



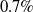
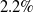
1. Introduction
Recently, the development of deep convolutional neural networks [Reference Simonyan and Zisserman1, Reference Huang, Liu, van der Maaten and Weinberger2] contributes to some significant breakthroughs in many traditional vision tasks, for example, object detection [Reference Wang, Zhang, Bertinetto, Hu and Torr3–Reference Zare, Yazdi, Masouleh, Zhang, Ajami and Ardekani5], robot vision [Reference Chen, Papandreou, Kokkinos, Murphy and Yuille6], and semantic segmentation [Reference Shelhamer, Long and Darrell7, Reference Kenye and Kala8]. For example, in data annotation, the manual labeling costs much time and money if a large training set needs to be established. The automated labeling helps reduce costs and improve efficiency if robots or machines can be trained to label data as humans. Few-shot learning is exactly proposed to train machines or robots to work like humans. Specifically, humans can easily learn a novel concept after seeing several examples from the same class. However, for machines or robots, the shortage of annotated samples [Reference Deng, Dong, Socher, Li, Li and Li9] always restricts the generalization ability of algorithms in the few-shot scenario. Current works [Reference Li, Han, Costain, Howard-Jenkins and Prisacariu10, Reference Choy, Gwak, Savarese and Chandraker11] suggest that the key point is whether there exist reliable correlations established by machines between supports and queries.
We propose a novel convolutional neural network architecture, named adaptive mining correlation network (AMCNet), to alleviate the aforementioned issues. As done in previous works [Reference Li, Han, Costain, Howard-Jenkins and Prisacariu10, Reference Rocco, Cimpoi, Arandjelović, Torii, Pajdla and Sivic12], we attach importance to middle-layer features due to their effectiveness for accurate correlations capture. More specifically, we utilize a weight-shared feature extractor to generate these middle-layer feature maps for 4D correlation tensors generation. For obtaining different levels of receptive fields over the support-related region, we introduce adaptive separable 4D kernel (AS-Conv4d) to adaptively learn generated correlation representations. AS-Conv4d consists of three separable 2D kernels. Due to the variable receptive field in support-related subspace, AS-Conv4d allows query-related subspace to take a more flexible strategy to integrate the information in support-related subspace.
Furthermore, we design a learnable pyramid correlation module (PCM) to squeeze and concatenate pyramid correlation tensors adaptively. It propagates the target-related information across different levels of feature via the top-down form. Based on the proposed AS-Conv4d and PCM, we build AMCNet. We confirm its efficacy in 1-shot and 5-shot scenarios with comprehensive experiments on the PASCAL-5
 $^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13].
$^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13].
The main contributions of this paper are summarized as follows:
-
(i) We develop a 4d kernel called AS-Conv4d. It encourages encoder in query-related subspace to take a more flexible strategy to absorb the information in support-related subspace.
-
(ii) Based on AS-Conv4d, we build PCM. It is conducive to automatically building the squeezed semantic feature for query segmentation by concatenating pyramid correlation with learnable mixing operation.
-
(iii) This work on the PASCAL-5
 $^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13] shows that our AMCNet achieves a mean Intersection-over-Union score of 63.5% for 1-shot scenario and 68.8% for 5-shot scenario, surpassing the state-of-the-art method by
$0.7\%$
and
$2.2\%$
.
$^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13] shows that our AMCNet achieves a mean Intersection-over-Union score of 63.5% for 1-shot scenario and 68.8% for 5-shot scenario, surpassing the state-of-the-art method by
$0.7\%$
and
$2.2\%$
.



The rest of this paper is organized as follows. In Section 2, the task of the few-shot semantic segmentation is briefly described. In Section 3, the presented modules including AS-Conv4d and PCM are clearly explained. We report the experimental results and corresponding analyses in Section 4. A conclusion of this work is in Section 5.
