



1. Introduction
The use of deep learning for processing natural language is becoming a standard, with excellent results in a diverse range of tasks. Two state-of-the-art neural architectures for text-related modelling are long short-term memory (LSTM) networks (Hochreiter and Schmidhuber Reference Hochreiter and Schmidhuber1997) and transformers (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017). LSTMs are recurrent neural networks that sequentially process text one token at a time, building up its internal representation in hidden states of the network. Due to the recurrent nature of LSTM, which degrades the efficiency of parallel processing, and improvements in performance, models based on the transformer architecture are gradually replacing LSTMs across many tasks. Transformers can process the text in parallel, using self-attention and positional embeddings to model the sequential nature of the text.
A common trend in using transformers is to pre-train them on large monolingual corpora with a general-purpose objective and then fine-tune them with a more specific objective, such as text classification. For example, the BERT (Bidirectional Encoder Representations from Transformers) architecture (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) uses transformers and is pretrained with masked language modelling and order of sentences prediction tasks to build a general language understanding model. During the fine-tuning for a specific downstream task, additional layers are added to the BERT model, and the model is trained on task-specific data to capture the specific knowledge required to perform the task.
Most of the research in the natural language processing (NLP) area focuses on English, ignoring the fact that English is specific in terms of the low amount of information expressed through morphology (English is a so-called analytical language). In our work, we adapt modern deep neural networks, namely LSTM and BERT, for several morphologically rich languages by explicitly including the morphological information. The languages we analyse contain rich information about grammatical relations in the morphology of words instead of in particles or relative positions of words (as is the case in English). For comparison, we also evaluate our adaptations on English. Although previous research has shown that the state-of-the-art methods such as BERT already capture some information contained in the morphology (Pires, Schlinger, and Garrette Reference Pires, Schlinger and Garrette2019; Edmiston Reference Edmiston2020; Mikhailov, Serikov, and Artemova Reference Mikhailov, Serikov and Artemova2021), this investigation is commonly done by analysing the internals, for example with probing. Probing studies examine whether a property is encoded inside a model, but not necessarily used. In contrast, we present methods which combine BERT with separately encoded morphological properties: universal part of speech tags (UPOS tags) and universal features (grammatical gender, tense, conjugation, declination, etc.). We evaluate them on three downstream tasks: named entity recognition (NER), dependency parsing (DP) and comment filtering (CF), and observe whether the additional information benefits the models. If it does, the BERT models use the provided additional information, meaning that they do not fully capture it in pre-training. We perform similar experiments on LSTM networks and compare the results for both architectures.
Besides English, we analyse 10 more languages in NER, 15 in DP and 5 in CF task. The choice of languages covers different language families but is also determined by the availability of resources and our limited computational resources. We describe the data in more detail in Section 3.
Our experiments show that the addition of morphological features has mixed effects depending on the task. Across the tasks where the added morphological features improve the performance, we show that (1) they benefit the LSTM-based models even if the features are noisy and (2) they benefit the BERT-based models only when the features are of high quality (i.e., human checked), suggesting that BERT models already capture the morphology of the language. We see room for improvement for large pretrained models either in designing pre-training objectives that can capture morphological properties or when high-quality features are available (rare in practice).
The remainder of this paper is structured as follows. In Section 2, we present different attempts to use morphological information in the three evaluation tasks and an overview of works studying the linguistic knowledge within neural networks. In Section 3, we describe the used datasets and their properties. In Section 4, we present the baseline models and models with additional morphological information, whose performance we discuss in Section 5. Finally, we summarize our work and present directions for further research in Section 6.
2. Related work
This section reviews the related work on the use of morphological information within the three evaluation tasks, mainly focusing on neural approaches. We split the review into four parts, one for each of the three evaluation tasks, followed by the works that study the linguistic knowledge contained within neural networks.
2.1 Morphological features in NER
Recent advances in NER are mostly based on deep neural networks. A common approach to NER is to represent the input text with word embeddings, followed by several neural layers to obtain the named entity label for each word on the output. In one of the earlier approaches, Collobert and Weston (Reference Collobert and Weston2008) propose an architecture that is jointly trained on six different tasks, including NER, and show that this transfer learning approach generalizes better than networks trained on individual tasks due to learning a joint representation of tasks. While the authors use Time Delay Neural Network (convolutional) layers (Waibel et al. Reference Waibel, Hanazawa, Hinton, Shikano and Lang1989) to model dependencies in the input, in subsequent works, various recurrent neural networks, such as LSTMs (Hochreiter and Schmidhuber Reference Hochreiter and Schmidhuber1997), are commonly used. For example, Huang et al. (Reference Huang, Xu and Yu2015) show that using unidirectional and bidirectional LSTM layers for NER results in comparable or better performance than approaches using convolutional layers.
In addition to word embeddings, these systems often use hand-crafted features, such as character-based features or affixes. The work of dos Santos and Guimarães (Reference dos Santos and Guimarães2015) outlines the inconvenience of constructing such features and proposes their automatic extraction using character embeddings and a convolutional layer. Authors combine the character-level features with word-level features to obtain competitive or improved results on Spanish and Portuguese NER. Multiple authors (Kuru, Can, and Yuret Reference Kuru, Can and Yuret2016; Lample et al. Reference Lample, Ballesteros, Subramanian, Kawakami and Dyer2016; Yang, Salakhutdinov, and Cohen Reference Yang, Salakhutdinov and Cohen2016) confirm the effectiveness of character embeddings and show that recurrent layers can be used to process them instead of convolutional layers.
While sequence modelling on the character level can already encode morphological information, several authors show that the performance of neural networks on the NER task can be improved by including additional information about the morphological properties of the text. Straková et al. (Reference Straková, Straka and Hajič2016) present a Czech NER system that surpasses the previous best system using only form, lemma and POS tag embeddings. Similarly, Güngör et al. (Reference Güngör, Yldz, Üsküdarli and Güngör2017) show that using morphological embeddings in addition to character and word embeddings improves performance on Turkish and Czech NER, while Simeonova et al. (Reference Simeonova, Simov, Osenova and Nakov2019) show that including additional morphological and POS features improves performance on Bulgarian NER. Güngör et al. (Reference Güngör, Güngör and Üsküdarli2019) extend the study of Güngör et al. (Reference Güngör, Yldz, Üsküdarli and Güngör2017) to three additional languages: Hungarian, Finnish and Spanish.
