Surface ozone is an air pollutant that contributes to hundreds of thousands of premature deaths annually. Accurate short-term ozone forecasts may allow improved policy actions to reduce the risk to human health. However, forecasting surface ozone is a difficult problem as its concentrations are controlled by a number of physical and chemical processes that act on varying timescales. We implement a state-of-the-art transformer-based model, the temporal fusion transformer, trained on observational data from three European countries. In four-day forecasts of daily maximum 8-hour ozone (DMA8), our novel approach is highly skillful (MAE = 4.9 ppb, coefficient of determination 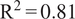 $ {\mathrm{R}}^2=0.81 $) and generalizes well to data from 13 other European countries unseen during training (MAE = 5.0 ppb,
$ {\mathrm{R}}^2=0.81 $) and generalizes well to data from 13 other European countries unseen during training (MAE = 5.0 ppb, 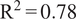 $ {\mathrm{R}}^2=0.78 $). The model outperforms other machine learning models on our data (ridge regression, random forests, and long short-term memory networks) and compares favorably to the performance of other published deep learning architectures tested on different data. Furthermore, we illustrate that the model pays attention to physical variables known to control ozone concentrations and that the attention mechanism allows the model to use the most relevant days of past ozone concentrations to make accurate forecasts on test data. The skillful performance of the model, particularly in generalizing to unseen European countries, suggests that machine learning methods may provide a computationally cheap approach for accurate air quality forecasting across Europe.
$ {\mathrm{R}}^2=0.78 $). The model outperforms other machine learning models on our data (ridge regression, random forests, and long short-term memory networks) and compares favorably to the performance of other published deep learning architectures tested on different data. Furthermore, we illustrate that the model pays attention to physical variables known to control ozone concentrations and that the attention mechanism allows the model to use the most relevant days of past ozone concentrations to make accurate forecasts on test data. The skillful performance of the model, particularly in generalizing to unseen European countries, suggests that machine learning methods may provide a computationally cheap approach for accurate air quality forecasting across Europe.

