
3 results
Visual similarity effects in the identification of Arabic letters: evidence with masked priming
-
- Journal:
- Language and Cognition , First View
- Published online by Cambridge University Press:
- 19 April 2024, pp. 1-21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
What are the letters e and é in a language with vowel reduction? The case of Catalan
-
- Journal:
- Applied Psycholinguistics / Volume 43 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 03 December 2021, pp. 193-210
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Jalapeno or jalapeño: Do diacritics in consonant letters modulate visual similarity effects during word recognition?
-
- Journal:
- Applied Psycholinguistics / Volume 41 / Issue 3 / May 2020
- Published online by Cambridge University Press:
- 24 July 2020, pp. 579-593
-
- Article
- Export citation
-
Prior research has shown that word identification times to DENTIST are faster when briefly preceded by a visually similar prime (dentjst; i↔j) than when preceded by a visually dissimilar prime (dentgst). However, these effects of visual similarity do not occur in the Arabic alphabet when the critical letter differs in the diacritical signs: for the target
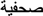 the visually similar one-letter replaced prime
the visually similar one-letter replaced prime 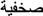 (compare
(compare 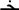 and
and 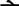 is no more effective than the visually dissimilar one-letter replaced prime
is no more effective than the visually dissimilar one-letter replaced prime 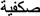 Here we examined whether this dissociative pattern is due to the special role of diacritics during word processing. We conducted a masked priming lexical decision experiment in Spanish using target words containing one of two consonants that only differed in the presence/absence of a diacritical sign: n and ñ. The prime-target conditions were identity, visually similar, and visually dissimilar. Results showed an advantage of the visually similar over the visually dissimilar condition for muñeca-type words (muneca-MUÑECA < museca-MUÑECA), but not for moneda-type words (moñeda-MONEDA = moseda-MONEDA). Thus, diacritical signs are salient elements that play a special role during the first moments of processing, thus constraining the interplay between the “feature” and “letter” levels in models of visual word recognition.
Here we examined whether this dissociative pattern is due to the special role of diacritics during word processing. We conducted a masked priming lexical decision experiment in Spanish using target words containing one of two consonants that only differed in the presence/absence of a diacritical sign: n and ñ. The prime-target conditions were identity, visually similar, and visually dissimilar. Results showed an advantage of the visually similar over the visually dissimilar condition for muñeca-type words (muneca-MUÑECA < museca-MUÑECA), but not for moneda-type words (moñeda-MONEDA = moseda-MONEDA). Thus, diacritical signs are salient elements that play a special role during the first moments of processing, thus constraining the interplay between the “feature” and “letter” levels in models of visual word recognition.
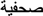 the visually similar one-letter replaced prime
the visually similar one-letter replaced prime 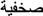 (compare
(compare 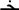 and
and 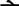 is no more effective than the visually dissimilar one-letter replaced prime
is no more effective than the visually dissimilar one-letter replaced prime 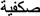 Here we examined whether this dissociative pattern is due to the special role of diacritics during word processing. We conducted a masked priming lexical decision experiment in Spanish using target words containing one of two consonants that only differed in the presence/absence of a diacritical sign:
Here we examined whether this dissociative pattern is due to the special role of diacritics during word processing. We conducted a masked priming lexical decision experiment in Spanish using target words containing one of two consonants that only differed in the presence/absence of a diacritical sign: 