>(1-\varepsilon)^{\tau+1}, \quad\text{and}\quad f(\varepsilon)<1,\qquad \text{for all }\varepsilon\in(0,1). \end{equation}
We then observe that, for any
 $b\in\mathbb{R}$
, we can bound
$b\in\mathbb{R}$
, we can bound
 $y^b{\textrm{e}}^{-((y-1)/c_1)^\tau}\leq {\textrm{e}}^{-f(\varepsilon)((y-1)/c_1)^\tau}$
for all
$y^b{\textrm{e}}^{-((y-1)/c_1)^\tau}\leq {\textrm{e}}^{-f(\varepsilon)((y-1)/c_1)^\tau}$
for all
 $y>t_d/(1-\varepsilon)$
when n is sufficiently large, since
$y>t_d/(1-\varepsilon)$
when n is sufficiently large, since
 $f(\varepsilon)<1$
holds (note that this upper bound holds for
$f(\varepsilon)<1$
holds (note that this upper bound holds for
 $\varepsilon>0$
fixed and also for
$\varepsilon>0$
fixed and also for
 $\varepsilon=K_1d^{-\gamma/2}$
and any constant
$\varepsilon=K_1d^{-\gamma/2}$
and any constant
 $K_1>0$
when
$K_1>0$
when
 $\tau>1$
). A bound similar to (A.10) also yields
$\tau>1$
). A bound similar to (A.10) also yields
 \begin{equation} \bigg(\frac{1-1/y}{\theta-1/y}\bigg)^d\leq \theta^{-d}\exp\!\bigg(\!-\!(1-\theta^{-1})\frac{d}{y-1}+(1-\theta^{-1})^2\frac{d}{(y-1)^2}\bigg). \end{equation}
\begin{equation} \bigg(\frac{1-1/y}{\theta-1/y}\bigg)^d\leq \theta^{-d}\exp\!\bigg(\!-\!(1-\theta^{-1})\frac{d}{y-1}+(1-\theta^{-1})^2\frac{d}{(y-1)^2}\bigg). \end{equation}
Combining both bounds and using that
 $(1-\theta^{-1})^2d/(y-1)^2\leq Cd^{1-2\gamma}$
for
$(1-\theta^{-1})^2d/(y-1)^2\leq Cd^{1-2\gamma}$
for
 $y>t_d/(1-\varepsilon)$
and some constant
$y>t_d/(1-\varepsilon)$
and some constant
 $C>0$
yields the upper bound
$C>0$
yields the upper bound
 \begin{equation} Kd\theta^{-d}\int_{t_d/(1-\varepsilon)}^\infty y^{-2}\exp\!\bigg(\!-\!(1-\theta^{-1})\frac{d}{y-1}-f(\varepsilon)\bigg(\frac{y-1}{c_1}\bigg)^\tau+Cd^{1-2\gamma}\bigg)\,\textrm{d} y, \end{equation}
\begin{equation} Kd\theta^{-d}\int_{t_d/(1-\varepsilon)}^\infty y^{-2}\exp\!\bigg(\!-\!(1-\theta^{-1})\frac{d}{y-1}-f(\varepsilon)\bigg(\frac{y-1}{c_1}\bigg)^\tau+Cd^{1-2\gamma}\bigg)\,\textrm{d} y, \end{equation}
where
 $K>0$
is a large constant. The exponential is decreasing in y for all
$K>0$
is a large constant. The exponential is decreasing in y for all
 $y>1+t_df(\varepsilon)^{-\gamma}$
. By the first inequality in (A.15), it thus follows that the exponential in the integral is maximised for
$y>1+t_df(\varepsilon)^{-\gamma}$
. By the first inequality in (A.15), it thus follows that the exponential in the integral is maximised for
 $y=t_d/(1-\varepsilon)>1+t_df(\varepsilon)^{-\gamma}$
. As a result, we obtain the upper bound
$y=t_d/(1-\varepsilon)>1+t_df(\varepsilon)^{-\gamma}$
. As a result, we obtain the upper bound
 \begin{equation} \begin{aligned} K{}&d\theta^{-d}\exp\!\bigg(\!-\!(1-\theta^{-1})(1-\varepsilon)\frac{d}{t_d}-f(\varepsilon)\bigg(\frac{t_d}{c_1(1-\varepsilon)}\bigg)^\tau+C'd^{1-2\gamma}\bigg)\\[5pt] ={}&Kd\theta^{-d}\exp\!\bigg(\!-\!\bigg(1-\varepsilon+\frac{f(\varepsilon)}{\tau(1-\varepsilon)^\tau}\bigg)\tau^\gamma \bigg(\frac{(1-\theta^{-1})d}{c_1}\bigg)^{1-\gamma}+C'd^{1-2\gamma}\bigg). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} K{}&d\theta^{-d}\exp\!\bigg(\!-\!(1-\theta^{-1})(1-\varepsilon)\frac{d}{t_d}-f(\varepsilon)\bigg(\frac{t_d}{c_1(1-\varepsilon)}\bigg)^\tau+C'd^{1-2\gamma}\bigg)\\[5pt] ={}&Kd\theta^{-d}\exp\!\bigg(\!-\!\bigg(1-\varepsilon+\frac{f(\varepsilon)}{\tau(1-\varepsilon)^\tau}\bigg)\tau^\gamma \bigg(\frac{(1-\theta^{-1})d}{c_1}\bigg)^{1-\gamma}+C'd^{1-2\gamma}\bigg). \end{aligned} \end{equation}
Here we change the constant C to a constant
 $C'>C$
, since
$C'>C$
, since
 \begin{equation} \frac{d}{t_d/(1-\varepsilon)-1}+f(\varepsilon)\bigg(\frac{t_d/(1-\varepsilon)-1}{c_1}\bigg)^\tau=(1-\varepsilon)\frac{d}{t_d}+f(\varepsilon)\bigg(\frac{t_d}{c_1(1-\varepsilon)}\bigg)^\tau+\mathcal{O}(d^{1-2\gamma}). \end{equation}
\begin{equation} \frac{d}{t_d/(1-\varepsilon)-1}+f(\varepsilon)\bigg(\frac{t_d/(1-\varepsilon)-1}{c_1}\bigg)^\tau=(1-\varepsilon)\frac{d}{t_d}+f(\varepsilon)\bigg(\frac{t_d}{c_1(1-\varepsilon)}\bigg)^\tau+\mathcal{O}(d^{1-2\gamma}). \end{equation}
We have that
 $1-\varepsilon+f(\varepsilon)/(\tau(1-\varepsilon)^\tau)>1+1/\tau=1/(1-\gamma)$
for all
$1-\varepsilon+f(\varepsilon)/(\tau(1-\varepsilon)^\tau)>1+1/\tau=1/(1-\gamma)$
for all
 $\varepsilon\in(0,1)$
by the first inequality in (A.15). Thus, the lower bound in (A.13) yields that for any
$\varepsilon\in(0,1)$
by the first inequality in (A.15). Thus, the lower bound in (A.13) yields that for any
 $\varepsilon>0$
fixed,
$\varepsilon>0$
fixed,
 \begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{1-(1-\varepsilon)/t_d<W<1\}}\right]=o\bigg(\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right]\bigg). \end{equation}
\begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{1-(1-\varepsilon)/t_d<W<1\}}\right]=o\bigg(\mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\right]\bigg). \end{equation}
Whilst this holds for all
 $\tau\in[1,2)$
, we need a stronger statement for
$\tau\in[1,2)$
