



1. Introduction
There has been considerable interest in studying preferential attachment (PA) random graphs ever since [Reference Barabási and Albert2] used them to explain the power-law degree distribution observed in some real-world networks, such as the World Wide Web. The primary feature of the stochastic mechanism consists of adding vertices sequentially over time, with some number of edges attached to them, and then connecting these edges to the existing graph in such a way that vertices with higher degrees are more likely to receive them. A general overview of PA random graphs can be found in the books [Reference Van der Hofstad19] and [Reference Van der Hofstad20]. In the basic models, vertices are born with the same constant ‘weight’ as their initial vertex attractiveness. To relax this assumption, [Reference Ergün and Rodgers15] introduced a class of PA graphs with additive fitness (referred to as Model A in [Reference Ergün and Rodgers15]), where fitness is defined as the random initial attractiveness. When the fitnesses are independent and identically distributed (i.i.d.), this family is the subject of recent works such as [Reference Iyer22] and [Reference Lodewijks and Ortgiese25], whose results we discuss in Section 1.3.2. In this paper, we study the local weak limit of this family and provide a rate of convergence for the total variation distance between the local neighbourhoods of the PA tree and its local weak limit. The result extends that of [Reference Berger, Borgs, Chayes and Saberi4], which considered PA graphs with constant initial attractiveness. As applications, we obtain limiting results for the degree distributions of the uniformly chosen vertex and its ancestors, where rates of convergence are also provided. Another objective of this article is to present the arguments of [Reference Berger, Borgs, Chayes and Saberi4] in more detail; this is the main reason we consider the PA tree instead of the case where multiple edges are possible.
Before we define the model, note that we view the edges as directed, with a newly born vertex always sending a single outgoing edge to an existing vertex in the graph. We define the weight of a vertex as its in-degree plus its fitness; each time a vertex receives an edge from another vertex, its weight increases by one. As we mostly work conditionally on the fitness sequence, we also introduce a conditional version of the model. Note that the seed graph is a single vertex that has a non-random fitness, but as we explain in Section 1.3.1 below, the choice of the seed graph and its fitness has no effect on the local weak limit. It is chosen purely to streamline the argument.
Definition 1. (
 $(\textbf{x},n)$
-sequential model and PA tree with additive fitness.) Given a positive integer n and a sequence
$(\textbf{x},n)$
-sequential model and PA tree with additive fitness.) Given a positive integer n and a sequence
 $\textbf{x}\,:\!=\,(x_i,i\geqslant 1)$
, with
$\textbf{x}\,:\!=\,(x_i,i\geqslant 1)$
, with
 $x_1>-1$
and
$x_1>-1$
and
 $x_i>0$
for
$x_i>0$
for
 $i\geqslant 2$
, we construct a sequence of random trees
$i\geqslant 2$
, we construct a sequence of random trees
 $(G_{i}, 1\leqslant i\leqslant n)$
as follows. The seed graph
$(G_{i}, 1\leqslant i\leqslant n)$
as follows. The seed graph
 $G_{1}$
consists of vertex 1 with initial attractiveness
$G_{1}$
consists of vertex 1 with initial attractiveness
 $x_1$
and degree 0. The graph
$x_1$
and degree 0. The graph
 $G_2$
is constructed by joining vertex 2 and vertex 1 by an edge, and equipping vertex 2 with initial attractiveness
$G_2$
is constructed by joining vertex 2 and vertex 1 by an edge, and equipping vertex 2 with initial attractiveness
 $x_2$
. For
$x_2$
. For
 $3\leqslant m\leqslant n$
,
$3\leqslant m\leqslant n$
,
 $G_m$
is constructed from
$G_m$
is constructed from
 $G_{m-1}$
by attaching one edge between vertex m and
$G_{m-1}$
by attaching one edge between vertex m and
 $k\in [m-1]$
, and the edge is directed towards vertex k with probability
$k\in [m-1]$
, and the edge is directed towards vertex k with probability
 \begin{equation*}\frac{D^{(in)}_{m-1,k}+x_k}{m-2+\sum^{m-1}_{j=1}x_j}\quad\text{for $1\leqslant k\leqslant m-1$,}\end{equation*}
\begin{equation*}\frac{D^{(in)}_{m-1,k}+x_k}{m-2+\sum^{m-1}_{j=1}x_j}\quad\text{for $1\leqslant k\leqslant m-1$,}\end{equation*}
where
 $D^{(in)}_{m,k}$
is the in-degree of vertex k in
$D^{(in)}_{m,k}$
is the in-degree of vertex k in
 $G_m$
, and
$G_m$
, and
 $D^{(in)}_{m,k}=0$
whenever
$D^{(in)}_{m,k}=0$
whenever
 $k\geqslant m$
. The mth attachment step is completed by assigning vertex m the initial attractiveness
$k\geqslant m$
. The mth attachment step is completed by assigning vertex m the initial attractiveness
 $x_m$
. We call the resulting graph
$x_m$
. We call the resulting graph
 $G_n$
an
$G_n$
an
 $(\textbf{x},n)$
-sequential model, and its law is denoted by Seq
$(\textbf{x},n)$
-sequential model, and its law is denoted by Seq
 $(\textbf{x})_n$
. Taking
$(\textbf{x})_n$
. Taking
 $X_1=x_1$
, we obtain the distribution PA
$X_1=x_1$
, we obtain the distribution PA
 $(\pi, X_1)_n$
of the PA tree with additive fitness from mixing Seq
$(\pi, X_1)_n$
of the PA tree with additive fitness from mixing Seq
 $(\textbf{x})_n$
with the distribution of the i.i.d. fitness sequence
$(\textbf{x})_n$
with the distribution of the i.i.d. fitness sequence
 $(X_i,i\geqslant 2)$
.
$(X_i,i\geqslant 2)$
.
1.1. Local weak convergence
The concept of local weak convergence was independently introduced by [Reference Aldous and Steele1] and [Reference Benjamini and Schramm3]. Here, we follow [Reference Van der Hofstad20, Section 2.3 and 2.4], and also [Reference Benjamini and Schramm3]. Informally, this involves exploring some random graph
 $G_n$
from vertex
$G_n$
from vertex
 $o_n$
, chosen uniformly at random from
$o_n$
, chosen uniformly at random from
 $G_n$
, and studying the distributional limit of the neighbourhoods of radius r rooted at
$G_n$
, and studying the distributional limit of the neighbourhoods of radius r rooted at
 $o_n$
for each
$o_n$
for each
 $r<\infty$
. We begin with a few definitions. A rooted graph is a pair (G,o), where
$r<\infty$
. We begin with a few definitions. A rooted graph is a pair (G,o), where
 $G=(V(G), E(G))$
is a graph with vertex set V(G) and edge set E(G), and
$G=(V(G), E(G))$
is a graph with vertex set V(G) and edge set E(G), and
 $o\in V(G)$
is the designated root in G. Next, let r be a finite positive integer. For any (G,o), denote by
$o\in V(G)$
is the designated root in G. Next, let r be a finite positive integer. For any (G,o), denote by
 $B_r(G,o)$
the rooted neighbourhood of radius r around o. More formally,
$B_r(G,o)$
the rooted neighbourhood of radius r around o. More formally,
 $B_r(G,o)=(V(B_r(G,o))), E(B_r(G,o)))$
, where
$B_r(G,o)=(V(B_r(G,o))), E(B_r(G,o)))$
, where
 \begin{align*}&V(B_r(G,o))=\{u\in V(G)\,:\, \text{the distance between} \textit{u} \text{and} \textit{o} \text{is at most} \textit{r} \text{edges}\}, \text{ and}\\&E(B_r(G,o))=\{\{u,v\}\in E(G)\,:\, u,v\in V(B_r(G,o))\}.\end{align*}
\begin{align*}&V(B_r(G,o))=\{u\in V(G)\,:\, \text{the distance between} \textit{u} \text{and} \textit{o} \text{is at most} \textit{r} \text{edges}\}, \text{ and}\\&E(B_r(G,o))=\{\{u,v\}\in E(G)\,:\, u,v\in V(B_r(G,o))\}.\end{align*}
We refer to
 $B_r(G,o)$
as the r-neighbourhood of vertex o, or simply as the local neighbourhood of o when the reference to r is not needed. Finally, two rooted graphs (G,o) and (H,o
′) are isomorphic, for which we write
$B_r(G,o)$
as the r-neighbourhood of vertex o, or simply as the local neighbourhood of o when the reference to r is not needed. Finally, two rooted graphs (G,o) and (H,o
′) are isomorphic, for which we write
 $(G,o) \cong (H,o^{\prime})$
, if there is a bijection
$(G,o) \cong (H,o^{\prime})$
, if there is a bijection
 $\psi\,:\,V(G)\to V(H)$
such that
$\psi\,:\,V(G)\to V(H)$
such that
 $\psi(o)=o^{\prime}$
and
$\psi(o)=o^{\prime}$
and
 $\{u,v\}\in E(G)$
if and only if
$\{u,v\}\in E(G)$
if and only if
 $\{\psi(u), \psi(v)\}\in E(H)$
. Below we define the local weak convergence of a sequence of finite random graphs
$\{\psi(u), \psi(v)\}\in E(H)$
. Below we define the local weak convergence of a sequence of finite random graphs
 $(G_{n},n\geqslant 1)$
using a criterion given in [Reference Van der Hofstad20, Theorem 2.14].
$(G_{n},n\geqslant 1)$
using a criterion given in [Reference Van der Hofstad20, Theorem 2.14].
Definition 2. (Local weak convergence.) Let
 $(G_{n},n\geqslant 1)$
be a sequence of finite random graphs. The local weak limit of
$(G_{n},n\geqslant 1)$
be a sequence of finite random graphs. The local weak limit of
 $G_{n}$
is (G, o) if, for all finite rooted graphs (H, v) and all finite r,
$G_{n}$
is (G, o) if, for all finite rooted graphs (H, v) and all finite r,
 \begin{equation}\frac{1}{n}\sum^n_{j=1}\mathbb{P}[(B_r(G_{n},j),j)\cong (H,v)]\overset{n\to\infty}{\longrightarrow}\mathbb{P}[(B_r(G,o),o)\cong (H,v)].\end{equation}
\begin{equation}\frac{1}{n}\sum^n_{j=1}\mathbb{P}[(B_r(G_{n},j),j)\cong (H,v)]\overset{n\to\infty}{\longrightarrow}\mathbb{P}[(B_r(G,o),o)\cong (H,v)].\end{equation}
The left-hand side of (1.1) is the probability that the r-neighbourhood of a randomly chosen vertex is isomorphic to (H, v). Note that the convergence in (1.1) is equivalent to the convergence of the expectations of all bounded and continuous functions with respect to an appropriate metric on rooted graphs; see e.g. [Reference Van der Hofstad20, Chapter 2].
1.2. Statement of the main results
In the main result, we fix
 $X_1>-1$
and assume that
$X_1>-1$
and assume that
 $(X_i,i\geqslant 2)$
are i.i.d. positive bounded variables with distribution
$(X_i,i\geqslant 2)$
are i.i.d. positive bounded variables with distribution
 $\pi$
. We write
$\pi$
. We write
 $\mu\,:\!=\,\mathbb{E} X_2<\infty$
and
$\mu\,:\!=\,\mathbb{E} X_2<\infty$
and
 \begin{equation}\chi\,:\!=\,\frac{\mu}{\mu+1}.\end{equation}
\begin{equation}\chi\,:\!=\,\frac{\mu}{\mu+1}.\end{equation}
We first define the local weak limit of the PA tree with additive fitness, which is an infinite rooted random tree that generalises the Pólya point tree introduced in [Reference Berger, Borgs, Chayes and Saberi4]. Hence, we refer to it simply as a
 $\pi$
-Pólya point tree, with
$\pi$
-Pólya point tree, with
 $\pi$
being the fitness distribution of the PA tree. Denote this random tree by
$\pi$
being the fitness distribution of the PA tree. Denote this random tree by
 $(\mathcal{T},0)$
, so that 0 is its root. We begin by explaining the Ulam–Harris labelling of trees that we use in the construction of
$(\mathcal{T},0)$
, so that 0 is its root. We begin by explaining the Ulam–Harris labelling of trees that we use in the construction of
 $(\mathcal{T},0)$
. Starting from the root 0, the children of any vertex
$(\mathcal{T},0)$
. Starting from the root 0, the children of any vertex
 $\bar v$
(if any) are generated recursively as
$\bar v$
(if any) are generated recursively as
 $(\bar v,j)$
,
$(\bar v,j)$
,
 $j\in \mathbb{N}$
, and we say that
$j\in \mathbb{N}$
, and we say that
 $\bar v$
is the parent of
$\bar v$
is the parent of
 $(\bar v,j)$
. With the convention
$(\bar v,j)$
. With the convention
 $B_0(\mathcal{T},0)=\{0\}$
, note that if
$B_0(\mathcal{T},0)=\{0\}$
, note that if
 $\bar v\,:\!=\,(0,v_1,\ldots,v_r)$
, then
$\bar v\,:\!=\,(0,v_1,\ldots,v_r)$
, then
 $(\bar v,i)\in \partial B_{r+1}\,:\!=\, V(B_{r+1}(\mathcal{T},0))\setminus V(B_{r}(\mathcal{T},0))$
. Furthermore, each vertex
$(\bar v,i)\in \partial B_{r+1}\,:\!=\, V(B_{r+1}(\mathcal{T},0))\setminus V(B_{r}(\mathcal{T},0))$
. Furthermore, each vertex
 $\bar v\in V((\mathcal{T},0))$
has a fitness
$\bar v\in V((\mathcal{T},0))$
has a fitness
 $X_{\bar v}$
and a random age
$X_{\bar v}$
and a random age
 $a_{\bar v}$
, where
$a_{\bar v}$
, where
 $0< a_{\bar v}\leqslant 1$
. We write
$0< a_{\bar v}\leqslant 1$
. We write
 $a_{\bar v,i}\,:\!=\,a_{(\bar v,i)}$
for convenience. Apart from the root vertex 0, there are two types of vertices, namely, type L (for ‘left’) and type R (for ‘right’). Vertex
$a_{\bar v,i}\,:\!=\,a_{(\bar v,i)}$
for convenience. Apart from the root vertex 0, there are two types of vertices, namely, type L (for ‘left’) and type R (for ‘right’). Vertex
 $\bar v$
belongs to type L if
$\bar v$
belongs to type L if
 $a_{\bar v,i}<a_{\bar v}$
for some
$a_{\bar v,i}<a_{\bar v}$
for some
 $i\geqslant 1$
, and to type R if
$i\geqslant 1$
, and to type R if
 $a_{\bar v,i}\geqslant a_{\bar v}$
for all
$a_{\bar v,i}\geqslant a_{\bar v}$
for all
 $i\geqslant 1$
. There is exactly one type-L vertex in
$i\geqslant 1$
. There is exactly one type-L vertex in
 $\partial B_r$
for each
$\partial B_r$
for each
 $r\geqslant 1$
, and the labels
$r\geqslant 1$
, and the labels
 $(0,1,1,\ldots,1)$
are assigned to these vertices. For any vertex
$(0,1,1,\ldots,1)$
are assigned to these vertices. For any vertex
 $\bar v$
, let
$\bar v$
, let
 \begin{equation}R_{\bar v}=\text{the number of type-R children of $\bar v$ in the $(\mathcal{T},0)$.}\end{equation}
\begin{equation}R_{\bar v}=\text{the number of type-R children of $\bar v$ in the $(\mathcal{T},0)$.}\end{equation}
We also label the type-R vertices in increasing order of their ages, so that if
 $\bar v$
is the root or belongs to type L, then
$\bar v$
is the root or belongs to type L, then
 $a_{\bar v,1}\leqslant a_{\bar v}\leqslant a_{\bar v,2}\leqslant \ldots\leqslant a_{\bar v,1+R_{\bar v}}$
, while if
$a_{\bar v,1}\leqslant a_{\bar v}\leqslant a_{\bar v,2}\leqslant \ldots\leqslant a_{\bar v,1+R_{\bar v}}$
, while if
 $\bar v$
belongs to type R, then
$\bar v$
belongs to type R, then
 $a_{\bar v}\leqslant a_{\bar v,1}\leqslant \ldots\leqslant a_{\bar v,R_{\bar v}}$
. See Figure 1 below for an illustration of
$a_{\bar v}\leqslant a_{\bar v,1}\leqslant \ldots\leqslant a_{\bar v,R_{\bar v}}$
. See Figure 1 below for an illustration of
 $(\mathcal{T},0)$
and the vertex ages. To understand how the vertex types and the ages above arise in the weak limit, consider the r-neighbourhood of a uniformly chosen vertex
$(\mathcal{T},0)$
and the vertex ages. To understand how the vertex types and the ages above arise in the weak limit, consider the r-neighbourhood of a uniformly chosen vertex
 $k_0$
in
$k_0$
in
 $G_n\sim \textrm{PA}(\pi,X_1)_n$
. Observe that there is a unique path from
$G_n\sim \textrm{PA}(\pi,X_1)_n$
. Observe that there is a unique path from
 $k_0$
to the initial vertex, unless
$k_0$
to the initial vertex, unless
 $k_0$
is itself the initial vertex. Apart from
$k_0$
is itself the initial vertex. Apart from
 $k_0$
, the vertices in the r-neighbourhood that belong to this path are called type-L vertices, and the remaining vertices are referred to as type-R vertices. The ages in
$k_0$
, the vertices in the r-neighbourhood that belong to this path are called type-L vertices, and the remaining vertices are referred to as type-R vertices. The ages in
 $(\mathcal{T},0)$
encode the (rescaled) arrival times of the vertices in the r-neighbourhood of vertex
$(\mathcal{T},0)$
encode the (rescaled) arrival times of the vertices in the r-neighbourhood of vertex
 $k_0$
, which determine their degree distributions. A comparison of the 2-neighbourhoods of the PA tree and
$k_0$
, which determine their degree distributions. A comparison of the 2-neighbourhoods of the PA tree and
 $(\mathcal{T},0)$
is given in Figure 1.
$(\mathcal{T},0)$
is given in Figure 1.

Figure 1. A comparison between the 2-neighbourhoods in
 $(\mathcal{T},0)$
(left) and the PA tree
$(\mathcal{T},0)$
(left) and the PA tree
 $G_n$
rooted at the uniformly chosen vertex
$G_n$
rooted at the uniformly chosen vertex
 $k_0$
(right). We assign Ulam–Harris labels as subscripts (
$k_0$
(right). We assign Ulam–Harris labels as subscripts (
 $k_{\bar v}$
) to the vertices in
$k_{\bar v}$
) to the vertices in
 $(G_n,k_0)$
to better compare the 2-neighbourhoods. In both figures, the vertex location corresponds to either its arrival time or its age. A vertex is a type-L (type-R) child if it lies on the dotted (solid) path. On the left,
$(G_n,k_0)$
to better compare the 2-neighbourhoods. In both figures, the vertex location corresponds to either its arrival time or its age. A vertex is a type-L (type-R) child if it lies on the dotted (solid) path. On the left,
 $R_0=2$
,
$R_0=2$
,
 $R_{0,1}=2$
,
$R_{0,1}=2$
,
 $R_{0,2}=1$
, and
$R_{0,2}=1$
, and
 $R_{0,3}=0$
. On the right, the dotted path starting from
$R_{0,3}=0$
. On the right, the dotted path starting from
 $k_0$
leads to the initial vertex. The 2-neighbourhoods are coupled so that they are isomorphic, and the vertex ages and rescaled arrival times are close to each other. The unlabelled vertices and their respective edges (dashed or dotted) are not coupled.
$k_0$
leads to the initial vertex. The 2-neighbourhoods are coupled so that they are isomorphic, and the vertex ages and rescaled arrival times are close to each other. The unlabelled vertices and their respective edges (dashed or dotted) are not coupled.
Definition 3. (
 $\pi$
-Pólya point tree.) A
$\pi$
-Pólya point tree.) A
 $\pi$
-Pólya point tree
$\pi$
-Pólya point tree
 $(\mathcal{T},0)$
is defined recursively as follows. The root 0 has an age
$(\mathcal{T},0)$
is defined recursively as follows. The root 0 has an age
 $a_0=U_0^{\chi}$
, where
$a_0=U_0^{\chi}$
, where
 $U_0\sim \textrm{U}[0,1]$
. Assuming that
$U_0\sim \textrm{U}[0,1]$
. Assuming that
 $\bar v\in \partial B_r$
and
$\bar v\in \partial B_r$
and
 $a_{\bar v}$
have been generated, we define its children
$a_{\bar v}$
have been generated, we define its children
 $(\bar v, j)\in \partial B_{r+1}$
for
$(\bar v, j)\in \partial B_{r+1}$
for
 $j=1,2,\ldots$
as follows. Independently of all random variables generated before, let
$j=1,2,\ldots$
as follows. Independently of all random variables generated before, let
 $X_{\bar v}\sim \pi$
and
$X_{\bar v}\sim \pi$
and
 \begin{align*}Z_{\bar v}\sim\begin{cases}\textrm{Gamma}(X_{\bar v}, 1),&\text{if $\bar v$ is the root or of type R;}\\\textrm{Gamma}(X_{\bar v}+1, 1),&\text{if $\bar v$ is of type L.}\end{cases}\end{align*}
\begin{align*}Z_{\bar v}\sim\begin{cases}\textrm{Gamma}(X_{\bar v}, 1),&\text{if $\bar v$ is the root or of type R;}\\\textrm{Gamma}(X_{\bar v}+1, 1),&\text{if $\bar v$ is of type L.}\end{cases}\end{align*}
If
 $\bar v$
is the root or of type L, let
$\bar v$
is the root or of type L, let
 $a_{\bar v, 1}|a_{\bar v}\sim\textrm{U}[0,a_{\bar v}]$
and
$a_{\bar v, 1}|a_{\bar v}\sim\textrm{U}[0,a_{\bar v}]$
and
 $(a_{\bar v, i},2\leqslant i\leqslant 1+R_{\bar v})$
be the points of a mixed Poisson point process on
$(a_{\bar v, i},2\leqslant i\leqslant 1+R_{\bar v})$
be the points of a mixed Poisson point process on
 $(a_{\bar v}, 1]$
with intensity
$(a_{\bar v}, 1]$
with intensity
 \begin{equation*}\lambda_{\bar v}(y)dy\,:\!=\,\frac{Z_{\bar v}}{\mu a^{1/\mu}_{\bar v}}y^{1/\mu-1}dy.\end{equation*}
\begin{equation*}\lambda_{\bar v}(y)dy\,:\!=\,\frac{Z_{\bar v}}{\mu a^{1/\mu}_{\bar v}}y^{1/\mu-1}dy.\end{equation*}
If
 $\bar v$
is of type R, then
$\bar v$
is of type R, then
 $(a_{\bar v, i},1\leqslant i\leqslant R_{\bar v})$
are sampled as the points of a mixed Poisson process on
$(a_{\bar v, i},1\leqslant i\leqslant R_{\bar v})$
are sampled as the points of a mixed Poisson process on
 $(a_{\bar v}, 1]$
with intensity
$(a_{\bar v}, 1]$
with intensity
 $\lambda_{\bar v}$
. We obtain
$\lambda_{\bar v}$
. We obtain
 $(\mathcal{T},0)$
by continuing this process ad infinitum.
$(\mathcal{T},0)$
by continuing this process ad infinitum.
Remark 1. When exploring the r-neighbourhood of the uniformly chosen vertex in the PA tree, the type-L vertices are uncovered via the incoming edge it received from the probed uniformly chosen vertex or type-L vertices. To account for the size-biasing effect of these edges, the type-L gamma variables in the
 $\pi$
-Pólya point tree thus have a unit increment in the shape parameter.
$\pi$
-Pólya point tree thus have a unit increment in the shape parameter.
We define the total variation distance between two probability distributions
 $\nu_1$
and
$\nu_1$
and
 $\nu_2$
as
$\nu_2$
as
 \begin{align}\mathop{d_{\textrm{TV}}}\left(\nu_1,\nu_2\right)=\inf\{\mathbb{P}[V\not = W]\,:\,(\textit{V},\textit{W}) \text{is a coupling of $\nu_1$ and $\nu_2$}\}. \end{align}
\begin{align}\mathop{d_{\textrm{TV}}}\left(\nu_1,\nu_2\right)=\inf\{\mathbb{P}[V\not = W]\,:\,(\textit{V},\textit{W}) \text{is a coupling of $\nu_1$ and $\nu_2$}\}. \end{align}
When proving the local weak convergence, we couple the random elements
 $(B_r(G_n, k_0), k_0)$
and
$(B_r(G_n, k_0), k_0)$
and
 $(B_r(\mathcal{T},0), 0)$
in the space of rooted graphs (modulo isomorphisms)
$(B_r(\mathcal{T},0), 0)$
in the space of rooted graphs (modulo isomorphisms)
 $\mathcal{G}$
so that they are isomorphic with high probability (w.h.p.), thus bounding their total variation distance. In the main theorem below, we emphasise that the convergence does not take into account the ages and fitness of the
$\mathcal{G}$
so that they are isomorphic with high probability (w.h.p.), thus bounding their total variation distance. In the main theorem below, we emphasise that the convergence does not take into account the ages and fitness of the
 $\pi$
-Pólya point tree, but they are essential for the graph construction and are used for the couplings later.
$\pi$
-Pólya point tree, but they are essential for the graph construction and are used for the couplings later.
Theorem 1. Suppose that the fitness distribution
 $\pi$
is supported on
$\pi$
is supported on
 $(0,\kappa]$
for some
$(0,\kappa]$
for some
 $\kappa<\infty$
. Let
$\kappa<\infty$
. Let
 $G_n\sim \textrm{PA}(\pi,X_1)_n$
, let
$G_n\sim \textrm{PA}(\pi,X_1)_n$
, let
 $k_0$
be a uniformly chosen vertex in
$k_0$
be a uniformly chosen vertex in
 $G_n$
, and let
$G_n$
, and let
 $(\mathcal{T},0)$
be the
$(\mathcal{T},0)$
be the
 $\pi$
-Pólya point tree. Then, given
$\pi$
-Pólya point tree. Then, given
 $r<\infty$
, there is a positive constant
$r<\infty$
, there is a positive constant
 $C\,:\!=\,C(X_1,\mu,r,\kappa)$
such that
$C\,:\!=\,C(X_1,\mu,r,\kappa)$
such that
 \begin{align}\mathop{d_{\textrm{TV}}}(\mathscr{L}((B_r(G_n,k_0),k_0)),\mathscr{L}((B_r(\mathcal{T},0),0) )\leqslant C (\log \log n)^{-\chi}\end{align}
\begin{align}\mathop{d_{\textrm{TV}}}(\mathscr{L}((B_r(G_n,k_0),k_0)),\mathscr{L}((B_r(\mathcal{T},0),0) )\leqslant C (\log \log n)^{-\chi}\end{align}
for all
 $n\geqslant 3$
. This implies that the local weak limit of
$n\geqslant 3$
. This implies that the local weak limit of
 $G_n$
is the
$G_n$
is the
 $\pi$
-Pólya point tree.
$\pi$
-Pólya point tree.
Next we state the limiting results for some degree statistics of the PA tree. The connection of the following results to [Reference Berger, Borgs, Chayes and Saberi4, Reference Bollobás, Riordan, Spencer and Tusnády7, Reference Van der Hofstad20, Reference Lodewijks and Ortgiese25, Reference Peköz, Röllin and Ross30] is discussed in detail later in Section 8, where we also give the probability mass functions of the limiting distributions. Recall that
 $D^{(in)}_{n,j}$
is the in-degree of vertex j in
$D^{(in)}_{n,j}$
is the in-degree of vertex j in
 $G_n\sim \textrm{PA}(\pi,X_1)_n$
. Define the degree of vertex j in
$G_n\sim \textrm{PA}(\pi,X_1)_n$
. Define the degree of vertex j in
 $G_n$
as
$G_n$
as
 \begin{equation}D_{n,j}\,:\!=\,D^{(in)}_{n,j}+1,\quad \text{with }D^0_n\,:\!=\,D_{n,k_0},\end{equation}
\begin{equation}D_{n,j}\,:\!=\,D^{(in)}_{n,j}+1,\quad \text{with }D^0_n\,:\!=\,D_{n,k_0},\end{equation}
so that
 $D^0_n$
is the degree of the uniformly chosen vertex. Let L(i) be the Ulam–Harris labels
$D^0_n$
is the degree of the uniformly chosen vertex. Let L(i) be the Ulam–Harris labels
 $(0,1,1,\dots,1)$
such that
$(0,1,1,\dots,1)$
such that
 $|(0,1,\dots,1)|=i+1$
, so that
$|(0,1,\dots,1)|=i+1$
, so that
 $k_{L[i]}$
is the type-L vertex that is exactly i edges away from
$k_{L[i]}$
is the type-L vertex that is exactly i edges away from
 $k_0$
. Type-L vertices are commonly known as the ancestors of
$k_0$
. Type-L vertices are commonly known as the ancestors of
 $k_0$
in fringe tree analysis (see e.g. [Reference Holmgren and Janson21]), where their degrees are often of particular interest. Fixing
$k_0$
in fringe tree analysis (see e.g. [Reference Holmgren and Janson21]), where their degrees are often of particular interest. Fixing
 $r\in \mathbb{N}$
, let
$r\in \mathbb{N}$
, let
 $D^0_n$
be as in (1.6) and
$D^0_n$
be as in (1.6) and
 \begin{equation*}D^i_n=D_{n,k_{L[i]}}\quad \text{if $k_{L[i]}\not = 1$ for all $1\leqslant i\leqslant r$;}\end{equation*}
\begin{equation*}D^i_n=D_{n,k_{L[i]}}\quad \text{if $k_{L[i]}\not = 1$ for all $1\leqslant i\leqslant r$;}\end{equation*}
and if
 $k_{L[i]}=1$
for some
$k_{L[i]}=1$
for some
 $i\leqslant r$
, let
$i\leqslant r$
, let
 \begin{align*}D^j_n=D_{n,k_{L[j]}}\quad \text{for $1\leqslant j<i$} \qquad\text{and}\quad D^j_n=-1\quad \text{for $i\leqslant j\leqslant r$}.\end{align*}
\begin{align*}D^j_n=D_{n,k_{L[j]}}\quad \text{for $1\leqslant j<i$} \qquad\text{and}\quad D^j_n=-1\quad \text{for $i\leqslant j\leqslant r$}.\end{align*}
As the probability that we see vertex 1 in the r-neighbourhood
 $B_r(G_n,k_0)$
tends to zero as
$B_r(G_n,k_0)$
tends to zero as
 $n\to\infty$
,
$n\to\infty$
,
 $(D^0_1,\ldots,D^r_n)$
can be understood as the joint degree sequence of
$(D^0_1,\ldots,D^r_n)$
can be understood as the joint degree sequence of
 $(k_0, k_{L[1]},\ldots,k_{L[r]})$
. The next result concerning this joint degree sequence follows directly from Theorem 1.
$(k_0, k_{L[1]},\ldots,k_{L[r]})$
. The next result concerning this joint degree sequence follows directly from Theorem 1.
Corollary 1. Retaining the notation above, assume that
 $\pi$
is supported on
$\pi$
is supported on
 $(0,\kappa]$
for some
$(0,\kappa]$
for some
 $\kappa<\infty$
. Define
$\kappa<\infty$
. Define
 $U_0\sim \textrm{U}[0,1]$
,
$U_0\sim \textrm{U}[0,1]$
,
 $a_{L[0]}=U^\chi_0$
, and given
$a_{L[0]}=U^\chi_0$
, and given
 $a_{L[i-1]}$
, let
$a_{L[i-1]}$
, let
 $a_{L[i]}\sim \textrm{U}\left[0,a_{L[i-1]}\right]$
for
$a_{L[i]}\sim \textrm{U}\left[0,a_{L[i-1]}\right]$
for
 $1\leqslant i\leqslant r$
. Independently from
$1\leqslant i\leqslant r$
. Independently from
 $\big(a_{L[i]}, 0\leqslant i\leqslant r\big)$
, let
$\big(a_{L[i]}, 0\leqslant i\leqslant r\big)$
, let
 $X_{L[i]}$
be i.i.d. random variables with distribution
$X_{L[i]}$
be i.i.d. random variables with distribution
 $\pi$
, and let
$\pi$
, and let
 \begin{align*}Z_{L[i]}\sim\begin{cases}\textrm{Gamma}(X_{L[i]},1) \quad\text{if $i=0$,}\\\textrm{Gamma}(X_{L[i]}+1,1)\quad \text{if $1\leqslant i\leqslant r$.}\end{cases}\end{align*}
\begin{align*}Z_{L[i]}\sim\begin{cases}\textrm{Gamma}(X_{L[i]},1) \quad\text{if $i=0$,}\\\textrm{Gamma}(X_{L[i]}+1,1)\quad \text{if $1\leqslant i\leqslant r$.}\end{cases}\end{align*}
Writing
 $L[0]=0$
, let
$L[0]=0$
, let
 $R_{L[i]}$
be conditionally independent variables with
$R_{L[i]}$
be conditionally independent variables with
 $R_{L[i]}\sim \textrm{Po}\Big(Z_{L[i]} \Big(a^{-1/\mu}_{L[i]}-1\Big)\Big)$
. Define
$R_{L[i]}\sim \textrm{Po}\Big(Z_{L[i]} \Big(a^{-1/\mu}_{L[i]}-1\Big)\Big)$
. Define
 $\overline{R}^{(r)}\,:\!=\,(R_0+1, R_{L[1]}+2,\ldots,R_{L[r]}+2)$
and
$\overline{R}^{(r)}\,:\!=\,(R_0+1, R_{L[1]}+2,\ldots,R_{L[r]}+2)$
and
 $\overline{D}^{(r)}_n \,:\!=\,\big(D^0_n, D^1_n,\ldots,D^r_n\big)$
. There is a positive constant
$\overline{D}^{(r)}_n \,:\!=\,\big(D^0_n, D^1_n,\ldots,D^r_n\big)$
. There is a positive constant
 $C\,:\!=\,C(X_1,\mu,r,\kappa)$
such that
$C\,:\!=\,C(X_1,\mu,r,\kappa)$
such that
 \begin{align*}d_{\textrm{TV}}\left(\mathscr{L}\Big(\overline{D}^{(r)}_n\Big)\Big), \mathscr{L}\big(\overline{R}^{(r)}\big)\right)\leqslant C(\log\log n)^{-\chi}\quad for\ all\ n\geqslant 3.\end{align*}
\begin{align*}d_{\textrm{TV}}\left(\mathscr{L}\Big(\overline{D}^{(r)}_n\Big)\Big), \mathscr{L}\big(\overline{R}^{(r)}\big)\right)\leqslant C(\log\log n)^{-\chi}\quad for\ all\ n\geqslant 3.\end{align*}
We now state a convergence result for
 $D^0_n$
in (1.6). In view of Definition 2, the limiting distribution of
$D^0_n$
in (1.6). In view of Definition 2, the limiting distribution of
 $D^0_n$
and the convergence rate can be read from Theorem 1. However, the theorem below holds without the assumption of bounded fitness and has a much sharper rate. The improvement in the rate can be understood as a consequence of the fact that
$D^0_n$
and the convergence rate can be read from Theorem 1. However, the theorem below holds without the assumption of bounded fitness and has a much sharper rate. The improvement in the rate can be understood as a consequence of the fact that
 $k_0$
only needs to be large enough so that w.h.p. it has a small degree, in contrast to having a small enough r-neighbourhood for all
$k_0$
only needs to be large enough so that w.h.p. it has a small degree, in contrast to having a small enough r-neighbourhood for all
 $r<\infty$
, as required when proving Theorem 1. In the interest of article length, we give the proof of this result only in the supplementary article [Reference Lo24].
$r<\infty$
, as required when proving Theorem 1. In the interest of article length, we give the proof of this result only in the supplementary article [Reference Lo24].
Theorem 2. Assume that the pth moment of the distribution
 $\pi$
is finite for some
$\pi$
is finite for some
 $p>4$
. Let
$p>4$
. Let
 $R_0\sim\textrm{Po}\Big(Z_0\Big(a^{-1/\mu}_0-1\Big)\Big)$
, where given
$R_0\sim\textrm{Po}\Big(Z_0\Big(a^{-1/\mu}_0-1\Big)\Big)$
, where given
 $X_0\sim \pi$
,
$X_0\sim \pi$
,
 $Z_0\sim \textrm{Gamma}(X_0,1)$
, and independently of
$Z_0\sim \textrm{Gamma}(X_0,1)$
, and independently of
 $Z_0$
,
$Z_0$
,
 $U_0\sim \textrm{U}[0,1]$
and
$U_0\sim \textrm{U}[0,1]$
and
 $a_0\,:\!=\,U^\chi_0$
. Writing
$a_0\,:\!=\,U^\chi_0$
. Writing
 $\xi_0=R_0+1$
, there are positive constants
$\xi_0=R_0+1$
, there are positive constants
 $C\,:\!=\,C(X_1,\mu,p)$
and
$C\,:\!=\,C(X_1,\mu,p)$
and
 $0<d<\chi(1/4-1/(2p))$
such that
$0<d<\chi(1/4-1/(2p))$
such that
 \begin{align}d_{\textrm{TV}}\left(\mathscr{L}\big(D^0_n\big), \mathscr{L}(\xi_0)\right) \leqslant Cn^{-d}\quad for\ all\ n\geqslant 1.\end{align}
\begin{align}d_{\textrm{TV}}\left(\mathscr{L}\big(D^0_n\big), \mathscr{L}(\xi_0)\right) \leqslant Cn^{-d}\quad for\ all\ n\geqslant 1.\end{align}
1.3. Possible extensions and related works
Below we discuss the possible ways of extending Theorem 1, although, to limit the length of this article, we refrain from pursuing these directions. We also give an overview of recent developments concerning PA graphs with additive fitness, and collect some results on the local weak convergence of related PA models.
1.3.1. Possible extensions
The convergence rate in (1.5) roughly follows from the fact that
 $k_0\geqslant n(\log\log n)^{-1}$
with probability at least
$k_0\geqslant n(\log\log n)^{-1}$
with probability at least
 $(\log \log n)^{-1}$
, and on this event, we can couple the two graphs so that the probability that
$(\log \log n)^{-1}$
, and on this event, we can couple the two graphs so that the probability that
 $(B_r(G_n,k_0),k_0)\cong (B_r(\mathcal{T},0),0)$
tends to one as
$(B_r(G_n,k_0),k_0)\cong (B_r(\mathcal{T},0),0)$
tends to one as
 $n\to\infty$
. It is likely possible to improve the rate by optimising this and similar choices of thresholds, as well as by making the dependence on the radius r explicit by carefully keeping track of the coupling errors, but with much added technicality.
$n\to\infty$
. It is likely possible to improve the rate by optimising this and similar choices of thresholds, as well as by making the dependence on the radius r explicit by carefully keeping track of the coupling errors, but with much added technicality.
[Reference Bubeck, Mossel and Rácz10, Theorem 1] established that when
 $X_i=1$
almost surely (a.s.) for all
$X_i=1$
almost surely (a.s.) for all
 $i\geqslant 2$
, the choice of the seed graph has no effect on the local weak limit. This is because w.h.p., the local neighbourhood does not contain any of the seed vertices. By simply replacing the seed graph in the proof, we can show that Theorem 1 holds for more general seed graphs. With some straightforward modifications to the proof, we can also show that when the fitness is bounded, the
$i\geqslant 2$
, the choice of the seed graph has no effect on the local weak limit. This is because w.h.p., the local neighbourhood does not contain any of the seed vertices. By simply replacing the seed graph in the proof, we can show that Theorem 1 holds for more general seed graphs. With some straightforward modifications to the proof, we can also show that when the fitness is bounded, the
 $\pi$
-Pólya point tree is the local weak limit of the PA trees with self-loops, and when each vertex in the PA model sends
$\pi$
-Pólya point tree is the local weak limit of the PA trees with self-loops, and when each vertex in the PA model sends
 $m\geqslant 2$
outgoing edges, the limit is a variation of the
$m\geqslant 2$
outgoing edges, the limit is a variation of the
 $\pi$
-Pólya point tree; see e.g. [Reference Berger, Borgs, Chayes and Saberi4] for the non-random unit fitness case.
$\pi$
-Pólya point tree; see e.g. [Reference Berger, Borgs, Chayes and Saberi4] for the non-random unit fitness case.
By adapting the argument of the recent paper [Reference Garavaglia, Hazra, van der Hofstad and Ray17], it is possible to show that the weak convergence in Theorem 1 holds for fitness distributions with finite pth moment for some
 $p>1$
. The convergence rate should be valid for fitness distributions with at least exponentially decaying tails, but the assumption of bounded fitness greatly simplifies the proof. The i.i.d. assumption is only needed so that the fitness variables that we see in the local neighbourhood are i.i.d., and for applying the standard moment inequality in Lemma 15. Hence, we believe the theorem to hold at least for a fitness sequence
$p>1$
. The convergence rate should be valid for fitness distributions with at least exponentially decaying tails, but the assumption of bounded fitness greatly simplifies the proof. The i.i.d. assumption is only needed so that the fitness variables that we see in the local neighbourhood are i.i.d., and for applying the standard moment inequality in Lemma 15. Hence, we believe the theorem to hold at least for a fitness sequence
 $\textbf{X}$
such that (1)
$\textbf{X}$
such that (1)
 $X_i$
has the same marginal distribution
$X_i$
has the same marginal distribution
 $\pi$
for all
$\pi$
for all
 $i\geqslant 2$
, and (2) for some
$i\geqslant 2$
, and (2) for some
 $m\geqslant 1$
, the variables in the collection
$m\geqslant 1$
, the variables in the collection
 $(X_i,i\in A)$
are independent for any A such that
$(X_i,i\in A)$
are independent for any A such that
 $\{i,j\in A\,:\, \lvert{i-j}\rvert>2m\}$
. If, in the limit, the vertex labels in the local neighbourhood are at least 2m apart from each other w.h.p., then (1) and (2) ensure that these vertices have i.i.d. fitness, while (2) alone may be sufficient for proving a suitable analogue of the standard moment inequality, Lemma 15. The weak convergence in Theorem 1 should hold in probability, meaning that as
$\{i,j\in A\,:\, \lvert{i-j}\rvert>2m\}$
. If, in the limit, the vertex labels in the local neighbourhood are at least 2m apart from each other w.h.p., then (1) and (2) ensure that these vertices have i.i.d. fitness, while (2) alone may be sufficient for proving a suitable analogue of the standard moment inequality, Lemma 15. The weak convergence in Theorem 1 should hold in probability, meaning that as
 $n\to\infty$
,
$n\to\infty$
,
 $\frac{1}{n}\sum^n_{j=1}\mathbb{1}[(B_r(G_n,j),j)\cong(H,v)]\to \mathbb{P}[(B_r(\mathcal{T},0),0)\cong (H,v)]$
. This convergence is valid in the case where the initial attractivenesses are equal a.s. [Reference Van der Hofstad20, Chapter 5], and for certain PA models where each newly added vertex sends a random number of outgoing edges [Reference Garavaglia, Hazra, van der Hofstad and Ray17]. For the PA tree with additive fitness, this could be proved by adapting the ‘second moment’ method used in [Reference Garavaglia, Hazra, van der Hofstad and Ray17, Reference Van der Hofstad20], which involves establishing that the r-neighbourhoods of two independently, uniformly chosen vertices in the PA tree are disjoint w.h.p.
$\frac{1}{n}\sum^n_{j=1}\mathbb{1}[(B_r(G_n,j),j)\cong(H,v)]\to \mathbb{P}[(B_r(\mathcal{T},0),0)\cong (H,v)]$
. This convergence is valid in the case where the initial attractivenesses are equal a.s. [Reference Van der Hofstad20, Chapter 5], and for certain PA models where each newly added vertex sends a random number of outgoing edges [Reference Garavaglia, Hazra, van der Hofstad and Ray17]. For the PA tree with additive fitness, this could be proved by adapting the ‘second moment’ method used in [Reference Garavaglia, Hazra, van der Hofstad and Ray17, Reference Van der Hofstad20], which involves establishing that the r-neighbourhoods of two independently, uniformly chosen vertices in the PA tree are disjoint w.h.p.
1.3.2. Related works
The fitness variables were assumed to be i.i.d. in [Reference Bhamidi5, Reference Iyer22, Reference Lodewijks and Ortgiese25]. In [Reference Lodewijks and Ortgiese25], martingale techniques were used to investigate the maximum degree for fitness distributions with different tail behaviours; the results are applicable to PA graphs with additive fitness that allow for multiple edges. The authors also studied the empirical degree distribution (e.d.d.), whose details we defer to Remark 4. The model is a special case of the PA tree considered in [Reference Iyer22], where vertices are chosen with probability proportional to a suitable function of their fitness and degree at each attachment step. Using Crump–Mode–Jagers (CMJ) branching processes, [Reference Iyer22] studied the e.d.d. and the condensation phenomenon. The same method was applied in [Reference Bhamidi5] to investigate the e.d.d., the height, and the degree of the initial vertex, assuming that the fitnesses are bounded. Note that these articles focused on ‘global’ results, which cannot be deduced from the local weak limit.
