


Introduction
A key prediction of input-based accounts of morphological development is that the pattern of errors in young children's speech will reflect the frequency distribution of different forms in the input. For instance, children's verb inflection errors tend to involve the use of a higher-frequency form of the verb when a lower-frequency form is required. Several recent studies have found support for this prediction (e.g., Matthews & Theakston, Reference Matthews and Theakston2006; Räsänen, Ambridge, & Pine, Reference Räsänen, Ambridge and Pine2014, Reference Räsänen, Ambridge and Pine2016; Aguado-Orea & Pine, Reference Aguado-Orea and Pine2015). However, the results of these studies are not definitive because of the distributional properties of the languages that have been studied thus far. Languages such as English or Spanish, with a uniform error pattern in which forms of a particular category are used instead of forms of some other categories across verbs (e.g., the bare verb form – e.g., play – in place of the third person singular form – e.g., plays), are not ideal for comparing input-based accounts of children's errors against other possible accounts, such as those based on the notion of morphosyntactic defaulting (e.g., from tense-marked to tenseless forms, e.g., He plays → He play; see Wexler, Reference Wexler1998).
The aim of the present study is to conduct perhaps the strongest test yet of the idea that young children's errors occur when high-frequency forms outcompete lower-frequency forms, by focusing on Japanese: a language in which there is considerable by-verb variation in the relative frequency with which verbs occur in different inflectional forms. In Japanese, in which all finite verbs are inflected for one of the two tense categories (past and nonpast), some verbs occur considerably more frequently in the past than nonpast form, with others showing the opposite pattern. Input-based accounts therefore predict a bi-directional error pattern such that children will incorrectly use past tense forms in nonpast contexts and nonpast tense forms in past contexts, with the by-verb patterning of these errors predicted by the relative frequency with which the relevant verb occurs in these two inflectional forms in the input. The present study tests this hypothesis using an elicited production methodology.
Effects of frequency on children's errors
The assumption that children's use and misuse of inflectional verb forms reflects the distributional properties of the input is central to input-based accounts of language acquisition. Input-based accounts are most associated with a constructivist view of acquisition (e.g., Ellis, Reference Ellis2002; Tomasello, Reference Tomasello2003; Bybee, Reference Bybee2006), but also include generativist accounts that assume at least some role for competition between stored forms (e.g., Prasada & Pinker, Reference Prasada and Pinker1993; Alegre & Gordon, Reference Alegre and Gordon1999; Clahsen, Reference Clahsen1999; Albright & Hayes, Reference Albright and Hayes2003; Hartshorne & Ullman, Reference Hartshorne and Ullman2006). Because, on this view, the learning process is fundamentally dependent on experience, frequency is considered a key explanatory factor for many different learning phenomena; and, indeed, the importance of this factor has been demonstrated empirically for many different domains (see, e.g., Ellis, Reference Ellis2002; Ambridge, Rowland, Theakston, & Kidd, Reference Ambridge2015, for reviews). The mechanism behind learners’ errors, including those that reflect the use of one inflectional form instead of another, is also assumed to be sensitive to input frequency. One of the effects of frequency is an increase in accessibility (cf. Bybee, Reference Bybee, Huebner and Ferguson1991, Reference Bybee2006, Reference Bybee2007): a form becomes more accessible as we experience that form repeatedly. This means that some linguistic forms become more accessible than others because of the difference in their frequency of occurrence in everyday language use. Indeed, relative input frequency, which represents the balance of accessibility or representational strength between different forms, has been shown to be a significant predictor of the errors that children produce when they have difficulty in accessing or retrieving the target form. For example, Räsänen, Ambridge, and Pine (Reference Räsänen, Ambridge and Pine2014) demonstrated that children's errors of using bare/infinitive forms (e.g., *He play) instead of third person singular (3sg) inflected forms (e.g., He plays) involve a frequency-based competition process, by showing that the relative frequency of bare/infinitive versus 3sg –s forms predicts children's error rate across verbs.Footnote 1
A similar phenomenon is reported in other languages. Spanish-learning children sometimes make subject–verb agreement errors in which they use the more frequent 3sg form in a non-3sg context (Radford & Ploennig-Pacheco, Reference Radford and Ploennig-Pacheco1995; Clahsen, Aveledo, & Roca, Reference Clahsen, Aveledo and Roca2002; Aguado-Orea & Pine, Reference Aguado-Orea and Pine2015). The same kind of error is also observed in Catalan (cf. Clahsen et al., Reference Clahsen, Aveledo and Roca2002), Italian (e.g., Pizzuto & Caselli, Reference Pizzuto and Caselli1992; Guasti, Reference Guasti1993) and Finnish (e.g., Räsänen et al., Reference Räsänen, Ambridge and Pine2016). To summarize, many studies have reported children's characteristic usage and error patterns in different languages, and some of these studies have suggested an explanation in terms the frequency distribution of different inflectional forms of the same verb in the input, which has been argued to support an input-based view of language acquisition.
Problems with the evidence for an input-based account
Although suggestive, the evidence summarized above does not yet constitute compelling support for an input-based view over rival accounts. This is because, for each of the languages and morphological systems studied so far, the balance between competing forms in the input is relatively similar across different verbs. For example, although the 48 English verbs used by Räsänen et al. (Reference Räsänen, Ambridge and Pine2014) varied considerably as to the extent of this bias, every verb was more frequent in bare than 3sg –s form. The situation is similar for Spanish, where the 3sg present tense form (which children sometimes use incorrectly in other contexts) is not only (a) the highest-frequency form for the majority of verbs but also (b) the phonologically simplest form and (c) – for regular verbs – homophonous with the highly frequent imperative (Aguado-Orea & Pine, Reference Aguado-Orea and Pine2015).
The properties of these languages therefore make it difficult to determine whether the overuse of a particular inflectional form by children reflects the outcome of a frequency-based competition process (with, perhaps, an additional role for phonology), or the operation of some kind of morphosyntactic default. This latter concept originates in generativist theories of acquisition (e.g., Radford & Ploennig-Pacheco, Reference Radford and Ploennig-Pacheco1995; Grinstead, Reference Grinstead1998, Wexler, Reference Wexler1998; Wexler, Schaeffer, & Bol, Reference Wexler, Schaeffer and Bol2004), and is a form that surfaces whenever – for whatever reason – the system is unable to assign (or ‘check’) tense (e.g., present) and agreement (e.g., 3sg). On this view, the reason that – for example – English children produce bare forms in 3sg contexts (e.g., *He play) is not that the bare form (play) is more frequent in the input than the 3sg form (plays), but that children pass through a stage in which they cannot assign both tense and agreement, and so default to the bare, nonfinite form instead (e.g., Wexler, Reference Wexler1998). A similar argument can be made for Spanish, with 3sg as the default form (Radford & Ploennig-Pacheco, Reference Radford and Ploennig-Pacheco1995; Grinstead, Reference Grinstead1998) and, as we will see, for Japanese, with past tense as the default form.
One way to distinguish frequency-based competition from morphosyntactic defaulting is to examine a linguistic system in which individual verbs differ with regard not only to the relative input frequency of two inflectional forms (e.g., past vs. present), but also to which form is more frequent (i.e., past > present for some verbs, present > past for others). If children make errors in both directions, in a way that is systematically related to the input, it would be difficult to argue that these errors reflect morphosyntactic defaulting, as opposed to probabilistic frequency-based competition between different forms of the relevant verb. The present study therefore focuses on Japanese, a language with a relatively complex verb system that shows exactly this property.
Japanese verb morphology
Japanese has a relatively complex verb system that makes extensive use of suffixation to mark inflectional distinctions. Finite verbs are always inflected for tense (nonpast or past); therefore, a basic form consists of a stem and tense marker, as in tabe-ru ‘eat-NONPAST’ and tabe-ta ‘eat-PAST’ (Japanese has neither infinitives, at least not in the form that is comparable to infinitives in English and other major European languages, nor subject–verb agreement). The nonpast and past are the only distinctions in Japanese tense inflections. Nonpast inflection is marked by –u or –ru, depending on the final segment of the stem, and is used to refer to both habitual and future events as well as for generic description. Semantic interpretation differs also depending on the semantic class of verbs; nonpast marking denotes a present state with stative verbs, and future actions or habitual actions with dynamic verbs. Past inflection is marked by –ta or –da that are again phonologically conditioned allomorphs. Past forms are used mainly to refer to past events, and are occasionally used to refer to a situation transpiring at the time of the speech, as in Atta! ‘Here it is!’, which is used when a speaker has found something that (s)he had been looking for. Crucially for our purposes, the frequency distribution of past vs. nonpast forms varies from verb to verb. For example, for tabe, ‘eat’, the nonpast form taberu (70 tokens in the child-directed speech data mentioned in the ‘Method’ section) is more frequent than the past form tabeta (30 tokens). Conversely, for wakar, ‘understand’, the past form wakatta (149 tokens) is more frequent than the nonpast form wakaru (100 tokens). Thus, even if we restrict ourselves to basic past and nonpast forms (the two most frequent forms), the frequency distribution varies substantially across verbs. Unlike, for example, English bare versus 3sg forms (where the former is more frequent for every verb), neither form – past or nonpast – is dominant in a verb-general manner. This verb-specific, bi-directional probabilistic patterning is key to the current study's aim of disentangling the effect of input frequency from that of unidirectional morphosyntactic defaulting.
