



1. Introduction
In the field of second language (L2) acquisition, there is an ongoing shift in perception towards written production. No longer a mere consequence of language learning, writing is now deemed a tool to facilitate the learning process itself. For instance, errors in written production are considered as additional learning opportunities, with research suggesting that written corrective feedback (WCF) not only targets linguistic accuracy but also promotes L2 writing acquisition (Manchón & Vasylets, Reference Manchón, Vasylets, Schwieter and Benati2019). Given this shift, WCF emerges as a catalyst for L2 writing acquisition.
Spelling accurately is among the key linguistic competencies that facilitate and indicate L2 writing progress. It influences vocabulary acquisition and retention (Brown & Ellis, Reference Brown and Ellis1994), and is important for reading and writing (Graham & Santangelo, Reference Graham and Santangelo2014). It is also a predominant factor in evaluating L2 writing (Rodríguez, Villoria & Paredes, Reference Rodríguez, Villoria and Paredes1997). Despite its relevance, spelling is often neglected in Spanish as a foreign language (SFL) pedagogy (Sánchez Jiménez, Reference Sánchez Jiménez2009), probably because Spanish orthography, unlike opaque orthographies like English, has a relatively high degree of grapheme–phoneme correspondence. Put simply, Spanish spelling can largely be predicted from pronunciation.
A commonplace resource for L2 teachers to explicitly target orthography is WCF, which appears to have a “substantive effect on L2 written accuracy” in immediate post-tests with a small to moderate effect size (Kang & Han, Reference Kang and Han2015: 10), independently of the WCF’s nature and characteristics (see Blázquez-Carretero, Reference Blázquez-Carretero, García Orta and Martín Santos2022, for an extensive review of WCF literature). Kang and Han’s (Reference Kang and Han2015) meta-analysis of experimental studies also provided evidence of improvement, even in delayed post-tests. Research therefore recommends that L2 learners write as much as possible to learn from their errors. Yet resource and time constraints limit the teacher’s opportunity to provide feedback (Lawley, Reference Lawley2016). With narrow time frames, students are encouraged to self- and peer-correct, usually with the guidance of teachers who provide detailed instructions. Despite a wealth of literature supporting the efficacy of autocorrection (Lázaro Ibarrola, Reference Lázaro Ibarrola2013), students often find the process difficult and tedious without professional assistance (Lawley, Reference Lawley2015). Lee (Reference Lee1997) notes that recognition of misspellings is crucial to self-correction but proves challenging for L2 learners if their mistakes are not previously highlighted. Heeding Lee and Lázaro Ibarrola’s findings, an aptly programmed software capable of detecting spelling errors would likely help L2 students to independently correct such errors. This is backed by empirical evidence on the positive effects for L2 learning of computer-generated WCF (Heift & Hegelheimer, Reference Heift, Hegelheimer, Nassaji and Kartchava2017; Li, Feng & Saricaoglu, Reference Li, Feng and Saricaoglu2017; Stevenson & Phakiti, Reference Stevenson and Phakiti2014). While frequently used generic spellcheckers (GSCs) like those embedded in Microsoft Word (MW) operate with an error-detecting software, these first language (L1)–oriented tools have been shown to disadvantage L2 learners (Blázquez-Carretero & Fan, Reference Blázquez-Carretero and Fan2019; Blázquez-Carretero & Woore, Reference Blázquez-Carretero and Woore2021; Heift & Rimrott, Reference Heift and Rimrott2008).
2. Limitations of existing spellcheckers for SFL learners
Most GSCs are built for native speakers. Given their main objective of facilitating and accelerating the user’s writing process, misspellings are automatically corrected. This is beneficial for proficient writers whose errors are mostly just slips (e.g. typos), otherwise known as performance errors (Brown, Reference Brown1994). For L2 students, whose errors mostly result from actual gaps in their target language knowledge (competence errors [Touchie, Reference Touchie1986]), autocorrection is not as useful. Indeed, the noticing hypothesis posits that “input does not become intake for language learning unless it is noticed, that is, consciously registered” (Schmidt, Reference Schmidt2010: 721). Therefore, GSCs arguably impede learners from benefitting from their errors; the software instantly modifies mistakes, hence curtailing learners’ conscious processing. Moreover, these mainstream spellcheckers suggest replacement words upon error detection. While a native speaker may effortlessly select the correct alternative, an L2 learner might find the task more challenging and less intuitive. There is sufficient evidence that L2 students are misled by these suggestions because they often presume the correct word to be listed, although this is not necessarily the case (Blázquez-Carretero & Fan, Reference Blázquez-Carretero and Fan2019; Heift & Rimrott, Reference Heift and Rimrott2008; Mitton & Okada, Reference Mitton and Okada2007). Apart from the quality of feedback, the capacity for error detection is equally important. Spellcheckers generally use a reference corpus to assess whether words are written correctly. Words absent from the corpus are highlighted, followed by either a list of alternatives or a correction executed by the software (Mitton, Reference Mitton2010). While this method’s detection rate is higher than 80% (Bestgen & Granger, Reference Bestgen and Granger2011; Blázquez-Carretero & Fan, Reference Blázquez-Carretero and Fan2019; Rimrott & Heift, Reference Rimrott and Heift2008), it only pertains to single-word errors, preventing GSCs from identifying context-specific mistakes should the misspelling correspond to an existent word (Blázquez-Carretero & Fan, Reference Blázquez-Carretero and Fan2019). As GSCs are L1-oriented, their built-in autocorrect and feedback mechanism is grounded on the notion that spelling errors are performance-based and typically involve single-letter violations. But L2 misspellings are more complex in nature (Heift & Schulze, Reference Heift and Schulze2007), generally requiring two or more operations to correct the error (i.e. edit distance; Ranalli & Yamashita, Reference Ranalli and Yamashita2022).