As observed in [Reference Sénizergues36], the model is closely related to the weighted random recursive trees introduced in [Reference Borovkov and Vatutin9]. By the Pólya urn representation (Theorem 3 below), the PA tree with additive fitness can be viewed as a special case of this model class, where the weights of the vertices are distributed as
 $\Big(S^{(X)}_{n,j}-S^{(X)}_{n,j-1}, {2\leqslant j\leqslant n}\Big)$
with
$\Big(S^{(X)}_{n,j}-S^{(X)}_{n,j-1}, {2\leqslant j\leqslant n}\Big)$
with
 $S^{(X)}_{n,0}=0$
and
$S^{(X)}_{n,0}=0$
and
 $S^{(X)}_{n,n}=1$
, and with
$S^{(X)}_{n,n}=1$
, and with
 $B^{(X)}_j$
and
$B^{(X)}_j$
and
 $S^{(X)}_{n,j}$
being the variables
$S^{(X)}_{n,j}$
being the variables
 $B_j$
and
$B_j$
and
 $S_{n,j}$
in (1.8) and (1.9) mixed over the fitness sequence
$S_{n,j}$
in (1.8) and (1.9) mixed over the fitness sequence
 $\textbf{X}$
. For weighted random recursive trees, [Reference Borovkov and Vatutin9] studied the average degree of a fixed vertex and the distance between a newly added vertex and the initial vertex. The joint degree sequence of fixed vertices, the height, and the profile were investigated in [Reference Sénizergues36], and a more refined result on the height was given in [Reference Pain and Sénizergues29]. For
$\textbf{X}$
. For weighted random recursive trees, [Reference Borovkov and Vatutin9] studied the average degree of a fixed vertex and the distance between a newly added vertex and the initial vertex. The joint degree sequence of fixed vertices, the height, and the profile were investigated in [Reference Sénizergues36], and a more refined result on the height was given in [Reference Pain and Sénizergues29]. For
 $\textbf{X}$
a deterministic sequence satisfying a certain growth condition, [Reference Sénizergues36] and [Reference Pain and Sénizergues29] showed that their results are applicable to the corresponding PA tree with additive fitness.
$\textbf{X}$
a deterministic sequence satisfying a certain growth condition, [Reference Sénizergues36] and [Reference Pain and Sénizergues29] showed that their results are applicable to the corresponding PA tree with additive fitness.
We now survey the local weak limit results developed for PA graphs. When
 $x_1=0$
and
$x_1=0$
and
 $x_i=1$
for all
$x_i=1$
for all
 $i\geqslant 2$
, the
$i\geqslant 2$
, the
 $(\textbf{x},n)$
-sequential model is the pure ‘sequential’ model in [Reference Berger, Borgs, Chayes and Saberi4] with no multiple edges, and it is a special case of the model considered in [Reference Rudas, Tóth and Valkó35], where the ‘weight’ function is the identity function plus one. Using the CMJ embedding method, [Reference Rudas, Tóth and Valkó35] studied the asymptotic distribution of the subtree rooted at a uniformly chosen vertex, which implies the local weak convergence of the PA family considered in that work. The urn representation of PA models was used in [Reference Berger, Borgs, Chayes and Saberi4], [Reference Van der Hofstad20, Chapter 5], [Reference Garavaglia16, Chapter 4], and [Reference Garavaglia, Hazra, van der Hofstad and Ray17] to study local weak limits. In particular, these works showed that the weak limit of several PA models with non-random fitness and possibly random out-degrees is a variant of the Pólya point tree [Reference Berger, Borgs, Chayes and Saberi4]. Again using the CMJ method, it can be shown that the local weak convergence result of [Reference Garavaglia, van der Hofstad and Litvak18] for a certain ‘continuous-time branching process tree’ implies that the PA tree with additive fitness converges in the directed local weak sense. Finally, a different PA model was considered in [Reference Bhamidi5, Reference Borgs, Chayes, Daskalakis and Roch8, Reference Dereich11, Reference Dereich and Ortgiese12], where the probability that a new vertex attaches to an existing vertex is proportional to its fitness times its degree. Currently, there are no results concerning the local weak convergence of this model class.
$(\textbf{x},n)$
-sequential model is the pure ‘sequential’ model in [Reference Berger, Borgs, Chayes and Saberi4] with no multiple edges, and it is a special case of the model considered in [Reference Rudas, Tóth and Valkó35], where the ‘weight’ function is the identity function plus one. Using the CMJ embedding method, [Reference Rudas, Tóth and Valkó35] studied the asymptotic distribution of the subtree rooted at a uniformly chosen vertex, which implies the local weak convergence of the PA family considered in that work. The urn representation of PA models was used in [Reference Berger, Borgs, Chayes and Saberi4], [Reference Van der Hofstad20, Chapter 5], [Reference Garavaglia16, Chapter 4], and [Reference Garavaglia, Hazra, van der Hofstad and Ray17] to study local weak limits. In particular, these works showed that the weak limit of several PA models with non-random fitness and possibly random out-degrees is a variant of the Pólya point tree [Reference Berger, Borgs, Chayes and Saberi4]. Again using the CMJ method, it can be shown that the local weak convergence result of [Reference Garavaglia, van der Hofstad and Litvak18] for a certain ‘continuous-time branching process tree’ implies that the PA tree with additive fitness converges in the directed local weak sense. Finally, a different PA model was considered in [Reference Bhamidi5, Reference Borgs, Chayes, Daskalakis and Roch8, Reference Dereich11, Reference Dereich and Ortgiese12], where the probability that a new vertex attaches to an existing vertex is proportional to its fitness times its degree. Currently, there are no results concerning the local weak convergence of this model class.
1.4. Proof overview
1.4.1. Pólya urn representation of the
 $(\textbf{x},n)$
-sequential model
$(\textbf{x},n)$
-sequential model

In the proof of Theorem 1, the key ingredient is an alternative definition of the
 $(\textbf{x},n)$
-sequential model in Definition 1, which relies on the fact that the dynamics of PA graphs can be represented as embedded classical Pólya urns. In a classical Pólya urn initially with a red balls and b black balls, a ball is chosen randomly from the urn, and is returned to the urn along with a new ball of the same colour. It is well-known that the a.s. limit of the proportion of red balls has the Beta(a,b) distribution; see e.g. [Reference Mahmoud27, Theorem 3.2, p.53]. Furthermore, by de Finetti’s theorem (see e.g. [Reference Mahmoud27, Theorem 1.2, p.29]), conditional on
$(\textbf{x},n)$
-sequential model in Definition 1, which relies on the fact that the dynamics of PA graphs can be represented as embedded classical Pólya urns. In a classical Pólya urn initially with a red balls and b black balls, a ball is chosen randomly from the urn, and is returned to the urn along with a new ball of the same colour. It is well-known that the a.s. limit of the proportion of red balls has the Beta(a,b) distribution; see e.g. [Reference Mahmoud27, Theorem 3.2, p.53]. Furthermore, by de Finetti’s theorem (see e.g. [Reference Mahmoud27, Theorem 1.2, p.29]), conditional on
 $\beta\sim\textrm{Beta}(a,b)$
, the indicators that a red ball is chosen at each step are distributed as independent Bernoulli variables with parameter
$\beta\sim\textrm{Beta}(a,b)$
, the indicators that a red ball is chosen at each step are distributed as independent Bernoulli variables with parameter
 $\beta$
. In the PA mechanism, an existing vertex i can be represented by some colour i in an urn, and its weight is given by the total weight of the balls in the urn. At each urn step, we choose a ball with probability proportional to its weight, and if vertex i is chosen at some step
$\beta$
. In the PA mechanism, an existing vertex i can be represented by some colour i in an urn, and its weight is given by the total weight of the balls in the urn. At each urn step, we choose a ball with probability proportional to its weight, and if vertex i is chosen at some step
 $j>i$
, we return the chosen ball, an extra ball of colour i with weight 1, and a ball of new colour j with weight
$j>i$
, we return the chosen ball, an extra ball of colour i with weight 1, and a ball of new colour j with weight
 $x_j$
to the urn. Classical Pólya urns are naturally embedded in this multi-colour urn; see [Reference Peköz, Röllin and Ross31]. The attachment steps of the graph can therefore be generated independently when conditioned on the associated beta variables.
$x_j$
to the urn. Classical Pólya urns are naturally embedded in this multi-colour urn; see [Reference Peköz, Röllin and Ross31]. The attachment steps of the graph can therefore be generated independently when conditioned on the associated beta variables.
Definition 4. (
 $(\textbf{x},n)$
-Pólya urn tree.) Given
$(\textbf{x},n)$
-Pólya urn tree.) Given
 $\textbf{x}$
and n, let
$\textbf{x}$
and n, let
 $T_j\,:\!=\,\sum^j_{i=1} x_i$
, and
$T_j\,:\!=\,\sum^j_{i=1} x_i$
, and
 $\big(B_j, 1\leqslant j\leqslant n\big)$
be independent random variables such that
$\big(B_j, 1\leqslant j\leqslant n\big)$
be independent random variables such that
 $B_1\,:\!=\,1$
and
$B_1\,:\!=\,1$
and
 \begin{equation}B_j \sim \textrm{Beta}\big(x_{j},j-1+T_{j-1}\big)\quad \text{for $2\leqslant j\leqslant n$.}\end{equation}
\begin{equation}B_j \sim \textrm{Beta}\big(x_{j},j-1+T_{j-1}\big)\quad \text{for $2\leqslant j\leqslant n$.}\end{equation}
Moreover, let
 $S_{n,0}\,:\!=\,0$
,
$S_{n,0}\,:\!=\,0$
,
 $S_{n,n}\,:\!=\,1$
, and
$S_{n,n}\,:\!=\,1$
, and
 \begin{equation}S_{n,j}\,:\!=\,\prod^{n}_{i=j+1}(1-B_i)\quad\text{for $1\leqslant j \leqslant n-1$.}\end{equation}
\begin{equation}S_{n,j}\,:\!=\,\prod^{n}_{i=j+1}(1-B_i)\quad\text{for $1\leqslant j \leqslant n-1$.}\end{equation}
We connect n vertices with labels
 $[n]\,:\!=\,\{1,\ldots,n\}$
as follows. Let
$[n]\,:\!=\,\{1,\ldots,n\}$
as follows. Let
 $I_j=\big[S_{n,j-1}, S_{n,j}\big)$
for
$I_j=\big[S_{n,j-1}, S_{n,j}\big)$
for
 $1\leqslant j \leqslant n$
. Conditionally on
$1\leqslant j \leqslant n$
. Conditionally on
 $\big(S_{n,j},1\leqslant j \leqslant n-1\big)$
, let
$\big(S_{n,j},1\leqslant j \leqslant n-1\big)$
, let
 $(U_j, 2\leqslant j\leqslant n)$
be independent variables such that
$(U_j, 2\leqslant j\leqslant n)$
be independent variables such that
 $U_j\,\sim\,\textrm{U}[0,S_{n,j-1}]$
. If
$U_j\,\sim\,\textrm{U}[0,S_{n,j-1}]$
. If
 $j<k$
and
$j<k$
and
 $U_k\in I_j$
, we attach an outgoing edge from vertex k to vertex j. We say that the resulting graph is an
$U_k\in I_j$
, we attach an outgoing edge from vertex k to vertex j. We say that the resulting graph is an
 $(\textbf{x},n)$
-Pólya urn tree and denote its law by
$(\textbf{x},n)$
-Pólya urn tree and denote its law by
 $\textrm{PU}(\textbf{x})_n$
.
$\textrm{PU}(\textbf{x})_n$
.
An example of the
 $(\textbf{x},n)$
-Pólya urn tree is given in Figure 2. Note that
$(\textbf{x},n)$
-Pólya urn tree is given in Figure 2. Note that
 $1-B_{j}$
in Definition 4 is
$1-B_{j}$
in Definition 4 is
 $\beta_{j-1}$
in [Reference Sénizergues36]. As we only work with
$\beta_{j-1}$
in [Reference Sénizergues36]. As we only work with
 $B_j$
and
$B_j$
and
 $S_{n,j}$
by fixing the sequence
$S_{n,j}$
by fixing the sequence
 $\textbf{x}$
, we omit
$\textbf{x}$
, we omit
 $\textbf{x}$
from their notation throughout this article. The
$\textbf{x}$
from their notation throughout this article. The
 $(\textbf{x},n)$
-Pólya urn tree is related to the
$(\textbf{x},n)$
-Pólya urn tree is related to the
 $(\textbf{x},n)$
-sequential model via the following result of [Reference Sénizergues36].
$(\textbf{x},n)$
-sequential model via the following result of [Reference Sénizergues36].

Figure 2. An example of the
 $(\textbf{x},n)$
-Pólya urn tree for
$(\textbf{x},n)$
-Pólya urn tree for
 $n=5$
, where
$n=5$
, where
 $U_i\sim\textrm{U}\left[0,S_{n,i-1}\right]$
for
$U_i\sim\textrm{U}\left[0,S_{n,i-1}\right]$
for
 $i=2,\ldots,5$
and an outgoing edge is drawn from vertices i to j if
$i=2,\ldots,5$
and an outgoing edge is drawn from vertices i to j if
 $U_i\in \left[S_{n,j-1}, S_{n,j}\right)$
.
$U_i\in \left[S_{n,j-1}, S_{n,j}\right)$
.
Theorem 3. ([Reference Sénizergues36, Theorem 1.1].) Let
 $G_n$
be an
$G_n$
be an
 $(\textbf{x},n)$
-Pólya urn tree. Then
$(\textbf{x},n)$
-Pólya urn tree. Then
 $G_n$
has the same law as the
$G_n$
has the same law as the
 $(\textbf{x},n)$
-sequential model; that is,
$(\textbf{x},n)$
-sequential model; that is,
 $\textrm{PU}(\textbf{x})_n\overset{d}{=} \textrm{Seq}(\textbf{x})_n$
.
$\textrm{PU}(\textbf{x})_n\overset{d}{=} \textrm{Seq}(\textbf{x})_n$
.
From now on, we work with the
 $(\textbf{x},n)$
-Pólya urn tree in place of the
$(\textbf{x},n)$
-Pólya urn tree in place of the
 $(\textbf{x},n)$
-sequential model.
$(\textbf{x},n)$
-sequential model.
1.4.2. Coupling for the non-random fitness case
When proving Theorem 1, we couple the (randomised) urn tree and the
 $\pi$
-Pólya point tree so that for all positive integers r, the probability that their r-neighbourhoods are not isomorphic is of order at most
$\pi$
-Pólya point tree so that for all positive integers r, the probability that their r-neighbourhoods are not isomorphic is of order at most
 $(\log\log n)^{-\chi}$
. To give a brief overview of the coupling, below we suppose that
$(\log\log n)^{-\chi}$
. To give a brief overview of the coupling, below we suppose that
 $X_i=1$
a.s. for
$X_i=1$
a.s. for
 $i\geqslant 2$
and only consider the
$i\geqslant 2$
and only consider the
 $r=1$
case. We couple the children of the uniformly chosen vertex in the urn tree
$r=1$
case. We couple the children of the uniformly chosen vertex in the urn tree
 $G_n$
and the root in the
$G_n$
and the root in the
 $\pi$
-Pólya point tree
$\pi$
-Pólya point tree
 $(\mathcal{T},0)$
so that, w.h.p., they have the same number of children, and the ages and the rescaled arrival times of these children are close enough. Note that for non-random fitness, the urn tree is simply an alternative definition of the PA tree with additive fitness. For
$(\mathcal{T},0)$
so that, w.h.p., they have the same number of children, and the ages and the rescaled arrival times of these children are close enough. Note that for non-random fitness, the urn tree is simply an alternative definition of the PA tree with additive fitness. For
 $G_n$
, we use the terms ‘age’ and ‘rescaled arrival times’ interchangeably.
$G_n$
, we use the terms ‘age’ and ‘rescaled arrival times’ interchangeably.
I. The ages of the roots. As mentioned before, the ages in
 $(\mathcal{T},0)$
encode the rescaled arrival times in
$(\mathcal{T},0)$
encode the rescaled arrival times in
 $G_n$
. Since, for any vertex in either
$G_n$
. Since, for any vertex in either
 $G_n$
or
$G_n$
or
 $(\mathcal{T},0)$
, the number of its children and the ages of its children depend heavily on its own age, we need to couple the uniformly chosen vertex
$(\mathcal{T},0)$
, the number of its children and the ages of its children depend heavily on its own age, we need to couple the uniformly chosen vertex
 $k_0$
in
$k_0$
in
 $G_n$
and the root of
$G_n$
and the root of
 $(\mathcal{T},0)$
so that their ages are close enough.
$(\mathcal{T},0)$
so that their ages are close enough.
II. The type-R children and a Bernoulli–Poisson coupling. Using the urn representation in Definition 4, the ages and the number of the type-R children of vertex
 $k_0$
can be encoded in a sequence of conditionally independent Bernoulli variables, where the success probabilities are given in terms of the variables
$k_0$
can be encoded in a sequence of conditionally independent Bernoulli variables, where the success probabilities are given in terms of the variables
 $B_i$
and
$B_i$
and
 $S_{n,i}$
in (1.8) and (1.9). See Figure 3 for an illustration. To couple this Bernoulli sequence to a suitable discretisation of the mixed Poisson point process in Definition 3, we use the beta–gamma algebra and the law of large numbers to approximate
$S_{n,i}$
in (1.8) and (1.9). See Figure 3 for an illustration. To couple this Bernoulli sequence to a suitable discretisation of the mixed Poisson point process in Definition 3, we use the beta–gamma algebra and the law of large numbers to approximate
 $B_i$
and
$B_i$
and
 $S_{n,i}$
for large enough i. Once we use these estimates to swap the success probabilities with simpler quantities, we can apply the standard Bernoulli–Poisson coupling.
$S_{n,i}$
for large enough i. Once we use these estimates to swap the success probabilities with simpler quantities, we can apply the standard Bernoulli–Poisson coupling.
III. The ages of the type-L children. It is clear that the number of type-L children of vertex
 $k_0$
and the number of type-L children of the root of
$k_0$
and the number of type-L children of the root of
 $(\mathcal{T},0)$
differ only when
$(\mathcal{T},0)$
differ only when
 $k_0=1$
, which occurs with probability
$k_0=1$
, which occurs with probability
 $n^{-1}$
. To couple their ages so that they are close enough, we use the estimates for
$n^{-1}$
. To couple their ages so that they are close enough, we use the estimates for
 $B_i$
and
$B_i$
and
 $S_{n,i}$
to approximate the distribution of the type-L child of vertex
$S_{n,i}$
to approximate the distribution of the type-L child of vertex
 $k_0$
. This completes the coupling of the 1-neighbourhoods. We reiterate that although the closeness of the ages is not part of the local weak convergence, we need to closely couple the ages of the children of vertex
$k_0$
. This completes the coupling of the 1-neighbourhoods. We reiterate that although the closeness of the ages is not part of the local weak convergence, we need to closely couple the ages of the children of vertex
 $k_0$
and of those of the root in
$k_0$
and of those of the root in
 $(\mathcal{T},0)$
, as otherwise we cannot couple the 2-neighbourhoods when we prove the theorem for all finite radii.
$(\mathcal{T},0)$
, as otherwise we cannot couple the 2-neighbourhoods when we prove the theorem for all finite radii.

Figure 3. An illustration of the relationship between the Bernoulli sequence on
 $((k_0/n)^\chi,1]$
constructed using
$((k_0/n)^\chi,1]$
constructed using
 $(\mathbb{1}[U_j \in I_{k_0}],k_0+1\leqslant j\leqslant n)$
and the
$(\mathbb{1}[U_j \in I_{k_0}],k_0+1\leqslant j\leqslant n)$
and the
 $(\textbf{x},n)$
-Pólya urn tree, where
$(\textbf{x},n)$
-Pólya urn tree, where
 $k_0$
is the uniformly chosen vertex, and
$k_0$
is the uniformly chosen vertex, and
 $U_j$
and
$U_j$
and
 $I_{k_0}$
are as in Definition 4. We put a point on
$I_{k_0}$
are as in Definition 4. We put a point on
 $(j/n)^\chi$
if vertex
$(j/n)^\chi$
if vertex
 $k_0$
receives the outgoing edge from vertex j. Here the type-R children of
$k_0$
receives the outgoing edge from vertex j. Here the type-R children of
 $k_0$
are
$k_0$
are
 $j_1$
,
$j_1$
,
 $j_2$
, and
$j_2$
, and
 $j_3$
. The rescaled arrival times
$j_3$
. The rescaled arrival times
 $((j/n)^\chi,k_0+1\leqslant j\leqslant n)$
are later used to discretise the mixed Poisson process in the coupling step.
$((j/n)^\chi,k_0+1\leqslant j\leqslant n)$
are later used to discretise the mixed Poisson process in the coupling step.
1.4.3. Random fitness and the general local neighbourhood
Here we summarise the additional ingredients needed for handling the random fitness and for coupling the neighbourhoods of any finite radius. When
 $\textbf{x}$
is a realisation of the fitness sequence
$\textbf{x}$
is a realisation of the fitness sequence
 $\textbf{X}$
,
$\textbf{X}$
,
 $B_i$
and
$B_i$
and
 $S_{n,i}$
can be approximated in the same way as in the case of non-random fitness if, w.h.p., the sums
$S_{n,i}$
can be approximated in the same way as in the case of non-random fitness if, w.h.p., the sums
 $\sum^i_{h=2}X_h$
are close to
$\sum^i_{h=2}X_h$
are close to
 $(i-1)\mu$
for all i greater than some suitably chosen function
$(i-1)\mu$
for all i greater than some suitably chosen function
 $\phi(n)$
. As
$\phi(n)$
. As
 $\textbf{X}$
is i.i.d., we can apply standard moment inequalities to show that this event occurs w.h.p. The remaining parts of the coupling are similar to the above. When coupling general r-neighbourhoods, we use induction over the neighbourhood radius. For any vertex in the neighbourhood other than the uniformly chosen vertex, the distributions of its degree and the ages of its children cannot be read from Definition 4, owing to the conditioning effects of the discovered edges in the breadth-first search that we define later. However, these effects can be quantified when we work conditionally on the fitness sequence. In particular, their distributions can be deduced from an urn representation of the
$\textbf{X}$
is i.i.d., we can apply standard moment inequalities to show that this event occurs w.h.p. The remaining parts of the coupling are similar to the above. When coupling general r-neighbourhoods, we use induction over the neighbourhood radius. For any vertex in the neighbourhood other than the uniformly chosen vertex, the distributions of its degree and the ages of its children cannot be read from Definition 4, owing to the conditioning effects of the discovered edges in the breadth-first search that we define later. However, these effects can be quantified when we work conditionally on the fitness sequence. In particular, their distributions can be deduced from an urn representation of the
 $(\textbf{x},n)$
-sequential model, conditional on the discovered edges. Consequently, the coupling argument for the root vertex can be applied to these non-root vertices as well.
$(\textbf{x},n)$
-sequential model, conditional on the discovered edges. Consequently, the coupling argument for the root vertex can be applied to these non-root vertices as well.
1.5. Article outline
The approximation results for
 $B_i$
and
$B_i$
and
 $S_{n,i}$
in (1.8) and (1.9) are stated in Section 2 and proved in Section 9. In Section 3, we define the tree exploration process, and we describe the offspring distributions of the root and of any type-L or type-R parent in the subsequent generations of the local neighbourhood in the
$S_{n,i}$
in (1.8) and (1.9) are stated in Section 2 and proved in Section 9. In Section 3, we define the tree exploration process, and we describe the offspring distributions of the root and of any type-L or type-R parent in the subsequent generations of the local neighbourhood in the
 $(\textbf{x},n)$
-Pólya urn tree, using the complementary result derived in [Reference Lo24, Section 10]. We also introduce a conditional analogue of the
$(\textbf{x},n)$
-Pólya urn tree, using the complementary result derived in [Reference Lo24, Section 10]. We also introduce a conditional analogue of the
 $\pi$
-Pólya point tree
$\pi$
-Pólya point tree
 $(\mathcal{T},0)$
in Section 4, which we need for coupling the urn tree and
$(\mathcal{T},0)$
in Section 4, which we need for coupling the urn tree and
 $(\mathcal{T},0)$
. We couple the 1-neighbourhoods in the urn tree and this analogue in Section 5, and their general r-neighbourhoods in Section 6. In Section 7, to prove Theorem 1, we couple the analogue and
$(\mathcal{T},0)$
. We couple the 1-neighbourhoods in the urn tree and this analogue in Section 5, and their general r-neighbourhoods in Section 6. In Section 7, to prove Theorem 1, we couple the analogue and
 $(\mathcal{T},0)$
. Finally, in Section 8 we discuss in more detail the connection of Corollary 1 and Theorem 2 to the previous works [Reference Berger, Borgs, Chayes and Saberi4, Reference Bollobás, Riordan, Spencer and Tusnády7, Reference Van der Hofstad20, Reference Lodewijks and Ortgiese25].
$(\mathcal{T},0)$
. Finally, in Section 8 we discuss in more detail the connection of Corollary 1 and Theorem 2 to the previous works [Reference Berger, Borgs, Chayes and Saberi4, Reference Bollobás, Riordan, Spencer and Tusnády7, Reference Van der Hofstad20, Reference Lodewijks and Ortgiese25].
2. Approximation of the beta and product beta variables
Let
 $B_i$
and
$B_i$
and
 $S_{n,i}$
be as in (1.8) and (1.9), where we treat
$S_{n,i}$
be as in (1.8) and (1.9), where we treat
 $\textbf{x}$
in
$\textbf{x}$
in
 $B_i$
and
$B_i$
and
 $S_{n,i}$
as a realisation of the fitness sequence
$S_{n,i}$
as a realisation of the fitness sequence
 $\textbf{X}\,:\!=\,(X_i,i\geqslant 1)$
. In this section, we state the approximation results for
$\textbf{X}\,:\!=\,(X_i,i\geqslant 1)$
. In this section, we state the approximation results for
 $B_i$
and
$B_i$
and
 $S_{n,i}$
, assuming that
$S_{n,i}$
, assuming that
 $X_1\,:\!=\,x_1>-1$
is fixed and
$X_1\,:\!=\,x_1>-1$
is fixed and
 $(X_i,i\geqslant 2)$
are i.i.d. positive variables with
$(X_i,i\geqslant 2)$
are i.i.d. positive variables with
 $\mu\,:\!=\,\mathbb{E} X_2<\infty$
and
$\mu\,:\!=\,\mathbb{E} X_2<\infty$
and
 $\mathbb{E}\big[X^p_2\big]<\infty$
for some
$\mathbb{E}\big[X^p_2\big]<\infty$
for some
 $p>2$
. These results are later used to derive the limiting degree distribution of the uniformly chosen vertex of the PA tree and the corresponding convergence rate, where the fitness is not necessarily bounded (Theorem 2). The proofs of the upcoming lemmas are deferred to Section 9. For the approximations, we require that w.h.p.,
$p>2$
. These results are later used to derive the limiting degree distribution of the uniformly chosen vertex of the PA tree and the corresponding convergence rate, where the fitness is not necessarily bounded (Theorem 2). The proofs of the upcoming lemmas are deferred to Section 9. For the approximations, we require that w.h.p.,
 $\textbf{X}$
is such that
$\textbf{X}$
is such that
 $\sum^i_{h=2} X_h$
is close enough to its mean
$\sum^i_{h=2} X_h$
is close enough to its mean
 $(i-1)\mu$
for all i sufficiently large. So given
$(i-1)\mu$
for all i sufficiently large. So given
 $0<\alpha<1$
and n, we define
$0<\alpha<1$
and n, we define
 \begin{equation}A_{\alpha,n} = \Bigg\{ \bigcap^\infty_{i=\lceil{\phi(n)\rceil}} \Bigg\{\Bigg|\sum^i_{h=2} X_h-(i-1)\mu\Bigg|\leqslant i^{\alpha} \Bigg\} \Bigg\},\end{equation}
\begin{equation}A_{\alpha,n} = \Bigg\{ \bigcap^\infty_{i=\lceil{\phi(n)\rceil}} \Bigg\{\Bigg|\sum^i_{h=2} X_h-(i-1)\mu\Bigg|\leqslant i^{\alpha} \Bigg\} \Bigg\},\end{equation}
where
 $\phi(n)=\Omega(n^{\chi})$
, with
$\phi(n)=\Omega(n^{\chi})$
, with
 $\chi$
as in (1.2). The first lemma is due to an application of standard moment inequalities.
$\chi$
as in (1.2). The first lemma is due to an application of standard moment inequalities.
Lemma 1. Assume that
 $\mathbb{E}\big[X^p_2\big]<\infty$
for some
$\mathbb{E}\big[X^p_2\big]<\infty$
for some
 $p>2$
. Given a positive integer n and
$p>2$
. Given a positive integer n and
 $1/2+1/p<\alpha<1$
, there is a constant
$1/2+1/p<\alpha<1$
, there is a constant
 $C\,:\!=\,C(\mu,\alpha,p)$
such that
$C\,:\!=\,C(\mu,\alpha,p)$
such that
 $\mathbb{P}[A_{\alpha,n}]\geqslant 1- Cn^{\chi[-p(\alpha-1/2)+1]}$
.
$\mathbb{P}[A_{\alpha,n}]\geqslant 1- Cn^{\chi[-p(\alpha-1/2)+1]}$
.
In the remainder of this article, we mostly work with a realisation
 $\textbf{x}$
of
$\textbf{x}$
of
 $\textbf{X}$
such that
$\textbf{X}$
such that
 $A_{\alpha,n}$
holds, which we denote (abusively) by
$A_{\alpha,n}$
holds, which we denote (abusively) by
 $\textbf{x}\in A_{\alpha,n}$
. Below we write
$\textbf{x}\in A_{\alpha,n}$
. Below we write
 $\mathbb{P}_{\textbf{x}}$
and
$\mathbb{P}_{\textbf{x}}$
and
 $\mathbb{E}_{\textbf{x}}$
to indicate the conditioning on a specific realisation of the fitness sequence
$\mathbb{E}_{\textbf{x}}$
to indicate the conditioning on a specific realisation of the fitness sequence
 $\textbf{x}$
. The next lemma, which extends [Reference Berger, Borgs, Chayes and Saberi4, Lemma 3.1], states that
$\textbf{x}$
. The next lemma, which extends [Reference Berger, Borgs, Chayes and Saberi4, Lemma 3.1], states that
 $S_{n,k}\approx(k/n)^\chi$
for large enough k and n when
$S_{n,k}\approx(k/n)^\chi$
for large enough k and n when
 $\textbf{x}\in A_{\alpha,n}$
. The proof relies on the fact that we can replace
$\textbf{x}\in A_{\alpha,n}$
. The proof relies on the fact that we can replace
 $\mathbb{E}_{\textbf{x}}[S_{n,k}]$
with
$\mathbb{E}_{\textbf{x}}[S_{n,k}]$
with
 $(k/n)^\chi$
when
$(k/n)^\chi$
when
 $\textbf{x}\in A_{\alpha,n}$
, and approximate
$\textbf{x}\in A_{\alpha,n}$
, and approximate
 $S_{n,k}$
with
$S_{n,k}$
with
 $\mathbb{E}_{\textbf{x}}[S_{n,k}]$
using a martingale argument. As
$\mathbb{E}_{\textbf{x}}[S_{n,k}]$
using a martingale argument. As
 $A_{\alpha,n}$
occurs w.h.p., the result allows us to substitute these
$A_{\alpha,n}$
occurs w.h.p., the result allows us to substitute these
 $S_{n,k}$
with
$S_{n,k}$
with
 $(k/n)^\chi$
when we construct a coupling for the
$(k/n)^\chi$
when we construct a coupling for the
 $(\textbf{x},n)$
-Pólya urn tree (Definition 4).
$(\textbf{x},n)$
-Pólya urn tree (Definition 4).
Lemma 2. Given a positive integer n and
 $1/2<\alpha<1$
, assume that
$1/2<\alpha<1$
, assume that
 $\textbf{x}\in A_{\alpha,n}$
. Then there are positive constants
$\textbf{x}\in A_{\alpha,n}$
. Then there are positive constants
 $C\,:\!=\,C(x_1,\mu,\alpha)$
and
$C\,:\!=\,C(x_1,\mu,\alpha)$
and
 $c\,:\!=\,c(x_1,\mu,\alpha)$
such that
$c\,:\!=\,c(x_1,\mu,\alpha)$
such that
 \begin{equation}\mathbb{P}_{\textbf{x}}\left[\max\limits_{\lceil{\phi(n)}\rceil \leqslant k \leqslant n}\left|S_{n,k}-\left(\frac{k}{n} \right)^{\chi}\right|\leqslant \delta_n \right] \geqslant 1-\varepsilon_n,\end{equation}
\begin{equation}\mathbb{P}_{\textbf{x}}\left[\max\limits_{\lceil{\phi(n)}\rceil \leqslant k \leqslant n}\left|S_{n,k}-\left(\frac{k}{n} \right)^{\chi}\right|\leqslant \delta_n \right] \geqslant 1-\varepsilon_n,\end{equation}
where
 $\phi(n)=\Omega(n^\chi)$
,
$\phi(n)=\Omega(n^\chi)$
,
 $\delta_n\,:\!=\,Cn^{-\chi(1-\alpha)/4}$
, and
$\delta_n\,:\!=\,Cn^{-\chi(1-\alpha)/4}$
, and
 $\varepsilon_n\,:\!=\,cn^{-\chi(1-\alpha)/2}$
.
$\varepsilon_n\,:\!=\,cn^{-\chi(1-\alpha)/2}$
.
Remark 2. For vertices whose arrival time is of order at most
 $n^\chi$
, the upper bound
$n^\chi$
, the upper bound
 $\delta_n$
in Lemma 2 is meaningful only when
$\delta_n$
in Lemma 2 is meaningful only when
 $\chi>(\alpha+3)/4$
, as otherwise
$\chi>(\alpha+3)/4$
, as otherwise
 $\delta_n$
is of order greater than
$\delta_n$
is of order greater than
 $(k/n)^\chi$
. However, the bound is still useful for studying the local weak limit of the PA tree, as w.h.p. we do not see vertices with arrival times that are o(n) in the local neighbourhood of the uniformly chosen vertex.
$(k/n)^\chi$
. However, the bound is still useful for studying the local weak limit of the PA tree, as w.h.p. we do not see vertices with arrival times that are o(n) in the local neighbourhood of the uniformly chosen vertex.
The last lemma is an extension of [Reference Berger, Borgs, Chayes and Saberi4, Lemma 3.2]. It says that on the event
 $A_{\alpha,n}$
, we can construct the urn tree by generating suitable gamma variables in place of
$A_{\alpha,n}$
, we can construct the urn tree by generating suitable gamma variables in place of
 $B_j$
in (1.8). These gamma variables are comparable to
$B_j$
in (1.8). These gamma variables are comparable to
 $Z_{\bar v}$
in the construction of the
$Z_{\bar v}$
in the construction of the
 $\pi$
-Pólya point tree (Definition 3), after assigning Ulam–Harris labels to the vertices of the urn tree. To state the result, we recall a distributional identity. Independently of
$\pi$
-Pólya point tree (Definition 3), after assigning Ulam–Harris labels to the vertices of the urn tree. To state the result, we recall a distributional identity. Independently of
 $B_j$
, let
$B_j$
, let
 $\big(\big(\mathcal{Z}_j,\mathcal{\widetilde Z}_{j-1}\big), 2\leqslant j\leqslant n\big)$
be conditionally independent variables such that
$\big(\big(\mathcal{Z}_j,\mathcal{\widetilde Z}_{j-1}\big), 2\leqslant j\leqslant n\big)$
be conditionally independent variables such that
 $\mathcal{Z}_j\sim \textrm{Gamma}(x_j,1)$
and
$\mathcal{Z}_j\sim \textrm{Gamma}(x_j,1)$
and
 $\mathcal{\widetilde Z}_j \sim \textrm{Gamma}(T_j+j,1)$
, where
$\mathcal{\widetilde Z}_j \sim \textrm{Gamma}(T_j+j,1)$
, where
 $T_j\,:\!=\,\sum^j_{i=1}x_i$
. Then by the beta–gamma algebra (see e.g. [Reference Lukacs26]),
$T_j\,:\!=\,\sum^j_{i=1}x_i$
. Then by the beta–gamma algebra (see e.g. [Reference Lukacs26]),
 \begin{equation*}\Big(B_j, \mathcal{\widetilde Z}_{j-1}+\mathcal{Z}_{j}\Big)=_d \left(\frac{\mathcal{Z}_{j}}{\mathcal{Z}_{j}+\mathcal{\widetilde Z}_{j-1}}, \mathcal{\widetilde Z}_{j-1}+\mathcal{Z}_{j}\right) \quad \text{for $2\leqslant j\leqslant n$,}\end{equation*}
\begin{equation*}\Big(B_j, \mathcal{\widetilde Z}_{j-1}+\mathcal{Z}_{j}\Big)=_d \left(\frac{\mathcal{Z}_{j}}{\mathcal{Z}_{j}+\mathcal{\widetilde Z}_{j-1}}, \mathcal{\widetilde Z}_{j-1}+\mathcal{Z}_{j}\right) \quad \text{for $2\leqslant j\leqslant n$,}\end{equation*}
where the two random variables on the right-hand side are independent. Using the law of large numbers, we prove the following.
Lemma 3. Given a positive integer n and
 $1/2<\alpha<3/4$
, let
$1/2<\alpha<3/4$
, let
 $\mathcal{Z}_{j}$
and
$\mathcal{Z}_{j}$
and
 $\mathcal{\widetilde Z}_j$
be as above. Define the event
$\mathcal{\widetilde Z}_j$
be as above. Define the event
 \begin{equation}E_{\varepsilon,j}\,:\!=\, \left\{\left|\frac{\mathcal{Z}_{j}}{\mathcal{Z}_{j}+\mathcal{\widetilde Z}_{j-1}}-\frac{\mathcal{Z}_{j}}{(\mu+1)j}\right|\leqslant \frac{\mathcal{Z}_{j}}{(\mu+1)j}\varepsilon\right\} \quad for\ 2\leqslant j\leqslant n.\end{equation}
\begin{equation}E_{\varepsilon,j}\,:\!=\, \left\{\left|\frac{\mathcal{Z}_{j}}{\mathcal{Z}_{j}+\mathcal{\widetilde Z}_{j-1}}-\frac{\mathcal{Z}_{j}}{(\mu+1)j}\right|\leqslant \frac{\mathcal{Z}_{j}}{(\mu+1)j}\varepsilon\right\} \quad for\ 2\leqslant j\leqslant n.\end{equation}
When
 $\textbf{x}\in A_{\alpha,n}$
, there is a positive constant
$\textbf{x}\in A_{\alpha,n}$
, there is a positive constant
 $C\,:\!=\,C(x_1,\alpha,\mu)$
such that
$C\,:\!=\,C(x_1,\alpha,\mu)$
such that
 \begin{equation}\mathbb{P}_{\textbf{x}}\Bigg[\bigcap^n_{j= \lceil{\phi(n)}\rceil}E_{\varepsilon,j} \Bigg]\geqslant 1-C(1+\varepsilon)^4\varepsilon^{-4}n^{\chi(4\alpha-3)},\end{equation}
\begin{equation}\mathbb{P}_{\textbf{x}}\Bigg[\bigcap^n_{j= \lceil{\phi(n)}\rceil}E_{\varepsilon,j} \Bigg]\geqslant 1-C(1+\varepsilon)^4\varepsilon^{-4}n^{\chi(4\alpha-3)},\end{equation}
where
 $\phi(n)=\Omega(n^\chi)$
. In addition,
$\phi(n)=\Omega(n^\chi)$
. In addition,
 \begin{equation}\mathbb{P}_{\textbf{x}}\Bigg[\bigcap^n_{j= \lceil{\phi(n)}\rceil} \big\{\mathcal{Z}_{j}\leqslant j^{1/2}\big\}\Bigg] \geqslant 1-\sum^n_{j= \lceil{\phi(n)}\rceil} j^{-2} \prod^{3}_{\ell=0} (x_j+\ell),\end{equation}
\begin{equation}\mathbb{P}_{\textbf{x}}\Bigg[\bigcap^n_{j= \lceil{\phi(n)}\rceil} \big\{\mathcal{Z}_{j}\leqslant j^{1/2}\big\}\Bigg] \geqslant 1-\sum^n_{j= \lceil{\phi(n)}\rceil} j^{-2} \prod^{3}_{\ell=0} (x_j+\ell),\end{equation}
and if
 $x_i \in (0,\kappa]$
for all
$x_i \in (0,\kappa]$
for all
 $i\geqslant 2$
, then there is a positive constant C such that
$i\geqslant 2$
, then there is a positive constant C such that
 \begin{equation}\mathbb{P}_{\textbf{x}}\Bigg[\bigcap^n_{j= \lceil{\phi(n)}\rceil} \big\{\mathcal{Z}_{j}\leqslant j^{1/2}\big\}\Bigg]\geqslant 1- C \kappa^4 n^{-\chi}.\end{equation}
\begin{equation}\mathbb{P}_{\textbf{x}}\Bigg[\bigcap^n_{j= \lceil{\phi(n)}\rceil} \big\{\mathcal{Z}_{j}\leqslant j^{1/2}\big\}\Bigg]\geqslant 1- C \kappa^4 n^{-\chi}.\end{equation}
3. Offspring distributions of the type-L and type-R parents in the urn tree
Recall that a vertex in the local neighbourhood of the uniformly chosen vertex
 $k_0$
in the PA tree is a type-L parent if it lies on the path from the uniformly chosen vertex to the initial vertex; otherwise it is a type-R parent. In this section, we state two main lemmas for the
$k_0$
in the PA tree is a type-L parent if it lies on the path from the uniformly chosen vertex to the initial vertex; otherwise it is a type-R parent. In this section, we state two main lemmas for the
 $(\textbf{x},n)$
-Pólya urn tree (Definition 4). In Lemma 5, for the root
$(\textbf{x},n)$
-Pólya urn tree (Definition 4). In Lemma 5, for the root
 $k_0$
or any type-L or type-R parent in the subsequent generations of the local neighbourhood, we encode its type-R children in a suitable Bernoulli sequence that we introduce later. In Lemma 6, we construct the distribution of the type-L children of the uniformly chosen vertex and any type-L parent in the subsequent generations. For vertex
$k_0$
or any type-L or type-R parent in the subsequent generations of the local neighbourhood, we encode its type-R children in a suitable Bernoulli sequence that we introduce later. In Lemma 6, we construct the distribution of the type-L children of the uniformly chosen vertex and any type-L parent in the subsequent generations. For vertex
 $k_0$
, these results follow immediately from the urn representation in Definition 4 and Theorem 3. For the non-root vertices, these lemmas cannot be deduced from Definition 4. Instead, we need an urn representation that accounts for the conditioning effects of the edges uncovered in the neighbourhood exploration. For more detail on this variant, we refer to the supplementary article [Reference Lo24, Section 10].
$k_0$
, these results follow immediately from the urn representation in Definition 4 and Theorem 3. For the non-root vertices, these lemmas cannot be deduced from Definition 4. Instead, we need an urn representation that accounts for the conditioning effects of the edges uncovered in the neighbourhood exploration. For more detail on this variant, we refer to the supplementary article [Reference Lo24, Section 10].
3.1. Breadth-first search
To construct the offspring distributions, we need to keep track of the vertices that we discover in the local neighbourhood. For this purpose, we have to precisely define the exploration process. We start with a definition.
Definition 5. (Breadth-first order.) Write
 $\bar w <_{UH} \bar y$
if the Ulam–Harris label
$\bar w <_{UH} \bar y$
if the Ulam–Harris label
 $\bar w$
is smaller than
$\bar w$
is smaller than
 $\bar y$
in the breadth-first order. This means that either
$\bar y$
in the breadth-first order. This means that either
 $|\bar w|< |\bar y|$
, or when
$|\bar w|< |\bar y|$
, or when
 $\bar w=(0,w_1,\ldots,w_q)$
and
$\bar w=(0,w_1,\ldots,w_q)$
and
 $\bar y=(0,v_1,\ldots,v_q)$
,
$\bar y=(0,v_1,\ldots,v_q)$
,
 $w_j<v_j$
for
$w_j<v_j$
for
 $j=\min\{l\,:\, v_l\not= w_l\}$
. If
$j=\min\{l\,:\, v_l\not= w_l\}$
. If
 $\bar w$
is either smaller than or equal to
$\bar w$
is either smaller than or equal to
 $\bar y$
in the breadth-first order, then we write
$\bar y$
in the breadth-first order, then we write
 $\bar w \leqslant_{UH} \bar y$
.
$\bar w \leqslant_{UH} \bar y$
.
As examples, we have
 $(0,2,3)<_{UH} (0,1,1,1)$
and
$(0,2,3)<_{UH} (0,1,1,1)$
and
 $(0,3,1,5)<_{UH} (0,3,4,2)$
. We run a breadth-first search on the
$(0,3,1,5)<_{UH} (0,3,4,2)$
. We run a breadth-first search on the
 $(\textbf{x},n)$
-Pólya urn tree
$(\textbf{x},n)$
-Pólya urn tree
 $G_n$
as follows.
$G_n$
as follows.
