



1. Introduction
Indoor mobile robots have developed rapidly in recent years thanks to the achievements of environment perception, mapping, and path planning. Especially in well-structured environments, such as hotels, exhibition halls, etc., the robots have achieved remarkable success because of the pre-established accurate maps by SLAM [Reference Hess, Kohler, Rapp and Andor1, Reference Kenye and Kala2, Reference Handa, Whelan, McDonald and Davison3, Reference Fuentes-Pacheco, Ruiz-Ascencio and Rendón-Mancha4] in such scenarios.
In these scenarios, the robot can accurately reach a fixed target location on the map, during which it can successfully avoid dynamic obstacles [Reference Emrah Dnmez and Dirik5, Reference Dnmez and Kocamaz6, Reference Wei, Zhang, Wu and Hu7, Reference Masutani, Mikawa, Maru and Miyazaki8, Reference Okumu, Dnmez and Kocamaz9] such as people. A typical example is that a hotel guest can get a toothbrush by just informing the service center that will employ a robot to send the toothbrush. However, the robots are limited in these tasks in which the fixed position of the targets is stored in advance.
We can still follow the above methods if the robot search almost fixed targets such as refrigerators and beds in indoor scenes. In fact, the techniques of SLAM, sensor-based obstacle detection, and path planning [Reference Pandey and Parhi10] have solved the tasks in such known scenarios. However, when looking for objects such as apples and remote controls, the positions of these objects are easy to be changed. For example, an apple can be on the table or the coffee table. Even if the robot has good location and obstacle avoidance capabilities, the robot still does not know where to find the target. Searching for “semi-dynamic objects” is still a non-trivial task.
The effective way to solve this problem is to introduce prior knowledge. Although the robot does not know the location of the apple, it can infer possible candidate targets through objects that often coexist with the cup (such as a table, a coffee table, etc.). We can transform the problem of searching for semi-dynamic objects into searching for related static objects. This idea has recently been widely used in visual semantic navigation [Reference Du, Yu and Zheng11, Reference Druon, Yoshiyasu, Kanezaki and Watt12, Reference Qiu, Pal and Christensen13].
However, using the pre-established fixed knowledge graph to help search for unseen objects is inefficient since the relation between the target and other objects is just learned by public datasets without considering the specific scenery. In our concern, the navigation target location is not fixed, or unseen objects that do not appear in the knowledge graph. This motivates us to develop a long-term object search method. As shown in Fig. 1, the core of this problem is how to develop a framework in which the robots can update the scene graph to describe the scenery during the search task.

Figure 1. The robot performs the task of searching for an apple. In the process of searching, the robot find a tomato (semi-dynamic object) in the fridge (static object). The robot can update the scene graph according to the location relationship of the object. The updated scene graph is helpful for the next search task.
Compared with the existing work [Reference Druon, Yoshiyasu, Kanezaki and Watt12, Reference Qiu, Pal and Christensen13, Reference Yang, Wang, Farhadi, Gupta and Mottaghi14, Reference Wortsman, Ehsani, Rastegari, Farhadi and Mottaghi15], our work can directly use the physical platform of the mobile robot. And comprehensively use the perceptual learning ability of the embodied intelligence field and the SLAM, path planning, and other technologies in the robotics field to build a target search platform with long-term learning ability. We use a scene graph to represent the concurrent relationship between the target object and other static objects. The robot can first explore around known static objects and gradually approach semi-dynamic objects. Because of the different initial positions of the robot, global path planning is realized by weighing the length of the path and the probability of object discovery. To memorize the scene quickly in the process of performing the task, we propose an incremental scene graph updating method in the semi-dynamic environment to dynamically update the scene graph. The updated scene graph will be helpful in planning a path for the next object search task. The main contributions of this study are summarized as follows:
For object search in a known environment, we propose a framework of object search combined with established navigation, semantic, and semantic relation maps. Global path planning is realized by weighing the length of the path and the probability of object discovery.
The robot can continuously update the semantic relation graph in a dynamic environment to memorize the position relation of objects in the scene.
Real-world experiments have shown that our proposed method can be applied perfectly to physical robots.
The rest of this paper is organized as follows. Section 2 demonstrates the related works of Map-based navigation approaches, Learning-based approaches, and Scene Graph. In Section 3, the problem definition is introduced. In Section 4, we introduce the framework we propose and its components in detail. In Section 5, we introduce the semi-dynamic object search and incremental scene graph updating. We introduce the experiment details and analysis in Section 6 and conclude our method in Section 7.
