



No CrossRef data available.
Published online by Cambridge University Press: 22 December 2022
We introduce a variant of Shepp’s classical urn problem in which the optimal stopper does not know whether sampling from the urn is done with or without replacement. By considering the problem’s continuous-time analog, we provide bounds on the value function and, in the case of a balanced urn (with an equal number of each ball type), an explicit solution is found. Surprisingly, the optimal strategy for the balanced urn is the same as in the classical urn problem. However, the expected value upon stopping is lower due to the additional uncertainty present.
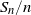 $S_n/n$
. Illinois J. Math. 9, 444–454.CrossRefGoogle Scholar
$S_n/n$
. Illinois J. Math. 9, 444–454.CrossRefGoogle Scholar