Definition 6. (Breadth-first search (BFS).) A BFS of
 $G_n$
splits the vertex set
$G_n$
splits the vertex set
 $V(G_n)=[n]$
into the random subsets
$V(G_n)=[n]$
into the random subsets
 $(\mathcal{A}_t, \mathcal{P}_t, \mathcal{N}_t)_{t\geqslant 0}$
as follows, where the letters respectively stand for active, probed, and neutral. We initialise the search with
$(\mathcal{A}_t, \mathcal{P}_t, \mathcal{N}_t)_{t\geqslant 0}$
as follows, where the letters respectively stand for active, probed, and neutral. We initialise the search with
 \begin{equation*}(\mathcal{A}_0, \mathcal{P}_0, \mathcal{N}_0)=(\{k_0\}, \varnothing, V(G_n)\setminus\{k_0\}),\end{equation*}
\begin{equation*}(\mathcal{A}_0, \mathcal{P}_0, \mathcal{N}_0)=(\{k_0\}, \varnothing, V(G_n)\setminus\{k_0\}),\end{equation*}
where
 $k_0$
is uniform in [n]. Given
$k_0$
is uniform in [n]. Given
 $(\mathcal{A}_{t-1}, \mathcal{P}_{t-1}, \mathcal{N}_{t-1})$
, where each vertex in
$(\mathcal{A}_{t-1}, \mathcal{P}_{t-1}, \mathcal{N}_{t-1})$
, where each vertex in
 $\mathcal{A}_{t-1}\cup\mathcal{P}_{t-1}$
already receives an additional Ulam–Harris label of the form
$\mathcal{A}_{t-1}\cup\mathcal{P}_{t-1}$
already receives an additional Ulam–Harris label of the form
 $\bar w$
,
$\bar w$
,
 $(\mathcal{A}_t, \mathcal{P}_t, \mathcal{N}_t)$
is generated as follows. Let
$(\mathcal{A}_t, \mathcal{P}_t, \mathcal{N}_t)$
is generated as follows. Let
 $v[1]=k_0$
, and let
$v[1]=k_0$
, and let
 $v[t]\in \mathbb{N}$
be the vertex in
$v[t]\in \mathbb{N}$
be the vertex in
 $\mathcal{A}_{t-1}$
that is the smallest in the breadth-first order:
$\mathcal{A}_{t-1}$
that is the smallest in the breadth-first order:
 \begin{equation}v[t]=k_{\bar y}\in \mathcal{A}_{t-1} \quad\text{if $\bar y<_{UH} \bar w$ for all $k_{\bar w}\in \mathcal{A}_{t-1}\setminus\{k_{\bar y}\}$.}\end{equation}
\begin{equation}v[t]=k_{\bar y}\in \mathcal{A}_{t-1} \quad\text{if $\bar y<_{UH} \bar w$ for all $k_{\bar w}\in \mathcal{A}_{t-1}\setminus\{k_{\bar y}\}$.}\end{equation}
Note that the Ulam–Harris labels appear as subscripts. Denote by
 $\mathcal{D}_t$
the set of vertices in
$\mathcal{D}_t$
the set of vertices in
 $\mathcal{N}_{t-1}$
that either receive an incoming edge from v[t] or send an outgoing edge to v[t]:
$\mathcal{N}_{t-1}$
that either receive an incoming edge from v[t] or send an outgoing edge to v[t]:
 \begin{equation*}\mathcal{D}_t \,:\!=\,\{j\in \mathcal{N}_{t-1}\,:\,\{j,v[t]\}\text{ or }\{v[t],j\}\in E(G_n)\},\end{equation*}
\begin{equation*}\mathcal{D}_t \,:\!=\,\{j\in \mathcal{N}_{t-1}\,:\,\{j,v[t]\}\text{ or }\{v[t],j\}\in E(G_n)\},\end{equation*}
where
 $\{i,j\}$
is the edge directed from vertex j to vertex
$\{i,j\}$
is the edge directed from vertex j to vertex
 $i<j$
. Then in the tth exploration step, we probe vertex v[t] by marking the neutral vertices attached to v[t] as active. That is,
$i<j$
. Then in the tth exploration step, we probe vertex v[t] by marking the neutral vertices attached to v[t] as active. That is,
 \begin{equation}(\mathcal{A}_t, \mathcal{P}_t, \mathcal{N}_t)=(\mathcal{A}_{t-1}\setminus\{v[t]\}\cup \mathcal{D}_t, \mathcal{P}_{t-1}\cup\{v[t]\}, \mathcal{N}_{t-1}\setminus \mathcal{D}_t),\end{equation}
\begin{equation}(\mathcal{A}_t, \mathcal{P}_t, \mathcal{N}_t)=(\mathcal{A}_{t-1}\setminus\{v[t]\}\cup \mathcal{D}_t, \mathcal{P}_{t-1}\cup\{v[t]\}, \mathcal{N}_{t-1}\setminus \mathcal{D}_t),\end{equation}
and if
 $v[t]=k_{\bar y}$
, we use the Ulam–Harris scheme to label the newly active vertices as
$v[t]=k_{\bar y}$
, we use the Ulam–Harris scheme to label the newly active vertices as
 $k_{\bar y,j}\,:\!=\,k_{(\bar y,j)}$
,
$k_{\bar y,j}\,:\!=\,k_{(\bar y,j)}$
,
 $j\in \mathbb{N}$
, in increasing order of their vertex arrival times, so that
$j\in \mathbb{N}$
, in increasing order of their vertex arrival times, so that
 $k_{\bar y,i}<k_{\bar y,j}$
for any
$k_{\bar y,i}<k_{\bar y,j}$
for any
 $i<j$
. If
$i<j$
. If
 $\mathcal{A}_{t-1}=\varnothing$
, we set
$\mathcal{A}_{t-1}=\varnothing$
, we set
 $(\mathcal{A}_t, \mathcal{P}_t, \mathcal{N}_t)=(\mathcal{A}_{t-1}, \mathcal{P}_{t-1}, \mathcal{N}_{t-1})$
.
$(\mathcal{A}_t, \mathcal{P}_t, \mathcal{N}_t)=(\mathcal{A}_{t-1}, \mathcal{P}_{t-1}, \mathcal{N}_{t-1})$
.
The characterisation of the BFS above is standard, and more details can be found in works such as [Reference Van der Hofstad19, Chapter 4] and [Reference Karp23]. The vertex labelling v[t] is very useful for the construction here, as the offspring distribution of v[t] depends on the vertex partition
 $(\mathcal{A}_{t-1}, \mathcal{P}_{t-1}, \mathcal{N}_{t-1})$
, whereas the vertex arrival times are helpful for identifying a type-L vertex in the BFS (see Lemma 4 below) and constructing the offspring distributions. On the other hand, we shall use the Ulam–Harris labels to match the vertices when we couple
$(\mathcal{A}_{t-1}, \mathcal{P}_{t-1}, \mathcal{N}_{t-1})$
, whereas the vertex arrival times are helpful for identifying a type-L vertex in the BFS (see Lemma 4 below) and constructing the offspring distributions. On the other hand, we shall use the Ulam–Harris labels to match the vertices when we couple
 $G_n$
and in the
$G_n$
and in the
 $\pi$
-Pólya point tree (Definition 3). Hereafter we ignore the possibility that
$\pi$
-Pólya point tree (Definition 3). Hereafter we ignore the possibility that
 $v[t]=1$
, because when t (or equivalently the number of discovered vertices) is not too large, the probability that
$v[t]=1$
, because when t (or equivalently the number of discovered vertices) is not too large, the probability that
 $v[t]=o(n)$
tends to zero as
$v[t]=o(n)$
tends to zero as
 $n\to\infty$
. For
$n\to\infty$
. For
 $t\geqslant 1$
, let
$t\geqslant 1$
, let
 $v^{(op)}[t]$
(resp.
$v^{(op)}[t]$
(resp.
 $v^{(oa)}[t]$
) be the vertex in
$v^{(oa)}[t]$
) be the vertex in
 $\mathcal{P}_{t-1}$
(resp.
$\mathcal{P}_{t-1}$
(resp.
 $\mathcal{A}_{t-1}$
) that has the earliest arrival time, where op and oa stand for oldest probed and oldest active. That is,
$\mathcal{A}_{t-1}$
) that has the earliest arrival time, where op and oa stand for oldest probed and oldest active. That is,
 \begin{equation}v^{(op)}[t]\,:\!=\,\min\{ j\,:\, j\in \mathcal{P}_{t-1}\}\quad\text{and}\quad v^{(oa)}[t]\,:\!=\,\min\{ j\,:\, j\in \mathcal{A}_{t-1}\}.\end{equation}
\begin{equation}v^{(op)}[t]\,:\!=\,\min\{ j\,:\, j\in \mathcal{P}_{t-1}\}\quad\text{and}\quad v^{(oa)}[t]\,:\!=\,\min\{ j\,:\, j\in \mathcal{A}_{t-1}\}.\end{equation}
3.2. Construction of the offspring distributions
To distinguish the urn tree
 $G_n$
from the other models, we apply Ulam–Harris labels of the form
$G_n$
from the other models, we apply Ulam–Harris labels of the form
 $k^{(\textrm{u})}_{\bar y}$
to its vertices; the superscript
$k^{(\textrm{u})}_{\bar y}$
to its vertices; the superscript
 $^{(\textrm{u})}$
stands for ‘urn’. An example is given in Figure 4. Define
$^{(\textrm{u})}$
stands for ‘urn’. An example is given in Figure 4. Define
noting that
 $R^{(\textrm{u})}_0$
is the in-degree of the uniformly chosen vertex
$R^{(\textrm{u})}_0$
is the in-degree of the uniformly chosen vertex
 $k^{(\textrm{u})}_0$
in
$k^{(\textrm{u})}_0$
in
 $G_n$
. Before we proceed further, we prove a simple lemma to help us identify when v[t] in (3.1) is a type-L vertex, which will be useful for constructing the offspring distributions later. The result can be understood as a consequence of the facts that in the tree setting, we uncover a new active type-L vertex immediately after we probe an active type-L vertex, and that the oldest probed vertex cannot be rediscovered as a child of another type-R vertex in the subsequent explorations.
$G_n$
. Before we proceed further, we prove a simple lemma to help us identify when v[t] in (3.1) is a type-L vertex, which will be useful for constructing the offspring distributions later. The result can be understood as a consequence of the facts that in the tree setting, we uncover a new active type-L vertex immediately after we probe an active type-L vertex, and that the oldest probed vertex cannot be rediscovered as a child of another type-R vertex in the subsequent explorations.

Figure 4. Each level corresponds to each time step of the BFS
 $(\textbf{x},n)$
-Pólya urn tree
$(\textbf{x},n)$
-Pólya urn tree
 $G_n$
. The vertices are arranged from left to right in increasing order of their arrival times. The small and large dots correspond to the probed and active vertices, respectively. The densely dotted path joins the uniformly chosen vertex and the discovered type-L vertices. Here,
$G_n$
. The vertices are arranged from left to right in increasing order of their arrival times. The small and large dots correspond to the probed and active vertices, respectively. The densely dotted path joins the uniformly chosen vertex and the discovered type-L vertices. Here,
 $\mathcal{P}_{3}=\big\{k^{(\textrm{u})}_{0},k^{(\textrm{u})}_{0,1},k^{(\textrm{u})}_{0,2}\big\}$
,
$\mathcal{P}_{3}=\big\{k^{(\textrm{u})}_{0},k^{(\textrm{u})}_{0,1},k^{(\textrm{u})}_{0,2}\big\}$
,
 $\mathcal{A}_{3}=\big\{k^{(\textrm{u})}_{0,3},k^{(\textrm{u})}_{0,1,1},k^{(\textrm{u})}_{0,1,2},k^{(\textrm{u})}_{0,1,3},k^{(\textrm{u})}_{0,2,1}\big\}$
,
$\mathcal{A}_{3}=\big\{k^{(\textrm{u})}_{0,3},k^{(\textrm{u})}_{0,1,1},k^{(\textrm{u})}_{0,1,2},k^{(\textrm{u})}_{0,1,3},k^{(\textrm{u})}_{0,2,1}\big\}$
,
 $v[4]=k^{(\textrm{u})}_{0,3}$
,
$v[4]=k^{(\textrm{u})}_{0,3}$
,
 $v^{(op)}[4]=k^{(\textrm{u})}_{0,1}$
, and
$v^{(op)}[4]=k^{(\textrm{u})}_{0,1}$
, and
 $v^{(oa)}[4]=k^{(\textrm{u})}_{0,1,1}$
.
$v^{(oa)}[4]=k^{(\textrm{u})}_{0,1,1}$
.
Lemma 4. Assume that
 $\mathcal{A}_{t-1}\cup \mathcal{P}_{t-1}$
does not contain vertex 1. If
$\mathcal{A}_{t-1}\cup \mathcal{P}_{t-1}$
does not contain vertex 1. If
 $t=2$
, then
$t=2$
, then
 $v^{(op)}[2]=k^{(\textrm{u})}_0$
and
$v^{(op)}[2]=k^{(\textrm{u})}_0$
and
 $v^{(oa)}[2]=k^{(\textrm{u})}_{0,1}$
, while if
$v^{(oa)}[2]=k^{(\textrm{u})}_{0,1}$
, while if
 $2<i\leqslant t$
, then
$2<i\leqslant t$
, then
 $v^{(op)}[i]$
and
$v^{(op)}[i]$
and
 $v^{(oa)}[i]$
are type-L children, where
$v^{(oa)}[i]$
are type-L children, where
 $v^{(oa)}[i]$
is the only type-L child in
$v^{(oa)}[i]$
is the only type-L child in
 $\mathcal{A}_{i-1}$
, and it receives an incoming edge from
$\mathcal{A}_{i-1}$
, and it receives an incoming edge from
 $v^{(op)}[i]$
.
$v^{(op)}[i]$
.
Proof. We prove the lemma by induction on
 $2\leqslant i\leqslant t$
. The base case is clear, since
$2\leqslant i\leqslant t$
. The base case is clear, since
 $\mathcal{P}_{1}=\big\{k^{(\textrm{u})}_0\big\}$
and
$\mathcal{P}_{1}=\big\{k^{(\textrm{u})}_0\big\}$
and
 $\mathcal{A}_{1}$
consists of its type-L and type-R children. Assume that the lemma holds for some
$\mathcal{A}_{1}$
consists of its type-L and type-R children. Assume that the lemma holds for some
 $2\leqslant i<t$
. If we probe a type-L child at time i, then
$2\leqslant i<t$
. If we probe a type-L child at time i, then
 $v[i]=v^{(oa)}[i]$
, and there is a vertex
$v[i]=v^{(oa)}[i]$
, and there is a vertex
 $u\in \mathcal{N}_{i-1}$
that receives the incoming edge emanating from v[i]. Hence, vertex u belongs to type L and
$u\in \mathcal{N}_{i-1}$
that receives the incoming edge emanating from v[i]. Hence, vertex u belongs to type L and
 $v^{(oa)}[i+1]=u$
. Furthermore,
$v^{(oa)}[i+1]=u$
. Furthermore,
 $v^{(op)}[i+1]=v[i]$
, as
$v^{(op)}[i+1]=v[i]$
, as
 $v^{(op)}[i]$
sends an outgoing edge to v[i] by assumption, implying
$v^{(op)}[i]$
sends an outgoing edge to v[i] by assumption, implying
 $v[i]<v^{(op)}[i]$
. If we probe a type-R vertex at time i, then
$v[i]<v^{(op)}[i]$
. If we probe a type-R vertex at time i, then
 $v[i]>v^{(oa)}[i]$
and we uncover vertices in
$v[i]>v^{(oa)}[i]$
and we uncover vertices in
 $\mathcal{N}_{i-1}$
that have later arrival times than v[i]. Setting
$\mathcal{N}_{i-1}$
that have later arrival times than v[i]. Setting
 $\mathcal{P}_{i}=\mathcal{P}_{i-1}\cup \{v[i]\}$
, we have
$\mathcal{P}_{i}=\mathcal{P}_{i-1}\cup \{v[i]\}$
, we have
 $v^{(op)}[i+1]=v^{(op)}[i]$
and
$v^{(op)}[i+1]=v^{(op)}[i]$
and
 $v^{(oa)}[i+1]=v^{(oa)}[i]$
, which are of type L.
$v^{(oa)}[i+1]=v^{(oa)}[i]$
, which are of type L.
To construct the offspring distributions for each parent in the local neighbourhood, we also need to define some notation and variables. Let
 $\mathcal{E}_0 =\varnothing$
, and for
$\mathcal{E}_0 =\varnothing$
, and for
 $t\geqslant 1$
, let
$t\geqslant 1$
, let
 $\mathcal{E}_t$
be the set of edges connecting the vertices in
$\mathcal{E}_t$
be the set of edges connecting the vertices in
 $\mathcal{A}_t \cup \mathcal{P}_t$
. Given a positive integer m, denote the set of vertices and edges in
$\mathcal{A}_t \cup \mathcal{P}_t$
. Given a positive integer m, denote the set of vertices and edges in
 $\mathcal{P}_t$
and
$\mathcal{P}_t$
and
 $\mathcal{E}_{t}$
whose arrival time in
$\mathcal{E}_{t}$
whose arrival time in
 $G_n$
is earlier than that of vertex m by
$G_n$
is earlier than that of vertex m by
 \begin{align}\mathcal{P}_{t, m}= \mathcal{P}_t\cap[m-1]\quad\text{and}\quad\mathcal{E}_{t, m}=\{\{h,i\}\in \mathcal{E}_t\,:\,i<m\},\end{align}
\begin{align}\mathcal{P}_{t, m}= \mathcal{P}_t\cap[m-1]\quad\text{and}\quad\mathcal{E}_{t, m}=\{\{h,i\}\in \mathcal{E}_t\,:\,i<m\},\end{align}
noting that
 $\{h,i\}$
is the edge directed from i to
$\{h,i\}$
is the edge directed from i to
 $h<i$
, and
$h<i$
, and
 $(\mathcal{A}_0, \mathcal{P}_0, \mathcal{N}_0)=(\{k_0\}, \varnothing, V(G_n)\setminus\{k_0\})$
and
$(\mathcal{A}_0, \mathcal{P}_0, \mathcal{N}_0)=(\{k_0\}, \varnothing, V(G_n)\setminus\{k_0\})$
and
 $\mathcal{E}_0=\varnothing$
. Below we use [t] in the notation to indicate the exploration step, and omit
$\mathcal{E}_0=\varnothing$
. Below we use [t] in the notation to indicate the exploration step, and omit
 $\textbf{x}$
for simplicity. Let
$\textbf{x}$
for simplicity. Let
 $\big(\big(\mathcal{Z}_{i}[t], \mathcal{\widetilde Z}_{i}[t]\big), 2\leqslant i\leqslant n, i\not \in \mathcal{P}_{t-1}\big)$
be independent variables, where
$\big(\big(\mathcal{Z}_{i}[t], \mathcal{\widetilde Z}_{i}[t]\big), 2\leqslant i\leqslant n, i\not \in \mathcal{P}_{t-1}\big)$
be independent variables, where
 \begin{equation}\mathcal{Z}_i[1]\sim \textrm{Gamma}(x_i,1)\quad\text{and}\quad \mathcal{\widetilde Z}_i[1]\sim \textrm{Gamma}(T_{i-1}+i-1,1),\end{equation}
\begin{equation}\mathcal{Z}_i[1]\sim \textrm{Gamma}(x_i,1)\quad\text{and}\quad \mathcal{\widetilde Z}_i[1]\sim \textrm{Gamma}(T_{i-1}+i-1,1),\end{equation}
with
 $T_i\,:\!=\,\sum^i_{j=1}x_j$
. Now, suppose that
$T_i\,:\!=\,\sum^i_{j=1}x_j$
. Now, suppose that
 $t\geqslant 2$
. Because of the size-bias effect of the edge
$t\geqslant 2$
. Because of the size-bias effect of the edge
 $\{v^{(op)}[t], v^{(oa)}[t]\}\in \mathcal{E}_{t-1}$
, we define
$\{v^{(op)}[t], v^{(oa)}[t]\}\in \mathcal{E}_{t-1}$
, we define
 \begin{align}\mathcal{Z}_{i}[t]\sim \textrm{Gamma}\big(x_{i}+\mathbb{1}\big[i=v^{(oa)}[t]\big],1\big), \quad i \in \mathcal{A}_{t-1}\cup \mathcal{N}_{t-1},\end{align}
\begin{align}\mathcal{Z}_{i}[t]\sim \textrm{Gamma}\big(x_{i}+\mathbb{1}\big[i=v^{(oa)}[t]\big],1\big), \quad i \in \mathcal{A}_{t-1}\cup \mathcal{N}_{t-1},\end{align}
so that the initial attractiveness of the type-L child
 $v^{(oa)}[t]$
is
$v^{(oa)}[t]$
is
 $x_{v^{(oa)}[t]}+1$
. The shape parameter of
$x_{v^{(oa)}[t]}+1$
. The shape parameter of
 $\mathcal{\widetilde Z}_i[t]$
defined below is the total weight of the vertices in
$\mathcal{\widetilde Z}_i[t]$
defined below is the total weight of the vertices in
 $\mathcal{A}_{t-1}\cup \mathcal{N}_{t-1}$
whose arrival time is earlier than the ith time step. This is because when a new vertex is added to the
$\mathcal{A}_{t-1}\cup \mathcal{N}_{t-1}$
whose arrival time is earlier than the ith time step. This is because when a new vertex is added to the
 $(\textbf{x},n)$
-sequential model conditional on having the edges
$(\textbf{x},n)$
-sequential model conditional on having the edges
 $\mathcal{E}_{t-1}$
, the recipient of its outgoing edge cannot be a vertex in
$\mathcal{E}_{t-1}$
, the recipient of its outgoing edge cannot be a vertex in
 $\mathcal{P}_{t-1}$
, and it is chosen with probability proportional to the current weights of the vertices in
$\mathcal{P}_{t-1}$
, and it is chosen with probability proportional to the current weights of the vertices in
 $\mathcal{A}_{t-1}\cup \mathcal{N}_{t-1}$
that arrive before the new vertex. Hence, define
$\mathcal{A}_{t-1}\cup \mathcal{N}_{t-1}$
that arrive before the new vertex. Hence, define
 \begin{align}\mathcal{\widetilde Z}_{i}[t]\sim\begin{cases}\textrm{Gamma}(T_{i-1}+i-1,1),&\text{if $2\leqslant i\leqslant v^{(oa)}[t]$;}\\\textrm{Gamma}(T_{i-1}+i,1),& \text{if $v^{(oa)}[t]<i<v^{(op)}[t]$;}\\\textrm{Gamma}\Big(T_{i-1}+i-\sum_{h\in \mathcal{P}_{t-1,i}}x_h - |\mathcal{E}_{t-1,i}|,1\Big),& \text{if $v^{(op)}[t]<i\leqslant n$.} \end{cases}\end{align}
\begin{align}\mathcal{\widetilde Z}_{i}[t]\sim\begin{cases}\textrm{Gamma}(T_{i-1}+i-1,1),&\text{if $2\leqslant i\leqslant v^{(oa)}[t]$;}\\\textrm{Gamma}(T_{i-1}+i,1),& \text{if $v^{(oa)}[t]<i<v^{(op)}[t]$;}\\\textrm{Gamma}\Big(T_{i-1}+i-\sum_{h\in \mathcal{P}_{t-1,i}}x_h - |\mathcal{E}_{t-1,i}|,1\Big),& \text{if $v^{(op)}[t]<i\leqslant n$.} \end{cases}\end{align}
Let
 $B_1[t]\,:\!=\,1$
and
$B_1[t]\,:\!=\,1$
and
 $B_i[t]\,:\!=\,0$
for
$B_i[t]\,:\!=\,0$
for
 $i \in \mathcal{P}_{t-1}$
, as the edges attached to
$i \in \mathcal{P}_{t-1}$
, as the edges attached to
 $\mathcal{P}_{t-1}$
are already determined. Furthermore, define
$\mathcal{P}_{t-1}$
are already determined. Furthermore, define
 \begin{equation}B_i[t]\,:\!=\,\frac{\mathcal{Z}_i[t]}{\mathcal{Z}_i[t]+\mathcal{\widetilde Z}_i[t]}\quad \text{for $i \in \mathcal{A}_{t-1}\cup \mathcal{N}_{t-1}$}.\end{equation}
\begin{equation}B_i[t]\,:\!=\,\frac{\mathcal{Z}_i[t]}{\mathcal{Z}_i[t]+\mathcal{\widetilde Z}_i[t]}\quad \text{for $i \in \mathcal{A}_{t-1}\cup \mathcal{N}_{t-1}$}.\end{equation}
Let
 $S_{n,0}[t]\,:\!=\,0$
,
$S_{n,0}[t]\,:\!=\,0$
,
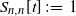 $S_{n,n}[t]\,:\!=\,1$
, and
$S_{n,n}[t]\,:\!=\,1$
, and
 \begin{equation}S_{n,i}[t]\,:\!=\,\prod^n_{j=i+1}\big(1-B_j[t]\big)= \prod^n_{j=i+1;j\not \in \mathcal{P}_{t-1}}\big(1-B_j[t]\big)\quad\text{for $1\leqslant i\leqslant n-1$,}\end{equation}
\begin{equation}S_{n,i}[t]\,:\!=\,\prod^n_{j=i+1}\big(1-B_j[t]\big)= \prod^n_{j=i+1;j\not \in \mathcal{P}_{t-1}}\big(1-B_j[t]\big)\quad\text{for $1\leqslant i\leqslant n-1$,}\end{equation}
where the second equality is true because
 $B_i[t]=0$
for
$B_i[t]=0$
for
 $i\in \mathcal{P}_{t-1}$
. Observe that by the beta–gamma algebra,
$i\in \mathcal{P}_{t-1}$
. Observe that by the beta–gamma algebra,
 $(B_i[1], 1\leqslant i\leqslant n)=_d (B_i,1\leqslant i\leqslant n)$
and
$(B_i[1], 1\leqslant i\leqslant n)=_d (B_i,1\leqslant i\leqslant n)$
and
 $(S_{n,i}[1],1\leqslant i\leqslant n)=_d (S_{n,i},1\leqslant i\leqslant n)$
, where
$(S_{n,i}[1],1\leqslant i\leqslant n)=_d (S_{n,i},1\leqslant i\leqslant n)$
, where
 $B_i$
and
$B_i$
and
 $S_{n,i}$
are as in (1.8) and (1.9). For
$S_{n,i}$
are as in (1.8) and (1.9). For
 $t\geqslant 2$
,
$t\geqslant 2$
,
 $(B_i[t], 1\leqslant i\leqslant n)$
are the beta variables in the urn representation of the
$(B_i[t], 1\leqslant i\leqslant n)$
are the beta variables in the urn representation of the
 $(\textbf{x},n)$
-sequential model, conditional on having the edges
$(\textbf{x},n)$
-sequential model, conditional on having the edges
 $\mathcal{E}_{t-1}$
; see [Reference Lo24, Section 10] for details. We construct a Bernoulli sequence that encodes the type-R children of vertex v[t] as follows. For
$\mathcal{E}_{t-1}$
; see [Reference Lo24, Section 10] for details. We construct a Bernoulli sequence that encodes the type-R children of vertex v[t] as follows. For
 $j\in \mathcal{N}_{t-1}$
and
$j\in \mathcal{N}_{t-1}$
and
 $v[t]+1\leqslant j\leqslant n$
, let
$v[t]+1\leqslant j\leqslant n$
, let
 $\mathbb{1}_{\textrm{R}}[j\to v[t]]$
be an indicator variable that takes value one if and only if vertex j sends an outgoing edge to v[t]; for
$\mathbb{1}_{\textrm{R}}[j\to v[t]]$
be an indicator variable that takes value one if and only if vertex j sends an outgoing edge to v[t]; for
 $j\not \in \mathcal{N}_{t-1}$
, let
$j\not \in \mathcal{N}_{t-1}$
, let
 $\mathbb{1}_{\textrm{R}}[j\to v[t]]=0$
with probability one, since the recipient of the incoming edge from vertex j is already in
$\mathbb{1}_{\textrm{R}}[j\to v[t]]=0$
with probability one, since the recipient of the incoming edge from vertex j is already in
 $\mathcal{P}_{t-1}$
. Note that if
$\mathcal{P}_{t-1}$
. Note that if
 $v[t]=k^{(\textrm{u})}_{\bar y}$
, then
$v[t]=k^{(\textrm{u})}_{\bar y}$
, then
 $R^{(\textrm{u})}_{\bar y}$
in (3.4) is equal to
$R^{(\textrm{u})}_{\bar y}$
in (3.4) is equal to
 $\sum^n_{j=v[t]+1}\mathbb{1}_{\textrm{R}}[j\to v[t]]$
. We also assume
$\sum^n_{j=v[t]+1}\mathbb{1}_{\textrm{R}}[j\to v[t]]$
. We also assume
 $\mathcal{N}_{t-1}\not =\varnothing$
, because for large n, w.h.p. the local neighbourhood of vertex
$\mathcal{N}_{t-1}\not =\varnothing$
, because for large n, w.h.p. the local neighbourhood of vertex
 $k_0$
does not contain all the vertices of
$k_0$
does not contain all the vertices of
 $G_n$
. To state the distribution of
$G_n$
. To state the distribution of
 $(\mathbb{1}_{\textrm{R}}[j\to v[t]],v[t]+1\leqslant j\leqslant n)$
, we use (3.9) and (3.10) to define
$(\mathbb{1}_{\textrm{R}}[j\to v[t]],v[t]+1\leqslant j\leqslant n)$
, we use (3.9) and (3.10) to define
 \begin{align}P_{j\to v[t]} \,:\!=\,\begin{cases}\frac{S_{n,v[t]}[t]}{ S_{n,j-1}[t]} B_{v[t]}[t], &\text{if $j \in \{v[t]+1,\ldots,n\}\cap\mathcal{N}_{t-1}$;}\\[6pt]0, &\text{if $j \in \{v[t]+1,\ldots,n\}\setminus \mathcal{N}_{t-1}$.}\end{cases}\end{align}
\begin{align}P_{j\to v[t]} \,:\!=\,\begin{cases}\frac{S_{n,v[t]}[t]}{ S_{n,j-1}[t]} B_{v[t]}[t], &\text{if $j \in \{v[t]+1,\ldots,n\}\cap\mathcal{N}_{t-1}$;}\\[6pt]0, &\text{if $j \in \{v[t]+1,\ldots,n\}\setminus \mathcal{N}_{t-1}$.}\end{cases}\end{align}
Definition 7. Given
 $(\mathcal{A}_{t-1},\mathcal{P}_{t-1},\mathcal{N}_{t-1})$
and
$(\mathcal{A}_{t-1},\mathcal{P}_{t-1},\mathcal{N}_{t-1})$
and
 $(B_j[t],v[t]\leqslant j\leqslant n)$
, let
$(B_j[t],v[t]\leqslant j\leqslant n)$
, let
 $Y_{j\to v[t]}$
,
$Y_{j\to v[t]}$
,
 $v[t]+1\leqslant j\leqslant n$
be conditionally independent Bernoulli variables, each with parameter
$v[t]+1\leqslant j\leqslant n$
be conditionally independent Bernoulli variables, each with parameter
 $P_{j\to v[t]}$
. Define this Bernoulli sequence by the random vector
$P_{j\to v[t]}$
. Define this Bernoulli sequence by the random vector
 \begin{equation*}\textbf{Y}^{(v[t],n)}_{\textrm{Be}}\,:\!=\,\left(Y_{(v[t]+1)\to v[t]},Y_{(v[t]+2)\to v[t]},\ldots,Y_{n\to v[t]}\right).\end{equation*}
\begin{equation*}\textbf{Y}^{(v[t],n)}_{\textrm{Be}}\,:\!=\,\left(Y_{(v[t]+1)\to v[t]},Y_{(v[t]+2)\to v[t]},\ldots,Y_{n\to v[t]}\right).\end{equation*}
With the preparations above, we are ready to state the main results of this section. For
 $t\geqslant 2$
, the following lemmas are immediate consequences of the urn representation of the
$t\geqslant 2$
, the following lemmas are immediate consequences of the urn representation of the
 $(\textbf{x},n)$
-sequential model conditional on the discovered edges; see [Reference Lo24, Section 10]. For
$(\textbf{x},n)$
-sequential model conditional on the discovered edges; see [Reference Lo24, Section 10]. For
 $t=1$
, they follow directly from Theorem 3. The first lemma states that we can encode the type-R children of the uniformly chosen vertex (the root) or a non-root parent in the local neighbourhood in a Bernoulli sequence; see Figure 3 in the case of the root.
$t=1$
, they follow directly from Theorem 3. The first lemma states that we can encode the type-R children of the uniformly chosen vertex (the root) or a non-root parent in the local neighbourhood in a Bernoulli sequence; see Figure 3 in the case of the root.
Lemma 5. Assume that
 $\mathcal{N}_{t-1} \not= \varnothing$
and
$\mathcal{N}_{t-1} \not= \varnothing$
and
 $\mathcal{A}_{t-1}\cup\mathcal{P}_{t-1}$
does not contain vertex 1. Then given
$\mathcal{A}_{t-1}\cup\mathcal{P}_{t-1}$
does not contain vertex 1. Then given
 $\big(\mathcal{A}_{t-1},\mathcal{P}_{t-1},\mathcal{N}_{t-1}\big)$
, the random vector
$\big(\mathcal{A}_{t-1},\mathcal{P}_{t-1},\mathcal{N}_{t-1}\big)$
, the random vector
 $\big(\mathbb{1}_{\textrm{R}}[j\to v[t]],v[t]+1\leqslant j\leqslant n\big)$
is distributed as
$\big(\mathbb{1}_{\textrm{R}}[j\to v[t]],v[t]+1\leqslant j\leqslant n\big)$
is distributed as
 $\textbf{Y}^{(v[t],n)}_{\textrm{Be}}$
.
$\textbf{Y}^{(v[t],n)}_{\textrm{Be}}$
.
Remark 3. When
 $|\mathcal{E}_{t-1}|=o(n)$
for some
$|\mathcal{E}_{t-1}|=o(n)$
for some
 $t\geqslant 2$
,
$t\geqslant 2$
,
 $P_{j\to v[t]}$
in (3.11) is approximately distributed as
$P_{j\to v[t]}$
in (3.11) is approximately distributed as
 $\big(S_{n,v[t]}/S_{n,j-1}\big)B_{v[t]}$
for n sufficiently large, with
$\big(S_{n,v[t]}/S_{n,j-1}\big)B_{v[t]}$
for n sufficiently large, with
 $B_j$
and
$B_j$
and
 $S_{n,j}$
as in (1.8) and (1.9). As we shall see later in the proof,
$S_{n,j}$
as in (1.8) and (1.9). As we shall see later in the proof,
 $|\mathcal{E}_{t-1}|=o(n)$
indeed occurs w.h.p.
$|\mathcal{E}_{t-1}|=o(n)$
indeed occurs w.h.p.
The next lemma states that when v[t] is the uniformly chosen vertex or a type-L parent, we can use the beta variables in (3.9) to obtain the distribution of the type-L child of v[t]. Observe that
 $(B_j[t],2\leqslant j\leqslant v[t]-1)$
does not appear in Definition 7, but is required for this purpose.
$(B_j[t],2\leqslant j\leqslant v[t]-1)$
does not appear in Definition 7, but is required for this purpose.
Lemma 6. Assume that
 $\mathcal{N}_{t-1} \not= \varnothing$
,
$\mathcal{N}_{t-1} \not= \varnothing$
,
 $\mathcal{A}_{t-1}\cup\mathcal{P}_{t-1}$
does not contain vertex 1, and v[t] is either the uniformly chosen vertex or of type L. Given
$\mathcal{A}_{t-1}\cup\mathcal{P}_{t-1}$
does not contain vertex 1, and v[t] is either the uniformly chosen vertex or of type L. Given
 $(\mathcal{A}_{t-1},\mathcal{P}_{t-1}, \mathcal{N}_{t-1})$
, let
$(\mathcal{A}_{t-1},\mathcal{P}_{t-1}, \mathcal{N}_{t-1})$
, let
 $S_{n,j}[t]$
be as in (3.10), and
$S_{n,j}[t]$
be as in (3.10), and
 $U\sim \textrm{U}[0,S_{n,v[t]-1}{[t]}]$
. For
$U\sim \textrm{U}[0,S_{n,v[t]-1}{[t]}]$
. For
 $1\leqslant j\leqslant v[t]-1$
, the probability that vertex j receives the only incoming edge from v[t] is given by the probability that
$1\leqslant j\leqslant v[t]-1$
, the probability that vertex j receives the only incoming edge from v[t] is given by the probability that
 $S_{n,j-1}[t] \leqslant U < S_{n,j}[t]$
.
$S_{n,j-1}[t] \leqslant U < S_{n,j}[t]$
.
4. An intermediate tree for graph couplings
As the
 $\pi$
-Pólya point tree
$\pi$
-Pólya point tree
 $(\mathcal{T},0)$
in Definition 3 does not have vertex labels that are comparable to the vertex arrival times of the
$(\mathcal{T},0)$
in Definition 3 does not have vertex labels that are comparable to the vertex arrival times of the
 $(\textbf{x},n)$
-Pólya urn tree
$(\textbf{x},n)$
-Pólya urn tree
 $G_n$
, we define a suitable conditional analogue of the
$G_n$
, we define a suitable conditional analogue of the
 $\pi$
-Pólya point tree. We call this analogue the intermediate Pólya point tree
$\pi$
-Pólya point tree. We call this analogue the intermediate Pólya point tree
 $(\mathcal{T}_{\textbf{x},n},0)$
, where vertex 0 is its root, and the subscripts are the parameters corresponding to
$(\mathcal{T}_{\textbf{x},n},0)$
, where vertex 0 is its root, and the subscripts are the parameters corresponding to
 $\textbf{x}$
and n of
$\textbf{x}$
and n of
 $G_n$
. All the variables of
$G_n$
. All the variables of
 $(\mathcal{T}_{\textbf{x},n},0)$
have the superscript
$(\mathcal{T}_{\textbf{x},n},0)$
have the superscript
 $^{(\textrm{i})}$
(for ‘intermediate’). Each vertex of
$^{(\textrm{i})}$
(for ‘intermediate’). Each vertex of
 $(\mathcal{T}_{\textbf{x},n},0)$
has an Ulam–Harris label
$(\mathcal{T}_{\textbf{x},n},0)$
has an Ulam–Harris label
 $\bar v$
, an age
$\bar v$
, an age
 $a^{(\textrm{i})}_{\bar v}$
, and a type (except for the root), which are defined similarly as in Section 1.2 for
$a^{(\textrm{i})}_{\bar v}$
, and a type (except for the root), which are defined similarly as in Section 1.2 for
 $(\mathcal{T},0)$
. Moreover, vertex
$(\mathcal{T},0)$
. Moreover, vertex
 $\bar v$
has an additional PA label
$\bar v$
has an additional PA label
 $k^{(\textrm{i})}_{\bar v}$
, which determines its initial attractiveness by taking
$k^{(\textrm{i})}_{\bar v}$
, which determines its initial attractiveness by taking
 $x_{k^{(\textrm{i})}_{\bar v}}$
. The distributions of the PA labels are constructed using gamma variables similar to (3.6), (3.7), and (3.8), and as we remark after the definition, the
$x_{k^{(\textrm{i})}_{\bar v}}$
. The distributions of the PA labels are constructed using gamma variables similar to (3.6), (3.7), and (3.8), and as we remark after the definition, the
 $k^{(\textrm{i})}_{\bar v}$
are approximately distributed as the vertices (or equivalently the arrival times)
$k^{(\textrm{i})}_{\bar v}$
are approximately distributed as the vertices (or equivalently the arrival times)
 $k^{(\textrm{u})}_{\bar v}$
in the local neighbourhood in
$k^{(\textrm{u})}_{\bar v}$
in the local neighbourhood in
 $G_n$
. Define
$G_n$
. Define
 \begin{equation}R^{(\textrm{i})}_{\bar v}=\text{the number of type-R children of vertex $\bar v$ in $(\mathcal{T}_{\textbf{x},n},0)$,}\end{equation}
\begin{equation}R^{(\textrm{i})}_{\bar v}=\text{the number of type-R children of vertex $\bar v$ in $(\mathcal{T}_{\textbf{x},n},0)$,}\end{equation}
which is analogous to
 $R_{\bar v}$
in (1.3) and
$R_{\bar v}$
in (1.3) and
 $R^{(\textrm{u})}_{\bar v}$
in (3.4). Finally, recall
$R^{(\textrm{u})}_{\bar v}$
in (3.4). Finally, recall
 $\chi$
in (1.2) and
$\chi$
in (1.2) and
 $\bar w\leqslant_{UH} \bar v$
whenever the Ulam–Harris label
$\bar w\leqslant_{UH} \bar v$
whenever the Ulam–Harris label
 $\bar w$
is smaller than
$\bar w$
is smaller than
 $\bar v$
in the breadth-first order (Definition 5).
$\bar v$
in the breadth-first order (Definition 5).
Definition 8. (Intermediate Pólya point tree.) Given n and
 $\textbf{x}$
,
$\textbf{x}$
,
 $(\mathcal{T}_{\textbf{x},n},0)$
is constructed recursively as follows. The root 0 has an age
$(\mathcal{T}_{\textbf{x},n},0)$
is constructed recursively as follows. The root 0 has an age
 $a^{(\textrm{i})}_0=U_0^\chi$
and an initial attractiveness
$a^{(\textrm{i})}_0=U_0^\chi$
and an initial attractiveness
 $x_{k^{(\textrm{i})}_0}$
, where
$x_{k^{(\textrm{i})}_0}$
, where
 $U_0\sim \textrm{U}[0,1]$
and
$U_0\sim \textrm{U}[0,1]$
and
 $k^{(\textrm{i})}_0=\lceil{nU_0}\rceil$
. Assume that
$k^{(\textrm{i})}_0=\lceil{nU_0}\rceil$
. Assume that
 $\Big(\Big(a^{(\textrm{i})}_{\bar w}, k^{(\textrm{i})}_{\bar w}\Big),\bar w \leqslant_{UH} \bar v\Big)$
and
$\Big(\Big(a^{(\textrm{i})}_{\bar w}, k^{(\textrm{i})}_{\bar w}\Big),\bar w \leqslant_{UH} \bar v\Big)$
and
 $\Big(\Big(R^{(\textrm{i})}_{\bar w},a^{(\textrm{i})}_{\bar w,j}, k^{(\textrm{i})}_{\bar w,j}\Big)$
,
$\Big(\Big(R^{(\textrm{i})}_{\bar w},a^{(\textrm{i})}_{\bar w,j}, k^{(\textrm{i})}_{\bar w,j}\Big)$
,
 $\bar w <_{UH} \bar v\Big)$
have been generated, so that
$\bar w <_{UH} \bar v\Big)$
have been generated, so that
 $k^{(\textrm{i})}_{\bar w}>1$
for
$k^{(\textrm{i})}_{\bar w}>1$
for
 $\bar w \leqslant_{UH} \bar v$
. If vertex
$\bar w \leqslant_{UH} \bar v$
. If vertex
 $\bar v$
is the root or belongs to type L, we generate
$\bar v$
is the root or belongs to type L, we generate
 $\Big(\Big(a^{(\textrm{i})}_{\bar v,j}, k^{(\textrm{i})}_{\bar v,j}\Big),1\leqslant j\leqslant 1+R^{(\textrm{i})}_{\bar v}\Big)$
as follows:
$\Big(\Big(a^{(\textrm{i})}_{\bar v,j}, k^{(\textrm{i})}_{\bar v,j}\Big),1\leqslant j\leqslant 1+R^{(\textrm{i})}_{\bar v}\Big)$
as follows:
-
1. We sample the age of its type-L child
$(\bar v,1)$
by letting
$U_{\bar v,1}\sim\textrm{U}[0,1]$
and
$a^{(\textrm{i})}_{\bar v,1}=a^{(\textrm{i})}_{\bar v} U_{\bar v,1}$
. -
2. Next we choose the PA label
$k^{(\textrm{i})}_{\bar v,1}$
. Suppose that
$t=|\{\bar w\,:\,\bar w\leqslant_{UH}\bar v\}|$
, so that
$t=1$
if
$\bar v=0$
. We define the conditionally independent variables
$\Big(\Big(\mathcal{Z}^{(\textrm{i})}_j[t], \mathcal{\widetilde Z}^{(\textrm{i})}_j[t]\Big), 2\leqslant j\leqslant n, j\not\in \big\{k^{(\textrm{i})}_{\bar w}\,:\,\bar w<_{UH}\bar v\big\}\Big)$
as follows. Let
$T_{j}\,:\!=\,\sum^j_{\ell=1} x_\ell$
. When
$\bar v=0$
, let when
\begin{align*}\mathcal{Z}^{(\textrm{i})}_j[1]\sim \textrm{Gamma}(x_j,1)\quad\text{and}\quad \mathcal{\widetilde Z}^{(\textrm{i})}_j[1]\sim \textrm{Gamma}(T_{j-1}+j-1,1);\end{align*}
$\bar v=(0,1,1,\ldots,1)$
, let
$\mathcal{Z}^{(\textrm{i})}_j[t]\sim \textrm{Gamma}\big(x_j + \mathbb{1}[j=k^{(\textrm{i})}_{\bar v}],1\big)$
, and where
\begin{align*}\mathcal{\widetilde Z}^{(\textrm{i})}_j[t]\sim\begin{cases}\textrm{Gamma}(T_{j-1}+j-1,1),& 2\leqslant j\leqslant k^{(\textrm{i})}_{\bar v},\\\textrm{Gamma}(T_{j-1}+j,1),& k^{(\textrm{i})}_{\bar v}<j<k^{(\textrm{i})}_{\bar v^{\prime}},\\\textrm{Gamma}\big(T_{j-1}+j+1-|\bar v|-W_{\bar v, j},1\big),& k^{(\textrm{i})}_{\bar v^{\prime}}<j\leqslant n,\end{cases}\end{align*}
and
\begin{equation*}W_{\bar v, j}\,:\!=\,\sum_{\big\{k^{(\textrm{i})}_{\bar w}<j:\bar w <_{UH} \bar v\big\}}\Big\{x_{k^{(\textrm{i})}_{\bar w}}+R^{(\textrm{i})}_{\bar w}\Big\},\end{equation*}
$\bar v^{\prime}=(0,1,1,\ldots,1)$
with
$|\bar v^{\prime}|=|\bar v|-1$
. For either the root or the type-L parent, define
$B^{(\textrm{i})}_1[t]\,:\!=\,1$
,
$B^{(\textrm{i})}_j[t]\,:\!=\,0$
for
$j \in \big\{k^{(\textrm{i})}_{\bar w}\,:\, \bar w <_{UH} \bar v\big\}$
and (4.2)then let
\begin{align}B^{(\textrm{i})}_j[t]\,:\!=\,\frac{\mathcal{Z}^{(\textrm{i})}_j[t]}{\mathcal{Z}^{(\textrm{i})}_j[t] + \mathcal{\widetilde Z}^{(\textrm{i})}_j[t]}\quad \text{for $j\in [n]\setminus \big\{k^{(\textrm{i})}_{\bar w}\,:\,\bar w<_{UH}\bar v\big\}$;}\end{align}
$S^{(\textrm{i})}_{n,0}[t]\,:\!=\,0$
,
$S^{(\textrm{i})}_{n,n}[t]\,:\!=\,1$
, and
$S^{(\textrm{i})}_{n,j}[t]\,:\!=\,\prod^n_{\ell=j+1}\Big(1-B^{(\textrm{i})}_\ell[t]\Big)$
for
$1\leqslant j\leqslant n-1$
. Momentarily define
$b\,:\!=\,k^{(\textrm{i})}_{\bar v}$
and
$c\,:\!=\,k^{(\textrm{i})}_{\bar v,1}$
; we choose the PA label c so that
$ S^{(\textrm{i})}_{n,c-1}[t]\leqslant U_{\bar v,1} S^{(\textrm{i})}_{n,b-1}[t] < S^{(\textrm{i})}_{n,c}[t]$
.