The influence of POS tags and morphological information on the NER performance of BERT models is less studied. Nguyen and Nguyen (Reference Nguyen and Nguyen2021) present a multi-task learning model which is jointly trained for POS tagging, NER and DP. Their multi-task learning approach can be seen as an implicit injection of additional POS tags into BERT. The system trained on multiple tasks outperforms the respective single-task baselines, indicating that the additional information is beneficial. More explicitly, Mohseni and Tebbifakhr (Reference Mohseni and Tebbifakhr2019) use morphological analysis as a preprocessing step to split the words into lemmas and affixes before passing them into a BERT model. Their system achieved first place in the NER shared task organized as part of the Workshop on NLP solutions for under-resourced languages 2019 (Taghizadeh et al. Reference Taghizadeh, Borhanifard, Pour, Farhoodi, Mahmoudi, Azimzadeh and Faili2019). However, they do not ablate the morphological analysis component, so it is unclear exactly how helpful it is in terms of the NER performance.
Our work extends the literature that studies the influence of POS tags and morphological information on the NER performance. For LSTM models, some works already explore this impact, though they are typically limited to one or a few languages. At the same time, we perform a study on a larger pool of languages from different language families. For BERT, we are not aware of any previous work that studies the influence of explicitly including POS tags or morphological information on the performance of the NER task. The existing work either adds the information implicitly (Nguyen and Nguyen Reference Nguyen and Nguyen2021) or does not show the extent to which the additional information is useful (Mohseni and Tebbifakhr Reference Mohseni and Tebbifakhr2019). In addition, existing analyses are limited to a single language. In contrast, our work explicitly adds POS tags or morphological information and shows how it affects the downstream (NER) performance on a larger pool of languages.
2.2 Morphological features in dependency parsing
Similarly to NER, recent progress in DP is dominated by neural approaches. Existing approaches introduce neural components into either a transition-based (Yamada and Matsumoto Reference Yamada and Matsumoto2003; Nivre Reference Nivre2003) or a graph-based parser (McDonald et al. Reference McDonald, Pereira, Ribarov and Hajič2005). Some works do not fall into either category, for example, they treat DP as a sequence-to-sequence task (Li et al. Reference Li, Cai, He and Zhao2018). The two categories differ in how dependency trees are produced from the output of prediction models. In the transition-based approach, a model is trained to predict a sequence of parsing actions that produce a valid dependency tree. In contrast, in the graph-based approach, a model is used to score candidate dependency trees via the sum of scores of their substructures (e.g., arcs).
One of the earlier successful approaches to neural DP was presented by Chen and Manning (Reference Chen and Manning2014), who replaced the commonly used sparse features with dense embeddings of words, POS tags and arc labels, in combination with the transition-based parser. This approach improved both the accuracy and parse speed. Pei et al. (Reference Pei, Ge and Chang2015) introduced a similar approach to graph-based parsers. Later approaches improve upon the earlier methods by automatically extracting more information that guides the parsing; for example, researchers use LSTM networks to inject context into local embeddings (Kiperwasser and Goldberg Reference Kiperwasser and Goldberg2016), apply contextual word embeddings (Kulmizev et al. Reference Kulmizev, de Lhoneux, Gontrum, Fano and Nivre2019) or train graph neural networks (Ji, Wu, and Lan Reference Ji, Wu and Lan2019).
The use of morphological features in DP, especially for morphologically rich languages, is common and predates neural approaches. For example, Marton et al. (Reference Marton, Habash and Rambow2010) study the contribution of morphological features for Arabic, Seeker and Kuhn (Reference Seeker and Kuhn2011) for German, Kapočiūtė-Dzikienė et al. (Reference Kapočiūtė-Dzikienė, Nivre and Krupavičius2013) for Lithuanian, Khallash et al. (Reference Khallash, Hadian and Minaei-Bidgoli2013) for Persian, etc. The majority of such works report improved results after adding morphological information. As our focus is on neural approaches, we mostly omit pre-neural approaches. Still, we note that the research area is extensive and has also been the topic of workshops such as the Workshop on statistical parsing of morphologically rich languages (Seddah, Koebler, and Tsarfaty Reference Seddah, Koebler and Tsarfaty2010). The largely positive results have motivated authors to continue adding morphological information also to neural systems, which already automatically learn features and may pick up this information. For example, Chen and Manning (Reference Chen and Manning2014) note that POS tag embeddings contribute to the strong performance of their neural system on English and Chinese, and Özateş et al. (Reference Özateş, Özgür, Güngör and Öztürk2018) note the usefulness of morphological embeddings for multiple agglutinative languages. Dozat et al. (Reference Dozat, Qi and Manning2017) report a similar trend in their work submitted to the CoNLL 2017 shared task (Hajič and Zeman Reference Hajič and Zeman2017). They emphasize that POS tags are helpful, but only if produced using a sufficiently accurate POS tagger.
Similarly as in NER, character embeddings improve the accuracy of LSTM-based dependency parsers. We use the term “LSTM-based” to refer to models that include an LSTM neural network (as opposed to a more recent transformer neural network Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017). Several authors (Ballesteros, Dyer, and Smith Reference Ballesteros, Dyer and Smith2015; Dozat et al. Reference Dozat, Qi and Manning2017; Lhoneux et al. Reference Lhoneux, Shao, Basirat, Kiperwasser, Stymne, Goldberg and Nivre2017) report that the use of character-based embeddings results in an improvement in the DP performance and can act as an approximate replacement for additional morphological information. Whether the embeddings present an approximate or complete replacement of morphological information is not entirely certain: Vania et al. (Reference Vania, Grivas and Lopez2018) show that models using character embeddings can still benefit from additional inclusion of morphological features. In contrast, Anderson and Gómez-Rodrguez (Reference Anderson and Gómez-Rodrguez2020) report that the addition of POS tag embeddings does not further help a parser using character embeddings unless the POS tags are of a practically unrealistic quality.
Multi-task learning approaches, where a model is jointly trained for dependency parsing and another task (such as POS or morphological tagging), are also a common way to inject additional information into dependency parsers (Straka Reference Straka2018; Lim et al. Reference Lim, Park, Lee and Poibeau2018; Nguyen and Verspoor 2018). Such approaches are popular in BERT-based parsers (Kondratyuk and Straka Reference Kondratyuk and Straka2019; Zhou et al. Reference Zhou, Zhang, Li and Zhang2020a; Lim et al. Reference Lim, Lee, Carbonell and Poibeau2020; Grünewald, Friedrich, and Kuhn Reference Grünewald, Friedrich and Kuhn2021) and seem to be more common than the alternative approach of using additional inputs in a single-task DP system. In our work, we use the alternative approach and explicitly include POS tags and morphological features in the form of their additional embeddings. We test the effect of the additional information on a sizable pool of languages from diverse language families. We perform several experiments to provide additional insight, testing the same effect with longer training, noisy information and language-specific BERT models.
