



1. Introduction
Natural language processing (NLP) is increasingly present in all human-computer interaction applications. Personal assistants, machine translation engines, chat bots or speech synthesis and recognition systems enable a more immersive virtual experience. Yet all these applications rely on the availability of high-quality language resources, as well as accurate automated knowledge processing and extraction tools. The lack of any of these items hinders the development of state-of-the-art applications in the target language or language group.
The fundamental text processing tasks refer to basic lexical annotations of an orthographic transcript. The annotations commonly include lemmatisation, part-of-speech (POS) tagging and phonemic transcription. However, it is also common to require syllabification, lexical stress marking or complete morphosyntactic descriptors (MSD). Some of the applications that can benefit from the extended list of annotations include language learning interfaces, machine translation tools or most prominently speech-based applications, and especially text-to-speech synthesis (TTS) systems. For example, lemma and morphosyntactic information can help a machine translation system distinguish between homographs in a specific context. Exposing the correct phonemic transcription, lexical stress and syllabification sequence of a word can speed up the learning process of a foreign language. Phonemic transcription is also essential in speech recognition systems, where the models generally learn representations of the speech signal at phone-level (Zeineldeen et al. Reference Zeineldeen, Zeyer, Zhou, Ng, Schlüter and Ney2020). For TTS systems, the complete lexical annotation of the orthographic transcript is essential, and many recent studies augment the text input with this annotation and, as a result, enhance the naturalness and adequacy of the output speech (Peiró-Lilja and Farrús Reference Peiró-Lilja and Farrús2020; Taylor and Richmond Reference Taylor and Richmond2020).
In this article, we describe the design and development of a large lexical dataset for Romanian which includes all the information enumerated above and the evaluation of the dataset’s usability in predicting different lexical tasks. The main contributions of our paper can be summarised as follows:
[C1] We introduce RoLEX,Footnote a the largest freely available lexical dataset for Romanian with over 330,000 tokens. It includes information about lemma, POS, syllabification, lexical stress and phonemic transcription; [C2] we thoroughly describe the process of:
-
(1) selecting the words in the dataset based on a speech corpus,
-
(2) annotating them automatically with reliable lemma and POS information and partially reliable syllabification, lexical stress marking and phonemic transcription and
-
(3) validating, both automatically and manually, an important part of the entries: this was not an entry-by-entry validation, which would have implied an extensive manual work effort that we could not afford; instead, error patterns and entries with high error probability were automatically identified and manually or automatically corrected.
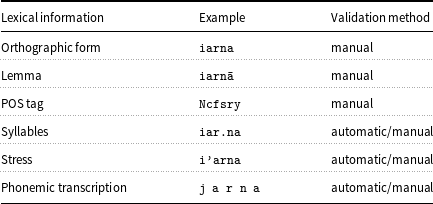
An overview of the information contained in RoLEX and the manner in which it was obtained and validated is presented in Table 1.
Table 1. An example entry from the RoLEX dataset and the manner in which the lexical information was validated. The example entry is for the word iarna, the equivalent of the definite form of the English noun ‘winter’
[C3] We analyse the accuracy of advanced neural network architectures in a task of concurrently predicting the syllabification, lexical stress marking and phonemic transcription from the context-free orthographic form of a word or from the orthographic form plus additional POS or MSD word tagging.
2. Related work
2.1. The Romanian language and Romanian lexical datasets
Romanian is an Indo-European Romance language with a rich history of Slavic, German, Turkish and Hungarian influences. The Romance origin lends the highly inflected verb forms for person, number, tense, mood, and voice, while a large number of Slavic loan words influence its phonology.
With respect to the language particularities and their automated learning and prediction, Stan and Giurgiu (Reference Stan and Giurgiu2018) acknowledge the regularities of the Romanian language that allow for implementing processing rules, but also enumerate the ambiguities that cannot be dealt with by these rules. For example, Romanian has 7 base syllabification rules (DOOM 2005), but there are several exceptions. Some are more general, like the hiatus-diphthong ambiguities or the different surfacing of the letter ‘i’ as a vocalic or non-vocalic element (Dinu, Niculae, and Sulea Reference Dinu, Niculae and Sulea2013). Others are rather particular, like the ones generated by foreign or compound words.
The Romanian phonetic spelling is generally a direct mapping from the orthographic form. Some exceptions are the two different sounds associated with letter ‘x’ (/cs/ and/gz/), or the several groups of letters (e.g., ‘ce’, ‘ci’, ‘ge’, ‘gi’, ‘che’, ‘chi’, ‘ghe’, ‘ghi’) that correspond to either a sound or two depending on the right-hand side phonetic neighbourhood of these groups. At the lexical level, non-homophone homographs are encountered. For example, the Romanian word ‘haină’ can be pronouncedFootnote b as/h a j n @/ (syl. hai.nă, stress: h’aină, En. coat) or as/h a i n @/ (syl. ha.i.nă, stress: ha’ină, En. wicked). This example also illustrates the hiatus-diphthong ambiguity that affects syllabification.
Even though it serves to distinguish between different lemmas or between different forms of the same lemma, unlike other Romance languages such as Italian or Spanish, lexical stress is not graphically marked in written Romanian.
Although it has a relatively large number of native speakers (around 25 million), Romanian is still considered a low-resourced language in terms of digital resources and NLP tools (Trandabat et al. Reference Trandabat, Irimia, Barbu Mititielu, Cristea and Tufiş2012). In the recent initiative called European Language Grid (Rehm et al. Reference Rehm, Berger, Elsholz, Hegele, Kintzel, Marheinecke, Piperidis, Deligiannis, Galanis, Gkirtzou, Labropoulou, Bontcheva, Jones, Roberts, Hajič, Hamrlová, Kačena, Choukri, Arranz, Vasiļjevs, Anvari, Lagzdiņš, Meļņika, Backfried, Dikici, Janosik, Prinz, Prinz, Stampler, Thomas-Aniola, Gómez-Pérez, Garcia Silva, Berrío, Germann, Renals and Klejch2020), Romanian continues to be under-represented (with only 183 resources, tools and services) as compared to English (3039), Spanish (789), French (809) or German (934).Footnote c
The available lexical resources include RoSyllabiDict, NaviRo and MaRePhor. RoSyllabiDict (Barbu Reference Barbu2008) is a dictionary that contains syllabification and stress marking information for 525,534 word forms, corresponding to 65,000 lemmas. The resource was created by implementing the standard set of Romanian syllabification rules, using an inventory of Romanian diphthongs and triphthongs and the partial syllabification information provided in the database of the online Romanian Explicative Dictionary – Dexonline.Footnote d Dexonline was also the source for stress marking in RoSyllabiDict. The authors maintain that they performed partial validation of their resource at syllabification level. NaviRo (Domokos, Buza, and Toderean Reference Domokos, Buza and Toderean2012) consists of more than 100,000 words extracted from Dexonline and transcribed in their phonemic form using an artificial neural network-based method starting from a seed set of manually transcribed entries. The authors report that they performed a manual check of the final dataset, but also mention that errors can still be found. MaRePhor (Toma et al. Reference Toma, Stan, Pura and Barsan2017) is a dictionary that provides phonemic transcription for 72,375 lemmas which make up the official list of the Romanian Scrabble Association. Therefore, this resource does not account for morphological variations. Two other resources, the Morphologic and Phonetic Dictionary of the Romanian Language (Diaconescu et al. Reference Diaconescu, Codirlasu, Ionescu, Rizea, Radulescu, Minca and Fulea2015a) and the Phonetic Dictionary of Romanian Syllables (Diaconescu et al. Reference Diaconescu, Codirlasu, Ionescu, Rizea, Radulescu, Minca and Fulea2015b), are only available as printed material.
