
2 results
Toward random walk-based clustering of variable-order networks
-
- Journal:
- Network Science / Volume 10 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 22 December 2022, pp. 381-399
-
- Article
- Export citation
-
Higher-order networks aim at improving the classical network representation of trajectories data as memory-less order
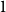 $1$
Markov models. To do so, locations are associated with different representations or “memory nodes” representing indirect dependencies between visited places as direct relations. One promising area of investigation in this context is variable-order network models as it was suggested by Xu et al. that random walk-based mining tools can be directly applied on such networks. In this paper, we focus on clustering algorithms and show that doing so leads to biases due to the number of nodes representing each location. To address them, we introduce a representation aggregation algorithm that produces smaller yet still accurate network models of the input sequences. We empirically compare the clustering found with multiple network representations of real-world mobility datasets. As our model is limited to a maximum order of
$1$
Markov models. To do so, locations are associated with different representations or “memory nodes” representing indirect dependencies between visited places as direct relations. One promising area of investigation in this context is variable-order network models as it was suggested by Xu et al. that random walk-based mining tools can be directly applied on such networks. In this paper, we focus on clustering algorithms and show that doing so leads to biases due to the number of nodes representing each location. To address them, we introduce a representation aggregation algorithm that produces smaller yet still accurate network models of the input sequences. We empirically compare the clustering found with multiple network representations of real-world mobility datasets. As our model is limited to a maximum order of
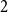 $2$
, we discuss further generalizations of our method to higher orders.
$2$
, we discuss further generalizations of our method to higher orders.

Higher-Order Networks
-
- Published online:
- 23 November 2021
- Print publication:
- 23 December 2021
-
- Element
- Export citation