2. Task Description
We follow OSLSM [Reference Shaban, Bansal, Liu, Essa and Bootstitle13] to partition the PASCAL VOC 2012 dataset [Reference Everingham, Eslami, van Gool, Williams, Winn and Zisserman14] into fourfold
 $\{F_i\}_{i=1}^4$
with category set
$\{F_i\}_{i=1}^4$
with category set
 $\{C_i\}_{i=1}^4$
, in which
$\{C_i\}_{i=1}^4$
, in which
 $C_i\cap C_j = \varnothing (i,j = 1,2,3,4 \mbox{ and } i\ne j)$
. We sample three of them to form the training set
$C_i\cap C_j = \varnothing (i,j = 1,2,3,4 \mbox{ and } i\ne j)$
. We sample three of them to form the training set
 $D_{\text{train}}$
and the remaining one for the test set
$D_{\text{train}}$
and the remaining one for the test set
 $D_{\text{test}}$
. Our network will be trained on
$D_{\text{test}}$
. Our network will be trained on
 $D_{\text{train}}$
and evaluated on
$D_{\text{train}}$
and evaluated on
 $D_{\text{test}}$
. For the few-shot setting, both
$D_{\text{test}}$
. For the few-shot setting, both
 $D_{\text{train}}$
and
$D_{\text{train}}$
and
 $D_{\text{test}}$
are arranged with the episodic paradigm [Reference Vinyals, Blundell, Lillicrap, Kavukcuoglu and Wierstra15], which suggests that for either
$D_{\text{test}}$
are arranged with the episodic paradigm [Reference Vinyals, Blundell, Lillicrap, Kavukcuoglu and Wierstra15], which suggests that for either
 $D_{\text{train}}$
or
$D_{\text{train}}$
or
 $D_{\text{test}}$
, each episode is comprised of a support and a query set. For example, we sample k image-mask pairs of class c to form the support set
$D_{\text{test}}$
, each episode is comprised of a support and a query set. For example, we sample k image-mask pairs of class c to form the support set
 $S(c)=\{I_s^i(c),M_s^i(c)\}_{i=1}^k$
, where for the episode of class c
$S(c)=\{I_s^i(c),M_s^i(c)\}_{i=1}^k$
, where for the episode of class c
 $I_s^i(c)$
and
$I_s^i(c)$
and
 $M_s^i(c)$
are the
$M_s^i(c)$
are the
 $i$
th support image and the corresponding mask, respectively; and then we random sample an example of class c but different from those supports to form the query set
$i$
th support image and the corresponding mask, respectively; and then we random sample an example of class c but different from those supports to form the query set
 $Q(c)=\{I_q(c),M_q(c)\}$
of this episode, where
$Q(c)=\{I_q(c),M_q(c)\}$
of this episode, where
 $I_q(c)$
and
$I_q(c)$
and
 $M_q(c)$
are the input query image and the ground-truth binary mask, respectively. Each batch of input data to the model is formulated by
$M_q(c)$
are the input query image and the ground-truth binary mask, respectively. Each batch of input data to the model is formulated by
 $I_q(c)$
and
$I_q(c)$
and
 $S(c)$
. The ground-truth mask
$S(c)$
. The ground-truth mask
 $M_q(c)$
serves as supervision to force the network to generate the predicted mask
$M_q(c)$
serves as supervision to force the network to generate the predicted mask
 $\hat{M}_q(c)$
during the training, while during the test it just plays a role in evaluating the performance of our network.
$\hat{M}_q(c)$
during the training, while during the test it just plays a role in evaluating the performance of our network.
3. Method
3.1. Semantic correlation generation
Most traditional semantic correlation learning methods [Reference Li, Han, Costain, Howard-Jenkins and Prisacariu10, Reference Rocco, Cimpoi, Arandjelović, Torii, Pajdla and Sivic12, Reference Yang and Ramanan16] pay attention to the pairwise similarity between the support and the query images. Following their works, we provide generated correlations formed by feature maps for later semantic encoding.