, we need a stronger statement for
 $\tau\in(1,2)$
, namely that (A.20) is true with
$\tau\in(1,2)$
, namely that (A.20) is true with
 $\varepsilon=K_1d^{-\gamma/2}$
(which does not hold for
$\varepsilon=K_1d^{-\gamma/2}$
(which does not hold for
 $\tau=1$
). We stress that all of the above steps also hold with this choice of
$\tau=1$
). We stress that all of the above steps also hold with this choice of
 $\varepsilon$
. Additionally, a Taylor expansion yields that
$\varepsilon$
. Additionally, a Taylor expansion yields that
 \begin{equation*} 1-\varepsilon+\frac{f(\varepsilon)}{\tau(1-\varepsilon)^\tau}=\frac{1}{1-\gamma}+\frac{\tau+1}{4}\varepsilon^2(1+o(1))>\frac{1}{1-\gamma}+\frac{\tau+1}{8}\varepsilon^2, \qquad \text{as }\varepsilon\downarrow 0. \end{equation*}
\begin{equation*} 1-\varepsilon+\frac{f(\varepsilon)}{\tau(1-\varepsilon)^\tau}=\frac{1}{1-\gamma}+\frac{\tau+1}{4}\varepsilon^2(1+o(1))>\frac{1}{1-\gamma}+\frac{\tau+1}{8}\varepsilon^2, \qquad \text{as }\varepsilon\downarrow 0. \end{equation*}
Using this in (A.18), we obtain
 \begin{equation*} \begin{aligned} \mathbb E \bigg[{}&\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{1-(1-\varepsilon)/t_d<W<1\}}\bigg]\\[5pt] &\leq K\theta^{-d}\exp\!\bigg(\!-\!\frac{\tau^\gamma}{1-\gamma} \bigg(\frac{(1-\theta^{-1})d}{c_1}\bigg)^{1-\gamma}+\!\bigg(\!C'-K_1^2\frac{(\tau+1)\tau^\gamma}{8}\bigg(\frac{(1-\theta^{-1})}{c_1}\bigg)^{1-\gamma}\bigg)d^{1-2\gamma}\bigg)\\[5pt] &=\theta^{-d}\exp\!\bigg(\!-\!\frac{\tau^\gamma}{1-\gamma} \bigg(\frac{(1-\theta^{-1})d}{c_1}\bigg)^{1-\gamma}-\widetilde K_1d^{1-2\gamma}(1+o(1))\bigg), \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \mathbb E \bigg[{}&\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{1-(1-\varepsilon)/t_d<W<1\}}\bigg]\\[5pt] &\leq K\theta^{-d}\exp\!\bigg(\!-\!\frac{\tau^\gamma}{1-\gamma} \bigg(\frac{(1-\theta^{-1})d}{c_1}\bigg)^{1-\gamma}+\!\bigg(\!C'-K_1^2\frac{(\tau+1)\tau^\gamma}{8}\bigg(\frac{(1-\theta^{-1})}{c_1}\bigg)^{1-\gamma}\bigg)d^{1-2\gamma}\bigg)\\[5pt] &=\theta^{-d}\exp\!\bigg(\!-\!\frac{\tau^\gamma}{1-\gamma} \bigg(\frac{(1-\theta^{-1})d}{c_1}\bigg)^{1-\gamma}-\widetilde K_1d^{1-2\gamma}(1+o(1))\bigg), \end{aligned} \end{equation*}
where the constant
 $\widetilde K_1$
is positive for all large
$\widetilde K_1$
is positive for all large
 $K_1$
and grows polynomially in
$K_1$
and grows polynomially in
 $K_1$
. Again using the lower bound in (A.13) implies that we need to choose
$K_1$
. Again using the lower bound in (A.13) implies that we need to choose
 $K_1$
sufficiently large so that
$K_1$
sufficiently large so that
 $\widetilde K_1>\widetilde K$
. This then implies that (A.20) holds for
$\widetilde K_1>\widetilde K$
. This then implies that (A.20) holds for
 $\tau>1$
with
$\tau>1$
with
 $\varepsilon=K_1d^{-\gamma/2}$
as well.
$\varepsilon=K_1d^{-\gamma/2}$
as well.
We now determine the limit of the probability on the right-hand side of (A.14). We again distinguish between the two cases
 $\tau=1$
and
$\tau=1$
and
 $\tau>1$
and start with the former. First, observe that
$\tau>1$
and start with the former. First, observe that
 $d^{1-\gamma}=\sqrt{d}$
when
$d^{1-\gamma}=\sqrt{d}$
when
 $\tau=1$
. Then, since
$\tau=1$
. Then, since
 $\mathbb{E}\left[X\right]=\textrm{Var}(X)=d+1$
and
$\mathbb{E}\left[X\right]=\textrm{Var}(X)=d+1$
and
 $\ell$
is as in (A.3), for a fixed
$\ell$
is as in (A.3), for a fixed
 $\varepsilon>0$
,
$\varepsilon>0$
,
 \begin{equation} \begin{aligned} \mathbb P{}&\bigg(X\leq \frac{\theta}{\theta-1}\bigg(1-\frac{1-\varepsilon}{\theta t_d}\bigg)\log\!\bigg(\frac n\ell\bigg)\!\bigg)\\[5pt] &=\mathbb{P}\left(\frac{X-\mathbb{E}\left[X\right]}{\sqrt{\textrm{Var}(X)}}\leq \frac{(K_{\theta,c_1,1}-x)\sqrt{d}-1}{\sqrt{d+1}}-\frac{(1-\varepsilon)(d+(K_{\theta,c_1,1}-x)\sqrt{d})}{\theta t_d\sqrt{d+1}}\right). \end{aligned}\end{equation}
\begin{equation} \begin{aligned} \mathbb P{}&\bigg(X\leq \frac{\theta}{\theta-1}\bigg(1-\frac{1-\varepsilon}{\theta t_d}\bigg)\log\!\bigg(\frac n\ell\bigg)\!\bigg)\\[5pt] &=\mathbb{P}\left(\frac{X-\mathbb{E}\left[X\right]}{\sqrt{\textrm{Var}(X)}}\leq \frac{(K_{\theta,c_1,1}-x)\sqrt{d}-1}{\sqrt{d+1}}-\frac{(1-\varepsilon)(d+(K_{\theta,c_1,1}-x)\sqrt{d})}{\theta t_d\sqrt{d+1}}\right). \end{aligned}\end{equation}
As
 $t_d=\sqrt{c_1(1-\theta^{-1})d}$
when
$t_d=\sqrt{c_1(1-\theta^{-1})d}$
when
 $\tau=1$
and with
$\tau=1$
and with
 $Z\sim \mathcal{N}(0,1)$
, this equals
$Z\sim \mathcal{N}(0,1)$
, this equals
 \begin{equation} \begin{aligned} \mathbb{P}\left(Z\leq K_{\theta,c_1,1}-x-(1-\varepsilon)K_{\theta,c_1,1}\right)+o(1)=1-\Phi( x-\varepsilon K_{\theta,c_1,1})+ o(1). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \mathbb{P}\left(Z\leq K_{\theta,c_1,1}-x-(1-\varepsilon)K_{\theta,c_1,1}\right)+o(1)=1-\Phi( x-\varepsilon K_{\theta,c_1,1})+ o(1). \end{aligned} \end{equation}
Combining this with (A.20) in (A.14) yields, for
 $\tau=1$
and any
$\tau=1$
and any
 $\varepsilon>0$
fixed,
$\varepsilon>0$
fixed,