2.3 Morphological features in comment filtering
The literature for the CF task covers multiple related tasks, such as hate speech, offensive speech, political trolling, detecting commercialism. Recent approaches involve variants of deep neural networks, though standard machine learning approaches are still popular, as shown in the survey of Fortuna and Nunes (Reference Fortuna and Nunes2018). These approaches typically use features such as character n-grams, word n-grams and sentiment of the sequence. Two examples are the works of Malmasi and Zampieri (Reference Malmasi and Zampieri2017), who classify hate speech in English tweets, and Van Hee et al. (Reference Van Hee, Lefever, Verhoeven, Mennes, Desmet, De Pauw, Daelemans and Hoste2015), who classify different levels of cyber-bullying in Dutch posts on ask.fm social site. Scheffler et al. (Reference Scheffler, Haegert, Pornavalai and Sasse2018) combine word embeddings with the features mentioned above to classify German tweets. They observe that combining both n-gram features and word embeddings brings only a small improvement over only using one of them. The effectiveness of using features describing syntactic dependencies for toxic comments classification on English Wikipedia comments is shown by Shtovba et al. (Reference Shtovba, Shtovba and Petrychko2019).
Neural architectures used include convolutional neural networks (Georgakopoulos et al. Reference Georgakopoulos, Tasoulis, Vrahatis and Plagianakos2018) and LSTM networks (Gao and Huang Reference Gao and Huang2017; Miok et al. Reference Miok, Nguyen-Doan, Škrlj, Zaharie and Robnik-Šikonja2019), typically improving the performance over standard machine learning approaches. The CF topic has also been the focus of shared tasks on identification and categorization of offensive language (Zampieri et al. Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019) and multilingual offensive language identification (Zampieri et al. Reference Zampieri, Nakov, Rosenthal, Atanasova, Karadzhov, Mubarak, Derczynski, Pitenis and Çöltekin2020). The reports of these tasks show the prevalence and general success of large pretrained contextual models such as BERT, though, surprisingly, the best performing model for the subtask B of SemEval-2019 Task 6 was rule-based (Han, Wu, and Liu Reference Han, Wu and Liu2019).
2.4 Linguistic knowledge combined with neural networks
Large pretrained models such as BERT show superior performance across many tasks. Due to a lack of theoretical understanding of this success, many authors study how and to what extent BERT models can capture various information, including different linguistic properties. An overview of recent studies in this area, sometimes referred to as BERTology, is compiled by Rogers et al. (Reference Rogers, Kovaleva and Rumshisky2020). Two common approaches to study BERT are (i) add additional properties to BERT models and observe the difference in performance on downstream tasks, (ii) a technique called probing (Conneau et al. Reference Conneau, Kruszewski, Lample, Barrault and Baroni2018), where the BERT model is trained (fine-tuned) to predict a studied property. As we have noted examples of (i) in previous sections, we focus on the probing attempts here.
For example, Jawahar et al. (Reference Jawahar, Sagot and Seddah2019) investigate what type of information is learned in different layers of the BERT English model and find that it captures surface features in lower layers, syntactic features in middle layers, and semantic features in higher layers. Similarly, Lin, Tan, and Frank (Reference Lin, Tan and Frank2019) find that BERT encodes positional information about tokens in lower layers and then builds increasingly abstract hierarchical features in higher layers. Tenney, Das, and Pavlick (Reference Tenney, Das and Pavlick2019) use probing to quantify where different types of linguistic properties are stored inside BERT’s architecture and suggest that BERT implicitly learns the steps performed in classical (non-end-to-end) NLP pipeline. However, Elazar et al. (Reference Elazar, Ravfogel, Jacovi and Goldberg2021) point out possible flaws in the probing technique, suggesting amnesic probing as an alternative. They arrive at slightly different conclusions about BERT layer importance; for example, they show that the POS information greatly affects the predictive performance in upper layers.
Probing studies for morphological properties were conducted by Edmiston (Reference Edmiston2020) and Mikhailov et al. (Reference Mikhailov, Serikov and Artemova2021). Concretely, they train a classifier to predict morphological features based on hidden layers of BERT. Based on the achieved high performance, Edmiston (Reference Edmiston2020) argues that monolingual BERT models capture significant amounts of morphological information and partition their embedding space into linearly separable regions, correlated with morphological properties. Mikhailov et al. (Reference Mikhailov, Serikov and Artemova2021) extend this work to multiple languages, performing probing studies on multilingual BERT models.
3. Data
In this section, we describe the datasets used in our experiments separately for each of the three tasks: NER, DP and CF.
3.1 Named entity recognition
In the NER experiments, we use datasets in 11 languages from different language families: Arabic, Chinese, Croatian, English, Estonian, Finnish, Korean, Latvian, Russian, Slovene and Swedish. The number of sentences and tags present in the datasets is shown in Table 1. The label sets used in datasets for different languages vary, meaning that some contain more fine-grained labels than others. To make results across different languages consistent, we use IOB-encoded labels present in all datasets: location (B/I-LOC), organization (B/I-ORG), person (B/I-PER) and “no entity” (O). We convert all other labels to the “no entity” label (O).
Table 1. The collected datasets for NER task and their properties: the number of sentences and tagged words. We display the results for the languages using their ISO 639-2 three-letter code, provided in the “Code” column

3.2 Dependency parsing
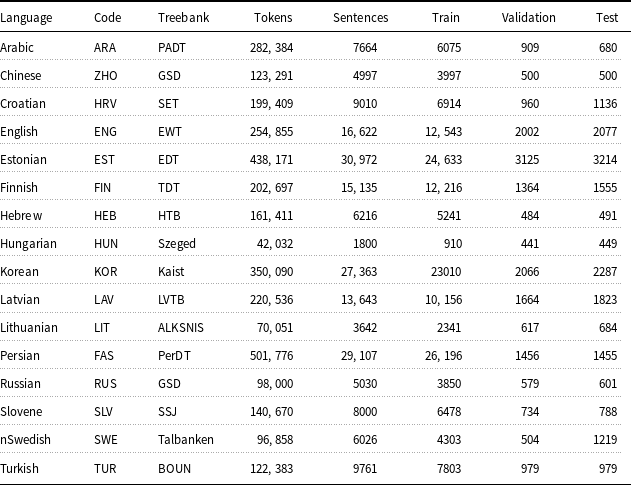
To test morphological neural networks on the DP task, we use datasets in 16 languages from different language families: Arabic, Chinese, Croatian, English, Estonian, Finnish, Hebrew, Hungarian, Korean, Latvian, Lithuanian, Persian, Russian, Slovene, Swedish and Turkish. We use the datasets from the Universal Dependencies (Nivre et al. Reference Nivre, Abrams, Agić, Ahrenberg, Aleksandravičiūtė, Antonsen, Aplonova, Aranzabe, Arutie and Asahara2020), which contain a collection of texts annotated with UPOS tags, XPOS tags (fine-grained POS), universal features and syntactic dependencies. We provide the summary of the datasets in Table 2. The splits we use are predefined by the authors of the datasets. While most of the annotations are manually verified, the universal features in the Chinese and English datasets and the UPOS tags and universal features in the Turkish dataset are only partially manually verified. For Korean, the dataset does not contain universal feature annotations.