2. Related work
Map-based navigation approaches: Classical navigation methods have divided the problem into two parts, mapping and path planning. A geometric map is usually built using SLAM [Reference Fuentes-Pacheco, Ruiz-Ascencio and Rendón-Mancha4, Reference DeSouza and Kak16] technology. Once the environment map has been constructed, the robot can use a path planning algorithm, such as
 $\mathrm{A}^{*}$
[Reference Hart, Nilsson and Raphael17] or
$\mathrm{A}^{*}$
[Reference Hart, Nilsson and Raphael17] or
 $\mathrm{RRT}^{*}$
[Reference Karaman and Frazzoli18], to generate a collision-free trajectory to reach the target location, even if there are obstacles [Reference Kattepur and Purushotaman19, Reference Krichmar, Hwu, Zou and Hylton20]. With the development of deep learning, some work [Reference Liang, Chen and Song21, Reference Chaplot, Gandhi, Gupta and Salakhutdinov22, Reference Tan, Di, Liu, Zhang and Sun23] built detailed semantic maps from images for complex indoor navigation learning in simulator [Reference Savva, Kadian, Maksymets, Zhao, Wijmans, Jain, Straub, Liu, Koltun, Malik, Parikh and Batra24, Reference Chang, Dai, Funkhouser, Halber, Niessner, Savva, Song, Zeng and Zhang25, Reference Cartillier, Ren, Jain, Lee, Essa and Batra26]. However, the above method of building a semantic map is based on the premise that the robot can obtain accurate camera coordinates. However, accurate indoor positioning of robots in unknown physical environments is still a problem. On the one hand, we provide accurate location information to the robot through SLAM. On the other hand, we combine semantic map and navigation map to assist the object search task.
$\mathrm{RRT}^{*}$
[Reference Karaman and Frazzoli18], to generate a collision-free trajectory to reach the target location, even if there are obstacles [Reference Kattepur and Purushotaman19, Reference Krichmar, Hwu, Zou and Hylton20]. With the development of deep learning, some work [Reference Liang, Chen and Song21, Reference Chaplot, Gandhi, Gupta and Salakhutdinov22, Reference Tan, Di, Liu, Zhang and Sun23] built detailed semantic maps from images for complex indoor navigation learning in simulator [Reference Savva, Kadian, Maksymets, Zhao, Wijmans, Jain, Straub, Liu, Koltun, Malik, Parikh and Batra24, Reference Chang, Dai, Funkhouser, Halber, Niessner, Savva, Song, Zeng and Zhang25, Reference Cartillier, Ren, Jain, Lee, Essa and Batra26]. However, the above method of building a semantic map is based on the premise that the robot can obtain accurate camera coordinates. However, accurate indoor positioning of robots in unknown physical environments is still a problem. On the one hand, we provide accurate location information to the robot through SLAM. On the other hand, we combine semantic map and navigation map to assist the object search task.
Learning-based approachs: To tackle the problem of object search in unknown scenes [Reference Liu, Di, Liu and Sun27, Reference Xinzhu, Xinghang, Di, Huaping and Fuchun28, Reference Li, Liu, Zhou and Sun29, Reference Tan, Xiang, Liu, Di and Sun30], Zhu et al. [Reference Zhu, Mottaghi, Kolve, Lim, Gupta, Fei-Fei and Farhadi31] first proposed a target-driven navigation task. They used a pair of twin networks with shared parameters to extract the features of the currently observed image and the target image information. Then, they used the A3C reinforcement learning algorithm as the decision-making part of the robot. After that, many navigation methods [Reference Yang, Wang, Farhadi, Gupta and Mottaghi14, Reference Wortsman, Ehsani, Rastegari, Farhadi and Mottaghi15, Reference Mousavian, Toshev, Fišer, Košecká, Wahid and Davidson32] use deep reinforcement learning and imitation learning to train navigation strategies. Yang et al. [Reference Yang, Wang, Farhadi, Gupta and Mottaghi14] used graph convolutional neural networks to combine the prior information of the scene into the deep reinforcement model, and the categories of target objects were also encoded as word vectors. Wortsman et al. [Reference Wortsman, Ehsani, Rastegari, Farhadi and Mottaghi15] also proposed a meta-reinforcement learning strategy that encourages agents to continue learning in a test environment using self-supervised interaction losses. Then, Mousavian et al. [Reference Mousavian, Toshev, Fišer, Košecká, Wahid and Davidson32] used the semantic mask obtained using the current state-of-the-art computer vision algorithm as the result of the current observation image and used the deep network to learn the navigation strategy. They are made great progress in simulation environments. However, the end-to-end learning methods require a series of abilities, such as object detection [Reference Redmon and Farhadi33], semantic prior [Reference Johnson, Krishna, Stark, Li, Shamma, Bernstein and Fei-Fei34], and obstacle avoidance [Reference Lenser and Veloso35]. The diversity of light, object materials, colors, and layouts in real environments have prevented the transfer of this progress in simulation platforms to real-world scenarios. The robot is still unable to adapt to the complex and changeable physical environment effectively. In the physical environment, the robot is likely to bump into people or other objects because of the defect of obstacle avoidance ability, and the cost of its wrong decision is very expensive.