Suppose that
 $I_s \in \mathbb{R}^{H\times W\times 3}$
and
$I_s \in \mathbb{R}^{H\times W\times 3}$
and
 $I_q\in \mathbb{R}^{H\times W\times 3}$
are a support RGB image and a query RGB image in the same episode, we get features
$I_q\in \mathbb{R}^{H\times W\times 3}$
are a support RGB image and a query RGB image in the same episode, we get features
 $F_s\in \mathbb{R}^{h'\times w'\times c}$
and
$F_s\in \mathbb{R}^{h'\times w'\times c}$
and
 $F_q\in \mathbb{R}^{h'\times w'\times c}$
via the backbone model which is pretrained on Imagenet [Reference Deng, Dong, Socher, Li, Li and Li9] as done in the previous few-shot segmentation works. We subsequently mask the extracted support feature
$F_q\in \mathbb{R}^{h'\times w'\times c}$
via the backbone model which is pretrained on Imagenet [Reference Deng, Dong, Socher, Li, Li and Li9] as done in the previous few-shot segmentation works. We subsequently mask the extracted support feature
 $F_s\in \mathbb{R}^{h'\times w'\times c}$
with the scaled-down mask
$F_s\in \mathbb{R}^{h'\times w'\times c}$
with the scaled-down mask
 $M_s\in \{0,1\}^{h'\times w'}$
to only retain the foreground region for accurate object localization as in ref. [Reference Tian, Zhao, Shu, Yang, Li and Jia17]:
$M_s\in \{0,1\}^{h'\times w'}$
to only retain the foreground region for accurate object localization as in ref. [Reference Tian, Zhao, Shu, Yang, Li and Jia17]:
 \begin{equation} F_s = F_s \odot M_s\in \mathbb{R}^{h'\times w'\times c} \end{equation}
\begin{equation} F_s = F_s \odot M_s\in \mathbb{R}^{h'\times w'\times c} \end{equation}
where
 $\odot$
is Hadamard product. We here flatten
$\odot$
is Hadamard product. We here flatten
 $F_s$
and
$F_s$
and
 $F_q$
to
$F_q$
to
 $F'_s\in \mathbb{R}^{h'w'\times c}$
and
$F'_s\in \mathbb{R}^{h'w'\times c}$
and
 $F'_q\in \mathbb{R}^{h'w'\times c}$
for the sake of convenience. Subsequently, the semantic correlation representation is established by cosine similarity:
$F'_q\in \mathbb{R}^{h'w'\times c}$
for the sake of convenience. Subsequently, the semantic correlation representation is established by cosine similarity:
 \begin{equation} C'=\frac{{F'}_q\cdot{F'}_s^T}{\left \|{F'}_q\right \|\left \|F'_s\right \|}\in \mathbb{R}^{h'w'\times h'w'} \end{equation}
\begin{equation} C'=\frac{{F'}_q\cdot{F'}_s^T}{\left \|{F'}_q\right \|\left \|F'_s\right \|}\in \mathbb{R}^{h'w'\times h'w'} \end{equation}
For each entry
 $c_{i} \in C'$
, the irrelevant matching scores ranging from −1.0 to 0 are mapped to 0 as:
$c_{i} \in C'$
, the irrelevant matching scores ranging from −1.0 to 0 are mapped to 0 as:
 \begin{equation} c_i = \text{max}(0, c_i) \end{equation}
\begin{equation} c_i = \text{max}(0, c_i) \end{equation}
Subsequently for the following correlation learning,
 $C' \in \mathbb{R}^{h'w'\times h'w'}$
is reshaped to
$C' \in \mathbb{R}^{h'w'\times h'w'}$
is reshaped to
 $C \in \mathbb{R}^{h'\times w'\times h'\times w'}$
.
$C \in \mathbb{R}^{h'\times w'\times h'\times w'}$
.