Consequently, researchers have developed systems better attuned to L2 misspellings by drawing from a database of their errors (Rimrott & Heift, Reference Rimrott and Heift2006) or from contextual information derived from L2 learner corpora (Nagata, Takamura & Neubig, Reference Nagata, Takamura and Neubig2017). A host of innovative and accessible web browser–integrated tools (e.g. Grammarly) incorporate advancements in machine learning and natural language processing technology (Ranalli, Reference Ranalli2018). However, not many are specifically designed for SFL learners, and those available show similar limitations as GSCs. Indeed, Blázquez-Carretero and Fan’s (Reference Blázquez-Carretero and Fan2019) comparison of three different SFL spellcheckers (LanguageTool, Stilus, and SpanishChecker) suggested global gains in error detection (all detected over 85% of the errors) but observed less success in adequate feedback provision (with MW’s 67% accuracy rate outperforming the rest).
Responding to these issues and limitations and drawing from related literature (Blázquez-Carretero, Reference Blázquez-Carretero2019; Blázquez-Carretero & Fan, Reference Blázquez-Carretero and Fan2019; Blázquez-Carretero & Woore, Reference Blázquez-Carretero and Woore2021; Harvey-Scholes, Reference Harvey-Scholes2018; Lawley, Reference Lawley2015, Reference Lawley2016), a team of researchers from the Universidad Nacional de Educación a Distancia decided to build a prototype spellchecker to help SFL students in self-correcting their written outputs. This tool is specially designed to tackle common SFL misspellings through WCF. Blázquez-Carretero and Woore (Reference Blázquez-Carretero and Woore2021) empirically demonstrated that SFL learners can benefit from error-specific, metalinguistic WCF targeting an underlying misconception.
The present study deals with the development of an online pedagogic spellchecker (PSC) able to detect and provide WCF to most SFL spelling errors by largely replicating Lawley’s (Reference Lawley2016) study, adapting it to the SFL context, and improving upon Lawley’s methodological gaps. First, the SFL learners’ interlanguage was accounted for through real data analysis within the framework of error analysis and corpus linguistics. When all misspellings in the CORANE corpus (Cestero Mancera & Penadés Martínez, Reference Cestero Mancera and Penadés Martínez2009) were identified and scrutinised, a selection process was implemented to overcome Lawley’s (Reference Lawley2016) less meticulous method of identifying errors he deemed worthy of WCF. A pedagogical WCF was carefully designed for each error selected, including potential violations of the same orthographic pattern despite non-occurrence in the corpus. Another corpus, CEDEL2 (Lozano, Reference Lozano2022), was subsequently used to compare the PSC’s efficacy in error recognition and feedback provision vis-à-vis MW’s spellchecker.Footnote 1 This pedagogic tool was tested on a much larger sample for increased reliability. To avoid biased results, one type of filter was exclusively compared with the other (i.e. MW spelling filter vs. PSC spelling filter), unlike Lawley (Reference Lawley2016), who drew favourable results on the PSC’s error-detection accuracy after comparing its combined bigram and spelling filters with MW’s spelling filter alone.
3. Building a spellchecker for SFL learners
Following Lawley’s (Reference Lawley2016) recommendations, the PSC contains a database of the commonest SFL misspellings, each supplied with its own pedagogic WCF. Equipped with a search-and-match facility, the software highlights the error and then provides corresponding feedback after the erroneous word is clicked on.
3.1 Identifying common spelling errors made by SFL learners
Real data from the CORANE corpus (Cestero Mancera & Penadés Martínez, Reference Cestero Mancera and Penadés Martínez2009) was used to identify common SFL spelling errors to build a sound database and design-appropriate feedback. The corpus comprises 957 compositions totalling 219,032 words, written by 290 SFL learners from 22 different L1 backgrounds whose Spanish proficiency ranges between A2 and C1 levels (CEFR; Council of Europe, 2001). At this stage, spelling error refers to any string of letters between spaces that is excluded from the Diccionario de la Lengua Española (Real Academia Española, 2014). However, grammatical errors like gender and/or number disagreement, lexical errors like the misuse of diacritic marks in homographs, and punctuation errors were not considered as misspellings; such errors can be better identified by analysing their surrounding linguistic context (see Blázquez-Carretero, Reference Blázquez-Carretero2019). This definition was deemed necessary to suit the research objectives as we neither aimed to categorise nor explore the origin of errors, but rather to understand and explain how spellcheckers can effectively detect errors and offer appropriate feedback, thereby paving the way to the wholesale improvement of L2-oriented spellcheckers.
Analysing CORANE (Cestero Mancera & Penadés Martínez, Reference Cestero Mancera and Penadés Martínez2009) yielded an initial list of 8,053 misspellings (3.68%).Footnote 2 An overwhelming majority (89.8%) contained a single error, that is, requiring only one “edit movement” (omission, substitution, incorporation, or transposition) for correction. The rest (10.2%) contained a combination of at least two errors within a word. Everything considered, the misspellings present in the corpus number 9,110.
3.2 Developing the pedagogic feedback
Given the profusion of spelling errors (9,110) and that a single-occurrence error does not necessarily constitute a recurrent problem, a methodological decision was taken to sift through the data and select only those resulting from violation of Spanish orthographic norms and patterns. Considering the lacuna in applied linguistics of a criterion for inclusion and exclusion of spelling errors, we established our own based on previous experiences in other domains of knowledge, specifically genetics (see Saint Pierre & Génin, Reference Saint Pierre and Génin2014). This is a novel methodological addition that was noticeably missing from Lawley (Reference Lawley2016). As Figure 1 shows, performance errors were discarded. First, a threshold was established at the individual level: a recurring orthographic deviation was deemed a competence error (i.e. if the same error appeared in half of the instances where the SFL learner intended to write that word, f1 ≥ 0.5). More challenging was categorising errors within a word used only once (f1 = 1) by a given SFL learner, since it is impossible to determine at the individual level whether such deviations result from a performance or a competence error. However, different SFL learners committing the same misspelling prompted us to tag this word as potentially problematic. Thus, a second threshold was established at the corpus level: infrequent errors were discarded (i.e. at least two different individuals should have committed the same misspelling for it to be considered a competence error).Footnote 3 However, upon Lawley’s (Reference Lawley2016) recommendation, all errors violating an orthographic regularity, regardless of the instances of occurrence, were included in the feedback and the database alike.