Given the scarcity of Romanian digital resources, as well as the disjoint information contained therein, we considered necessary to aggregate the different lexical information already available in some of the resources into a uniform dataset, with a principled bottom-up design and development. Additional requirements refer to the broad coverage of both morphological and lexical levels and the use of effective semi-automatic validation and correction steps.
2.1.1. Large lexicons for other languages
While for English the most known and used dataset is CMU Pronouncing Dictionary (CMUDict),Footnote e whose development as an open-source lexicon for speech recognition research started in the 90’s, similar lexical datasets were gradually developed for other languages: PhonItalia (Goslin, Galluzzi, and Romani Reference Goslin, Galluzzi and Romani2014) is a phonological lexicon for Italian that also includes syllabification and stress information, together with numerous lexical statistics for 120,000 word forms; for French, there is a phonetic lexicon (de Mareüil et al. Reference de Mareüil, d’Alessandro, Yvon, Aubergé, Vaissière and Amelot2000) comprising 310,332 word forms corresponding to 27,873 unique lemmas, and 10,000 proper names, with information about lemma, morphosyntactic description, automatically generated and partially corrected phonetic transcription; for European Portuguese, the web interface Procura-PALavras (P-PAL) (Soares et al. Reference Soares, Iriarte, De Almeida, Simões, Costa, Machado, França, Comesaña, Rauber and Rato2018) offers access to a lexical database based on a corpus of over 227 million words that contains very rich information (including morphosyntactic information, stress, syllabification and pronunciation) for around 208,000 word forms corresponding to approximately 53,000 lemmas; ArabLEX (Halpern Reference Halpern2022) is a very large lexicon covering over 530 million general vocabulary and proper noun words, with a variety of grammatical, morphological and phonological information, including stress and phonemic-phonetic transcription; LC-STAR German Phonetic lexiconFootnote f has 102,169 entries (55,507 common word entries extracted from a corpus of over 15 million words, 46,662 proper names and 6,763 words representing specific vocabulary for applications controlled by voice translated from English) with phonetic transcriptions given in SAMPA; the ILSP Psycholinguistic Resource (IPLR) (Protopapas et al. Reference Protopapas, Tzakosta, Chalamandaris and Tsiakoulis2012) is a Greek lexical database with 217,000 entries comprising automatically generated information about syllabification, stress and phonetic transcription, while GreekLex2 (Kyparissiadis et al. Reference Kyparissiadis, van Heuven, Pitchford and Ledgeway2017) is a lexical database that guarantees accurate syllabification, orthographic information predictive of stress and phonetic information for 35,000 words.
2.2. Lexical information prediction
To the best of our knowledge, the concurrent prediction and evaluation of all three lexical tasks is performed only in van Esch, Chua, and Rao (Reference van Esch, Chua and Rao2016) and Lőrincz (2020). van Esch et al. (Reference van Esch, Chua and Rao2016) uses an in-house dataset to improve the phonemic transcription and lexical stress marking by implicitly learning these tasks in a joint recurrent network-based sequence prediction. Lőrincz (2020) evaluates recurrent and convolutional (CNN) networks’ performance in the concurrent prediction for English (41.04% WER) and Romanian (13.36% WER).
However, there are many studies which address the automatic annotation of each lexical task individually by employing different rule-based, traditional machine learning or deep learning approaches. Within these studies, the main focus language is English. For example, (Pearson et al. Reference Pearson, Kuhn, Fincke and Kibre2000) present decision tree-based methods for lexical stress and syllabification prediction. In (Webster Reference Webster2004; Dou et al. Reference Dou, Bergsma, Jiampojamarn and Kondrak2009), decision tree and Support Vector Machine methods are evaluated for stress prediction and then used for grapheme to phoneme conversion modules in TTS systems. The phonemic transcription of English is also widely studied, and all levels of complexity algorithms were applied. The most recent approaches include neural sequence-to-sequence models, as described in (Yao and Zweig Reference Yao and Zweig2015; Milde, Schmidt, and Köhler Reference Milde, Schmidt and Köhler2017; Chae et al. Reference Chae, Park, Bang, Suh, Park, Kim and Park2018; Yolchuyeva, Németh, and Gyires-Tóth Reference Yolchuyeva, Németh and Gyires-Tóth2019a). The reported word error rates (WER) are between 20% and 25% for the CMUDict dataset. An encoder-decoder model with attention (Toshniwal and Livescu Reference Toshniwal and Livescu2016) and a convolutional architecture combined with n-grams (Rao et al. Reference Rao, Peng, Sak and Beaufays2015) achieve similar results when applied to the same dataset. Transformer-based architectures are proposed in Sun et al. (Reference Sun, Tan, Gan, Liu, Zhao, Qin and Liu2019); Yolchuyeva, Németh, and Gyires-Tóth (Reference Yolchuyeva, Németh and Gyires-Tóth2019b); Stan (Reference Stan2020) and slightly improve the error rates. Sun et al. (Reference Sun, Tan, Gan, Liu, Zhao, Qin and Liu2019) report a WER around 20% obtained with a model enriched through knowledge distillation using unlabelled source words.
For Romanian, the three lexical tasks were also subject to a series of studies covering Marcus Contextual Grammars (Dinu Reference Dinu2003), rule-based methods (Toma and Munteanu Reference Toma and Munteanu2009), decision trees and linear models (Cucu et al. Reference Cucu, Buzo, Besacier and Burileanu2014), cascaded sequential models (Ciobanu, Dinu, and Dinu Reference Ciobanu, Dinu and Dinu2014; Dinu et al. Reference Dinu, Ciobanu, Chitoran and Niculae2014) or neural network-based approaches (Boroş, Dumitrescu, and Pais Reference Boroş, Dumitrescu and Pais2018; Stan and Giurgiu Reference Stan and Giurgiu2018; Stan Reference Stan2019, Reference Stan2020). The reported WER for stress prediction is 2.36%, while the reported WERs for the phonemic transcription are between 1% and 3%. However, because the studies use different datasets, the error rates are not directly comparable to the results presented in this paper. We hope that with the availability of the RoLEX lexicon, future lexical information prediction tools will have a common reference point.