Previous studies of Japanese children's verb acquisition
Naturalistic studies of verb inflection in early child Japanese (e.g., Clancy, Reference Clancy and Slobin1985; Shirai, Reference Shirai, Nakajima and Otsu1993, Reference Shirai1998; Sano, Reference Sano2002; Kato, Sato, Chikuda, Miyoshi, Sakai, & Koizumi, Reference Kato2003; Shirai & Miyata, Reference Shirai and Miyata2006) have generally argued that acquisition is rapid, with children typically using a number of different inflections by the age of two years, and making few errors (though with naturalistic data, it is difficult to determine the extent to which children's use of inflection is productive). The earliest forms typically include the simple past and nonpast forms, though other forms such as imperatives and negative nonpast forms also appear early for some verbs. These earliest forms have been confirmed by a more systematic corpus-based study, Otomo, Miyata, and Shirai (Reference Otomo, Miyata and Shirai2015), in which they found a strong negative correlation between the age of acquisition of inflectional morphemes and their input frequency (both type and token frequency), suggesting input as an important determinant of earliest inflections.
More relevant for our purposes is a naturalistic study by Murasugi (Reference Murasugi and Nakayama2015) and Murasugi, Nakatani, and Fuji (Reference Murasugi, Nakatani and Fuji2010), which found that children's errors were likely to reflect the use of a past-tense form in contexts where this inflectional form is not appropriate. These authors concluded that the past tense form functions as a morphosyntactic default (or ‘Root Infinitive analogue’). However, these findings are difficult to interpret as a defaulting account, given that the analysis is more descriptive than systematic, and given the rarity of errors reflecting the use of non-target inflections in naturalistic corpora.
Also relevant is a naturalistic study by Tatsumi and Pine (Reference Tatsumi and Pine2016), who observed a correlation across 50 verbs between the proportion of past versus all other inflected forms in the input and in children's spontaneous speech. Importantly, this correlation was observed individually within each parent–child dyad, even after partialling out the relative frequency of past versus other forms in child-directed speech in general. This suggests that children's relative usage of different inflectional forms reflects the actual input to which they are exposed, rather than simply general properties of the target language (e.g., that both parents and children are more likely to talk about the past for some actions/verbs than others). Although this study did not investigate children's errors, its broader implication is that the relative strength of different inflectional forms in children's linguistic knowledge depends on their distribution in the input language. Another implication is that verb-specific variation in the distribution of different inflectional forms can be a powerful tool for statistically testing input-based predictions.
The Aspect Hypothesis
Because the aim of the present study is to investigate whether children's by-verb production of past versus nonpast forms is sensitive to the distribution of these forms in the input, it is crucial to control for any other factor that may influence the production of past versus nonpast forms. One such factor is lexical aspect (aktionsart), in particular, telicity. Telicity refers to whether the action described by a verb is complete, or has “an inherent endpoint” (Shirai & Andersen, Reference Shirai and Andersen1995, p. 744), in which case it is termed telic (if not, atelic). According to the Aspect Hypothesis (Shirai & Andersen, Reference Shirai and Andersen1995), cross-linguistically, children's early use of past versus nonpast/present/progressive forms is governed mainly by aspect: young children use past inflection predominantly with achievement and accomplishment verbs, and nonpast/present/progressive inflection with activity verbs (see also Antinucci & Miller, Reference Antinucci and Miller1976; Wagner, Reference Wagner2002; Johnson & Fey, Reference Johnson and Fey2006). Thus, it is important to determine whether any apparent by-verb effect of input frequency (past versus nonpast bias) is in fact an effect of telicity in disguise.
It is reasonable to suppose some degree of correlation between telicity and the proportion of past versus nonpast forms in the input, given that even adult speakers show a preference for telic past forms and atelic nonpast/present/progressive forms (e.g., Andersen, Reference Andersen, Hyltenstam and Viborg1993; Andersen & Shirai, Reference Andersen, Shirai, Ritchie and Bhatia1996; Wagner, Reference Wagner2006, for English). Indeed, children's early over-reliance on telicity has been argued to result from the predominance of telic past forms and atelic nonpast/present/progressive forms in the input (Shirai & Andersen, Reference Shirai and Andersen1995). With regard to Japanese, Shirai (Reference Shirai, Nakajima and Otsu1993) found the predicted preponderance of telic over stative past forms in a single child's data, but this finding was not replicated in a subsequent corpus study with three children (Shirai, Reference Shirai1998). Thus, although it is unclear whether the Aspect Hypothesis holds for Japanese, the close link between telicity and past/nonpast verb use cross-linguistically means that it is important to control for telicity when investigating any link between verbs’ past/nonpast distributions and children's experimental production data. This is achieved, in the present study, by means of a rating task that yields a continuous measure of sentence telicity, which is included as a control predictor in the regression analyses.
The current study
The aim of the current study is to test an input-based prediction regarding the patterning of children's errors over two inflectional forms – past and nonpast – making use of a particular property of Japanese: specifically, the fact that past forms outnumber nonpast forms in the input for some verbs, with others showing the opposite pattern. The prediction is that children will make errors in both directions, using past forms in nonpast contexts, and vice versa, with the likelihood of each determined by the relative frequency of these two forms in the input language (even after controlling for sentence telicity). This type of bi-directional pattern, if observed, would be difficult to explain under an account that posits past (or, indeed, nonpast) as a default form.
Study 1
Method
Participants
Twenty-two Japanese-speaking children (13 girls and 9 boys) aged between 3;2 and 5;8 (M = 51·86, SD = 10·25 in months) participated in the experiment. All were monolingual speakers reported as showing no linguistic impairment. The children were recruited and tested at two nurseries in Tokyo, Japan. Twenty Japanese-speaking adults (mainly university students) provided telicity ratings.
Design and materials
Twenty verbs were selected for use in the study; 10 biased towards past tense and 10 towards nonpast tense in terms of input frequency. Frequency counts were taken from the child-directed speech (both mothers and fathers) of the ArikaM and Nanami subcorpora of the MiiPro corpus (Nisisawa & Miyata, Reference Nisisawa and Miyata2009, Reference Nisisawa and Miyatam2010) in the CHILDES database (MacWhinney, Reference MacWhinney2000). For each verb, the token frequency of (a) the simple past form (e.g., tabeta ‘ate’) and (b) the simple nonpast form (e.g., taberu ‘(will) eat(s)’) was obtained, using the FREQ function of the CLAN program (MacWhinney, Reference MacWhinney2000). Past-biased verbs and nonpast-biased verbs (see Table 1) were selected on the basis that – with one exception – the relevant bias was significantly different from chance (i.e., to 0·5 past vs. nonpast) by a binomial test (p < ·005 in all cases). As far as possible, the past-biased verbs and nonpast-biased verbs were matched for morphophonological class (vowel-ending and consonant-ending of three types of sound euphony). This required the inclusion of one past-biased verb (fum ‘step on’) for which the relevant bias was not significantly different from chance by a binomial test (p = ·172). All verbs were chosen to be easily depicted in pictures and familiar to children.
Table 1. Test Verbs for Study 1
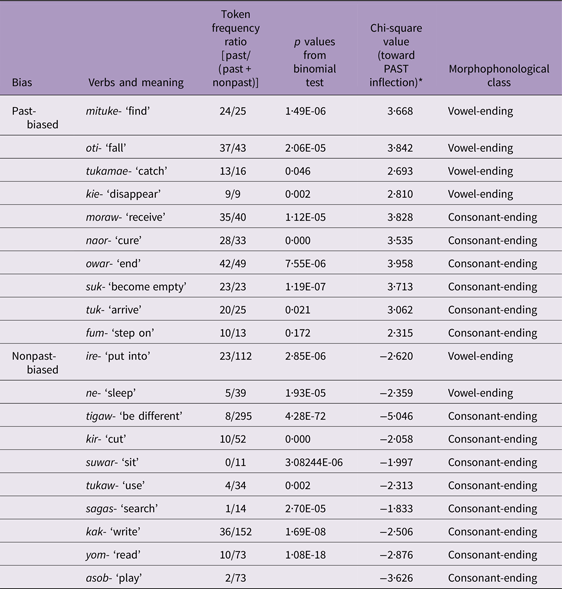
Notes. * In the model analyses, these chi-square values were put directionality to represent the bias toward the inflectional form of target context (PAST or NONPAST).
Procedure
The study elicited past and nonpast verb forms for the 20 test verbs using an elicited production sentence-completion paradigm. Children were tested individually by a native Japanese-speaking experimenter in two 10–15-minute sessions conducted on consecutive days. On Day 1, children completed a repetition task designed to introduce them to the target verb associated with each of the pictures to be shown on Day 2, and to the principle of producing each verb in both past and nonpast form. On Day 2, children completed the elicited production test, in which they produced past and nonpast verb forms in order to complete otherwise verbless prompt sentences produced by the experimenter. The entire Day 2 session was audio-recorded. The experimenter also took note of children's responses by hand.
On Day 1, children were asked to repeat training sentences (the same as the test sentences; see ‘Appendix’) produced by the experimenter. Children were given the following instructions: “Here is a girl called Kana-chan. She does the same things every day. I'm going to talk about her, so please repeat what I say.” For each trial, the target verb was presented twice: once in past-tense form with kinoo ‘yesterday’ and once in nonpast form with asita ‘tomorrow’, as in the examples below:
(1) Past tense sentence:
Kana-chan wa kinoo namae o kaita
Kana-chan topic yesterday name accusative write-past
‘Kana-chan wrote the name yesterday.’
(2) Nonpast sentence:
Kana-chan wa asita namae o kaku
Kana-chan topic tomorrow name accusative write-nonpast
‘Kana-chan will write the name tomorrow.’