-
3. We generate the ages and the PA labels of the type-R children. Let
$\Big(a^{(\textrm{i})}_{\bar v,j},2\leqslant j\leqslant 1+R^{(\textrm{i})}_{\bar v}\Big)$
be the points of a mixed Poisson process on
$\big(a^{(\textrm{i})}_{\bar v},1\big]$
with intensity (4.3)Then choose
\begin{equation}\lambda^{(\textrm{i})}_{\bar v}(y)dy\,:\!=\,\frac{\mathcal{Z}^{(\textrm{i})}_{b}[t]}{\mu \big(a^{(\textrm{i})}_{\bar v}\big)^{1/\mu}} y^{1/\mu-1} dy.\end{equation}
$k^{(\textrm{i})}_{\bar v,j}$
,
$2\leqslant j\leqslant 1+R^{(\textrm{i})}_{\bar v}$
, such that (4.4)
\begin{equation}\Big(\Big(k^{(\textrm{i})}_{\bar v,j}-1\Big)/n\Big)^\chi <a^{(\textrm{i})}_{\bar v,j}\leqslant \big(k^{(\textrm{i})}_{\bar v,j}/n\big)^\chi.\end{equation}


































If
 $\bar v$
is of type R, let
$\bar v$
is of type R, let
 $\mathcal{Z}_{b}[t]\sim \textrm{Gamma}(x_{b},1)$
and apply Step 3 only to obtain
$\mathcal{Z}_{b}[t]\sim \textrm{Gamma}(x_{b},1)$
and apply Step 3 only to obtain
 $\Big(\Big(a^{(\textrm{i})}_{\bar v,j}, k^{(\textrm{i})}_{\bar v,j}\Big), 1\leqslant j\leqslant R^{(\textrm{i})}_{\bar v}\Big)$
. We build
$\Big(\Big(a^{(\textrm{i})}_{\bar v,j}, k^{(\textrm{i})}_{\bar v,j}\Big), 1\leqslant j\leqslant R^{(\textrm{i})}_{\bar v}\Big)$
. We build
 $(\mathcal{T}_{\textbf{x},n},0)$
by iterating this process, and terminate the construction whenever there is some vertex
$(\mathcal{T}_{\textbf{x},n},0)$
by iterating this process, and terminate the construction whenever there is some vertex
 $\bar v$
such that
$\bar v$
such that
 $b=1$
.
$b=1$
.
We now discuss the distributions of the PA labels above. Clearly,
 $k^{(\textrm{i})}_0$
is uniform in [n]. Observe that t above is essentially the number of breadth-first exploration steps in
$k^{(\textrm{i})}_0$
is uniform in [n]. Observe that t above is essentially the number of breadth-first exploration steps in
 $(\mathcal{T}_{\textbf{x},n},0)$
, starting from the root 0. Suppose that we have completed
$(\mathcal{T}_{\textbf{x},n},0)$
, starting from the root 0. Suppose that we have completed
 $t-1$
exploration steps in
$t-1$
exploration steps in
 $G_n$
, starting from its uniformly chosen vertex
$G_n$
, starting from its uniformly chosen vertex
 $k^{(\textrm{u})}_0$
, and the resulting neighbourhood is coupled to that of vertex
$k^{(\textrm{u})}_0$
, and the resulting neighbourhood is coupled to that of vertex
 $0\in V((\mathcal{T}_{\textbf{x},n},0))$
so that they are isomorphic and
$0\in V((\mathcal{T}_{\textbf{x},n},0))$
so that they are isomorphic and
 $k^{(\textrm{i})}_{\bar w}=k^{(\textrm{u})}_{\bar w}$
for all
$k^{(\textrm{i})}_{\bar w}=k^{(\textrm{u})}_{\bar w}$
for all
 ${\bar w}$
in the neighbourhoods. If
${\bar w}$
in the neighbourhoods. If
 $v[t]=k^{(\textrm{u})}_{\bar v}$
, a moment’s thought shows that the total weight of the vertices
$v[t]=k^{(\textrm{u})}_{\bar v}$
, a moment’s thought shows that the total weight of the vertices
 $\big\{k^{(\textrm{i})}_{\bar w}<j\,:\,\bar w<_{UH} \bar v\big\}$
and the vertex set
$\big\{k^{(\textrm{i})}_{\bar w}<j\,:\,\bar w<_{UH} \bar v\big\}$
and the vertex set
 $\mathcal{P}_{t-1,j}$
satisfy
$\mathcal{P}_{t-1,j}$
satisfy
 \begin{equation*}W_{\bar v,j}+|\bar v|-1=\sum_{h\in \mathcal{P}_{t-1,j}}x_h+|\mathcal{E}_{t-1,j}|,\end{equation*}
\begin{equation*}W_{\bar v,j}+|\bar v|-1=\sum_{h\in \mathcal{P}_{t-1,j}}x_h+|\mathcal{E}_{t-1,j}|,\end{equation*}
where
 $\mathcal{P}_{t-1,j}$
and
$\mathcal{P}_{t-1,j}$
and
 $\mathcal{E}_{t-1,j}$
are as in (3.5). Hence, recalling the gammas in (3.7) and (3.8), it follows that
$\mathcal{E}_{t-1,j}$
are as in (3.5). Hence, recalling the gammas in (3.7) and (3.8), it follows that
 $\mathcal{Z}_j[t]=_d\mathcal{Z}^{(\textrm{i})}_j[t]$
and
$\mathcal{Z}_j[t]=_d\mathcal{Z}^{(\textrm{i})}_j[t]$
and
 $\mathcal{\widetilde Z}_j[t]=_d\mathcal{\widetilde Z}^{(\textrm{i})}_j[t]$
for any j. So by Lemma 6,
$\mathcal{\widetilde Z}_j[t]=_d\mathcal{\widetilde Z}^{(\textrm{i})}_j[t]$
for any j. So by Lemma 6,
 $k^{(\textrm{i})}_{\bar v}=_d k^{(\textrm{u})}_{\bar v}$
if
$k^{(\textrm{i})}_{\bar v}=_d k^{(\textrm{u})}_{\bar v}$
if
 $\bar v$
is a type-L child. However,
$\bar v$
is a type-L child. However,
 $k^{(\textrm{i})}_{\bar v}$
is only approximately distributed as
$k^{(\textrm{i})}_{\bar v}$
is only approximately distributed as
 $k^{(\textrm{u})}_{\bar v}$
if
$k^{(\textrm{u})}_{\bar v}$
if
 $\bar v$
is of type R. The discretised Poisson point process that generates these PA labels will be coupled to the Bernoulli sequence in Lemma 5 that encodes the type-R children of
$\bar v$
is of type R. The discretised Poisson point process that generates these PA labels will be coupled to the Bernoulli sequence in Lemma 5 that encodes the type-R children of
 $k^{(\textrm{u})}_{\bar v}$
. When
$k^{(\textrm{u})}_{\bar v}$
. When
 $k^{(\textrm{i})}_{\bar v}=1$
, it must be the case that
$k^{(\textrm{i})}_{\bar v}=1$
, it must be the case that
 $\bar v=0$
or
$\bar v=0$
or
 $\bar v=(0,1,\ldots,1)$
. We stop the construction in this case to avoid an ill-defined
$\bar v=(0,1,\ldots,1)$
. We stop the construction in this case to avoid an ill-defined
 $\mathcal{Z}^{(\textrm{i})}_1[t]$
when
$\mathcal{Z}^{(\textrm{i})}_1[t]$
when
 $-1<x_1\leqslant 0$
and
$-1<x_1\leqslant 0$
and
 $k^{(\textrm{i})}_0=1$
, and also because vertex 1 cannot have a type-L neighbour, so Steps 1 and 2 are unnecessary in this case. Nevertheless, for
$k^{(\textrm{i})}_0=1$
, and also because vertex 1 cannot have a type-L neighbour, so Steps 1 and 2 are unnecessary in this case. Nevertheless, for
 $r<\infty$
and any vertex
$r<\infty$
and any vertex
 $\bar v$
in the r-neighbourhood of vertex
$\bar v$
in the r-neighbourhood of vertex
 $0\in V((\mathcal{T}_{\textbf{x},n},0))$
, the probability that
$0\in V((\mathcal{T}_{\textbf{x},n},0))$
, the probability that
 $k^{(\textrm{i})}_{\bar v}=1$
tends to zero as
$k^{(\textrm{i})}_{\bar v}=1$
tends to zero as
 $n\to\infty$
.
$n\to\infty$
.
5. Proof of the base case
Recall that, as in Section 3.2,
 $k^{(\textrm{u})}_{\bar v}$
are the vertices in the local neighbourhood of the uniformly chosen vertex
$k^{(\textrm{u})}_{\bar v}$
are the vertices in the local neighbourhood of the uniformly chosen vertex
 $k^{\textrm{(u)}}_0$
of the
$k^{\textrm{(u)}}_0$
of the
 $(\textbf{x},n)$
-Pólya urn tree
$(\textbf{x},n)$
-Pólya urn tree
 $G_n$
in Definition 4. Let
$G_n$
in Definition 4. Let
 $\chi$
be as in (1.2), and let
$\chi$
be as in (1.2), and let
 $(\mathcal{T}_{\textbf{x},n},0)$
be the intermediate Pólya point tree in Definition 8, with
$(\mathcal{T}_{\textbf{x},n},0)$
be the intermediate Pólya point tree in Definition 8, with
 $k^{(\textrm{i})}_{\bar v}$
and
$k^{(\textrm{i})}_{\bar v}$
and
 $a^{(\textrm{i})}_{\bar v}$
being the PA label and the age of vertex
$a^{(\textrm{i})}_{\bar v}$
being the PA label and the age of vertex
 $\bar v$
in the tree. Here, we couple
$\bar v$
in the tree. Here, we couple
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
so that with probability tending to one,
$(\mathcal{T}_{\textbf{x},n},0)$
so that with probability tending to one,
 $(B_1\big(G_n,k^{(\textrm{u})}_0\big),k^{(\textrm{u})}_0)\cong (B_1(\mathcal{T}_{\textbf{x},n},0),0)$
,
$(B_1\big(G_n,k^{(\textrm{u})}_0\big),k^{(\textrm{u})}_0)\cong (B_1(\mathcal{T}_{\textbf{x},n},0),0)$
,
 $\big(k^{(\textrm{u})}_{0,j}/n\big)^\chi \approx a^{(\textrm{i})}_{0,j}$
, and
$\big(k^{(\textrm{u})}_{0,j}/n\big)^\chi \approx a^{(\textrm{i})}_{0,j}$
, and
 $k^{(\textrm{u})}_{0,j}=k^{(\textrm{i})}_{0,j}$
. For convenience, we also refer to the rescaled arrival time
$k^{(\textrm{u})}_{0,j}=k^{(\textrm{i})}_{0,j}$
. For convenience, we also refer to the rescaled arrival time
 $(k/n)^\chi$
of vertex k in
$(k/n)^\chi$
of vertex k in
 $G_n$
simply as its age. Let
$G_n$
simply as its age. Let
 $U_0\sim \textrm{U}[0,1]$
,
$U_0\sim \textrm{U}[0,1]$
,
 $a^{(\textrm{i})}_0=U^{\chi}_0$
, and
$a^{(\textrm{i})}_0=U^{\chi}_0$
, and
 $k^{(\textrm{u})}_0=\lceil{nU_0}\rceil$
, where
$k^{(\textrm{u})}_0=\lceil{nU_0}\rceil$
, where
 $a^{(\textrm{i})}_0$
is the age of vertex 0. By a direct comparison to Definition 8,
$a^{(\textrm{i})}_0$
is the age of vertex 0. By a direct comparison to Definition 8,
 $a^{(\textrm{i})}_0\approx \big(k^{(\textrm{u})}_0/n\big)^\chi$
and the initial attractiveness of vertex 0 is
$a^{(\textrm{i})}_0\approx \big(k^{(\textrm{u})}_0/n\big)^\chi$
and the initial attractiveness of vertex 0 is
 $x_{k^{(\textrm{u})}_0}$
. Under this coupling we define the event
$x_{k^{(\textrm{u})}_0}$
. Under this coupling we define the event
 \begin{equation}\mathcal{H}_{1,0}=\big\{a^{(\textrm{i})}_0>(\log \log n)^{-\chi} \big\},\end{equation}
\begin{equation}\mathcal{H}_{1,0}=\big\{a^{(\textrm{i})}_0>(\log \log n)^{-\chi} \big\},\end{equation}
which guarantees that we choose a vertex of low degree in
 $G_n$
. To prepare for the coupling, let
$G_n$
. To prepare for the coupling, let
 $\big(\big(\mathcal{Z}_j[1],\mathcal{\widetilde Z}_{j}[1]\big),2\leqslant j\leqslant n\big)$
and
$\big(\big(\mathcal{Z}_j[1],\mathcal{\widetilde Z}_{j}[1]\big),2\leqslant j\leqslant n\big)$
and
 $\big(S_{n,j}[1],1\leqslant j\leqslant n\big)$
be as in (3.6) and (3.10). We use
$\big(S_{n,j}[1],1\leqslant j\leqslant n\big)$
be as in (3.6) and (3.10). We use
 $\big(S_{n,j}[1],1\leqslant j\leqslant n\big)$
to construct the distribution of the type-R children of
$\big(S_{n,j}[1],1\leqslant j\leqslant n\big)$
to construct the distribution of the type-R children of
 $k^{(\textrm{u})}_0$
, and for sampling the initial attractiveness of vertex
$k^{(\textrm{u})}_0$
, and for sampling the initial attractiveness of vertex
 $(0,1)\in V((\mathcal{T}_{\textbf{x},n},0))$
. Furthermore, let the ages
$(0,1)\in V((\mathcal{T}_{\textbf{x},n},0))$
. Furthermore, let the ages
 $\Big(a^{(\textrm{i})}_{0,j},1\leqslant j\leqslant 1+R^{(\textrm{i})}_0\Big)$
and
$\Big(a^{(\textrm{i})}_{0,j},1\leqslant j\leqslant 1+R^{(\textrm{i})}_0\Big)$
and
 $R^{(\textrm{u})}_0$
be as in Definition 8 and (3.4). Below we define a coupling of
$R^{(\textrm{u})}_0$
be as in Definition 8 and (3.4). Below we define a coupling of
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
, and for this coupling we define the events that the children of
$(\mathcal{T}_{\textbf{x},n},0)$
, and for this coupling we define the events that the children of
 $k^{(\textrm{u})}_0$
have low degrees, the 1-neighbourhoods are isomorphic and of size at most
$k^{(\textrm{u})}_0$
have low degrees, the 1-neighbourhoods are isomorphic and of size at most
 $(\log n)^{1/r}$
, and the ages are close enough as
$(\log n)^{1/r}$
, and the ages are close enough as
 \begin{align}&\mathcal{H}_{1,1} = \Big\{a^{(\textrm{i})}_{0,1}>(\log \log n)^{-2\chi}\Big\},\nonumber\\&\mathcal{H}_{1,2}= \bigg\{ R^{(\textrm{u})}_0= R^{(\textrm{i})}_0,\text{ for $\bar v\in V(B_1(\mathcal{T}_{\textbf{x},n},0))$, $k^{(\textrm{u})}_{\bar v}=k^{(\textrm{i})}_{\bar v}$,}\bigg|a^{(\textrm{i})}_{\bar v}-\bigg(\frac{k^{(\textrm{u})}_{\bar v}}{n}\bigg)^\chi \bigg|\leqslant C_1 b(n)\bigg\},\nonumber\\&\mathcal{H}_{1,3}=\Big\{R^{(\textrm{i})}_0<(\log n)^{1/r}\Big\},\end{align}
\begin{align}&\mathcal{H}_{1,1} = \Big\{a^{(\textrm{i})}_{0,1}>(\log \log n)^{-2\chi}\Big\},\nonumber\\&\mathcal{H}_{1,2}= \bigg\{ R^{(\textrm{u})}_0= R^{(\textrm{i})}_0,\text{ for $\bar v\in V(B_1(\mathcal{T}_{\textbf{x},n},0))$, $k^{(\textrm{u})}_{\bar v}=k^{(\textrm{i})}_{\bar v}$,}\bigg|a^{(\textrm{i})}_{\bar v}-\bigg(\frac{k^{(\textrm{u})}_{\bar v}}{n}\bigg)^\chi \bigg|\leqslant C_1 b(n)\bigg\},\nonumber\\&\mathcal{H}_{1,3}=\Big\{R^{(\textrm{i})}_0<(\log n)^{1/r}\Big\},\end{align}
where
 $R^{(\textrm{i})}_{0}$
and
$R^{(\textrm{i})}_{0}$
and
 $R^{(\textrm{u})}_{0}$
are as in (3.4) and (4.1),
$R^{(\textrm{u})}_{0}$
are as in (3.4) and (4.1),
 $b(n)\,:\!=\,n^{-\frac{\chi}{12}}(\log\log n)^{\chi}$
, and
$b(n)\,:\!=\,n^{-\frac{\chi}{12}}(\log\log n)^{\chi}$
, and
 $C_1\,:\!=\,C_1(x_1,\mu)$
will be chosen in the proof of Lemma 8 below. Because the initial attractivenesses of the vertices (0,j) and
$C_1\,:\!=\,C_1(x_1,\mu)$
will be chosen in the proof of Lemma 8 below. Because the initial attractivenesses of the vertices (0,j) and
 $k^{(\textrm{u})}_{0,j}$
match and their ages are close enough on the event
$k^{(\textrm{u})}_{0,j}$
match and their ages are close enough on the event
 $\mathcal{H}_{1,2}$
, we can couple the Bernoulli and the mixed Poisson sequences that encode their type-R children, and hence the 2-neighbourhoods. The event
$\mathcal{H}_{1,2}$
, we can couple the Bernoulli and the mixed Poisson sequences that encode their type-R children, and hence the 2-neighbourhoods. The event
 $\mathcal{H}_{1,1}$
ensures that the local neighbourhood of
$\mathcal{H}_{1,1}$
ensures that the local neighbourhood of
 $k^{(\textrm{u})}_0$
grows slowly, and on the event
$k^{(\textrm{u})}_0$
grows slowly, and on the event
 $\mathcal{H}_{1,3}$
, the number of vertex pairs that we need to couple for the 2-neighbourhoods is not too large. So by a union bound argument, the probability that any of the subsequent couplings fail tends to zero as
$\mathcal{H}_{1,3}$
, the number of vertex pairs that we need to couple for the 2-neighbourhoods is not too large. So by a union bound argument, the probability that any of the subsequent couplings fail tends to zero as
 $n\to\infty$
. The aim of this section is to show that when
$n\to\infty$
. The aim of this section is to show that when
 $\sum^j_{i=2}x_i\approx (j-1)\mu$
for all j sufficiently large, we can couple the two graphs so that
$\sum^j_{i=2}x_i\approx (j-1)\mu$
for all j sufficiently large, we can couple the two graphs so that
 $\bigcap^3_{i=0}\mathcal{H}_{1,i}$
occurs w.h.p. Thus, let
$\bigcap^3_{i=0}\mathcal{H}_{1,i}$
occurs w.h.p. Thus, let
 $A_n\,:\!=\,A_{2/3,n}$
be as in (2.1) with
$A_n\,:\!=\,A_{2/3,n}$
be as in (2.1) with
 $\alpha=2/3$
; this
$\alpha=2/3$
; this
 $\alpha$
is chosen to simplify the calculation, and can be chosen under the assumption of bounded fitness. Recall that
$\alpha$
is chosen to simplify the calculation, and can be chosen under the assumption of bounded fitness. Recall that
 $\mathbb{P}_{\textbf{x}}$
indicates the conditioning on a specific realisation of the fitness sequence
$\mathbb{P}_{\textbf{x}}$
indicates the conditioning on a specific realisation of the fitness sequence
 $\textbf{x}$
. The main result is the lemma below; it serves as the base case when we inductively prove an analogous result for the general radius
$\textbf{x}$
. The main result is the lemma below; it serves as the base case when we inductively prove an analogous result for the general radius
 $r<\infty$
. Because
$r<\infty$
. Because
 $B_1(\mathcal{T}_{\textbf{x},n},0)$
approximately distributes as the 1-neighbourhood of the
$B_1(\mathcal{T}_{\textbf{x},n},0)$
approximately distributes as the 1-neighbourhood of the
 $\pi$
-Pólya point tree after randomisation of
$\pi$
-Pólya point tree after randomisation of
 $\textbf{x}$
, and Lemma 1 says that
$\textbf{x}$
, and Lemma 1 says that
 $\mathbb{P}[A^c_n]=O\big(n^{-b}\big)$
for some
$\mathbb{P}[A^c_n]=O\big(n^{-b}\big)$
for some
 $b>0$
, it follows from the lemma below and (1.4) that (1.5) of Theorem 1 holds for
$b>0$
, it follows from the lemma below and (1.4) that (1.5) of Theorem 1 holds for
 $r=1$
.
$r=1$
.
Lemma 7. Assume that
 $x_j\in (0,\kappa]$
for
$x_j\in (0,\kappa]$
for
 $j\geqslant 2$
and
$j\geqslant 2$
and
 $\textbf{x}\in A_n$
. Let
$\textbf{x}\in A_n$
. Let
 $\mathcal{H}_{1,j}$
,
$\mathcal{H}_{1,j}$
,
 $j=0,\ldots,3$
, be as in (5.1) and (5.2). Then there is a coupling of
$j=0,\ldots,3$
, be as in (5.1) and (5.2). Then there is a coupling of
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
$(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
 $C\,:\!=\,C(x_1,\mu,\kappa)$
such that
$C\,:\!=\,C(x_1,\mu,\kappa)$
such that
 \begin{align}\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^3_{j=0}\mathcal{H}_{1,j}\Bigg)^c\Bigg]\leqslant C (\log \log n)^{-\chi}\quad for\ all\ n\geqslant 3.\end{align}
\begin{align}\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^3_{j=0}\mathcal{H}_{1,j}\Bigg)^c\Bigg]\leqslant C (\log \log n)^{-\chi}\quad for\ all\ n\geqslant 3.\end{align}
The proof of Lemma 7 consists of several lemmas, which we now develop. From the definitions of
 $a^{(\textrm{i})}_0$
and
$a^{(\textrm{i})}_0$
and
 $a^{(\textrm{i})}_{0,1}$
, it is obvious that the probabilities of the events
$a^{(\textrm{i})}_{0,1}$
, it is obvious that the probabilities of the events
 $\mathcal{H}_{1,0}$
and
$\mathcal{H}_{1,0}$
and
 $\mathcal{H}_{1,1}$
tend to one as
$\mathcal{H}_{1,1}$
tend to one as
 $n\to\infty$
, and by Chebyshev’s inequality, we can show that this is also true for the event
$n\to\infty$
, and by Chebyshev’s inequality, we can show that this is also true for the event
 $\mathcal{H}_{1,3}$
. We take care of
$\mathcal{H}_{1,3}$
. We take care of
 $\mathcal{H}_{1,2}$
in the lemma below, whose proof is the core of this section.
$\mathcal{H}_{1,2}$
in the lemma below, whose proof is the core of this section.
Lemma 8. Retaining the assumptions and the notation of Lemma 7, there is a coupling of
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
$(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
 $C\,:\!=\,C(x_1,\mu,\kappa)$
such that
$C\,:\!=\,C(x_1,\mu,\kappa)$
such that
 \begin{align*}\mathbb{P}_{\textbf{x}}\left[\mathcal{H}_{1,0}\cap \mathcal{H}_{1,1} \cap \mathcal{H}^c_{1,2}\right]&\leqslant C n^{-\beta}(\log \log n)^{1-\chi}\quad for\ all\ n\geqslant 3, \end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\left[\mathcal{H}_{1,0}\cap \mathcal{H}_{1,1} \cap \mathcal{H}^c_{1,2}\right]&\leqslant C n^{-\beta}(\log \log n)^{1-\chi}\quad for\ all\ n\geqslant 3, \end{align*}
where
 $0<\gamma<\chi/12$
and
$0<\gamma<\chi/12$
and
 $\beta=\min\{\chi/3-4\gamma,\gamma\}$
.
$\beta=\min\{\chi/3-4\gamma,\gamma\}$
.
Given that the vertices
 $k^{(\textrm{u})}_0\in V\big(\big(G_n,k^{(\textrm{u})}_0\big)\big)$
and
$k^{(\textrm{u})}_0\in V\big(\big(G_n,k^{(\textrm{u})}_0\big)\big)$
and
 $0\in V((\mathcal{T}_{\textbf{x},n},0))$
are coupled, we prove Lemma 8 as follows. Note that
$0\in V((\mathcal{T}_{\textbf{x},n},0))$
are coupled, we prove Lemma 8 as follows. Note that
 $v[1]=k^{(\textrm{u})}_0$
, where v[t] is as in (3.1). We first couple
$v[1]=k^{(\textrm{u})}_0$
, where v[t] is as in (3.1). We first couple
 $\textbf{Y}^{(v[1],n)}_{\textrm{Be}}$
in Definition 7 and a discretisation of the mixed Poisson process that encodes the ages and the PA labels that are of type R. Then we couple the type-L vertices
$\textbf{Y}^{(v[1],n)}_{\textrm{Be}}$
in Definition 7 and a discretisation of the mixed Poisson process that encodes the ages and the PA labels that are of type R. Then we couple the type-L vertices
 $k^{(\textrm{u})}_{0,1}$
and
$k^{(\textrm{u})}_{0,1}$
and
 $(0,1)\in V((\mathcal{T}_{\textbf{x},n},0))$
so that on the event
$(0,1)\in V((\mathcal{T}_{\textbf{x},n},0))$
so that on the event
 $\mathcal{H}_{1,0}\cap \mathcal{H}_{1,1}$
, we have
$\mathcal{H}_{1,0}\cap \mathcal{H}_{1,1}$
, we have
 $k^{(\textrm{i})}_{0,1}=k^{(\textrm{u})}_{0,1}$
and
$k^{(\textrm{i})}_{0,1}=k^{(\textrm{u})}_{0,1}$
and
 $\big(k^{(\textrm{u})}_{0,1}/n\big)^\chi\approx a^{(\textrm{i})}_{0,1}$
w.h.p. For the means of the discretised Poisson process, we define
$\big(k^{(\textrm{u})}_{0,1}/n\big)^\chi\approx a^{(\textrm{i})}_{0,1}$
w.h.p. For the means of the discretised Poisson process, we define
 \begin{align}\lambda^{[1]}_{v[1]+1}\,:\!=\,\int^{\left(\frac{v[1]+1}{n}\right)^\chi}_{a^{(\textrm{i})}_0} \frac{\mathcal{Z}_{v[1]}[1]}{\big(a^{(\textrm{i})}_0\big)^{1/\mu}\mu} y^{1/\mu-1} dy\quad \text{and} \quad\lambda^{[1]}_{j}\,:\!=\,\int^{\left(\frac{j}{n}\right)^\chi}_{\left(\frac{j-1}{n}\right)^\chi} \frac{\mathcal{Z}_{v[1]}[1]}{\big(a^{(\textrm{i})}_0\big)^{1/\mu}\mu} y^{1/\mu-1} dy\nonumber\\\end{align}
\begin{align}\lambda^{[1]}_{v[1]+1}\,:\!=\,\int^{\left(\frac{v[1]+1}{n}\right)^\chi}_{a^{(\textrm{i})}_0} \frac{\mathcal{Z}_{v[1]}[1]}{\big(a^{(\textrm{i})}_0\big)^{1/\mu}\mu} y^{1/\mu-1} dy\quad \text{and} \quad\lambda^{[1]}_{j}\,:\!=\,\int^{\left(\frac{j}{n}\right)^\chi}_{\left(\frac{j-1}{n}\right)^\chi} \frac{\mathcal{Z}_{v[1]}[1]}{\big(a^{(\textrm{i})}_0\big)^{1/\mu}\mu} y^{1/\mu-1} dy\nonumber\\\end{align}
for
 $v[1]+2\leqslant j \leqslant n$
, where
$v[1]+2\leqslant j \leqslant n$
, where
 $\mathcal{Z}_{v[1]}[1]$
is the gamma variable in (3.6).
$\mathcal{Z}_{v[1]}[1]$
is the gamma variable in (3.6).
Definition 9. Given
 $v[1]=k^{(\textrm{u})}_0$
,
$v[1]=k^{(\textrm{u})}_0$
,
 $a^{(\textrm{i})}_0$
, and
$a^{(\textrm{i})}_0$
, and
 $\mathcal{Z}_{v[1]}[1]$
, let
$\mathcal{Z}_{v[1]}[1]$
, let
 $V_{j\to v[1]}$
,
$V_{j\to v[1]}$
,
 $v[1]+1\leqslant j\leqslant n$
, be conditionally independent Poisson random variables, each with parameter
$v[1]+1\leqslant j\leqslant n$
, be conditionally independent Poisson random variables, each with parameter
 $\lambda^{[1]}_{j}$
as in (5.4). Define this Poisson sequence by the random vector
$\lambda^{[1]}_{j}$
as in (5.4). Define this Poisson sequence by the random vector
 \begin{equation*}\textbf{V}^{(v[1],n)}_{\textrm{Po}}\,:\!=\,\left(V_{(v[1]+1)\to v[1]},V_{(v[1]+2)\to v[1]},\ldots,V_{n\to v[1]}\right).\end{equation*}
\begin{equation*}\textbf{V}^{(v[1],n)}_{\textrm{Po}}\,:\!=\,\left(V_{(v[1]+1)\to v[1]},V_{(v[1]+2)\to v[1]},\ldots,V_{n\to v[1]}\right).\end{equation*}
Next, we define the events that ensure that
 $P_{j\to v[1]}$
is close enough to
$P_{j\to v[1]}$
is close enough to
 $\lambda^{[1]}_j$
. Let
$\lambda^{[1]}_j$
. Let
 $\phi(n)=\Omega(n^\chi)$
, and let
$\phi(n)=\Omega(n^\chi)$
, and let
 $C^\star\,:\!=\,C^\star(x_1,\mu)$
be a positive constant such that (2.2) of Lemma 2 holds with
$C^\star\,:\!=\,C^\star(x_1,\mu)$
be a positive constant such that (2.2) of Lemma 2 holds with
 $\delta_n=C^\star n^{-\frac{\chi}{12}}$
. Let
$\delta_n=C^\star n^{-\frac{\chi}{12}}$
. Let
 $\mathcal{Z}_{j}[1]$
,
$\mathcal{Z}_{j}[1]$
,
 $B_j[1]$
, and
$B_j[1]$
, and
 $S_j[1]$
be as in (3.6), (3.9), and (3.10). Given
$S_j[1]$
be as in (3.6), (3.9), and (3.10). Given
 $0<\gamma<\chi/12$
, define the events
$0<\gamma<\chi/12$
, define the events
 \begin{equation} \begin{split}&F_{1,1}=\left\{\max_{\lceil{\phi(n)}\rceil\leqslant j \leqslant n}\left|S_{n,j}[1] - \left(\frac{j}{n}\right)^\chi\right|\leqslant C^\star n^{-\frac{\chi}{12}}\right\},\\& F_{1,2} = \bigcap^n_{j=\lceil{\phi(n)}\rceil}\left\{\left| B_{j}[1]-\frac{\mathcal{Z}_{j}[1]}{(\mu+1)j}\right|\leqslant \frac{\mathcal{Z}_{j}[1]n^{-\gamma}}{(\mu+1)j}\right\}, \\& F_{1,3} = \bigcap^n_{j=\lceil{\phi(n)}\rceil}\big\{\mathcal{Z}_{j}[1]\leqslant j^{1/2}\big\}.\end{split}\end{equation}
\begin{equation} \begin{split}&F_{1,1}=\left\{\max_{\lceil{\phi(n)}\rceil\leqslant j \leqslant n}\left|S_{n,j}[1] - \left(\frac{j}{n}\right)^\chi\right|\leqslant C^\star n^{-\frac{\chi}{12}}\right\},\\& F_{1,2} = \bigcap^n_{j=\lceil{\phi(n)}\rceil}\left\{\left| B_{j}[1]-\frac{\mathcal{Z}_{j}[1]}{(\mu+1)j}\right|\leqslant \frac{\mathcal{Z}_{j}[1]n^{-\gamma}}{(\mu+1)j}\right\}, \\& F_{1,3} = \bigcap^n_{j=\lceil{\phi(n)}\rceil}\big\{\mathcal{Z}_{j}[1]\leqslant j^{1/2}\big\}.\end{split}\end{equation}
The next lemma is the major step towards proving Lemma 8, as it implies that we can couple the ages and the initial attractivenesses of the type-R children of the uniformly chosen vertex
 $k^{(\textrm{u})}_0\,:\!=\,v[1]\in V\big(G_n,k^{(\textrm{u})}_0\big)$
and those of the root
$k^{(\textrm{u})}_0\,:\!=\,v[1]\in V\big(G_n,k^{(\textrm{u})}_0\big)$
and those of the root
 $0\in V(\mathcal{T}_{\textbf{x},n},0)$
.
$0\in V(\mathcal{T}_{\textbf{x},n},0)$
.
Lemma 9. Retaining the assumptions and the notation in Lemma 8, let
 $\textbf{Y}^{(v[1],n)}_{\textrm{Be}}$
and
$\textbf{Y}^{(v[1],n)}_{\textrm{Be}}$
and
 $\textbf{V}^{(v[1],n)}_{\textrm{Po}}$
be as in Definitions 7 and 9, and let
$\textbf{V}^{(v[1],n)}_{\textrm{Po}}$
be as in Definitions 7 and 9, and let
 $F_{1,i}$
,
$F_{1,i}$
,
 $i=1,2,3$
, be as in (5.5). Then we can couple the random vectors so that there is a positive constant
$i=1,2,3$
, be as in (5.5). Then we can couple the random vectors so that there is a positive constant
 $C\,:\!=\,C(x_1,\mu,\kappa)$
such that
$C\,:\!=\,C(x_1,\mu,\kappa)$
such that
 \begin{align*}\mathbb{P}_{\textbf{x}}\bigg[\Big\{\textbf{Y}^{(v[1],n)}_{\textrm{Be}}\not=\textbf{V}^{(v[1],n)}_{\textrm{Po}}\Big\}\cap \bigcap^3_{i=1} F_{1,i} \cap \mathcal{H}_{1,0}\bigg]\leqslant C n^{-\gamma} (\log \log n)^{1-\chi}\quad for\ all\ n\geqslant 3.\end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\bigg[\Big\{\textbf{Y}^{(v[1],n)}_{\textrm{Be}}\not=\textbf{V}^{(v[1],n)}_{\textrm{Po}}\Big\}\cap \bigcap^3_{i=1} F_{1,i} \cap \mathcal{H}_{1,0}\bigg]\leqslant C n^{-\gamma} (\log \log n)^{1-\chi}\quad for\ all\ n\geqslant 3.\end{align*}
Sketch of proof. We summarise the proof here and defer the details to [Reference Lo24]. On the event
 $F_{1,1}\cap F_{1,2}\cap \mathcal{H}_{1,0}$
, a little calculation shows that the Bernoulli success probability
$F_{1,1}\cap F_{1,2}\cap \mathcal{H}_{1,0}$
, a little calculation shows that the Bernoulli success probability
 $P_{j\to v[1]}$
in (3.11) is close enough to
$P_{j\to v[1]}$
in (3.11) is close enough to
 \begin{equation}\widehat P_{j\to v[1]}\,:\!=\,\left(\frac{v[1]}{j}\right)^\chi \frac{\mathcal{Z}_{v[1]}[1]}{(\mu+1)v[1]},\end{equation}
\begin{equation}\widehat P_{j\to v[1]}\,:\!=\,\left(\frac{v[1]}{j}\right)^\chi \frac{\mathcal{Z}_{v[1]}[1]}{(\mu+1)v[1]},\end{equation}
while the event
 $F_{1,3}$
ensures that
$F_{1,3}$
ensures that
 $\widehat P_{j\to v[1]}\leqslant 1$
. The Poisson mean
$\widehat P_{j\to v[1]}\leqslant 1$
. The Poisson mean
 $\lambda^{[1]}_j\approx \widehat P_{j\to v[1]}$
as
$\lambda^{[1]}_j\approx \widehat P_{j\to v[1]}$
as
 $a^{(\textrm{i})}_0\approx (v[1]/n)^\chi$
. Hence, we use
$a^{(\textrm{i})}_0\approx (v[1]/n)^\chi$
. Hence, we use
 $\widehat P_{j\to v[1]}$
in (5.6) as means of constructing two intermediate Bernoulli and Poisson random vectors, and then explicitly couple the four processes. It is enough to consider the coupling under the event
$\widehat P_{j\to v[1]}$
in (5.6) as means of constructing two intermediate Bernoulli and Poisson random vectors, and then explicitly couple the four processes. It is enough to consider the coupling under the event
 $\bigcap^3_{j=1} F_{1,j}\cap \mathcal{H}_{1,0}$
, because when
$\bigcap^3_{j=1} F_{1,j}\cap \mathcal{H}_{1,0}$
, because when
 $\textbf{x}\in A_{n}$
, Lemmas 2 and 3 imply that
$\textbf{x}\in A_{n}$
, Lemmas 2 and 3 imply that
 $F_{1,1}$
,
$F_{1,1}$
,
 $F_{1,2}$
, and
$F_{1,2}$
, and
 $F_{1,3}$
occur with probability tending to one as
$F_{1,3}$
occur with probability tending to one as
 $n\to\infty$
.
$n\to\infty$
.
Below we use Lemmas 2, 3, and 9 to prove Lemma 8.