3.2. Adaptive separable 4D kernel
Full 4D convolution implementation scheme is revisited in this section, and then we introduce our AS-Conv4d for comparison. The formulation of full 4D convolution is
 \begin{equation} (K*C)(x, y) = \sum _{u, v} K(u, v)C(x-u, y-v) \end{equation}
\begin{equation} (K*C)(x, y) = \sum _{u, v} K(u, v)C(x-u, y-v) \end{equation}
where
 $C(x, y)\in \mathbb{R}^{H_q\times W_q\times H_s\times W_s}$
represents correlation tensor which is established by cosine similarity, and
$C(x, y)\in \mathbb{R}^{H_q\times W_q\times H_s\times W_s}$
represents correlation tensor which is established by cosine similarity, and
 $K\in \mathbb{R}^{d\times d\times d\times d}$
is 4D convolution kernel. Although some works [Reference Li, Han, Costain, Howard-Jenkins and Prisacariu10, Reference Rocco, Cimpoi, Arandjelović, Torii, Pajdla and Sivic12] in terms of semantic correlation learning have verified its efficacy, it is so difficult to form an encoder by full 4D convolution kernel on few-shot semantic segmentation because of quadratic complexity [Reference Yang and Ramanan16].
$K\in \mathbb{R}^{d\times d\times d\times d}$
is 4D convolution kernel. Although some works [Reference Li, Han, Costain, Howard-Jenkins and Prisacariu10, Reference Rocco, Cimpoi, Arandjelović, Torii, Pajdla and Sivic12] in terms of semantic correlation learning have verified its efficacy, it is so difficult to form an encoder by full 4D convolution kernel on few-shot semantic segmentation because of quadratic complexity [Reference Yang and Ramanan16].
Furthermore, we propose a novel 4D kernel called AS-Conv4d to make the query feature flexibly absorb the relevant information of the support feature. AS-Conv4d fixes the search window size of query-related subspace and changes the search window size of support-related subspace. Specifically, we factorize a 4D filter
 $K(x, y)\in \mathbb{R}^{d\times d\times d\times d}$
into three 2D filters
$K(x, y)\in \mathbb{R}^{d\times d\times d\times d}$
into three 2D filters
 $K_1(x)$
,
$K_1(x)$
,
 $K_2(y)$
,
$K_2(y)$
,
 $K_3(y)\in \mathbb{R}^{d\times d}$
as:
$K_3(y)\in \mathbb{R}^{d\times d}$
as:
 \begin{equation} (K*C)(x, y)=K_1(x)*\{[K_2(y)+K_3(y)]*C(x, y)\} \end{equation}
\begin{equation} (K*C)(x, y)=K_1(x)*\{[K_2(y)+K_3(y)]*C(x, y)\} \end{equation}
where
 $x\in \mathbb{R}^{2}$
and
$x\in \mathbb{R}^{2}$
and
 $y\in \mathbb{R}^{2}$
are the position of the query-related subspace and the support-related subspace in semantic correlation, respectively. Note that
$y\in \mathbb{R}^{2}$
are the position of the query-related subspace and the support-related subspace in semantic correlation, respectively. Note that
 $K_2$
and
$K_2$
and
 $K_3$
are different shapes of 2D filter. For instance, in our work, we set
$K_3$
are different shapes of 2D filter. For instance, in our work, we set
 $K_2$
to the size of
$K_2$
to the size of
 $3\times 3$
and set
$3\times 3$
and set
 $K_3$
to the size of
$K_3$
to the size of
 $5\times 5$
. In comparison with previous 4D kernels [Reference Rocco, Cimpoi, Arandjelović, Torii, Pajdla and Sivic12, Reference Yang and Ramanan16], AS-Conv4d not only reduces computational complexity
$5\times 5$
. In comparison with previous 4D kernels [Reference Rocco, Cimpoi, Arandjelović, Torii, Pajdla and Sivic12, Reference Yang and Ramanan16], AS-Conv4d not only reduces computational complexity
 $O(d^4)$
to
$O(d^4)$
to
 $O(d^2)$
but also keeps a better balance between receptive field and spatial resolution and thus builds a closer connection between query and support subspace.
$O(d^2)$
but also keeps a better balance between receptive field and spatial resolution and thus builds a closer connection between query and support subspace.