Children repeated both sentences for each of 20 training pairs (i.e., one for each of the target verbs subsequently elicited on Day 2), while viewing a picture depicting the sentence (see Figure 1). Both the order of verbs and the order of past and nonpast sentences were randomized individually for each participant. Our goal in having children repeat each verb in both past and nonpast form was to train them on the appropriate target verb for each picture, while avoiding biasing them towards either form.

Figure 1. Test pictures (corresponds to weather sentence and test sentences respectively in the example of test trials below).
On Day 2, the experimenter introduced the elicitation test session, with the following instructions: “Today we are going to talk about Kana-chan again. Let's just talk together.” First, children completed a brief warm-up session, which followed the same format as the test trials, but using an irregular verb (su ‘do’ in a sentence kana-chan wa kinoo/asita hamigaki o sita/suru ‘Kana-chan brushed / will brush her teeth yesterday/tomorrow’).
For each test trial, the experimenter first introduced the target context (i.e., past or nonpast) by talking about the weather, using the same adverbs as in the training session, kinoo and asita, combined with a weather verb (e.g., ‘Yesterday was cloudy / Tomorrow will be cloudy’). This set-up sentence was designed to semantically prime either a past (yesterday) or nonpast (tomorrow) context, without using the specific verb form to be elicited from the children. Evidence from previous studies (e.g., Wagner, Reference Wagner2001; Valian, Reference Valian2006) suggests that temporal adverbs (here, ‘yesterday/today’) boost children's sensitivity to tense marking on verbs (here, weather verbs), at least from three years of age. Five different weather predicates were used (kumor ‘become cloudy’, hare ‘become sunny’, ame ga fur ‘rain’, atatakaku nar ‘become warm’, and samuku nar ‘become cold’), in order to ensure that the verb was never of the same morphological class as the target verb, hence avoiding unwanted morphological priming. During this interaction, children were shown a picture corresponding to the weather in the priming sentence (see Figure 1). Next, the experimenter produced the target sentence, omitting the verb (which, due to the verb-final word order of Japanese, is always the last word of the sentence; see ‘Appendix’). In this way, children were naturally prompted to produce the target verb. For this part of the process, children were shown another picture that depicted the scene of the test sentence. A complete example trial is shown below. Each child completed 40 trials (both a past target and a nonpast target trial for each of the 20 verbs), with the exception of three participants who began, but chose not to complete the test session.
(3) Test trial for past form target:
experimenter: Kinoo wa kumotta.
yesterday topic become.cloudy-past
Kana-chan wa kinoo namae o …
Kana-chan topic yesterday name accusative
‘Yesterday was cloudy. Kana-chan … the name yesterday’
child: kaita
write-past
‘wrote’
(4) Test trial for nonpast form target:
experimenter: Asita wa kumoru.
tomorrow topic become.cloudy-nonpast
Kana-chan wa asita namae o …
Kana-chan topic tomorrow name accusative
‘Tomorrow will be cloudy. Kana-chan … the name tomorrow’
child: kaku
write-nonpast
‘will write’
Sentence-telicity ratings
A rating task was used to obtain a continuous measure of sentence telicity, for use as a control predictor in the statistical analyses. Twenty Japanese-speaking adults were shown, in written form, the target sentences from the main part of the study (i.e., one past and one nonpast sentence for each verb), together with the corresponding test pictures. Participants were asked to rate on a scale of 1–10 the extent to which each sentence denoted a sense of endpoint/completion. This rating rask was administered using PsychoPy2 (Pierce, Reference Peirce2007). Although some studies have obtained telicity ratings for individual stem forms (e.g., Wulff, Ellis, Römer, Bardovi-Harlig, & Leblanc, Reference Wulff2009), this is not possible in Japanese, since the verb stem is an abstraction that does not have either a written or spoken form that is straightforwardly recognizable. Given this need to obtain ratings for past and nonpast verb forms (rather than stems), we decided to present these forms in the test sentences, rather than in isolation, to control for the possibility that the arguments present in the test sentences might have affected children's responses in the main part of the study (e.g., Wagner, Reference Wagner2006, reports a bias for linking transitive sentences to telic meanings).
Analyses
Children's responses were dummy coded in terms of correct and error responses (correct = 1 if the child's response matched the target form, and correct = 0 if the child's response was inflected for the other tense [past in a nonpast context or vice versa]), with all other responses excluded. These excluded responses (N = 49) included inflected forms other than simple past and nonpast forms (e.g., oti-tyat-ta ‘fall-COMPLETIVE-PAST’), nouns (e.g., keeki ‘cake’), and non-target verbs. Also excluded were a further 54 trials in which children produced no response, for a final total of 777 scorable responses (103 exclusions). Predictor variables were target context (past target context = 0·5, nonpast target context = –0·5), age (in months), rated telicity of the target sentence (the mean across all 20 raters), and input frequency bias. The input frequency bias measure was a (log transformed) chi-square statistic that was calculated on the basis of token counts of verb forms in the child-directed speech sample (MiiPro corpus; Nisisawa & Miyata, Reference Nisisawa and Miyata2009, Reference Nisisawa and Miyatam2010) For example, the bias toward past inflection for the verb mituke ‘find’ was calculated from the token count of past and nonpast inflection of this verb (mituketa and mitukeru) and those of all other verbs in the data following the formula χ 2 = (ad-bc)2*(a + b+c + d)/(a + c)(c + d)(b + d)(a + b) (see Table 2). This value represents the extent to which the particular bias towards the target inflection (past over nonpast in this case) for mituke ‘find’ differs from the bias shown by all other verbs in the input (this chi-square measure was also used in Tatsumi, Ambridge, & Pine; Reference Shirai2017). The chi-square values were natural-log transformed (ln(1 + n)) and polarity (+/–) set to indicate whether a verb is biased towards or against a target inflection (see, e.g., Gries, Reference Gries2015, for discussion).
Table 2. Contingency Table for the Chi-Square Calculation

Although the measure is not based on the individual participants’ input (which is not available), our assumption is that it constitutes a reasonable approximation of the general by-verb distribution of past versus nonpast forms in child-directed speech. Of course, if the present studies fail to find any relationship between children's experimental production data and this input measure, the use of an unrepresentative corpus would constitute one possible explanation. On the other hand, if we do find a relationship between children's experimental production data and this input measure, it is extremely improbable that this finding is due merely to chance (indeed the Bayesian statistical analysis we use yields an intuitive estimate of the probability that the true size of any such effect is zero). More generally, the finding that participants’ behavior is predicted by the frequency of items in a corpus of data that does not represent their individual input is extremely well established for both adults (e.g., Brysbaert & New, Reference Brysbaert and New2009) and children (Bannard & Matthews, Reference Bannard and Matthews2008), see Ambridge et al. (Reference Ambridge2015) for a review.
Predictions
An input-based account of acquisition straightforwardly predicts a correlation between the bias for the target versus the non-target form in the input (as operationalized by the chi-square input frequency bias predictor) and children's production of correct versus incorrect forms. Importantly, the account predicts that this effect of input bias will be observed even after controlling for telicity, and any observed interactions of telicity by other factors (see below). However, an input-based account does not make any a priori predictions regarding interactions with context (past versus nonpast) or with telicity; these interactions are therefore investigated in an exploratory fashion.
The predictions of the aspect hypothesis as they apply to the present elicited production study (as opposed to corpus studies) are less straightforward, as several possible predictions seem to us to be broadly consistent with the account:
(a) a main effect of telicity on production of correct responses, such that a high degree of telicity (completeness) helps children to recognize both that a past form is required in past target contexts, and that a past form should not be produced in nonpast target contexts.
(b) an interaction of telicity by context, such that a high degree of telicity helps children to produce past forms in past contexts, but has no effect – or even a detrimental effect – on children's performance in nonpast target contexts.
(c) an interaction of telicity by input bias, such that (a) occurs only for verbs that show no particular bias towards past or nonpast form in the input, leaving children without a ‘preferred’ form to produce.
(d) a three-way interaction (telicity by context by input bias) such that (c) holds for nonpast contexts but not past contexts or vice versa (depending on which context children seem to find easier).
Due to the existence of a range of possible predictions, we do not test a priori predictions regarding the effects of telicity (or interactions of the input bias predictor with context and/or telicity), but instead conduct exploratory analyses investigating all possible main effects and interactions. Fortunately, the Bayesian approach that we adopted (largely for practical reasons, see below), is well suited to such exploratory analyses, as – unlike conventional frequentist analyses – it does not assume a hypothesis-testing framework in which directional hypotheses are tested (and null hypotheses either rejected or not rejected). It is also important to bear in mind that the main goal of the present study is to test for an effect of input bias above and beyond telicity – which is included largely as a control predictor – and not to conduct a detailed investigation of the aspect hypothesis.
