1 results
Sentiment analysis of code-mixed Dravidian languages leveraging pretrained model and word-level language tag
-
- Journal:
- Natural Language Processing ,
- Published online by Cambridge University Press:
- 11 September 2024, pp. 1-23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The exponential growth of social media data in the era of Web 2.0 has necessitated advanced techniques for sentiment analysis. While sentiment analysis in monolingual datasets has received significant attention that in code-mixed datasets still need to be studied more. Code-mixed data often contain a mixture of monolingual content (might be in transliterated form), single-script but multilingual content, and multi-script multilingual content. This paper explores the issue from three important angles. What will be the best strategy to deal with the data for sentiment detection? Whether to train the classifier with the whole of the dataset or only with the pure code-mixed subset from the dataset? How much important is the language identification (LID) for the task? If LID is to be done, how, and when will it be used to yield the best performance? We explore the questions in the light of three datasets of Tamil–English, Kannada–English, and Malayalam–English YouTube social media comments. Our solution incorporated mBERT and an optional LID module. We report our results using a set of metrics like precision, recall,
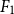 $F_1$ score, and accuracy. The solutions provide considerable performance gain and some interesting insights for sentiment analysis from code-mixed data.
$F_1$ score, and accuracy. The solutions provide considerable performance gain and some interesting insights for sentiment analysis from code-mixed data.