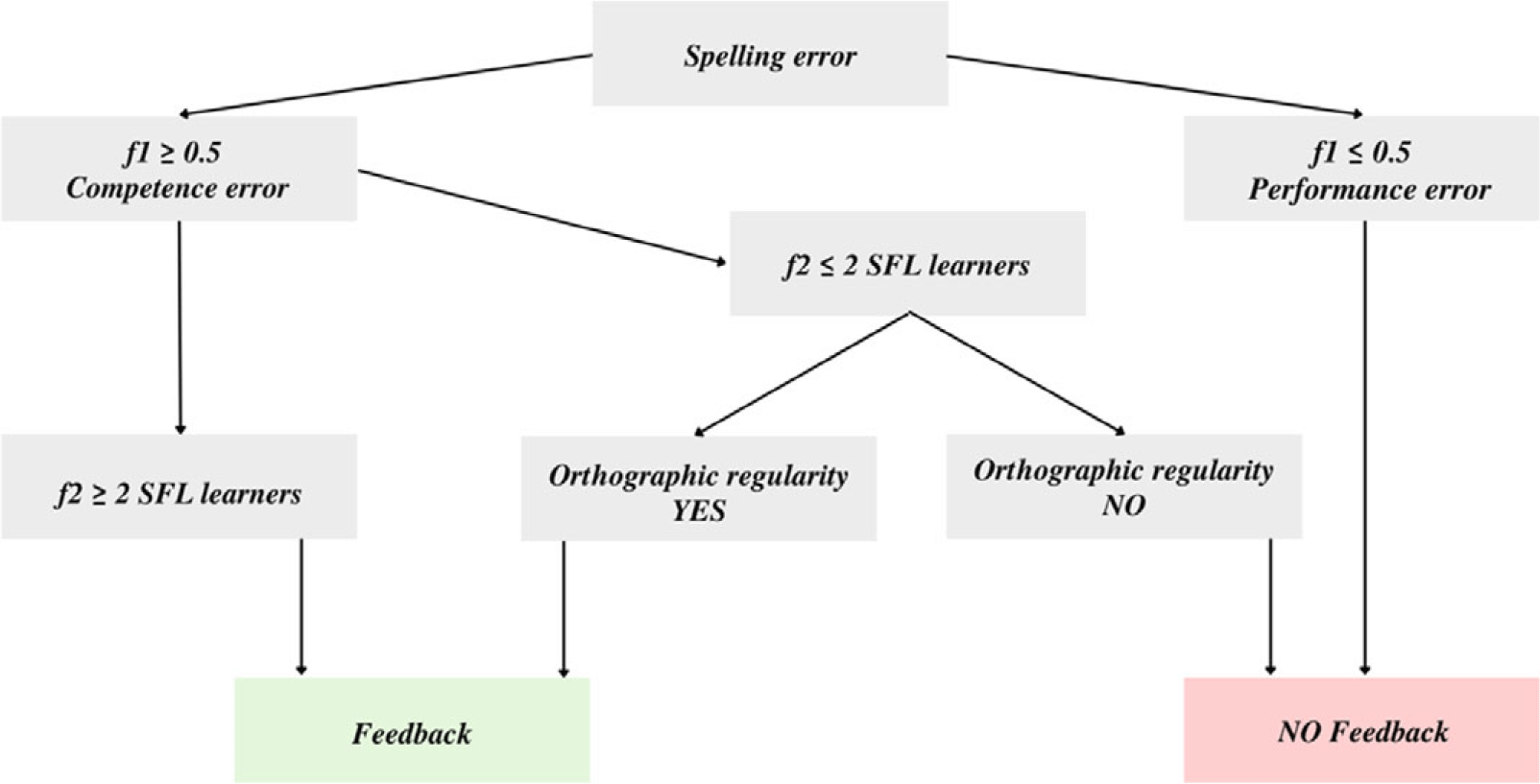
Figure 1. Error selection process
An initial database of 4,379 spelling errors was compiled. A pedagogic WCF was designed to address each, grounded on Long’s (Reference Long, Ritchie and Bhatia1996) interaction hypothesis (i.e. that L2 acquisition requires exposure to input, meaning negotiation through interaction, feedback reception, and output production), its potential application to computer-based language learning environments (Grgurović, Chapelle & Shelley, Reference Grgurović, Chapelle and Shelley2013), and the empirically proven efficacy of explicit feedback as a correction method in virtual environments (Blázquez-Carretero & Woore, Reference Blázquez-Carretero and Woore2021; Heift, Reference Heift2008; Lin, Liu & Paas, Reference Lin, Liu and Paas2017). Following Cotos’s (Reference Cotos2011) criteria and Lawley’s (Reference Lawley2016) recommendations, the feedback must (a) be specific for each error, (b) indicate the error type, (c) explain the error clearly and concisely, and (d) encourage self-correction. Below is the feedback prepared for the error *psicologo instead of psicólogo (psychologist).Footnote 4
psicologo
The correct spelling is psicólogo.
In Spanish, all words ending in -ologo have an accent on the first o → ólogo.
monólogo (monologue)
sociólogo (sociologist)
arqueólogo (archaeologist)
The composition of a PSC-generated WCF generally includes
-
1. the misspelling (*psicologo), so that SFL learners may discern their interlanguage during the process of interaction and negotiation of meaning (Grgurović et al., Reference Grgurović, Chapelle and Shelley2013).