Table 2. Dependency parsing datasets and their properties: the treebank, number of tokens, number of sentences and the information about the size of splits. We display the dataset information using the language ISO 639-2 three-letter code provided in the “Code” column
3.3 Comment filtering
While comparable datasets exist across different languages for the NER and DP task, no such standard datasets exist for the CF task. For that reason, in our experiments on CF, we select languages for which adequate datasets exist, that is large, of sufficient quality, and reasonably balanced across classes. We provide a summary of the used datasets in Table 3.
Table 3. Comment filtering datasets and their properties: number of examples, size of the split and class distribution inside subsets

For English experiments, we use a subset of toxic comments from Wikipedia’s talk page edits used in Jigsaw’s toxic comment classification challenge (Wulczyn, Thain, and Dixon Reference Wulczyn, Thain and Dixon2017). The comments are annotated with six possible labels: toxic, severe toxic, obscene language, threats, insults and identity hate (making a total of six binary target variables). We extracted comments from four categories: toxic, severe toxic, threats and identity hate, a total of 21,541 instances. We randomly chose the same amount of comments that do not fall in any of the mentioned categories, obtaining the final dataset of 43,082 instances, using 60% randomly selected examples as the training, 20% as the validation and 20% as the test set.
For Korean experiments, we use a dataset of comments from a Korean news platform (Moon, Cho, and Lee Reference Moon, Cho and Lee2020), annotated as offensive, hateful or clean. We group the offensive and hateful examples to produce a binary classification task. As the test set labels are private, we instead use the predefined validation set as the test set and set aside 20% of the training set as the new validation set.
For Slovene experiments, we use the IMSyPP-sl dataset (Evkoski et al. Reference Evkoski, Mozetič, Ljubešić and Novak2021), containing tweets annotated for fine-grained hate speech. The tweets are annotated with four possible labels: appropriate (i.e., not offensive), inappropriate, offensive or violent. Each tweet is annotated twice, and we only keep a subset for which both labels agree. To produce a binary classification task, we group the tweets labelled as inappropriate, offensive or violent into a single category. We use the predefined split into a training and test set and additionally remove 20% of examples from the training set for use in the validation set.
For Arabic, Greek and Turkish experiments, we use datasets from the OffensEval 2020 shared task on multilingual offensive language identification (Zampieri et al. Reference Zampieri, Nakov, Rosenthal, Atanasova, Karadzhov, Mubarak, Derczynski, Pitenis and Çöltekin2020). The datasets are composed of tweets annotated for offensive language: a tweet is either deemed offensive or not offensive. We use the predefined splits into training and test sets provided by the authors. We randomly remove 20% of the examples from the original training sets to create the validation sets. As the Turkish training set proved to be too heavily imbalanced, we decided to randomly remove half of the unoffensive examples from it before creating the validation set.
4. Neural networks with morphological features
This section describes the architectures of neural networks used in our experiments. Their common property is that we enhance standard word embeddings based inputs with embeddings of morphological features. We work with recent successful neural network architectures, LSTMs and transformers, that is BERT models. A detailed description of architectures is available in the following subsections, separately for each evaluation task. We describe the baseline architecture and the enhanced one for each task and architecture.
4.1 Named entity recognition models
In the NER task, we use two baseline neural networks (LSTM and BERT) and the same two models with additional morphological information: POS tag embeddings and universal feature embeddings. The baseline models and their enhancements are displayed in Figure 1.

Figure 1. The baseline LSTM-based (left) and BERT-based (right) models for the NER task, along with our modifications with morphological information. The dotted border of POS vectors and morphological feature vectors (feats) marks that their use is optional and varies across experiments. The
 $\odot$
symbol between layers represents the concatenation operation. The
$\odot$
symbol between layers represents the concatenation operation. The
 $w_i$
symbol stands for token i; in case of LSTM, tokens enter the model sequentially, and we show the unrolled network, while BERT processes all tokens simultaneously.
$w_i$
symbol stands for token i; in case of LSTM, tokens enter the model sequentially, and we show the unrolled network, while BERT processes all tokens simultaneously.
The first baseline model (left-hand side of Figure 1) is a unidirectional (left-to-right) LSTM model, which takes as an input a sequence of tokens, embedded using 300-dimensional fastText embeddings (Bojanowski et al. Reference Bojanowski, Grave, Joulin and Mikolov2017). These embeddings are particularly suitable for morphologically rich languages as they work with subword inputs.Footnote a For each input token, its LSTM hidden state is extracted and passed through the linear layer to compute its tag probabilities.
The second baseline model (right-hand side of Figure 1) is the cased multilingual BERT base model (bert-base-multilingual-cased). In our experiments, we follow the sequence tagging approach suggested by the authors of BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019). The input sequence is prepended with a special token [CLS] and passed through the BERT model. The output of the last BERT hidden layer is passed through the linear layer to obtain the predictions for NER tags.
Both baseline models (LSTM and BERT) are enhanced with the same morphological information: POS tag embeddings and universal feature embeddings for each input token. We embedded the POS tags using 5-dimensional embeddings. For each of the 23 universal features used (we omitted the Typo feature, as the version of the used tagger did not annotate this feature), we independently constructed 3-dimensional embeddings, meaning that we obtained a 69-dimensional universal embedding. We embedded the features independently due to a large number of their combinations and treated them equally in the DP and CF experiments. We selected the size of the embeddings based on the results of preliminary experiments on Slovene and Estonian languages. We automatically obtained the POS tags and morphological features using the Stanza system (Qi et al. Reference Qi, Zhang, Zhang, Bolton and Manning2020). In the enhanced architectures, we included another linear layer before the final linear classification layer to model possible interactions.
4.2 Dependency parsing models
As the baseline model in the DP task, we use the deep biaffine graph-based dependency parser (Dozat and Manning Reference Dozat and Manning2016). The enhancements with the morphological information are at the input level. The baseline model and its enhancements are shown in Figure 2.

Figure 2. The deep biaffine graph-based dependency parser along with our enhancements at the input level. The dotted border of input embedding vectors, POS vectors and morphological features (feats) is optional and varies across experiments. The
 $\odot$
symbol between layers represents the concatenation operation. The
$\odot$
symbol between layers represents the concatenation operation. The
 $w_i$
symbol stands for token i; tokens enter the LSTM model sequentially, and we show the unrolled network.
$w_i$
symbol stands for token i; tokens enter the LSTM model sequentially, and we show the unrolled network.