Scene Graph: Many researchers [Reference Du, Yu and Zheng11, Reference Druon, Yoshiyasu, Kanezaki and Watt12, Reference Li, Di, Liu and Sun36] have noticed a concurrence between objects, for example, the remote control often appears next to the television. This concurrence between objects has been studied for tasks such as image retrieval [Reference Johnson, Krishna, Stark, Li, Shamma, Bernstein and Fei-Fei34] using scene graphs, visual relation detection [Reference Zhang, Kyaw, Chang and Chua37], and visual question-answering [Reference Wu, Shen, Wang, Dick and Van Den Hengel38]. By learning this relationship, the robot can narrow the scope of the search and improve the efficiency of object search. Qiu et al. [Reference Qiu, Pal and Christensen13] proposed a hierarchical object relation learning method to solve the problem of object-driven navigation. Although this method of using object relationships can help the robot determine where to go, in the face of a real-world complex, the robot still does not know how to go because of the lack of robot navigation ability. Zeng et al. [Reference Zeng, Röfer and Jenkins39] used the spatial relationship between room landmarks and target objects to introduce a semantic link map model to predict the next best view posture to search for the target objects. However, no connection exists between the tasks performed by the robot. The robot performing the last task will be helpful for the next task in our method, even if the target object is different.
3. Problem formulation
We set a semi-dynamic environment
 $E_{t}$
that changes with time, and all objects in the room
$E_{t}$
that changes with time, and all objects in the room
 $O=\left \{o_{1}, \ldots, o_{n} \right \}$
, which contains static object
$O=\left \{o_{1}, \ldots, o_{n} \right \}$
, which contains static object
 $ o_{s}$
and semi-dynamic object
$ o_{s}$
and semi-dynamic object
 $ o_{d}$
(explained in detail in Section 4.2).
$ o_{d}$
(explained in detail in Section 4.2).
When the robot executes the search task at a certain time
 $ t$
, given the robot’s initial scene graph
$ t$
, given the robot’s initial scene graph
 $SG_{t}=(O, E)$
, where each node
$SG_{t}=(O, E)$
, where each node
 $o \in O$
represents the category of an object. Each edge
$o \in O$
represents the category of an object. Each edge
 $e \in E$
represents the value of the relationship between a static object and a semi-dynamic object
$e \in E$
represents the value of the relationship between a static object and a semi-dynamic object
 $Rel\left (o_{d}, o_{s} \right ) \in [0,1]$
.
$Rel\left (o_{d}, o_{s} \right ) \in [0,1]$
.
The robot is placed at the initial position
 $p_t$
in the environment
$p_t$
in the environment
 $E_{t}$
and gives the robot a semi-dynamic object target
$E_{t}$
and gives the robot a semi-dynamic object target
 $O_{\text{target}}$
, such as a cup. The robot passes through the scene graph to establish the association between
$O_{\text{target}}$
, such as a cup. The robot passes through the scene graph to establish the association between
 $ o_{\text{target}}$
and the static object
$ o_{\text{target}}$
and the static object
 $ o_{s}$
. The robot plans a most efficient path to find the semi-dynamic object and gets close to the object.
$ o_{s}$
. The robot plans a most efficient path to find the semi-dynamic object and gets close to the object.
The position of semi-dynamic objects will change over time, such as a mobile phone is sometimes on the table and sometimes on the sofa. Therefore, in the search process, the robot needs to continuously obtain the experience of correlation between objects in
 $E_{t}$
, it can be denoted
$E_{t}$
, it can be denoted
 $ Exp_t$
. At the end of the task, these associated experiences are used to update the scene graph:
$ Exp_t$
. At the end of the task, these associated experiences are used to update the scene graph:
 \begin{equation} SG_{t+1} = \operatorname{UPDATE}(SG_{t}; Exp_t ) \end{equation}
\begin{equation} SG_{t+1} = \operatorname{UPDATE}(SG_{t}; Exp_t ) \end{equation}
The robot can use the updated scene graph
 $ SG_{t+1}$
for path planning of the next task.
$ SG_{t+1}$
for path planning of the next task.