3. RoLEX development and validation
The development of RoLEX started within the ReTeRom project,Footnote g whose aim is to collect a large Romanian bimodal corpus, which can serve as training and testing material for improving available instruments for processing spoken and written Romanian. The corpus is a large collection of texts assembled from news articles, interviews on contemporary subjects, radio talk shows, tales and novels, and Wikipedia articles. The key characteristic of this corpus is its bimodality: it contains spoken Romanian language aligned with its written counterpart, either transcribed (in the case of interviews and talk shows) or originally written (in the rest of the cases). For the RoLEX development, only the written component was considered.
Being a corpus-based dataset (thus, a better representation of the language in use) makes it more appropriate for use in real-life applications. The corpus aggregated for RoLEX development contains transcriptions of the following speech corpora: the oral component of CoRoLaFootnote h (Barbu Mititelu, Tufiş, and Irimia Reference Barbu Mititelu, Tufiş and Irimia2018) (821,294 tokens), RSC (Georgescu et al. Reference Georgescu, Cucu, Buzo and Burileanu2020) (590,190 tokens), SSC-train (1,262,030 tokens), SSC-eval (Georgescu, Cucu, and Burileanu Reference Georgescu, Cucu and Burileanu2017) (36,424 tokens) corpora, SWARA (Stan et al. Reference Stan, Dinescu, Ţiple, Meza, Orza, Chirilă and Giurgiu2017) (15,070 tokens) and MARA (Stan et al. Reference Stan, Lőrincz, Nuţu and Giurgiu2021) (95,567 tokens). The quality of the starting corpus data varies from high-quality transcripts to documents that contain spelling and grammar errors or texts that lack punctuation, diacritics and capitalisation. Other subsets of the data are just lists of words or sub-sentential sequences. Some parts of the initial data collection were already processed: tokenised, lemmatised and POS-tagged with various degrees of correctness.
From the initial data collection, the first step in obtaining the lexical dataset was to extract a list of words containing correct contemporary Romanian words with no grammatical or spelling errors. The development of this dataset was based on a curated general lexicon of over 1.1 million entries of the Romanian language under development, called TBL,Footnote i containing lemma and morphosyntactic descriptorFootnote j information. The difference between TBL and RoLEX is the fact that the latter is derived from a set of contemporary texts, as opposed to just an exhaustive dictionary-like list of words as in TBL.
Two methodologies of lexicon extraction had to be adopted, depending on whether a reliable processed version of a document could be obtained or not. For the grammatically correct texts, the TEPROLIN web service (Ion Reference Ion2018) was used to perform lexical segmentation (tokenisation), lemmatisation and POS-tagging.
The less accurate textual data could not be processed by automatic means since the tools are usually trained on correct grammatical texts and would, therefore, generate poor results on incorrect input data. In this situation, the lexical segmentation task is trivialised: the text was automatically tokenised at each blank space. The resulting tokens were checked against TBL for correctness. The contracted sequences, marked by a hyphen in Romanian, were treated separately. These sequences were segmented at the hyphen, which was successively attached to the different contraction components, generating two different possibilities for the segment tuples. The correct segmentation was identified by looking up the segments in TBL. For example, the sequence ‘schimbându-şi’ (En. changing-Cl.poss.refl.3) generated the tuples (‘schimbându-’, ‘şi’) and (‘schimbându’, ‘-şi’). The correct segmentation can be identified automatically by checking if TBL contains both terms of the segment tuple: for (‘schimbându-’, ‘şi’) we find that ‘şi’ is a word in TBL, but it has a different morphosyntactic annotation and role (namely the conjunction equivalent to the En. and) than the one intended in the sequence (reflexive/possessive pronominal clitic), and ‘schimbându-’ is not a correct Romanian word,Footnote k so the tuple is no longer considered as a possible segmentation; for (‘schimbându’, ‘-şi’) both words occur in TBL, so this is the only correct segmentation of the sequence. Other sequences, like ‘n-am’ (En. not-have), both possible segmentations have the component words present in TBL (‘n-’, ‘am’, ‘n’ and ‘-am’); therefore, a manual examination is necessary to choose the right segmentation.
In a next step, TBL was used to identify all the entries linked to a specific form: if TBL contains the word form, all the corresponding (lemma, MSD) pairs associated with it and all the morphological variants of these lemmas are recovered and transferred to RoLEX. Treating the possible homonymy, which leads to POS and lemma ambiguities, was not a purpose at this step of generating RoLEX. Duplicated lexicon entries due to two methodologies used for different sub-corpora were searched for and eliminated. On the other hand, if a word form is not found in TBL, it is extracted in a separate list, to be manually validated and annotated.
We envisioned, from the very beginning, that the manual validation/correction work for the dataset will be time consuming and looked for strategies to make this work as efficient as possible. As described in Section 5, a more automatised and efficient technique for organising and reducing the manual correction effort can be employed, but at this point, the main solutions we found were (i) dividing the correction task by partitioning the dataset into parts with different risks and types of errors; (ii) automatising most of the correction tasks by means of linguistic rules.
Aside from the list of words which required complete or partial manual annotation, the automatically and semi-automatically generated lexical dataset was distributed to the correction team members for manual inspection, alongside instructions about the types of errors they needed to focus on. As all the annotators were expert linguists and the correction task was rather trivial, without ambiguities, we were not concerned with inter-annotator agreement and each data sample was distributed to only one annotator.
The automatic and semi-automatic annotation process, as well as the manual validation procedure with a focus on identified exceptions and rules are described in the next sections.
3.1. Validation and annotation of lemma and morphological information
Because the largest part of the initial lexicon was obtained by querying TBL, the lemma and MSD for these entries were directly transferred to RoLEX. This solution also overcame the problem of incorrect morphosyntactic annotations found in the initial textual corpus.
For the new words, strategies for reducing manual work could also be applied in some cases, such as that of very productive morphological processes. A largely applied principle in lexicography is not to record exhaustive lists of words created by means of very productive derivation mechanisms, which are well mastered by a language’s speaker. Words newly coined by means of these mechanisms are dealt with by recognising these productive rules and listing the components in the lexicon (e.g., very frequent prefixes, such as ‘re-’ and the numerous verbal roots it attaches to). In our case, a specific type of new words is represented by a list of words formed by adding the prefix ‘ne-’ (En. un-) (even ‘nemai-’, in which the adverb ‘mai’ (En. more) is inserted between the prefix and the root) to gerund and participle forms of verbs; they were automatically dealt with by separating the prefix and the gerund suffix and looking up the roots in TBL, as they contain the lemma and MSD that also apply to the prefixed forms.
Only after automatising all the possible tasks, the remaining words were evaluated one by one and annotated with the corresponding lemma and MSD tag. Entries for their morphological variants were also created. Some frequently identified errors were typos (missing, extra or shifted letters), missing diacritics and lexical segmentation errors. 8,000 new entries (missing from TBL) were corrected/developed and integrated into RoLEX. They are also envisaged for the further extension of TBL.