 \begin{equation} \begin{aligned} \mathbb E\bigg[{}&\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\\[5pt] &\leq \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg](1-\Phi(x-\varepsilon K_{\theta,c_1,1}))(1+o(1)). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \mathbb E\bigg[{}&\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\\[5pt] &\leq \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg](1-\Phi(x-\varepsilon K_{\theta,c_1,1}))(1+o(1)). \end{aligned} \end{equation}
When
 $\tau\in(1,2)$
, we adapt (A.21) and (A.22) with
$\tau\in(1,2)$
, we adapt (A.21) and (A.22) with
 $\varepsilon=K_1d^{-\gamma/2}$
to obtain
$\varepsilon=K_1d^{-\gamma/2}$
to obtain
 \begin{equation} \begin{aligned} \mathbb P{}&\bigg(X\leq \frac{\theta}{\theta-1}\bigg(1-\frac{1-\varepsilon}{\theta t_d}\bigg)\log\!\bigg(\frac n\ell\bigg)\!\bigg)\\[5pt] &=\mathbb{P}\left(\frac{X-\mathbb{E}\left[X\right]}{\sqrt{\textrm{Var}(X)}}\leq \frac{K_{\theta,c_1,1}d^{1-\gamma}-x\sqrt{d}-1}{\sqrt{d+1}}-\frac{(1-K_1d^{-\gamma/2})(d+(K_{\theta,c_1,1}-x)\sqrt{d})}{\theta t_d\sqrt{d+1}}\right). \end{aligned}\end{equation}
\begin{equation} \begin{aligned} \mathbb P{}&\bigg(X\leq \frac{\theta}{\theta-1}\bigg(1-\frac{1-\varepsilon}{\theta t_d}\bigg)\log\!\bigg(\frac n\ell\bigg)\!\bigg)\\[5pt] &=\mathbb{P}\left(\frac{X-\mathbb{E}\left[X\right]}{\sqrt{\textrm{Var}(X)}}\leq \frac{K_{\theta,c_1,1}d^{1-\gamma}-x\sqrt{d}-1}{\sqrt{d+1}}-\frac{(1-K_1d^{-\gamma/2})(d+(K_{\theta,c_1,1}-x)\sqrt{d})}{\theta t_d\sqrt{d+1}}\right). \end{aligned}\end{equation}
We observe that
 $d/(\theta t_d)=K_{\theta,c_1,1}d^{1-\gamma}$
, so that the right-hand side can be simplified as
$d/(\theta t_d)=K_{\theta,c_1,1}d^{1-\gamma}$
, so that the right-hand side can be simplified as
 \begin{equation} \mathbb{P}\left(\frac{X-\mathbb{E}\left[X\right]}{\sqrt{\textrm{Var}(X)}}\leq -x+o(1)+\mathcal{O}(d^{1/2-3\gamma/2})\right)=1-\Phi(x)+o(1). \end{equation}
\begin{equation} \mathbb{P}\left(\frac{X-\mathbb{E}\left[X\right]}{\sqrt{\textrm{Var}(X)}}\leq -x+o(1)+\mathcal{O}(d^{1/2-3\gamma/2})\right)=1-\Phi(x)+o(1). \end{equation}
Here, the last step follows from the fact that
 $\mathcal{O}(d^{1/2-3\gamma/2})=o(1)$
when
$\mathcal{O}(d^{1/2-3\gamma/2})=o(1)$
when
 $\tau<2$
since
$\tau<2$
since
 $1/2-3\gamma/2<0$
. We also stress that this is possible only when
$1/2-3\gamma/2<0$
. We also stress that this is possible only when
 $\varepsilon$
tends to zero with d. If
$\varepsilon$
tends to zero with d. If
 $\varepsilon$
were fixed, this would yield a limit of one rather than
$\varepsilon$
were fixed, this would yield a limit of one rather than
 $1-\Phi(x)$
.
$1-\Phi(x)$
.
Combining this with (A.20) when
 $\tau>1$
and
$\tau>1$
and
 $\varepsilon=K_1d^{-\gamma}$
yields
$\varepsilon=K_1d^{-\gamma}$
yields
 \begin{equation} \begin{aligned} \mathbb E\bigg[{}&\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\\[5pt] &\leq \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg](1-\Phi(x))(1+o(1)). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \mathbb E\bigg[{}&\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\\[5pt] &\leq \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg](1-\Phi(x))(1+o(1)). \end{aligned} \end{equation}
In a similar way, we construct a matching lower bound (up to error terms). Namely, for
 $\varepsilon\in(0,1)$
,
$\varepsilon\in(0,1)$
,
 \begin{equation} \begin{aligned} \mathbb E\bigg[{}&\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left( X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\\[5pt] &\geq \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{1-(1+\varepsilon)/t_d<W<1\}}\bigg]\mathbb{P}\left( X<\frac{\theta}{\theta-1}\bigg(1-\frac{1+\varepsilon}{\theta t_d}\bigg)\log(n/\ell)\right). \end{aligned}\end{equation}
\begin{equation} \begin{aligned} \mathbb E\bigg[{}&\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left( X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\\[5pt] &\geq \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\{1-(1+\varepsilon)/t_d<W<1\}}\bigg]\mathbb{P}\left( X<\frac{\theta}{\theta-1}\bigg(1-\frac{1+\varepsilon}{\theta t_d}\bigg)\log(n/\ell)\right). \end{aligned}\end{equation}
Again, we let
 $\varepsilon$
be fixed when
$\varepsilon$
be fixed when
 $\tau=1$
and set
$\tau=1$
and set
 $\varepsilon=K_1d^{-\gamma/2}$
for some large constant
$\varepsilon=K_1d^{-\gamma/2}$
for some large constant
 $K_1$
when
$K_1$
when
 $\tau>1$
. As in (A.21) and (A.22), for the probability on the right-hand side we have
$\tau>1$
. As in (A.21) and (A.22), for the probability on the right-hand side we have
 \begin{equation} \mathbb{P}\left(X<\frac{\theta}{\theta-1}\bigg(1-\frac{1+\varepsilon}{\theta t_d}\bigg)\log(n/\ell)\right)=1-\Phi(x+\varepsilon K_{\theta,c_1,1})+o(1) \end{equation}
\begin{equation} \mathbb{P}\left(X<\frac{\theta}{\theta-1}\bigg(1-\frac{1+\varepsilon}{\theta t_d}\bigg)\log(n/\ell)\right)=1-\Phi(x+\varepsilon K_{\theta,c_1,1})+o(1) \end{equation}
when
 $\tau=1$
and
$\tau=1$
and
 $\varepsilon>0$
is fixed, and similarly to (A.24) and (A.25),