Proof of Lemma 8. We bound the right-hand side of
 \begin{align}&\mathbb{P}_{\textbf{x}}\big[\mathcal{H}^c_{1,2}\cap \mathcal{H}_{1,1}\cap\mathcal{H}_{1,0}\big] \nonumber\\&\leqslant \mathbb{P}_{\textbf{x}}\Bigg[\bigcap^3_{j=1} F_{1,j} \cap \bigcap^1_{j=0}\mathcal{H}_{1,j}\cap \mathcal{H}^c_{1,2} \Bigg] + \mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^3_{j=1} F_{1,j}\Bigg)^c\Bigg]\nonumber\\&\leqslant \mathbb{P}_{\textbf{x}}\Bigg[\bigcap^3_{j=1} F_{1,j} \cap \bigcap^1_{j=0}\mathcal{H}_{1,j}\cap \mathcal{H}^c_{1,2} \Bigg]+\mathbb{P}_{\textbf{x}}\big[ F^c_{1,3}\big]+ \mathbb{P}_{\textbf{x}}\big[F^c_{1,2} \big]+\mathbb{P}_{\textbf{x}}\big[ F^c_{1,1} \big],\end{align}
\begin{align}&\mathbb{P}_{\textbf{x}}\big[\mathcal{H}^c_{1,2}\cap \mathcal{H}_{1,1}\cap\mathcal{H}_{1,0}\big] \nonumber\\&\leqslant \mathbb{P}_{\textbf{x}}\Bigg[\bigcap^3_{j=1} F_{1,j} \cap \bigcap^1_{j=0}\mathcal{H}_{1,j}\cap \mathcal{H}^c_{1,2} \Bigg] + \mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^3_{j=1} F_{1,j}\Bigg)^c\Bigg]\nonumber\\&\leqslant \mathbb{P}_{\textbf{x}}\Bigg[\bigcap^3_{j=1} F_{1,j} \cap \bigcap^1_{j=0}\mathcal{H}_{1,j}\cap \mathcal{H}^c_{1,2} \Bigg]+\mathbb{P}_{\textbf{x}}\big[ F^c_{1,3}\big]+ \mathbb{P}_{\textbf{x}}\big[F^c_{1,2} \big]+\mathbb{P}_{\textbf{x}}\big[ F^c_{1,1} \big],\end{align}
under a suitable coupling of
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
. We start by handling the last three terms. First, apply (2.6) of Lemma 3 to obtain
$(\mathcal{T}_{\textbf{x},n},0)$
. We start by handling the last three terms. First, apply (2.6) of Lemma 3 to obtain
 \begin{align}\mathbb{P}_{\textbf{x}}\big[ F^c_{1,3} \big]=\mathbb{P}_{\textbf{x}}\Bigg[\bigcup^n_{j= \phi(n)}\big\{\mathcal{Z}_j[1]\geqslant j^{1/2}\big\}\Bigg]\leqslant C \kappa^4 n^{-\chi},\end{align}
\begin{align}\mathbb{P}_{\textbf{x}}\big[ F^c_{1,3} \big]=\mathbb{P}_{\textbf{x}}\Bigg[\bigcup^n_{j= \phi(n)}\big\{\mathcal{Z}_j[1]\geqslant j^{1/2}\big\}\Bigg]\leqslant C \kappa^4 n^{-\chi},\end{align}
where C is a positive constant. Since
 $\textbf{x}\in A_n$
, we can apply (2.4) of Lemma 3 (with
$\textbf{x}\in A_n$
, we can apply (2.4) of Lemma 3 (with
 $\varepsilon=n^{-\gamma}$
,
$\varepsilon=n^{-\gamma}$
,
 $0<\gamma<\chi/12$
, and
$0<\gamma<\chi/12$
, and
 $\alpha=2/3$
) and Lemma 2 to deduce that
$\alpha=2/3$
) and Lemma 2 to deduce that
 \begin{align}\mathbb{P}_{\textbf{x}}\big[F^c_{1,2}\big]=\mathbb{P}_{\textbf{x}}\Bigg[\bigcup^n_{j=\lceil{\phi(n)}\rceil}\left\{\left| B_j[1]-\frac{\mathcal{Z}_j[1]}{(\mu+1)j}\right|\geqslant\frac{\mathcal{Z}_j[1] n^{-\gamma}}{(\mu+1)j}\right\}\Bigg]\leqslant Cn^{4\gamma-\frac{\chi}{3}},\nonumber\\\mathbb{P}_{\textbf{x}}\big[ F^c_{1,1} \big]\leqslant \mathbb{P}_{\textbf{x}}\left[\max_{\lceil{\phi(n)}\rceil\leqslant k\leqslant n} \left|S_{n,k}[1]-\left(\frac{k}{n}\right)^\chi\right|\geqslant C^\star n^{-\frac{\chi}{12}}\right]\leqslant c n^{-\frac{\chi}{6}}, \end{align}
\begin{align}\mathbb{P}_{\textbf{x}}\big[F^c_{1,2}\big]=\mathbb{P}_{\textbf{x}}\Bigg[\bigcup^n_{j=\lceil{\phi(n)}\rceil}\left\{\left| B_j[1]-\frac{\mathcal{Z}_j[1]}{(\mu+1)j}\right|\geqslant\frac{\mathcal{Z}_j[1] n^{-\gamma}}{(\mu+1)j}\right\}\Bigg]\leqslant Cn^{4\gamma-\frac{\chi}{3}},\nonumber\\\mathbb{P}_{\textbf{x}}\big[ F^c_{1,1} \big]\leqslant \mathbb{P}_{\textbf{x}}\left[\max_{\lceil{\phi(n)}\rceil\leqslant k\leqslant n} \left|S_{n,k}[1]-\left(\frac{k}{n}\right)^\chi\right|\geqslant C^\star n^{-\frac{\chi}{12}}\right]\leqslant c n^{-\frac{\chi}{6}}, \end{align}
where
 $C\,:\!=\,C(x_1,\gamma,\mu)$
and
$C\,:\!=\,C(x_1,\gamma,\mu)$
and
 $c\,:\!=\,c(x_1,\mu)$
. Note that
$c\,:\!=\,c(x_1,\mu)$
. Note that
 $ \mathbb{P}_{\textbf{x}}\big[F^c_{1,2}\big]\to 0$
as
$ \mathbb{P}_{\textbf{x}}\big[F^c_{1,2}\big]\to 0$
as
 $n\to\infty$
thanks to our choice of
$n\to\infty$
thanks to our choice of
 $\gamma$
. Next, we give the appropriate coupling to bound the first probability of (5.7). Let the vertices
$\gamma$
. Next, we give the appropriate coupling to bound the first probability of (5.7). Let the vertices
 $k^{(\textrm{u})}_0\in V\big(G_n,k^{(\textrm{u})}_0\big)$
and
$k^{(\textrm{u})}_0\in V\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $0\in V(\mathcal{T}_{\textbf{x},n},0)$
be coupled as in the beginning of this section. Assume that they are such that the event
$0\in V(\mathcal{T}_{\textbf{x},n},0)$
be coupled as in the beginning of this section. Assume that they are such that the event
 $\mathcal{H}_{1,0}$
occurs, and the variables
$\mathcal{H}_{1,0}$
occurs, and the variables
 $\big(\big(\mathcal{Z}_j[1],\mathcal{\widetilde Z}_{j}[1]\big),2\leqslant j\leqslant n\big)$
are such that
$\big(\big(\mathcal{Z}_j[1],\mathcal{\widetilde Z}_{j}[1]\big),2\leqslant j\leqslant n\big)$
are such that
 $\bigcap^3_{j=1}F_{1,j}$
holds. We first argue that under the event
$\bigcap^3_{j=1}F_{1,j}$
holds. We first argue that under the event
 $\bigcap^3_{j=1}F_{1,j}\cap \mathcal{H}_{1,0}$
, their type-R children can be coupled so that w.h.p.,
$\bigcap^3_{j=1}F_{1,j}\cap \mathcal{H}_{1,0}$
, their type-R children can be coupled so that w.h.p.,
 $R^{(\textrm{u})}_0=R^{(\textrm{i})}_0$
and
$R^{(\textrm{u})}_0=R^{(\textrm{i})}_0$
and
 $k^{(\textrm{u})}_{0,j}=k^{(\textrm{i})}_{0,j}$
for
$k^{(\textrm{u})}_{0,j}=k^{(\textrm{i})}_{0,j}$
for
 $j=2,\ldots,1+R^{(\textrm{i})}_0$
. In view of Definitions 4 and 8, this follows readily from Lemma 9. It remains to prove that under this coupling,
$j=2,\ldots,1+R^{(\textrm{i})}_0$
. In view of Definitions 4 and 8, this follows readily from Lemma 9. It remains to prove that under this coupling,
 $\big|(k^{(\textrm{u})}_0/n)^\chi-a^{(\textrm{i})}_0\big|$
and
$\big|(k^{(\textrm{u})}_0/n)^\chi-a^{(\textrm{i})}_0\big|$
and
 $\big|a^{(\textrm{i})}_{0,j}-(k^{(\textrm{u})}_{0,j}/n)^\chi\big|$
are sufficiently small. Since
$\big|a^{(\textrm{i})}_{0,j}-(k^{(\textrm{u})}_{0,j}/n)^\chi\big|$
are sufficiently small. Since
 $k^{(\textrm{u})}_0=\Big\lceil{n \Big(a^{(\textrm{i})}_0\Big)^{1/\chi}}\Big\rceil$
, and for
$k^{(\textrm{u})}_0=\Big\lceil{n \Big(a^{(\textrm{i})}_0\Big)^{1/\chi}}\Big\rceil$
, and for
 $j=2,\ldots,1+R^{(\textrm{i})}_0$
,
$j=2,\ldots,1+R^{(\textrm{i})}_0$
,
 $k^{(\textrm{u})}_{0,j}$
satisfies
$k^{(\textrm{u})}_{0,j}$
satisfies
 $k^{(\textrm{u})}_{0,j}>k^{(\textrm{u})}_0$
and
$k^{(\textrm{u})}_{0,j}>k^{(\textrm{u})}_0$
and
 $\Big(\Big(k^{(\textrm{u})}_{0,j}-1\Big)/n\Big)^\chi<a^{(\textrm{i})}_{0,j}\leqslant \Big(k^{(\textrm{u})}_{0,j}/n\Big)^\chi$
, it is enough to bound
$\Big(\Big(k^{(\textrm{u})}_{0,j}-1\Big)/n\Big)^\chi<a^{(\textrm{i})}_{0,j}\leqslant \Big(k^{(\textrm{u})}_{0,j}/n\Big)^\chi$
, it is enough to bound
 $(\ell/n)^\chi-((\ell-1)/n)^\chi$
for
$(\ell/n)^\chi-((\ell-1)/n)^\chi$
for
 $k^{(\textrm{u})}_0+1\leqslant \ell\leqslant n$
. For such
$k^{(\textrm{u})}_0+1\leqslant \ell\leqslant n$
. For such
 $\ell$
, we use the fact that
$\ell$
, we use the fact that
 $k^{(\textrm{u})}_0>n(\log\log n)^{-1}$
on the event
$k^{(\textrm{u})}_0>n(\log\log n)^{-1}$
on the event
 $\mathcal{H}_{1,0}$
and the mean value theorem to obtain
$\mathcal{H}_{1,0}$
and the mean value theorem to obtain
 \begin{equation}\mathbb{1}[\mathcal{H}_{1,0}] \left[\left(\frac{\ell}{n}\right)^\chi- \left(\frac{\ell-1}{n}\right)^\chi\right] \leqslant \mathbb{1}[\mathcal{H}_{1,0}] \frac{\chi}{n} \left(\frac{n}{\ell-1}\right)^{1-\chi} \leqslant \frac{\chi(\log\log n)^{1-\chi}}{n}.\end{equation}
\begin{equation}\mathbb{1}[\mathcal{H}_{1,0}] \left[\left(\frac{\ell}{n}\right)^\chi- \left(\frac{\ell-1}{n}\right)^\chi\right] \leqslant \mathbb{1}[\mathcal{H}_{1,0}] \frac{\chi}{n} \left(\frac{n}{\ell-1}\right)^{1-\chi} \leqslant \frac{\chi(\log\log n)^{1-\chi}}{n}.\end{equation}
Next, we couple the type-L child of
 $k^{(\textrm{u})}_0\in V\big(G_n,k^{(\textrm{u})}_0\big)$
and
$k^{(\textrm{u})}_0\in V\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $0\in V(\mathcal{T}_{\textbf{x},n},0)$
so that
$0\in V(\mathcal{T}_{\textbf{x},n},0)$
so that
 $k^{(\textrm{u})}_{0,1}=k^{(\textrm{i})}_{0,1}$
and
$k^{(\textrm{u})}_{0,1}=k^{(\textrm{i})}_{0,1}$
and
 $\Big(k^{(\textrm{u})}_{0,1}/n\Big)^\chi\approx a^{(\textrm{i})}_{0,1}$
. Independently from
$\Big(k^{(\textrm{u})}_{0,1}/n\Big)^\chi\approx a^{(\textrm{i})}_{0,1}$
. Independently from
 $a^{(\textrm{i})}_0$
, let
$a^{(\textrm{i})}_0$
, let
 $U_{0,1}\sim \textrm{U}[0,1]$
and
$U_{0,1}\sim \textrm{U}[0,1]$
and
 $a^{(\textrm{i})}_{0,1}=U_{0,1}a^{(\textrm{i})}_0$
. Recalling
$a^{(\textrm{i})}_{0,1}=U_{0,1}a^{(\textrm{i})}_0$
. Recalling
 $v[2]=k^{(\textrm{u})}_{0,1}$
in the BFS, it follows from Definitions 4 and 8 that we can define
$v[2]=k^{(\textrm{u})}_{0,1}$
in the BFS, it follows from Definitions 4 and 8 that we can define
 $k^{(\textrm{u})}_{0,1}$
to satisfy
$k^{(\textrm{u})}_{0,1}$
to satisfy
 \begin{equation*}S_{n,v[2]-1}[1]\leqslant U_{0,1}S_{n,v[1]-1}[1]< S_{n,v[2]}[1],\end{equation*}
\begin{equation*}S_{n,v[2]-1}[1]\leqslant U_{0,1}S_{n,v[1]-1}[1]< S_{n,v[2]}[1],\end{equation*}
or equivalently,
 \begin{equation}S_{n,v[2]-1}[1]\leqslant \frac{a^{(\textrm{i})}_{0,1}}{a^{(\textrm{i})}_0}S_{n,v[1]-1}[1]< S_{n,v[2]}[1],\end{equation}
\begin{equation}S_{n,v[2]-1}[1]\leqslant \frac{a^{(\textrm{i})}_{0,1}}{a^{(\textrm{i})}_0}S_{n,v[1]-1}[1]< S_{n,v[2]}[1],\end{equation}
and take
 $k^{(\textrm{u})}_{0,1}=k^{(\textrm{i})}_{0,1}$
. Now we show that under this coupling,
$k^{(\textrm{u})}_{0,1}=k^{(\textrm{i})}_{0,1}$
. Now we show that under this coupling,
 $a^{(\textrm{i})}_{0,1}\approx \big(k^{(\textrm{u})}_{0,1}/n\big)^\chi$
on the ‘good’ event
$a^{(\textrm{i})}_{0,1}\approx \big(k^{(\textrm{u})}_{0,1}/n\big)^\chi$
on the ‘good’ event
 $\mathcal{H}_{1,0}\cap \mathcal{H}_{1,1}\cap F_{1,1}$
. Observe that
$\mathcal{H}_{1,0}\cap \mathcal{H}_{1,1}\cap F_{1,1}$
. Observe that
 $S_{n,v[2]}[1]=\Omega\big((\log \log n)^{-3\chi}\big)$
on the good event, because for n large enough,
$S_{n,v[2]}[1]=\Omega\big((\log \log n)^{-3\chi}\big)$
on the good event, because for n large enough,
 \begin{align*}S_{n,v[2]}[1]&\geqslant U_{0,1}S_{n,v[1]-1}[1]\geqslant (\log \log n)^{-2\chi}\left[\left(\frac{v[1]-1}{n}\right)^\chi-C^\star n^{-\frac{\chi}{12}}\right]\\&\geqslant (\log \log n)^{-2\chi}\big[(\log \log n)^{-\chi} -2C^\star n^{-\frac{\chi}{12}}\big].\end{align*}
\begin{align*}S_{n,v[2]}[1]&\geqslant U_{0,1}S_{n,v[1]-1}[1]\geqslant (\log \log n)^{-2\chi}\left[\left(\frac{v[1]-1}{n}\right)^\chi-C^\star n^{-\frac{\chi}{12}}\right]\\&\geqslant (\log \log n)^{-2\chi}\big[(\log \log n)^{-\chi} -2C^\star n^{-\frac{\chi}{12}}\big].\end{align*}
Since
 $S_{n,j}[1]$
increases with j, the last calculation implies that
$S_{n,j}[1]$
increases with j, the last calculation implies that
 $|S_{n,j}[1]-(j/n)^\chi|\leqslant C^\star n^{-\frac{\chi}{12}}$
for
$|S_{n,j}[1]-(j/n)^\chi|\leqslant C^\star n^{-\frac{\chi}{12}}$
for
 $j=k^{(\textrm{u})}_{0,1},k^{(\textrm{u})}_{0,1}-1$
. Furthermore, a little calculation shows that on the event
$j=k^{(\textrm{u})}_{0,1},k^{(\textrm{u})}_{0,1}-1$
. Furthermore, a little calculation shows that on the event
 $\mathcal{H}_{1,0}\cap F_{1,1}$
, there is a constant
$\mathcal{H}_{1,0}\cap F_{1,1}$
, there is a constant
 $c\,:\!=\,c(x_1,\mu)$
such that
$c\,:\!=\,c(x_1,\mu)$
such that
 \begin{align*}\Big|\Big(S_{n,v[1]-1}[1]/a^{(\textrm{i})}_0\Big)-1\Big| = c n^{-\frac{\chi}{12}}(\log \log n)^{\chi}.\end{align*}
\begin{align*}\Big|\Big(S_{n,v[1]-1}[1]/a^{(\textrm{i})}_0\Big)-1\Big| = c n^{-\frac{\chi}{12}}(\log \log n)^{\chi}.\end{align*}
Swapping
 $\Big(S_{n,v[1]-1}[1]/a^{(\textrm{i})}_0\Big)$
,
$\Big(S_{n,v[1]-1}[1]/a^{(\textrm{i})}_0\Big)$
,
 $S_{n,v[2]}[1]$
, and
$S_{n,v[2]}[1]$
, and
 $S_{n,v[2]-1}[1]$
in (5.11) for one,
$S_{n,v[2]-1}[1]$
in (5.11) for one,
 $(v[2]/n)^\chi$
, and
$(v[2]/n)^\chi$
, and
 $((v[2]-1)/n)^\chi$
at the costs above, we conclude that there exists
$((v[2]-1)/n)^\chi$
at the costs above, we conclude that there exists
 $\widehat C\,:\!=\,\widehat C(x_1,\mu)$
such that on the good event,
$\widehat C\,:\!=\,\widehat C(x_1,\mu)$
such that on the good event,
 $\big|a^{(\textrm{i})}_{0,1}-\big(k^{(\textrm{u})}_{0,1}/n\big)^\chi\big|\leqslant \widehat Cn^{-\frac{\chi}{12}}(\log \log n)^{\chi}$
. Hence, we can take
$\big|a^{(\textrm{i})}_{0,1}-\big(k^{(\textrm{u})}_{0,1}/n\big)^\chi\big|\leqslant \widehat Cn^{-\frac{\chi}{12}}(\log \log n)^{\chi}$
. Hence, we can take
 $C_1\,:\!=\,\widehat C \vee \chi$
for the event
$C_1\,:\!=\,\widehat C \vee \chi$
for the event
 $\mathcal{H}_{1,2}$
and apply Lemma 9 to obtain
$\mathcal{H}_{1,2}$
and apply Lemma 9 to obtain
 \begin{align}\mathbb{P}_{\textbf{x}}\Bigg[\bigcap^3_{j=1} F_{1,j} \cap \mathcal{H}^c_{1,2} \cap \mathcal{H}_{1,1}\cap\mathcal{H}_{1,0}\Bigg]&= \mathbb{P}_{\textbf{x}}\bigg[\Big\{\textbf{Y}^{(v[1],n)}_{\textrm{Be}}\not=\textbf{V}^{(v[1],n)}_{\textrm{Po}}\Big\}\cap \bigcap^3_{j=1} F_{1,j} \cap \bigcap^1_{j=0}\mathcal{H}_{1,j}\bigg]\nonumber\\&\leqslant \mathbb{P}_{\textbf{x}}\bigg[\Big\{\textbf{Y}^{(v[1],n)}_{\textrm{Be}}\not=\textbf{V}^{(v[1],n)}_{\textrm{Po}}\Big\}\cap \bigcap^3_{j=1} F_{1,j} \cap \mathcal{H}_{1,0}\bigg]\nonumber\\&\leqslant C n^{-\gamma} (\log \log n)^{1-\chi},\end{align}
\begin{align}\mathbb{P}_{\textbf{x}}\Bigg[\bigcap^3_{j=1} F_{1,j} \cap \mathcal{H}^c_{1,2} \cap \mathcal{H}_{1,1}\cap\mathcal{H}_{1,0}\Bigg]&= \mathbb{P}_{\textbf{x}}\bigg[\Big\{\textbf{Y}^{(v[1],n)}_{\textrm{Be}}\not=\textbf{V}^{(v[1],n)}_{\textrm{Po}}\Big\}\cap \bigcap^3_{j=1} F_{1,j} \cap \bigcap^1_{j=0}\mathcal{H}_{1,j}\bigg]\nonumber\\&\leqslant \mathbb{P}_{\textbf{x}}\bigg[\Big\{\textbf{Y}^{(v[1],n)}_{\textrm{Be}}\not=\textbf{V}^{(v[1],n)}_{\textrm{Po}}\Big\}\cap \bigcap^3_{j=1} F_{1,j} \cap \mathcal{H}_{1,0}\bigg]\nonumber\\&\leqslant C n^{-\gamma} (\log \log n)^{1-\chi},\end{align}
where
 $C\,:\!=\,C(x_1,\mu,\kappa)$
is as in Lemma 9. The lemma is proved by applying (5.8), (5.9), and (5.12) to (5.7).
$C\,:\!=\,C(x_1,\mu,\kappa)$
is as in Lemma 9. The lemma is proved by applying (5.8), (5.9), and (5.12) to (5.7).
Before proving Lemma 7, we require a final result that says that under the graph coupling, the event that vertex
 $k^{(\textrm{u})}_0$
has a low degree occurs w.h.p. The next lemma is proved in [Reference Lo24] using Chebyshev’s inequality. Recall that
$k^{(\textrm{u})}_0$
has a low degree occurs w.h.p. The next lemma is proved in [Reference Lo24] using Chebyshev’s inequality. Recall that
 $A_n\,:\!=\,A_{2/3,n}$
is the event in (2.1) with
$A_n\,:\!=\,A_{2/3,n}$
is the event in (2.1) with
 $\alpha=2/3$
.
$\alpha=2/3$
.
Lemma 10. Assume that
 $x_i\in (0,\kappa]$
for
$x_i\in (0,\kappa]$
for
 $i\geqslant 2$
and
$i\geqslant 2$
and
 $\textbf{x}\in A_n$
. Let
$\textbf{x}\in A_n$
. Let
 $\mathcal{H}_{1,i}$
,
$\mathcal{H}_{1,i}$
,
 $0,\ldots,3$
, be as in (5.2). There is a coupling of
$0,\ldots,3$
, be as in (5.2). There is a coupling of
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
, with a positive integer p and a positive constant
$(\mathcal{T}_{\textbf{x},n},0)$
, with a positive integer p and a positive constant
 $C\,:\!=\,C(p,\kappa)$
such that
$C\,:\!=\,C(p,\kappa)$
such that
 \begin{equation*}\mathbb{P}_{\textbf{x}}\Bigg[\bigcap^2_{i=0} \mathcal{H}_{1,i}\cap \mathcal{H}^c_{1,3}\Bigg]\leqslant C (\log n)^{-\frac{p}{r}}(\log \log n)^{\frac{p}{\mu+1}}\quad for\ all\ n\geqslant 3. \end{equation*}
\begin{equation*}\mathbb{P}_{\textbf{x}}\Bigg[\bigcap^2_{i=0} \mathcal{H}_{1,i}\cap \mathcal{H}^c_{1,3}\Bigg]\leqslant C (\log n)^{-\frac{p}{r}}(\log \log n)^{\frac{p}{\mu+1}}\quad for\ all\ n\geqslant 3. \end{equation*}
We now complete the proof of Lemma 7 by applying Lemmas 8 and 10.
Proof of Lemma 7. The lemma follows from bounding the right-hand side of
 \begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^3_{i=0} \mathcal{H}_{1,i}\Bigg)^c\Bigg]&=\mathbb{P}_{\textbf{x}}\big[ \mathcal{H}^c_{1,0}\big]+\sum^3_{i=1}\mathbb{P}_{\textbf{x}}\Bigg[\bigcap^{i-1}_{j=0}\mathcal{H}_{1,j}\cap \mathcal{H}^c_{1,i}\Bigg],\end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^3_{i=0} \mathcal{H}_{1,i}\Bigg)^c\Bigg]&=\mathbb{P}_{\textbf{x}}\big[ \mathcal{H}^c_{1,0}\big]+\sum^3_{i=1}\mathbb{P}_{\textbf{x}}\Bigg[\bigcap^{i-1}_{j=0}\mathcal{H}_{1,j}\cap \mathcal{H}^c_{1,i}\Bigg],\end{align*}
under the coupling in the proof of Lemma 8. To bound
 $\mathbb{P}_{\textbf{x}}\big[ \mathcal{H}^c_{1,0}\big]$
and
$\mathbb{P}_{\textbf{x}}\big[ \mathcal{H}^c_{1,0}\big]$
and
 $\mathbb{P}_{\textbf{x}}\big[\mathcal{H}_{1,0}\cap \mathcal{H}^c_{1,1}\big]$
, recall that
$\mathbb{P}_{\textbf{x}}\big[\mathcal{H}_{1,0}\cap \mathcal{H}^c_{1,1}\big]$
, recall that
 $a^{(\textrm{i})}_0=U^\chi_0$
and
$a^{(\textrm{i})}_0=U^\chi_0$
and
 $a^{(\textrm{i})}_{0,1}=U_{0,1} a^{(\textrm{i})}_{0}$
, where
$a^{(\textrm{i})}_{0,1}=U_{0,1} a^{(\textrm{i})}_{0}$
, where
 $U_{0}$
and
$U_{0}$
and
 $U_{0,1}$
are independent standard uniform variables. Hence,
$U_{0,1}$
are independent standard uniform variables. Hence,
 \begin{align}\mathbb{P}_{\textbf{x}}\big[\mathcal{H}_{1,0}\cap \mathcal{H}^c_{1,1}\big]&=\mathbb{E}\Big[\mathbb{1}\big[ \mathcal{H}_{1,0}\big]\mathbb{P}_{\textbf{x}}\Big[U_{0,1}\leqslant \big(a^{(\textrm{i})}_0\big)^{-1}(\log \log n)^{-2\chi}|U_0\Big]\Big]\nonumber\\&\leqslant \mathbb{P}_{\textbf{x}}\big[U_{0,1}\leqslant (\log \log n)^{-\chi}\big]\nonumber\\&= (\log \log n)^{-\chi}, \end{align}
\begin{align}\mathbb{P}_{\textbf{x}}\big[\mathcal{H}_{1,0}\cap \mathcal{H}^c_{1,1}\big]&=\mathbb{E}\Big[\mathbb{1}\big[ \mathcal{H}_{1,0}\big]\mathbb{P}_{\textbf{x}}\Big[U_{0,1}\leqslant \big(a^{(\textrm{i})}_0\big)^{-1}(\log \log n)^{-2\chi}|U_0\Big]\Big]\nonumber\\&\leqslant \mathbb{P}_{\textbf{x}}\big[U_{0,1}\leqslant (\log \log n)^{-\chi}\big]\nonumber\\&= (\log \log n)^{-\chi}, \end{align}
and
 $\mathbb{P}_{\textbf{x}}\big[ \mathcal{H}^c_{1,0}\big]=\mathbb{P}_{\textbf{x}}\big[U_0\leqslant(\log \log n)^{-1}\big]=(\log \log n)^{-1}$
. Bounding the remaining probabilities using Lemmas 8 and 10 completes the proof.
$\mathbb{P}_{\textbf{x}}\big[ \mathcal{H}^c_{1,0}\big]=\mathbb{P}_{\textbf{x}}\big[U_0\leqslant(\log \log n)^{-1}\big]=(\log \log n)^{-1}$
. Bounding the remaining probabilities using Lemmas 8 and 10 completes the proof.
6. Proof of the general case
Recall the definitions of
 $k^{(\textrm{u})}_{\bar w}, a^{(\textrm{i})}_{\bar w}$
, and
$k^{(\textrm{u})}_{\bar w}, a^{(\textrm{i})}_{\bar w}$
, and
 $k^{(\textrm{i})}_{\bar w}$
in the beginning of Section 3.2 and Definition 8. In this section, we inductively couple the uniformly rooted Pólya urn graph
$k^{(\textrm{i})}_{\bar w}$
in the beginning of Section 3.2 and Definition 8. In this section, we inductively couple the uniformly rooted Pólya urn graph
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and the intermediate Pólya point tree
$\big(G_n,k^{(\textrm{u})}_0\big)$
and the intermediate Pólya point tree
 $(\mathcal{T}_{\textbf{x},n},0)$
in Definition 8 so that w.h.p.,
$(\mathcal{T}_{\textbf{x},n},0)$
in Definition 8 so that w.h.p.,
 $\Big(B_r\big(G_n,k^{(\textrm{u})}_0\big),k^{(\textrm{u})}_0\Big)\cong (B_r(\mathcal{T}_{\textbf{x},n},0),0)$
, and for
$\Big(B_r\big(G_n,k^{(\textrm{u})}_0\big),k^{(\textrm{u})}_0\Big)\cong (B_r(\mathcal{T}_{\textbf{x},n},0),0)$
, and for
 $k^{(\textrm{u})}_{\bar w}\in V\Big(B_r\big(G_n,k^{(\textrm{u})}_0\big)\Big)$
and
$k^{(\textrm{u})}_{\bar w}\in V\Big(B_r\big(G_n,k^{(\textrm{u})}_0\big)\Big)$
and
 $\bar w\in V(B_r(\mathcal{T}_{\textbf{x},n},0)$
, their ages are close enough
$\bar w\in V(B_r(\mathcal{T}_{\textbf{x},n},0)$
, their ages are close enough
 $\Big(\Big(k^{(\textrm{u})}_{\bar w}/n\Big)^\chi\approx a^{(\textrm{i})}_{\bar w}\Big)$
and their PA labels and arrival times match
$\Big(\Big(k^{(\textrm{u})}_{\bar w}/n\Big)^\chi\approx a^{(\textrm{i})}_{\bar w}\Big)$
and their PA labels and arrival times match
 $\big(k^{(\textrm{i})}_{\bar w}=k^{(\textrm{u})}_{\bar w}\big)$
. Given a positive integer r, let
$\big(k^{(\textrm{i})}_{\bar w}=k^{(\textrm{u})}_{\bar w}\big)$
. Given a positive integer r, let
 $L[q]\,:\!=\,(0,1,\ldots,1)$
and
$L[q]\,:\!=\,(0,1,\ldots,1)$
and
 $|L[q]|=q+1$
for
$|L[q]|=q+1$
for
 $2\leqslant q\leqslant r$
, so that L[q] and
$2\leqslant q\leqslant r$
, so that L[q] and
 $k^{(\textrm{u})}_{L[q]}$
are the type-L children in
$k^{(\textrm{u})}_{L[q]}$
are the type-L children in
 $\partial \mathfrak{B}_q\,:\!=\,V(B_q(\mathcal{T}_{\textbf{x},n},0))\setminus V(B_{q-1}(\mathcal{T}_{\textbf{x},n},0))$
and
$\partial \mathfrak{B}_q\,:\!=\,V(B_q(\mathcal{T}_{\textbf{x},n},0))\setminus V(B_{q-1}(\mathcal{T}_{\textbf{x},n},0))$
and
 $\partial \mathcal{B}_q\,:\!=\,V\Big(B_q\big(G_n,k^{(\textrm{u})}_0\big)\Big)\setminus V\Big(B_{q-1}\big(G_n,k^{(\textrm{u})}_0\big)\Big)$
. Let
$\partial \mathcal{B}_q\,:\!=\,V\Big(B_q\big(G_n,k^{(\textrm{u})}_0\big)\Big)\setminus V\Big(B_{q-1}\big(G_n,k^{(\textrm{u})}_0\big)\Big)$
. Let
 $\chi/12\,:\!=\,\beta_1>\beta_2>\cdots>\beta_r>0$
, so that
$\chi/12\,:\!=\,\beta_1>\beta_2>\cdots>\beta_r>0$
, so that
 $n^{-\beta_q}>n^{-\beta_{q-1}}(\log \log n)^{q\chi}$
for n large enough. To ensure that we can couple the
$n^{-\beta_q}>n^{-\beta_{q-1}}(\log \log n)^{q\chi}$
for n large enough. To ensure that we can couple the
 $(q+1)$
-neighbourhoods for
$(q+1)$
-neighbourhoods for
 $1\leqslant q\leqslant r-1$
, we define the coupling events analogous to
$1\leqslant q\leqslant r-1$
, we define the coupling events analogous to
 $\mathcal{H}_{1,i}$
,
$\mathcal{H}_{1,i}$
,
 $i=1,2,3$
, in (5.2):
$i=1,2,3$
, in (5.2):
 \begin{align}\mathcal{H}_{q,1}&=\Big\{a^{(\textrm{i})}_{L[q]}>(\log \log n)^{-\chi(q+1)}\Big\},\nonumber\\\mathcal{H}_{q,2}&= \bigg\{ \Big(B_{q}\big(G_n,k^{(\textrm{u})}_0\big),k^{(\textrm{u})}_0\Big)\cong (B_{q}(\mathcal{T}_{\textbf{x},n},0),0),\text{ with }k^{(\textrm{u})}_{\bar v}=k^{(\textrm{i})}_{\bar v}\nonumber\\&\qquad \text{ and }\bigg|a^{(\textrm{i})}_{\bar v}-\bigg(\frac{k^{(\textrm{u})}_{\bar v}}{n}\bigg)^\chi\bigg|\leqslant C_q n^{-\beta_q} \text{ for $\bar v\in V(B_{q}(\mathcal{T}_{\textbf{x},n},0))$} \bigg\},\nonumber\\\mathcal{H}_{q,3}&=\Big\{R^{(\textrm{i})}_{\bar v}<(\log n)^{1/r} \text{ for $\bar v\in V(B_{q-1}(\mathcal{T}_{\textbf{x},n},0))$}\Big\},\end{align}
\begin{align}\mathcal{H}_{q,1}&=\Big\{a^{(\textrm{i})}_{L[q]}>(\log \log n)^{-\chi(q+1)}\Big\},\nonumber\\\mathcal{H}_{q,2}&= \bigg\{ \Big(B_{q}\big(G_n,k^{(\textrm{u})}_0\big),k^{(\textrm{u})}_0\Big)\cong (B_{q}(\mathcal{T}_{\textbf{x},n},0),0),\text{ with }k^{(\textrm{u})}_{\bar v}=k^{(\textrm{i})}_{\bar v}\nonumber\\&\qquad \text{ and }\bigg|a^{(\textrm{i})}_{\bar v}-\bigg(\frac{k^{(\textrm{u})}_{\bar v}}{n}\bigg)^\chi\bigg|\leqslant C_q n^{-\beta_q} \text{ for $\bar v\in V(B_{q}(\mathcal{T}_{\textbf{x},n},0))$} \bigg\},\nonumber\\\mathcal{H}_{q,3}&=\Big\{R^{(\textrm{i})}_{\bar v}<(\log n)^{1/r} \text{ for $\bar v\in V(B_{q-1}(\mathcal{T}_{\textbf{x},n},0))$}\Big\},\end{align}
where
 $R^{(\textrm{i})}_{\bar v}$
is as in (4.1) and
$R^{(\textrm{i})}_{\bar v}$
is as in (4.1) and
 $C_q\,:\!=\,C_q(x_1,\mu)$
will be chosen in the proof of Lemma 12 below. Let
$C_q\,:\!=\,C_q(x_1,\mu)$
will be chosen in the proof of Lemma 12 below. Let
 $A_n\,:\!=\,A_{2/3,n}$
be the event in (2.1), and let
$A_n\,:\!=\,A_{2/3,n}$
be the event in (2.1), and let
 $\mathbb{P}_{\textbf{x}}$
indicate the conditioning on a specific realisation of the fitness sequence
$\mathbb{P}_{\textbf{x}}$
indicate the conditioning on a specific realisation of the fitness sequence
 $\textbf{x}$
. The next lemma is the key result of this section; it essentially states that if we can couple
$\textbf{x}$
. The next lemma is the key result of this section; it essentially states that if we can couple
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
so that
$(\mathcal{T}_{\textbf{x},n},0)$
so that
 $\Big(B_{q}\big(G_n,k^{(\textrm{u})}_0\big),k^{(\textrm{u})}_0\Big)\cong (B_{q}(\mathcal{T}_{\textbf{x},n},0),0)$
w.h.p., then we can achieve this for the
$\Big(B_{q}\big(G_n,k^{(\textrm{u})}_0\big),k^{(\textrm{u})}_0\Big)\cong (B_{q}(\mathcal{T}_{\textbf{x},n},0),0)$
w.h.p., then we can achieve this for the
 $(q+1)$
-neighbourhoods too.
$(q+1)$
-neighbourhoods too.
Lemma 11. Let
 $\mathcal{H}_{q,i}$
,
$\mathcal{H}_{q,i}$
,
 $1\leqslant q\leqslant r-1$
,
$1\leqslant q\leqslant r-1$
,
 $i=1,2,3$
, be as in (5.2) and (6.1). Assume that
$i=1,2,3$
, be as in (5.2) and (6.1). Assume that
 $x_i\in (0,\kappa]$
for
$x_i\in (0,\kappa]$
for
 $i\geqslant 2$
and
$i\geqslant 2$
and
 $\textbf{x}\in A_n$
. Given
$\textbf{x}\in A_n$
. Given
 $r<\infty$
and
$r<\infty$
and
 $1\leqslant q\leqslant r-1$
, if there is a coupling of
$1\leqslant q\leqslant r-1$
, if there is a coupling of
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
$(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
 $C\,:\!=\,C(x_1,\mu,\kappa,q)$
such that
$C\,:\!=\,C(x_1,\mu,\kappa,q)$
such that
 \begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^{3}_{i=1}\mathcal{H}_{q,i}\Bigg)^c\Bigg]\leqslant C (\log \log n)^{-\chi} \quad for\ all\ n\geqslant 3,\end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^{3}_{i=1}\mathcal{H}_{q,i}\Bigg)^c\Bigg]\leqslant C (\log \log n)^{-\chi} \quad for\ all\ n\geqslant 3,\end{align*}
then there is a coupling of
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
$(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
 $C^{\prime}\,:\!=\,C^{\prime}(x_1,\mu,\kappa,q)$
such that
$C^{\prime}\,:\!=\,C^{\prime}(x_1,\mu,\kappa,q)$
such that
 \begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^{3}_{i=1}\mathcal{H}_{q+1,i}\Bigg)^c\Bigg]\leqslant C^{\prime} (\log \log n)^{-\chi} \quad for\ all\ n\geqslant 3.\end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^{3}_{i=1}\mathcal{H}_{q+1,i}\Bigg)^c\Bigg]\leqslant C^{\prime} (\log \log n)^{-\chi} \quad for\ all\ n\geqslant 3.\end{align*}
Since Lemma 7 implies that such a graph coupling exists for
 $r=1$
, combining Lemmas 7 and 11 yields the following corollary, which is instrumental in proving Theorem 1.
$r=1$
, combining Lemmas 7 and 11 yields the following corollary, which is instrumental in proving Theorem 1.
Corollary 2. Retaining the assumptions and the notation in Lemma 11, there is a coupling of
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
$(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
 $C\,:\!=\,C(x_1,\mu,\kappa,r)$
such that
$C\,:\!=\,C(x_1,\mu,\kappa,r)$
such that
 \begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^{3}_{i=1}\mathcal{H}_{r,i}\Bigg)^c\Bigg]\leqslant C (\log \log n)^{-\chi} \quad for\ all\ n\geqslant 3. \end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^{3}_{i=1}\mathcal{H}_{r,i}\Bigg)^c\Bigg]\leqslant C (\log \log n)^{-\chi} \quad for\ all\ n\geqslant 3. \end{align*}
The proof of Lemma 11 is in the same vein as that of Lemma 7. Fixing
 $1\leqslant q\leqslant r-1$
, we may assume that the two graphs are already coupled so that the event
$1\leqslant q\leqslant r-1$
, we may assume that the two graphs are already coupled so that the event
 $\bigcap^3_{i=1}\mathcal{H}_{q,i}$
has occurred. On the event
$\bigcap^3_{i=1}\mathcal{H}_{q,i}$
has occurred. On the event
 $\mathcal{H}_{q,1}$
, it is clear from the definitions of
$\mathcal{H}_{q,1}$
, it is clear from the definitions of
 $a^{(\textrm{i})}_{L[q+1]}$
and
$a^{(\textrm{i})}_{L[q+1]}$
and
 $\mathcal{H}_{q+1,1}$
that
$\mathcal{H}_{q+1,1}$
that
 $\mathcal{H}_{q+1,1}$
occurs w.h.p., while on the event
$\mathcal{H}_{q+1,1}$
occurs w.h.p., while on the event
 $\mathcal{H}_{q,1}\cap \mathcal{H}_{q,3}$
, we can easily show that
$\mathcal{H}_{q,1}\cap \mathcal{H}_{q,3}$
, we can easily show that
 $\mathcal{H}_{q+1,3}$
occurs w.h.p. So for most of the proof, we handle the event
$\mathcal{H}_{q+1,3}$
occurs w.h.p. So for most of the proof, we handle the event
 $\mathcal{H}_{q+1,2}$
. To couple the graphs so that
$\mathcal{H}_{q+1,2}$
. To couple the graphs so that
 $\mathcal{H}_{q+1,2}$
occurs w.h.p., we consider the vertices of
$\mathcal{H}_{q+1,2}$
occurs w.h.p., we consider the vertices of
 $\partial \mathcal{B}_q$
and
$\partial \mathcal{B}_q$
and
 $\partial \mathfrak{B}_q$
in the breadth-first order, and couple
$\partial \mathfrak{B}_q$
in the breadth-first order, and couple
 $k^{(\textrm{u})}_{\bar w}\in \partial \mathcal{B}_q$
and
$k^{(\textrm{u})}_{\bar w}\in \partial \mathcal{B}_q$
and
 $\bar w\in \partial \mathfrak{B}_q$
so that w.h.p., the numbers of children they have are the same and not too large, and the children’s ages are close enough. Recall the definition of v[t] in (3.1). If
$\bar w\in \partial \mathfrak{B}_q$
so that w.h.p., the numbers of children they have are the same and not too large, and the children’s ages are close enough. Recall the definition of v[t] in (3.1). If
 $v[t]=k^{(\textrm{u})}_{\bar w}$
, the associated events are as follows:
$v[t]=k^{(\textrm{u})}_{\bar w}$
, the associated events are as follows:
 \begin{align}\mathcal{K}_{t,1}&= \bigg\{R^{(\textrm{u})}_{\bar w}=R^{(\textrm{i})}_{\bar w},\text{ and for $1\leqslant j\leqslant 1+R^{(\textrm{i})}_{\bar w}$,}\nonumber\\&\hspace{2cm}k^{(\textrm{i})}_{\bar w,j}=k^{(\textrm{u})}_{\bar w,j}\text{ and }\bigg|a^{(\textrm{i})}_{\bar w,j}-\bigg(\frac{k^{(\textrm{u})}_{\bar w,j}}{n}\bigg)^\chi\bigg| \leqslant C_{q+1} n^{-\beta_{q+1}}\bigg\}, \\\mathcal{K}_{t,2}&=\Big\{R^{(\textrm{i})}_{\bar w}<(\log n)^{1/r}\Big\},\nonumber\end{align}
\begin{align}\mathcal{K}_{t,1}&= \bigg\{R^{(\textrm{u})}_{\bar w}=R^{(\textrm{i})}_{\bar w},\text{ and for $1\leqslant j\leqslant 1+R^{(\textrm{i})}_{\bar w}$,}\nonumber\\&\hspace{2cm}k^{(\textrm{i})}_{\bar w,j}=k^{(\textrm{u})}_{\bar w,j}\text{ and }\bigg|a^{(\textrm{i})}_{\bar w,j}-\bigg(\frac{k^{(\textrm{u})}_{\bar w,j}}{n}\bigg)^\chi\bigg| \leqslant C_{q+1} n^{-\beta_{q+1}}\bigg\}, \\\mathcal{K}_{t,2}&=\Big\{R^{(\textrm{i})}_{\bar w}<(\log n)^{1/r}\Big\},\nonumber\end{align}
where
 $R^{(\textrm{u})}_{\bar w}$
and
$R^{(\textrm{u})}_{\bar w}$
and
 $R^{(\textrm{i})}_{\bar w}$
are as in (3.4) and (4.1), and
$R^{(\textrm{i})}_{\bar w}$
are as in (3.4) and (4.1), and
 $C_{q+1}$
and
$C_{q+1}$
and
 $\beta_{q+1}$
are as in the event
$\beta_{q+1}$
are as in the event
 $\mathcal{H}_{q+1,2}$
. Below we only consider the coupling of the type-L children in detail, because the type-R case can be proved similarly. Observe that for n large enough, there must be a type-L child in
$\mathcal{H}_{q+1,2}$
. Below we only consider the coupling of the type-L children in detail, because the type-R case can be proved similarly. Observe that for n large enough, there must be a type-L child in
 $\partial \mathcal{B}_q$
on the event
$\partial \mathcal{B}_q$
on the event
 $\bigcap^3_{j=1}\mathcal{H}_{q,j}$
. Define
$\bigcap^3_{j=1}\mathcal{H}_{q,j}$
. Define
 $v[\tau[q]]=k^{(\textrm{u})}_{L[q]}$
, so that
$v[\tau[q]]=k^{(\textrm{u})}_{L[q]}$
, so that
 \begin{equation*}\tau[1]=2\quad\text{and}\quad\tau[q]=\Big|V\Big(B_{q-1}\big(G_n,k^{(\textrm{u})}_0\big)\Big)\Big|+1\quad\text{for $2\leqslant q \leqslant r-1$}\end{equation*}
\begin{equation*}\tau[1]=2\quad\text{and}\quad\tau[q]=\Big|V\Big(B_{q-1}\big(G_n,k^{(\textrm{u})}_0\big)\Big)\Big|+1\quad\text{for $2\leqslant q \leqslant r-1$}\end{equation*}
are the exploration times of the type-L children. Noting that
 \begin{align*}\big(\mathcal{A}_{\tau[q]-1},\mathcal{P}_{\tau[q]-1}, \mathcal{N}_{\tau[q]-1}\big)=\Big(\partial \mathcal{B}_q,V\Big(B_{q-1}\big(G_n,k^{(\textrm{u})}_0\big)\Big),V(G_n)\setminus V\Big(B_{q}\big(G_n,k^{(\textrm{u})}_0\big)\Big)\Big),\end{align*}
\begin{align*}\big(\mathcal{A}_{\tau[q]-1},\mathcal{P}_{\tau[q]-1}, \mathcal{N}_{\tau[q]-1}\big)=\Big(\partial \mathcal{B}_q,V\Big(B_{q-1}\big(G_n,k^{(\textrm{u})}_0\big)\Big),V(G_n)\setminus V\Big(B_{q}\big(G_n,k^{(\textrm{u})}_0\big)\Big)\Big),\end{align*}
we let
 \begin{align*}\Big(\Big(\mathcal{Z}_j[\tau[q]], \mathcal{\widetilde Z}_{j}[\tau[q]]\Big),j\in \mathcal{A}_{\tau[q]-1}\cup \mathcal{N}_{\tau[q]-1}\Big)\quad \text{and} \quad \left(S_{n,j}[\tau[q]],1\leqslant j\leqslant n\right)\end{align*}
\begin{align*}\Big(\Big(\mathcal{Z}_j[\tau[q]], \mathcal{\widetilde Z}_{j}[\tau[q]]\Big),j\in \mathcal{A}_{\tau[q]-1}\cup \mathcal{N}_{\tau[q]-1}\Big)\quad \text{and} \quad \left(S_{n,j}[\tau[q]],1\leqslant j\leqslant n\right)\end{align*}
be as in (3.7), (3.8), and (3.10). For convenience, we also define
 \begin{equation}\zeta_q\,:\!=\,\mathcal{Z}_{v[\tau[q]]}{[\tau[q]]},\quad \text{so that }\zeta_q\sim\textrm{Gamma}(x_{v[\tau[q]]}+1,1).\end{equation}
\begin{equation}\zeta_q\,:\!=\,\mathcal{Z}_{v[\tau[q]]}{[\tau[q]]},\quad \text{so that }\zeta_q\sim\textrm{Gamma}(x_{v[\tau[q]]}+1,1).\end{equation}
We use
 $(S_{n,j}[\tau[q]],1\leqslant j\leqslant n)$
to generate the children of vertex
$(S_{n,j}[\tau[q]],1\leqslant j\leqslant n)$
to generate the children of vertex
 $v[\tau[q]]$
, and let
$v[\tau[q]]$
, and let
 $\Big(a^{(\textrm{i})}_{L[q],j},2\leqslant j\leqslant 1+R^{(\textrm{i})}_{L[q]}\Big)$
be the points of the mixed Poisson process on
$\Big(a^{(\textrm{i})}_{L[q],j},2\leqslant j\leqslant 1+R^{(\textrm{i})}_{L[q]}\Big)$
be the points of the mixed Poisson process on
 $\Big(a^{(\textrm{i})}_{L[q]},1\Big]$
with intensity
$\Big(a^{(\textrm{i})}_{L[q]},1\Big]$
with intensity
 \begin{equation}\frac{\zeta_q}{\mu \Big(a^{(\textrm{i})}_{L[q]}\Big)^{1/\mu}} y^{1/\mu-1} dy,\end{equation}
\begin{equation}\frac{\zeta_q}{\mu \Big(a^{(\textrm{i})}_{L[q]}\Big)^{1/\mu}} y^{1/\mu-1} dy,\end{equation}
and
 $a^{(\textrm{i})}_{L[q],1} \sim \textrm{U}\Big[0,a^{(\textrm{i})}_{L[q]}\Big]$
. In the sequel, we develop lemmas analogous to Lemmas 8 and 10 to show that on the event
$a^{(\textrm{i})}_{L[q],1} \sim \textrm{U}\Big[0,a^{(\textrm{i})}_{L[q]}\Big]$
. In the sequel, we develop lemmas analogous to Lemmas 8 and 10 to show that on the event
 $\bigcap^3_{j=1} \mathcal{H}_{q,j}$
, we can couple the vertices
$\bigcap^3_{j=1} \mathcal{H}_{q,j}$
, we can couple the vertices
 $v[\tau[q]]\in \partial\mathcal{B}_q$
and
$v[\tau[q]]\in \partial\mathcal{B}_q$
and
 $\tau[q]\in \partial \mathfrak{B}_q$
so that the events
$\tau[q]\in \partial \mathfrak{B}_q$
so that the events
 $\mathcal{K}_{\tau[q],1}$
and
$\mathcal{K}_{\tau[q],1}$
and
 $\mathcal{K}_{\tau[q],2}$
occur w.h.p. As in the 1-neighbourhood case, the difficult part is proving the claim for
$\mathcal{K}_{\tau[q],2}$
occur w.h.p. As in the 1-neighbourhood case, the difficult part is proving the claim for
 $\mathcal{K}_{\tau[q],1}$
. From now on we write
$\mathcal{K}_{\tau[q],1}$
. From now on we write
 \begin{equation}\overline{\mathcal{H}}_{q,l}\,:\!=\,\bigcap^3_{j=1} \mathcal{H}_{q,j}\cap \big\{|\partial\mathcal{B}_q|=l\big\} \quad for\ all\ l\geqslant 1. \end{equation}
\begin{equation}\overline{\mathcal{H}}_{q,l}\,:\!=\,\bigcap^3_{j=1} \mathcal{H}_{q,j}\cap \big\{|\partial\mathcal{B}_q|=l\big\} \quad for\ all\ l\geqslant 1. \end{equation}
Lemma 12. Retaining the assumptions and the notation in Lemma 11, let
 $\beta_q$
,
$\beta_q$
,
 $\mathcal{K}_{\tau[q],1}$
, and
$\mathcal{K}_{\tau[q],1}$
, and
 $\overline{\mathcal{H}}_{q,l}$
be as in (6.1), (6.2), and (6.5). Then there is a coupling of
$\overline{\mathcal{H}}_{q,l}$
be as in (6.1), (6.2), and (6.5). Then there is a coupling of
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
$(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
 $C\,:\!=\,C(x_1,\mu,\kappa,q)$
such that
$C\,:\!=\,C(x_1,\mu,\kappa,q)$
such that
 \begin{align*}\mathbb{P}_{\textbf{x}}\Big(\overline{\mathcal{H}}_{q,l} \cap \mathcal{H}_{q+1,1}\cap \mathcal{K}^c_{\tau[q],1} \Big)\leqslant C n^{-d}(\log\log n)^{q+1}(\log n)^{q/r}\quad for\ all\ n\geqslant 3\ \text{and} l\geqslant 1, \end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\Big(\overline{\mathcal{H}}_{q,l} \cap \mathcal{H}_{q+1,1}\cap \mathcal{K}^c_{\tau[q],1} \Big)\leqslant C n^{-d}(\log\log n)^{q+1}(\log n)^{q/r}\quad for\ all\ n\geqslant 3\ \text{and} l\geqslant 1, \end{align*}
where
 $0<\gamma<\chi/12$
and
$0<\gamma<\chi/12$
and
 $d\,:\!=\,\min\big\{\chi/3-4\gamma,\gamma, 1-\chi,\beta_q\big\}$
.