Models
We adopted a Bayesian approach to statistical analyses using R (R Core Team, 2017), because conventional frequentist mixed effects models fitted using lme4 (Bates, Maechler, Bolker, & Walker, Reference Bates, Maechler, Bolker and Walker2015) would not converge with anything close to maximal random effects structure (Barr, Levy, Scheepers, & Tily, Reference Barr2013); for example, in most cases, it was not possible to include a random intercept for verb. In contrast, all of the Bayesian models reported below – built using the R package brms (Bürkner, Reference Bürkner2017) – used maximal random effects structure: random intercepts for participant and verb and by-participant random slopes (including all possible interactions) for all main effects and interactions (no random slope for verb is meaningful given the design). All predictors were scaled into standard deviation units (z-scores) allowing us to use the same relatively uninformative prior (M = 0, SD = 1) across all predictors. This prior was chosen simply on the basis that, in a normal distribution centered around zero, the majority of observations (roughly 68%) fall with one standard deviation of the mean (95% within two). For example, the syntax for the main model reported in Study 1 was as follows (all data and code can be found on the website of the Open Science Framework <https://osf.io/xyavf/>):
 $$\eqalign{& {\rm brm}\bigg({\rm formula} = {\rm correct} \sim \left( {{\rm 1} + {\rm telicity} \;^{\ast}\; {\rm context}\; ^{\ast} {\rm input}\_{\rm bias} \vert {\rm subject}} \right) \cr & \quad + \left( {{\rm 1} \vert {\rm verb}} \right)+ {\rm telicity}\; ^{\ast}\; {\rm context}\; ^{\ast}\; {\rm input}\_{\rm bias}, \cr & \quad {\rm data} = {\rm study} 1, {\rm family} = {\rm bernoulli}(), {\rm set}\_{\rm prior} \cr & \quad \left({^{\prime \prime} {\rm normal}\left({0,1} \right){^{\prime \prime}, {\rm class} = ^{\prime \prime} {\rm b} ^{\prime \prime}}} \right), {\rm cores} = 4, {\rm warmup} \cr & \quad = 2000, {\rm iter} = 5000, {\rm chains} = 4, {\rm control} \cr & \quad = {\rm list}\left({{\rm adapt}\_{\rm delta} = 0\,{99}}\right)\bigg)}$$
$$\eqalign{& {\rm brm}\bigg({\rm formula} = {\rm correct} \sim \left( {{\rm 1} + {\rm telicity} \;^{\ast}\; {\rm context}\; ^{\ast} {\rm input}\_{\rm bias} \vert {\rm subject}} \right) \cr & \quad + \left( {{\rm 1} \vert {\rm verb}} \right)+ {\rm telicity}\; ^{\ast}\; {\rm context}\; ^{\ast}\; {\rm input}\_{\rm bias}, \cr & \quad {\rm data} = {\rm study} 1, {\rm family} = {\rm bernoulli}(), {\rm set}\_{\rm prior} \cr & \quad \left({^{\prime \prime} {\rm normal}\left({0,1} \right){^{\prime \prime}, {\rm class} = ^{\prime \prime} {\rm b} ^{\prime \prime}}} \right), {\rm cores} = 4, {\rm warmup} \cr & \quad = 2000, {\rm iter} = 5000, {\rm chains} = 4, {\rm control} \cr & \quad = {\rm list}\left({{\rm adapt}\_{\rm delta} = 0\,{99}}\right)\bigg)}$$We report only simultaneous models, which demonstrate the effect of each main effect (or interaction) above and beyond all the other predictors included in the model (e.g., Wurm & Fisicaro, Reference Wurm and Fisicaro2014). However, individual effects are interpretable only in the absence of collinearity between the predictors. Fortunately, none of the predictor variables showed large correlations (all rs falling between –0·21 and –0·03), and all Variance Inflation Factors were below 2 (1·35–1·70).
Finally, we note a further advantage of adopting a Bayesian approach: Bayesian models yield ‘p’ values (pMCMC values) and credible intervals (cf. frequentist confidence intervals) that, unlike their frequentist counterparts, can be interpreted intuitively: The pMCMC value represents the probability that the true size of the effect is (for positive effects) zero or lower (for negative effects, zero or higher). The 95% credible interval represents an interval which contains, with 95% probability, the true value of the effect in question.
Results of Study 1
Table 3 shows the total number of valid responses and the rate of correct responses in past and nonpast tense contexts for Study 1. These data show that children produced similar numbers of valid responses in the two target contexts (390/440 = 88·6% in past and 387/440 = 88·0% in nonpast contexts). They also show that they were more likely to produce past tense forms in nonpast tense contexts (42%) than nonpast tense forms in past tense contexts (17%), as shown in Figure 2. Importantly, however, children did produce both types of error. Nor were bi-directional errors restricted to a small subgroup of children, with 14/22 making at least one error of each type. These data therefore count against the idea that verb-marking errors in Japanese reflect the use of a single morphosyntactic default form. The rate of correct responses for each test sentence and target context can be found in the ‘Appendix’.
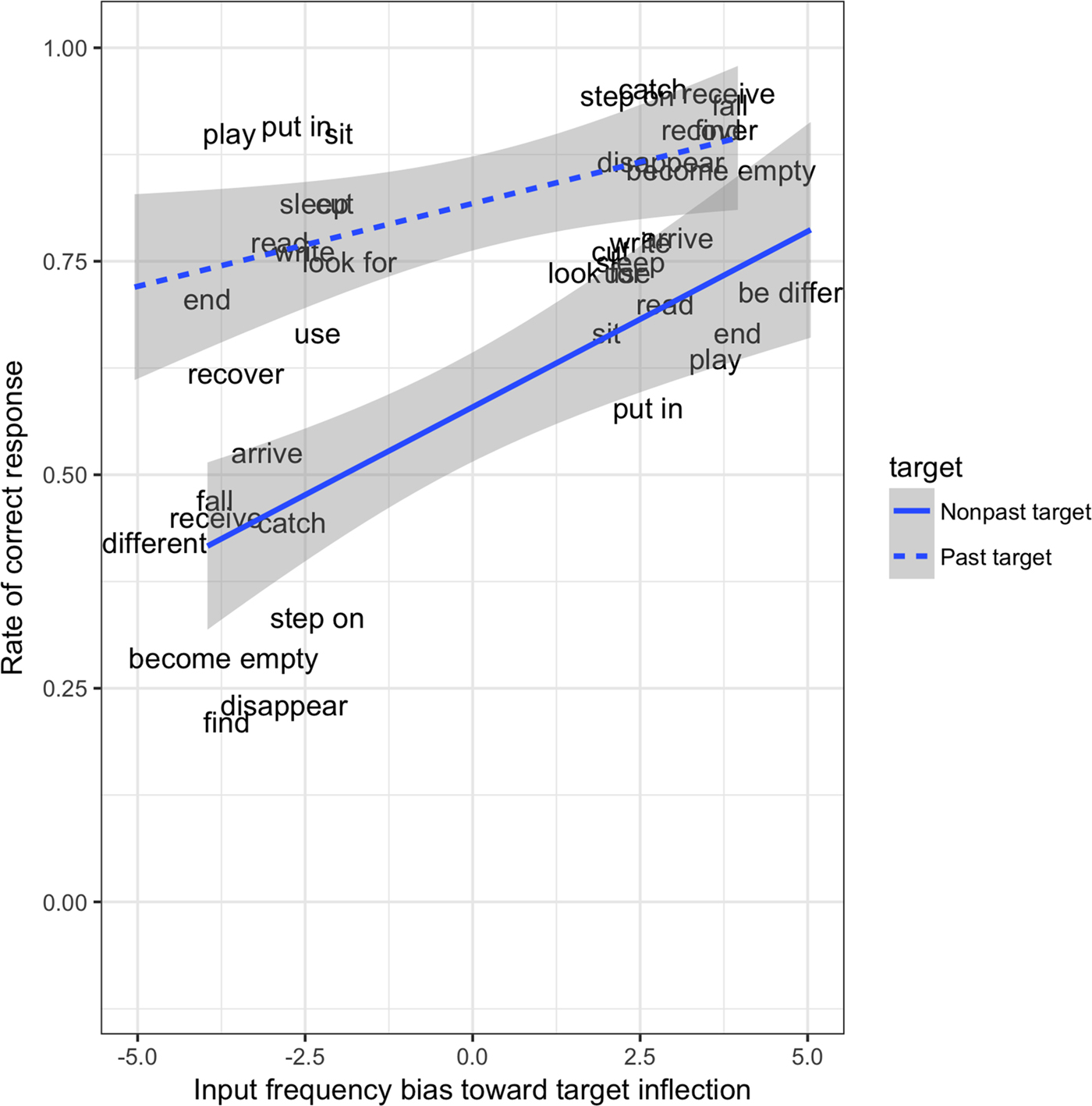
Figure 2. Children's correct responses by input frequency bias of target forms in past and nonpast target contexts (Study 1).
Table 3. Children's Responses by Target Context in Study 1

Children's age was not included in the full model because a prior Bayesian model analysis revealed that this factor did not significantly predict children's response pattern (M = 0·01, SE = 0·02, pMCMC = 0·29, CI [–0·02, 0·04]). The full Bayesian model fitted to the children's data contained the predictor variables of (a) target context, (b) input frequency bias towards the target form (chi-square measure), and (c) telicity (all centered) fully crossed. The 95% credible intervals of these fixed effects are shown in Figure 3. This model revealed a large (M = 1·30, SE = 0·81) but variable (pMCMC = 0·06, CI [–0·34, 2·84]) effect of target context, such that children provided more correct responses in past target contexts (M = 0·83, SE = 0·38) than in nonpast target contexts (M = 0·58, SE = 0·49). Although this pMCMC value narrowly misses the conventional frequentist cut-off of p < ·05 (which explains the very wide 95% credible interval including zero in Figure 3), it still suggests that an effect of context is more likely than not. Indeed, since pMCMC values can be interpreted intuitively as the probability that the true effect is zero, a value of 0·06 indicates that we can say, with 94% probability, that an effect of context is present in these data. Similarly, these data also suggest, with 93% probability, a main effect of telicity (M = 0·28, SE = 0·20, pMCMC = 0·07, CI [–0·11, 0·68]), corresponding to the first possible telicity prediction set out above: (a) a high degree of telicity (completeness) helps children to recognize both that a past form is required in past target contexts, and that a past form should not be produced in nonpast target contexts. However, visual inspection of Figure 4 suggests instead the correctness of the second possible telicity prediction set out above: (b) a high degree of telicity helps children to produce past forms in past contexts, but has no effect – or even a detrimental effect – on children's performance in nonpast target contexts. However, no such interaction was observed (M = –0·12, SE = 0·34, pMCMC = 0·36, CI [–0·78, 0·55]), possibly because our study is underpowered to detect small interactions.