$\varepsilon>0$
is fixed, and similarly to (A.24) and (A.25),
 \begin{equation} \mathbb{P}\left(X<\frac{\theta}{\theta-1}\bigg(1-\frac{1+K_1d^{-\gamma/2}}{\theta t_d}\bigg)\log(n/\ell)\right)=1-\Phi(x)+o(1) \end{equation}
\begin{equation} \mathbb{P}\left(X<\frac{\theta}{\theta-1}\bigg(1-\frac{1+K_1d^{-\gamma/2}}{\theta t_d}\bigg)\log(n/\ell)\right)=1-\Phi(x)+o(1) \end{equation}
when
 $\tau\in(1,2)$
and
$\tau\in(1,2)$
and
 $\varepsilon=K_1d^{-\gamma/2}$
. It remains to bound the expected value on the right-hand side of (A.27). We instead consider the expected value
$\varepsilon=K_1d^{-\gamma/2}$
. It remains to bound the expected value on the right-hand side of (A.27). We instead consider the expected value
 \begin{equation*} \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\big\{0<W<1-\frac{1+\varepsilon}{t_d}\big\}}\bigg]=\int_0^{1-(1+\varepsilon)/t_d}\frac{d(\theta-1)x^{d-1}}{(\theta-1+x)^{d+1}}(1-x)^{-b}{\textrm{e}}^{-(x/(c_1(1-x)))^\tau}\,\textrm{d} x. \end{equation*}
\begin{equation*} \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\big\{0<W<1-\frac{1+\varepsilon}{t_d}\big\}}\bigg]=\int_0^{1-(1+\varepsilon)/t_d}\frac{d(\theta-1)x^{d-1}}{(\theta-1+x)^{d+1}}(1-x)^{-b}{\textrm{e}}^{-(x/(c_1(1-x)))^\tau}\,\textrm{d} x. \end{equation*}
We first bound
 $(1-x)^{-b}\leq t_d^{b\vee 0}$
and
$(1-x)^{-b}\leq t_d^{b\vee 0}$
and
 $(\theta-1)/(\theta-1+x)\leq 1$
, and split the integral into two parts by dividing the integration range into
$(\theta-1)/(\theta-1+x)\leq 1$
, and split the integral into two parts by dividing the integration range into
 $(0,1-2(1+\varepsilon)/t_d)$
and
$(0,1-2(1+\varepsilon)/t_d)$
and
 $(1-2(1+\varepsilon)/t_d,1-(1+\varepsilon)/t_d)$
. This yields the upper bound
$(1-2(1+\varepsilon)/t_d,1-(1+\varepsilon)/t_d)$
. This yields the upper bound
 \begin{equation*} \frac{dt_d^{b\vee 0}}{\theta-1}\int_0^{1-2(1+\varepsilon)/t_d} \bigg(\frac{x}{\theta-1+x}\bigg)^{d-1}\,\textrm{d} x+2dt_d^{b\vee 0} \int_{1-2(1+\varepsilon)/t_d}^{1-(1+\varepsilon)/t_d} \bigg(\frac{x}{\theta-1+x}\bigg)^d {\textrm{e}}^{-(x/(c_1(1-x)))^\tau}\, \textrm{d} x. \end{equation*}
\begin{equation*} \frac{dt_d^{b\vee 0}}{\theta-1}\int_0^{1-2(1+\varepsilon)/t_d} \bigg(\frac{x}{\theta-1+x}\bigg)^{d-1}\,\textrm{d} x+2dt_d^{b\vee 0} \int_{1-2(1+\varepsilon)/t_d}^{1-(1+\varepsilon)/t_d} \bigg(\frac{x}{\theta-1+x}\bigg)^d {\textrm{e}}^{-(x/(c_1(1-x)))^\tau}\, \textrm{d} x. \end{equation*}
Using the fact that
 $x\mapsto x/(\theta-1+x)$
is increasing on (0,1) and applying a variable transformation
$x\mapsto x/(\theta-1+x)$
is increasing on (0,1) and applying a variable transformation
 $x=1-1/y$
in the second integral, we obtain the upper bound
$x=1-1/y$
in the second integral, we obtain the upper bound
 \begin{equation*} \frac{dt_d^{b\vee 0}(\theta+o(1))}{\theta-1}\bigg(\frac{1-2(1+\varepsilon)/t_d}{\theta-2(1+\varepsilon)/t_d}\bigg)^d+2dt_d^{b\vee 0} \int_{t_d/(2(1+\varepsilon))}^{t_d/(1+\varepsilon)} y^{-2}\bigg(\frac{1-1/y}{\theta-1/y}\bigg)^d {\textrm{e}}^{-((y-1)/c_1)^\tau}\, \textrm{d} y. \end{equation*}
\begin{equation*} \frac{dt_d^{b\vee 0}(\theta+o(1))}{\theta-1}\bigg(\frac{1-2(1+\varepsilon)/t_d}{\theta-2(1+\varepsilon)/t_d}\bigg)^d+2dt_d^{b\vee 0} \int_{t_d/(2(1+\varepsilon))}^{t_d/(1+\varepsilon)} y^{-2}\bigg(\frac{1-1/y}{\theta-1/y}\bigg)^d {\textrm{e}}^{-((y-1)/c_1)^\tau}\, \textrm{d} y. \end{equation*}
We now use (A.16) and steps similar to those that yielded (A.17). We can then bound this from above by
 \begin{equation*}\begin{aligned} K{}&dt_d^{b\vee 0}\theta^{-d}\exp\!\bigg(\!-\!(1-\theta^{-1})\frac{2(1+\varepsilon)d}{t_d}\bigg) \\[5pt] &+dt_d^{b\vee 0}\theta^{-d}\!\int_{t_d/(2(1+\varepsilon))}^{t_d/(1+\varepsilon)}y^{-2}\exp\!\bigg(\!-\!(1-\theta^{-1})\frac{d}{y-1}-\bigg(\frac{y-1}{c_1}\bigg)^\tau+(1-\theta^{-1})^2\frac{d}{(y-1)^2}\bigg)\,\textrm{d} y, \end{aligned}\end{equation*}
\begin{equation*}\begin{aligned} K{}&dt_d^{b\vee 0}\theta^{-d}\exp\!\bigg(\!-\!(1-\theta^{-1})\frac{2(1+\varepsilon)d}{t_d}\bigg) \\[5pt] &+dt_d^{b\vee 0}\theta^{-d}\!\int_{t_d/(2(1+\varepsilon))}^{t_d/(1+\varepsilon)}y^{-2}\exp\!\bigg(\!-\!(1-\theta^{-1})\frac{d}{y-1}-\bigg(\frac{y-1}{c_1}\bigg)^\tau+(1-\theta^{-1})^2\frac{d}{(y-1)^2}\bigg)\,\textrm{d} y, \end{aligned}\end{equation*}
for some constant
 $K>0$
. As
$K>0$
. As
 $2(1+\varepsilon)>1/(1-\gamma)$
for all
$2(1+\varepsilon)>1/(1-\gamma)$
for all
 $\tau\geq 1$
and any
$\tau\geq 1$
and any
 $\varepsilon>0$
, it follows from the choice of
$\varepsilon>0$
, it follows from the choice of
 $t_d$
and the lower bound in (A.13) that the first term is negligible compared to
$t_d$
and the lower bound in (A.13) that the first term is negligible compared to
 $\mathbb{E}\left[(W/(\theta-1+W)^d\right]$
, both when
$\mathbb{E}\left[(W/(\theta-1+W)^d\right]$
, both when
 $\tau>1$
and
$\tau>1$
and
 $\varepsilon=K_1d^{-\gamma/2}$
, and when
$\varepsilon=K_1d^{-\gamma/2}$
, and when
 $\tau=1$
and
$\tau=1$
and
 $\varepsilon$
is fixed.
$\varepsilon$
is fixed.
