



1. Introduction
Text mining can provide valuable insights, but the text data need to be adequately preprocessed first, just like numerical data (Kalra and Aggarwal Reference Kalra and Aggarwal2018). Real-world data are dirty (Hernández and Stolfo Reference Hernández and Stolfo1998), so data scientists spend more than half of the time preprocessing and organizing the data (Gabernet and Limburn Reference Gabernet and Limburn2017; CrowdFlower 2017). For example, Twitter data contain HTML tags and user mentions, so researchers have to remove the formatting from the data before feeding the corpus into any text model (Angiani et al. Reference Angiani, Ferrari, Fontanini, Fornacciari, Iotti, Magliani and Manicardi2016). Many text analysis models deal with words (Aggarwal and Zhai Reference Aggarwal and Zhai2012; Kutuzov et al. Reference Kutuzov, Fares, Oepen and Velldal2017); hence, breaking down the text into words (i.e., tokenization) is also a necessary preprocessing step (Karthikeyan et al. Reference Karthikeyan, Jotheeswaran, Balamurugan and Chatterjee2020). Text preprocessing refers to these operations that prepare the corpus for analysis (Anandarajan, Hill, and Nolan Reference Anandarajan, Hill and Nolan2019). Text preprocessing methods are not just essential to natural language processing (NLP), but they have actual implications to the modeling results (Samad, Khounviengxay, and Witherow Reference Samad, Khounviengxay and Witherow2020), just like raw data with errors can distort the regression output (Chai Reference Chai2020) .
Text preprocessing also has a quantitative impact on the natural language applications. Forst and Kaplan (Reference Forst and Kaplan2006) showed that precise tokenization increased the coverage of grammars in German from 68.3 percent to 73.4 percent. Gomes, Adán-Coello, and Kintschner (Reference Gomes, Adán-Coello and Kintschner2018) also showed that text preprocessing can boost the accuracy by more than 20 percent in sentiment analysis of social media data. Zhou et al. (Reference Zhou, Siddiqui, Seliger, Blumenthal, Kang, Doerfler and Fink2019) improved hypoglycemia detection by filtering stopwords and signaling medications in clinical notes in the US, which increased the F1 score by between 5.3 percent and 7.4 percent. According to Camacho-Collados and Pilehvar (Reference Camacho-Collados and Pilehvar2018), there is a high variance in model performance (
 $\pm$
2.4 percent on average) depending on the text preprocessing method, especially with smaller sizes of training data. Trieschnigg, Kraaij, and de Jong (Reference Trieschnigg, Kraaij and de Jong2007) discovered that different tokenization choices can result in a variability of more than 40 percent in the precision of biomedical document retrieval. The variance is large enough for researchers to choose a different model for better performance, while the real issue is choosing the appropriate methods in text preprocessing. Cohen, Hunter, and Pressman (Reference Cohen, Hunter and Pressman2019) found out that in clinical text mining, tokenization choices can make the difference between getting publishable results or not, which indirectly contribute to the problem of false discoveries (Leek and Jager Reference Leek and Jager2017). These examples provide the evidence that text preprocessing plays a much more important role than most people have realized (Hickman et al. Reference Hickman, Thapa, Tay, Cao and Srinivasan2020). Researchers need to make decisions in working with a dataset, and Nugent (Reference Nugent2020) pointed out that human subjective decisions are as important as the machine learning algorithm itself.
$\pm$
2.4 percent on average) depending on the text preprocessing method, especially with smaller sizes of training data. Trieschnigg, Kraaij, and de Jong (Reference Trieschnigg, Kraaij and de Jong2007) discovered that different tokenization choices can result in a variability of more than 40 percent in the precision of biomedical document retrieval. The variance is large enough for researchers to choose a different model for better performance, while the real issue is choosing the appropriate methods in text preprocessing. Cohen, Hunter, and Pressman (Reference Cohen, Hunter and Pressman2019) found out that in clinical text mining, tokenization choices can make the difference between getting publishable results or not, which indirectly contribute to the problem of false discoveries (Leek and Jager Reference Leek and Jager2017). These examples provide the evidence that text preprocessing plays a much more important role than most people have realized (Hickman et al. Reference Hickman, Thapa, Tay, Cao and Srinivasan2020). Researchers need to make decisions in working with a dataset, and Nugent (Reference Nugent2020) pointed out that human subjective decisions are as important as the machine learning algorithm itself.
Nevertheless, text preprocessing is more complex and difficult than it seems. Text contains many kinds of lexical information as described in the book The Lexicon (Ježek Reference Ježek2016), such as concept, grammar, syntax, and morphology. For example, grammar may not be important in topic modeling or text classification, but grammar is essential to end-user applications like question-answering or summarization (Torres-Moreno Reference Torres-Moreno2014). Different types of text corpora require different preprocessing methods, so text preprocessing is not a one-size-fits-all process (Yuhang, Yue, and Wei Reference Yuhang, Yue and Wei2010; Denny and Spirling Reference Denny and Spirling2018). Recent advances of pretrained language models like Bidirectional Encoder Representations from Transformers (BERT) (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018) has brought NLP to an unprecedented level (Wang, Gu, and Tang Reference Wang, Gu and Tang2020), but preprocessing the text corpus is still necessary to get the data ready for the input (Kaviani and Rahmani Reference Kaviani and Rahmani2020; Armengol Estapé Reference Armengol Estapé2021). Example preprocessing operations include text normalization and unpacking hashtags (Polignano et al. Reference Polignano, Basile, De Gemmis, Semeraro and Basile2019). There are still many decisions to be made, because the number of possible models grows exponentially with the abundance of hyperparameters in neural networks. With eight binary hyperparameters, the number of possible models is as high as
 $2^8=256$
(Dodge et al. Reference Dodge, Gururangan, Card, Schwartz and Smith2019). For instance, do we choose uniform or term frequency-inverse document frequency (TF-IDF) weights? Do we retain multiword expressions? If yes, what is the cutoff frequency? It is practically infeasible to try every single combination to find the best-performing model, so researchers should narrow down the search space, that is, find which preprocessing choices are more appropriate for the target application.
$2^8=256$
(Dodge et al. Reference Dodge, Gururangan, Card, Schwartz and Smith2019). For instance, do we choose uniform or term frequency-inverse document frequency (TF-IDF) weights? Do we retain multiword expressions? If yes, what is the cutoff frequency? It is practically infeasible to try every single combination to find the best-performing model, so researchers should narrow down the search space, that is, find which preprocessing choices are more appropriate for the target application.
Therefore, we would like to discuss various text preprocessing methods by summarizing the commonly used practices and pointing out their limitations. These methods include removing formatting, tokenization, text normalization, handling punctuation, removing stopwords, stemming and lemmatization, n-gramming, and identifying multiword expressions. Figure 1 shows a common order of application of the text preprocessing modules, but in some cases, punctuation is handled (or even removed) during the tokenization stage (Welbers, Van Atteveldt, and Benoit Reference Welbers, Van Atteveldt and Benoit2017; Mullen et al. Reference Mullen, Benoit, Keyes, Selivanov and Arnold2018). Researchers have performed text normalization and punctuation handling in either order (Bollmann Reference Bollmann2019; Zupon, Crew, and Ritchie Reference Zupon, Crew and Ritchie2021), so we list the two modules in parallel in the diagram.
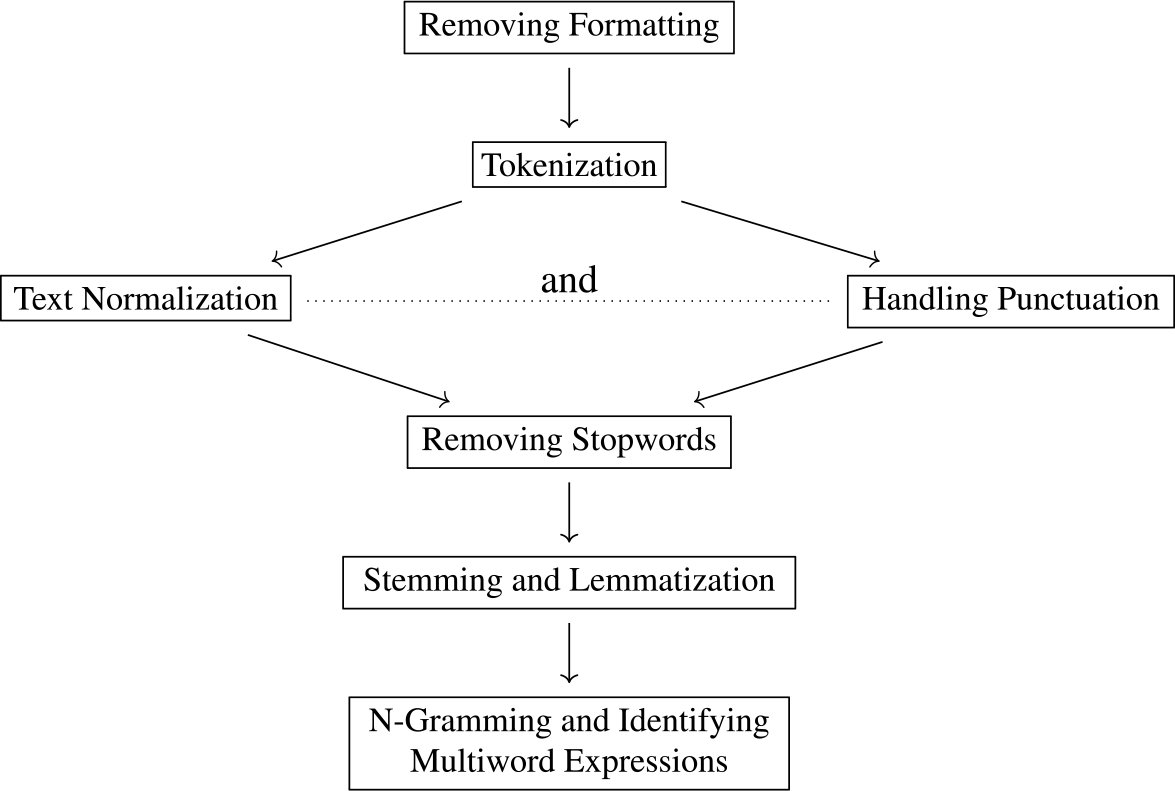
Figure 1. A common order of application of the text preprocessing modules.
Our objective is to serve a variety of NLP applications and provide researchers guidance on selecting preprocessing methods for their text corpus. Kathuria, Gupta, and Singla (Reference Kathuria, Gupta and Singla2021) also created a description of common text preprocessing techniques, but their main goal is to compare various open-source text mining tools such as Weka, Rapid Miner,
 $\mathsf{R}$
, and Python Jupyter Notebook. Many survey papers in text preprocessing are focused on a specific NLP application, such as text classification (HaCohen-Kerner, Miller, and Yigal Reference HaCohen-Kerner, Miller and Yigal2020) or sentiment analysis in Brazilian Portuguese (Cirqueira et al. Reference Cirqueira, Pinheiro, Jacob, Lobato and Santana2018). Other relevant survey papers like Vijayarani, Ilamathi, and Nithya (Reference Vijayarani, Ilamathi and Nithya2015) and Nayak et al. (Reference Nayak, Kanive, Chandavekar and Balasubramani2016) seem to discuss the detailed implementation of text preprocessing, rather than the potential impact on the NLP applications.
$\mathsf{R}$
, and Python Jupyter Notebook. Many survey papers in text preprocessing are focused on a specific NLP application, such as text classification (HaCohen-Kerner, Miller, and Yigal Reference HaCohen-Kerner, Miller and Yigal2020) or sentiment analysis in Brazilian Portuguese (Cirqueira et al. Reference Cirqueira, Pinheiro, Jacob, Lobato and Santana2018). Other relevant survey papers like Vijayarani, Ilamathi, and Nithya (Reference Vijayarani, Ilamathi and Nithya2015) and Nayak et al. (Reference Nayak, Kanive, Chandavekar and Balasubramani2016) seem to discuss the detailed implementation of text preprocessing, rather than the potential impact on the NLP applications.
In this article, the text preprocessing methods described are primarily for English, but some methods also apply to other languages. For example, Kannan and Gurusamy (Reference Kannan and Gurusamy2014) showed that English and French can be tokenized in similar ways due to the space-delimited nature in both languages. Here, we explicitly specify the language name to acknowledge the importance of data statement for NLP (Bender and Friedman Reference Bender and Friedman2018). There are more than 7000 languages in the world,Footnote 1 but English accounts for the vast majority of NLP research (Bender Reference Bender2011; Mieke Reference Mieke2016). Munro (Reference Munro2015) pointed out that many researchers fail to name the language of their data, which is obviously English. We would like to be inclusive and do not assume that English is the default language studied in this field.
We also encourage researchers to use “text preprocessing” when referring to operations covered in this review article, unless this term is explicitly defined otherwise. Many researchers use “text cleaning” and “text preprocessing” interchangeably (Kunilovskaya and Plum Reference Kunilovskaya and Plum2021), but we adopt the latter to highlight the goal of getting the text corpus ready for input to NLP models (Aye Reference Aye2011). Kadhim (Reference Kadhim2018) extended the term “text preprocessing” to the operations of converting text to numerical data (e.g., TF-IDF), and they clearly stated that the aim is to represent each document as a feature vector of individual words. We agree that this aspect is equally important, but “data representation” is a more appropriate term (Dařena Reference Dařena2019). Finally, we make a distinction between “text preprocessing” and “data preprocessing”, where the latter refers to a broader range of data transformations, including scaling and feature selection on numerical/vectorized representations of text (García et al. 2016). One example is that Al Sharou, Li, and Specia (Reference Al Sharou, Li and Specia2021) uses “data preprocessing” to indicate the handling of all nonstandard appearance of language units (e.g., casing, hashtags, code-switching, emoji, URL, and punctuation). Another example is the Keras preprocessing module,Footnote 2 which organizes files in a tree of folders into the Keras internal dataset format by creating batches of text, including truncating the text to a preset maximum length. This belongs to “data preprocessing”, but not “text preprocessing”.
The rest of the paper is organized as follows. In Section 2, we outline the NLP-related application types—information extraction, end-user applications, and building block applications. In Section 3, we review and evaluate several commonly used text preprocessing practices. In Section 4, we provide examples from three types of specialized text corpora—technical datasets, social media data, and text with numerical ratings. In Section 5, we conclude by reemphasizing the importance of text preprocessing. General text preprocessing methods have merits, but for further improvement of data quality, text preprocessing needs to be tailored to the particular dataset.
2. NLP application types
NLP applications are generally divided into three types: information extraction, end-user applications, and building block applications (Jusoh Reference Jusoh2018). Information extraction retrieves useful information from the text corpus (Tang et al. Reference Tang, Hong, Zhang and Li2008); such applications include information retrieval, topic modeling, and classification tasks (Albalawi, Yeap, and Benyoucef Reference Albalawi, Yeap and Benyoucef2020). End-user applications take input directly from human users and provide output to them (Shaikh et al. Reference Shaikh, More, Puttoo, Shrivastav and Shinde2019). These require more comprehension in machine reading; examples are machine translation, question-answering, reasoning, text summarization, and sentence condensation (Zeng et al. Reference Zeng, Li, Li, Hu and Hu2020). Building block applications enhance the performance of the first two types of NLP applications (Taboada et al. Reference Taboada, Meizoso, Martínez, Riano and Alonso2013), and common building blocks in NLP are part-of-speech (POS) tagging, named entity recognition (NER), and dependency parsing (Alonso, Gómez-Rodríguez, and Vilares Reference Alonso, Gómez-Rodríguez and Vilares2021). Our discussion on text preprocessing methods in this article is built to serve a wide range of NLP applications. We start with an information extraction standpoint because its text preprocessing methodology is relatively straightforward (Adnan and Akbar Reference Adnan and Akbar2019a), then we explain why some preprocessing methods are inappropriate for end-user applications. We also explain how text preprocessing contributes to the success of building block NLP applications, and eventually to the text model performance (Liu and Özsu Reference Liu and Özsu2009).
For information extraction, most text preprocessing methods would suffice for constructive results (Allahyari et al. Reference Allahyari, Pouriyeh, Assefi, Safaei, Trippe, Gutierrez and Kochut2017; Kalra and Aggarwal Reference Kalra and Aggarwal2018), but customized preprocessing methods can further improve the performance of information extraction (Adnan and Akbar Reference Adnan and Akbar2019b). As an example of a successful preprocessing application, Yazdani et al. (Reference Yazdani, Ghazisaeedi, Ahmadinejad, Giti, Amjadi and Nahvijou2020) built an automated misspelling correction system for Persian clinical text, with up to 90 percent detection rate and 88 percent correction accuracy. Using the Sastrawi library stemmerFootnote 3 also improves the exact match rate in Indonesian to 92 percent, compared with 82 percent by using the Porter stemmer (Rosid et al. Reference Rosid, Fitrani, Astutik, Mulloh and Gozali2020). If the goal of information extraction is to reveal the semantic structure of text for further end-user applications, the preprocessing methods also need to cater to the latter (Grishman Reference Grishman2015).
