
We study the position of the computable setting in the “common theory of locality” developed in [4, 5] for local problems on 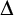 $\Delta $-regular trees,
$\Delta $-regular trees, 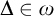 $\Delta \in \omega $. We show that such a problem admits a computable solution on every highly computable
$\Delta \in \omega $. We show that such a problem admits a computable solution on every highly computable 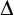 $\Delta $-regular forest if and only if it admits a Baire measurable solution on every Borel
$\Delta $-regular forest if and only if it admits a Baire measurable solution on every Borel 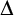 $\Delta $-regular forest. We also show that if such a problem admits a computable solution on every computable maximum degree
$\Delta $-regular forest. We also show that if such a problem admits a computable solution on every computable maximum degree 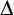 $\Delta $ forest then it admits a continuous solution on every maximum degree
$\Delta $ forest then it admits a continuous solution on every maximum degree 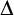 $\Delta $ Borel graph with appropriate topological hypotheses, though the converse does not hold.
$\Delta $ Borel graph with appropriate topological hypotheses, though the converse does not hold.
The clustered chromatic number of a class of graphs is the minimum integer
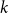 $k$
such that for some integer
$k$
such that for some integer
 $c$
every graph in the class is
$c$
every graph in the class is
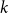 $k$
-colourable with monochromatic components of size at most
$k$
-colourable with monochromatic components of size at most
 $c$
. We determine the clustered chromatic number of any minor-closed class with bounded treedepth, and prove a best possible upper bound on the clustered chromatic number of any minor-closed class with bounded pathwidth. As a consequence, we determine the fractional clustered chromatic number of every minor-closed class.
$c$
. We determine the clustered chromatic number of any minor-closed class with bounded treedepth, and prove a best possible upper bound on the clustered chromatic number of any minor-closed class with bounded pathwidth. As a consequence, we determine the fractional clustered chromatic number of every minor-closed class.
It is standard in chemistry to represent a sequence of reactions by a single overall reaction, often called a complex reaction in contrast to an elementary reaction. Photosynthesis
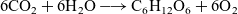 $6 \text{CO}_2+6 \text{H}_2\text{O} \longrightarrow \text{C}_6\text{H}_{12}\text{O}_6 + 6 \text{O}_2$
is an example of such complex reaction. We introduce a mathematical operation that corresponds to summing two chemical reactions. Specifically, we define an associative and non-communicative operation on the product space
$6 \text{CO}_2+6 \text{H}_2\text{O} \longrightarrow \text{C}_6\text{H}_{12}\text{O}_6 + 6 \text{O}_2$
is an example of such complex reaction. We introduce a mathematical operation that corresponds to summing two chemical reactions. Specifically, we define an associative and non-communicative operation on the product space
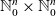 ${\mathbb{N}}_0^n\times {\mathbb{N}}_0^n$
(representing the reactant and the product of a chemical reaction, respectively). The operation models the overall effect of two reactions happening in succession, one after the other. We study the algebraic properties of the operation and apply the results to stochastic reaction networks (RNs), in particular to reachability of states, and to reduction of RNs.
${\mathbb{N}}_0^n\times {\mathbb{N}}_0^n$
(representing the reactant and the product of a chemical reaction, respectively). The operation models the overall effect of two reactions happening in succession, one after the other. We study the algebraic properties of the operation and apply the results to stochastic reaction networks (RNs), in particular to reachability of states, and to reduction of RNs.
Given a fixed graph H that embeds in a surface 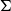 $\Sigma$
, what is the maximum number of copies of H in an n-vertex graph G that embeds in
$\Sigma$
, what is the maximum number of copies of H in an n-vertex graph G that embeds in 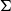 $\Sigma$
? We show that the answer is
$\Sigma$
? We show that the answer is 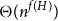 $\Theta(n^{f(H)})$
, where f(H) is a graph invariant called the ‘flap-number’ of H, which is independent of
$\Theta(n^{f(H)})$
, where f(H) is a graph invariant called the ‘flap-number’ of H, which is independent of 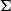 $\Sigma$
. This simultaneously answers two open problems posed by Eppstein ((1993) J. Graph Theory17(3) 409–416.). The same proof also answers the question for minor-closed classes. That is, if H is a
$\Sigma$
. This simultaneously answers two open problems posed by Eppstein ((1993) J. Graph Theory17(3) 409–416.). The same proof also answers the question for minor-closed classes. That is, if H is a 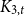 $K_{3,t}$
minor-free graph, then the maximum number of copies of H in an n-vertex
$K_{3,t}$
minor-free graph, then the maximum number of copies of H in an n-vertex 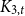 $K_{3,t}$
minor-free graph G is
$K_{3,t}$
minor-free graph G is 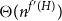 $\Theta(n^{f'(H)})$
, where f′(H) is a graph invariant closely related to the flap-number of H. Finally, when H is a complete graph we give more precise answers.
$\Theta(n^{f'(H)})$
, where f′(H) is a graph invariant closely related to the flap-number of H. Finally, when H is a complete graph we give more precise answers.
A graph G is called a
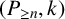 $(P_{\geq n},k)$
-factor-critical covered graph if for any
$(P_{\geq n},k)$
-factor-critical covered graph if for any
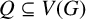 $Q\subseteq V(G)$
with
$Q\subseteq V(G)$
with
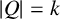 $|Q|=k$
and any
$|Q|=k$
and any
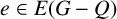 $e\in E(G-Q)$
,
$e\in E(G-Q)$
,
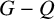 $G-Q$
has a
$G-Q$
has a
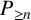 $P_{\geq n}$
-factor covering e. We demonstrate that (i) a
$P_{\geq n}$
-factor covering e. We demonstrate that (i) a
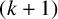 $(k+1)$
-connected graph G with at least
$(k+1)$
-connected graph G with at least
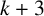 $k+3$
vertices is a
$k+3$
vertices is a
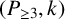 $(P_{\geq 3},k)$
-factor-critical covered graph if its toughness
$(P_{\geq 3},k)$
-factor-critical covered graph if its toughness
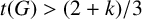 $t(G)>{(2+k)}/{3}$
; (ii) a
$t(G)>{(2+k)}/{3}$
; (ii) a
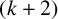 $(k+2)$
-connected graph G is a
$(k+2)$
-connected graph G is a
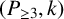 $(P_{\geq 3},k)$
-factor-critical covered graph if its isolated toughness
$(P_{\geq 3},k)$
-factor-critical covered graph if its isolated toughness
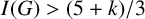 $I(G)>{(5+k)}/{3}$
. Furthermore, we show that the conditions on
$I(G)>{(5+k)}/{3}$
. Furthermore, we show that the conditions on
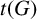 $t(G)$
and
$t(G)$
and
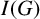 $I(G)$
are sharp.
$I(G)$
are sharp.
We give the crossing number of the join product 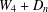 $W_{4}+D_{n}$, where
$W_{4}+D_{n}$, where 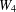 $W_{4}$ is the wheel on five vertices and
$W_{4}$ is the wheel on five vertices and 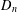 $D_{n}$ consists of
$D_{n}$ consists of  $n$ isolated vertices. The proof is based on calculating the minimum number of crossings between two different subgraphs from the set of subgraphs which do not cross the edges of the graph
$n$ isolated vertices. The proof is based on calculating the minimum number of crossings between two different subgraphs from the set of subgraphs which do not cross the edges of the graph 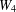 $W_{4}$ and from the set of subgraphs which cross the edges of
$W_{4}$ and from the set of subgraphs which cross the edges of 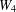 $W_{4}$ exactly once.
$W_{4}$ exactly once.