-
2. the correct spelling with the highlighted error in bold (psicólogo) for SFL learners to notice their error (Lee, Reference Lee1997; Schmidt, Reference Schmidt1990) and benefit from a direct WCF (van Beuningen et al., Reference van Beuningen, de Jong and Kuiken2008).
-
3. a brief explanation of the likely reason behind the error and its solution. (In Spanish, all words ending in -ologo have an accent on the first o → ólogo.) Kang and Han’s (Reference Kang and Han2015) meta-analysis reveals that explicit WCF promotes writing accuracy and L2 learning. Concision is important to avoid saturating the learner’s working memory (Kellogg, Reference Kellogg2001; Manchón, Reference Manchón, Byrnes and Manchón2014), and exceptions are excluded as they “make learning the rule more difficult” (Nation, Reference Nation1990: 48). Exceptions usually refer to deviations from the indicated pattern, obscure words, or low-frequency terms, such as homologo (“I homologate”), prologo (“I preface”), and monologo (“I soliloquize”). Indeed, “exceptions should not be introduced until the rule has been learned” (Nation, Reference Nation1990: 48).
-
4. examples of correctly spelled words illustrating the orthographic pattern (monólogo, sociólogo, arqueólogo). Indeed, among the psycholinguistic determinants of vocabulary learning is the recurrence of a letter sequence in a given language (Barcroft & Rott, Reference Barcroft and Rott2010). Examples were selected based on variables facilitating vocabulary acquisition, like frequency of use (Ellis & Beaton, Reference Ellis and Beaton1993), orthographic similarity to cognates in other languages (Kelley & Kohnert, Reference Kelley and Kohnert2012), and/or belonging to the same word family (Webb, Reference Webb2021).
Among the commonest misspellings were accentuation errors (50.8% of errors detected in CORANE). Of these, 155 resulted from the lack of graphic accent in words ending in -ión (e.g. *avion [plane] or *asociacion [association]). Words ending in -n, -s, or a vowel require an orthographic accent if the stress is on the last syllable (the common explanation in the SFL classroom). However, this pattern is complex, necessitating further examples. A more visual, succinct WCF was provided to inhibit L2 working memory saturation (Kellogg, Reference Kellogg2001; Manchón, Reference Manchón, Byrnes and Manchón2014): “In Spanish, all words ending in -ion have an accent on the o → ión”. Indeed, it is a learning strategy already employed by SFL students (Blázquez-Carretero & Woore, Reference Blázquez-Carretero and Woore2023).
The common misspelling of diferente (*differente appears seven times from five different learners) is likely linked to language interference (Figueredo, Reference Figueredo2006). The corresponding WCF (“In Spanish, there are no words with ff”) not only assists SFL learners on this occasion but also guides them in future instances involving English cognates like coffee (café) or office (oficina).
Other errors are morphological, as when SFL learners erroneously add affixes to root words (Marcos-Miguel, Reference Marcos-Miguel2013; Sánchez-Gutiérrez, Reference Sánchez-Gutiérrez2013). This, however, can easily be explained as an orthographic regularity, since “[…] there are clear rules indicating how suffixes are appended to words” (Goulandris, Reference Goulandris, Brown and Ellis1994: 416).
afortunadomente
The correct spelling is afortunadamente.
In Spanish, adverbs ending in -mente are formed by adding the suffix to the feminine form of the adjective.

Lexical consistency is another orthographic regularity that helps L2 students to learn and remember patterns (Goulandris, Reference Goulandris, Brown and Ellis1994). Hence, for errors like *discotequa (misspelled discoteca “discotheque”), the PSC offers easy-to-remember etymological WCF: “In Spanish, -teca is a common suffix indicating some sort of storage, collection, or exhibition”. Occasionally, visual clues aid L2 learners in retrieving the spelling of analogous words (Goswani, Reference Goswami1988). Indeed, Blázquez-Carretero and Woore (Reference Blázquez-Carretero and Woore2021) found that SFL students adopt this learning strategy to correct their spelling. Sometimes, only examples of high-frequency words containing the letter sequence were offered:
dia
The correct spelling is día.
mía (mine)
fría (cold)
guía (guide)
Some misspellings, depending on the grapheme replaced, can lead to various possible replacements:
Major
¿Do you mean mejor o mayor?
For example:
Juan juega mejor al tenis que Luís. (Juan plays tennis better than Luis.)
Si Juan tiene 20 años y Luís 18, Juan es mayor que Luís. (If Juan is 20 years old and Luis 18, Juan is older than Luis.)
Here, a GSC would have problems deciding which to propose: replacing the a with an e results in mejor (better) and the j with a y in mayor (older). Both are high-frequency terms in Spanish (mejor appears 80,404 times and mayor 87,561 in the CREA corpus [Real Academia Española, 2008]). Without context, it is impossible to determine the SFL learner’s intention. Thus, the PSC’s WCF does not merely offer an alternative, but also interacts with the learner and provides examples of context-based usage because “incidental learning via guessing from context is the most important of all sources of vocabulary learning” (Nation, Reference Nation2001: 232).
The PSC can also detect and provide WCF on certain errors that a GSC might overlook as they are existing, albeit infrequent, words, like ingles (groins), tenia (tapeworm), or ultimo (I finalise). While CREA registers 203, 251, and 124 hits for each word respectively, most SFL learners originally intended the more widely used inglés (English), tenía (he/she had), and último (last) with 10,070, 66,996, and 45,718 occurrences respectively in the same corpus. Hence, a WCF was developed for all these terms, noting that one of either is used much more frequently.