For end-user applications, text preprocessing is still crucial but how the methods are implemented is of paramount importance (Kulkarni and Shivananda Reference Kulkarni and Shivananda2019; Chang et al. Reference Chang, Chiam, Fu, Wang, Zhang and Danescu-Niculescu-Mizil2020). Tokenizing the corpus can identify words, and sentence splitting can find sentence boundaries (Zhang and El-Gohary Reference Zhang and El-Gohary2017). Such segmentation of the corpus text is helpful in machine comprehension, especially for question-answering and text summarization (Widyassari et al. Reference Widyassari, Rustad, Shidik, Noersasongko, Syukur and Affandy2022). Stemming and stopword removal are useful to narrow down the search space, but the system needs to output full sentences to respond to the end user (Babar and Patil Reference Babar and Patil2015; Lende and Raghuwanshi Reference Lende and Raghuwanshi2016). However, applying some preprocessing methods in the wrong way can be detrimental to end-user applications. For instance, removing punctuation too early from the corpus will result in failure to identify sentence boundaries, leading to inaccurate translation (Peitz et al. Reference Peitz, Freitag, Mauser and Ney2011). In multilingual question-answering, the mix of different languages requires special handling in the preprocessing phase, otherwise the system will have a large number of out-of-vocabulary (OOV) words from the default single language (Loginova, Varanasi, and Neumann Reference Loginova, Varanasi and Neumann2018).
For building block applications, adequate text preprocessing is necessary to leverage these NLP building blocks to their full potential (Thanaki Reference Thanaki2017; Sarkar Reference Sarkar2019), while improper choices in text preprocessing can hinder their performance (Reber Reference Reber2019). For example, the accuracy of POS tagging can generally be improved through spelling normalization (Schuur Reference Schuur2020), especially in historical texts where archaic word forms are mapped to modern ones in the POS training database (Bollmann Reference Bollmann2013). NER can benefit from the detection of multiword expressions, since an entity often contains more than one word (Tan and Pal Reference Tan and Pal2014; Nayel et al. Reference Nayel, Shashirekha, Shindo and Matsumoto2019). On the other hand, tokenization errors can lead to difficulties in NER (Akkasi, Varoğlu, and Dimililer Reference Akkasi, Varoğlu and Dimililer2016). For instance, “CONCLUSIONGlucose” should be segmented as “conclusion” and “glucose”, but splitting on letter case change will result in a partial entity “lucose”. Finally, although removing stopwords is helpful in information retrieval (El-Khair Reference El-Khair2017), this preprocessing method hurts dependency parsing (Fundel, Küffner, and Zimmer Reference Fundel, Küffner and Zimmer2007) because it may destroy the dependencies between entities such as prepositions (Agić, Merkler, and Berović Reference Agić, Merkler and Berović2013).
We also briefly explain the training of word embeddings because the process is similar to the text mining tasks (Jiang et al. Reference Jiang, Li, Huang and Jin2015; Ye et al. Reference Ye, Shen, Ma, Bunescu and Liu2016). Word2vec (Mikolov et al. Reference Mikolov, Chen, Corrado and Dean2013) creates a vector representation to intuitively measure the similarity between words. Both continuous bag-of-words model and continuous skip-gram model are used to predict the nearby words given the current word. GloVe (Pennington, Socher, and Manning Reference Pennington, Socher and Manning2014) leverages the conditional probability for word frequency in a word–word co-occurrence matrix, and the dimensionality reduction contributes to better performance. Embeddings from Language Model (Peters et al. Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018) uses Long Short-Term Memory (LSTM) to capture context-dependent word meanings, allowing for richer word representations. BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018) is the state-of-the-art language representation model, and it pretrains deep bidirectional representations in more than 100 languages. BERT uses a masked language model for bidirectional conditioning and predicts the next sentence for question-answering. BERT also supports cased and uncased versions of models (Kitaev, Cao, and Klein Reference Kitaev, Cao and Klein2019; Ji, Wei, and Xu Reference Ji, Wei and Xu2020), and we will discuss more about letter case normalization in Section 3.3.
Nevertheless, word embeddings with neural networks are not a cure-all solution for NLP applications (Abraham et al. Reference Abraham, Dutta, Mandal, Bhattacharya and Dutta2018; Agre, van Genabith, and Declerck Reference Agre, van Genabith and Declerck2018) for two reasons: the first reason is the necessary text preprocessing, and the second reason is the limitations of word embeddings themselves. Segmenting text into words (i.e., tokenization) is a prerequisite of creating word embeddings (Kudo and Richardson Reference Kudo and Richardson2018). In text ranking with BERT, document preprocessing reduces the data size of potentially relevant information in the corpus, making computationally expensive models scalable (Lin, Nogueira, and Yates Reference Lin, Nogueira and Yates2020). Woo, Kim, and Lee (Reference Woo, Kim and Lee2020) also validated combinations of text preprocessing techniques to optimize the performance of sentence models. But even with the best intention and preparation, word embeddings still have limitations in applications such as reasoning (i.e., natural language inference) (Zhou et al. Reference Zhou, Duan, Liu and Shum2020). Word embeddings also face difficulties in low-resource scenarios (Hedderich et al. Reference Hedderich, Lange, Adel, Strötgen and Klakow2020) such as minority languages (e.g., Tibetan) (Congjun and Hill Reference Congjun and Hill2021), due to an insufficient corpus on the language itself. Finally, potential bias in the data can propagate to the word embeddings, leading to unintended consequences such as unfair or discriminatory decisions (Papakyriakopoulos et al. Reference Papakyriakopoulos, Hegelich, Serrano and Marco2020; Basta, Costa-jussà, and Casas Reference Basta, Costa-jussà and Casas2021).
3. Commonly used text preprocessing practices
Extensive information is available for commonly used text preprocessing practices, including books and programming documentation (Lambert Reference Lambert2017). Open-source tools in Python include the natural language toolkit NLTK (Bird, Loper, and Klein Reference Bird, Loper and Klein2009) and scikit-learn (Pedregosa et al. Reference Pedregosa, Varoquaux, Gramfort, Michel, Thirion, Grisel, Blondel, Prettenhofer, Weiss, Dubourg, Vanderplas, Passos, Cournapeau, Brucher, Perrot and Duchesnay2011) for machine learning. Both packages have been continuously maintained and updated over the past decade. In addition to Python,
 $\mathsf{R}$
is also a popular tool in text modeling, with the book Text Mining with
$\mathsf{R}$
is also a popular tool in text modeling, with the book Text Mining with
 $\mathsf{R}$
: A Tidy Approach (Silge and Robinson Reference Silge and Robinson2017). These resources provide guidance to alleviate the pain of text preprocessing, but manual work is still required even with the aid of integrated software like H2O.aiFootnote 4 or Microsoft Azure Machine Learning Studio. Many parameter settings are available for fine-tuning, and for best results, different types of text corpora require different preprocessing methods (Yuhang et al. Reference Yuhang, Yue and Wei2010). However, to the best of our knowledge, there is not a set of comprehensive guidelines that can advise researchers on which text preprocessing practices to apply to a brand-new text corpus.
$\mathsf{R}$
: A Tidy Approach (Silge and Robinson Reference Silge and Robinson2017). These resources provide guidance to alleviate the pain of text preprocessing, but manual work is still required even with the aid of integrated software like H2O.aiFootnote 4 or Microsoft Azure Machine Learning Studio. Many parameter settings are available for fine-tuning, and for best results, different types of text corpora require different preprocessing methods (Yuhang et al. Reference Yuhang, Yue and Wei2010). However, to the best of our knowledge, there is not a set of comprehensive guidelines that can advise researchers on which text preprocessing practices to apply to a brand-new text corpus.
Hence, we would like to review some text preprocessing techniques and evaluate their strengths and weaknesses in terms of NLP so that researchers can determine which methods are most appropriate for their text data. For each method, we start with a brief description, explain its advantages and applications, and then discuss potential issues and situations when they are of concern. We can attempt to propose remedies, but a trade-off always exists between undercorrection and overcorrection. Each text corpus is different, and the goal of text mining also varies by project. This section is not a step-by-step execution guide on text preprocessing. We try to keep the methods sequential, but the methods discussed here do not have to be executed in the same order as in Figure 1. For instance, the information in punctuation is essential for question-answering (Ferret et al. Reference Ferret, Grau, Hurault-Plantet, Illouz, Jacquemin, Monceaux and Vilnat2002) and sentiment detection (Rosenthal and McKeown Reference Rosenthal and McKeown2013), so for these tasks we should keep the punctuation in the corpus until much later stages.
3.1 Removing formatting
Removing formatting in text usually needs to be done before any other preprocessing. If the data came from web scraping, the text would contain HTML markup, which needs to be removed first. For example, the original text string with HTML tags can be “
 $<\!\textrm{p}\!>$
actual content
$<\!\textrm{p}\!>$
actual content
 $<$
/p
$<$
/p
 $>$
”, and we want the “actual content” without the tags. The Python library BeautifulSoup (version 4.9.1 by Richardson Reference Richardson2020) is a popular tool for removing HTML tags, and the command to import this library is from bs4 import BeautifulSoup. In addition to the official documentation,Footnote 5 the book Website Scraping with Python (Hajba Reference Hajba2018) also contains a full chapter on using the BeautifulSoup library to extract and navigate content in HTML format. For the
$>$
”, and we want the “actual content” without the tags. The Python library BeautifulSoup (version 4.9.1 by Richardson Reference Richardson2020) is a popular tool for removing HTML tags, and the command to import this library is from bs4 import BeautifulSoup. In addition to the official documentation,Footnote 5 the book Website Scraping with Python (Hajba Reference Hajba2018) also contains a full chapter on using the BeautifulSoup library to extract and navigate content in HTML format. For the
 $\mathsf{R}$
community, the
$\mathsf{R}$
community, the
 $\mathsf{R}$
package textclean (Rinker Reference Rinker2018b) is also available for removing formatting, such as the function replace
$\mathsf{R}$
package textclean (Rinker Reference Rinker2018b) is also available for removing formatting, such as the function replace
 $\_$
html. This package also replaces common web symbols with their text equivalents, such as “¢” to “cents” and “£” to “pounds”. Finally, regular expressions can remove a wide range of text patterns, such as a person’s email signatures and “[8:05 AM]” in chat messages. Most programming languages support regular expressions, and manual preprocessing offers greatest flexibility in removing formatting. However, manual preprocessing using regular expressions is not only time-consuming but also error-prone (Shalaby, Zadrozny, and Jin Reference Shalaby, Zadrozny and Jin2019). This can easily introduce unwanted and unexpected artifacts to a corpus (or some parts of it). Hence, we recommend doing so only when the patterns cannot be handled by standard libraries, which are more rigorously tested for correctness (Goyvaerts and Levithan Reference Goyvaerts and Levithan2012).
$\_$
html. This package also replaces common web symbols with their text equivalents, such as “¢” to “cents” and “£” to “pounds”. Finally, regular expressions can remove a wide range of text patterns, such as a person’s email signatures and “[8:05 AM]” in chat messages. Most programming languages support regular expressions, and manual preprocessing offers greatest flexibility in removing formatting. However, manual preprocessing using regular expressions is not only time-consuming but also error-prone (Shalaby, Zadrozny, and Jin Reference Shalaby, Zadrozny and Jin2019). This can easily introduce unwanted and unexpected artifacts to a corpus (or some parts of it). Hence, we recommend doing so only when the patterns cannot be handled by standard libraries, which are more rigorously tested for correctness (Goyvaerts and Levithan Reference Goyvaerts and Levithan2012).
3.2 Tokenization
Tokenization decomposes each text string into a sequence of words (technically tokens) for computational analysis (Singh and Saini Reference Singh and Saini2014; Al-Khafaji and Habeeb Reference Al-Khafaji and Habeeb2017), and the choices in tokenization are more important than many researchers have realized (Habert et al. Reference Habert, Adda, Adda-Decker, de Marëuil, Ferrari, Ferret, Illouz and Paroubek1998; Verspoor et al. Reference Verspoor, Dvorkin, Cohen and Hunter2009). Given the sentence “I downloaded this software on-the-fly”, how many words will it contain after tokenization? The question boils down to whether “on-the-fly” is regarded as a compound word or separated into three words “on”, “the”, and “fly”. Although a white space between two words is often used as an explicit delimiter (Webster and Kit Reference Webster and Kit1992), we should not simply tokenize on white space (Clough Reference Clough2001). According to Barrett and Weber-Jahnke (Reference Barrett and Weber-Jahnke2011), there is not a universal tokenization method for English texts, not to mention other languages with different linguistic features. The Python NLTK tokenizer package is a useful tool to separate a text string into word tokens, but researchers still have to make subjective decisions based on the corpus (Nugent Reference Nugent2020). Trieschnigg et al. (Reference Trieschnigg, Kraaij and de Jong2007) showed that these subjective decisions, including tokenization, can contribute much more to model performance than the algorithm choice.
According to Cohen et al. (Reference Cohen, Hunter and Pressman2019), tokenization options can make the difference between getting a publishable result or not. For example, the type-token ratio is used to measure lexical richness, which indicates the quality of vocabulary in a corpus (Malvern and Richards Reference Malvern and Richards2012). Type-token ratio is calculated by dividing the number of types (distinct words) by the number of tokens (total words). But the terms “type” and “token” are loosely defined, and questions arise when we make decisions to count “on-the-fly” as one word or three words. Then, some researchers try various definitions of “type” and “token” and select one that produces a statistically significant result (Cohen et al. Reference Cohen, Hunter and Pressman2019). Such strategy is essentially p-hacking and hurts reproducibility in research (Head et al. Reference Head, Holman, Lanfear, Kahn and Jennions2015). A better practice is to be clear and consistent with the definitions of these terms in the tokenization process. Most existing literature does not specify the tokenization methods in detail, including some papers with actual implications for diagnosis of serious neurological and psychiatric disorders (Posada et al. Reference Posada, Barda, Shi, Xue, Ruiz, Kuan, Ryan and Tsui2017; Nasir et al. Reference Nasir, Aslam, Tariq and Ullah2020). Therefore, we need to think carefully about the potential impact from NLP to the published results, especially in clinical settings. We will further discuss the tokenization challenges for biomedical text in Section 3.2.1 and for various natural languages in Section 3.2.2.
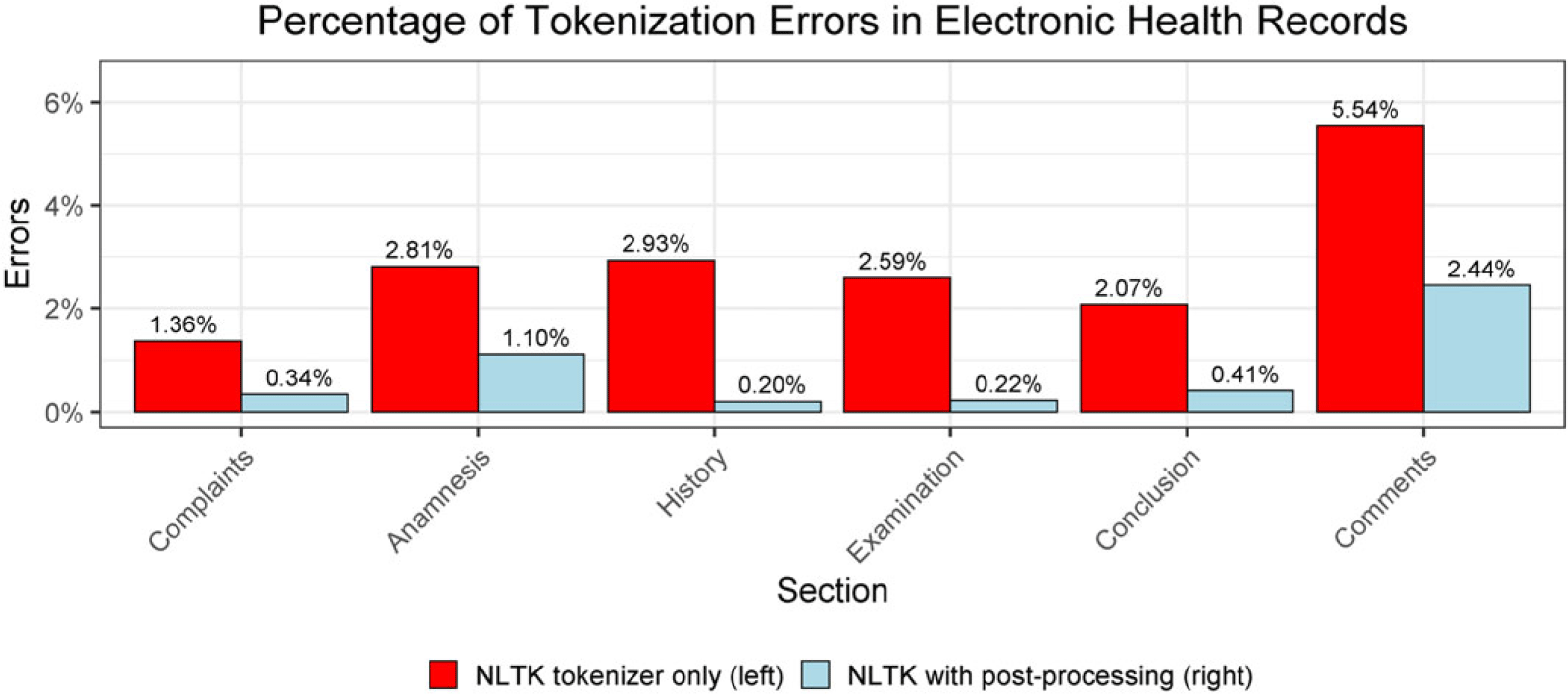
Figure 2. Postprocessing after using the NLTK tokenizer reduces the tokenization errors. The data are from Table 1 in Grön and Bertels (Reference Grön and Bertels2018).