The baseline parser combines a multi-layer bidirectional LSTM network with a biaffine attention mechanism to jointly optimize prediction of arcs and arc labels. We leave the majority of baseline architectural hyperparameters at values described in the original paper (3-layer bidirectional LSTM with 100-dimensional input word embeddings and the hidden state size of 400).
In our experiments, we concatenate the non-contextual word embeddings with various types of additional information. The first additional input is contextual word embeddings, which we obtain either by using the hidden states of an additional single-layer unidirectional LSTM or by using a learned linear combination of all hidden states of an uncased multilingual BERT base model (bert-base-multilingual-uncased). To check whether the results depend on using cased or uncased BERT model, we rerun experiments for a small sample of languages with the cased version, using identical hyperparameters, and present the results in Appendix B. The conclusions drawn from both types are similar; the improvements of enhanced models are statistically insignificant for only one out of the eight sampled languages when using a cased BERT model.
Although the LSTM layers are already present in the baseline parser, we include an additional LSTM layer at the input level to explicitly encode the context, keeping the experimental settings similar across our three evaluation tasks, that is we have one setting with added LSTM and one setting with added BERT. The second additional input is universal POS embeddings (UPOS), and the third is universal feature embeddings (feats). These embeddings are concatenated separately for each token of the sentences. The size of the additional LSTM layer, POS tag embeddings and universal feature embedding are treated as tunable hyperparameters. As the baseline input embeddings, we use pretrained 100-dimensional fastText embeddings, which we obtain by reducing the dimensionality of publicly available 300-dimensional vectors with fastText’s built-in dimensionality reduction tool.
In DP experiments, we use POS tags and morphological features of two origins. The first source is human annotations provided in the used datasets. The second source of morphological information is predictions of Stanza models (Qi et al. Reference Qi, Zhang, Zhang, Bolton and Manning2020). These two origins are used to assess the quality of morphological information, namely we check if manual human annotations provide any benefit compared to automatically determined POS tags and features.
4.3 Comment filtering models
We add additional morphological information to standard LSTM and BERT models in the CF evaluation task. The baseline and enhanced models for this task are similar to those in the NER evaluation, though we operate at the sequence level here instead of the token level in the NER task. The architecture of models is shown in Figure 3. As baselines, we take a single-layer unidirectional LSTM network (the top part of Figure 3) and the multilingual base uncased BERT model (bert-base-multilingual-uncased; the bottom part of Figure 3). The difference in the used BERT dialect (uncased as opposed to the cased in the NER task) is due to better performance detected in preliminary experiments.

Figure 3. The baseline LSTM (top) and BERT (bottom) models for the CF task, along with our modifications with morphological information. The dotted border of UPOS vectors and morphological features (feats) marks that their use is optional and varies across experiments. The
 $\odot$
symbol between layers represents the concatenation operation. The
$\odot$
symbol between layers represents the concatenation operation. The
 $w_i$
symbol stands for token i; in the case of LSTM, tokens enter the model sequentially, and we show the unrolled network, while BERT processes all tokens simultaneously.
$w_i$
symbol stands for token i; in the case of LSTM, tokens enter the model sequentially, and we show the unrolled network, while BERT processes all tokens simultaneously.
In the LSTM baseline model, the words of the input sequence are embedded using pretrained 300-dimensional fastText embeddings. As the representation of the whole sequence, we take the output of the last hidden state, which then passes through the linear layer to obtain the prediction scores. In the BERT baseline model, we take the sequence classification approach suggested by the authors of BERT. The input sequence is prepended with the special [CLS] token and passed through BERT. The sequence representation corresponds to the output of the last BERT hidden layer for the [CLS] token, which is passed through a linear layer to obtain the prediction scores.
We augment the baseline models with POS tags and universal feature embeddings, as in other tasks. We obtain the tags for each token separately using the Stanza system (Qi et al. Reference Qi, Zhang, Zhang, Bolton and Manning2020). We combine the obtained embeddings using three different pooling mechanisms: mean, weighted combination or LSTM pooling. Given the POS tag or universal feature embeddings, the mean pooling outputs the mean of all token embeddings. The weighted pooling outputs the weighted combination of token embeddings, and the LSTM pooling outputs the last hidden state obtained by passing the sequence of embeddings through the LSTM network. Both the embedding sizes and the type of pooling are treated as tunable hyperparameters. The coefficients of the weighted combination are learned by projecting the sequence embeddings into a sequence of independent dimension values, which are normalized with the softmax. This compresses the embedding sequence, establishes its fixed length and allows different morphological properties to have a different impact on the sequence representation. This approach tests the contextual encoding of morphological properties. For example, we might learn that the adjectives are assigned a higher weight than other POS tags due to their higher emotional contents that often indicates insults.
5. Evaluation
In this section, we first present the evaluation scenario for the three evaluation tasks, followed by the results presented separately for each of the tasks. We end the section with additional experiments performed on the DP task. In the additional experiments, we investigate the effect of additional morphological features in three situations where we tweak one aspect of the training procedure at a time: (1) we increase the maximum training time of our models by additional 5 epochs, (2) we replace the human-annotated features with the ones automatically predicted by machine learning models, and (3) we replace the embeddings from general multilingual BERT with those from more specific multilingual and monolingual BERT models.
5.1 Experimental settings
The experimental settings differ between the three evaluation tasks, so we describe them separately for each task, starting with the NER task and then the DP and CF tasks. One aspect that is common across all three tasks is that we skip the experiments involving universal features on Korean, as the features are not available for any of the bigger Korean Universal Dependencies corpora; therefore, the Stanza models cannot be used to predict them either.
5.1.1 Experimental settings for NER
For NER, we train each BERT model for 10 epochs and each LSTM model for 50 epochs. These parameters were determined during preliminary testing on the Slovene dataset. The selected numbers of epochs are chosen to balance the performance and training times of the models. All NER models are evaluated using 10-fold cross-validation.
We assess the performance of the models with the
 $F_1$
score, which is a harmonic mean of precision and recall measures. This measure is typically used in NER in a way that precision and recall are calculated separately for each of the three entity classes (location, organization and person, but not “no entity”). We compute the weighted average over the class scores for each metric, using the frequencies of class values in the datasets as the weights. Ignoring the “no entity” (O) label is a standard approach in the NER evaluation and disregards words that are not annotated with any of the named entity tags, that is the assessment focuses on the named entities.
$F_1$
score, which is a harmonic mean of precision and recall measures. This measure is typically used in NER in a way that precision and recall are calculated separately for each of the three entity classes (location, organization and person, but not “no entity”). We compute the weighted average over the class scores for each metric, using the frequencies of class values in the datasets as the weights. Ignoring the “no entity” (O) label is a standard approach in the NER evaluation and disregards words that are not annotated with any of the named entity tags, that is the assessment focuses on the named entities.