3.3. Model architecture
An encoder–decoder architecture is implemented to learn different levels of semantic correlations
 $\{C_i\}_{i=3}^5$
which are cast over all intermediate convolutional layers, that is, the third to the fifth convolution layers in ResNet50. In our encoder, we utilize three parallel sequences, which are informed by a series of 4D convolutions, group normalizations [Reference Wu and He18], and ReLU activations, to learn different levels of semantic correlations
$\{C_i\}_{i=3}^5$
which are cast over all intermediate convolutional layers, that is, the third to the fifth convolution layers in ResNet50. In our encoder, we utilize three parallel sequences, which are informed by a series of 4D convolutions, group normalizations [Reference Wu and He18], and ReLU activations, to learn different levels of semantic correlations
 $\{C_i\}_{i=3}^5$
. And then with the top-down form of PCM, we mix the compressed pyramid correlations
$\{C_i\}_{i=3}^5$
. And then with the top-down form of PCM, we mix the compressed pyramid correlations
 $\{C_i\}_{i=3}^5$
to spread relevant information to lower layers, that is, from
$\{C_i\}_{i=3}^5$
to spread relevant information to lower layers, that is, from
 $C_5$
to
$C_5$
to
 $C_3$
.
$C_3$
.
Specifically for encoding as illustrated in Fig. 1, our AMCNet learns correlations by squeezing the shape of the support-related 2D subspace
 $(H_s, W_s)$
while maintaining the query-related subspace
$(H_s, W_s)$
while maintaining the query-related subspace
 $(H_q, W_q)$
, and then PCM concatenates adjacent pyramid layers. After two PCMs, we propagate
$(H_q, W_q)$
, and then PCM concatenates adjacent pyramid layers. After two PCMs, we propagate
 $C_5$
to
$C_5$
to
 $C_4$
and
$C_4$
and
 $C_{54}$
to
$C_{54}$
to
 $C_3$
for the mixed squeezed correlation
$C_3$
for the mixed squeezed correlation
 $C_{543}$
, then we utilize global average pooling over
$C_{543}$
, then we utilize global average pooling over
 $(H_s, W_s)$
to produce the encoding result
$(H_s, W_s)$
to produce the encoding result
 $Z\in R^{H_q\times W_q\times c}$
which denotes abstract semantic correspondence learned by our model in original correlations for the following decoding.
$Z\in R^{H_q\times W_q\times c}$
which denotes abstract semantic correspondence learned by our model in original correlations for the following decoding.

Fig. 1. The frameworks of semantic correlation encoder and decoder in our AMCNet.
We implement a simple decoder network as illustrated in Fig. 1 (bottom), which is built by 2D convolutions and ReLU activations. The condensed representation
 $Z$
is input to it, and then we can get the predicted segmentation mask
$Z$
is input to it, and then we can get the predicted segmentation mask
 $\hat{M}_q \in \{0, 1\}^{H\times W}$
. We utilize cross-entropy loss to optimize the learnable parameters in our model as follows:
$\hat{M}_q \in \{0, 1\}^{H\times W}$
. We utilize cross-entropy loss to optimize the learnable parameters in our model as follows:
 \begin{equation} \text{CELoss}=\sum _{x, y}[M_q(x, y)\times \text{log}(\hat{M}_q(x,y))+(1-M_q(x,y))\times \text{log}(1-\hat{M}_q(x,y))] \end{equation}
\begin{equation} \text{CELoss}=\sum _{x, y}[M_q(x, y)\times \text{log}(\hat{M}_q(x,y))+(1-M_q(x,y))\times \text{log}(1-\hat{M}_q(x,y))] \end{equation}
where
 $\hat{M}_q$
and
$\hat{M}_q$
and
 $M_q$
represent the prediction result and the ground-truth over all pixel locations
$M_q$
represent the prediction result and the ground-truth over all pixel locations
 $(x, y)$
. While test,
$(x, y)$
. While test,
 $\hat{M}_q$
is compared with
$\hat{M}_q$
is compared with
 $M_q$
by the Intersection-over-Union score for the evolution of our model.
$M_q$
by the Intersection-over-Union score for the evolution of our model.