3.2.1 Tokenization for biomedical text
In this section, we use biomedical text as an example of how domain-dependent tokenization can be done and the impact it has on downstream tasks. Biomedical text can be regarded as a sublanguage because it is substantially different than documents written in general language. The former contains more syntactic use of word-internal punctuation, such as “/” (forward slash) and “-” (dash) among the biomedical terms (Temnikova et al. Reference Temnikova, Nikolova, Baumgartner, Angelova and Cohen2013). This phenomenon applies not only in English but also in other languages such as Bulgarian, French, and Romanian (Névéol et al. Reference Névéol, Robert, Anderson, Cohen, Grouin, Lavergne, Rey, Rondet and Zweigenbaum2017; Mitrofan and Tufiş Reference Mitrofan and Tufiş2018). Moreover, Grön and Bertels (Reference Grön and Bertels2018) showed that many errors in processing biomedical clinical text are due to missing white space or nonstandard use of punctuation, such as “2004:hysterectomie” and “2004 : hysterectomie”. A custom script for postprocessing can reduce the tokenization errors, after the corpus of electronic health records is divided into words using the NLTK tokenizer. Figure 2 illustrates that the percentage of tokenization errors is reduced in the sections of complaints, anamnesis, history, examination, conclusion, and comments. The data are from Table 1 in Grön and Bertels (Reference Grön and Bertels2018). The postprocessing includes Greek letter normalization and break point identification (Jiang and Zhai Reference Jiang and Zhai2007). For instance, “MIP-1-
 $\alpha$
” and “MIP-1
$\alpha$
” and “MIP-1
 $\alpha$
” should both tokenize to “MIP 1 alpha”. Note that the hyphen does more than separating elements in a single entity, so simply removing it is not always appropriate. The hyphen in parentheses “(-)” can also indicate a knocked-out gene, such as “PIGA (-) cells had no growth advantage” in Cohen et al. (Reference Cohen, Ogren, Fox and Hunter2005).
$\alpha$
” should both tokenize to “MIP 1 alpha”. Note that the hyphen does more than separating elements in a single entity, so simply removing it is not always appropriate. The hyphen in parentheses “(-)” can also indicate a knocked-out gene, such as “PIGA (-) cells had no growth advantage” in Cohen et al. (Reference Cohen, Ogren, Fox and Hunter2005).
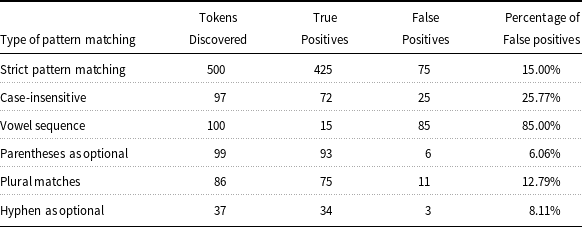
Table 1. Number and percentage of false positives for each type of pattern matching. The data are from Table 3 in Cohen et al. (Reference Cohen, Acquaah-Mensah, Dolbey and Hunter2002), and the rows after the first one refer to the extra tokens discovered beyond strict pattern matching
Trieschnigg et al. (Reference Trieschnigg, Kraaij and de Jong2007) also pointed out that tokenization decisions can contribute more to system performance than the text model itself. The text string “NF-
 $\kappa$
B/CD28-responsive” has at least 12 different tokenization results, depending on the preprocessing techniques used. The various approaches in tokenization resulted in up to 46 percent difference in the precision for document retrieval. The baseline version “nf
$\kappa$
B/CD28-responsive” has at least 12 different tokenization results, depending on the preprocessing techniques used. The various approaches in tokenization resulted in up to 46 percent difference in the precision for document retrieval. The baseline version “nf
 $\kappa$
b cd responsive” keeps only lowercase letters without numbers, and this achieves 32 percent precision in document retrieval. Another version “NF-
$\kappa$
b cd responsive” keeps only lowercase letters without numbers, and this achieves 32 percent precision in document retrieval. Another version “NF-
 $\kappa$
B/CD28-responsive” has only 17 percent, where the text string is separated by white space without further normalization. A custom tokenizer result “nf kappa nfkappa b cd 28 respons bcd28respons” has 40 percent precision, which is the highest among the 12 combinations attempted by Trieschnigg et al. (Reference Trieschnigg, Kraaij and de Jong2007). The last version replaces Greek letters with their English names and stems the word from “response” to “respons”. This version also regards “nf”, “kappa”, and “nfkappa” as different tokens to increase the likelihood of getting a match. The same applies to the separate tokens “b”,“cd”, “28”, “respons”, and the combined token “bcd28respons”. In addition to precision, we should also examine the recall to capture as many relevant gene names as they exist in the biomedical corpus.
$\kappa$
B/CD28-responsive” has only 17 percent, where the text string is separated by white space without further normalization. A custom tokenizer result “nf kappa nfkappa b cd 28 respons bcd28respons” has 40 percent precision, which is the highest among the 12 combinations attempted by Trieschnigg et al. (Reference Trieschnigg, Kraaij and de Jong2007). The last version replaces Greek letters with their English names and stems the word from “response” to “respons”. This version also regards “nf”, “kappa”, and “nfkappa” as different tokens to increase the likelihood of getting a match. The same applies to the separate tokens “b”,“cd”, “28”, “respons”, and the combined token “bcd28respons”. In addition to precision, we should also examine the recall to capture as many relevant gene names as they exist in the biomedical corpus.
Biomedical information retrieval often incorporates approximate string matching (a.k.a. fuzzy matching) for gene names (Morgan et al. Reference Morgan, Lu, Wang, Cohen, Fluck, Ruch, Divoli, Fundel, Leaman and Hakenberg2008; Cabot et al. Reference Cabot, Soualmia, Dahamna and Darmoni2016), because this allows small variations to be considered as the same gene name. Verspoor, Joslyn, and Papcun (Reference Verspoor, Joslyn and Papcun2003) discovered that approximately 6 percent of gene oncology terms are exact matches in the biomedical text, showing the necessity of non-exact matches to find the remaining 94 percent. For example, Figure 3 depicts that tokenization choices of the gene name “alpha-2-macroglobulin” lead to different results of pattern matching in biomedical text. With a strict pattern matching heuristic, there were 1846 gene names found in the corpus. Then, more flexible pattern matching methods can find additional gene names and increase the recall. For instance, the case-insensitive heuristic found an extra 864 gene names, and the vowel sequence heuristicFootnote 6 discovered an extra 586 matches. The data in Figure 3 are from Table 2 in Cohen et al. (Reference Cohen, Acquaah-Mensah, Dolbey and Hunter2002), and the concern of low precision (i.e., false positives) can be mitigated by discarding weaker matches. For each type of pattern matching used, Table 1 lists the number and percentage of false positives in the discovered tokens. The data are from Table 3 in Cohen et al. (Reference Cohen, Acquaah-Mensah, Dolbey and Hunter2002), and the rows after the first one refer to the extra tokens discovered beyond strict pattern matching. Most pattern matching schemes generated fewer than one-third of false positives, except that the vowel sequence heuristic produced 85% of false positives.

Figure 3. Tokenization decisions in the gene “alpha-2-macroglobulin” lead to different pattern matching results. The data are from Table 2 in Cohen et al. (Reference Cohen, Acquaah-Mensah, Dolbey and Hunter2002).
Approximate string matching in tokenization is also helpful in NER of biomedical and chemical terms (Akkasi et al. Reference Akkasi, Varoğlu and Dimililer2016; Bhasuran et al. Reference Bhasuran, Murugesan, Abdulkadhar and Natarajan2016; Kaewphan et al. Reference Kaewphan, Mehryary, Hakala, Salakoski and Ginter2017), but the tokenization methods still have room for improvement. Both Cohen et al. (Reference Cohen, Tanabe, Kinoshita and Hunter2004) and Groza and Verspoor (Reference Groza and Verspoor2014) show that choices in handling punctuation affect the tokenization results and eventually affect NER as well. Term variation can easily result in poor results of biomedical concept recognition, especially in noncanonical forms. A slight change such as “apoptosis induction” versus “induction of apoptosis” can result in the two entities being assigned into different equivalence classes (Cohen et al. Reference Cohen, Roeder, Baumgartner, Hunter and Verspoor2010).
Pretrained word embeddings for biomedical text are gradually increasing in popularity (Wang et al. Reference Wang, Liu, Afzal, Rastegar-Mojarad, Wang, Shen, Kingsbury and Liu2018), and one example is the BioBERT (Lee et al. Reference Lee, Yoon, Kim, Kim, Kim, So and Kang2020), which is pretrained on PubMed abstracts and PMC (PubMed Central) articles. Since different language models have different requirements on letter casing and punctuation, the BERT model (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018) supports multiple variants of input catering to various NLP applications (Ek, Bernardy, and Chatzikyriakidis Reference Ek, Bernardy and Chatzikyriakidis2020). Nevertheless, researchers still need to tokenize biomedical text into words before they can leverage pretrained embeddings and do it in accordance with the preprocessing protocol used in preparing the embedding training corpus (Corbett and Boyle Reference Corbett and Boyle2018; Pais et al. Reference Pais, Ion, Avram, Mitrofan and Tufis2021). Another challenge in leveraging these pretrained word embeddings is that word vectors may not reflect the internal structure of the words. For instance, the related words “deltaproteobacteria” and “betaproteobacteria” should be close (but not too close) in the embedding space; however, this relationship is not accounted for in the word2vec or GloVe models. Zhang et al. (Reference Zhang, Chen, Yang, Lin and Lu2019) proposed BioWordVec to leverage the subword information in pretraining, allowing the model to better predict new vocabulary from the subwords in the corpus.
3.2.2 Tokenization for various natural languages
Beyond general English and biomedical texts, tokenizing non-English corpora also has challenges that can affect the text mining performance. Most languages have compound terms that span multiple tokens, such as “sin embargo” (however) in Spanish and “parce que” (because) in French (Grana, Alonso, and Vilares Reference Grana, Alonso and Vilares2002). Habert et al. (Reference Habert, Adda, Adda-Decker, de Marëuil, Ferrari, Ferret, Illouz and Paroubek1998) applied eight different tokenization methods on a French corpus of size 450,000 and attempted to concatenate the compound terms (see Section 3.7 for multiword expressions). The number of words in the corpus differed by more than 10 percent, while the number of sentences could range from approximately 14,000 to more than 33,000. French also has contractions similar to English (e.g. “don’t” means “do not”) (Hofherr Reference Hofherr and Ackema2012). The article “l” (the) can be attached to the following noun, such as “l’auberge” (the hostel). The preposition “d” (of) works similarly, such as “noms d’auberge” (names of hostels). More details on handling word-internal punctuation will be discussed in Section 3.4.2.
Consider the case of Arabic tokenization. In Arabic, a single word can be segmented into at most four independent tokens, including prefix(es), stem, and suffix(es) (Attia Reference Attia2007). One example is the Arabic word “
![]() ” (“and our book”, or “wktAbnA” as the Buckwalter transliteration). This word is separated into three tokens: the prefix “
” (“and our book”, or “wktAbnA” as the Buckwalter transliteration). This word is separated into three tokens: the prefix “![]() ” “w” (and), the stem “
” “w” (and), the stem “![]() ” “ktAb” (book), and a possessive pronoun “
” “ktAb” (book), and a possessive pronoun “![]() ‘nA” (our) (Abdelali et al. Reference Abdelali, Darwish, Durrani and Mubarak2016). Note that Arabic writes from right to left, so the first token starts from the rightmost part of the word (Aliwy Reference Aliwy2012). Most text preprocessing systems now have a simple configuration for right-to-left languages (Litvak and Vanetik Reference Litvak and Vanetik2019), and the Python NLTK module nltk.corpus.reader.udhr supports major right-to-left languages including Arabic and Hebrew.Footnote 7
‘nA” (our) (Abdelali et al. Reference Abdelali, Darwish, Durrani and Mubarak2016). Note that Arabic writes from right to left, so the first token starts from the rightmost part of the word (Aliwy Reference Aliwy2012). Most text preprocessing systems now have a simple configuration for right-to-left languages (Litvak and Vanetik Reference Litvak and Vanetik2019), and the Python NLTK module nltk.corpus.reader.udhr supports major right-to-left languages including Arabic and Hebrew.Footnote 7
It is challenging to tokenize CJK languages because they use characters rather than letters, and each language contains thousands of characters (Zhang and LeCun Reference Zhang and LeCun2017). As a result, CJK tokenizers often encounter the OOV problem, and it is possible to get OOV characters as well as OOV words (Moon and Okazaki Reference Moon and Okazaki2021). Plus, CJK languages do not contain white space as obvious word boundaries in the corpus (Moh and Zhang Reference Moh and Zhang2012). Researchers have attempted to mitigate these problems by borrowing information from a parallel corpus of another language, commonly in multilingual corpora for translation (Luo, Tinsley, and Lepage Reference Luo, Tinsley and Lepage2013; Zhang and Komachi Reference Zhang and Komachi2018). Thanks to recent advances in neural networks and pretrained models like BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018), there has been progress in identifying CJK words that span multiple characters (Hiraoka, Shindo, and Matsumoto Reference Hiraoka, Shindo and Matsumoto2019). Moreover, tokenization results can be improved by leveraging subword information within the same language (Moon and Okazaki Reference Moon and Okazaki2020), and even subword pooling from other similar languages (Ács, Kádár, and Kornai Reference Ács, Kádár and Kornai2021). Tokenization in multiple languages helps not only in machine translation (Domingo et al. Reference Domingo, Garca-Martnez, Helle, Casacuberta and Herranz2018) but also in adversarial text generation (Li et al. Reference Li, Shao, Song, Qiu and Huang2020).
3.3 Text normalization
After the corpus is tokenized into words, text normalization is often the next step in preprocessing (Zhang et al. Reference Zhang, Baldwin, Ho, Kimelfeld and Li2013). Text normalization is defined as mapping noncanonical language to standardized writing (Lusetti et al. Reference Lusetti, Ruzsics, Göhring, Samardžić and Stark2018), and this consolidates text signals and decreases sparsity of the search space (Bengfort, Bilbro, and Ojeda Reference Bengfort, Bilbro and Ojeda2018). Text normalization is especially useful in dealing with large amounts of nonstandard writings, such as social media data (Baldwin and Li Reference Baldwin and Li2015; Lourentzou, Manghnani, and Zhai Reference Lourentzou, Manghnani and Zhai2019) and speech-to-text output in automatic speech recognition (Yolchuyeva, Németh, and Gyires-Tóth Reference Yolchuyeva, Németh and Gyires-Tóth2018; Chua et al. Reference Chua, Van Esch, Coccaro, Cho, Bhandari and Jia2018). One example is automatic correction of misspellings (Tan et al. Reference Tan, Hu, Hu, Li and Yen2020), for example “mountian” becomes “mountain”; otherwise, these misspellings will greatly increase the number of OOV words (Piktus et al. Reference Piktus, Edizel, Bojanowski, Grave, Ferreira and Silvestri2019). Appropriate letter casing is also beneficial in NER, because it is easier to recognize named entities in this form (Bodapati, Yun, and Al-Onaizan Reference Bodapati, Yun and Al-Onaizan2019). Generally speaking, stemming and lemmatization (Section 3.6) both belong to the text normalization area (Korenius et al. Reference Korenius, Laurikkala, Järvelin and Juhola2004; Samir and Lahbib Reference Samir and Lahbib2018), and the most common form of letter case normalization is converting the entire corpus to lowercase letters (Manning, Raghavan, and Schütze Reference Manning, Raghavan and Schütze2008). This is not only due to its prevalence and availability in programming languages (Thanaki Reference Thanaki2017) but also due to its demonstrated success in text classification performance (HaCohen-Kerner et al. Reference HaCohen-Kerner, Miller and Yigal2020). But despite its popularity, converting everything to lowercase can be problematic in certain NLP applications like text summarization and sentence boundary disambiguation, where uppercase at the beginning of the text may indicate the start of a sentence (Abdolahi and Zahedh Reference Abdolahi and Zahedh2017).