5.1.2 Experimental settings for dependency parsing
We train each DP model for a maximum of 10 epochs, using an early stopping tolerance of 5 epochs. All models are evaluated using predefined splits into training, validation and testing sets, determined by the respective treebank authors and maintainers (see Table 2). The final models, evaluated on the test set, are selected based on the maximum mean of unlabeled and labelled attachment scores (UAS and LAS) on the validation set. The UAS and LAS are standard accuracy metrics in DP. The UAS score is defined as the proportion of tokens assigned the correct syntactic head. In contrast, the LAS score is the proportion of tokens that are assigned the correct syntactic head as well as the dependency label (Jurafsky and Martin Reference Jurafsky and Martin2009). As both scores are strongly correlated in most models, we only report the LAS scores to make the presentation clearer.
5.1.3 Experimental settings for comment filtering
In our CF experiments, we train BERT models for a maximum of 10 epochs and LSTM models for a maximum of 50 epochs, using early stopping with the tolerance of 5 epochs.
We evaluate the models using the macro
 $F_1$
score, computed as the unweighted mean of the
$F_1$
score, computed as the unweighted mean of the
 $F_1$
scores for each label. We use fixed training, validation and test sets, described in Table 3. As we have observed noticeable variance in the preliminary experiments, we report the mean metrics over five runs for each setting, along with the standard deviation.
$F_1$
scores for each label. We use fixed training, validation and test sets, described in Table 3. As we have observed noticeable variance in the preliminary experiments, we report the mean metrics over five runs for each setting, along with the standard deviation.
5.2 Experimental results
In this section, we compare the results of baseline models with their enhancements using additional morphological information. We split the presentation into three parts, according to the evaluation task: NER, DP and CF.
5.2.1 Results for the NER task
For the NER evaluation task, we present results of the baseline NER models and models enhanced with the POS tags and universal features, as introduced in Section 4.1. Table 4 shows the results for LSTM and BERT models for 11 languages. We compute the statistical significance of the differences between the baseline LSTM and BERT models and their best performing counterparts with morphological additions. We use the Wilcoxon signed-rank test (Wilcoxon, Katti, and Wilcox Reference Wilcoxon, Katti and Wilcox1970) and underline the statistically significant differences at
 $p=0.01$
level.
$p=0.01$
level.
Table 4.
 $F_1$
scores of different models on the NER task in 11 languages. The left part of the table shows the results for the LSTM models and the right part for the BERT models. The best scores for each language and neural architecture are marked with the bold typeface. Best scores for which the difference to the respective baseline is statistically significant are underlined
$F_1$
scores of different models on the NER task in 11 languages. The left part of the table shows the results for the LSTM models and the right part for the BERT models. The best scores for each language and neural architecture are marked with the bold typeface. Best scores for which the difference to the respective baseline is statistically significant are underlined

The baseline models involving BERT outperform their LSTM counterparts across all languages by a large margin. When adding POS tags or universal features to the LSTM-based models, we observe an increase in performance over the baselines for nine languages. For five (Arabic, Korean, Latvian, Russian and Swedish), the increase in the
 $F_1$
score is not statistically significant; for three of them, the difference is under 0.01. For the remaining four languages (Croatian, Estonian, Finnish and Slovene), the increase is statistically significant and ranges from
$F_1$
score is not statistically significant; for three of them, the difference is under 0.01. For the remaining four languages (Croatian, Estonian, Finnish and Slovene), the increase is statistically significant and ranges from
 $0.015\%$
(Finnish and Croatian) to
$0.015\%$
(Finnish and Croatian) to
 $0.045\%$
(Slovene). The two languages for which we observe no improvement after adding morphological information to the LSTM-based models are English and Chinese.
$0.045\%$
(Slovene). The two languages for which we observe no improvement after adding morphological information to the LSTM-based models are English and Chinese.
In BERT-based models, the additional information does not make a practical difference. For all languages except Slovene and Latvian, the increase in
 $F_1$
values over the baseline is below 0.005. However, we note that the better results on Slovene are possibly a result of the optimistically high quality of the additional morphological information. The Stanza model with which we obtained the predictions for Slovene was trained for a different task, but on the same dataset as we use for NER. Still, the improvements are not statistically significant, so we do not explore the effect further.
$F_1$
values over the baseline is below 0.005. However, we note that the better results on Slovene are possibly a result of the optimistically high quality of the additional morphological information. The Stanza model with which we obtained the predictions for Slovene was trained for a different task, but on the same dataset as we use for NER. Still, the improvements are not statistically significant, so we do not explore the effect further.
Table 5. LAS scores for different models on the DP task in different languages using (a) LSTM or (b) BERT contextual embeddings. The best scores for each language and each type of contextual embeddings are marked with the bold typeface. Statistically significant differences at
 $p=0.01$
level in the best scores compared to the baseline of the same architecture are underlined
$p=0.01$
level in the best scores compared to the baseline of the same architecture are underlined

5.2.2 Results for the dependency parsing task
For the DP evaluation task, we present LAS scores in Table 5. On the left, we show the results obtained with the parser containing additional LSTM embeddings, and on the right, with the parser containing additional BERT embeddings. For each, we report the results without and with additional POS tag and universal feature inputs (as introduced in Section 4.2). We also statistically test the differences in the scores between the best performing enhanced variants and their baselines without morphological additions. As the splits are fixed in the DP tasks, we use the Z-test for the equality of two proportions (Kanji Reference Kanji2006) at
 $p=0.01$
level. The null hypothesis is that the scores of compared models are equal. We underline the best result for languages where the null hypothesis can be rejected.
$p=0.01$
level. The null hypothesis is that the scores of compared models are equal. We underline the best result for languages where the null hypothesis can be rejected.
Table 6.
 $F_1$
scores for baseline and enhanced models on the CF task in different languages. The left part of the table shows results for LSTM models, and the right part shows the results for BERT models. We report the mean and standard deviation over five runs. The highest mean score for each language is marked with the bold typeface separately for LSTM and BERT models. Note, however, that none of the improvements over the baselines is statistically significant at
$F_1$
scores for baseline and enhanced models on the CF task in different languages. The left part of the table shows results for LSTM models, and the right part shows the results for BERT models. We report the mean and standard deviation over five runs. The highest mean score for each language is marked with the bold typeface separately for LSTM and BERT models. Note, however, that none of the improvements over the baselines is statistically significant at
 $p=0.01$
level
$p=0.01$
level

Similarly to NER, the models involving BERT embeddings outperform the baselines involving LSTM embeddings on all 16 languages by a large margin. The models with the added POS tags or universal features noticeably improve over baselines with only LSTM embeddings for all languages. The increase ranges between
 $2.44 \%$
(Russian) and
$2.44 \%$
(Russian) and
 $10.42 \%$
(Lithuanian). All compared differences between the LSTM baselines and the best enhanced variants are statistically significant at
$10.42 \%$
(Lithuanian). All compared differences between the LSTM baselines and the best enhanced variants are statistically significant at
 $p=0.01$
.