Detecting the most frequent SFL misspellings is less challenging than the near impossible task of providing specific WCF for every single potential error. Therefore, the PSC works with two databases: one containing the most common SFL spelling errors and a reference corpus of 100 million correctly spelled words drawing from recent literature (e.g. stories, essays, articles, and news) (see San Mateo, Reference San Mateo2016). A search-and-match detection system will then compare inputted text with both databases. If the misspelled word is a common error or follows a potentially problematic spelling pattern for SFL learners, a WCF is provided (e.g. *officina with the inexistent double f). Otherwise, the PSC uses the reference corpus to verify the spelling and highlight the input should it be absent from the corpus (e.g. *ofizina). In place of feedback, SFL learners are advised to consult a dictionary, a valuable self-correction strategy (Nesi, Reference Nesi2014).
However, this search-and-match system fails to identify errors where the input is a homophone or an existing lexical item, as in *tu hablas (*your talk) (tu [your] and tú [you] are actual words). Evidently, SFL learners and L1 speakers alike commit such errors. For better service, the PSC was further equipped with a detection system able to spot errors in word pairs by analysing the frequency with which words tend to appear together (collocations) (see Blázquez-Carretero, Reference Blázquez-Carretero2019, on the development of this filter).
Overall, 379 WCF were designed, tackling 4,653 misspellings in CORANE and covering 25,609 potential errors. For activation, all feedback was programmed into the PSC alongside the database. Once the search-and-match algorithm was developed, the reference corpus built, and WCFs included, the PSC was ready for trial.
4. Testing the efficacy of the PSC detecting and providing WCF
With the PSC operative, an empirical study was executed to determine its efficacy in both error detection and feedback provision. We lifted 60 compositions comprising 11,475 words written by beginner-level, intermediate, and advanced SFL learners from CEDEL2 (Lozano, Reference Lozano2022). Once the misspellings were identified, the compositions were run through the PSC’s and MW’s spelling filters to answer these research questions:
RQ1: How effective is the PSC compared to MW in detecting SFL learners’ spelling errors?
RQ2: How effective is the PSC vis-à-vis MW in providing adequate feedback to each detected error?
RQ3: Do results vary across different SFL proficiency levels?
4.1 Materials and sampling
To evaluate the PSC’s efficacy, we chose the corpus CEDEL2 (Lozano, Reference Lozano2022) containing 802,019 words, involving 2,578 participants from two different L1 backgrounds (as of February 2019).Footnote 5 CEDEL2 was piloted before conducting the study to explore other possible variables relevant to sample selection. Fifteen compositions comprising 2,732 words were randomly chosen. Unsurprisingly, a positive Pearson’s correlation between proficiency levelFootnote 6 and essay length was found (r (13) = .545, p = .036) versus a significant negative Pearson’s correlation between proficiency level and number of misspellings (r (13) = .642, p < .001). Simply put, more advanced SFL learners tend to write longer texts and commit fewer errors. Additionally, take-home essays contain a considerably lower percentage of errors (M = 6.56%, SD = 8.99%) versus in-class tasks with no support for students (M = 9.25%, SD = 4.8%); an independent sample t-test revealed a statistically significant difference (t 5 = 0.526, p = 0.31). Finally, to account for the wide-ranging corpus content (with 14 different topic/prompts), the final sample was selected using blocked stratified randomisation considering these variables: proficiency level, use of supporting materials, and topic/prompt. We also adapted Sinclair’s (Reference Sinclair1991) grammatical analysis technique for this study’s objectives to determine a sound sample size, ensuring reliable results. An initial sample of 30 compositions (5,521 words) by 30 different SFL learners was selected. Two university-level SFL professors identified, first individually and then together, 577 spelling errors. They categorised these based on the edit distance required to correct the misspelling. A second sample of 30 compositions (5,954 words) by 30 different SFL learners was then selected, revealing 642 errors. As the second sample has a similar error-per-word rate with no new categories of error, “the research would have covered a critical mass of data” (Harvey-Scholes, Reference Harvey-Scholes2018: 149).
Final sampling (11,475 words) settled on 60 compositions (20 for each proficiency level, representing all topic/prompts, and executed without supporting materials). This quadruples Lawley’s (Reference Lawley2016) sample size (2,648 words) and falls within the range of successful ones from similar studies: Hernández García’s (Reference Hernández García2017) contained 7,184 words, San Mateo’s (Reference San Mateo2016) 9,500, Chacón-Beltrán’s (Reference Chacón-Beltrán2017) 12,063, and Harvey-Scholes’s (Reference Harvey-Scholes2018) 13,644.
4.2 Method and analysis
The selected 60 compositions were inputted one by one on the PSC. We first tallied the detected misspellings, followed by the number of errors that received adequate WCF. The same compositions were inputted on MW with the spellchecker activated but the grammar checker and autocorrection feature deactivated. As with the PSC, we first counted the errors detected by MW. Then, its proposed alternatives (feedback) were analysed to verify (1) whether the correct word figured in the drop-down list and (2) in which position the correct replacement word appeared on the list (see Blázquez-Carretero & Fan, Reference Blázquez-Carretero and Fan2019). If the correct word failed to appear in first position, MW’s feedback was deemed inadequate. There is widespread conviction among L2 learners that the first suggestion is always the correct replacement (Blázquez-Carretero & Woore, Reference Blázquez-Carretero and Woore2023; Heift & Rimrott, Reference Heift and Rimrott2008; Rimrott & Heift, Reference Rimrott and Heift2006), which is not always the case (Blázquez-Carretero, Reference Blázquez-Carretero2019; Rimrott & Heift, Reference Rimrott and Heift2008). Indeed, L2 learners often choose an inappropriate replacement when the first alternative in the list is incorrect (Rimrott & Heift, Reference Rimrott and Heift2008). A statistical comparison of the data gathered from PSC and MW followed. The frequency of misspellings was standardised and defined as number of errors/100 words, since the number of errors/composition was influenced by the total number of words (i.e. the longer the text, the more probable that an SFL learner commits misspellings).