$d\,:\!=\,\min\big\{\chi/3-4\gamma,\gamma, 1-\chi,\beta_q\big\}$
.
Similar to Lemma 8, the key step is to couple the type-R children of vertex
 $k^{(\textrm{u})}_{L[q]}$
. Let the Bernoulli sequence
$k^{(\textrm{u})}_{L[q]}$
. Let the Bernoulli sequence
 $\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
be as in Definition 7, which by Lemma 5 encodes the type-R children of vertex
$\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
be as in Definition 7, which by Lemma 5 encodes the type-R children of vertex
 $k^{(\textrm{u})}_{L[q]}$
. Additionally, define
$k^{(\textrm{u})}_{L[q]}$
. Additionally, define
 \begin{align}M_{L[q]}\,:\!=\,\min\Big\{j\in [n]\,:\, (j/n)^\chi\geqslant a^{(\textrm{i})}_{L[q]}\Big\}.\end{align}
\begin{align}M_{L[q]}\,:\!=\,\min\Big\{j\in [n]\,:\, (j/n)^\chi\geqslant a^{(\textrm{i})}_{L[q]}\Big\}.\end{align}
We want to use the bins
 $\Big(a^{(\textrm{i})}_{L[q]}, ((j/n)^\chi)^n_{j=M_{L[q]}}\Big)$
to construct the discretised mixed Poisson process that encodes the ages and the PA labels, i.e.
$\Big(a^{(\textrm{i})}_{L[q]}, ((j/n)^\chi)^n_{j=M_{L[q]}}\Big)$
to construct the discretised mixed Poisson process that encodes the ages and the PA labels, i.e.
 $\Big(\Big(a^{(\textrm{i})}_{L[q],j},k^{(\textrm{i})}_{L[q],j}\Big),2\leqslant j\leqslant 1+R^{(\textrm{i})}_{L[q]}\Big)$
. However, it is possible that
$\Big(\Big(a^{(\textrm{i})}_{L[q],j},k^{(\textrm{i})}_{L[q],j}\Big),2\leqslant j\leqslant 1+R^{(\textrm{i})}_{L[q]}\Big)$
. However, it is possible that
 $M_{L[q]}\not =v[\tau[q]]+1$
, in which case the numbers of Bernoulli and Poisson variables do not match and a modification of
$M_{L[q]}\not =v[\tau[q]]+1$
, in which case the numbers of Bernoulli and Poisson variables do not match and a modification of
 $\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
is needed. If
$\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
is needed. If
 $M_{L[q]}\leqslant v[\tau[q]]$
, define
$M_{L[q]}\leqslant v[\tau[q]]$
, define
 $Y_{j\to v[\tau[q]]}$
,
$Y_{j\to v[\tau[q]]}$
,
 $M_{L[q]}\leqslant j \leqslant v[\tau[q]]$
, as Bernoulli variables with means
$M_{L[q]}\leqslant j \leqslant v[\tau[q]]$
, as Bernoulli variables with means
 $P_{j\to v[\tau[q]]}\,:\!=\,0$
, and concatenate the vectors
$P_{j\to v[\tau[q]]}\,:\!=\,0$
, and concatenate the vectors
 $\big(Y_{j\to v[\tau[q]]},M_{L[q]}\leqslant j \leqslant v[\tau[q]]\big)$
and
$\big(Y_{j\to v[\tau[q]]},M_{L[q]}\leqslant j \leqslant v[\tau[q]]\big)$
and
 $\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
. This corresponds to the fact that vertex j cannot send an outgoing edge to vertex
$\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
. This corresponds to the fact that vertex j cannot send an outgoing edge to vertex
 $v[\tau[q]]$
in
$v[\tau[q]]$
in
 $\big(G_n,k^{(\textrm{u})}_0\big)$
. If
$\big(G_n,k^{(\textrm{u})}_0\big)$
. If
 $M_{L[q]}\geqslant v[\tau[q]]+1$
, let
$M_{L[q]}\geqslant v[\tau[q]]+1$
, let
 $\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
be as in Definition 7. Saving notation, we redefine
$\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
be as in Definition 7. Saving notation, we redefine
 \begin{align}\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}\,:\!=\, \left(Y_{\widetilde M_{L[q]}\to v[\tau[q]]}, Y_{(\widetilde M_{L[q]}+1)\to v[\tau[q]]}, \ldots, Y_{n\to v[\tau[q]]}\right),\end{align}
\begin{align}\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}\,:\!=\, \left(Y_{\widetilde M_{L[q]}\to v[\tau[q]]}, Y_{(\widetilde M_{L[q]}+1)\to v[\tau[q]]}, \ldots, Y_{n\to v[\tau[q]]}\right),\end{align}
where
 \begin{equation}\widetilde M_{L[q]}\,:\!=\,\min\big\{M_{L[q]}, v[\tau[q]]+1\big\}.\end{equation}
\begin{equation}\widetilde M_{L[q]}\,:\!=\,\min\big\{M_{L[q]}, v[\tau[q]]+1\big\}.\end{equation}
We also make the following adjustment so that the upcoming Poisson random vector is a discretisation of the mixed Poisson point process on
 $\big(a^{(\textrm{i})}_{L[q]},1\big]$
, and is still comparable to the modified
$\big(a^{(\textrm{i})}_{L[q]},1\big]$
, and is still comparable to the modified
 $\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
. When
$\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
. When
 $M_{L[q]}\leqslant v[\tau[q]]+1$
, define the Poisson means
$M_{L[q]}\leqslant v[\tau[q]]+1$
, define the Poisson means
 \begin{align}\lambda^{[\tau[q]]}_{M_{L[q]}}\,:\!=\,\int^{\left(\frac{M_{L[q]}}{n}\right)^\chi}_{a^{(\textrm{i})}_{L[q]}}\frac{\zeta_q}{\mu \big(a^{(\textrm{i})}_{L[q]}\big)^{1/\mu}} y^{1/\mu-1} dy,\quad\lambda^{[\tau[q]]}_{j}\,:\!=\,\int^{\left(\frac{j}{n}\right)^\chi}_{\left(\frac{j-1}{n}\right)^\chi}\frac{\zeta_q}{\mu \big(a^{(\textrm{i})}_{L[q]}\big)^{1/\mu}} y^{1/\mu-1}dy \end{align}
\begin{align}\lambda^{[\tau[q]]}_{M_{L[q]}}\,:\!=\,\int^{\left(\frac{M_{L[q]}}{n}\right)^\chi}_{a^{(\textrm{i})}_{L[q]}}\frac{\zeta_q}{\mu \big(a^{(\textrm{i})}_{L[q]}\big)^{1/\mu}} y^{1/\mu-1} dy,\quad\lambda^{[\tau[q]]}_{j}\,:\!=\,\int^{\left(\frac{j}{n}\right)^\chi}_{\left(\frac{j-1}{n}\right)^\chi}\frac{\zeta_q}{\mu \big(a^{(\textrm{i})}_{L[q]}\big)^{1/\mu}} y^{1/\mu-1}dy \end{align}
for
 $M_{L[q]}+1\leqslant j\leqslant n$
. When
$M_{L[q]}+1\leqslant j\leqslant n$
. When
 $M_{L[q]}\geqslant v[\tau[q]]+2$
, we let
$M_{L[q]}\geqslant v[\tau[q]]+2$
, we let
 \begin{equation}\lambda^{[\tau[q]]}_{j}\,:\!=\,0\quad\text{for $v[\tau[q]]+1\leqslant j< M_{L[q]}$,}\end{equation}
\begin{equation}\lambda^{[\tau[q]]}_{j}\,:\!=\,0\quad\text{for $v[\tau[q]]+1\leqslant j< M_{L[q]}$,}\end{equation}
in addition to (6.9), so that there are no Poisson points outside the interval
 $\big(a^{(\textrm{i})}_{L[q]},1\big]$
.
$\big(a^{(\textrm{i})}_{L[q]},1\big]$
.
Definition 10. Given
 $k^{(\textrm{u})}_{L[q]}$
,
$k^{(\textrm{u})}_{L[q]}$
,
 $a^{(\textrm{i})}_{L[q]}$
, and
$a^{(\textrm{i})}_{L[q]}$
, and
 $\zeta_q$
defined in (6.3), let
$\zeta_q$
defined in (6.3), let
 $\widetilde M_{L[q]}$
be as in (6.8); for
$\widetilde M_{L[q]}$
be as in (6.8); for
 $\widetilde M_{L[q]}+1\leqslant j\leqslant n$
, let
$\widetilde M_{L[q]}+1\leqslant j\leqslant n$
, let
 $V_{j\to v[\tau[q]]}$
be conditionally independent Poisson random variables, each with parameters
$V_{j\to v[\tau[q]]}$
be conditionally independent Poisson random variables, each with parameters
 $\lambda^{[\tau[q]]}_j$
given in (6.9) and (6.10). Define this (mixed) Poisson sequence by the random vector
$\lambda^{[\tau[q]]}_j$
given in (6.9) and (6.10). Define this (mixed) Poisson sequence by the random vector
 \begin{equation*}\textbf{V}_\textrm{Po}^{(v[\tau[q]],n)}\,:\!=\,\Big(V_{\widetilde M_{L[q]}\to v[\tau[q]]},V_{(\widetilde M_{L[q]}+1)\to v[\tau[q]]},\ldots,V_{n\to v[\tau[q]]}\Big).\end{equation*}
\begin{equation*}\textbf{V}_\textrm{Po}^{(v[\tau[q]],n)}\,:\!=\,\Big(V_{\widetilde M_{L[q]}\to v[\tau[q]]},V_{(\widetilde M_{L[q]}+1)\to v[\tau[q]]},\ldots,V_{n\to v[\tau[q]]}\Big).\end{equation*}
We proceed to define the events analogous to
 $F_{1,j}$
,
$F_{1,j}$
,
 $j=1,2,3$
, in (5.5). On these events,
$j=1,2,3$
, in (5.5). On these events,
 $P_{j\to v[\tau[q]]}$
in (3.11) and
$P_{j\to v[\tau[q]]}$
in (3.11) and
 $\lambda^{[\tau[q]]}_j$
are close enough for most j, and so we can couple the point processes as before. Let
$\lambda^{[\tau[q]]}_j$
are close enough for most j, and so we can couple the point processes as before. Let
 $\phi(n)=\Omega(n^\chi)$
,
$\phi(n)=\Omega(n^\chi)$
,
 $0<\gamma<\chi/12$
,
$0<\gamma<\chi/12$
,
 $\mathcal{Z}_{j}{[\tau[q]]}$
,
$\mathcal{Z}_{j}{[\tau[q]]}$
,
 $B_{j}{[\tau[q]]}$
, and
$B_{j}{[\tau[q]]}$
, and
 $S_{n,j}{[\tau[q]]}$
be as in (3.7), (3.9), and (3.10), and let
$S_{n,j}{[\tau[q]]}$
be as in (3.7), (3.9), and (3.10), and let
 $C^\star_q\,:\!=\,C^\star_q(x_1,\mu)$
be a positive constant that we specify later. Define
$C^\star_q\,:\!=\,C^\star_q(x_1,\mu)$
be a positive constant that we specify later. Define
 \begin{align}& F_{\tau[q],1}=\left\{\max_{\lceil{\phi(n)}\rceil\leqslant j\leqslant n}\left|S_{n,j}{[\tau[q]]}-\left(\frac{j}{n}\right)^\chi\right|\leqslant C^\star_q n^{-\frac{\chi}{12}}\right\},\nonumber\\& F_{\tau[q],2}=\bigcap^{n}_{\substack{j=\lceil{\phi(n)}\rceil;j\not \in\mathcal{P}_{\tau[q]-1}}}\left\{\left|B_{j}{[\tau[q]]}-\frac{\mathcal{Z}_{j}{[\tau[q]]}}{(\mu+1)j}\right|\leqslant \frac{\mathcal{Z}_{j}{[\tau[q]]}n^{-\gamma}}{(\mu+1)j}\right\},\nonumber\\& F_{\tau[q],3} = \bigcap^n_{j=\lceil{\phi(n)}\rceil;j\not \in\mathcal{P}_{\tau[q]-1} }\big\{\mathcal{Z}_{j}{[\tau[q]]}\leqslant j^{1/2}\big\}.\end{align}
\begin{align}& F_{\tau[q],1}=\left\{\max_{\lceil{\phi(n)}\rceil\leqslant j\leqslant n}\left|S_{n,j}{[\tau[q]]}-\left(\frac{j}{n}\right)^\chi\right|\leqslant C^\star_q n^{-\frac{\chi}{12}}\right\},\nonumber\\& F_{\tau[q],2}=\bigcap^{n}_{\substack{j=\lceil{\phi(n)}\rceil;j\not \in\mathcal{P}_{\tau[q]-1}}}\left\{\left|B_{j}{[\tau[q]]}-\frac{\mathcal{Z}_{j}{[\tau[q]]}}{(\mu+1)j}\right|\leqslant \frac{\mathcal{Z}_{j}{[\tau[q]]}n^{-\gamma}}{(\mu+1)j}\right\},\nonumber\\& F_{\tau[q],3} = \bigcap^n_{j=\lceil{\phi(n)}\rceil;j\not \in\mathcal{P}_{\tau[q]-1} }\big\{\mathcal{Z}_{j}{[\tau[q]]}\leqslant j^{1/2}\big\}.\end{align}
The following analogue of Lemma 9 is the main ingredient for proving Lemma 12.
Lemma 13. Retaining the assumptions and the notation in Lemma 12, let
 $\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
,
$\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
,
 $\textbf{V}_\textrm{Po}^{(v[\tau[q]],n)}$
, and
$\textbf{V}_\textrm{Po}^{(v[\tau[q]],n)}$
, and
 $F_{\tau[q],i}$
,
$F_{\tau[q],i}$
,
 $i=1,2,3$
, be as in Definition 7, Definition 10, and (6.11). Then we can couple the random vectors so that there is a positive constant
$i=1,2,3$
, be as in Definition 7, Definition 10, and (6.11). Then we can couple the random vectors so that there is a positive constant
 $C=C(x_1,\mu,\kappa,q)$
such that
$C=C(x_1,\mu,\kappa,q)$
such that
 \begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\Big\{\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}\not = \textbf{V}_\textrm{Po}^{(v[\tau[q]],n)}\Big\}\cap \bigcap^3_{i=1} F_{\tau[q], i}\cap \overline{\mathcal{H}}_{q,l}\Bigg]\leqslant C n^{-d}(\log \log n)^{q+1}(\log n)^{q/r}\end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\Big\{\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}\not = \textbf{V}_\textrm{Po}^{(v[\tau[q]],n)}\Big\}\cap \bigcap^3_{i=1} F_{\tau[q], i}\cap \overline{\mathcal{H}}_{q,l}\Bigg]\leqslant C n^{-d}(\log \log n)^{q+1}(\log n)^{q/r}\end{align*}
for all
 $n\geqslant 3$
, where
$n\geqslant 3$
, where
 $d\,:\!=\,\min\{\beta_q,\gamma,1-\chi \}$
.
$d\,:\!=\,\min\{\beta_q,\gamma,1-\chi \}$
.
Sketch of proof. We only highlight the main steps here, leaving the details to [Reference Lo24]. As in the proof of Lemma 9, we construct a Bernoulli and a Poisson sequence using suitable means
 $\widehat P_{j\to v[\tau[q]]}$
,
$\widehat P_{j\to v[\tau[q]]}$
,
 $\widetilde M_{L[q]}\leqslant j\leqslant n$
, with
$\widetilde M_{L[q]}\leqslant j\leqslant n$
, with
 $\widetilde M_{L[q]}$
as in (6.8). Then we couple the four processes. However, this time we need to handle the cases where we couple a Bernoulli variable with mean zero and a Poisson variable with positive mean, or vice versa. We take care of these cases by choosing the appropriate
$\widetilde M_{L[q]}$
as in (6.8). Then we couple the four processes. However, this time we need to handle the cases where we couple a Bernoulli variable with mean zero and a Poisson variable with positive mean, or vice versa. We take care of these cases by choosing the appropriate
 $\widehat P_{j\to v[\tau[q]]}$
. First we observe that on the event
$\widehat P_{j\to v[\tau[q]]}$
. First we observe that on the event
 $\Big(\bigcap^3_{j=1} F_{\tau[q], j}\Big)\cap\Big(\bigcap^3_{j=1} \mathcal{H}_{q,j}\Big)$
,
$\Big(\bigcap^3_{j=1} F_{\tau[q], j}\Big)\cap\Big(\bigcap^3_{j=1} \mathcal{H}_{q,j}\Big)$
,
 $P_{j\to v[\tau[q]]}$
is close enough to
$P_{j\to v[\tau[q]]}$
is close enough to
 \begin{equation}\widehat P_{j\to v[\tau[q]]}\,:\!=\,\left(\frac{v[\tau[q]]}{j}\right)^\chi \frac{\zeta_q}{(\mu+1)v[\tau[q]]}\quad \leqslant 1\end{equation}
\begin{equation}\widehat P_{j\to v[\tau[q]]}\,:\!=\,\left(\frac{v[\tau[q]]}{j}\right)^\chi \frac{\zeta_q}{(\mu+1)v[\tau[q]]}\quad \leqslant 1\end{equation}
for
 $j\in \{v[\tau[q]]+1,\ldots, n\}\setminus V\Big(B_q\big(G_n,k^{(\textrm{u})}_0\big)\Big)$
, whereas for
$j\in \{v[\tau[q]]+1,\ldots, n\}\setminus V\Big(B_q\big(G_n,k^{(\textrm{u})}_0\big)\Big)$
, whereas for
 $\max\{M_{L[q]},v[\tau[q]]+1\}\leqslant j\leqslant n$
, we have
$\max\{M_{L[q]},v[\tau[q]]+1\}\leqslant j\leqslant n$
, we have
 \begin{equation*}\lambda^{[\tau[q]]}_j\approx \widehat P_{j\to v[\tau[q]]}\end{equation*}
\begin{equation*}\lambda^{[\tau[q]]}_j\approx \widehat P_{j\to v[\tau[q]]}\end{equation*}
because
 $a^{(\textrm{i})}_{L[q]}\approx (v[\tau[q]]/n)^\chi$
on the event
$a^{(\textrm{i})}_{L[q]}\approx (v[\tau[q]]/n)^\chi$
on the event
 $\mathcal{H}_{q,2}$
. Hence, we can couple
$\mathcal{H}_{q,2}$
. Hence, we can couple
 $Y_{j\to v[\tau[q]]}$
and
$Y_{j\to v[\tau[q]]}$
and
 $V_{j\to v[\tau[q]]}$
for
$V_{j\to v[\tau[q]]}$
for
 $j\in\{\max\{M_{L[q]},v[\tau[q]]+1\},\ldots, n\}\setminus V\Big(B_q\big(G_n,k^{(\textrm{u})}_0\big)\Big)$
as in Lemma 9. When
$j\in\{\max\{M_{L[q]},v[\tau[q]]+1\},\ldots, n\}\setminus V\Big(B_q\big(G_n,k^{(\textrm{u})}_0\big)\Big)$
as in Lemma 9. When
 $j \in V\Big(B_q\big(G_n,k^{(\textrm{u})}_0\big)\Big)$
, the Bernoulli variable
$j \in V\Big(B_q\big(G_n,k^{(\textrm{u})}_0\big)\Big)$
, the Bernoulli variable
 $Y_{j\to v[\tau[q]]}$
has mean zero, and we couple it to a Bernoulli variable with mean (6.12) as in Lemma 9. By a little computation,
$Y_{j\to v[\tau[q]]}$
has mean zero, and we couple it to a Bernoulli variable with mean (6.12) as in Lemma 9. By a little computation,
 \begin{equation}|\partial \mathcal{B}_{j}|<1+j(\log n)^{j/r},\quad\Big|V\Big(B_j\big(G_n,k^{(\textrm{u})}_0\big)\Big)\Big|< 1+j+ j^2(\log n)^{j/r}\end{equation}
\begin{equation}|\partial \mathcal{B}_{j}|<1+j(\log n)^{j/r},\quad\Big|V\Big(B_j\big(G_n,k^{(\textrm{u})}_0\big)\Big)\Big|< 1+j+ j^2(\log n)^{j/r}\end{equation}
for
 $1\leqslant j\leqslant q$
on the event
$1\leqslant j\leqslant q$
on the event
 $\mathcal{H}_{q,3}$
. Because the
$\mathcal{H}_{q,3}$
. Because the
 $\widehat P_{j\to v[\tau[q]]}$
are sufficiently small and there are at most
$\widehat P_{j\to v[\tau[q]]}$
are sufficiently small and there are at most
 $O((\log n)^{q/r})$
such pairs of Bernoulli variables, we can use a union bound to show that the probability that
$O((\log n)^{q/r})$
such pairs of Bernoulli variables, we can use a union bound to show that the probability that
 $Y_{j\to v[\tau[q]]}\not =V_{j\to v[\tau[q]]}$
for any such j tends to zero as
$Y_{j\to v[\tau[q]]}\not =V_{j\to v[\tau[q]]}$
for any such j tends to zero as
 $n\to\infty$
. We now consider the coupling of
$n\to\infty$
. We now consider the coupling of
 $Y_{j\to v[\tau[q]]}$
and
$Y_{j\to v[\tau[q]]}$
and
 $V_{j\to v[\tau[q]]}$
for
$V_{j\to v[\tau[q]]}$
for
 $\widetilde M_{L[q]}\leqslant j\leqslant \max\Big\{M_{L[q]},k^{(\textrm{u})}_{L[q]}+1\Big\}$
. In Table 1 below, we give the possible combinations of the Bernoulli and Poisson means, and our choice of intermediate means. As indicated in the table, we choose
$\widetilde M_{L[q]}\leqslant j\leqslant \max\Big\{M_{L[q]},k^{(\textrm{u})}_{L[q]}+1\Big\}$
. In Table 1 below, we give the possible combinations of the Bernoulli and Poisson means, and our choice of intermediate means. As indicated in the table, we choose
 $\widehat P_{j\to v[\tau[q]]}>0$
whenever
$\widehat P_{j\to v[\tau[q]]}>0$
whenever
 $P_{j\to v[\tau[q]]}>0$
. When
$P_{j\to v[\tau[q]]}>0$
. When
 $M_{L[q]}\leqslant v[\tau[q]]$
, we couple
$M_{L[q]}\leqslant v[\tau[q]]$
, we couple
 $V_{j\to v[\tau[q]]}$
and a Poisson variable with mean zero, while when
$V_{j\to v[\tau[q]]}$
and a Poisson variable with mean zero, while when
 $M_{L[q]}\geqslant v[\tau[q]]+2$
,
$M_{L[q]}\geqslant v[\tau[q]]+2$
,
 $V_{j\to v[\tau[q]]}\,:\!=\,0$
by construction, and it is coupled with a Poisson variable with mean (6.12). However, the number of these pairs is small because
$V_{j\to v[\tau[q]]}\,:\!=\,0$
by construction, and it is coupled with a Poisson variable with mean (6.12). However, the number of these pairs is small because
 $M_{L[q]}\approx v[\tau[q]]+1$
when
$M_{L[q]}\approx v[\tau[q]]+1$
when
 $a^{(\textrm{i})}_{L[q]}\approx ( v[\tau[q]]/n)^\chi$
. Consequently, another union bound argument shows that the probability that any of these couplings fail tends to zero as
$a^{(\textrm{i})}_{L[q]}\approx ( v[\tau[q]]/n)^\chi$
. Consequently, another union bound argument shows that the probability that any of these couplings fail tends to zero as
 $n\to\infty$
.
$n\to\infty$
.
We are now ready to prove Lemma 12.
Table 1. Combinations of means for
 $\widetilde M_{L[q]}\leqslant j \leqslant \max\{M_{L[q]},k^{(\textrm{u})}_{L[q]}+1\}$
. Note that
$\widetilde M_{L[q]}\leqslant j \leqslant \max\{M_{L[q]},k^{(\textrm{u})}_{L[q]}+1\}$
. Note that
 $j=k^{(\textrm{u})}_{L[q]}+1$
when
$j=k^{(\textrm{u})}_{L[q]}+1$
when
 $M_{L[q]}=k^{(\textrm{u})}_{L[q]}+1$
, and in that case, the coupling is the same as that of Lemma 9.
$M_{L[q]}=k^{(\textrm{u})}_{L[q]}+1$
, and in that case, the coupling is the same as that of Lemma 9.

Proof of Lemma 12. Recall the definition of
 $\overline{\mathcal{H}}_{q,l}$
in (6.5). We bound the right-hand side of
$\overline{\mathcal{H}}_{q,l}$
in (6.5). We bound the right-hand side of
 \begin{align}&\mathbb{P}_{\textbf{x}}\Big[\overline{\mathcal{H}}_{q,l} \cap \mathcal{H}_{q+1,1}\cap \mathcal{K}^c_{\tau[q],1} \Big]\nonumber\\&\leqslant \mathbb{P}_{\textbf{x}}\Bigg[\overline{\mathcal{H}}_{q,l} \cap \bigcap^3_{j=1} F_{\tau[q],j}\cap \mathcal{H}_{q+1,1}\cap \mathcal{K}^c_{\tau[q],1} \Bigg]+\mathbb{P}_{\textbf{x}}\Bigg[ \overline{\mathcal{H}}_{q,l}\cap\Bigg(\bigcap^3_{j=1} F_{\tau[q],j}\Bigg)^c \Bigg]\nonumber\\&\leqslant \mathbb{P}_{\textbf{x}}\Bigg[\overline{\mathcal{H}}_{q,l}\cap \bigcap^3_{j=1} F_{\tau[q],j}\cap \mathcal{H}_{q+1,1} \cap \mathcal{K}^c_{\tau[q],1} \Bigg] + \sum^3_{j=1} \mathbb{P}_{\textbf{x}}\Big[\overline{\mathcal{H}}_{q,l} \cap F^c_{\tau[q],j}\Big], \end{align}
\begin{align}&\mathbb{P}_{\textbf{x}}\Big[\overline{\mathcal{H}}_{q,l} \cap \mathcal{H}_{q+1,1}\cap \mathcal{K}^c_{\tau[q],1} \Big]\nonumber\\&\leqslant \mathbb{P}_{\textbf{x}}\Bigg[\overline{\mathcal{H}}_{q,l} \cap \bigcap^3_{j=1} F_{\tau[q],j}\cap \mathcal{H}_{q+1,1}\cap \mathcal{K}^c_{\tau[q],1} \Bigg]+\mathbb{P}_{\textbf{x}}\Bigg[ \overline{\mathcal{H}}_{q,l}\cap\Bigg(\bigcap^3_{j=1} F_{\tau[q],j}\Bigg)^c \Bigg]\nonumber\\&\leqslant \mathbb{P}_{\textbf{x}}\Bigg[\overline{\mathcal{H}}_{q,l}\cap \bigcap^3_{j=1} F_{\tau[q],j}\cap \mathcal{H}_{q+1,1} \cap \mathcal{K}^c_{\tau[q],1} \Bigg] + \sum^3_{j=1} \mathbb{P}_{\textbf{x}}\Big[\overline{\mathcal{H}}_{q,l} \cap F^c_{\tau[q],j}\Big], \end{align}
starting from the last three terms. Using (6.13), a computation similar to that for Lemma 2 shows that there are positive constants
 $C^\star_q=C^\star_q(x_1,\mu)$
and
$C^\star_q=C^\star_q(x_1,\mu)$
and
 $c^\star=c^\star(x_1,\mu,q)$
such that
$c^\star=c^\star(x_1,\mu,q)$
such that
 \begin{equation}\mathbb{P}_{\textbf{x}}\left[{\overline{\mathcal{H}}_{q,l}\cap\left\{\max_{\lceil{\phi(n)}\rceil\leqslant j\leqslant n}\bigg|S_{n,j}{[\tau[q]]}-\bigg(\frac{j}{n}\bigg)^\chi\bigg|\leqslant C^\star_q n^{-\frac{\chi}{12}}\right\}}\right]\leqslant c^\star n^{-\tfrac{\chi}{6}},\end{equation}
\begin{equation}\mathbb{P}_{\textbf{x}}\left[{\overline{\mathcal{H}}_{q,l}\cap\left\{\max_{\lceil{\phi(n)}\rceil\leqslant j\leqslant n}\bigg|S_{n,j}{[\tau[q]]}-\bigg(\frac{j}{n}\bigg)^\chi\bigg|\leqslant C^\star_q n^{-\frac{\chi}{12}}\right\}}\right]\leqslant c^\star n^{-\tfrac{\chi}{6}},\end{equation}
which bounds
 $\mathbb{P}_{\textbf{x}}\Big[ \overline{\mathcal{H}}_{q,l}\cap F^c_{\tau[q],1}\Big]$
. Combining (6.13) and the argument of Lemma 3 also yields
$\mathbb{P}_{\textbf{x}}\Big[ \overline{\mathcal{H}}_{q,l}\cap F^c_{\tau[q],1}\Big]$
. Combining (6.13) and the argument of Lemma 3 also yields
 \begin{equation}\mathbb{P}_{\textbf{x}}\Big[ \overline{\mathcal{H}}_{q,l} \cap F^c_{\tau[q],3}\Big]\leqslant C \kappa^4 n^{-\chi}\quad\text{and}\quad\mathbb{P}_{\textbf{x}}\Big[ \overline{\mathcal{H}}_{q,l} \cap F^c_{\tau[q],2}\Big]\leqslant C^{\prime}n^{4\gamma-\tfrac{\chi}{3}},\end{equation}
\begin{equation}\mathbb{P}_{\textbf{x}}\Big[ \overline{\mathcal{H}}_{q,l} \cap F^c_{\tau[q],3}\Big]\leqslant C \kappa^4 n^{-\chi}\quad\text{and}\quad\mathbb{P}_{\textbf{x}}\Big[ \overline{\mathcal{H}}_{q,l} \cap F^c_{\tau[q],2}\Big]\leqslant C^{\prime}n^{4\gamma-\tfrac{\chi}{3}},\end{equation}
for some positive constants
 $C\,:\!=\,C(q)$
,
$C\,:\!=\,C(q)$
,
 $C^{\prime}=C^{\prime}(x_1,\gamma,\mu,q)$
, and
$C^{\prime}=C^{\prime}(x_1,\gamma,\mu,q)$
, and
 $0<\gamma<\chi/12$
. Next, we bound the first term under a suitable coupling of the vertices
$0<\gamma<\chi/12$
. Next, we bound the first term under a suitable coupling of the vertices
 $k^{(\textrm{u})}_{L[q]}\in \partial \mathcal{B}_q$
and
$k^{(\textrm{u})}_{L[q]}\in \partial \mathcal{B}_q$
and
 $L[q]\in \partial \mathfrak{B}_q$
, starting from their type-R children. Assume that
$L[q]\in \partial \mathfrak{B}_q$
, starting from their type-R children. Assume that
 \begin{gather*}\Big(\Big(k^{(\textrm{u})}_{\bar w}, k^{(\textrm{i})}_{\bar w}, a^{(\textrm{i})}_{\bar w}\Big), \bar w\in V\Big(B_q(\mathcal{T}_{\textbf{x},n},0)\Big)\Big),\quad\Big(\Big(R^{(\textrm{u})}_{\bar w}, R^{(\textrm{i})}_{\bar w}\Big),\bar w \in V(B_{q-1}(\mathcal{T}_{\textbf{x},n},0))\Big),\\\Big(\Big(\mathcal{Z}_j[\tau[q]], \mathcal{\widetilde Z}_{j}[\tau[q]]\Big),j\in [n]\setminus V(B_{q-1}(\mathcal{T}_{\textbf{x},n},0))\Big)\end{gather*}
\begin{gather*}\Big(\Big(k^{(\textrm{u})}_{\bar w}, k^{(\textrm{i})}_{\bar w}, a^{(\textrm{i})}_{\bar w}\Big), \bar w\in V\Big(B_q(\mathcal{T}_{\textbf{x},n},0)\Big)\Big),\quad\Big(\Big(R^{(\textrm{u})}_{\bar w}, R^{(\textrm{i})}_{\bar w}\Big),\bar w \in V(B_{q-1}(\mathcal{T}_{\textbf{x},n},0))\Big),\\\Big(\Big(\mathcal{Z}_j[\tau[q]], \mathcal{\widetilde Z}_{j}[\tau[q]]\Big),j\in [n]\setminus V(B_{q-1}(\mathcal{T}_{\textbf{x},n},0))\Big)\end{gather*}
are coupled so that
 $\textrm{E}_q\,:\!=\,\bigcap^3_{j=1}\mathcal{H}_{q,j}\cap \bigcap^3_{j=1}F_{\tau[q],j}$
occurs. In view of Definitions 8 and 7, it follows from Lemma 13 that on the event
$\textrm{E}_q\,:\!=\,\bigcap^3_{j=1}\mathcal{H}_{q,j}\cap \bigcap^3_{j=1}F_{\tau[q],j}$
occurs. In view of Definitions 8 and 7, it follows from Lemma 13 that on the event
 $\textrm{E}_q$
, there is a coupling such that
$\textrm{E}_q$
, there is a coupling such that
 $R^{(\textrm{u})}_{L[q]}=R^{(\textrm{i})}_{L[q]}$
and
$R^{(\textrm{u})}_{L[q]}=R^{(\textrm{i})}_{L[q]}$
and
 $k^{(\textrm{u})}_{L[q],j}=k^{(\textrm{i})}_{L[q],j}$
for
$k^{(\textrm{u})}_{L[q],j}=k^{(\textrm{i})}_{L[q],j}$
for
 $2\leqslant j\leqslant 1+R^{(\textrm{i})}_{L[q]}$
w.h.p. Note that
$2\leqslant j\leqslant 1+R^{(\textrm{i})}_{L[q]}$
w.h.p. Note that
 $k_{L[q],j}\geqslant M_{L[q]}$
when
$k_{L[q],j}\geqslant M_{L[q]}$
when
 $\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
and
$\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}$
and
 $\textbf{V}_\textrm{Po}^{(v[\tau[q]],n)}$
are coupled. Thus, using
$\textbf{V}_\textrm{Po}^{(v[\tau[q]],n)}$
are coupled. Thus, using
 $M_{L[q]}\geqslant n (a^{(\textrm{i})}_{L[q]})^{1/\chi}$
, a little calculation shows that there is a constant
$M_{L[q]}\geqslant n (a^{(\textrm{i})}_{L[q]})^{1/\chi}$
, a little calculation shows that there is a constant
 $\widehat c\,:\!=\,\widehat c(\mu)$
such that
$\widehat c\,:\!=\,\widehat c(\mu)$
such that
 \begin{align*}\mathbb{1}\bigg[\bigcap^2_{i=1}\mathcal{H}_{q,i}\bigg] \left[\left(\frac{j}{n}\right)^\chi-\left(\frac{j-1}{n}\right)^\chi\right] \leqslant \frac{\widehat c(\log\log n)^{(1+q)(1-\chi)}}{n},\quad M_{L[q]}\leqslant j\leqslant n,\end{align*}
\begin{align*}\mathbb{1}\bigg[\bigcap^2_{i=1}\mathcal{H}_{q,i}\bigg] \left[\left(\frac{j}{n}\right)^\chi-\left(\frac{j-1}{n}\right)^\chi\right] \leqslant \frac{\widehat c(\log\log n)^{(1+q)(1-\chi)}}{n},\quad M_{L[q]}\leqslant j\leqslant n,\end{align*}
implying that the ages of the type-R children are close enough. We proceed to couple the type-L child of
 $k^{(\textrm{u})}_{L[q]}\in \partial \mathcal{B}_q$
and
$k^{(\textrm{u})}_{L[q]}\in \partial \mathcal{B}_q$
and
 $L[q]\in \partial \mathfrak{B}_q$
on the event
$L[q]\in \partial \mathfrak{B}_q$
on the event
 $\textrm{E}_q\cap \mathcal{H}_{q+1}$
. Independently from all the variables generated so far, let
$\textrm{E}_q\cap \mathcal{H}_{q+1}$
. Independently from all the variables generated so far, let
 $U_{L[q],1}\sim\textrm{U}[0,1]$
. Set
$U_{L[q],1}\sim\textrm{U}[0,1]$
. Set
 \begin{equation*}a^{(\textrm{i})}_{L[q],1}\,:\!=\,a^{(\textrm{i})}_{L[q+1]}=U_{L[q],1} a^{(\textrm{i})}_{L[q]},\end{equation*}
\begin{equation*}a^{(\textrm{i})}_{L[q],1}\,:\!=\,a^{(\textrm{i})}_{L[q+1]}=U_{L[q],1} a^{(\textrm{i})}_{L[q]},\end{equation*}
so that
 $a^{(\textrm{i})}_{L[q],1}$
is the age of vertex
$a^{(\textrm{i})}_{L[q],1}$
is the age of vertex
 $(L[q],1)\in \partial \mathfrak{B}_{q+1}$
. Temporarily defining
$(L[q],1)\in \partial \mathfrak{B}_{q+1}$
. Temporarily defining
 $f\,:\!=\,k^{(\textrm{u})}_{L[q]}$
and
$f\,:\!=\,k^{(\textrm{u})}_{L[q]}$
and
 $g\,:\!=\,k^{(\textrm{u})}_{L[q],1}$
, we define g to satisfy
$g\,:\!=\,k^{(\textrm{u})}_{L[q],1}$
, we define g to satisfy
 \begin{align}S_{n,g-1}[\tau[q]]\leqslant U_{L[q],1} S_{n,f-1}[\tau[q]]< S_{n,g}[\tau[q]].\end{align}
\begin{align}S_{n,g-1}[\tau[q]]\leqslant U_{L[q],1} S_{n,f-1}[\tau[q]]< S_{n,g}[\tau[q]].\end{align}
In light of Definition 8 and Lemma 6,
 $k^{(\textrm{i})}_{L[q],1}=g$
. To establish
$k^{(\textrm{i})}_{L[q],1}=g$
. To establish
 $a^{(\textrm{i})}_{L[q],1}\approx (g/n)^\chi$
, we first show that we can substitute
$a^{(\textrm{i})}_{L[q],1}\approx (g/n)^\chi$
, we first show that we can substitute
 $S_{n,j}[\tau[q]]$
with
$S_{n,j}[\tau[q]]$
with
 $(j/n)^\chi$
for
$(j/n)^\chi$
for
 $j=g-1,g$
at a small enough cost. A straightforward computation shows that on the event
$j=g-1,g$
at a small enough cost. A straightforward computation shows that on the event
 $\textrm{E}_q \cap \mathcal{H}_{q+1,1}$
,
$\textrm{E}_q \cap \mathcal{H}_{q+1,1}$
,
 \begin{align*}U_{L[q],1}\geqslant (\log\log n)^{-(q+2)\chi}\quad\text{and}\quad f\geqslant n(\log\log n)^{-(q+1)} - C_q n^{1-\beta_q/\chi},\end{align*}
\begin{align*}U_{L[q],1}\geqslant (\log\log n)^{-(q+2)\chi}\quad\text{and}\quad f\geqslant n(\log\log n)^{-(q+1)} - C_q n^{1-\beta_q/\chi},\end{align*}
where
 $C_q$
is the constant in the event
$C_q$
is the constant in the event
 $\mathcal{H}_{q,2}$
. Consequently, there is a constant
$\mathcal{H}_{q,2}$
. Consequently, there is a constant
 $C\,:\!=\,C(x_1,\mu,q)$
such that on the event
$C\,:\!=\,C(x_1,\mu,q)$
such that on the event
 $\textrm{E}_q\cap \mathcal{H}_{q+1,1}$
,
$\textrm{E}_q\cap \mathcal{H}_{q+1,1}$
,
 \begin{align}S_{n,g}[\tau[q]]&\geqslant U_{L[q],1} S_{n,f-1}[\tau[q]]\geqslant (\log\log n)^{-(q+2)\chi} \left[\left(\frac{f-1}{n}\right)^\chi - C^\star_q n^{-\frac{\chi}{12}}\right]\nonumber\\&\geqslant C (\log\log n)^{-(2q+3)\chi}. \end{align}
\begin{align}S_{n,g}[\tau[q]]&\geqslant U_{L[q],1} S_{n,f-1}[\tau[q]]\geqslant (\log\log n)^{-(q+2)\chi} \left[\left(\frac{f-1}{n}\right)^\chi - C^\star_q n^{-\frac{\chi}{12}}\right]\nonumber\\&\geqslant C (\log\log n)^{-(2q+3)\chi}. \end{align}
This implies that
 $g=\Omega(n^\chi)$
, and so
$g=\Omega(n^\chi)$
, and so
 $|S_{n,j}[\tau[q]]-(j/n)^\chi|\leqslant C^\star_q n^{-\chi/12}$
for
$|S_{n,j}[\tau[q]]-(j/n)^\chi|\leqslant C^\star_q n^{-\chi/12}$
for
 $j=g-1, g$
. Additionally, a direct calculation yields
$j=g-1, g$
. Additionally, a direct calculation yields
 \begin{align*}\left|\Big(S_{n,f-1}[\tau[q]]/a^{(\textrm{i})}_{L[q]}\Big)-1\right|\leqslant \widetilde Cn^{-\beta_q}(\log \log n)^{(q+1)\chi}\end{align*}
\begin{align*}\left|\Big(S_{n,f-1}[\tau[q]]/a^{(\textrm{i})}_{L[q]}\Big)-1\right|\leqslant \widetilde Cn^{-\beta_q}(\log \log n)^{(q+1)\chi}\end{align*}
for some
 $\widetilde C\,:\!=\,\widetilde C(x_1,\mu,q)$
. By replacing
$\widetilde C\,:\!=\,\widetilde C(x_1,\mu,q)$
. By replacing
 $S_{n,j}[\tau[q]]$
,
$S_{n,j}[\tau[q]]$
,
 $j=g-1, g$
, in (6.17) with
$j=g-1, g$
, in (6.17) with
 $a^{(\textrm{i})}_{L[q]}$
and
$a^{(\textrm{i})}_{L[q]}$
and
 $(j/n)^\chi$
at the costs above, and using
$(j/n)^\chi$
at the costs above, and using
 $\beta_{q+1}<\beta_q$
, we conclude that, on the event
$\beta_{q+1}<\beta_q$
, we conclude that, on the event
 $\textrm{E}_q\cap \mathcal{H}_{q+1,1}$
, there is a constant
$\textrm{E}_q\cap \mathcal{H}_{q+1,1}$
, there is a constant
 $\widehat C\,:\!=\,\widehat C(x_1,\mu,q)$
such that
$\widehat C\,:\!=\,\widehat C(x_1,\mu,q)$
such that
 $|a^{(\textrm{i})}_{L[q],1}-(g/n)^\chi|\leqslant \widehat Cn^{-\beta_{q+1}}$
. Now, pick
$|a^{(\textrm{i})}_{L[q],1}-(g/n)^\chi|\leqslant \widehat Cn^{-\beta_{q+1}}$
. Now, pick
 $C_{q+1}\,:\!=\,\widehat C\vee \widehat c$
for the event
$C_{q+1}\,:\!=\,\widehat C\vee \widehat c$
for the event
 $\mathcal{K}_{\tau[q],1}$
and
$\mathcal{K}_{\tau[q],1}$
and
 $\mathcal{H}_{q+1,2}$
. By Lemma 13, there is a positive constant
$\mathcal{H}_{q+1,2}$
. By Lemma 13, there is a positive constant
 $C\,:\!=\,C(x_1,\mu,\kappa,q)$
such that
$C\,:\!=\,C(x_1,\mu,\kappa,q)$
such that
 \begin{align}\mathbb{P}_{\textbf{x}}\Bigg[\overline{\mathcal{H}}_{q,l}\cap \bigcap^3_{j=1} F_{\tau[q],j}\cap \mathcal{H}_{q+1,1}\cap \mathcal{K}^c_{\tau[q],1} \Bigg]&\leqslant \mathbb{P}_{\textbf{x}}\Bigg[\!\Big\{\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}\not = \textbf{V}_\textrm{Po}^{(v[\tau[q]],n)}\Big\}\cap \bigcap^3_{j=1} F_{\tau[q], j}\cap \overline{\mathcal{H}}_{q,l}\Bigg]\nonumber\\&\leqslant C n^{-d}(\log \log n)^{q+1}(\log n)^{q/r},\end{align}
\begin{align}\mathbb{P}_{\textbf{x}}\Bigg[\overline{\mathcal{H}}_{q,l}\cap \bigcap^3_{j=1} F_{\tau[q],j}\cap \mathcal{H}_{q+1,1}\cap \mathcal{K}^c_{\tau[q],1} \Bigg]&\leqslant \mathbb{P}_{\textbf{x}}\Bigg[\!\Big\{\textbf{Y}_\textrm{Be}^{(v[\tau[q]],n)}\not = \textbf{V}_\textrm{Po}^{(v[\tau[q]],n)}\Big\}\cap \bigcap^3_{j=1} F_{\tau[q], j}\cap \overline{\mathcal{H}}_{q,l}\Bigg]\nonumber\\&\leqslant C n^{-d}(\log \log n)^{q+1}(\log n)^{q/r},\end{align}
where
 $d=\min\{\beta_q,\gamma,1-\chi\}$
. The lemma follows from applying (6.15), (6.16), and (6.19) to (6.14).