$p=0.01$
.
Contrary to the results observed on the NER task, adding morphological features to the models with BERT embeddings improves the performance scores for all languages. The increase ranges from
 $0.57 \%$
(Russian) and
$0.57 \%$
(Russian) and
 $4.45 \%$
(Chinese). The increase is not statistically significant only for one language (Russian). For the remaining 15 languages, the increase is over one per cent and statistically significant.
$4.45 \%$
(Chinese). The increase is not statistically significant only for one language (Russian). For the remaining 15 languages, the increase is over one per cent and statistically significant.
Interestingly, for some languages, the enhanced parsers with LSTM come close in terms of LAS to the baseline parsers with BERT, For two languages (Lithuanian and Latvian), they even achieve better LAS scores.
5.2.3 Results for the comment filtering task
Table 6 shows the CF results for LSTM and BERT baselines and their enhancements, described in Section 4.3. We compute the statistical significance of the differences between the baseline LSTM and BERT models and their best performing counterparts with morphological additions. To do so, we use the unpaired t-test (Student 1908) and check for statistical significance at
 $p=0.01$
level, as in the other two tasks.
$p=0.01$
level, as in the other two tasks.
All BERT-based models outperform the LSTM-based models by a large margin in all languages. Adding POS tags and universal features to neural architectures of either type does not seem to significantly benefit their
 $F_1$
score in general. Although the mean scores of the best performing enhanced models are often higher, the difference is under 0.010 in most cases. The exceptions are Greek (
$F_1$
score in general. Although the mean scores of the best performing enhanced models are often higher, the difference is under 0.010 in most cases. The exceptions are Greek (
 $+0.017$
) and Slovene (
$+0.017$
) and Slovene (
 $+0.010$
) for LSTM models, and Korean (
$+0.010$
) for LSTM models, and Korean (
 $+0.010$
) for BERT models, although the improvements are not statistically significant due to the noticeable standard deviation of the scores. On the other hand, the enhanced models perform practically equivalently or slightly worse on Arabic. As the performance scores do not statistically differ with the best set of hyperparameters, we do not further analyse the effect of different pooling types on the performance. However, we did not observe any pooling approach to perform best consistently.
$+0.010$
) for BERT models, although the improvements are not statistically significant due to the noticeable standard deviation of the scores. On the other hand, the enhanced models perform practically equivalently or slightly worse on Arabic. As the performance scores do not statistically differ with the best set of hyperparameters, we do not further analyse the effect of different pooling types on the performance. However, we did not observe any pooling approach to perform best consistently.
5.3 Additional experiments
To further analyse the impact of different aspects of the proposed morphological enhancements, we conducted several studies on the DP task, where the datasets and evaluation settings allow many experiments. Similarly as in Section 5.2.2, we statistically evaluate differences in performance between the baseline model and the best enhancement using the Z-test for the equality of two proportions. In cases where the null hypothesis can be rejected at
 $p=0.01$
level, we underline the respective compared score. We test the impact of additional training time (Section 5.3.1), quality of morphological information (Section 5.3.2) and different variants of BERT models (Section 5.3.3).
$p=0.01$
level, we underline the respective compared score. We test the impact of additional training time (Section 5.3.1), quality of morphological information (Section 5.3.2) and different variants of BERT models (Section 5.3.3).
5.3.1 Additional training time
To test if the observed differences in performance are due to random variation in the training of models, which could be reduced with longer training times, we increase the maximum training time from 10 to 15 epochs. We show the results in Table 7.
Table 7. LAS scores achieved by models that are trained for up to 5 additional epochs (a maximum training time of 15 epochs instead of 10). The results for 10 epochs are presented in Table 5. Statistically significant differences in best scores at
 $p=0.01$
level compared to the baselines of the same architecture are underlined
$p=0.01$
level compared to the baselines of the same architecture are underlined

We can observe that longer training times slightly increases the scores for all model variants, though their relative order stays the same. The models with added morphological features still achieve better results, so the performance increases do not seem to be the effect of random fluctuations in training due to the number of training steps. All improvements over baselines of the parsers using LSTM embeddings remain statistically significant. In contrast, for the parsers using BERT embeddings, the improvements for two languages are now no longer statistically significant (Croatian and Russian).
5.3.2 Quality of morphological information
In the second additional experiment, we evaluate the impact of the quality of morphological information. We replace the high-quality (human-annotated) POS tags and morphological features used in Section 4.2 with those predicted by machine learning models. In this way, we test a realistic setting where the morphological information is at least to a certain degree noisy. We obtain POS tags and morphological features from Stanza models prepared for the tested languages (Qi et al. Reference Qi, Zhang, Zhang, Bolton and Manning2020). To avoid overly optimistic results, we use models that are not trained on the same datasets used in our DP experiments. This is possible for a subset of nine languages. We note the used Stanza models in Appendix A, together with the proportion of tokens, for which POS tags and all universal features are correctly predicted (i.e., their accuracy).
We show the results of DP models, trained with predicted morphological features in Table 8.
Table 8. LAS scores achieved by DP models that are trained with predicted (noisy) instead of human-annotated morphological features. We provide the accuracy of predicted UPOS tags and universal features in Appendix A. Statistically significant differences in the best scores compared to baselines at
 $p=0.01$
level are underlined
$p=0.01$
level are underlined

The general trend is that using predicted features results in much smaller (best case) performance increases, though some languages still see significant increases. For LSTM models, the increases range from
 $0.62\%$
(Persian) to
$0.62\%$
(Persian) to
 $2.41\%$
(Finnish), with six out of nine being statistically significant. For BERT models, the increases are all statistically insignificant and range from
$2.41\%$
(Finnish), with six out of nine being statistically significant. For BERT models, the increases are all statistically insignificant and range from
 $-0.10\%$
(i.e., decrease, Slovene) to
$-0.10\%$
(i.e., decrease, Slovene) to
 $0.66\%$
(Finnish). These results are consistent with the results of our NER experiments in Section 5.2.1, where we have no access to human-annotated features and find that noisy features only help LSTM-based models.
$0.66\%$
(Finnish). These results are consistent with the results of our NER experiments in Section 5.2.1, where we have no access to human-annotated features and find that noisy features only help LSTM-based models.