4.3 Results
4.3.1 Evaluating the detection capacity
Overall, 1,218 spelling errors were detected (i.e. 10.6% of 11,475 words were misspelled). The PSC detected 1,109 among these, while MW highlighted 1,011. Table 1 shows that SFL learners misspelled an average of one per 10 words (M = 11.5, SD = 6.22). The PSC’s average error detection rate was 92.5% – that is, 9.3% higher than MW’s (83.2%). Another important finding is PSC’s lowest error detection rate at 50%. At its worst, the PSC detected one of two errors, effectively outperforming MW, sometimes detecting as few as 20% of misspellings.
Table 1. Summary statistics of measures of spelling errors and feedback adequacy

Note. PSC = pedagogic spellchecker; MW = Microsoft Word.
The primary reason behind this is that MW overlooks misspellings corresponding with words documented in its reference corpus regardless of frequency, such as intimo (I become close), arboles (you hoist [present subjunctive]), or frio (I fry). Furthermore, MW failed to detect errors written in upper case, which are treated as proper nouns not requiring correction. Unlike MW, the PSC managed to spot these thanks to its secondary database of common SFL errors. However, the PSC failed to identify L1 words (e.g. *for, *fashion). A closer look at the surrounding linguistic context of these words revealed that the PSC’s reference corpus (San Mateo, Reference San Mateo2016) contained some passages written directly in English. A thorough revision of said corpus may address these gaps for future studies.
Finally, both spellcheckers increased their error detection efficacy when jointly using spelling and grammar filters. Combining both, the PSC identified 1,168 errors (95.9%), while MW identified 1,106 (90.8%). The PSC’s bigram filter (see Blázquez-Carretero, Reference Blázquez-Carretero2019) failed to identify words inputted in English (e.g. the, bell). The same applies to MW’s grammar filter, but with the further limitation of overlooking incorrect capitalisation (e.g. *Julio [July]) and lack of diacritic accents in instances of infrequent collocation (e.g. MW detected the misspelling in hablamos *ingles [we speak English] but not en *ingles [in English]).
4.3.2 Evaluating the adequacy of the WCF
The PSC’s mean correct feedback-to-error ratio (i.e. the number of adequate WCF/the number of spelling errors) was 71.8%, slightly lower than MW’s 72.9% (see Table 1). Globally (see Table 2), the PSC provided pedagogical WCF to 838 errors (75.6% of the total detected), while MW suggested the correct alternative to 815 misspellings (80.6% of the total detected) thanks to the edit-distance algorithm’s reliability in solving single-letter violations. The correct alternative was placed second in 4.75% of cases (48 errors) and third in 1.58% (16 errors).
Table 2. Number of errors detected and written corrective feedback (WCF) provided

Note. PSC = pedagogic spellchecker; Beg. = beginner; Inter. = intermediate; Adv. = advanced; Det.= detected; MW = Microsoft Word; W = wrong WCF; No = no WCF.
Figure 2 shows that the correct alternative to *attendo (i.e. atiendo [I’m paying attention]) appears second to atando (I’m lacing). As MW’s algorithm prioritises the spelling that requires a shorter edit distance, substituting e for a gains preference over adding an i because the second requires a longer edit and is hence deemed less precise.

Figure 2. Microsoft Word’s feedback for *attendo
Conversely, the PSC draws on a database of common SFL misspellings. Thanks to its search-and-match facility, each error appearing in the database or following an orthographic pattern is provided a tailored pedagogic WCF after the error is clicked on. For example, the digraph <tt> does not exist in Spanish, prompting the PSC to offer this WCF to the error *attendo (see Figure 3).

Figure 3. Pedagogic spellchecker’s feedback for *attendo
To avoid misleading the L2 learner with inaccurate WCF, the PSC does not address errors absent from its database. In contrast, MW failed to provide the correct alternative in 12% of cases (121 errors), which could be highly confusing for SFL learners. In Figure 4, we see that no suggestion matches with either por ciento (percent) or invierno (winter), misspelled as *percento and *vierno.

Figure 4. Microsoft Word’s feedback for *percento and *vierno
In exceptional cases (11 errors or 1.08% of the total detected), MW provided absolutely no feedback (see Figure 5).

Figure 5. Microsoft Word’s feedback for *journalísmo
Overall, MW failed to list the correct alternative in the first position to 64 errors and provided wrong feedback (121) or no feedback (11) to 132 errors, amounting to 196 incorrect and potentially misleading feedback.
4.3.3 Evaluating efficacy across proficiency levels
Finally, we analysed the correlation between learner proficiency and each spellchecker’s capacity for error detection and feedback provision. As shown in Table 2, beginner-level SFL learners wrote fewer words (2,605) while committing 345 misspellings, intermediate learners 3,585 words with 497 misspellings, and advanced learners 5,285 words with 352 misspellings. Regarding the average number of errors per 100 words, advanced SFL learners made approximately 50% fewer misspellings (7.87) than their beginner-level (13.2) and intermediate (13.5) peers (see Table 3).
Table 3. Mean scores of spelling errors and feedback adequacy per proficiency level

Note. PSC = pedagogic spellchecker; MW = Microsoft Word.
Table 3 displays the PSC’s detection rate according to proficiency level, demonstrating a 90.8% effectivity for beginners, 93.6% for intermediates, and 93.1% for advanced, each scoring higher than MW by 8.13%, 11.3%, and 8.50% respectively. A paired sample t-test (see Table 4) revealed that this difference is significant across all proficiency levels: beginners (t (19) = 2.125, p < .05), intermediates (t (19) = 2.59, p < .05), and advanced (t (19) = 3.171, p < .01).
Table 4. Spelling error detection rates per SFL learners’ proficiency level

Note. SFL = Spanish as a foreign language.
* Denotes significance at 5% alpha.