3.2. Validation and correction for syllabification, stress marking and phonemic transcription
The rest of the lexical annotations–syllabification, lexical stress and phonemic transcription were partially obtained from the RoSyllabiDict and MaRePhor dictionaries. The entries not found in the two datasets were automatically annotated with the front-end tool developed in Stan et al. Reference Stan, Yamagishi, King and Aylett(2011). The tool, referred to as RoTTS, is used in text-to-speech synthesis systems and uses decision trees trained on a small in-house lexical dataset to predict each information individually.
The data were divided between entries coming from dictionaries and entries generated by the RoTTS tool. The starting hypothesis was that the two dictionaries primarily used for annotation (RoSyllabiDict and MaRePhor) were, as their authors claimed, partially validated before launching. Therefore, in theory, fewer errors for our dataset entries annotated based on these resources should have been encountered and the focus should have been more on the entries annotated with the RoTTS tool. In practice, MaRePhor has phonemic transcription only for words’ lemmas, leaving their morphological variants to be annotated automatically. Although RoSyllabiDict offers syllabification and stress marking information for some morphological variants, the morphological paradigms are often incomplete. Also, both resources lack morphosyntactic information, which makes it impossible for RoTTS to correctly annotate ambiguous cases.
Some ambiguous entries are shown in the examples from Table 2. In Example 1, assigning the correct MSD annotation helps identify the right lemma of the word in focus, and therefore, it determines the syllabification, which in turn, according to rules concerning the phonemic transcription of the vowels and semi-vowels, determines the transcription. In Example 1.1, the initial ‘i’ is a vowel, while in 1.2 it is a semi-vowel part of the triphthong ‘iei’ always transcribed as/j e j/ (see Table 4 for more examples of hiatus/diphthong/triphthong occurrences of the same strings of letters). Example 2 is even more problematic: the two words share the POS and most of the morphological characteristics: type of noun (common), number (plural), case invariant, indefinite form; it is only the value of the gender attribute that distinguishes between the two words: masculine for Example 2.1 and feminine for Example 2.2. This type of specific ambiguity is rare in Romanian.
Table 2. Ambiguous entries for syllabification, stress marking and phonemic transcription

Table 3. Letters and letter groups that create ambiguities in the phonemic transcription. For the vocalic letters, we also note their vowel/semi-vowel phonemic value

Table 4. Examples for the use of vowel sequences in Romanian as hiatus or as diphthong or triphthong.

For the data coming from the dictionaries, the correction stage targeted especially entries which had different lemmas and/or MSD descriptors associated with the same form. For the RoTTS generated annotations, many other types of possible errors were encountered and the correction benefited from further division of the task, as well as from the design of a set of lexical rules, as it will be described in the next section. Because the automatic validation/correction of phonemic transcription depends on applying rules on correct syllabification and stress marking information, the order in which the annotation levels are corrected is (i) syllabification; (ii) stress marking; (iii) phonemic transcription (except proper names and abbreviations, which are treated separately and corrected manually). For all the three annotation levels, in the first step a list of rules was derived from the data and used to automatically annotate or detect incorrect annotations of the entries. The result was then validated by the expert linguists.
3.2.1. Syllabification correction stage
In this step, we identified the situations which are likely to produce syllabification errors, as listed below:
-
• words that contain syllables longer than four letters: this is a rare case in the language: according to Dinu and Dinu (Reference Dinu and Dinu2006), 13% of the syllables in their corpus of 4,276 words contain at least 5 letters;
-
• words that contain syllables with more than one vowel: in Romanian, the letters ‘a’, ‘â’, ‘î’, ‘ă’ are always vowels, thus, syllables that have a combination of two of these letters are, therefore, incorrect;
-
• words that contain letters that could represent either vowels or semi-vowels (see Table 3): this is the distinction between hiatus and diphthong or triphthong, that influences the transcription as a vowel or as a semi-vowel. The vowels involved in hiatus undergo vowel transcription, excepting the cases when they are involved in other diphthongs or triphthongs right near the hiatus (see examples in Table 4);
-
• proper nouns and abbreviations: the annotation for these words was automatically generated with RoTTS and contained many errors; some reasons for this are: foreign proper nouns usually preserve the pronunciation from their original language (which differ from the Romanian one in the case of many languages, for example English, German, French, Spanish, etc.), Romanian proper nouns may also have atypical pronunciations (e.g., some proper nouns are homographs of common nouns, but the two words are not homophones: ‘Curea’ stressed C’urea versus ‘curea’ (En. belt) stressed cure’a), the syllabification for the abbreviations is not well dealt with by RoTTS; 5,540 proper names and 373 abbreviations were manually corrected in the process, at all levels of lexical information: syllabification, lexical stress marking and phonemic transcription;
-
• compound words: are a problem for RoTTS, which does not deal well with the hyphen in the syllabification step.
3.2.2. Stress marking correction stage
It is essential, at this level, to review the homographs that are not homophones because, as it can be seen below,Footnote l stress can distinguish between words implicitly, through lemmas and/or POSes (e.g., ‘război’) or different morphological variants of the same word (e.g., ‘atribui’). It can also influence syllabification and phonemic transcription. Although most of the cases affect two words, there are cases of homography affecting three words: for example, the form ‘dudui’ can be stressed as: (i) d’udui when it is the second person singular of the present tense of the verb ‘a dudui’ (En. to whirr), (ii) dud’ui when it is the indefinite plural of the noun ‘duduie’ (En. madam), (iii) dudu’i when it is the infinitive or the third person singular past simple form of the same verb ‘a dudui’ (Băcilă Reference Băcilă2011).