The main advantages of letter case normalization are consistency and consolidation of word variation (Şeker and Eryiğit Reference Şeker and Eryiğit2012). For instance, “Large” and “large” would be recognized as the same word because the letter case does not change the meaning of the word (Bokka et al. Reference Bokka, Hora, Jain and Wambugu2019; Rahm and Do Reference Rahm and Do2000). Some obviously proper nouns can also benefit from the lowercasing; for example “Europe” and “europe” refers to the exact same thing, so the two tokens can be consolidated into one. Note that different languages have different capitalization schemes; for example, German capitalizes all nouns, not just proper nouns as in English (Labusch, Kotz, and Perea Reference Labusch, Kotz and Perea2022). In biomedical data, case and format normalization improves the recall of finding a match of gene names, because a gene often has multiple variations of its name (Section 3.2.1 and Cohen et al. Reference Cohen, Acquaah-Mensah, Dolbey and Hunter2002). Even in neural networks, conversion to lowercase keeps the text feature extraction simple and reduces the number of distinct tokens (Preethi Reference Preethi2021). Lowercasing is also used in information retrieval because search queries do not have accurate capitalization, so the query cannot rely on capital letters to match against a corpus (Barr, Jones, and Regelson Reference Barr, Jones and Regelson2008). Especially in many speech recognition systems, the user’s input does not have inherent capitalization (Beaufays and Strope Reference Beaufays and Strope2013), which often results in all lowercase words in the query.
However, converting to lowercase can result in loss of semantic information where the letter capitalization indicates something other than the lowercase word. Some acronyms have different meanings than the same spelling in all lowercase—for example, “US” (United States) and “us” (a first-person plural pronoun). In addition to acronyms, many nouns have different meanings when they are in proper case, compared with in lowercase. Examples include last names such as Bush, Cooper, and Green. As a result, lowercasing is not very useful in NER, because the text model needs to identify proper nouns from the letter cases (Campbell et al. Reference Campbell, Li, Dagli, Acevedo-Aviles, Geyer, Campbell and Priebe2016). The lack of letter case information also contributes to the POS mistagging rate (Foster et al. Reference Foster, Cetinoglu, Wagner, Le Roux, Hogan, Nivre, Hogan and Van Genabith2011). In these NLP applications, truecasing (Lita et al. Reference Lita, Ittycheriah, Roukos and Kambhatla2003) is needed to achieve a balance between consolidating word variations and distinguishing proper nouns (Duran et al. Reference Duran, Avanço, Alusio, Pardo and Nunes2014). Moreover, words in ALL-CAPS can also be used to emphasize a strong emotion, so the capitalization is related to higher sentiment intensity. For example, the comment “The conference is AWESOME!” conveys a stronger emotion than “The conference is awesome!”. Hutto and Gilbert (Reference Hutto and Gilbert2014) compared the ratings on a Likert scale (from positive to negative) from comments on social media and discovered that the comments with ALL-CAPS express higher sentiment intensity than the ones without.
Handling accented words in languages like French and Spanish faces similar issues as converting letters to lowercase (Reference Zweigenbaum and GrabarZweigenbaum and Grabar 2002). Both text preprocessing steps normalizes the corpus at the character level, that is, character normalization. De-accenting works like lowercasing; the process replaces all accented characters (e.g., “àáâä”) with non-accented ones (e.g., “a”). This is helpful in information retrieval because words in queries may not be appropriately accented (Grabar et al. Reference Grabar, Zweigenbaum, Soualmia and Darmoni2003), but some semantic information is unavoidably lost. For instance, consider the Spanish word “té” (tea) with an accent and the word “te” (reflexive pronoun of “you”) without an accent. Removing the accent will map both words to the same token “te”, and the information of “tea” disappears. How to re-accent words from an unaccented corpus has been a challenging research problem (Zweigenbaum and Grabar Reference Zweigenbaum and Grabar2002b; Novák and Siklósi Reference Novák and Siklósi2015).
3.4 Handling punctuation
Although many researchers remove punctuation in a text corpus at the beginning of text preprocessing (Kwartler Reference Kwartler2017), punctuation conveys information beyond the words and should not always be ignored. Punctuation separates word strings to clarify meaning and conveys semantic information to human readers (Baldwin and Coady Reference Baldwin and Coady1978). Here is an example from Truss (Reference Truss2006): “Go, get him doctors!” means telling someone to find doctors for a male patient, because the comma separates the two clauses “Go” and “get him doctors”. In comparison, “Go get him, doctors!” means telling the doctors to catch a guy, because the clause “Go get him” is a command directed at the doctors. In NLP, punctuation also provides syntactic information for parsing, such as identifying complex sentences (Jones Reference Jones1994) and tokenizing biomedical terms (Díaz and López 2015). For example, a string “cd28-responsive” can be parsed into “cd28” and “responsive” (split words on the dash), or in a single token “cd28-responsive” (Trieschnigg et al. Reference Trieschnigg, Kraaij and de Jong2007).
According to Corpus Linguistics (Lüdeling and Kytö Reference Lüdeling and Kytö2008), punctuation is generally divided into three categories: sentence-final punctuation, sentence-internal punctuation, and word-internal punctuation.
-
(1) Sentence-final punctuation indicates the end of a sentence, such as a period, an exclamation mark, and a question mark.
-
(2) Sentence-internal punctuation are used in the middle of a sentence, including commas, parentheses, semicolons, colons, etc.
-
(3) Word-internal punctuation exists within a word, and examples include apostrophes and dashes.
These categories are neither mutually exclusive nor exhaustive; that is, a punctuation mark can belong to multiple categories or neither. For instance, languages such as Spanish have sentence-initial punctuation, which indicates sentence boundaries like sentence-final punctuation. One example is the “¿” (the inverted question mark) in the sentence “¿Dónde está el baño?” (Where is the bathroom?) But “¿” can also be used as sentence-internal punctuation, for example “Ana, ¿qué haces hoy?” (Ana, what are you doing today?) (Miller Reference Miller2014). English has complexity in punctuation as well. The period often marks the end of a sentence, but it can also be used in word-internal abbreviations, such as “e.g.” and “U.S.A.” The apostrophe can exist in both word-internal (e.g., “don’t”) and sentence-final (the end of a single quotation mark). The overlap can cause ambiguity in text segmentation, that is, tokenizing the corpus to detect words and sentences (Grefenstette and Tapanainen Reference Grefenstette and Tapanainen1994; Huang and Zhang Reference Huang, Zhang, Liu and Özsu2009).
The level of importance of breaking the corpus into sentences varies in NLP applications. For instance, text classification and topic modeling focus on the text documents, so each sentence itself is less of a concern (Blei, Ng, and Jordan Reference Blei, Ng and Jordan2003; Korde and Mahender Reference Korde and Mahender2012). But on the other hand, certain end-user applications rely heavily on the sentences from the corpus breakdown: text summarization needs sentence extraction as a prerequisite (Patil et al. Reference Patil, Pharande, Nale and Agrawal2015); machine translation of documents requires sentence segmentation (Matusov et al. Reference Matusov, Leusch, Bender and Ney2005; Kim and Zhu Reference Kim and Zhu2019); and question-answering utilizes the syntactic information from sentences (Li and Croft Reference Li and Croft2001). When breaking the corpus into sentences is important, this is often done first before we can continue the rest of preprocessing, such as identifying the entity’s POS from a sentence. Breaking into sentences is harder than it appears, due to not only the multiple functions of the period but also the nonstandard usage of punctuation in informal text (Villares-Maldonado 2017). Methods for sentence boundary disambiguation include maximum entropy approach (Reynar and Ratnaparkhi Reference Reynar and Ratnaparkhi1997; Le and Ho Reference Le and Ho2008), decision tree induction (Kiss and Strunk Reference Kiss and Strunk2006; Wong, Chao, and Zeng Reference Wong, Chao and Zeng2014), and other trainable sentence segmentation algorithms (Indurkhya and Damerau Reference Indurkhya and Damerau2010; Sadvilkar and Neumann Reference Sadvilkar and Neumann2020).
We need to distinguish separating punctuation from strings (Section 3.4.1) and removing punctuation (Section 3.4.2). Separating punctuation from strings means that we split a string into words or shorter strings based on the punctuation. Splitting a string into words on punctuation is essentially tokenization (see Section 3.2). This can be straightforward for a simple sentence like “I have a dog.” or “Cindy is my sister, and David is my brother.” But there is confusion in splitting the sentence “Then Dr. Smith left.” The first period is word-internal punctuation, while the second period is sentence-final punctuation. In the biomedical domain, tokenizing the sentence “I studied E. coli in a 2.5 percent solution.” will cause problems because the period following the uppercase “E” indicates an acronym rather than the end of the sentence. Also, “E. coli” is a biomedical term (Arens Reference Arens2004). When we separate a string into shorter strings via punctuation, discourse parsing is also of interest to understand the hierarchical and syntactic structure of the text string (Soricut and Marcu Reference Soricut and Marcu2003; Peldszus and Stede Reference Peldszus and Stede2015). On the other hand, removing punctuation means that we permanently eliminate punctuation from the corpus. Then, the corpus is reduced to words and numbers, and each token is separated by blank space. The reduced dataset may be easier to analyze in some cases, but researchers should be cautious in removing punctuation because the lost information will not return to the corpus later. When punctuation contains emotional context such as repeated exclamation marks “!!!” (Liu Reference Liu2015), removing punctuation can be detrimental in sentiment analysis, especially in social media data (Koto and Adriani Reference Koto and Adriani2015).
3.4.1 Separating punctuation from strings
Researchers often need to separate punctuation from strings in text preprocessing—not only to obtain the words but also to retrieve the syntactic information conveyed in the punctuation (Nunberg Reference Nunberg1990; Briscoe Reference Briscoe1996). For example, in the sentence “We sell cars, scooters, and bikes.”, the two commas separate the noun objects and the period indicates the end of the sentence. This shows that punctuation provides grammatical information to POS tagging (Olde et al. Reference Olde, Hoeffner, Chipman, Graesser and Research Group1999). Note that inconsistent use of punctuation can be worse than no punctuation (Bollmann Reference Bollmann2013), and in this case, discarding punctuation is preferable. Furthermore, using punctuation to separate text into shorter strings is helpful in machine translation, especially for long and complicated sentences (Yin et al. Reference Yin, Ren, Jiang and Kuroiwa2007). Parsing punctuation as part of input not only improves the quality of translation between European languages (Koehn, Arun, and Hoang Reference Koehn, Arun and Hoang2008) but also provides bilingual sentence alignment for a Chinese-English corpus (Yeh Reference Yeh2003).
We would like to highlight the application of discourse parsing, because this is a difficult research problem central to many tasks such as language modeling, machine translation, and text categorization (Joty et al. Reference Joty, Carenini, Ng and Murray2019). Discourse parsing needs the punctuation information to identify the relations between segments of text (Ji and Eisenstein Reference Ji and Eisenstein2014). Punctuation marks can serve as discourse markers to separate a text string into shorter parts, along with many conjunction words (Marcu Reference Marcu2000). A sentence with or without sentence-internal punctuation can have different meanings, and here is an example from Truss (Reference Truss2004): “A panda eats shoots and leaves.” means that a panda eats shoots and also eats leaves. But the sentence with a comma, “A panda eats, shoots and leaves.”, means that a panda eats something, shoots a gun, and leaves the scene. Figure 4(a) and (b) depict the two hierarchical structures, respectively. The syntactic structure from punctuation feeds into discourse structure (Venhuizen et al. Reference Venhuizen, Bos, Hendriks and Brouwer2018). For more complicated text structures, Ghosh et al. (Reference Ghosh, Johansson, Riccardi and Tonelli2011) leveraged a cascade of conditional random fields to automate discourse parsing, based on different sets of lexical, syntactic, and semantic characteristics of the text.
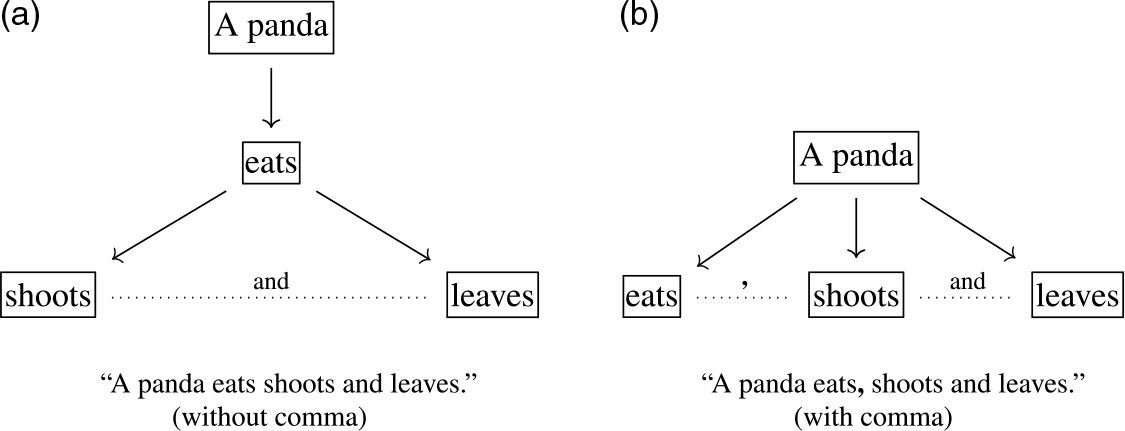
Figure 4. Hierarchical structure of a sentence with or without a comma. The sentence example is from Truss (Reference Truss2004).
Another issue we would like to discuss is the challenge of parsing nonstandard use of punctuation in social media text (Farzindar and Inkpen Reference Farzindar and Inkpen2020). Text messages often contain repeated punctuation such as “!!” and “??”, and these symbols are typically used as an emphasis of emotion, without adding extra lexical information (Liu and Jansen Reference Liu and Jansen2013). This emotional context is helpful in sentiment analysis (Rosenthal and McKeown Reference Rosenthal and McKeown2013), while in many other applications, it is acceptable to map repeated punctuation to a single one (Verma and Marchette Reference Verma and Marchette2019). We also need to be careful in processing emoticons because each of them should be assigned to a token, rather than being separated into characters (Rahman Reference Rahman2017). We recommend starting with a predefined list of emoticons to identify them in the text corpus, and one example list is available on Wikipedia.Footnote 8 Emoticons that contain all punctuation are easier to detect, such as “:)” and “:-(”. On the other hand, emoticons that contain both letters and punctuation are relatively harder to detect, such as “:p” and “;D” (Clark and Araki Reference Clark and Araki2011). In addition, the symbol @ can be part of an emoticon “@_@” or can be used as a mention to another user on social media. Similarly, the symbol # can be part of another emoticon “#)” or serve as the start of a hashtag. More about mentions (@username) and hashtags (#hashtag) will be discussed in Section 4.2.
Finally, if researchers are unsure whether the information from punctuation would be needed in their NLP work, we recommend separating punctuation from strings first. In this way, researchers still have the option to remove the punctuation tokens later. In comparison, if researchers remove punctuation from the corpus in the beginning, it is much harder to restore the punctuation unless they are willing to restart from the raw data.
3.4.2 Removing punctuation
Removing punctuation generally simplifies the text analysis and allows researchers to focus on words in the text corpus (Gentzkow, Kelly, and Taddy Reference Gentzkow, Kelly and Taddy2017; Denny and Spirling Reference Denny and Spirling2018). According to Carvalho, de Matos, and Rocio (Reference Carvalho, de Matos and Rocio2007), removing punctuation improves the performance of information retrieval. In NLP applications where punctuation is not of primary interest, it is easier to remove punctuation from the corpus than to normalize the nonstandard usage of punctuation for consistency (Cutrone and Chang Reference Cutrone and Chang2011; Fatyanosa and Bachtiar Reference Fatyanosa and Bachtiar2017). This is why many introductory books on NLP include removing punctuation as an early step of text preprocessing (Dinov Reference Dinov2018; Kulkarni and Shivananda Reference Kulkarni and Shivananda2019).
Moreover, many text mining models do not handle nonword characters well, so removing these characters beforehand is helpful in such situations. For instance, word2vec (Mikolov et al. Reference Mikolov, Chen, Corrado and Dean2013) takes a text corpus as input and produces efficient word representations in vector space, but word2vec does not support punctuation due to the optimized design toward words. Even when a text mining model allows nonword characters, it treats a word with punctuation as a different token than the same word without punctuation. Hence, the punctuation symbols can hurt the performance of modern parsers. The problem is that when punctuation exists in the input text, many parsers heavily rely on this feature, making it difficult to handle sentences with nonstandard use of punctuation. As a result, prediction suffers from punctuation inconsistency, and previous researchers have referred to the situation as “a nightmare at test time” (Søgaard, de Lhoneux, and Augenstein Reference Søgaard, de Lhoneux and Augenstein2018). Removing punctuation as feature deletion improves the robustness of a model (Globerson and Roweis Reference Globerson and Roweis2006).