We thus focus on the integral only from now on. We bound the final term in the second integral from above by
 $C_2 d^{1-2\gamma}$
for some constant
$C_2 d^{1-2\gamma}$
for some constant
 $C_2>0$
. The remainder in the exponent is increasing for
$C_2>0$
. The remainder in the exponent is increasing for
 $y<1+t_d$
. With the same reasoning as in (A.19), we can bound the integral from above by
$y<1+t_d$
. With the same reasoning as in (A.19), we can bound the integral from above by
 \begin{equation} \theta^{-d}d\exp\!\bigg(\!-\!\bigg((1+\varepsilon)+\frac{1}{\tau(1+\varepsilon)^\tau}\bigg)\tau^\gamma \bigg(\frac{(1-\theta^{-1})d}{c_1}\bigg)^{1-\gamma}+C'_{\!\!2}d^{1-2\gamma}\bigg) \end{equation}
\begin{equation} \theta^{-d}d\exp\!\bigg(\!-\!\bigg((1+\varepsilon)+\frac{1}{\tau(1+\varepsilon)^\tau}\bigg)\tau^\gamma \bigg(\frac{(1-\theta^{-1})d}{c_1}\bigg)^{1-\gamma}+C'_{\!\!2}d^{1-2\gamma}\bigg) \end{equation}
for some
 $C'_{\!\!2}>C_2$
. Since
$C'_{\!\!2}>C_2$
. Since
 $(1+\varepsilon)+\tau^{-1}(1+\varepsilon)^{-\tau}>1/(1-\gamma)$
for any
$(1+\varepsilon)+\tau^{-1}(1+\varepsilon)^{-\tau}>1/(1-\gamma)$
for any
 $\varepsilon>0$
, it follows from the lower bound in (A.13) that this upper bound is negligible compared to
$\varepsilon>0$
, it follows from the lower bound in (A.13) that this upper bound is negligible compared to
 $\mathbb{E}\left[(W/(\theta-1+W)^d\right]$
for any
$\mathbb{E}\left[(W/(\theta-1+W)^d\right]$
for any
 $\tau\geq 1$
when
$\tau\geq 1$
when
 $\varepsilon$
is fixed. Combined with (A.28) this yields, for
$\varepsilon$
is fixed. Combined with (A.28) this yields, for
 $\tau=1$
and
$\tau=1$
and
 $\varepsilon$
fixed,
$\varepsilon$
fixed,
 \begin{equation*} \begin{aligned} \mathbb E\bigg[{}&\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\\[5pt] &\geq \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg](1-\Phi( x+\varepsilon K_{\theta,c_1,1}))(1+o(1)). \end{aligned}\end{equation*}
\begin{equation*} \begin{aligned} \mathbb E\bigg[{}&\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\\[5pt] &\geq \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg](1-\Phi( x+\varepsilon K_{\theta,c_1,1}))(1+o(1)). \end{aligned}\end{equation*}
Combining this with (A.23), since
 $\varepsilon$
can be taken arbitrarily small and by the continuity of
$\varepsilon$
can be taken arbitrarily small and by the continuity of
 $\Phi$
, we finally arrive at
$\Phi$
, we finally arrive at
 \begin{align*} &\mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\\[5pt] &= \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg](1-\Phi(x))(1+o(1)), \end{align*}
\begin{align*} &\mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\\[5pt] &= \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg](1-\Phi(x))(1+o(1)), \end{align*}
which proves (A.4) when
 $\tau=1$
.
$\tau=1$
.
To obtain the same result for
 $\tau>1$
with
$\tau>1$
with
 $\varepsilon=K_1d^{-\gamma/2}$
, we use a Taylor expansion to find that
$\varepsilon=K_1d^{-\gamma/2}$
, we use a Taylor expansion to find that
 \begin{equation*} (1+\varepsilon)+\tau^{-1}(1+\varepsilon)^{-\tau}=\frac{1}{1-\gamma}+\frac{\tau+1}{2}\varepsilon^2(1+o(1))>\frac{1}{1-\gamma}+\frac{\tau+1}{4}\varepsilon^2, \qquad \text{as }\varepsilon \downarrow 0. \end{equation*}
\begin{equation*} (1+\varepsilon)+\tau^{-1}(1+\varepsilon)^{-\tau}=\frac{1}{1-\gamma}+\frac{\tau+1}{2}\varepsilon^2(1+o(1))>\frac{1}{1-\gamma}+\frac{\tau+1}{4}\varepsilon^2, \qquad \text{as }\varepsilon \downarrow 0. \end{equation*}
Using this in (A.30) yields, for some constant
 $\widetilde K_1>0$
, the upper bound
$\widetilde K_1>0$
, the upper bound
 \begin{equation*} \theta^{-d}\exp\!\bigg(\!-\!\frac{\tau^\gamma}{1-\gamma} \bigg(\frac{(1-\theta^{-1})d}{c_1}\bigg)^{1-\gamma}-\bigg(\frac{\tau+1}{4}K_1^2 \tau^\gamma\frac{(1-\theta^{-1})}{c_1}\bigg)^{1-\gamma}- C'_{\!\!2}\bigg)d^{1-2\gamma}\bigg). \end{equation*}
\begin{equation*} \theta^{-d}\exp\!\bigg(\!-\!\frac{\tau^\gamma}{1-\gamma} \bigg(\frac{(1-\theta^{-1})d}{c_1}\bigg)^{1-\gamma}-\bigg(\frac{\tau+1}{4}K_1^2 \tau^\gamma\frac{(1-\theta^{-1})}{c_1}\bigg)^{1-\gamma}- C'_{\!\!2}\bigg)d^{1-2\gamma}\bigg). \end{equation*}
As in the proof of the upper bound, we conclude that (A.13) implies that choosing
 $K_1$
large enough yields, for
$K_1$
large enough yields, for
 $\tau>1$
and
$\tau>1$
and
 $\varepsilon=K_1d^{-\gamma/2}$
,
$\varepsilon=K_1d^{-\gamma/2}$
,
 \begin{equation*} \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\big\{0<W<1-\frac{1+\varepsilon}{t_d}\big\}}\bigg]=o\bigg(\mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg]\bigg). \end{equation*}
\begin{equation*} \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{1}_{\big\{0<W<1-\frac{1+\varepsilon}{t_d}\big\}}\bigg]=o\bigg(\mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg]\bigg). \end{equation*}
Combining this with (A.29) in (A.27), we thus arrive at
 \begin{equation*} \mathbb E\bigg[\!\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\geq \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg](1-\Phi( x)(1+o(1)). \end{equation*}
\begin{equation*} \mathbb E\bigg[\!\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{\theta-1}\bigg)\log(n/\ell)\right)\bigg]\geq \mathbb E\bigg[\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\bigg](1-\Phi( x)(1+o(1)). \end{equation*}
Together with (A.26), this establishes (A.4) for
 $\tau>1$
and concludes the proof.
$\tau>1$
and concludes the proof.