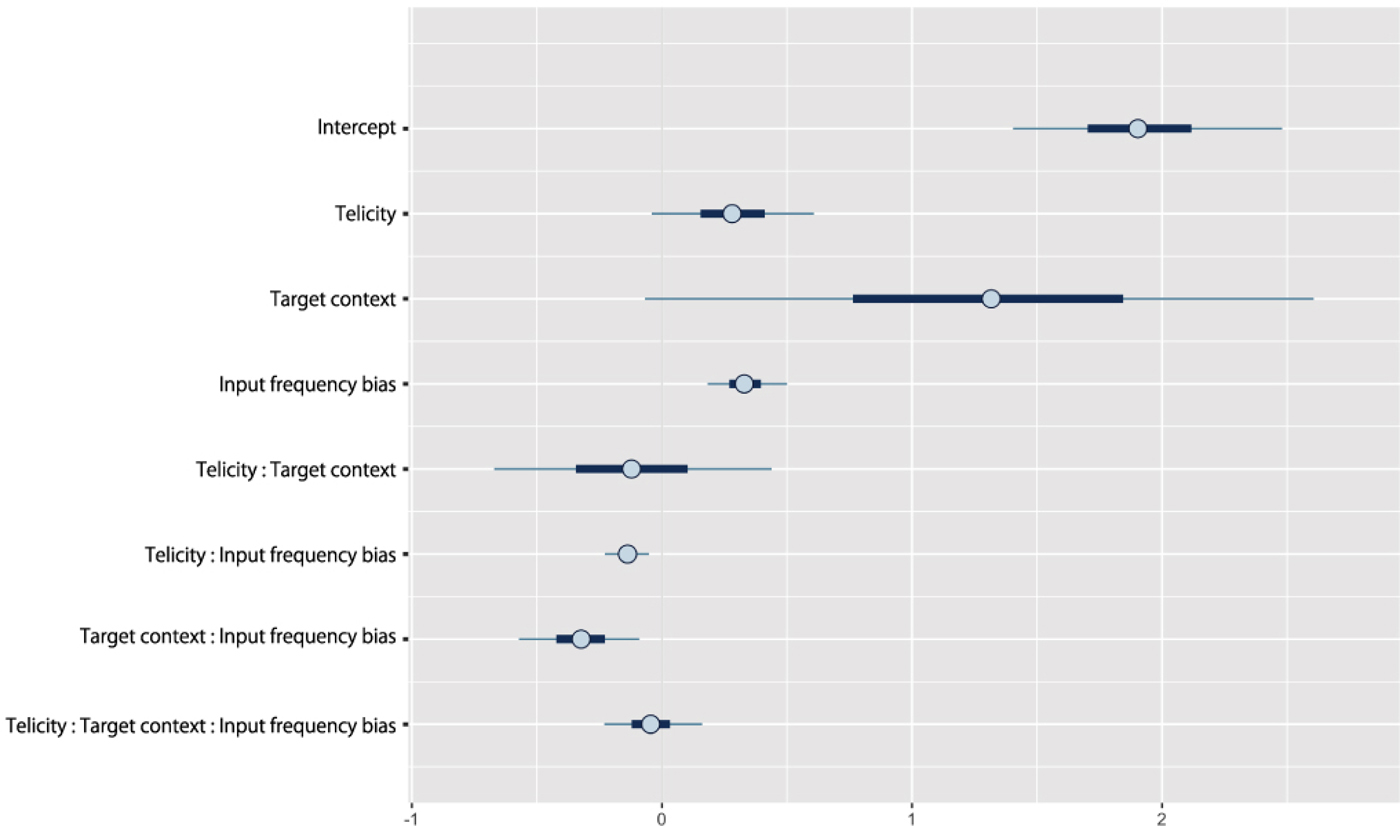
Figure 3. 95% credible intervals for fixed effects in the model (Study 1).
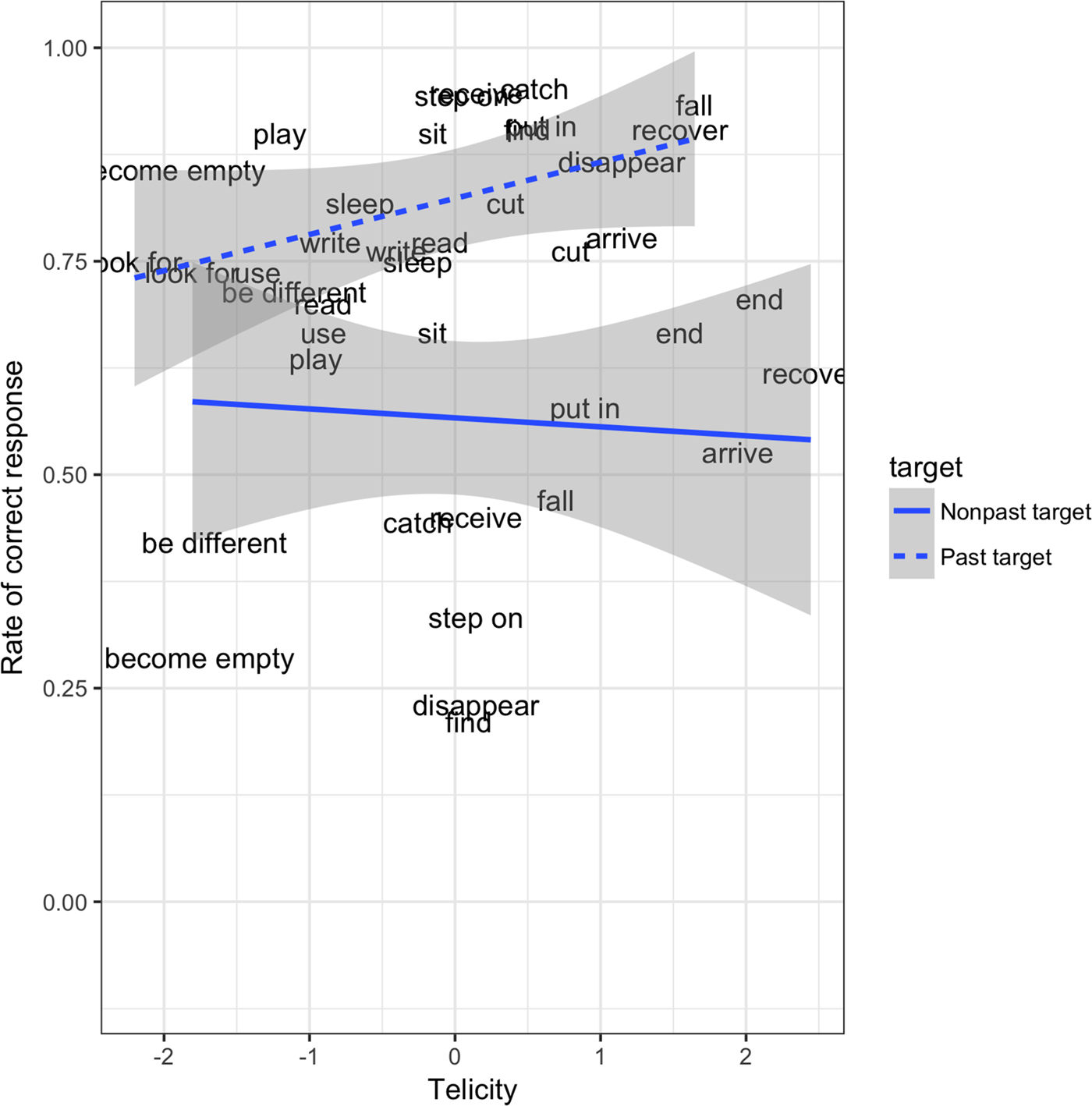
Figure 4. Children's correct responses by telicity in past and nonpast target contexts (Study 1).
Crucially, however, the model revealed a highly reliable effect of the input-bias predictor (M = 0·33, SE = 0·10, pMCMC < 0·001, CI [0·15, 0·54]), demonstrating that – in line with our central prediction – children are more likely to produce the correct form (past in past contexts, nonpast in nonpast contexts) when that verb is more frequent in the target form (past in past contexts, nonpast in nonpast contexts) than the competing form; and, importantly, that this effect holds even after controlling for telicity.
At the same time, the model revealed an interaction of input bias by target context (M = –0·33, SE = 0·15, pMCMC = 0·01, CI [–0·63, –0·04]), with the negative polarity of this interaction indicating that the effect of input bias is larger for nonpast forms (coded as –0·5) than past forms (coded as + 0·5), presumably as a result of a ceiling effect in past contexts (see Figure 2). The model also revealed an interaction of input bias by telicity (M = –0·14, SE = 0·05, pMCMC = 0·005, CI [–0·25, –0·04]), with the negative polarity of this interaction indicating that input frequency effects are smaller when telicity is high (presumably because high telicity encourages children to produce past forms, regardless of their input frequency). No three-way interaction was observed (M = –0·04, SE = 0·12, pMCMC = 0·34, CI [–0·27, 0·21])
Separate models by target context
In order to better understand the interactions described above, we ran separate models for past and nonpast contexts. The model for past contexts showed weak evidence for an effect of input bias (M = 0·20, SE = 0·16, pMCMC = 0·09, CI [–0·10, 0·54]) in the expected positive direction, little evidence for an effect of telicity (M = 0·28, SE = 0·41, pMCMC = 0·23, CI [–0·55, 1·10]), and evidence for an interaction (M = –0·20, SE = 0·12, pMCMC = 0·04, CI [–0·45, 0·03]). This suggests that, in line with the interpretation above, children show close to ceiling performance with past forms, yielding a very small effect of input bias, though one that is larger for low telicity verbs (presumably because high telicity verbs are almost always correctly produced in past form in past contexts, regardless of their input frequency).