The common types of homonymy that introduce ambiguities are as follows:
-
(1) Lexical homographs
-
a. different POSes:
-
i. război (En. war ), noun, răzb’oi;
-
ii. război (En. (to) fight ), verb, războ’i
-
-
b. the same POS, different meanings
-
i. ţarină (En. tsarina ), noun, ţar’ină
-
ii. ţarină (En. cultivated land ), noun, ţ’arină
-
-
-
(2) Lexico-grammatical homographs
-
a. same POS
-
i. fotografii (En. photos ), fotograf’ii
-
ii. fotografii (En. photographers ), fotogr’afii
-
-
b. different POSes
-
i. data (En. the date ), noun, d’ata
-
ii. data (En. (to) date ) verb, dat’a
-
-
-
(3) Morphological homographs
-
a. different forms in the inflectional paradigm of the same verbal lemma
-
i. atribui (En. (to) assign ), verb first or second person singular, present tense, atr’ibui
-
ii. atribui (En. (to) assign ), verb third person singular, past tense infinitive, atribu’i
-
-
3.2.3. Phonemic transcription correction stage
The phonetic alphabet adopted by our dataset is based on the SAMPA notation.Footnote m The difference between the official SAMPA phonetic notations and our phoneme list lies in our extension of the phonemes inventory as follows:
-
(1) introducing two notations for transcribing the two possible pronunciations corresponding to letter ‘x’ (which is not dealt with in SAMPA):/gz/ or/cs/. These notations are in line with the treatment of ‘x’ as a single consonant in the syllabification phase: for example, the word ‘examen’ contains the syllables: e.xa.men which correspond to the transcription/e gz a m e n/; if we had transcribed the word as/e g z a m e n/, then the syllabification rule according to which two consonants between two vowel belong to different syllables, that is VCCV
 $~\gt ~$
VC.CV, would not have been observed and an exception should have been formulated;
$~\gt ~$
VC.CV, would not have been observed and an exception should have been formulated; -
(2) introducing two new notations to distinguish between the voiceless palatal plosives/k_j/ and the voiced palatal plosive/g_j/, on the one hand, and the voiceless velar plosive/k/ and the voiced velar plosive/g/, on the other hand, as they are different sounds, given their different positions of articulation;
-
(3) introducing the special notation/je/ for the pronunciation of the letter ‘e’ when occurring in only two contexts: the initial position in the forms of the personal pronoun and in the forms of the verb ‘a fi’ (En. to be). In all its other occurrences in initial position of a word, e should never be pronounced like this.Footnote n

Table 3 presents the phonemic transcription of the letters and letter groups in Romanian that introduce ambiguities and, therefore, can cause transcription errors. The following rules were derived and implemented for the automatic correction of the phonemic transcription:
-
(1) Rules for the letter/sound groups ‘ce/ci/ge/gi/che/chi/ghe/ghi’, concerning the transcription of the final vowels (‘e’, ‘i’):
-
– Case I: the group is a word ending:
-
a. when the group forms a syllable by itself, the final letter (‘e’/‘i’) is a vowel (transcribed/e/ or/i/); Examples: tre.ce (En. (to) pass)/t r e tS e/, ghi.ci (En. (to) guess)/g_j i tS i/, mer.ge (En. (to) walk, (to) go, (to) function)/m e r gZ e/, a.mă.gi (En. (to) deceive)/a m @ gZ i/, u.re.che (En. ear)/u r e k_j e/, o.chi (En. (to) aim)/o k_j i/, ve.ghe (En. watch)/v e g_j e/, zbu.ghi (En. (to) gush)/z b u g_j i/;
-
b. the group does not form a syllable by itself, the final letter ‘i’ has ‘zero’ phonetic value (it is not transcribed); Examples: mici (En. small, pl.)/m i tS/, lungi (En. long, pl.)/l u n gZ/, ochi (En. eyes)/o k_j/, unghi (En. angle)/u n g_j/, o.blici (En. oblique, pl.)/o b l i tS/;
-
-
– Case II: the group stands as a syllable ending inside the word:
-
a. the final letter (‘e’/‘i’) is always a vowel (transcribed/e/ or/i/); Examples: er.ba.ce.e (En. herbaceous, fem. sg.)/e r b a tS e e/, sal.ci.e (En. willow)/s a l tS i e/, ge.o.log (En. geologist, masc.)/gZ e o l o g/, spon.gi.os (En. spongy, masc. sg.)/s p o n gZ i o s/, în.che.ia (En. (to) finish)/1 n k_j e j a/, în.chi.na (En. (to) dedicate, (to) worship)/1 n k_j i n a/, ghe.ţar (En. glacier)/g_j e tS a r/, ghi.o.cel (En. snowdrop)/g_j i o tS e l/;
-
-
– Case III: the group is inside the syllable;
-
a. the final letter (‘e’/‘i’) is a vowel (transcribed/e/ or/i/), when the group is followed by a consonant; Examples: cer.ta (En. (to) scold)/tS e r t a/, în.cin.ge (En. (to) heat)/1 n tS i n gZ e/, ger.man/gZ e r m a n/, ar.gint (En. silver)/a r gZ i n t/, chel.tui (En. (to) spend, indicative, present)/k_j e l t u j/, chin.gă (En. strap)/k_j i n g @/;
-
b. when the group is followed by one or two vowels/semi-vowels, the rules for diphthongs and triphthongs transcription are applied:
-
i. when descendant diphthongs are involved: for example, for the sequence ‘cei’ in the word ‘cercei’ (En. earrings), we reproduce the/tS/ symbol, followed by the descendant diphthong transcription of ‘ei’, which is/e j/; in the case of the word ‘mijloc’iu’ (En. middle one), we know that the group of letters ‘iu’ is a descendant diphthong transcribed as/i w/, because ‘i’ bears the stress marking, and therefore ‘u’ is the semi-vowel; Examples: cer.cei/tS e r tS e j/, mij.lo.ciu/m i Z l o tS i w/, a.po.geu (En. climax)/a p o gZ e w/, han.giu (En. innkeeper)/h an gZ i w/, în.chei (En. (to) finish, 1st person, sg.)/1 n k_j e j/, mu.chii (En. edges)/m u k_j i j/, pâr.ghii (En. leverages)/p 1 r g_j i j/;
-
ii. for the ascending diphthongs and for ascending and centred triphthongs, the last letter of the group ‘ce/ci/ge/gi/che/chi/ghe/ghi’ is not transcribed (it has ‘zero’ value, because in the diphthong or triphthong it is a semi-vowel); Examples: cea.ţă (En. fog)/tS a ts @/, pi.cior (En. leg)/p i tS o r/, gea.nă (En. eyelid)/gZ a n @/, giu.va.er (En. gem)/gZ u v a e r/, chea.mă (En. (to) call, imperative, singular)/k_j a m @/, chiar (En. even)/k_j a r/, ghea.ţă (En. ice)/g_j a ts @/, ghioz.dan (En. shoolbag)/g_j o z d a n/;
-
-
-
-
(2) Rules for diphthong and triphthong transcriptions: in Romanian, most of these groups can be classified in a deterministic manner, without supplementary context information. The diphthongs can be ascending (semi-vowel + vowel) or descending (vowel + semi-vowel). The triphthongs can be ascending (semi-vowel + semi-vowel + vowel) or centred (vowel + semi-vowel + vowel). The diphthong ‘iu’ is the only exception: it can be both descending (e.g., in ‘fiu’/f i w/, ‘hangiu’/h a n gZ i w/, ‘mijlociu’/m i Z l o tS i w/) and ascending (e.g., in ‘iubit’/j u b i t/, ‘iute’ (En. fast) j u t e/). The ascendance of ‘iu’ can be identified if ‘i’ in the diphthong is correctly stressed: if ‘i’ bares a stress mark, ‘iu’ is a descending diphthong and otherwise is an ascending one. In Table 4, you can see examples for all the diphthongs and triphthongs in Romanian and also of the same letter group in their hiatus form.