Nevertheless, removing punctuation also removes the underlying semantic information from the corpus, which can have a negative effect on some NLP applications. In sentiment analysis, emotions in a sentence can be expressed from different punctuation, so removing punctuation would have a negative effect on the analysis results (Effrosynidis, Symeonidis, and Arampatzis Reference Effrosynidis, Symeonidis and Arampatzis2017). For example, “He liked the cake!” is different than “He liked the cake?”. Generally,“!” expresses a stronger emotion, while “?” often reverses the intention of the sentence. Wang et al. (Reference Wang, Liu, Song and Lu2014a) built a model using both words and punctuation to identify product reviews as positive or negative, and the model performed better than using only words without punctuation. In digital forensics, punctuation is also an important feature for authorship identification. The ALIAS (Automated Linguistic Identification and Assessment System) methodology performs many computation linguistic calculations to distinguish text written by different authors, and one aspect is the frequency and types of punctuation (Craiger and Shenoi Reference Craiger and Shenoi2007). A sentence in quotation marks can refer to a conversation or a quote from existing literature, so the writing style in that sentence can be highly different from the author’s usual style. This information can be used to determine who said what (Pareti et al. Reference Pareti, O’Keefe, Konstas, Curran and Koprinska2013), and Thione and van den Berg (Reference Thione and van den Berg2007) developed a US patent to use the quotation marks in text for speaker attribution.
If researchers decide to remove punctuation from the text corpus, a straightforward way to do so is using regular expressions. This is part of string processing in almost all programming languages. A starting list is the ASCII printable characters,Footnote 9 which consist of a white space, punctuation, uppercase English letters, lowercase English letters, and the numbers 0–9. Note that different languages have different space characters (e.g., Chinese vs. English) (Craven Reference Craven2004). In Python, the code from string import punctuation provides a string of commonly used punctuation symbols, including the open and close brackets. In
 $\mathsf{R}$
, the regular expression [:punct:] from the function grep also gives the same set of punctuation symbols as Python does. The
$\mathsf{R}$
, the regular expression [:punct:] from the function grep also gives the same set of punctuation symbols as Python does. The
 $\mathsf{R}$
package tm (Feinerer and Hornik Reference Feinerer and Hornik2018) has a function removePunctuation for easy implementation.
$\mathsf{R}$
package tm (Feinerer and Hornik Reference Feinerer and Hornik2018) has a function removePunctuation for easy implementation.
We need to be careful in treating word-internal punctuation, especially contractions (e.g., “you’re” vs. “you are”). Although most contractions drop out during the stopword removal phase since they are stopwords, some contractions have non-ignorable semantic meaning (e.g., “n’t” means “not”). Python NLTK includes the package contractions to split contracted words, and GutenTagFootnote 10 as an extension toolkit makes it possible to preserve within-word hyphenations and contractions (Brooke, Hammond, and Hirst Reference Brooke, Hammond and Hirst2015). We can also map contractions into their non-contracted forms (e.g., map “don’t” into “do not”) using a predefined list,Footnote 11 and this is beneficial to negation handling (Anderwald Reference Anderwald2003). For higher precision of contraction-splitting, we can use the Python library pycontractions (Beaver Reference Beaver2019) to incorporate context to determine the original form of ambiguous contractions. For example, the sentence “I’d like to know how I’d done that!” contains two “I’d”—the first one is from “I would” and the second one is from “I had”. However, many researchers remove punctuation without handling the contractions (Battenberg Reference Battenberg2012; Soriano, Au, and Banks Reference Soriano, Au and Banks2013; Xue et al. Reference Xue, Chen, Hu, Chen, Zheng and Zhu2020), so the demonstrations in this article do not include the contraction-mapping step.
3.5 Removing stopwords
Stopwords refer to the words that do not distinguish one text document from another in the corpus (Ferilli, Esposito, and Grieco Reference Ferilli, Esposito and Grieco2014), and this concept was first developed by Hans Peter Luhn (Reference Luhn1959). Examples include “the” and “or” because they are extremely common across documents, leading to little distinction among each document. Note that every stopword still has semantic content; for example, “the person” has a slightly different meaning than “a person”. It is inappropriate to say that stopwords are meaningless, just because their content does not differentiate text documents in the corpus. Stopwords are usually removed in the text preprocessing stage (Rajaraman and Ullman Reference Rajaraman and Ullman2011), so that text models can focus on the distinctive words for better performance (Babar and Patil Reference Babar and Patil2015; Raulji and Saini Reference Raulji and Saini2016). Otherwise, these nondistinctive words (i.e., stopwords) with high number of occurrences may distort the results of a machine learning algorithm (Armano, Fanni, and Giuliani Reference Armano, Fanni and Giuliani2015), especially in information retrieval (Zaman, Matsakis, and Brown Reference Zaman, Matsakis and Brown2011) and topic modeling (Wallach Reference Wallach2006). Removing stopwords greatly reduces the number of total words (“tokens”) but not significantly reduces the number of distinct words, that is, vocabulary size (Manning et al. Reference Manning, Raghavan and Schütze2008). Hvitfeldt and Silge (Reference Hvitfeldt and Silge2021) showed that even removing a small number of stopwords can moderately decrease the token count in the corpus, without a large influence on text mining models.
Nevertheless, stopwords are crucial for some NLP applications that require reasoning of text. In dependency parsing, stopwords are informative in understanding the connection between words in a sentence (Elming et al. Reference Elming, Johannsen, Klerke, Lapponi, Alonso and Søgaard2013; Poria et al. Reference Poria, Agarwal, Gelbukh, Hussain and Howard2014). For instance, the words “from” and “to” in “from Seattle to Houston” show the relationship between the nouns “Seattle” and “Houston” (Nivre Reference Nivre2005). Moreover, syntactic analysis of stopwords enables author identification (Arun, Suresh, and Madhavan Reference Arun, Suresh and Madhavan2009), and patterns of stopword usage can also be examined to detect plagiarism (Stamatatos Reference Stamatatos2011). An example of stopword-related feature is how often one uses pronouns to refer to a specific name (Sánchez-Vega et al. Reference Sánchez-Vega, Villatoro-Tello, Montes-y Gómez, Rosso, Stamatatos and Villaseñor-Pineda2019).
Stopwords can be divided into two categories—general and domain-specific. General stopwords include prepositions (e.g., “at”), pronouns (e.g., “you”), determiners (e.g., “the”), auxiliaries (e.g., “was”), and other words with relatively less semantic meaning. A predefined stopword list provides general stopwords that can be removed from the corpus in preprocessing (Nothman, Qin, and Yurchak Reference Nothman, Qin and Yurchak2018). On the other hand, domain-specific stopwords are words with non-ignorable semantic meaning in general, but they appear in almost every document in the specific domain. For example, the words “method”, “algorithm”, and “data” are considered domain-specific stopwords in a text corpus of machine learning papers (Fan, Doshi-Velez, and Miratrix Reference Fan, Doshi-Velez and Miratrix2017). In addition to predefining a list of domain-specific stopwords for removal, we can also leverage the TF-IDF scores to identify the corpus-specific stopwords. These words typically have a high TF and/or a low IDF, making them too prevalent to distinguish one document from another in the corpus (Kaur and Buttar Reference Kaur and Buttar2018). Other methods to automatically identify domain-specific stopwords include entropy (information theory) (Makrehchi and Kamel Reference Makrehchi and Kamel2008; Gerlach, Shi, and Amaral Reference Gerlach, Shi and Amaral2019) and Kullback–Leibler divergence (Lo, He, and Ounis Reference Lo, He and Ounis2005; Sarica and Luo Reference Sarica and Luo2020).
3.5.1 Existing stopword lists
According to Manning et al. (Reference Manning, Raghavan and Schütze2008), most researchers use a predefined stopword list to filter out the general stopwords, and the list typically includes fewer than 1000 words in their surface forms. For instance, “have” and “has” count as two separate stopwords in the list. Shorter lists include the Python NLTK (127 English stopwords) (Bird et al. Reference Bird, Loper and Klein2009) and the
 $\mathsf{R}$
package stopwords (175 stopwords) (Benoit, Muhr, and Watanabe Reference Benoit, Muhr and Watanabe2017). For longer lists, the Onix Text Retrieval Toolkit (Lextek International n.d) provides two versions—one with 429 words and the other with 571 words, where both lists are available in the
$\mathsf{R}$
package stopwords (175 stopwords) (Benoit, Muhr, and Watanabe Reference Benoit, Muhr and Watanabe2017). For longer lists, the Onix Text Retrieval Toolkit (Lextek International n.d) provides two versions—one with 429 words and the other with 571 words, where both lists are available in the
 $\mathsf{R}$
package lexicon (Rinker Reference Rinker2018a). Although Atwood (Reference Atwood2008) optimized the SQL query performance for information retrieval by removing the 10,000 most common English words from their corpus, this is an extreme case and we do not recommend removing so many stopwords. Schofield, Magnusson, and Mimno (Reference Schofield, Magnusson and Mimno2017) showed that a list of approximately 500 stopwords would already remove 40–50 percent of the corpus. Zipf (Reference Zipf1949) showed that the distribution of words is right-skewed, and that the word with the nth highest frequency is expected to appear only
$\mathsf{R}$
package lexicon (Rinker Reference Rinker2018a). Although Atwood (Reference Atwood2008) optimized the SQL query performance for information retrieval by removing the 10,000 most common English words from their corpus, this is an extreme case and we do not recommend removing so many stopwords. Schofield, Magnusson, and Mimno (Reference Schofield, Magnusson and Mimno2017) showed that a list of approximately 500 stopwords would already remove 40–50 percent of the corpus. Zipf (Reference Zipf1949) showed that the distribution of words is right-skewed, and that the word with the nth highest frequency is expected to appear only
 $1/n$
times as likely as the word with the highest frequency. Figure 5 is an illustration of the Zipf’s law, assuming that the most frequent word appears 1 million times in a hypothetical corpus. Zhang (Reference Zhang2008) and Corral, Boleda, and Ferrer-i Cancho (Reference Corral, Boleda and Ferrer-i Cancho2015) also show that stopwords are often the most common words in the corpus, which applies to most languages like English, French, or Finnish.
$1/n$
times as likely as the word with the highest frequency. Figure 5 is an illustration of the Zipf’s law, assuming that the most frequent word appears 1 million times in a hypothetical corpus. Zhang (Reference Zhang2008) and Corral, Boleda, and Ferrer-i Cancho (Reference Corral, Boleda and Ferrer-i Cancho2015) also show that stopwords are often the most common words in the corpus, which applies to most languages like English, French, or Finnish.
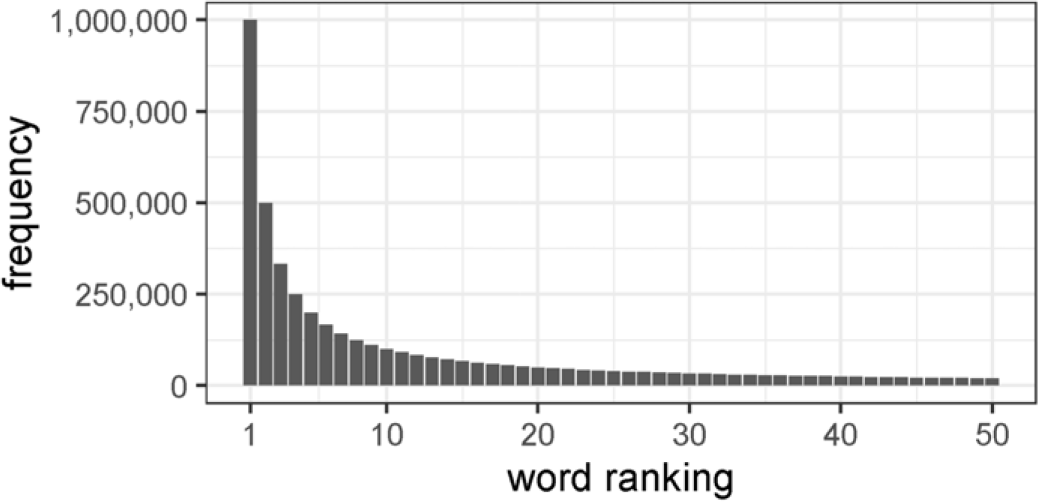
Figure 5. Illustration of the Zipf’s law (Zipf Reference Zipf1949).
An existing list often serves as a starting point for removing stopwords, and many researchers modify the list before use (Blanchard Reference Blanchard2007; Heimerl et al. Reference Heimerl, Lohmann, Lange and Ertl2014), in order to optimize text mining results (Amarasinghe, Manic, and Hruska Reference Amarasinghe, Manic and Hruska2015). For instance, since the list contains several words for negation (e.g., “no”, “not”), removing these words would alter the meaning of the context. Then the negation words should be excluded from the stopword list, and more details are discussed in Section 3.5.2. In addition to standard stopword lists, alternative options include publicly available e-books, such as Alice’s Adventures in Wonderland by Lewis Carroll, which can be used as a benchmark corpus to filter out nontechnical words from a technical database (Brooke et al. Reference Brooke, Hammond and Hirst2015). Project GutenbergFootnote 12 contains more than 60,000 e-books, whose US copyrights have expired.Footnote 13 Even better, this corpus is directly available in the
 $\mathsf{R}$
package gutenbergr (Robinson Reference Robinson2018). Good candidates for a stopword list should be a book of general content, so the technical words in the database would be more likely to stay. Since a book usually contains thousands of words, using one book as a stopword list would be sufficient. Choosing multiple books provides limited benefits because most general words (e.g., “where” and “say”) have already been removed by the first book.
$\mathsf{R}$
package gutenbergr (Robinson Reference Robinson2018). Good candidates for a stopword list should be a book of general content, so the technical words in the database would be more likely to stay. Since a book usually contains thousands of words, using one book as a stopword list would be sufficient. Choosing multiple books provides limited benefits because most general words (e.g., “where” and “say”) have already been removed by the first book.
There is a trade-off between using shorter stopword lists and longer ones, and it is up to the researchers to determine which works best for their text dataset. Using a shorter stopword list preserves more semantic information in the corpus, but the vocabulary size reduction may be insufficient. Using a longer stopword list further reduces the data, but words with potentially important information may also be accidentally eliminated from the corpus. Since words removed at the beginning would not return to the scope of data analysis, we need to be more cautious in using a longer stopword list (Fox Reference Fox1989). Therefore, we recommend starting from a short stopword list to retain potentially important “stopwords”. If the text mining results contain too many irrelevant words, we can gradually remove them by adding more words to the stopword list. This is a reversible process because if we find key insights are missing in the new version of the corpus, we can always select an earlier version with a smaller amount words removed.
3.5.2 Known issues with removing stopwords
Even in NLP applications where removing stopwords is safe and appropriate, we need to remember that the removed stopwords are permanently excluded from the corpus and will not re-enter the model (Yang and Wilbur Reference Yang and Wilbur1996). Therefore, we have to beware of unintentional removal of important text information. Some phrases contain only stopwords, and the whole phrase is removed if we filter out stopwords at the beginning. Examples include the band “The The” and the phrase “to be or not to be” from Hamlet. Multiword expressions consisting of both stopwords and non-stopwords face a slightly better situation. For example, the novel title “Gone with the Wind” becomes “Gone Wind” after we remove stopwords—the phrase still exists, but it is no longer understandable.
Being able to find stopwords is crucial for titles, especially in a search engine for media and/or e-commerce content (Lazarinis Reference Lazarinis2007). Although information retrieval generally ignores stopwords (Singhal Reference Singhal2001), Google Search allows the user to put a phrase in quotation marks for exact matching,Footnote 14 and so do most other search engines (White and Morris Reference White and Morris2007; Wilson Reference Wilson2009). Hence in text preprocessing, when the subject indicates that the corpus may have stopword-formed phrases, n-gramming should be done first to preserve the semantic information of these phrases. Moreover, if the NLP application involves dependency parsing or semantic reasoning, we have to be careful in removing stopwords, especially prepositions (Hartrumpf, Helbig, and Osswald Reference Hartrumpf, Helbig and Osswald2006). For example, the sentence “The box is in the house, and the toy is in the box.” will mean something different if we remove both “in”s. Hansen et al. (Reference Hansen, Hansen, Simonsen and Lioma2018) suggested not removing stopwords at all in syntax dependency parsing, because they may contain important syntactic information for sentence structure.
Finally, researchers should exclude “no” and “not” from the stopword list, because filtering out negation terms often reverts the meaning of the whole phrase. For example, the sentence “Zach doesn’t know physics.” becomes “zach know physics” (opposite meaning) after we remove the stopwords. It is possible to retain semantic information through antonym replacement or bigram creation. For instance, “not good” can be replaced with “bad” or “not
 $\_$
good” (as a bigram) (Perkins Reference Perkins2014; Chai Reference Chai2017). However, neither approach is perfect because the scope of “not” may be different than the word immediately following the negation (Councill, McDonald, and Velikovich Reference Councill, McDonald and Velikovich2010). Consider the sentence “He was not driving the car and she left to go home.” If we simply invert “not drive”, we lose the context that someone else may be driving the car instead (Fancellu, Lopez, and Webber Reference Fancellu, Lopez and Webber2016). Automatically detecting the scope of negation is a challenging problem (Blanco and Moldovan Reference Blanco and Moldovan2011), and recent advances include using deep learning approaches (Qian et al. Reference Qian, Li, Zhu, Zhou, Luo and Luo2016) and bidirectional LSTM (Fancellu et al. Reference Fancellu, Lopez, Webber and He2017; Morante and Blanco Reference Morante and Blanco2021).