** Denotes significance at 1% alpha.
Meanwhile, both spellcheckers yielded different feedback-to-error ratios (see Table 3). The PSC’s ratio starts at 65.7% for beginners and steadily increases with the proficiency level until it reaches 76.4% for advanced learners. The same upwards slope contingent on SFL competency is observed with MW, from 66.8% (beginner) to 80.1% (advanced). However, although MW scored a higher feedback-to-error ratio for beginners and advanced learners, the PSC yielded the highest ratio for intermediate learners. As illustrated in Table 5, a paired sample t-test discloses no significant difference between the correct feedback-to-detected-error ratio of both spellcheckers. For beginners, the PSC scored 1.13% lower on average than MW (t (19) = −0.201, p > .05). For intermediate learners, the PSC posed a higher, albeit statistically, insignificant ratio of approximately 1.58% than MW (t (19) = 0.305, p > .05). Lastly, MW’s correct feedback-to-detected-error ratio of 3.71% is higher than PSC’s, although still statistically insignificant (t (19) = −0.811, p > .05).
Table 5. Correct feedback-to-error ratio per SFL learners’ proficiency level

Note. SFL = Spanish as a foreign language.
5. Discussion
5.1 The PSC detects more than 90% of the spelling errors
The spellcheckers under scrutiny (the PSC and MW) display a high error detection rate, spotting over 80% of the misspellings present in 60 essays written by SFL students. The present findings indicate a sound method behind the creation of a competitive PSC with a well-designed detection engine adapted to L2 contexts. Furthermore, they corroborate the results of previous studies suggesting a near 90% capacity for error recognition (Blázquez-Carretero & Fan, Reference Blázquez-Carretero and Fan2019; Rimrott & Heift, Reference Rimrott and Heift2008).
The PSC significantly identified more SFL spelling errors than its generic counterpart, demonstrating that the former is a more effective detection software than the latter in L2 learning environments. MW’s main drawback is its failure to detect errors among words present in their reference corpus. Another disadvantage is MW’s incapability to spot capitalised misspellings, automatically tagging them as acceptable proper nouns. In contrast, the PSC highlighted more misspellings thanks to its second database, developed from real data and containing the commonest SFL orthographic errors. This validated Lawley’s (Reference Lawley2016) suggestion that the detection capacity of L2-oriented spellcheckers can be strengthened by enriching the database of correct words (dictionary or corpus), conducting detailed studies of frequently occurring errors among L2 learners, and including potential errors based on orthographic patterns.
5.2 The PSC provides feedback to 69% of the spelling errors
Both spellcheckers successfully provided WCF to two of three misspellings detected in the 60 compositions. However, feedback quality differed. Although our findings confirm Rimrott and Heift’s (Reference Rimrott and Heift2006, Reference Rimrott and Heift2008) argument that MW’s edit-distance algorithm effectively fulfils its primary purpose of correcting performance-based single-letter violations, relying on L1-oriented spellcheckers arguably poses certain disadvantages for SFL learners. Besides limitations in error detection, MW’s autocorrection feature limits learner awareness, impeding them from recognising the gap between their interlanguage and proper usage in the target language. As the noticing hypothesis posits, this curtails the possibility of learning from one’s errors (Schmidt, Reference Schmidt1990, Reference Schmidt2010). Secondly, in approximately one of three misspellings, MW offered an incorrect replacement word, validating Mitton and Okada’s (Reference Mitton and Okada2007) conclusions. This poses a problem as L2 learners tend to select an inappropriate substitute for their error (Blázquez-Carretero & Woore, Reference Blázquez-Carretero and Woore2023; Heift & Rimrott, Reference Heift and Rimrott2008). In one of 10 instances, the correct word did not even figure among the suggested alternatives, so that the feedback provided may ultimately be counterproductive not only for self-correction but also for L2 acquisition. Finally, and most evidently, MW does not explain orthographic regularities even if teaching spelling rules explicitly proves more effective than implicit learning (Blázquez-Carretero & Woore, Reference Blázquez-Carretero and Woore2021; Graham & Santangelo, Reference Graham and Santangelo2014). Despite MW’s usefulness for competent writers who accidentally commit misspellings, it was never designed as a didactic tool for non-native writers, most of whose errors are competence-based. Hence, MW proves far less satisfactory in addressing L2 needs.
In contrast, not only does the PSC reveal the learning gap (how SFL learners write versus how they ought to write), its pedagogic feedback detailing orthographic patterns also imparts understanding of why certain errors are committed and how these can be avoided in future writing. This encourages deep learning (Lee, Reference Lee2013), since profound cognitive processes are involved when L2 learners are stimulated to notice the gap, understand its root cause, and rewrite their misspelling. Furthermore, the short-term storage required by these actions may be a viable catalyst for L2 learning (Lázaro Ibarrola, Reference Lázaro Ibarrola2013). This is precisely why the PSC was not designed to autocorrect but to provide specific WCF explaining common errors, and to require the learner to rewrite the word rather than offer alternatives that can be selected with a simple mouse click.
WCF has been proved to help L2 learners in immediately correcting their writing (Kang & Han, Reference Kang and Han2015), demonstrating further that such improvements were maintained in delayed post-tests (Bitchener & Knoch, Reference Bitchener and Knoch2010). There is also “modest evidence” that computer-generated WCF has a positive effect on the produced output (Stevenson & Phakiti, Reference Stevenson and Phakiti2014: 62) and can facilitate error correction (Li et al., Reference Li, Feng and Saricaoglu2017). This was confirmed by Blázquez-Carretero and Woore (Reference Blázquez-Carretero and Woore2021), who empirically evaluated the PSC’s feedback provision. Also noteworthy is the synchronous nature of WCF in contrast with the common pedagogic habit of providing feedback after the writing process. As such, L2 learners can self-correct while committing an error, thus immediately incorporating the feedback into their output. This encourages autonomous learning and revision while narrowing the unproductive temporal gap between error and correction (Guichon, Bétrancourt & Prié, Reference Guichon, Bétrancourt and Prié2012; Warschauer, Reference Warschauer2010).