$d=\min\{\beta_q,\gamma,1-\chi\}$
. The lemma follows from applying (6.15), (6.16), and (6.19) to (6.14).
The following analogue of Lemma 10 shows that under the graph coupling, w.h.p.
 $v[\tau[q]]$
has at most
$v[\tau[q]]$
has at most
 $(\log n)^{1/r}$
children. We omit the proof as it is similar to that of Lemma 10.
$(\log n)^{1/r}$
children. We omit the proof as it is similar to that of Lemma 10.
Lemma 14. Retaining the assumptions and the notation in Lemma 11, let
 $\mathcal{K}_{\tau[q],j}$
and
$\mathcal{K}_{\tau[q],j}$
and
 $\overline{\mathcal{H}}_{q,j}$
be as in (6.2) and (6.5). Then, given positive integers
$\overline{\mathcal{H}}_{q,j}$
be as in (6.2) and (6.5). Then, given positive integers
 $r<\infty$
and
$r<\infty$
and
 $q<r$
, there is a coupling of
$q<r$
, there is a coupling of
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
, with an integer
$(\mathcal{T}_{\textbf{x},n},0)$
, with an integer
 $p>0$
and a constant
$p>0$
and a constant
 $C\,:\!=\,C(\kappa,p)>0$
such that
$C\,:\!=\,C(\kappa,p)>0$
such that
 \begin{equation*}\mathbb{P}_{\textbf{x}}\Big[\overline{\mathcal{H}}_{q,l}\cap \mathcal{K}_{q,1}\cap\mathcal{K}^c_{q,2}\Big]\leqslant C (\log n)^{-\frac{p}{r}}(\log \log n)^{\frac{p(q+1)}{\mu+1}}\quad for\ all\ n\geqslant 3. \end{equation*}
\begin{equation*}\mathbb{P}_{\textbf{x}}\Big[\overline{\mathcal{H}}_{q,l}\cap \mathcal{K}_{q,1}\cap\mathcal{K}^c_{q,2}\Big]\leqslant C (\log n)^{-\frac{p}{r}}(\log \log n)^{\frac{p(q+1)}{\mu+1}}\quad for\ all\ n\geqslant 3. \end{equation*}
We now apply Lemmas 12 and 14 to prove Lemma 11.
Proof of Lemma 11. We begin by stating the type-R analogues of Lemmas 12 and 14. Suppose that
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
are coupled so that for a type-R child
$(\mathcal{T}_{\textbf{x},n},0)$
are coupled so that for a type-R child
 $v[t]=k^{(\textrm{u})}_{\bar w}\in \partial \mathcal{B}_q$
, the event
$v[t]=k^{(\textrm{u})}_{\bar w}\in \partial \mathcal{B}_q$
, the event
 \begin{align}\mathcal{H}_{q+1,1}\cap \mathcal{J}_{q,l,t}\,:\!=\,\mathcal{H}_{q+1,1}\cap \overline{\mathcal{H}}_{q,l}\cap \bigcap_{\{s<t\,:\,v[s]\in \partial \mathcal{B}_q\}} (\mathcal{K}_{s,1}\cap\mathcal{K}_{s,2})\end{align}
\begin{align}\mathcal{H}_{q+1,1}\cap \mathcal{J}_{q,l,t}\,:\!=\,\mathcal{H}_{q+1,1}\cap \overline{\mathcal{H}}_{q,l}\cap \bigcap_{\{s<t\,:\,v[s]\in \partial \mathcal{B}_q\}} (\mathcal{K}_{s,1}\cap\mathcal{K}_{s,2})\end{align}
has occurred for some
 $l\geqslant2$
, where
$l\geqslant2$
, where
 $ \mathcal{H}_{q+1,1}$
,
$ \mathcal{H}_{q+1,1}$
,
 $\overline{\mathcal{H}}_{q,l}$
,
$\overline{\mathcal{H}}_{q,l}$
,
 $\mathcal{K}_{s,1}$
, and
$\mathcal{K}_{s,1}$
, and
 $\mathcal{K}_{s,2}$
are as in (6.1), (6.5), and (6.2). Let
$\mathcal{K}_{s,2}$
are as in (6.1), (6.5), and (6.2). Let
 $\Big(\Big(\mathcal{Z}_j[t], \mathcal{\widetilde Z}_{j-1}[t]\Big),j \in \mathcal{A}_{t-1}\cup \mathcal{N}_{t-1}\Big)$
and
$\Big(\Big(\mathcal{Z}_j[t], \mathcal{\widetilde Z}_{j-1}[t]\Big),j \in \mathcal{A}_{t-1}\cup \mathcal{N}_{t-1}\Big)$
and
 $\left(S_{n,j}[t],1\leqslant j\leqslant n\right)$
be as in (3.7), (3.8), and (3.10). We use these variables to generate the type-R children of
$\left(S_{n,j}[t],1\leqslant j\leqslant n\right)$
be as in (3.7), (3.8), and (3.10). We use these variables to generate the type-R children of
 $k^{(\textrm{u})}_{\bar w}$
, and to sample the points
$k^{(\textrm{u})}_{\bar w}$
, and to sample the points
 $\Big(a^{(\textrm{i})}_{\bar w,i},1\leqslant i\leqslant R^{(\textrm{i})}_{\bar w}\Big)$
of the mixed Poisson process with intensity (6.4), where
$\Big(a^{(\textrm{i})}_{\bar w,i},1\leqslant i\leqslant R^{(\textrm{i})}_{\bar w}\Big)$
of the mixed Poisson process with intensity (6.4), where
 $\zeta_q$
and
$\zeta_q$
and
 $a^{(\textrm{i})}_{L[q]}$
are replaced with
$a^{(\textrm{i})}_{L[q]}$
are replaced with
 $\mathcal{Z}_{k^{(\textrm{i})}_{\bar w}}[t]\sim \textrm{Gamma}\big(x_{k^{(\textrm{i})}_{\bar w}},1\big)$
and
$\mathcal{Z}_{k^{(\textrm{i})}_{\bar w}}[t]\sim \textrm{Gamma}\big(x_{k^{(\textrm{i})}_{\bar w}},1\big)$
and
 $a^{(\textrm{i})}_{\bar w}$
. Note that
$a^{(\textrm{i})}_{\bar w}$
. Note that
 $v[t]>k^{(\textrm{u})}_{L[q]}$
, and on the event
$v[t]>k^{(\textrm{u})}_{L[q]}$
, and on the event
 $\mathcal{J}_{q,l,t}$
, the number of discovered vertices up to time t can be bounded as
$\mathcal{J}_{q,l,t}$
, the number of discovered vertices up to time t can be bounded as
 \begin{align*}|\mathcal{A}_{t-1}\cup \mathcal{P}_{t-1}|\leqslant 2+q+(q+1)^2(\log n)^{(q+1)/r},\end{align*}
\begin{align*}|\mathcal{A}_{t-1}\cup \mathcal{P}_{t-1}|\leqslant 2+q+(q+1)^2(\log n)^{(q+1)/r},\end{align*}
as implied by (6.13). Hence, we can proceed similarly as for Lemmas 12 and 13. In particular, there is a coupling of
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
, with positive constants
$(\mathcal{T}_{\textbf{x},n},0)$
, with positive constants
 $C\,:\!=\,C(x_1,\mu,\kappa,q)$
and
$C\,:\!=\,C(x_1,\mu,\kappa,q)$
and
 $c\,:\!=\,c(\kappa,p)$
such that for
$c\,:\!=\,c(\kappa,p)$
such that for
 $n\geqslant 3$
,
$n\geqslant 3$
,
 \begin{align}&\mathbb{P}_{\textbf{x}}\left[\mathcal{K}^c_{t,1}\cap \mathcal{J}_{q,l,t}\right]\leqslant C n^{-d}(\log \log n)^{q+1} (\log n)^{\frac{q+1}{r}},\nonumber\\&\mathbb{P}_{\textbf{x}}\left[\mathcal{K}^c_{t,2}\cap \mathcal{K}_{t,1}\cap \mathcal{J}_{q,l,t}\right]\leqslant c (\log n)^{-\frac{p}{r}}(\log \log n)^{\frac{p(q+1)}{\mu+1}},\end{align}
\begin{align}&\mathbb{P}_{\textbf{x}}\left[\mathcal{K}^c_{t,1}\cap \mathcal{J}_{q,l,t}\right]\leqslant C n^{-d}(\log \log n)^{q+1} (\log n)^{\frac{q+1}{r}},\nonumber\\&\mathbb{P}_{\textbf{x}}\left[\mathcal{K}^c_{t,2}\cap \mathcal{K}_{t,1}\cap \mathcal{J}_{q,l,t}\right]\leqslant c (\log n)^{-\frac{p}{r}}(\log \log n)^{\frac{p(q+1)}{\mu+1}},\end{align}
where
 $d=\min\{\chi/3-4\gamma,1-\chi,\gamma,\beta_q\}$
. Define
$d=\min\{\chi/3-4\gamma,1-\chi,\gamma,\beta_q\}$
. Define
 $\widetilde{\mathcal{H}}_q\,:\!=\,\bigcap^3_{j=1}{\mathcal{H}}_{q,j}$
. To bound
$\widetilde{\mathcal{H}}_q\,:\!=\,\bigcap^3_{j=1}{\mathcal{H}}_{q,j}$
. To bound
 ${\mathbb{P}}_{\textbf{x}}\big[\widetilde{\mathcal{H}}_{q+1}^c\big]$
using Lemma 12, Lemma 14, and (6.21), we use
${\mathbb{P}}_{\textbf{x}}\big[\widetilde{\mathcal{H}}_{q+1}^c\big]$
using Lemma 12, Lemma 14, and (6.21), we use
 \begin{align}&\mathbb{P}_{\textbf{x}}\big[\big(\widetilde{\mathcal{H}}_{q+1}\big)^c\big]\leqslant \mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{H}}_{q+1}^c\cap \widetilde{\mathcal{H}}_{q} \Big] + \mathbb{P}_{\textbf{x}}\big[\widetilde{\mathcal{H}}_{q}^c\big]\nonumber\\&=\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^{3}_{j=2}\mathcal{H}_{q+1,j}\Bigg)^c \cap \mathcal{H}_{q+1,1}\cap \widetilde{\mathcal{H}}_{q} \Bigg] + \mathbb{P}_\textbf{x}\Big[\mathcal{H}^c_{q+1,1}\cap \widetilde{\mathcal{H}}_{q}\Big]+ \mathbb{P}_{\textbf{x}}\big[\widetilde{\mathcal{H}}_{q}^c\big]\nonumber\\&=\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap_{\{s\,:\,v[s]\in \partial\mathcal{B}_q \}}(\mathcal{K}_{s,1}\cap\mathcal{K}_{s,2})\Bigg)^c\cap \mathcal{H}_{q+1,1}\cap \widetilde{\mathcal{H}}_{q}\Bigg]\end{align}
\begin{align}&\mathbb{P}_{\textbf{x}}\big[\big(\widetilde{\mathcal{H}}_{q+1}\big)^c\big]\leqslant \mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{H}}_{q+1}^c\cap \widetilde{\mathcal{H}}_{q} \Big] + \mathbb{P}_{\textbf{x}}\big[\widetilde{\mathcal{H}}_{q}^c\big]\nonumber\\&=\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^{3}_{j=2}\mathcal{H}_{q+1,j}\Bigg)^c \cap \mathcal{H}_{q+1,1}\cap \widetilde{\mathcal{H}}_{q} \Bigg] + \mathbb{P}_\textbf{x}\Big[\mathcal{H}^c_{q+1,1}\cap \widetilde{\mathcal{H}}_{q}\Big]+ \mathbb{P}_{\textbf{x}}\big[\widetilde{\mathcal{H}}_{q}^c\big]\nonumber\\&=\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap_{\{s\,:\,v[s]\in \partial\mathcal{B}_q \}}(\mathcal{K}_{s,1}\cap\mathcal{K}_{s,2})\Bigg)^c\cap \mathcal{H}_{q+1,1}\cap \widetilde{\mathcal{H}}_{q}\Bigg]\end{align}
 \begin{align}&\hspace{5cm}+\mathbb{P}_\textbf{x}\Big[\widetilde{\mathcal{H}}_{q}\cap \mathcal{H}^c_{q+1,1}\Big]+\mathbb{P}_\textbf{x}\big[\widetilde{\mathcal{H}}^c_{q}\big],\end{align}
\begin{align}&\hspace{5cm}+\mathbb{P}_\textbf{x}\Big[\widetilde{\mathcal{H}}_{q}\cap \mathcal{H}^c_{q+1,1}\Big]+\mathbb{P}_\textbf{x}\big[\widetilde{\mathcal{H}}^c_{q}\big],\end{align}
where the last equality follows from
 \begin{equation*}\Bigg(\bigcap^{3}_{j=2}\mathcal{H}_{q+1,j}\Bigg)^c \cap \widetilde{\mathcal{H}}_{q}= \Bigg(\bigcap_{\{s\,:\,v[s]\in \partial\mathcal{B}_q \}}(\mathcal{K}_{s,1}\cap\mathcal{K}_{s,2})\Bigg)^c \cap \widetilde{\mathcal{H}}_{q}.\end{equation*}
\begin{equation*}\Bigg(\bigcap^{3}_{j=2}\mathcal{H}_{q+1,j}\Bigg)^c \cap \widetilde{\mathcal{H}}_{q}= \Bigg(\bigcap_{\{s\,:\,v[s]\in \partial\mathcal{B}_q \}}(\mathcal{K}_{s,1}\cap\mathcal{K}_{s,2})\Bigg)^c \cap \widetilde{\mathcal{H}}_{q}.\end{equation*}
The lemma is proved once we show that the probabilities in (6.22) and (6.23) are of order at most
 $(\log\log n)^{-\chi}$
. By assumption, there is a constant
$(\log\log n)^{-\chi}$
. By assumption, there is a constant
 $C\,:\!=\,C(x_1,\mu,\kappa,q)$
such that
$C\,:\!=\,C(x_1,\mu,\kappa,q)$
such that
 $\mathbb{P}_{\textbf{x}}\big[\widetilde{\mathcal{H}}_{q}^c\big] \leqslant C (\log\log n)^{-\chi}$
. Recall that
$\mathbb{P}_{\textbf{x}}\big[\widetilde{\mathcal{H}}_{q}^c\big] \leqslant C (\log\log n)^{-\chi}$
. Recall that
 $a^{(\textrm{i})}_{L[q],1}=U_{L[q],1}a^{(\textrm{i})}_{L[q]}$
, where
$a^{(\textrm{i})}_{L[q],1}=U_{L[q],1}a^{(\textrm{i})}_{L[q]}$
, where
 $U_{L[q],1}\sim\textrm{U}[0,1]$
is independent of
$U_{L[q],1}\sim\textrm{U}[0,1]$
is independent of
 $a^{(\textrm{i})}_{L[q]}$
. Thus, similarly to (5.13),
$a^{(\textrm{i})}_{L[q]}$
. Thus, similarly to (5.13),
 \begin{align*}\mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{H}}_{q}\cap \mathcal{H}^c_{q+1,1}\Big]\leqslant (\log \log n)^{-\chi}.\end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{H}}_{q}\cap \mathcal{H}^c_{q+1,1}\Big]\leqslant (\log \log n)^{-\chi}.\end{align*}
For (6.22), define
 \begin{equation*}\widetilde{\mathcal{K}}_{q,s,j}=\mathcal{K}_{\Big|V\Big(B_q\big(G_n,k^{(\textrm{u})}_0\big)\Big)\Big|+s,j}\end{equation*}
\begin{equation*}\widetilde{\mathcal{K}}_{q,s,j}=\mathcal{K}_{\Big|V\Big(B_q\big(G_n,k^{(\textrm{u})}_0\big)\Big)\Big|+s,j}\end{equation*}
for
 $j=1,2$
and
$j=1,2$
and
 $1\leqslant s\leqslant |\partial\mathcal{B}_q|$
. Note that
$1\leqslant s\leqslant |\partial\mathcal{B}_q|$
. Note that
 $|\partial \mathcal{B}_q|\leqslant c[n,q]\,:\!=\, \lfloor{1+q(\log n)^{\frac{q}{r}}}\rfloor$
on the event
$|\partial \mathcal{B}_q|\leqslant c[n,q]\,:\!=\, \lfloor{1+q(\log n)^{\frac{q}{r}}}\rfloor$
on the event
 $\mathcal{H}_{q,3}$
, and so
$\mathcal{H}_{q,3}$
, and so
 \begin{align*}&\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap_{\{s\,:\,v[s]\in \partial\mathcal{B}_q \}}(\mathcal{K}_{s,1}\cap\mathcal{ K}_{s,2})\Bigg )^c\cap \mathcal{H}_{q+1,1}\cap \widetilde{\mathcal{H}}_{q}\Bigg]\\&\qquad = \mathbb{P}_{\textbf{x}}\left[{\bigcup^{c[n,q]}_{l=1}\left\{{\{|\partial\mathcal{B}_q|=l\}\cap \left({\bigcap^l_{s=1}\Big(\mathcal{\widetilde K}_{q,s,1}\cap\mathcal{\widetilde K}_{q,s,2}\Big)}\right)^c}\right\}\cap \mathcal{H}_{q+1,1}\cap \widetilde{\mathcal{H}}_{q}}\right].\end{align*}
\begin{align*}&\mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap_{\{s\,:\,v[s]\in \partial\mathcal{B}_q \}}(\mathcal{K}_{s,1}\cap\mathcal{ K}_{s,2})\Bigg )^c\cap \mathcal{H}_{q+1,1}\cap \widetilde{\mathcal{H}}_{q}\Bigg]\\&\qquad = \mathbb{P}_{\textbf{x}}\left[{\bigcup^{c[n,q]}_{l=1}\left\{{\{|\partial\mathcal{B}_q|=l\}\cap \left({\bigcap^l_{s=1}\Big(\mathcal{\widetilde K}_{q,s,1}\cap\mathcal{\widetilde K}_{q,s,2}\Big)}\right)^c}\right\}\cap \mathcal{H}_{q+1,1}\cap \widetilde{\mathcal{H}}_{q}}\right].\end{align*}
By a union bound, and recalling the definition of
 $\overline{\mathcal{H}}_{q,l}$
in (6.5), the probability above is at most
$\overline{\mathcal{H}}_{q,l}$
in (6.5), the probability above is at most
 \begin{align}&\sum^{c[n,q]}_{l=1}\bigg\{\mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{K}}^c_{q,1,2}\cap \widetilde{\mathcal{K}}_{q,1,1}\cap\mathcal{H}_{q+1,1}\cap\overline{\mathcal{H}}_{q,l}\Big]+ \mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{K}}^c_{q,1,1}\cap\mathcal{H}_{q+1,1}\cap \overline{\mathcal{H}}_{q,l}\Big]\nonumber\\&\quad+\sum^l_{s=2} \mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{K}}^c_{q,s,2}\cap \widetilde{\mathcal{K}}_{q,s,1}\cap\mathcal{H}_{q+1,1}\cap \mathcal{J}_{q,l,s}\Big]+\mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{K}}^c_{q,s,1}\cap\mathcal{H}_{q+1,1}\cap \mathcal{J}_{q,l,s}\Big]\bigg\}. \end{align}
\begin{align}&\sum^{c[n,q]}_{l=1}\bigg\{\mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{K}}^c_{q,1,2}\cap \widetilde{\mathcal{K}}_{q,1,1}\cap\mathcal{H}_{q+1,1}\cap\overline{\mathcal{H}}_{q,l}\Big]+ \mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{K}}^c_{q,1,1}\cap\mathcal{H}_{q+1,1}\cap \overline{\mathcal{H}}_{q,l}\Big]\nonumber\\&\quad+\sum^l_{s=2} \mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{K}}^c_{q,s,2}\cap \widetilde{\mathcal{K}}_{q,s,1}\cap\mathcal{H}_{q+1,1}\cap \mathcal{J}_{q,l,s}\Big]+\mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{K}}^c_{q,s,1}\cap\mathcal{H}_{q+1,1}\cap \mathcal{J}_{q,l,s}\Big]\bigg\}. \end{align}
We bound (6.24) using (6.21), Lemma 12, and Lemma 14, where we choose
 $p>2(r-1)$
in Lemma 14 so that
$p>2(r-1)$
in Lemma 14 so that
 \begin{equation*}\sum^{c[n,q]}_{l=1}\sum^l_{s=2} \mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{K}}^c_{q,s,2}\cap \widetilde{\mathcal{K}}_{q,s,1}\cap \mathcal{J}_{q,l,s}\Big]\to 0\end{equation*}
\begin{equation*}\sum^{c[n,q]}_{l=1}\sum^l_{s=2} \mathbb{P}_{\textbf{x}}\Big[\widetilde{\mathcal{K}}^c_{q,s,2}\cap \widetilde{\mathcal{K}}_{q,s,1}\cap \mathcal{J}_{q,l,s}\Big]\to 0\end{equation*}
as
 $n\to\infty$
. It follows that there is a constant
$n\to\infty$
. It follows that there is a constant
 $C\,:\!=\,C(x_1,\mu,\kappa,q)$
such that (6.24) is bounded by
$C\,:\!=\,C(x_1,\mu,\kappa,q)$
such that (6.24) is bounded by
 $C(\log\log n)^{-\chi}$
.
$C(\log\log n)^{-\chi}$
.
7. Completion of the local weak limit proof
Equipped with Corollary 2, we can prove Theorem 1.
Proof of Theorem 1. In view of (1.1), it is enough to establish (1.5) of Theorem 1. Let
 $G^{\prime}_n\sim \textrm{PA}(\pi,X_1)_n$
(Definition 1), let
$G^{\prime}_n\sim \textrm{PA}(\pi,X_1)_n$
(Definition 1), let
 $k_0$
be its randomly chosen vertex, let
$k_0$
be its randomly chosen vertex, let
 $(\mathcal{T}_{\textbf{X},n},0)$
be the intermediate Pólya point tree
$(\mathcal{T}_{\textbf{X},n},0)$
be the intermediate Pólya point tree
 $(\mathcal{T}_{\textbf{x},n},0)$
randomised over
$(\mathcal{T}_{\textbf{x},n},0)$
randomised over
 $\textbf{X}$
, and let
$\textbf{X}$
, and let
 $(\mathcal{T},0)$
be the
$(\mathcal{T},0)$
be the
 $\pi$
-Pólya point tree in Definition 3. By the triangle inequality for the total variation distance, for any
$\pi$
-Pólya point tree in Definition 3. By the triangle inequality for the total variation distance, for any
 $r<\infty$
we have
$r<\infty$
we have
 \begin{align*}&d_{\textrm{TV}}\left(\mathscr{L}\left(\left(B_r\left(G^{\prime}_n,k_0\right),k_0\right)\right), \mathscr{L}\left((B_r(\mathcal{T},0),0)\right)\right)\nonumber\\&\quad \leqslant d_{\textrm{TV}}\left(\mathscr{L}\left(\left(B_r\left(G^{\prime}_n,k_0\right),k_0\right)\right), \mathscr{L}\left(\left(B_r(\mathcal{T}_{\textbf{X},n},0),0\right)\right)\right)\\&\hspace{5cm}+ d_{\textrm{TV}}\left(\mathscr{L}\left(\left(B_r(\mathcal{T}_{\textbf{X},n},0),0\right)\right), \mathscr{L}\left((B_r(\mathcal{T},0),0)\right)\right).\end{align*}
\begin{align*}&d_{\textrm{TV}}\left(\mathscr{L}\left(\left(B_r\left(G^{\prime}_n,k_0\right),k_0\right)\right), \mathscr{L}\left((B_r(\mathcal{T},0),0)\right)\right)\nonumber\\&\quad \leqslant d_{\textrm{TV}}\left(\mathscr{L}\left(\left(B_r\left(G^{\prime}_n,k_0\right),k_0\right)\right), \mathscr{L}\left(\left(B_r(\mathcal{T}_{\textbf{X},n},0),0\right)\right)\right)\\&\hspace{5cm}+ d_{\textrm{TV}}\left(\mathscr{L}\left(\left(B_r(\mathcal{T}_{\textbf{X},n},0),0\right)\right), \mathscr{L}\left((B_r(\mathcal{T},0),0)\right)\right).\end{align*}
Let
 $A_n\,:\!=\,A_{2/3,n}$
be as in (2.1). Applying Jensen’s inequality to the total variation distance, the above is bounded by
$A_n\,:\!=\,A_{2/3,n}$
be as in (2.1). Applying Jensen’s inequality to the total variation distance, the above is bounded by
 \begin{align*}&\mathbb{E} \left[d_{\textrm{TV}}\left(\mathscr{L}\left(\left(B_r\left(G^{\prime}_n,k_0\right),k_0\right)|\textbf{X}\right),\mathscr{L}\left((B_r(\mathcal{T}_{\textbf{X},n},0),0)|\textbf{X}\right)\right)\right]\\&\hspace{3cm}+ d_{\textrm{TV}}\left(\mathscr{L}\left((B_r(\mathcal{T}_{\textbf{X},n},0),0)\right), \mathscr{L}\left((B_r(\mathcal{T},0),0)\right)\right)\\&\leqslant \mathbb{E} \left[\mathbb{1}[ A_n]d_{\textrm{TV}}\left(\mathscr{L}\left(\left(B_r\left(G^{\prime}_n,k_0\right),k_0\right)|\textbf{X}\right),\mathscr{L}\left((B_r(\mathcal{T}_{\textbf{X},n},0),0)|\textbf{X}\right)\right)\right] \\&\hspace{3cm}+\mathbb{P}\left[ A^c_n\right] + d_{\textrm{TV}}\left(\mathscr{L}\left(\left(B_r\left(\mathcal{T}_{\textbf{X},n},0\right),0\right)\right), \mathscr{L}\left((B_r(\mathcal{T},0),0)\right)\right).\end{align*}
\begin{align*}&\mathbb{E} \left[d_{\textrm{TV}}\left(\mathscr{L}\left(\left(B_r\left(G^{\prime}_n,k_0\right),k_0\right)|\textbf{X}\right),\mathscr{L}\left((B_r(\mathcal{T}_{\textbf{X},n},0),0)|\textbf{X}\right)\right)\right]\\&\hspace{3cm}+ d_{\textrm{TV}}\left(\mathscr{L}\left((B_r(\mathcal{T}_{\textbf{X},n},0),0)\right), \mathscr{L}\left((B_r(\mathcal{T},0),0)\right)\right)\\&\leqslant \mathbb{E} \left[\mathbb{1}[ A_n]d_{\textrm{TV}}\left(\mathscr{L}\left(\left(B_r\left(G^{\prime}_n,k_0\right),k_0\right)|\textbf{X}\right),\mathscr{L}\left((B_r(\mathcal{T}_{\textbf{X},n},0),0)|\textbf{X}\right)\right)\right] \\&\hspace{3cm}+\mathbb{P}\left[ A^c_n\right] + d_{\textrm{TV}}\left(\mathscr{L}\left(\left(B_r\left(\mathcal{T}_{\textbf{X},n},0\right),0\right)\right), \mathscr{L}\left((B_r(\mathcal{T},0),0)\right)\right).\end{align*}
We prove that each term on the right-hand side is of order at most
 $(\log\log n)^{-\chi}$
, starting from the expectation. Let
$(\log\log n)^{-\chi}$
, starting from the expectation. Let
 $\mathcal{H}_{r,j}$
,
$\mathcal{H}_{r,j}$
,
 $j=1,2,3$
, be as in (6.1). For the
$j=1,2,3$
, be as in (6.1). For the
 $(\textbf{x},n)$
-Pólya urn tree
$(\textbf{x},n)$
-Pólya urn tree
 $G_n$
with
$G_n$
with
 $\textbf{x}\in A_n$
, Corollary 2 implies that there is a coupling of
$\textbf{x}\in A_n$
, Corollary 2 implies that there is a coupling of
 $\big(G_n,k^{(\textrm{u})}_0\big)$
and
$\big(G_n,k^{(\textrm{u})}_0\big)$
and
 $(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
$(\mathcal{T}_{\textbf{x},n},0)$
, with a positive constant
 $C\,:\!=\,C(x_1,\mu,\kappa,r)$
such that
$C\,:\!=\,C(x_1,\mu,\kappa,r)$
such that
 \begin{align}\mathbb{P}_{\textbf{x}}\left[B_r(\mathcal{T}_{\textbf{x},n},0),0\not \cong \Big(B_r\Big(G_n,k^{(\textrm{u})}_0\Big),k^{(\textrm{u})}_0\Big)\right]\leqslant \mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^{3}_{j=1}\mathcal{H}_{r,j}\Bigg)^c\Bigg] \leqslant C (\log \log n)^{-\chi} ;\end{align}
\begin{align}\mathbb{P}_{\textbf{x}}\left[B_r(\mathcal{T}_{\textbf{x},n},0),0\not \cong \Big(B_r\Big(G_n,k^{(\textrm{u})}_0\Big),k^{(\textrm{u})}_0\Big)\right]\leqslant \mathbb{P}_{\textbf{x}}\Bigg[\Bigg(\bigcap^{3}_{j=1}\mathcal{H}_{r,j}\Bigg)^c\Bigg] \leqslant C (\log \log n)^{-\chi} ;\end{align}
following from the definition (1.4) of the total variation distance, the expectation is at most
 $C(\log \log n)^{-\chi}$
. The probability
$C(\log \log n)^{-\chi}$
. The probability
 $\mathbb{P}[ A^c_n]$
can be bounded using Lemma 1 (with
$\mathbb{P}[ A^c_n]$
can be bounded using Lemma 1 (with
 $\alpha=2/3$
). We now couple
$\alpha=2/3$
). We now couple
 $(B_r(\mathcal{T},0),0)$
and
$(B_r(\mathcal{T},0),0)$
and
 $(B_r(\mathcal{T}_{\textbf{X},n},0),0)$
to bound the last term. For this coupling, denote by E the event that the PA labels in
$(B_r(\mathcal{T}_{\textbf{X},n},0),0)$
to bound the last term. For this coupling, denote by E the event that the PA labels in
 $B_r(\mathcal{T}_{\textbf{X},n},0)$
are distinct, that is,
$B_r(\mathcal{T}_{\textbf{X},n},0)$
are distinct, that is,
 $k^{(\textrm{i})}_{\bar w}\not= k^{(\textrm{i})}_{\bar v}$
for any
$k^{(\textrm{i})}_{\bar w}\not= k^{(\textrm{i})}_{\bar v}$
for any
 $\bar w\not =\bar v$
. We first construct
$\bar w\not =\bar v$
. We first construct
 $B_r(\mathcal{T}_{\textbf{X},n},0)$
; then on the event E, we set
$B_r(\mathcal{T}_{\textbf{X},n},0)$
; then on the event E, we set
 $B_r(\mathcal{T},0)$
as
$B_r(\mathcal{T},0)$
as
 $B_r(\mathcal{T}_{\textbf{X},n},0)$
, inheriting the Ulam–Harris labels, ages, types, and fitness from the latter. If the PA labels are not distinct, we generate
$B_r(\mathcal{T}_{\textbf{X},n},0)$
, inheriting the Ulam–Harris labels, ages, types, and fitness from the latter. If the PA labels are not distinct, we generate
 $B_r(\mathcal{T},0)$
independently from
$B_r(\mathcal{T},0)$
independently from
 $B_r(\mathcal{T}_{\textbf{X},n},0)$
. Under this coupling,
$B_r(\mathcal{T}_{\textbf{X},n},0)$
. Under this coupling,
 \begin{align}\mathbb{P}[(B_r(\mathcal{T}_{\textbf{X},n},0),0)\not \cong (B_r(\mathcal{T},0),0)]= \mathbb{P}[\{(B_r(\mathcal{T}_{\textbf{X},n},0),0)\not\cong (B_r(\mathcal{T},0),0)\}\cap\textrm{E}^c]. \end{align}
\begin{align}\mathbb{P}[(B_r(\mathcal{T}_{\textbf{X},n},0),0)\not \cong (B_r(\mathcal{T},0),0)]= \mathbb{P}[\{(B_r(\mathcal{T}_{\textbf{X},n},0),0)\not\cong (B_r(\mathcal{T},0),0)\}\cap\textrm{E}^c]. \end{align}
From the definition of
 $\mathcal{H}_{r,2}$
in (6.1), we can use (7.1) and Lemma 1 to bound the second term in (7.2) by
$\mathcal{H}_{r,2}$
in (6.1), we can use (7.1) and Lemma 1 to bound the second term in (7.2) by
 $\mathbb{P}[\textrm{E}^c]\leqslant \mathbb{P}\left[\left(\bigcap^3_{j=1}\mathcal{H}_{r,j}\right)^c\right]\leqslant C(\log\log n)^{-\chi}$
. So, once again by (1.4),
$\mathbb{P}[\textrm{E}^c]\leqslant \mathbb{P}\left[\left(\bigcap^3_{j=1}\mathcal{H}_{r,j}\right)^c\right]\leqslant C(\log\log n)^{-\chi}$
. So, once again by (1.4),
 \begin{equation*}d_{\textrm{TV}}\left(\mathscr{L}\left((B_r(\mathcal{T}_{\textbf{X},n},0),0)\right), \mathscr{L}\left((B_r(\mathcal{T},0),0)\right)\right)\leqslant C(\log\log n)^{-\chi},\end{equation*}
\begin{equation*}d_{\textrm{TV}}\left(\mathscr{L}\left((B_r(\mathcal{T}_{\textbf{X},n},0),0)\right), \mathscr{L}\left((B_r(\mathcal{T},0),0)\right)\right)\leqslant C(\log\log n)^{-\chi},\end{equation*}
which concludes the proof.
8. Remarks on the limiting distributions of the degree statistics
In this section, we discuss the connection of Corollary 1 and Theorem 2 to [Reference Berger, Borgs, Chayes and Saberi4, Reference Bollobás, Riordan, Spencer and Tusnády7, Reference Van der Hofstad20, Reference Lodewijks and Ortgiese25, Reference Peköz, Röllin and Ross30]. To this end, we state the probability mass function of the limiting distributions of the degrees of the uniformly chosen vertex
 $k_0$
in PA
$k_0$
in PA
 $(\pi,X_1)_n$
and its type-L neighbour
$(\pi,X_1)_n$
and its type-L neighbour
 $k_{L[1]}$
. These results are direct consequences of Corollary 1 and Theorem 2 (see [Reference Lo24] for a detailed proof). We also show that both probability mass functions also exhibit power-law behaviour, which follows from a dominated convergence argument (see [Reference Lodewijks and Ortgiese25]). Below we write
$k_{L[1]}$
. These results are direct consequences of Corollary 1 and Theorem 2 (see [Reference Lo24] for a detailed proof). We also show that both probability mass functions also exhibit power-law behaviour, which follows from a dominated convergence argument (see [Reference Lodewijks and Ortgiese25]). Below we write
 $a_n\sim b_n$
to indicate
$a_n\sim b_n$
to indicate
 $\lim_{n\to\infty} a_n/b_n=1$
. We start with the degree of the uniformly chosen vertex.
$\lim_{n\to\infty} a_n/b_n=1$
. We start with the degree of the uniformly chosen vertex.
Proposition 1. Retaining the assumptions and the notation in Theorem 2, let
 $\xi_0$
be as in the theorem. The probability mass function of the distribution of
$\xi_0$
be as in the theorem. The probability mass function of the distribution of
 $\xi_0$
is
$\xi_0$
is
 \begin{align}p_{\pi}(j)= (\mu+1)\int^\infty_0 \frac{\Gamma(x+j-1)\Gamma(x+\mu+1)}{\Gamma(x)\Gamma(x+\mu+j+1)} d\pi(x),\qquad j\geqslant 1.\end{align}
\begin{align}p_{\pi}(j)= (\mu+1)\int^\infty_0 \frac{\Gamma(x+j-1)\Gamma(x+\mu+1)}{\Gamma(x)\Gamma(x+\mu+j+1)} d\pi(x),\qquad j\geqslant 1.\end{align}
Furthermore, if
 $\mathbb{E} X^{\mu+1}_2<\infty$
, then as
$\mathbb{E} X^{\mu+1}_2<\infty$
, then as
 $j\to\infty$
,
$j\to\infty$
,
 \begin{equation}p_{\pi}(j)\sim C_{\pi} j^{-(\mu+2)},\qquad C_{\pi}\,:\!=\,(\mu+1)\int^\infty_0 \frac{\Gamma(x+\mu+1)}{\Gamma(x)} d\pi(x).\end{equation}
\begin{equation}p_{\pi}(j)\sim C_{\pi} j^{-(\mu+2)},\qquad C_{\pi}\,:\!=\,(\mu+1)\int^\infty_0 \frac{\Gamma(x+\mu+1)}{\Gamma(x)} d\pi(x).\end{equation}
Remark 4. We use Proposition 1 to relate Theorem 2 to some known results.
-
(i) When
$\pi$
is a point mass at 1,
$(p_{\pi}(j),j\geqslant 1)$
is the probability mass function of
$\textrm{Geo}_1(\sqrt{U})$
(also known as the Yule–Simon distribution), which is a mixture of geometric distributions on the positive integers, with the parameter sampled according to the distribution of
$\sqrt{U}$
, where
$U\sim\textrm{U}(0,1)$
. For such a fitness sequence and a model that allows for self-loops, [Reference Bollobás, Riordan, Spencer and Tusnády7] established that the limiting empirical degree distribution is
$(p_{\pi}(j),j\geqslant 1)$
; furthermore, using Stein’s method, [Reference Peköz, Röllin and Ross30, Theorem 6.1] showed that the total variation distance is at most
$n^{-1}\log n$
. -
(ii) In the multiple-edge setting, and assuming only the fitness has a finite mean, [Reference Lodewijks and Ortgiese25] used stochastic approximation to obtain the a.s. limit of the empirical degree distribution. Theorem 2 and Proposition 1 are special cases of [Reference Lodewijks and Ortgiese25, Theorems 2.4 and 2.6], but the distributional representation and the rate in Theorem 2 are new.







In the following, we give the limiting probability mass function of the degree of the type-L neighbour
 $k_{L[1]}$
of the uniformly chosen vertex
$k_{L[1]}$
of the uniformly chosen vertex
 $k_0$
, which shows that the distribution also exhibits power-law behaviour. When the PA tree has constant initial attractiveness, the proposition is a special case of [Reference Berger, Borgs, Chayes and Saberi4, Lemma 5.2] and [Reference Van der Hofstad20, Lemma 5.9].
$k_0$
, which shows that the distribution also exhibits power-law behaviour. When the PA tree has constant initial attractiveness, the proposition is a special case of [Reference Berger, Borgs, Chayes and Saberi4, Lemma 5.2] and [Reference Van der Hofstad20, Lemma 5.9].
Proposition 2. Retaining the assumptions and the notation in Theorem 1, let
 $R_{L[1]}$
be as in the theorem. The probability mass function of the random variable
$R_{L[1]}$
be as in the theorem. The probability mass function of the random variable
 $R_{L[1]}+2$
in the theorem is given by
$R_{L[1]}+2$
in the theorem is given by
 \begin{align}q_{\pi}(j)=\mu(\mu+1)(j-1)\int^\infty_0\frac{\Gamma(x+j-1)\Gamma(x+\mu+1)}{\Gamma(x+1)\Gamma(x+\mu+j+1)}d\pi(x),\qquad j\geqslant 2.\end{align}
\begin{align}q_{\pi}(j)=\mu(\mu+1)(j-1)\int^\infty_0\frac{\Gamma(x+j-1)\Gamma(x+\mu+1)}{\Gamma(x+1)\Gamma(x+\mu+j+1)}d\pi(x),\qquad j\geqslant 2.\end{align}
Furthermore, if
 $\mathbb{E} X^\mu_2<\infty$
, then as
$\mathbb{E} X^\mu_2<\infty$
, then as
 $j\to\infty$
,
$j\to\infty$
,
 \begin{align*}q_{\pi}(j)\sim C_{\pi}j^{-(\mu+1)},\qquad C_{\pi}=\mu(\mu+1)\int^\infty_0\frac{\Gamma(x+\mu+1)}{\Gamma(x+1)} d\pi(x).\end{align*}
\begin{align*}q_{\pi}(j)\sim C_{\pi}j^{-(\mu+1)},\qquad C_{\pi}=\mu(\mu+1)\int^\infty_0\frac{\Gamma(x+\mu+1)}{\Gamma(x+1)} d\pi(x).\end{align*}
Comparing Propositions 1 and 2, we see that in the limit, the degree of vertex
 $k_{L[1]}$
has a heavier tail than the degree of
$k_{L[1]}$
has a heavier tail than the degree of
 $k_0$
. This is due to the fact that
$k_0$
. This is due to the fact that
 $k_{L[1]}$
has received an incoming edge from
$k_{L[1]}$
has received an incoming edge from
 $k_0$
, and so
$k_0$
, and so
 $k_{L[1]}$
is more likely to have a higher degree than
$k_{L[1]}$
is more likely to have a higher degree than
 $k_0$
.
$k_0$
.
9. Proofs for the approximation results
Here we prove the lemmas in Section 2. The arguments are adapted from [Reference Peköz, Röllin and Ross33] and have a similar flavour to the arguments of [Reference Bloem-Reddy and Orbanz6], both of which studied different PA models. For the proofs below, we recall that
 $\phi(n)=\Omega(n^\chi)$
, where
$\phi(n)=\Omega(n^\chi)$
, where
 $\chi$
is as in (1.2).
$\chi$
is as in (1.2).
Proof of Lemma 1. Given
 $p>2$
, choose
$p>2$
, choose
 $1/2+1/p<\alpha<1$
. Let
$1/2+1/p<\alpha<1$
. Let
 $A_{\alpha,n}$
be as in (2.1), let
$A_{\alpha,n}$
be as in (2.1), let
 $T^\star_m\,:\!=\,\sum^m_{i=2}X_i$
, and let
$T^\star_m\,:\!=\,\sum^m_{i=2}X_i$
, and let
 $C_p$
be the positive constant given in Lemma 15 below, which bounds the moment of a sum of variables in terms of the moments of the summands. Then
$C_p$
be the positive constant given in Lemma 15 below, which bounds the moment of a sum of variables in terms of the moments of the summands. Then

where
 $p(\alpha-1/2)>1$
and
$p(\alpha-1/2)>1$
and
 $\mathbb{E}[|X_2-\mu|^{p}]<\infty$
. The lemma follows from the fact that
$\mathbb{E}[|X_2-\mu|^{p}]<\infty$
. The lemma follows from the fact that
 $\phi(n)=\Omega(n^\chi)$
.