$\_$
good” (as a bigram) (Perkins Reference Perkins2014; Chai Reference Chai2017). However, neither approach is perfect because the scope of “not” may be different than the word immediately following the negation (Councill, McDonald, and Velikovich Reference Councill, McDonald and Velikovich2010). Consider the sentence “He was not driving the car and she left to go home.” If we simply invert “not drive”, we lose the context that someone else may be driving the car instead (Fancellu, Lopez, and Webber Reference Fancellu, Lopez and Webber2016). Automatically detecting the scope of negation is a challenging problem (Blanco and Moldovan Reference Blanco and Moldovan2011), and recent advances include using deep learning approaches (Qian et al. Reference Qian, Li, Zhu, Zhou, Luo and Luo2016) and bidirectional LSTM (Fancellu et al. Reference Fancellu, Lopez, Webber and He2017; Morante and Blanco Reference Morante and Blanco2021).
3.6 Stemming and lemmatization
Both stemming and lemmatization normalize words to their base forms to reduce the vocabulary size of a text corpus (Manning et al. Reference Manning, Raghavan and Schütze2008). For example, “enjoys” and “enjoyed” are assigned to the same token “enjoy”. This decreases the space of word representation and improves the performance not only in information retrieval (Rajput and Khare Reference Rajput and Khare2015) but also in automatic text summarization (Torres-Moreno Reference Torres-Moreno2012). Liu et al. (Reference Liu, Christiansen, Baumgartner and Verspoor2012) created a lemmatizer tool for biomedical text and achieved an accuracy of 97.5 percent in a given collection of biomedical articles. Stemming and lemmatization have gained success in many NLP applications (Khyani et al. Reference Khyani, Siddhartha, Niveditha and Divya2020), but as a caveat, researchers are making a trade-off between semantic information and signal consolidation (Tabii et al. Reference Tabii, Lazaar, Al Achhab and Enneya2018).
3.6.1 Comparison of stemming and lemmatization
Before we compare stemming and lemmatization, we need to distinguish between inflectional and derivational morphology. Inflectional morphology refers to the word modification for grammatical purposes (e.g., verb tense, singular or plural noun form), without changing the word’s meaning or POS (Baerman Reference Baerman2015). When we normalize the word “enjoyed” to its base form “enjoy”, we are removing the inflectional morpheme from the word. On the other hand, derivational morphology adds a morpheme to the word and changes its semantic meaning and/or its POS (Crystal Reference Crystal1999). When we normalize the word “enjoyable” (adjective) to its base form “enjoy” (verb), the removed suffix is derivational because it changed the word from a verb to an adjective.
Stemming uses rules to reduce each word to its root (stem), and this strips off both inflectional and derivational variations. For English words, a commonly used stemming method is the Porter algorithm (Porter Reference Porter1980), along with the
 $\mathsf{R}$
package SnowballC (Bouchet-Valat Reference Bouchet-Valat2019).Footnote 15 This algorithm implements suffix stripping rules for word reduction, such as replacing “ies” with “i” and removing the last “s” before a consonant other than “s” (making a plural noun singular). The Porter algorithm also uses regular expressions and determines which rule takes priority. For instance, “hopping” becomes “hop”, but “falling” becomes “fall”, not “fal”. Due to the removal of suffixes, some tokens are not valid words and look like typos, such as “enjoi” (enjoy) and “challeng” (challenge). Other stemming algorithms include the Lovins stemmer (Lovins Reference Lovins1968) and the Lancaster stemmer (Paice and Hooper Reference Paice and Hooper2005).
$\mathsf{R}$
package SnowballC (Bouchet-Valat Reference Bouchet-Valat2019).Footnote 15 This algorithm implements suffix stripping rules for word reduction, such as replacing “ies” with “i” and removing the last “s” before a consonant other than “s” (making a plural noun singular). The Porter algorithm also uses regular expressions and determines which rule takes priority. For instance, “hopping” becomes “hop”, but “falling” becomes “fall”, not “fal”. Due to the removal of suffixes, some tokens are not valid words and look like typos, such as “enjoi” (enjoy) and “challeng” (challenge). Other stemming algorithms include the Lovins stemmer (Lovins Reference Lovins1968) and the Lancaster stemmer (Paice and Hooper Reference Paice and Hooper2005).
Lemmatization groups the inflectional forms of each word to its lemma (Sinclair Reference Sinclair2018), but lemmatization also considers the POS of the word (Bergmanis and Goldwater Reference Bergmanis and Goldwater2018) (e.g., noun, verb, adjective, or adverb). The WordNetLemmatizer package in Python NLTK analyzes the POS tag in a sentence input and lemmatizes each word, using the English lexical database WordNet.Footnote 16 The lemmatizer can also be used on isolated words by mapping to a single, most common lemma, or provide different outputs based on the specified POS tag. For instance, the word “leaves” can have the lemma “leave” (verb) or “leaf” (noun). Another example is mapping “better” and “best” to the same lemma “good”, which would not have been picked up by a stemmer. Lemmatization is especially useful in parsing morphologically rich languages, whose grammatical relations (e.g., subject, verb, object) are indicated by changes to the words (Tsarfaty et al. Reference Tsarfaty, Seddah, Goldberg, Kübler, Candito, Foster, Versley, Rehbein and Tounsi2010). Examples of such languages include Turkish, Finnish, Slovene, and Croatian (Gerz et al. Reference Gerz, Vulić, Ponti, Naradowsky, Reichart and Korhonen2018).
Lemmatization has a higher time complexity than stemming, but given modern big data technology, we do not need to be overly concerned about computational speed. Assume that the text corpus contains N words, and that each sentence has M words on average. Stemming takes O(N) time because the algorithm processes each word exactly once throughout the corpus. In comparison, lemmatization takes O(MN) time because the algorithm reads in the whole sentence to identify the context and POS tag beforehand. A compromise is context-free lemmatization, which produces the appropriate lemmas without using the whole context (Namly et al. Reference Namly, Bouzoubaa, El Jihad and Aouragh2020). By leveraging existing inflection tables, this method has achieved some success in English, Dutch, and German (Nicolai and Kondrak Reference Nicolai and Kondrak2016). Nevertheless, the actual computation time is often acceptable for either method. Mubarak (Reference Mubarak2017) lemmatized 7.4 million Arabic (a morphologically rich language) words on a personal laptop within 2 minutes, indicating that the computational speed is usually fast. Note that English has only eight inflectional morphemes,Footnote 17 and many researchers still use stemming for simplicity (Kao and Poteet Reference Kao and Poteet2007; Meyer, Hornik, and Feinerer Reference Meyer, Hornik and Feinerer2008).
3.6.2 Known issues
Neither stemming nor lemmatization is perfect. Both methods suffer from over-consolidation of words—assigning two word forms with clearly different meanings to the same token, such as mapping both “computer” and “computation” to the token “comput” (Jivani Reference Jivani2011). A known way to avoid over-consolidation is to use the lempos format (lemma with POS tag, e.g., “set
 $\_$
NOUN”), as implemented by Akhtar, Sahoo, and Kumar (Reference Akhtar, Sahoo and Kumar2017) and Ptaszynski et al. (Reference Ptaszynski, Lempa, Masui, Kimura, Rzepka, Araki, Wroczynski and Leliwa2019). Moreover, some words require context to determine its true base form or lemma. A fundamental question to ask is whether we should perform stemming and/or lemmatization in the first place. The answer would be “yes” in most cases, but depending on the goal of the text data mining project, we may have to reconsider the pros and cons of consolidating word forms before making the decision.
$\_$
NOUN”), as implemented by Akhtar, Sahoo, and Kumar (Reference Akhtar, Sahoo and Kumar2017) and Ptaszynski et al. (Reference Ptaszynski, Lempa, Masui, Kimura, Rzepka, Araki, Wroczynski and Leliwa2019). Moreover, some words require context to determine its true base form or lemma. A fundamental question to ask is whether we should perform stemming and/or lemmatization in the first place. The answer would be “yes” in most cases, but depending on the goal of the text data mining project, we may have to reconsider the pros and cons of consolidating word forms before making the decision.
A risk of consolidating word forms is the loss of sentiment information (Haddi, Liu, and Shi Reference Haddi, Liu and Shi2013; Potts nd). Words of the same root can have different sentiments, but they are mapped to the same token. For example, both “objective” (positive) and “objection” (negative) are mapped to “object” under the Porter stemming algorithm. As a result, we do not know whether the token “object” indicates something positive or negative. Bao et al. (Reference Bao, Quan, Wang and Ren2014) also show that both stemming and lemmatization negatively affect Twitter sentiment classification. Even conservative lemmatization can have a negative impact on POS tagging and NER (Cambria et al. Reference Cambria, Poria, Gelbukh and Thelwall2017). Some named entities would not be recognizable after the corpus is lemmatized, such as the American rock band “Guns N’ Roses” versus “gun n rose”. Therefore, it is better to perform these NLP steps before we lemmatize the corpus.
Another risk is losing the spelling variation as a writing style element, which can be detrimental to authorship attribution (Stamatatos Reference Stamatatos2008). For instance, spelling discrepancies exist between American English and British English, such as “center” versus “centre” and “canceled” (one “l”) versus “cancelled” (two “l”s). Assume we have two documents—one in American English and the other in British English. The two documents should be written by different people, since it is unlikely that someone would use both forms in writing. But after we perform stemming/lemmatization and map each pair to the same token, we cannot distinguish between the two English variations. One potential solution is to identify the words with spelling variations and add an underline character to each word, making the stemmer/lemmatizer “think” they are different tokens. In this way, the algorithm would preserve these words in their original forms.
3.7 N-gramming and identifying multiword expressions
N-gramming is a text preprocessing approach to analyze the phrases consisting of n words in the corpus, that is, n-grams (Dunning Reference Dunning1994). Some n-grams have special meaning (e.g., “New York” and “neighborhood watch”), and they are called multiword expressions (Blei and Lafferty Reference Blei and Lafferty2009; Masini Reference Masini2019). The formal definition of multiword expressions is “a class of linguistic forms spanning conventional word boundaries that are both idiosyncratic and pervasive across different languages,” as stated by Constant et al. (Reference Constant, Eryiğit, Monti, Van Der Plas, Ramisch, Rosner and Todirascu2017). Although some multiword expressions come from n-grams, others are syntactically flexible and may contain different forms that map to the same expression (Sag et al. Reference Sag, Baldwin, Bond, Copestake and Flickinger2002). For instance, the two sentences “Please contact the Customer Help Desk.” and “Please contact the Customer Helpdesk.” mean the same thing. It is challenging to identify the two multiword expressions “customer help desk” (three words) and “customer helpdesk” (two words), since neither may have enough occurrences in the corpus to be detected. Given the complexity of multiword expressions, Sailer and Markantonatou (Reference Sailer and Markantonatou2018) regarded them as a difficult problem in NLP applications and computational linguistics. Fortunately, there are programming tools to reduce the burden of n-gramming the corpus. The Python modules include Phraser in gensim (Řehůřek and Sojka Reference Řehůřek and Sojka2010) and nltk.tokenize.mwe in NLTK (Bird et al. Reference Bird, Loper and Klein2009). The
 $\mathsf{R}$
packages include quanteda (Benoit et al. Reference Benoit, Watanabe, Wang, Nulty, Obeng, Müller and Matsuo2018) and udpipe (Wijffels Reference Wijffels2021). However, post hoc human judgment is often necessary in identifying the true multiword expressions (Seretan Reference Seretan2011; Poddar Reference Poddar2016).
$\mathsf{R}$
packages include quanteda (Benoit et al. Reference Benoit, Watanabe, Wang, Nulty, Obeng, Müller and Matsuo2018) and udpipe (Wijffels Reference Wijffels2021). However, post hoc human judgment is often necessary in identifying the true multiword expressions (Seretan Reference Seretan2011; Poddar Reference Poddar2016).
Retaining multiword expressions is essential because many text mining models rely on the bag-of-words assumption and disregard word order (Wang, McCallum, and Wei Reference Wang, McCallum and Wei2007), a.k.a. bag-of-words models. Although bag-of-words models are fast and efficient (Joulin et al. Reference Joulin, Grave, Bojanowski and Mikolov2016), their failure to account for word order results in losing semantic meaning (Wallach Reference Wallach2006). An example is “milk chocolate” versus “chocolate milk”, where the two phrases consist of the same words but have different meanings. Word order encodes discourse information (Kaiser and Trueswell Reference Kaiser and Trueswell2004), especially in free word order languages with significant inflection and discourse functions reflected in the word order (Slioussar Reference Slioussar2011). These languages include Finnish, Hindi, Russian, Turkish, and many more (Hoffman Reference Hoffman1996). Hence, we need n-gramming to preserve multiword expressions as tokens, so each multiword expression will not be separated in the permutation phase of the model. Das et al. (Reference Das, Pal, Mondal, Dalui and Shome2013) also showed that n-gramming helps in keyword extraction because the approach can include named entities, many of which are multiword expressions such as WHO (World Health Organization).
Multiword expressions are important for a wide variety of NLP tasks, including topic identification (Koulali and Meziane Reference Koulali and Meziane2011) and machine translation (Lambert and Banchs Reference Lambert and Banchs2006; Tan and Pal Reference Tan and Pal2014). Detecting multiword expressions is also beneficial to word sense disambiguation, that is, determining which meaning of the word is used in a particular context (Masini Reference Masini2005; Finlayson and Kulkarni Reference Finlayson and Kulkarni2011). N-gramming detects and retains many multiword expressions (e.g., “White House” and “New Jersey”) before we feed the data into a statistical model, so these multiword expressions will not be separated in the analysis (Bekkerman and Allan Reference Bekkerman and Allan2004). This is a useful approach with demonstrated success in many text mining applications (Doraisamy and Rüger Reference Doraisamy and Rüger2003; Los and Lubbers Reference Los and Lubbers2019). With the increasing popularity of word embeddings, more advanced methods like deep learning and L1 regularization are available to identify multiword expressions (Berend Reference Berend2018; Ashok, Elmasri, and Natarajan Reference Ashok, Elmasri and Natarajan2019). We emphasize that n-gramming is not a panacea for retaining multiword expressions or semantic information. Any text preprocessing technique will result in some loss of semantic information from the corpus (Fesseha et al. Reference Fesseha, Xiong, Emiru, Diallo and Dahou2021), and in an extreme case, n-gramming even decreased cross-lingual model performance (Kamps, Adafre, and De Rijke Reference Kamps, Adafre and De Rijke2004).
Before getting into the construction of n-grams and detection of multiword expressions, we also add that n-grams play a major role in creating probabilistic language models (Bengio et al. Reference Bengio, Ducharme, Vincent and Jauvin2003; Qudar and Mago Reference Qudar and Mago2020), such as the conditional probability of words occurring together. N-grams can represent linguistic patterns and indicate the perplexity of the language model (Toral et al. Reference Toral, Pecina, Wang and Van Genabith2015). Perplexity is defined as the inverse probability of the observed test data (Gamallo, Campos, and Alegria Reference Gamallo, Campos and Alegria2017), or the effective number of equally likely words identified by the language model (Lafferty and Blei Reference Lafferty and Blei2006). The perplexity measure is especially useful in comparing the complexity of multilingual language models (Buck, Heafield, and Van Ooyen Reference Buck, Heafield and Van Ooyen2014; Zeng et al. Reference Zeng, Xu, Chong, Chng and Li2017. Note that our focus is on the n-gramming process itself, rather than the maintenance of word order. Recovering Chomsky’s Deep Structure across languages is a completely different research field in linguistics (Chomsky Reference Chomsky1969; Lan Reference Lan1996).
3.7.1 Constructing N-grams from a text document
We create n-grams as phrases of n consecutive words in a text document (Gries and Mukherjee Reference Gries and Mukherjee2010), using a moving window of length n across the text, that is, “shingling” (Broder et al. Reference Broder, Glassman, Manasse and Zweig1997; Huston, Culpepper, and Croft Reference Huston, Culpepper and Croft2014). We use the definition of word-based n-grams, which is different than the character-based n-gram definition, which refers to a string of n characters (Houvardas and Stamatatos Reference Houvardas and Stamatatos2006). Words are also called unigrams, while bigrams and trigrams denote the two-word and three-word phrases in the corpus, respectively.