The operating environment of our robot is a semi-dynamic scene, which allows the robot to build auxiliary maps
 $M$
in advance, including navigation
$M$
in advance, including navigation
 $M_{nav}$
and semantic maps
$M_{nav}$
and semantic maps
 $M_{sem}$
, before performing the object search task. The navigation map consists of several navigable viewpoints
$M_{sem}$
, before performing the object search task. The navigation map consists of several navigable viewpoints
 $N_{nav}$
, and the distance between the navigable viewpoints and adjacent navigable viewpoints is 0.25 m. On the basis of this, the robot can not only obtain the accurate pose
$N_{nav}$
, and the distance between the navigable viewpoints and adjacent navigable viewpoints is 0.25 m. On the basis of this, the robot can not only obtain the accurate pose
 $x_{t} \in \mathbb{R}^{3}$
but also realize the path planning from one viewpoint to another.
$x_{t} \in \mathbb{R}^{3}$
but also realize the path planning from one viewpoint to another.
4. Framework
4.1. Overview
The search target of the robot belongs to a semi-dynamic object, and the robot tends to find the target object near the static object. When the target is found, the nearest navigable viewpoint is reached. As shown in Fig. 2, the robot combines the semantic map and the scene graph to plan a path that is most likely to find the target object within the shortest distance. The path consists of the starting point of the robot, the nearest navigable viewpoint of the static object with a non-zero relation value to the target object, and the endpoint. When the robot finds the target object, the robot carries out local semantic reconstruction of the target object. It reaches the nearest navigable viewpoint of the target object, which is the destination.

Figure 2. The architecture overview of our propose navigation method equipped with the scene graph and semantic map.
In the process of searching the target object along the path, the robot will store the relationship pairs between semi-dynamic objects and static objects in the experience pool, such as the bowl with the table and the cup with the sink. Then, the scene graph is updated through such relationship pairs to help find the target faster next time. Specifically, our method updates the object relationship value between semi-dynamic objects and static objects and then adjusts the path of the next search target object.
4.2. Scene graph
Following the classification of objects by Meyer-Delius et al. [Reference Meyer-Delius, Hess, Grisetti and Burgard40], we have slightly modified the classification as follows:
Static objects: objects are large and not easily moved in a room are called static objects. For example, a refrigerator is a static object in a kitchen scene, and a bed is a static object in a bedroom. Such objects will help the robot to find semi-dynamic objects.
Semi-dynamic object: it is static during the search process, but its position can be easily changed, such as an apple or cup. This type of object is what the robot’s search target.
Dynamic objects: The position of an object changes easily, even during the search, such as moving people and moving pet dogs. Such objects are not the search target of the robot.
Following Yang et al. [Reference Yang, Wang, Farhadi, Gupta and Mottaghi14], we also extract the relationship between semi-dynamic and static objects from the image captions in the Visual Genome dataset (VG) [Reference Krishna, Zhu, Groth, Johnson, Hata, Kravitz, Chen, Kalantidis, Li, Shamma, Bernstein and Fei-Fei41]. But the difference is that our relationship graph has definite values for the strength of the relationship between objects. For a semi-dynamic object
 $ o_{d}$
and a static object
$ o_{d}$
and a static object
 $ o_{s }$
, the object relationship can be expressed as
$ o_{s }$
, the object relationship can be expressed as
 $ Rel\left (o_{d}, o_{s} \right ) \in [0,1]$
, the larger the value, the closer the relationship between them.
$ Rel\left (o_{d}, o_{s} \right ) \in [0,1]$
, the larger the value, the closer the relationship between them.
 $ Rel\left (o_{d}, o_{s} \right )$
can be calculated as follows:
$ Rel\left (o_{d}, o_{s} \right )$
can be calculated as follows:
 \begin{equation} \operatorname{Rel}(o_{d}, o_{s})=\frac{C(o_{d}, o_{s})}{C(o_{d})} \end{equation}
\begin{equation} \operatorname{Rel}(o_{d}, o_{s})=\frac{C(o_{d}, o_{s})}{C(o_{d})} \end{equation}
where
 $ C(d, s)$
represents the number of times that the semi-dynamic object
$ C(d, s)$
represents the number of times that the semi-dynamic object
 $ d$
and a static object
$ d$
and a static object
 $ s$
appear together in the image captions, and
$ s$
appear together in the image captions, and
 $ C(d)$
represents the total number of the semi-dynamic object appears in the image caption. In addition, we combine aliases of objects, such as “Cellphone” and “Phone”.
$ C(d)$
represents the total number of the semi-dynamic object appears in the image caption. In addition, we combine aliases of objects, such as “Cellphone” and “Phone”.