-
(3) Rule for the final ‘whispered’ i: If the last or the only syllable in the word does not bear stress and it ends with a sequence of the form ‘vowel + consonant + (optional consonant) + i’, then the final ‘i’ is transcribed as ‘i_0’. Examples: ‘primăveri’ (En. springs)/p r i m @ v e r i_0/, ‘beţi’ (En. drunk, pl.)/b e ts i_0/, ‘conţi’ (En. counts)/c o n ts i_0/, ‘cerbi’ (En. deer, pl.)/tS e r b i_0/; exceptions from the rule are the groups ‘ci/gi/chi/ghi’ (for which the rule I.b is applied) and the sequences ‘consonant + liquid consonant (/l/ or/r/) +/i/’: ‘co.dri’ (En. old forests)/c o d r i/, ‘cio.cli’ (En. grave-digger)/tS o c l i/.
For the words containing the letter or letter groups ‘x’, ‘ki’ and ‘qu’, no automatic correction rules could be determined. Therefore, the entries containing the letter ‘x’, which can be pronounced as either/ks/ or/gz/, were manually corrected. Manually correcting only the entries for which the word form coincides with the lemma is enough, since the pronunciation of this letter does not change in the inflection process and can be safely extended to its all inflected forms. The words containing the letter groups ‘ki’ and ‘qu’ were processed so that the groups be transcribed as/k_j i/ and/k_j/, respectively, to deal with the ambiguities presented in Table 3.
Based on the automatic processes, the derived rules and manual correction, the entire RoLEX dataset was validated and finalised to contain all the linguistic information set forth. Details of its final content are described in the following subsection.
Table 5. RoLEX dataset statistics

3.3. RoLEX statistics
With the dataset in place, we performed a series of statistics over its lexical components. In the final form, RoLEX contains 330,866 entries and represents the largest phonological validated dataset freely available for Romanian. Table 5 presents an overview of its contents. We add here a remark regarding the number of distinct syllables found in RoLEX. Previous studies of the Romanian syllable distribution (Dinu Reference Dinu2004; Dinu et al. Reference Dinu and Dinu2006), performed on the DOOM dictionary (Reference Română1982), identified 6496 type syllables. The work in Barbu (Reference Barbu2008), also based on DOOM, but coupled with a paradigmatic mechanism of automatic inflectional generation, refers to an extended dataset of 525,530 entries in which 8,600 syllable types were identified. In contrast, our dataset, being a corpus-based one, has particularities that produce 979 new type syllables derived from (i) foreign proper nouns that come with specific phonetic properties; (ii) Romanian proper nouns, including some that preserve the old Romanian orthography (namely, the use of the letter ‘î’ in word internal position); (iii) new and/or borrowed words; (iv) forms occurring in contractions and displaying apheresis; (v) archaisms or regional variants of words; and (vi) interjections.
A detailed statistic of the phoneme counts within RoLEX is shown in Figure 1. The top three most common phonemes being the vowels ‘e’, ‘i’ and ‘a’, followed by the consonants ‘r’, ‘t’ and ‘n’. A separate set of statistics refers to the number of syllables within a word (see Figure 2a) and the position of the stressed syllable within the word (see Figure 2b). The majority of the Romanian words have 3 to 5 syllables, and the most common stress pattern falls on the penultimate or ante-penultimate syllable. Although the lexical stress seems to adhere to a pattern, we will show in the evaluation section that the stress marking poses most problems for the automatic lexical information prediction tool.

Figure 1. Phoneme counts in RoLEX.

Figure 2. (a) Histogram of the number of syllables per word and (b) violin plot of the stressed syllable position given the number of syllables in a word as computed from the RoLEX dataset.
In terms of morphological content, Table 6 shows RoLEX’s counts for each POS. It can be noticed that the highly flexing POS in Romanian, especially verbs, but also some pronouns, adjectives and nouns, take up 99% of the entire dataset.
4. Concurrent lexical information prediction
When such a large high-quality language resource is available, lexical information predictors should be easily and accurately trained. With the recent advancements of core deep learning strategies, as well as deep learning within NLP, predicting a single task at a time can become trivial (for some languages), as well as time and resource consuming. Predicting multiple lexical information at the same time using a single network would be both advantageous and challenging. Such predictors could also exploit the correlations and additional information that would inherently become available in this scenario. As a result, in the rest of the paper we focus on deriving simultaneous lexical information starting from the orthographic form of a context-free word.Footnote o The selected tasks for the concurrent prediction are as follows: phonemic transcription, syllabification and lexical stress marking. Examples of such input-output pairs are shown in Table 7.
Table 6. RoLEX POS statistics
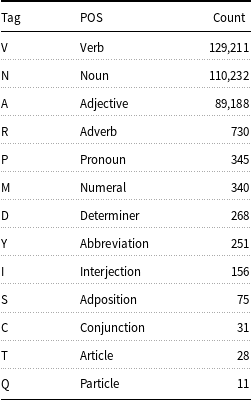
Table 7. Examples of input-output pairs for the concurrent prediction task. Dots mark the syllabification. The lexical stress is marked with an apostrophe before the stressed vowel. The phonemic transcription uses the SAMPA notation

Within this setup, the machine learning algorithm needs to learn a sequence-to-sequence (S2S) mapping. Among the various state-of-the-art neural architectures, CNN (Gehring et al. Reference Gehring, Auli, Grangier, Yarats and Dauphin2017) and attention-based (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) networks have shown the highest accuracy in NLP pipelines (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019). In the early stages of this study, we first performed a CNN versus Transformer evaluation. However, the CNN results were less accurate than those of the Transformer,Footnote p so we resumed to using only the latter.
The Transformer architecture is shown in Figure 3 and is composed of an encoder and a decoder structure. Both structures contain a sequence of attention, normalisation and feed forward layers. An important aspect of the Transformer, beneficial to the tasks addressed in this article, is the multi-head attention. By enabling the network to focus on multiple areas of the input sequence, the decoded output can, at each time step, look both into the future and into the past input characters, and adjust the predictions accordingly, yielding a higher accuracy.
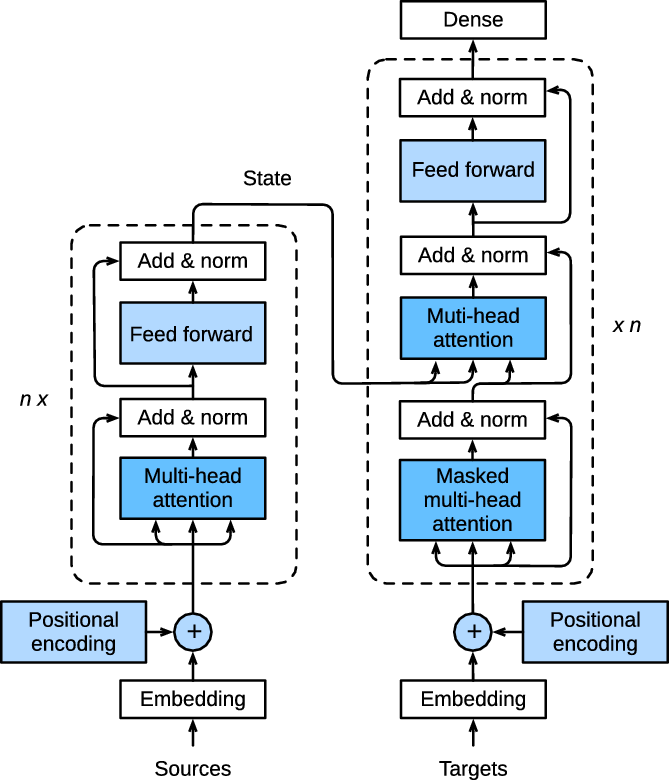
Figure 3. Transformer architecture (Zhang et al. Reference Zhang, Lipton, Li and Smola2020).