The model for nonpast contexts showed strong evidence for an effect of input bias (M = 0·53, SE = 0·15, pMCMC < 0·001, CI [0·26, 0·87]), and relatively weak evidence for telicity (M = 0·31, SE = 0·29, pMCMC = 0·13, CI [–0·26, 0·91]), and for the interaction (M = –0·13, SE = 0·09, pMCMC = 0·07, CI [–0·32, 0·05]). This suggest that, in line with the interpretation above, children's worse performance in nonpast contexts translates into a larger effect of input bias, with less room for an effect of telicity. However, as for past forms, there is some evidence to suggest that the effect of input bias is larger for low telicity verbs.
Discussion of Study 1
The results of Study 1 provide support for the prediction that Japanese children will show a bi-directional pattern of verb-marking error, using past tense forms in nonpast tense contexts and vice versa, with the likelihood of both types of error determined by the relative frequency of these two forms in the input language. The role of telicity is complex, and would require separate investigation in a dedicated study, but perhaps the most straightforward interpretation of the pattern of main effects and interactions outlined above is that a high degree of telicity (completeness) helps children to produce past forms of verbs that are rarely encountered in that form in the input. Whether or not this interpretation is correct, the important point for our purposes is that Study 1 provides clear evidence of an effect of input bias (with 99·9% probability in the main analysis), above and beyond any effect of telicity.
Although, in this respect, the findings are exactly as would be predicted by a constructivist account, they also reveal an unexpected general bias in children's responses, such that they produced more past forms than nonpast forms (i.e., they produced more correct forms, and fewer errors, in past than nonpast target contexts). One interpretation of this bias is that it reflects a genuine advantage for past tense over nonpast tense forms in Japanese, resulting from differences in the properties of past and nonpast tense forms (such as, for example, their relative phonological regularity). Another is that it is a task-specific effect, which reflects the fact that 11 children appeared to be relatively insensitive to the context manipulation, and instead ‘chose’ one particular form – past or nonpast – which they stuck to on over 75% of trials, regardless of target context. On this explanation, the apparent past bias reflects nothing more than the fact that more children happened to pick past (9 children) than nonpast (2 children) as their form of choice. A third possibility is that the apparent advantage for past forms, which we did not specifically predict in advance, is nothing more than a chance finding. Indeed, note that, although large, the context effect was highly variable between children and items, and – as a result – yielded a 95% confidence interval that overlapped zero.
In order to differentiate between these possibilities, we decided to conduct a modified replication designed to investigate whether the advantage for past forms – and, more importantly, the effect of input-frequency bias – would replicate in a second group of children, even with modifications designed to reduce both (a) children's tendency to perseverate on a particular form (past or nonpast) and (b) overall rates of correct responding. These modifications constituted (a) an extended repetition and warm-up session, designed to increase children's sensitivity to the context manipulation, and (b) testing younger children, designed to increase overall rates of error.
Study 2
Method
Participants
Twenty-six Japanese-speaking children (18 girls and 8 boys) aged between 2;7 and 4;11 (M = 46·38, SD = 7·58 months) participated in the experiment. All were monolingual speakers reported as showing no linguistic impairment. The children were recruited and tested at two nurseries in Tokyo, Japan.
Design and materials
The test verbs and sentences were the same as for Study 1 (see ‘Appendix’). The basic procedure was also the same as for Study 1, but with two changes. First, on Day 1, children repeated both the test sentences and – unlike for Study 1 – the weather sentences. Because the weather sentences contain both a temporal adverb (‘yesterday/tomorrow’) and a verb inflected for either past or nonpast (though from a different morphophonological class to the target verb), having children additionally repeat these sentences was designed to increase their sensitivity to the context manipulation in general, and to highlight the way that the target context is systematically flagged up by the weather sentence. Second, children completed a more extensive warm-up session, which included five verbs (as opposed to just two in Study 1) each in both past and nonpast target context. Unlike in Study 1, the experimenter corrected any mistakes made by the children during the warm-up.
Results of Study 2
Table 4 shows the total number of valid responses and the rate of correct responses in past and nonpast contexts for Study 2. These data show that children produced similar numbers of valid responses in the two target contexts (407/520 = 78·3% in past and 422/520 = 81·2% in nonpast contexts). They also show that children made errors in both directions (with the vast majority of children (23/26) making at least one error of each type). However, as in Study 1, children were considerably more likely to produce past tense forms in nonpast contexts (51%) than nonpast forms in past tense contexts (19%) as can be seen in Figure 5. The rate of correct responses for each test sentence and target context can be found in the ‘Appendix’.
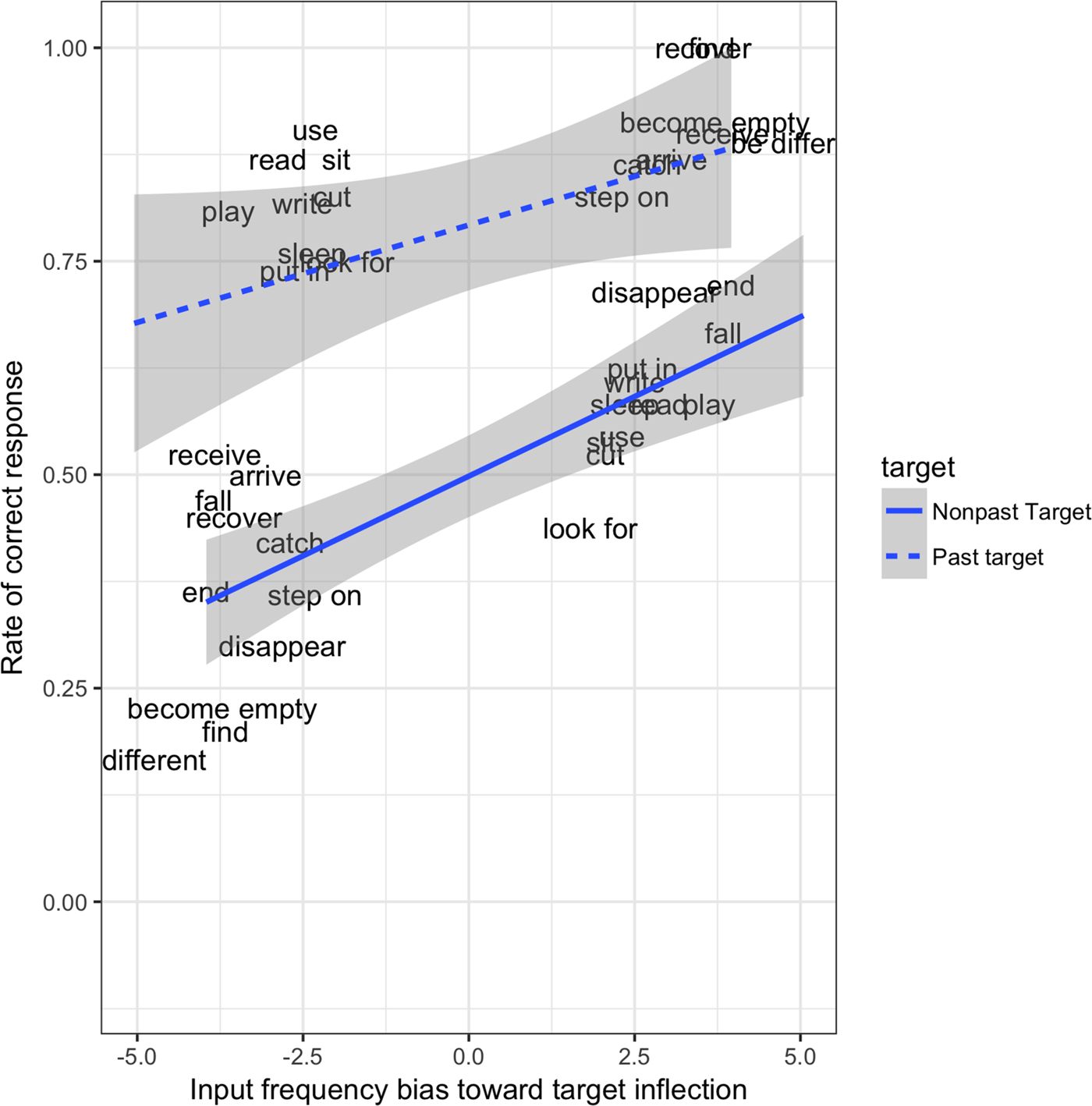
Figure 5. Children's correct responses by input frequency bias of target forms in past and nonpast target contexts (Study2).
Table 4. Children's Responses by Target Context in Study 2

Again, a Bayesian mixed-effects regression model was fitted to children's data with target context, input frequency bias for target inflection, and telicity fully crossed. The low correlations between these factors (all rs = −0.19 to 0) do not suggest multicollinearity. Again, children's age was not included because a preliminary analysis suggested no effect (M = 0·01., SE = 0·02, pMCMC = 0·26, CI [–0·03, 0·05]).
