


Let G be a complex classical group, and let V be its defining representation (possibly plus a copy of the dual). A foundational problem in classical invariant theory is to write down generators and relations for the ring of G-invariant polynomial functions on the space 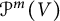 $\mathcal P^m(V)$ of degree-m homogeneous polynomial functions on V. In this paper, we replace
$\mathcal P^m(V)$ of degree-m homogeneous polynomial functions on V. In this paper, we replace 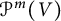 $\mathcal P^m(V)$ with the full polynomial algebra
$\mathcal P^m(V)$ with the full polynomial algebra 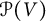 $\mathcal P(V)$. As a result, the invariant ring is no longer finitely generated. Hence, instead of seeking generators, we aim to write down linear bases for bigraded components. Indeed, when G is of sufficiently high rank, we realize these bases as sets of graphs with prescribed number of vertices and edges. When the rank of G is small, there arise complicated linear dependencies among the graphs, but we remedy this setback via representation theory: in particular, we determine the dimension of an arbitrary component in terms of branching multiplicities from the general linear group to the symmetric group. We thereby obtain an expression for the bigraded Hilbert series of the ring of invariants on
$\mathcal P(V)$. As a result, the invariant ring is no longer finitely generated. Hence, instead of seeking generators, we aim to write down linear bases for bigraded components. Indeed, when G is of sufficiently high rank, we realize these bases as sets of graphs with prescribed number of vertices and edges. When the rank of G is small, there arise complicated linear dependencies among the graphs, but we remedy this setback via representation theory: in particular, we determine the dimension of an arbitrary component in terms of branching multiplicities from the general linear group to the symmetric group. We thereby obtain an expression for the bigraded Hilbert series of the ring of invariants on 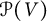 $\mathcal P(V)$. We conclude with examples using our graphical notation, several of which recover classical results.
$\mathcal P(V)$. We conclude with examples using our graphical notation, several of which recover classical results.