The Transformer’s hyperparameter selection is based on the strategy introduced in (Stan Reference Stan2020). The set of hyperparameters which were optimised are shown in Table 8. The optimisation used a randomly selected 150,000 entries subset of RoLEX and evaluated the fitness of the individuals using the word error rate measured for 500 held-out samples. The evolution took place over 10 generations with a population size of 10. This setup does by no mean explore the entire hyperparameter space, yet it allows to evaluate some key topological aspects of the network and prevent overfitting.
The derived Transformer structure uses 3 encoder units, 4 decoder units, 4 attention heads, a hidden layer of 1024 nodes and an embedding dimension of 128. The embedding weights are randomly initialised before training. The batch size was set to 512, and the Adam optimiser was used to update the weights with an initial learning rate of
 $2*10^{-4}$
. After 50 epochs, the learning rate was reduced by a factor of 0.2. An early stopping criterion based on the validation loss over 5 epochs stopped the training process.
$2*10^{-4}$
. After 50 epochs, the learning rate was reduced by a factor of 0.2. An early stopping criterion based on the validation loss over 5 epochs stopped the training process.
5. Evaluation
5.1 Romanian: RoLEX
The evaluation of the newly built RoLEX dataset attempts to answer the following five questions:
-
[Q1] Is the performance of prediction tools trained on RoLEX better than of those trained on other available Romanian datasets?
-
[Q2] Can the prediction tools trained on a smaller, randomly selected subset of entries from RoLEX obtain similar performance measures to those obtained when trained on the entire dataset?
-
[Q3] Can the prediction tools trained on a smaller, carefully selected subset of entries from RoLEX obtain similar performance measures to those obtained when trained on the entire dataset?
-
[Q4] What is the contribution of each of the three lexical tasks (i.e., phonemic transcription, syllabification and lexical stress assignment) to the global error rates?
-
[Q5] To what extent do supplemental lexical input features, in the form of POS or morphosyntactic description (MSD) tags, improve the overall accuracy of the prediction tools?
To answer these questions, a 20% randomly selected subset of the RoLEX entries was held out and used in all testing scenarios. Word error rate (WER) and symbol error rate (SER) were used as objective metrics. The WER was measured as the percentage of incorrectly predicted output sequences. The SER is very similar to the phone error rate, but we would like to make the distinction that the prediction also includes the syllabification and lexical stress symbols. The SER was computed using the Levenshtein distance (Levenshtein Reference Levenshtein1966) between the predicted and target sequences. For homographs, the pronunciation with the lowest Levenshtein distance was selected. Because the output of the network contains 3 separate types of lexical information, the WER and SER were also computed over the output sequence when removing either the syllable marks, the lexical stress marks, or both. This computation helps us understand which task imposed more learning and prediction problems for the neural network.
As a preliminary step, the accuracy of the selected neural architecture for each individual task was examined. The results are shown in Table 9 and used the same train-test split as in the following experiments. It can be noticed that the largest error rates are encountered for the lexical stress prediction.
Table 8. Set of genes and gene values used in the evolution strategy. The first column marks the gene ID within the genome

Table 9. WER and SER measures for individual task predictions

In trying to answer [Q1], we compared the accuracy of the RoLEX-based prediction with the one obtained from the combined information available in MaRePhor, RoSyllabiDict and DEX, while using the same neural architecture. The latter set contains around 72,000 entries and obtained a WER of 10.47%, and a SER of 3.93% for the combined prediction when using only the orthographic form of the word as input. In the same setup, the RoLEX-based prediction halved the error rates of the predictions, with a 5.6% WER, and a 1.97% SER. Given that RoLEX is about five times the size of the MaRePhor-based dataset and more morphologically diverse, the accuracy leap was not unexpected. When also using the MSD information, available in RoLEX and not available in the other resources, the results become highly accurate (3.08% WER and 1.08% SER), with most of the errors pertaining to exceptions. This shows once again the value of extended, manually validated resources, with complex annotation.
A combination of the WER and SER results for answering [Q2], [Q4] and [Q5] is shown in Figure 4. The results are grouped by the increasing number of randomly selected entries used in the training process. The different colour shades mark the lexical information maintained in the prediction, meaning that the network still predicts the complete lexical information, but we do not take into account all of it. The hatch pattern indicates the information used as input to the neural network: only the orthographic form of the word (Ortho); the orthographic form plus the POS tag (wPOS); or the orthographic form plus the complete MSD tag (wMSD).

Figure 4. (a) WERs and (b) SERs for different amounts of randomly selected training samples, evaluated for the complete lexical information prediction (PH + ACC + SYLL); by discarding the syllable information (PH + ACC); by discarding the lexical stress information (PH + SYLL); and by discarding both the syllable and the lexical stress information (PH). Figures also show results of the networks using as input only word forms (Ortho); word forms plus POS tags (wPOS); word forms plus MSD tags (wMSD).
For [Q2], it can be noticed that beyond 100,000 entries the accuracy gains seem to plateau, yet there is still a 15% relative WER improvement going from 100,000 entries to the complete dataset in the Ortho:PH + SYLL + ACC setup.
With respect to the influence of each of the three tasks ([Q4]), the lexical stress poses the most problems. On average, the lexical stress errors amount to 60% of the overall errors (compare PH + ACC + SYLL with PH + SYLL). This was to be expected for Romanian, as the lexical stress does not adhere to any predefined rules and it is mostly dependent on the word’s inflection (DOOM 2005). A similar result was found in (Stan and Giurgiu Reference Stan and Giurgiu2018) and also in the individual task predictions shown in Table 9. Another important aspect to notice in these results for [Q4] is the fact that the error rates of the concurrently predicted phonemic transcriptions (Ortho:PH) – when discarding the other tasks – are better than those obtained when the network predicts just this task: 1.60% WER, 0.45% SER (see Table 9). This means that, again as expected, although the network had a more complex learning task, the presence of the other lexical information in the output sequence helps the individual tasks’ learning.
In scenario [Q5], the additional lexical information appended to the input in the form of the POS or complete MSD tags should help the network differentiate non-homophone homographs. RoLEX contains only 2000 such type of homographs and we did not envision that the error rate would be significantly impacted by their discrimination. But solving this disambiguation problem can bring more linguistic accuracy to the overall system. Also, when POS and MSD information is used to improve the task’s performance, the assumption is that they can compensate for some missing words in the training data. For example, the network can learn to associate certain morphological suffixes (and their specific pronunciations) to certain POSes or MSDs. This assumption holds true across all random dataset partitions and all output sequence tasks presented in Figure 4. MSD systems (wMSD) perform better than the POS systems (wPOS), which in turn are less erroneous than the orthographic ones (Ortho).