$\phi(n)=\Omega(n^\chi)$
.
The next lemma can be found in [Reference Petrov34, Item 16, p.60], where [Reference Dharmadhikari and Jogdeo13] is credited.
Lemma 15. Let
 $Y_1,\ldots,Y_n$
be independent random variables such that for
$Y_1,\ldots,Y_n$
be independent random variables such that for
 $i=1,\ldots,n$
,
$i=1,\ldots,n$
,
 $\mathbb{E} Y_i=0$
and
$\mathbb{E} Y_i=0$
and
 $\mathbb{E} |Y_i|^p<\infty$
for some
$\mathbb{E} |Y_i|^p<\infty$
for some
 $p\geqslant 2$
. Let
$p\geqslant 2$
. Let
 $W_n\,:\!=\,\sum^n_{i=1}Y_i$
; then
$W_n\,:\!=\,\sum^n_{i=1}Y_i$
; then
 \begin{equation*}\mathbb{E}\big[|W_n|^p\big]\leqslant C_p n^{p/2-1}\sum^{n}_{i=1}\mathbb{E}\big[|Y_i|^p\big],\end{equation*}
\begin{equation*}\mathbb{E}\big[|W_n|^p\big]\leqslant C_p n^{p/2-1}\sum^{n}_{i=1}\mathbb{E}\big[|Y_i|^p\big],\end{equation*}
where
 \begin{equation*}C_p\,:\!=\,\frac{1}{2}p(p-1)\max \big(1, 2^{p-3}\big)\left[1+\frac{2}{p}K^{(p-2)/2m}_{2m}\right],\end{equation*}
\begin{equation*}C_p\,:\!=\,\frac{1}{2}p(p-1)\max \big(1, 2^{p-3}\big)\left[1+\frac{2}{p}K^{(p-2)/2m}_{2m}\right],\end{equation*}
and the integer m satisfies the condition
 $2m\leqslant p\leqslant 2m+2$
and
$2m\leqslant p\leqslant 2m+2$
and
 $ K_{2m}=\sum^m_{i=1}\frac{i^{2m-1}}{(i-1)!}$
.
$ K_{2m}=\sum^m_{i=1}\frac{i^{2m-1}}{(i-1)!}$
.
Keeping the notation
 $T_i\,:\!=\,\sum^i_{h=1}x_h$
and
$T_i\,:\!=\,\sum^i_{h=1}x_h$
and
 $\phi(n)=\Omega(n^\chi)$
, we now prove Lemma 2 under the assumption that the event
$\phi(n)=\Omega(n^\chi)$
, we now prove Lemma 2 under the assumption that the event
 $A_{\alpha,n}$
holds for the realisation of the fitness sequence
$A_{\alpha,n}$
holds for the realisation of the fitness sequence
 $\textbf{x}$
(written as
$\textbf{x}$
(written as
 $\textbf{x}\in A_{\alpha,n}$
). We use the subscript
$\textbf{x}\in A_{\alpha,n}$
). We use the subscript
 $\textbf{x}$
in
$\textbf{x}$
in
 $\mathbb{P}_{\textbf{x}}$
and
$\mathbb{P}_{\textbf{x}}$
and
 $ \mathbb{E}_{\textbf{x}}$
to indicate the conditioning on
$ \mathbb{E}_{\textbf{x}}$
to indicate the conditioning on
 $\textbf{X}=\textbf{x}$
. The first step is to derive an expression for
$\textbf{X}=\textbf{x}$
. The first step is to derive an expression for
 $\mathbb{E}_{\textbf{x}}[S_{n,k}]$
that holds for any realisation of the fitness sequence, where we modify a moment formula used in proving [Reference Sénizergues36, Proposition 1.3].
$\mathbb{E}_{\textbf{x}}[S_{n,k}]$
that holds for any realisation of the fitness sequence, where we modify a moment formula used in proving [Reference Sénizergues36, Proposition 1.3].
Lemma 16. Let
 $T_i$
be as above, and let
$T_i$
be as above, and let
 $B_i$
,
$B_i$
,
 $S_{n,i}$
be as in (1.8) and (1.9). Then for
$S_{n,i}$
be as in (1.8) and (1.9). Then for
 $1\leqslant k < n$
and a positive integer p,
$1\leqslant k < n$
and a positive integer p,
 \begin{equation}\mathbb{E}_{\textbf{x}}\big[S_{n,k}^p\big]= \left[\prod^{p-1}_{h=0}\frac{T_k+k+h}{T_n+n-1+h}\right] \prod^{p-1}_{j=0}\prod^{n-1}_{i=k+1}\left[1+\frac{1}{T_{i}+i-1+j}\right].\end{equation}
\begin{equation}\mathbb{E}_{\textbf{x}}\big[S_{n,k}^p\big]= \left[\prod^{p-1}_{h=0}\frac{T_k+k+h}{T_n+n-1+h}\right] \prod^{p-1}_{j=0}\prod^{n-1}_{i=k+1}\left[1+\frac{1}{T_{i}+i-1+j}\right].\end{equation}
Proof. Since
 $(B_i,1\leqslant i\leqslant n)$
are independent beta random variables, we use the moment formula of the beta distribution to show that for
$(B_i,1\leqslant i\leqslant n)$
are independent beta random variables, we use the moment formula of the beta distribution to show that for
 $p\geqslant 1$
,
$p\geqslant 1$
,
 \begin{align*}\mathbb{E}_{\textbf{x}}\big[S^p_{n,k}\big]&=\prod^n_{i=k+1}\mathbb{E}\left[\left(1-B_i\right)^p\right]=\prod^n_{i=k+1}\prod^{p-1}_{j=0}\frac{T_{i-1}+i-1+j}{T_i+i-1+j},\\&= \prod^{p-1}_{j=0} \left\{\frac{(T_k+k+j)}{(T_n+n-1+j)}\frac{(T_n+n-1+j)}{(T_k+k+j)}\prod^n_{i=k+1}\frac{T_{i-1}+i-1+j}{T_i+i-1+j}\right\}.\end{align*}
\begin{align*}\mathbb{E}_{\textbf{x}}\big[S^p_{n,k}\big]&=\prod^n_{i=k+1}\mathbb{E}\left[\left(1-B_i\right)^p\right]=\prod^n_{i=k+1}\prod^{p-1}_{j=0}\frac{T_{i-1}+i-1+j}{T_i+i-1+j},\\&= \prod^{p-1}_{j=0} \left\{\frac{(T_k+k+j)}{(T_n+n-1+j)}\frac{(T_n+n-1+j)}{(T_k+k+j)}\prod^n_{i=k+1}\frac{T_{i-1}+i-1+j}{T_i+i-1+j}\right\}.\end{align*}
Noting that
 $T_k+k+j$
and
$T_k+k+j$
and
 $T_n+n-1+j$
in the second product above cancel with
$T_n+n-1+j$
in the second product above cancel with
 $(T_n+n-1+j)/(T_k+k+j)$
, we can rewrite the final term as
$(T_n+n-1+j)/(T_k+k+j)$
, we can rewrite the final term as
 \begin{align*}\mathbb{E}_{\textbf{x}}\big[S^p_{n,k}\big]&=\left[\prod^{p-1}_{h=0}\frac{T_k+k+h}{T_n+n-1+h}\right]\prod^{n-1}_{i=k+1} \prod^{p-1}_{j=0}\frac{T_{i}+i+j}{T_{i}+i-1+j}\\&=\left[\prod^{p-1}_{h=0}\frac{T_k+k+h}{T_n+n-1+h}\right] \prod^{p-1}_{j=0}\prod^{n-1}_{i=k+1}\left[1+\frac{1}{T_{i}+i-1+j}\right],\end{align*}
\begin{align*}\mathbb{E}_{\textbf{x}}\big[S^p_{n,k}\big]&=\left[\prod^{p-1}_{h=0}\frac{T_k+k+h}{T_n+n-1+h}\right]\prod^{n-1}_{i=k+1} \prod^{p-1}_{j=0}\frac{T_{i}+i+j}{T_{i}+i-1+j}\\&=\left[\prod^{p-1}_{h=0}\frac{T_k+k+h}{T_n+n-1+h}\right] \prod^{p-1}_{j=0}\prod^{n-1}_{i=k+1}\left[1+\frac{1}{T_{i}+i-1+j}\right],\end{align*}
hence concluding the proof.
Taking
 $k=1$
in (9.1) recovers the original formula of [Reference Sénizergues36], where
$k=1$
in (9.1) recovers the original formula of [Reference Sénizergues36], where
 $T_i$
here is
$T_i$
here is
 $A_i$
in [Reference Sénizergues36]. Next, we use the moment formula to show that when
$A_i$
in [Reference Sénizergues36]. Next, we use the moment formula to show that when
 $\textbf{x}\in A_{\alpha, n}$
, the difference between the mean of
$\textbf{x}\in A_{\alpha, n}$
, the difference between the mean of
 $S_{n,k}$
and
$S_{n,k}$
and
 $(k/n)^\chi$
is small enough for large n and
$(k/n)^\chi$
is small enough for large n and
 $k\geqslant \lceil{\phi(n)}\rceil$
.
$k\geqslant \lceil{\phi(n)}\rceil$
.
Lemma 17. Given
 $1/2<\alpha<1$
and a positive integer n, assume that
$1/2<\alpha<1$
and a positive integer n, assume that
 $\textbf{x}\in A_{\alpha,n}$
. Then there is a positive constant
$\textbf{x}\in A_{\alpha,n}$
. Then there is a positive constant
 $C\,:\!=\,C(x_1,\mu,\alpha)$
such that for all
$C\,:\!=\,C(x_1,\mu,\alpha)$
such that for all
 $\lceil{\phi(n)}\rceil \leqslant k\leqslant n$
,
$\lceil{\phi(n)}\rceil \leqslant k\leqslant n$
,
 \begin{equation}\left|\mathbb{E}_{\textbf{x}}[S_{n,k}]- \left(\frac{k}{n}\right)^{\chi }\right|\leqslant C n^{\chi (\alpha-1)}.\end{equation}
\begin{equation}\left|\mathbb{E}_{\textbf{x}}[S_{n,k}]- \left(\frac{k}{n}\right)^{\chi }\right|\leqslant C n^{\chi (\alpha-1)}.\end{equation}
Proof. We first prove the upper bound for
 $\mathbb{E}_{\textbf{x}}[S_{n,k}]$
, using the techniques for proving [Reference Peköz, Röllin and Ross33, Lemma 4.4]. Applying the formula (9.1) (with
$\mathbb{E}_{\textbf{x}}[S_{n,k}]$
, using the techniques for proving [Reference Peköz, Röllin and Ross33, Lemma 4.4]. Applying the formula (9.1) (with
 $p=1$
), for
$p=1$
), for
 $\textbf{x}\in A_{\alpha,n}$
and
$\textbf{x}\in A_{\alpha,n}$
and
 $k\geqslant \lceil{\phi(n)}\rceil$
, we obtain
$k\geqslant \lceil{\phi(n)}\rceil$
, we obtain
 \begin{equation}\mathbb{E}_{\textbf{x}}[S_{n,k}]\leqslant \frac{k(\mu+1)+k^\alpha+b}{n(\mu+1)-n^\alpha+b-1} \prod^{n-1}_{i=k+1} \left[1+\frac{1}{i\mu-i^{\alpha}+i+b-1}\right],\end{equation}
\begin{equation}\mathbb{E}_{\textbf{x}}[S_{n,k}]\leqslant \frac{k(\mu+1)+k^\alpha+b}{n(\mu+1)-n^\alpha+b-1} \prod^{n-1}_{i=k+1} \left[1+\frac{1}{i\mu-i^{\alpha}+i+b-1}\right],\end{equation}
where
 $b\,:\!=\,x_1-\mu$
. We rewrite the first term on the right-hand side of (9.3) as follows:
$b\,:\!=\,x_1-\mu$
. We rewrite the first term on the right-hand side of (9.3) as follows:
 \begin{align*}\left(\frac{k}{n}\right)\frac{\mu+1+k^{-1+\alpha}+k^{-1}b}{\mu+1-n^{-1+\alpha}+n^{-1}(b-1)}&= \left(\frac{k}{n}\right)\left[1+\frac{k^{\alpha-1}+n^{\alpha-1}+(k^{-1}-n^{-1})b+n^{-1}}{\mu+1-n^{\alpha-1}+n^{-1}(b-1)}\right]\\& \leqslant \frac{k}{n}\big(1+\overline Ck^{\alpha-1}\big)\\&\leqslant \frac{k}{n}\big(1+\overline Cn^{\chi(\alpha-1)}\big),\end{align*}
\begin{align*}\left(\frac{k}{n}\right)\frac{\mu+1+k^{-1+\alpha}+k^{-1}b}{\mu+1-n^{-1+\alpha}+n^{-1}(b-1)}&= \left(\frac{k}{n}\right)\left[1+\frac{k^{\alpha-1}+n^{\alpha-1}+(k^{-1}-n^{-1})b+n^{-1}}{\mu+1-n^{\alpha-1}+n^{-1}(b-1)}\right]\\& \leqslant \frac{k}{n}\big(1+\overline Ck^{\alpha-1}\big)\\&\leqslant \frac{k}{n}\big(1+\overline Cn^{\chi(\alpha-1)}\big),\end{align*}
where
 $\overline C\,:\!=\,\overline C(x_1,\mu,\alpha)$
is some positive constant. To bound the product term on the right-hand side of (9.3), we take the logarithm and bound
$\overline C\,:\!=\,\overline C(x_1,\mu,\alpha)$
is some positive constant. To bound the product term on the right-hand side of (9.3), we take the logarithm and bound
 \begin{equation*}\left|\sum^{n-1}_{i=k+1}\log\left(1+\frac{1}{i(\mu+1)-i^{\alpha}+b-1}\right)-\frac{1}{\mu+1}\log\left(\frac{n}{k}\right)\right|.\end{equation*}
\begin{equation*}\left|\sum^{n-1}_{i=k+1}\log\left(1+\frac{1}{i(\mu+1)-i^{\alpha}+b-1}\right)-\frac{1}{\mu+1}\log\left(\frac{n}{k}\right)\right|.\end{equation*}
By the triangle inequality, we have
 \begin{align}&\left|\sum^{n-1}_{i=k+1} \log \left(1+\frac{1}{i\mu-i^{\alpha}+i+b-1}\right)-\frac{1}{\mu+1}\log\left(\frac{n}{k}\right)\right|\nonumber\\& \quad\leqslant \left|\sum^{n-1}_{i=k+1} \log \left(1+\frac{1}{i\mu-i^{\alpha}+i+b-1}\right)-\frac{1}{i(\mu+1)-i^\alpha+b-1}\right| \end{align}
\begin{align}&\left|\sum^{n-1}_{i=k+1} \log \left(1+\frac{1}{i\mu-i^{\alpha}+i+b-1}\right)-\frac{1}{\mu+1}\log\left(\frac{n}{k}\right)\right|\nonumber\\& \quad\leqslant \left|\sum^{n-1}_{i=k+1} \log \left(1+\frac{1}{i\mu-i^{\alpha}+i+b-1}\right)-\frac{1}{i(\mu+1)-i^\alpha+b-1}\right| \end{align}
 \begin{align}+ \left|\sum^{n-1}_{j=k+1}\frac{1}{j(\mu+1)-j^\alpha+b-1} - \frac{1}{\mu+1}\log\left(\frac{n}{k}\right)\right|. \end{align}
\begin{align}+ \left|\sum^{n-1}_{j=k+1}\frac{1}{j(\mu+1)-j^\alpha+b-1} - \frac{1}{\mu+1}\log\left(\frac{n}{k}\right)\right|. \end{align}
We use the fact that
 $y-\log(1+y)\leqslant y^2$
for
$y-\log(1+y)\leqslant y^2$
for
 $y\geqslant 0$
to bound (9.4). Letting
$y\geqslant 0$
to bound (9.4). Letting
 $y_i=(i(\mu+1)-i^{\alpha}+b-1)^{-1}$
, this implies that (9.4) is bounded by
$y_i=(i(\mu+1)-i^{\alpha}+b-1)^{-1}$
, this implies that (9.4) is bounded by
 $\sum^n_{i=k+1} y^2_i$
for
$\sum^n_{i=k+1} y^2_i$
for
 $k\geqslant \lceil{\phi(n)}\rceil$
and n large enough, and by an integral comparison,
$k\geqslant \lceil{\phi(n)}\rceil$
and n large enough, and by an integral comparison,
 \begin{equation*}\sum^n_{i=k+1}y^2_i=O(n^{-\chi}).\end{equation*}
\begin{equation*}\sum^n_{i=k+1}y^2_i=O(n^{-\chi}).\end{equation*}
For (9.5), we have
 \begin{align*}& \left|\sum^{n-1}_{i=k+1}\frac{1}{i(\mu+1)-i^\alpha+b-1}-\frac{1}{(\mu+1)}\log\left(\frac{n}{k}\right)\right|\\&\qquad= \left|\sum^{n-1}_{i=k+1}\left(\frac{1}{i(\mu+1)-i^\alpha+b-1}-\frac{1}{(\mu+1)i}\right)+O\big(k^{-1}\big)\right|\\&\qquad \leqslant \sum^{n-1}_{i=k+1}\left|\frac{i^{\alpha}-b+1}{i(\mu+1)(i(\mu+1)-i^\alpha+b-1)}\right|+O\big(k^{-1}\big)\\&\qquad\leqslant C^{\prime}\sum^{n-1}_{i=k+1}i^{-2+\alpha}+ O\big(k^{-1}\big)\\& \qquad \leqslant C^{\prime}(1-\alpha)^{-1}[\phi(n)]^{\alpha-1}+ O\big(n^{-\chi}\big),\end{align*}
\begin{align*}& \left|\sum^{n-1}_{i=k+1}\frac{1}{i(\mu+1)-i^\alpha+b-1}-\frac{1}{(\mu+1)}\log\left(\frac{n}{k}\right)\right|\\&\qquad= \left|\sum^{n-1}_{i=k+1}\left(\frac{1}{i(\mu+1)-i^\alpha+b-1}-\frac{1}{(\mu+1)i}\right)+O\big(k^{-1}\big)\right|\\&\qquad \leqslant \sum^{n-1}_{i=k+1}\left|\frac{i^{\alpha}-b+1}{i(\mu+1)(i(\mu+1)-i^\alpha+b-1)}\right|+O\big(k^{-1}\big)\\&\qquad\leqslant C^{\prime}\sum^{n-1}_{i=k+1}i^{-2+\alpha}+ O\big(k^{-1}\big)\\& \qquad \leqslant C^{\prime}(1-\alpha)^{-1}[\phi(n)]^{\alpha-1}+ O\big(n^{-\chi}\big),\end{align*}
where
 $C^{\prime}\,:\!=\,C^{\prime}(x_1,\mu,\alpha)$
is some positive constant. Combining the bounds above, a little calculation shows that there are positive constants
$C^{\prime}\,:\!=\,C^{\prime}(x_1,\mu,\alpha)$
is some positive constant. Combining the bounds above, a little calculation shows that there are positive constants
 $\overline C\,:\!=\,\overline C(x_1,\mu,\alpha)$
and
$\overline C\,:\!=\,\overline C(x_1,\mu,\alpha)$
and
 $\widetilde C\,:\!=\,\widetilde C(x_1,\mu,\alpha)$
such that for
$\widetilde C\,:\!=\,\widetilde C(x_1,\mu,\alpha)$
such that for
 $\textbf{x}\in A_{\alpha,n}$
and
$\textbf{x}\in A_{\alpha,n}$
and
 $\lceil{\phi(n)}\rceil\leqslant k\leqslant n$
,
$\lceil{\phi(n)}\rceil\leqslant k\leqslant n$
,
 \begin{align*}\mathbb{E}_{\textbf{x}}[S_{n,k}]\leqslant (k/n)^\chi \big(1+\overline Cn^{\chi(\alpha-1)}\big) \exp\big\{\widetilde C n^{\chi(\alpha-1)}\big\}.\end{align*}
\begin{align*}\mathbb{E}_{\textbf{x}}[S_{n,k}]\leqslant (k/n)^\chi \big(1+\overline Cn^{\chi(\alpha-1)}\big) \exp\big\{\widetilde C n^{\chi(\alpha-1)}\big\}.\end{align*}
Since
 $e^{x}=1+x+O(x^2)$
for x near zero, there is a positive constant
$e^{x}=1+x+O(x^2)$
for x near zero, there is a positive constant
 $C\,:\!=\, C(x_1,\mu,\alpha)$
such that for
$C\,:\!=\, C(x_1,\mu,\alpha)$
such that for
 $\lceil{\phi(n)}\rceil\leqslant k\leqslant n$
and n large enough,
$\lceil{\phi(n)}\rceil\leqslant k\leqslant n$
and n large enough,
 \begin{align*}\mathbb{E}_{\textbf{x}}[S_{n,k}]\leqslant (k/n)^\chi\big(1+ C n^{\chi(\alpha-1)}\big)\leqslant (k/n)^\chi + Cn^{\chi(\alpha-1)},\end{align*}
\begin{align*}\mathbb{E}_{\textbf{x}}[S_{n,k}]\leqslant (k/n)^\chi\big(1+ C n^{\chi(\alpha-1)}\big)\leqslant (k/n)^\chi + Cn^{\chi(\alpha-1)},\end{align*}
hence proving the desired upper bound. The lower bound can be proved by noting that for
 $\lceil{\phi(n)}\rceil\leqslant k\leqslant n$
,
$\lceil{\phi(n)}\rceil\leqslant k\leqslant n$
,
 \begin{equation*}\mathbb{E}_{\textbf{x}}[S_{n,k}]\geqslant \frac{k(\mu+1)-k^\alpha+b}{n(\mu+1)+n^\alpha+b-1}\prod^n_{i=k+1} \left[1+\frac{1}{i\mu+i^{\alpha}+i+b-1}\right],\end{equation*}
\begin{equation*}\mathbb{E}_{\textbf{x}}[S_{n,k}]\geqslant \frac{k(\mu+1)-k^\alpha+b}{n(\mu+1)+n^\alpha+b-1}\prod^n_{i=k+1} \left[1+\frac{1}{i\mu+i^{\alpha}+i+b-1}\right],\end{equation*}
and repeating the calculations above. The details are omitted.
With Lemma 17 and a martingale argument, we can prove Lemma 2.
Proof of Lemma 2. Let
 $\hat \delta_n=Cn^{\chi(\alpha-1)/4}$
, where
$\hat \delta_n=Cn^{\chi(\alpha-1)/4}$
, where
 $C\,:\!=\,C(x_1,\mu,\alpha)$
is the positive constant in (9.2) of Lemma 17. Writing
$C\,:\!=\,C(x_1,\mu,\alpha)$
is the positive constant in (9.2) of Lemma 17. Writing
 $K\,:\!=\,\lceil{\phi(n)}\rceil$
, define
$K\,:\!=\,\lceil{\phi(n)}\rceil$
, define
 \begin{equation*}\widetilde E_{n,\hat \delta_n}\,:\!=\, \left\{\max\limits_{K \leqslant k \leqslant n} \left|S_{n,k}-\left(\frac{k}{n}\right)^{\chi}\right| \geqslant 2\hat \delta_n\right\}.\end{equation*}
\begin{equation*}\widetilde E_{n,\hat \delta_n}\,:\!=\, \left\{\max\limits_{K \leqslant k \leqslant n} \left|S_{n,k}-\left(\frac{k}{n}\right)^{\chi}\right| \geqslant 2\hat \delta_n\right\}.\end{equation*}
The lemma follows from bounding
 $\mathbb{P}_{\textbf{x}}\Big[\widetilde E_{n,\hat \delta_n}\Big]$
under the assumption
$\mathbb{P}_{\textbf{x}}\Big[\widetilde E_{n,\hat \delta_n}\Big]$
under the assumption
 $\textbf{x}\in A_{\alpha,n}$
. By the triangle inequality, we have
$\textbf{x}\in A_{\alpha,n}$
. By the triangle inequality, we have
 \begin{align*}\mathbb{P}_{\textbf{x}}\Big[\widetilde E_{n,\hat \delta_n}\Big]&\leqslant \mathbb{P}_{\textbf{x}}\bigg[\max\limits_{K \leqslant k \leqslant n}\left|S_{n,k}-\mathbb{E}_{\textbf{x}}[S_{n,k}]\right|+\max\limits_{K \leqslant j \leqslant n}\left|\mathbb{E}_{\textbf{x}}[S_{n,j}]-(j/n)^{\chi}\right|\geqslant 2\hat \delta_n \bigg].\end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\Big[\widetilde E_{n,\hat \delta_n}\Big]&\leqslant \mathbb{P}_{\textbf{x}}\bigg[\max\limits_{K \leqslant k \leqslant n}\left|S_{n,k}-\mathbb{E}_{\textbf{x}}[S_{n,k}]\right|+\max\limits_{K \leqslant j \leqslant n}\left|\mathbb{E}_{\textbf{x}}[S_{n,j}]-(j/n)^{\chi}\right|\geqslant 2\hat \delta_n \bigg].\end{align*}
Applying Lemma 17 to bound the difference between
 $(j/n)^\chi$
and
$(j/n)^\chi$
and
 $\mathbb{E}_{\textbf{x}}[S_{n,j}]$
, we obtain
$\mathbb{E}_{\textbf{x}}[S_{n,j}]$
, we obtain
 \begin{align*}\mathbb{P}_{\textbf{x}}\Big[\widetilde E_{n,\hat \delta_n}\Big] \leqslant \mathbb{P}_{\textbf{x}}\left[\max\limits_{K \leqslant k \leqslant n}\left|S_{n,k}-\mathbb{E}_{\textbf{x}}[S_{n,k}]\right|\geqslant \hat \delta_n\right]\leqslant \mathbb{P}_{\textbf{x}}\left[\max\limits_{K \leqslant k \leqslant n}\left|S_{n,k}(\mathbb{E}_{\textbf{x}}[S_{n,k}])^{-1}-1\right|\geqslant \hat \delta_n\right],\end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\Big[\widetilde E_{n,\hat \delta_n}\Big] \leqslant \mathbb{P}_{\textbf{x}}\left[\max\limits_{K \leqslant k \leqslant n}\left|S_{n,k}-\mathbb{E}_{\textbf{x}}[S_{n,k}]\right|\geqslant \hat \delta_n\right]\leqslant \mathbb{P}_{\textbf{x}}\left[\max\limits_{K \leqslant k \leqslant n}\left|S_{n,k}(\mathbb{E}_{\textbf{x}}[S_{n,k}])^{-1}-1\right|\geqslant \hat \delta_n\right],\end{align*}
where the second inequality is due to
 $\mathbb{E}_{\textbf{x}}[S_{n,k}]\leqslant 1$
. We bound the right-hand side of the above using a martingale argument. Recall that
$\mathbb{E}_{\textbf{x}}[S_{n,k}]\leqslant 1$
. We bound the right-hand side of the above using a martingale argument. Recall that
 $\mathbb{E}_{\textbf{x}}[S_{n,k}]=\prod^n_{j=k+1}\mathbb{E}[1-B_j]$
. Define
$\mathbb{E}_{\textbf{x}}[S_{n,k}]=\prod^n_{j=k+1}\mathbb{E}[1-B_j]$
. Define
 $ M_0\,:\!=\,1$
, and for
$ M_0\,:\!=\,1$
, and for
 $j=1,\ldots,n-K$
, let
$j=1,\ldots,n-K$
, let
 \begin{equation*}M_{j}\,:\!=\,\prod^{n}_{i=n-j+1}\frac{1-B_i}{\mathbb{E}[1-B_i]}=\frac{S_{n,n-j}}{\mathbb{E}[S_{n,n-j}]}.\end{equation*}
\begin{equation*}M_{j}\,:\!=\,\prod^{n}_{i=n-j+1}\frac{1-B_i}{\mathbb{E}[1-B_i]}=\frac{S_{n,n-j}}{\mathbb{E}[S_{n,n-j}]}.\end{equation*}
Let
 $\mathcal{F}_{j}$
be the
$\mathcal{F}_{j}$
be the
 $\sigma$
-algebra generated by
$\sigma$
-algebra generated by
 $(B_i,n-j+1\leqslant i \leqslant n)$
for
$(B_i,n-j+1\leqslant i \leqslant n)$
for
 $1\leqslant j\leqslant n-K$
, with
$1\leqslant j\leqslant n-K$
, with
 $\mathcal{F}_0=\varnothing$
. It follows that
$\mathcal{F}_0=\varnothing$
. It follows that
 $\big(\big(M_{j}, \mathcal{F}_{j}\big),0\leqslant j\leqslant n-K\big)$
is a martingale with
$\big(\big(M_{j}, \mathcal{F}_{j}\big),0\leqslant j\leqslant n-K\big)$
is a martingale with
 $\mathbb{E}[M_{j}]=1$
. Since
$\mathbb{E}[M_{j}]=1$
. Since
 $(M_j-1)^2$
is a submartingale, Doob’s inequality [Reference Durrett14, Theorem 4.4.2, p.204] yields
$(M_j-1)^2$
is a submartingale, Doob’s inequality [Reference Durrett14, Theorem 4.4.2, p.204] yields
 \begin{align}\mathbb{P}_{\textbf{x}}\Big[\widetilde E_{n,\hat \delta_n}\Big]\leqslant\mathbb{P}_{\textbf{x}}\left[\max\limits_{0 \leqslant j\leqslant n-K}\left|M_{j}-1\right|\geqslant\hat \delta_n \right] \leqslant \hat \delta_n^{-2}\textrm{Var}_{\textbf{x}}(M_{n-K}), \end{align}
\begin{align}\mathbb{P}_{\textbf{x}}\Big[\widetilde E_{n,\hat \delta_n}\Big]\leqslant\mathbb{P}_{\textbf{x}}\left[\max\limits_{0 \leqslant j\leqslant n-K}\left|M_{j}-1\right|\geqslant\hat \delta_n \right] \leqslant \hat \delta_n^{-2}\textrm{Var}_{\textbf{x}}(M_{n-K}), \end{align}
where
 $\textrm{Var}_{\textbf{x}}(M_{n-K})$
is the variance conditional on
$\textrm{Var}_{\textbf{x}}(M_{n-K})$
is the variance conditional on
 $\textbf{x}$
. We use the formulas for the first and second moments of the beta distribution to bound the variance:
$\textbf{x}$
. We use the formulas for the first and second moments of the beta distribution to bound the variance:
 \begin{align*}\textrm{Var}_{\textbf{x}}(M_{n-K})&=\mathbb{E}_{\textbf{x}}\big[(M_{n-K})^2\big]-1=\bigg[\prod^n_{j=K+1}\frac{(T_{j-1}+j)}{(T_{j-1}+j-1)}\frac{(T_j+j-1)}{(T_{j}+j)}\bigg]-1\\& = \prod^n_{j=K+1}\left[1+\frac{T_j-T_{j-1}}{(T_j+j)(T_{j-1}+j-1)}\right]-1.\end{align*}
\begin{align*}\textrm{Var}_{\textbf{x}}(M_{n-K})&=\mathbb{E}_{\textbf{x}}\big[(M_{n-K})^2\big]-1=\bigg[\prod^n_{j=K+1}\frac{(T_{j-1}+j)}{(T_{j-1}+j-1)}\frac{(T_j+j-1)}{(T_{j}+j)}\bigg]-1\\& = \prod^n_{j=K+1}\left[1+\frac{T_j-T_{j-1}}{(T_j+j)(T_{j-1}+j-1)}\right]-1.\end{align*}
Below we allow the positive constant
 $C^{\prime}=C^{\prime}(x_1,\mu,\alpha)$
to vary from line to line. As
$C^{\prime}=C^{\prime}(x_1,\mu,\alpha)$
to vary from line to line. As
 $\big|\sum^j_{i=2}x_i - (j-1)\mu\big| \leqslant j^\alpha $
for all
$\big|\sum^j_{i=2}x_i - (j-1)\mu\big| \leqslant j^\alpha $
for all
 $K+1\leqslant j\leqslant n$
when
$K+1\leqslant j\leqslant n$
when
 $\textbf{x}\in A_{\alpha,n}$
, a little computation yields
$\textbf{x}\in A_{\alpha,n}$
, a little computation yields
 \begin{align}\textrm{Var}_{\textbf{x}}(M_{n-K})&\leqslant \prod^n_{j=K+1}\left[1+\frac{\mu +j^\alpha+(j-1)^\alpha}{\{(\mu+1)j-\mu-j^\alpha+x_1 \}\{(\mu+1) j-2\mu-j^\alpha+x_1-1\}}\right]-1\nonumber\\&\leqslant \prod^n_{j=K+1} \big(1+ C^{\prime}j^{\alpha-2}\big)-1\nonumber\\&\leqslant C^{\prime} K^{\alpha-1}. \end{align}
\begin{align}\textrm{Var}_{\textbf{x}}(M_{n-K})&\leqslant \prod^n_{j=K+1}\left[1+\frac{\mu +j^\alpha+(j-1)^\alpha}{\{(\mu+1)j-\mu-j^\alpha+x_1 \}\{(\mu+1) j-2\mu-j^\alpha+x_1-1\}}\right]-1\nonumber\\&\leqslant \prod^n_{j=K+1} \big(1+ C^{\prime}j^{\alpha-2}\big)-1\nonumber\\&\leqslant C^{\prime} K^{\alpha-1}. \end{align}
Applying (9.7) to (9.6) completes the proof.
We conclude this section with the proof of Lemma 3, recalling that
 $\mathcal{Z}_j\sim \textrm{Gamma}(x_j,1)$
and
$\mathcal{Z}_j\sim \textrm{Gamma}(x_j,1)$
and
 $\mathcal{\widetilde Z}_j \sim \textrm{Gamma}(T_j+j,1)$
.
$\mathcal{\widetilde Z}_j \sim \textrm{Gamma}(T_j+j,1)$
.
Proof of Lemma 3. Writing
 $T_j\,:\!=\,\sum^j_{i=1}x_i$
and
$T_j\,:\!=\,\sum^j_{i=1}x_i$
and
 $Y_j\sim \textrm{Gamma}(T_j+j-1,1)$
, we first prove (2.4). Letting
$Y_j\sim \textrm{Gamma}(T_j+j-1,1)$
, we first prove (2.4). Letting
 $E_{\varepsilon,j}$
be as in (2.3), we have
$E_{\varepsilon,j}$
be as in (2.3), we have
 \begin{align*}\mathbb{P}_{\textbf{x}}\big[E^c_{\varepsilon,j}\big]&= \mathbb{P}_{\textbf{x}}\left[\left|\frac{\mathcal{Z}_{j}}{\mathcal{Z}_{j}+\mathcal{\widetilde Z}_{j-1}}-\frac{\mathcal{Z}_{j}}{(\mu+1)j}\right|\geqslant\frac{\mathcal{Z}_{j}}{(\mu+1)j}\varepsilon\right]\\&=\mathbb{P}_{\textbf{x}}\left[\left|\frac{(\mu+1)j}{\mathcal{Z}_{j}+\mathcal{\widetilde Z}_{j-1}}-1\right|\geqslant\varepsilon\right]\\&\leqslant \mathbb{P}_{\textbf{x}}\left[\left|\frac{\mathcal{Z}_{j}+\mathcal{\widetilde Z}_{j-1}}{(\mu+1)j}-1\right|\geqslant\frac{\varepsilon}{1+\varepsilon}\right]\\&=\mathbb{P}_{\textbf{x}}\left[\left|\frac{Y_j}{(\mu+1)j}-1\right|\geqslant\frac{\varepsilon}{1+\varepsilon}\right],\end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\big[E^c_{\varepsilon,j}\big]&= \mathbb{P}_{\textbf{x}}\left[\left|\frac{\mathcal{Z}_{j}}{\mathcal{Z}_{j}+\mathcal{\widetilde Z}_{j-1}}-\frac{\mathcal{Z}_{j}}{(\mu+1)j}\right|\geqslant\frac{\mathcal{Z}_{j}}{(\mu+1)j}\varepsilon\right]\\&=\mathbb{P}_{\textbf{x}}\left[\left|\frac{(\mu+1)j}{\mathcal{Z}_{j}+\mathcal{\widetilde Z}_{j-1}}-1\right|\geqslant\varepsilon\right]\\&\leqslant \mathbb{P}_{\textbf{x}}\left[\left|\frac{\mathcal{Z}_{j}+\mathcal{\widetilde Z}_{j-1}}{(\mu+1)j}-1\right|\geqslant\frac{\varepsilon}{1+\varepsilon}\right]\\&=\mathbb{P}_{\textbf{x}}\left[\left|\frac{Y_j}{(\mu+1)j}-1\right|\geqslant\frac{\varepsilon}{1+\varepsilon}\right],\end{align*}
and by Chebyshev’s inequality,
 \begin{equation*}\mathbb{P}_{\textbf{x}}\big[E^c_{\varepsilon,j}\big]\leqslant \left(\frac{1+\varepsilon}{\varepsilon}\right)^4 \mathbb{E}_{\textbf{x}}\left[\left(\frac{Y_j}{(\mu+1)j}-1\right)^4\right].\end{equation*}
\begin{equation*}\mathbb{P}_{\textbf{x}}\big[E^c_{\varepsilon,j}\big]\leqslant \left(\frac{1+\varepsilon}{\varepsilon}\right)^4 \mathbb{E}_{\textbf{x}}\left[\left(\frac{Y_j}{(\mu+1)j}-1\right)^4\right].\end{equation*}
Then (2.4) follows from bounding the moment above under the assumption
 $\textbf{x}\in A_{\alpha,n}$
, and applying a union bound. Let
$\textbf{x}\in A_{\alpha,n}$
, and applying a union bound. Let
 $a_j\,:\!=\,T_j+j-1$
. Using the moment formula for the standard gamma distribution, a little calculation shows that the moment is equal to
$a_j\,:\!=\,T_j+j-1$
. Using the moment formula for the standard gamma distribution, a little calculation shows that the moment is equal to
 \begin{align*}&\frac{\mathbb{E}_{\textbf{x}}\big[Y^{4}_j\big]}{(\mu+1)^4j^4}-\frac{4\mathbb{E}_{\textbf{x}}\big[Y^{3}_j\big]}{(\mu+1)^3j^3}+\frac{6\mathbb{E}_{\textbf{x}}\big[Y^{2}_j\big]}{(\mu+1)^2 j^2 }-\frac{4\mathbb{E}_{\textbf{x}}[Y_j]}{(\mu+1)j}+1\\&=\frac{\prod^3_{k=0}(a_j+k)}{(\mu+1)^4j^4}-\frac{4\prod^2_{k=0}(a_j+k)}{(\mu+1)^3j^3}+\frac{6\prod^1_{k=0}(a_j+k)}{(\mu+1)^2j^2}-\frac{4 a_j}{(\mu+1)j}+1.\end{align*}
\begin{align*}&\frac{\mathbb{E}_{\textbf{x}}\big[Y^{4}_j\big]}{(\mu+1)^4j^4}-\frac{4\mathbb{E}_{\textbf{x}}\big[Y^{3}_j\big]}{(\mu+1)^3j^3}+\frac{6\mathbb{E}_{\textbf{x}}\big[Y^{2}_j\big]}{(\mu+1)^2 j^2 }-\frac{4\mathbb{E}_{\textbf{x}}[Y_j]}{(\mu+1)j}+1\\&=\frac{\prod^3_{k=0}(a_j+k)}{(\mu+1)^4j^4}-\frac{4\prod^2_{k=0}(a_j+k)}{(\mu+1)^3j^3}+\frac{6\prod^1_{k=0}(a_j+k)}{(\mu+1)^2j^2}-\frac{4 a_j}{(\mu+1)j}+1.\end{align*}
Noting that
 $|a_j-(\mu+1)j|\leqslant j^\alpha+x_1+\mu+1$
for
$|a_j-(\mu+1)j|\leqslant j^\alpha+x_1+\mu+1$
for
 $j\geqslant \phi(n)$
, a direct computation shows that there is a positive constant
$j\geqslant \phi(n)$
, a direct computation shows that there is a positive constant
 $C\,:\!=\,C(x_1, \mu,\alpha)$
such that
$C\,:\!=\,C(x_1, \mu,\alpha)$
such that
 \begin{equation}\mathbb{E}_{\textbf{x}}\left[\left(\frac{Y_j}{(\mu+1)j}-1\right)^4\right]\leqslant Cj^{4\alpha-4}.\end{equation}
\begin{equation}\mathbb{E}_{\textbf{x}}\left[\left(\frac{Y_j}{(\mu+1)j}-1\right)^4\right]\leqslant Cj^{4\alpha-4}.\end{equation}
We now prove (2.4) using (9.8). Let
 $C\,:\!=\,C(x_1,\alpha,\mu)$
be a positive constant that may vary at each step of the calculation. Then
$C\,:\!=\,C(x_1,\alpha,\mu)$
be a positive constant that may vary at each step of the calculation. Then
 \begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\bigcup^n_{j= \lceil{\phi(n)}\rceil} E^c_{\varepsilon,j}\Bigg]&\leqslant \sum^n_{j= \lceil{\phi(n)}\rceil}\mathbb{P}_{\textbf{x}}\big[E^c_{\varepsilon,j}\big]\leqslant C \left(\frac{1+\varepsilon}{\varepsilon}\right)^4 \sum^n_{j=\lceil{\phi(n)}\rceil} j^{4\alpha-4} \\&\leqslant C \left(\frac{1+\varepsilon}{\varepsilon}\right)^4 \int^\infty_{\lceil{\phi(n)}\rceil-1} y^{4\alpha-4} dy\quad \leqslant C(1+\varepsilon)^4\varepsilon^{-4}n^{\chi(4\alpha-3)},\end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\bigcup^n_{j= \lceil{\phi(n)}\rceil} E^c_{\varepsilon,j}\Bigg]&\leqslant \sum^n_{j= \lceil{\phi(n)}\rceil}\mathbb{P}_{\textbf{x}}\big[E^c_{\varepsilon,j}\big]\leqslant C \left(\frac{1+\varepsilon}{\varepsilon}\right)^4 \sum^n_{j=\lceil{\phi(n)}\rceil} j^{4\alpha-4} \\&\leqslant C \left(\frac{1+\varepsilon}{\varepsilon}\right)^4 \int^\infty_{\lceil{\phi(n)}\rceil-1} y^{4\alpha-4} dy\quad \leqslant C(1+\varepsilon)^4\varepsilon^{-4}n^{\chi(4\alpha-3)},\end{align*}
as required. Next, we use a union bound and Chebyshev’s inequality to prove (2.5) as follows:
 \begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\bigcup^n_{j=\lceil{\phi(n)}\rceil}\Big\{\mathcal{Z}_{j}\geqslant j^{1/2}\Big\}\Bigg]\leqslant \sum^n_{j= \lceil{\phi(n)}\rceil} \mathbb{E}_{\textbf{x}} \big[\mathcal{Z}^4_{j}\big] j^{-2}= \sum^n_{j= \lceil{\phi(n)}\rceil} j^{-2} \prod^{3}_{\ell=0} (x_j+\ell).\end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\bigcup^n_{j=\lceil{\phi(n)}\rceil}\Big\{\mathcal{Z}_{j}\geqslant j^{1/2}\Big\}\Bigg]\leqslant \sum^n_{j= \lceil{\phi(n)}\rceil} \mathbb{E}_{\textbf{x}} \big[\mathcal{Z}^4_{j}\big] j^{-2}= \sum^n_{j= \lceil{\phi(n)}\rceil} j^{-2} \prod^{3}_{\ell=0} (x_j+\ell).\end{align*}
If we further assume
 $x_2 \in (0, \kappa]$
, then there are positive numbers C
′ and C
′′ such that
$x_2 \in (0, \kappa]$
, then there are positive numbers C
′ and C
′′ such that
 \begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\bigcup^n_{j=\lceil{\phi(n)}\rceil}\big\{\mathcal{Z}_{j}\geqslant j^{1/2}\big\}\Bigg]\leqslant C^{\prime} \kappa^4 \sum^n_{j= \lceil{\phi(n)}\rceil} j^{-2} \leqslant C^{\prime} \kappa^4 \int^{\infty}_{\phi(n)-1} y^{-2} dy \leqslant C^{\prime\prime} \kappa^4 n^{-\chi},\end{align*}
\begin{align*}\mathbb{P}_{\textbf{x}}\Bigg[\bigcup^n_{j=\lceil{\phi(n)}\rceil}\big\{\mathcal{Z}_{j}\geqslant j^{1/2}\big\}\Bigg]\leqslant C^{\prime} \kappa^4 \sum^n_{j= \lceil{\phi(n)}\rceil} j^{-2} \leqslant C^{\prime} \kappa^4 \int^{\infty}_{\phi(n)-1} y^{-2} dy \leqslant C^{\prime\prime} \kappa^4 n^{-\chi},\end{align*}
proving (2.6).
Acknowledgements
The author is grateful to the referees and Nathan Ross for their careful reading of the manuscript and numerous helpful suggestions, and to Tejas Iyer for pointing out the connection to the work [Reference Garavaglia, van der Hofstad and Litvak18].
Funding information
This research was completed when the author was a Ph.D. student at the University of Melbourne. The author was supported by an Australian Government Research Training Program scholarship, and partially by ACEMS and the David Lachlan Hay Memorial Fund.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/apr.2023.54.














































 Open access
Open access