4. Experiment
4.1. Implementation details
ResNet50 [Reference Zhang, Lin, Liu, Yao and Shen19, Reference Zhang, Lin, Liu, Guo, Wu and Yao20] and ResNet101 [Reference Tian, Zhao, Shu, Yang, Li and Jia17] with the weights pretrained on ImageNet [Reference Deng, Dong, Socher, Li, Li and Li9] are utilized as the backbone in our network. We use Adam to train the whole model on a GeForce RTX 3080 GPU. During training, the learning rate, batch size, and image size are 0.001, 8, and 400
 $\times$
400 for PASCAL-
$\times$
400 for PASCAL-
 $5^i$
and COCO-
$5^i$
and COCO-
 $20^i$
datasets, and the epoch is 300 for PASCAL-
$20^i$
datasets, and the epoch is 300 for PASCAL-
 $5^i$
dataset and the epoch is 40 for COCO-
$5^i$
dataset and the epoch is 40 for COCO-
 $20^i$
dataset.
$20^i$
dataset.
4.2. Evaluation metrics
The mean Intersection-over-Union (mIoU) and the foreground-background Intersection-over-Union (FB-IoU) are utilized for evaluation in this work. The mIoU is formulated by
 $\text{mIoU}=\frac{1}{m}\sum _{i=1}^{m}\text{IoU}_i$
where
$\text{mIoU}=\frac{1}{m}\sum _{i=1}^{m}\text{IoU}_i$
where
 $\text{IoU}_i$
is the Intersection-over-Union score of class i and m is the number of categories in the test set. The FB-IoU is formulated by
$\text{IoU}_i$
is the Intersection-over-Union score of class i and m is the number of categories in the test set. The FB-IoU is formulated by
 $\text{FB}$
-
$\text{FB}$
-
 $\text{IoU}=\frac{1}{2}\sum _{i=0}^{1}\text{IoU}_i$
, where the foreground class 1 represents all object categories included in the test set, while the background class 0 includes all pixels outside the foreground area.
$\text{IoU}=\frac{1}{2}\sum _{i=0}^{1}\text{IoU}_i$
, where the foreground class 1 represents all object categories included in the test set, while the background class 0 includes all pixels outside the foreground area.
4.3. Experiments on PASCAL-5
$^i$

We extend our work to K-shot scenario (
 $K\gt 1$
). A query image
$K\gt 1$
). A query image
 $I_q$
and the corresponding
$I_q$
and the corresponding
 $K$
support image-mask pairs
$K$
support image-mask pairs
 $S=\{(I_s^k,M_s^k)\}^K_{k=1}$
are input into the proposed AMCNet, and then our network outputs
$S=\{(I_s^k,M_s^k)\}^K_{k=1}$
are input into the proposed AMCNet, and then our network outputs
 $K$
query mask predictions
$K$
query mask predictions
 $\{\hat{M}_q^k\}^K_{k=1}$
in a forward way. These predictions
$\{\hat{M}_q^k\}^K_{k=1}$
in a forward way. These predictions
 $\{\hat{M}_q^k\}^K_{k=1}$
play an important role in the pixel-wise voting. Specifically, if at least half of
$\{\hat{M}_q^k\}^K_{k=1}$
play an important role in the pixel-wise voting. Specifically, if at least half of
 $K$
voters at this location
$K$
voters at this location
 $(x, y)$
is 0, the prediction result at this location
$(x, y)$
is 0, the prediction result at this location
 $(x, y)$
is labeled as a background pixel; otherwise, this location is labeled as a foreground pixel. In this work, following most of works [Reference Shaban, Bansal, Liu, Essa and Bootstitle13, Reference Tian, Zhao, Shu, Yang, Li and Jia17, Reference Zhang, Lin, Liu, Yao and Shen19–Reference Rakelly, Shelhamer, Darrell, Efros and Levine24], we take
$(x, y)$
is labeled as a background pixel; otherwise, this location is labeled as a foreground pixel. In this work, following most of works [Reference Shaban, Bansal, Liu, Essa and Bootstitle13, Reference Tian, Zhao, Shu, Yang, Li and Jia17, Reference Zhang, Lin, Liu, Yao and Shen19–Reference Rakelly, Shelhamer, Darrell, Efros and Levine24], we take
 $K=5$
for comprehensively evaluating our model performance.
$K=5$
for comprehensively evaluating our model performance.