Despite the manipulations designed to increase children's sensitivity to the target context, this model revealed an effect of context almost identical in size to Study 1 (M = 1·54, SE = 0·78), and – if anything – more reliable but still variable (pMCMC = 0·03, CI [0·02, 3·04]); again children provided more correct responses in past target contexts (M = 0·81, SE = 0·39) than nonpast target contexts (M = 0·49 , SE = 0·50). Unlike Study 1, this model revealed little to no evidence for a main effect of telicity (M = 0·13, SE = 0·18, pMCMC = 0·23, CI [–0·22, 0·49]) and – like Study 1 – little-to-no evidence for an interaction between telicity and target context (pMCMC = 0·38, CI [–0·76, 0·49]); see Figure 6 for 95% credible intervals.
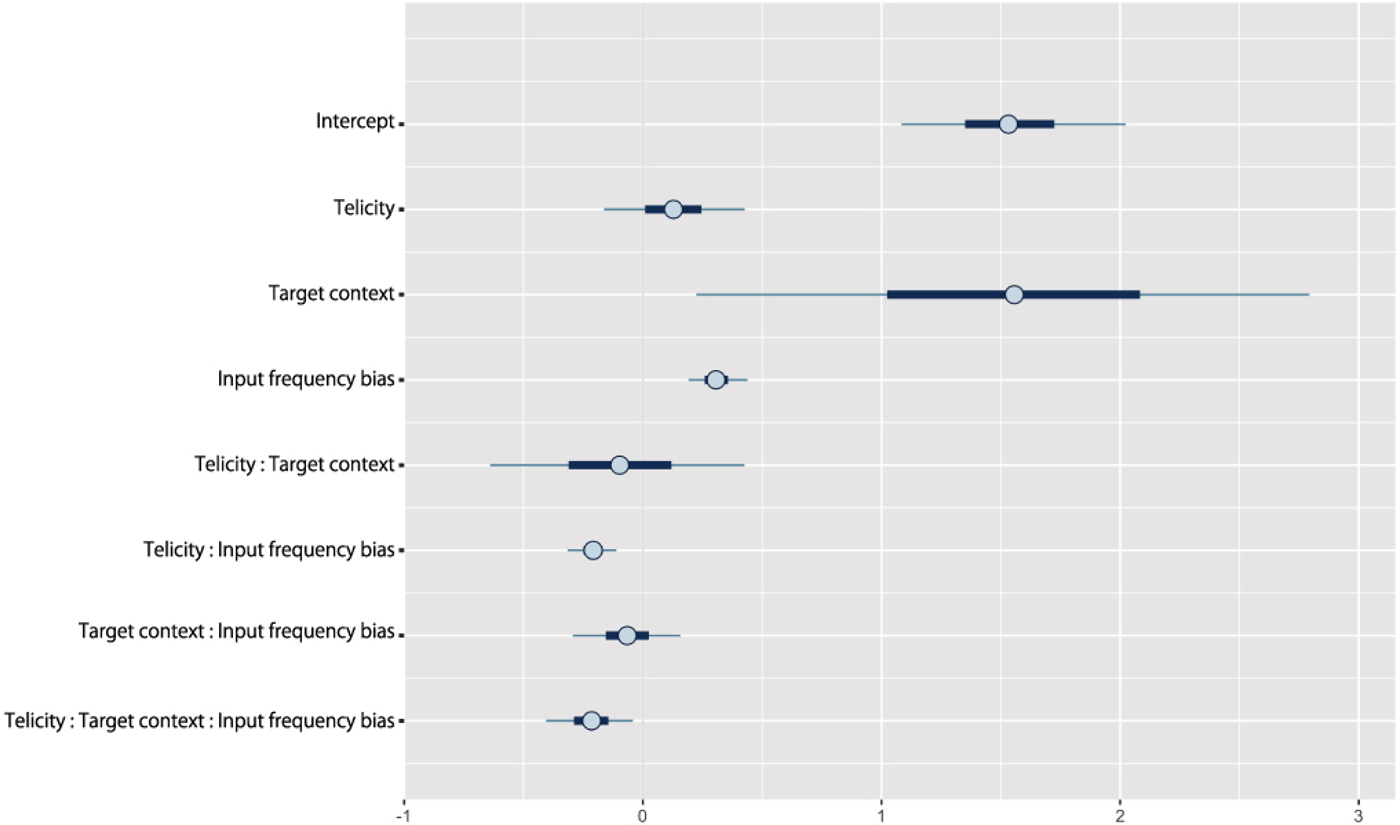
Figure 6. 95% credible intervals for fixed effects in the model (Study 2).
Crucially, replicating the findings of Study 1, this model yielded a highly reliable effect of input frequency (M = 0·31, SE = 0·08, p < ·001, CI [0·17, 0·47]) above and beyond telicity (see Figure 5). Furthermore, unlike Study 1, there was little to no evidence to suggest that this effect differed for past and nonpast contexts (interaction M = −0·07, SE = 0·14, pMCMC = 0·31, CI [–0·34, 0·20]) (see Figure 7). Replicating a finding from Study 1, the model also revealed an interaction between input bias and telicity (M = –0·21, SE = 0·06, pMCMC = 0·002, CI [–0·34, –0·09]), with the negative polarity of this interaction again indicating that input frequency effects are smaller when telicity is high. However, unlike for Study 1, this interaction was mediated by a three-way interaction (M = –0·22, SE = 0·11, pMCMC = 0·02, CI [–0·45, –0·01]).
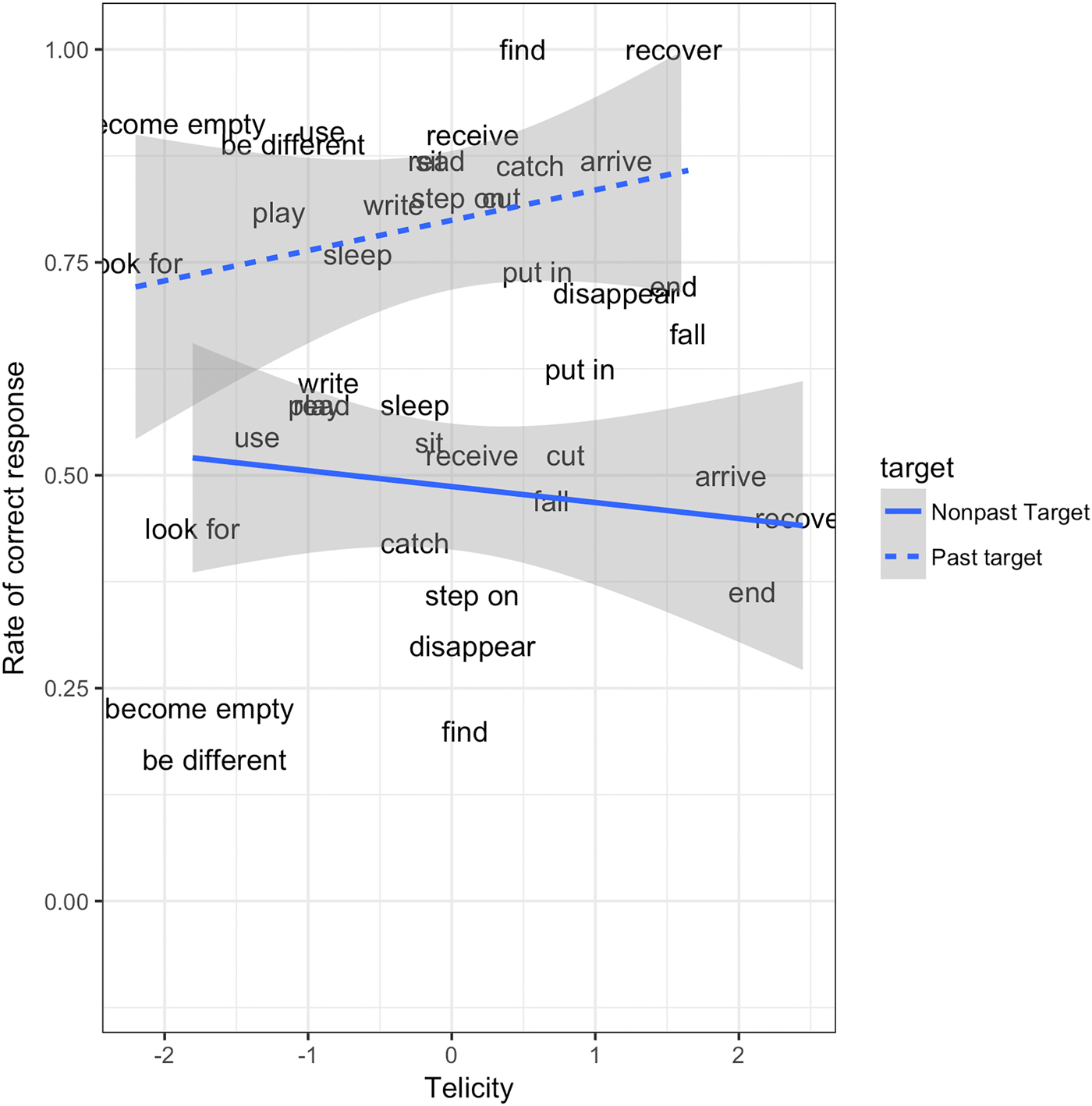
Figure 7. Children's correct responses by telicity in past and nonpast target contexts (Study 2).