A document consisting of n words would have n unigrams,
 $n-1$
bigrams, and
$n-1$
bigrams, and
 $n-2$
trigrams. For example, the text “one should be humble while studying advanced calculus” contains eight unigrams, seven bigrams, and six trigrams as below:
$n-2$
trigrams. For example, the text “one should be humble while studying advanced calculus” contains eight unigrams, seven bigrams, and six trigrams as below:
-
Unigrams: “one”, “should”, “be”, “humble”, “while”, “studying”, “advanced”, “calculus”
-
Bigrams: “one should”, “should be”, “be humble”, “humble while”, “while studying”, “studying advanced”, “advanced calculus”
-
Trigrams: “one should be”, “should be humble”, “be humble while”, “humble while studying”, “while studying advanced”, “studying advanced calculus”
The ordering of text preprocessing modules is key to success. Converting the string of text into unigrams is equivalent to tokenization (see Section 3.2), and this is a prerequisite for removing stopwords and n-gramming (Putra, Gunawan, and Suryatno Reference Putra, Gunawan and Suryatno2018; Chaudhary and Kshirsagar Reference Chaudhary and Kshirsagar2018). Note that this example inputs a full sentence in raw text, without stopword removal or stemming/lemmatization. As a result, the unigrams contain general stopwords such as “one” and “be”, which are not ideal. The unigram “studying” is not reverted to its base form “study”, either. That’s why removing stopwords and stemming/lemmatization are often performed before n-gramming (Anandarajan et al. Reference Anandarajan, Hill and Nolan2019; Arief and Deris Reference Arief and Deris2021), as illustrated in Figure 1.
In terms of semantic meaning, only the phrase “advanced_calculus” seems special enough to be a multiword expression because it is the name of a college-level class. We need systematic methods to determine which n-grams are multiword expressions and which are not (Baldwin and Kim Reference Baldwin and Kim2010). Moreover, n-gramming has limitations because some multiword expressions are not n consecutive words (i.e., n-grams). They may skip a few words in between and hence are called skip-grams (Guthrie et al. Reference Guthrie, Allison, Liu, Guthrie and Wilks2006). This reflects the challenge of modeling long-distance dependencies in natural languages (Deoras, Mikolov, and Church Reference Deoras, Mikolov and Church2011; Merlo Reference Merlo2019).
In general, multiword expressions should be both practically and statistically significant. Practical significance means that the phrase is of practical interest, that is, it occurs many times in the corpus. Rare phrases should be removed from the n-gram pool (Grobelnik and Mladenic Reference Grobelnik and Mladenic2004). On the other hand, statistical significance means that the words forming the multiword expression have a relatively high probability to stay together (Brown et al. Reference Brown, Desouza, Mercer, Pietra and Lai1992). Thus, a multiword expression should be an n-gram of statistical interest, rather than n words that just happen to appear together many times. Sections 3.7.2 and 3.7.3 will discuss the practical and statistical significance requirements for multiword expressions. This is by no means the only way to determine which n-grams are multiword expressions; other methods include finding the longest common subsequence (Duan et al. Reference Duan, Lu, Wu, Hu and Tian2006) and using linguistic features of each sentence (Boukobza and Rappoport Reference Boukobza and Rappoport2009).
3.7.2 Multiword expressions: Practical significance
For practical significance, the easiest way is to set a minimum frequency and consider any n-gram to be a multiword expression if its number of occurrences is higher than the cutoff (Wei et al. Reference Wei, Miao, Chauchat, Zhao and Li2009). Since general stopwords have been removed from the corpus, uninformative bigrams (e.g., “you are”, “is an”) are less likely to appear. The article “a”, “an”, or “the” often precedes a noun, and such bigrams (e.g., “the artist”) are not helpful, either. Setting a cutoff frequency ensures that the multiword expressions are of practical interest, and this approach has proven success in computational linguistics (Pantel and Pennacchiotti Reference Pantel and Pennacchiotti2006; Lahiri and Mihalcea Reference Lahiri and Mihalcea2013). As a note of caution, Wermter and Hahn (Reference Wermter and Hahn2005) showed that a high number of occurrences does not always mean the n-gram is a term, that is, a multiword expression with special meaning. An example is in the biomedical field, the phrase “t cell response” has a higher frequency than “long terminal repeat”, but the latter is a term while the former is not.
The cutoff frequency can be determined empirically, and Microsoft Azure Machine Learning Studio recommends a starting value of 5 as the minimum frequency for multiword expressions (Microsoft 2019). Previous researchers had success in using the cutoff frequency of 5, while they analyzed a corpus of 450 political blog posts, with around 289,000 total words at the time when the corpus was ready for n-gramming (Soriano et al. Reference Soriano, Au and Banks2013; Au Reference Au2014). Inevitably, a low threshold of minimum frequency results in a steep increase in computation time as the corpus gets larger due to the need of processing the massive number of low-frequency n-grams (Brants et al. Reference Brants, Popat, Xu, Och and Dean2007). The New York Times Annotated Corpus (Sandhaus Reference Sandhaus2008) contains more than 1.8 million newspaper articles and more than 1.05 billion words, so Berberich and Bedathur (Reference Berberich and Bedathur2013) set the cutoff frequency to 100. The ClueWeb09 dataset (Callan et al. Reference Callan, Hoy, Yoo and Zhao2009) is even larger, with more than 50 million web documents and more than 21.4 billion English words. Accordingly, Berberich and Bedathur (Reference Berberich and Bedathur2013) increased the cutoff frequency to 1000. The Google Syntactic Ngrams English corpus (Goldberg and Orwant Reference Goldberg and Orwant2013) consists of more than 345 billion words, and Ng, Bansal, and Curran (Reference Ng, Bansal and Curran2015) set the cutoff frequency to as high as 10,000.
The histograms of n-grams for each n are right-skewed (Ha et al. Reference Ha, Hanna, Ming and Smith2009; Bardoel Reference Bardoel2012). The distribution generally follows the power law (Jean-Baptiste Reference Jean-Baptiste1916; Newman Reference Newman2005), just like the illustration of Zipf’s law (Zipf Reference Zipf1949) in Figure 5. The vast majority of bigrams appear only once, and the phenomenon of trigrams is more extreme. Dressel (Reference Dressel2016) demonstrated that only 19 percent of the trigrams occurred more than once in their corpus before stopwords were removed. We also n-grammed the publicly available e-book Wuthering Heights from Project Gutenberg (Robinson Reference Robinson2018), which contains 120,772 total words and 9207 total distinct words in the corpus. Table 2 provides the n-gram statistics of Wuthering Heights: over a quarter of unigrams (words) appear 5 or more times in the corpus, so it is viable to further examine the frequency trends of the unigrams. For bigrams, more than three-quarters of them appear only once, leaving us with about a quarter of the unique bigrams to analyze. Finally, more than 90 percent of the trigrams and 4-grams appear only once in the corpus, showing that only a small percentage of longer n-grams may be of interest.
Table 2. The n-gram statistics of Wuthering Heights
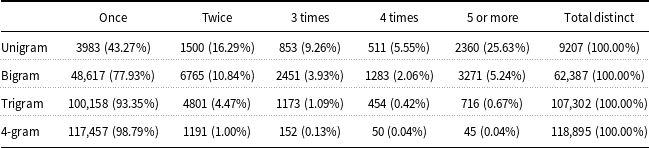
Remark. N-grams should not be calculated over sentence boundaries (Buerki Reference Buerki2017), but Huston, Moffat, and Croft (Reference Huston, Moffat and Croft2011) showed that using sentence boundaries as separation can greatly reduce the number of 4-grams produced. Since the majority of longer n-grams will be dropped by the thresholding, empirically it does not matter whether sentence boundaries are considered in the n-gramming process.
3.7.3 Multiword expressions: Statistical significance
For statistical significance, we focus on conditional probability (Jurafsky and Martin Reference Jurafsky and Martin2008)—given one or more words, the probability of another word immediately following the sequence. In mathematical notation, a string of n words is written as
 $w_1 w_2 \cdots w_n$
. For the bigram
$w_1 w_2 \cdots w_n$
. For the bigram
 $w_1 w_2$
, the conditional probability of
$w_1 w_2$
, the conditional probability of
 $w_2$
following
$w_2$
following
 $w_1$
is
$w_1$
is
 \begin{equation}P(w_2 | w_1) = \dfrac{P(w_1 w_2)}{P(w_1)} = \dfrac{\text{Count}(w_1 w_2)}{\text{Count}(w_1)},\end{equation}
\begin{equation}P(w_2 | w_1) = \dfrac{P(w_1 w_2)}{P(w_1)} = \dfrac{\text{Count}(w_1 w_2)}{\text{Count}(w_1)},\end{equation}
where the function Count(s) outputs the frequency of the word string s in the corpus.
Assuming the corpus contains N words, we have the probability of getting each word as
 $P(w) = \text{Count}(w)/N$
, and the probability of getting each bigram as
$P(w) = \text{Count}(w)/N$
, and the probability of getting each bigram as
 $P(w v) = \text{Count}(w v)/(N-1)$
. The only difference is that the corpus contains
$P(w v) = \text{Count}(w v)/(N-1)$
. The only difference is that the corpus contains
 $N-1$
bigrams. When N is sufficiently large, N and
$N-1$
bigrams. When N is sufficiently large, N and
 $N-1$
are asymptotically equal, so we do not make a distinction in calculating
$N-1$
are asymptotically equal, so we do not make a distinction in calculating
 $P(w_2 | w_1)$
.
$P(w_2 | w_1)$
.
To determine whether the bigram
 $w_1 w_2$
is a multiword expression, we test against the two competing hypotheses:
$w_1 w_2$
is a multiword expression, we test against the two competing hypotheses:
-
 $H_0:\; P(w_2 | w_1) \leq P(w_2)$
$H_0:\; P(w_2 | w_1) \leq P(w_2)$
-
$H_1:\; P(w_2 | w_1) > P(w_2)$


The framework is adopted from Chai (Reference Chai2022). This is a one-sided hypothesis test because only a large
 $P(w_2 | w_1)$
is of interest. When the p-value is less than 0.05, we reject
$P(w_2 | w_1)$
is of interest. When the p-value is less than 0.05, we reject
 $H_0$
and conclude that
$H_0$
and conclude that
 $w_1 w_2$
is a multiword expression.
$w_1 w_2$
is a multiword expression.
We can extend the bigram testing scheme to n-grams, but the conditional probability of seeing the nth word given the first
 $n-1$
words,
$n-1$
words,
 $P(w_n | w_1 \cdots w_{n-1})$
, is unreasonable to compute. Chances are high that the
$P(w_n | w_1 \cdots w_{n-1})$
, is unreasonable to compute. Chances are high that the
 $(n-1)$
word phrase appears only once in the corpus, making this conditional probability 100 percent, which is not what we are looking for. Instead, we can approximate the conditional probability with
$(n-1)$
word phrase appears only once in the corpus, making this conditional probability 100 percent, which is not what we are looking for. Instead, we can approximate the conditional probability with
 \begin{equation}P(w_n | w_1 \cdots w_{n-1}) \approx P(w_n | w_{n-1}) = \dfrac{\text{Count}(w_{n-1} w_n)}{\text{Count}(w_{n-1})},\end{equation}
\begin{equation}P(w_n | w_1 \cdots w_{n-1}) \approx P(w_n | w_{n-1}) = \dfrac{\text{Count}(w_{n-1} w_n)}{\text{Count}(w_{n-1})},\end{equation}
where the Markov assumption states that
 $w_n$
depends on only the previous word
$w_n$
depends on only the previous word
 $w_{n-1}$
(Fosler-Lussier Reference Fosler-Lussier1998; Tran and Sharma Reference Tran and Sharma2005). Then, the n-gramming question is reduced to whether
$w_{n-1}$
(Fosler-Lussier Reference Fosler-Lussier1998; Tran and Sharma Reference Tran and Sharma2005). Then, the n-gramming question is reduced to whether
 $w_{n-1} w_n$
is a multiword expression, and the hypothesis testing framework still applies.
$w_{n-1} w_n$
is a multiword expression, and the hypothesis testing framework still applies.
Many automated tools are available to perform n-gramming, but most of them simply pull all n-grams from the input text. For example, the function tokens_ngrams in the
 $\mathsf{R}$
package quanteda (Benoit et al. Reference Benoit, Watanabe, Wang, Nulty, Obeng, Müller and Matsuo2018) generates the n-grams, but this package does not provide support for how to test n-grams for multiword expressions. It is still up to the researcher to determine which ones are multiword expressions of length n, that is, the n-grams of interest. Fortunately, the implementation of Equation (1) is not difficult for bigrams. The n-gramming results can also be affected by the choices within other text preprocessing operations, such as tokenization, letter case normalization, and stopword removal (Al-Molegi et al. Reference Al-Molegi, Alsmadi, Najadat and Albashiri2015; Jimenez et al. Reference Jimenez, Maxime, Le Traon and Papadakis2018).
$\mathsf{R}$
package quanteda (Benoit et al. Reference Benoit, Watanabe, Wang, Nulty, Obeng, Müller and Matsuo2018) generates the n-grams, but this package does not provide support for how to test n-grams for multiword expressions. It is still up to the researcher to determine which ones are multiword expressions of length n, that is, the n-grams of interest. Fortunately, the implementation of Equation (1) is not difficult for bigrams. The n-gramming results can also be affected by the choices within other text preprocessing operations, such as tokenization, letter case normalization, and stopword removal (Al-Molegi et al. Reference Al-Molegi, Alsmadi, Najadat and Albashiri2015; Jimenez et al. Reference Jimenez, Maxime, Le Traon and Papadakis2018).
A manual way to create multiword expressions of length 3 or 4 is to run the bigram generation and testing algorithm twice (Henry Reference Henry2016). If the concatenation of a word and a bigram passes the test, the trigram becomes a multiword expression of length 3. If the concatenation of two bigrams passes the test, the 4-gram becomes a multiword expression of length 4. One drawback is that
 $w_1 w_2 w_3$
being a multiword expression does not always imply
$w_1 w_2 w_3$
being a multiword expression does not always imply
 $w_1 w_2$
and/or
$w_1 w_2$
and/or
 $w_2 w_3$
are also multiword expressions. But given the Markov assumption in Equation (2), we can safely presume that counterexamples are rare, that is,
$w_2 w_3$
are also multiword expressions. But given the Markov assumption in Equation (2), we can safely presume that counterexamples are rare, that is,
 $w_3$
mostly depends on only the previous word
$w_3$
mostly depends on only the previous word
 $w_2$
.
$w_2$
.
For an n-gram to be a multiword expression, both practical and statistical significance are essential requirements. Practical significance requires each multiword expression to appear a minimum number of times in the corpus, so the selected n-grams would be presumed to have semantic importance. Statistical significance ensures that the multiword expressions are unlikely to be words co-occurring by chance (Dror et al. Reference Dror, Baumer, Shlomov and Reichart2018), but the conditional probability
 $P(w_2 | w_1)$
would not be accurate without
$P(w_2 | w_1)$
would not be accurate without
 $w_1 w_2$
of sufficient frequency in the corpus, that is, practical significance.
$w_1 w_2$
of sufficient frequency in the corpus, that is, practical significance.
3.7.4 N-gramming: Computational issues
Although the number of total n-grams grows linearly with the total number of words in the document, detecting multiword expressions in the corpus is computationally expensive due to the large number of distinct n-grams (McNamee and Mayfield Reference McNamee and Mayfield2007; Vilares et al. Reference Vilares, Vilares, Alonso and Oakes2016). If the vocabulary contains V distinct words, the number of distinct unigrams of the corpus has O(V) complexity. As the length n increases, the size of the n-gram pool grows exponentially—the complexity increases to
 $O(V^2)$
for distinct bigrams and to
$O(V^2)$
for distinct bigrams and to
 $O(V^3)$
for distinct trigrams. Nevertheless, the effort needed may not generate a good return of investment, especially for long n-grams. For aggregated statistics of text data, the n-gram frequency is right-skewed and most of the detected n-grams appear only once in the corpus. Accordingly, most studies do not investigate the corpus past 4-grams (Lin and Hovy Reference Lin and Hovy2003; Barrón-Cedeño and Rosso Reference Barrón-Cedeño and Rosso2009), not to mention longer n-grams. As a result, long multiword expressions are difficult to detect in n-gramming (Raff and Nicholas Reference Raff and Nicholas2018; Raff et al. Reference Raff, Fleming, Zak, Anderson, Finlayson, Nicholas and McLean2019).
$O(V^3)$
for distinct trigrams. Nevertheless, the effort needed may not generate a good return of investment, especially for long n-grams. For aggregated statistics of text data, the n-gram frequency is right-skewed and most of the detected n-grams appear only once in the corpus. Accordingly, most studies do not investigate the corpus past 4-grams (Lin and Hovy Reference Lin and Hovy2003; Barrón-Cedeño and Rosso Reference Barrón-Cedeño and Rosso2009), not to mention longer n-grams. As a result, long multiword expressions are difficult to detect in n-gramming (Raff and Nicholas Reference Raff and Nicholas2018; Raff et al. Reference Raff, Fleming, Zak, Anderson, Finlayson, Nicholas and McLean2019).
The good news is that long multiword expressions may be discovered via researchers’ understanding of the data content. The presence of such phrases may follow patterns and/or contain non-ignorable information, and we can apply subject matter knowledge of the corpus to create a list of long n-grams which are likely to be multiword expressions. We should retrieve these phrases directly from the data, rather than shingling the entire corpus to generate all n-grams when n is large. After obtaining the frequency of such phrases, we can determine whether it is appropriate to remove them from the corpus. If the answer is yes, then the text corpus can be further reduced. Below are some scenarios that produce long multiword expressions. Upon detection, these phrases can be easily removed without losing excessive semantic information.