We report the performance comparison with state-of-the-arts on PASCAL-5
 $^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13] in Tables I and II. We can actually see either for the mIoU or the FB-IoU evaluation, and our AMCNet records new state-of-the-art in both 1-shot and 5-shot scenarios. Specifically, for the ResNet50-based methods in Table I, AMCNet achieves 63.5% and 68.8% in terms of mIoU for the 1-shot and 5-shot settings, respectively, which surpasses the state-of-the-art by 0.7% and 2.2%.
$^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13] in Tables I and II. We can actually see either for the mIoU or the FB-IoU evaluation, and our AMCNet records new state-of-the-art in both 1-shot and 5-shot scenarios. Specifically, for the ResNet50-based methods in Table I, AMCNet achieves 63.5% and 68.8% in terms of mIoU for the 1-shot and 5-shot settings, respectively, which surpasses the state-of-the-art by 0.7% and 2.2%.
Table I. Comparison with state-of-the-arts on PASCAL-5
 $^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13] in mIoU.
$^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13] in mIoU.

Best results in bold.
Table II. Comparison with state-of-the-arts on PASCAL-5
 $^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13] in FB-IoU and Params.
$^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13] in FB-IoU and Params.

Params: the number of learnable parameters.
Furthermore, as shown in Table II, AMCNet also achieves the best performance in FB-IoU, that is, 76.4% and 80.0% for the ResNet50-based methods, while only requiring the slightest number of learning parameters, which confirms the effectiveness of AMCNet on the topic of few-shot semantic segmentation.
Finally, in comparison with the state-of-the-art methods, AMCNet has the slightest learnable parameters, which means that it can effectively reduce memory consumption while achieving the best segmentation performance. Especially in industry, it is very important to cut down computation for pursuing time efficiency.
4.4. Experiments on COCO-20
$^i$

We also extend our experiments on COCO-20
 $^i$
[Reference Lin, Maire, Belongie, Hays, Perona, Ramanan, Dollár and Zitnick28], a more challenging dataset including total 80 object classes. As shown in Table III, Our AMCNet also outperforms the state-of-the-art method in both the 1-shot scenario and the 5-shot scenario. For instance, AMCNet surpasses the state-of-the-art method CMN [Reference Xie, Xiong, Liu, Yao and Shao26] by 1.6% and 2.7% with the mIoU scores in the 1-shot and the 5-shot scenarios. The significant performance improvement on COCO-20
$^i$
[Reference Lin, Maire, Belongie, Hays, Perona, Ramanan, Dollár and Zitnick28], a more challenging dataset including total 80 object classes. As shown in Table III, Our AMCNet also outperforms the state-of-the-art method in both the 1-shot scenario and the 5-shot scenario. For instance, AMCNet surpasses the state-of-the-art method CMN [Reference Xie, Xiong, Liu, Yao and Shao26] by 1.6% and 2.7% with the mIoU scores in the 1-shot and the 5-shot scenarios. The significant performance improvement on COCO-20
 $^i$
[Reference Lin, Maire, Belongie, Hays, Perona, Ramanan, Dollár and Zitnick28] denotes the remarkable capability of our AMCNet to handle complex scenes.
$^i$
[Reference Lin, Maire, Belongie, Hays, Perona, Ramanan, Dollár and Zitnick28] denotes the remarkable capability of our AMCNet to handle complex scenes.
Table III. Comparison with state-of-the-arts on COCO-20
 $^i$
[Reference Lin, Maire, Belongie, Hays, Perona, Ramanan, Dollár and Zitnick28] in mIoU.
$^i$
[Reference Lin, Maire, Belongie, Hays, Perona, Ramanan, Dollár and Zitnick28] in mIoU.

Best results in bold.