These results indicate that adding predicted morphological features to models with BERT embeddings might not be practically useful, since their quality needs to be very high. However, since human-annotated morphological features improve the performance on the DP task, this suggests that there could be room for improvement in BERT pre-training. It seems that the pre-training tasks of BERT (masked language modelling and next sentence prediction) do not fully capture the morphological information present in the language. However, it is unlikely that the models could capture all information present in the ground truth annotations, as humans can disambiguate the grammatical role of a word even where syncretism occurs.
5.3.3 Variants of BERT model
In the third additional experiment, we revert to using the ground truth morphological annotations but replace the embeddings obtained from the multilingual-uncased BERT model with those obtained from more specific multilingual BERT models and monolingual BERT models. In experiments involving multilingual BERT models, we test the Croatian/Slovene/English CroSloEngual BERT, Finnish/Estonian/English FinEst BERT (Ulčar and Robnik-Šikonja Reference Ulčar and Robnik-Šikonja2020), and Bulgarian/Czech/Polish/Russian Slavic BERT (Arkhipov et al. Reference Arkhipov, Trofimova, Kuratov and Sorokin2019). In experiments with monolingual BERT models, we use the Arabic bert-base-arabic (Safaya, Abdullatif, and Yuret Reference Safaya, Abdullatif and Yuret2020), English bert-base-cased (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019), Estonian ESTBert (Tanvir et al. Reference Tanvir, Kittask, Eiche and Sirts2021), Finnish FinBERT (Virtanen et al. Reference Virtanen, Kanerva, Ilo, Luoma, Luotolahti, Salakoski, Ginter and Pyysalo2019), Hebrew AlephBERT (Seker et al. Reference Seker, Bandel, Bareket, Brusilovsky, Greenfeld and Tsarfaty2021), Hungarian huBERT (Nemeskey Reference Nemeskey2021), Korean bert-kor-base, Persian ParsBERT (Farahani et al. Reference Farahani, Gharachorloo, Farahani and Manthouri2021), Russian RuBert (Kuratov and Arkhipov Reference Kuratov and Arkhipov2019), Swedish bert-base-swedish-cased, Turkish BERTurk and Chinese bert-base-chinese models.
We only performed the experiments for a subset of studied languages for which we were able to find more specific BERT models. The aim is to check if the additional morphological features improve the performance of less general, that is more language-specific BERT models. These are trained on a lower number of languages, and larger amounts of texts in the included languages, compared to the original multilingual BERT model (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) that was trained on 104 languages simultaneously. Due to this language-specific training, we expect these BERT models to capture the nuances of the languages better, thus possibly benefiting less from the additional morphological features.
We show the results in Table 9. In most cases, the specific multilingual BERT models, even without additional features, do as well as or better than the best performing original multilingual BERT model with additional features. The only worse LAS scores are achieved on Russian. This indicates that the more specific multilingual BERT models are generally better suited for the DP task than the original multilingual models. The addition of morphological features increases the LAS even further. The improvements range from
 $0.54\%$
(Slovene) to
$0.54\%$
(Slovene) to
 $2.23\%$
(Estonian) and are statistically significant for four out of six languages.
$2.23\%$
(Estonian) and are statistically significant for four out of six languages.
Table 9 LAS scores in the DP task achieved by more specific multilingual (top) and monolingual (bottom) BERT models. The more specific multilingual BERT models were trained on a smaller set of languages (three or five) than the original multilingual BERT model (104). For the base parsers with BERT embeddings, we display the improvement in LAS over using the original multilingual BERT for 104 languages (
 $\uparrow_{mtl}$
). Statistically significant differences of best scores to mBERT baselines at
$\uparrow_{mtl}$
). Statistically significant differences of best scores to mBERT baselines at
 $p=0.01$
level are underlined
$p=0.01$
level are underlined

The monolingual models without additional features set an even higher baseline performance. The results of including additional information are mixed, though surprisingly many languages still see a significant increase in LAS. Out of twelve languages, the improvements are significant for eight and not significant for four languages.
These results indicate that the additional morphological features contain valuable information for the DP task, which the more specific BERT models still do not capture entirely. However, they improve over massively multilingual (i.e., more general) models. We suspect the increase would be even less pronounced if we experimented with “large” (as opposed to base-sized) variants, for example, the large English BERT would likely benefit even less from additional morphological information. We leave this line of experiments for further work.
6. Conclusion
We analysed adding explicit morphological information in the form of embeddings for POS tags and universal features to two currently dominant neural network architectures used in NLP: LSTM networks and transformer-based BERT models. We compared models enhanced with morphological information with baselines on three tasks (NER, DP and CF). To obtain general conclusions, we used a variety of morphologically rich languages from different language families. We make the code to rerun our experiments publicly available.Footnote b
The results indicate that adding morphological information to CF prediction models is not beneficial, but it improves the performance in the NER and DP tasks. For the DP task, the improvement depends on the quality of the morphological features. The additional morphological features consistently benefited LSTM-based models for NER and DP, both when they were of high quality and predicted (noisy). For BERT-based models, the predicted features do not make any practical difference for the NER and DP task but improve the performance in the DP task when they are of high quality. Testing different variants of BERT shows that language-specialized variants enhance the performance on the DP task and the additional morphological information is still beneficial, although less and less as we shift from multilingual towards monolingual models.
Comparing different BERT variants indicates that BERT models do not entirely capture the language morphology. Since the release of BERT, several new pre-training objectives have been proposed, such as syntactic and semantic phrase masking (Zhou et al. Reference Zhou, Zhang, Zhao and Zhang2020b) and span masking (Joshi et al. Reference Joshi, Chen, Liu, Weld, Zettlemoyer and Levy2020). In further work, it makes sense to apply these models to the DP task to test how well they capture the morphology. Further, the effect of morphological features could be analysed on additional tasks and languages since the explicit morphological information does not seem to benefit them equally.
Acknowledgements
This work was supported by European Union’s Horizon 2020 Programme project EMBEDDIA (Cross-Lingual Embeddings for Less-Represented Languages in European News Media, grant no. 825153). The research was supported by the Slovene Research Agency through research core funding no. P6-0411 and the young researcher grant as well the Ministry of Culture of the Republic of Slovenia through project Development of Slovene in Digital Environment (RSDO). The Titan X Pascal used for a part of this research was donated by the NVIDIA Corporation.
Appendix A. Used Stanza models

Appendix B. Results of dependency parsing with cased multilingual BERT
Table B1 shows the results of a subset of the main dependency parsing experiments performed using a cased multilingual BERT model (bert-base-multilingual-cased). However, the conclusions drawn from Tables 5 and B1 are the same.
Table B1. LAS achieved using a cased (instead of uncased) multilingual BERT model on a random sample of eight languages in the DP task. Statistically significant differences between baselines and best scores at
 $p=0.01$
level are underlined
$p=0.01$
level are underlined





