4.3. Semantic map
As shown in Fig. 2, on the boundary of all navigable viewpoints, the navigable viewpoint of the median coordinate of all navigable viewpoints on the boundary is taken as the sampling point. The robot captures information about the room by collecting RGB and depth images of the view every 45 degrees at each sampling point. As shown in Fig. 3, Similar to ref. [Reference Chaplot, Gandhi, Gupta and Salakhutdinov22], we first perform local semantic reconstruction for a single view of a single sampling point. We can obtain the robot pose
 $x_{t} \in \mathbb{R}^{3}$
through SLAM, which represents the coordinates and orientation of the robot on the navigation map. In the real world, we can predict the semantic mask of the current observation by the existing target detector Mask-RCNN [Reference He, Gkioxari, Dollár and Girshick42] and project it into the point cloud.
$x_{t} \in \mathbb{R}^{3}$
through SLAM, which represents the coordinates and orientation of the robot on the navigation map. In the real world, we can predict the semantic mask of the current observation by the existing target detector Mask-RCNN [Reference He, Gkioxari, Dollár and Girshick42] and project it into the point cloud.

Figure 3. (a) Local semantic reconstruction: The robot obtains the semantic point cloud of each static object from the RGB and depth image observed on the pose
 $x_{t} \in \mathbb{R}^{3}$
. (b) Semantic map generation: it consists of two parts: first, the global semantic reconstruction is carried out, and then the semantic map is projected from top to bottom.
$x_{t} \in \mathbb{R}^{3}$
. (b) Semantic map generation: it consists of two parts: first, the global semantic reconstruction is carried out, and then the semantic map is projected from top to bottom.
The robot performs local semantic reconstruction at each perspective of each sampling point. In order to overcome the shortcoming of insufficient environmental information obtained from a single perspective, we integrate semantic point clouds generated by multiple sampling points and multiple perspectives to complete local to global semantic reconstruction. The voxel of static objects contains semantic information in the whole room. By projecting from top to bottom, we can get a semantic map with information about the spatial distribution of static objects.
5. Simultaneous search and scene graph updating
5.1. Semi-dynamic object search
In order to facilitate the robot to reach the nearest navigable viewpoint of the static object
 $ o_{s}$
, we perform the following calculations on the objects on the semantic map: (a) calculate the center of mass of an object semantic point cloud as the object’s position absolute position
$ o_{s}$
, we perform the following calculations on the objects on the semantic map: (a) calculate the center of mass of an object semantic point cloud as the object’s position absolute position
 ${l o c}_{s}$
in the semantic map. (b) the nearest viewpoint: a navigable viewpoint
${l o c}_{s}$
in the semantic map. (b) the nearest viewpoint: a navigable viewpoint
 $N_{s} \subset N_{\text{nav}}$
that is closest to the absolute position of the static object. (c) the appropriate observation angle
$N_{s} \subset N_{\text{nav}}$
that is closest to the absolute position of the static object. (c) the appropriate observation angle
 $\theta _{\mathrm{s}}$
: according to the position of the object and the nearest navigable viewpoint, the robot can calculate the angle at which the robot can observe the static object after moving to the navigable viewpoint.
$\theta _{\mathrm{s}}$
: according to the position of the object and the nearest navigable viewpoint, the robot can calculate the angle at which the robot can observe the static object after moving to the navigable viewpoint.
For semi-dynamic objects, the search strategy is that the robot first looks for the area around the static objects related to the target object and then gradually approaches the target object. Specifically, the robot will first search in the room where the starting point is located. If it does not find it, the remaining unexplored rooms are sorted according to the size of
 $Rel\left (o_{target}, R \right )$
, which can be defined as the sum of all
$Rel\left (o_{target}, R \right )$
, which can be defined as the sum of all
 $Rel\left (o_{d}, o_{s} \right )$
in room
$Rel\left (o_{d}, o_{s} \right )$
in room
 $R$
. According to the sorted results, the robot selects the next room to explore until the robot finds the target object.
$R$
. According to the sorted results, the robot selects the next room to explore until the robot finds the target object.
Because of the difference in initial positions, the robot needs to weigh the path’s length against the probability of finding the object. We propose a path length weighting (WPL) method to evaluate all possible paths. If there are n static objects associated with
 $ o_{target}$
in the room, then the number of all possible search paths is
$ o_{target}$
in the room, then the number of all possible search paths is
 $n!$
. The WPL can be expressed as
$n!$
. The WPL can be expressed as
 \begin{equation} W P L=\sum _{i=0}^{n} \frac{L_{i}}{\left (1+\alpha * Rel \left (o_{target}, o_{s}\right ) \right ) * 2^{i}} \end{equation}
\begin{equation} W P L=\sum _{i=0}^{n} \frac{L_{i}}{\left (1+\alpha * Rel \left (o_{target}, o_{s}\right ) \right ) * 2^{i}} \end{equation}
Among them,
 $L_{i}$
represents the distance from the previous position to the nearest navigable viewpoint of the static object.
