


No CrossRef data available.
Published online by Cambridge University Press: 01 July 2021
We consider stochastic differential equations of the form 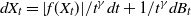 $dX_t = |f(X_t)|/t^{\gamma} dt+1/t^{\gamma} dB_t$, where f(x) behaves comparably to
$dX_t = |f(X_t)|/t^{\gamma} dt+1/t^{\gamma} dB_t$, where f(x) behaves comparably to 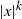 $|x|^k$ in a neighborhood of the origin, for
$|x|^k$ in a neighborhood of the origin, for 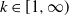 $k\in [1,\infty)$. We show that there exists a threshold value
$k\in [1,\infty)$. We show that there exists a threshold value 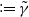 $ \,{:}\,{\raise-1.5pt{=}}\, \tilde{\gamma}$ for
$ \,{:}\,{\raise-1.5pt{=}}\, \tilde{\gamma}$ for 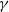 $\gamma$, depending on k, such that if
$\gamma$, depending on k, such that if 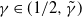 $\gamma \in (1/2, \tilde{\gamma})$, then
$\gamma \in (1/2, \tilde{\gamma})$, then 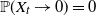 $\mathbb{P}(X_t\rightarrow 0) = 0$, and for the rest of the permissible values of
$\mathbb{P}(X_t\rightarrow 0) = 0$, and for the rest of the permissible values of 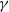 $\gamma$,
$\gamma$, 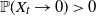 $\mathbb{P}(X_t\rightarrow 0)>0$. These results extend to discrete processes that satisfy
$\mathbb{P}(X_t\rightarrow 0)>0$. These results extend to discrete processes that satisfy 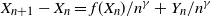 $X_{n+1}-X_n = f(X_n)/n^\gamma +Y_n/n^\gamma$. Here,
$X_{n+1}-X_n = f(X_n)/n^\gamma +Y_n/n^\gamma$. Here, 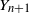 $Y_{n+1}$ are martingale differences that are almost surely bounded.
$Y_{n+1}$ are martingale differences that are almost surely bounded.
This result shows that for a function F whose second derivative at degenerate saddle points is of polynomial order, it is always possible to escape saddle points via the iteration 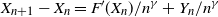 $X_{n+1}-X_n =F'(X_n)/n^\gamma +Y_n/n^\gamma$ for a suitable choice of
$X_{n+1}-X_n =F'(X_n)/n^\gamma +Y_n/n^\gamma$ for a suitable choice of 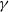 $\gamma$.
$\gamma$.
 $\mathbb{R}^d $. SIAM J. Control Optimization 29, 999–1018.CrossRefGoogle Scholar
$\mathbb{R}^d $. SIAM J. Control Optimization 29, 999–1018.CrossRefGoogle Scholar