Questions [Q1, Q2, Q4, Q5] analysed the dataset from the given, available resource perspective. However, the development of such a large resource is extremely time consuming and requires expert linguists to perform the manual annotation. Therefore, in [Q3] we investigate if the careful design and selection of entries can minimise the required manual annotation and validation processes as a more efficient alternative to the validation techniques described in Section 3. Three new subsets of RoLEX were generated. The subsets are based on the number and nature of the forms of content words (adjectives, nouns and verbs), which have a rich morphology in Romanian: LEMMA subset contains 30,150 entries, corresponding to all forms for the function words and the lemma form for the content words; 1-FORM subset contains 30,150 entries, corresponding to all forms for the function words and one form for content words, where the selection of the form was performed such that the combined entries ensured the morphological diversity within the corresponding POS category; 2-FORMS subset contains 55,185 entries and is similar to 1-FORM but with two forms for each content word entry. The results of the concurrent prediction using these subsets are shown in Figure 5.

Figure 5 (a) WERs and (b) SERs at for the LEMMA, 1-FORM, and 2-FORMS subsets, evaluated for the complete lexical information prediction (PH + ACC + SYLL); by discarding the syllable information (PH + ACC); by discarding the lexical stress information (PH + SYLL); and by discarding both the syllable and the lexical stress information (PH). Figures also show results of the networks using as input only word forms (Ortho); word forms plus POS tags (wPOS); word forms plus MSD tags (wMSD).
The first thing to notice is the very high error rates for the LEMMA subset – twice as high as the rates achieved by the randomly selected 5,000 entries (see Scenario [Q2]). This can be explained by the very low morphological diversity within the subset. In this case, the POS or MSD tags cannot truly compensate for the lack of morphological variation within the training set. More so, the POS information reduces the accuracy of the prediction. Compare for example the 41.56% WER of wPOS:PH + ACC + SYLL vs. 40.13% WER for Ortho:PH + ACC + SYLL. One exception is the wPOS:PH setup where the POS tags help the phonemic transcription better than the Ortho or wMSD inputs. However, it seems that the complete MSD tags do aid the concurrent prediction process and lower the WER and SER by approximately 10% relative. We should reiterate the fact that the test set is the same across all evaluation scenarios and includes entries with various morphological forms.
By thoroughly analysing the network’s predictions, we discovered that most of the errors are a consequence of a biased learning of lexical stress behaviour. In the LEMMA set, more than half of the entries and the majority of the verbs have the lexical stress marking on the last syllable. This feature is not characteristic of Romanian’s diverse morphological forms. Also, there are numerous errors for syllabification and phonemic transcription in the morphological termination of the words. This means that using only dictionary forms of the entries is not a correct manner to go about selecting the core entries of a lexical dataset.
Looking at the 1-FORM and 2-FORMS results in conjunction with the randomly selected subsets, we can see that the careful design of morphologically diverse entries yields performances comparable to those obtained by twice as many random entries: compare the WER of 1-FORM versus the WER of 50,000 random entries, and the WER of 2-FORMS to the WER the 100,000 random subset (see Scenario [Q2]). These results demonstrate that a strategic morphological selection of the entries substantially reduces the amount of necessary manual validation work for the same target performance. However, the selection process needs to be adapted according to the characteristics of the target language.
5.2. English: CMUDict
The ability to concurrently predict the three lexical tasks in any language using the same neural architecture can enable the development of a flexible multi-lingual framework. We therefore test the Transformer-based structure’s feasibility and accuracy for the English CMUDict dictionary, as well. This pronunciation dictionary, developed by the Carnegie Mellon University, consists of more than 135,000 entries, each being associated with its phonemic transcription and lexical stress. The original phonemic and lexical stress transcriptions from CMUDict were combined with the syllabificationFootnote q derived by a method described in (Bartlett, Kondrak, and Cherry Reference Bartlett, Kondrak and Cherry2009). This augmented dataset was used in our experiments and contains 129,420 entries. The results are summarised in Table 10.
Table 10. WERs and SERs for the complete lexical information prediction over the augmented CMUDict English dataset

The train-validation-test split follows that of Yolchuyeva et al. Reference Yolchuyeva, Németh and Gyires-Tóth(2019a), with the remark that a fraction of the entries (less than 0.2% of the test set) were not present in the augmented version of the CMUDict. POS/MSD information was not available for the English entries, so that only the concurrent prediction of phonemic transcription, lexical stress and syllabification based on the orthographic representation of the word entries was evaluated. Again, the WERs and SERs of the predicted phonemic transcription (PH) when discarding the other lexical information are comparable to the ones obtained by the state-of-the-art methods (Yolchuyeva et al. Reference Yolchuyeva, Németh and Gyires-Tóth2019b). As was the case for Romanian, the results show that concurrent task learning can lead to a better performance of the individual tasks – also indicated by van Esch et al. Reference van Esch, Chua and Rao(2016).
6. Conclusions
Creating and testing tools for processing language are to a large extent sustained by the existence of language resources, on which the tools are trained and/or tuned, and against which they are further tested. When a language lacks such a resource (mainly because of the costs involved), alternative, multi-lingual approaches are sought. This article introduced the collection, development, annotation and validation of an extended Romanian lexical dataset, named RoLEX, comprising over 330,000 entries. The dataset is the largest of this kind for Romanian and even the most comprehensive as far as the types of information consistently and systematically encoded are concerned: each entry contains lemma, morphosyntactic information, syllabification, stress and phonetic information.
To test RoLEX’s feasibility in deriving automatic lexical annotation tools, we used the dataset to train a concurrent prediction, Transformer-based neural network. The network was set to predict the phonemic transcription, lexical stress and syllabification of a written word (i.e., having its orthographic form as input), or with the additional help of POS tags, or full morphosyntactic descriptions. The evaluation included the analysis of 5 different scenarios which targeted the amount and quality of training data, input augmentation and the cumulative effect of each task in the overall error. The results show very high accuracy for all tasks and are in line with state-of-the-art methods applied to each individual task. We also showed that by carefully selecting data subsets that reflect the morphological diversity of the language, manual validation can be significantly reduced if an incremental setting of validation-training-validation is designed. As future work, we aim to deliver the full prediction system as a freely accessible API, and we already started to use the combined lexical information as input for end-to-end speech synthesis systems.
Acknowledgement
The research presented herein received funding from the Romanian Ministry of Research and Innovation, PCCDI–UEFISCDI, project number PN-III-P1-1.2-PCCDI-2017-0818/73. AS was partially funded by Zevo Technology through project number 21439/28.07.2021.
Competing interests
The authors declare none.