$L_{i}$
represents the distance from the previous position to the nearest navigable viewpoint of the static object.
 $Rel \left (o_{target}, o_{s} \right )$
represents the relationship value between the static object and the target object. The hyperparameter
$Rel \left (o_{target}, o_{s} \right )$
represents the relationship value between the static object and the target object. The hyperparameter
 $ \alpha$
can control the influence of the object relationship value on the path. Choose the path with the smallest WPL value as the path searched by the robot.
$ \alpha$
can control the influence of the object relationship value on the path. Choose the path with the smallest WPL value as the path searched by the robot.
We divide static objects into two types: container type, such as refrigerator and microwave oven, and non-container type, such as table and bed. For container-like static objects, the robot needs to open the container and find the target. When the robot reaches the vicinity of a non-container static object, the robot will rotate 45 degrees left and right to find the target object. If the robot finds an object on the planned path, it will perform a local 3D semantic reconstruction of the target object and find the navigable viewpoint and orientation closest to the target object to approach the target object. If the target is not found, the task is failed.
5.2. Incremental scene graph updating
Because the object relationship is extracted from the visual genome, and it is not necessarily suitable for all scenes, and the position of the semi-dynamic object may change with time, the robot needs to update the value of the relationship between the semi-dynamic object and the static object. When the robot is performing a search task, if a semi-dynamic object is found on the navigable viewpoint
 $ N_{s}$
closest to a static object
$ N_{s}$
closest to a static object
 $ o_{s}$
, the robot considers the relationship between the static object and the dynamic object as relationship pair. The robot can store this relationship pair in the experience pool. Only when the area of the detected object mask reaches a certain threshold, the object is considered to be seen. Therefore, to a certain extent, when the distance between the semi-dynamic object and the static object is relatively close, the robot can store this relationship pair in the experience pool. At the end of the task, the robot updates the relationship graph based on the relationship pairs in the experience pool. For each semi-dynamic object
$ o_{s}$
, the robot considers the relationship between the static object and the dynamic object as relationship pair. The robot can store this relationship pair in the experience pool. Only when the area of the detected object mask reaches a certain threshold, the object is considered to be seen. Therefore, to a certain extent, when the distance between the semi-dynamic object and the static object is relatively close, the robot can store this relationship pair in the experience pool. At the end of the task, the robot updates the relationship graph based on the relationship pairs in the experience pool. For each semi-dynamic object
 $ o_{d}$
, the strategy for updating the object relationship between it and the static object
$ o_{d}$
, the strategy for updating the object relationship between it and the static object
 $ o_{s}$
is as follows:
$ o_{s}$
is as follows:
 \begin{equation} Rel\left (o_{d}, o_{s}\right )^{\prime }= \begin{cases}{Rel\left (o_{d}, o_{s}\right )}, &\text{ if } o_{d} \text{ is not visible } \\ \\[-9pt] Rel\left (o_{d}, o_{s}\right )/ 2, &\text{ if } o_{d} \text{ is visible but not at } N_{s} \\ \\[-9pt] Rel\left (o_{d}, o_{s}\right )/ 2 + 0.5, &\text{ if } o_{d} \text{ is visible at } N_{s} \\ \\[-9pt] \end{cases} \end{equation}
\begin{equation} Rel\left (o_{d}, o_{s}\right )^{\prime }= \begin{cases}{Rel\left (o_{d}, o_{s}\right )}, &\text{ if } o_{d} \text{ is not visible } \\ \\[-9pt] Rel\left (o_{d}, o_{s}\right )/ 2, &\text{ if } o_{d} \text{ is visible but not at } N_{s} \\ \\[-9pt] Rel\left (o_{d}, o_{s}\right )/ 2 + 0.5, &\text{ if } o_{d} \text{ is visible at } N_{s} \\ \\[-9pt] \end{cases} \end{equation}
Among them,
 $ Rel\left (o_{d}, o_{s} \right )$
and
$ Rel\left (o_{d}, o_{s} \right )$
and
 $ Rel\left (o_{d}, o_{s} \right )^{\prime }$
are the relationship values between
$ Rel\left (o_{d}, o_{s} \right )^{\prime }$
are the relationship values between
 $ o_{d}$
and
$ o_{d}$
and
 $ o_{s}$
before and after the update, respectively.
