
8 results
A semi-supervised anomaly detection approach for detecting mechanical failures
-
- Article
-
- You have access
- HTML
- Export citation
Almost exact recovery in noisy semi-supervised learning
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 11 November 2024, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Joint micrograph denoising and protein localization in cryo-electron microscopy
-
- Journal:
- Biological Imaging / Volume 4 / 2024
- Published online by Cambridge University Press:
- 06 March 2024, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
9 - Advanced Examples: Semi-supervised, Ensembles, Deep Learning Model Deployment
- from Part III - Machine Learning for Big Data
-
- Book:
- Large-Scale Data Analytics with Python and Spark
- Published online:
- 15 December 2023
- Print publication:
- 23 November 2023, pp 305-368
-
- Chapter
- Export citation
Cross-modal distillation for flood extent mapping
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 07 November 2023, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The increasing intensity and frequency of floods is one of the many consequences of our changing climate. In this work, we explore ML techniques that improve the flood detection module of an operational early flood warning system. Our method exploits an unlabeled dataset of paired multi-spectral and synthetic aperture radar (SAR) imagery to reduce the labeling requirements of a purely supervised learning method. Prior works have used unlabeled data by creating weak labels out of them. However, from our experiments, we noticed that such a model still ends up learning the label mistakes in those weak labels. Motivated by knowledge distillation and semi-supervised learning, we explore the use of a teacher to train a student with the help of a small hand-labeled dataset and a large unlabeled dataset. Unlike the conventional self-distillation setup, we propose a cross-modal distillation framework that transfers supervision from a teacher trained on richer modality (multi-spectral images) to a student model trained on SAR imagery. The trained models are then tested on the Sen1Floods11 dataset. Our model outperforms the Sen1Floods11 baseline model trained on the weak-labeled SAR imagery by an absolute margin of
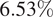 $ 6.53\% $ intersection over union (IoU) on the test split.
$ 6.53\% $ intersection over union (IoU) on the test split.
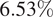
SSL-GAN-RoBERTa: A robust semi-supervised model for detecting Anti-Asian COVID-19 hate speech on social media
-
- Journal:
- Natural Language Engineering , First View
- Published online by Cambridge University Press:
- 03 August 2023, pp. 1-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ASPER: Answer Set Programming Enhanced Neural Network Models for Joint Entity-Relation Extraction
-
- Journal:
- Theory and Practice of Logic Programming / Volume 23 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 25 July 2023, pp. 765-781
-
- Article
-
- You have access
- HTML
- Export citation
Semi-supervised machine learning with word embedding for classification in price statistics
-
- Journal:
- Data & Policy / Volume 2 / 2020
- Published online by Cambridge University Press:
- 07 September 2020, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