5.3 The PSC provides WCF to two out of three words independently of the proficiency level of the learners
Results suggest that, irrespective of L2 proficiency level, the PSC was constantly and significantly more effective in detecting errors than MW. Both spellcheckers fared equally in the number of misspellings found to which appropriate WCF was provided.
As expected, higher-proficiency SFL learners made fewer mistakes compared to their lower-proficiency peers. However, spelling accuracy improvement seems to only occur once the learner has reached advanced proficiency (further investigation is necessary to understand why and when this happens). Their errors also differ in nature. Beginners tended to write more words directly in their L1 and committed more randomised misspellings (skewing more than one letter), which sometimes hindered the spellcheckers from providing appropriate WCF. This explains why both spellcheckers displayed a lower accuracy rate in feedback provision at this level (around 60%) than at higher-proficiency levels. Contrarily, single-letter violations are frequently attributed to advanced learners. On many occasions, intermediate and advanced learners were guilty of hypercorrection to the point of misgeneralising spelling patterns (e.g. placing more accents than necessary instead of omitting uncertain ones). This proved the reliability of MW’s edit-distance algorithm in suggesting the correct alternative for an ortho-typographical error. However, MW autocorrects most errors, inhibiting students’ active error recognition and subsequent learning (Schmidt, Reference Schmidt1990, Reference Schmidt2010). The PSC, in contrast, never autocorrects. Despite the impossibility of providing feedback to every single error, especially in cases where it does not result from misunderstanding or ignorance of a spelling pattern, the PSC’s accurate detection of around 90% of the errors offers a huge advantage, considering that error recognition is a necessary first step to addressing the problem (Schmidt, Reference Schmidt1990, Reference Schmidt2010).
6. Conclusions and implications
Research suggests that it is desirable for L2 learners to self-correct their writing (Quinn, Reference Quinn2015; Vickers & Ene, Reference Vickers and Ene2006) not only to compensate for resource and time constraints but also to encourage “deep processing” (Craik & Tulving, Reference Craik and Tulving1975). Since learners need to draw on external resources and their L2 knowledge to self-correct, the process stimulates and promotes independent learning (Park & Kim, Reference Park, Kim and Leow2019). However, L2 students might fail to identify their errors (Lee, Reference Lee1997) and/or properly address them. Spellcheckers thus emerge as a sustainable learning resource to overcome these limitations.
Considering GSCs to be inadequate didactic tools in an L2 environment (Blázquez-Carretero & Fan, Reference Blázquez-Carretero and Fan2019; Heift & Rimrott, Reference Heift and Rimrott2008), there remains a compelling reason to build a reliable pedagogic software to improve L2 spelling competency. There are strong arguments in favour of a spellchecker especially crafted for SFL learners. An L2-oriented software capable of targeting SFL errors that vastly differ from L1 mistakes and of giving WCF illustrating patterns and rules governing Spanish orthography would ultimately facilitate spelling accuracy (Blázquez-Carretero & Woore, Reference Blázquez-Carretero and Woore2021). Furthermore, Lawley (Reference Lawley2016) and Blázquez-Carretero and Woore (Reference Blázquez-Carretero and Woore2023) evidenced that L2 students prefer a spellchecker specifically tailored to their needs.
This study presents immediate implications to the development of spellcheck packages and L2 pedagogy alike as it illustrates how complex spelling rules can be easily adapted and rendered accessible to SFL learners. Consequently, providing SFL teachers and students with an online error detection tool adept at offering feedback with an explanation of why the error was committed and how it can be corrected avoids recourse to time-consuming tasks like editing and self-correction.
The student is enabled to autocorrect confidently and autonomously, which not only serves as a learning opportunity during the writing process but also saves considerable time and effort on the teacher’s part. It is demanding for the latter to give feedback as precise as that provided by the PSC for every single error committed by their students, and to further ensure sufficient awareness and future application. Given orthography’s importance in L2 acquisition and the observable difficulties in adequately addressing orthographic issues in diverse L2 learning set-ups, Lee (Reference Lee2013) persuasively argues for teachers to be relieved of this burden by delegating the task to a pedagogic tool specifically crafted for L2 peer- and self-correction. As such, teachers would significantly save time that could potentially be allotted to more pressing aspects of L2 writing acquisition requiring human attention, like content, argumentation, organisational structure, or register (Chen & Cheng, Reference Chen and Cheng2008).
New technologies have been observed to influence L2 writing processes as editing is rendered increasingly feasible and accessible to a diverse set of learners. These advancements are redrawing the landscape of L2 writing acquisition, effectively altering classroom practices and learning timetables. In sum, technologically aided delivery of WCF, subject to constant updates and improvements, would doubtless enable diligent L2 students to learn autonomously and, perhaps, empower them to progress at a much faster rate.
Acknowledgements
This study would not have been possible without the seminal work of Dr. James Lawley. I would like to express my gratitude to the Departamento de Lengua y Literatura Españolas, Teoría de la Literatura y Lingüística General of the Facultad de Filología of the University of Santiago de Compostela (Spain) for their support, with special thanks to Prof. Mª Victoria Vázquez Rozas and Mª José Rodríguez Espiñeira. I am also grateful to Prof. Jillian Melchor, Prof. Cecilia Blázquez, Dr. Alberto Cifuentes Negrete, and the anonymous reviewers for their invaluable feedback on earlier versions of this paper.
Ethical statement and competing interests
This research is based on publicly available anonymised corpus data. This research is original, and I declare that I have no conflict of interest.
About the author
Miguel Blázquez-Carretero is Associate Professor and Spanish Section Coordinator of the Department of European Languages, University of the Philippines Diliman. He is the leading consultant of the Philippines’ Department of Education (DepEd) on Spanish curricular design and founded the first Association of Spanish Teachers (AFELE) in the country.
Author ORCIDs
Miguel Blázquez-Carretero, https://orcid.org/0000-0003-4001-328X