Lemma A.2. Consider the same conditions as in Lemma 5.1, and let
 $\varepsilon\in(0\vee (c(1-\theta^{-1})-(1-\mu)),\mu)$
and
$\varepsilon\in(0\vee (c(1-\theta^{-1})-(1-\mu)),\mu)$
and
 $\widetilde X\sim\textit{Gamma}(d_n+\lfloor d_n^{1/4}\rfloor +1,1)$
. Then
$\widetilde X\sim\textit{Gamma}(d_n+\lfloor d_n^{1/4}\rfloor +1,1)$
. Then
 \begin{equation*} \mathbb{E}\!\left[\!\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\mathbb{P}_W\!\left(\widetilde X\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log\!(n^{1-\mu+\varepsilon})\!\right)\!\right]\geq \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\right](1-o(1)). \end{equation*}
\begin{equation*} \mathbb{E}\!\left[\!\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\mathbb{P}_W\!\left(\widetilde X\leq \bigg(1+\frac{W}{\theta-1}\bigg)\log\!(n^{1-\mu+\varepsilon})\!\right)\!\right]\geq \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\right](1-o(1)). \end{equation*}
We observe that this result is similar in nature to (A.2) in Lemma A.1. However, as we now have
 $\ell=n^{\mu-\varepsilon}$
, rather than a precise parametrisation in terms of
$\ell=n^{\mu-\varepsilon}$
, rather than a precise parametrisation in terms of
 $d_n$
as in Lemma A.1, we can make a more general statement here (though not as precise and useful) that does not require Condition C2 of Assumption 2.1.
$d_n$
as in Lemma A.1, we can make a more general statement here (though not as precise and useful) that does not require Condition C2 of Assumption 2.1.
Proof. Fix
 $\delta\in(0,(1-(\theta-1)(c/(1-\mu+\varepsilon)-1)\wedge 1))$
. It is readily checked that by the choice of
$\delta\in(0,(1-(\theta-1)(c/(1-\mu+\varepsilon)-1)\wedge 1))$
. It is readily checked that by the choice of
 $\varepsilon$
, such a
$\varepsilon$
, such a
 $\delta$
exists. We bound the expected value from below by writing
$\delta$
exists. We bound the expected value from below by writing
 \begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\mathbb{1}_{\{1-\delta<W\leq1\}}\right]\mathbb{P}\left(\hat X\leq \bigg(1+\frac{1-\delta}{\theta-1}\bigg)\log (n^{1-\mu+\varepsilon})\right), \end{equation}
\begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\mathbb{1}_{\{1-\delta<W\leq1\}}\right]\mathbb{P}\left(\hat X\leq \bigg(1+\frac{1-\delta}{\theta-1}\bigg)\log (n^{1-\mu+\varepsilon})\right), \end{equation}
where
 $\hat X\sim\text{Gamma}(c\log n+\lfloor (c\log n)^{1/4}\rfloor +1,1)$
, which stochastically dominates
$\hat X\sim\text{Gamma}(c\log n+\lfloor (c\log n)^{1/4}\rfloor +1,1)$
, which stochastically dominates
 $\widetilde X$
as
$\widetilde X$
as
 $d_n\leq c\log n$
. It thus remains to prove two things: the probability converges to one, and the expected value is asymptotically equal to
$d_n\leq c\log n$
. It thus remains to prove two things: the probability converges to one, and the expected value is asymptotically equal to
 $\mathbb{E}\left[(W/(\theta-1+W))^{d_n}\right]$
. Together, these statements prove the lemma. We start with the former. By the choice of
$\mathbb{E}\left[(W/(\theta-1+W))^{d_n}\right]$
. Together, these statements prove the lemma. We start with the former. By the choice of
 $\delta$
, it follows that
$\delta$
, it follows that
 \begin{equation*} c_{\delta,\theta,\varepsilon}\;:\!=\;\bigg(1+\frac{1-\delta}{\theta-1}\bigg)\frac{1-\mu+\varepsilon}{c} >1. \end{equation*}
\begin{equation*} c_{\delta,\theta,\varepsilon}\;:\!=\;\bigg(1+\frac{1-\delta}{\theta-1}\bigg)\frac{1-\mu+\varepsilon}{c} >1. \end{equation*}
Thus, as
 $\hat X/(c\log n)\buildrel {a.s.}\over{\longrightarrow} 1$
, the probability in (A.31) equals
$\hat X/(c\log n)\buildrel {a.s.}\over{\longrightarrow} 1$
, the probability in (A.31) equals
 $1-o(1)$
. It remains to prove that
$1-o(1)$
. It remains to prove that
 \begin{equation*} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\mathbb{1}_{\{1-\delta<W\leq1\}}\right]= \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\right](1-o(1)), \end{equation*}
\begin{equation*} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\mathbb{1}_{\{1-\delta<W\leq1\}}\right]= \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\right](1-o(1)), \end{equation*}
which is equivalent to showing that
 \begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\mathbb{1}_{\{W\leq 1-\delta\}}\right]=o\bigg( \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\right]\bigg). \end{equation}
\begin{equation} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\mathbb{1}_{\{W\leq 1-\delta\}}\right]=o\bigg( \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\right]\bigg). \end{equation}
By Theorem 3.2, for any
 $\xi>0$
and n sufficiently large,
$\xi>0$
and n sufficiently large,
 \begin{equation*} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\right]=p_{\geq d_n}\geq (\theta+\xi)^{-d_n}. \end{equation*}
\begin{equation*} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\right]=p_{\geq d_n}\geq (\theta+\xi)^{-d_n}. \end{equation*}
So, take
 $\xi\in(0,\delta(\theta-1)/(1-\delta))$
. Then, as
$\xi\in(0,\delta(\theta-1)/(1-\delta))$
. Then, as
 $x\mapsto x/(\theta-1+x)$
is increasing in x,
$x\mapsto x/(\theta-1+x)$
is increasing in x,
 \begin{equation*} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\mathbb{1}_{\{W\leq 1-\delta\}}\right]\leq \bigg(\frac{1-\delta}{\theta-\delta}\bigg)^{d_n}=\bigg(\theta+\frac{\delta(\theta-1)}{1-\delta}\bigg)^{-d_n}=o\big((\theta+\xi)^{-d_n}\big), \end{equation*}
\begin{equation*} \mathbb{E}\left[\bigg(\frac{W}{\theta-1+W}\bigg)^{d_n}\mathbb{1}_{\{W\leq 1-\delta\}}\right]\leq \bigg(\frac{1-\delta}{\theta-\delta}\bigg)^{d_n}=\bigg(\theta+\frac{\delta(\theta-1)}{1-\delta}\bigg)^{-d_n}=o\big((\theta+\xi)^{-d_n}\big), \end{equation*}
so that (A.32) follows. Combined with the lower bound on the probability in (A.31), it yields the desired lower bound.
Lemma A.3. Consider the same definitions and assumptions as in Proposition 5.1 (but without indices). Let
 $c\;:\!=\;\limsup_{n\to\infty} d/\log n$
and assume that
$c\;:\!=\;\limsup_{n\to\infty} d/\log n$
and assume that
 $c\in[0,\theta/(\theta-1))$
. Then
$c\in[0,\theta/(\theta-1))$
. Then
 \begin{equation*} \frac{1}{n^\gamma}=o\bigg(\mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{(\theta-1)}\bigg)\log(n/\ell)\right)\right]\bigg) \end{equation*}
\begin{equation*} \frac{1}{n^\gamma}=o\bigg(\mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{(\theta-1)}\bigg)\log(n/\ell)\right)\right]\bigg) \end{equation*}
holds for
 $\gamma=1$
when
$\gamma=1$
when
 $c\in[0,1/(\theta-1)]$
, and for
$c\in[0,1/(\theta-1)]$
, and for
 $\gamma$
sufficiently large when
$\gamma$
sufficiently large when
 $c\in(1/(\theta-1),\theta/(\theta-1))$
.
$c\in(1/(\theta-1),\theta/(\theta-1))$
.