Separate models by target context
In order to better understand these interactions, we again ran separate models for past and nonpast contexts. The model for past contexts replicated findings of the equivalent model for Study 1, with (a) evidence for an effect of input bias (though this time, more reliable; M = 0·36, SE = 0·22, pMCMC = 0·04, CI [–0·06, 0·82]), (b) little to no evidence for an effect of telicity (M = 0·14, SE = 0·53, pMCMC = 0·39, CI [–0·91, 1·20]), and (c) evidence for a negative interaction between the two (M = –0·40, SE = 0·20, pMCMC = 0·02, CI [–0·81, –0·03]), which again appears to reflect the fact that high telicity verbs are almost always correctly produced in past form in past contexts, regardless of their input frequency.
The model for nonpast contexts showed exactly the same pattern with (a) evidence for an effect of input bias (M = 0·31, SE = 0·08, pMCMC < ·001, CI [0·15, 0·49]), (b) little to no evidence for an effect of telicity (M = 0·11, SE = 0·20, pMCMC = 0·28, CI [–0·30, 0·52]), and (c) evidence for a negative interaction between the two (M = –0·11, SE = 0·07, pMCMC = 0·04, CI [–0·25, 0·01]), which again appears to reflect the fact that high telicity verbs are almost always correctly produced in past form in past contexts, regardless of their input frequency. The three-way interaction observed in the main analysis appears to reflect the fact that the negative interaction of input frequency by telicity is of greater magnitude in past contexts (M = –0·40, SE = 0·20, pMCMC = 0·02, CI [–0·81, –0·03]) than nonpast contexts (M = –0·11, SE = 0·07, pMCMC = 0·04, CI [–0·25, 0·01]). Thus, the role of telicity is not straightforward, but, again, our findings are consistent with the possibility that a high degree of telicity (completeness) helps children to produce past forms of verbs that are rarely encountered in that form in the input. Crucially, however, the important point for our purposes is that Study 2 replicates the finding of Study 1 of a clear effect of input bias (with 99·9% probability in the main analysis), above and beyond any effect of telicity.
Discussion of Study 2
The results of Study 2 provide further support for the prediction that Japanese children will show a bi-directional pattern of verb-marking error, which is conditioned by the frequency bias of past and nonpast tense forms in the input language. Furthermore, the evidence for the possibility that this effect is larger for nonpast than past contexts (i.e., for the interaction of input frequency bias by target context) was considerably weaker for Study 2 (pMCMC = 0·31, CI [–0·34, 0·20]) than for Study 1 (pMCMC = 0·01, CI [–0·63, –0·04]). This suggests that, although the modifications made to Study 2 did not affect the overall advantage shown for past forms, they did – if anything – increase children's sensitivity to the distributional properties of the input, by reducing perseveration responses (in fact, in stark contrast with Study 1, all children used both forms at least once). The findings of Study 2 again replicate those of Study 1 in demonstrating that, although telicity is playing some role – perhaps by increasing rates of correct past production for low-frequency past forms – input frequency bias is playing an important role above and beyond telicity.
An important goal of Study 2 was investigating the replicability not only of the predicted effect of input frequency bias, but also of the non-predicted effect of context: an overall advantage for past forms (i.e., children made more correct responses, and fewer errors, in past than nonpast contexts). In fact, not only did this finding survive the modifications designed to increase children's sensitivity to the context manipulation; numerically, the advantage for past forms actually increased. Taken together, then, the findings of Study 1 and Study 2 suggest that an advantage for past over nonpast forms is a genuine phenomenon in Japanese children's performance, at least in our experimental setting. At first glance, this last finding might seem to be consistent with the claim that in Japanese, the past tense form functions as a morphosyntactic default (e.g., Murasugi et al., Reference Murasugi, Nakatani and Fuji2010; Murasugi, Reference Murasugi and Nakayama2015). However, such an account cannot explain either the bi-directional pattern of error or the effects of input frequency found in our data. In addition, a general preference for past forms is not supported either by previous studies on the acquisition of Japanese, as detailed in the ‘Introduction’. Two possible alternative explanations (discussed in more detail below) are that this general past form advantage reflects (a) task-specific differences between our past and nonpast stimuli (that are not necessarily true of Japanese more generally) and/or (b) the greater phonological regularity of past tense versus nonpast tense forms in Japanese.
General discussion
The aim of the present study was to test the claim of input-based accounts of language acquisition that children's inflectional errors reflect competition between different forms of the same verb in memory, with the accessibility or representational strength of each form related to the frequency distribution of that form in the input. In order to distinguish this possibility from the alternative possibility that errors reflect the use of a morphosyntactic default form, we focused on the Japanese verb system, in which past forms outnumber nonpast forms in the input for some verbs, with others showing the opposite pattern.
Our results provide support for an input-based account in two ways. First, they reveal a bi-directional pattern of verb-marking error in which children produce past tense forms in nonpast tense contexts and nonpast tense forms in past tense contexts. This bi-directional pattern is very difficult to explain in terms of the use of a morphosyntactic default. Second, they show that the likelihood of making both types of error is related to the frequency bias with which past and nonpast tense forms of the verb occur in the input language. This finding provides direct support for the idea that children's inflectional errors reflect competition between different forms of the same verb in memory.
With regard to telicity, our findings are less clear (and, indeed, we included telicity primarily as a control predictor, rather than with the aim of testing the aspect hypothesis). Nevertheless, our findings do suggest some role for telicity. Determining the precise nature of this role will require further studies dedicated to this question (and, given the findings of the present study, it is vital that such studies control for input frequency). For now, the most likely possibility seems to be that a high degree of telicity (completeness) helps children to produce past forms of verbs that are rarely encountered in that form in the input. Whether future studies confirm or disconfirm this possibility, the important point for our purposes is that, across two studies, the predicted effect of relative input frequency was observed above and beyond any effects of telicity.
Also observed across both studies was a non-predicted general advantage for past over nonpast forms (and, again, the nature of simultaneous regression means that this advantage was observed above and beyond input frequency and telicity). This raises the question of whether, as suggested by a reviewer, the present results are “as consistent with a default account, with past tense as default, as in Murasugi, as they are with [a] frequency account”. Certainly, Murasugi's account could explain why children produce a large number of past forms in nonpast contexts. However, it is difficult to see how this account could – even in principle – explain why children also produce nonpast forms in past contexts at a rate that is (a) by no means negligible (17% and 19% in Studies 1 and 2, respectively), and (b) again related to input frequency.
That said, the finding of a general advantage for past forms – which, like the observed effects of telicity, highlights the importance of considering factors beyond input frequency – requires an explanation. One possibility is that this finding is caused by a particular feature of the present methodology. For example, although we used asita ‘tomorrow’ to set up a future interpretation for the nonpast sentences, in the language in general, nonpast forms are used for both future and habitual meanings. If children interpreted the target nonpast forms as habitual rather than future, their use following asita ‘tomorrow’ may have seemed unnatural. Another feature of the present methodology that may have contributed to an (apparent) past advantage is the use of still pictures which, by their very nature, could be argued to show events that have – in some sense – already happened by the point of depiction. An alternative possibility is that the observed past advantage is genuine (rather than a methodological artefact), and reflects the greater phonological regularity of past versus nonpast forms in Japanese: for past forms, the final mora is always –ta or –da, whereas for nonpast tense forms, the final mora consists of the final segment of the verb plus –(r)u, which means that nonpast tense forms can end in a wider range of different moras.
These explanations are inevitably somewhat speculative, and would require future research. Whether or not one or more of these suggestions are correct, it is clear that the results of the present study provide strong support for the idea that the patterning of children's verb-marking errors is determined at least in part by frequency-sensitive competition between past and nonpast forms of the same verb in memory. As we noted in the ‘Introduction’, the results of previous studies that have reported such effects (e.g., Rasanen et al., Reference Räsänen, Ambridge and Pine2014; Aguado-Orea & Pine, Reference Aguado-Orea and Pine2015) are not definitive because they rely on the consistent production of one form in place of another (bare/infinitive form for 3sg –s in English; 3sg for 3pl in Spanish), and hence are also consistent with accounts based on morphosyntactic defaulting. Focusing on Japanese verbs, which show a verb-specific, bi-directional probabilistic patterning, has allowed us to overcome this difficulty, and to differentiate between input-based and defaulting hypotheses. The wider implication is that studying languages with different statistical patterns of usage to the Indo-European languages that are more typically studied may be a useful way of distinguishing between theories that, for many languages, make similar predictions. Future cross-linguistic research into children's use of verb inflection should take into account factors other than input frequency, such as morphological and phonological complexity and regularity (and, when investigating past and nonpast verb forms, telicity). In the meantime, the findings of the present study constitute perhaps the most direct evidence to date that children's inflectional errors reflect not morphosyntactic defaulting but competition between different forms of the same verb in memory, with the accessibility or representational strength of each form related to the relative frequency of each form in the input.
Acknowledgements
The authors are post-doctoral researcher, Professor, and Professor in the International Centre for Language and Communicative Development (LuCiD) at the University of Liverpool. The support of the Economic and Social Research Council [ES/L008955/1] is gratefully acknowledged. The first author would like to thank the Japanese Student Services Organization (JASSO) and the Ministry of Education, Culture, Sports, Science and Technology of Japan for the PhD scholarship that made the current study possible. We are grateful to all the nurseries for their help and assistance related to the experiment. We also thank Franklin Chang for his help with the analyses, Colin Bannard for his helpful suggestions for revision, and Reiko Aso for her help in recruiting the children.
Appendix List of test sentences, telicity scores, and rate of correct responses














 Open access
Open access