$ o_{s}$
before and after the update, respectively.
As shown in Fig. 4, the robot according to the relationship pairs store in the experience pool in the process of finding the cup in Fig. 2. The scene graph is updated based on the relationship of the experience pool and has no direct relationship with the task’s success. If the task is successful, but no other semi-dynamic objects are found during the search, there is only one relationship pair of the target object and the static object in the experience pool. If the search task fails and no other semi-dynamic objects are found during the search process, the experience pool is empty, and the relationship graphs of all semi-dynamic objects are not updated.

Figure 4. Update the original relationship graph according to the relationship pair corresponding to the bowl and cup in the experience pool. Please note that the semantic relationship values in the updated scene graph on the right have changed compared to the left.

Figure 5. The top view of the combined room, and the location of the starting point.
6. Experiment
We conduct experiments in the simulator and physical environment, respectively. To verify the effectiveness of our proposed method, we use path length (PL) as an evaluation indicator; it can be defined as the total mileage of the robot from the starting point to the discovery of the object.
6.1. Simulation experiment
We first conduct our experiments in Ai2thor [Reference Kolve, Mottaghi, Han, VanderBilt, Weihs, Herrasti, Gordon, Zhu, Gupta and Farhadi43] simulation environment. The simulator includes four different room categories: kitchen, living room, bedroom, and bathroom. As shown in the Fig. 5, similar to ref. [Reference Gan, Zhang, Wu, Gong and Tenenbaum44], we take a room in each room category to form a home scene together. To verify the adaptability of our method, the robot distributes two starting points in each room. When the robot arrives at the door of a room, it can be directly teleported to any other room. The list of our static objects is as follows: Sink, Table, Microwave, Fridge, Shelf, Sofa, Bed, Toilet, Bathtub, Stoveburner, Desk. In the simulation environment, the detection results from the robot’s perspective, such as the object category and mask, are provided by the simulator. The robot can detect even objects that are far away. In addition, to simulate the real scene, we set a threshold for each object, and the object is considered visible if it masks above a certain threshold.
6.1.1. Comparison of different methods
In this experiment, we count the robot’s success rate in finding different objects and the path length in the case of mission success. To ensure the unity of the task, we removed the bowl, laptop, and pillow in the living room, phone, and vase in the bedroom and kept only one Toilet paper in the bathroom. The positions of other objects remain unchanged. Our benchmark includes the following methods:
The shortest distance priority (SDP): The robot arrives next to the static object related to the target object in the shortest path, regardless of the object relationship value, that is,
 $ \alpha = 0$
in Eq. (4). The robot randomly selects the next room to search.
$ \alpha = 0$
in Eq. (4). The robot randomly selects the next room to search.The relationship value priority (RVP): The robot only considers the scene graph, sorts according to the value of the object relationship, and arrives next to the corresponding static objects in turn. The robot selects the next room to search according to the value of
$Rel\left (o_{target}, R \right )$
.Ours: The robot integrates the position of the static object in the scene graph and the semantic map, and weighs the length of the search path and the probability of finding the object. We set
$ \alpha = 10$
in Eq. (4).



In this experiment, because the semantic map containing the spatial distribution information of static objects is used to search for semi-dynamic objects, the robot can achieve a 100% success rate. From Table I, we can see that if the scene graph is not considered, the robot does not know that the target object can be found in that room, and can only blindly search for the static object. However, after adding the scene graph, our method can significantly reduce the search path length of most objects.
Table I. The robot uses different methods to search for the results of the path length.

However, for laptops and vases, after adding the scene graph, the length of the search path is increased. Our analysis shows that the scene graph we extract from VG does not completely conform to the current spatial distribution of semi-dynamic and static objects. In addition, after the introduction of WPL, the robot weighs the distance and the probability of finding the target, once again shortening the length of the search path.
6.1.2. Long-term object search
In this experiment, our main purpose is to verify that we can realize the memory of the scene by updating the scene graph, which can significantly reduce the length of the search path in a dynamic environment. As shown in Table II, the bold font indicates that the position of the object has changed. Some semi-dynamic objects appear in different positions in a room. Every time the robot looks for an object, it will start from eight starting points.
Table II. The distribution of semi-dynamic objects in the scene.

It can be seen from Fig. 6 that whether it is to update only the relationship pair related to the target object in the experience pool or to update all the relationship pairs in the experience pool. Compared with not updating the scene graph, the average path length after updating the scene graph is shortened by 25.27%. In the task of searching for an object once performed by the robot, updating the semantic relationship value of the target object will help the robot to find the target object next time. We use the scene graph update method can effectively shorten the path length of the target search. During the search process, the robot will also find other semi-dynamic objects. If all semi-dynamic objects are found in the search process, updated scene graph will help the robot to quickly find the newly discovered semi-dynamic objects in next tasks. It can be found that updating other objects during the search process can significantly help the next search task.