Proof. We first consider the case
 $c\in[0,1/(\theta-1)]$
, for which we can set
$c\in[0,1/(\theta-1)]$
, for which we can set
 $\gamma=1$
. We consider two sub-cases: (i) d is bounded from above, and (ii) d diverges (but d is at most
$\gamma=1$
. We consider two sub-cases: (i) d is bounded from above, and (ii) d diverges (but d is at most
 $(1/(\theta-1))\log n(1+o(1))$
for all n large). For (i) we immediately have that
$(1/(\theta-1))\log n(1+o(1))$
for all n large). For (i) we immediately have that
 \begin{equation*} \mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{(\theta-1)}\bigg)\log(n/\ell)\right)\geq \mathbb{P}(X<\log(n/\ell))\geq \mathbb{P}\left(X<(1-\xi)(1-\theta^{-1})(d+1)\right), \end{equation*}
\begin{equation*} \mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{(\theta-1)}\bigg)\log(n/\ell)\right)\geq \mathbb{P}(X<\log(n/\ell))\geq \mathbb{P}\left(X<(1-\xi)(1-\theta^{-1})(d+1)\right), \end{equation*}
when n is sufficiently large and
 $\xi$
small, since
$\xi$
small, since
 $\ell\leq n\exp\!(\!-\!(1-\xi)(1-\theta^{-1})(d+1))$
for any
$\ell\leq n\exp\!(\!-\!(1-\xi)(1-\theta^{-1})(d+1))$
for any
 $\xi>0$
. Since X is finite almost surely for all
$\xi>0$
. Since X is finite almost surely for all
 $n\in\mathbb{N}$
as d is bounded, the probability on the right-hand side is strictly positive. The expected value that remains is again bounded from below by a positive constant, since d is bounded from above. It thus follows that
$n\in\mathbb{N}$
as d is bounded, the probability on the right-hand side is strictly positive. The expected value that remains is again bounded from below by a positive constant, since d is bounded from above. It thus follows that
 $1/n$
negligible compared to the expected value.
$1/n$
negligible compared to the expected value.
For (ii), we obtain a lower bound by restricting the weight W in the expected value to
 $(1-\delta,1]$
for some small
$(1-\delta,1]$
for some small
 $\delta>0$
. This yields the lower bound
$\delta>0$
. This yields the lower bound
 \begin{equation} \begin{aligned} \mathbb E\bigg[{}&\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{(\theta-1)}\bigg)\log(n/\ell)\right)\mathbb{1}_{\{W\in(1-\delta,1]\}}\bigg]\\[5pt] &\geq (1-\theta^{-1})\bigg(\frac{1-\delta}{\theta-\delta}\bigg)^{d}\mathbb{P}\left(X<\frac{\theta-\delta}{\theta-1}\log(n/\ell)\right)\mathbb{P}\left({W\in(1-\delta,1]}\right). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \mathbb E\bigg[{}&\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{(\theta-1)}\bigg)\log(n/\ell)\right)\mathbb{1}_{\{W\in(1-\delta,1]\}}\bigg]\\[5pt] &\geq (1-\theta^{-1})\bigg(\frac{1-\delta}{\theta-\delta}\bigg)^{d}\mathbb{P}\left(X<\frac{\theta-\delta}{\theta-1}\log(n/\ell)\right)\mathbb{P}\left({W\in(1-\delta,1]}\right). \end{aligned} \end{equation}
Note that
 $\mathbb{P}({W\in(1-\delta,1]})$
is strictly positive for any
$\mathbb{P}({W\in(1-\delta,1]})$
is strictly positive for any
 $\delta\in(0,1)$
by Condition C1. Furthermore, since
$\delta\in(0,1)$
by Condition C1. Furthermore, since
 $\ell\leq n\exp\!(\!-\!(1-\xi)(1-\theta^{-1})(d+1))$
for any
$\ell\leq n\exp\!(\!-\!(1-\xi)(1-\theta^{-1})(d+1))$
for any
 $\xi>0$
,
$\xi>0$
,
 \begin{equation*} \frac{\theta-\delta}{\theta-1}\log(n/\ell)\geq (1-\delta/\theta)(1-\xi)(d+1)\;=\!:\;(1-\varepsilon)(d+1). \end{equation*}
\begin{equation*} \frac{\theta-\delta}{\theta-1}\log(n/\ell)\geq (1-\delta/\theta)(1-\xi)(d+1)\;=\!:\;(1-\varepsilon)(d+1). \end{equation*}
Applying this inequality to the probability on the right-hand side of (A.33) together with the equivalence between sums of exponential random variables and Poisson random variables via Poisson processes, we conclude that
 \begin{equation} \mathbb{P}\left(X<\frac{\theta-\delta}{\theta-1}\log\!\bigg(\frac{n}{\ell}\bigg)\right)\geq \mathbb{P}\left(X<(1-\varepsilon)(d+1)\right)=\mathbb{P}\left(P_1\geq d+1\right)\geq\mathbb{P}\left(P_1=d+1\right), \end{equation}
\begin{equation} \mathbb{P}\left(X<\frac{\theta-\delta}{\theta-1}\log\!\bigg(\frac{n}{\ell}\bigg)\right)\geq \mathbb{P}\left(X<(1-\varepsilon)(d+1)\right)=\mathbb{P}\left(P_1\geq d+1\right)\geq\mathbb{P}\left(P_1=d+1\right), \end{equation}
where
 $P_1\sim \text{Poi}((1-\varepsilon)(d+1))$
. With Stirling’s formula this yields
$P_1\sim \text{Poi}((1-\varepsilon)(d+1))$
. With Stirling’s formula this yields
 \begin{equation} \begin{aligned} \mathbb{P}\left(P_1=d+1\right)&={\textrm{e}}^{-(1-\varepsilon)(d+1)}\frac{((1-\varepsilon)(d+1))^{d+1}}{(d+1)!}\\[5pt] &=(1+o(1)){\textrm{e}}^{\varepsilon(d+1)}(1-\varepsilon)^{d+1}\frac{1}{\sqrt{2\pi d}}\\[5pt] &=(1+o(1))\frac{(1-\varepsilon){\textrm{e}}^\varepsilon}{\sqrt{2\pi d}}{\textrm{e}}^{d(\!\log(1-\varepsilon)+\varepsilon)}, \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \mathbb{P}\left(P_1=d+1\right)&={\textrm{e}}^{-(1-\varepsilon)(d+1)}\frac{((1-\varepsilon)(d+1))^{d+1}}{(d+1)!}\\[5pt] &=(1+o(1)){\textrm{e}}^{\varepsilon(d+1)}(1-\varepsilon)^{d+1}\frac{1}{\sqrt{2\pi d}}\\[5pt] &=(1+o(1))\frac{(1-\varepsilon){\textrm{e}}^\varepsilon}{\sqrt{2\pi d}}{\textrm{e}}^{d(\!\log(1-\varepsilon)+\varepsilon)}, \end{aligned} \end{equation}
where we observe that the exponent is strictly negative for any
 $\varepsilon\in(0,1)$
. Finally, combining (A.35) with (A.34) in (A.33), and since
$\varepsilon\in(0,1)$
. Finally, combining (A.35) with (A.34) in (A.33), and since
 $(1-\delta)/(\theta-\delta)\geq (1-\delta)/\theta$
, we arrive at the lower bound
