4 results
15 - ‘Schubert Would Have No Objection if He Knew about It’: Franz Liszt’s Reception of Schubert’s Music
- from Part IV - Understanding Schubert’s Writing for the Piano
-
-
- Book:
- Schubert's Piano
- Published online:
- 31 August 2024
- Print publication:
- 17 October 2024, pp 301-323
-
- Chapter
- Export citation
4 - Schubert’s Four-Hand Piano Music
- from Part I - The Piano in Schubert’s World
-
-
- Book:
- Schubert's Piano
- Published online:
- 31 August 2024
- Print publication:
- 17 October 2024, pp 70-90
-
- Chapter
- Export citation
2 - Methodological Preliminaries
-
- Book:
- A Historical Phonology of Central Chadic
- Published online:
- 26 May 2022
- Print publication:
- 02 June 2022, pp 27-75
-
- Chapter
- Export citation
Testing the Validity of Automatic Speech Recognition for Political Text Analysis
-
- Journal:
- Political Analysis / Volume 27 / Issue 3 / July 2019
- Published online by Cambridge University Press:
- 19 February 2019, pp. 339-359
-
- Article
- Export citation
-
The analysis of political texts from parliamentary speeches, party manifestos, social media, or press releases forms the basis of major and growing fields in political science, not least since advances in “text-as-data” methods have rendered the analysis of large text corpora straightforward. However, a lot of sources of political speech are not regularly transcribed, and their on-demand transcription by humans is prohibitively expensive for research purposes. This class includes political speech in certain legislatures, during political party conferences as well as television interviews and talk shows. We showcase how scholars can use automatic speech recognition systems to analyze such speech with quantitative text analysis models of the “bag-of-words” variety. To probe results for robustness to transcription error, we present an original “word error rate simulation” (WERSIM) procedure implemented in
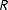 $R$. We demonstrate the potential of automatic speech recognition to address open questions in political science with two substantive applications and discuss its limitations and practical challenges.
$R$. We demonstrate the potential of automatic speech recognition to address open questions in political science with two substantive applications and discuss its limitations and practical challenges.