4.5. Results analyses
Experiments show that our AMCNet achieves the best performance on both PASCAL-5
 $^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13] and COCO-20
$^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13] and COCO-20
 $^i$
[Reference Lin, Maire, Belongie, Hays, Perona, Ramanan, Dollár and Zitnick28] datasets. For the PASCAL-5
$^i$
[Reference Lin, Maire, Belongie, Hays, Perona, Ramanan, Dollár and Zitnick28] datasets. For the PASCAL-5
 $^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13] dataset, we improve the best mIoU score to 63.5% in 1-shot scenario and 68.8% in 5-shot scenario. For the COCO-20
$^i$
[Reference Shaban, Bansal, Liu, Essa and Bootstitle13] dataset, we improve the best mIoU score to 63.5% in 1-shot scenario and 68.8% in 5-shot scenario. For the COCO-20
 $^i$
[Reference Lin, Maire, Belongie, Hays, Perona, Ramanan, Dollár and Zitnick28] dataset, we improve the best mIoU score to 40.9% in 1-shot scenario and 45.8% in 5-shot scenario. Some predicted results for 5-shot semantic segmentation are shown in Fig. 2. The images of Fig. 2(a) are the densely annotated support samples, while the first column images of Fig. 2(b) are the query images with the predicted mask and the second column images of Fig. 2(b) are the query images with the ground-truth mask. We change the transparency level of binary masks and then integrate them with corresponding RGB images for the convenience of comparison. Note that for simulating 5-shot setting, the support and the query samples are different instances although they are from the same category.
$^i$
[Reference Lin, Maire, Belongie, Hays, Perona, Ramanan, Dollár and Zitnick28] dataset, we improve the best mIoU score to 40.9% in 1-shot scenario and 45.8% in 5-shot scenario. Some predicted results for 5-shot semantic segmentation are shown in Fig. 2. The images of Fig. 2(a) are the densely annotated support samples, while the first column images of Fig. 2(b) are the query images with the predicted mask and the second column images of Fig. 2(b) are the query images with the ground-truth mask. We change the transparency level of binary masks and then integrate them with corresponding RGB images for the convenience of comparison. Note that for simulating 5-shot setting, the support and the query samples are different instances although they are from the same category.

Fig. 2. Images with binary mask: images of (a) are the support images, the first column of (b) images are the predicted results, and the second column images of (b) are the ground-truths.
As shown in Fig. 2, we can see that although there exist large intra-class variations in the object category of dining table, dog, horse, motorbike, and person, our model still has a remarkable ability to segment a novel concept after only seeing a few examples. This confirms the remarkable ability of our AMCNet to segment novel concepts although large intra-class variations exist in few-shot scenario. Furthermore, it is worth noting that our AMCNet achieves the best performance with the fewest learnable parameters (6.5M for ResNet-based models). More qualitative examples of the proposed AMCNet can be seen in Fig. 3. As illustrated in Fig. 3, due to the more flexible receptive field of AS-Conv4d and the appropriate mixing operation of PCM, AMCNet has a remarkable ability to retain essential semantic information across different scales and thus has a good performance for the capture of both the large and small objects.

Fig. 3. More qualitative examples of our models. The first, third, fifth, and seventh columns are the predicted results, and the second, fourth, sixth, and eighth columns are the ground truths.
5. Conclusion
In this paper, a fully convolutional network-based upon pseudo-dense 4D convolutions is proposed to handle complex few-shot semantic segmentation. Despite under limited supervision, experiment on benchmarks has verified the superiority of the proposed adaptive separable 4D convolutional kernel (AS-Conv4d) and PCM in fine-grained segmentation. We comprehensively incorporate them into our AMCNet on the PASCAL-5
 $^i$
and COCO-20
$^i$
and COCO-20
 $^i$
datasets and update the state-of-the-art records. Possible future work includes extending our work from few-shot to zero-shot scenario.
$^i$
datasets and update the state-of-the-art records. Possible future work includes extending our work from few-shot to zero-shot scenario.
Financial support
This work was supported by the Key R&D Program of Guangdong Province (2021B0101200001) and by the Guangdong Basic and Applied Basic Research Foundation (2020B1515120071, 2021B1515120017).
Competing interests
No conflicts.
Author Contributions
Zhifu Huang designed and implemented the research and wrote the manuscript. Bin Jiang assisted in the research and edited the manuscript. Yu Liu directed the research and reviewed the manuscript.