$(1-\delta)/(\theta-\delta)\geq (1-\delta)/\theta$
, we arrive at the lower bound
 \begin{equation} (1+o(1))\frac{(1-\theta^{-1})\mathbb{P}\left({W\in(1-\delta,1]}\right)(1-\varepsilon){\textrm{e}}^\varepsilon}{\sqrt{2\pi d}}\exp\!(d(\!\log(1-\varepsilon)+\varepsilon+\log((1-\delta)/\theta))). \end{equation}
\begin{equation} (1+o(1))\frac{(1-\theta^{-1})\mathbb{P}\left({W\in(1-\delta,1]}\right)(1-\varepsilon){\textrm{e}}^\varepsilon}{\sqrt{2\pi d}}\exp\!(d(\!\log(1-\varepsilon)+\varepsilon+\log((1-\delta)/\theta))). \end{equation}
By choosing
 $\delta$
and
$\delta$
and
 $\xi$
(used in the definition of
$\xi$
(used in the definition of
 $\varepsilon$
) sufficiently small,
$\varepsilon$
) sufficiently small,
 $\log(1-\varepsilon)+\varepsilon$
can be set arbitrarily close to zero (though negative), and
$\log(1-\varepsilon)+\varepsilon$
can be set arbitrarily close to zero (though negative), and
 $\log((1-\delta)/\theta)=\log(1-\delta)-\log\theta$
can be set arbitrarily close to (though smaller than)
$\log((1-\delta)/\theta)=\log(1-\delta)-\log\theta$
can be set arbitrarily close to (though smaller than)
 $-\log \theta$
. Since
$-\log \theta$
. Since
 $-\log \theta >-(\theta -1)$
and
$-\log \theta >-(\theta -1)$
and
 $c\in[0,1/(\theta-1)]$
, it follows that for some small
$c\in[0,1/(\theta-1)]$
, it follows that for some small
 $\kappa>0$
and
$\kappa>0$
and
 $\delta$
,
$\delta$
,
 $\xi$
sufficiently small, for all n sufficiently large,
$\xi$
sufficiently small, for all n sufficiently large,
 \begin{equation*} \frac{1}{\sqrt{d}}\exp\!(d(\!\log(1-\varepsilon)+\varepsilon+\log((1-\delta)/\theta)))\geq \exp\!(\!-\!(1-\kappa)\log n)=n^{-(1-\kappa)}, \end{equation*}
\begin{equation*} \frac{1}{\sqrt{d}}\exp\!(d(\!\log(1-\varepsilon)+\varepsilon+\log((1-\delta)/\theta)))\geq \exp\!(\!-\!(1-\kappa)\log n)=n^{-(1-\kappa)}, \end{equation*}
which, together with (A.33), yields the desired result.
For the case
 $c\in(1/(\theta-1),\theta/(\theta-1))$
, we follow the same approach but now use the fact that
$c\in(1/(\theta-1),\theta/(\theta-1))$
, we follow the same approach but now use the fact that
 $d\leq (\theta/(\theta-1))\log n$
for all n large. We thus obtain the lower bound
$d\leq (\theta/(\theta-1))\log n$
for all n large. We thus obtain the lower bound
 \begin{equation*} \mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{(\theta-1)}\bigg)\log(n/\ell)\right)\right]\geq {\textrm{e}}^{-C d}\geq n^{-C\theta/(\theta-1)}, \end{equation*}
\begin{equation*} \mathbb{E}\left[\frac{\theta-1}{\theta-1+W}\bigg(\frac{W}{\theta-1+W}\bigg)^{d}\mathbb{P}_W\!\left(X<\bigg(1+\frac{W}{(\theta-1)}\bigg)\log(n/\ell)\right)\right]\geq {\textrm{e}}^{-C d}\geq n^{-C\theta/(\theta-1)}, \end{equation*}
for some large constant
 $C>0$
. The desired result holds for
$C>0$
. The desired result holds for
 $\gamma>C\theta/(\theta-1)$
, which concludes the proof.
$\gamma>C\theta/(\theta-1)$
, which concludes the proof.
Lemma A.4. Fix
 $\ell,n\in \mathbb{N}$
such that
$\ell,n\in \mathbb{N}$
such that
 $\ell<n$
. Suppose
$\ell<n$
. Suppose
 $f\;:\;\mathbb{R}\to \mathbb{R}$
is a positive integrable function, increasing on
$f\;:\;\mathbb{R}\to \mathbb{R}$
is a positive integrable function, increasing on
 $[\ell,x^*]$
and decreasing on
$[\ell,x^*]$
and decreasing on
 $[x^*,n]$
, where
$[x^*,n]$
, where
 $x^*\in(\ell,n)$
is not necessarily an integer. Then
$x^*\in(\ell,n)$
is not necessarily an integer. Then
 \begin{equation*} \int_{\ell}^n f(x)\, \textrm{d} x-f(x^*)\leq \sum_{j = \ell +1}^n f(j) \leq \int_{\ell}^n f(x)\, \textrm{d} x + f(x^*). \end{equation*}
\begin{equation*} \int_{\ell}^n f(x)\, \textrm{d} x-f(x^*)\leq \sum_{j = \ell +1}^n f(j) \leq \int_{\ell}^n f(x)\, \textrm{d} x + f(x^*). \end{equation*}
Proof. As f is increasing on
 $[\ell,\lfloor x^* \rfloor]$
and decreasing on
$[\ell,\lfloor x^* \rfloor]$
and decreasing on
 $[\lceil x^*\rceil,n]$
, we directly have that
$[\lceil x^*\rceil,n]$
, we directly have that
 \begin{equation*} \begin{aligned} \sum_{j=\ell+1}^n f(j)=f(\lceil x^*\rceil)+\sum_{j=\ell+1}^{\lfloor x^*\rfloor} f(j)+\sum_{j=\lceil x^*\rceil+1}^n f(j)\leq f(x^*)+\int_\ell^{\lfloor x^*\rfloor}f(x)\,\textrm{d} x+\int_{\lceil x^*\rceil}^nf(x)\,\textrm{d} x. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \sum_{j=\ell+1}^n f(j)=f(\lceil x^*\rceil)+\sum_{j=\ell+1}^{\lfloor x^*\rfloor} f(j)+\sum_{j=\lceil x^*\rceil+1}^n f(j)\leq f(x^*)+\int_\ell^{\lfloor x^*\rfloor}f(x)\,\textrm{d} x+\int_{\lceil x^*\rceil}^nf(x)\,\textrm{d} x. \end{aligned} \end{equation*}
The final two terms can be combined into a single integral from
 $\ell$
to n to yield an upper bound, since f(x) is positive for all
$\ell$
to n to yield an upper bound, since f(x) is positive for all
 $x\in\mathbb{R}$
.
$x\in\mathbb{R}$
.
For the lower bound, we use an equivalent approach and the fact that
 \begin{equation*} \int_{\lfloor x^*\rfloor}^{\lceil x^*\rceil}f(x)\,\textrm{d} x\leq f(x^*) \end{equation*}
\begin{equation*} \int_{\lfloor x^*\rfloor}^{\lceil x^*\rceil}f(x)\,\textrm{d} x\leq f(x^*) \end{equation*}
to obtain the desired lower bound.
Acknowledgements
I wish to thank the anonymous referees for providing comments and suggestions that helped to substantially improve the presentation of the article as well as generalise some of the results.
Funding information
B. Lodewijks was supported by the grant GrHyDy ANR-20-CE40-0002.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.

 Open access
Open access