-
The sales limitation phrase “must be 18 or older” is a multiword expression in a text corpus of digital advertisements. This phrase indicates the product’s legal age range, so the product should not be marketed to underage people such as middle school students. But from a computational advertising standpoint, this multiword expression does not provide any information about the product itself, making it difficult to match ads to users (Soriano et al. Reference Soriano, Au and Banks2013).
-
In a political blog corpus about the 2012 Trayvon Martin shooting incident,Footnote 18 the research group at Duke Statistical Science discovered an extremely long multiword expression—because one blogger included the Second Amendment to the United States Constitution in every post as a signature. The statement is “A well regulated Militia, being necessary to the security of a free State, the right of the people to keep and bear Arms, shall not be infringed.” Although controversial, this shows the blogger’s perspective toward gun laws (Chai Reference Chai2017).
The decision to apply n-gramming for text preprocessing or not depends on the NLP application. N-gramming is beneficial to applications that focus on words and phrases as consecutive words, such as text classification (Beitzel et al. Reference Beitzel, Jensen, Lewis, Chowdhury and Frieder2007; Narala, Rani, and Ramakrishna Reference Narala, Rani and Ramakrishna2017) and probabilistic topic modeling (Acree Reference Acree2016; Luiz et al. Reference Luiz, Olden, Kennard, Crook, Douglas, Saunders and King2019). N-gramming also identifies multiword expressions, which can enhance the vocabulary database in word embeddings (Goodman, Zimmerman, and Hudson Reference Goodman, Zimmerman and Hudson2020). In machine translation, n-gramming can be used for the hard-to-translate parts, because translation is not a one-to-one mapping between words (Du, Yu, and Zong Reference Du, Yu and Zong2018). But since n-gramming does not provide context to phrases, this approach will be of limited help in logical reasoning (Bernardy and Chatzikyriakidis Reference Bernardy and Chatzikyriakidis2019; Zhou et al. Reference Zhou, Duan, Liu and Shum2020). Instead, special techniques are needed for multiword expressions (Rikters and Bojar Reference Rikters and Bojar2017) and also for proper names (e.g., transliteration from Latin to Cyrillic characters) (Petic and G fu 2014; Mansurov and Mansurov Reference Mansurov and Mansurov2021).
4. Dataset examples
In this section, we provide three examples of text corpora which require more advanced preprocessing methods, that is, methods catering to the nature of the text data. The first example is a technical dataset, where removing stopwords should be done after stemming and n-gramming to preserve the technical phrases. The second example is social media data, where removing formatting is of heavy focus and special handling is needed in text normalization. The third example is survey text with numerical ratings, and we should retain negation in every step of text preprocessing, especially during stopword removal. All seven text preprocessing modules in Figure 1 apply, but the discussion will be on the specific adaptation. This is by no means a comprehensive list, but the methods will provide a foundation for unconventional text corpora beyond the three categories described here.
4.1 Technical datasets
For datasets with technical content, we recommend using publicly available e-books on Project Gutenberg as a starting filter to remove stopwords, especially the e-books with general content. Leveraging Project Gutenberg eliminates the subjectivity of deciding which words should be included in the stopword list, increasing the reproducibility of the work. Since many researchers examine the predefined stopword list and manually add or remove a few words beforehand, it is more difficult to reproduce their results unless they publish the exact stopword list they used in the project (Nothman et al. Reference Nothman, Qin and Yurchak2018). Existing literature has proposed automated methods to extract domain-specific stopwords with improved text classification results (Ayral and Yavuz Reference Ayral and Yavuz2011; Makrehchi and Kamel Reference Makrehchi and Kamel2017). But given the amount of technical expertise and work required, the automation may not be worthwhile, or even feasible (Arora et al. Reference Arora, Sabetzadeh, Briand and Zimmer2016). Using an e-book from Project Gutenberg to remove stopwords is an easier way to achieve potentially better results than using a standard stopword list.
An example of a technical corpus is the JSM (Joint Statistical Meetings) abstract collection (Bi Reference Bi2016), which contains more than 3000 abstracts and 700 sessions from the 2015 JSM.Footnote 19 JSM is one of the world’s largest conferences in statistics, and the abstracts obviously contain much technical jargon. Common phrases in this dataset include “maximum likelihood estimation” and “time series”. Bi (Reference Bi2016) eliminated all HTML formatting and punctuation from the corpus, tokenized the corpus into English words, and converted all letters to lowercase. The stopword removal process for the JSM abstract collection contains three steps:
-
(1) Stem and n-gram the JSM abstract collection.
-
(2) Stem and n-gram a publicly available e-book from Project Gutenberg.
-
(3) Remove anything from (1) that exists in (2).
In Step 1, note that n-gramming is required before we compare the two datasets and remove the words also in Project Gutenberg. Some statistical terminology contains words that may be considered a stopword, so we need to preserve these n-grams first. For example, after the stopword “one” is removed, the term “one sample t-test” is not equivalent to a “sample t-test”. Assume the word “two” precedes both terms, then “two one sample t-tests” is different from a “two sample t-test”. The former means conducting an independent one-sample t-test on each of the two samples, and the latter means conducting a single t-test to compare the two given samples.
In Step 2, appropriate choices of a filtering book should be something completely unrelated to statistics, such as Little Busybodies: The Life of Crickets, Ants, Bees, Beetles, and Other Busybodies by Jeanette Augustus Marks and Julia Moodyand. If the technical dataset includes medical content, such as citation networks from PubMed,Footnote 20 then using an e-book about insects may not be appropriate. Otherwise, content related to insect bites would be filtered out by the e-book. A better choice is Herein is Love by Reuel L. Howe, which is an interpretation about love from the Bible.
In Step 3, the intersection with the filtering book is removed from the corpus of JSM abstracts. This step removes most of the general content and keeps the technical terms in the corpus. This not only reduces the vocabulary size but also prepares the corpus for topic modeling and conference scheduling optimization. Although most JSM abstracts contain self-identified keywords, an automated system is still needed for conference session scheduling given the large number of abstracts (Sweeney Reference Sweeney2020; Frigau, Wu, and Banks Reference Frigau, Wu and Banks2021). Most conferences have moved to virtual in COVID times, but Patro et al. (Reference Patro, Chakraborty, Ganguly and Gummadi2020) emphasized that scheduling remains a challenge due to time zones, sign language interpreter hours, etc. Availability of on-demand recordings may change the equation, because participants have the opportunity to watch the recorded talks after the conference.
4.2 Social media data
Social media data contain information from user posts, and text analytics of such data can generate insights of business value and/or research interest (Mostafa Reference Mostafa2013). Particularly, Twitter has an abundance of unstructured text data (Kwak et al. Reference Kwak, Lee, Park and Moon2010), and text mining applications include (and are not limited to) opinion mining (Pak and Paroubek Reference Pak and Paroubek2010), stock market prediction (Bollen, Mao, and Zeng Reference Bollen, Mao and Zeng2011), and even how people communicate under emergency situations (Mendoza, Poblete, and Castillo Reference Mendoza, Poblete and Castillo2010; Vieweg et al. Reference Vieweg, Hughes, Starbird and Palen2010). In addition to the text preprocessing methodology described in Section 3, preprocessing social media text comes with unique challenges due to ungrammatical language, misspellings, and typos (Batrinca and Treleaven Reference Batrinca and Treleaven2015). Many resources are available for social media text preprocessing, such as the Google Refine Footnote 21 desktop application software and the book Python Social Media Analytics (Chatterjee and Krystyanczuk Reference Chatterjee and Krystyanczuk2017). These are excellent and helpful tools, and they describe the whole text preprocessing pipeline.
Therefore, we point out some key differences between preprocessing a traditional text dataset and preprocessing a social media text corpus. Although preprocessing a social media text corpus takes considerable time, the preprocessing step is worth the effort because the resulting corpus leads to successful implementation of text mining algorithms (Irfan et al. Reference Irfan, King, Grages, Ewen, Khan, Madani, Kolodziej, Wang, Chen and Rayes2015).
First, a text corpus from social media often contains HTML tags and URL paths which were generated from web scraping. We can use regular expressions to remove the web-generated characters, just like the process of removing punctuation described in Section 3.4.2. One caveat is to consider whether to remove punctuation or remove web-generated characters first, because the order of removing different types of nonword characters matters in the code development. For instance, many URLs start with https://, and if we remove the colon (:) first, then the URL prefix would be https// instead.
Next, hashtags and mentions in Twitter are extremely helpful in processing tweets, but due to their distinct structures, it is important to identify them as separate entities before we remove all punctuation. Hashtags start with the # sign (e.g., #hashtag), and they often indicate the main terms of the tweet, which are useful in topic identification (Zubiaga et al. Reference Zubiaga, Spina, Marítnez and Fresno2015) and event detection (Wang et al. Reference Wang, Tokarchuk and Poslad2014b; Cai et al. Reference Cai, Yang, Li and Huang2015). Mentions start with the @ symbol (e.g., @username) and refer directly to another Twitter user, making them helpful in NER (Yamada et al. Reference Yamada, Takeda and Takefuji2015; Gorrell et al. Reference Gorrell, Petrak and Bontcheva2015). All mentions (@) can also be converted into stopwords (Metzler et al. Reference Metzler, Baginski, Niederkrotenthaler and Garcia2021) or masked for certain tasks (Abd-Alrazaq et al. Reference Abd-Alrazaq, Alhuwail, Househ, Hamdi and Shah2020). If we remove punctuation before processing the hashtags and mentions, the unexpected word in a sentence can mess up NLP models such as POS tagging (Kaufmann and Kalita Reference Kaufmann and Kalita2010).
Moreover, text from online social media often contains abbreviations not in a standard English dictionary, such as “cu” (see you) and “idk” (I don’t know) (Pennell and Liu Reference Pennell and Liu2011; Kozakou Reference Kozakou2017). These terms, also known as Internet slang, need to be explicitly defined. Nevertheless, this task is relatively difficult because we require an unconventional dictionary to translate slang words into their proper reference words, such as the Internet Slang Dictionary (Jones Reference Jones2006). But given the fast-growing content on the web, the static dictionaries about Internet slang risk being outdated due to not keeping up with the current trends. It is possible to automatically detect such spelling variants (Barteld Reference Barteld2017), but this is an extensive research topic outside the text preprocessing scope.
After the preprocessing of social media data is complete, we recommend text mining methods which specialize in short texts. Many topic modeling techniques, especially the ones based on the standard latent Dirichlet allocation (LDA), work better for longer documents and have decreased performance over short texts (Li et al. Reference Li, Wang, Zhang, Sun and Ma2016). This is due to their probabilistic nature of identifying the topic distribution over words in each document (Chen, Yao, and Yang Reference Chen, Yao and Yang2016), which becomes a challenge for shorter documents like social media data (Chen et al. Reference Chen, Zhang, Liu, Ye and Lin2019). One potential solution is auxiliary word embeddings (Li et al. Reference Li, Duan, Wang, Zhang, Sun and Ma2017), that is, incorporating external words to the sample space of the dataset. In this way, each word in the short text can be either generated directly from the Dirichlet multinomial distribution or sampled from the estimated probabilities by the word embeddings in the corresponding topic (Nguyen et al. Reference Nguyen, Billingsley, Du and Johnson2015). Despite the challenges of preprocessing and analyzing social media data, many researchers have successfully generated insights from the massive database of information. Sophisticated models can provide recommendations for companies to develop their social media marketing strategy (He, Zha, and Li Reference He, Zha and Li2013), and even a simple gender classification of Facebook names can improve an online dating platform’s accuracy of targeted advertising (Tang et al. Reference Tang, Ross, Saxena and Chen2011).
4.3 Text with numerical ratings
Some datasets contain text records with a numerical rating assigned to each text comment, such as surveys, online reviews, and performance evaluations. The numerical ratings are regarded as metadata, and they should also be incorporated in the data preprocessing phase. There are other types of metadata we can utilize, such as dates, authors, and locations. Nevertheless, we decided to emphasize the numerical ratings in surveys because analysis of survey text is relatively rare, due to its complexity compared with the numerical counterparts (Schuman and Presser Reference Schuman and Presser1996; Roberts et al. Reference Roberts, Stewart, Tingley, Lucas, Leder-Luis, Gadarian, Albertson and Rand2014). When preprocessing the text with numerical ratings, we need to ensure correctness of which rating is associated with which text comment and beware of missing cells which can mess up the alignment. But more often than not, the rating errors are made by the respondents (Saal, Downey, and Lahey Reference Saal, Downey and Lahey1980). Therefore, it is important to identify potential data errors and make correction efforts, so combined analysis of text and numerical data is required.
The problem of text-rating mismatch is especially prevalent in surveys because respondents may get confused with the rating scale (Fisher Reference Fisher2019). A 1–10 rating scale has at least two different meanings: 1 (least important) to 10 (most important) and 1 (most important) to 10 (least important). Appropriate survey design and instructions can mitigate the problem (Fowler Reference Fowler1995; Friedman and Amoo Reference Friedman and Amoo1999), but text-rating inconsistencies are inevitable in a survey response dataset (Fisher Reference Fisher2013). For example, in an employee satisfaction dataset with the rating scale from 1 (least satisfied) to 10 (most satisfied), a respondent wrote “Love my work – very varied.” and gave a “1” rating (Chai Reference Chai2019). The respondent was obviously confused by the rating scale because the comment shows satisfaction with his/her work.
Preserving negation is essential to the survey text, because removing the negation term will result in an opposite meaning and ambiguity of text-rating assignment. If another respondent wrote “I don’t like my job,” then the “3” rating is appropriate. But if we accidentally remove “don’t” as a stopword, the text comment becomes “I like my job,” and the originally correct rating “3” becomes inappropriate. Section 3.5 explains that many existing stopword lists contain negation terms like “no” and “not”. Hence, researchers should exclude them from the list so that negation can be retained in the corpus.
A potential solution to validate a text-rating dataset is to estimate the rating from the text using the supervised latent Dirichlet allocation (sLDA) (McAuliffe and Blei Reference McAuliffe and Blei2008), which is a supervised topic model for text mining. Compared with the LDA (Blei et al. Reference Blei, Ng and Jordan2003) for topic modeling, sLDA is supervised because it takes the record labels (i.e., numerical ratings) into account. After we train the sLDA model using the text-rating dataset, we can estimate the rating from a particular text record and compare it with the actual rating (Fisher and Lee Reference Fisher and Lee2011). If the estimated rating is very different from the actual rating in the record, then the rating is likely a response error. We should flag the record and reconsider its accuracy.
5. Conclusion
Researchers and practitioners need to know which text preprocessing modules to apply in what order, and whether a generic or specific model is preferable. General text preprocessing methods apply for most datasets, but more content-specific methods are needed to preserve additional semantic information. There is a trade-off between the effort in data preprocessing and the resulting data quality, so advanced text preprocessing methods are considered add-ons to the general methods. Which text preprocessing methods are useful depend on both the corpus and the goal of text mining (White et al. Reference White, Togneri, Liu and Bennamoun2018). Therefore, we provide some guidelines to select the appropriate text preprocessing methods for a given dataset. For publicly available datasets such as 20 Newsgroups and WebKB (World Wide Knowledge Base),Footnote 22 previous researchers have done the preprocessing and published their methodology (Miah Reference Miah2009; Albishre, Albathan, and Li Reference Albishre, Albathan and Li2015). But when we receive a whole-new text corpus for a specific application, we have to preprocess the data with little guidance. This is the key application for the compare-and-contrast of various text preprocessing methods.
This article has set up a framework in selecting the appropriate text preprocessing methods for a given corpus. Most of the literature we reviewed here used text corpora written in English, but some concepts are applicable to other languages. For instance, most languages contain stopwords, and their word frequency distributions follow the Zipf’s law (Zipf Reference Zipf1949). Nevertheless, the complexity of each necessary text preprocessing step would vary by language. CJK (Chinese, Japanese, and Korean) require more complex tokenizers due to the character-based nature of the languages (Zhang and LeCun Reference Zhang and LeCun2017), as well as the lack of white space as obvious word boundaries (Moh and Zhang Reference Moh and Zhang2012). On the other hand, morphologically rich languages like Turkish and Finnish require more complex stemmers/lemmatizers due to their wide range of derivational and inflectional word variation (Przepiórkowski et al. Reference Przepiórkowski, Piasecki, Jassem and Fuglewicz2012; Nuzumlalı and Özgür 2014).
Acknowledgments
The author is grateful for the support of Microsoft in writing this manuscript. The author would like to thank Prof. David Banks, her PhD advisor at Duke University, who motivated her to do research in text mining. The author would also like to thank the anonymous reviewers for the detailed comments, which greatly improved the manuscript.
Conflicts of interest
The author is employed at Microsoft Corporation, and she completed a PhD in statistical science from Duke University.






