Figure 6. The robot consumes the path length according to the updated scene graph.
Figure 7 shows in detail the trajectories of the robot using the updated and the un-updated scene graph. If the robot finds an object on the planned path, it will perform a local 3D semantic reconstruction of the target object and find the navigable viewpoint and orientation closest to the target object to approach the target object. As shown by the blue line, when the robot reaches the cup in location 2, it will perform a local 3D semantic reconstruction of the target object and find the navigable viewpoint and orientation closest to the target object and reach location 3.

Figure 7. The trajectory of without updating (yellow) and with updating the scene graph (gree) to find pillows. The trajectory of blue to find cup.
6.2. Real-world experiment
To verify the effectiveness of the long-term target search method in a real-world indoor environment. We construct an experimental scene of about 60 square meters in an office area, including two rooms and a bathroom. The robot is custom built on a business general base, with a 2D Hokuyo Lidar used for localization, and a Kinect RGBD camera for perception. To resolve the limited computation resources on the robot in long processing times by the computer vision software, we use Intel NUC11PHKi7C with Nvidia RTX2060 GPU. A picture of the robot can be seen in Fig. 8(a). After semantic reconstruction, the semantic map of the scene is as shown in Fig. 8(b). In addition, we also artificially set up an obstacle in each task.
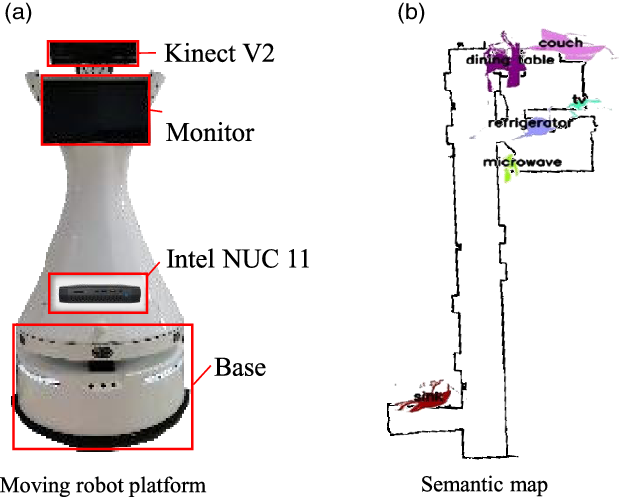
Figure 8. Our moving robot platform and semantic map of the real-world experimental scene.
Figure 9 shows the path of our robot looking for dynamic objects. We place the cup next to the sink and the scissors on the dining table. During the first search for the cup, the robot plans the path according to the initial scene graph. Although the robot can find the object, it has a long walking route as shown in Fig. 9(a). Because the robot finds the cup next to the sink during the last task, the relationship of the cup will be updated. When the robot looking for the cup for the second time, the robot is more inclined to look for it next to the sink as shown in Fig. 9(b). It is worth noting that in the process of searching for the cup first time, the scissors are found on the table, so the robot can quickly find the scissors in the task of finding the scissors in Fig. 9(c). If the connection between the table and the scissors is not established, the robot does not know where it is more likely to find. According to the distance to the static object, the robot first searches inside the refrigerator and microwave and then searches near the table. The results shall be better viewed in the supplementary videos.

Figure 9. The trajectory of the robot in the real environment.
7. Conclusions
In this paper, we propose a long-term target search method in a semi-dynamic indoor scene, and it can effectively find objects that are easy to move. First, the robot builds a navigation map for path planning, a semantic map containing the location information of static objects, and a scene graph containing the closeness of the relationship between static objects and semi-dynamic objects. Then the path length weighting method is used to balance the distance and the probability of finding an object. Finally, to establish a scene-specific scene graph, we propose a method of scene memory to be applied to update the scene graph. We conduct experiments in both simulation and physical environments, which demonstrate the effectiveness of our method. However, when semi-dynamic objects are placed in areas without static objects, it will be difficult for the robot to find the target. In future work, our main work is how to find semi-dynamic objects that are less related to static objects.
Acknowledgment
This work was supported in part by the National Natural Science Fund for Distinguished Young Scholars under Grant 62025304 and was supported by Joint Fund of Science & Technology Department of Liaoning Province and State Key Laboratory of Robotics, China (2020-KF-22-06).












