We perform a meta analysis of gender differences in the standard windfall gains dictator game (DG) by collecting raw data from 53 studies with 117 conditions, giving us 15,016 unique individual observations. We find that women on average give 4 percentage points more than men (Cohen’s 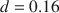 ), and that this difference decreases to
), and that this difference decreases to 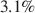 points (Cohen’s
points (Cohen’s 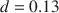 ) if we exclude studies where dictators can only give all or nothing. The gender difference is larger if the recipient in the DG is a charity, compared to the standard DG with an anonymous individual as the recipient (a 10.9 versus a
) if we exclude studies where dictators can only give all or nothing. The gender difference is larger if the recipient in the DG is a charity, compared to the standard DG with an anonymous individual as the recipient (a 10.9 versus a 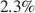 points gender difference). These effect sizes imply that many individual studies on gender differences are underpowered; the median power in our sample of standard DG studies is only
points gender difference). These effect sizes imply that many individual studies on gender differences are underpowered; the median power in our sample of standard DG studies is only 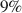 to detect the meta-analytic gender difference at the
to detect the meta-analytic gender difference at the 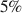 significance level. Moving forward on this topic, sample sizes should thus be substantially larger than what has been the norm in the past.
significance level. Moving forward on this topic, sample sizes should thus be substantially larger than what has been the norm in the past.

